Latent Factor Model(LFM)
유저와 아이템을 잠재적 요인을 사용해 표현할 수 있다고 보는 모델입니당! 다양하고 복잡한 유저와 아이템들의 특성을 몇 개의 벡터로 compact하게 표현하공, 이를 Representation이라고도 해용
유저와 아이템을 같은 차원에 투영하여 벡터로 표현하여 나타내용. 차원의 개수는 여러 개이고, 각 차원의 의미는 모델 학습을 통해 생성되며, 표면적으로 무엇을 의미하는지 알 수 없어요
대신! 같은 벡터 공간에서 유저와 아이템 벡터가 놓일 경우 유저와 아이템 유사한 정도를 알 수 있습니당
위를 보시면 유저와 영화가 같은 공간에 투영이 되어 있어용. 이를 기반으로 해서 추천을 제공하는 것을 Latent Factor ModelLFM이라고 합니당!
Singular Value Decomposition(SVD)
Rating Matrix 에 대해 유저와 아이템의 잠재 요인을다포함할 수 있는 행렬로 분해해용
분해 목록
1. 유저 잠재 요인 행렬
2. 잠재 요인 대각 행렬
3. 아이템 잠재 요인 행렬
행렬 분해 방식 중 하나이고, 차원을 축소해서 수백, 수억 차원짜리를 압축compact해용
선형 대수학에서 차원 축소 기법 중 하나로 분류됩니당. 여기서 언급은 없지만 주성분분석PCA도 차원 축소 기법 중 하나에용. 선형 대수학에선 이를 Demension Reduction Model이라고도 불린다고 합니당.
이 기법은 실제 Netflix Prize에서 추천 시스템에 적용된 단일 알고리즘으로 가장 좋은 성능을 보인다고 해용! 물론 지금은 SVD 원리를 차용하되, 다양한 최적화 기법을 적용한 MF가 더 많이 사용 됩니당 SGC, ALS, BPR 등
그림과 수식으로 표현해봅시다
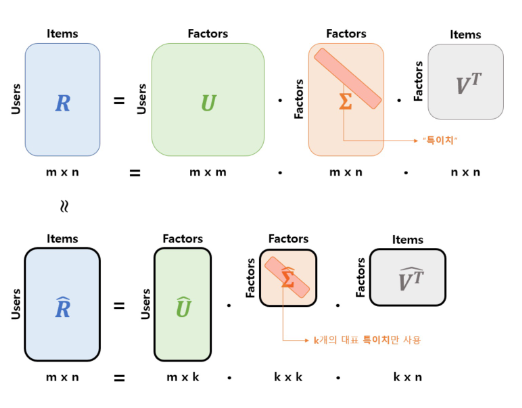
Full SVD :
-
: 유저의
Latent Vector- 의 열
column벡터는 의 '좌측' 특이치 벡터Singular Vector
- 의 열
-
: 아이템의
Latent Vector- 의 열
column벡터는 의 '우측' 특이치 벡터Singular Vector
- 의 열
-
:
Latent Vector의 중요도- 을 '고윳값 분해'해서 얻은 직사각 대각 행렬로, 대각 원소들은 의 특이치
Singular Value입니다 - 여기서 직사각 대각 행렬은 강조 표시된 부분에 각 아이템의 중요도를 내림차순으로 기입되 있습니다
- 을 '고윳값 분해'해서 얻은 직사각 대각 행렬로, 대각 원소들은 의 특이치
-
참고(선형 대수학 관련 수식)
, (, 는 직교행렬)
Truncated SVD :
- 대표 값으로 사용된
k개의 특이값Sigular Value만 사용하며,k는 하이퍼 파라미터에용 직접 설정해서 적절한 값을 찾아야 함 - 평점 예측 결과인 은 축소된 에 의해 계산됩니닷
굳이 이래야 하나요?
네! 이렇게 하면 약간의 오차를 허용하는 한에서 연산 속도를 높일 수 있습니다!
최종적으로 이랑 비슷한 을 만들어 적절한 결과를 유추하게 됩니당. 두 수치가 조금 다르지만, truncate를 통해 결과에 영향을 크게 주지 않는 선에서 퍼포먼스 성능을 이끌어 낼 수 있어용 k가 너무 크면 성능이 그대로, 너무 작으면 결과가 달라짐
여기서 k개의 Latent Factor의 의미는 유추할 수 있지만, 정확히 어떤 특성을 가지는지는 알 수가 없다고 해용 선호하는게 무엇이구나 정도만 알 수 있음
SVD의 문제점
분해Decomposition하려는 행렬의 Knowledge가 불완전하면 정의되지가 않아용 ㅠ.
그래서 sparsity가 높은 데이터의 경우 결측치가 매우 많고, 실제 데이터는 대부분 sparse matrix이라 결측된 entry를 모두 채워Imputation, Dense matrix를 만들어 SVD를 수행해야 해용.
결국 이런 Imputation은 데이터 양을 상당히 증가 시켜 결국 퍼포먼스 비용이 높아져용...
(ex.결측된 entry를 0이나 유저/아이템의 평균 평점으로 채움)
게다가, 정확하지 않은 imputation은 데이터를 왜곡시키고, 예측 성능을 떨어뜨리게 됩니당. 행렬의 entry가 너무 적으면 SVD 적용 시 과적합overfitting되기가 쉽습니당
따라서! 보통은SVD 원리를 차용하되, MF를 학습하기 위한 '근사적'인 방법을 활용합니당 Full SVD부터 시작하는게 아니라, 처음부터 k개의 정해 놓은 차원으로 시작하는 방식
Matrix FactorizationMF에 대한 내용은 다음에 다룰게용!
