
참고한 서적 : https://hongong.hanbit.co.kr/r-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D/ (혼자 공부하는 R언어)📌이번 주차내용
→ R언어에서의 데이터 조작에 사용하는 패키지
→ R언어에서의 이상치 및 결측치 처리와 관련된 내용🎁 dplyr 패키지 🎁
dplyr 패키지가 무엇인고?
우리는 dplyr 패키지에 대해서 스쳐가듯이 어디에서 살펴본 적이 있다!
Chapter 3의 HOT한 패키지 활용하기 파트에서 데이터 조작 → dplyr 패키지라는 내용이 있었다!
그렇다. dplyr 패키지는 데이터 처리와 관련된 패키지로, 우리는 이 패키지를 통해서 여러가지 처리를 손쉽게 할 수 있기 때문에 잠시 dplyr 패키지에 대해서 알아보도록 하자!
dplyr 패키지 설치 & 로드
# dplyr 패키지 설치 및 로드!!
install.packages("dplyr")
library(dplyr)
# mtcars 데이터셋 구조 확인!!
nrow(mtcars)
str(mtcars)> # mtcars 데이터셋 구조 확인
> nrow(mtcars)
[1] 32
# mtcars 데이터셋을 이용해볼 것인데, 여기에는 연료 소비와 관련된 변수 11개
# 그리고 자동차 모델 32종에 대한 정보가 담겨있다!
> str(mtcars)
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...데이터 추출 및 정렬
dplyr 패키지 → 데이터 셋에서 필요한 데이터만 쏙 골라 추출 혹은 기준에 따라 정렬 가능함!
filter() → 행(row) 추출
# filter() : 조건에 맞는 데이터 추출
# filter(데이터, 조건문) 형태로 사용
filter(mtcars, cyl == 4) # 실린더 개수가 4기통인 자동차만 추출!> # filter() : 조건에 맞는 데이터 추출
> # filter(데이터, 조건문) 형태로 사용
> filter(mtcars, cyl == 4) # 실린더 개수가 4기통인 자동차만 추출!
mpg cyl disp hp drat wt qsec vs am gear carb
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2filter()에다가 여러가지 조건을 붙여서 데이터 추출하기
# 두 가지 조건에 맞는 데이터 필터링
# & 연산자를 통해 2개 이상의 조건을 지정할 수 있다!
# 실린더 6기통 이상 + 연비가 20miles/gallon인 자동차 추출
filter(mtcars, cyl >= 6 & mpg > 20)> # 두 가지 조건에 맞는 데이터 필터링
> # & 연산자를 통해 2개 이상의 조건을 지정할 수 있다!
> # 실린더 6기통 이상 + 연비가 20miles/gallon인 자동차 추출
> filter(mtcars, cyl >= 6 & mpg > 20)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1select() → 열(column) 추출
# 지정한 변수만 추출
# select(데이터, 변수명1, 변수명2, ...) 형태로 사용
# head + select를 사용하여 select를 통해 뽑아낸 데이터 중 앞에서 6개만 확인
head(select(mtcars, am, gear))> # 지정한 변수만 추출
> # select(데이터, 변수명1, 변수명2, ...) 형태로 사용
> # head + select를 사용하여 select를 통해 뽑아낸 데이터 중 앞에서 6개만 확인
> head(select(mtcars, am, gear))
am gear
Mazda RX4 1 4
Mazda RX4 Wag 1 4
Datsun 710 1 4
Hornet 4 Drive 0 3
Hornet Sportabout 0 3
Valiant 0 3arrange() → 데이터 정렬
# 오름차순 정렬
# arrange(데이터, 변수명1, 변수명2, ...) 형태로 사용
# arrange(데이터, 변수명1, 변수명2, ..., desc(변수명)) desc 사용시 내림차순!
head(arrange(mtcars, wt)) # 무게를 기준으로 오름차순 정렬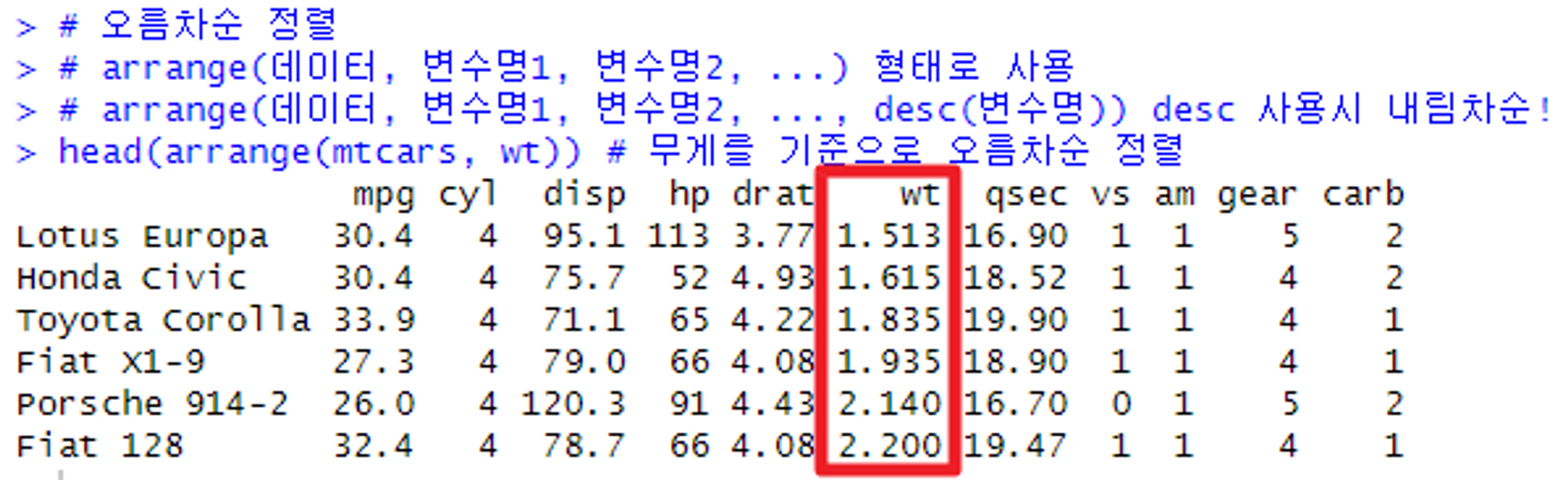
arrange() 오름차순 + 내림차순 사용하기
# 오름차순 정렬 + 내림차순 정렬
# 1번째 기준 : mpg(오름차순)
# 2번째 기준 : wt(내림차순)
head(arrange(mtcars, mpg, desc(wt)))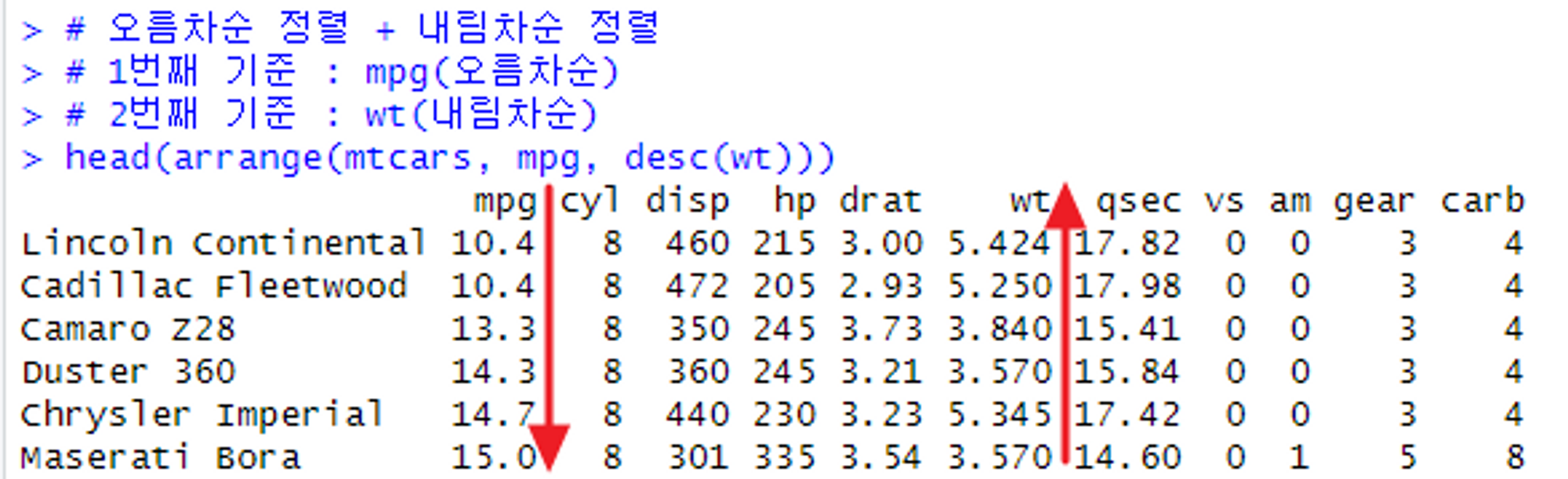
데이터 추가 및 중복 데이터 제거 방법
mutate() → 열 추가
# 새로운 열 추가
# mutate(데이터, 추가할 변수 이름 = 조건1, ...) 형태로 사용
# 기존 열을 가공한 후 그 결과값을 기존 열 or 새로운 열에 할당 가능!
head(mutate(mtcars, years = "1974"))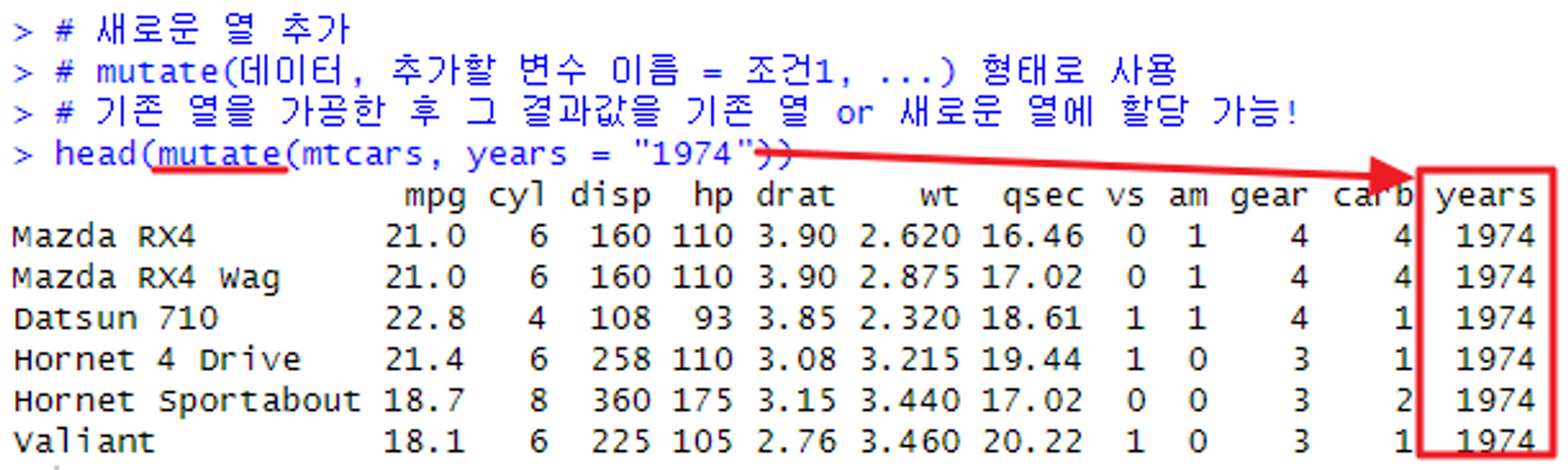
distinct() → 중복 제거
# 중복 값 제거
# distinct(데이터, 변수명) 형태로 사용
distinct(mtcars, cyl)
distinct(mtcars, gear)> # 중복 값 제거
> # distinct(데이터, 변수명) 형태로 사용
> distinct(mtcars, cyl) # cyl 열에서 같은 값들에 대한 중복 제거
cyl
Mazda RX4 6
Datsun 710 4
Hornet Sportabout 8
> distinct(mtcars, gear) # gear 열에서 같은 값들에 대한 중복 제거
gear
Mazda RX4 4
Hornet 4 Drive 3
Porsche 914-2 5distinct()에서 여러 열을 한꺼번에 지정하기
# 여러가지 열에 대한 중복 값 제거
distinct(mtcars, cyl, gear)> distinct(mtcars, cyl, gear) # cyl & gear의 값이 동일한 값일 때만 중복이 제거된다.
cyl gear
Mazda RX4 6 4
Datsun 710 4 4
Hornet 4 Drive 6 3
Hornet Sportabout 8 3
Toyota Corona 4 3
Porsche 914-2 4 5
Ford Pantera L 8 5
Ferrari Dino 6 5데이터 요약 & 샘플 추출
summarise() → 데이터 전체 요약
# 데이터 요약
# summarise(데이터, 요약할 변수명 = 기술통계 함수) 형태로 사용
#cyl의 평균, 최대, 최소에 대한 데이터를 요약!
summarise(mtcars, cyl_mean = mean(cyl), cyl_min = min(cyl), cyl_max = max(cyl))> # 데이터 요약
> # summarise(데이터, 요약할 변수명 = 기술통계 함수) 형태로 사용
> #cyl의 평균, 최대, 최소에 대한 데이터를 요약!
