🔊 내용
우리는 캐글 동물 데이터를 바탕으로 Multi-Class Classification 를 실습한다.
모델 구현을 위해 다섯 단계를 진행한다.
🌑 데이터셋 다운로드
🌓 이미지와 레이블 불러오기
🌕 전처리와 데이터 분할
🌗 모델 생성과 학습
🌑 신규 이미지 예측
💾 데이터셋
-
animal image dataset <링크>
pandacatdog
🥕 환경
python 3.7tensorflow 2.6keras 2.6colab
📁 프로젝트
├── animals
│ ├── panda [1,000 entries]
│ ├── dogs [1,000 entries]
│ └── cats [1,000 entries]
├── images
│ ├── panda.jpg
│ ├── dog.jpg
│ └── cat.jpg
└── model.ipynb🌑 데이터셋 다운로드
링크를 통해 동물 이미지 데이터셋을 다운받는다.
압축을 풀어주면 animals/ 그리고 images/ 폴더를 볼 수 있다.
animals/폴더는 훈련 데이터셋images/는 테스트셋을 의미한다.
또한 우리의 목적은 <panda, dogs, cats> 중 하나의 클래스로 예측하는 것이며
각각의 이미지에 대한 클래스는 상위 폴더 이름이 될 것이다.
마지막으로 📁 프로젝트를 참고하여 디렉토리를 구성하자.
❝ 이제 소스를 작성할 준비가 끝났다. ❞
model.ipynb 에 차근히 코딩을 해보자.
🌓 이미지와 레이블 불러오기
먼저 animals/ 디렉토리 내 전체 이미지 개수를 확인해보자.
❝ 여러가지 방법이 있겠지만 손쉬운 방법이 있다. ❞
imutils.paths.list_images() 사용하면 된다.
이미지 3,000 장 존재하면 성공이다.
이제 파일 경로를 image_paths 변수에 담아보자.
from imutils import paths
search_dir = "animals"
image_paths = sorted(
list(paths.list_images(search_dir))
)
print(">>> image count =", len(image_paths))>>> image count = 3000image_paths 에 담긴 각각의 이미지 경로 하나씩 불러온다.
그리고 이미지는 images 에 저장하고 레이블은 labels 변수에 담는다.
❝ 각각의 이미지에 대한 레이블은 어디 있을까 ? ❞
❝ 폴더 이름을 잘라내어 레이블로 만든다. ❞
이해를 돕기 위해 이미지와 레이블 파트로 나뉘어 설명한다.
우선 실제 이미지 경로를 하나씩 꺼내어
해당 경로 이미지를 cv2.imread() 통해 불러온다.
그리고 cv2.resize() 로 크기를 균일하게 변경한다.
❝ 이미지 크기가 각기 다르기 때문이다. ❞
마지막으로 이를 images 리스트에 순차적으로 담아준다.
레이블 생성도 마찬가지로 이미지 경로가 필요하다.
print(image_path)>>> data/animals/panda/panda_01000.jpg우리가 필요한 부분은 panda/ 이며 .split() 으로 잘라주면 된다.
또한 os.path.sep 를 이용하면 구분자를 손쉽게 찾아낼 수 있으므로
뒤에서 두번째 위치 [-2] 를 찾아낸다.
마지막으로 labels 에 저장한다.
import os
import cv2
from tqdm import tqdm
image_dim = (180, 180, 3)
images = []
labels = []
for image_path in tqdm(image_paths):
image = cv2.imread(image_path)
image = cv2.resize(
image, (image_dim[1], image_dim[0])
)
images.append(image)
label = image_path.split(os.path.sep)[-2]
labels.append([label])
print(">>> images count =", len(images))
100%|██████████| 3000/3000 [10:44<00:00, 4.65it/s]
>>> images count = 3000🌕 전처리와 데이터 분할
전처리는 두가지 작업을 할 예정이다.
첫째로 이미지 값을 0 에서 1 사이의 값으로 변환한다.
❝ 그렇다. 스케일링 작업이다. ❞
둘째는 One-Hot Encoding 작업이다.
현재 레이블은 panda, dogs 또는 cats 이다.
