YOLOv3논문
◇ One Stage Detector◇
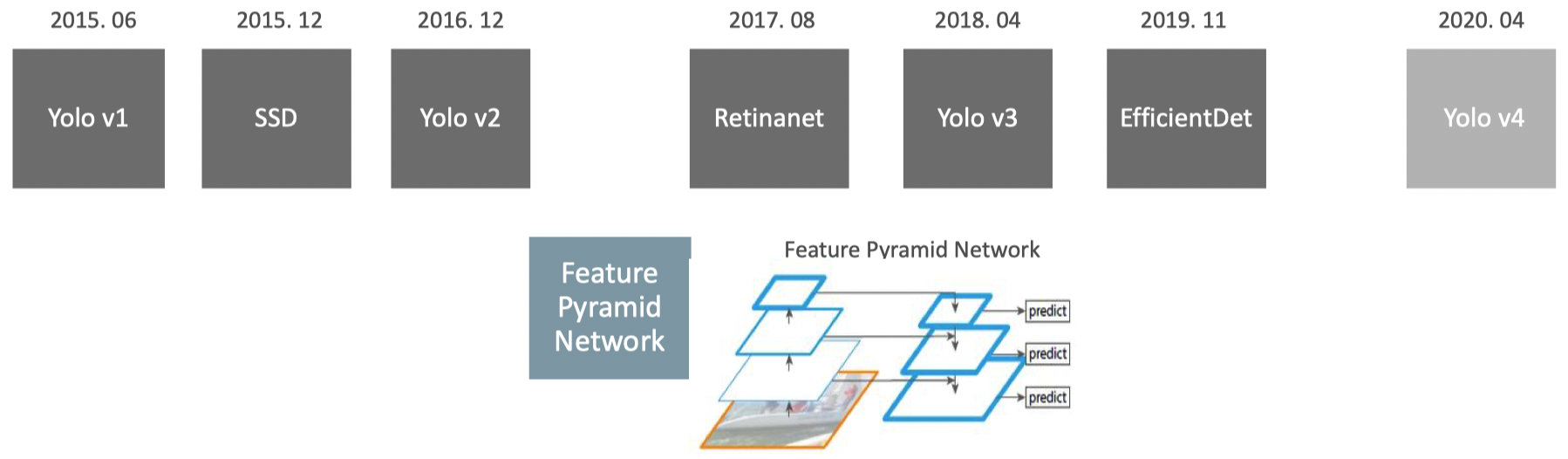
◇YOLO –v1, v2, v3 비교◇

anchor box 기반의 모델과 더 뛰어난 Backbone 구성, 다양한 성능 향상 테크닉을 적용하면서 발전됨.
◇Yolo v3 의 특징◇
- Feature Pyramid Network 유사한 기법을 적용하여 3개의 Feature Map Output에서 각각 3개의 서로 다른 크기와 scale을 가진 anchor box 로 Detection
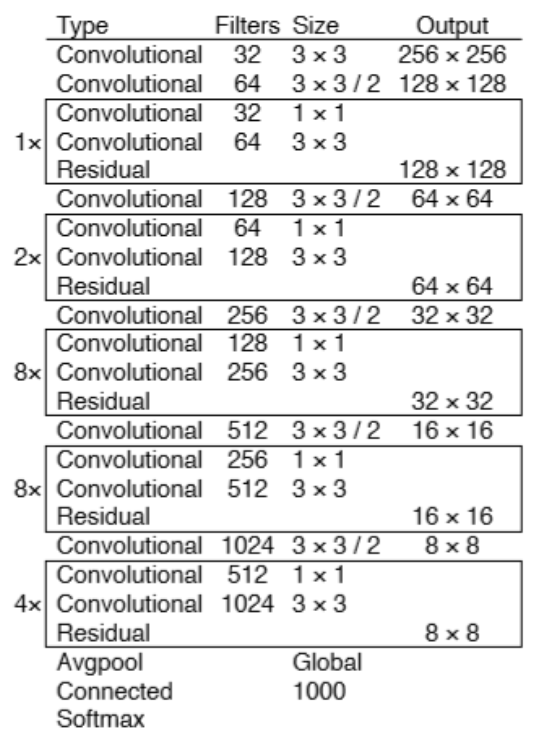
- Backbone 성능 향상 - Darknet53
