캐글 시작은 이유한님의 캐글 스터디 전용 커리큘럼으로 하기로 했다.
제일 처음은 Binary classification: Tabular data의 Titanic이다.
Exploratory data analysis, visualization, machine learning 글을 참고하여 정리했다.
그에 앞서 스스로 문제를 읽고 파악해보려고 한다.
Overview
타이타닉호의 탑승객 정보를 토대로 어떤 유형에 속한 사람이 생존을 많이 했는지 알아보는 것이 프로젝트의 목표다.
캐글에서는 train.csv와 test.csv 파일로 데이터를 나누어 제공한다.
데이터는 아래 표처럼 생겼다.

설명이 필요한 변수를 몇 개 적어보자면 다음과 같다.
- survived: 생존 유무 (0: 사망, 1: 생존)
- pclass: 티켓 클래스(1: 퍼스트, 2: 세컨드, 3: 써드)
- sibsp: 타이타닉에 함께 탑승한 형제자매, 배우자 수
- parch: 타이타닉에 함께 탑승한 부모, 자식 수
- embarked: 승선 항구(C: Cherbourg, Q: Queenstown, S: Southampton)
캐글을 처음 사용하거나 문제를 해결하는 플로우가 잡히질 않는다면 Alexis Cook's Titanic Tutorial을 따라하고 커리큘럼을 하는 것을 추천한다.
타이타닉 프로세스는 크게 5가지로 나눌 수 있다.
1. Data Analysis
2. Feature Engineering
3. Modeling
4. Prediction
5. Evaluation
가장 먼저 학습 데이터로 사용할 데이터에 이상이 있는지, 데이터의 특징을 파악한다.
탑승객 정보(성별, 나이 등)가 feature로 주어져있기 때문에 feature와 생존유무 사이 상관관계를 알아볼 수 있다. 혹은 새로운 feature를 만들거나 학습 효과를 높이기 위해 preprocessing을 거친다.
그 다음, preprocessed data로 학습할 모델을 만들고 결과를 예측한다.
마지막으로 모델의 성능을 평가하고 이를 바탕으로 모델을 개선하는 과정을 반복한다.
데이터 분석하기
캐글 notebook을 사용하면 데이터가 저장된 path를 프린트하는 코드가 적혀있다. 이를 사용해서 파일을 불러오면 된다.
보통 분석할 데이터는 깔끔하지 않다. 변수 이름이 더럽거나, missing value나 anomaly가 있다. 우선 이상한 값이 있는지 확인해보자.
train_data.isnull().sum()
test_data.isnull().sum()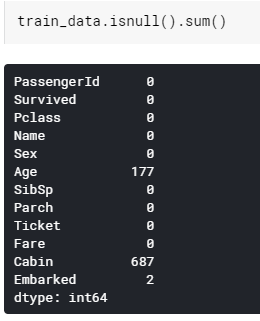
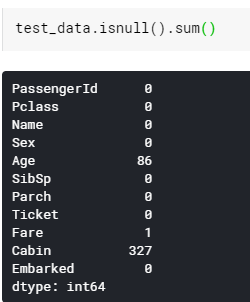
Feature 중에서 Age, Fare(test만), Cabin, Embarked에 null 값이 있다는 것을 알 수 있다.
Survived 여부를 판단하는 모델을 만들기 위해서는 train data에 survived/dead 분포가 고르게 있어야 한다.
f,ax=plt.subplots(1,2,figsize=(18,8))
train_data['Survived'].value_counts().plot.pie(autopct='%1.1f%%',ax=ax[0])
ax[0].set_title('Pie plot: Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=train_data,ax=ax[1])
ax[1].set_title('Count plot: Survived')
plt.show()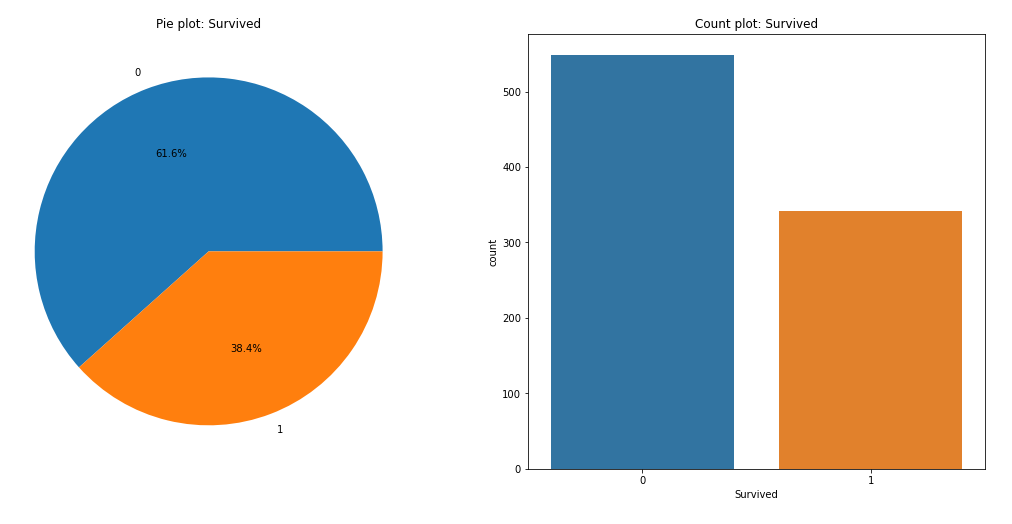
산 사람이 38.4%, 죽은 사람이 61.6%로 train data의 분포가 적절하다는 것을 알 수 있다.
