개요
이번 학기 학부 졸업 프로젝트 과제의 주제로 현재 COVID-19의 확산과 무인화 경향에 힘입어 "딥러닝 기반 얼굴인식을 활용한 본인인증 시스템"을 개발해보았다.
이번 포스팅에서는 위와 같은 프로젝트 수행 과정에서 ArcFace를 활용한 얼굴인식 모델을 구현해보는 과정을 간략하게 소개한다.
1. ArcFace를 활용한 안면인식 모델 개발
@ ArcFace
ArcFace는 Metric Leaning의 한 종류로 Metric Leaning은 그 활용과 학습 방법이 여타 다른 딥러닝 활용 방법과 조금은 다르다.
- 우선 매우 많은 클래스 종류를 가진 분류(Classification) 문제를 학습시킨다.
- 안면인식의 경우에는 매우 많고 다양한 사람들의 얼굴 이미지를 입력으로, 그 사람이 어떤 사람인지 분류해내는 것을 학습하게 된다.
- 이 분류 문제를 학습하면서 입력 이미지에 대한 Embedding을 부가적으로 학습하게 된다.
- 동일한 클래스의 이미지들은 서로 가깝게 위치하도록, 다른 클래스의 이미지들은 서로 멀리 떨어지도록 Embedding을 구성할 수 있게 학습하게 된다.
- 따라서 ArcFace에 동일한 두 사람의 얼굴 이미지를 입력하면 두 이미지에 대한 Embedding은 서로 매우 가깝게 위치하도록, 다른 두 사람의 얼굴 이미지를 입력하면 서로 매우 멀리 떨어뜨리도록 학습하게 된다.
- 이렇게 학습한 Embedding network를 활용할 때는 분류 레이어 (Classification layer)는 떼어내고 활용하게 된다.
- 이번 프로젝트에서는 이렇게 학습된 Embedding network에 두 사람의 얼굴 이미지를 입력해 각각 이미지에 대한 Embedding을 추출하고 이 두 Embedding의 거리를 계산해 일정 거리보다 멀면 다른 사람으로, 가까우면 동일한 사람으로 판별하는 시스템을 만들게 된다.
@ 한국인 얼굴 사진(K-Face) 데이터
데이터의 출처.
한국인 얼굴 사진(K-Face) 데이터베이스는 "한국정보화진흥원"의 "영상분야 지식베이스 구축" 사업과 "인공지능학습용 AI데이터 구축"사업의 일환으로 구축되었다. 데이터는 무료이지만 AI Hub의 허가를 통해 제공받아야 한다(링크).