❝ 컴퓨터가 읽을 수 있는 형태로 바꿔주자. ❞
sklearn.preprocessing.MultiLabelBinarizer() 사용하여 원핫 인코딩을 할 수 있다.
| Label Name | One-Hot Encoding |
|---|---|
| panda | [1, 0, 0] |
| dogs | [0, 1, 0] |
| cats | [0, 0, 1] |
import numpy as np
from sklearn.preprocessing import MultiLabelBinarizer
images = np.array(images, dtype='float32') / 255.0
labels = np.array(labels)
mlb = MultiLabelBinarizer()
enc_labels = mlb.fit_transform(labels)
print(">>> classes name =", mlb.classes_)>>> classes name = ['cats' 'dogs' 'panda']이제 데이터를 분할해보자.
sklearn.model_selection.train_test_split() 으로 데이터 분할을 한다.
Train 데이터 80% 그리고 Test 데이터 20% 를 사용하고자 한다.
from sklearn.model_selection import train_test_split
seed = 47
(x_train, x_test, y_train, y_test) = train_test_split(
images, enc_labels, test_size=0.2, random_state=seed
)
print(">> train test shape = {} {}".format(
x_train.shape, y_train.shape)
)🌗 모델 생성과 학습
모델은 VGGNet 을 참고하여 컨볼루션 크기와 네트워크 깊이를 조절하였다.
여기서 주의할 점은 마지막 출력을 Soft-Max 로 한다는 점이다.
tensorflow.keras.layers.Activation('softmax')
기억해두자.
Multi-Class Classification 의 마지막 출력은 Soft-Max 이다.
❝ 출력을 Soft-Max 로 안하는 코드도 있던데 ? ❞
구현 방법에 차이로 틀린 건 아니다.
그러나 Binary, Multi-Class, Multi-Label 모두
마지막 출력 함수가 다르기에 하나의 포맷을 추천한다.
위 물음은 하단 모델 컴파일 부분에서 설명하겠다.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from tensorflow.keras.layers import Activation, Flatten, Dropout, Dense
class Classifier:
def build(width, height, depth, classes):
model = Sequential()
input_shape = (height, width, depth)
model.add(Conv2D(32, (3, 3), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(2048))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(classes))
model.add(Activation('softmax'))
return model
model = Classifier.build(
width=image_dim[1], height=image_dim[0], depth=image_dim[2],
classes=len(mlb.classes_)
)이제 모델을 컴파일 해보자.
optimizer 에 tensorflow.keras.optimizers 을 사용하면
학습률 등을 디테일하게 조절할 수 있다.
이제 Loss Function 에 대해 이야기 해보자.
위에서 마지막 출력을 Soft-Max 로 안하는 경우도 있다고 했다.
그런 경우에는 CategoricalCrossentropy(from_logits=True) 으로 변경하면 된다.
그럼 Cross-Entropy 를 계산함에 있어 다르게 동작한다고 한다.
❝ 결과의 차이는 없어보인다. ❞
다만 Tensorflow 공식 홈페이지에서는
from_logits=True 방식이 Numerical stable 하다고 한다.
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.optimizers import Adam
batch_size = 32
epoch = 200
learning_rate = 1e-3
decay = learning_rate / epoch
optimizer = Adam(
learning_rate=learning_rate,
decay=decay
)
loss = CategoricalCrossentropy(from_logits=False)
model.compile(
loss=loss,
optimizer=optimizer,
metrics=['accuracy']
)❝ 이제 거의 다 왔다. 힘내자. ❞
우리는 작은 이미지로 학습을 시키려한다.
따라서 데이터를 증강시키도록 한다.
Kera 에 ImageDataGenerator() 함수를 이용하도록 하자.
- 회전과 위치 변경 등으로 이미지 복제
from tensorflow.keras.preprocessing.image import ImageDataGenerator
aug = ImageDataGenerator(
rotation_range=25, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest'
)❝ 드디어 모델 학습 과정이다. ❞
이 과정에서 GPU 를 사용했다.