Sex
Feature는 pclass, sex, age, sibsp, parch, ticket, fare, cabin, embarked, 총 9개가 있다. 가장 먼저 sex와 survival의 상관관계를 보자. Female/male 두 가지 유형이 있어서 가장 간단하다.
f, ax = plt.subplots(1, 2, figsize=(20, 10))
train_data[['Sex', 'Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex', hue='Survived', data=train_data, ax=ax[1])
ax[1].set_title('Sex: Survived vs Dead')
plt.show()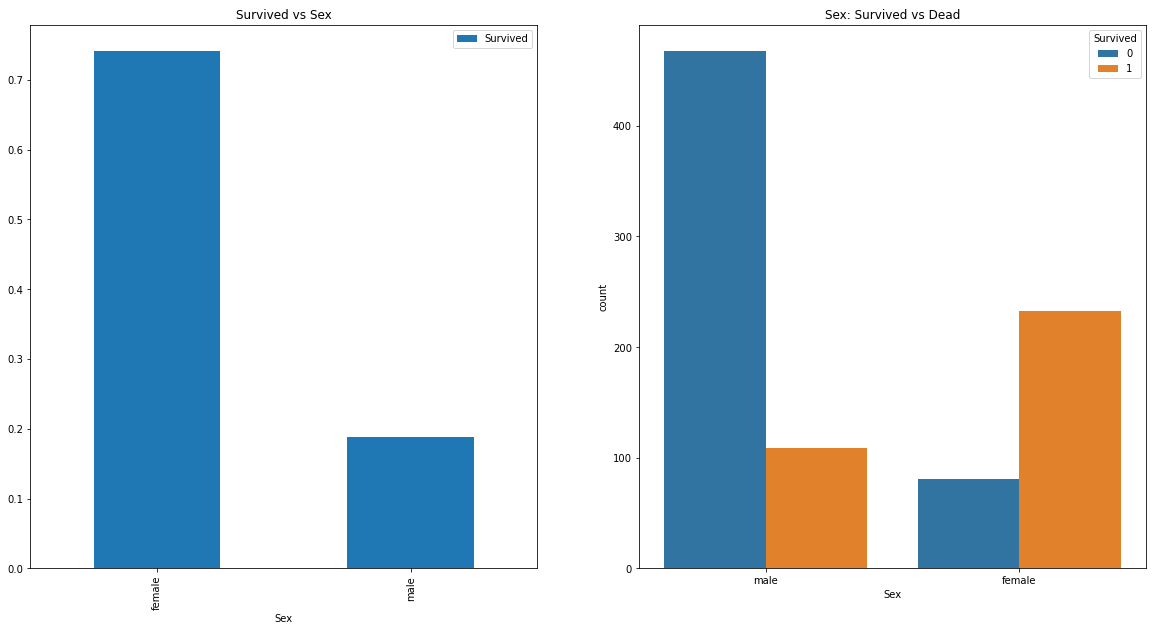
언뜻 봐도 성별에 따라 생존 확률에 큰 차이가 나타나는 것을 알 수 있다. 수치로 보면 여성 중 생존자 비율이 75%, 남성 중 생존자 비율이 19%이다.
Sex가 생존 확률을 예측하는데 중요한 feature라고 판단할 수 있다.
Pclass
Pclass는 1(first), 2(second), 3(third), 세 가지 유형이 있다. 유형별로 생존자 분포를 보면 다음과 같다.
f, ax = plt.subplots(1, 2, figsize=(18, 8))
train_data['Pclass'].value_counts().plot.bar(ax=ax[0])
ax[0].set_title('Number of Passengers by Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass', hue='Survived', data=train_data, ax=ax[1])
ax[1].set_title('Pclass: Survived vs Dead')
plt.show()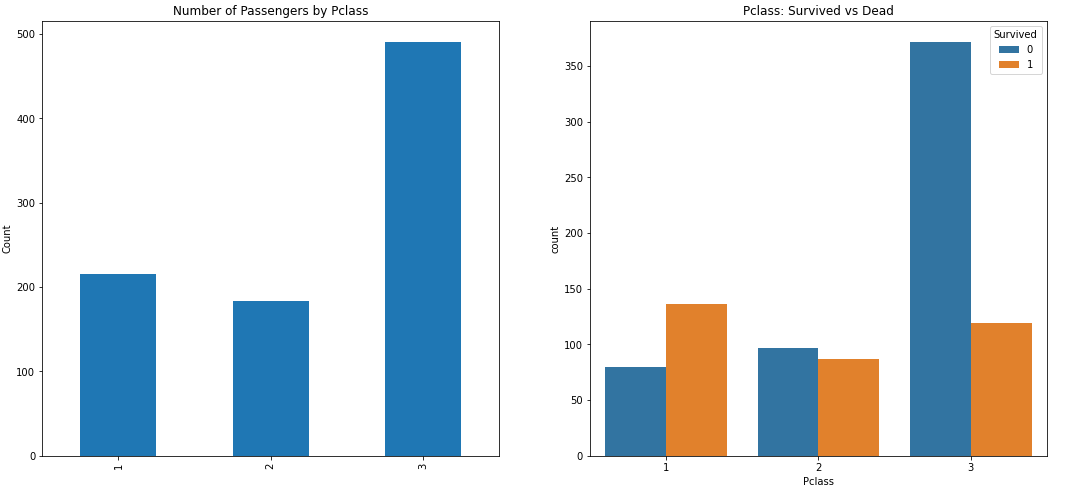
클래스가 높을수록 (1>2>3) 생존 확률이 높은 것을 알 수 있다. 수치로 보면 퍼스트는 63%, 세컨드는 47%, 써드는 24%이다.
Pclass가 생존 확률과 관련이 있다고 판단할 수 있다.
Sex & Pclass
결국 마지막에 우리가 만드는 모델은 feature 하나만 사용하는 것이 아니라 여러 features를 복합적으로 사용한다. (그래야 정확성과 신뢰도가 좋으니까) 앞에서 Sex와 Pclass가 유의미한 feature라고 판단했으니 두 개를 함께 고려했을 때 생존 여부와의 관계를 살펴보자.
sns.factorplot('Pclass', 'Survived', hue='Sex', data=train_data)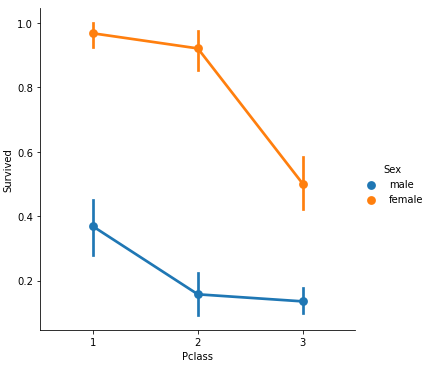
클래스와 상관없이 여성이 남성보다 생존 확률이 높고, 성별과 상관없이 클래스가 높을수록 생존 확률이 높다는 것을 알 수 있다. 특히, 퍼스트 클래스 여성은 생존 확률이 거의 100%라는 것을 알 수 있다.
