DataFrame Index 설정
df.set_index
df.set_index(
keys,
*,
drop: 'bool' = True,
append: 'bool' = False,
inplace: 'bool' = False,
verify_integrity: 'bool' = False,
) -> 'DataFrame | None'
drop : index로 설정한 column을 DataFrame 내에서 삭제할 지 결정append : 기존에 존재하던 index를 삭제한 후, Column으로 추가할 지 결정inplace : 원본 객체를 변경할지 결정
df.reset_index
df.reset_index(
level: 'IndexLabel | None' = None,
*,
drop: 'bool' = False,
inplace: 'bool' = False,
col_level: 'Hashable' = 0,
col_fill: 'Hashable' = '',
allow_duplicates: 'bool | lib.NoDefault' = <no_default>,
names: 'Hashable | Sequence[Hashable] | None' = None,
) -> 'DataFrame | None'
drop : 기존에 존재하던 index를 삭제한 후, Column으로 추가할 지 결정inplace : 원본 객체를 변경할지 결정
DataFrame 데이터 CRUD
index로 데이터 조회하기
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris = pd.DataFrame(iris.data, columns=iris.feature_names)
iris[1:4]
column으로 데이터 조회하기
df[’column’] : 하나의 column으로 Series 형식으로 반환df[['column1', 'column2']] : 여러 개의 column으로 DataFrame 형식으로 반환
ser = iris['sepal length (cm)'].head(4)
assert type(ser) == pd.core.series.Series
df = iris[['sepal length (cm)', 'sepal width (cm)']].head(4)
assert type(df) == pd.core.frame.DataFrame
iloc, loc 으로 데이터 조회하기
Row 데이터 추가
| 방법 | 기준 | 방향 | 주 용도 |
|---|
pd.concat([df1, df2], axis=0) | index or column 위치 | 상하/좌우 | 단순 이어붙이기 |
df.merge(df2) | column | 좌우 (기본) | SQL join처럼 관계 병합 |
df.join(df2) | index | 좌우 | merge보다 간단하게 index 기반 병합 |
pd.concat 함수
- row 방향 (axis=0)
- 아래로 쭉 붙이기 → “학생 점수 목록에 학생 추가” 느낌
- column 방향 (axis=1)
- 옆으로 붙이기 → “학생들 점수에 과목 추가” 느낌
pd.concat(
objs: 'Iterable[Series | DataFrame] | Mapping[HashableT, Series | DataFrame]',
*,
axis: 'Axis' = 0,
join: 'str' = 'outer',
ignore_index: 'bool' = False,
keys: 'Iterable[Hashable] | None' = None,
levels=None,
names: 'list[HashableT] | None' = None,
verify_integrity: 'bool' = False,
sort: 'bool' = False,
copy: 'bool | None' = None,
) -> 'DataFrame | Series'
score = pd.DataFrame({'국어': [100, 80], '수학':[75, 90],
'영어':[90, 95]}, index=['장화', '홍련'])
new_students = pd.DataFrame({'국어': [70, 85], '수학':[65, 100],
'영어':[95, 65]}, index=['콩쥐', '팥쥐'])
score = pd.concat([score, new_students])
new_student1 = pd.Series({'국어':85, '수학':55, '영어':95}, name='해님').to_frame().transpose()
score = pd.concat([score, new_student1])
score
df.merge 함수
- 열(column)을 기준으로 조인함 (SQL의 JOIN처럼 동작)
df.merge(
right: 'DataFrame | Series',
how: 'MergeHow' = 'inner',
on: 'IndexLabel | AnyArrayLike | None' = None,
left_on: 'IndexLabel | AnyArrayLike | None' = None,
right_on: 'IndexLabel | AnyArrayLike | None' = None,
left_index: 'bool' = False,
right_index: 'bool' = False,
sort: 'bool' = False,
suffixes: 'Suffixes' = ('_x', '_y'),
copy: 'bool | None' = None,
indicator: 'str | bool' = False,
validate: 'MergeValidate | None' = None,
) -> 'DataFrame'
product = pd.DataFrame({'상품코드':['G1', 'G2', 'G3', 'G4'],
