
참고한 서적 : https://hongong.hanbit.co.kr/r-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D/ (혼자 공부하는 R언어)📌이번 주차내용
→ R언어에서의 데이터 처리 및 분석(빈도 등)
→ R언어에서 얻은 데이터의 시각화 처리🎁 데이터 수집 🎁
데이터를 준비하기 위한 방법에는 크게 2가지가 존재한다!
→ 외부에서 만들어진 데이터를 불러와서 준비하는 방법
→ 내부에서 데이터를 직접 입력해서 준비하는 방법
각각의 방법에 대해서 자세히 알아보도록 하자.
직접 데이터 입력하기
원시 데이터 입력 : R에서 분석할 데이터를 직접 입력하여 저장하는 단계를 의미한다.
# R에서 원시 데이터를 입력하는 방법
# 벡터 만들기와 방식이 동일하다!
변수명 <- c(값)ID &<- c(1, 2, 3, 4, 5)
ID
SEX <- c("F", "M", "F", "M", "F")
SEX
# View 함수를 통해 데이터 프레임 조회
DATA <- data.frame(ID = ID, SEX = SEX)
View(DATA)# 실행 결과(Console 탭에서의 결과물, 아래 이미지는 Script 탭에서의 데이터프레임)
> ID <- c(1, 2, 3, 4, 5)
> ID
[1] 1 2 3 4 5
> SEX <- c("F", "M", "F", "M", "F")
> SEX
[1] "F" "M" "F" "M" "F"
> # View 함수를 통해 데이터 프레임 조회
> DATA <- data.frame(ID = ID, SEX = SEX)
> View(DATA)
데이터 조회
데이터 조회는 위에서 살펴본 방식처럼, Console 탭 혹은 View() 함수를 통해 확인할 수 있다.
이 중 View()를 통해 데이터 뷰어를 활용하는 방법은 데이터를 표 형태로 편리하게 살펴볼 수 있다!
외부 데이터 불러오기- txt 파일
이제부터는 외부에서 데이터를 불러오는 방법에 대해서 알아보도록 하자.
제일 먼저 알아볼 방식은, txt 파일을 불러오는 방법이다!
TXT 파일은 read.table() 함수를 이용하여 데이터프레임 형태로 가지고 올 수 있다.
# R에서 read.table()을 사용하는 방법
read.table("원시 데이터", header = FALSE, skip = 0, nrows = -1, sep = "", ...)read.table()에서 자주 사용하는 옵션들에 대해서 간단히 알아보도록 하자.
참고로, 아래 옵션들은 사용하지 않을 경우 구문에서 생략할 수 있다!(생략하면 기본값으로 들어감)
header : 원시 데이터의 1행이 변수명인지 아닌지 판단
skip : 특정 행까지 제외하고 데이터를 가져옴
nrows : 특정 행까지 데이터를 가져옴
sep : 데이터의 구분 문자를 지정함
TXT 파일 불러오기 예시
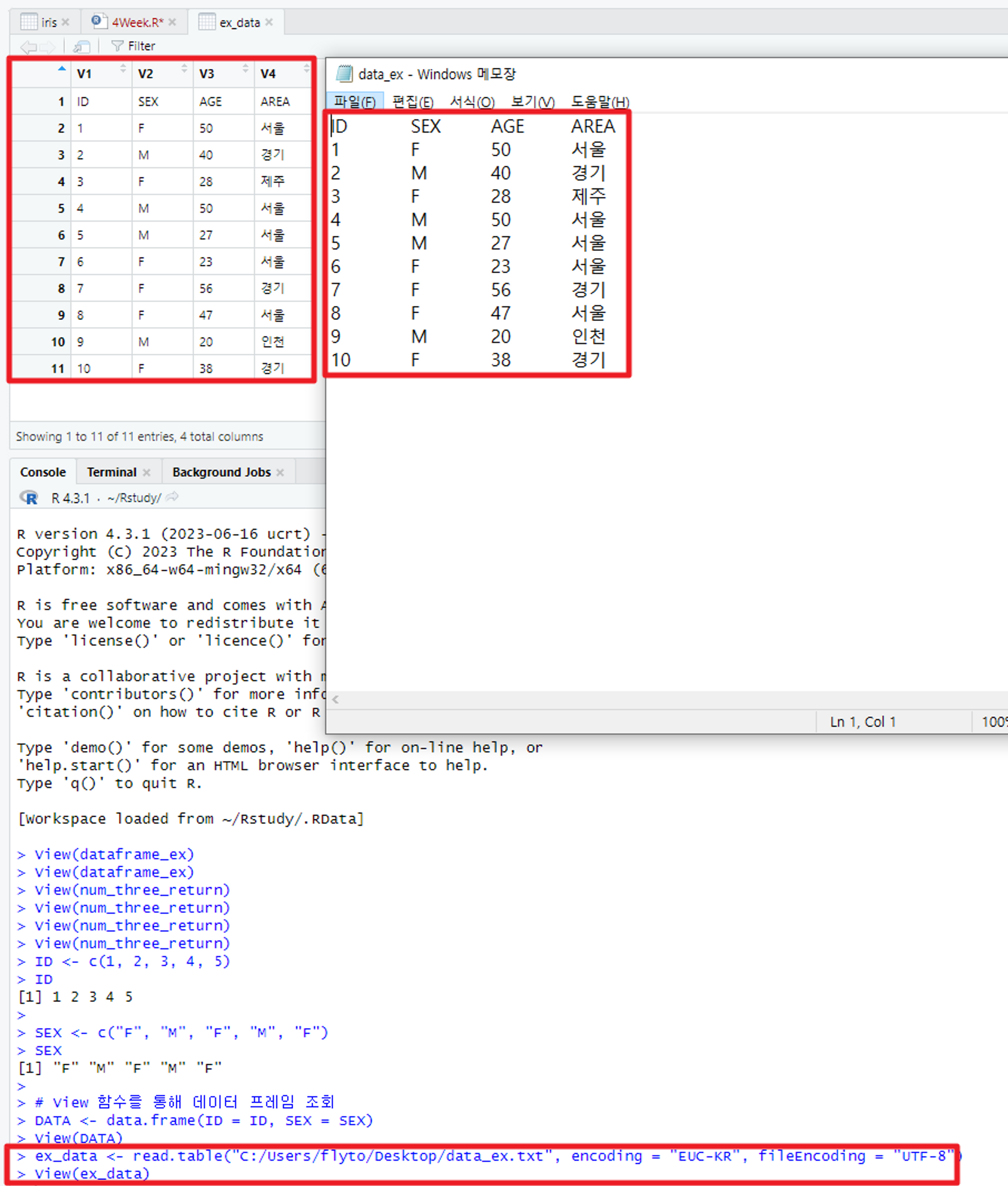
TXT 파일의 경로를 정확히 하고 read.table을 쓰면 해당 데이터를 데이터 프레임 형태로 읽음!
참고로 데이터 프레임 맨 상단의 V1, V2 등은 Rstudio에서 임의로 변수명을 지정한 것이다.
데이터를 가져오면서 원시 데이터의 변수명이 값이 되버리는 현상이 발생하게 되었다.
이는 read.table()의 header 옵션을 지정해주면 해결할 수 있다!
header 옵션
header : 원시 데이터의 1행이 변수명인지 아닌지 판단하는 옵션!
header = TRUE를 지정하여 원시 데이터 1행이 변수명임을 전달해주도록 하자.
이제부터는 우리가 가져올 원시 데이터의 1행이 변수명이라면, header 옵션을 사용하자!
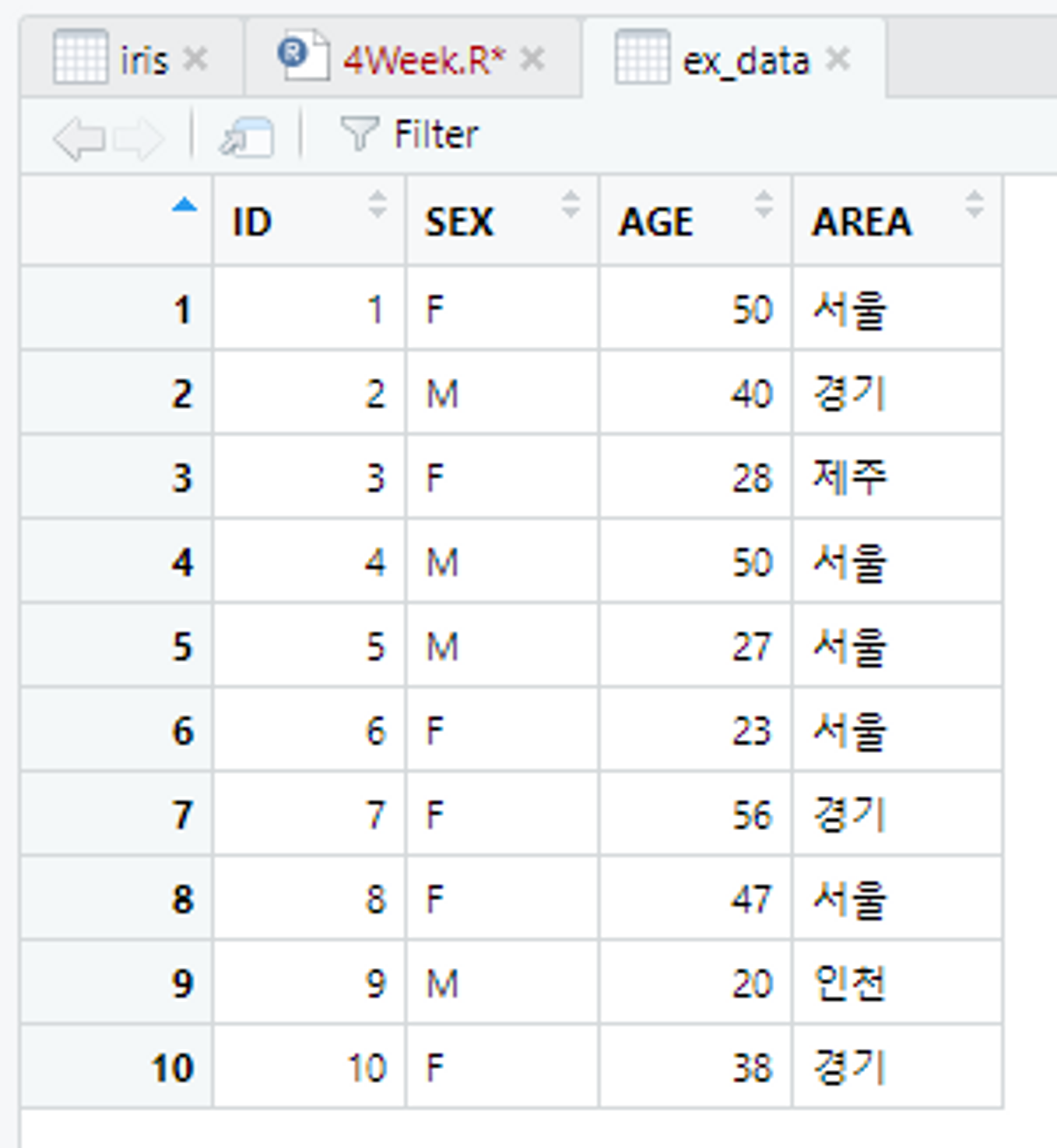
만약 원시 데이터에 변수명으로 사용할 행이 존재하지 않다면 col.names 옵션을 써도 좋다.