Embarked
탑승한 항구에 따라 생존 확률이 다른지 가정을 세우기 어려웠다. 그럴 때는 데이터를 확인해보면 된다.
# Survived vs Embarked (plot)
f, ax = plt.subplots(1, 2, figsize=(20, 10))
sns.countplot('Embarked', data=train_data, ax=ax[0])
ax[0].set_title('Number of Passengers Boarded')
sns.countplot('Embarked', hue='Survived', data=train_data, ax=ax[1])
ax[1].set_title('Embarked vs Survived')
plt.show()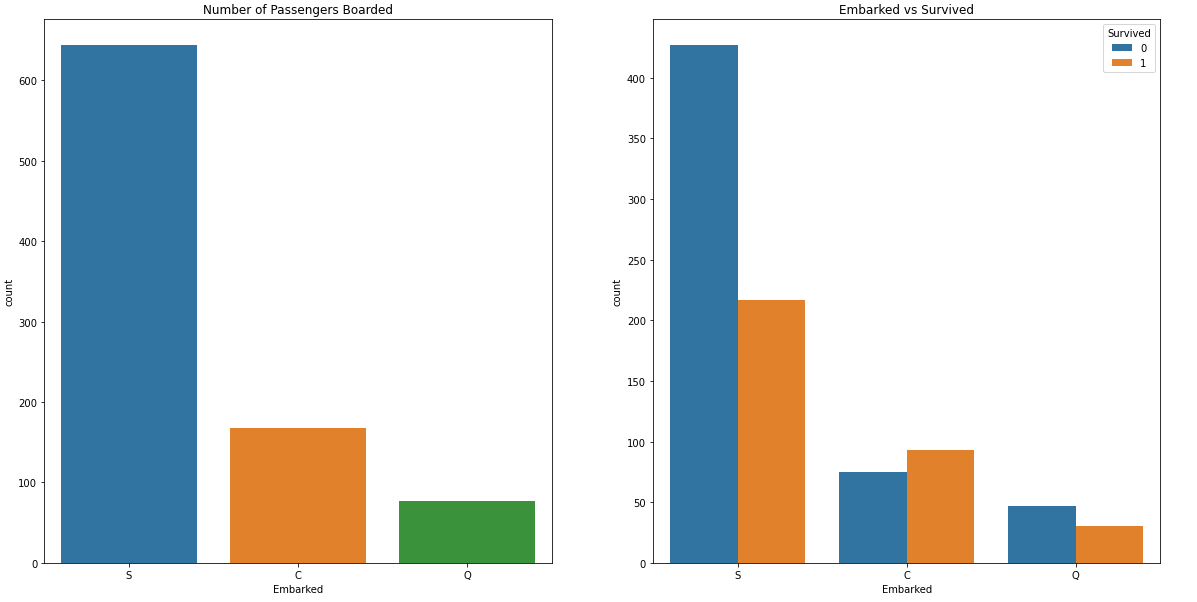
S(Southampton)에서 탑승한 사람이 압도적으로 많았다. 비율로 생존자를 파악해보면 C(Cherbourg)가 55%, Q(Queenstown)가 38%, S(Southampton)가 33%였다.
C의 생존 확률이 Q, S보다 높은 이유가 다른 feature의 영향 때문인지, Embarked의 고유한 특성인지 알아보기 위해 Embarked도 성별, 클래스로 나누어 수치를 자세히 살펴보자.
f, ax = plt.subplots(1, 2, figsize=(20, 10))
sns.countplot('Embarked', hue='Sex', data=train_data, ax=ax[0])
ax[0].set_title('Number of Passengers Boarded')
sns.countplot('Embarked', hue='Pclass', data=train_data, ax=ax[1])
ax[1].set_title('Embarked vs Survived')
plt.show()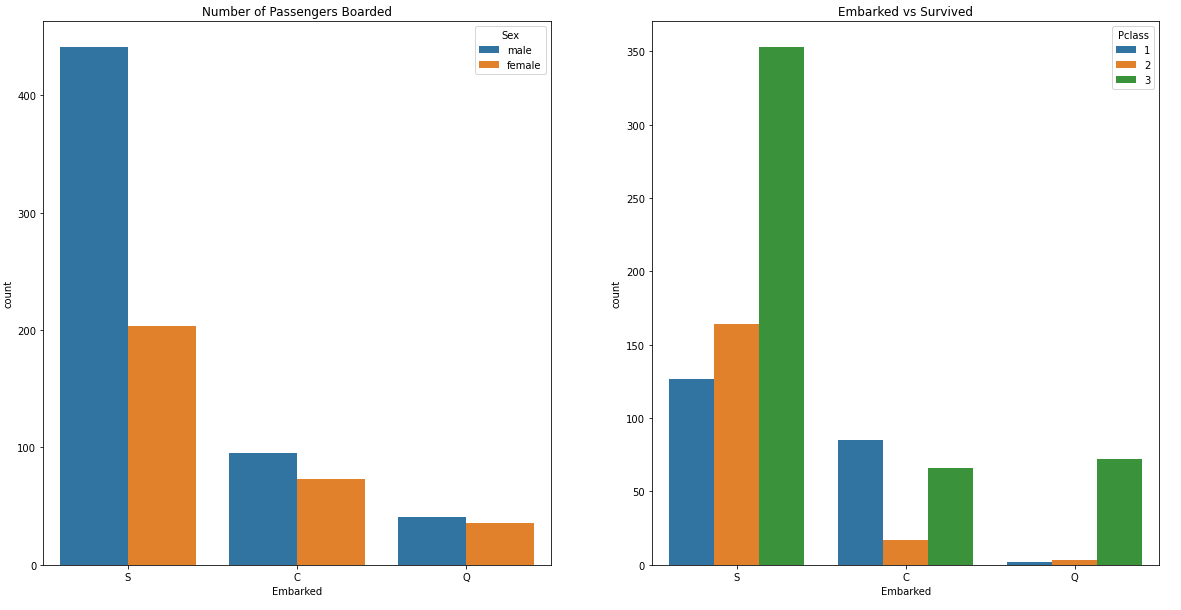
S 탑승객에는 남성과 3rd 클래스가 많다. 앞서 이런 특성을 가진 사람들이 생존 확률이 낮다는 것을 확인하였기 때문에 S의 생존확률이 낮게 나온 것이다.
