글자체 font를 구분하는 딥러닝 모델을 설계해보자
데이터
데이터는 이미지 데이터로 된 폰트 이미지이며 분류 클래스는 [굴림, 궁서, 나눔고딕, 맑은고딕, 바탕, 서울남산] 총 6개의 클래스가 있다.
-
굴림(15077개 이미지)

-
궁서(15065개 이미지)

-
나눔고딕(15019개 이미지)

-
맑은고딕(15058개 이미지)

-
바탕(15041개 이미지)

-
서울남산(15030개 이미지)

개발(coding)
모든 과정은 주피터 노트북 환경에서 개발하였으며 먼저 필요한 라이브러리를 임포트
-
데이터가 있는 경로를 설정하고 그 후 클래스 종류 이미지 크기 등을 지정
-
이미지와 라벨(폰트)를 매칭하도록 리스트로 저장하며 라벨은 문자체에서 ont-hot encoding으로 변환
-
리스트를 학습 데이터와 평가 데이터로 분할 후 numpy 파일로 저장

-
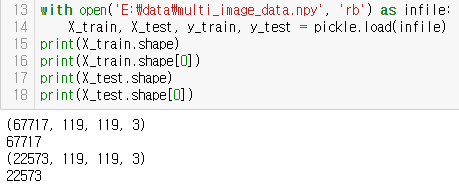
저장한 numpy파일을 로드하고 shape 확인(여기서 학습 데이터 수는 67717, 평가 데이터는 22573인 것을 확인)
-
데이터 표준화

-
모델 작성
모델은 CNN 아키텍쳐 구조를 이용하였으며 커널 사이즈 3*3, 활성화 함수는 relu, padding 조건은 same, 완전연결 계층에서의 활성화 함수는 softmax(범주형 라벨이기 때문에), 컴파일 단계에서 loss는 categorical crossentropy, optimizer는 adam, 측정지표는 정확도로 설정, 모델 저장 경로와 early stopping 설정

-
학습(training)
epoch은 50, 배치사이즈 32, 평가데이터 비율 0.2로 설정

-
평가(inference)

-
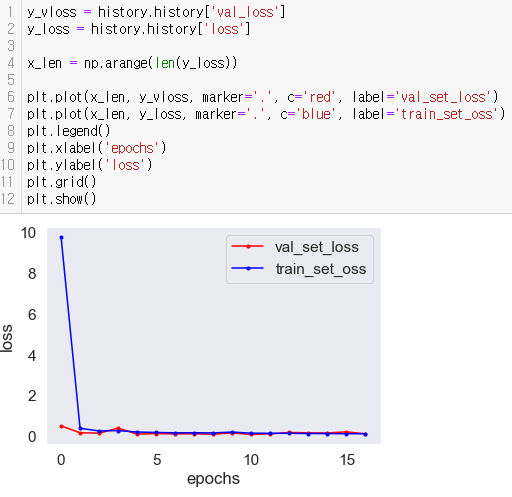
loss visualization
에폭 진행에 따른 loss 변화
후기
-
아직 cnn 모델이 간단하고 더 정교화 하지 않아 정확도 면에서 떨어지는 부분이 있으나 이는 반복 학습으로 어느 정도 방향성을 잡아야 할 것 같음
-
기존의 cnn 모델 아키텍처를 더 연구하여 적용해 볼 예정