col.names : 원시 데이터의 변수명을 매개변수로 전달해준 데이터를 이용하여 표시한다.
row.names : 가져온 원시 데이터의 행 쪽에 이름을 부여하고 싶을 경우 사용
# varname이라는 백터를 할당하여 이를 col.names에 전달하여 변수명으로 사용
varname <- c("ID", "SEX", "AGE", "AREA")
ex_data <- read.table("C:/Users/flyto/Desktop/data_ex.txt", encoding = "EUC-KR",
fileEncoding = "UTF-8", col.names = varname)
View(ex_data)skip 옵션
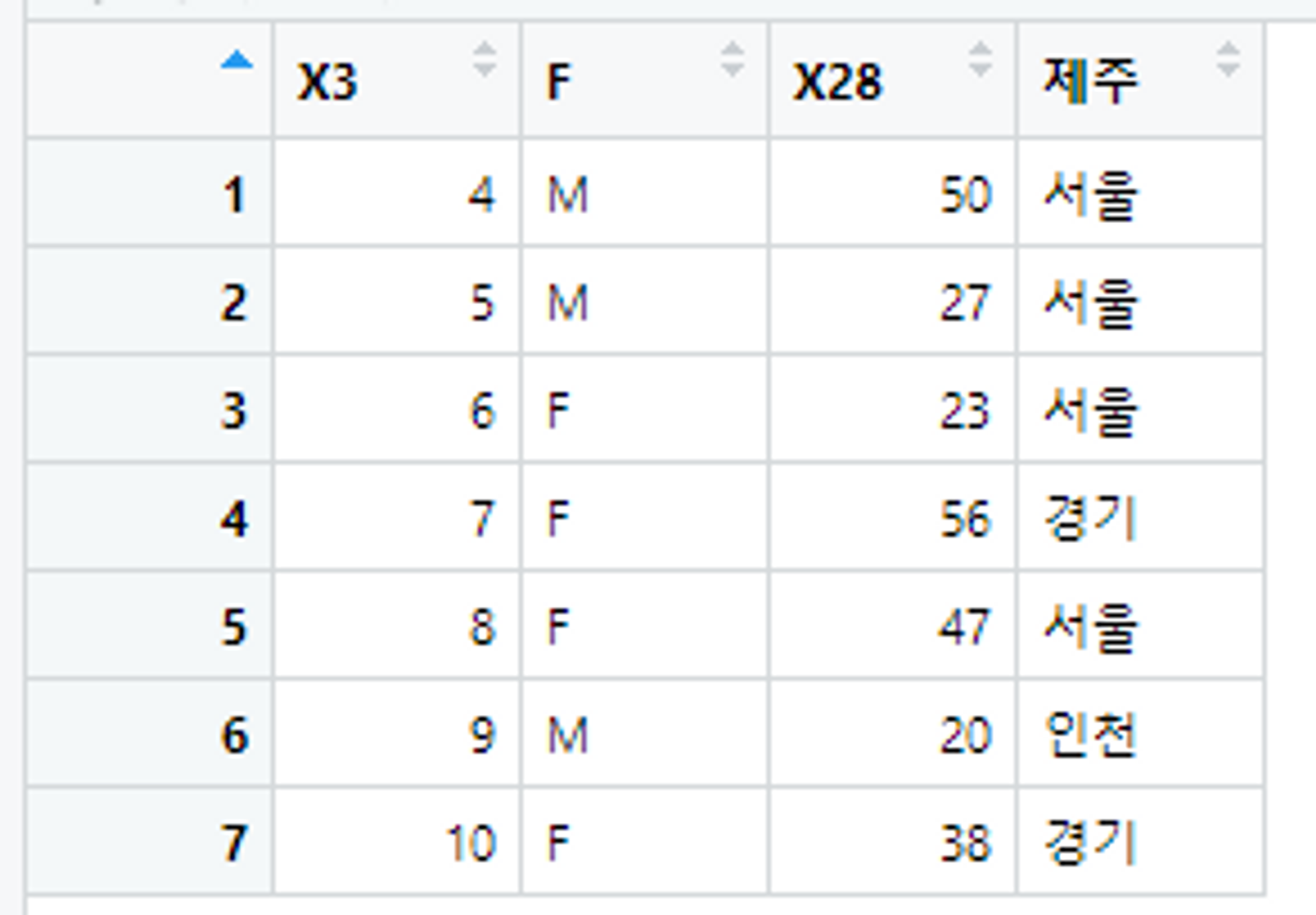
skip : 데이터 전체가 아닌, 옵션에 지정한 특정 행까지 제외하고 그 이후 행부터 가져온다.
# skip을 이용해서 3줄 건너뛰고 데이터 가져오기
# 기존의 ex_data에서 3줄을 건너뛰면 아래 이미지와 같은 결과가 나오게 된다.
ex_data <- read.table("C:/Users/flyto/Desktop/data_ex.txt", encoding = "EUC-KR", header = TRUE, fileEncoding = "UTF-8", skip = 3)
