이전에 본 replacement policy에 이은 cleaning policy를 알아보자.
cleaning policy는 언제 수정된 page를 secondary disk에 wirte back 해야할지를 결정하는 정책이다.
만약 메모리에 공간이 없을 때, page 요청을 하면 replacement가 수행된다. 이 때 page-out할 때, disk에 써야할까? 이는 modify bit(dirty bit)으로 처리할 수 있다.(수정 안됐으면 write to disk x)
두 정책을 알아보자.
- Precleaning: page가 교체되기전에(I/O 연산이 적을때) 디스크에 wirte back한다. 그런데 교체되기전에 많은 수정이 발생하면 I/O 연산이 많아진다. 이는 비효율적이다.
- Demand cleaning: 페이지가 교체될 때, write back하는 방법이다. 위의 방법과 다르게 중복된 I/O 연산를 최소화한다.
Page Buffering
일반적으론 메모리가 가득 찼을 때, 페이지 하나를 page-out하고 disk에서 로드할 페이지를 page-in 한다. 이 때 out 되는 페이지가 수정되었다면 두 번의 I/O가 발생한다.
이 때 들어오는 page에 대한 응답성이 떨어질 수 있다.
page buffer를 사용하면 frame의 일부분을 free frame으로 사용한다. 요청된 page를 free frame에 추가하고, out될 page를 list에 추가해 둘을 연결한다.
그럼 새로 들어오는 페이지는 응답성이 증가한다.
disk I/O 연산이 적을 때, cleaning을 하면 I/O 연산을 효율적으로 수행할 수 있다.
그리고 바로 out되지 않고 늦추기 때문에 이 페이지에 대한 요청이 cleaning 되기전에 온다면 I/O를 발생시키지 않고 read 할 수 있다.(메모리에는 존재하지만 page table에서는 삭제된다.)
이 말은 버퍼를 cache로 사용할 수 있다는 것이다.
이 아이디어를 확장해 list에 수정된 페이지를 저장해 수정되지 않은 페이지와 구분하면 I/O를 효율적으로 수행할 수 있다.(한 번에 I/O write back 처리)
Enhanced Second-Chance
강화된 second chance는 dirty bit을 사용하여 replacement를 더 효율적으로 수행할 수 있다.
(refernce bit, modified bit)의 format으로 바라보자.
이왕 수정되지 않은 페이지를 더더욱 교체 대상으로 보는 것이다.
- (0, 0): 접근, 수정 모두 안된 페이지이다. 교체로 최적이다.
- (0, 1): 접근은 안되었지만 수정되었다. 얘는 추가적인 I/O가 발생한다.
- (1, 0): 접근 되었다. 나중에 사용할 수도 있다.
- (1, 1): 접근과 수정 모두 되었다.
Thrashing
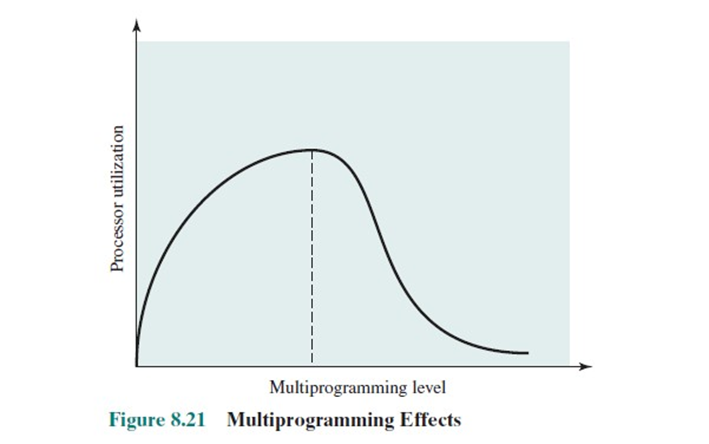
메모리에 로드될 수 있는 프로세스의 수가 많다면 각각의 프로세스에게 할당될 수 있는 프레임 수는 당연히 줄어들 것이다. CPU 활용률을 높히기 위해 프로세스 수를 생각없이 늘린다면 page faults 수는 증가할 것이다.
이렇게 프로세스가 어떠한 task를 수행하는 것보다 paging에 시간을 더 소모한다면 이를 Thrashing이라 칭한다.
CPU 사용률을 높히기 위해 메모리에 수용할 수 있는 프로세스 수를 늘렸는데 page faults가 많이 발생해 오히려 사용률이 줄어들 것이다.
Resident Set Policy
각각의 프로세스마다 할당해줄 프레임 수를 결정하는 정책이다.
모든 프로세스에게 고정된 frame 수를 할당해준다. 그럼 page-out도 자신의 page로 수행해야한다. 이를 local replacement라 칭한다.
그러므로 variable-allocation policy를 중점적으로 알아보자.
이는 지역 교체와 전역 교체를 합친 정책이다. 둘 다 발생할 수 있다.