데이터의 구성
데이터의 구성은 AI Hub의 공식 GitHub repository에서 공개되어 있는 내용을 참고했다.
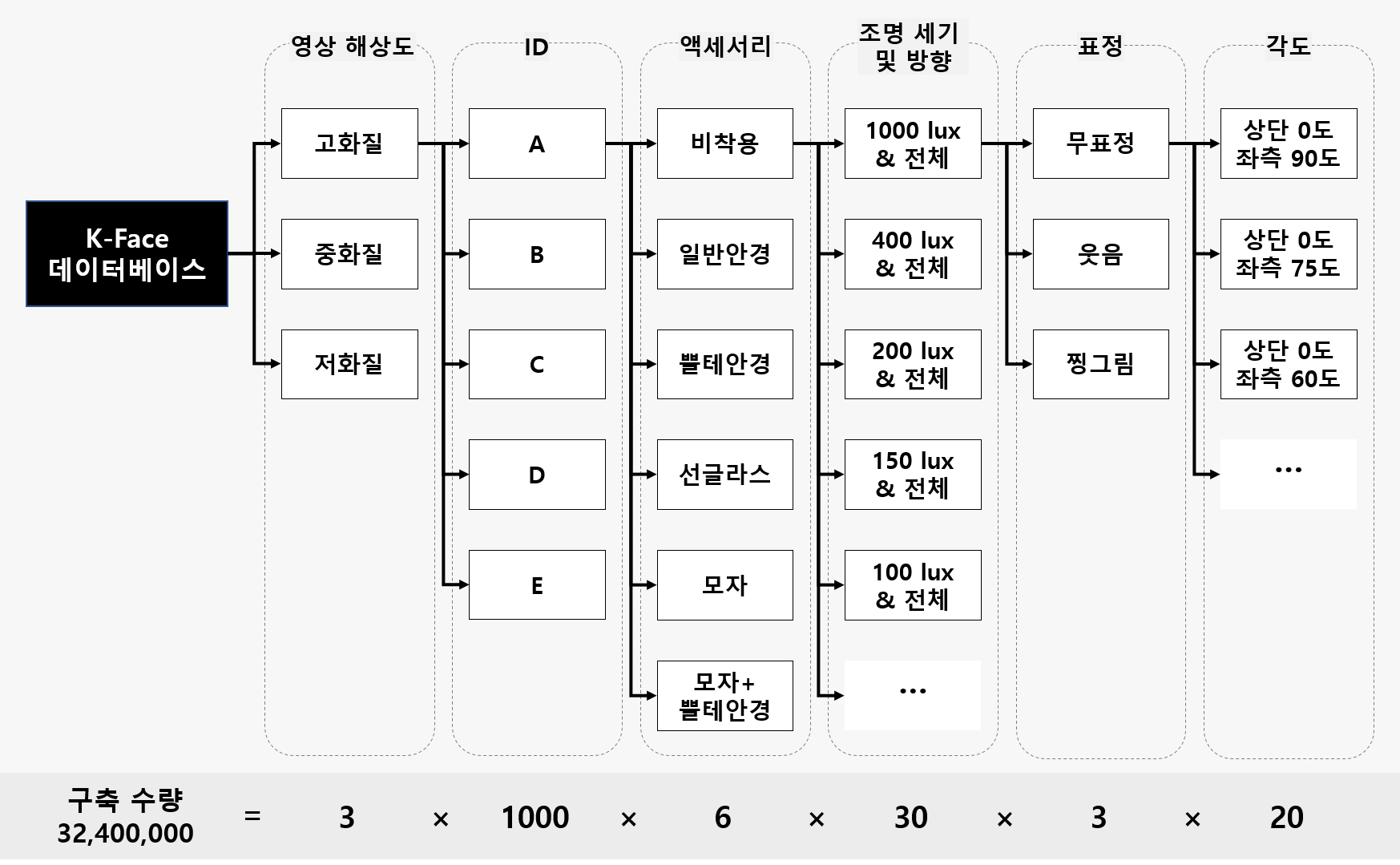
제공받은 K-Face 데이터셋의 구조는 다양한 영상 해상도, Class ID, 액세서리 유무, 조명 위치 및 세기, 표정, 포즈 방향에 따라 구성되어 있다.
- 해상도 3종 (High [864, 576], Middle [346, 230], Low [173, 115])
- 액세서리 6종 (S001 ~ S006)
- 조명 30종 (L1 ~ L30) (조도 30 lightings)
- 표정 3종 (E01 ~ E03)
- 각도 20종 (C1 ~ C20) (20 views)
특징점 위치 및 인덱스
뿐만 아니라 다양한 얼굴의 특징점, Bounding Box도 일부 데이터에 한해 제공하고 있다.

- Bounding Box 검출 대상
- 촬영 각도: 촬영되는 모든 각도
- 조명(4 종류): L1 (1000 Lux), L3 (200 Lux), L6 (40 Lux), L7 (0 Lux)
- 표정(3종류): E01 (무표정), E02 (활짝웃음), E03 (찡그림)
- 액세서리(1종류): S001 (보통)
데이터 전처리 과정
- 하드웨어의 한계와 학습의 효율을 고려하여 고, 중, 저화질의 이미지 중 중화질의 이미지를 사용했다.
- 전체 데이터에서 얼굴인식 task에 적합하도록 얼굴 영역을 추출할 수 있는 조명 4종류, 표종 3종류 액세서리 1종류에 대한 이미지만을 사용했다.
- 총 4종류의 조명 세기 중에 피사체가 확실하게 식별되는 L1, L3 조명 세기만 학습에 사용했다.
- 나머지 L6, L7의 밝기는 굉장히 어두워서 제외했다.
- 다양한 촬영 각도 중 얼굴의 정면이 확실하게 식별되는 4종류의 촬영 각도("C6", "C7", "C8", "C9")를 선별하고 이를 학습에 사용했다.
- (400명) x (조명 2종) x (촬영각도 4종) x (표정 3종) = 총 9,600장
- 이 중 10명의 인원에 대한 이미지는 모델의 검증을 위한 데이터로 사용했다.