View(ex_data)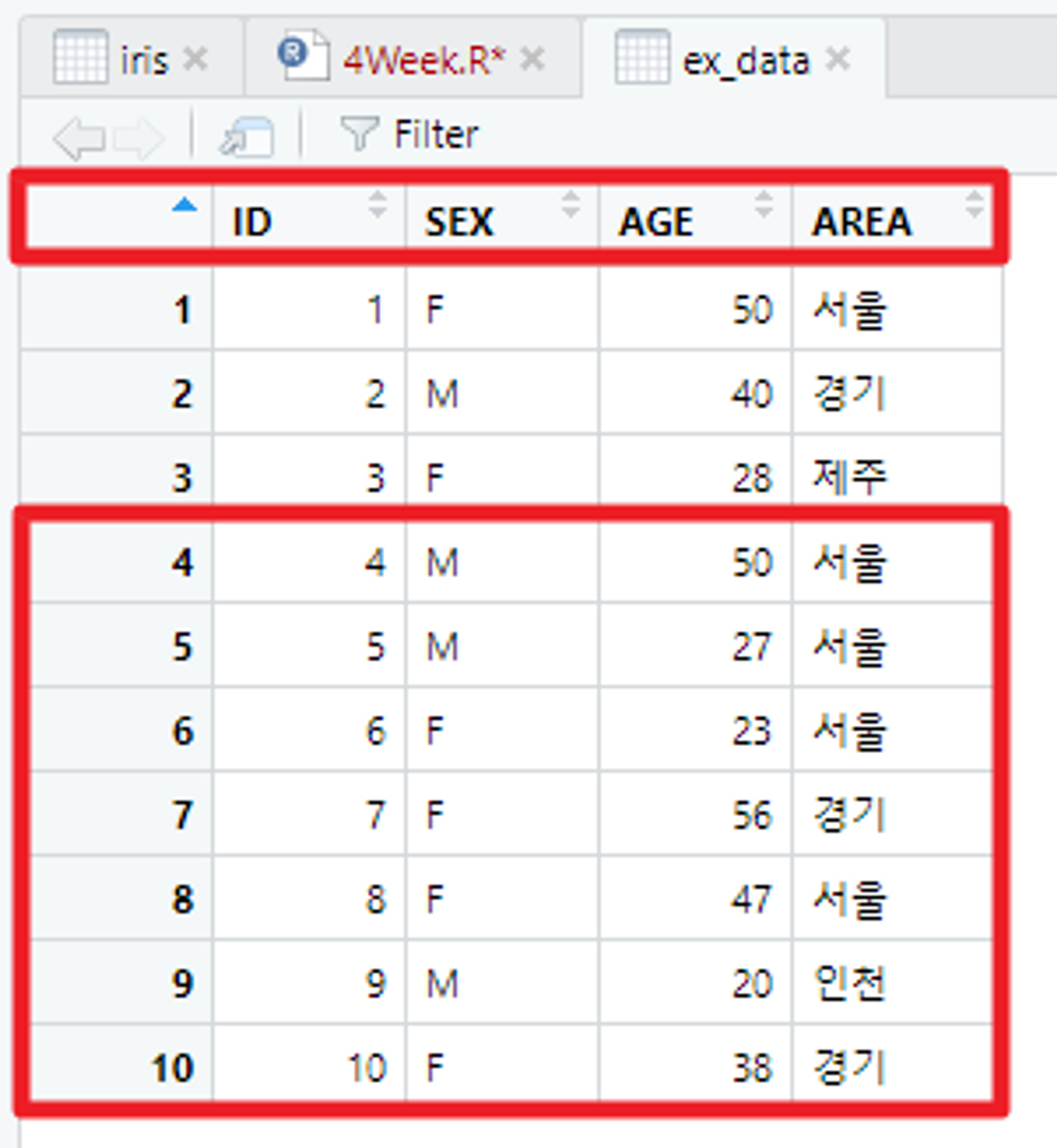
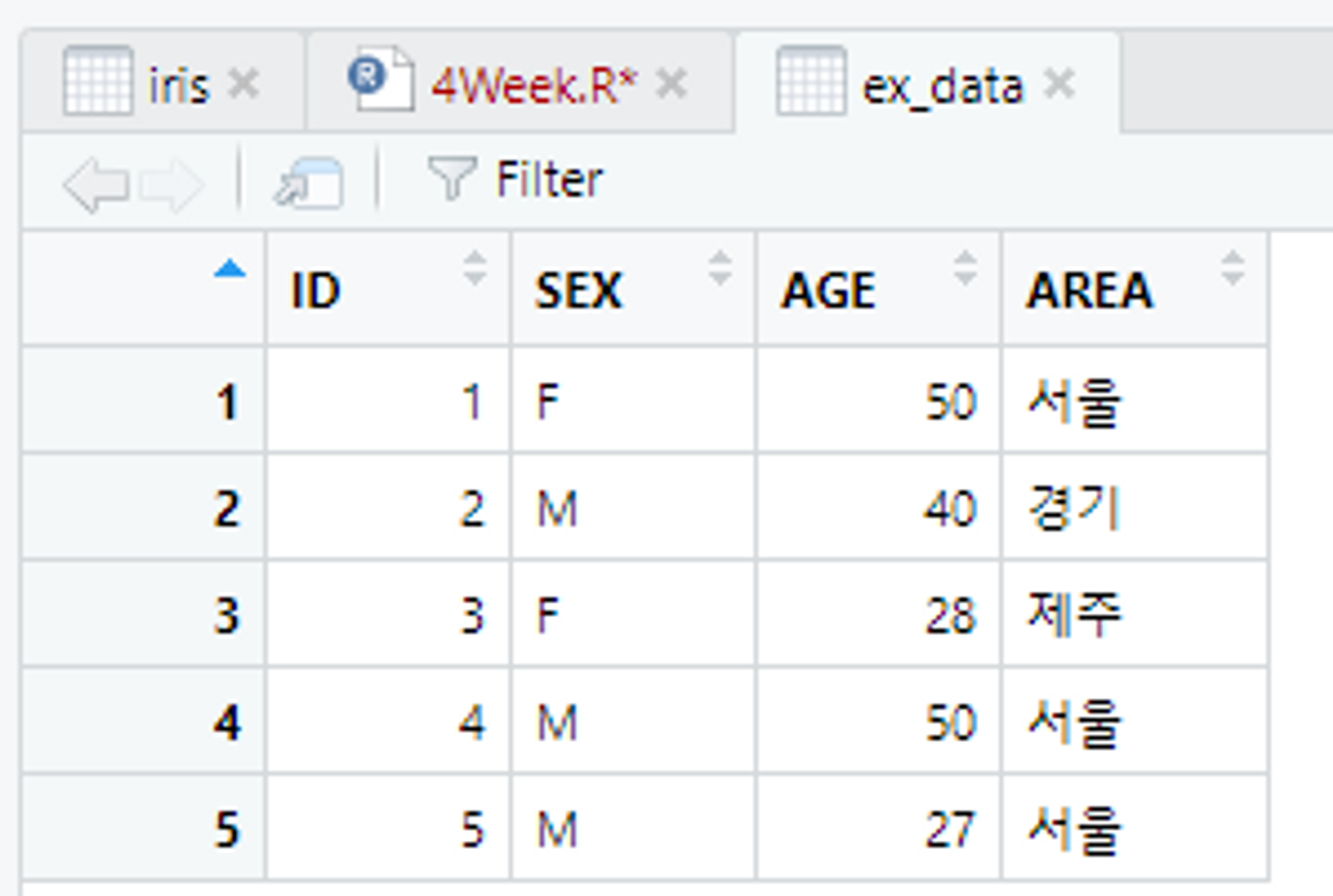
nrows 옵션
nrows : 몇 개의 행을 불러올 것인지에 대한 내용 설정
# nrows를 이용해서 5줄 까지 가져오기
# headers로 인해 1행이 변수명이 되고 이후에 1행~5행을 가져옴!
ex_data <- read.table("C:/Users/flyto/Desktop/data_ex.txt", encoding = "EUC-KR", header = TRUE, fileEncoding = "UTF-8", nrows = 5)
View(ex_data)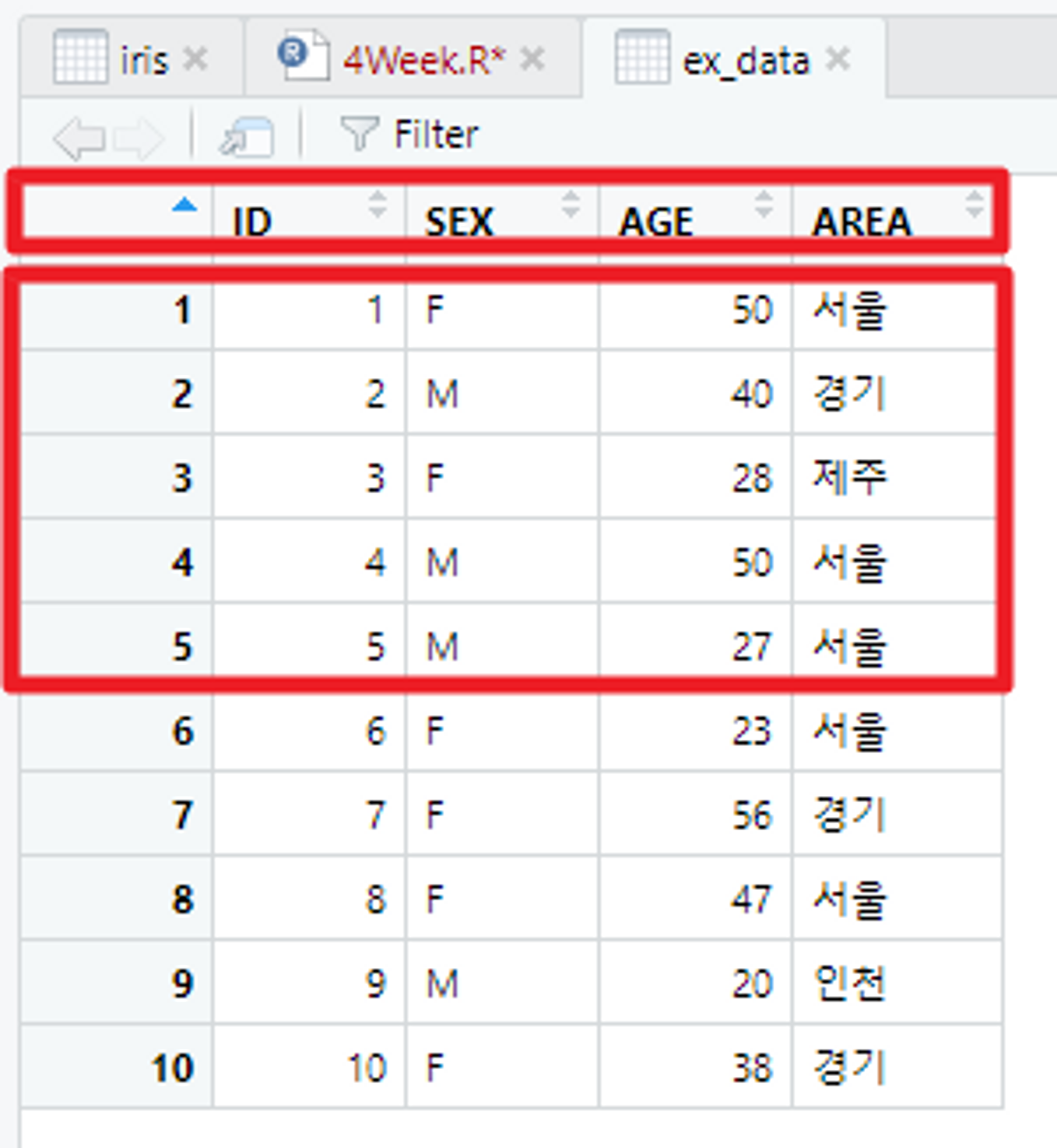
sep 옵션
sep : 데이터 구분자를 지정하는 옵션. 이는 우리가 가져올 데이터의 구분자에 따라 옵션을 설정함!
# 우리가 가져올 데이터의 구분자에 따라 sep 옵션을 설정한다.
# 예를 들어 , 을 통해 데이터들이 구분되어있을 경우 sep=","를 옵션으로 준다.
ex_data <- read.table("C:/Users/flyto/Desktop/data_ex.txt", encoding = "EUC-KR",
header = TRUE, fileEncoding = "UTF-8", sep=",")
View(ex_data)외부 데이터 불러오기 - csv 파일
CSV 파일은 쉼표(,)를 이용해 열을 구분하는 데이터이다.
CSV 파일을 가져올 때는 read.csv() 함수를 사용하며 read.table() 함수와 사용법이 비슷하다!
# R에서 코드로 CSV 파일을 불러오는 방법
ex_data <- read.csv("CSV파일 디렉터리 경로")
View(ex_data)외부 데이터 불러오기 - 액셀 파일
액셀 파일은 활용하는 원시 데이터 중 가장 많이 활용하는 파일이다.
액셀 파일의 경우, R언어에서 read_excel() 함수를 통해 가져온다.
주의할 점은, read_excel()은 내장 함수가 아니기 때문에 따로 readxl패키지를 설치해야 한다!
# readxl 패키지 설치 및 로드
install.packages('readxl')
library(readxl)# 액셀 데이터 read.excel로 불러오기
excel_data_ex <- read.excel("액셀 파일 디렉터리 경로")
View(excel_data_ex)참고로 read_excel 함수는 기본값으로 1번째 시트탭에 해당하는 데이터를 불러온다.
만약 여러 개의 시트탭 중 1번째 외의 탭 데이터를 불러오기 위해서는 sheet옵션을 설정!
→ read_excel(…. , sheet = 2)(2번째 시트 탭의 데이터를 불러옴)
외부 데이터 불러오기 - XML, JSON 파일
XML 그리고 JSON은 웹에서 사용하는 데이터 파일로, 이들의 특징을 간단히 알아보도록 하자.
XML : HTML과 비슷하지만 데이터를 보여주는 것이 아닌, 저장하고 전달하는 목적으로 만들어짐.
HTML처럼 태그가 미리 정의되어 있지 않고 태그를 사용자가 직접 정의한다.
JSON : JSON도 데이터를 전달하는 목적으로 만들어진 파일 형식이다. 서버-클라이언트 통신 간에 데이터를 받아 객체 혹은 변수에 할당해서 많이 사용하며, XML파일보다 구문이 짧고 속도가 빨라 실무에서 흔히 사용하는 데이터이다.
XML 파일 가져오기
# xmlToDataFrame() : XML파일을 데이터 프레임으로 변환하는 함수
# 해당 함수를 사용하기 위해서는 따로 패키지를 설치해주어야 함!
install.packages("XML")
library(XML)# XML 파일 불러오기
xml_data <- xmlToDataFrame("XML파일 디렉터리 경로")
View(xml_data)JSON 파일 가져오기
# JSON파일은 데이터 안에 다시 데이터가 중첩된 구조로 이루어져 있다.
# 그리고 속성 - 값으로 이루어진 것이 특징인 데이터이다.
# 아래는 JSON 데이터 예시
{
"이름" : "나혼공",
"나이" : 999
}# fromJSON() : JSON파일을 가져오는 함수
# 해당 함수를 사용하기 위해서는 따로 패키지를 설치해주어야 함!
install.packages("jsonlite")
#library(jsonlite)# fromJSON은 JSON을 데이터 프레임으로 가져오는 함수가 아니다.
# 그렇기 때문에 실행결과는 View가 아닌 str()사용!
json_data <- fromJSON("JSON파일 디렉터리 경로")
str(json_data)🎁 데이터 관측 🎁
데이터 관측 파트에 들어가기에 앞서
우리는 지금까지 원시 데이터를 조회할 때 View() 함수로 데이터 프레임 전체를 조회하였다.
그런데, 이제 데이터가 방대해질 경우에는 전체 데이터를 불러올 때는 많은 시간이 소요될 수 있다.
그렇기 때문에 실제 데이터 분석에서 데이터를 파악할 때는 데이터 요약 방법을 이용한다!
이제부터는 내장 데이터 확인 및 데이터를 요약하여 특성을 파악하는 방법들을 알아보도록 하자.
전체 데이터 확인하기
여기서부터는 R에서 기본적으로 제공하는 내장 데이터 세트를 살펴보도록 하자.