'상품명':['우유', '감자', '빵', '치킨']})
sale = pd.DataFrame({'주문번호':[1001, 1002, 1002, 1003, 1004],
'상품코드':['G4', 'G3', 'G1', 'G3', 'G5'],
'주문수량':[1, 4, 2, 2, 3]})
sale.merge(product, on='상품코드', how='left')
df.join 함수
- 인덱스를 기준으로 조인함 (기본적으로 인덱스를 사용)
df.join(
other: 'DataFrame | Series | Iterable[DataFrame | Series]',
on: 'IndexLabel | None' = None,
how: 'MergeHow' = 'left',
lsuffix: 'str' = '',
rsuffix: 'str' = '',
sort: 'bool' = False,
validate: 'JoinValidate | None' = None,
) -> 'DataFrame'
product = pd.DataFrame({'상품코드':['G1', 'G2', 'G3', 'G4'],
'상품명':['우유', '감자', '빵', '치킨']})
sale = pd.DataFrame({'주문번호':[1001, 1002, 1002, 1003, 1004],
'상품코드':['G4', 'G3', 'G1', 'G3', 'G5'],
'주문수량':[1, 4, 2, 2, 3]})
sale.set_index('상품코드').join(product.set_index('상품코드')).reset_index()
Column 데이터 추가, 삭제
science = [80, 70, 90, 85, 75]
score['과학'] = science
score['학년'] = 1
score
score['총점'] = score[score.columns.drop('학년')].sum(axis=1)
score
DataFrame 데이터 삭제 (df.drop)
df.drop 함수 사용
axis=0 , labelsindexcolumnsinplace : 작업 수행의 결과를 객체에 반영할지 결정
df.drop(
labels: 'IndexLabel | None' = None,
*,
axis: 'Axis' = 0,
index: 'IndexLabel | None' = None,
columns: 'IndexLabel | None' = None,
level: 'Level | None' = None,
inplace: 'bool' = False,
errors: 'IgnoreRaise' = 'raise',
) -> 'DataFrame | None'
df.drop(['팥쥐', '해님'])
df.drop(index=['팥쥐', '해님'])
df.drop(columns= ['학년', '총점'])
데이터 필터링
df[ 조건식 ]df[ 조건1 & 조건2 & (조건3 | 조건4) ]- ⚠️ &, |, ~ 비트 연산자는 우선순위가 높아서, 조건들을 괄호로 감싸줘야 합니다!
import pandas as pd
students = pd.DataFrame({'이름':['장화','홍련','콩쥐','팥쥐','해님','달님'],
'국어': [70, 85, None, 100, None, 85],
'수학':[65, 100, 80, 95, None, 70]})
students
students[(students['국어'] >= 80) & (students['수학'] >= 80)]
데이터 변환
import pandas as pd
students = pd.DataFrame({'이름':['장화','홍련','콩쥐','팥쥐','해님','달님'],
'국어': [70, 85, None, 100, None, 85],
'수학':[65, 100, 80, 95, None, 70]})
def evaluate_score(score):
if score >= 90:
return 'A'
elif score >= 80:
return 'B'
elif score >= 70:
return 'C'
else:
return 'F'
students_grades = students.drop(columns='이름').map(evaluate_score).rename(mapper=lambda x: x + '_등급', axis=1)
students.join(students_grades)
| 특징 | transform() | apply() |
|---|
| 반환 형태 | 원래 시리즈와 같은 길이 | 자유로운 형태 (리스트, DataFrame 등) |
| 주 용도 | 값 변환 (예: 평균, 표준화 등) | 복잡한 계산, 그룹 집계 등 |
| 그룹 사용 | O | O |
| 함수 이름 | 적용 대상 | 적용 범위 | 반환 형태 | 주 용도 |
|---|
map() | Series, DataFrame | 요소(Element) 단위 | Series / DataFrame | 값 치환, dict 매핑, 간단한 계산 |
apply() | Series / DataFrame | Series: 요소 | | |
| DataFrame: 행/열 단위 | 자유로움 (Series, Scalar 등) | 복잡한 함수, 집계, 커스텀 계산 | | |
| ~~applymap()~~
(Deprecated) | DataFrame | 요소(Element) 단위 | DataFrame | 모든 셀에 함수 적용 |
| transform() | Series / GroupBy | 요소(Element) 단위 | 원래와 같은 shape | 그룹별 평균, 정규화 등 값 변환 |
apply 함수
- 목적: 행(row)이나 열(column) 또는 그룹 전체에 함수 적용.
- 입력과 출력의 shape가 바뀔 수 있음.