그리고 .fit_generator() 으로 데이터를 증강하여 학습시킨다.
history = model.fit_generator(
aug.flow(
x_train, y_train, batch_size=batch_size
),
validation_data=(x_test, y_test),
steps_per_epoch=len(x_train) // batch_size,
epochs=epoch, verbose=1
)Epoch 1/200
75/75 [==============================] - 40s 113ms/step - loss: 1.5247 - accuracy: 0.5562 - val_loss: 3.1929 - val_accuracy: 0.3150
Epoch 2/200
75/75 [==============================] - 8s 102ms/step - loss: 0.9905 - accuracy: 0.6021 - val_loss: 1.8746 - val_accuracy: 0.3500
Epoch 3/200
75/75 [==============================] - 8s 102ms/step - loss: 0.9192 - accuracy: 0.6221 - val_loss: 3.2068 - val_accuracy: 0.3500
Epoch 4/200
75/75 [==============================] - 8s 102ms/step - loss: 0.8743 - accuracy: 0.6292 - val_loss: 1.3691 - val_accuracy: 0.3967
Epoch 5/200
75/75 [==============================] - 8s 102ms/step - loss: 0.7978 - accuracy: 0.6508 - val_loss: 1.2389 - val_accuracy: 0.4250
Epoch 6/200
75/75 [==============================] - 8s 102ms/step - loss: 0.7651 - accuracy: 0.6629 - val_loss: 2.1172 - val_accuracy: 0.4283
Epoch 7/200
75/75 [==============================] - 8s 103ms/step - loss: 0.7412 - accuracy: 0.6696 - val_loss: 0.7568 - val_accuracy: 0.6783
...................................................................................................................................
Epoch 197/200
75/75 [==============================] - 8s 105ms/step - loss: 0.0873 - accuracy: 0.9725 - val_loss: 0.6421 - val_accuracy: 0.8567
Epoch 198/200
75/75 [==============================] - 8s 106ms/step - loss: 0.0817 - accuracy: 0.9708 - val_loss: 0.6350 - val_accuracy: 0.8217
Epoch 199/200
75/75 [==============================] - 8s 108ms/step - loss: 0.0875 - accuracy: 0.9712 - val_loss: 0.5505 - val_accuracy: 0.8600
Epoch 200/200
75/75 [==============================] - 8s 108ms/step - loss: 0.0623 - accuracy: 0.9779 - val_loss: 0.4870 - val_accuracy: 0.8850우리 모델의 Loss 와 Accuracy 를 눈으로 확인해보자.
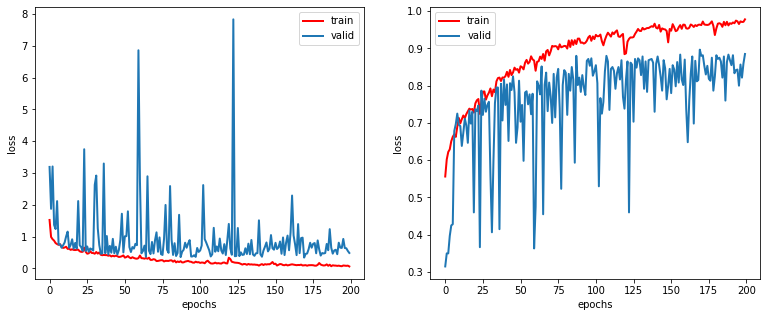
🌑 신규 이미지 예측
동일한 방법으로 images/ 디렉토리의 파일 경로를 읽는다.
test_image_paths = sorted(
list(
paths.list_images("images/")
)
)
print(">>> test image path =", test_image_paths)>>> test image path = ['images/cat.jpg', 'images/dog.jpg', 'images/panda.jpg']이미지와 예측 레이블을 각각 출력해보자.
print(">>> class index =", mlb.classes_)
for image_path in test_image_paths:
test_image = cv2.imread(image_path)
test_image = cv2.resize(
test_image, (96, 96)
)
cv2_imshow(test_image)
test_image = test_image.astype("float") / 255.0
test_image = np.expand_dims(test_image, axis=0)
proba = model.predict(test_image)[0]
print(
np.round(proba, 3)
)
idx = np.argmax(proba)
print(">>> predict class =", mlb.classes_[idx])>>> class index = ['cats' 'dogs' 'panda']
[0.091 0.875 0.034]
>>> predict class = dogs
[0.001 0.999 0. ]
>>> predict class = dogs
[0. 0. 1.]
>>> predict class = panda오늘 우리는 Multi-Class Classification 을 코드로 살펴보았다.
이제 그만 알아보자.
다음 포스트에서는 Multi-Label Classification 을 알아보자.
🍀 참고