> summarise(mtcars, cyl_mean = mean(cyl), cyl_min = min(cyl), cyl_max = max(cyl))
cyl_mean cyl_min cyl_max
1 6.1875 4 8📌 참고 : 요약할 변수명을 따로 입력하지 않으면 기술통계 함수의 이름이 열 이름으로 쓰임!
group_by() → 그룹별 요약
# 그룹별 요약
# group_by(데이터, 변수명)
# 데이터를 지정한 조건에 따라 그룹으로 묶는 역할!
gr_cyl <- group_by(mtcars, cyl) # gr_cyl 변수에 group_by 함수의 결과를 담음
summarise(gr_cyl, n()) # 이후 summarise로 요약, 이 때 기술통계 함수는 데이터 개수를 구하는 n()사용> # 그룹별 요약
> # group_by(데이터, 변수명)
> # 데이터를 지정한 조건에 따라 그룹으로 묶는 역할!
> gr_cyl <- group_by(mtcars, cyl) # gr_cyl 변수에 group_by 함수의 결과를 담음
> summarise(gr_cyl, n()) # 이후 summarise로 요약, 이 때 기술통계 함수는 데이터 개수를 구하는 n()사용
# cyl열 그룹을 데이터 요약한 결과!
# 실린더 개수는 4, 6, 8개 이며 이에 해당하는 데이터 개수는 11, 7, 14개!
# A tibble: 3 × 2(행 x 열)
cyl `n()`
<dbl> <int>
1 4 11
2 6 7
3 8 14group_by + n_distinct() → 그룹별 요약 + 특정 데이터에 대한 중복 제거
# cyl 열 그룹에 대한 데이터 중 gear값이 중복인 데이터를 제외한 개수를 구해줌!
gr_cyl <- group_by(mtcars, cyl)
summarise(gr_cyl, n_distinct(gear))> # cyl 열 그룹에 대한 데이터 중 gear값이 중복인 데이터를 제외한 개수를 구해줌!
> gr_cyl <- group_by(mtcars, cyl)
> summarise(gr_cyl, n_distinct(gear))
# 실린더 개수는 4, 6, 8개이지만 거기서 중복된 gear값을 가진 데이터가 제외된 결과.
# A tibble: 3 × 2
cyl `n_distinct(gear)`
<dbl> <int>
1 4 3
2 6 3
3 8 2 📌 주의! `n() & n_distinct()` 함수는 단독으로 사용할 수 없다.
위 함수들은 `summarise(), mutate(), filter()`함수에서만 사용할 수 있다!
sample_n() → 전체 데이터에서 샘플 데이터를 개수 기준으로 추출
# 전체 데이터에서 샘플 데이터를 개수 기준으로 추출
# sample_n(데이터, 샘플 추출할 개수) 형태로 사용
# 샘플 데이터 10개 추출
sample_n(mtcars, 10)> # 전체 데이터에서 샘플 데이터를 개수 기준으로 추출
> # sample_n(데이터, 샘플 추출할 개수) 형태로 사용
> # 샘플 데이터 10개 추출
> sample_n(mtcars, 10)
# 무작위로 추출하기 때문에 결과가 매번 달라진다!
mpg cyl disp hp drat wt qsec vs am gear carb
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1sample_frac() → 전체 데이터에서 샘플 데이터를 비율 기준으로 추출
# 전체 데이터에서 샘플 데이터를 비율 기준으로 추출
# sample_frac(데이터, 샘플 추출할 비용) 형태로 사용
# 전체 데이터 중 20%를 샘플로 추출
sample_frac(mtcars, 0.2)> # 전체 데이터에서 샘플 데이터를 비율 기준으로 추출
> # sample_frac(데이터, 샘플 추출할 비용) 형태로 사용
> # 전체 데이터 중 20%를 샘플로 추출(mtcars 32개 데이터중 20%인 6개가 추출됨)
> sample_frac(mtcars, 0.2)
# 이 또한 무작위로 추출하기 때문에 결과가 매번 달라진다!
mpg cyl disp hp drat wt qsec vs am gear carb
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4파이프 연산자(%>%)(pipe operator)
# 파이프 연산자는 아래와 같은 형태로 사용함
# 함수를 연달아 사용할 때 함수 결괏값을 변수로 저장하지 않아도 되는 점이 좋다!
데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트# 파이프 연산자를 통해 그룹별 요약
# 열을 그룹으로 묶은 결과를 새 변수에 할당하여 summarise()로 요약했었음
# 그러나 %>%를 사용하면 코드의 가독성을 개선할 수 있다!
# cyl 열 그룹에 대한 데이터 요약 후 %>%로 넘겨서 요약
group_by(mtcars, cyl) %>% summarise(n())> # 파이프 연산자를 통해 그룹별 요약
> # 열을 그룹으로 묶은 결과를 새 변수에 할당하여 summarise()로 요약했었음
> # 그러나 %>%를 사용하면 코드의 가독성을 개선할 수 있다!
> # cyl 열 그룹에 대한 데이터 요약 후 %>%로 넘겨서 요약
> group_by(mtcars, cyl) %>% summarise(n())
# 실행 결과는 같음을 볼 수 있음
# A tibble: 3 × 2
cyl `n()`
<dbl> <int>
1 4 11
2 6 7
3 8 14🎁 데이터 가공 🎁
필요한 데이터 추출
여기서부터는 전체 데이터 중 필요한 데이터만 쏘옥 뽑아내는 방법을 알아보자!
데이터를 추출하는 형태로는 크게 2가지 방식이 존재한다.
- 사용할 변수를 선택하는 방식
- 원하는 조건 값에 맞는 데이터를 추출하는 방식
데이터 가공에 사용할 함수들은 dplyr 패키지에 포함된 함수들이다.
따라서 해당 글에서는 실습을 진행할 때 dplyr 패키지를 미리 로드한 후 실행함!
library(dplyr) # dplyr 패키지 로드# https://github.com/newstars/hongongR/blob/main/Data/Sample1.xlsx 데이터셋 사용
library(readxl)
exdata1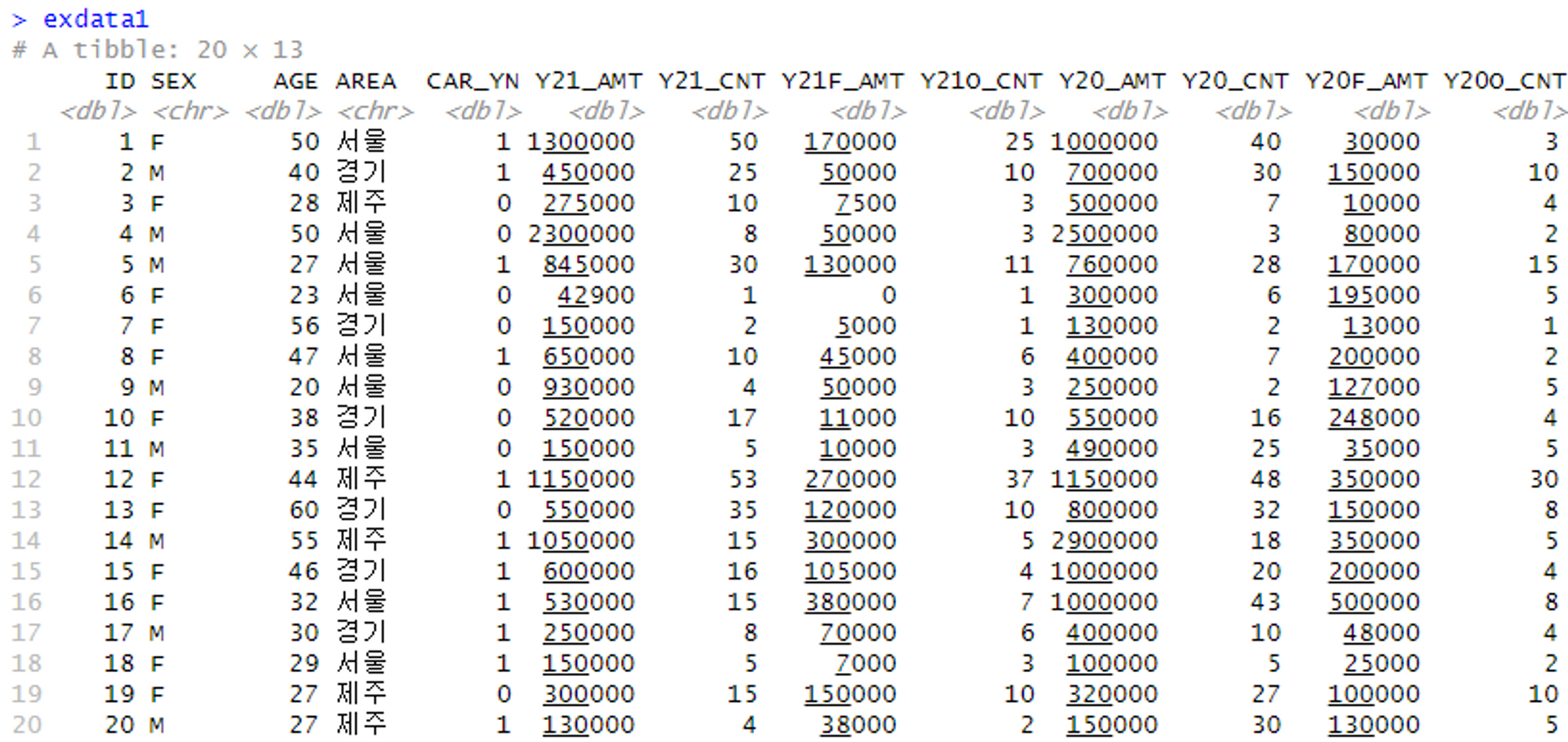
선택한 변수만 추출하는 법 → select()
# 선택한 변수 추출(여기서는 ID 기준)
exdata1 %>% select(ID)> # 선택한 변수 추출(ID 기준)
> exdata1 %>% select(ID)
# ID 변수만 선택하여 추출함!
# A tibble: 20 × 1
ID
<dbl>
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 11
12 12
13 13
14 14
15 15
16 16
17 17
18 18
19 19
20 20# 여러 개의 변수 추출
exdata1 %>% select(ID, AREA, Y21_CNT)> # 여러 개의 변수 추출
> exdata1 %>% select(ID, AREA, Y21_CNT)