# R에 내장된 데이터 세트 목록 확인
data()
# iris 데이터 조회
# 아래 이미지를 보면, 5개의 column과 150개의 관측치를 보유하고 있음을 알 수 있다.
iris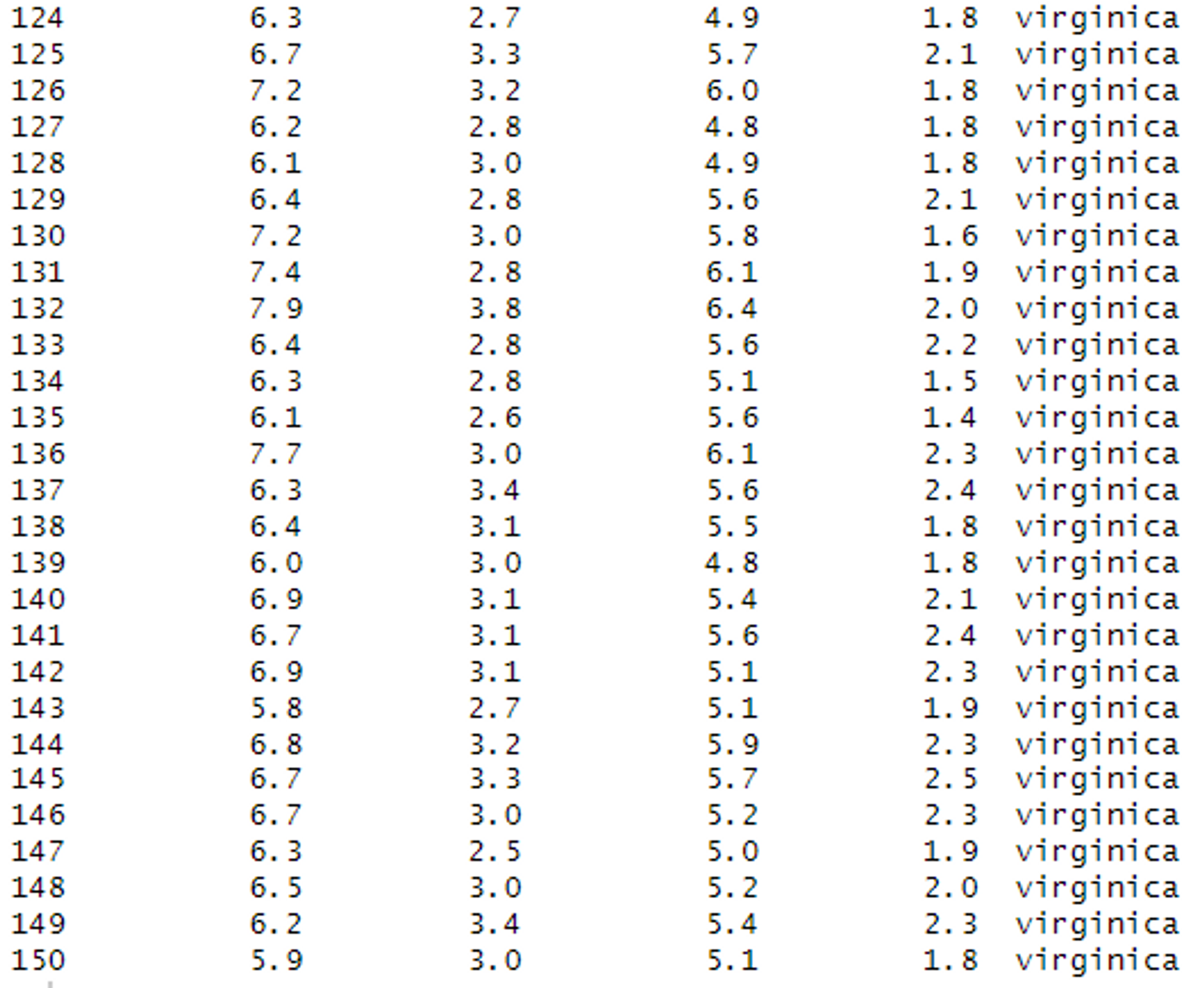
데이터 요약 확인하기
데이터 요약을 확인에는 여러 가지 방법이 존재한다.
데이터의 양이 많을 경우, 데이터 구조를 한눈에 확인하거나 혹은 데이터 중 일부 값만 확인한다!
데이터 구조 확인 - str() 함수를 통한 데이터 구조 파악
# str() : 데이터 구조를 확인할 수 있다.
str(변수명)# iris 데이터 세트의 구조 확인
str(iris)
‘data.frame’ : 150 obx. of 5 variables : 이 데이터는 데이터 프레임 + 5개 컬럼 + 150개 관측치
$ 이름 : 컬럼명을 의미함
num : 숫자형 데이터임을 의미함
Species : 어떤 범주로 구성되어 있는지. 여기서는 Factor 자료형 + setosa, versicolor, … 등의 3 levels로 구성되어 있음을 의미함
Factor : 연속성이 없는 범주형 자료를 표현하는 데이터 유형
데이터 세트 컬럼 및 관측치 확인을 통한 데이터 단순 파악
데이터를 더욱 단순하게 확인하는 방법으로는 데이터의 열과 행 개수만 확인하는 방법이 있다.
ncol() : 데이터 프레임 컬럼(열)의 개수 확인
nrow() : 데이터 프레임 관측치(행)의 개수 확인
dim() : 데이터 프레임 컬럼 및 관측치의 개수 확인
# iris 데이터 세트의 열과 행 확인
dim(iris)
ncol(iris)
nrow(iris)# 위 코드 실행 결과
> # iris 데이터 세트의 열과 행 확인
> dim(iris)
[1] 150 5 # 관측치(행) 150개 열 5개로 구성
> ncol(iris)
[1] 5
> nrow(iris)
[1] 150데이터 세트 컬럼명 확인하기 - ls() 함수
# 데이터 세트의 컬럼명 확인
ls(iris)> # 데이터 세트의 컬럼명 확인
> ls(iris)
[1] "Petal.Length" "Petal.Width" "Sepal.Length" "Sepal.Width" "Species"데이터 앞 뒷 부분 값 확인하기 - head() & tail() 함수
# 옵션 n을 이용해 확인을 원하는 개수를 변경할 수 있다.
# 참고로 수량을 따로 설정하지 않았을 경우, 둘 다 기본값은 n = 3이다.
head(변수명, n = 수량) # 앞 부분부터
tail(변수명, n = 수량) # 뒷 부분부터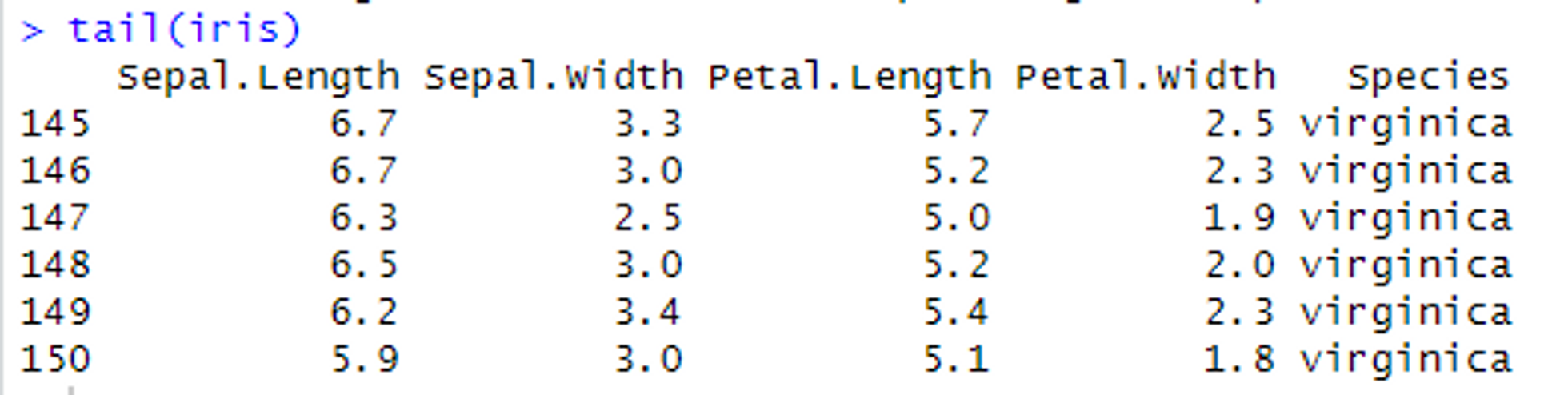
기술통계량 확인
기술통계량 : 데이터들의 중앙값 혹은 평균 등 데이터를 요약한 대푯값을 의미한다!
이 기술통계량은 여러가지 기술통계 함수를 통해 값을 추출해낼 수 있다.
기술통계 함수 중에 자주 그리고 접하기 쉬운 몇 가지 함수에 대해서 알아보도록 하자.
평균 그리고 중앙값 - mean() & median()
mean(변수명) # 이 친구는 평균값을 구해준다
median(변수명) # 이 친구는 데이터의 중앙값(가운데에 있는 값)을 구해준다# iris 데이터의 Sepal.Length에 대한 평균 그리고 중앙값 구하기
# 데이터 세트 안의 값 중 원하는 값에 대해서만 접근할 때는 데이터 프레임명$변수명 사용!
mean(iris$Sepal.Length)
median(iris$Sepal.Length)# 코드 실행 결과
> # iris 데이터의 Sepal.Length에 대한 평균 그리고 중앙값 구하기
> mean(iris$Sepal.Length)
[1] 5.843333
> median(iris$Sepal.Length)
[1] 5.8최댓값과 최솟값 그리고 범위 - min() & max() & range()
최솟값 : 데이터 중 가장 작은 값
최댓값 : 데이터 중 가장 큰 값
이상치 : 데이터에서 정상적인 범주를 벗어난 값. 가끔가다 데이터 중 지나치게 크거나 작은 값 등
min(변수명) # 최솟값
max(변수명) # 최댓값
range(변수명) # 최댓값 ~ 최솟값 범위# iris 데이터의 최대 최소 그리고 범위 구하기
min(iris$Sepal.Length)
max(iris$Sepal.Length)
range(iris$Sepal.Length)# 코드 실행 결과
> # iris 데이터의 최대 최소 그리고 범위 구하기
> min(iris$Sepal.Length)
[1] 4.3
> max(iris$Sepal.Length)
[1] 7.9
> range(iris$Sepal.Length)
[1] 4.3 7.9분위수(quantile) - 데이터의 범위 중 경계에 해당하는 값들
분위수 : 데이터를 크기 순으로 나열했을 때 경계에 해당하는 값들을 말한다.
특히 여기서 데이터들을 4등분 한 경계 지점의 관측값들을 사분위수라고 말한다.
제1사분위수 : 제 0.25분위수, 하위 25%에 해당하는 값이다.
제2사분위수 : 제 0.5분위수, 딱 50%에 해당하는 값이다.
제3사분위수 : 제 0.75분위수, 하위 75% 혹은 상위 25%에 해당하는 값이다.
제4사분위수 : 제1분위수, 100%에 해당하는 값이다.
# quantile() : 분위수를 구하는 함수
# quantile()의 옵션으로 probs를 주면 제n사분위수를 구할 수 있다.
# 사용법 : quantile(변수명, probs = 0 ~ 1)
# probs : 0.25 / 0.50 / 0.75 / 0.80(차례대로 제1,2,3사분위수 그리고 제0.8분위수)분산 그리고 표준편차 - var() & sd()
산포도 : 데이터가 대푯값에서 어느정도 퍼져있는지를 의미하는 말
분산 : 데이터가 평균으로부터 퍼진 정도를 설명하는 통계량
표준편차 : 데이터 값이 퍼진 정도를 설명하는 통계량
# var(변수명) : 분산을 구해줌(분산이 작을수록 데이터가 평균값에 몰림)
# sd(변수명) : 표준편차를 구해줌(표준편차는 클수록 데이터게 넓게 퍼짐)첨도와 왜도 - kurtosi() & skew()
첨도 : 데이터 분포가 정규분포대비 뾰족한 정도를 설명하는 통계량
왜도 : 데이터 분포의 비대칭성을 설명하는 통계량
# kurtosi(변수명) : 첨도를 구해줌, 통계량이 0보다 크면 정규분포 대비 그래프 곡선이 뾰족!
# skew(변수명) : 왜도를 구해줌, 통계량이 0에 가까울수록 좌우대칭, 0보다 크면 왼쪽 치우침# 첨도 & 왜도 함수를 사용하기 위한 패키기 설치 진행
install.packages("psych")
library(psych)데이터 빈도 분석
빈도분석 : 데이터의 항목별 빈도 및 빈도 비율을 나타내는 방법! 데이터 분포 파악시 유용함
# freq() : 데이터 빈도 분석시에 주로 사용
# freq()를 사용하기 위한 패키지 설치 진행
install.package("descr")
library(descr)🎁 데이터 탐색 🎁
들어가기에 앞서
그래프 : 데이터를 간결하고 쉽게 이해할 수 있도록 이미지 or 시각화한 것
데이터 탐색 파트에서는 다양한 그래프들에 대해서 알아보도록 하자!
