[paper-review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Paper Review
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. 올바르지 못한 내용에 대한 피드백을 환영합니다 :)
1 Introduction
[@ 개요]
Transformer로 불리우는 Self-attention 기반의 모델은 자연어 처리(NLP; Natural Language Processing)에서 주류가 되었다. 거대한 말뭉치(corpus)에 학습되어 여러 작은 특정 태스크에 미세조정되기 간편해지며 많은 연구에서 사랑받고 있는 모델이다.
하지만 컴퓨터 비전(Computer Vision)에서는 여전히 CNN이 폭넓게 사용되고 있다. NLP에서의 Transformer의 성공을 기반으로 많은 연구들이 CNN을 일부분 혹은 전부 대체하려는 시도들이 많이 있었는데, CNN을 Transformer로 전부 대체하려는 연구들은 컴퓨팅 비용 측면에서는 비용을 많이 줄이는 등의 효과가 있었지만 성능면에서 ResNet 기반의 아키텍처 등에 뒤떨어지는 모습을 보였다.
[@ Vision Transformer (ViT)]
NLP에서의 Transformer scaling successes에 영감을 받아 가능한 최소한의 수정을 거친 Standard Transformer를 곧바로 이미지에 적용하는 실험을 진행했다.
이미지를 몇몇 패치(patch)들로 나누고 이 패치들을 선형 임베딩(Linear embedding)에 통과시켜 임베딩으로 만들고 이를 시퀀스로 만들어 Transformer의 입력으로 주어질 수 있도록 했다. 이렇게 입력 이미지에서 쪼개진 패치들은 NLP에서의 "token"들과 같은 단위로 취급될 수 있다.
ImageNet과 같은 mid-sized 규모의 데이터셋에서 별다른 강력한 제약없이 위 모델을 학습시킬 경우 ResNet 계열의 모델보다 몇 퍼센트나 낮은 결과를 보였다. 여기서 저자들은 Transformer에는 inductive bias가 CNN에 비해 많이 부족하다고 생각했다.
- Inductive bias
- translation equivariance: 이미지 내에서 물체의 위치가 바뀌어도 그 특성을 똑같이 잡아낼 수 있는 능력 - 참고: https://ganghee-lee.tistory.com/43
- localty: Transformer는 역시 global한 상관관계(멀리 떨어진 요소들 간의 상관관계)를 훌륭하게 잡아낼 수 있지만 지역적인 상관관계(가깝게 붙어있는 요소들 간의 상관관계)를 잡아내는 데에는 CNN만한 것이 없다.
하지만 거대한(14M ~ 300M) 규모의 데이터셋에서 모델이 학습된다면 상황이 바뀐다. 저자들은 이 경우 대규모 학습이 영향이 inductive bias의 부족함에 대한 영향을 충분히 압도한다는 것을 관찰했다.
또한 대규모 데이터셋에서의 사전 학습 이후에 소규모 데이터가 있는 작업으로 전이학습(transfer learning)에 사용될 때 우수한 결과를 보임을 확인했다.
2 Related Work
[@ Transformer]
- Vaswani et al. - 기계 번역(Machine translation) task에 Transformer가 처음으로 제안되었지만 이후 많은 NLP분야 state-of-the-art 방법론의 기조가 되었다.
- Devlin et al. & *Radford et al. - Transformer는 대규모 말뭉치에서 사전 학습되고 이후 각각 task에 맞게 미세조정(fine-tune)하여 사용되고 있다.
- * Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding with unsupervised learning. Technical Report, 2018.
[@ Naive application of self-attention to images]
Transformer의 근간이 되는 Self-attention을 이미지에 사용하는 가장 Naive한 방법은 이미지의 모든 픽셀에 대해 다른 모든 픽셀에 관한 상관관계를 계산하는 것이다. 이 방법은 이미지의 픽셀 수에 대해 4제곱으로 계산 복잡도가 증가하기 때문에 실해상도에 해당하는 이미지에 대해선 적용되기 어려웠다.
- Parmar et al. - 각 픽셀에 대해 다른 모든 픽셀에 대해 계산하지 않고 local neighborhood 픽셀 들에 대해서만 self-attention을 계산했다.
- Hu et al., Ramachandran et al., Zhao et al. - 이렇게 지역적으로만 self-attention을 계산하는 것은 convolution을 대체할 수 있을 것이라 생각한 연구도 있었다.