- train set: (390명) x (조명 2종류) x (촬영각도 4종류) x (표정 3종류) = 총 9,360장
- validation set: (10명) x (조명 2종류) x (촬영각도 4종류) x (표정 3종류) = 총 240장
- 이 중 10명의 인원에 대한 이미지는 모델의 검증을 위한 데이터로 사용했다.

@ 얼굴인식 모델 개발
ArcFace 모델의 소스코드는 "peteryuX"님의 GitHub을 참고했다. 이 GitHub에서 감사하게도 거대한 얼굴인식 데이터셋인 MS-Celeb-1M 데이터에서 학습한 모델을 제공하고 있었으며 이를 활용했다.
이번 프로젝트의 목표는 한국인에 대한 얼굴인식이었기 때문에 사전학습 모델을 우리가 확보한 K-Face 이미지에 적합하게 미세조정(Fine-Tuning)하는 방향으로 수행했다.
@ 모델 검증
검증 데이터셋 10명, 240장에 대한 동일인물 구별 실험을 설계했다.
- 240장의 사진 중 랜덤한 두 사진을 선택하여 사진쌍을 생성
- 생성할 때 선택된 사진쌍이 동일인물인 경우 200쌍과 동일인물이 아닐 경우 200쌍, 총 400쌍의 사진쌍을 생성했다.
앞에서 학습한 모델이 각각 사진쌍에 대해서 512차원의 임베딩 벡터를 추출하도록하고 그 두 임베딩의 거리를 측정하여 임계값보다 작으면 동일인물, 크면 동일인물이 아닌 것으로 분류했다.
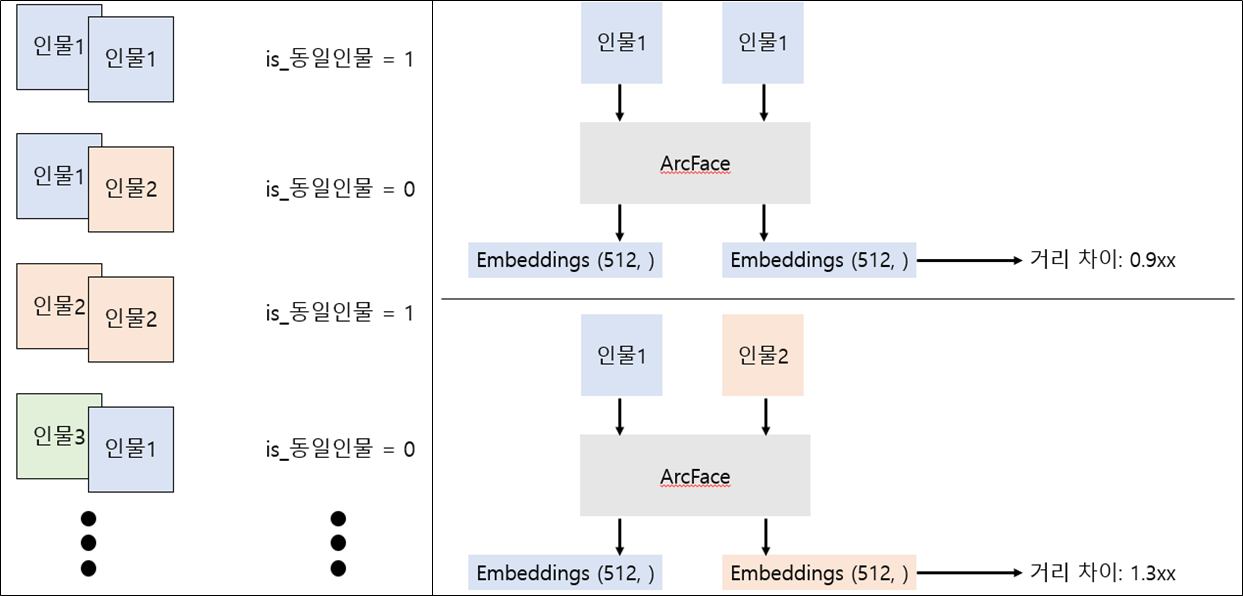
마지막으로 여기서 사용되는 임계값을 의 범위에서 씩 늘려가며 반복실험했다.
@ 검증 결과
위에서 수행한 실험에 대해 ROC Curve를 그려본 결과이다.