막대 그래프 그리기
freq() 함수
# freq()의 사용법
# plot = T라 할경우, 데이터에 대한 막대 그래프가 함께 출력된다
freq(변수명, plot = T, main = '그래프 제목)-
우선 액셀파일 하나를 불러와서 데이터 확인
# descr 패키지 설치 및 로드 install.packages("descr") library(descr) # Sample1.xlsx 파일을 활용해보자! library(readxl) exdata1 <- read_excel("C:/Users/flyto/Desktop/Sample1.xlsx") exdata1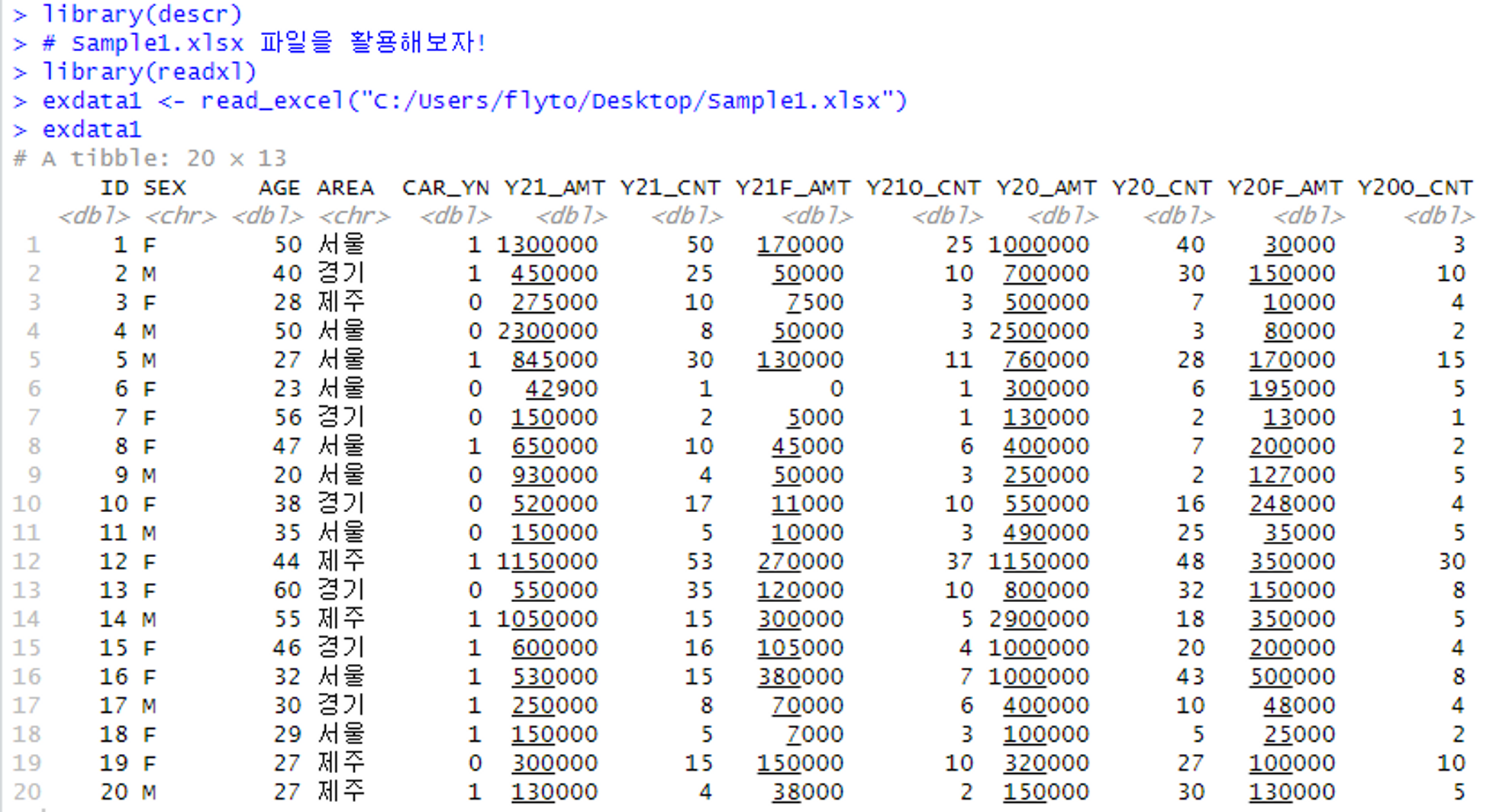
-
데이터가 정상적으로 확인되었다면 freq()를 통해 데이터 시각화 및 활용
# 가져온 데이터로 막대 그래프 그리기! freq(exdata1$SEX, plot = T, main = '성별(barplot)')# 실행 결과 > # 가져온 데이터로 막대 그래프 그리기!(Plots 탭에서 그래프가 표시됨) > freq(exdata1$SEX, plot = T, main = '성별(barplot)') exdata1$SEX Frequency Percent F 12 60 M 8 40 Total 20 100
barplot() 함수
앞에서 따로 패키지를 설치하여 막대그래프를 그렸던 freq()와는 달리, barplot()은 바로 그릴 수 있다!
다만 barplot()에서는 빈도 분포를 구하는 기능이 없어서, table()함수를 함께 사용한다.
# barplot()의 사용법
barplot(변수명, ylim = c(y축 범위), main = "그래프 제목", xlab = "x축 제목", ylab = "y축 제목", names = c("컬럼 제목", ...), col = c("색상",...), ...)ylim : 출력할 y축 범위를 지정함. c() 함수를 통해 벡터 형태로 지정!
main : 그래프 제목 지정
xlab : x축 제목 지정
ylab : y축 제목 지정
names : c() 함수를 사용해 벡터 형태로 컬럼 제목 지정
col : c() 함수를 사용해 벡터 형태로 그래프 색상 지정
# barplot()은 table()함수의 결과처럼 표 형태로 데이터가 존재할 때 빈도를 출력 가능함
# 따라서 빈도수를 이용할 때 freq()가 아닌 table()을 barplot()에 사용한다
dist_sex <- table(exdata1$SEX)