- 더 유연하게 가공이 가능하지만, 경우에 따라 성능이 느릴 수 있음.
import pandas as pd
df = pd.DataFrame({
'group': ['A', 'A', 'B', 'B'],
'value': [10, 20, 30, 40]
})
df.groupby('group')['value'].mean()
df.groupby('group')['value'].apply('mean')
df.groupby('group')['value'].apply(lambda x: x.mean())
- 목적: 원래 시리즈의 형태를 유지하면서 값을 변환할 때 사용합니다.
- 입력과 출력의 shape가 같습니다. (즉, row 수가 변하지 않음).
- 주로 그룹별 표준화, 평균 대체 등에 사용합니다.
import pandas as pd
df = pd.DataFrame({
'group': ['A', 'A', 'B', 'B'],
'value': [10, 20, 30, 40]
})
df.groupby('group')['value'].transform('mean')
df.groupby('group')['value'].transform(lambda x: x.mean())
이상치 처리
import numpy as np
import pandas as pd
np.random.seed(1000)
df = pd.DataFrame(np.random.normal(loc=0, scale=1, size=1000))
q1, q2 = df.quantile([0.1, 0.9]).values.reshape(-1)
df[(df[0] >= q1) & (df[0] <= q2)]
df.quantile
df.**quantile**(
q: 'float | AnyArrayLike | Sequence[float]' = 0.5,
axis: 'Axis' = 0,
numeric_only: 'bool' = False,
interpolation: 'QuantileInterpolation' = 'linear',
method: "Literal['single', 'table']" = 'single',
) -> 'Series | DataFrame'
(그저 참고만!) pd.qcut
1d ndarray or Series 에 대해서 등분이 가능하다!
pd.qcut(
x,
q,
labels=None,
retbins: 'bool' = False,
precision: 'int' = 3,
duplicates: 'str' = 'raise',
)
결측치 처리
df.isna()df.notna() or df.notnull()
결측치 개수 파악
import pandas as pd
students = pd.DataFrame({'이름':['장화','홍련','콩쥐','팥쥐','해님','달님'],
'국어': [70, 85, None, 100, None, 85],
'수학':[65, 100, 80, 95, None, 70]})
students.isna().sum()
students.isna().sum(axis=1)
결측값 제거
df.dropna(
*,
axis: 'Axis' = 0,
how: 'AnyAll | lib.NoDefault' = <no_default>,
thresh: 'int | lib.NoDefault' = <no_default>,
subset: 'IndexLabel | None' = None,
inplace: 'bool' = False,
ignore_index: 'bool' = False,
) -> 'DataFrame | None'
| 파라미터 | 설명 |
|---|
| axis | 0: 행 기준 (기본값), 1: 열 기준 |
| how | 'any': NaN이 하나라도 있으면 제거'all': 모두 NaN일 때만 제거 |
| thresh | NaN 아닌 값이 최소 몇 개 이상 있어야 유지 |
| subset | 특정 컬럼만 기준으로 결측 체크 |
| inplace | True이면 원본을 직접 수정 |
| ignore_index | True면 인덱스를 리셋한 새 DF 리턴 |
결측값 치환
df.fillna(
value: 'Hashable | Mapping | Series | DataFrame | None' = None,
*,
method: 'FillnaOptions | None' = None,
axis: 'Axis | None' = None,
inplace: 'bool_t' = False,
limit: 'int | None' = None,
downcast: 'dict | None | lib.NoDefault' = <no_default>,
) -> 'Self | None'
| 파라미터 | 설명 |
|---|
| value | NaN을 대체할 값 (숫자, 딕셔너리, 시리즈 등 가능) |
| method | 'ffill': 앞값으로 채움 |
| 'bfill': 뒷값으로 채움 | |
| axis | 채우는 방향 (기본: index 방향) |
| inplace | True면 원본 DataFrame 직접 수정 |
| limit | 최대 몇 개까지만 채울지 (연속 NaN 기준) |
| downcast | 자료형을 가능한 한 작게 변환 (예: float64 → float32) |
df.replace(
to_replace=None,
value=<no_default>,
*,
inplace: 'bool_t' = False,
limit: 'int | None' = None,
regex: 'bool_t' = False,
method: "Literal['pad', 'ffill', 'bfill'] | lib.NoDefault" = <no_default>,
) -> 'Self | None'
| 파라미터 | 설명 |
|---|
| to_replace | 바꾸려는 대상 값 (단일값, 리스트, 딕셔너리, 정규식 등 가능) |
| value | 바꿀 값 (단일값 또는 to_replace와 매핑된 값들) |
| inplace | True면 원본 수정 |
| limit | 교체할 최대 개수 제한 |
| regex | 정규식 사용 여부 (True면 to_replace를 regex로 처리) |