# A tibble: 20 × 3
ID AREA Y21_CNT
<dbl> <chr> <dbl>
1 1 서울 50
2 2 경기 25
3 3 제주 10
4 4 서울 8
5 5 서울 30
6 6 서울 1
7 7 경기 2
8 8 서울 10
9 9 서울 4
10 10 경기 17
11 11 서울 5
12 12 제주 53
13 13 경기 35
14 14 제주 15
15 15 경기 16
16 16 서울 15
17 17 경기 8
18 18 서울 5
19 19 제주 15
20 20 제주 4선택한 변수만 제외하고 추출하는 법 → select() 응용
# 선택한 변수 제외하고 추출
# 결과 이미지를 보면 기존 exdata1에서 AREA가 사라진 결과가 나옴!
exdata1 %>% select(-AREA)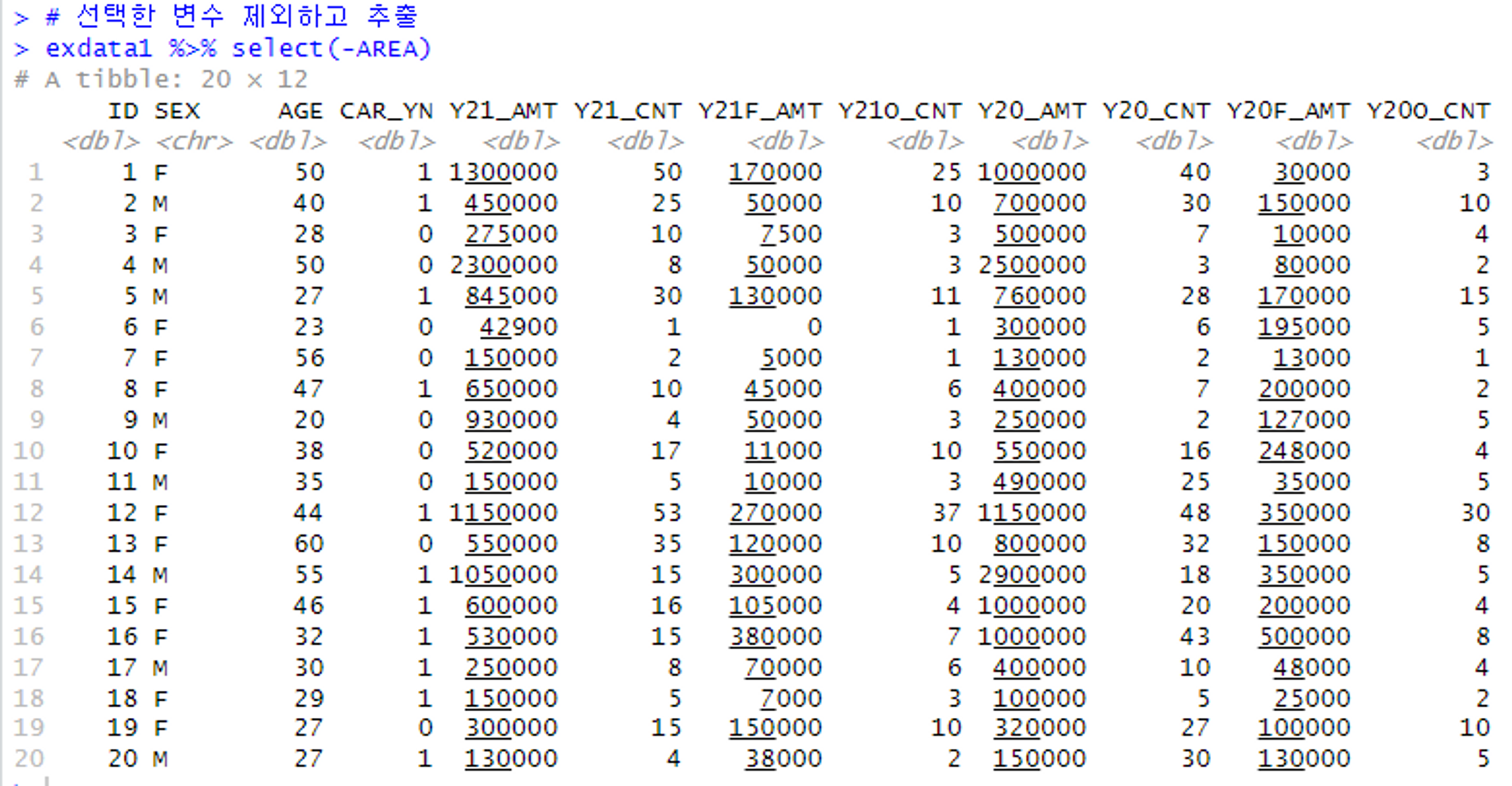
필요한 데이터만 추출하는 법(조건에 맞는 데이터 추출) → filter()
# 조건에 만족하는 데이터만 추출
exdata1 %>% filter(AREA == '서울')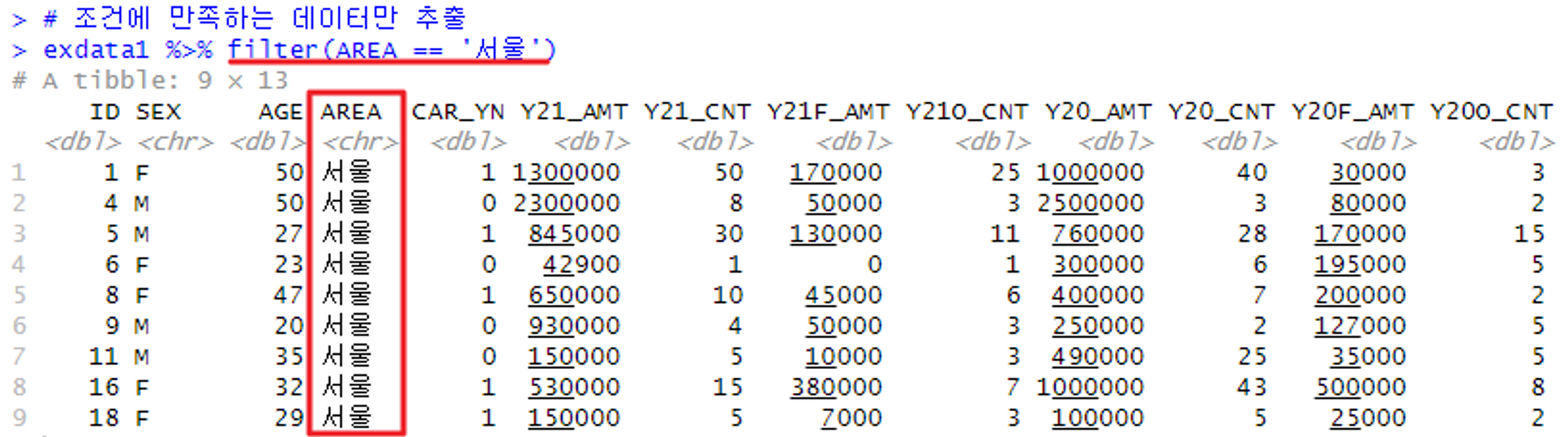
# 조건 여러개 지정 가능!
exdata1 %>% filter(AREA == '서울' & Y21_CNT >= 10)
데이터 정렬
오름차순 정렬하는 법 → arrange()