C 탑승객은 성비가 비슷하고 1st 클래스 비율이 높다. 1st 클래스일 때 생존 확률이 높았으므로 C의 생존확률이 높게 나온 것이다.
Q 탑승객은 성비가 비슷하고 3rd 클래스 비율이 매우 높다. 생존 확률이 낮은 이유에 클래스가 큰 영향을 준 것으로 볼 수 있다.
Embarked의 null 값은 가장 최빈값으로 치환했다.
Fare
지금부터 살펴볼 feature는 나이, 요금, 동반가족 수로 numeric value다. 우선 요금부터 살펴보기로 했다. 클래스가 높을수록 요금이 비쌀테니 앞서 살펴본 Pclass와 비슷한 양상을 보일 것이라 추측할 수 있다. 그 전에 어떤 값을 갖는지 알아보려고 한다. (뜬금없는 데이터나 anomaly를 체크하기 위한 목적이다)
f, ax = plt.subplots(1,3,figsize=(20,10))
sns.distplot(train_data.loc[train_data['Pclass'] == 1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(train_data.loc[train_data['Pclass'] == 2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(train_data.loc[train_data['Pclass'] == 3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
plt.show()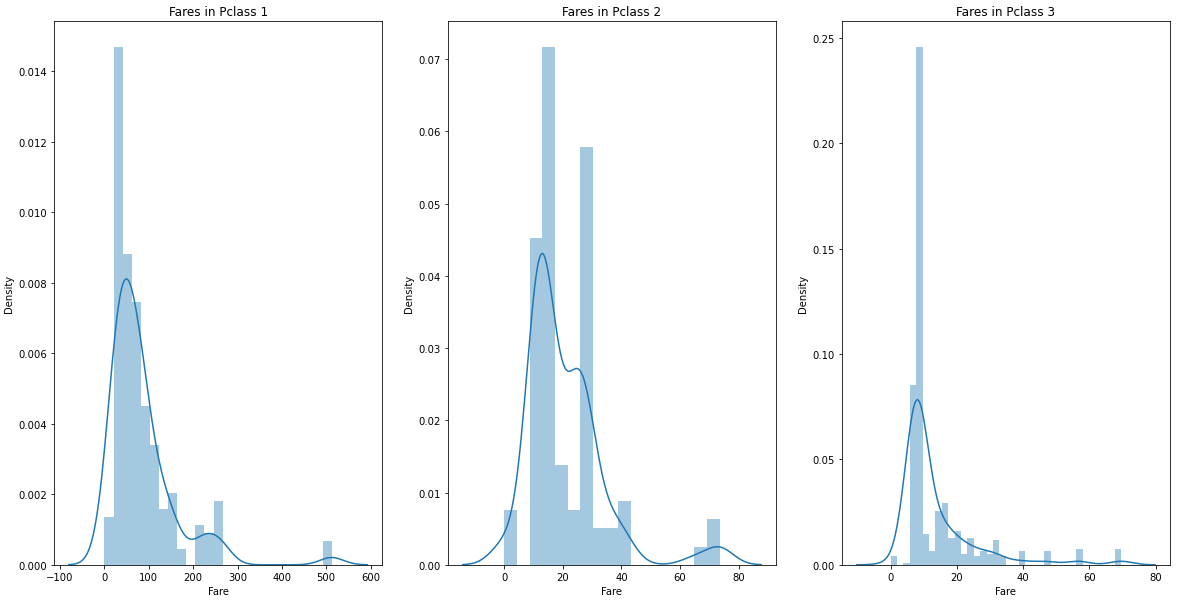
x축인 fare를 살펴보면 클래스가 높을수록 중심축에 해당하는 fare 값이 크다는 것을 알 수 있다. 그 밖의 특이점은 분산이 크다는 것이다.
Pclass=1인 그래프를 보면 fare가 500이 넘는 값도 존재한다는 것을 볼 수 있다. 정말로 요금이 500이 넘었을 수도 있고, 아니면 이상치일 수도 있다. 전체 통계를 보면 평균이 32이고 상위 25%에 해당하는 값이 31이고 최댓값이 512이다.
이렇게 불균형한 feature는 학습 성능을 저하하는 요인이 될 수 있다. 모델이 극단적인 값에 몹시 예민하게 반응할 수 있기 때문이다.
지금처럼 이상한 값이나 좋지 않은 데이터를 처리하기 위해 preprocessing을 거쳐야 하고, 여러 글에서는 feature engineering의 일부라고 말한다. 이상치를 다루는 방법은 매우 많다.
- 이상한 값이 있는 row를 그냥 제거하거나
- 불균형한 데이터를 변형하여 대칭하게 바꾸거나
- 범위를 나누어 labeling 하거나
2, 3번은 해당 방법을 사용한 kaggle 글을 링크로 걸었다. 어떤 방법이 더 좋은지는 데이터마다 다르기 때문에 정답은 없다.