| method | pad/ffill/bfill 방식으로 결측치 대체 가능 (to_replace=None일 때만) |
[DEPRECATED] df.fillna(method=’ffill’), df.fillna(method=’bfill’)
df.ffill()
df.bfill()
중복값 삭제
df.drop_duplicates(
subset: 'Hashable | Sequence[Hashable] | None' = None,
*,
keep: 'DropKeep' = 'first',
inplace: 'bool' = False,
ignore_index: 'bool' = False,
) -> 'DataFrame | None'
| 파라미터 | 설명 |
|---|
| subset | 중복 여부를 판단할 기준 컬럼 (리스트 가능) |
| keep | 'first': 첫 번째만 남김 (기본값) |
'last': 마지막만 남김
False: 전부 제거 |
| inplace | True면 원본 수정 |
| ignore_index | True면 인덱스를 0부터 다시 매김 |
데이터 정렬
index 정렬
df.sort_index(
*,
axis: 'Axis' = 0,
level: 'IndexLabel | None' = None,
ascending: 'bool | Sequence[bool]' = True,
inplace: 'bool' = False,
kind: 'SortKind' = 'quicksort',
na_position: 'NaPosition' = 'last',
sort_remaining: 'bool' = True,
ignore_index: 'bool' = False,
key: 'IndexKeyFunc | None' = None,
) -> 'DataFrame | None'
| 파라미터 | 설명 |
|---|
| axis | 0: 행 인덱스 기준 (기본값)1: 열 인덱스 기준 |
| level | 멀티인덱스일 때 정렬 기준 level |
| ascending | 오름차순 정렬 여부 (True 기본) |
| inplace | True면 원본을 직접 수정 |
| kind | 정렬 알고리즘 (quicksort, mergesort 등) |
| na_position | NaN 위치: 'first' 또는 'last' (기본: 'last') |
| sort_remaining | 멀티인덱스에서 나머지 level도 정렬할지 여부 |
| ignore_index | 정렬 후 인덱스를 0부터 다시 매길지 |
| key | 정렬 전 인덱스를 변형하는 함수 지정 가능 |
values 정렬
df.sort_values(
by: 'IndexLabel',
*,
axis: 'Axis' = 0,
ascending: 'bool | list[bool] | tuple[bool, ...]' = True,
inplace: 'bool' = False,
kind: 'SortKind' = 'quicksort',
na_position: 'str' = 'last',
ignore_index: 'bool' = False,
key: 'ValueKeyFunc | None' = None,
) -> 'DataFrame | None'
| 파라미터 | 설명 |
|---|
| by | 정렬 기준이 될 컬럼 이름 또는 컬럼 리스트 |
| axis | 0: 행 정렬 (기본값), 1: 열 정렬 |
| ascending | True: 오름차순, False: 내림차순리스트로 컬럼별 개별 설정 가능 |
| inplace | True면 원본 수정 |
| kind | 정렬 알고리즘 (quicksort, mergesort, 등) |
| na_position | NaN 위치 ('first' or 'last') |
| ignore_index | 정렬 후 인덱스를 0부터 다시 매길지 여부 |
| key | 정렬 전에 값을 가공할 함수 지정 가능 |
데이터 결합
| 방법 | 기준 | 방향 | 주 용도 |
|---|
pd.concat([df1, df2], axis=0) | index or column 위치 | 상하/좌우 | 단순 이어붙이기 |
df.merge(df2) | column | 좌우 (기본) | SQL join처럼 관계 병합 |
df.join(df2) | index | 좌우 | merge보다 간단하게 index 기반 병합 |
pd.concat 함수
- row 방향 (axis=0)
- 아래로 쭉 붙이기 → “학생 점수 목록에 학생 추가” 느낌
- column 방향 (axis=1)
- 옆으로 붙이기 → “학생들 점수에 과목 추가” 느낌
pd.concat(
objs: 'Iterable[Series | DataFrame] | Mapping[HashableT, Series | DataFrame]',
*,
axis: 'Axis' = 0,
join: 'str' = 'outer',
ignore_index: 'bool' = False,
keys: 'Iterable[Hashable] | None' = None,
levels=None,
names: 'list[HashableT] | None' = None,
verify_integrity: 'bool' = False,
sort: 'bool' = False,
copy: 'bool | None' = None,
) -> 'DataFrame | Series'
score = pd.DataFrame({'국어': [100, 80], '수학':[75, 90],
'영어':[90, 95]}, index=['장화', '홍련'])
new_students = pd.DataFrame({'국어': [70, 85], '수학':[65, 100],
'영어':[95, 65]}, index=['콩쥐', '팥쥐'])
score = pd.concat([score, new_students])
new_student1 = pd.Series({'국어':85, '수학':55, '영어':95}, name='해님').to_frame().transpose()
score = pd.concat([score, new_student1])
score