- Child et al. - Sparse Transformer는 scalable approximations를 global self-attention에 적용하여 이미지에 사용될 수 있도록 했다.
- Weissenborn et al., Ho et al., Wang et al. - scale attention을 사용하는 또다른 방법은 각기 다른 크기의 block에 self-attention을 적용하는 것이다.
[@ Related works with ViT]
- Cordonnier et al. - 크기의 patch를 입력 이미지에서 추출하고 마지막에 full self-attention을 적용했다. 본 논문의 연구에선 바닐라 Transformer 모델이 대규모 사전 학습을 거쳐 CNN 기반 모델보다 더 나아질 수 있음에 초점을 맞추고 있다.
- Chen et al. - image GPT (iGPT)는 이미지의 해상도와 색 영역을 줄인 후에 Transformer를 적용하는 모델이다. 이 모델은 생성 모델처럼 비지도학습 방법으로 학습된다.
3 Method
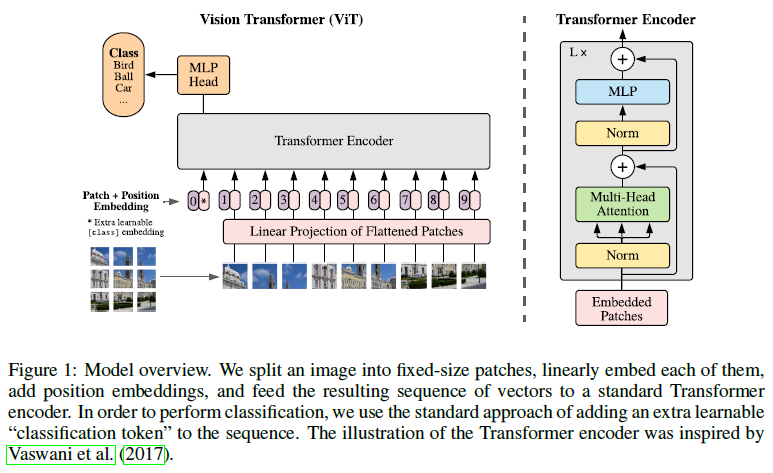
3.1 Vision Transformer (ViT)
- 입력 이미지 를 Transformer의 입력 형태인 1D 토큰 시퀀스로 변환
- , 기존 입력 이미지의 해상도
- , 기존 입력 이미지 채널 수
- , 입력 이미지를 쪼갠 패치의 크기
- , 패치의 수
아래는 한 이미지 패치를 flatten하는 과정을 나타낸 것이다.
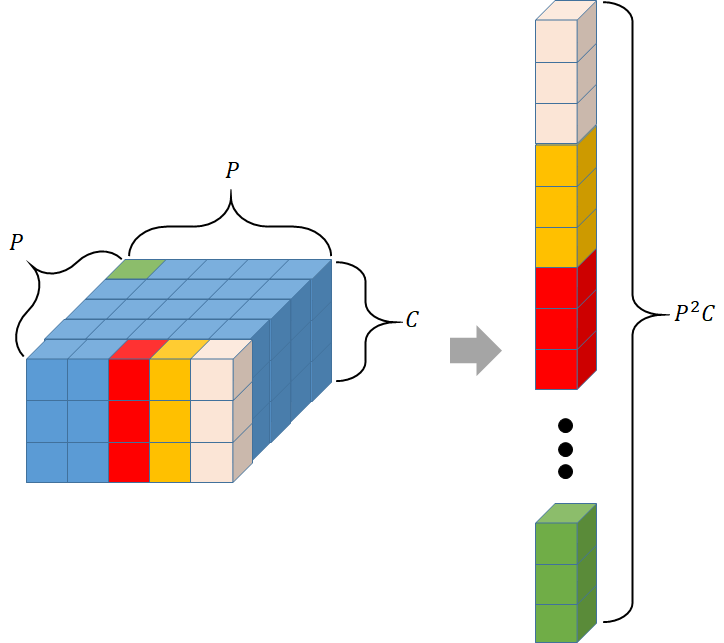
이것을 다시 Transformer의 선형 임베딩 를 통해 입력 차원 로 매핑한다.
