문서
https://docs.ultralytics.com/models/yolo11/
Overview
YOLO11은 Ultralytics YOLO 시리즈의 최신 버전으로, 실시간 객체 탐지 분야에서 정확도, 속도, 효율성 측면에서 혁신을 이루었다. 이전 YOLO 버전들의 발전을 바탕으로, YOLO11은 아키텍처와 학습 방법에서 중요한 개선을 도입하여, 다양한 컴퓨터 비전 작업에 적합한 다재다능한 선택지를 제공한다.
Key Features
-
향상된 기능 추출: YOLO11은 향상된 백본 및 넥 아키텍처를 채택하여 더 정밀한 객체 감지와 복잡한 작업 수행을 위한 기능 추출 능력을 강화합니다.
-
효율성과 속도에 최적화: YOLO11은 세밀하게 설계된 아키텍처와 최적화된 학습 파이프라인을 도입하여 처리 속도를 높이는 동시에 정확성과 성능의 최적 균형을 유지합니다.
-
더 적은 파라미터로 더 높은 정확성: 모델 설계의 발전으로 YOLO11m은 COCO 데이터셋에서 더 높은 mAP(평균 정밀도)를 달성하면서 YOLOv8m보다 22% 적은 파라미터를 사용하여 계산 효율성을 유지하면서도 정확도를 유지합니다.
-
환경에 따른 적응성: YOLO11은 엣지 디바이스, 클라우드 플랫폼 및 NVIDIA GPU를 지원하는 시스템을 포함한 다양한 환경에서 원활하게 배포될 수 있어 최대 유연성을 보장합니다.
-
