신경망과 임베딩
서론
공부를 하다보니, 임베딩 챕터에서 순환 신경망이나 LSTM, CNN에 대해서 다루는 내용이 있었다. 왜 임베딩에서 이를 소개하나 (GPT와 함께) 고찰을 해보았을 때
임베딩(Embedding)은 “단어 → 숫자 벡터” 변환
원래 텍스트는 숫자가 아니라 모델이 바로 처리할 수 없음.
임베딩 레이어는 단어(혹은 토큰)를 고정 길이의 실수 벡터로 변환.
이 벡터 안에는 단어의 의미적/통계적 특성이 압축돼 있음.
RNN / LSTM / CNN은 “임베딩 벡터 → 패턴 학습” 변환
RNN, LSTM, CNN을 소개하는 이유는, 임베딩을 거친 벡터 시퀀스를 처리하는 방법들 중 하나
RNN (Recurrent Neural Network)
순차 데이터(문장, 음성 등)의 시간 흐름을 반영.
입력: 임베딩 벡터 시퀀스
출력: 시퀀스 패턴(문맥 정보 포함)
한 단어의 의미를 앞뒤 문맥과 결합해 이해.
LSTM (Long Short-Term Memory)
RNN의 일종이지만 장기 의존성(Long-term dependency) 문제를 해결.
멀리 떨어진 단어의 영향도 잘 반영.
예:
"The book that you gave me **was** interesting" 에서
‘was’가 ‘book’과 맞는 동사를 고르는 데 도움.
CNN (Convolutional Neural Network) in NLP
원래 이미지용이었지만, 1D convolution으로 텍스트 패턴도 잘 뽑아냄.
특정 길이의 n-gram(예: bigram, trigram) 특징을 효율적으로 추출.이러한 이유에서 임베딩 챕터에서 소개하는 것으로 생각된다.
본론
순환 신경망 (Recurrent Neural Network, RNN)
순환 신경망은 순서가 있는 연속적인 데이터를 처리하는데 적합한 구조를 가지고 있다.
순환 신경망은 각 시점(Time step)의 데이터가 이전 시점의 데이터와 독립적이지 않다는 특성 때문에 효과적으로 작동한다.
예를 들어, 매일매일의 환율을 기록하다보면, 오늘의 환율과 가장 밀접한 관계가 있는건 어제의 환율일 것이고, 어제의 환율과 가장 관련 있는건 얻그제일 것이다. 이렇게 특정 시점에서의 데이터가 이전 시점의 영향을 받는 데이터를 연속형 데이터라 한다.
자연어 데이터 또한 연속적인 데이터의 일종이라고 볼 수 있는데, 당연한 것이, 모든 글과 사람이 하는 말들은 특유의 순서, 문법, 관용어 등의 특성 있기 때문이다.
예를 들어,
"12시가 되면은 "
"새해 복 많이 "
빈칸은 한국인이라면 누구나 맞출 수 있을 것이다.
또한 긴 문장일수록 앞선 단어들과 뒤따르는 단어들 사이에 강한 상관관계가 존재한다.
"건강한 삶을 살기 위해서는, 적어도 12시 전에는 수면에 _ 것이 좋습니다."
빈칸은 '수면에'라는 앞선 문맥과 상호 작용해 전체적인 의미를 결정한다. 따라서, 자연어 처리 또한 문맥과 상호작용을 모델링해 정확한 의미 파악이 필요하다.
다시 순환 신경망 이야기로 돌아와서, 연속적인 데이터를 처리하는 것에 적합하다. 순환 신경망은 이전에 처리한 데이터를 다음 단계에 활용하고 현재 입력 데이터와 함께 모델 내부에서 과거의 사앹를 기억해 현재 상태를 예측하는데 사용한다.