# 오름차순 정렬(나이 오름차순)
exdata1 %>% arrange(AGE)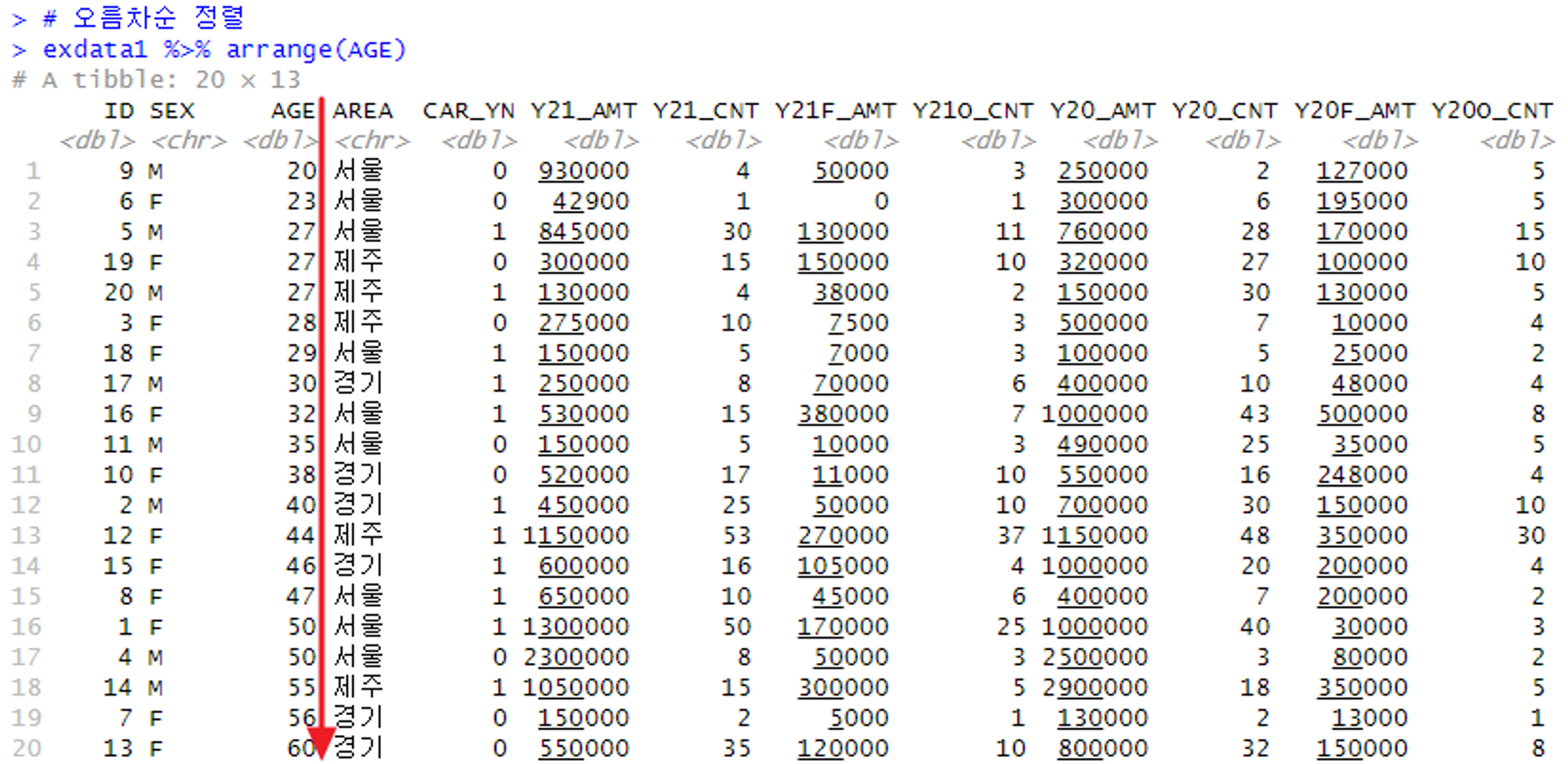
# 내림차순 정렬(Y21_AMT 내림차순)
# arrange + desc를 함께 사용함
exdata1 %>% arrange(desc(Y21_AMT))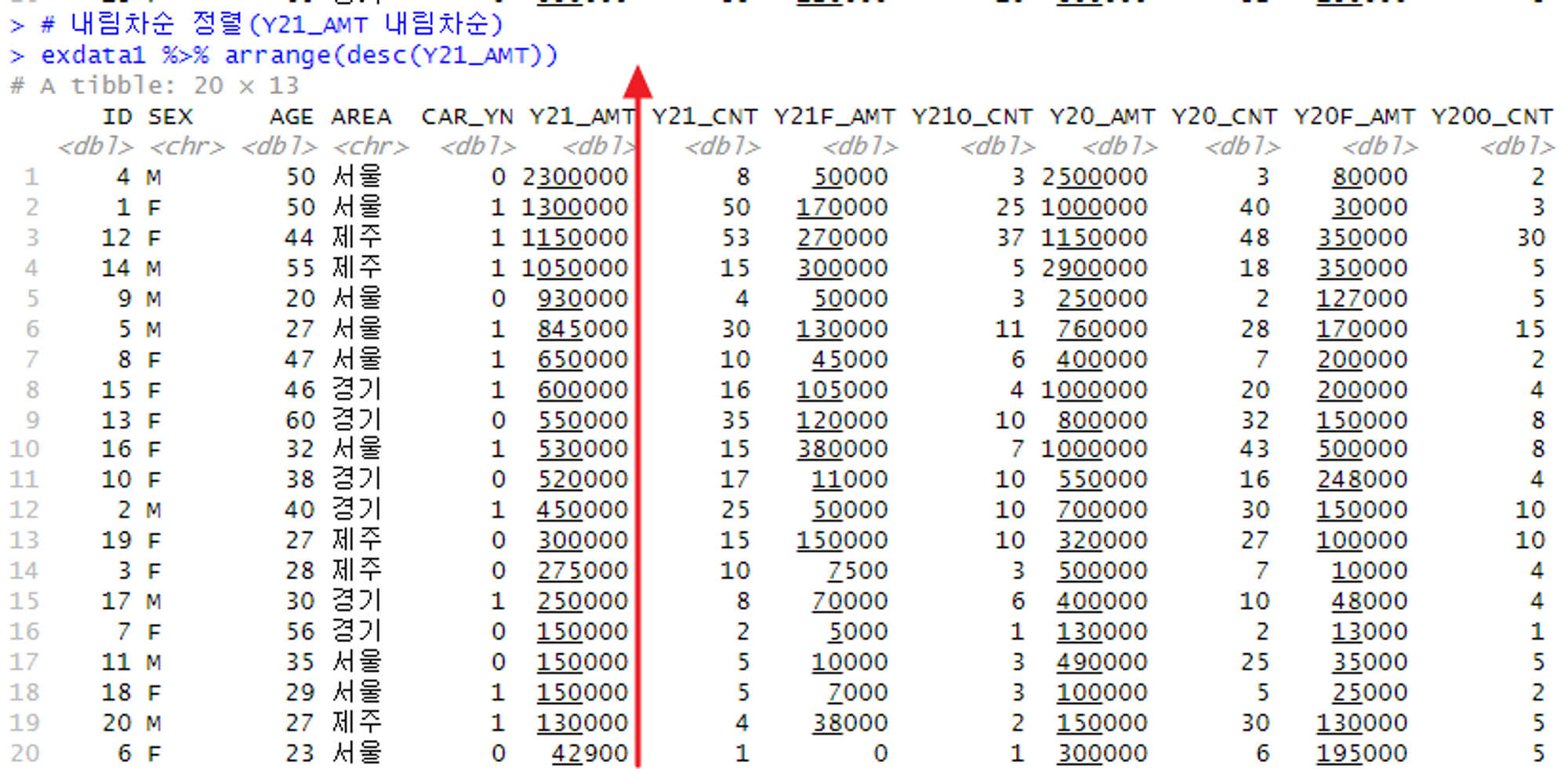
중첩 정렬하기
# 중첩 정렬
# 변수 하나만이 아닌, 여러 변수를 기준으로 중첩 정렬할 수 있음
# 정렬 기준으로 삼을 변수를 쉼표(,)를 통해 나열할 수 있다!
# AGE 에서는 오름차순(1순위 기준)
# Y21_AMT 에서는 내림차순(2순위 기준)
exdata1 %>% arrange(AGE, desc(Y21_AMT))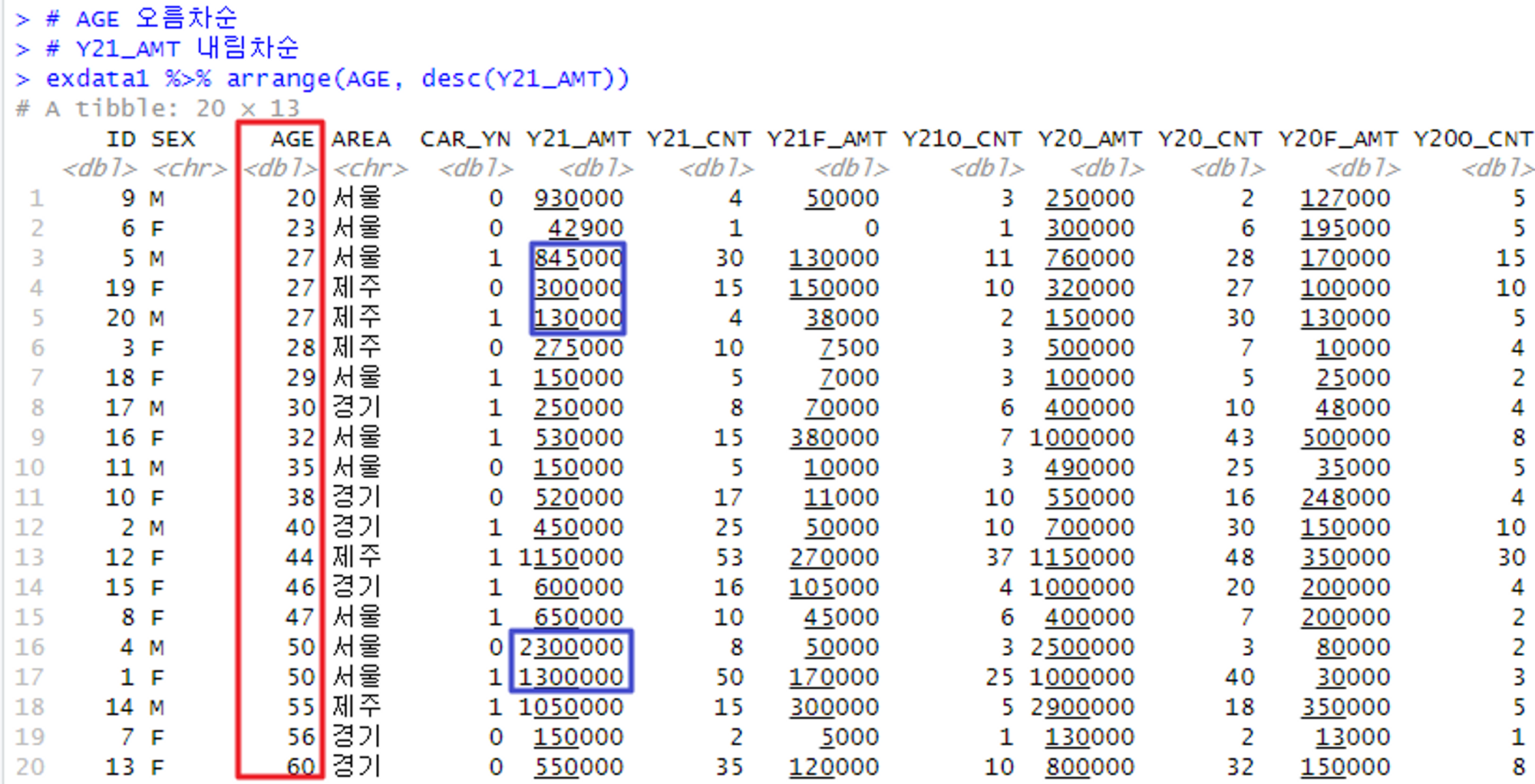
데이터 요약
데이터 요약에서는 summarise() group_by() 함수를 자주 사용한다.
그리고 어떤 데이터로 요약할지는 기술통계 함수를 활용한다!
# 변수 값 합산
# 여기서는 Y21_AMT를 합산한 값을 TOT_Y21_AMT 라는 변수명을 가진 열에 할당함
exdata1 %>% summarise(TOT_Y21_AMT = sum(Y21_AMT))> # 변수 값 합산
> # 여기서는 Y21_AMT를 합산한 값을 TOT_Y21_AMT 라는 변수명을 가진 열에 할당함
> exdata1 %>% summarise(TOT_Y21_AMT = sum(Y21_AMT))
# A tibble: 1 × 1
TOT_Y21_AMT
<dbl>
1 12322900그룹별 합계 도출하는 법 → summarise() & group_by()
# 변수 값을 그룹별로 합산
# group_by() -> summarise()를 연계하여 사용함
# AREA 변수 값에 따른 Y21_AMT 변수 합계 도출
exdata1 %>% group_by(AREA) %>% summarise(SUM_Y21_AMT = sum(Y21_AMT))> exdata1 %>% group_by(AREA) %>% summarise(SUM_Y21_AMT = sum(Y21_AMT))
# A tibble: 3 × 2
AREA SUM_Y21_AMT
<chr> <dbl>
1 경기 2520000
2 서울 6897900
3 제주 2905000데이터 결합(join, 2개 이상의 테이블 결합)
세로 결합
- 결합할 테이블에 있는 변수명을 기준으로 결합
- 각 테이블의 서로 다른 변수도 결합하는 테이블에 추가된다.
- 공통 변수를 기준으로 결합하고 서로 겹치치 않는 변수는 새로운 테이블에 추가!
- 세로 결합의 경우
bind_rows()함수를 사용한다.
# 실습에 사용한 파일 2개는 다음 링크에 있습니다!
https://github.com/newstars/hongongR/blob/main/Data/Sample2_m_history.xlsx
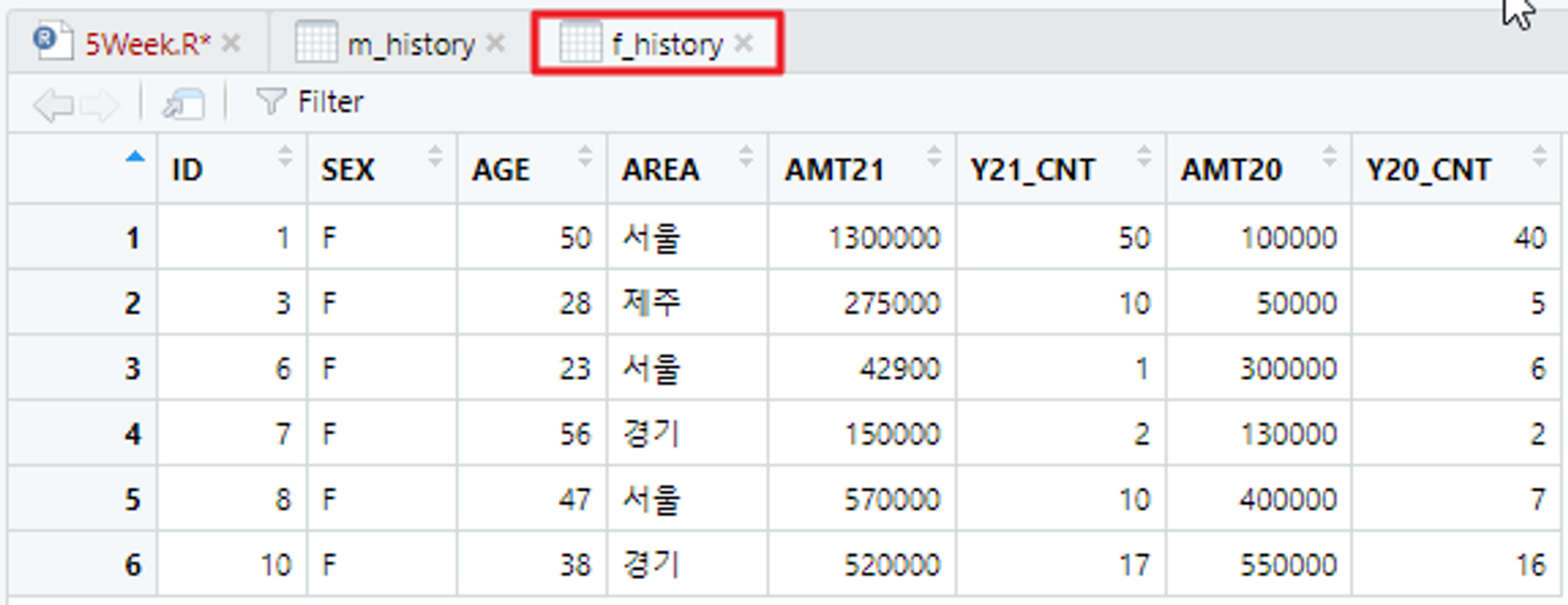
https://github.com/newstars/hongongR/blob/main/Data/Sample3_f_history.xlsx# 남성 카드 이용 금액 & 여성 카드 이용 금액 데이터 파일을 불러옴
library(readxl)
m_history <- read_excel("C:/Users/flyto/Desktop/Sample2_m_history.xlsx")
f_history <- read_excel("C:/Users/flyto/Desktop/Sample3_f_history.xlsx")
View(m_history)
View(f_history)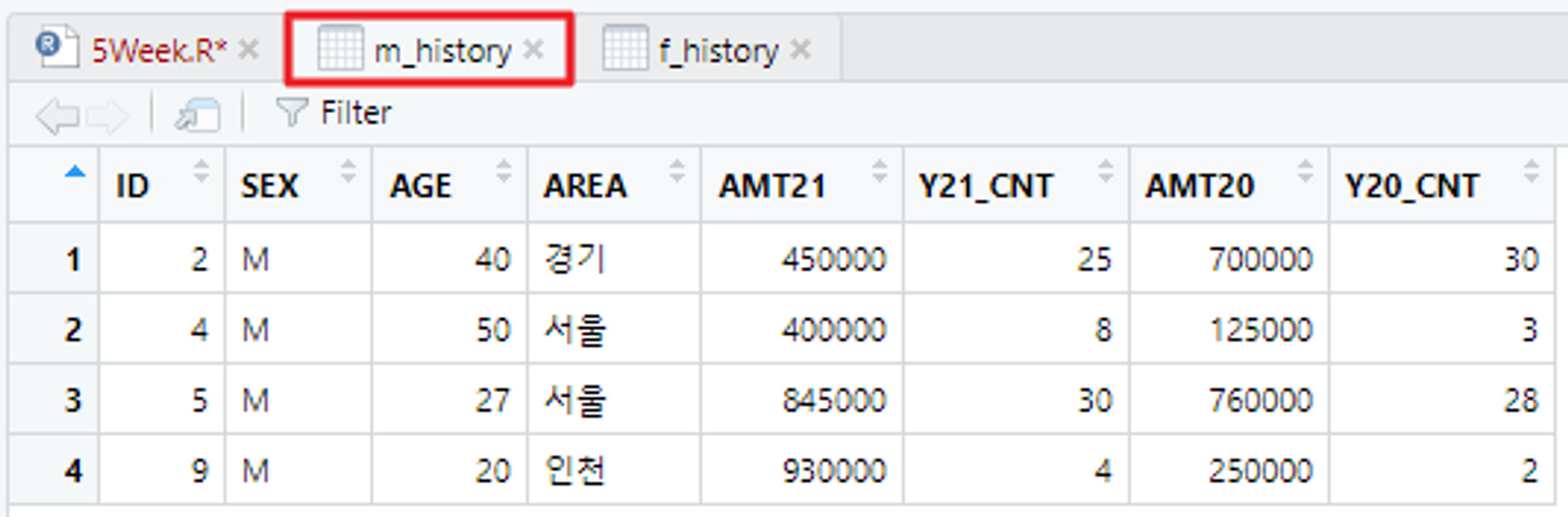
# 테이블 세로로 결합! m_history + f_history
# 두 테이블을 결합한 exdata_bindjoin 테이블 생성!
exdata_bindjoin <- bind_rows(m_history, f_history)
View(exdata_bindjoin)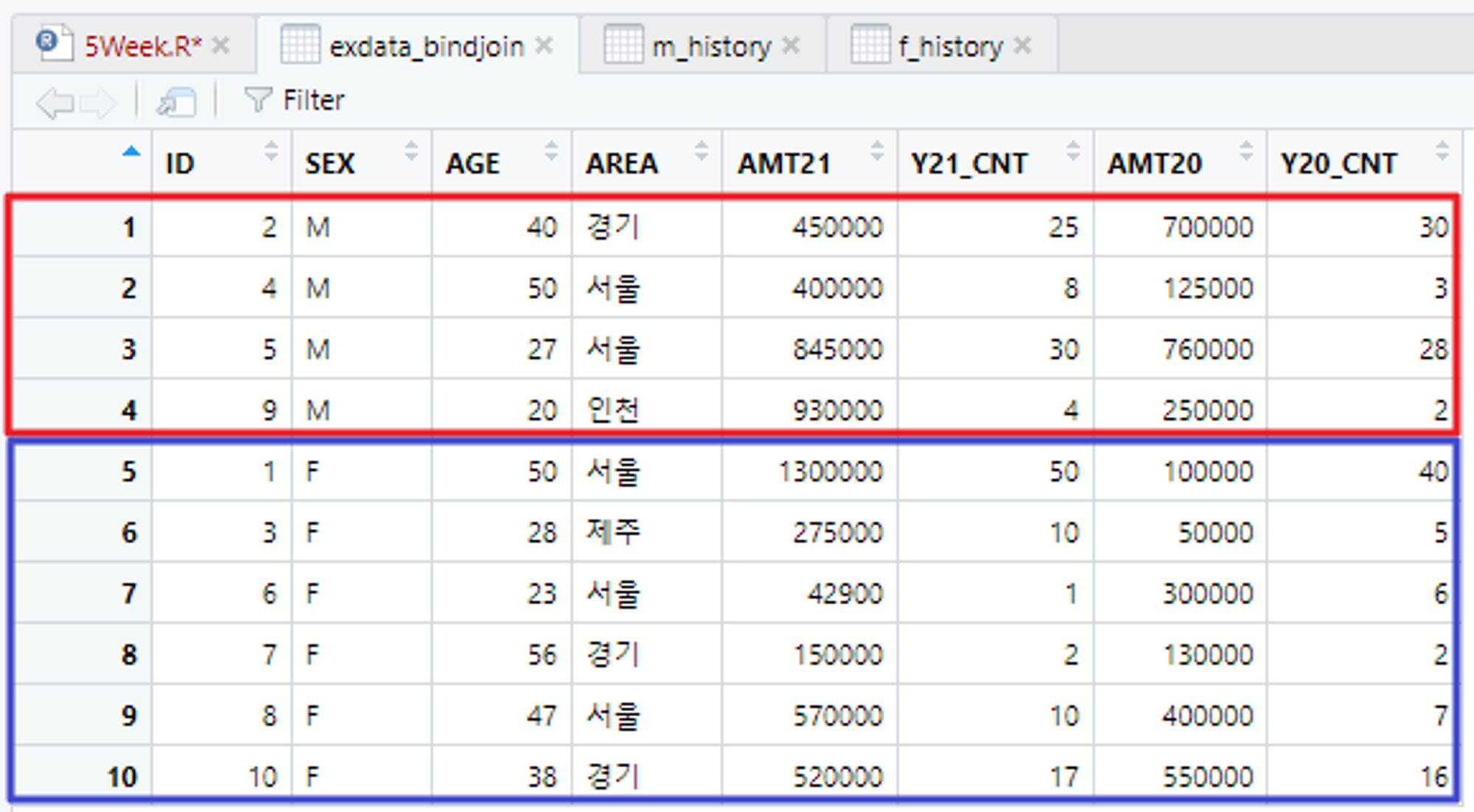
가로 결합
- 세로 결합과 비교했을 때 살짝 복잡한 형태
- 가로 결합의 경우 테이블 결합 기준이 되는
by=”변수명”에 사용할 변수(=key)가 필요함 - 키 변수는 결합할 각 테이블에 있어야 하며 한쪽이라도 없으면 실행되지 않는다.
