Collaborative Filtering, 줄여서 CF
많은 유저들로부터 얻은 기호 정보를 이용해 유저의 관심사를 자동으로 예측하게 하는 방법입니당. 여기서 Collaboratvie는 집단지성, 다수의 의견을 반영합니당.
협업Collaborative을 위해선 서로 다른 유저와 서로 다른 기호의 데이터가 필요하고, 이를 통해 성향 비슷한 사람을 파악해 추천이 가능해집니당.
많은 유저들의 데이터가 축적될 수록 집단 지성이 높아지고, 추천은 정확해지며, 추천 시스템에서 많이 쓰이는 하나의 기법입니당.
Example)
1. 이 상품을 구매한 유저가 구맨한 다른 상품들
2. 이 영화를 선호하는 유저가 관람한 다른 영화들
예시
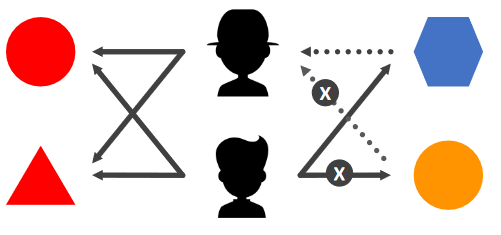
- 유저 A와 비슷한 성향을 가진 유저들이 선호하는 아이템을 추천!
- 아이템이 가진 속성을 사용하지 않으면서도 높은 성능을 보여용
note
- 쿠팡 같은 경우엔 구매, PV 등 서로 다른
지표에 따라 구분해서 하는 경우 있음- 피봇 수행 시 유저-아이템에서 아이템-유저로 변함
CF의 목적은?
| i1 | i2 | i3 | |
|---|---|---|---|
| u1 | 4 | 3 | (예측 필요) |
| u2 | (예측 필요) | 3 | (예측 필요) |
행렬 내 빈 값을 예측하는 것이 목적이라 보면 됩니다. 각 평점을 기반으로 빈 값을 채워서 평점을 예측한다고 보시면 됩니당.
그러면 어떻게 하는거죠?
- 주어진 데이터를 활용해 유저-아이템 행렬을 생성
유사도기준을 정하고, 유저 혹은 아이템 간의유사도를 구한다.- 주어진 평점과
유사도를 활용하여 행렬의 비어 있는 값평점을 예측합니다.
어떤 특징이 있냐면요...
- 구현이 간단하고 이해가 쉬움
- 아이템이나 유저가 계속 늘어날 경우 확장성 저하 Scalabiity
Sparse한 데이터의 경우 성능 저하 Spasity
여기서 Sparsity란?
유저-아이템 행렬의 전체 entry 가운데 비어있는 비율입니당.
주어진 데이터를 활용해 유저-아이템 행렬을 만들 때 행렬의 대부분 entry는 비어있습니다. 이러한 행렬을 Sparse Matrix라고도 합니다.
협업 필터링Collaborative Filtering을 적용하려면 적어도 sparsity가 99.5 %를 넘지 않도록 하는 것이 좋다**고 해용
User-based, Item-based
User-based
유저간의 유사도를 구하는게 핵심인 CF입니당.
두 유저가 얼마나 유사한 아이템을 선호하는지에 대한 척도인, 유저간의 유사도를 구해서 자신과 유사도가 높은 유저들이 선호하는 아이템을 추천하는 방식입니닷.
예시
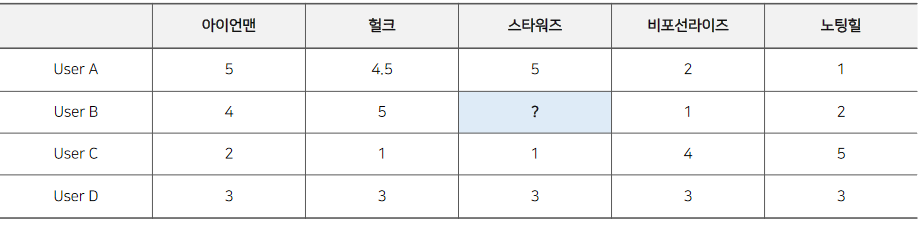
딱 봐도 유저 B는 유저 A와 비슷한 취향을 가졌기 때문에 유저 B의 스타워즈에 대한 선호도는 높을 것으로 예측되용.
이는 유저 A와 유저 B의 유사도가 높다highly correlated라고 할 수 있습니당.
