토큰화가 필요한 이유
자연어 처리는 컴퓨터가 인간의 언어를 이해하고 해석 및 생성하는 기술을 의미하며, 이를 달성하기 위해선 인간 언어의 구조, 의미, 맥락을 분석하고 이해할 수 있어야한다. 이러한 이해도를 갖추기 위해선 다음과 같은 문제가 해결되어야 한다.
- 모호성(Ambiguity): 인간의 언어는 단어와 구가 사용되는 맥락에 따라 여러 의미를 갖게 되어 모호한 경우가 많다. 알고리즘은 다양한 의미를 이해하고 구분해야한다.
- 가변성(Variability): 인간의 언어는 다양한 사투리, 신조어, 약어 등이 존재하는 가변적 언어다. 알고리즘은 이런 가변성을 다룰 수 있어야 한다.
- 구조(Structure): 인간의 언어는 문장이나 구의 의미를 이해할 때 구문(Syntactic)을 파악하여 의미를 해석한다. 알고리즘은 구조나 문법적 요소를 이해하고 추론할 수 있어야한다.
위와 같은 문제를 이해하고 구분할 수 있는 모델을 만드려면 우선 말뭉치(Corpus)라 불리는 언어 자료의 집합을 일정한 단위인 토큰(Token)으로 나눠야 한다. 말뭉치는 기사, 리뷰, 저널이나 칼럼 등 목적에 따라 다양한 소스에서 추출되는 텍스트 데이터를 의미한다. 그리고 여기서 토큰은 개별 단어나 문장 부호와 같은 텍스트를 의미하며 여러 문장을 일일히 토큰으로 나눔으로써 컴퓨터가 자연어를 더 잘 이해할 수 있게 돕는다. 이러한 과정을 토큰화(Tokenization)이라 한다.
예시
- 입력: '안녕하세요. 이로운입니다. 자연어 처리 공부는 매우 재밌습니다.'
- 결과: ['안녕', '하세요', '이로운', '입니다', '.', '자연어', '처리', '공부', '는', '매우', '재밌습', '니다', '.']
물론 토큰을 나누는 기준은 시스템이나 주어진 상황에 따라 유연히 정할 수 있다. 일반적으론 공백이나 쉼표, 마침표, 사전 기준(단어 기준), 어절 등으로 나눈다. 당연하지만, 큰 어휘 사전을 구축할수록 학습 비용의 증대는 물론이고 차원의 저주에 빠질 수 있다.
토큰화 실습
정말 간단하게 split 기능만으로도 테스트 해볼 수 있다.
sentence = "안녕하세요? 이로운입니다. 문장이 어 떻 게 나눠지는지 볼까요?"
tokenize = sentence.split()
print(tokenize)결과
['안녕하세요?', '이로운입니다.', '문장이', '어', '떻', '게', '나눠지는지', '볼까요?']split은 구분자를 입력으로 받는데, 입력하지 않으면 기본적으론 공백(띄어쓰기)를 따라간다. 따라서, 결과를 살펴보면 일부러 한글자씩 띄어놓은 어 떻 게가 나뉜 것을 보인다. 그럼 이번엔 글자 단위로 나눠보자.
sentence = "안녕하세요? 이로운입니다. 문장이 어 떻 게 나눠지는지 볼까요?"
tokenize = list(sentence)
print(tokenize)['안', '녕', '하', '세', '요', '?', ' ', '이', '로', '운', '입', '니', '다', '.', ' ', '문', '장', '이', ' ', '어', ' ', '떻', ' ', '게', ' ', '나', '눠', '지', '는', '지', ' ', '볼', '까', '요', '?']list는 공백을 포함한 모든 글자를 한 글자씩 나눈다. 영어의 경우엔 알파벳 단위로 나눈다.