- 키 변수 기준으로 각 테이블의 변수명이 다를 경우 변수명을 우선 통일해야 한다!
# left_join() 함수
# 지정한 변수 & 테이블1을 기준으로 테이블2의 변수들을 결합함
left_join(테이블1, 테이블2, by = "변수명")
# inner_join() 함수
# 테이블1 & 테이블2에서 기준으로 지정한 변수 값이 동일할 때만 결합
inner_join(테이블1, 테이블2, by = "변수명")
# full_join() 함수
# 테이블1 & 테이블2에서 기준으로 지정한 변수 값 전체를 결합함
full_join(테이블1, 테이블2, by = "변수명")# 실습에 사용한 파일 2개는 다음 링크에 있습니다!
https://github.com/newstars/hongongR/blob/main/Data/Sample4_y21_history.xlsx
https://github.com/newstars/hongongR/blob/main/Data/Sample5_y20_history.xlsx# 엑셀 파일 불러오기
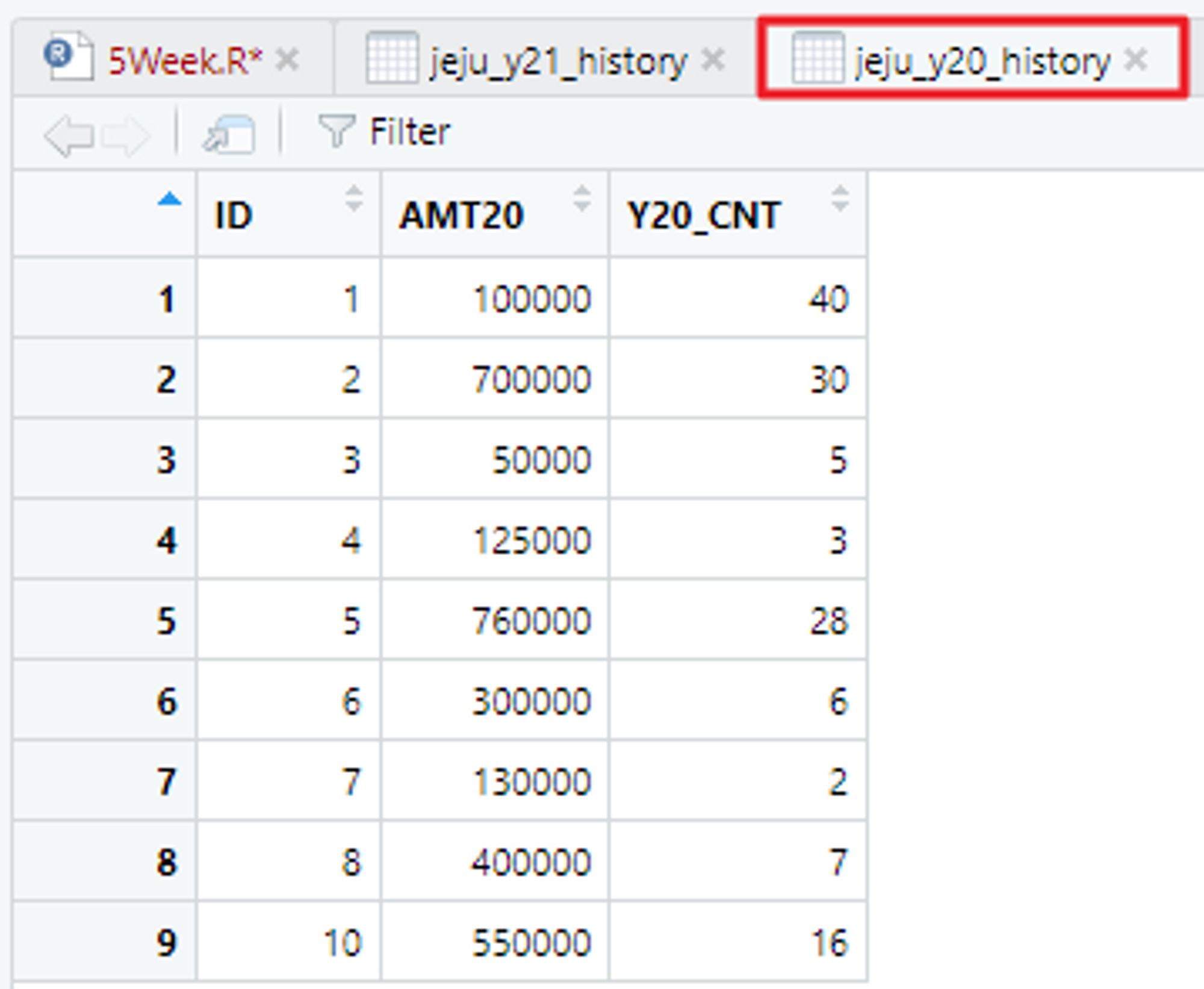
# 제주 지역에서의 21년 & 20년 카드 이용 금액을 새로운 테이블 변수를 만들어 저장
jeju_y21_history <- read_excel("C:/Users/flyto/Desktop/Sample4_y21_history.xlsx")
jeju_y20_history <- read_excel("C:/Users/flyto/Desktop/Sample5_y20_history.xlsx")
View(jeju_y21_history)
View(jeju_y20_history)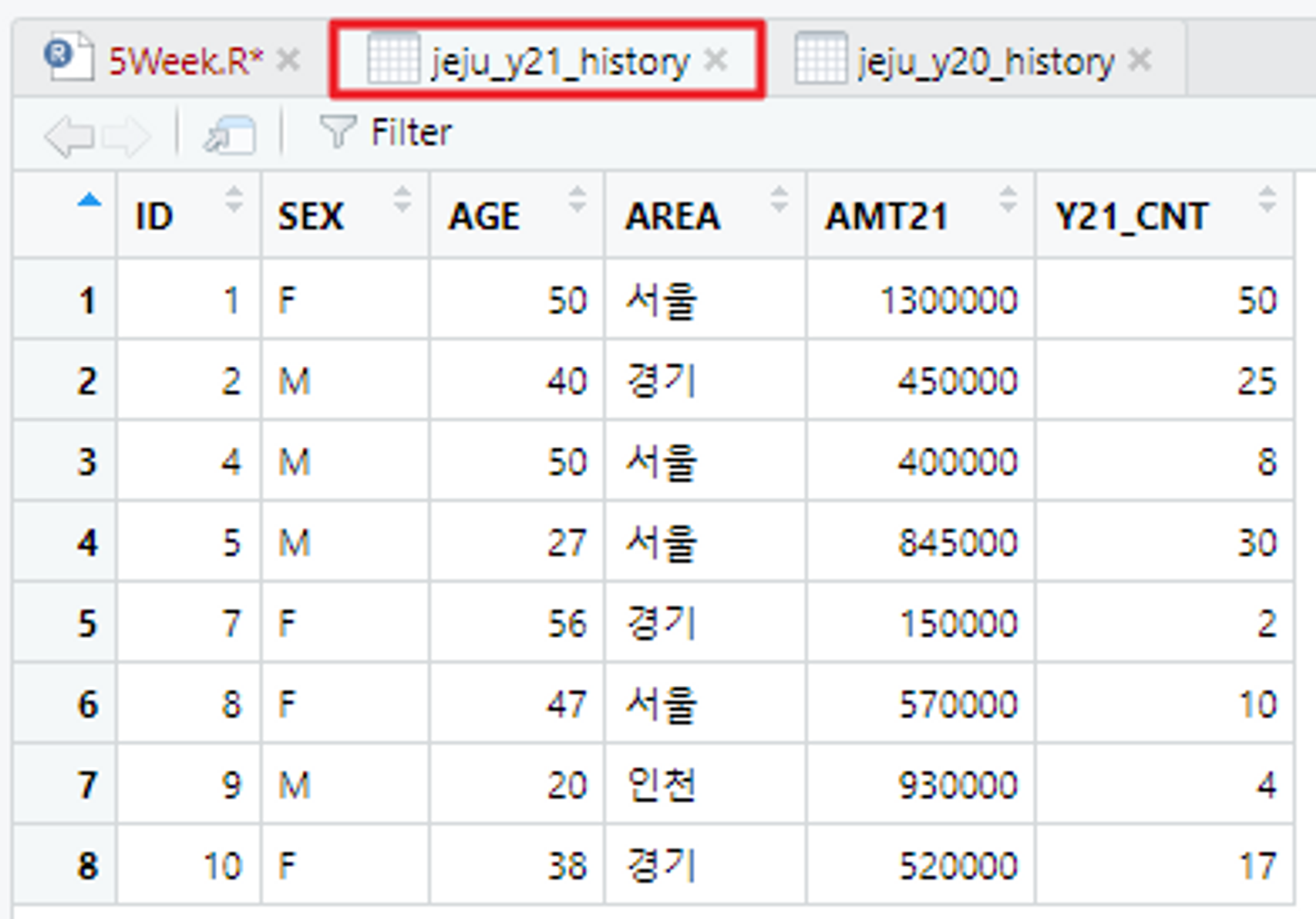
위에서 두 테이블의 공통점은 ID 변수가 있기 때문에, 이를 키 변수로 삼아 결합할 수 있다!
