Theory of Unconstained Optimization
Optimality Conditions
Lemma:
Suppose that is differentiable at . If there is a vector such that , then is a descent direction of at .
- sketch of proof: for .
추후 나올 Gradient Descent 또는 SGD의 기본 원리이다.
Theorem: First-Order Necessary Optimality Conditions (FONC)
Suppose is differentiable at .
If is a local minimum, then .
Theorem: Second-Order Optimality Conditions
Suppose is twice differentiable at .\
[Necessary] If is a local minimum, then and is positive semidefinite.\
[Sufficient] If and is positive definite, then is a strict local minimum.
Determining Local Optima
-
Find the critical points of by solving the system of simultneous equations: .
-
Let .
-
Then
-
and implies that has a local maximum at the point .
-
and implies that has a local minimum at the point .
-
implies that has neither a local maximum nor a local minimum at the point , it has instead a saddle point.
-
implies that the test is inconclusive, so some other technique must be used to solve the problem.
-
Line Search Strategy
Line Search
Line search는 numerical analysis에서 (근사) 해를 찾는 기법으로 복잡한 diffrentiable function에 대해 적절하게 사용될 수 있다.
기본적으로 주어진 점 에서 search direction 를 계산하고, 해당 방향으로 positive scalar인 step length 만큼 이동하여 새로운 점 을 찾는다.
따라서, line search method는 적절한 search direction과 step length를 선택하는 것이 중요하다.
Step length는 일반적인 learning algorithm에서 learning rate와 같다.
는 descent direction, i.e. , 으로 정하는 것이 합리적이며 많은 line search methods에서, 는 다음과 같은 form을 갖는다.
where is a symmetric and nonsingular matrix.
The Wolfe Conditions
The Wolfe condition은 inexact line search 방법에서 step length를 결정하기 위한 기준을 제공한다.
- [Armijo condition : ]
새로운 점에서의 함수 값이 현재 점에서의 값보다 충분히 감소해야 한다. - [curvature condition : ]
새로운 점에서의 경사가 원래 경사의 배 이상이어야 한다. (너무 멀리 가지 않고, 너무 평평한 구역에 위치하지 않도록 한다.)
Line Search Methods
- Steepest Descent
- The rate-of-convergence is linear.
- Global convergence if satisfies the Wolfe conditions.
우리가 흔히 말하는 Gradient Descent 방법이다.
-
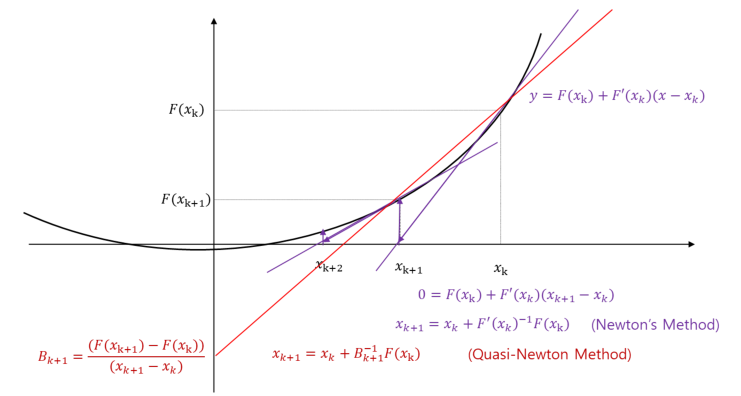
Quasi-Newton Method
- The rate-of-convergence is superlinear.
- Global convergence if satisfies the Wolfe conditions.
- The BFGS method is the most popular.
-
Newton's Method
- The rate-of-convergence is quadrtic.
- Local convergence.