평점을 예측해봅니다(Rating Prediction)
Average
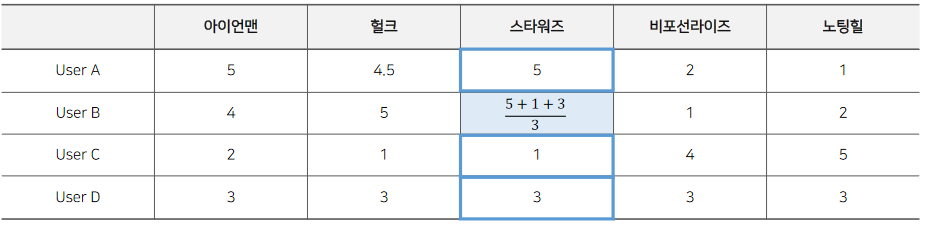
다른 유저들의 스타워즈에 대한 rating을 모두 사용하여 평균을 내는 방식입니당.
유저 B의 입장에서 볼 때 A와 C의 rating을 동일하게 반영하게 되죠. 이 경우 유사도가 낮은 C, D에 대한 정보가 반영되어 좋은 결과를 예측하기 어려워 잘 안쓰인다고 합니당. 그래도 알아둬요!
Weighted Average
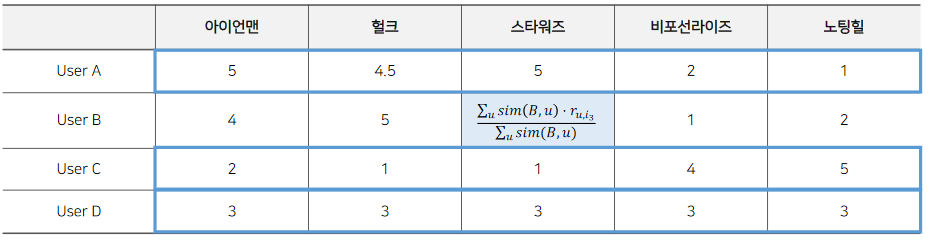
Average의 경우 유사도가 적은 유저의 평점을 지나치게 반영해서 좋을 결과를 내기가 여러워용.
그래서! 유저 간의 유사도 값을 weight로 사용하여 rating의 평균을 내는 방식을 활용할 수 있습니다.
여기서, 유저 B의 입장에서 볼 때, 유저 A의 rating은 많이 반영되고, 유저 C의 rating은 적게 반영되어 예측 평점이 구해져용.
수식 정리
-
유저 , 아이템 에 대해 평점 데이터 가 존재할 때, 유저 의 아이템 에 대한 평점을 예측
-
아이템 에대한 평점이 있으면서 유저 와 유사한 유저들의 집합을 라 하면,
-
Average
-
Weighted Average
-
Note
- sim :
유사도함수, B: 기준, u : A, C, D prime: 아이템 를 소비하면서 유저 와 비슷한 성향인 유저hat: 데이터에 대한 정답
이게 다가 아닙니다(feat. Absolute Rating)
유저의 평점은 절대적이라기 보단 '상대적'입니당.
긍정긍정한 친구는 왠만하면 5점을 주고 아무리 아이템이 별로여도 3점을 주는 반면, 부정부정한 친구는 거의 1~2점을 주고 아주 가끔씩 4점을 주는 경우가 있어용
이렇게 서로의 평가 기준이 달라서 성향이 같더라도 예측을 하기가 어렵습니당...
그래서 이를 우린 편차Deviation을 통해 해결합니당!
Deviation
-
모든 평점 데이터를
deviation데이터로 바꾼 뒤,predicted rating이 아닌predicted deviation을 구합니다. -
predicted deviation: 유저 평균rating+predicted deviation확인된 평점에 대한 편차
deviation
Deviation을 적용한 Weighted Average
위 편차deviation을 적용한 수식은 아래와 같아용
-
Using
Deviation -
Using
Absolute Rating(비교하라고 띄워놨어요)
K Nearest Neighbors(KNN) Collaborative Filtering
아이템 에 대한 평점 예측을 위해서는 아이템 에 대한 평가를 한 유저()의 데이터를 사용해야 합니당.
그러면 에 속한 모든 유저와의 유사도를 구해야 하죵. 이때 모든 유저를 사용할 경우 연산은 많아지고 오히려 성능이 저하됩니당Scalability...
그래서 에 속한 유저 가운데 유저 와 가장 유사한 k명의 유저를 이용해 평점을 예측하는데, 이를 K Nearest NeighborsKNN Collaborative Filtering이라고 해용.
여기서, '유사'하다는 것은 정의한 유사도 값이 '크다'는 것을 의미해용 0 : 유사도 X, 1 : 완전 동일
보통 K = 25~50를 많이 사용하지만 직접 튜닝해야 하는 하이퍼 파라미터hyper parameter입니당(하이퍼 파라미터hyper parameter : 모델링할 때 사용자가 직접 세팅해주는 값).