가로 결합 - 1번째 테이블을 기준으로 가로 결합(left_join)
# 첫 번째 테이블 기준으로 가로 결합
# 21년도 카드 이용 금액(1번째 테이블)
# 20년도 카드 이용 금액(2번째 테이블)
# 이 때 키 값은 ID
bind_col <- left_join(jeju_y21_history, jeju_y20_history, by = "ID")
View(bind_col)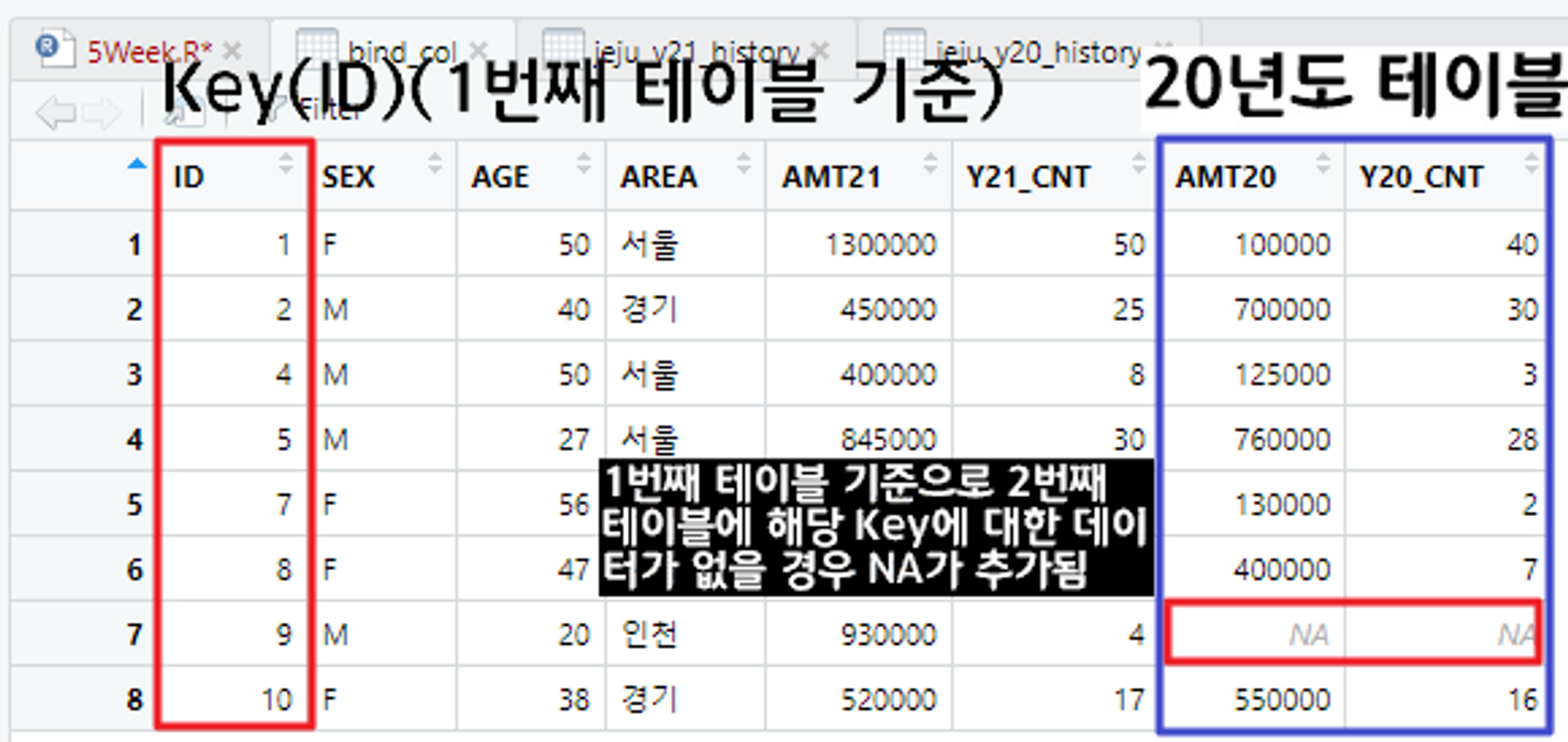
가로 결합 - 기준이 되는 테이블의 Key 값이 동일할 때만 결합(inner_join)
# 키 변수가 동일할 때만 가로 결합
# 21년도 카드 이용 금액(1번째 테이블)
# 20년도 카드 이용 금액(2번째 테이블)
# 1번째 테이블 기준으로 ID값이 동일한 경우에만 가로 결합 진행
bind_col_inner <- inner_join(jeju_y21_history, jeju_y20_history, by = "ID")
View(bind_col_inner)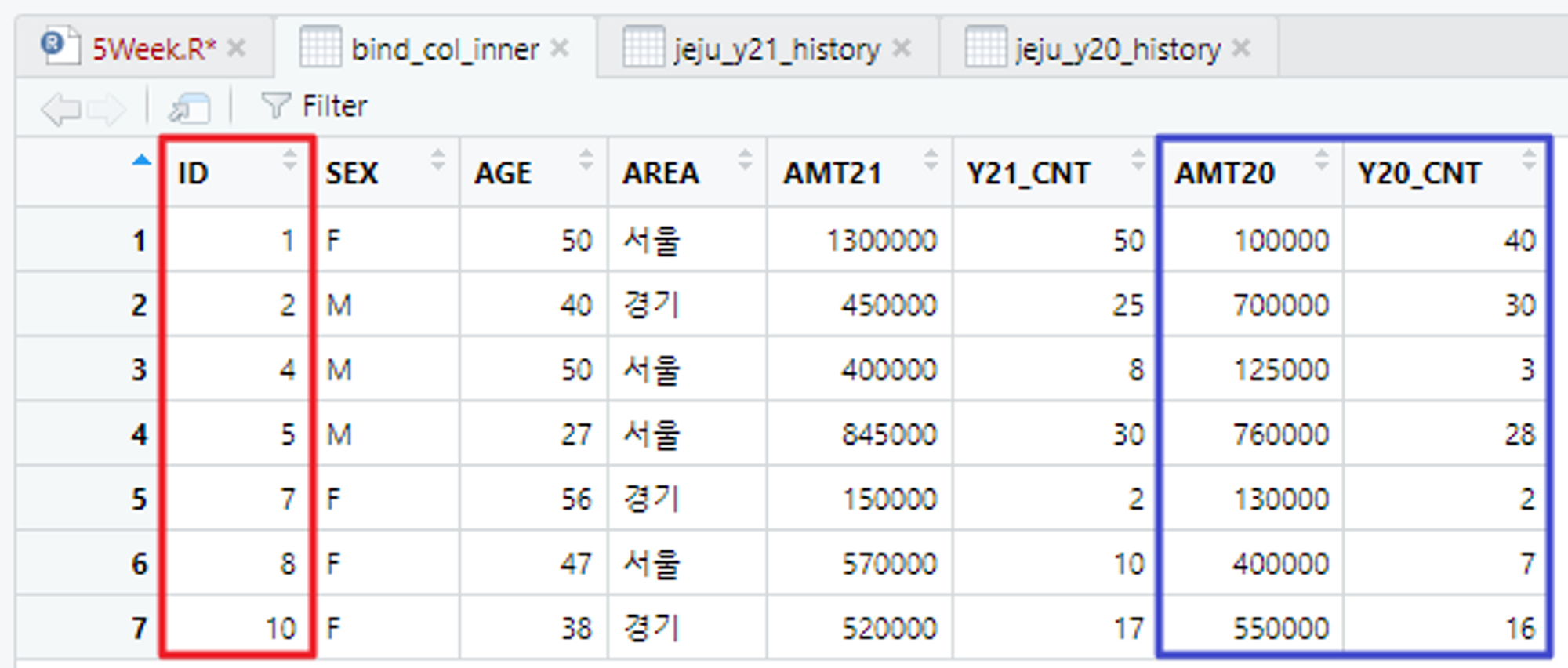
여기서는 Key값이 1, 2번째 테이블에 둘 다 존재하는 경우에만 결합을 진행한다.
21년도 → [1, 2, 4, 5, 7, 8, 9, 10]
20년도 → [1, 2, 3, 4, 5, 6, 7, 8, 10]
따라서 여기에서 Key값이 둘 다 존재하는 [1, 2, 4, 5, 7, 8, 10]에 대해서만 결합이 진행된다.
이는 1번째 테이블의 ID를 기준으로 결합을 진행하는 left_join과 결과값이 다름을 볼 수 있다!
가로 결합 - 키 변수를 기준으로 모두 가로 결합(full_join)
# 키 변수를 기준으로 모두 가로 결합
# 21년도 카드 이용 금액(1번째 테이블)
# 20년도 카드 이용 금액(2번째 테이블)
# ID 기준으로 모든 데이터가 가로 결합
bind_col_full <- full_join(jeju_y21_history, jeju_y20_history, by = "ID")
View(bind_col_full)
# ID : 9에대한 AMT20, Y20_CNT 값은 존재하지 않으므로 NA가 들어간다
# 위와 같은 흐름으로 ID : 3, 6에 대한 5개 관측값이 존재하지 않으므로 NA가 들어간다.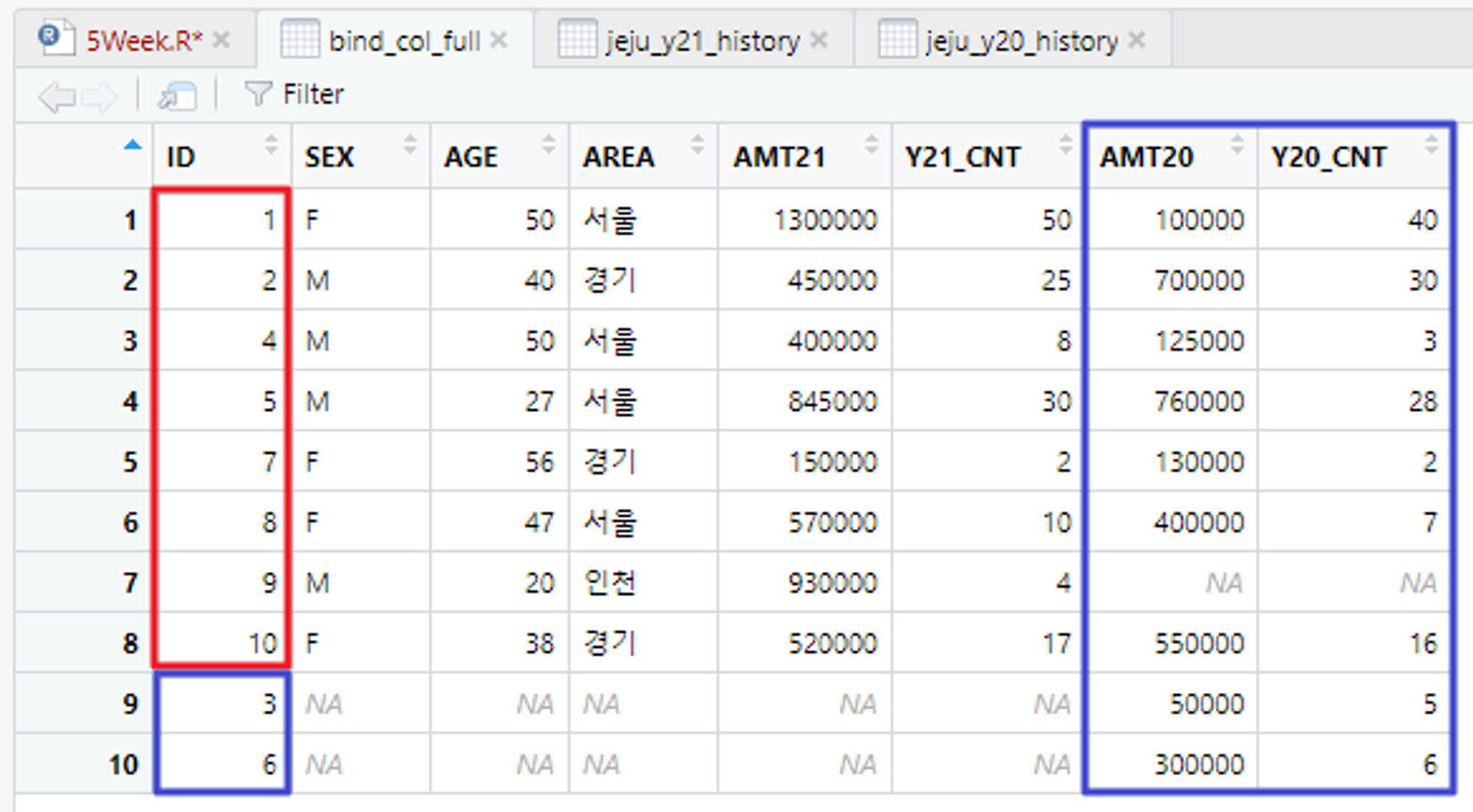
🎁 데이터 구조 변형 🎁
데이터 재구조화 : 동일한 데이터에 대해서 목적에 따라 데이터 구조를 변형하는 과정
reshape2 패키지 : 데이터의 구조를 분석하기 편한 형태로 가공하기 좋은 패키지
# reshape2 패키지를 설치해주자!
install.packages("reshape2")melt 함수(넓은 모양 데이터 → 긴 모양 데이터 변환)
# melt() 함수 사용법
# id.vars & measure.vars 옵션은 기준 열에 따라 재배치할 열을 결정하는 옵션!
melt(데이터, id.vars = "기준 열", measure.vars = "변환 열")airquality 내장 데이터셋을 이용하여 melt() 함수 사용해보기
# airquality 데이터 세트 확인하기(p.249)
head(airquality)> # airquality 데이터 세트 확인(head를 써서 6행까지만 출력)
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6# 변수명 소문자로 통일(Ozone, Solar.R 등등을 소문자로 통일)
names(airquality) <- tolower(names(airquality))
head(airquality)> # 변수명 소문자로 통일(Ozone, Solar.R 등등을 소문자로 통일)
> names(airquality) <- tolower(names(airquality))
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6# 열-> 행 전환(melt 함수 이용)
library(reshape2)
melt_test <- melt(airquality)
head(melt_test)> # 열-> 행 전환(melt 함수 이용)
> library(reshape2)
> melt_test <- melt(airquality)
# 기준이 될 열을 지정하지 않아 모든 열을 반환한다는 뜻
No id variables; using all as measure variables
# 변수명이 variable 열의 값이 됨!
> head(melt_test)
variable value
1 ozone 41
2 ozone 36
3 ozone 12
4 ozone 18
5 ozone NA
6 ozone 28# 기준을 정해 열을 행으로 전환
# month, wind 변수를 식별자로 지정
# ozone 값을 반환하도록 코드 작성
melt_test2 <- melt(airquality, id.vars = c("month", "wind"),
measure.vars = "ozone")
head(melt_test2)> # 기준을 정해 열을 행으로 전환
> # month, wind 변수를 식별자로 지정
> # ozone 값을 반환하도록 코드 작성
> melt_test2 <- melt(airquality, id.vars = c("month", "wind"),
+ measure.vars = "ozone")
> head(melt_test2)
month wind variable value
1 5 7.4 ozone 41
2 5 8.0 ozone 36
3 5 12.6 ozone 12
4 5 11.5 ozone 18
5 5 14.3 ozone NA
6 5 14.9 ozone 28cast 함수(긴 모양 데이터 → 넓은 모양 데이터 변환)
cast 함수는 하나의 함수지만 데이터 유형에 따라 사용하는 함수가 2가지로 나누어진다.
