[paper-review] DocUNet: Document Image Unwarping via A Stacked U-Net
Ma, K., Shu, Z., Bai, X., Wang, J., & Samaras, D. (2018). Docunet: document image unwarping via a stacked U-Net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4700-4709).
Abstract
- 문서 이미지에서 텍스트 인식을 더 효과적으로 수행하기 위해 구부러지거나 접힌 문서를 정렬하는 것은 필수적인 절차이다.
- Stacked U-net을 통해 이러한 접히거나 구부러진 문서 이미지들을 펼쳐내는 방법론을 제안한다.
- 실생활에서 촬영될 수 있는 왜곡 문서 이미지를 수집하여 동일 task에 대한 벤치마크를 처음으로 구축하였다.

1. Introduction
최근 모바일 카메라의 보급이 늘어나며 문서를 촬영해 스캔하는 것이 문서를 스캔하는 가장 간편한 방법이 되었다. 이렇게 촬영된 문서들은 주머니 속에서 구겨진 영수증처럼 손상되거나 왜곡된 상태로 촬영된다.
- 먼저 왜곡된 문서 이미지를 적절하게 복원하는 방법을 공식화했다.
- 원본 이미지 를 픽셀 단위로 결과 이미지 로 매핑하는 함수를 찾는 것.
- 이렇게 공식화했을 때, 이 task는 semantic segmentation과 유사하다고 볼 수 있음.
- semantic segmentation: 픽셀 단위로 어떤 class에 속하는지 분류하는 task
- Paper's task: 픽셀 단위로 어떤 2차원 벡터로 변환되는지 회귀예측하는 task
- 분류 문제인 semantic segmentation과 다르게 본 연구의 task는 회귀 문제이기 때문에 손실함수를 새롭게 정의해야함.
3. Dataset
- 실생활에서 어떤 2차원 벡터로 변환되었는지 실제 레이블이 있는 대규모 데이터를 얻는 것은 불가능에 가깝다. 따라서 학습을 위해 합성한 가데이터를 100,000장 생성했다.
- 무작위로 비틀어 mesh grid를 생성하고 이에 맞추어 문서 이미지를 왜곡함.
- 모델의 평가를 위해 공개적인 벤치마크로 사용될 데이터셋이 없다.
- 여러 실생활 촬영조건을 만들어 130개의 이미지를 직접 촬영하여 동일 task에 벤치마크 데이터셋을 생성함.
3.1. Distorted Image Synthesis in 2D
Perturbed mesh generation
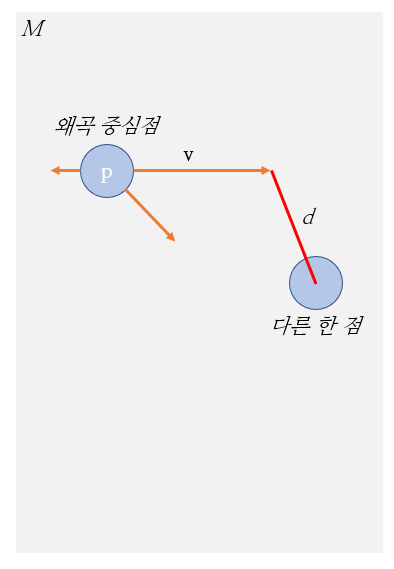
1. 이미지 가 주어지면 이를 왜곡하기 위한 mesh grid 을 생성한다.
2. 안에 임의의 정점 가 왜곡의 기준점으로 채택된다.
3. 왜곡의 방향 및 강도가 로 정의되며 랜덤하게 생성된다.
4. 안에 를 제외한 다른 정점들에게 이 왜곡이 전달되는 정도인 가중치 를 정의한다.
- for folds:
- for curves:
- 는 안의 를 제외한 다른 정점들과 와의 거리.
- 는 왜곡이 전파되는 정도.
- 가 보다 1정도 크면 왜곡을 전역적으로 만들겠다는 의미.
- 가 충분히 작은 값이면 왜곡을 왜곡 중심점 주변에만 지역적으로 왜곡을 만들겠다는 의미.

