Constrained Optimization
General Constrained Optimization
minimizesubject tof(x)gi(x)≤0,i=1,…,lhj(x)=0,j=1,…,m
-
f : objective function.
-
gi : inequality constraints.
-
hj : equality constraints.
-
제약 조건을 만족하는 x의 집합을 feasible set 이라고 한다.
-
점 x에 대해 A(x)={i:gi(x)=0}∪{j:hj(x)=0}을 active set 이라고 한다.
-
주어진 점 x∗과 active set A(x∗)에 대해, {∇gi(x∗),i∈A(x∗)}이 linearly independent이면, LICQ (Linearly Independence Constraint Qualification)가 성립한다고 말한다.
LICQ 성립 시, active constraint의 gradient는 0이 될 수 없다.
- The problem can be rewrite as:
minimizesubject tof(x)g(x)≤0h(x)=0
- 주어진 문제의 Lagrangian 은 다음과 같이 정의된다.
L(x,ν)=f(x)+i=1∑lλigi(x)+j=1∑mνjhj(x)=f(x)+λTg(x)+νTh(x)
Karush-Kuhn-Tucker (KKT) Conditions
Motivation for the KKT Conditions
하나의 inequality constraint를 가진 optimization problem을 고려하자.
minimizesubject tof(x)g(x)≤0
이는 다음과 같이 표현될 수 있다.
minimizef∞−step(x):={f(x)0if g(x)≤0if g(x)>0=f(x)+∞⋅1g(x)>0
이 때, f∞−step=λ≥0max L(x,λ) where L(x,λ)=f(x)+λg(x).
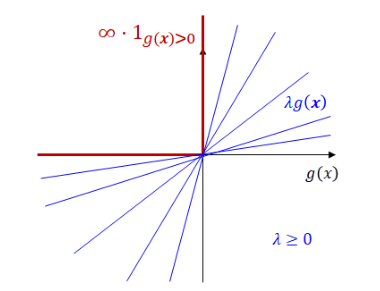
따라서, 해당 optimization problem은 다음과 같이 새롭게 표현될 수 있다:
xminλ≥0maxL(x,λ):=f(x)+λg(x)
KKT Conditions
Theorem: First-Order Necessary Conditions (KKT conditions)
Suppose that x∗ is a local solution of constrained optimization problem and the LICQ holds at x∗.
minimizesubject tof(x)gi(x)≤0,i=1,…,lhj(x)=0,j=1,…,m
Then there is a Lagrangian multiplier vector (λ∗,ν∗), such that the following KKT conditions are satisfied at (x∗,λ∗,ν∗):
(1)∇xL(x∗,λ∗,ν∗)=∇xf(x∗)+i=1∑lλi∗∇xgi(x∗)+j=1∑mνj∗∇xhj(x∗)=0(2)gi(x∗)≤0,∀i(3)hj(x∗)=0,∀j(4)λi∗≥0,∀i(5)λi∗gi(x∗)=0,∀i
각 조건은 다음과 같이 불린다.
- (1): Stationarity 조건
- (2), (3): Primal feasibility 조건
- (4): Dual feasibility 조건
- (5): Complementary slackness 조건
Lagrangian Duality
Primal and Dual Problem
minimizesubject tof(x)gi(x)≤0,i=1,…,lhj(x)=0,j=1,…,m
or
xminλ≥0,νmaxL(x,λ,ν):=f(x)+λTg(x)+νTh(x)
λ≥0,νmaxD(λ,ν):=xminL(x,λ,ν)
Duality Theorem
Weak Duality
Dual problem의 optimal value는 primal problem의 optimal value의 lower bound이다.
Theorem: Weak Duality
Let x and (λ,ν) be a feasible solution to primal and dual problems, respectively.
Then f(x)≥D(λ,ν).
Moreover, if f(x∗)=D(λ∗,ν∗), then x∗ and (λ∗,ν∗) solves the primal and dual problems, respectively.
- Duality gap: f(x∗)−D(λ∗,ν∗)
Strong Duality
Convex optimization problem의 경우, dual problem과 primal problem의 optimal value는 같다.
Theorem: Strong Duality
Let f,gi be convex and hj be affine for all i,j. Then f(x∗)=D(λ∗,ν∗) if the optimal value is finite.
- Affine functions f(x1,...,xn)=A1x1+...+Anxn+b 형태의 function.
Wolfe Duality
Strong Duality를 이용하면 주어진 optimization 문제를 다르게 표현할 수 있다.
Theorem: Wolfe Duality
Let f,gi be convex, hj be affine for all i,j, and x∗ be an optimal solution of the primal.
Then (x∗,λ∗,ν∗) at which LICQ holds solves the Wolfe dual problem of the form
minimizesubject toL(x,λ,ν)∇xL(x,λ,ν)=0λ≥0
∇xL(x,λ,ν)=0는 L(x,λ,ν)의 local optima에 대한 조건이다.
Linear and Quadratic Programming
Linear Programming (LP)
minimizesubject tocTxAx=bx≥0
- Lagrangian dual L(x,λ,ν)=cTx−λTx+νT(b−Ax)은 convex이다.
- 따라서, c−λ−ATν=0 and λ≥0 일 때, minimum을 얻는다.
* Check that c−λ−ATν=0 and λ≥0 ⟺ ATν≤c.
- 그 결과, dual problem은 다음과 같다.
maximizesubject tobTνATν≤c
Quadratic Programming (QP)
minimizesubject to21xTHx+dTxAx≤b
where H is symmetric and positive semidefinite. (따라서, objective function은 convex이다.)
- Lagrangian dual L(x,λ)=21xTHx+dTx+λT(Ax−b)은 convex이다.
- 따라서, Hx+ATλ+d=0 or x=−H−1(d+ATλ) 일 때, minimum을 얻는다.
- 그 결과, dual problem은 다음과 같다.
maximizesubject to21λTDλ+λTc−21dTH−1dλ≥0
where D=−AH−1A and c=−b−AH−1d.
이 dual problem은 단순히 nonnegative domain에서의 concave quadratic function maximization 문제이기에, 상대적으로 쉽게 풀 수 있다.
