Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.

Abstract
-
새로운 객체 탐지(Object detection) 모델 YOLO를 소개한다.
- 이전의 객체 탐지 모델들은 이미지 분류 모델(classifiers)를 기반으로 한다.
- YOLO는 객체 탐지를 하나의 신경망이 bounding box와 class probalities를 예측하는 하나의 회귀(regression) 문제로 다루는 모델이다.
-
YOLO는 매우 빠르고, 강건하다.
- 초당 45프레임의 속도로 이미지를 처리할 수 있다.
- 간소화된 버전의 Fast YOLO는 155프레임까지도 처리할 수 있다.
- 이미지의 배경을 물체로 인식하는 false positive error를 다른 모델보다 적게 범한다.
- Natural image는 물론, artwork image에도 잘 적용될 수 있는 모델이다.
1. Introduction
기존 객체 탐지에 대한 연구
- Deformable Parts Models (DPM)
- Sliding Window 방식을 채택
- Sliding Window: 이미지 전체를 동일하게 나눈 공간에서 분류 모델(classifier)가 동일하게 작동하여 클래스를 분류하는 방식
- R-CNN
- bounding box가 될 것이라고 생각되는 곳에 임시로 bounding box를 생성.
- 그 공간에 대해 모두 분류 모델(classifier)가 작동, 클래스를 분류.
- post-processing으로 bounding box의 위치를 정리하고, 중복으로 감지된 bounding box를 제거.
이러한 방법들은 각각 구성 요소들이 매우 많아 각각 요소들을 따로 최적화해야하며, 매우 느린 속도를 가지고 있다.
YOLO (You Only Look Once)

- 매우 빠르다. 하나의 회귀 문제로 객체 탐지 모델을 재정의했기 때문에 복잡한 파이프라인이 필요없다.
- 이미지를 전체적, 전역적으로(globally) 살핀다. DPM이나 R-CNN계열의 모델들은 구역을 정해놓고 그 구역을 지역적으로(locally) 보기 때문에 큰 시야로 이미지를 보지 못한다.
- 물체의 일반화된 특징 표현(generalizable representation)들을 학습할 수 있다.
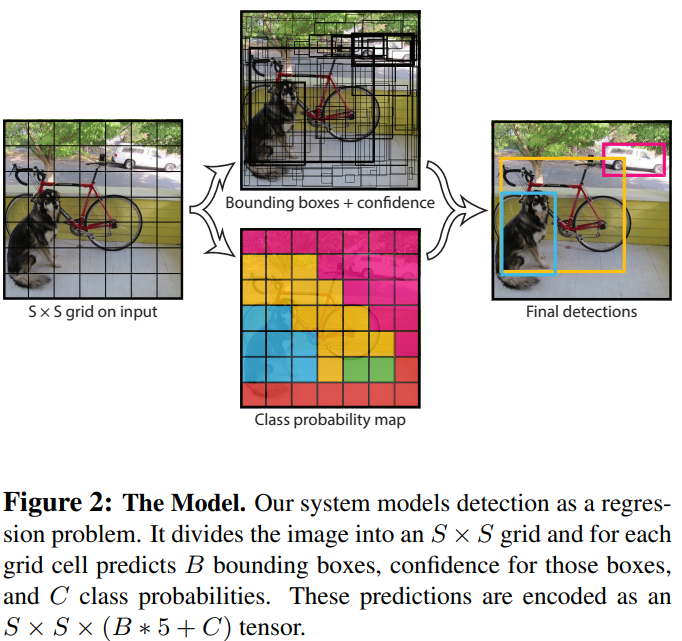
2. Unified Detection
-
입력 이미지를 grid로 나눈다.
- 한 grid 안에 탐지하고자 하는 물체의 중앙점이 들어가면 그 물체를 탐지할 수 있는 기회가 주어진다.
-
grid는 bounding box 와 confidence score를 예측한다.
- confidence score, : (grid안에 물체가 잘 담겼는지) X (bounding box의 예측이 잘 이루어졌는지), grid에 물체가 없으면 0이 된다.
- bounding box는 , confidence score로 총 다섯 가지로 이루어진다.
-
grid는 grid안에 물체가 있을 때, 그 물체가 어떤 클래스에 속할 확률, 조건부확률 를 구한다.
- 각 bounding box는 하나의 클래스만 예측하도록 했음.
2.1. Network Design
기본적인 단일 CNN 아키텍처와 비슷하다.

