
군집분석(Clustering)을 이용한 문제 해결 (K-Means)
- 서로 유사한 데이터는 동일 그룹으로, 유사하지 않은 데이터는 다른 그룹으로 분류하는 군집분석 (Clustering)
K-Means알고리즘- K개의 centroid를 임시 지정한 뒤, 각 데이터들을 가장 가까운 centroid가 속한 그룹에 할당
- 다시 centroid 업데이트 후, centroid 가 변하지 않을 때까지 반복
package import
import pandas as pd
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
import scipy.stats as stats
# from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
print(f"pandas version: {pd.__version__}")
print(f"numpy version: {np.__version__}")
print(f"matplotlib version: {matplotlib.__version__}")
print(f"scipy version: {scipy.__version__}")
print(f"sklearn version: {sklearn.__version__}")데이터 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/iris.csv")
df
df.info()
df.describe()데이터 전처리
# species 컬럼의 값을 0,1,2 LabelEncoding
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
df["species"] = labelEncoder.fit_transform(df["species"])
df분석 데이터 준비
y_variable = "species"
x_variables = df.columns.drop(y_variable)
X = df[x_variables]
y = df[y_variable]모델 적용 및 데이터 분석 수행
sklearn.cluster.KMeans클래스 활용sklearn.cluster.KMeans( n_clusters=8, *, init='k-means++', n_init='auto', max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='lloyd', )
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters=3, n_init=10, max_iter=500, random_state=42)
cluster.fit(X)
y_pred = cluster.predict(X)
print(f"centroids = {cluster.cluster_centers_}")
print(f"y_pred = {y_pred}")
df["predict_cluster"] = y_pred
df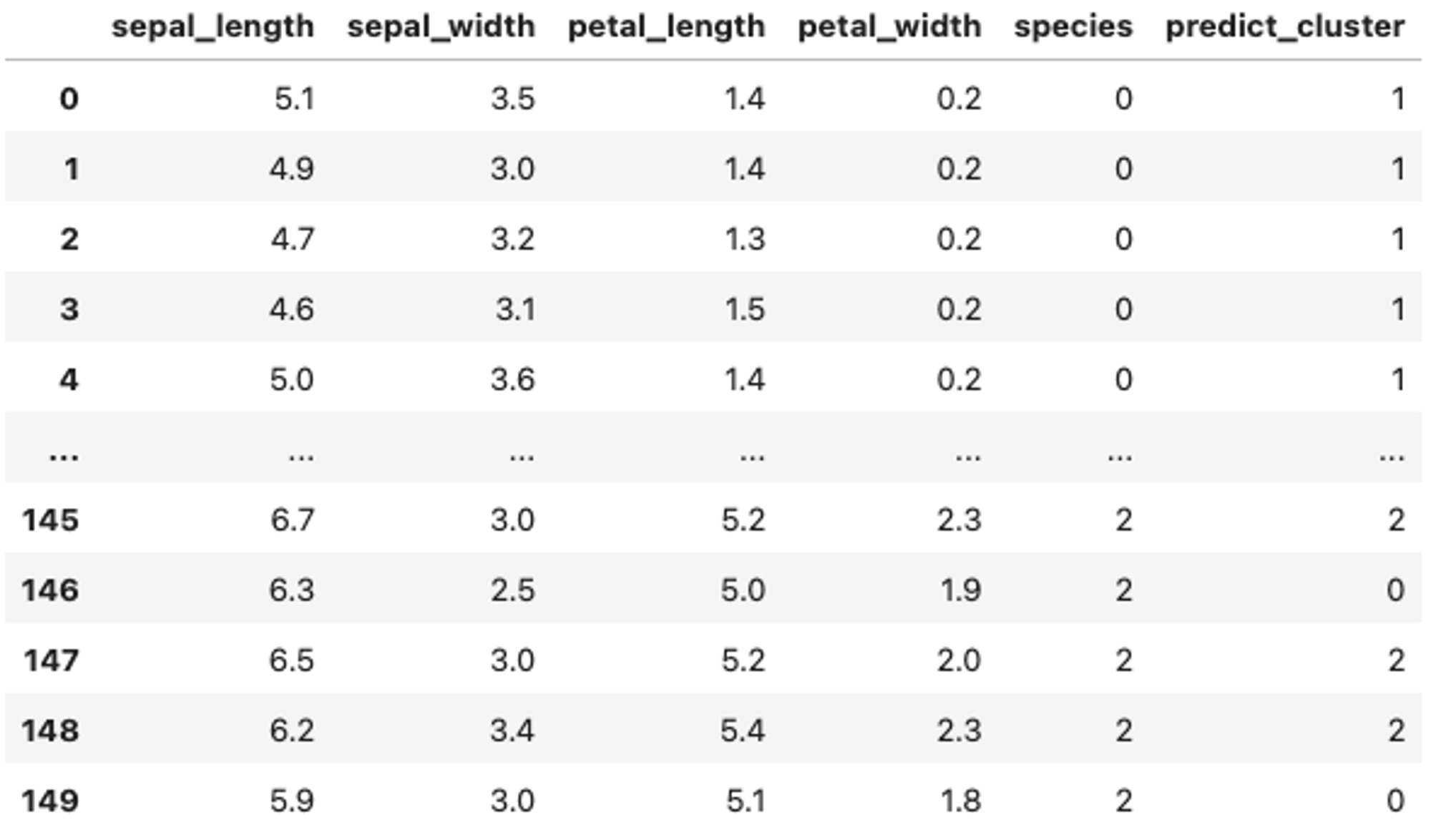
데이터 모델링 성능 평가
import matplotlib.pyplot as plt
for k in range(1, 10):
