[paper-review] Page Segmentation using a Convolutional Neural Network with Trainable Co-occurrence Features
Paper Review
Lee, J., Hayashi, H., Ohyama, W., & Uchida, S. (2019, September). Page segmentation using a convolutional neural network with trainable co-occurrence features. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 1023-1028). IEEE.
Abstract
문서 분석(document analysis)에 있어 문서 분할(page segmentation)은 문서 이미지를 의미적 구역으로 나누는 기초적인 작업이다. 이러한 page segmentation을 하는데 있어 co-occurrence features는 정확한 분할을 위해 texture-like periodic 정보를 추출하는 데에도 유용하다. (즉, 텍스트 라인과 같이 반복적으로 주기적으로 등장하는 정보들도 중요하다.)
하지만 co-occurrence features를 CNN이 추출할 수 있다고는 어렵다고 볼 수 있다.
따라서,
- trainable multiplication layers (TMLs)를 CNN과 함께 사용해 page segmentation을 수행하는 방법론을 제안한다.
- TML은 feature map에서 co-occurrence features를 추출하는 데 특성화된 레이어이다.
본 연구에서는 TML과 U-Net을 결합하여 픽셀 단위의 page segmentation을 수행하며 기존 U-Net에 비해 TML을 곁들인 방법이 성능을 향상시킬 수 있음을 보인다.
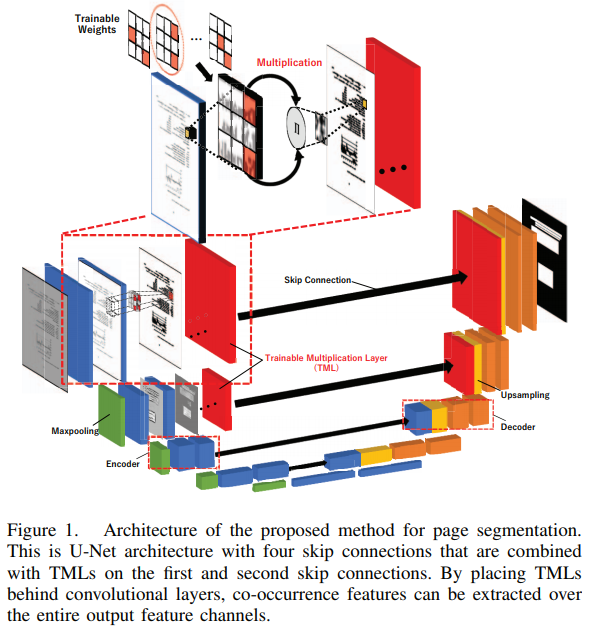
Introduction
page segmentation, 특히 픽셀 단위의 semantic segmentation을 잘 수행하기 위해선 문서 전체의 맥락을 고려하면서 각 픽셀의 클래스를 추정하기 위한 특징을 적절하게 추출하는 것이 중요하다.
@ CNN architecture
- 지금까지 제안된 많은 특징 추출(feature extraction) 방법론 중 CNN architecture를 활용하는 방법론들이 최근 semantic segmentation의 주류가 되고 있다.
- convolution 및 deconvolution 구조를 end-to-end 방식으로 학습하여 모델의 특성을 명확하게 설계하지 않고도 모델을 학습시킬 수 있다.
@ CNN extracts co-occurrence features?
인간이 문서 안의 텍스트를 유심히 보지 않고도 인식할 수 있는데, 이는 인간이 각각 문자의 지역적인 정보와 전체 텍스트 구역의 texture(맥락?)를 모두 고려하기 때문이다.
일반적인 CNN 기반의 architecture들은 지역적(local) 특징들을 추출하는 데 강력하지만 co-occurrence 및 texture features를 추출하는 능력을 가졌다고 보기는 어렵다.
Related Work
@ the methods using texture-based features
- Lin et al.
- gray level co-occurrence matrix (GLCM)을 통한 texture features를 page segmentation에 활용
- GLCM으로 texture features를 추출하고 -means 알고리즘으로 군집화를 수행하여 heuristic rule을 기반으로 분류(classification)를 수행
- 이 분류 결과가 page segmentation의 결과
- Oyedotun el al.
- Lin et al.의 CLCM texture features를 feedforward 신경망의 입력 값으로 활용
- text, graphics, background의 세 가지 클래스로 분류
@ U-Net architecture
- Ronneberger et al.
- biomedical image segmentation을 위해 U-Net을 최초로 제안
- Ma et al.
- 두 개의 U-Net을 stack으로 쌓아 문서의 왜곡 보정을 수행함
- distorted 3D 문서를 2D 문서로 평평하게 펼치는 작업
Proposed Method
논문에서 제안하는 trainable multiplication layers (TMLs)을 곁들인 U-Net architecture는
- convolution layers의 local features
- U-Net의 skip connection 구조를 통한 location information
- TMLs의 texture-like features
위 1, 2, 3을 모두 결합해 end-to-end로 학습할 수 있다.
