◇ Open CV DNN으로 Yolo inference 구현 ◇
◇ OpenCV 에서 Yolo를 이용한 Object Detection ◇
- OpenCV Yolo inference 코드는 기존 OpenCV inference코드와 다름.
- 3개의 Output Feature Map 에서 직접 Object Detection 정보 추출
Tensorflow api 와 한것이 다르다 다크넷 을 다운로드받아야한다. (번거로움)
직접 오브젝트 정보를 추춣해야한다.
◇ Pretrained된 inference 모델 로딩 방법 ◇
- Weight 모델 파일과 config 파일은 Darknet 사이트에 Download 가능
- cv2.dnn.readNetFromDarknet(config 파일, weight 모델 파일)으로 pretrained된 inference 모델 로딩.
- readNetFromDarket(config 파일, weight 모델 파일)에서 config 파일 인자가 weight 모델 파일 인자보다 먼저 위치함에 유의
◇ 3개의 scale Output Layer에서 직접 Detection 결과 추출 ◇
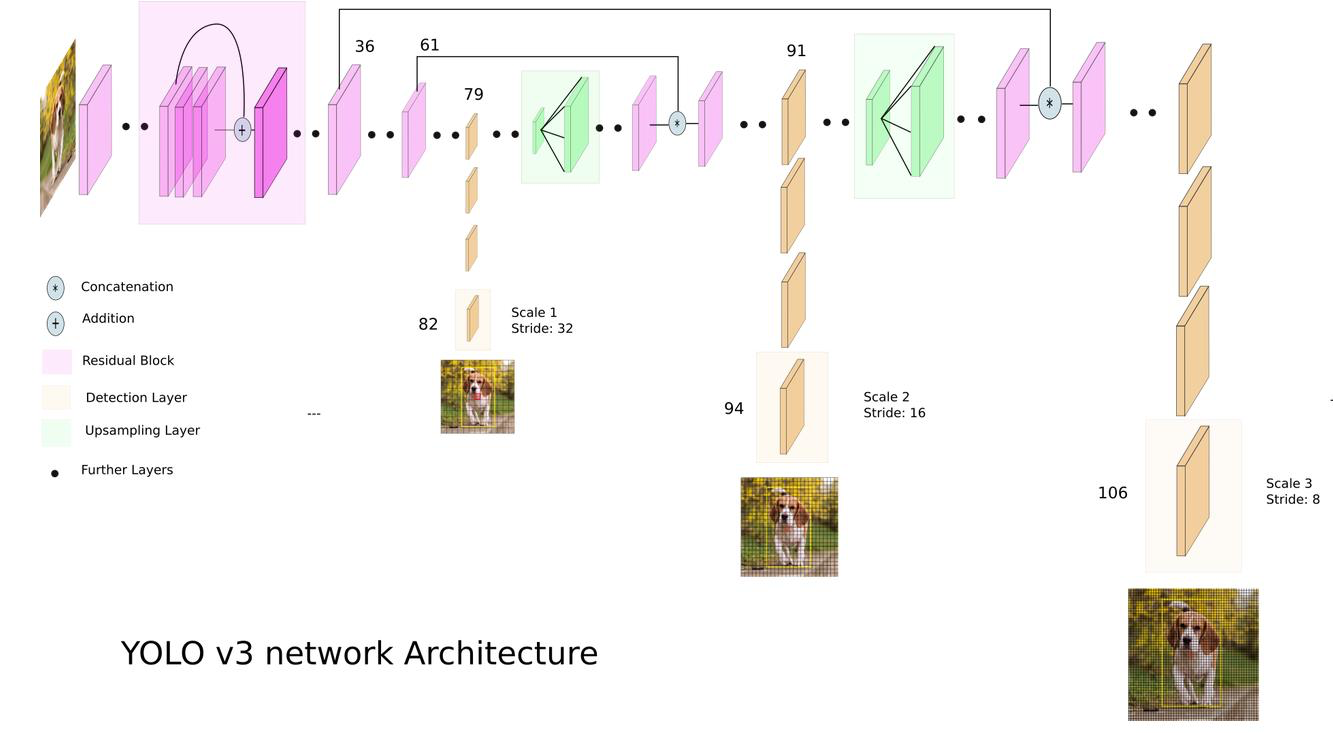
82번 Layer / 94번 Layer / 106번 Layer
- 사용자가 직접, 3개의 다른 Scal별로 구성된 output layer에서 Object Detect 결과를 추출해야 함.
- 사용자가 직접, NMS(Non Maximum Suppressing)로 최종 결과 필터링 해야 함.
◇ Bounding box 정보 추출 시 직접 85개의 구성에서 추출 ◇
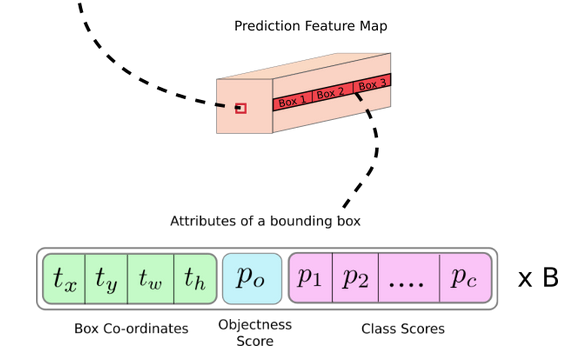
Coco 데이터 세트로 Pretrained 된 모델에서 bounding box 정보 추출하기
• Bounding Box 정보를 4개의 Box 좌표, 1개의 Object Score, 그리고 80개의 Class score(Coco는 80개의 Object Category임)로 구성된 총 85개의 정보 구성에서 정보 추출 필요.
• Class id와 class score는 이 80개 vector에서 가장 높은 값을 가지는 위치 인덱스와 그 값임.
◇ 추출 좌표의 변환 ◇
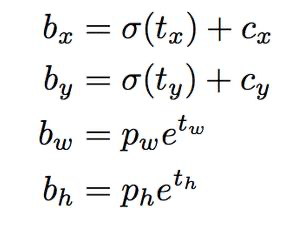
OpenCV Yolo로 추출한 좌표는 Detected된 Object의 center와 width, height 값이므로 이를 좌상단, 우하단 좌표로 변경 필요.
◇ OpenCV 로 Yolo Inference 구현 절차 ◇
1.cv1.dnn.readNetFromDarknet(config 파일, weight 모델 파일)으로 pretrained된 inference 모델 로딩
- config 파일 위치 주의
- 사용자가 3개의 다른 Scale 별로 구성된 output layer에서 Obect Detect 결과 추출
- Detected된 Object당 85개의 vector를 가짐, 4개의 위치 정는 center 점의 x,y 좌표와 width, height이므로 이를 좌상단, 우하단 좌표로 변경 필요
- Class id 와 class score는 이 80개 vetor에서 가장 높은 값은 가지는 위치 인덱스와 그 값.
- 사용자가 직접, NMS(Non Mazimum Suppressing)로 최종 결과 필터링 해야 함
- OpenCV에서 제공하는 NMS함수로 NMS최종 필터링 된 Object 시각화
참고자료
Deep System’s YOLO

DA/DA/AE