cluster = KMeans(n_clusters=k, n_init=10, max_iter=500, random_state=42)
cluster.fit(X)
print(k, cluster.inertia_)
x = list(map(lambda cluster: cluster.fit(X).inertia_, map(lambda k: KMeans(n_clusters=k, n_init=10, max_iter=500, random_state=42), range(1, 10))))
plt.plot(range(1, 10), x)
# 출력 결과
1 681.3706
2 152.3479517603579
3 78.85144142614601
4 57.228473214285714
5 46.461172672672674
6 39.03998724608725
7 34.3058152958153
8 30.132440554614472
9 28.29063524195103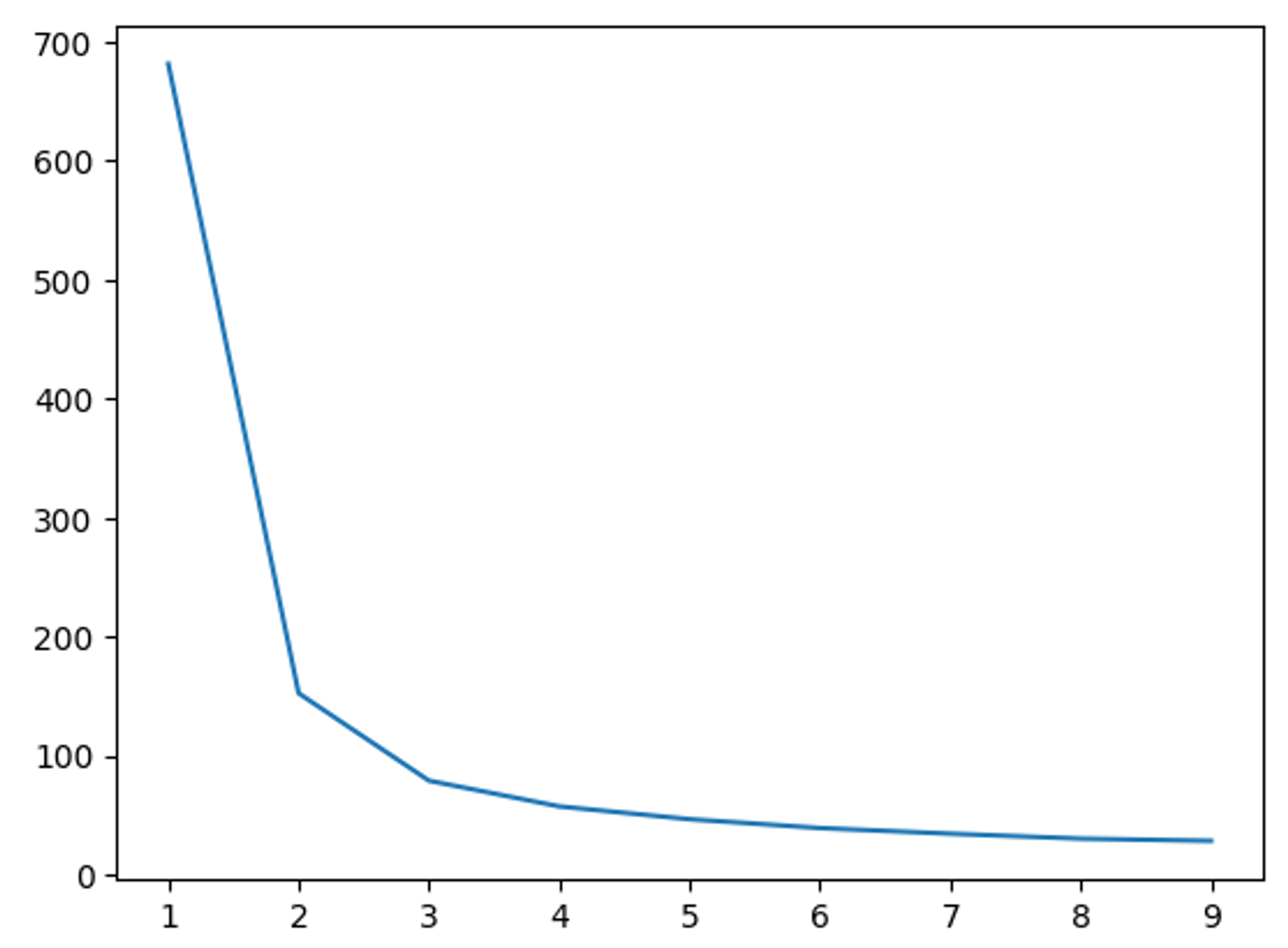
연관분석 (Association Rule)을 이용한 문제 해결
- 하나의 거래나 사건에 포함된 항목 간의 관련성을 파악하여, 둘 이상의 항목들로 구성된 연관성 규칙을 도출한다.
- 장바구니 분석 (Market Basket Analysis)

package import
import numpy as np
import pandas as pd
import sklearn
import mlxtend
from mlxtend.frequent_patterns import apriori, association_rules