광범위한 지원 작업: 객체 감지, 인스턴스 분할, 이미지 분류, 포즈 추정, 방향 객체 감지(OBB)를 포함하여 YOLO11은 다양한 컴퓨터 비전 과제를 해결할 수 있도록 설계되었습니다.
Supported Tasks and Modes

이 표는 YOLO11 모델의 다양한 변형들을 개괄적으로 보여주며, 특정 작업에 대한 적용성과 추론(Inference), 검증(Validation), 학습(Training), 내보내기(Export)와 같은 운영 모드와의 호환성을 강조합니다. 이러한 유연성 덕분에 YOLO11은 실시간 감지부터 복잡한 분할 작업에 이르기까지 광범위한 컴퓨터 비전 응용 분야에 적합합니다.
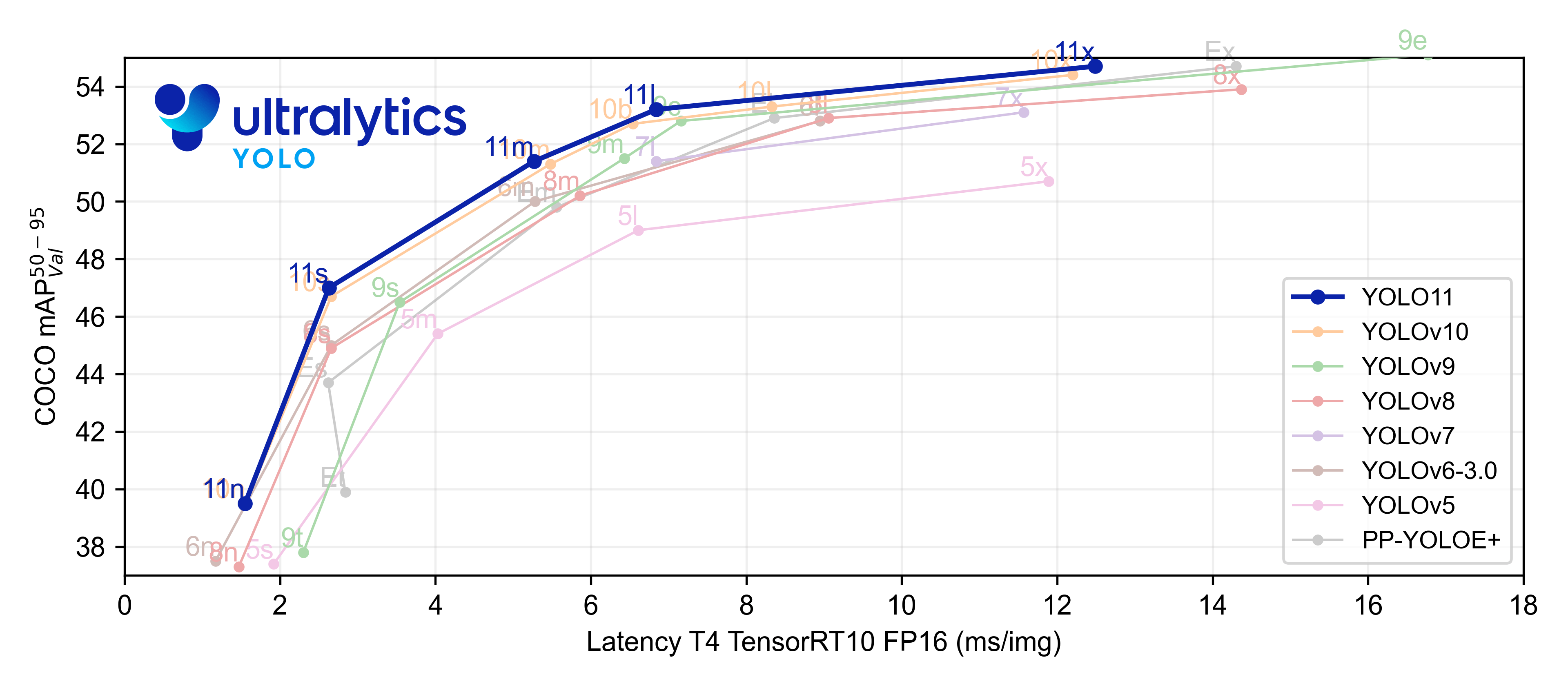
Performance Metrics
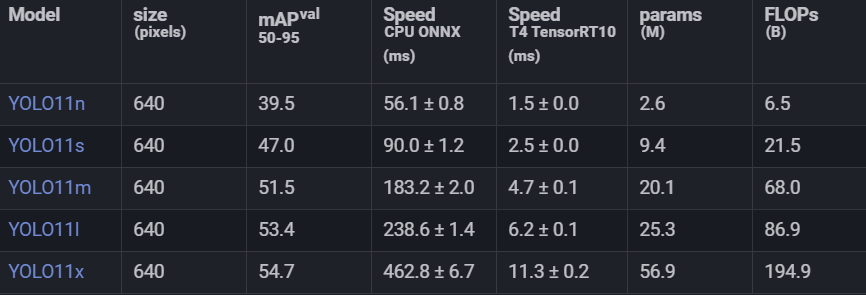
이번 yolov11에서는 object detection, instance segmentation, pose estimation, oriented detection, classification task를 지원한다. 하지만 현재 yolov11은 v10과 달리 nms-free 모델은 아닌것 같다.
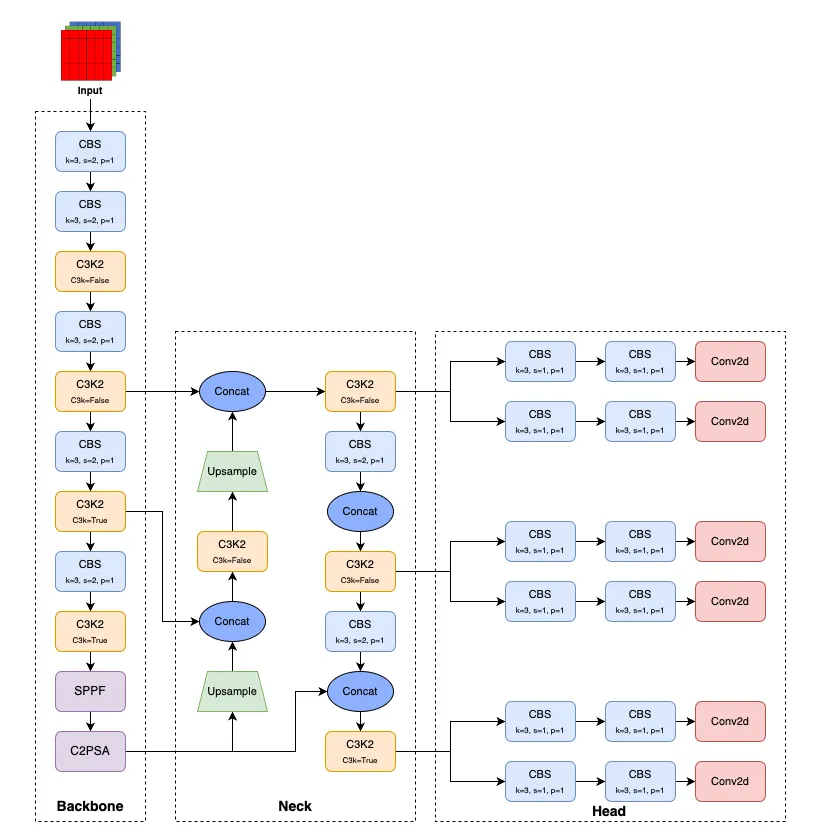
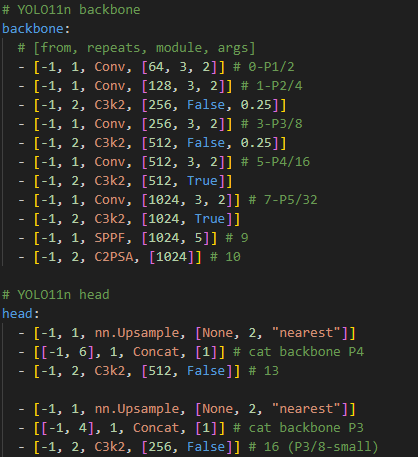
Model Architecture
이번 yolov11에 사용된 모델 구조에 대해 살펴보자.