df.merge 함수
- 열(column)을 기준으로 조인함 (SQL의 JOIN처럼 동작)
df.merge(
right: 'DataFrame | Series',
how: 'MergeHow' = 'inner',
on: 'IndexLabel | AnyArrayLike | None' = None,
left_on: 'IndexLabel | AnyArrayLike | None' = None,
right_on: 'IndexLabel | AnyArrayLike | None' = None,
left_index: 'bool' = False,
right_index: 'bool' = False,
sort: 'bool' = False,
suffixes: 'Suffixes' = ('_x', '_y'),
copy: 'bool | None' = None,
indicator: 'str | bool' = False,
validate: 'MergeValidate | None' = None,
) -> 'DataFrame'
product = pd.DataFrame({'상품코드':['G1', 'G2', 'G3', 'G4'],
'상품명':['우유', '감자', '빵', '치킨']})
sale = pd.DataFrame({'주문번호':[1001, 1002, 1002, 1003, 1004],
'상품코드':['G4', 'G3', 'G1', 'G3', 'G5'],
'주문수량':[1, 4, 2, 2, 3]})
sale.merge(product, on='상품코드', how='left')
df.join 함수
- 인덱스를 기준으로 조인함 (기본적으로 인덱스를 사용)
df.join(
other: 'DataFrame | Series | Iterable[DataFrame | Series]',
on: 'IndexLabel | None' = None,
how: 'MergeHow' = 'left',
lsuffix: 'str' = '',
rsuffix: 'str' = '',
sort: 'bool' = False,
validate: 'JoinValidate | None' = None,
) -> 'DataFrame'
product = pd.DataFrame({'상품코드':['G1', 'G2', 'G3', 'G4'],
'상품명':['우유', '감자', '빵', '치킨']})
sale = pd.DataFrame({'주문번호':[1001, 1002, 1002, 1003, 1004],
'상품코드':['G4', 'G3', 'G1', 'G3', 'G5'],
'주문수량':[1, 4, 2, 2, 3]})
sale.set_index('상품코드').join(product.set_index('상품코드')).reset_index()
데이터 통계치 요약
df.groupby
- groupby 이후 사용할 메서드
- count()
- sum()
- min(), max()
- idxmin(), idxmax()
- mean(), median(), mode()
- std(ddof=1), var(ddof=1)
- transform(func)
- apply(func)
df.groupby(
by=None,
axis: 'Axis | lib.NoDefault' = <no_default>,
level: 'IndexLabel | None' = None,
as_index: 'bool' = True,
sort: 'bool' = True,
group_keys: 'bool' = True,
observed: 'bool | lib.NoDefault' = <no_default>,
dropna: 'bool' = True,
) -> 'DataFrameGroupBy'
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = pd.Series(iris.target).map({i: v for i, v in enumerate(iris.target_names)})
assert all(df.groupby(by='target').mean() == df.groupby('target').apply('mean'))
df.groupby(by='target').mean()
도수분포표
df.value_counts(subset)
df.value_counts(
subset: 'IndexLabel | None' = None,
normalize: 'bool' = False,
sort: 'bool' = True,
ascending: 'bool' = False,
dropna: 'bool' = True,
) -> 'Series'
ser.value_counts()
ser.value_counts(
normalize: 'bool' = False,
sort: 'bool' = True,
ascending: 'bool' = False,
bins=None,
dropna: 'bool' = True,
) -> 'Series'
교차표 (crosstab)
pd.crosstab(
index,
columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins: 'bool' = False,
margins_name: 'Hashable' = 'All',
dropna: 'bool' = True,
normalize: "bool | Literal[0, 1, 'all', 'index', 'columns']" = False,
) -> 'DataFrame'
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = pd.Series(iris.target).map({i: v for i, v in enumerate(iris.target_names)})
df['petal width level'] = pd.qcut(df['petal width (cm)'], 3, ['short', 'middle', 'long'])
pd.crosstab(index=df['petal width level'], columns=df['target'])
Pivot Table
values 에 배열을 넣으면 columns 가 멀티 인덱스가 된다.
