이미지 분류 작업에서 SOTA를 달성했던 ViT모델의 고유한 한계로 인해 Detection, Segmentation등과 같은 복잡한 작업에서 활용되지 못하는 문제를 해결하기 위해 Self-Attention메커니즘을 BackBone으로 활용하기 위해 등장한 모델이 Swin Transformer모델입니다. 해당 모델이 등장하면서 대부분의 SOTA모델이 Transformer Architechure를 활용한 모델로 대체되게 됩니다.
ViT관련한 내용을 참조하시려면, 아래의 링크 참조하시면 됩니다.
https://velog.io/@rlaxodns/%EB%85%BC%EB%AC%B8Vision-Transformers-Swin-Transformers
1. 서론
- 기존의 ViT(Vison Transformer 모델이 사용하던 Patch + Position Embedding 기법과 더불어 W-MSA, SW-MSA 기법을 도입하여 기존에 ViT가 하지 못하던 Detection과 Segmentation작업을 수행 가능.
- ViT에서 다양한 이미지 작업을 수행하지 못하던 이유는 NLP작업과 달리 이미지는 1) 해상도에 따른 픽셀의 차이가 존재하며, 2) 이미지 내에서도 물체의 크기가 다르기 때문에 동일한 크기의 Patch에 따라서 이미지의 정보를 추출하는 ViT모델에서는 이미지 Detection 등 복잡한 작업을 수행할 수 없었다.
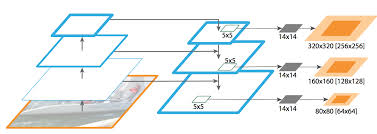
위의 구조는 FPN(Feature Pyramid Network)으로 다양한 객체 탐지모델에서 활용된다. 다음과 같은 구조가 활용되는 이유는 위에서 설명한 바와 같이 이미지 내에서 물체의 크기가 다양하기 때문에 다양한 크기의 객체를 탐지할 수 있도록 하기 위해 다양한 크기의 이미지를 학습하도록 한다.
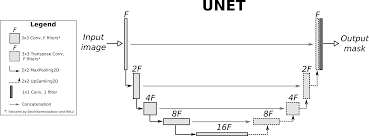
위의 구조는 U-Net의 아키텍쳐이다. 해당 모델의 Segmentation 작업의 대표적인 모델로 다양한 해상도의 이미지를 학습시키므로써 고유한 각 픽셀값을 분할하여 '객체분할'작업을 수행할 수 있게 해준다. Encoder부분에서 이미지의 전역적인 Context정보를 추출하고 Decoder를 통해서 원본 크기로 복원하면서 픽셀 단위의 정보를 재구성하게 된다.
2. Hierachical Architechure
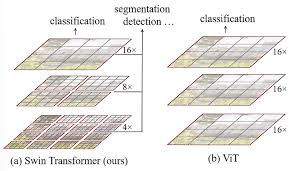
[Swin Transformer: Hierachical Architechure]
위에서 설명한 바와 같이 FPN과 U-Net의 인코더-디코더 구조와 매우 흡사한 것을 알 수 있다.
위와 같은 기법으로는 아래와 같다.
- <계층적 특징 맵>
- Swin transformer는 입력 이미지를 작은 패치들로 나누어, 깊은 층으로 갈수록 패치들을 병합하면서 점차 큰 영역 정보를 추출한다.
- 계층적 특징을 추출하면서 이미지의 전역적인 정보와 지역적인 세부 정보 모두를 효과적으로 포착할 수 있어 다양한 비전 작업에서 활용 가능하게 된다.
-
<Local Widow 내에서 Self-Attention>
- 기존의 ViT는 이미지의 모든 패치들 간의 Self-Attention을 진행했기 때문에 이미지의 크기에 제곱으로 증가하는 문제점이 있었다.