- Multi Labels 예측 : Softmax가 아닌 Sigmoid 기반의 Logistic classifier로 개별 Object의 Multi labels 예측 - 조금 더 성능을 높이기 위해 수행했다고함
◇YOLO V3 모델 아키텍처◇
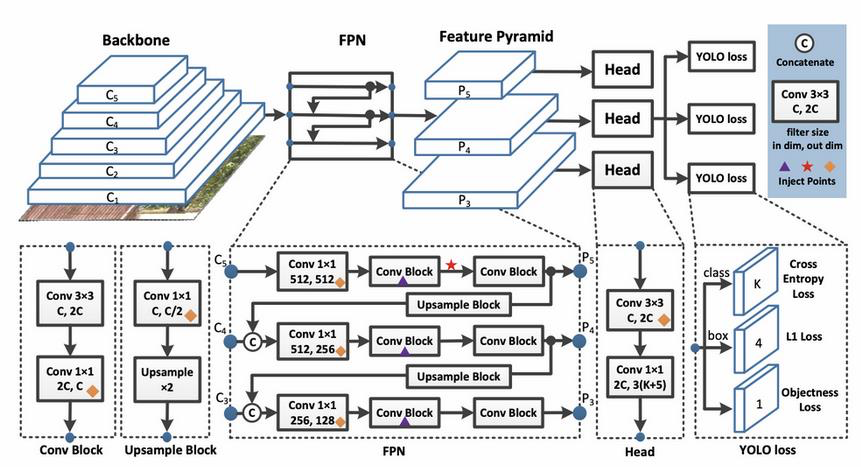
◇YOLO v3 Network 구조◇
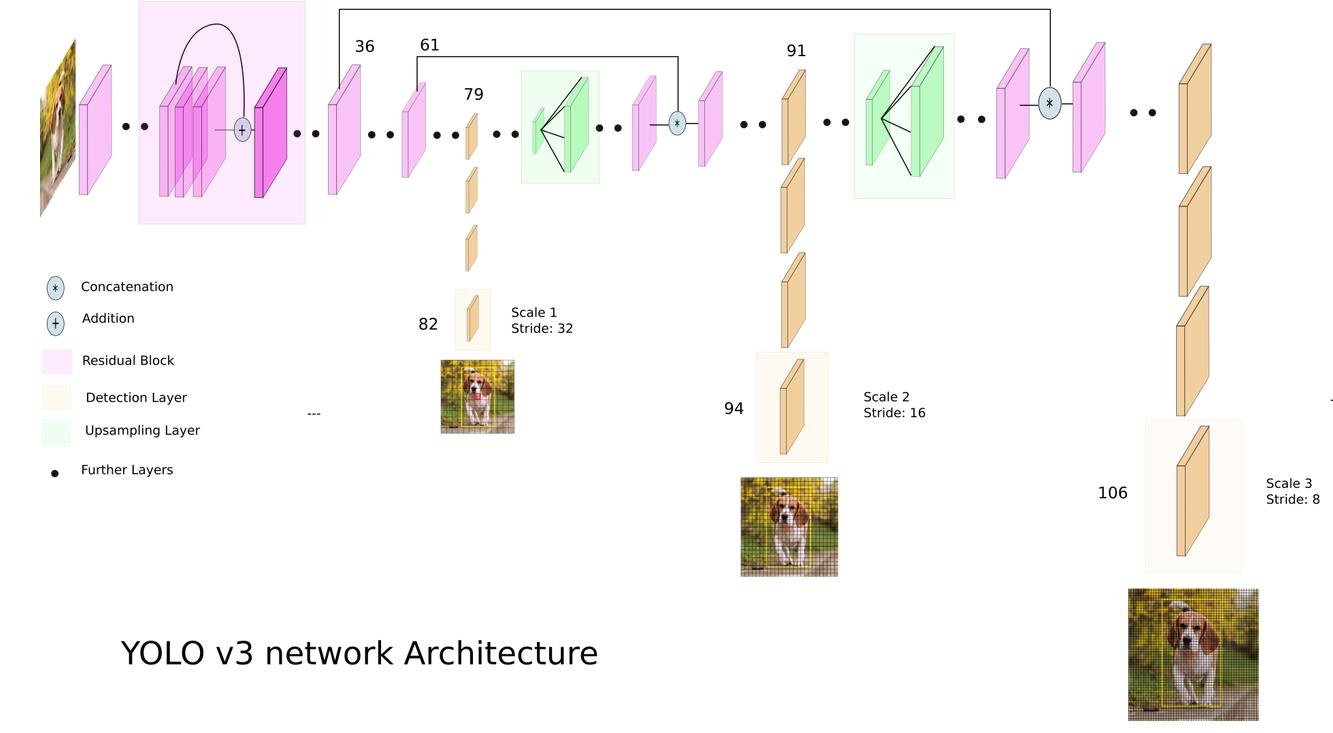
레즈넷 skip-connection
82번 레이서 94레이어 등 번호가 붙어있어서 OPENCV에서 조절
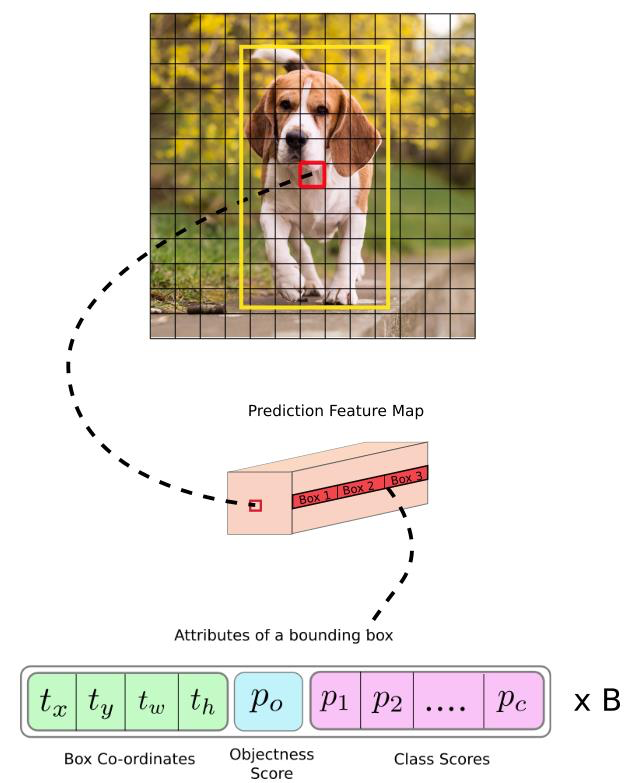