dist_sex
barplot(dist_sex)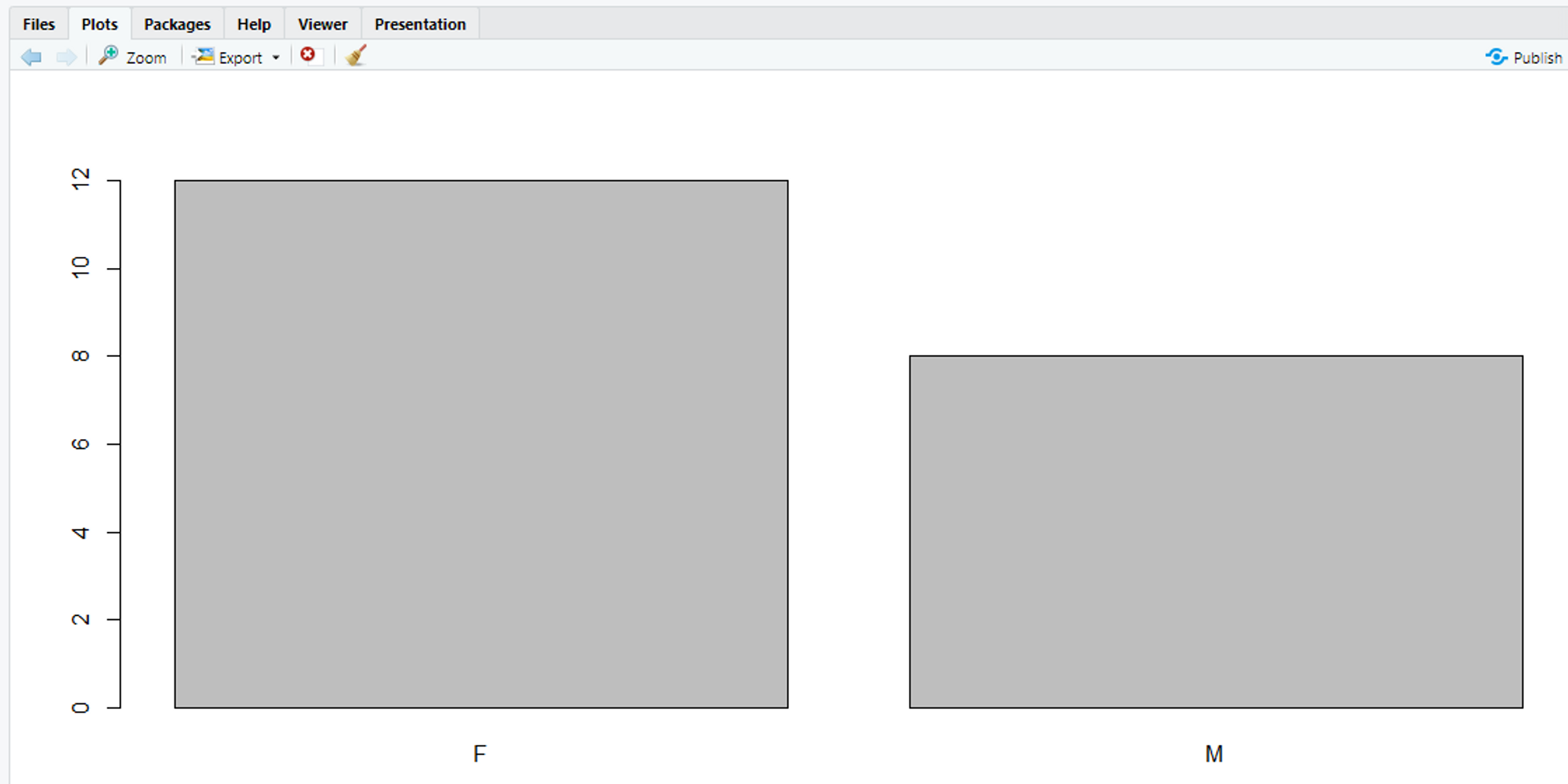
# 막대 그래프의 색상 변경 해보기!
barplot(dist_sex, ylim = c(0, 14), main = "BARPLOT", xlab = "SEX",
ylab = "FREQUENCY", names = c("Female", "Male"),
col = c("pink", "navy"))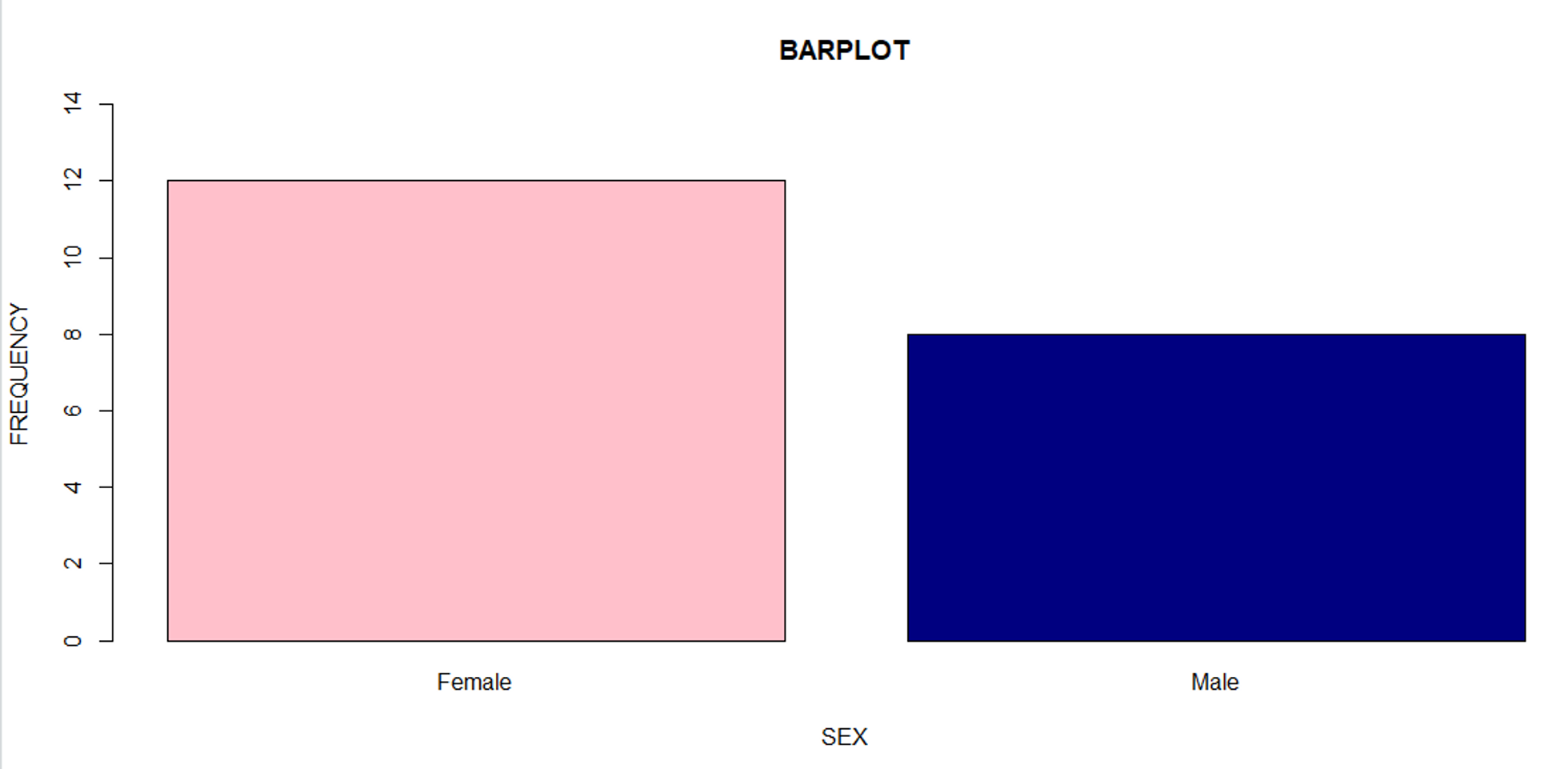
상자 그림(boxplot)
상자 그림 : 데이터의 분포를 비교하거나 이상치를 판단할 때 주로 사용하는 그래프!
이상치(outlier) : 데이터 분포에서 심하게 벗어난 극단의 데이터를 말한다.
# 상자 그림 그리기!
# 상자 그림에서 이상치는 최댓값 혹은 최솟값 라인 바깥에 동그라미로 표기된다.
boxplot(exdata1$Y21_CNT, exdata1$Y20_CNT)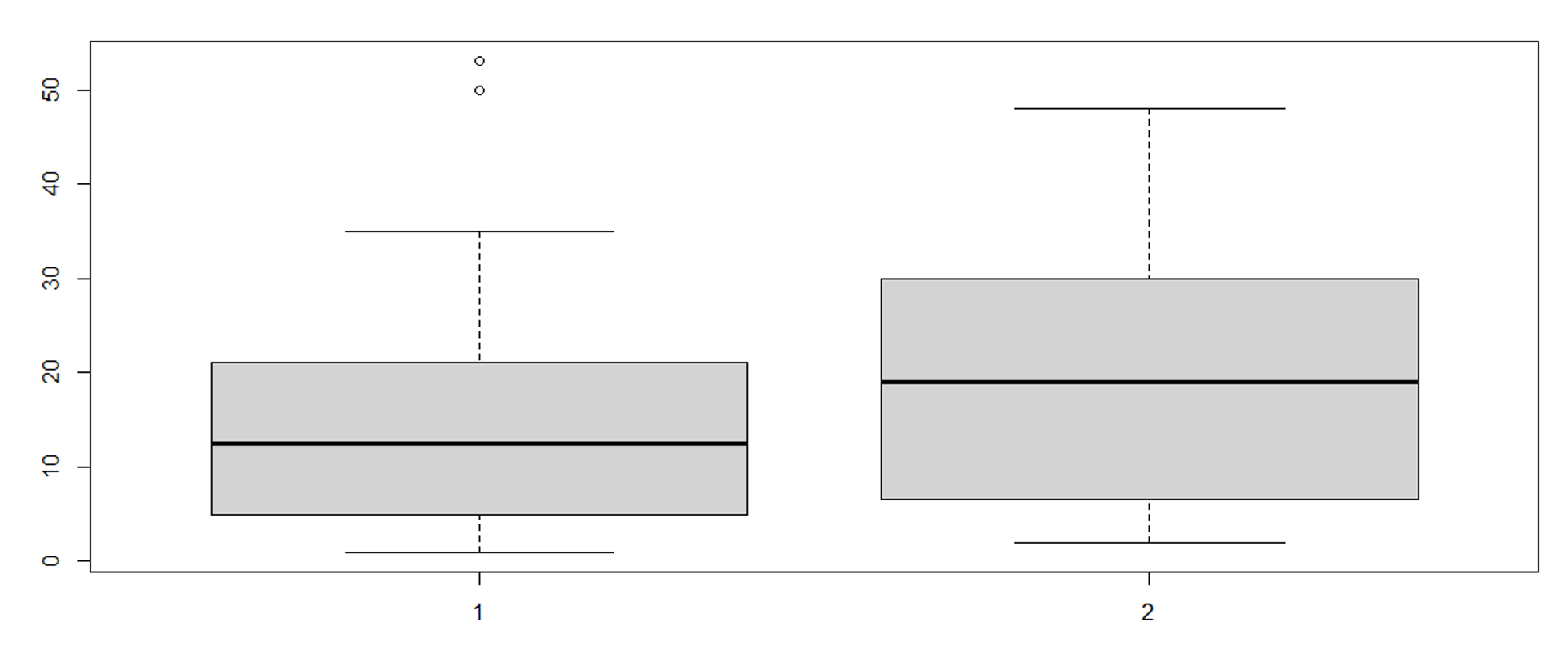
# 그래프 가독성 높이기!
# y축 범위 변경 & 그래프 제목 부여 & 컬럼 제목 부여
boxplot(exdata1$Y21_CNT, exdata1$Y20_CNT, ylim = c(0, 60),
main = "boxplot", names = c("21년건수", "20년건수"))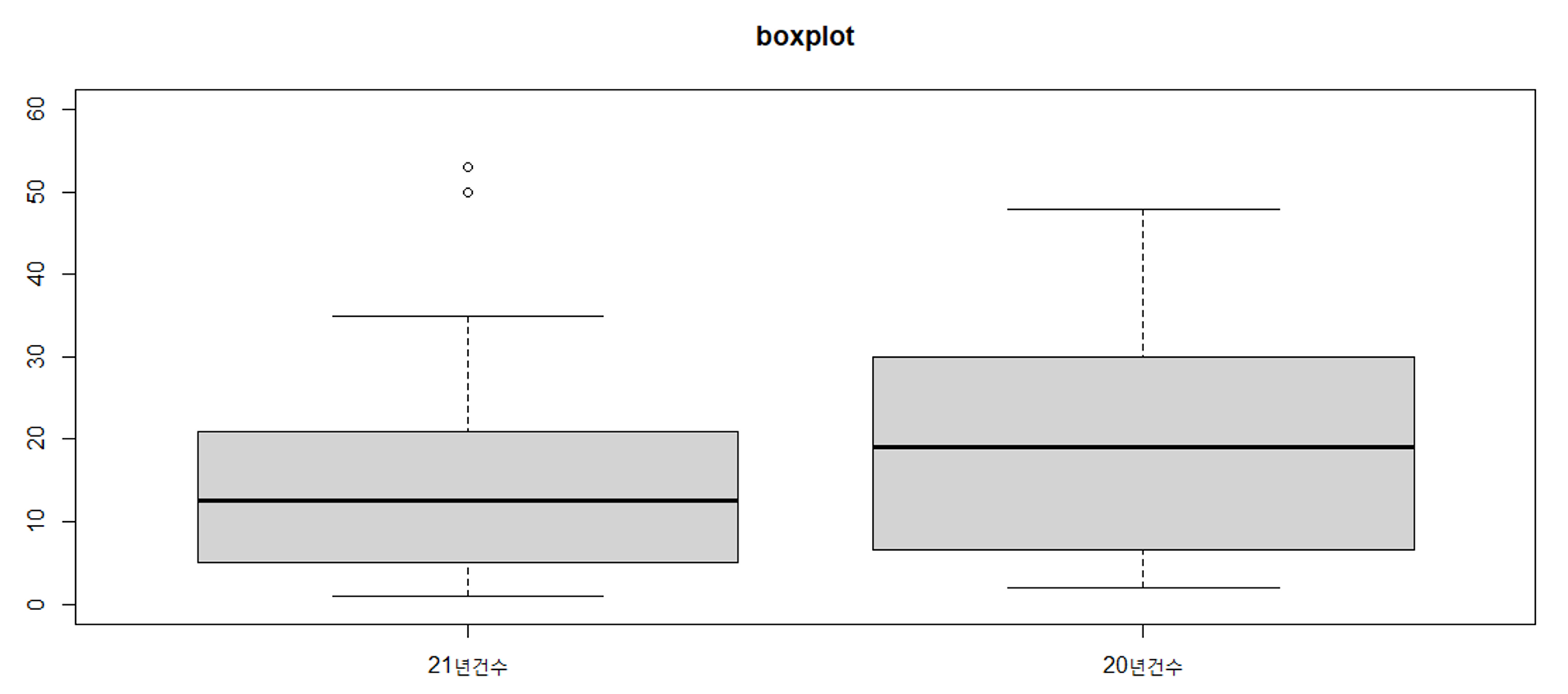
히스토그램
히스토그램 : 연속형 데이터를 일정하게 나눈 구간(계급)을 가로 축으로, 각 구간에 해당하는 데이터 수(도수)를 세로 축으로 그려낸 그래프이다. 히스토그램을 통해 구간별 관측치 분포를 빠르게 파악할 수 있다는 장점이 존재함!