[@ Position embedding]
또한 ViT에는 Self-attention만 있기 때문에 위치 정보를 제공해줄 position embedding ()을 더해주어야 한다. position embedding에는 2D 위치정보를 제공해주는 것도 실험해봤지만 눈에 띄는 성능 향상이 없어 기존 1D position embedding을 사용했다고 언급하고 있다.
[@ CLS token]
concatenated patch embedding에 가 추가되고 positional embedding, 의 차원도 로 1이 추가되어 있음을 확인할 수 있는데, BERT에서의 [class]토큰처럼 클래스 정보를 모델에 제공해주었기 때문이다.
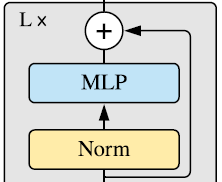
[@ Transformer encoder]
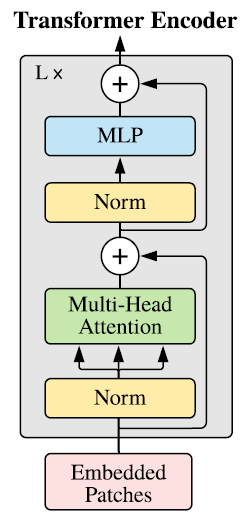
기존 Transformer 구조와 비슷하게 구성되어 있다. 위와 같은 Transformer encoder block이 번 반복되어 feature를 만들게 된다.
- : Multi-head Self-Attention
- : Layer Norm, Normalization Layer
- : Multi-Layer Perceptron, 논문에서는 "GELU" activation function을 사용한다.
- : output of Transformer encoder blocks
[@ Inductive bias]
앞서 저자들은 Vision Transformer가 이미지에서의 inductive bias가 더 적다고 언급했다.
CNN에서는 전체 모델에 걸쳐 localty 및 2차원 neightborhood structure나 translation equivatiance 등의 inductive bias가 각 레이어에서 반영된다.
하지만 ViT에선 MLP에서만 이러한 특징들이 반영될 수 있으며 self-attention 레이어들은 모두 전역적인 상관관계를 잡아내는 데 특화된 레이어이다.
[@ Hybrid Architecture]
이미지 패치를 단순 시퀀스로 펼쳐서 사용하는 대신 CNN의 feature map을 사용하는 방법이 대안이 될 수 있다. 입력 이미지를 다양한 CNN을 통해 feature map을 추출하고 flatten -> Transformer의 입력 차원으로 projection을 수행하면 Transformer의 입력 시퀀스의 형태로 변환할 수 있다.
3.2 Fine-Tuning and Higher Resolution
ViT는 이전의 Transformer가 그랬던 것처럼 사전에 거대한 데이터에 학습되고 downstream task 목적에 맞게 미세 조정되어 사용되는 것이 더욱더 효과적이다. 사전에 학습된 prediction head를 제거하고 0으로 초기화된 feedforward 레이어를 추가하여 downstream task의 클래스 수에 맞게 결과값의 형태를 변형해주었다.
[@ position embedding interpolation]
- 높은 해상도의 이미지로 미세 조정을 할 때 유용한 점이 많았다.
- 이 때에도 patch size는 동일하게 유지했고 그 결과로 입력 시퀀스의 길이가 달라지게 된다.
- 입력 시퀀스는 길이가 달라지더라도 괜찮지만 이와 동반하는 position embedding은 더 이상 의미를 가지지 못하게 된다.
- 따라서 2D interpolation을 통해 사전학습된 position embedding에 변화를 주었다.
4 Experiments
4.1 Setup
[@ Datasets]
- Train
- ILSVRC-2012 ImageNet: 1K classes, 1.3M images
- ImageNet-21K: 21K classes, 14M images
- JFT: 18K classes, 303M high-resolution images
- transfer learning
- ImageNet: original validation set, ReaL labels는 제거
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- VTAB: 1000개의 작은 학습 샘플을 통한 미세조정을 통해 전이학습의 성능을 파악하는 classification suite이다. 세 가지 task는 아래와 같이 구성된다.
- Natural - Pets, CIFAR, etc.
- Specialized - medical and satelite imagery
- Stuructured - geometric understanding
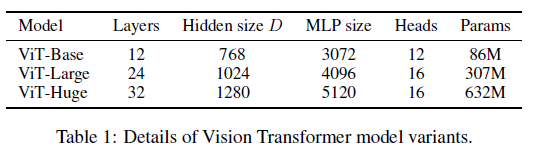
[@ model variants]
Devlin et al.에서의 BERT 세팅과 동일하게 설정
ViT-L/16은 Large모델의 patch size를 적용한 모델을 나타낸다. 저자들은 patch size가 줄어들수록 입력 이미지가 더 잘게 쪼개지며 Transformer encoder의 입력 토큰 수가 늘어나므로 계산량이 더 늘어난다고 강조하고 있다.
