
SparkSession vs SparkContext vs SQLContext
Spark 기본 아키텍처 및 용어 Spark 애플리케이션은 클러스터의 드라이버 프로그램과 익스큐터 그룹으로 구성됩니다. Driver는 Spark 애플리케이션의 기본 프로그램을 실행하고 작업 실행을 조정하는 SparkContext를 생성하는 프로세스입니다. executo
Spark sql vs Hivecontext
(둘이 명확하게 다르구나! 하고 느낀건 hive의 UDF를 spark sql에서 호출하지 못했을때 였나? 너무 당연한 결과지만...ㅎㅎ)sc = pyspark.SparkContext(conf=conf).getOrCreate()sqlContext = HiveContext
도움
https://swalloow.github.io/hive-metastore-issue/https://medium.com/@an_chee/why-using-mixed-case-field-names-in-hive-spark-sql-is-a-bad-idea
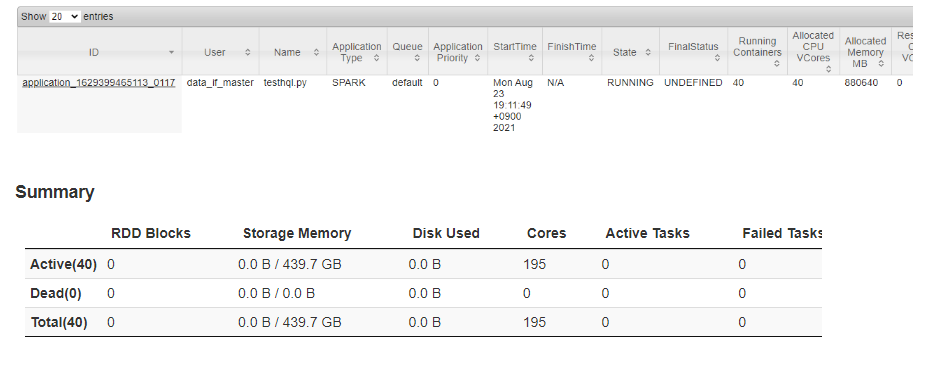
spark에서 메모리 할당이 어떻게 될까