acast() : 데이터를 변형하여 벡터, 행렬, 배열 형태로 반환함
dcast() : 데이터를 변형하여 데이터 프레임 형태로 반환함
dcast() 함수(데이터 프레임 형태로 반환 가능)
# dcast() 함수 사용법
dcast(데이터, 기준 열 ~ 변환 열)# 열을 행으로 바꿈
# month, day를 식별자로 지정, 나머지 열을 행으로 반환
# na.rm = FALSE(결측치 포함)(결측치 : 측정한 데이터 중 변수 값이 측정되지 않은 경우, NA)
library(reshape2)
aq_melt <- melt(airquality, id.vars = c("month", "day"), na.rm = FALSE)
head(aq_melt)> # 열을 행으로 바꿈
> library(reshape2)
> aq_melt <- melt(airquality, id.vars = c("month", "day"), na.rm = FALSE)
> head(aq_melt)
month day variable value
1 5 1 ozone 41
2 5 2 ozone 36
3 5 3 ozone 12
4 5 4 ozone 18
5 5 5 ozone NA
6 5 6 ozone 28acast() 함수(벡터, 행렬, 배열 형태로 반환 가능)
# acast() 함수 사용법
acast(데이터, 기준 열 ~ 변환 열 ~ 분리 기준 열)# 행을 변수로 바꿈
# dcast()에서 얻어낸 aq_melt를 이용
# 오존, 태양 복사, 바람, 온도를 변수로 바꾸어 배열을 만듦
# 아래 이미지와 같은 느낌으로 생성됨
acast(aq_melt, day ~ month ~ variable)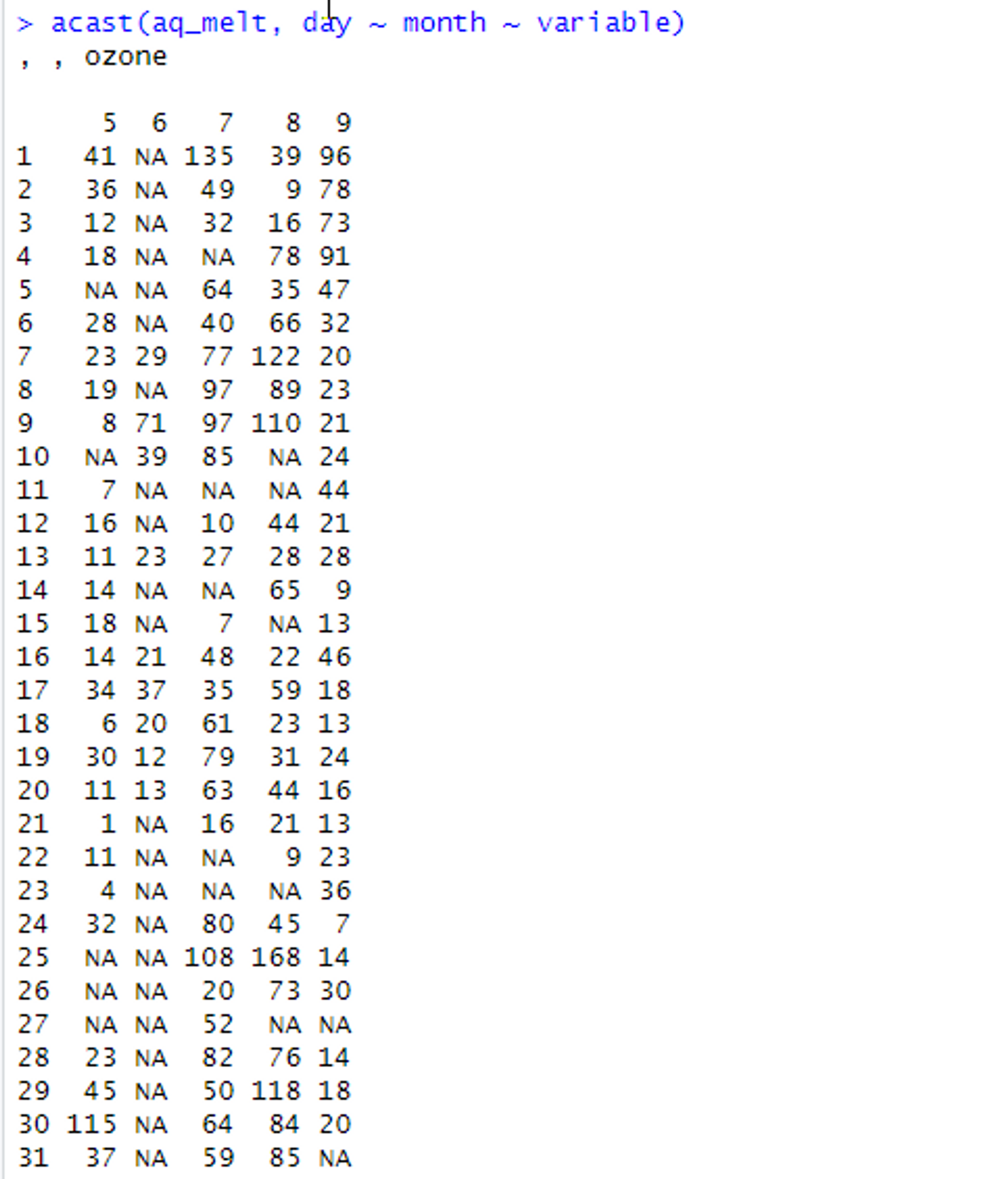
🎁 데이터 정제 🎁
데이터 정제 : 데이터 분석 시 결과 오류 혹은 결과 왜곡 방지를 위해 데이터를 가공하는 과정
그 중에서도 특히 원시 데이터에서 **결측치 & 이상치**를 처리해준다.
결측치(missing value) : 누락된 값(NA 등)
이상치(Outlier) : 일반적인 값보다 편차가 큰 값
결측치(missing value) 확인
결측치 = 결측값 = NA(Not Available)
데이터가 결측치가 존재하는 경우, 결측치를 제외하거나 다른 값으로 대체하는 작업을 해준다.
# 데이터 결측치를 확인하는 기본 함수
# 결측치를 확인하여 결괏값을 TRUE or FALSE로 반환(결측치의 경우 TRUE로 반환)
is.na(변수명)
# table(is.na()) 함수는 결측치 빈도를 확인, 결측치의 개수를 반환함
table(is.na(변수명))결측치 확인 예제
# 결측치 확인
x <- c(1, 2, NA, 4, 5)
x
sum(x)
is.na(x)
table(is.na(x))> # 결측치 확인
> x <- c(1, 2, NA, 4, 5)
> x
[1] 1 2 NA 4 5
# 연산 시 NA가 나오는 경우는 is.na()를 통해 결측치를 확인해주자!
> sum(x)
[1] NA
# is.na()를 통해 TRUE를 확인한다면, 결측치가 존재한다는 뜻!
> is.na(x)
[1] FALSE FALSE TRUE FALSE FALSE
# table(is.na())는 결측치의 개수를 수치로 받아볼 수 있다.
> table(is.na(x))
FALSE TRUE
4 1결측치 제외
# 결측치 제외 후 연산 진행
x <- c(1, 2, NA, 4, 5)
x
sum(x)
is.na(x)
sum(x, na.rm = T)> # 결측치 제외 후 연산 진행
> x <- c(1, 2, NA, 4, 5)
> x
[1] 1 2 NA 4 5
> sum(x)
[1] NA
> is.na(x)
[1] FALSE FALSE TRUE FALSE FALSE
# na.rm = T 옵션을 통해 결측치를 제외하고 연산 진행!
> sum(x, na.rm = T)
[1] 12결측치 개수 확인
# 데이터 세트의 결측치의 총 개수 확인 가능
sum(is.na(변수명))
# 각 컬럼(column)의 결측치의 개수 확인 가능
colSums(is.na(변수명))airquality 데이터 셋의 결측치 개수 확인 - is.na() 활용
# airquality 데이터 세트 결측치 확인
# 153 행까지 데이터가 출력된다.
# 출력 결과 중에 TRUE가 존재함으로 보아 데이터 세트에 결측치가 존재함을 확인 가능!
data(airquality)
is.na(airquality)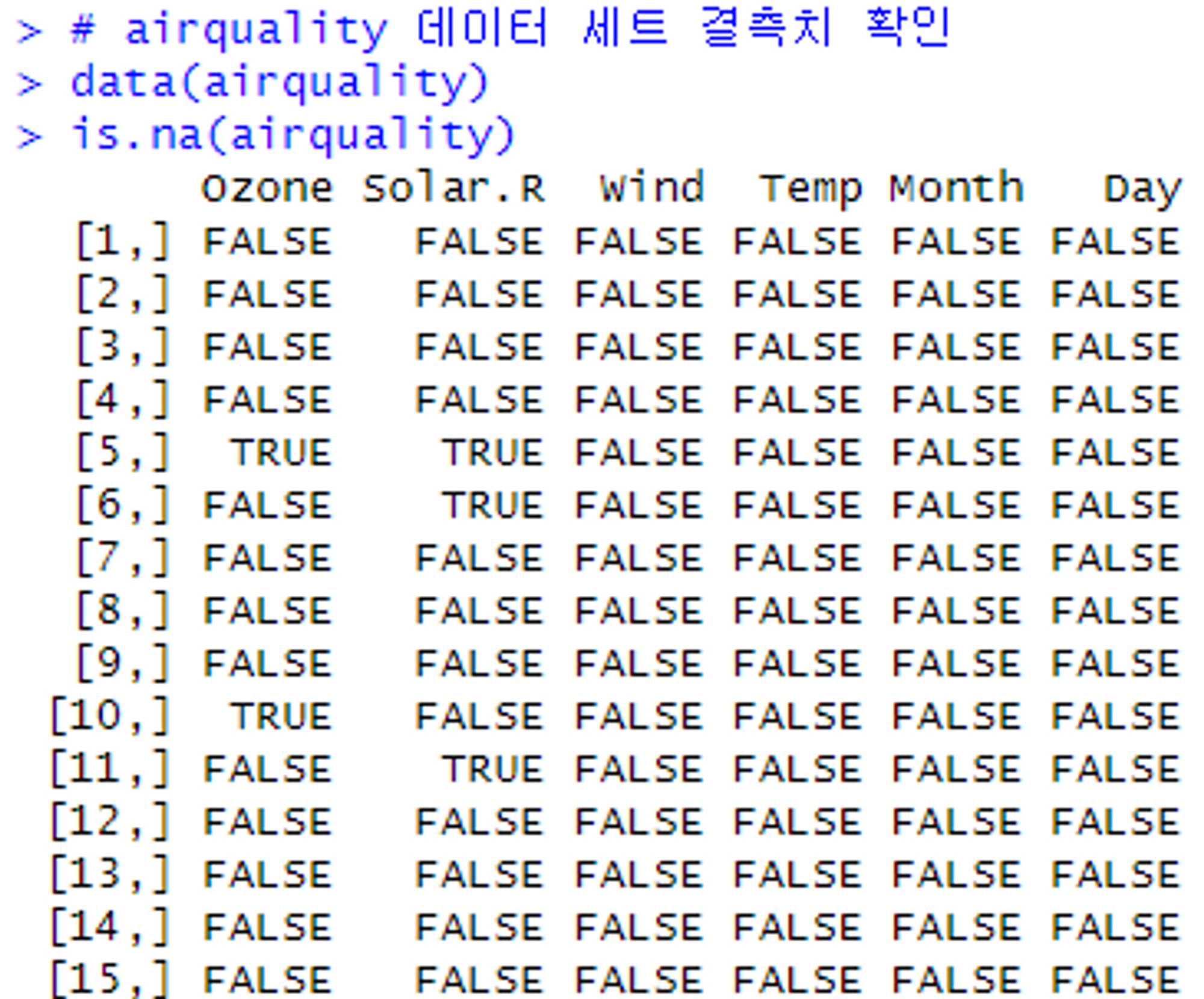
# 데이터 세트에 있는 결측치 '전체 개수 확인'
sum(is.na(airquality))> # 데이터 세트에 있는 결측치 전체 개수 확인
> sum(is.na(airquality))
[1] 44 # 결측치가 44개 존재함!colSums()를 통해 컬럼별 결측치 개수 확인
# 컬럼별 결측치 개수 확인
colSums(is.na(airquality))> # 컬럼별 결측치 개수 확인
> colSums(is.na(airquality))
Ozone Solar.R Wind Temp Month Day
37 7 0 0 0 0결측치 제거하기
# na.omit() : 결측치를 제거하는 함수
na.omit(변수명)# airquality 데이터셋에서 결측치가 있는 행 제거
# 결측치가 존재하는 중간중간의 행들이 삭제됨!(ex. 5, 6행 & 10, 11행 ...)
data(airquality)
na.omit(airquality)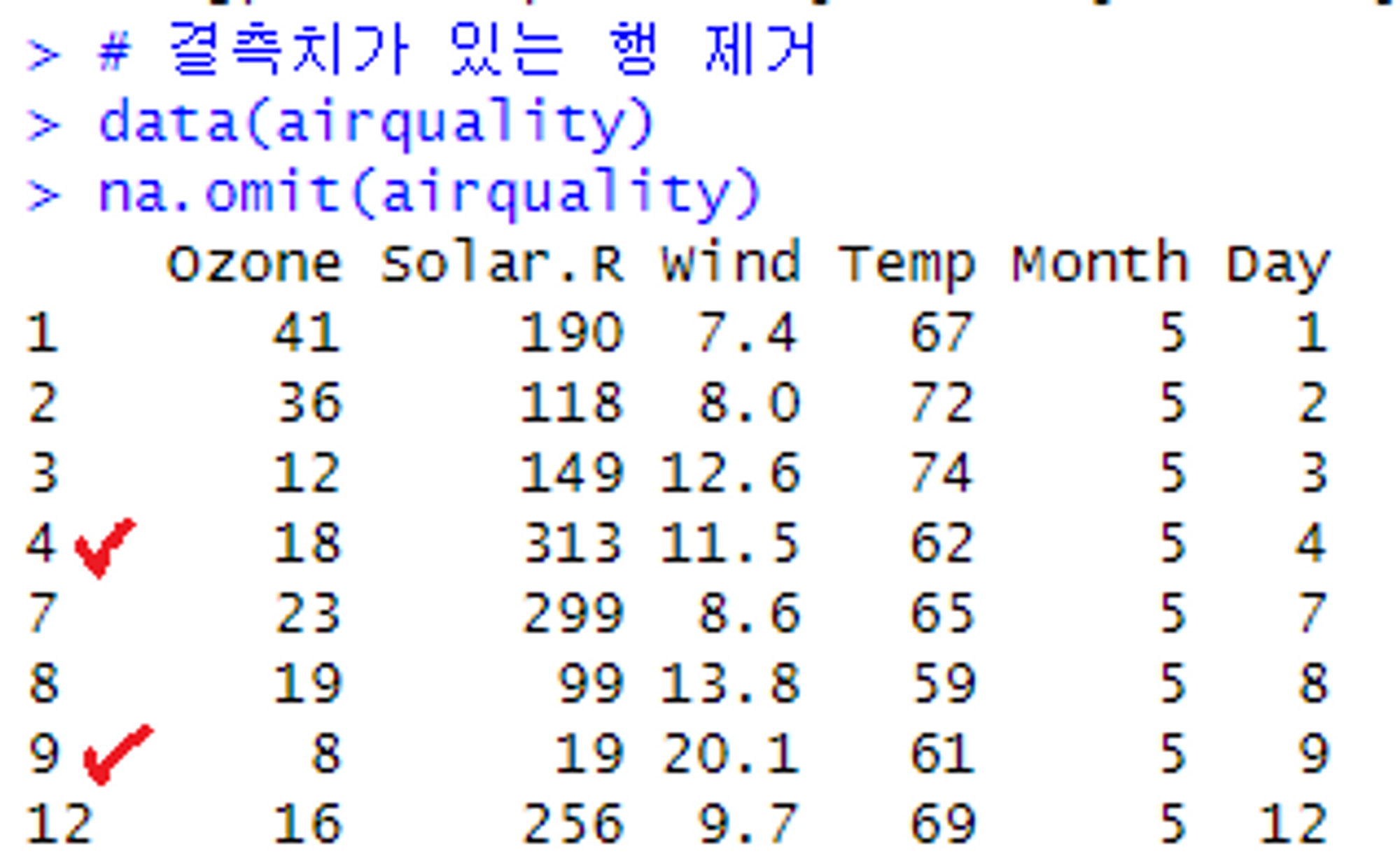
결측치 대체하기
# 결측치를 제거하는 것 외에도 다른 값으로 대체할 수도 있다!
변수명[is.na(변수명)] <- 대체할 값# airquality 데이터셋에서 결측치를 0으로 대체
data(airquality)
airquality[is.na(airquality)] <- 0
colSums(is.na(airquality)) # 컬럼별로 결측치가 있는지 체크함!> # airquality 데이터셋에서 결측치를 0으로 대체
> data(airquality)
> airquality[is.na(airquality)] <- 0
# colSums를 통해 각 열에서의 관측치를 확인해본 결과, 이제 결측치가 존재하지 않음!
> colSums(is.na(airquality))
Ozone Solar.R Wind Temp Month Day
0 0 0 0 0 0이상치(Outlier) 확인
이상치 = 극단치 = 데이터에서 정상적 범주를 벗어난 값
이상치는 분석 결과를 왜곡하기에, 주로 결측치로 만들어 제거하는 방법을 사용하기도 한다.
