Zhou, X., Wang, D., & Krähenbühl, P. (2019). Objects as points. arXiv preprint arXiv:1904.07850.

Abstract
- 대부분 기존 object detector는 많은 수의 후보 구역들을 선정하고 이들이 진짜 물체를 담고 있는지 분류하는 방식을 사용한다.
- 이는 굉장히 비효율적이며 추가적인 후처리가 필요하다.
- 본 논문에서는 Keypoint estimation을 통해 물체(Objects)를 단 하나의 점으로 예측한다.
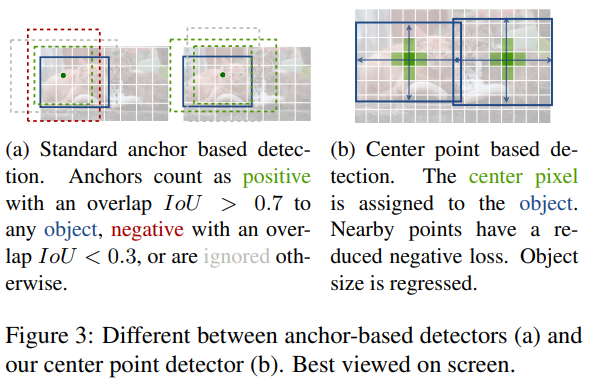
Object detection with implicit anchors.
- CenterNet은 기존 anchor box를 사용하는 one-stage detector와 비슷하지만, 다름.
- box overlap이 아니라, 위치(point)를 가지고 anchor를 할당
- 한 가지 크기의 anchor를 사용
- 더 큰 output resolution을 가짐.
3. Preliminary
- I∈RW×H×3: 입력 이미지
- Y^∈[0,1]RW×RH×C: CenterNet이 만들고자 하는 keypoint heatmap
- R=4: feature extractor를 거치면서 해상도가 줄어들게 되는 비율
- Y^x,y,c=1: keypoint를 의미
- Y^x,y,c=0: background를 의미
- CornetNet에서와 비슷하게 keypoint heatmap(Y^) 및 offset map을 뽑아낸다.
- keypoint prediction loss
Ldet=−N1xyc∑{(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc)if Yxyc=1otherwise,α=2,β=4
- offset loss
Loff=N1p∑∣Op~^−(Rp−p~)∣
- O^∈RRW×RH×2: x좌표에 대한 offset값, y좌표에 대한 offset값으로 총 두 개
- p∈R2: ground truth keypoints
- p~=⌊Rp⌋
4. Objects as Points
size loss
- object k의 bounding box 좌표를 (x1(k),y1(k),x2(k),y2(k))라고 할 때,
- center point는 pk=(2x1(k)+x2(k),2y1(k)+y2(k))
- 물체의 크기를 나타내는 sk=(x2(k)−x1(k),y2(k)−y1(k))
- 물체의 크기를 조정하는데 기여하는 size loss
Lsize=N1k=1∑N∣S^pk−sk∣
- S^∈RRW×RH×2: x좌표에 대한 size값, y좌표에 대한 size값으로 총 두 개
overall loss
Ldet=Lk+λsizeLsize+λoffLoffλsize=0.1,λoff=1
- 모든 keypoints Y^, offset O^, size S^는 단일 네트워크에서 비롯된 것이며, 총 C+4(offset 2 + size 2)개의 채널 output이 생성된다.
From points to bounding boxes
- ExtremeNet에서처럼 상위 100개의 peak point를 저장.
- P^c: 클래스 c에 속하는 n개의 peak(=center) point
- P^={(x^i,y^i)}i=1n
- 이 peak point의 픽셀 값 Y^xiyic를 그 탐지 confidence score처럼 활용할 수도 있다.
- 최종 bounding box는 아래와 같이 그릴 수 있다.
(x^i+δx^i−w^i/2,y^i+δy^i−h^i/2,x^i+δx^i+w^i/2,y^i+δx^i+h^i/2) - (δx^i,δy^i)=O^x^i,y^i: offset 예측 값
- (w^i,h^i)=S^x^i,y^i: size 예측 값