[@ Baseline CNNs]
- ResNet (BiT)
- ResNet 베이스
- Batch Normalization을 Group Normalization으로 대체
- 대체함으로써 전이 학습의 성능을 올릴 수 있음
- Hybrids model (Section 3.1의 [@ Hybrid Architecture])
- CNN feature map의 한 픽셀을 하나의 Transformer 입력 토큰의 크기(=patch size)으로 함
- (i). regular
ResNet50의Stage 4output을 사용 - (ii). (i)에서의 모델에서
Stage 4를 제거하고Stage 3의 output을 사용
단, (i)과 (ii)의 output 레이어 수를 동일하게 하기 위해 (ii)의 output인Stage 3의 레이어 수를Stage 4의 레이어 수와 같게 하였음
- (i). regular
- CNN feature map의 한 픽셀을 하나의 Transformer 입력 토큰의 크기(=patch size)으로 함
[@ Training & Fine-tuning]
- From scratch
- Adam optimizer,
- batch size
- weight decay
- Fine-tuning
- SGD optimizer
- batch size
- High resolution
- for
ViT-L/16 - for
ViT-H/14
- for
[@ Metrics]
Fine-tuning에 대한 결과를 few-shot accuracy 또는 fine-tuning accuracy로 평가했다.
- Fine-tuning accuracy - 각각 fine-tuning 대상인 downstream 데이터셋에 대한 정확도를 의미한다.
- Few-show accuracy
- Fine-tuning accuracy를 계산하기에 downstream 데이터셋이 너무 큰 경우에 대체적인 척도
- 학습 이미지의 특징 표현(representation)을 로 정의되는 target vector로 "Regulizerd least-squares regression"으로 풀어내는 과정에서 퍼포먼스를 측정한다.
- 는 downstream 데이터셋의 클래스 수
4.2 Comparison to State of the Art
본 논문에서 제안하는 ViT-L/16이 기존 State-of-the-art 방법들에 비해 성능도 좋았으며 컴퓨팅 비용 면에서도 효율적이었다. 심지어 더 큰 모델 ViT-H/14는 이를 더 뛰어넘는 성능을 보였다.
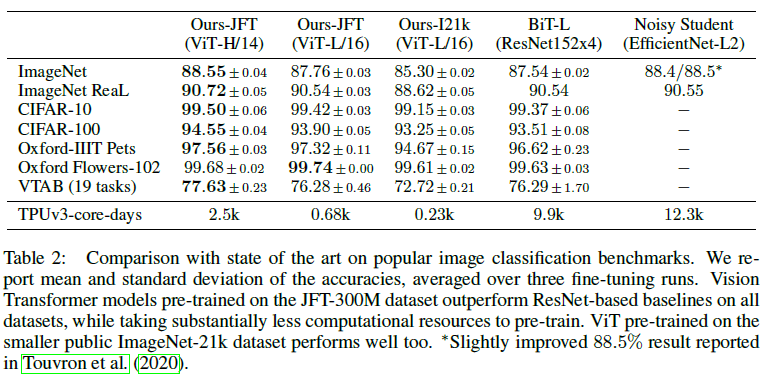
4.3 Pre-training Data Requirements
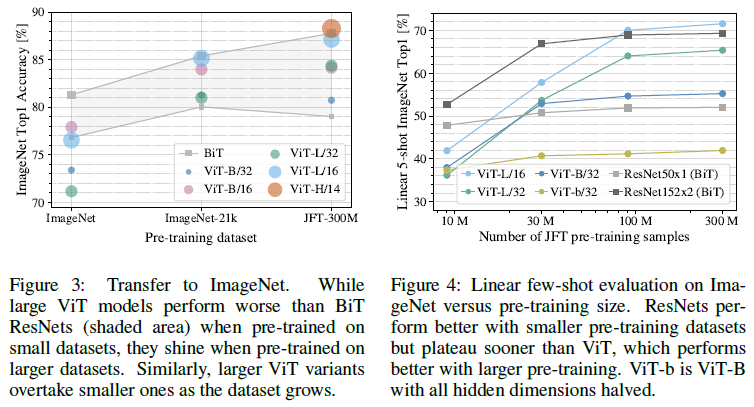
Figure 3. Vision Transformer는 거대한 대규모 데이터셋인 JFT-300M에 사전 학습했을 때 좋은 성능을 보였다.