◇YOLO v3 Output Feature Map◇


◇ Darknet-53 특성◇
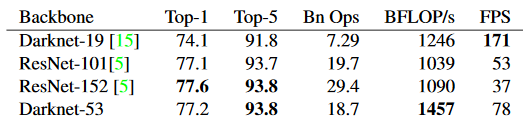
- BELOP 초당 연산횟수
- TOP5 정확도 레드넷은 FPS가 다크넷에 비해 상대적으로 낮은것을 확인가능하다.
욜로 논문은 많이 친절하지 않다
◇ Multi Labels 예측◇
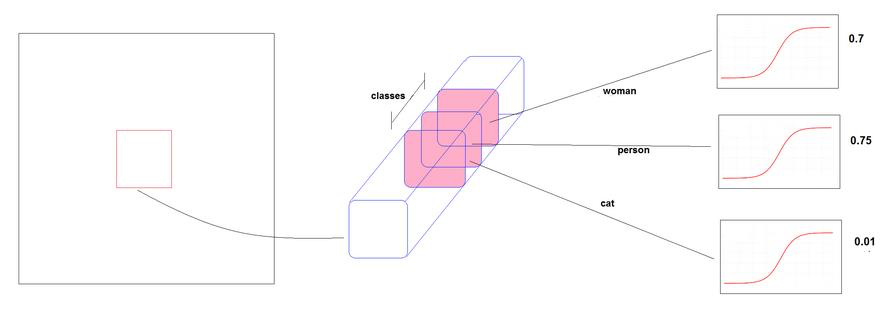
- 여러 개의 독립적인 Logistic Classifier 사용
- 소프트맥스대신 적용한 Multi Labels 예측
◇ Training◇
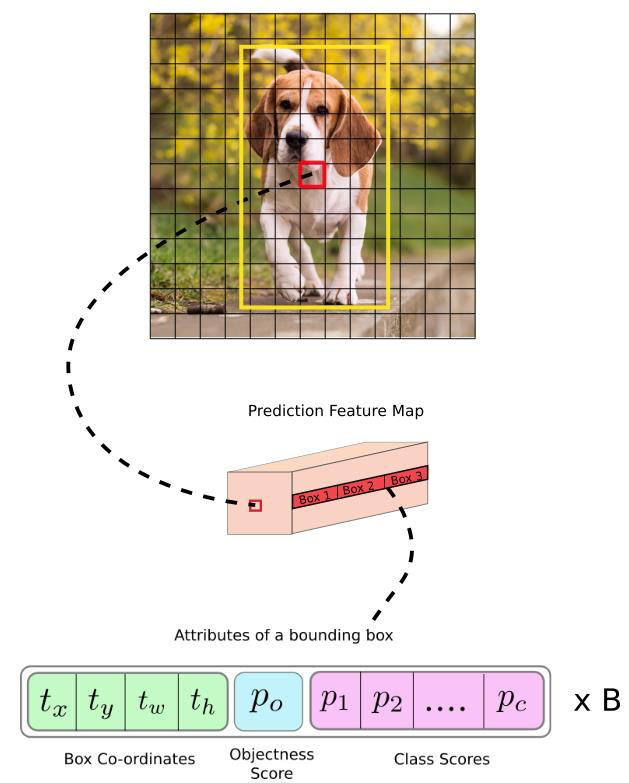
