[paper-review] SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
Paper Review
Bai, Yancheng, et al. "Sod-mtgan: Small object detection via multi-task generative adversarial network." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
Abstract
- 작은 물체의 탐지(small object detection)의 문제는 기존의 object detection의 주된 연구 주제가 아니었다.
- Multi-task Generative Adversarial Networks(MTGAN)을 소개한다.
- MTGAN은 object detector가 탐지해낸 작은 크기의 이미지를 입력으로 받아 아래 세 가지를 예측하게 된다.
- Generator:
- 저해상도 이미지를 통해 고해상도의 이미지로 변환
- Discriminator:
- 고해상도의 이미지가 원래 고해상도인지 Generator가 만든 고해상도 이미지 인지
- 물체의 클래스
- 더 정확한 bounding box
- Generator:
1. Introduction
- 작은 물체는 그 물체 자체에 object detector들이 탐지하기에 그 물체와 배경을 구분하기에 충분한 정보가 담겨 있지 않기 때문에 작은 물체를 탐지해내는 것은 항상 어려운 문제이다.
3. MTGAN for Small Object Detection
3.1. GAN
먼저, 전체적인 MTGAN의 손실함수는 기존 GAN의 형태를 따르고 있다.
- 은 각각 저해상도, 고해상도 이미지
- 는 클래스 레이블, 는 ground-truth bounding box
- 는 각각 의 파라미터
특이한 점은 생성 모델 의 입력 값이 랜덤 노이즈가 아니라 저해상도 이미지라는 점이다.
또, 판별 모델 가 단순히 의 학습을 돕는 용도로만 사용되지 않고 (1) 물체의 클래스 정보, (2) bounding box도 예측한다는 점이다.
3.2. Network Architecture
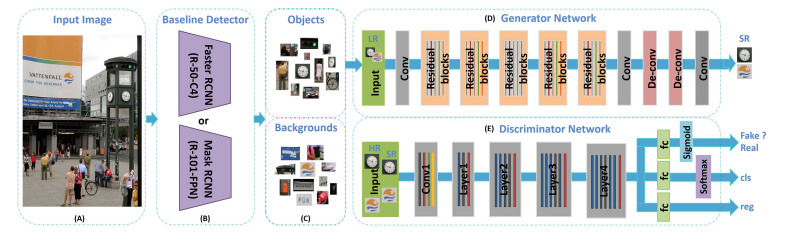
Generator Network ()
- 생성 모델은 먼저 baseline detector가 예측한 물체 영역을 잘라내 입력으로 받는다.
- 이는 저해상도(low-resolution; LR) 이미지이고, 생성 모델 를 거쳐 초고해상도(super-resolved; SR) 이미지가 된다.
Discriminator Network ()
- ResNet-50이나 ResNet-101과 같은 CNN을 거쳐 세 갈래의 fully-connected layer( layer)로 갈라진다.
- : 기존 GAN모델의 판별 모델이 하던 고유의 기능, 생성 모델이 만든 이미지인지 진짜 고해상도 이미지인지 판별하는 기능이다.
- : 물체의 클래스 카테고리를 분류하는 기능을 한다.
- : bounding box의 좌표 값들을 회귀 예측(regression)한다.
3.3. Overall Loss Function
pixel-wise loss.
이미지의 유사도를 나타내는 손실이다. 단순 픽셀끼리의 차이를 Mean Squared Error (MSE)로 계산한다.
이 손실을 그대로 사용하면 선명한 이미지를 생성하지 못하고 smooth한 텍스쳐의 blurred 이미지를 만들게 된다.
Adversarial loss.
이미지를 선명하게 만들 수 있도록 adversarial loss의 도입이 필요하다.
Classification loss.
물체의 클래스의 분류를 위한 손실이다.
는 위에서 언급한 로 볼 수 있다.
Regression loss.
bounding box의 더 정확한 위치 지정을 위한 손실이다.
- : true bounding box의 좌표 값들로 이루어진 벡터
- : 가 예측하는 bounding box 좌표 값들로 이루어진 벡터
- bounding box 좌표값들의 차이를 최소화하려는 의미를 담고 있다.
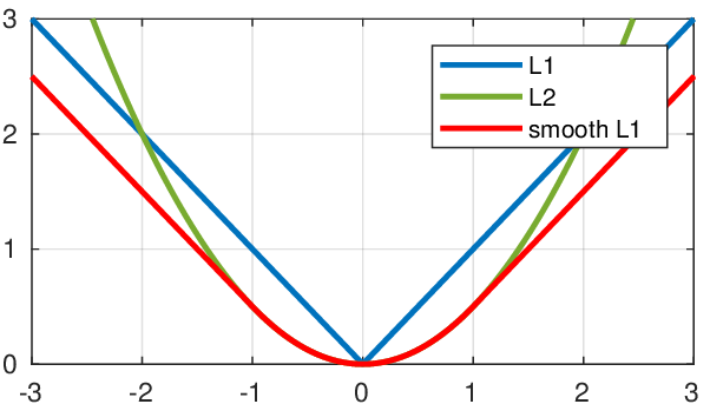
- 의 사용은 loss와 loss의 장점을 모두 가져갈 수 있게 한다.
- 의 의미는 이 입력받은 이미지가 물체를 담고 있을 경우에만 이 손실을 더해준다는 의미이다. 즉, 물체를 담고 있지 않으면 bounding box의 손실은 제외된다.
- 아마 이 배경(background)를 의미하는 클래스 넘버인듯?
Objective Function.
최종 손실함수는 아래와 같이 정의된다.