형태소 토큰화
형태소 토근화(Morpheme Tokenization)란 텍스트를 의미를 가진 가장 작은 단위인 형태소 단위로 토큰화 하는 것을 말한다. 형태소 토큰화는 특히 한국어와 같은 교착어(Agglutinative language)를 다룰 때 중요하게 수행된다. 한국어는 대부분의 언어와 달리 각 단어가 띄어쓰기로 구분되지 않고, 다양한 접사와 조사가 어근에 붙어 하나의 낱말을 이루므로 각 형태소를 적절히 구분해 처리해야 한다. 예를 들어,
- 밥을 맛있게 먹어보자.
- Let's enjoy our meal.
이 문장에선 '밥'이라는 어근에 '을'이 붙어 하나의 의미를 이룬다. 영어로 표현하자면, 여기선 'meal'이라는 한 단어로 표현된다. 그리고 '맛있게' 라는 어절도 사실은 '맛'과 접사, 조사(사실 국어 문법 용어를 자세히 모릅니다. 죄송합니다.)가 붙어 생성된 말이다. 이러한 형태소 분석을 통해 문장 내 각 형태소의 역할을 파악할 수 있으며, 문장을 수월하게 이해하고 처리할 수 있다.
실습
이번엔 KoNLPy라는 한국어 자연어 처리를 위해 개발된 라이브러리를 활용해 한국어에 대한 형태소 분석을 실습해보자. (pip3 install konlypy)로 설치해주자.
from konlpy.tag import Okt
okt = Okt()
sentence = "라이브러리를 사용하여 어떻게 나뉘는지 봅시다?"
nouns = okt.nouns(sentence)
phrase = okt.phrases(sentence)
morphs = okt.morphs(sentence)
pos = okt.pos(sentence)
print("명사 : ", nouns)
print("구 : ", phrase)
print("형태소 : ", morphs)
print("품사 : ", pos)명사 : ['라이브러리', '사용']
구 : ['라이브러리', '사용']
형태소 : ['라이브러리', '를', '사용', '하여', '어떻게', '나뉘는지', '봅시다', '?']
품사 : [('라이브러리', 'Noun'), ('를', 'Josa'), ('사용', 'Noun'), ('하여', 'Verb'), ('어떻게', 'Adjective'), ('나뉘는지', 'Verb'), ('봅시다', 'Verb'), ('?', 'Punctuation')]Okt 객체는 문장을 입력받아 명사, 구, 형태소, 품사 등의 정보를 추출하는 여러 가지 메서드를 제공하며, 이것을 활용해 문장을 분석한 예시이다.
이번엔 NLTK 라이브러리를 활용해보자. NLTK는 토큰화, 형태소 분석, 구문 분석, 개체명 인식 등 다양한 기능을 제공하는 라이브러리이고, 영어를 주 목적으로 개발됐지만, 네덜란드어, 프랑스어 등 다양한 언어도 지원한다. (pip3 install nltk로 설치하자.)
import nltk
nltk.download('punkt_tab')
nltk.download('averaged_perceptron_tagger_eng')
from nltk import tokenize
from nltk import tag
sentence = "The time now is 23:03, and I am hungry... I want to eat pizza."
word_tokens = tokenize.word_tokenize(sentence)
print("Word Tokens:", word_tokens)
sent_tokens = tokenize.sent_tokenize(sentence)
print("Sentence Tokens:", sent_tokens)
pos = tag.pos_tag(word_tokens)
print("POS Tags:", pos)우선 punkt 모델과 averaged_perceptron_tagger가 필요한데, 두 모델 모두 대규모의 영어 말뭉치가 학습되었고 punkt 모델은 통계 기반 모델이며 Averaged Perceptron Tagger는 퍼셉트론 기반으로 품사 태깅을 수행한다. 주어진 문장 분석의 결과를 출력해보자.
Word Tokens: ['The', 'time', 'now', 'is', '23:03', ',', 'and', 'I', 'am', 'hungry', '...', 'I', 'want', 'to', 'eat', 'pizza', '.']
Sentence Tokens: ['The time now is 23:03, and I am hungry...', 'I want to eat pizza.']토큰화 결과는 윗문장같이, 공백을 기준으로 단어를 분리하고, 구두점 등을 처리해 각각의 단어 토큰이 추출되었다.