# R에서 히스토그램을 함수를 그리는 방법
hist(변수명)# exdata1의 나이를 기반으로 히스토그램 그리기
hist(exdata1$AGE, xlim = c(0, 60), ylim = c(0, 7), main = "AGE분포")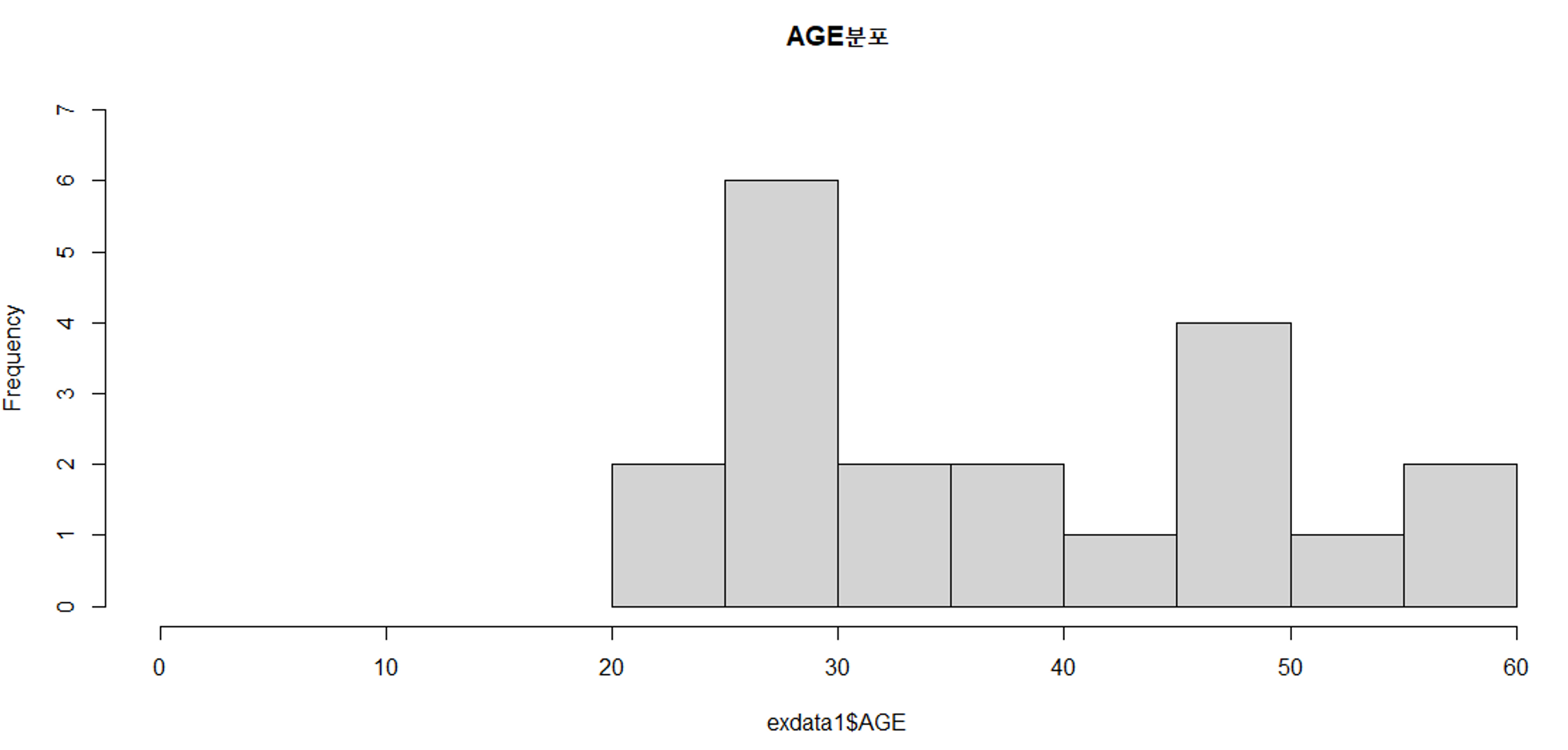
파이차트
파이차트 : 데이터 범주 구성 비례에 따라 원을 %만큼 나누어 표현하는 그래프
# R에서 파이차트를 그리는 방법
pie(변수명)# 파이차트 그려보기!
# mtcars : 미국의 모터트렌드 잡지에서 32개의 차종을 비교한 데이터셋
# pie() 함수에 빈도분석 기능이 없기때문에 빈도 분석을 위해 table()을 써서 넘겨줌!
data(mtcars)
x <- table(mtcars$gear)
pie(x)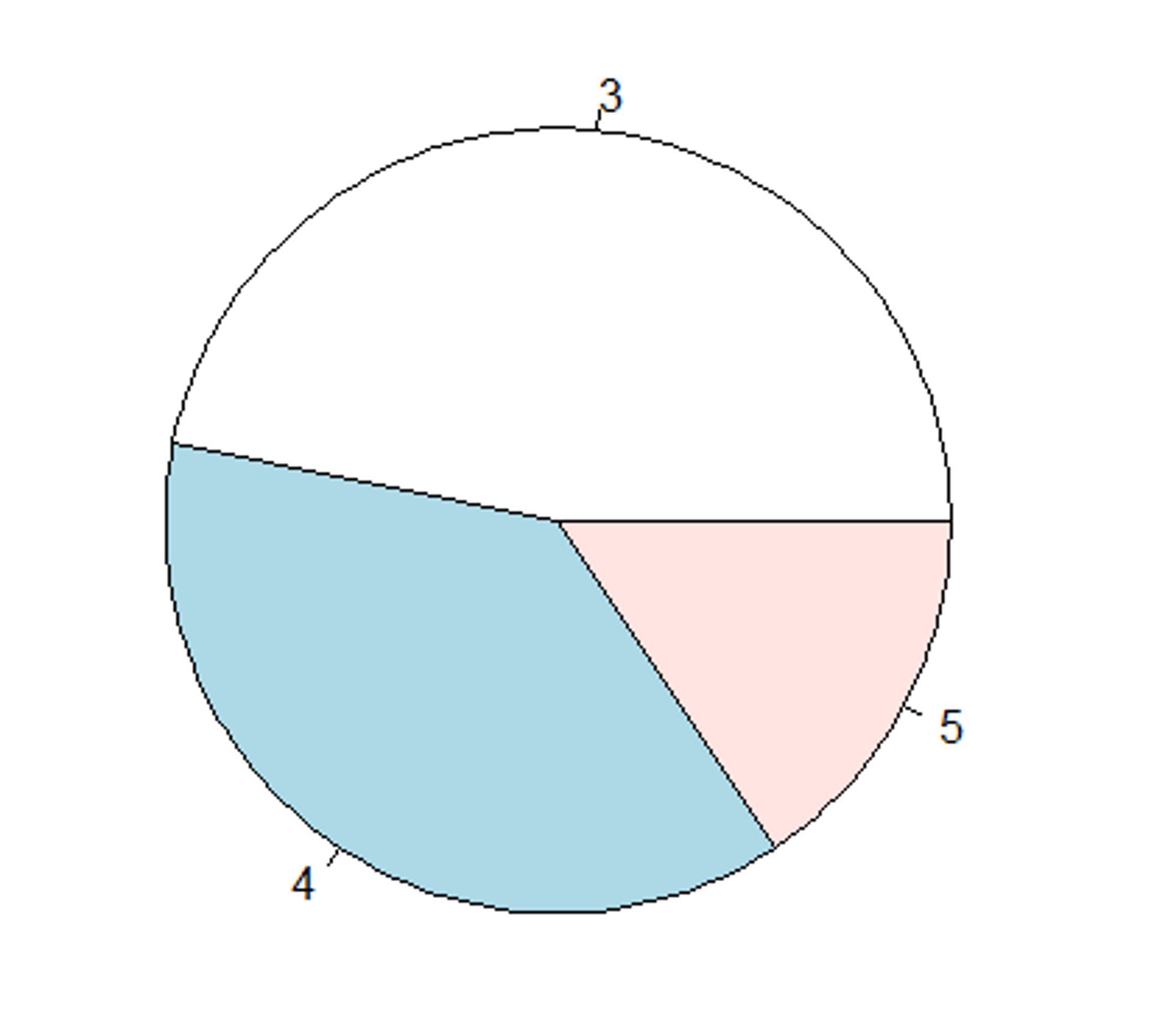
줄기-잎 그림
줄기-잎 그림 : 변수 값을 자릿수로 분류하여 시각화하는 방법.
큰 자릿수의 값은 줄기에 표현, 작은 자릿수의 값은 잎에 표현하여 데이터의 전체적인 형태를 파악!
# R에서 줄기-잎 그림을 그리는 방법
# scale = 줄기의 수(데이터를 나누는 구간)(기본값 = 1)
# 예시
stem(변수명, scale = 1)# 줄기-잎 그림 그려보기!
x = c(1, 2, 3, 4, 7, 8, 8, 5, 9, 6, 9, 1, 1, 2, 3, 3, 3, 6, 7, 2)
stem(x)# 실행 결과
> # 줄기-잎 그림 그려보기!
> x = c(1, 2, 3, 4, 7, 8, 8, 5, 9, 6, 9, 1, 1, 2, 3, 3, 3, 6, 7, 2)
> stem(x)
# |(수직선) 기호를 기준으로 여기서는 줄기는 일의자리, 잎은 소수점을 의미한다.
The decimal point is at the |
0 | 000 (1, 1, 1)
2 | 0000000 (2, 2, 2, 3, 3, 3, 3)
4 | 00 (4, 5)
6 | 0000 (6, 6, 7, 7)
8 | 0000 (8, 8, 9, 9)산점도(Scatter)
산점도(산포도) : 연속형 숫자 변수들에서 변수들간의 관계를 점으로 나타낸 시각적 자료
# R에서 산점도를 표시하는 방법
plot(x, y)# 산점도 그려보기!