df.pivot_table(
**values**=None,
**index**=None,
**columns**=None,
**aggfunc**: 'AggFuncType' = 'mean',
fill_value=None,
margins: 'bool' = False,
dropna: 'bool' = True,
margins_name: 'Level' = 'All',
observed: 'bool | lib.NoDefault' = <no_default>,
sort: 'bool' = True,
) -> 'DataFrame'
score = {'학년':[1, 1, 1, 1, 2, 2],
'반':['A', 'A', 'B', 'B', 'C', 'C'],
'성별':['여자', '남자', '여자', '남자', '여자', '남자'],
'성적': [76, 88, 85, 72, 68, 70]}
print(score)
score.pivot_table(values='성적', index=['학년', '반'], columns=['성별'])
melt (pivot 반대)
df.melt(
id_vars=None,
value_vars=None,
var_name=None,
value_name: 'Hashable' = 'value',
col_level: 'Level | None' = None,
ignore_index: 'bool' = True,
) -> 'DataFrame'
score = {'학년':[1, 1, 1, 1, 2, 2],
'반':['A', 'A', 'B', 'B', 'C', 'C'],
'성별':['여자', '남자', '여자', '남자', '여자', '남자'],
'성적': [76, 88, 85, 72, 68, 70]}
print(score)
pivot = score.pivot_table(values='성적', index=['학년', '반'], columns=['성별'], aggfunc='min').map(int)
print(pivot)
pivot.reset_index().melt(id_vars=['학년','반'],var_name='성별',value_name='성적')
pivot시, values 파라미터에 단일값을 넣었을 경우
- values='성적' (단일 컬럼)
- 결과는 일반적인 DataFrame이고,
- columns에 지정한 컬럼이 단일 수준의 열 인덱스로 들어감.
score = {'학년':[1, 1, 1, 1, 2, 2],
'반':['A', 'A', 'B', 'B', 'C', 'C'],
'성별':['여자', '남자', '여자', '남자', '여자', '남자'],
'성적': [76, 88, 85, 72, 68, 70]}
pivot = score.pivot_table(values='성적', index=['학년', '반'], columns='성별')
assert set(pivot.columns) == {'여자', '남자'}
pivot
- 이 경우 열은 '남자', '여자' 이런 식으로 나옴.
- 즉, 단일 레벨 열 인덱스가 생성됨.
melt_table = pivot.reset_index().melt(id_vars=['학년', '반'], var_name='성별', value_name='성적')
melt_table
pivot시, values 파라미터에 배열값을 넣었을 경우
- 결과는 멀티 인덱스 열(columns) 구조로 만들어짐.
- columns에 해당하는 값이 두 레벨의 컬럼 인덱스가 됨:
- ('성적', '여자'), ('성적', '남자')
score = {'학년':[1, 1, 1, 1, 2, 2],
'반':['A', 'A', 'B', 'B', 'C', 'C'],
'성별':['여자', '남자', '여자', '남자', '여자', '남자'],
'성적': [76, 88, 85, 72, 68, 70]}
pivot = score.pivot_table(values=['성적'], index=['학년', '반'], columns='성별')
pivot
pivot.columns
- 이 경우 열은 다중 인덱스 형태이기 때문에, .melt()를 바로 쓰면 오류가 나거나 의도대로 동작하지 않을 수 있음.
