Vaswani, Ashish, et al. "Attention is all you need." arXiv preprint arXiv:1706.03762 (2017).
Abstract
- 시퀀스 형태의 데이터를 다루는 모델은 Recurrent, Convolutional 형태를 기반으로 한다.
- 이러한 RNN, CNN을 모두 배제하고 Attention 메커니즘만으로 구성한 Transformer를 소개한다.
2. Background
- RNN을 기반으로 하는 모델들이 좋은 성능을 보여주었지만, RNN의 구조적인 한계로 인해 Long-term dependency의 문제를 항상 동반했다.
3. Model Architecture
Transformer는 아래의 특징을 가진다.
- encoder-decoder의 형태를 따른다.
self-attention,point-wise의 stack으로 encoder 및 decoder가 구성된다.- 이 모든 요소들은 fully connected layer로 구성된다.
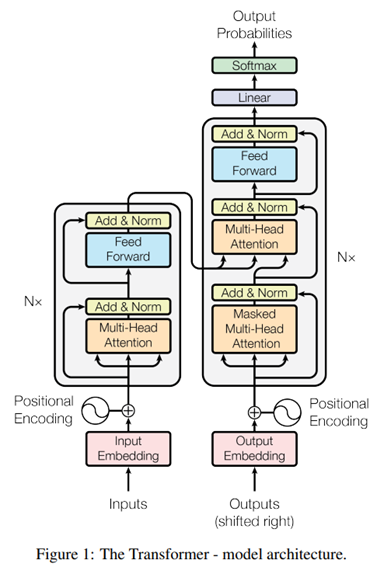
3.1. Encoder and Decoder Stacks
Encoder. 총 6개의 layer의 stack이다.
- 두 개의 multi-head self-attention layer
- 두 개의 position-wise fully connected feed-forward network layer
- 두 개의 normalization network layer
위의 그림 1처럼 residual한 연결()로 모델이 구성된다.
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2Decoder. decoder 역시 6개의 layer로 구성된다.
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2decoder에서 encoder와 다른 점은
- encoder의 결과를 사용해 multi-head attention을 수행할 layer가 하나 더 있다는 것
- decoder는 뒷 부분의 단어를 참고하지 않고 결과를 예측해야 하기 때문에 뒷 부분의 정보는 가린다(masking)는 점.
- 즉, 번째에 대한 예측은 번째의 정보를 반영해선 안된다.
3.2. Attention
3.2.1. Scaled Dot-product Attention
본 논문에서 사용하는 attention function은 Scaled Dot-product Attention으로 부르고 있다.
예시로, "Thinking Machines"라는 문장을 입력 받았을 때,
- 는 해당 단어에 대한 임베딩 벡터이다. (논문에서는 차원으로 했다.)
- 이 때, Query, key라는 차원의 벡터를 각 단어의 임베딩 로 부터 만든다.
- 동일하게 value라는 차원의 벡터를 각 단어의 임베딩 로 부터 만든다.
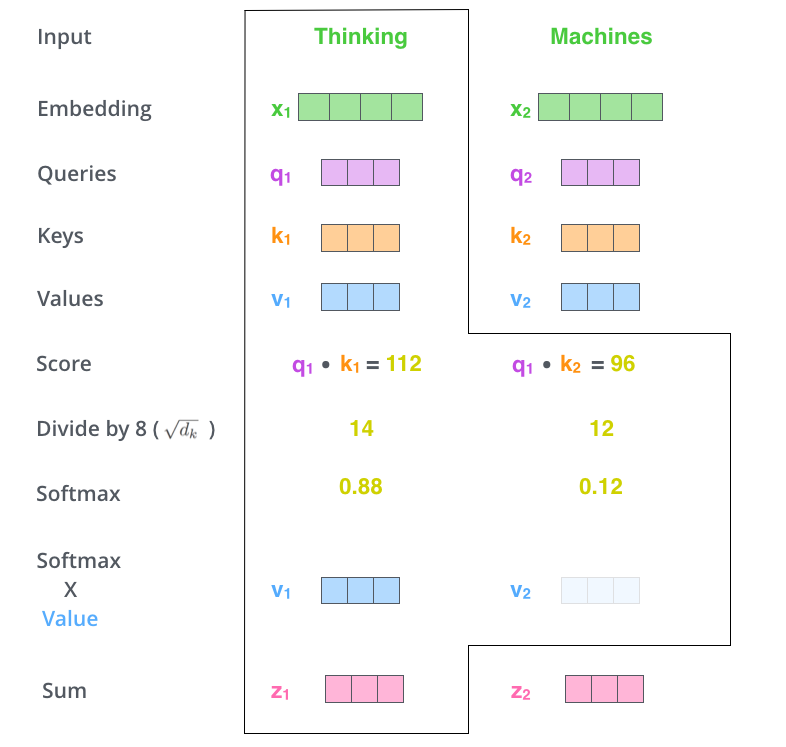
실제 학습시에는 벡터로 계산하지 않고 행렬로 통합하여 계산한다.