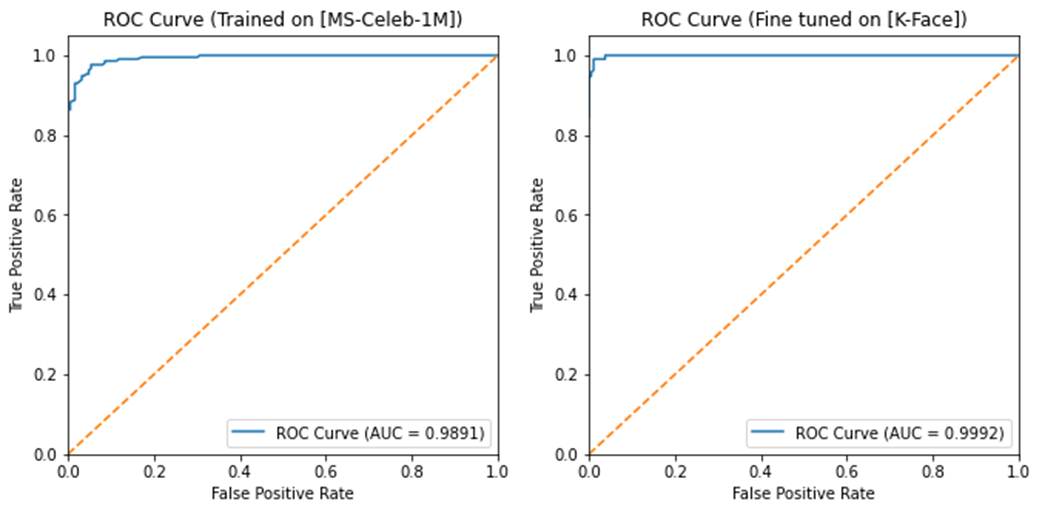
미세조정 이전에도 충분히 높은 성능을 보여주었지만, 미세조정 후에 AUC가 0.1정도 향상되었다
2. 본인인증 시스템 구축
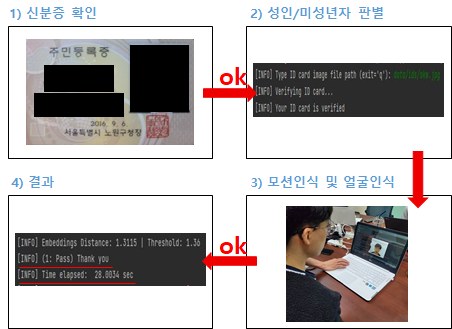
위에서 학습한 ArcFace 딥러닝 모델을 기반으로 아주 기본적인 형태의 본인인증 시스템을 만들 수 있었다.
시스템의 입력 값은 자신의 신분증과 실시간으로 촬영된 자신의 얼굴 사진이다.
- 먼저 사용자는 자신의 신분증을 입력한다.
- 이번 프로젝트에서 구현한 형태는 미리 이미지 파일로 저장해놓고 사진 파일명을 입력하는 형태로 이루어지는 형태이다.
- 신분증에서 Tesseract를 활용한 OCR을 진행한 후 생년월일 부분을 추출하여 성인임을 판별한다.
- 사용자의 실시간 얼굴 사진을 촬영한다.
- 이 때, 사진을 도용하는 것을 방지하기 위해 시스템은 특정 모션을 수행하도록 요구
- 모션을 올바르게 수행했을 때만 다음 단계로 이동할 수 있다.
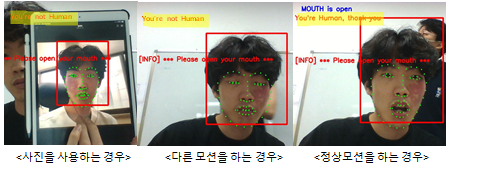
- 입력받은 신분증 이미지와 촬영한 실시간 얼굴 이미지에서 얼굴 영역을 dlib 오픈소스 라이브러리를 통해 추출한다.
- 추출한 얼굴 영역을 입력으로 하여 위에서 학습한 ArcFace 모델을 통해 두 이미지에 대한 Embedding을 추출한다.
- (5)에서 추출한 두 Embedding의 거리를 계산하여 일정 값보다 가까우면 동일인물임을, 가깝지 않으면 동일인물이 아님을 출력한다.

안녕하세요 유익한 포스트 잘 봤습니다. peteryuX"님의 GitHub을 참고해서 테스트를 하려는데 잘 안되네요ㅠ,, 혹시 파인튜닝 하신 모델 받아볼수 있을까요??