학부 졸업 프로젝트를 수행하며 Tensorflow를 통해 딥러닝 모델을 구현하던 중 Tensorflow의 학습 데이터 포맷인 TFRecord라는 파일을 만날 수 있었다. 딥러닝 모델의 구현을 위해 GitHub을 뒤져보던 중 *.tfrecord라는 새로운 파일 확장자를 만났고, 용량도 별로 되지 않는 것이 모든 데이터를 담고 있다는 것을 보니 머릿속에 "다뤄야 한다"라는 생각이 들었다.
그렇다면 TFRecord 파일 포맷은 무엇인가?
TFRecord 파일 포맷이란.
조금만 구글링을 해보니 이미 선배분들이 정리해놓은 포스팅을 많이 볼 수 있었다.
TFRecord 파일은 tensorflow의 학습 데이터등을 저장하기 위한 바이너리 데이터 포맷으로, 구글의 Protocol Buffer 포맷으로 데이터를 파일에 Serialize하여 저장한다.
TFRecord 파일의 필요성은 아래와 같다.
1. CSV 파일에서와 같이 숫자나 텍스트 데이터를 읽을 때는 크게 지장이 없지만, 이미지 데이터를 읽을 경우 이미지는 JPEG나 PNG형태의 파일로 저장되어 있고 이에 대한 메타 데이터와 레이블은 별도의 파일에 저장되어 있기 때문에, 학습 데이터를 읽을 때 메타데이터나 레이블 파일 하나만 읽는 것이 아니라 이미지 파일도 별도로 읽어야 하기 때문에, 코드가 복잡해진다.
2. 이미지를 JPG나 PNG 포맷으로 읽어서 매번 디코딩을 하게되면, 그 성능이 저하되서 학습단계에서 데이터를 읽는 부분에서 많은 성능 저하가 발생한다.
[출처] 조대협님의 블로그
딥러닝을 공부하면서 모델을 돌리면서 많이 느꼈던 애로사항이다. 아직 좋은 하드웨어를 구하지 못해서 구글의 Colab 환경을 많이 사용했는데, 내 구글 드라이브에 저장해놓은 데이터를 Colab 환경에 불러오는 시간이 만만치 않아 대기시간이 길어지는 경우가 종종있었다. (기분 탓인지는 모르겠지만, 파일 불러오는 시간이 학습 시간보다 더 오래 걸리는 것 같다는 생각도 한적이 있다.)
TFRecord 파일 생성
아래의 내용과 예시 소스코드는 tensorflow 공식문서와 'peteryuX'님의 'arcface-tf2' 레포지토리를 참고했다.
TFRecord 파일 생성은 기록하고자 하는 데이터의 feature들을 python dictionary 형태로 정의한 후에, 데이터 하나씩 tf.train.Example 객체로 만들어 tf.io.TFRecordWriter를 통해서 파일로 저장한다.
코드를 통해 살펴보자.
1. 데이터 변환 함수
tensorflow 공식문서에 따르면 tf.train.Example객체는 아래와 같은 유형의 데이터 타입을 담을 수 있다.
tf.train.BytesListstringbyte
tf.train.FloatListfloat(float32)double(float64)
tf.train.Int64Listboolenumint32uint32int64uint64
기록하고자하는 데이터의 타입에 따라 아래와 같은 변환 함수를 사용해 데이터를 기록할 수 있다. 예를 들어 문자열 타입의 데이터는 tf.train.BytesList의 객체로 기록하는 것이다.
# The following functions can be used to convert a value to a type compatible
# with tf.train.Example.
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))):
value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))이제 이 함수들을 통해 데이터를 하나씩 기록해보자
2. tf.train.Example 객체로 저장
def make_example(img_str, source_id, filename):
# Create a dictionary with features that may be relevant.
feature = {'image/source_id': _int64_feature(source_id),
'image/filename': _bytes_feature(filename),
'image/encoded': _bytes_feature(img_str)}
return tf.train.Example(features=tf.train.Features(feature=feature))기록할 데이터를 함수의 파라미터로 받고 이들을 python dictionary 형태로 묶어 tf.train.Example 객체로 변환한다. 본 예제코드에서는 얼굴인식을 위한 데이터를 저장하는 것인데, 각각 source_id는 클래스 ID를, filename은 이미지 파일의 이름, encoded는 이미지 파일 자체를 의미한다.
3. tf.io.TFRecordWriter를 통한 파일 생성
원본 데이터의 디렉토리 구조는 아래와 같이 일반적인 Classification 데이터의 구조를 가진다.