print(f"pandas version: {pd.__version__}")
print(f"numpy version: {np.__version__}")
print(f"sklearn version: {sklearn.__version__}")
print(f"mlxtend version: {mlxtend.__version__}")데이터 불러오기
# data load
df = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/dataset/main/retail_dataset.csv")
df
df.info()데이터 전처리
mlxtend.preprocessing.TransactionEncoder활용- Transaction Encoding
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
transaction_data = df.transpose().apply(lambda x: x.dropna().to_list()).to_list()
transaction_encoder = TransactionEncoder()
data = pd.DataFrame(transaction_encoder.fit_transform(transaction_data), columns=transaction_encoder.columns_).astype(int)
data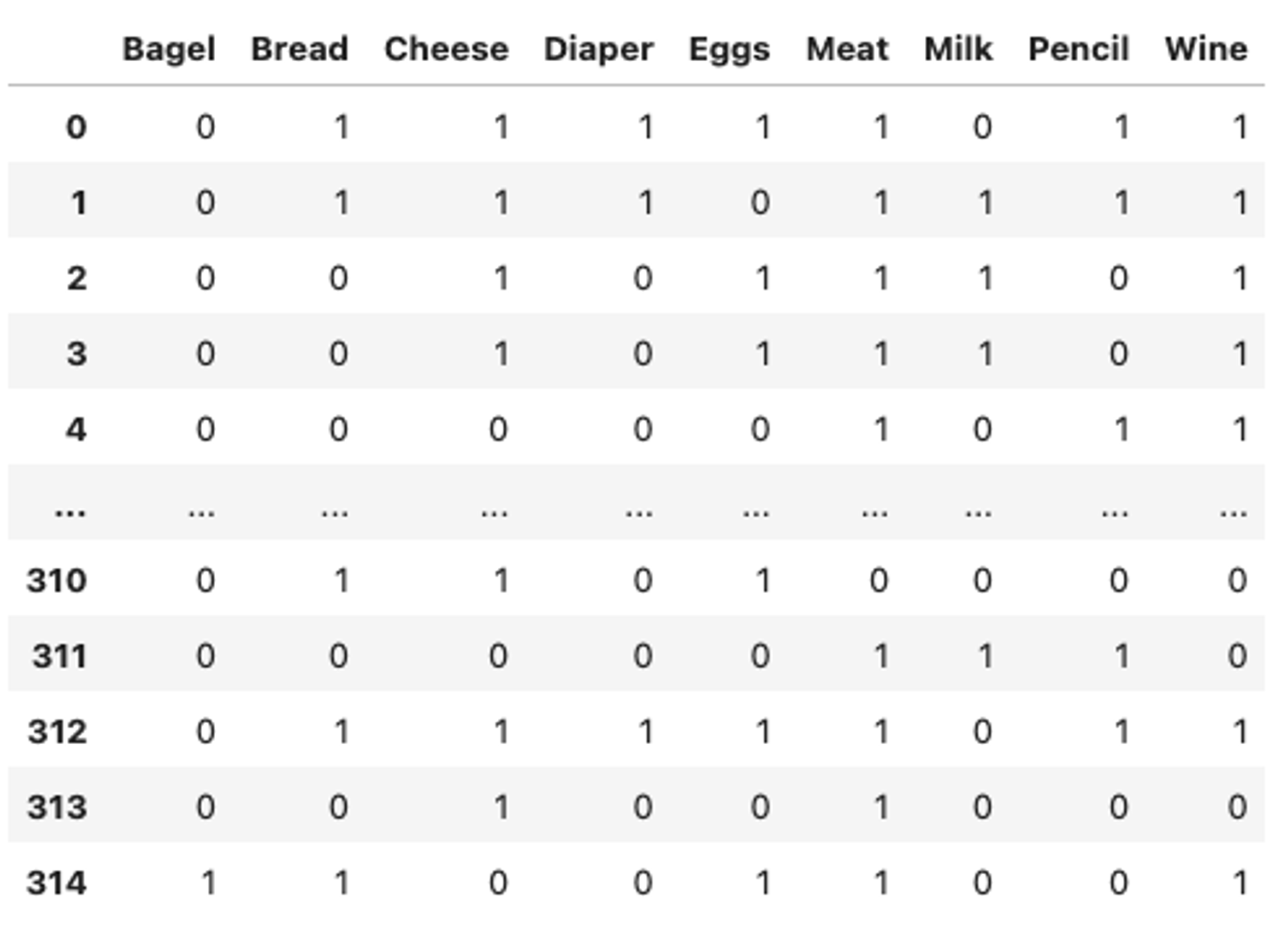
모델 적용 및 데이터 분석 수행
mlxtend.frequent_patterns.apriori 함수