YOLO11은 YOLOv8의 C2F 모듈을 대체하기 위해 C3K2 모듈을 도입했으며, SPPF 모듈 뒤에 C2PSA 모듈을 추가했습니다.
-
backbone
-
head

C3K2 network architecture
C3K2는 실제로 C2F 모듈의 변형된 버전입니다. 핵심 차이점은 c3k 매개변수의 설정에 있습니다. c3k가 False로 설정되면, C3K2 모듈은 C2F 모듈과 유사하게 동작하며, 표준 병목 구조를 사용합니다. 반대로, c3k가 True로 설정되면, 병목 모듈이 C3 모듈로 대체됩니다. 아래 그림에서 이를 확인할 수 있습니다.
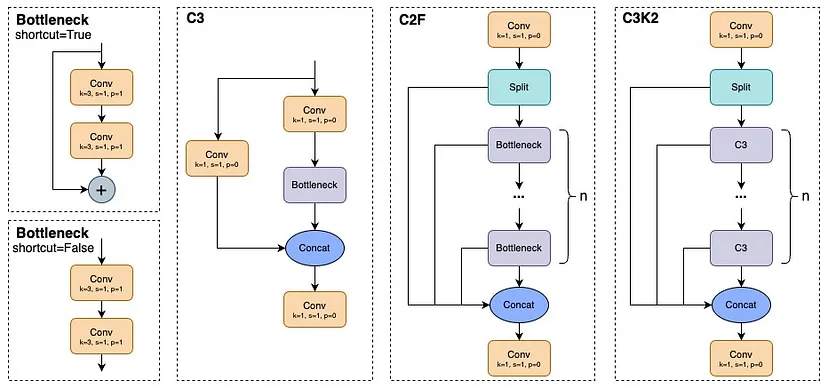
- 구조 : C3k2는 여러 개의 경량화된 합성곱(convolution) 레이어로 구성된 블록이다. 이 블록은 주로 C3의 변형으로, 각 레이어가 특정 수의 필터를 사용해 정보를 효과적으로 압축하고, 동시에 깊이(depth)를 늘려 다양한 특징을 학습할 수 있게 설계되어있다.
- 특징 : 이 레이어는 데이터 흐름을 원할하게 하면서도 정보 손실을 줄여, 작은 객체를 보다 잘 탐지할 수 있도록 돕는다.
C2f (C2 Block):
- 구조: C2f는 두 개의 병렬 경량 합성곱 레이어를 포함하고 있다. 이 구조는 다른 스케일의 정보를 동시에 처리할 수 있도록 하여, 서로 다른 크기의 객체를 잘 탐지 할 수 있게 설계되었다.
- 특징: C2f는 경량화와 효율성을 중시하며, 다양한 해상도의 특징을 통합하여 탐지 성능을 높이는데 중점을 두고 있다. 하지만, 이 구조는 깊이와 넓이 측면에서 C3k2만큼의 유연성을 제공하지는 않을 수 있다.
그리고 backbone의 마지막 부분을 보면 v11에서는 C2PSA를 사용하고, v10에서는 PSA를 사용했다.
