
해당 시리즈의 포스트는 개념 및 이론 정리와 개인적인 코딩 기록이 혼용되어 포스팅됩니다. 참고 부탁드립니다.
JSX가 무엇인지에 대해선 이전에 정리했던 " JSX란? " 포스팅을 참고하도록 하자.
📌 어디에서 key를 작성했지?
이전 포스팅에서 Todo List를 만드는 과정을 다시 보자. 이때 코드를 다시 살펴보면 key속성을 찾아볼 수 있다.
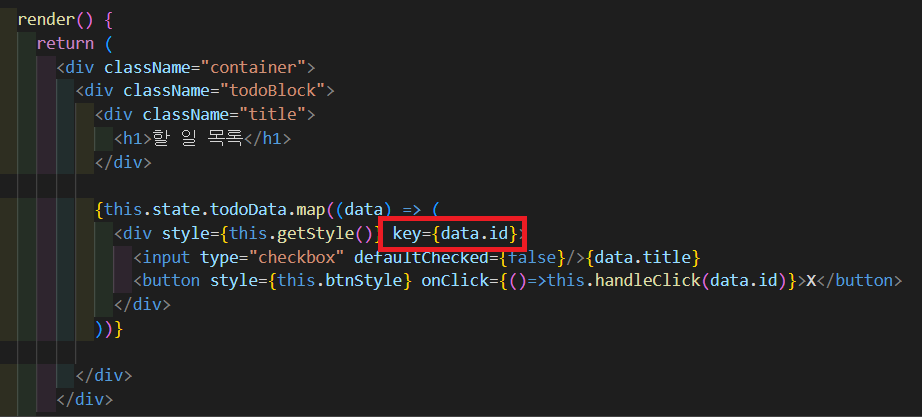
위 붉은색 박스에 보이듯이 map을 이용해 나열해주는 요소에 key속성을 부여해 두었다.
❓ 만약 key를 작성하지 않는다면?
여기에 만약 key속성을 작성해주지 않았다면 어땠을까?
바로 아래와 같은 error가 발생한다.
Warning: Each child in an array or iterator should have a unique "key" prop ...경고 메세지를 보면 나열된 각 요소는 유니크한 key를 지녀야한다고 나타난다.
그렇다면 이 key속성이 대체 어떤 역할을 하기에 작성해주라고 친절히 경고 메세지까지 띄워주는 것일까?
📌 JSX에서 key가 갖는 의미
JSX를 이용해 우리가 코드를 작성할 때 key는 각 요소를 구별해주는 역할을 해준다. 즉, 일종의 명찰같은 것이다.
이것이 왜 필요한지는 이전에 공부했던 virtual DOM을 다시 살펴보자.
1. virtual DOM과 rendering
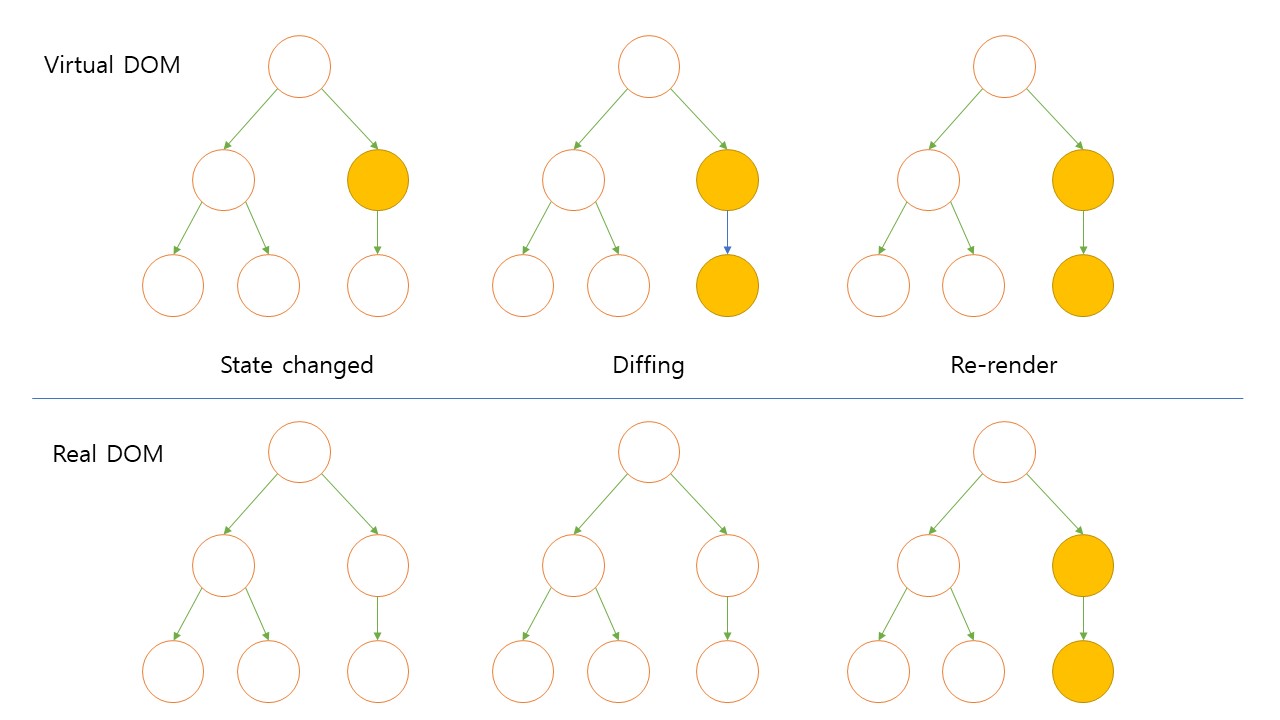
이전에 공부했듯이 virtual DOM은 효율적인 렌더링을 위해 고안된 것으로써, 렌더링할 때마다 모든 요소를 재작성하는 것이 아니라 이전 DOM과 변경된 부분만 비교하여 모두 재작성할 필요없이 바뀐 부분만 반영해준다.
