이 논문은 Differential Transformer(이하 DIFF Transformer)에 대해 설명하고 있습니다. DIFF Transformer는 주어진 문맥에서 중요한 정보에 대한 주의를 강조하고 불필요한 정보를 제거하여, Transformer가 직면하는 주의 소음 문제를 해결하려는 새로운 모델입니다.
1. 개요
Transformer는 최근 연구에서 중요한 문맥 정보를 제대로 인식하지 못하는 문제가 밝혀졌습니다. DIFF Transformer는 이러한 주의 소음을 줄이기 위해 두 개의 소프트맥스 주의 맵을 사용하여 소음을 제거하는 차동 주의 메커니즘을 도입했습니다. 이를 통해 필요한 정보에 집중하면서 불필요한 정보에 주의를 덜 기울이게 됩니다. 실험 결과 DIFF Transformer는 Transformer에 비해 대규모 언어 모델과 관련된 다양한 작업에서 더 높은 성능을 보였으며, 특히 긴 문맥 처리와 중요한 정보 검색, 환각 완화, 문맥 학습에서 강점을 나타냈습니다.
2. DIFF Transformer 구조
DIFF Transformer는 기본 Transformer 구조를 유지하면서 기존의 소프트맥스 주의를 차동 주의 메커니즘으로 대체했습니다. 이 메커니즘은 차동 증폭기처럼 두 신호 간의 차이를 사용하여 주의 소음을 제거합니다. Multi-head 주의 메커니즘이 사용되며, 각 층은 두 개의 주요 모듈(차동 주의 모듈과 피드 포워드 네트워크)로 구성되어 있습니다. 이러한 구조를 통해 DIFF Transformer는 중요한 정보에 높은 주의 점수를 할당하고 불필요한 문맥 정보에 대한 주의를 줄여 줍니다.
Q1, Q2 차이
Q1과 Q2는 differential attention 메커니즘을 구현하기 위해 입력 쿼리 벡터 Q를 두 그룹으로 나눈 결과입니다. 이 구조는 소프트맥스 주의 맵을 두 개 계산하고, 이들의 차이를 구해 불필요한 주의 소음을 제거합니다.
- 메커니즘은 다음과 같은 단계로 작동합니다:
- 쿼리와 키의 분할: 입력 벡터 X를 쿼리 벡터 Q와 키 벡터 K로 투영하고, 이를 두 개의 독립적인 벡터 Q1, Q2 및 K1, K2로 분할합니다
- Attention 계산
- Q1과 K1을 사용하여 첫 번째 attention 맵을 생성한다
- 마찬가지로 Q2와 K2를 사용하여 두 번째 attention 맵을 생성한다.
- Differential
- 최종 attention 맵은 두 개의 attention 간의 차이로 계산하며 아래와 같다. 여기서 λ는 학습 가능한 스칼라 값으로, 두 개의 attention의 가중치를 조절하여 소음 제거 효과를 최적화합니다.
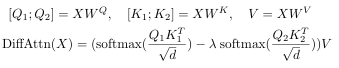
Transformer에서 입력 벡터를 두 개의 쿼리 벡터(Q1과 𝑄2)와 두 개의 키 벡터(K1과 K2)로 분할하는 기준은 단순히 모델 파라미터를 기반으로 합니다. 즉, 입력 벡터를 두 개의 독립적인 부분으로 나누어 각 부분을 독립적으로 처리합니다.
이 분할은 특정 정보나 특성에 따라 이루어지는 것이 아니라, 입력 벡터의 값이 무작위로 나뉘어 모델의 두 소프트맥스 주의 맵을 독립적으로 학습하도록 하는 방식입니다. 이를 통해 두 주의 맵이 서로 다른 소프트맥스 결과를 생성하고, 이 차이를 통해 공통의 주의 소음(irrelevant attention)을 제거할 수 있습니다.
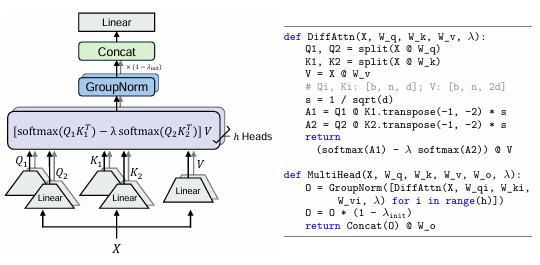
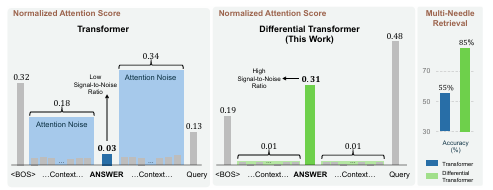
위 그림은 Multi-Head Differential Attention 의 구조를 보여줍니다. 이 구조는 두 개의 소프트맥스 attention 맵을 사용하여 불필요한 정보, 즉 "attention 소음"을 제거하고 중요한 정보에 집중하는 방식으로 작동합니다. 이를 통해 Transformer가 직면했던 주요 문제 중 하나인 불필요한 문맥에 대한 과도한 attention을 완화합니다.
멀티헤드 메커니즘과 Group Normalization
DIFF Transformer는 멀티헤드 attention 메커니즘을 사용하여 각 attention 헤드가 독립적으로 정보에 집중할 수 있도록 합니다. 각 헤드마다 고유의 투영 매트릭스를 사용하여 서로 다른 특성을 학습하게 됩니다.
Group Normalization: 각 헤드에 대해 GroupNorm이 적용되어 각 헤드의 통계적 특성을 균일하게 만들어 주고, 이는 학습의 안정성을 높입니다.
최종적으로, 각 헤드의 결과가 다시 결합(Concat)되고 선형 투영을 통해 다음 레이어로 전달됩니다. 뒤에 붙는 (1-λ_init)은 Group Normalization 후 고정된 값으로 각 헤드에 적용되어, Transformer의 그래디언트 흐름을 유사하게 유지하면서 안정적으로 학습이 진행되도록 합니다.
3. 실험 및 평가
DIFF Transformer는 다양한 크기와 길이의 데이터에 대해 확장성이 뛰어났으며, 일반 Transformer에 비해 적은 파라미터와 학습 토큰으로도 유사한 성능을 달성할 수 있었습니다. 긴 문맥에서의 테스트 결과에서도 Transformer보다 더 낮은 음수 로그 가능도를 보이며, 더 긴 문맥에서도 일관된 성능을 발휘하는 것이 확인되었습니다. 또한, 주요 정보 검색 및 문맥 학습에서 DIFF Transformer가 Transformer보다 높은 정확도를 유지하며, 환각 평가에서는 잘못된 정보를 생성할 확률이 낮았습니다.
4. 결론
DIFF Transformer는 불필요한 문맥 정보를 효과적으로 제거하고 필요한 정보에 대한 주의를 높여줌으로써 Transformer 모델의 단점을 개선하는 아키텍처입니다. DIFF Transformer는 FlashAttention과 결합하여 메모리 효율성을 높일 수 있으며, 모델의 양자화를 통해 추가적인 효율성을 기대할 수 있습니다.