입력은 연속형 데이터를 입력 받으며, 각 시점마다 은닉 상태(Hidden state: 주어진 시점 까지의 입력 시퀀스 에 대한 조건부 확률 분포를 표현하기 위한, 고정 차원의 실수 벡터 표현으로서, 네트워크의 재귀적 계산에 의해 갱신되는 내부 상태 변수)형태로 저장한다. 각 시점의 데이터를 입력으로 받아 은닉 상태와 출력값을 계산하는 노드를 순환 신경망의 셀(Cell)이라 한다.
순환 신경망의 셀은 아래 그림 및 수식과 같이 이전 시점의 은닉 상태 을 입력으로 받아 현재 시점의 은닉 상태 를 계산한다.
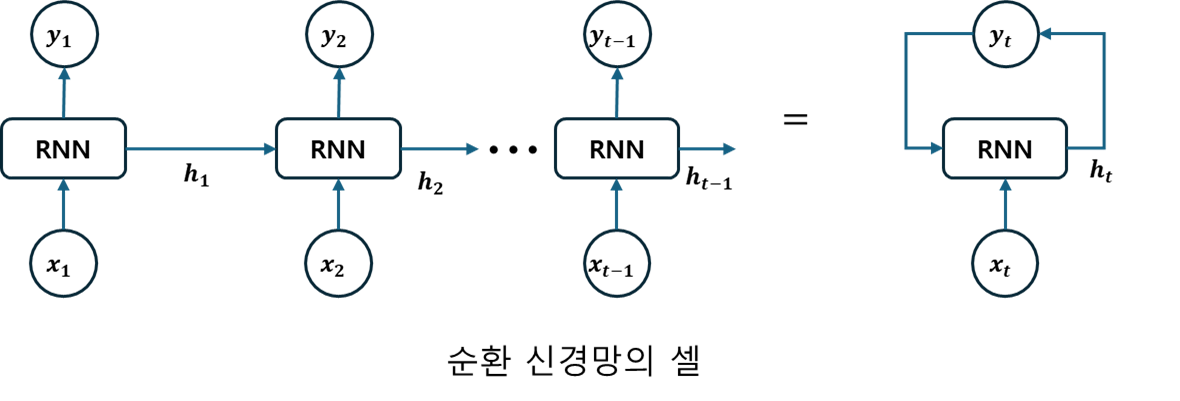
순환 신경망은 각 시점 에서 입력값과 이전 시점의 은닉 상태 를 이용해 현재 시점의 은닉 상태와 출력값을 계산한다. 여기서 는 순환 신경망의 은닉 상태를 계산하기 위한 활성화 함수를 의미하며, 활성화 함수는 가중치()와 편항()를 이용하여 은닉 상태를 계산하는데, 이때 는 이전 시점의 은닉 상태에 대한 가중치를, 는 입력값에 대한 가중치를, 는 은닉 상태 의 편향을 의미한다.
출력값은 아래의 수식을 거쳐 계산된다.
는 순환 신경망의 출력값을 계산하기 위한 활성화 함수를 의미하며 마찬가지로 가중치와 편향이 반영된다. 는 현재 시점의 은닉 상태 에 대한 가중치를, 는 출력값 의 편향을 의미한다. 순환 신경망의 출력값을 이전 시점의 정보를 입력 받아 현재 시점에 활용하기에, 연속형 데이터를 처리하는데 적합한 구조를 가지고 있음을 다시 확인해볼 수 있다.
순환 신경망은 다양한 구조로 설계될 수 있는데, 단순 순환 구조부터 일대다 구조, 다대일 구조, 다대다 구조 등이 있다. 하나씩 알아보자.
일대다 구조
일대다 구조는 하나의 입력 시퀀스에 대해 여러 개의 출력값을 생성하는 순환 신경망을 말한다. 예를 들면, 일대다 구조를 사용하여 문장을 입력하고 각 단어의 품사를 출력하는 작업이 일대다 구조의 예시이고, 이미지를 입력하면 이미지에 대한 여러 설명을 제공하는 것도 일대다 구조이다.
이러한 일대다 구조를 구현하기 위해서는 출력 시퀀스의 길이를 미리 알고 있어야 한다. 이를 위해, 입력 시퀀스를 처리하면서 시퀀스의 정보를 활용해 출력 시퀀스의 길이를 예측하는 모델을 함께 구현해야 한다.