A. Trainable Multiplication Layer
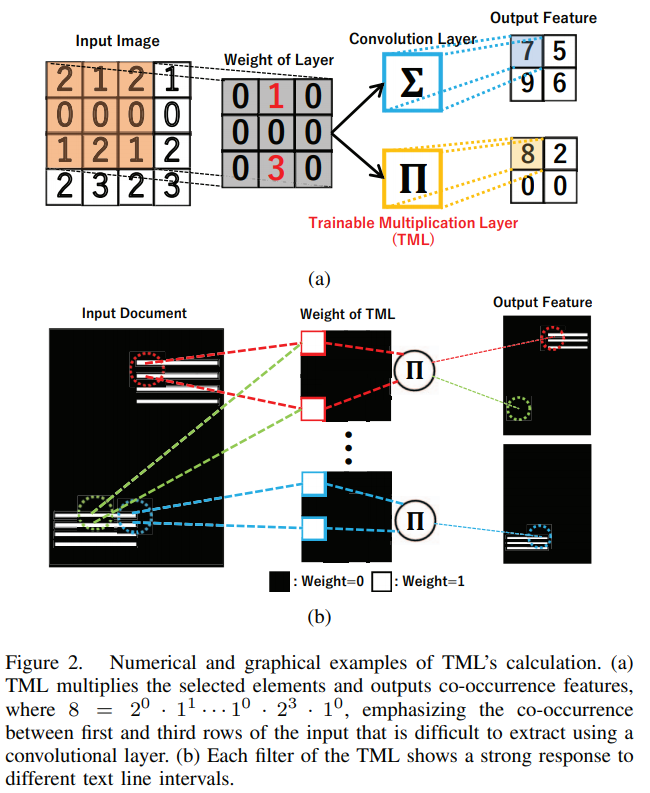
- TMLs: 입력 이미지 에 대하여 (: 이미지의 크기, : 이미지 채널 수)
- : 입력 이미지의 픽셀 값
- : 번째 filter 가중치 값
- 각각의 filter들이 feature map 전체에 걸쳐 여러번 지수적으로(exponentially) 계산되며 인접한 픽셀 값이 강조되어 학습된다. 결국 texture-like features를 추출할 수 있게된다.
그림 2(b)와 같이 텍스트 라인은 문서 이미지에서 vertically and regularly하게 반복되고 한 텍스트 라인 안에서 문자들은 horizontally and regularly하게 정렬되어 있다.
결과적으로 TML은 이러한 특성을 고려하여 계산함으로써 텍스트 라인인 것과 텍스트 라인이 아닌 것을 구분하게 된다.
Experiment
A. Experimental Setup
1) Datasets and Preprocessing
- ICDAR2017
- 1,500개의 학술 논문 중 2,000 페이지의 문서
- Classes: "수식", "표", "그림이나 이미지" -> "텍스트" or "not 텍스트"로 통합
- 직사각형의 bounding box 형태로 label 구성됨
- PRimA Layout Analysis datasets
- 잡지 및 학술 출판물로 구성
- Classes: ICDAR2017과 동일하게 "텍스트" or "not 텍스트"로 통합
- 직사각형의 bounding box 형태로 label 구성됨

- 그림처럼 , grayscale 이미지로 조정
2) Proposed Network Architecture
@ U-Net detail
- encoder filters: 64개
- filter size:
- zero padding 적용
@ TML types
- 총 4회의 skip connection 중 상단 2회의 skip connection에 TMLs을 적용
- filters: 64개 = 1 + 20 + 43
- filter size:
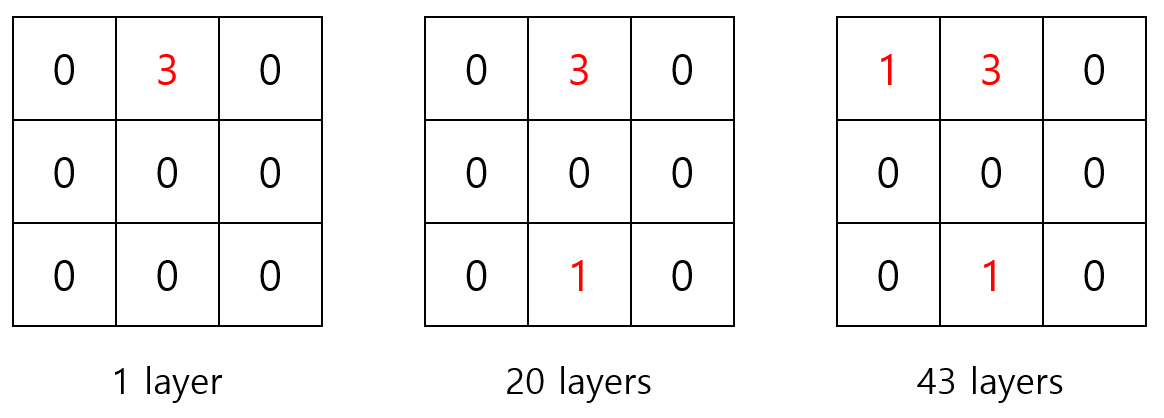