논문의 저자들이 의도한 바를 나름대로 해석하면 아래와 같을 것 같다.
Perturbed image generation

4. DocUNet
4.1. Network Architecture
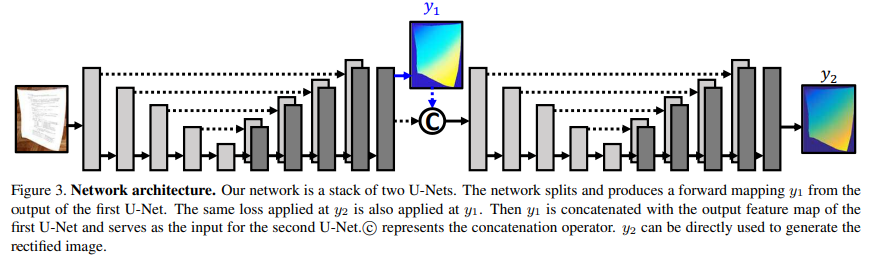
[그림 3]처럼 U-Net을 두 번 쌓은 구조를 가지고 있다.
- 첫 번째 U-Net은 1차 예측 결과 과 feature map을 결합(concatenate)하여 두 번째 U-Net에 입력으로 전달한다.
- 두 번째 U-Net에서 refined 예측 결과 를 output으로 출력한다.
- 과 에 학습할 때는 동일한 손실함수를 동일하게 적용했다.
- 실제로 적용할 때(test할 때)는 만 실제 결과값으로 사용했다.
- input:
- output:
- from distorted image to the rectified image
일반적인 Semantic segmentation과 다른 점
- semantic segmentation의 output은
- 는 클래스의 갯수만큼 classification!
- 논문에서 제안하는 task의 output은
- 좌표를 회귀 예측하는 regression문제이다
- 공간 하나는 좌표 값, 다른 하나는 좌표 값.
4.2. Loss Function
모델의 최종 손실함수는 element-wise loss와 shift invariant loss의 조합으로 구성했다.
element-wise loss
- 일반적인 Mean Squared Error의 구성
- 의 픽셀 수
- 모델의 예측 값
- 모델의 ground truth
shift invariant loss
- 는 의 값이 얼마나 잘 예측하는지에는 관심이 없다.
- 변환 전 픽셀과 변환 후 픽셀이 최대한 멀리 떨어지지 않도록 방지하기 위한 손실함수로 해석된다.
combination
로 했을 때, 를 다시 정리해보면,
첫 번째 항이 단순 element-wise loss임을 알 수 있다.
두 번째 항은 예측 값에서의 두 픽셀 값 사이의 거리가 실제 값에서의 거리와 비슷할 경우 손실함수를 줄여주는 역할을 한다.
이는 Scale-Invariant Error로 알려져 있는데, 논문의 저자들은 반복 실험을 통해 loss보다 loss를 사용하는게 더 낫다는 것을 발견하여 loss를 사용하였다.
따라서 최종 손실함수는
- 는 두 번째 항의 강도를 조절하는 역할, 논문에서는 모든 실험에 을 사용했다.
hinge loss for background pixels
[그림 5]의 샘플을 보면 약간의 배경을 가지고 있음을 알 수 있는데, 이 배경 픽셀들에는 음수 값 이 할당되어 있다. 모델이 학습할 때는 이를 어느정도의 음수 값으로만 예측하도록 해도 되며 꼭 로 예측을 강제할 필요는 없다. 따라서 배경 픽셀에 대해서는 hinge loss를 아래와 같이 적용했다.
이는 전경(문서) 픽셀에는 적용하지 않았다.
5. Experiments
5.1. Benchmarks
Images & Ground truth: 다양한 환경에서 다양한 contents와 format을 가진 문서 65장을 두 번씩 촬영하여 총 130장의 이미지를 만들었다. 타이트하고 평평하게 펼쳐지게 스캔된 문서들을 label로 가지고 있다.

Evaluation Scheme: 이전의 연구들에선 두 가지 평가 항목이 제안되었다.
- OCR의 정확도를 기반한 평가
- 이미지의 유사도를 기반한 평가
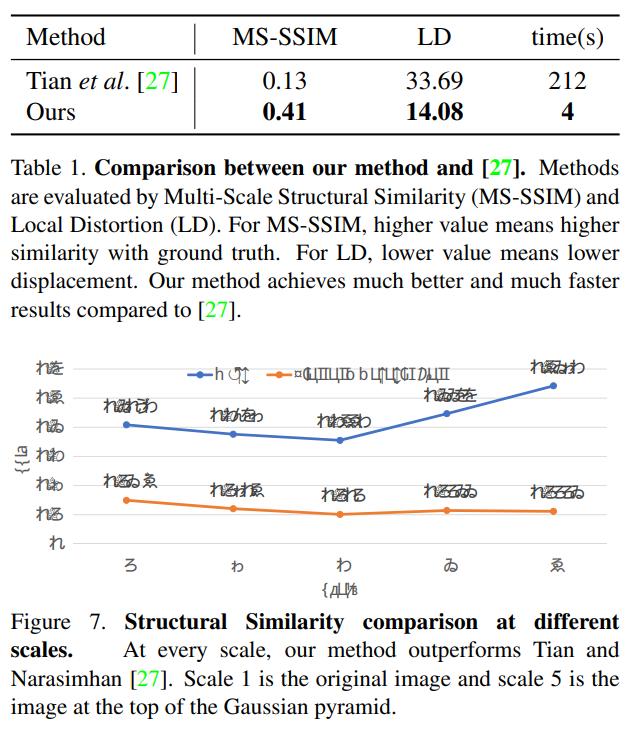
논문에서는 두 번째 방법을 택했으며, 첫 번째 방법이 OCR의 모듈의 성능에 따라 크게 좌우된다는 것을 이유로 들었다. 이미지 유사도를 측정하기 위한 척도로는 MS-SSIM (Multi-Scale Structural Similarity)와 LD (Local Distortion)으로 선택했다.
5.3. Results