mlxtend.frequent_patterns.apriori(
df,
min_support=0.5,
use_colnames=False,
max_len=None,
verbose=0,
low_memory=False,
)mlxtend.frequent_patterns.association_rules 함수
mlxtend.frequent_patterns.association_rules(
df,
metric='confidence',
min_threshold=0.8,
support_only=False,
)from mlxtend.frequent_patterns import apriori, association_rules
freq_items = apriori(data, min_support=0.2, use_colnames=True).sort_values("support", ascending=False)
print(freq_items.head())
# 출력 결과
support itemsets
1 0.504762 (Bread)
2 0.501587 (Cheese)
6 0.501587 (Milk)
5 0.476190 (Meat)
4 0.438095 (Eggs)from mlxtend.frequent_patterns import association_rules
association_rules(freq_items, metric="confidence", min_threshold=0.6)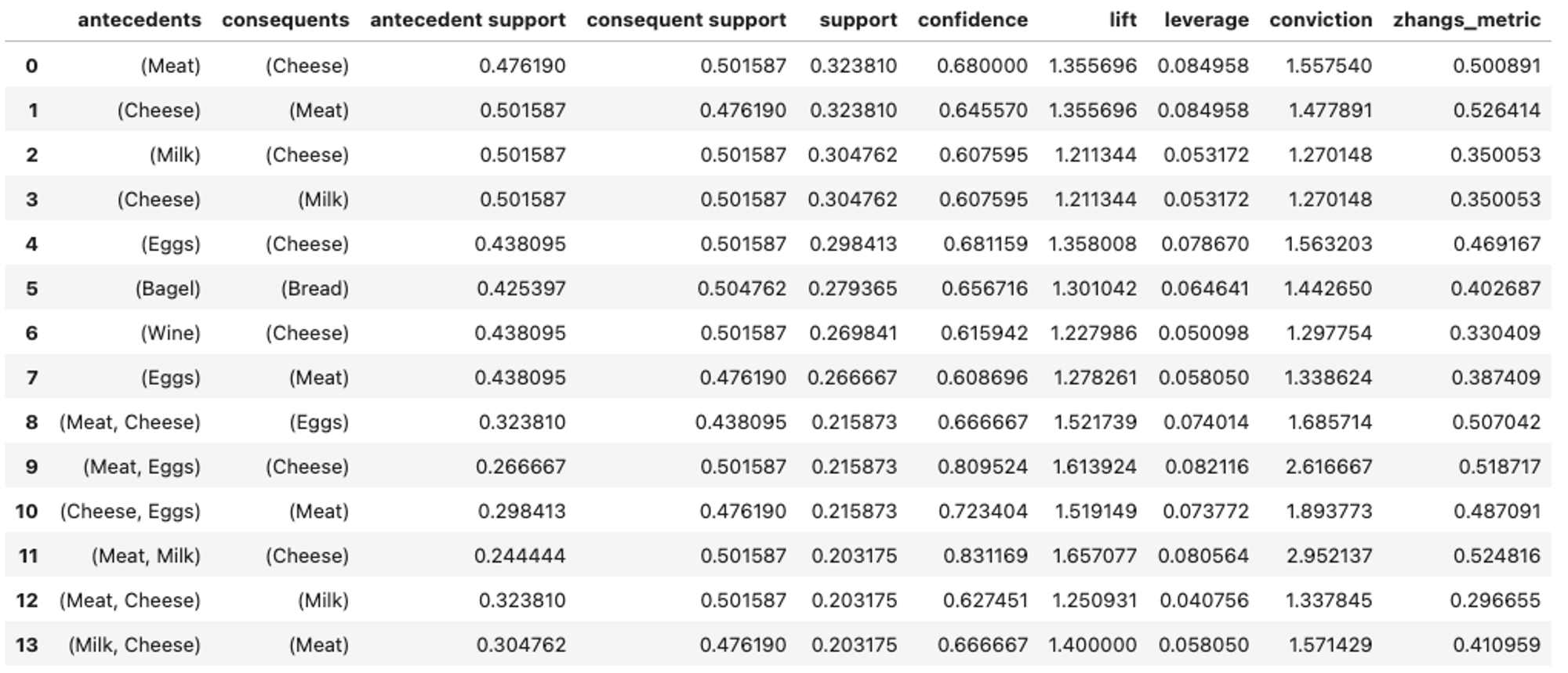

Hello velog!