- 먼저 열 이름을 단일 인덱스로 평탄화 필요
pivot.columns = pivot.columns.get_level_values(1)
melt_table = pivot.reset_index().melt(id_vars=['학년', '반'], var_name='성별', value_name='성적')
melt_table
pivot시 values 파라미터 주의사항 요약
| 값 설정 방식 | 결과 형태 | 열 인덱스 | melt 시 주의할 점 |
|---|
| '성적' (str) | 단일 값 | 일반 인덱스 | 바로 melt 가능 |
| '성적' | 여러 값 가능 | 멀티 인덱스 | columns 평탄화 필요 |
Multi Index 관련 함수
pd.MultiIndex.droplevel(self, level: 'IndexLabel' = 0) -> 'Index'
pd.MultiIndex.get_level_values(self, level) -> 'Index'
문자열 데이터 핸들링
| Accessor | 대상 타입 | 설명 | 사용 예시 |
|---|
.str | 문자열 (object, string) | 문자열 관련 메서드 제공 | s.str.replace(' ', '_') |
.dt | 날짜/시간 (datetime64) | 날짜/시간 정보 추출 및 포맷팅 | s.dt.year, s.dt.day_name() |
.cat | 카테고리 (category) | 카테고리 관리 및 처리 | s.cat.codes, s.cat.remove_unused_categories() |
.sparse | 희소 데이터 (SparseDtype) | 메모리 절약형 희소 데이터 연산 | s.sparse.density |
.flags | Series/DataFrame | 내부 설정값 확인 및 설정 | s.flags.allows_duplicate_labels |
.array | ExtensionArray-backed Series | 내부 배열에 직접 접근 | s.array (예: nullable int, string 등) |
upper, lower, capitalize, title
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df
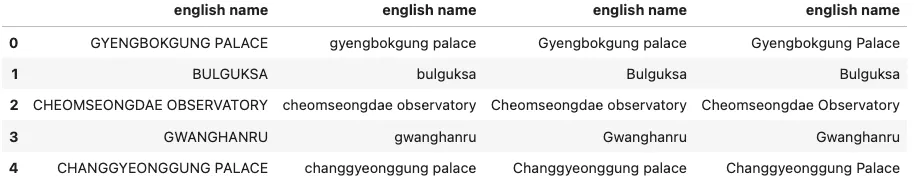
pd.concat([
df['english name'].str.upper(),
df['english name'].str.lower(),
df['english name'].str.capitalize(),
df['english name'].str.title()
], axis=1)
strip, lstrip, rstrip
strip()
- 문자열의 시작과 끝에서 지정된 문자열 제거
- 기본값은 SPACE
lstrip()rstrip()
str[2:4], split
str[3:6]
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df['location'].str[0:2]
split
pandas.core.strings.accessor.StringMethods.split(
pat: 'str | re.Pattern | None' = None,
*,
n=-1,
expand: 'bool' = False,
regex: 'bool | None' = None,
) -> 'Series | Index | DataFrame | MultiIndex'
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df['location'].str.split(n=2, expand=True)
replace
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df['english name'].str.replace(' ', '_')
pandas.core.strings.accessor.StringMethods.extract(
pat: 'str',
flags: 'int' = 0,
expand: 'bool' = True
) -> 'DataFrame | Series | Index'
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df['location'].str.extract("(\\d+-?\\d+)")
contains, startswith, endswith
import pandas as pd
df = pd.DataFrame({
'name':['광화문','호미곶', '첨성대', '광하루원', '창경궁'],
'english name': ['Gyengbokgung Palace',
'bulguksa',
'cheomseongdae observatory',
'gwanghanru',
'Changgyeonggung Palace'],
'location':['서울 종로구 사직로 161',
'경북 포항시 남구 호미곶면 대보리 150',
'경북 경주시 인왕동 839-1',
'전북 남원시 요천로 1447',
'서울 종로구 창경궁로 185']
})
df['english name'].str.contains('gung')
df['location'].str.startswith('서울')
df['english name'].str.endswith('Palace')
날짜 데이터 핸들링
pd.to_datetime