- 하지만, Local Window내에서만 어텐션 연산을 진행하기 때문에 이미지의 크기에 따라서 연산량이 선형적으로 증가한다. 덕분에 큰 이미지도 효율적으로 처리가 가능하다.
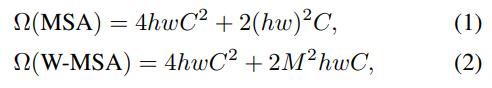
:h, w = 높이, 넓이의 patch수
:M = Local window의 사이즈
- <다양한 해상도의 특징 활용>
- 다양한 해상도의 특징맵을 생성하기 때문에 단순히 낮은 해상도의 특징만을 사용하는 기존 방식보다 더욱 풍부한 정보를 제공하고
- 이러한 특징 덕분에 세밀한 객체 인식이나 경계 검출 등, 정밀도가 중요한 작업에서 큰 장점을 가진다.
위와 같은 특징들 덕분에 다양한 비전 작업에서 강력한 백본 모델로 활용이 가능하다.
3. Overall Architechure
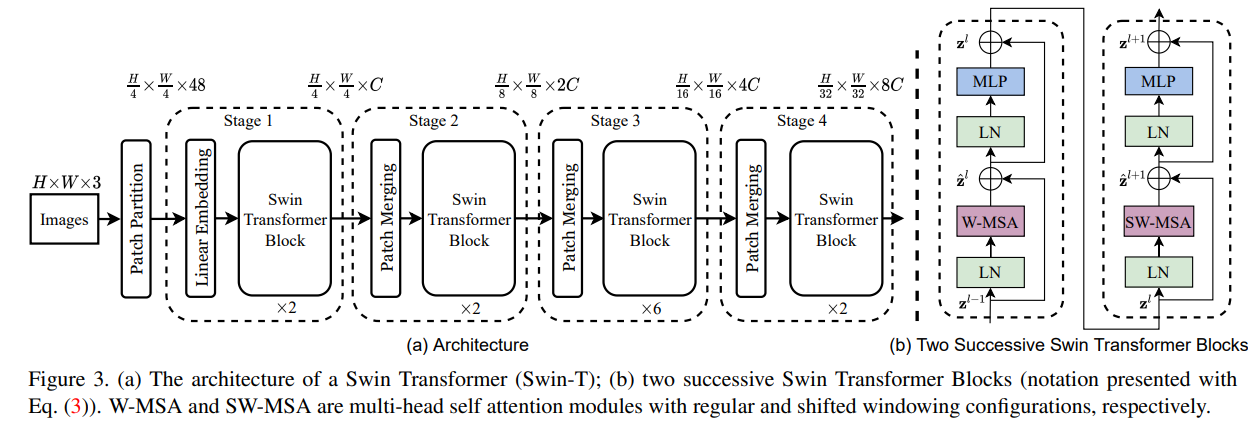
3.1 Patch Merging
-
Swin Transformer의 전반적인 구조는 위와 같다. 왼쪽의 그림과 같이 4개의 스테이지를 거치게 된다. 그러면서 각 스테이지마다 Patch Merging을 거치면서 이미지의 공간 차원을 줄이게 된다. 이러한 과정을 거치면서 이미지의 전역적인 부분을 학습할 수 있게 되면서 더욱 다양한 정보를 학습할 수 있게 만들어준다.
-
각 스테이지를 거치면서 는 2씩 증가하게 되는데 이러한 이유는 Patch의 비율을 2씩 점진적으로 키워가기 때문이다.
3.2 Swin Transformer Block
각 스테이지마다 Swin Transformer Block을 거치게 되는데, 이는 위 그림의 오른쪽과 같다.
Layer Normalization과 Residual Connection을 거치게 되는데, 핵심적인 변경점은 W-MSA와 SW-MSA이다.