POS Tags: [('The', 'DT'), ('time', 'NN'), ('now', 'RB'), ('is', 'VBZ'), ('23:03', 'CD'), (',', ','), ('and', 'CC'), ('I', 'PRP'), ('am', 'VBP'), ('hungry', 'JJ'), ('...', ':'), ('I', 'PRP'), ('want', 'VBP'), ('to', 'TO'), ('eat', 'VB'), ('pizza', 'NN'), ('.', '.')]품사 추출 결과는 이렇게 출력되었으며 상세한 정보는 아래 표를 참고하자.
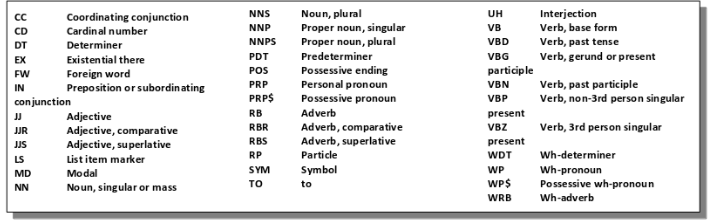
(출처 : https://pythonspot.com/nltk-speech-tagging/#google_vignette)
spaCy도 널리 사용되는 라이브러리 중 하나이다. 싸이썬(Cython) 기반으로 개발된 오픈 라이브러리로, NLTK 대비 더 빠른 속도와 정확도를 지향한다. (알고리즘은 비교적 적다고 한다.). 본 튜토리얼의 목적이나 실효성을 고려했을 때, 앞으로 가급적이면 spaCy를 애용할 계획이다.
설치는 다음과 같이 하자. (아마 기존 라이브러리들보다 오래걸릴 것이다.)
pip3 install spacy
python3 -m spacy download en_core_web_sm그리고 spaCy로 품사 태깅과 토큰화 및 표제화(Lemmatization)까지 시도해보자. 표제화란 단어의 원형을 찾는다.
import spacy
nlp = spacy.load("en_core_web_sm")
sentence = "The time now is 23:03, and I am hungry... I want to eat pizza."
doc = nlp(sentence)
for token in doc:
print(f"Token: {token.text}, POS: {token.pos_}, Lemma: {token.lemma_}, Is Stop Word: {token.is_stop}")결과는 다음과 같다.
Token: The, POS: DET, Lemma: the, Is Stop Word: True
Token: time, POS: NOUN, Lemma: time, Is Stop Word: False
Token: now, POS: ADV, Lemma: now, Is Stop Word: True
Token: is, POS: AUX, Lemma: be, Is Stop Word: True
Token: 23:03, POS: NUM, Lemma: 23:03, Is Stop Word: False
Token: ,, POS: PUNCT, Lemma: ,, Is Stop Word: False
Token: and, POS: CCONJ, Lemma: and, Is Stop Word: True
Token: I, POS: PRON, Lemma: I, Is Stop Word: True
Token: am, POS: AUX, Lemma: be, Is Stop Word: True
Token: hungry, POS: ADJ, Lemma: hungry, Is Stop Word: False
Token: ..., POS: PUNCT, Lemma: ..., Is Stop Word: False
Token: I, POS: PRON, Lemma: I, Is Stop Word: True
Token: want, POS: VERB, Lemma: want, Is Stop Word: False
Token: to, POS: PART, Lemma: to, Is Stop Word: True
Token: eat, POS: VERB, Lemma: eat, Is Stop Word: False
Token: pizza, POS: NOUN, Lemma: pizza, Is Stop Word: False
Token: ., POS: PUNCT, Lemma: ., Is Stop Word: FalsespaCy는 사전 학습된 모델을 기반으로 처리하기에 모델 불러오기 함수를 통해 모델을 설정하고 작업을 수행한다. 품사 태그는 spaCy 사이트를 참고하자.
