
🍀 단어변환
dfs가 부족하여 dfs를 이용한 풀이가 많다 보니까 bfs에 대한 풀이법을 찾기가 좀 어려웠다. 또한 버그를 손쉽게 찾기위해서 코드도 어느 정도 간결한 것이 좋다 보니 이것저것 다양한 시도를 많이 해 봤다. javascript로는 dfs풀이를 했으며 python으로는 bfs를 이용하여 구현하였다.
단어를 words 중에 1개를 선택하여 다음 단어 선택을 위해 단어들을 걸러줘야하는데 이것이 runing(가지치기) 개념이다. 조건을 이용하여 사전에 탐색을 차단하여 퍼포먼스를 늘리는 방식이다. 이 문제를 풀기 위해서는 어차피 가지치기가 필요하다고 생각했다. 이 문제에서 가지치기를 적용할 수 있는 곳은 두 번째 조건인 words에 있는 단어로만 변환할 수 있습니다.에 있다. 서로 다른 문자열이 1개만 존재해야 다음 탐색을 진행할 수 있다는 의미가 되며 서로 다른 문자열이 0, 2, 3, ..., begin의 길이는 다음 탐색 대상이 될 수 없음을 의미한다.
1️⃣ Javascript
위에서 가지치기 대상인 words에 있는 단어로만 변환할 수 있습니다.에 대한 코드를 먼저 작성해보자. 나는 이에 대한 함수명을 countDifferent로 명명했다. 이 함수가 return하는 것은 두 문자열에서 다른 단어 개수로 pruning할 때 사용된다. 따라서, 이 함수의 return 값이 1인 단어들만 다음 탐색단어로 queue에 push하기 전에 filtering 역할을 수행한다.
// 방법 ①
function countDifferent(str1, str2){
let result = 0;
for (let idx = 0; idx < str1.length; idx++){
if (str1[idx] !== str2[idx]) result += 1;
}
return result;
}
// 방법 ②
const countDifferent = (str1, str2) => [...str1].reduce(
(acc, cur, idx) => acc + (str1[idx] !== str2[idx]), 0
)방법 1과 같이 구현할 수도 있지만 방법 2와 같이 reduce를 이용하면 손쉽게 짤 수 있다. 항상 느끼는 것이지만 reduce는 정말 거의 무적같은 느낌이다.
dfs로 푼 풀이는 2가지가 있는데 dfs를 응용하고자 여러 방법으로 풀었다. 두 번째 풀이는 첫 번째 풀이를 토대로 한다.
첫 번째 풀이
target과 동일할 때 그 때의 깊이(여기서 count) 를 answer 배열에 담아서 최소값을 return하는 식으로 구현하였다. 전체적인 로직은 아래와 같다.
로직
- 현재 단어 방문
- 현재 단어가 target과 같다면 answer에 push
- 다른 문자열의 개수가 1이며 방문하지 않았다면 방문
위의 3개의 로직을 게속 반복해주는 재귀형태
구현
const countDifferent = (str1, str2) => [...str1].reduce(
(acc, cur, idx) => acc + (str1[idx] !== str2[idx]), 0
)
function solution(begin, target, words) {
const answer = [];
const visited = Array(begin.length).fill(false);
function findMinConverted(currentStr, count){
let minConvertedCount = 0;
if (currentStr === target) return answer.push(count);
for (let idx = 0; idx < words.length; idx++){
if (countDifferent(currentStr, words[idx]) === 1 && !visited[idx]){
visited[idx] = true;
findMinConverted(words[idx], count + 1)
visited[idx] = false;
}
}
}
findMinConverted(begin, 0);
return answer.length > 0 ? Math.min(...answer) : 0
}여기서 중요한 것은 leaf node(depth가 최하위)인 단어를 선택했다면 다음 탐색을 위해서 방문처리를 해제 해 주어야한다.
두 번째 풀이
첫 번째 풀이는 dfs를 쉽게 구현하기 위해서 findMinConverted라는 solution 함수 내부에 helper function을 이용하였다. 여기서 helper function을 제외한 순수 재귀함수로 구현해보고 싶다는 생각이 강하게 들었다. 이로 인해 꽤 많은 시간을 썼지만 해결하고 나서 생각해보니 나도 내 풀이에 가끔 놀란다.(이런 코드들이 나중에 보면 이해하는데 시간이 걸림...ㅜㅜ)
순수 재귀 함수로 구현을 하려다 보니 visited, 현재 단어가 target과 같다면 어디에 저장해야 하는가??? 라는 자문에 멘붕이 왔었다. 하지만, 하고자하면 길이 보이듯이 해결방법이 떠올랐다.