<논문에서 사용한 TML 타입의 예시 (단, filter의 크기는 실제와 다름)>
@ Squeeze-and-excitation (SE)
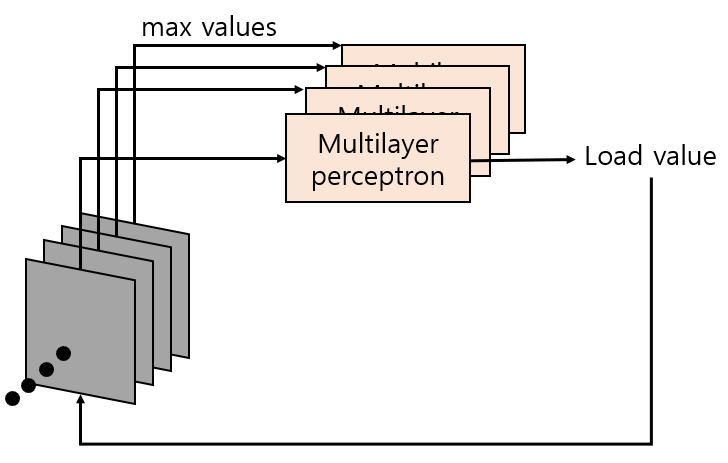
- 각 filter channel을 거친 output features에서 최댓값을 선정함
- 1에서 선정한 각각 최댓값을 입력으로하는 multilayer perceptron을 각 채널에 두어 load value를 계산함
- 2에서 계산한 load value를 TML의 output features에 곱함
B. Results
@ Visualization
- Gray: True positive
- Blue: True negative
- Pink: False positive
- Cyan: False negative

@ Pool Prediction

문서 속 이미지에 있는 텍스트를 텍스트 영역으로 인식하는 것 때문에 precision이 낮아짐.
C. Discussion
@ Quantitative Results
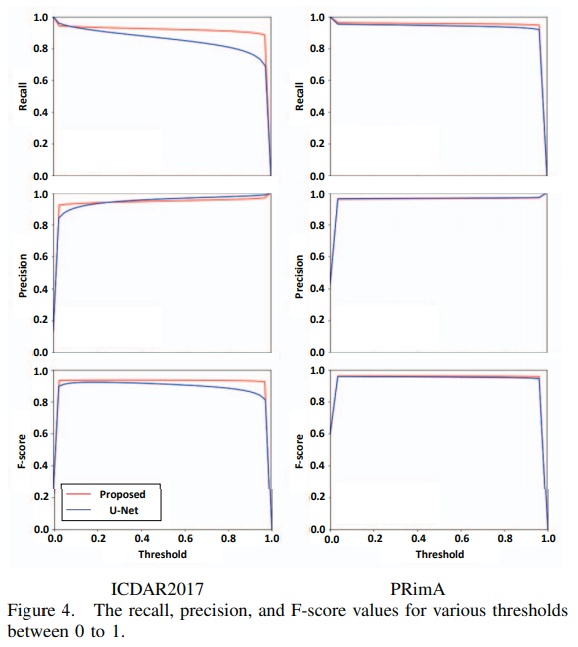
기존 U-Net에서의 recall 값은 임계값에 따라 달라지는 반면 논문에서 제안하는 아키텍처는 일관되게 높은 recall 값을 보여준다.
@ TML의 효과
아래는 각각 TML의 output features를, 기존 U-Net에서의 첫 skip connection에서의 output features를 시각화한 것이다.
확실히 TML에서의 output features가 좀 더 명확한 것을 볼 수 있다.

@ co-occurrence features와 문서 이미지에서의 periodic features의 상관관계
아래 그림에서 왼쪽 샘플은 "표", "수식", "그림" 영역을 포함하는 이미지이다.
- "그림" 영역에 비해 "수식" 및 "표" 영역이 좀 더 periodic한 영역이라고 볼 수 있다.
- "그림" 영역에 대한 두 아키텍처의 예측 성능을 큰 차이가 없지만,
- TML을 곁들이는 경우 "수식", "표" 영역에 대한 예측 성능이 확연히 좋은 모습을 볼 수 있다.
따라서 TML을 곁들이는 경우가 periodic features를 더 잘 인식할 수 있다고 결론내릴 수 있다.