# 가로 : Sepal.Length & 세로 : Sepal.Width
data(iris)
plot(x = iris$Sepal.Length, y = iris$Petal.Width)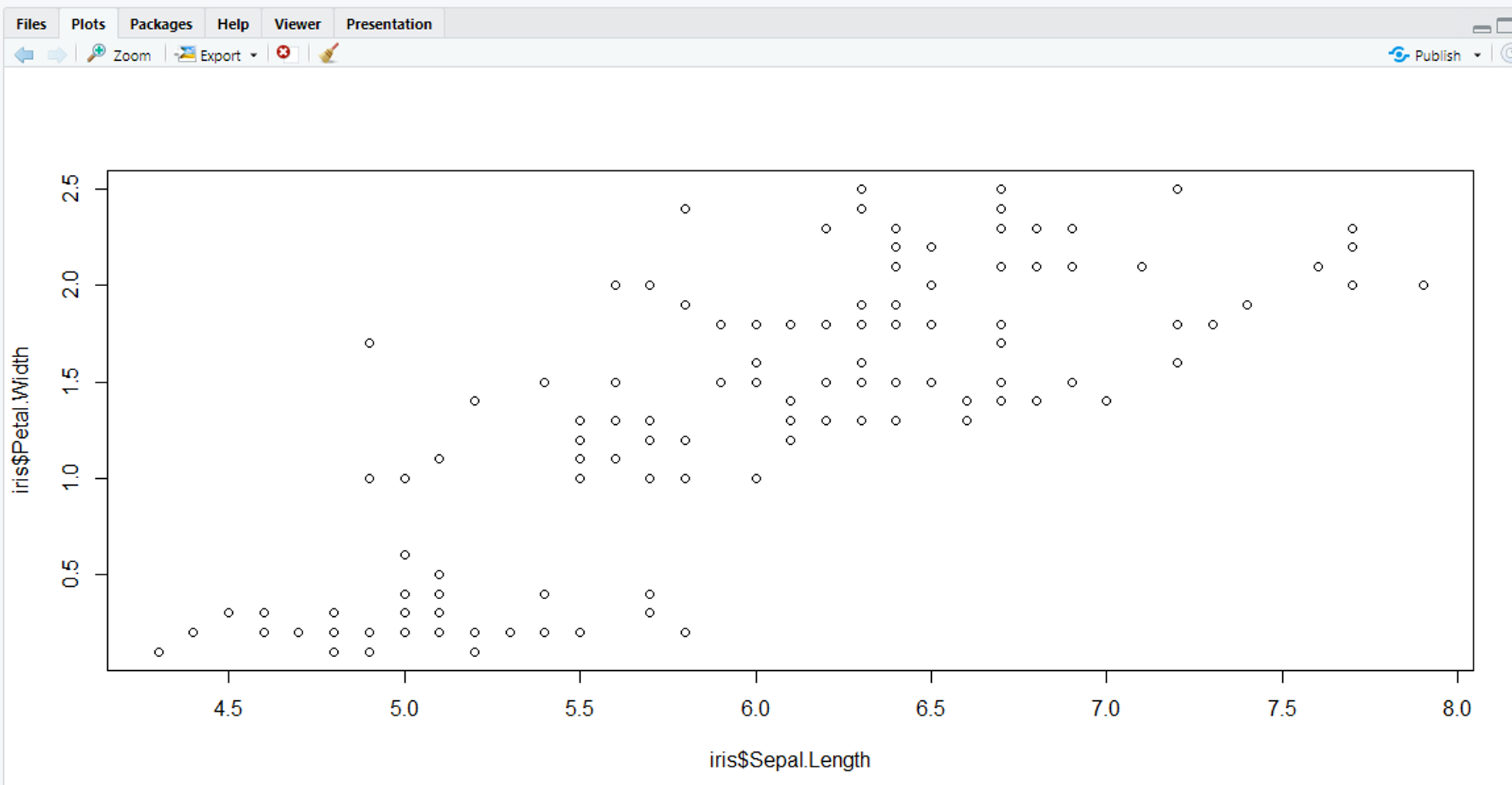
산점도 행렬
산점도 행렬 : 산점도들을 행렬로 표현한 것
# R에서 산점도 행렬을 표시하는 방법
pairs(변수명)# 산점도 행렬 그려보기!
data(iris)
pairs(iris)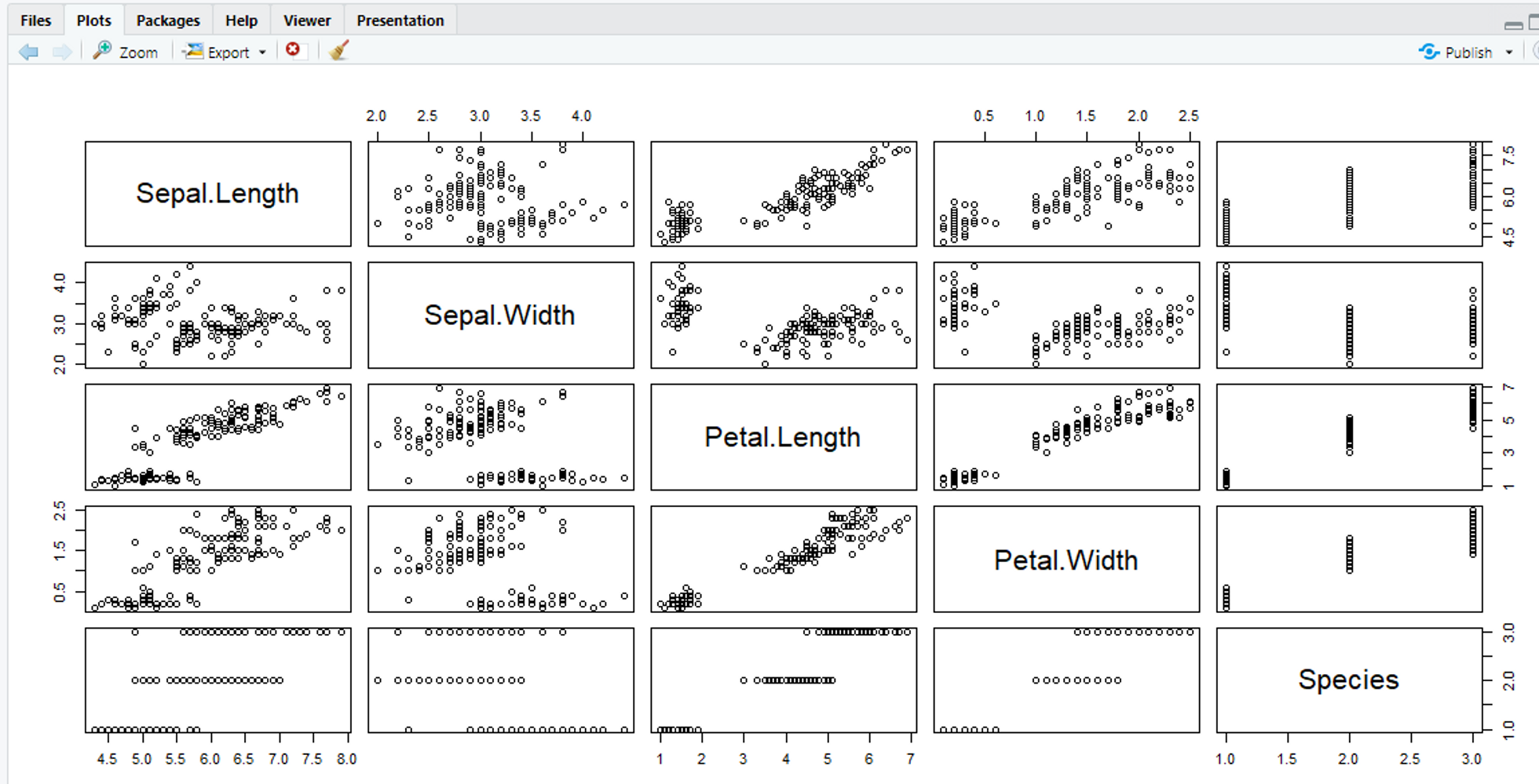
산점도 행렬 - paris.panel() 이용
# 산점도 행렬은 psych 패키지 내부의 paris.panel()함수를 이용해서 그릴 수 있다!
# pairs.panel() 사용을 위한 패키지 설치 진행
install.packages("psych")
library(psych)# pairs.panel()을 이용하여 산점도 행렬 그리기!
data(iris)
pairs.panels(iris)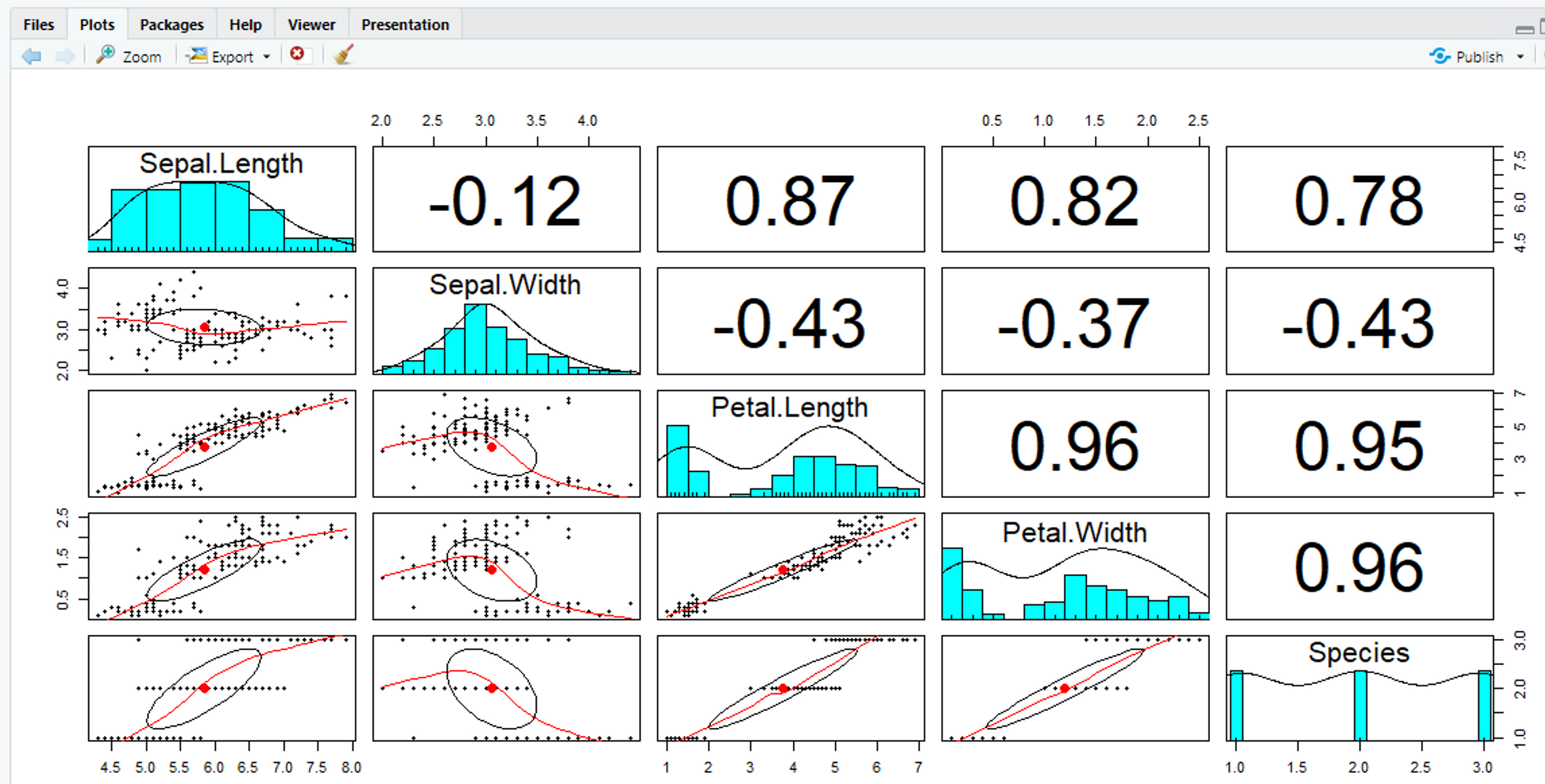
🥃 기본 미션 🥃
169p Iris 내장 데이터 세트 데이터 구조 출력 및 인증
# iris 데이터 세트의 구조 확인
str(iris)
🍸 선택 미션 🍸
191p 상자 그림 그래프 각 요약 값 정리
이상치 : 데이터에서 정상적인 범주를 벗어난 값
최댓값 : 데이터에서 가장 큰 값
제3사분위수 : 제 0.75분위수, 하위 75% 혹은 상위 25%에 해당하는 값
중앙값(제2사분위수) : 제 0.5분위수, 딱 50%에 해당하는 값
제1사분위수 : 제 0.25분위수, 하위 25%에 해당하는 값
최솟값 : 데이터에서 가장 작은 값


좋은 정보 얻어갑니다, 감사합니다.