하위 단어 토큰화
형태소 분석은 중요한 전처리 과정 중 하나이다. 그러나, 언어는 시간이 지남에 따라 변화하고 새로운 단어나 표현이 등장하며, 텍스트에는 늘 올바른 문법과 표현만 담겨있진 않다. 예를 들어,
- 문장 : '이 식당은 돈쭐날만 한 식당이다.'
- 결과 : ['이', '식당', '은', '돈쭐날', '만', '한', '식당', '이', '다']
돈쭐내다라는 신조어를 해석하지 못해, 이렇게 형태소 토큰화를 정확하게 수행하지 못한 것을 확인할 수 있다. 이를 해결하기 위해, 하위 단어 토큰화(Subword tokenization)을 수행한다. 하위 단어 토큰화는 하나의 단어가 빈번하게 사용되는 하위 단어의 조합으로 나누어 토큰화한다. 예시로, 'Reinforcement'는 'Rein', 'Force', 'Ment' 등으로 나눠서 처리할 수 있다. 하위 단어 토큰화를 적용하면, 단어의 길이를 줄일 수 있어 처리 속도가 빨라질 뿐 아니라, OOV(Out of vocabulary, 사전에 없는 단어)신조어, 은어, 고유어 등의 문제를 해결할 수 있다.
바이트 페어 인코딩 (Byte pair encoding, BPE)
하위 단어 토큰화 방법으로는 바이트 페어 인코딩, 워드피스, 유니그램 모델 등이 있으며 이 중 대표적인 바이트 페어 인코딩에 대해 다뤄본다. 본래는 텍스트 데이터에서 빈번히 등장하는 글자 쌍의 조합을 찾아 부호화하는 압축 알고리즘으로 초기에는 개발되었으나, 현재는 자연어 처리 분야에서 하위 단어 토큰화를 위한 방법으로 사용된다.
본 방법은 연속된 글자 쌍이 더 이상 나타나지 않거나, 정해진 어휘 사전 크기에 도달할 때까지 조합 탐지와 부호화를 반복하며 이 과정에서 자주 등장하는 단어는 하나의 토큰이 되고, 덜 등장하는 단어는 여러 토큰의 조합으로 표현된다. 예로
- 원문 : 'abracadabra'
- Step 1 : AracadAra
- Step 2 : ABcadAB
- Step 3 : CcadC
가장 많이 등장한 빈도수는 'ab'이므로, 입력 데이터에서 A로 치환한다. 그 다음은 'ra'가 가장 빈도수가 높다. 이를 다시 B로 치환하고 'AB'가 또 다시 연속되므로 이를 C로 치환한다. 이렇게 데이터 압축을 시행하며, 현재는 토크나이저로써 단순 치환을 너머 어휘 사전에 추가한다. 이제 문장으로 넘어가서, 특정 문단을 분석했더니 아래와 같이 나왔다고 가정하자.
- 빈도 사전 : "low" : 5 / "lower" : 2 / "newest", 6 / "widest", 3
- 어휘 사전 : "low", "lower", "newest", "widest"
빈도 사전을 바이트 페어 인코딩으로 재구성하면, 가장 자주 등장한 글자 쌍은 e s 가 총 9번으로 가장 많이 등장했으니, 빈도 사전에서 'es'로 병합하고 어휘 사전에 추가한다. 이런 식으로 반복하다보면
- 어휘 사전 : "d" "e" "i" "l" "n" "o" "r" "s" "t" "w" "es" "est" ...
이런 식으로 결과가 나올 것이다. 따라서, 기존 말뭉치에 없던 단어라도, 기존 어휘 사전을 참고해 토큰화할 수 있을 것이다.
워드피스
워드피스는 바이트 페어 인코딩 토크나이저와 유사한 방법으로 학습되지만, 빈도 기반이 아닌 확률 기반으로 글자 쌍을 병합한다.