🛠️문제해결
방문처리(visited) 👉🏻 현재 단어는 이미 선택했으므로 현재 단어는 제외한 선택지를 다음 함수 호출의 인자값으로 넘겨줌으로써 해결. 즉, 다음 단어 선택지에서 방문한 문자열은 배제
[...words.slice(0, index), ...words.slice(index + 1)]현재 단어에 대한 최소 횟수 저장 👉🏻 함수 내부의 값 함수가 종료되기 전에 사라지지 않으니 다음 words의 요소를 다음 함수의 return 값으로 매칭시키기 위해 map 메서드를 이용함으로써 해결
- 선택할 수 있는 단어가 없을 시: return Infinity
- 선택할 수 있는 단어가 있을 시: map을 이용하여 현재 단어 횟수 + 1
countDifferent(begin, str) === 1 ? solution(str, target, [...words.slice(0, index), ...words.slice(index + 1)]) + 1 : Infinity
구현
const countDifferent = (str1, str2) => [...str1].reduce(
(acc, cur, idx) => acc + (str1[idx] !== str2[idx]), 0
)
function solution(begin, target, words) {
if (!words.includes(target)) return 0;
if (begin === target) return 1;
const currentCounts = words.map((str, index) =>
countDifferent(begin, str) === 1
? solution(str, target, [...words.slice(0, index), ...words.slice(index + 1)]) + 1
: Infinity
);
return Math.min(...currentCounts);
}2️⃣ Python
이 풀이는 dfs보다는 bfs를 이용한 풀이가 더 나은 풀이라 생각하여 python으로 풀 때는 bfs 알고리즘을 이용하여 구현하였다. 여기서 구현하는데 오래 걸린 이유는 breadth 즉, depth 또는 level의 값 = 최소 단어 변환 횟수인데 이것을 구하는데 애먹었었다. 처음에 짰을 때 하나의 단어 탐색을 할 때마다 answer가 1씩 증가가 되는데... 목표는 tree구조로 생각하면 sibling 단어들은 같은 단어 변환 횟수(answer)를 가져야하는 것이다. 이는 각 너비에 해당하는 단어들을 배열로 만듬으로써 배열 기준으로 값을 1씩 count하였다. 설명이 어려울 거 같아서 그림을 만들어 보았다.
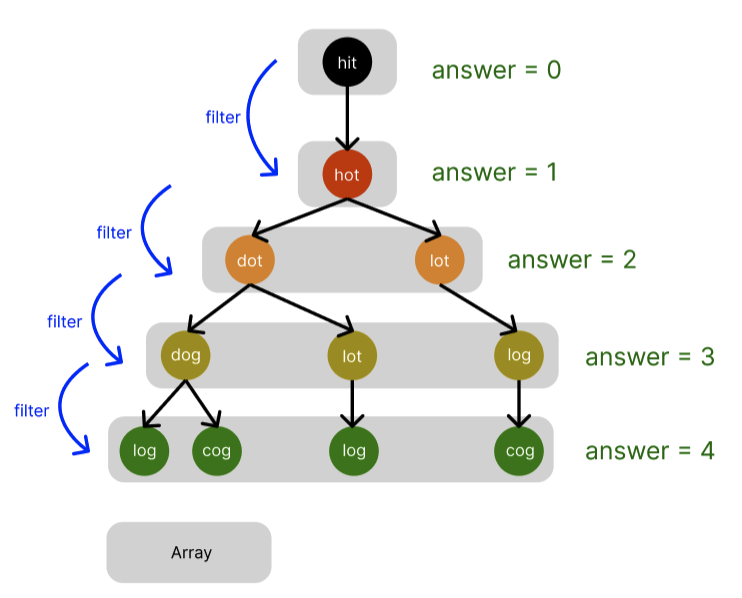
위의 회색 박스는 배열을 의미하며 다음 선택 단어들이 들어있는 배열이 queue에 들어간다.
좀 더 설명하자면 아래와 같다.
⑴ q = [[hit]]
for => [hit]
- 현재 단어 = hit, 다음 단어들 = hot
- queue에 push할 단어들 =[hot]
- answer = 0⑵ q = [[hot]]
for => [hot]
- 현재 단어 = hot, 다음 단어들 = dot, lot
- queue에 push할 단어들 =[dot, lot]
- answer = 1⑶ q = [[dot, lot]]
for => [dot, lot]
- 현재 단어 = dot, 다음 단어들 = dog, lot
- 현재 단어 = lot, 다음 단어들 = log
- queue에 push할 단어들 =[dog, lot, log]
- answer = 2⑷ q = [[dog, lot, log]]
for => [dog, lot, log]
- 현재 단어 = dog, 다음 단어들 = log, cog
- 현재 단어 = lot, 다음 단어들 = log
- 현재 단어 = log, 다음 단어들 = cog
- queue에 push할 단어들 =[log, cog, log, cog]
- answer = 3⑸ q = [[log, cog, log, cog]]
for => [log, cog, log, cog]
- 현재 단어 = log, 다음 단어들 = lot, cog
- 현재 단어 = cog 👉🏻 target을 찾았으므로 탐색 종료🚫
- answer = 4 👉 return answer
queue에서 동작 원리는 위와같다. queue에 push할 단어들은 아래 코드에서 next_strs로 명명했다.
구현
from collections import deque
def canGo(str1, str2):
count = 0
for idx in range(len(str1)):
if str1[idx] != str2[idx]: count += 1
return count
def solution(begin, target, words):
if target not in words: return 0
q = deque([[begin]])
visited = []
answer = -1
while q:
answer += 1
current_strs = q.popleft()
next_strs = []
# 현재 level탐색 중 target이 있다면 break
if target in current_strs: break
# 다음에 선택할 단어들 filtering
for current_str in current_strs:
visited.append(current_str)
next_strs += list(filter(
lambda x: x not in visited and canGo(x, current_str) == 1, words)
)
q.append(next_strs[:])
return answer🔥 마치며
javascript로 하루, python으로 하루 이렇게 해서 하루를 기준으로 나누어서 풀었다. 기존에는 python, javascript로 하루 안에 풀었는데 가면서 어려운 문제를 다루다 보니 내가 작성한 코드가 이해가 안 갈 때가 종종 생기기 시작했다. 따라서 나에게 조금 어려웠던 문제들을 선택적으로 하루에 거쳐서 다른 언어로 다른 풀이도 고민해보면서 풀어보는 것으로 전략을 바꾸었다. 이렇게 바꾼 이유는 다양한 사고력을 기르기 위함과 익숙치 않은 알고리즘에 대해서 더 깊이 파악하고 이해하기 위해서이다.

항상 응원해요 ❤️