Exploratory data analysis, visualization, machine learning에서는 log를 씌워 2번 방법을 사용했다.
test_data.loc[test_data.Fare.isnull(), 'Fare'] = test_data['Fare'].mean()
train_data['Fare'] = train_data['Fare'].map(lambda x: np.log(x) if x > 0 else 0)
test_data['Fare'] = test_data['Fare'].map(lambda x: np.log(x) if x > 0 else 0)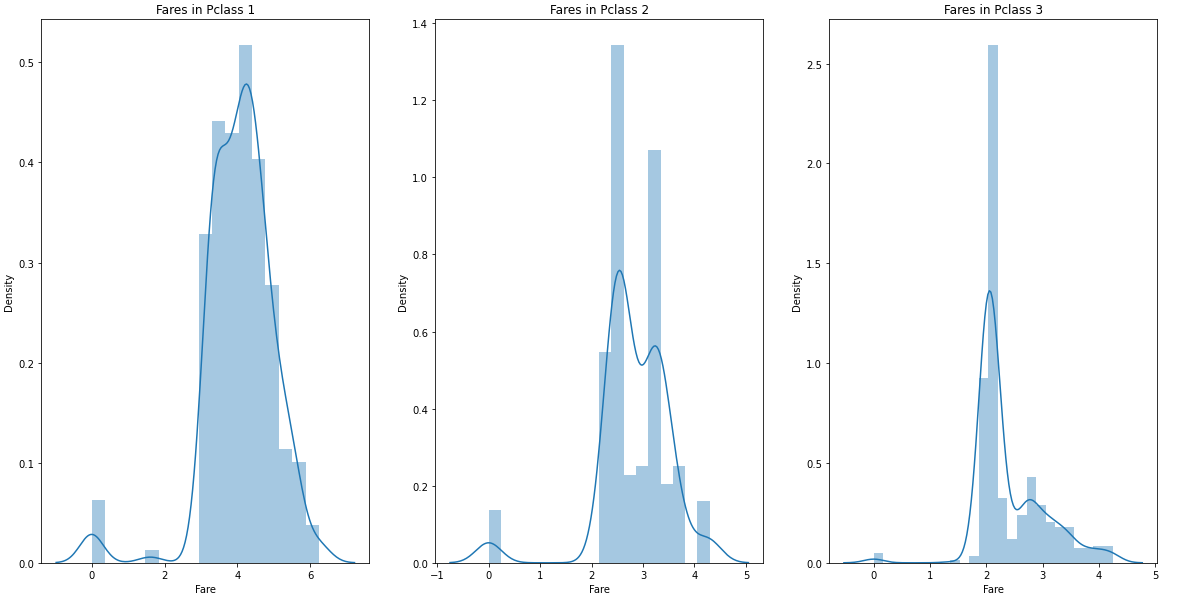
한결 대칭을 이룬다는 것을 볼 수 있다.
Age
나이 데이터를 살펴보면 다음과 같다.
f, ax = plt.subplots(1, 1, figsize=(10, 5))
sns.kdeplot(train_data.loc[train_data['Survived'] == 1]['Age'], ax=ax)
sns.kdeplot(train_data.loc[train_data['Survived'] == 0]['Age'], ax=ax)
plt.legend(['Survived == 1', 'Survived == 0'])
plt.show()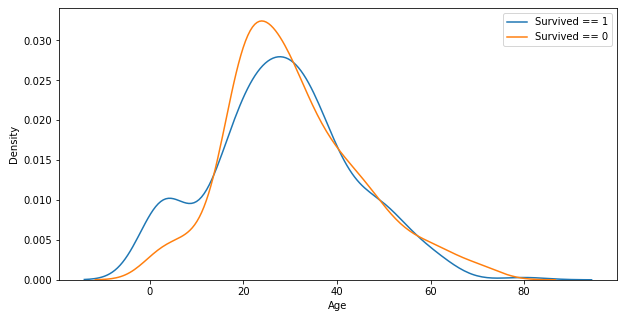
Age는 나름 Gaussian distribution으로 보이는 것 같다. 특이점은 Age=0~10인 어린 탑승객에서 생존자와 사망자 간 차이가 뚜렷하다는 점이다.
나이는 연속적인 값이기 때문에 범위를 나누어 labeling하는 것이 좋을 것 같다. Group size 역시 개인의 판단이다. 0~80살까지 있어서 16개씩 5개의 그룹으로 나누어보았다.
train_data['Age_band'] = 0
train_data.loc[train_data['Age'] < 16, 'Age_band'] = 0
train_data.loc[(train_data['Age'] >= 16) & (train_data['Age'] < 32), 'Age_band'] = 1
train_data.loc[(train_data['Age'] >= 32) & (train_data['Age'] < 48), 'Age_band'] = 2