Convolution layers 뒤에는 bounding box의 요소들을 예측하는 fully-connected layer를 덧붙이는 구조이다.
2.2. Training
기존의 이미지 분류(classification), 객체 탐지(object detection) 문제들과는 약간씩 다르기 때문에 몇 가지 Trick이 필요하다.
- bounding box의 예측을 회귀 문제처럼 풀었기 때문에, 값을 0과 1사이로 정규화했다. 기존 신경망이 잘 다뤄왔던 parameter 범위가 0과 1사이 값이기 때문이다.
- leaky Relu 활성화함수를 사용했다.
- confidence score에 대한 제약 parameter;
- 대부분의 grid는 물체를 포함하고 있지 않는 경우가 많다.
- 그렇기에 모델은 손실을 줄이기 위해 모든 grid에 confidence score를 0으로 만들어버리는 경향을 가질 수 있다.
- bounding box의 예측 실패에 대한 손실의 양은 늘리고, 물체를 포함하지 않는 confidence score의 손실은 줄이는 hyper-parameter이다.
- 를 사용했다.
- bounding box의 를 곧바로 예측하지 않고 그 제곱근 값()을 예측하도록 한다.
- 크고 작은 bounding box에 모두 동일한 변화량으로 예측을 하면 안된다.
- 학습 횟수(epoch)마다 각 bounding box 크기 비율에 맞게 크기 조정이 일어나게 한다.
- Training 단계에서 학습 횟수(epoch)마다 실시간으로 grid안에 어떤 bounding box가 가장 적절한지 판단하도록 장치했다.
- 한 grid안에 여러 bounding box가 생성되는 것을 방지하기 위함이다.
- 여러 bounding box 중에서 IOU값이 가장 높은 bounding box를 골라내줄 것이다.
Training 단계에서의 loss function
는 번째 grid에서 물체가 나타나는 경우 1, 아니면 0
는 번째 grid에서 번째 bounding box가 "적절한" bounding box이면 1, 아니면 0 (마지막 Trick)
et cetera.
- Pascal VOC 2007, 2012 데이터셋에서 학습, 검증 데이터셋을 사용 135회 학습.
- batch size 64, momentum 0.9, decay 0.0005
- learning rate
- 첫 epoch에서 에서 까지 점차 높임.
- 75회는 .
- 그 다음 30회 .
- 마지막 30회는 .
- 0.5의 비율로 Dropout.
2.4. Limitation of YOLO
-
새 떼처럼 아주 작은 물체들이 무리 짓고 있는 것을 탐지는 것에 약점을 가지고 있다.
- 학습할 때, 5번 Trick으로 인해 하나의 grid에 하나의 bounding box만 생성하도록 아주 강력한 제약을 가하고 있다.
-
일반적인 비율을 가지지 않고 특별한 비율을 가진 물체를 인식하는 것에 약점을 가진다.
-
크고 작은 bounding box에 대해 동일한 비율로 손실을 갖는다.
- 같은 오차에도 큰 bounding box에는 미미한 영향을 주겠지만, 작은 bounding box에는 큰 영향을 줄 것이다.
4. Experiment
4.1. Comparison to Other Real-Time Systems

다른 real-time 모델들에 비해서 엄청난 수준의 성능향상을 보였으며, 다른 속도가 느린 복잡한 모델들에 비해서도 대등한 정도의 성능이다.
4.2. VOC 2007 Error Analysis
Fast R-CNN과 YOLO가 범하는 오차에 대한 분석이다.
오차의 유형은 아래와 같이 정의했다.
- Correct: 클래스를 올바르게 분류하고, bounding box 예측 기록
- Localization: 클래스를 올바르게 분류하고, bounding box 예측 기록
- Similar: 클래스를 잘 분류하지 못하고, bounding box 예측 기록
- Other: 클래스는 틀리고, bounding box 예측 기록
- Background: 모든 물체에 대한 bounding box 예측 기록

- Fast R-CNN은 물체가 있음에도 잘 분류하지 못하는 Background error의 비율이 많다.
- YOLO는 물체를 잘 분류하고 그 위치를 정확하게 예측하지 못하는 Localization error의 비율이 많았다.
6. Conclusion
- 통합된(unified) 객체 탐지(object detection) 모델 YOLO를 소개.
- 전체 이미지를 직접적으로 학습.
- Real-time 객체 탐지 모델의 state-of-the-art를 달성.
- artwork image에도 잘 작동할 수 있음.
- 실사용에 적용할 수 있을만한 빠르고 강건한 모델임.