.
|-- 0
| |-- ****.jpg
| |-- ****.jpg
| |-- ...
|
|-- 1
| |-- ****.jpg
| |-- ***.jpg
| |-- ...
|
|-- 2
| |-- ****.jpg
| |-- ...
...아래는 위 디렉토리의 이름과 생성할 tfrecord 파일명을 입력받아 tfrecord 파일을 생성하는 함수이다.
0, 1, 2, ...의 디렉토리 명을 클래스 ID로 보고 차례로 sample python list에 담아 하나씩 저장한다. 그 다음 list에 담은 샘플들을 섞고 다시 차례로 *.tfrecord파일에 적는 함수이다.
def main(dataset_path, output_path):
samples = []
print("Reading data list...")
for id_name in tqdm(os.listdir(dataset_path)):
img_paths = glob(os.path.join(dataset_path, id_name, '*.jpg'))
for img_path in img_paths:
filename = os.path.join(id_name, os.path.basename(img_path))
samples.append((img_path, id_name, filename))
random.shuffle(samples)
print("Writing tfrecord file...")
with tf.io.TFRecordWriter(output_path) as writer:
for img_path, id_name, filename in tqdm(samples):
tf_example = make_example(img_str=open(img_path, 'rb').read(),
source_id=int(id_name),
filename=str.encode(filename))
writer.write(tf_example.SerializeToString())전체 코드는 다음과 같다.
import os
from tqdm import tqdm
from glob import glob
import random
import tensorflow as tf
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))):
value = value.numpy()
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def make_example(img_str, source_id, filename):
# Create a dictionary with features that may be relevant.
feature = {'image/source_id': _int64_feature(source_id),
'image/filename': _bytes_feature(filename),
'image/encoded': _bytes_feature(img_str)}
return tf.train.Example(features=tf.train.Features(feature=feature))
def main(dataset_path, output_path):
samples = []
print("Reading data list...")
for id_name in tqdm(os.listdir(dataset_path)):
img_paths = glob(os.path.join(dataset_path, id_name, '*.jpg'))
for img_path in img_paths:
filename = os.path.join(id_name, os.path.basename(img_path))
samples.append((img_path, id_name, filename))
random.shuffle(samples)
print("Writing tfrecord file...")
with tf.io.TFRecordWriter(output_path) as writer:
for img_path, id_name, filename in tqdm(samples):
tf_example = make_example(img_str=open(img_path, 'rb').read(),
source_id=int(id_name),
filename=str.encode(filename))
writer.write(tf_example.SerializeToString())
if __name__ == "__main__":
main("kface", "kface_bin.tfrecord")
회귀 문제에 대한 tfrecord 파일 생성 예제를 하나 더 보자.
회귀 문제에 대한 label은 .csv나 .txt같은 별도의 파일에 저장하는 경우가 많다. 아래는 이미지 파일명과 그 label값을 함께 적어놓은 .csv파일의 예시이다.
"metadata.csv"
filename,label
0000971160_1, 6.094467065223975
0000971160_2, -8.213548899809783
0000971160_3, -16.811467943863377
0000971160_4, -0.44434946696166655
0000971160_5, -26.681545004531852
0000971160_6, 17.006392102458875
0000971160_7, -18.696981688745513
0000971160_8, 16.358331838072285
...이와 같이 저장된 파일도 같은 방식으로 tfrecord파일로 저장할 수 있다.
def make_example(img_str, label, filename):
feature = {'encoded': _bytes_feature(img_str),
'label': _float_feature(label),
'filename': _bytes_feature(filename)}
return tf.train.Example(features=tf.train.Features(feature=feature))
def main(dataset_path, output_path):
samples = []
with open(f"{dataset_path}/metadata.csv") as f:
f.readline()
lines = f.readlines()
for line in tqdm(lines):
filename, label = line.split(',')
img_path = os.path.join(dataset_path, mode.split('_')[0], f"{filename}.png")
label = float(label.replace('\n', ''))
samples.append((img_path, label, filename))
random.shuffle(samples)
with tf.io.TFRecordWriter(output_path) as writer:
for img_path, label, filename in tqdm(samples):
tf_example = make_example(img_str=open(img_path, 'rb').read(),
label=label,
filename=str.encode(filename+".png"))
writer.write(tf_example.SerializeToString())달라진 점이라면 메타데이터에서 정보를 가져와 활용한다는 것과 그에 맞게 label의 type에 맞게 make_example 함수를 조정했다는 것이다.