train_data.loc[(train_data['Age'] >= 48) & (train_data['Age'] < 64), 'Age_band'] = 3
train_data.loc[train_data['Age'] >= 64, 'Age_band'] = 4
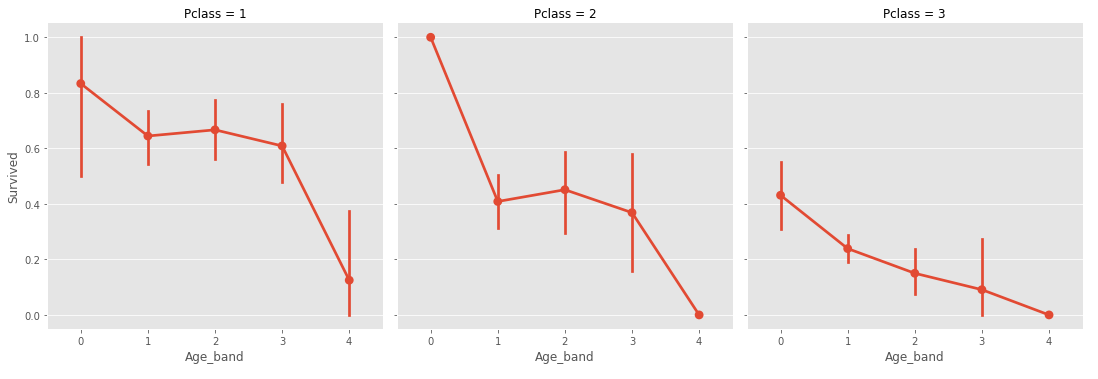
sns.factorplot('Age_band', 'Survived', data=train_data, col='Pclass')
plt.show()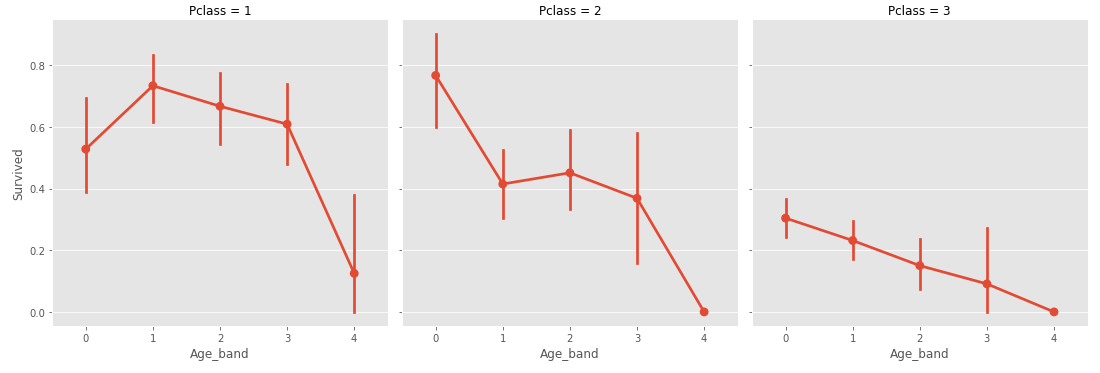
전반적으로 나이가 어릴수록 생존률이 높다는 것을 알 수 있다. 64~80살인 탑승객이 13명 정도라 고령층을 일반화하기는 어려우나 청년과 중년층에 비해 영유아층이 생존률이 높기 때문에 그렇게 판단하였다. Group size를 더 작게하면 그래프가 달라질 수 있을 것 같다.
참고로 Age에 있는 null값을있는 null값을 median으로 채우고 그래프를 보면 다음과 같다.
SibSp & Parch
SibSp와 Parch는 각각 Sibling + Spouse와 Parent + Child이다. 그래프를 그려보면 다음과 같다.
f,ax=plt.subplots(1,2,figsize=(20,8))
sns.barplot('SibSp','Survived',data=train_data,ax=ax[0])
ax[0].set_title('SibSp vs Survived')
sns.barplot('Parch','Survived',data=train_data,ax=ax[1])
ax[1].set_title('SibSp vs Survived')
plt.show()
sns.factorplot('SibSp', 'Survived', data=train_data)
sns.factorplot('Parch', 'Survived', data=train_data)
plt.show()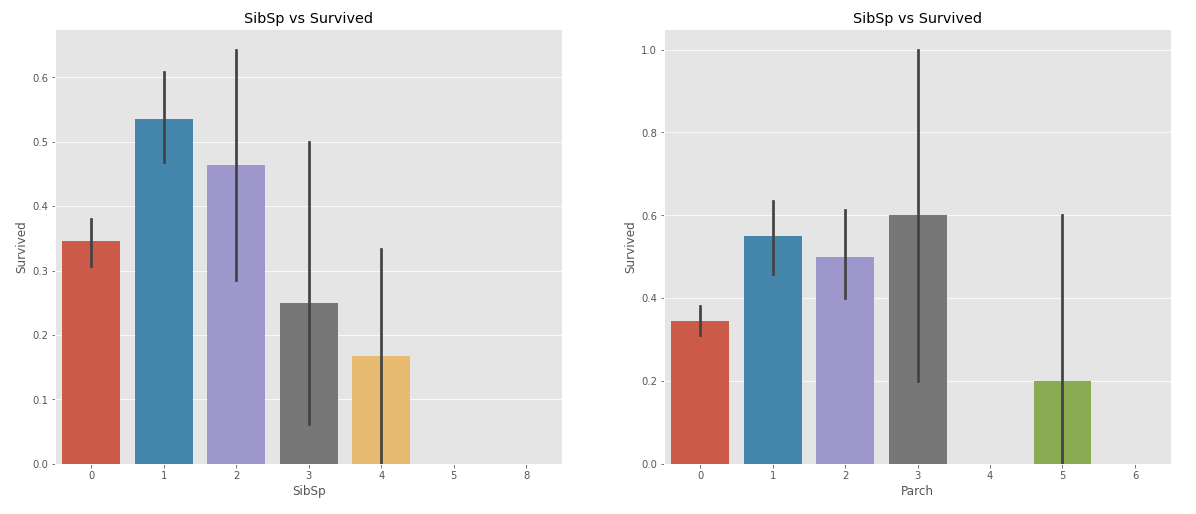
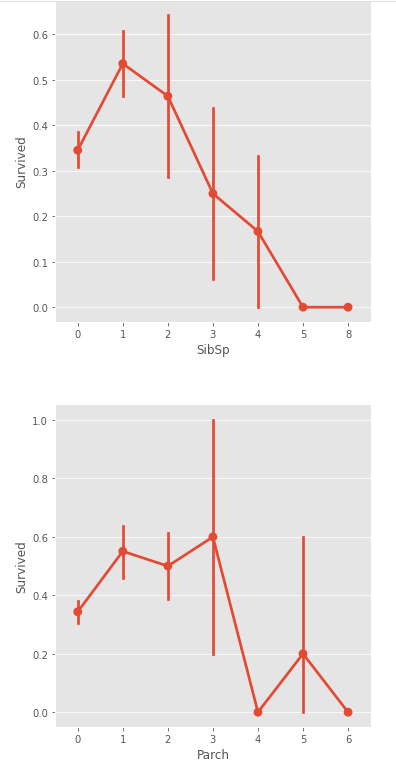
SibSp와 Parch는 비슷한 양상을 보인다. Age처럼 큰 값을 갖는 탑승객 수가 적어서 일반화하기 어려우나 4명 이상이 될때는 생존률이 감소하는 것을 볼 수 있다.
