[paper-review] Neural Machine Translation by Jointly Learning to Align and Translate
Paper Review
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
Abstract
- 기계 번역(Machine Translation)을 위한 신경망(Neural nets)은 Encoder-Decoder 계열의 모델이었다.
- Encoder-Decoder 계열의 모델들이 가지는 병목 문제(bottleneck)를 완화할 수 있는 아키텍처의 제안.
1. Introduction
- 대부분 이전에 제안되었던 기계 번역 모델은 Encoder-Decoder 계열의 모델들이었다.
- 이 계열의 모델들은 Encoder가 번역하고자하는 소스 문장(source sentence)을 일정한 길이의 벡터로 압축하기 때문에 소스 문장의 길이가 길어질수록 성능이 악화되는 단점을 보여줌.
- 본 논문에서 제안하는 아키텍처는 소스 문장을 고정된 길이로 압축하지 않는다.
- 긴 문장의 모든 정보의 손실을 완화할 수 있음.
2. Background: Neural Machine Translation
기계 번역(Machine translation)이란 소스 문장(source sentence) 가 주어졌을 때, 그에 매칭되는 번역 타겟 문장(target sentence) 가 적절한 번역 문장일 조건부확률(Conditional probability)을 최대화하는 task로 볼 수 있다.
이 작업을 수행하는데 있어 최근 많은 연구들이 신경망을 도입하고 있다. (Neural Machine Translation)
2.1. RNN Encoder-Decoder
Encoder-Decoder 프레임워크
-
Encoder
- 입력 문장; hidden states; context vector;
- 이고, 와 는 각각 비선형 함수(non-linear function)를 사용한다.
-
Decoder
- 아래의 요소들로 다음 단어 를 예측.
- Encoder에서 얻는 context vector
- 이전에 예측해두었던 단어들()
- RNN의 hidden state
- 아래의 요소들로 다음 단어 를 예측.
3. Learning to Align and Translate
본 논문에서 소개하는 새로운 아키텍처는 다음과 같이 구성된다.
- bidirectional RNN encoder
- 소스 문장을 통해 학습해, 번역을 수행하는 decoder
3.1. Decoder: General Description
Decoder에 대해 먼저 살피면,
아래와 같이 조건부확률을 정의한다.
2.1에서 다루었던 것과 비슷해 보이지만 각각 타겟 단어 에 대해 개별적인 context vector 가 개별적으로 들어가 있다.
여기서 사용하는 는 어떻게 계산되는지 살펴보면,
는 아래의 두 요소로 계산할 수 있다.
- Encoder에서 특별하게 계산된 annotations;
- 주의! 직관적인 이해를 위한 수식이다.
- Encoder가 이 계산을 하는 과정은 3.2에서 다룬다.
- RNN의 hidden state;
- 먼저, feedforward neural network인 alignment model 로 소스 문장의 번째 단어와 타겟 문장의 번째 단어끼리의 연관성 점수를 계산한다.
- 이 값들을
softmax계산하여 0~1 사이 값으로 만든다.
- 위에서 계산한 와 의 weighted sum을 로 한다.
Decoder의 역할
- Decoder에서 alignment model 를 통해 소스 문장에서 "attention"할 부분을 결정.
- Encoder가 소스 문장의 모든 정보를 담아내야 한다는 부담을 덜 수 있다.
3.2. Encoder: Bidirectional RNN for Annotating Sequences
Decoder가 사용할 annotations; ()를 계산한다.
Encoder는 아래의 과정을 통해 소스 문장의 정보를 encode한다.
1). 정방향 RNN (forward RNN) 과 역방향 RNN (backward RNN) 으로 hidden states를 뽑아낸다.
- 주의! 직관적인 이해를 위한 수식이다.
- forward hidden states
- backward hidden states
2). forward, backward hidden states를 concatenation
- annotation
- 대상 단어의 앞, 뒤 단어를 폭 넓게 담은 정보를 얻는다.
Q. 하필 Bidirectional RNN (BiRNN)을 사용하는 이유?
이 아키텍처에서 Encoder는 각 단어의 annotation이 이전 단어만 아니라 다음 단어의 정보도 가진다면 성능향상을 기대할 수 있다.
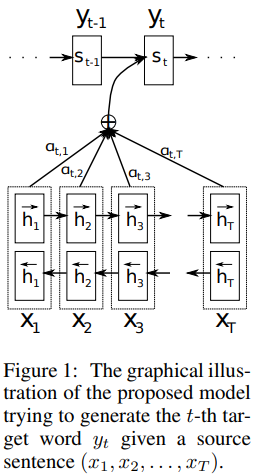
그림 1을 통해 이해를 도울 수 있다.
4. Experiment Setting
- 영어-to-불어 번역 task에 평가.
- [1]에서 사용한 RNN Encoder-Decoder와 성능 비교.
- ACL WMT'14의 말뭉치 쌍을 데이터셋으로 사용.
4.1. Dataset
[1]에서 사용한 과정에 따라 말뭉치의 단어 수를 줄였으며, 필요에 따라 Encoder의 사전학습이 필요하면 다른 말뭉치를 사용할 수 있겠지만 본 논문의 실험에선 따로 사용하지 않았다.