W-MSA: Local window 안에서의 Self-Attention을 수행
SW-MSA: Local window 간의 Self-Attention을 수행
3.2.1 W-MSA & SW-MSA
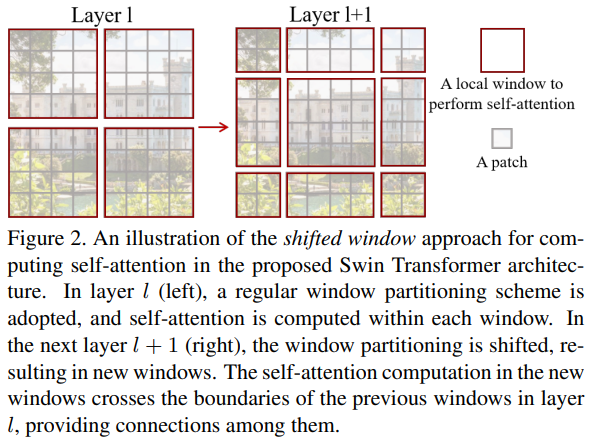
- 기존의 나누어준 Patch들을 에서 Local Window로 묶어주고 해당 윈도우 내에서 self-attention을 수행한다.
- 이후 에서 연결되지 않았던 Local Window를 이동시켜서 연결시켜주면서 더욱 다양한 학습을 진행할 수 있게 해준다.
3.2.2 Efficient batch computation for shifted configuration
위의 SW-MSA기법을 적용하면서 원래 2×2 개의 윈도우가 3×3 윈도우로 늘어난다면 계산량이 2.25배 증가하는 등 비효율적일 수 있다. 이러한 문제를 해결하기 위해서 Batch크기에 따라서 을 묶어주고 사이클릭 시프트 후 하나의 배치 윈도우는 원래 인접해있던 영역이 아닌 여러 개의 작은 서브 윈도우로 구성될 수 있다.
그래서 마스킹 메커니즘을 도입해, 각 서브 윈도우 내부에서만 self-attention이 계산되도록 제한하고 해당 과정 덕분에 계산 효율은 높게 유지되면서 윈도우 간의 경계 문제도 해결할 수 있게 된다.
3.2.3 Cyclic Shift & Reverse Cyclic Shift
- Swin Transformer에서는 윈도우 기반 self-attention(W-MSA)을 보완하기 위해 “사이클릭 시프트”와 “리버스 사이클릭 시프트”라는 두 가지 연산을 사용
- 윈도우 경계에 걸친 정보 교환을 가능하게 하면서도 계산 효율성을 유지
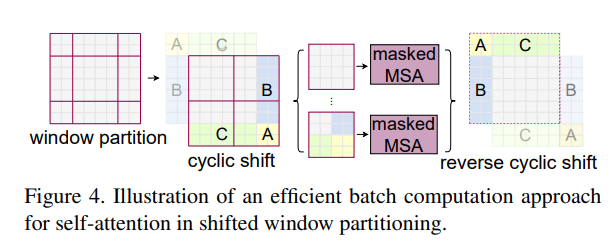
[Cyclic Shift]
- 윈도우 경계 정보 교환: 고정된 윈도우 내에서는 정보 교환이 제한되는데, 윈도우를 이동시킴으로써 인접 윈도우 간에 정보를 주고받을 수 있게 된다.
- 효율적 배치 처리: 사이클릭 시프트는 전체 윈도우의 수를 변경하지 않으면서도, 이동된 윈도우를 한 배치로 묶어 효율적으로 self-attention을 계산
[Reverse Cyclic Shift]
리버스 사이클릭 시프트는 사이클릭 시프트로 이동한 특징 맵을 원래 위치로 복원하는 연산
위 두 가지 기법을 적용하면서 윈도우 별로 나누어진 이미지가 서로 인접한 위치가 아니었기 때문에 Mask 적용하여 셀프 어텐션을 적용하게 된다. 이를 통해 더욱 연산량 자체는 줄이면서 더욱 다양한 크기의 이미지를 학습할 수 있게 해준다.