Item-based Collaborative Filtering
Item-based CF는 두 아이템이 유저로부터 얼마나 유사한 평가를 받았는지 확인하여, 아이템 선호도를 바탕으로 연관성이 높은 다른 아이템을 추천하는 방식이에용.
즉, 아이템 간의 유사도를 구합니당!
위 표를 보면 직관적으로 스타워즈는 아이언맨, 헐크와의 유사도가 높습니다. 반대로 비포 선라이즈, 노팅힐은 스타워즈와의 유사도가 낮죵.
따라서, 유저 B의 스타워즈에 대한 평점은 아이언맨, 헐크와 비슷하게 높을 것이다! 라고 생각하고 추천을 수행하는 것이죠.
예시
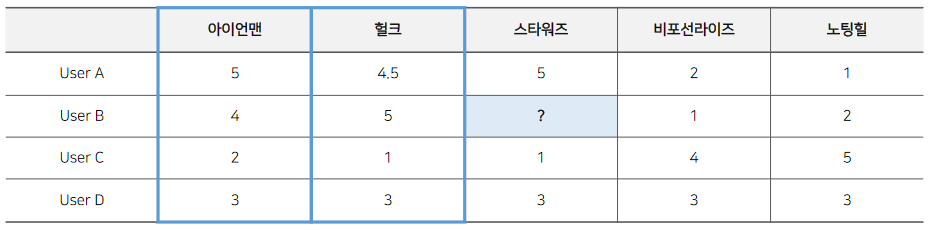
- 스타워즈와 가장 유사도가 큰 아이언맨
0.7, 헐크0.9를 활용해 예측하면유저 B의 스타워즈에 대한 예측 평점은, 점
Rating Prediction(User-based와 동일)
평점 예측Rating Prediction에선 기존 User-based랑 같은 수식을 쓰지만 사용하는 파라미터가 쪼오금 달라용
- 유저 , 아이템 에 대해 평점 데이터 가 존재할 때, 유저 의 아이템 에 대한 평점을 예측
- 아이템 에대한 평점이 있으면서 유저 와 유사한 유저들의 집합을 라 하면,
-
Average
-
Weighted Average
편차Deviation을 적용한 수식은 아래와 같아용.
-
Average With Deviation
-
Weighted Average With Deviation
User-based vs. Item-based
두 CF를 비교하자면,
User-based
- 유사한 Neighborhood의 수
K가 늘어날 수록 성능 증가 Item-based보다 더 다양한 추천 결과들이 제공 DiversitySparsity,Cold Start에 비교적 취약Pearson 유사도를 사용할 때 성능이 높음
Item-based
- 실제 서비스에서
user-based보다 높은 성능을 냅니다 - 아이템 간의
유사도를 사용하는 것이 상치/에러값으로 부터 영향을 크게 받지 않습니다Robust- 아이템 기준의 Neighborhood들이 사용자 기준의 Neighborhood보다 덜 변하기 때문
- 추천에 대한 이유를 설명하기 훨씬 쉽습니다
- 유저가 과거에 선호했던 다른 아이템과 비슷하기 때문에 추천
Cosine 유사도를 사용할 때 성능이 높습니다
제가 들은걸 말하자면
둘다 구현 난이도는 차이는 거의 없다고 합니당. User가 좀더 다양한거, Item은 인기있는거 위주로 추천해주며 item이 높은 성능을 내는 경우가 많다고 합니당.
물론 케바케로 사용합니당(신규 유입 적은데 아이템이 엄청 많이 증가하는 경우 User-based로 가야함). 당연히 유사도 성능 평가는 실제 테스트를 해봐야 알 수 있어용.
CF도 완벽한건 아니랍니당(feat. 한계)
- Cold Start
- 데이터가 충분하지 않으면 추천 성능이 저하됩니다
- 데이터가 전혀 없는 신규 유저, 아이템의 경우 추천이 '불가능'합니다
- 계산 효율
- 유저와 아이템이 늘어날 수록
유사도계산이 늘어납니다 - 유저, 아이템이 많아야 정확한 예측을 하지만 반대로 시간이 오래 걸립니다
- 유저와 아이템이 늘어날 수록
- Long-tail 추천의 한계
- 많은 유저들이 선호하는 소수의 아이템이 보통
CF추천 결과로 나타납니다 - 따라서,
long-tail을 이루는 비주류의item이 추천되기가 어렵습니다
- 많은 유저들이 선호하는 소수의 아이템이 보통
오늘은 여기까지~!
