
인공지능을 통해 해결하고자 하는 문제는 크게 회귀(Regression)과 분류(Classification)으로 나눌 수 있다. 회귀 문제는 주어진 데이터들의 입력값과 출력값으로 입력과 출력 간의 관계성을 찾는 문제를 말한다. 회귀의 예측값은 실수이며, 예측 결과가 연속성을 지닌다는 특징을 가진다. 본 포스트에서는 회귀 문제 중 가장 단순한 형태인 선형 회귀에 대해 알아보고, 학생들의 공부 시간과 지능을 바탕으로 수학 점수를 예측하는 선형 회귀 모델을 구현한다.
- 일러두기: 이 포스트에 사용된 학습 데이터는 Chat GPT로부터 임의로 생성받은 것이다.
Linear Regression
회귀 문제 중 입력과 출력 간의 선형적 관계성이 존재하는 것을 선형 회귀(Linear Regression)라고 한다. 즉, 선형 회귀는
에서 들로 이루어진 벡터 를 구하는 문제라고 할 수 있다.
Mean Squared Error
입력값 벡터 에 대해 예측한 출력값 와 실제 출력값 사이의 오차를 구하는 함수를 Cost Function이라고 한다. 매우 다양한 형태의 함수를 cost function으로 사용할 수 있지만, 선형 회귀를 진행할 때에는 Mean Squared Error(MSE)를 주로 사용한다. MSE는 다음과 같은 수식으로 표현할 수 있다.
Gradient Descent
Cost Function으로 구한 오차를 줄이는 방법에는 여러 가지가 있다. 그 중 오차의 기울기의 역방향으로 를 조정하여 오차를 줄이는 방법을 Gradient Descent라고 한다. 학습률을 라고 할 때, 는 다음과 같은 식을 따라 업데이트된다.
MSE는 convex function이고 flat한 곳이 발생하지 않으므로 GD를 사용하여 미분이 0이 되는 지점이 global minimum이 된다.
구현
본 연구에서는 행렬로 표현된 데이터를 편리하게 처리하고자 numpy를 사용하였다. 학생들의 지능과 수학 공부 시간, 수학 점수 데이터를 포함하는 csv데이터를 불러오기 위하여 pandas 라이브러리를 사용하였다. 또 처리가 완료된 데이터를 3차원 그래프 상에 plot하기 위하여 matplotlib을 사용하였다.
입력값 벡터 가 2차원 벡터이므로 는 편향을 포함하여 3차원 벡터가 된다. 을 임의의 값으로 초기화하고, 와 epoch를 설정한다. 본 연구에서는 , , epoch으로 설정하였다. 이후 반복문을 통해 로
를 계산한다. 이때
이다. 이렇게 구해진 를 이용하여 MSE를 구하고, 그 MSE를 각각의 가중치에 대해 편미분하여 다음과 같은 수식으로 가중치를 업데이트한다.
코드 전문
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import pandas as pd
data = pd.read_csv('math.csv')
x1 = data['Hours Studied'].values
x2 = data['Intelligence'].values
y = data['Math Score'].values
w0 = 3
w1 = 2
w2 = 10
lr = 0.0000001
epoch = 20001
for i in range(epoch):
prediction = w0 + w1 * x1 + w2 * x2
err = y - prediction
w0_diff = 2/len(err) * sum(err)
w1_diff = 2/len(err) * sum(err * x1)
w2_diff = 2/len(err) * sum(err * x2)
w0 = w0 + lr * w0_diff
w1 = w1 + lr * w1_diff
w2 = w2 + lr * w2_diff
if i % 50 == 0:
print("diff", w1_diff, w2_diff, w0_diff)
print("epoch = %.f, w0 = %.04f, w1 = %.04f, w2 = %.04f, e = %.04f" % (i, w0, w1, w2, err.mean()))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x1, x2, y, s = 40, c = "blue")
ax.plot(x1, x2, prediction)
plt.show()결과 및 제언
모든 epoch을 순회한 후, 결과로 구해진 를 반영하여 그래프를 그리고, 주어진 데이터들의 포인트와 경향성이 일치하는지 확인한다. 그 결과는 다음과 같았다.
이를 plot한 결과는 다음과 같다.
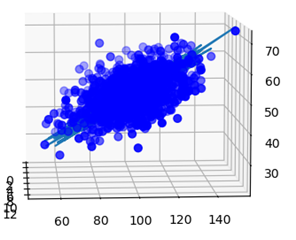
주어진 데이터포인트들과 회귀분석을 통해 얻은 그래프가 일치하는 경향성을 보이는 것을 가시적으로 확인할 수 있었다. 또, 새로운 데이터가 추가되었을 때, 해당 함수식에 새로운 데이터 벡터를 대입하면 그 데이터의 실제 결과와 유사한 를 출력하는 것을 확인할 수 있었다.
그러나 본 데이터는 매우 높은 epoch수에 비해 과적합을 충분히 막지 못했다는 한계를 가진다. 따라서 과적합을 막기 위한 몇 가지 방안을 적용한다면 더욱 정확도 높은 모델을 구현할 수 있을 것으로 생각된다.


잘봤습니다. 좋은 글 감사합니다.