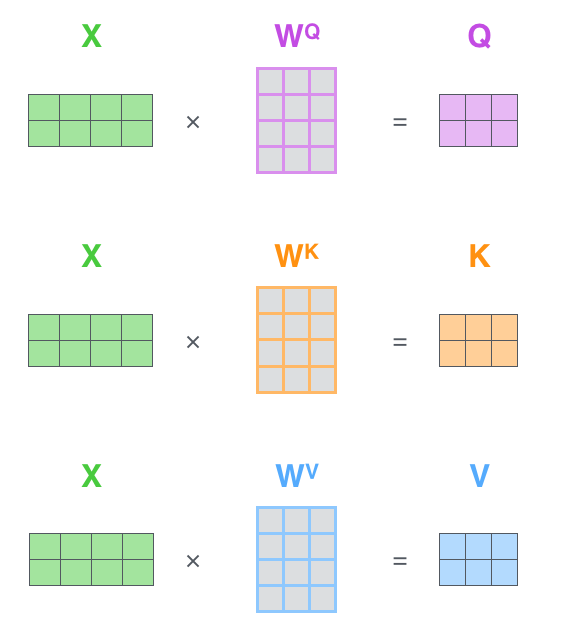
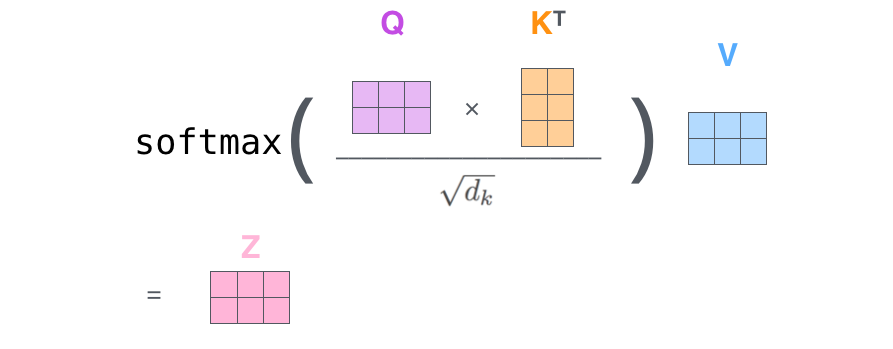
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights3.2.2. Multi-Head Attention
위의 Scaled Dot-product Attention의 병렬적인 계산을 수행하는 Multi-head Attention을 적용하면 다음의 두 가지 장점이 있다.
- 한 문장을 "Multi-head의 개수"번 만큼 여러번 살펴보면 각 Multi-head는 같은 한 문장을 여러 각도로 살펴보게(attention) 된다.
- 한 문장을 여러 부분으로 나누어 서로서로 Multi-head가 어떻게 서로를 바라보는지 다양한 정보를 취합할 수 있게된다.
논문에서는 head의 수를 8개로 했다.