워드피스는 학습 과정에서 확률적인 정보를 사용한다. 모델이 새로운 하위 단어를 생성할 때 이전 하위 단어와 함께 나타날 확률을 계산해 가장 높을 확률을 가진 하위 단어를 선택한다. 이렇게 선택된 하위 단어는 이후에 더 높은 확률로 선택될 가능성이 높으며, 이를 통해 모델이 좀 더 정확한 하위 단어로 분리할 수 있다. 수식으로 나타내면 아래와 같다.
는 빈도를 나타내는 함수이며, 와 는 병합하려는 하위 단어를 의미한다. 그러므로 는 와 가 조합된 글자 쌍의 빈도를 의미한다. 결론적으로, 수식이 의미하는 바는 각각이 등장한 빈도 대비 글자 쌍의 빈도를 고려하므로, 두 글자가 적게 나왔지만 글자 쌍이 많이 나왔다면 높은 점수가 나오고 병합하는 것이 적절한지를 판단하게 된다.
토크나이저스 기반 워드피스 예제
토크나이저스 라이브러리는 허깅 페이스의 라이브러리로 워드피스 API를 제공한다. 또한 토크나이저스는 정규화와 사전 토큰화 기능을 제공하는데, 정규화는 일관된 형식으로 텍스트를 표준화하고 모호한 경우를 방지하기 위해, 일부 문자를 대체하거나 제거하는 등의 작업을 수행한다. 사전 토큰화는 입력 문장을 토큰화하기 전에 단어와 같은 작은 단위로 나누는 기능을 제공한다. 공백 혹은 구두점을 기준으로 입력 문장을 미리 나눠 텍스트 데이터를 효율적으로 처리한다. 이제 워드피스 토크나이저를 실습해보자. (pip3 install tokenizers로 설치하자.)
학습용 데이터는 지금 이 글을 한번 과감히 써보겠다. 아마, 마크다운 언어의 문법이나 수식이 있어 마냥 잘 되진 않을 것으로 예상한다. 만약 본인의 데이터가 없다면, 크롤링을 하는 것을 추천한다. (학습용으로만 쓰자.)
코드는 아래와 같다.
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.normalizers import Sequence, NFD, Lowercase
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(WordPiece())
tokenizer.normalizer = Sequence([NFD(), Lowercase()])
tokenizer.pre_tokenizer = Whitespace()
tokenizer.train(["corpus.txt"])
tokenizer.save("tokenizer.json")토크나이저스로 워드피스 모델을 불러온 뒤, 정규화 방식(유니코드 정규화, NFD)과 사전 토큰화 방식(pre_tokenizers)을 적용하고 학습 시킨 뒤, json 형태로 모델을 저장한다.
이제 모델을 불러와 토큰화를 진행해보자.
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.normalizers import Sequence, NFD, Lowercase
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.decoders import WordPiece as WordPieceDecoder
tokenizer = Tokenizer.from_file("tokenizer.json")
tokenizer.decoder = WordPieceDecoder()
sentence = "너, 토큰화 잘할 수 있어? 어디 한 번 보자."
sentence_list = ["너, 토큰화 잘할 수 있어?", "어디 한 번 보자.", "과연?"]
encoded_sentence = tokenizer.encode(sentence)
encoded_sentece_list = tokenizer.encode_batch(sentence_list)
print("One sentence tokenized:", encoded_sentence.tokens)
print("Multiple sentences tokenized:", [enc.tokens for enc in encoded_sentece_list])이제 결과를 보자
One sentence tokenized: ['너', ',', '토큰화', '잘', '##할', '수', '있어', '?', '어', '##ᄃ', '##ᅵ', '한', 'ᄇ', '##ᅥᆫ', '보', '##자', '.']
Multiple sentences tokenized: [['너', ',', '토큰화', '잘', '##할', '수', '있어', '?'], ['어', '##ᄃ', '##ᅵ', '한', 'ᄇ', '##ᅥᆫ', '보', '##자', '.'], ['과', '##연', '?']]학습 데이터 자체가 크지 않고, 마크다운 문법들이 포함되어 있다보니, 확실히 결과가 썩 좋진 않다. 하지만 그래도 어느정도는 성공한 모습을 확인할 수 있다.