\--num-executors 39 --executor-memory 20g --executor-cores 5 \\→ 컨테이너 안에 excutor 생성 되므로 yarn UI에서는 컨테이너 40개와 (익스큐터 +1로 생김) vcore는 동일하게 40개로 생김vcore의 경
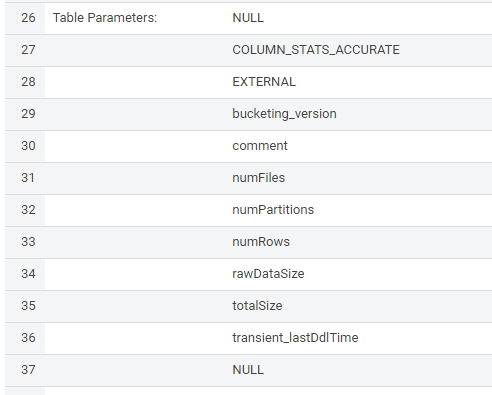
hive로 만든 테이블의 데이터가 spark에서 select 되지 않을때
원인 : hive에서 생성한 테이블을 가지고 spark에서 select 할때 데이터를 읽지 못하는 이슈가 있다. 로그에도 정확한 에러가 나오지 않아 찾기 쉽지 않다INSERT가 되지 않아 디버깅을 하다보니 hive에서는 select가 되지만 spark에서는 spark
[yarn] Memory
yarn은 다양한 app 이 구동될 때 자원을 제공하고, 자원은 container 라는 단위로 제공된다.container는 cpu와 memory로 구성이 되어있다.예를 들어 spark에서 wordcount app을 실행시킨다고 하자.이 app이 1.5gb의 memory
[hive] JOIN