수치를 살펴보면 SibSp와 Parch가 0인 탑승객이 600명이 넘는다. 그리고 이들은 생존률이 50%를 넘지 못한다. SibSp와 Parch에서 생존률이 50%를 넘는 집단은 값이 1~3인 그룹인데 이 역시 중요한 지표로 쓸 수 있을 것 같다.
SibSp와 Parch 값을 더해 FamilySize라는 새로운 feature를 만드는 사람도 있고 여기에 Alone이라는 SibSp=0 & Parch=0인 집단을 새로 만드는 사람도 있다. 새로 만든 features가 유의미할지 살펴보자.
train_data['Family_size'] = 0
train_data['Family_size'] = train_data['SibSp'] + train_data['Parch']
train_data['Alone'] = 0
train_data.loc[train_data.Family_size == 0, 'Alone'] = 1
f, ax = plt.subplots(1, 2, figsize=(20, 10))
sns.barplot('Family_size', 'Survived', data=train_data, ax=ax[0])
sns.barplot('Alone', 'Survived', data=train_data, ax=ax[1])
plt.show()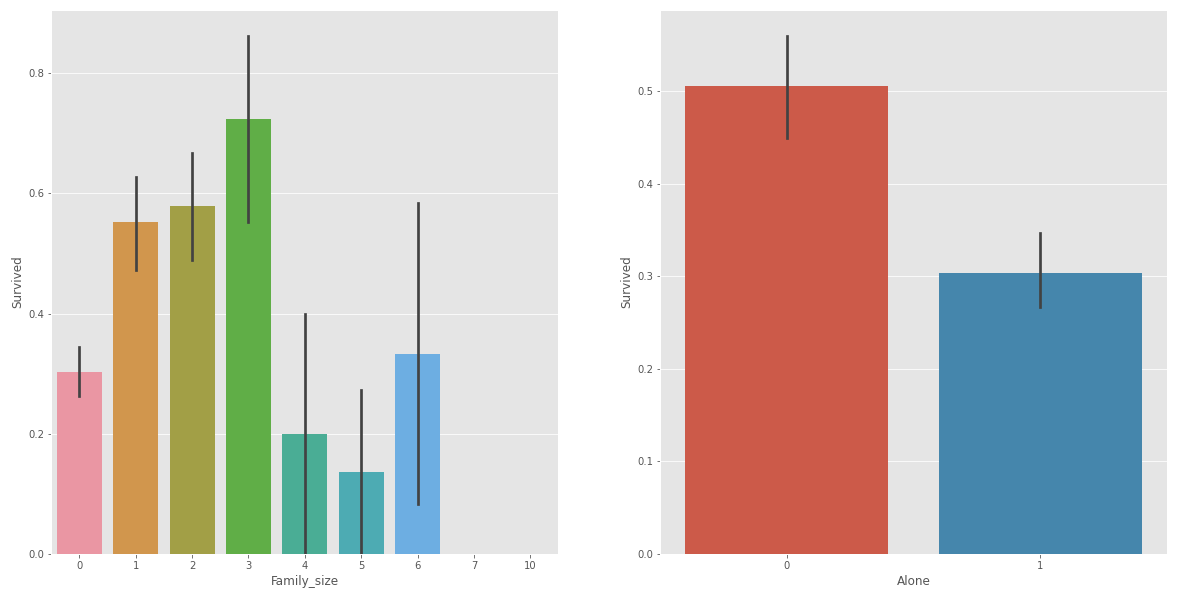
앞에서 추정한 특징이 더 두드러지기게 나타났다. 학습할 때 사용할 수 있을 것 같다.
Cabin & Ticket
Cabin과 Ticket은 string feature다. 우선 Cabin은 NaN 값이 전체의 78%여서 학습데이터에서 배제하기로 했다. Ticket 값은 대략 아래와 같이 생겼다.
패턴이나 포맷을 찾을 수 없어서 ticket feature도 학습데이터에서 배제하기로 했다.
지금까지 feature를 살펴본 결과, 모델을 학습시킬 때 사용할 feature로 Pclass, Sex, Age(Age_band), SibSp, Parch(Family_size, Alone), Fare(log), Embarked가 적합하다고 결론을 내렸다. (겁나 많다)
이제 모델을 설계하는 단계...는 아니고 아직 손봐야할 feature가 남았다.
String to Numeric
Sex와 Embarked는 값이 string인데 이를 학습데이터로 곧바로 넣기보다는 수치로 변환해서 넣는 게 좋다. Sex={'Female', 'Male'}이고 Embarked={'C', 'Q', 'S'}여서 순서대로 번호를 부여하면 된다. 사용하지 않는 feature를 제거하고 나면 아래와 같은 train data가 탄생한다.
train_data['Embarked'] = train_data['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
train_data['Sex'] = train_data['Sex'].map({'female': 0, 'male': 1})
train_data.head()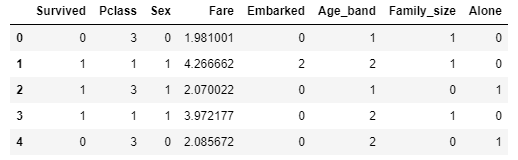
여기서 fare까지 grouping하는 사람도 있는데 우선은 이 데이터로 학습을 시키려한다. Heatmap을 사용하면 feature별 correlation을 확인할 수 있다.
