모델 기반 협업 필터링이란?
기존 이웃 기반 CF
유저 , 아이템 에 대해 평점 데이터 가 존재할 때, 유저 의 아이템 에 대한 평점을 예측한다면,
1) User-based : 아이템 에 대한 평점이 있으면서 유저 와 유사한 유저들의 집합을 라 한다면,
2) Item-based : 유저 가 평가를 한 다른 아이템 중에서 아이템 와 유사한 아이템들의 집합을 라한다면,
기존의 CF는 Memory-based CF라고도 불리며, 유저와 아이템을 직접 연관시켜 추천하기 때문에 설명력이 높고 적용이 용이해용
- 특징
- 구현이 쉽고 간단
- 유저-아이템 간의
유사도에 크게 의존 - 데이터의
Sparsity에 매우 취약 그러나 대부분의 Real World의 데이터는Sparse합니다 - 추천 결과를 생성할 때마다 많은 연산은 요구 유저, 아이템이 늘어날 수록 확장성
Scalability이 떨어집니당
기존엔 있는 데이터를 기반으로 했다면, 이번엔 Deep Learning 기반으로 추천하여 문제를 극복하는 방식으로 좀더 자동화에 가까워집니당
Model-based Collaborative Filtering 특징
Parametric Machine Learning
주어진 데이터를 사용하여 모델을 학습해용. 데이터의 정보가 데이터 패턴Parameter의 형태로 모델에 압축되면서 지속적인 최적화Optimization을 통해 업데이트를 수행합니당. 이는 Machine Learning 방식이에용
데이터의 패턴 = 유저-아이템의 '잠재적' 특성
이웃 기반 CF는 유저-아이템 벡터를 데이터를 통해 '계산'된 형태로 저장하고 있는 반면, Model-based CF의 경우 유저, 아이템 벡터는 모두 '학습'을 통해 변하는 Parameter가 됩니당!
Real World에서는 Matrix Factorization 기법이 가장 많이 사용
최근에 MF 원리를 Deep Learning에 응용한 모델이 더 높은 성능을 내고 있다고 해용.
그렇다고 하지만 현업에서 자주 사용되진 않고 논문에 주로 사용된다고 합니당.
Model-based Collaborative Filtering의 장단점
모델의 학습/서빙
유저-아이템 데이터는 학습에만 사용되고, 학습된 모델은 '압축'된 형태로 저장이 됩니당.
그래서 이미 학습된 모델을 통해 추천 결과를 서빙하기 때문에 속도가 빠릅니다
Sparsicty/Scalability 극복
이웃 기반 CF에 비해 sparse한 데이터에서도 좋은 성능을 보여용! 이는 가지고 있는 데이터만으로 학습해서 결과를 예측하기 때문이졉.
사용자, 아이템 개수가 늘어나도 마찬가지로 좋은 성능을 보입니다
Overfitting 방지
이웃 기반 CF와 비교했을 때 전체 데이터의 패턴을 학습하도록 모델이 작동해서 편향적인 예측 결과를 방지할 수도 있어용
LImited Coverage
이웃 기반 CF의 경우 공통의 유저 / 아이템을 많이 공유해야만 유사도 값이 정확해져용...
유사도` 값이 정확하지 않은 경우 이웃의 효과를 보기 어려운 반면, 공유가 안되더라도 학습이 잘된다고 합니당
Rating Matrix(Explicit Feedback)
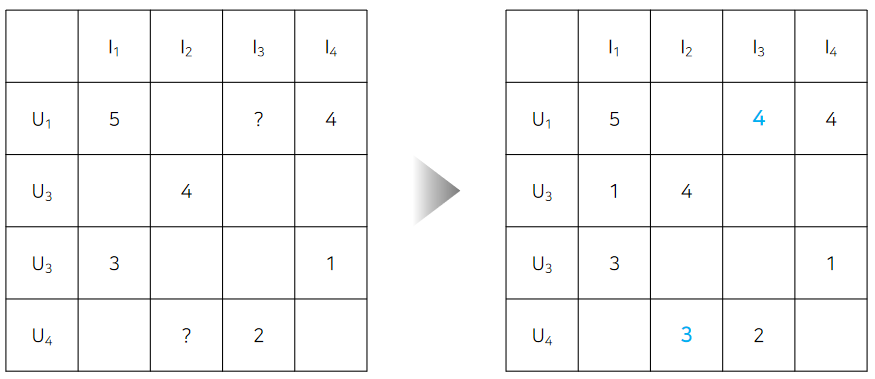
주어진 Matrix에 평점을 기반으로 유저가 아이템에 '주게 될' 평점을 예측하는 방식입니당
User-item Matrix(Implicit Feedback)
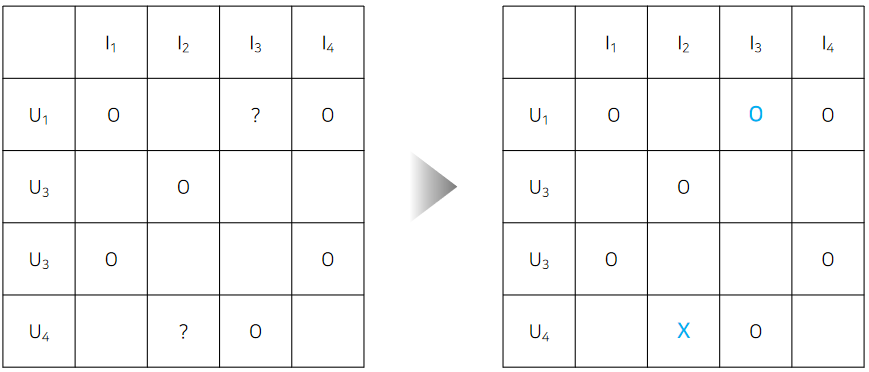
이 경우엔 몇몇 아이템에 흥미를 가져서 '클릭'을 했어용
그리고 '클릭'을 안한 아이템에 대해서(관심이 없거나 또는 노출이 안되었거나) '클릭'을 하게될 것인가 아닌가에 대한 '예측'을 합니당