앵커박스별로 Loss를 계산한다
3개의 앵커박스 , 맨아래 1개 한박스당 정보 / pascal 에서는 붉은부분 20개 , coco에서는 80개
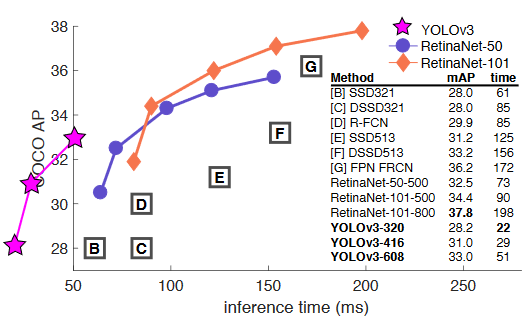
◇ YOLO v3 성능 비교 ◇
COCO(IOU 0.5 ~ 0.95 기준)
COCO(IOU 0.5 기준)
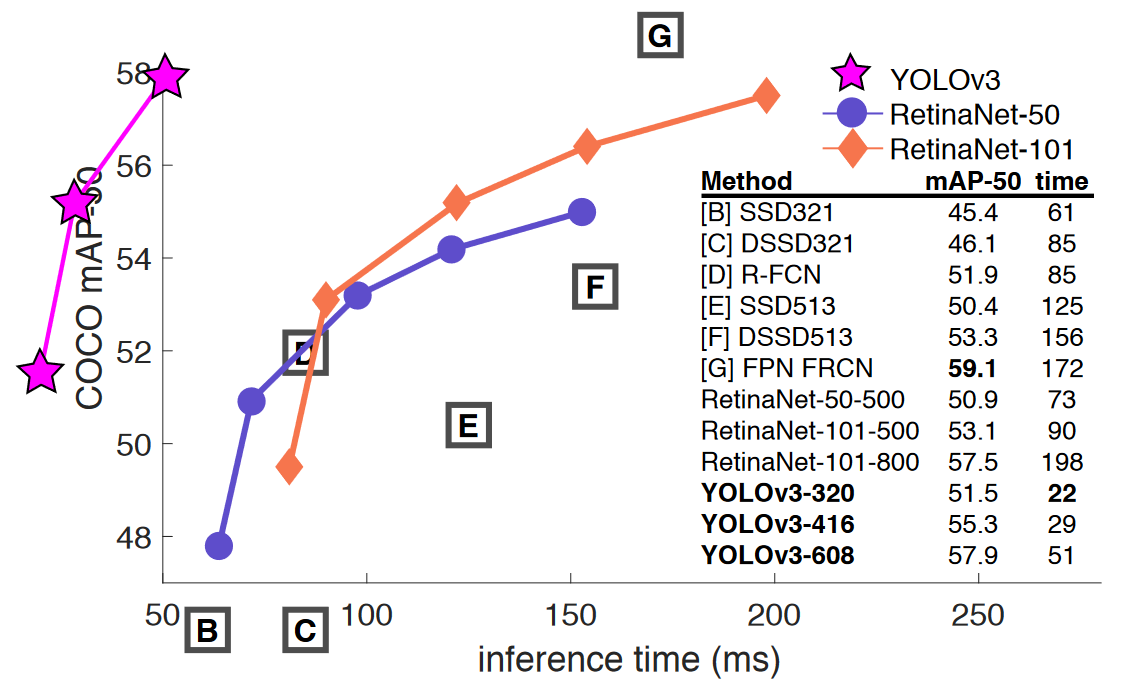
- 욜로v3는 inference time은 매우 뛰어나다 70ms
- 당시 gpu 하드웨어 성능이 낮았었던 때,
- 예측성능은 좀 떨어진다.
- Iou 0.5 하면 예측성능도 좋고 인퍼런스도 빠르다

DA/DA/AE