TFRecord 파일 tf.data.Dataset으로 변환
이렇게 만든 tfrecord 파일을 읽는 방법도 간단하다.
def _parse_tfrecord():
def parse_tfrecord(tfrecord):
features = {'image/source_id': tf.io.FixedLenFeature([], tf.int64),
'image/filename': tf.io.FixedLenFeature([], tf.string),
'image/encoded': tf.io.FixedLenFeature([], tf.string)}
x = tf.io.parse_single_example(tfrecord, features)
x_train = tf.image.decode_jpeg(x['image/encoded'], channels=3)
y_train = tf.cast(x['image/source_id'], tf.float32)
x_train = _transform_images()(x_train)
y_train = _transform_targets(y_train)
return (x_train, y_train), y_train
return parse_tfrecord
def _transform_images():
def transform_images(x_train):
x_train = tf.image.resize(x_train, (128, 128))
x_train = tf.image.random_crop(x_train, (112, 112, 3))
x_train = tf.image.random_flip_left_right(x_train)
x_train = tf.image.random_saturation(x_train, 0.6, 1.4)
x_train = tf.image.random_brightness(x_train, 0.4)
x_train = x_train / 255
return x_train
return transform_images
def _transform_targets(y_train):
return y_train기록한 tfrecord 파일을 입력받아 tf.io.parse_single_example()로 하나씩 풀어주면 된다. 이렇게 불러온 데이터를 사용하고자하는 모델에 맞게 전처리해주고 알맞은 형태의 return값을 반환한다.
def load_tfrecord_dataset(tfrecord_name, batch_size, shuffle=True, buffer_size=10240):
"""load dataset from tfrecord"""
raw_dataset = tf.data.TFRecordDataset(tfrecord_name)
raw_dataset = raw_dataset.repeat()
if shuffle:
raw_dataset = raw_dataset.shuffle(buffer_size=buffer_size)
dataset = raw_dataset.map(
_parse_tfrecord(),
num_parallel_calls=tf.data.experimental.AUTOTUNE
)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return datasettf.data.TFRecordDataset의 객체를 생성하여 .map()함수를 통해 앞서 정의한 변환과정을 적용해주면 데이터 사용 준비가 마무리된다.
TFRecord와 Generator의 속도 비교
그렇다면 python generator를 사용한 tensorflow 데이터셋과 TFRecord를 사용한 tensorflow 데이터셋의 시간차이를 살펴보자.
Google의 Colab 환경에서 진행했고 위에서 소개한 Classification 문제에 대한 데이터셋을 비교에 사용했다. 총 이미지 수는 9360장, 클래스의 종류는 390가지이다.
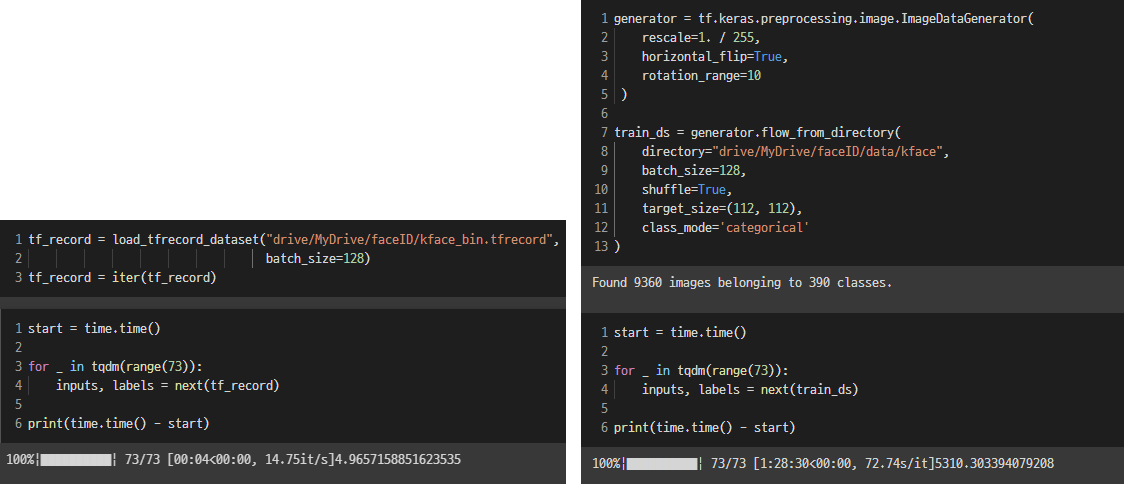
왼쪽은 TFRecord를 사용한 시간으로 5초 남짓 소요되었지만, 오른쪽 Generator를 통해 디렉토리에서 직접 데이터를 가져오는 방식은 한시간 반 정도의 어마어마한 차이를 보였다.