pd.to_datetime(df['created_at'], format='%Y-%m-%d %H:%M:%S')
pd.to_datetime(
arg: 'DatetimeScalarOrArrayConvertible | DictConvertible',
errors: 'DateTimeErrorChoices' = 'raise',
dayfirst: 'bool' = False,
yearfirst: 'bool' = False,
utc: 'bool' = False,
format: 'str | None' = None,
exact: 'bool | lib.NoDefault' = <no_default>,
unit: 'str | None' = None,
infer_datetime_format: 'lib.NoDefault | bool' = <no_default>,
origin: 'str' = 'unix',
cache: 'bool' = True,
) -> 'DatetimeIndex | Series | DatetimeScalar | NaTType | None'
import pandas as pd
df = pd.DataFrame({"created_at": [
"2025-01-04 04:20:25",
"2025-01-04 05:35:12",
"2025-01-04 06:02:49"
]})
df["created_at"] = pd.to_datetime(df["created_at"])
df
strptime, strftime 함수
datetime.datetime.strptimedatetime.datetime.strftime
from datetime import datetime
datetime.strftime(datetime.today(), format="%F %T")
datetime.strptime("2025-01-04 04:20:25", "%Y-%m-%d %H:%M:%S")
timedelta
from datetime import timedelta
delta = timedelta(days=1, seconds=5, microseconds=0, milliseconds=0, minutes=10, hours=1, weeks=1)
datetime_data = datetime.strptime("2025-01-04 04:20:25", "%Y-%m-%d %H:%M:%S")
datetime_data += delta
datetime.strftime(datetime_data, "%Y-%m-%d %H:%M:%S")
날짜 표준 변환 Spec
| 지정자 | 추천 | 설명 |
|---|
| %a | ⭐ | 축약된 요일명. |
| %A | ⭐ | 전체 요일명. |
| %b | ⭐ | 축약된 월명. |
| %B | ⭐ | 전체 월명. |
| %c | | 로케일 형식의 날짜/시간. |
| %C | | 세기 수[00-99]로 연도는 100으로 나누고 정수로 자릅니다. |
| %d | ⭐ | 월의 일[01-31]. |
| %D | | 날짜 형식(%m/%d/%y와 동일). |
| %e | | 한 자릿수가 공백으로 선행된다는 점을 제외하고 %d와 동일합니다[1-31]. |
| %g | | ISO 주 날짜의 두 자리 연도 부분[00,99]. |
| %F | ⭐ | ISO 날짜 형식(%Y-%m-%d와 동일). |
| %G | | ISO 주 날짜의 네 자리 연도 부분. 음수일 수 있습니다. |
| %h | | %b와 동일합니다. |
| %H | ⭐ | 24시간 형식의 시간[00-23]. |
| %I | | 12시간 형식의 시간[01-12]. |
| %j | ⭐ | 연도의 일[001-366]. |
| %m | ⭐ | 월[01-12]. |
| %M | ⭐ | 분[00-59]. |
| %n | | 줄 바꾸기 문자. |
| %p | ⭐ | AM 또는 PM 스트링. |
| %r | | 로케일의 AM/PM 형식 시간. 로케일 시간 형식을 사용할 수 없는 경우 디폴트는 POSIX 시간 AM/PM 형식입니다(%I:%M:%S %p). |
| %R | | 초가 없는 24시간 형식(%H:%M과 동일). |
| %S | ⭐ | 초[00-61]. 초의 범위는 윤초 및 이중 윤초를 허용합니다. |
| %t | | 탭 문자. |
| %T | ⭐ | 초가 있는 24시간 형식(%H:%M:%S와 동일). |
| %u | | 요일[1,7]. 월요일은 1이고 일요일이 7입니다. |
| %U | | 연도의 주 번호[00-53]. 일요일은 첫 번째 요일입니다. |
| %V | | 연도의 ISO 주 번호[01-53]. 월요일은 첫 번째 요일입니다. 새 연도에 1월 1일을 포함하는 주가 4일 이상을 포함하면 주 1로 간주됩니다. 그렇지 않으면 작년의 마지막 주이고, 다음 연도는 새 연도의 주 1입니다. |
| %w | | 요일[0,6]. 일요일은 0입니다. |
| %W | ⭐ | 연도의 주 번호[00-53]. 월요일은 첫 번째 요일입니다. |
| %x | | 로케일 형식의 날짜. |
| %X | | 로케일 형식의 시간. |
| %y | ⭐ | 두 자리 연도[00,99]. |
| %Y | ⭐ | 4자리 연도. 음수일 수 있습니다. |
| %z | | UTC 오프셋. 출력은 형식 +HHMM 또는 -HHMM의 스트링입니다. 여기서 +는 GMT 동쪽, -는 GMT 서쪽을 의미합니다. HH는 GMT에서 시간 수를 나타내고 MM은 GMT에서의 분 수를 나타냅니다. |
| %Z | | 시간대명. |
| %% | | % 문자. |