이렇게 DOM에서 각 요소를 구분짓는 값이 될 수 있는
key는 특히나map()메소드를 사용할 때 필수적으로 부여해주어야 한다. 그렇지 않을 경우 경고창이 뜬다.
하지만 이때 약간의 디테일을 살펴볼 필요가 있다.
1-1. 디테일 살펴보기
❓ 만약 다음과 같은 변화가 있다면 react는 어떻게 반응할까?
📢 경우 1
/* before */
<ul>
<li>1</li>
<li>2</li>
</ul>
/* after */
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>이전 요소 뒤에 추가될 때엔 기존 요소의 자리는 변화하지 않았기 때문에 추가된 요소만 인지하고 다른 것은 리렌더링할 필요 없이 새로운 요소만 추가해준다.
그러나 다음처럼 앞에 추가한다면 어떨까?
📢 경우 2
/* before */
<ul>
<li>1</li>
<li>2</li>
</ul>
/* after */
<ul>
<li>3</li>
<li>1</li>
<li>2</li>
</ul>이렇게 되면 react가 모든 요소가 변화되었다고 인식하고 전부 리렌더링하게 되어버린다.
때문에 virtual DOM만을 믿고 모든 것을 맡기기엔 맹점이 있기에 react가 확실히 식별/구분하기 위해 우리가 명찰을 달아줄 필요가 있는 것이다.
그리고 이때 우리가 바뀐 부분을 식별할 수 있도록 달아주는 명찰이란??
바로 이 역할을 하는 것이 key인 것이다.
이러한
key값에는 확실히 구분될 수 있는 유니크한 값이 필요하다.Todo List를 만들 때는 배열의 각 요소에 id라는 property를
Date.now()를 이용해 중복될 수 없는 값을 부여해 주었다.
우리는 이 key를 이용해 각 요소를 식별/구분하고 항목의 삭제, 변경, 추가 등 기능을 실행하게 된다.
2. index가 아닌 key인 이유
우리(사람)는 그냥 눈으로 내용의 차이를 구별하여 간단히 인식이 가능하지만 코드를 읽는 컴퓨터의 입장에서는 모두 같은 <div>태그일 뿐이다.
그 안에 작성된 contents는 코드가 아니다.
그렇기 때문에 이런 태그들의 차이를 인식하고 구분지어줄 안정적이며 특별한 속성이 필요하고, 그 역할을 key가 해주는 것이다.
그렇다면 이쯤에서 드는 의문,
index가 자동적으로 부여될텐데 왜 굳이 key를 다시 부여하는 거지?
그 이유는 바로 index도 각 요소에 유니크한 번호를 지니게하기는 하지만, 만약 요소가 추가, 제거되면 index는 그것에 맞춰 각 index값도 변경되기 때문이다.
arr = ['a','b','c','d']
/* 각 index는
'a': 0
'b': 1
'c': 2
'd': 3
*/
// 요소가 추가되거나 삭제 되면?
arr.shift()
arr.push('e')
/* 각 index를 다시 보면,
b: 0
c: 1
d: 2
e: 3
*/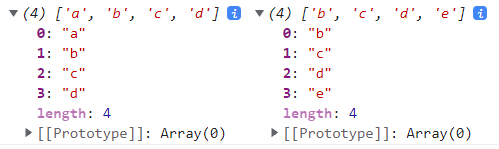
console창에 각각 변화 전과 후를 찍어서 확인해보면 알 수 있듯이 배열의 변화에 따라 각 요소가 지니고 있던 index값도 변하였다.
즉, 중복된 index값을 지닐 순 없기에 유니크하지만 동시에 순서에 따라 가지고 있던 index값이 변할 수 있기에 불변의 속성은 아닌 것이다.
유니크하지만 영구적으로 한 요소에 종속되진 않는 속성이기 때문에 비추천하고, key의 사용을 권장하는 것 !
But! key값에 'index를 넣어주는 것'은 다른 얘기
index 자체만으로 구분 짓는 요소가 될 수 없다는 것은 위에 이미 설명해서 이해했을 것이다.
그러나 이러한 index값을 key에 넣는 것은 또다른 개념이다.
index로 0부터 시작하는 Number가 부여되었을 것이고 이 값만을 key에 넣어주는 것이기 때문에 key안에 들어간 이 숫자는 해당 요소의 고유 값이 되는 것이다.
예시
index = 1
key = {index}라는 코드로 컴포넌트를 생성index가 변해도 이미 key는 생성된 순간의 index값을 가져와 부여되었기 때문에
key=1로 되어 있다.
- 출처: John An님의 강의 클릭시 해당 강의 링크로 이동
잘못된 부분에 대한 지적은 얼마든지 환영입니다.
감사합니다.