- ImageNet에 학습할 때에는 weight decay, dropout, label smoothing과 같은 다양한 regularization을 적용했음에도 기존 ResNet 기반 모델보다 성능이 좋지 않았다.
- ImageNet-21K에 학습할 때에는 기존 ResNet과 성능이 비슷하다.
- JFT-300M에 학습했을 때에만 기존 모델의 성능을 뛰어넘을 수 있었다.
Figure 4. 두 번째로 JFT-300M에 랜덤 샘플링을 거쳐 각각 9M, 30M, 90M 크기의 subset을 만들어 실험을 진행했다. 다른 추가적인 regularization이나 hyper-parameters의 세팅을 모두 동일하게 진행했다.
- 역시 작은 크기의 데이터셋에서 학습할 경우 기존 방법들이 더 성능이 좋았다.
- CNN의 inductive bias가 작은 데이터셋에는 효과적으로 작동할지 모르지만 데이터가 굉장한 규모로 주어질 때는 이미지 내의 패턴들을 곧바로 학습하는 것이 효과적임을 알 수 있었다.
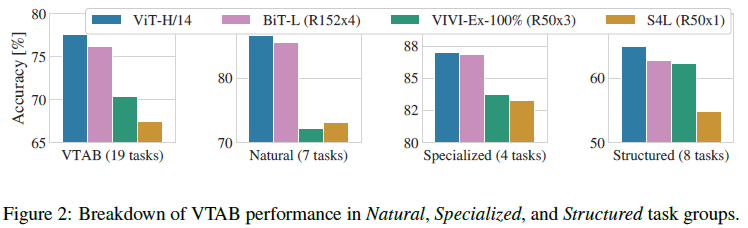
4.4 Scaling Study
여기에서는 JFT-300M에서 사전학습하고 전이 학습에서의 성능을 비교한다. ResNet 기반의 세팅 7가지, Vision Transformer 6가지, Hybrids 모델 5가지 세팅을 비교한다.
[@ Figure 5.]
- Vision Transformer는 ResNets 보다 performance/compute의 trade-off를 두 배에서 네 배 가량 압도하는 모습을 보였다.
- Hybrid 모델들은 계산 비용이 적었을 때 Vision Transformer의 성능을 앞서는 모습을 보였다. 이는 계산 비용이 늘어남에 따라 그 차이가 줄어들기는 한다.
4.5 Inspecting Vision Transformer
[@ How the Vision Transformer processes image data]
Vision Transformer의 첫 레이어는 flattened 이미지를 저차원으로 매핑하게 된다. 이 과정에서 학습된 embedding filter의 상위 구성요소를 시각화 했을 때(Figure 7. Left), CNN에서 볼 수 있었던 저차원에서의 basis function 들을 닯아있음을 볼 수 있다.
[@ position embedding]
Transformer encoder로 입력이 주어지기 전에 position embedding을 각각 토큰에 추가해주었다. 이 각 패치에서 학습된 position embedding의 유사도를 시각화 했을 때(Figure 7. Center), 각 패치들이 비슷한 위치에 있을 때 비슷한 position embedding을 가지는 것을 볼 수 있다.
이를 통해 이미지 내부의 거리 개념을 encoding하고 있음을 알 수 있다.
[@ Can Self-attention allows ViT to see the entire image?]
Self-attention이 실제로 이미지 전체에 대해서 정보를 취합할 수 있도록 하는지 살펴본다.
이미지 내부에서 정보가 결합되는 공간 간의 거리의 평균을 attention 가중치를 기반으로 계산했고 이를 시각화 했다.(Figure 7. Right)
모델의 낮은 레이어에서부터 이미지 전체에서 정보를 결합함을 확인할 수 있다. 점점 레이어 위치가 높아질수록 평균 attention distance가 좁아지며 local하게 정보를 결합한다.

attend하는 물체도 의미있는 단위로 모델이 잘 attend하고 있음을 Figure 6.에서 확인할 수 있다.