프로세스에게 할당되는 프레임의 수는 고정되지 않는다. 변한다.
그렇다면 page-out될 페이지는 자신의 프로세스 또는 모든 페이지들 중 선택될 수 있다.
Working set Model
locality가 크다는 것은 특정 시점까지 발생한 한 프로세스의 페이지 접근이 동일한 페이지에서 자주 발생하는 것을 의미한다.
반대로 locality가 작다면 다양한 페이지를 접근한다는 것이다.
Working set Model은 locality에 기반한다. 특정 시점에서 현재까지 접근된 페이지들을 W로 표현하는데 이 W에 포함된 페이지들만 메모리에 할당하도록 W를 지속적으로 계산하고 working set에 없는 페이지들을 page-out 하겠다는 것이다. (필요한 부분을 중점적으로 할당한다.)
- 는 t시점까지 접근된 개의 프로세스의 집합이다. 가 10이라면 현재까지 접근된 10개의 프로세스를 확인한다는 것이다.
- 을 만족한다.
- 을 만족한다.
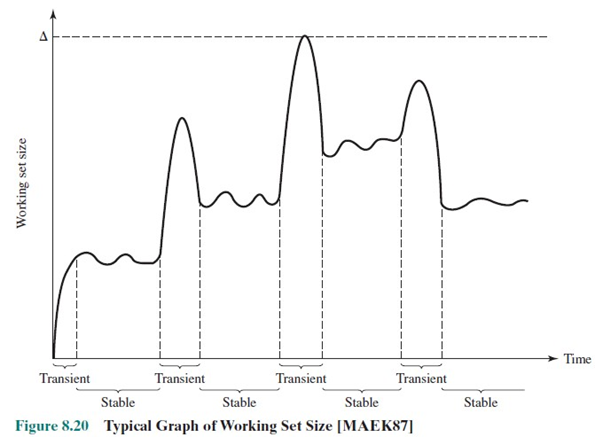
위는 시간에 따른 working set 크기의 변화이다. locality는 작아지거나 커지거나 둘을 반복한다.
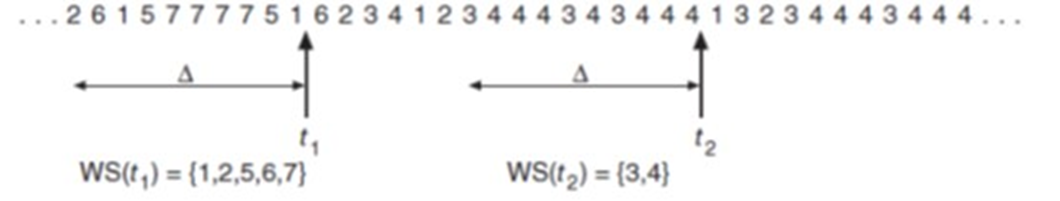
locality가 왼쪽은 작고 오른쪽은 크다.
working-set model은 위의 조건을 기반으로 주기적으로 working set에 존재하지 않는 page를 out한다.
즉 메모리에 로드된 페이지들을 working set과 같도록 잘 관리한다는 것이다.
그러나 t시점에서 계속해서 만큼의 프로세스를 측정하는 것은 굉장히 비효율적이다.
시간 tagging과 time-ordered queue 관리, 즉 LRU와 같은 문제점이 발생한다.(정책을 지키기 위한 오버헤드가 큼)
또한 최적의 는 아무도 알지 못한다. 너무 작다면, locality를 거의 보장하지 못하며 너무 크다면 불필요한 페이지까지 로드된다. 한 번 접근된 페이지가 모두 메모리에 로드되는 것이다.
Page-Fault Frequency
이 방법은 working set 전략에 비슷한 성능을 내고 오버헤드는 줄인 방법이다.
두 개의 한계점을 사용하며 수용가능한 page-fault frequency rate를 유지한다.
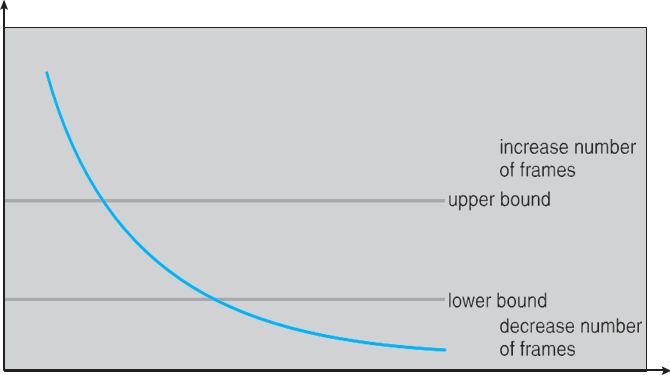
만약 상한보다 page fault가 많이 발생하면 할당할 수 있는 frame 수를 늘린다.
하한보다 작으면 frame 수를 줄인다.