셔플조인셔플 조인은 셔플(Shuffle) 단계에서 조인을 처리합니다. 두 개의 테이블을 조인할 때 각 테이블을 맵(Map) 단계에서 읽고, 파티션 키를 조인 키로 설정하여 셔플 단계에서 조인 키를 기준으로 리듀서로 데이터가 이동되고 테이블을 조인합니다.어떤형태의 데이터
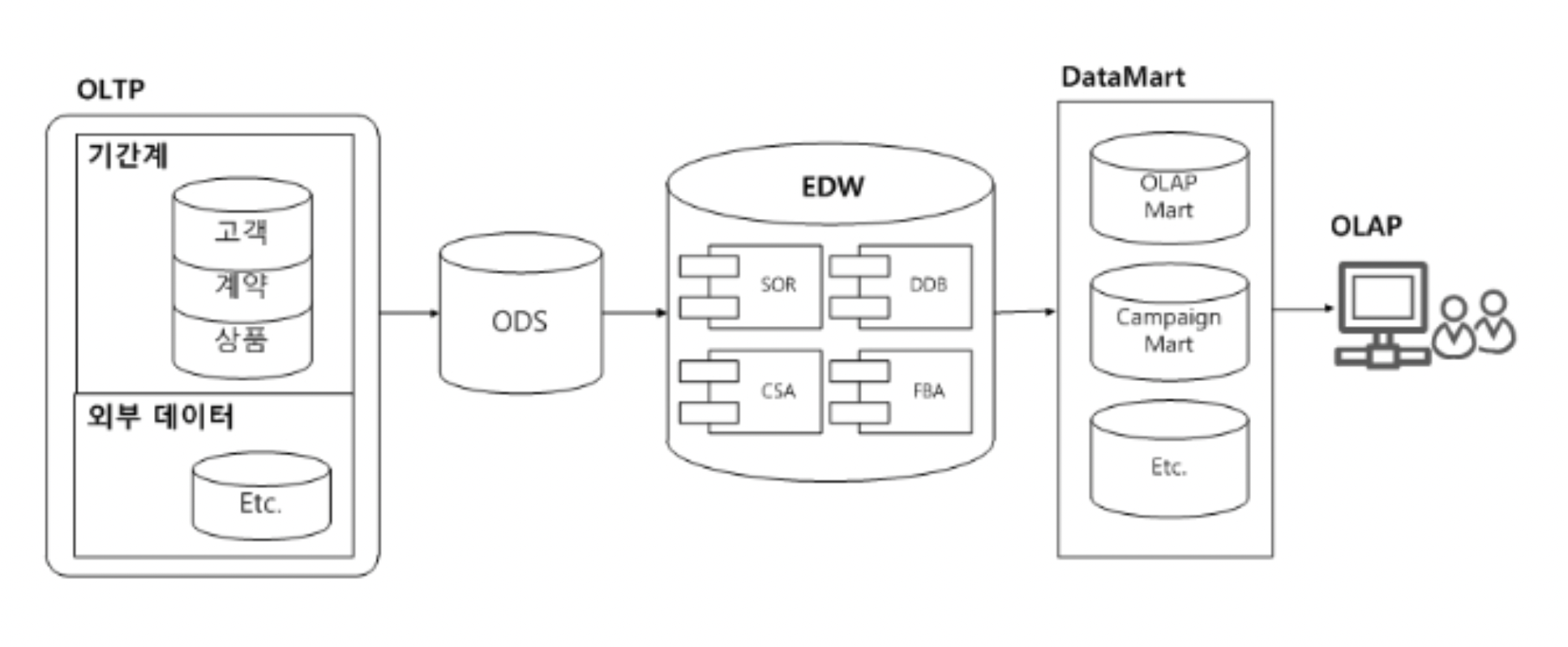
EDW란? ODS, DW, DM, OLAP
ODS 운영계 시스템의 데이터는 트랜잭션을 중심으로 설계되어 있기 때문에, 운영계 시스템 데이터를 대상으로 데이터 분석을 진행할 경우 효용성이 매우 떨어집니다. 그래서 데이터 분석을 위한 DW(Data Warehouse)를 설계하고, 데이터를 보관하게 됩니다. OD
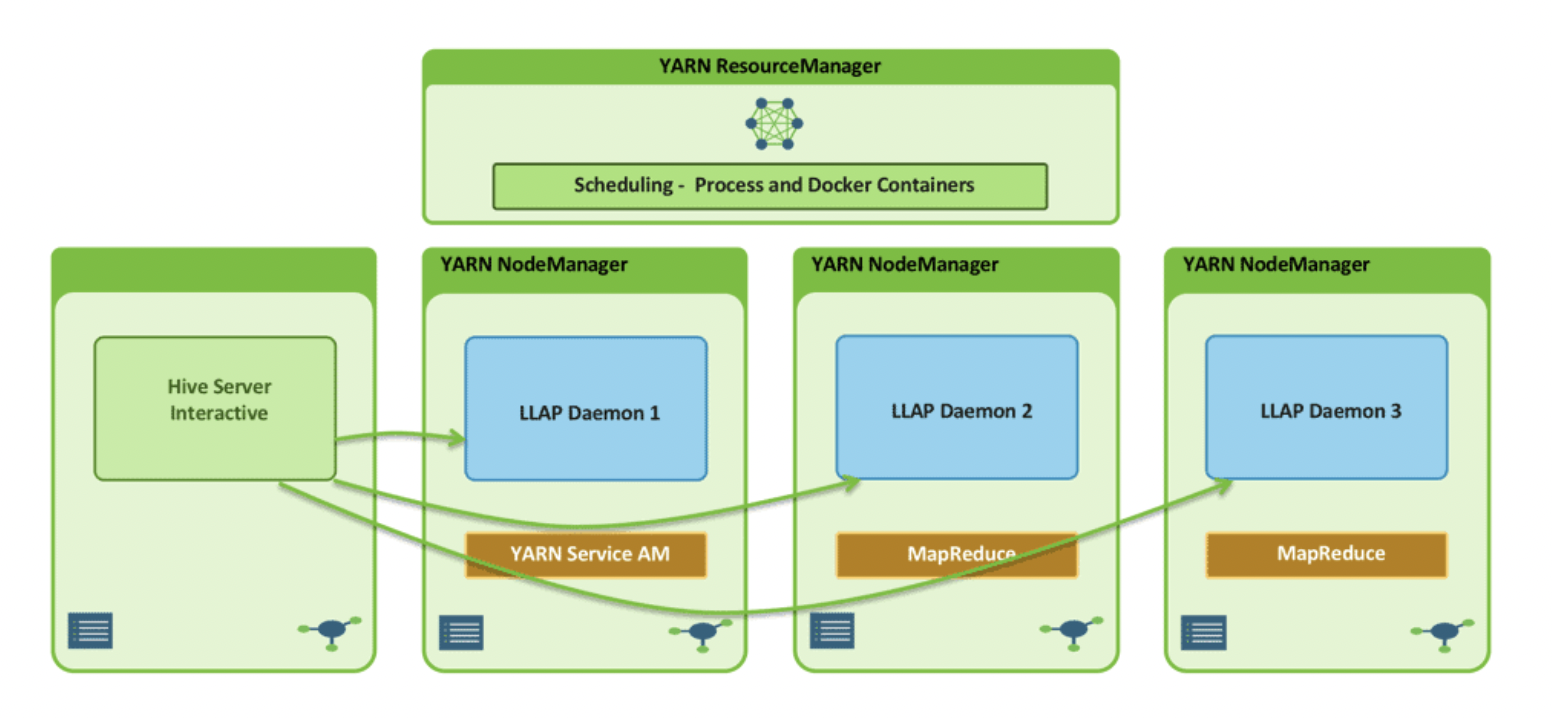
LLAP를 알아보자
Apache Tez가 포함 된 Hive LLAP는 Hive 2.x에서 사용할 수있다. Tez는 Hive LLAP와 함께 실행되어 더 빠른 쿼리를 지원한다.LLAP은 asynchronous spindle-aware IO, prefetching and caching of