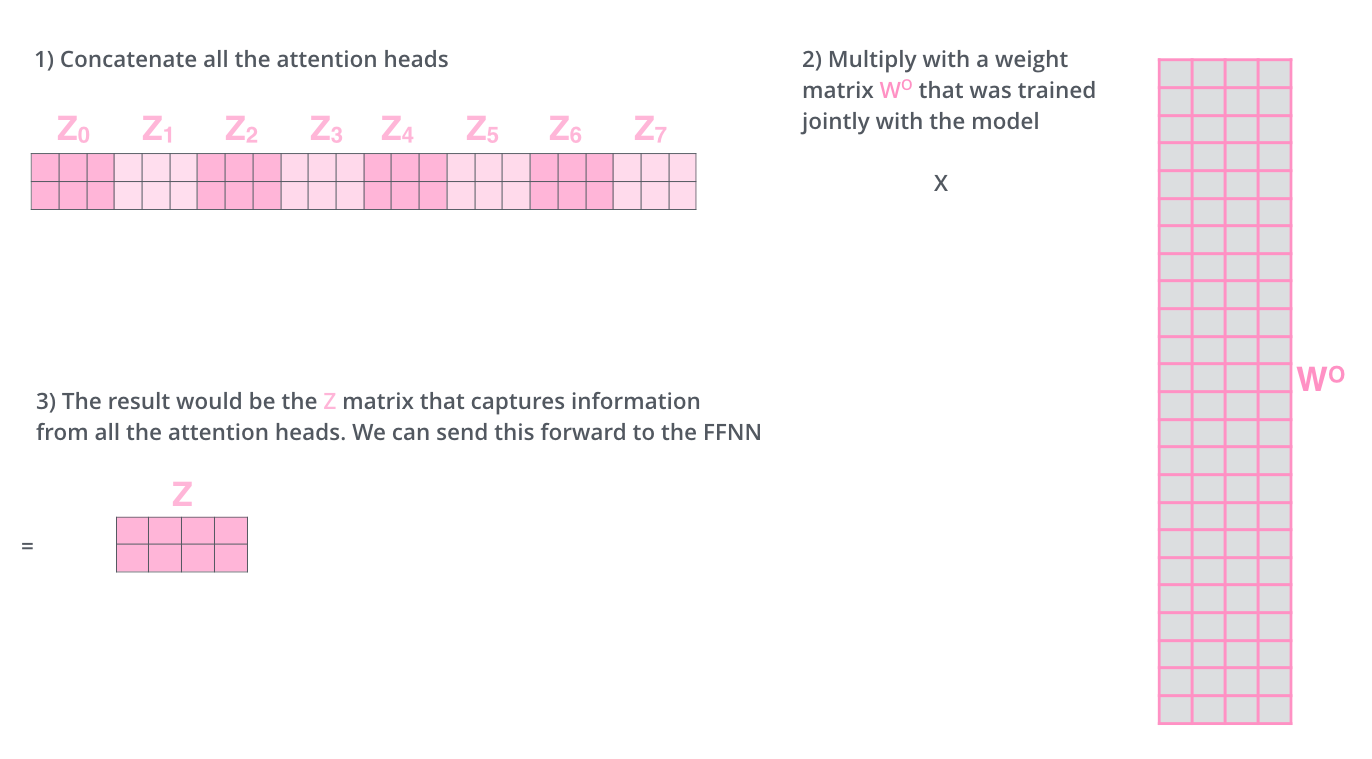
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights3.3. Position-wise Feed-Forward Networks
encoder와 decoder에는 fully connected feed-forward network도 함께 구성되어 있다.
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])3.5. Positional Encoding
현재까지 attention 메커니즘만을 이용했기 때문에, Sequential 정보는 전혀 포함되지 않았다.
따라서 단어 임베딩 에 "positional encodings"를 더해주어서 문장의 "순서" 정보를 제공한다.
positional encodings은 단어 임베딩 와 같은 차원 수, 을 갖는다.
는 문장에서의 단어 위치이고, 는 단어 임베딩 벡터의 차원, 인덱스를 나타낸다.
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)4. Why Self-Attention
- layer 당 총 계산 복잡도의 완화
- 계산의 병렬 처리 가능
- 멀리 떨어진 단어 간의 연관성(long-range dependencies)을 학습 가능
5. Training
5.1. Training Data and Batching
- WMT 2014 English-German
- size: 4.5 million sentence pairs
- source-target vocab size: 37000 tokens
- WMT 2014 English-French
- size: 36 million sentence pairs
- source-target vocab size: 32000 tokens
5.3. Optimizer
Adam optimizer with
아래와 같은 규칙으로 learning rate를 조정
이는 첫 만큼은 선형적으로 증가하다가, 그 이후엔 첨자 감소하게 된다.
으로 설정했다.
5.4. Regularization
Residual Dropout 각 sub-layer에 입력과 normalization layer 중간에 dropout을 수행했다. 기본적으로 을 설정했다.
encoder와 decoder의 선언을 했던 코드 블럭을 참고하면 쉽게 이해할 수 있다.
Label Smoothing 의 label smoothing을 적용했다. 이유는 모르겠지만 BLEU 점수는 향상시켜주는 효과가 있었다.
7. Conclusion
- 시퀀스 변환 모델 (sequence transduction model) 중 최초로 encoder-decoder에 recurrent layer를 배제하고, attention만을 사용한 모델 Transformer를 설계
- 또다른 attention-based 모델의 미래가 기대되며, 다른 task에 적용될 수 있을 것으로 예상됨.
참고자료
[1]. 정민수님의 "Attention is All You Need(transformer) paper 정리"
[2]. Tensorflow <Transformer> Tutorial