4. Experiments
4.1. Training and Validation Datasets
- COCO 데이터셋을 모든 실험에서 사용했으며 물체의 크기가 large/medium/small인 기준은 아래와 같다.
- Large: 이상의 픽셀 사이즈를 가지는 물체
- medium: 이상, 미만의 픽셀 사이즈를 가지는 물체
- small: 미만의 픽셀 사이즈를 가지는 물체
- 대략적으로 COCO 데이터셋의 41%의 물체가 small 사이즈를 갖는다.
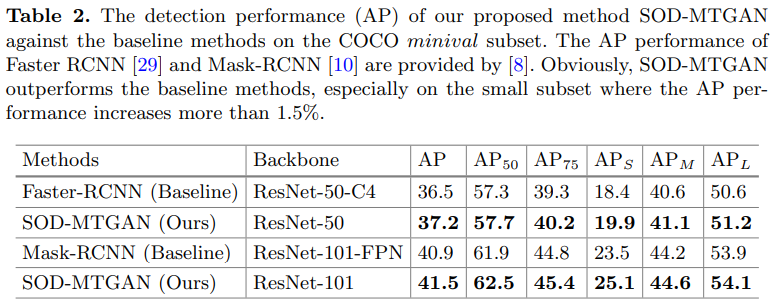
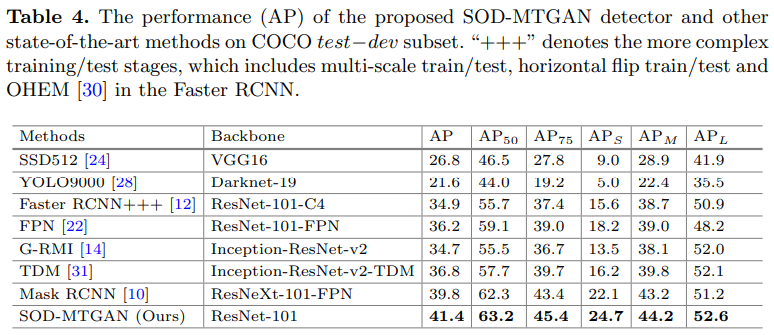
작은 물체에서의 정확도()에서의 향상폭이 높은 모습을 볼 수 있다.
4.3. Ablation Studies
(1) Influence of the Multi-task GAN (MTGAN).
Table 2의 결과를 보면 MTGAN의 영향력을 볼 수 있다.

(2) Influence of the Regression Branch.
- 기존 object detector가 작은 물체에 대해 bounding box를 약간 빗나가게 잡아주던 것을 MTGAN에서 다시 바로 잡아주면서 영향력을 발휘하고 있다.
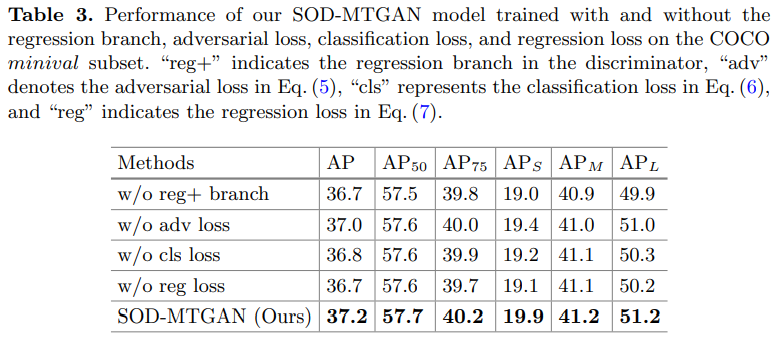
- Table 3의 첫 번째줄과 다섯 번째줄의 결과 차이는 0.9%로 나타나고 있다.
(3) Influence of the Several Losses.
- Adversarial loss: object detection에 중요한 정보인 세밀한 표현들을 Adversarial loss가 잡아주고 있는 것으로 생각된다. Table 3 둘 째줄과 다섯 째줄의 결과 차이는 0.5%로 나타나고 있다.
- Classification loss: Table 3의 셋 째줄과 다섯 째줄의 결과 차이는 0.7%로 나타나고 있으며, 이로인해 물체의 클래스 정보를 예측하려할 때, Generator가 더 세밀한 정보를 복원하도록 할 수 있음을 알 수 있다.
- Regression loss: Table 3의 넷 째줄과 다섯 째줄의 결과 차이가 0.8%로 나타나고 있다. classification loss와 비슷하게 정확한 bounding box를 예측하려 할 때, Generator가 더 세밀한 정보를 복원하도록 할 수 있음을 알 수 있다.
4.4. State-of-the-Art Comparison
4.5. Qualitative Results

5. Conclusion
- Multi-task GAN (MTGAN)의 핵심은 object detector가 감지한 작은 물체의 이미지를 복원하여 object detection의 성능을 높이고자 함에 있다.
- COCO 데이터셋에 대한 폭 넓은 실험으로 작은 물체 탐지(small object detection)에 대한 성능을 높일 수 있음을 알 수 있었다.
리뷰...
GAN을 Object detection에 활용한다는 점이 재미있었으나, 직접적으로 활용한다기 보단 후처리의 방법론이라는 느낌을 지울 수 없었다. 그렇다면 backbone object detector의 성능에 크게 좌우되는 방법론인 것 같다.
추후에 GAN이 Region proposal 과정이나 classification 등의 object detection 프로세스에 직접적으로 영향을 끼치는 방향의 연구도 재미있을 법한 부분인 것 같다.