이상치는 상자 그림을 이용하면 쉽게 파악할 수 있다!
상자 그림을 통해 이상치 확인하기!
# 이상치 확인
data(mtcars)
boxplot(mtcars$wt)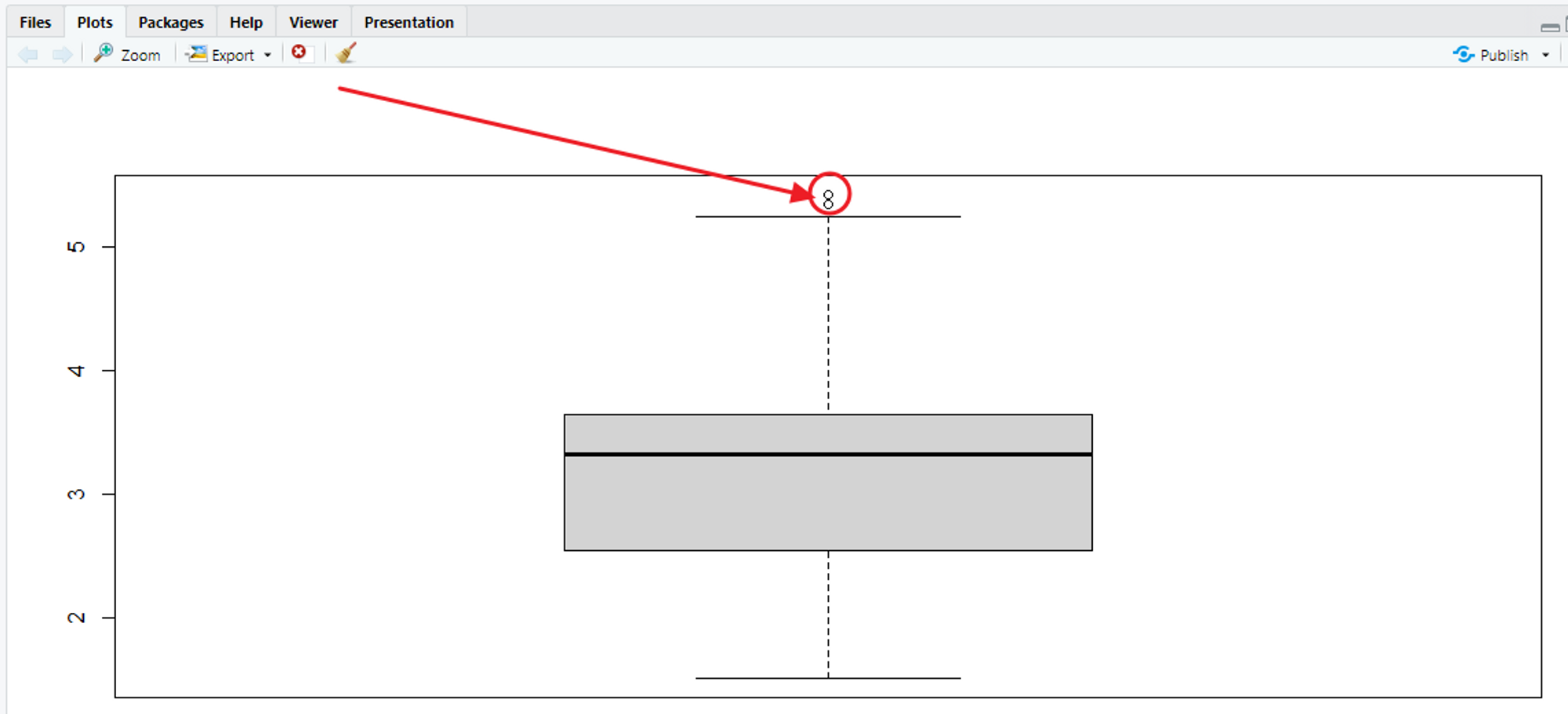
# 상자 그림의 기술통계량을 확인하여 이상치에 해당하는 값의 범위 확인
# 최저 이상치 경계 / 1사분위수 / 중앙값 / 3사분위수 / 최고 이상치 경계값!
boxplot(mtcars$wt)$stats> # 이상치 확인
> data(mtcars)
> boxplot(mtcars$wt)
> # 상자 그림의 기술통계량을 확인하여 이상치에 해당하는 값의 범위 확인
> # 최저 이상치 경계 / 1사분위수 / 중앙값 / 3사분위수 / 최고 이상치 경계값!
> boxplot(mtcars$wt)$stats
[,1]
[1,] 1.5130
[2,] 2.5425
[3,] 3.3250
[4,] 3.6500
[5,] 5.2500
# 즉 여기서 1.5130 ~ 5.2500을 벗어나는 값이 이상치인 것이다!이상치 처리하기
# 이상치를 결측치로 변환하여 처리해보도록 하자!
# ifelse() 함수를 통해 처리해줌
ifelse(조건문, 조건이 참일 때 실행, 조건이 거짓일 때 실행)# 이상치 확인
mtcars$wt > 5.25> # 이상치 확인
> mtcars$wt > 5.25
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[27] FALSE FALSE FALSE FALSE FALSE FALSE# 값 중 5.2500을 넘어가는 값을 결측치로 변환해주는 작업
# 결측치로 변환된 값은 NA로 표시됨을 확인할 수 있다!
mtcars$wt <- ifelse(mtcars$wt > 5.25, NA, mtcars$wt)
mtcars$wt
🥃 기본 미션 🥃
244p 확인 문제 2번 풀기
exdata1 테이블에서 AGE가 30세 이하 + Y20_CNT가 10건 이상인 데이터를 exdata2 테이블로 생성
(단, 파이프 연산자를 사용하기)# 225p 확인문제 2번
exdata2 <- exdata1 %>% filter(AGE <= 30 & Y20_CNT >= 10)
exdata2
🍸 선택 미션 🍸
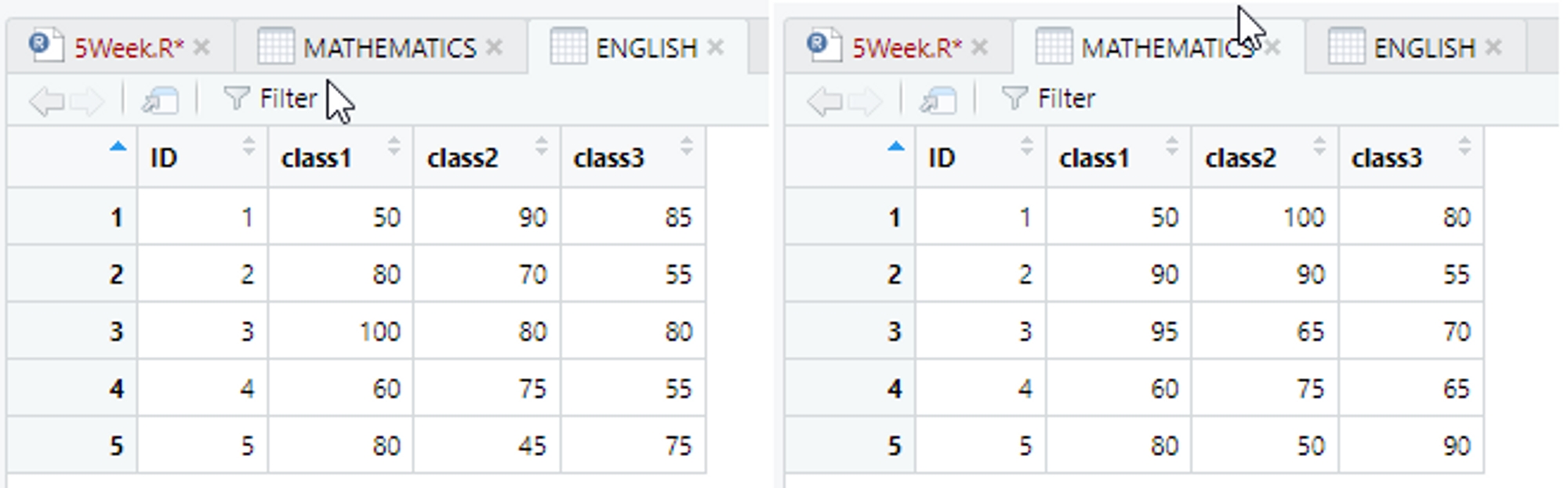
261p 확인 문제 4번 풀기
https://github.com/newstars/hongongR/blob/main/Data/middle_mid_exam.xlsx
위 엑셀 파일을 가져온 후 특정 실행 결과에 맞추어 코드 작성하기!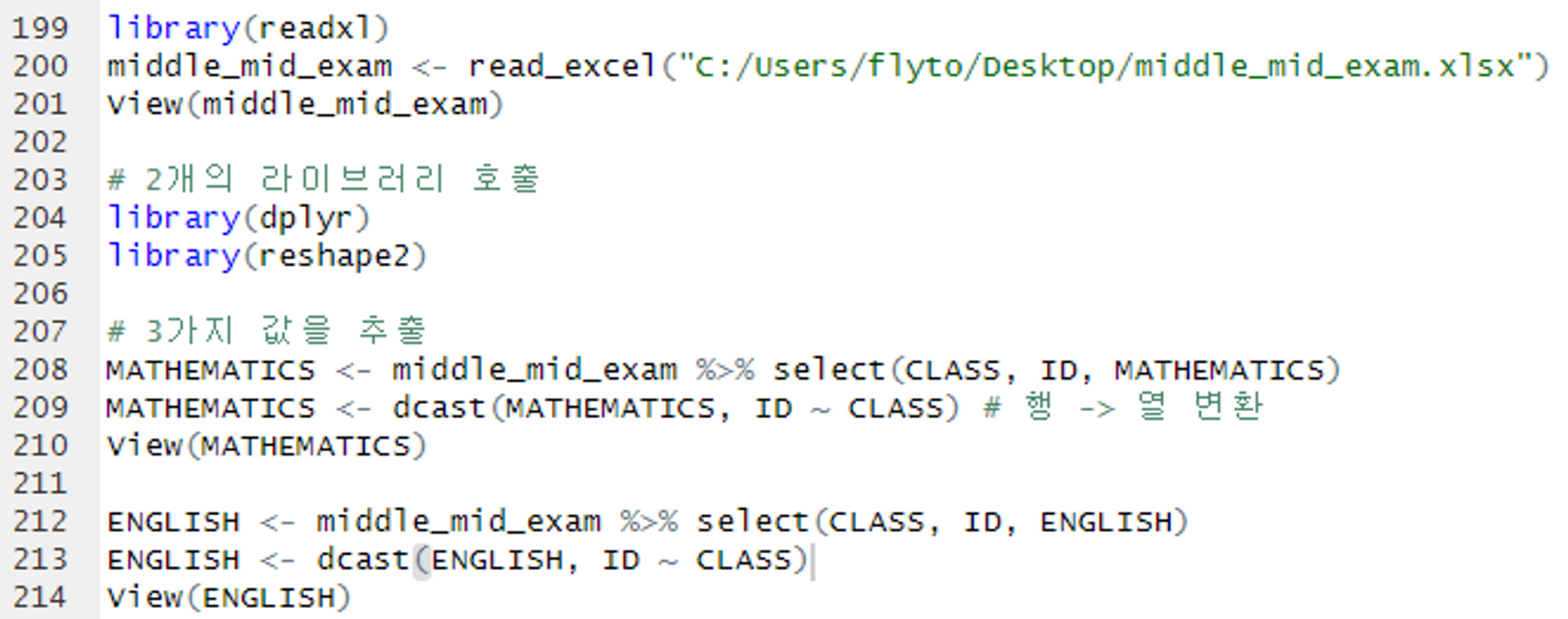

글 잘 봤습니다.