C2PSA network architecture
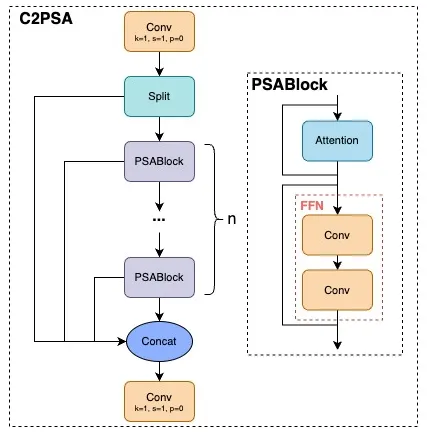
C2PSA 모듈은 C2F 모듈을 확장한 버전으로, PSA을 통합하여 다중 헤드 어텐션 메커니즘과 피드포워드 신경망을 통해 기능 추출을 향상시킵니다. PSA는 입력 특징의 위치적 측면을 우선시하여 모델이 이러한 특징의 공간적 지도를 유지할 수 있도록 합니다. 이 기능을 통해 데이터 내의 공간적 관계에 대한 모델의 이해력이 강화됩니다.
또한, 이 모듈은 선택적 잔차 연결을 허용하는 shortcut connection을 포함하고 있어, 기울기 전파를 최적화하고 네트워크 학습의 효율성을 높여줍니다.
더불어, 피드포워드 레이어는 입력 특징을 고차원 공간으로 변환하여 모델이 복잡한 비선형 관계를 포착할 수 있도록 합니다. 이 변환은 더욱 풍부한 특징 표현을 학습하는 데 있어 매우 중요합니다.
C2PSA는 두 개의 독립된 브랜치로 구성되는데, 각각의 브랜치는 서로 다른 공간적 정보와 채널 간 상호작용을 처리한다. 이로 인해 객체의 다양한 특징을 더 잘 포착할 수 있다. 즉, 하나의 브랜치가 객체의 전반적인 형태와 위치 정보를 포착하는 반면, 다른 브랜치는 더 미세한 세부 정보를 추출하는 역할을 한다.
이 방식은 개체의 여러 해상도에서 중요한 특징을 더 잘 추출할 수 있게 하며, 특히 크기가 작은 객체를 탐지하는 데 유리하다. 기존 PSA는 모든 정보를 한 번에 처리했기 때문에 정보 손실이 있을 수 있었으나, C2PSA는 이를 분리해 보다 세밀하게 정보를 처리할 수 있다.
Head Architecture
-
모듈 구성 (Modules):
일단 v11은 C3k2 모듈을 사용하고, v10은 C2f 모듈을 주로 사용한다. C3k2는 더 작은 커널 크기를 사용해 성능을 최적화하는 반면에, C2f는 피처를 더 많이 분리하여 다층 피처를 효과적으로 처리하는 구조이다. 또한, v11의 경우엔 P5 스케일에서 C2PSA 모듈이 추가되었는데, 이는 C2와 PSA(Pyramid Split Attention) 기법을 결합하여 피처맵의 전역적 중요성을 고려한 구조이다. -
업샘플링 전략 (Upsampling Strategy):
두 모델 모두 nn.Upsample을 사용해 해상도를 증가시키지만, v11에서는 업샘플링된 피처맵을 C3k2블록과 결합해 사용하고 v10은 C2f 모듈과 결합한다. -
Detection head:
v11의 head는 v10과 마찬가지로 P3, P4, P5의 세 가지 피처맵을 기반으로 탐지를 수행하지만, v11의 최종 탐지 모듈로 v8에서 사용하던 Detect를 사용하고, v10은 v10Detect를 사용한다. v10Detect를 사용할 경우 one-to-one, one-to-many를 활용해 nms-free를 이용할 수 있지만, v11은 아닌듯 하다. v10에서는 P5 단계에 C2fCIB 모듈이 포함되어있는데, 이는 C2f블록에 추가적인 CIB(Cross Iteration Batchnorm)기법을 더해 성능을 향상시키는 구조이다. -
레이어 반복 횟수:
v11은 C3k2 블록에서 반복 횟수가 상대적으로 적고, v10에서는 C2f 블록에서 더 많은 반복 횟수가 적용되어, 피처의 상세한 처리가 이루어진다.따라서 v11은 보다 경량화된 구조와 새로운 모듈을 도입해 성능을 높였으며, v10은 C2f와 CIB 같은 모듈로 더 깊이 있는 피처 처리를 강조한 모델이다.
[출처]

YOLOv11은 최신 구조를 탐색하는 과정에서 ONNX/NPU 호환성을 희생한 모델이어서 Hailo-8 NPU가 이해할 수 있는 언어(HEF)로 변환하는데 힘들다고 하던데 맞나요?