- Validation Dataset: WMT의 news-test-2012, news-test-2013을 사용
- Test Dataset: WMT'14의 news-test-2014를 사용했고, 당연히 학습엔 참여시키지 않았다.
Preprocessing
- 평소와 비슷한 tokenization을 사용해 vocabulary size는 30,000
- ([UNK])같은 특수 token을 사용하지 않았음.
- lowercasing, stemming 같은 전처리도 거치지 않았음.
4.2. Models
- 논문에서 제안하는 모델을 RNNsearch
- [1]에서 제안하는 모델을 RNNencdec
각 모델이 학습할 수 있는 최대 단어 수를 30개, 50개로 제한하여 총 네 가지 variation을 만들 수 있다.
RNNsearch-30, RNNsearch-50, RNNencdec-30, RNNencdec-50
5. Results
5.1. Quantitative Results
표 1에서 각 모델에 대한 BLEU score를 비교할 수 있다.
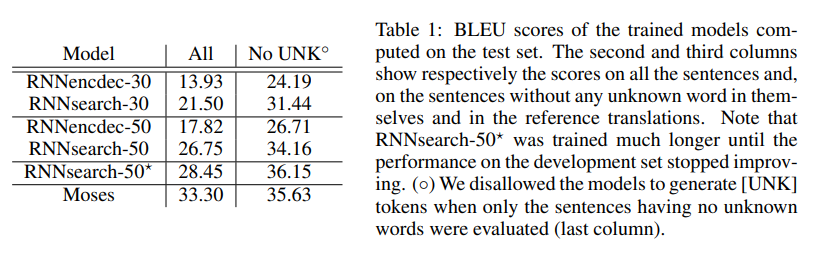
그림 2에서 처음에 언급했던 "고정 길이의 context vector를 사용하는 것이 모델의 성능을 제한하는 요소일 것이다." 라는 가정이 어느정도 맞다는 것을 볼 수 있다.
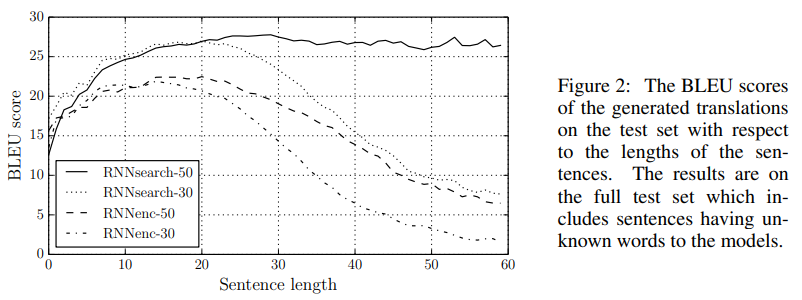
RNNsearch가 비교적 문장 길이에 강건한 모습을 볼 수 있다.
5.2. Qualitative Analysis
5.2.1. Alignment
그림 3에서 위에 언급했던 annotation weights 를 시각화한 것을 볼 수 있다.
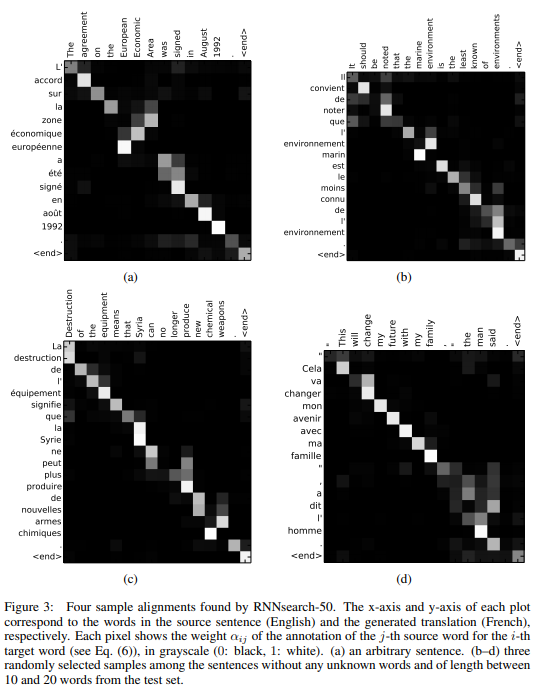
영어와 불어 간에 전체적인 어순의 일치를 볼 수 있다.
일부 형용사와 명사의 어순이 다른 점도 볼 수 있었는데, (a)에서
- [European Economic Area] 처럼 서로 다른 어순에 올바르게 매칭되었다.
5.2.2. Long Sentences


위에서 차례로 "원문", "RNNencdec의 번역", "RNNsearch의 번역" 이다.
7. Conclusion
- 고정 길이 벡터에 입력 문장을 encode하는 기존 encoder-decoder의 문제점을 개선
- Encoder가 전체 문장의 정보를 하나의 벡터에 담아내야하는 부담을 덜어낼 수 있는 아키텍처 제안
- 정량적, 정성적 분석을 통해 논문에서 제안하는 아키텍처의 성능을 보임.
- 기존 기계 번역 테크닉을 추가하면 더 좋은 성능을 보일 것이라 희망.
References
[1] Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014).