sns.heatmap(train_data.corr(), annot=True, cmap='RdYlGn', linewidths=0.2, annot_kws={'size':18})
fig = plt.gcf()
fig.set_size_inches(18, 15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()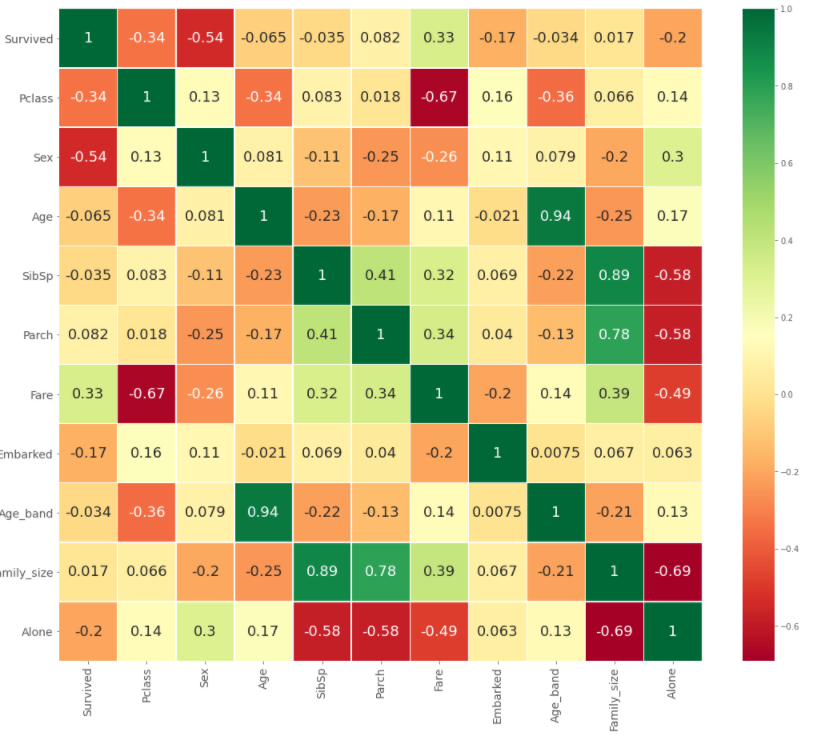
모델링하기 전 진짜 마지막으로, train_data를 바꾼 방법대로 test_data를 수정한다.
모델링
Machine learning model을 만들 차례다. 예측 모델의 성능을 좌우하는 것은 크게 모델을 구성하는 알고리즘과 parameter가 있다.
Titanic 문제는 예측해야하는 Target class(Survived)가 있고 Binary(0 또는 1)이기 때문에 Binary Classification Problem으로 정의할 수 있다.
EDA To Prediction(DieTanic)에서 여러 Classification Algorithm을 소개하고 있는데 지금 따라하고 있는 글에서는 RandomForest를 사용하고 있어서 RandomForest를 사용한다.
RandomForest는 간단히 말하면 학습 데이터를 기반으로 Decision Tree를 만드는데 이 tree를 랜덤으로 여러 개 만들고 이를 종합하여 target class를 예측하는 기법이다. 자세한 건 나중에 알아보기로 하고 우선 sklearn의 default setting으로 학습시켜보자. (결과가 궁금하니까)
글에서는 train_data를 바로 학습시키지 않고 train_data를 쪼개서 train set과 valid set을 만든다. train set으로 학습하고 valid set으로 모델의 성능을 우선 평가한다고 보면 된다.
sklearn에서 train_test_split(training set 나눠주는 용도), RandomForestClassifier, metrics(모델 성능 평가 용도)를 사용할 예정이다.
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split
X_train = train_data.drop('Survived', axis=1).values
target_label = train_data['Survived'].values
X_test = test_data.values
X_tr, X_vld, y_tr, y_vld = train_test_split(X_train, target_label, test_size=0.3, random_state=2018)
model = RandomForestClassifier()
model.fit(X_tr, y_tr)
prediction = model.predict(X_vld)
print ('Total : {}, Accuracy: {}'.format(y_vld.shape[0], 100 * metrics.accuracy_score(prediction, y_vld)))
82%가 나왔다. 오~
Feature Importance
모델이 학습할 때 어떤 feature의 영향을 많이 받았는지 feature importance를 통해 알 수 있다.
feature_importance = model.feature_importances_
series_feat_imp = pd.Series(feature_importance, index=test_data.columns)
plt.figure(figsize=(8, 8))
series_feat_imp.sort_values(ascending=True).plot.barh()
plt.xlabel('Feature importance')
plt.ylabel('Feature')
plt.show()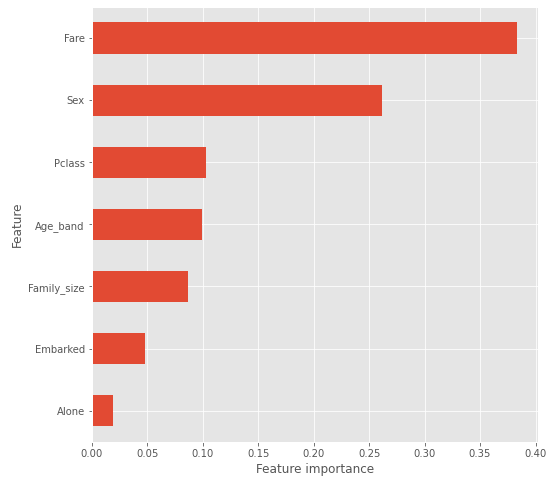
이 모델에서는 fare가 가장 큰 영향력을 갖고 있다. 모델을 바꾸면 순서가 달라질 수 있다. 이 결과를 토대로 모델 학습에 사용할 feature를 개선하면 된다.
Submit
test data로 predict한 결과를 제출했다.

Accuracy가 74%가 나왔다. 글을 따라하기 전에 한 결과가 77%였는데 그보다 정확도가 낮게 나왔다.
보통 70~80%가 평균이라서 크게 신경쓰지 않아도 된다지만 짜증나니까 좀 더 올려보자.
version 5까지 만들어서 78%로 만들었다. Parameter Tuning을 하면서 최적 조건을 찾아 모델을 수정한 결과다.
from sklearn.model_selection import GridSearchCV
n_estimators = range(100, 1000, 100)
max_depths = range(3, 8, 1)
hyper = {'n_estimators': n_estimators, 'max_depth': max_depths}
gd = GridSearchCV(estimator=RandomForestClassifier(random_state=0), param_grid=hyper, scoring='accuracy', n_jobs=4, verbose=True)
gd.fit(X_train, target_label)
print (gd.best_score_)
print (gd.best_estimator_)Parameter Tuning하는 코드는 이 글과 이 글을 참고했다. 앞으로 따라해볼 글에서 조금씩 따왔다.
다음번에는 다른 방법으로 Titanic을 풀어볼 예정이다. 끝!