다대일 구조
다대일 구조는 여러 개의 입력 시퀀스에 대해 하나의 출력값을 생성하는 순환 신경망 구조다. 예를 들면, 특정 문장에 대해 하나의 키워드를 뽑아내는 작업이나 부정/긍정 등의 이진 분류를 하는 작업들은 모두 다대일 구조이다.
다대다 구조
다대다 구조는 입력 시퀀스와 출력 시퀀스의 길이가 여러 개인 경우에 사용되는 신경망 구조이다. 다양한 분야에서 다대다 구조를 활용하는데, 이때, 입력 시퀀스와 출력 시퀀스의 길이가 서로 다른 경우가 있을 수 있다. 따라서, 길이를 맞추기 위해 패딩을 추가하거나 잘라내는 등의 전처리 과정이 수행된다.
다대다 구조는 기본적으로 시퀀스-시퀀스(Seq2Seq) 구조로 이루어져 있다. Seq2Seq는 입력 시퀀스를 처리하는 인코더와 출력 시퀀스를 생성하는 디코더로 구성된다.
양방향 순환 신경망
양방향 순환 신경망은 시간 방향을 양방향으로 처리할 수 있도록 고안된 방식이다. 순환 신경망은 현재 시점의 입력값을 처리하는데 이전 시점의 은닉 상태를 이용하는데, 양방향 순환 신경망에선 이전 시점의 은닉 상태뿐만 아니라 이후 시점의 은닉 상태도 활용한다.
예를 들어, "햄버거는 맥도날드와 __, 버거킹이 유명하다." 라는 문장에서 빈칸에 들어갈 단어를 예측해야 한다면, 앞문장뿐만 아니라, 뒷문장도 참고해야 함을 알 수 있다.
이처럼 양방향 순환 신경망은 특정 시점 이후의 데이터도 예측하는데 사용될 수 있다.
다중 순환 신경망
다중 순환 신경망은 여러 개의 순환 신경망을 연결하여 구성한 모델로, 각 순환 신경망이 서로 다른 정보를 처리하도록 설계되어 있다.
단층 퍼셉트론을 여러 개 쌓아 다층 퍼셉트론 구조를 만들고 더 복잡한 문제를 해결하듯, 순환 신경망도 여러 층을 쌓아 활용될 수 있다. 이렇게 여러 개의 층으로 구성된 RNN은 다양한 특징을 추출할 수 있어 성능이 향상될 수 있고 더 복잡한 패턴을 학습할 수 있다. 하지만, 신경망 층이 많아질수록 학습 시간이 오래 걸리고 기울기 소실 문제가 발생할 가능성이 높아진다.
장단기 메모리 LSTM: Long Short-Term Memory
장단기 메모리는 기존 순환 신겸앙이 갖고 있던 기억력 부족과 기울기 소실 문제를 해결한 모델이다. 일반적인 순환 신경망은 특정 시점에서 이전 입력 데이터의 정보를 이용해 출력값을 예측하는 구조이므로 시간적으로 먼 과거의 정보는 잘 기억하지 못한다.
하지만, 어떤 데이터에선 다음 시점의 데이터를 유추하기 위해 훨씬 이전의 데이터에서 힌트를 얻어야 할 수도 있다. 예를 들어,
"메시는 아르헨티나에서 태어나 FC 바르셀로나에서 최고의 선수가 되었고, 클럽팀에서는 다수의 우승컵과 개인 수상 이력을 완벽히 채웠고, 2022년, 클럽팀 뿐만 아니라 _ 를 이끌고 월드컵 최정상에도 올랐다."
여기서 빈칸은 훨씬 앞의 아르헨티나에서 힌트를 얻어야 한다. 단순 순환 신경망의 경우, 앞선 시점의 정보를 끊임없이 반영하기에 학습 데이터의 크기가 커질수록 앞서 학습한 정보가 충분히 전달되지 않는다는 단점이 있다.
이러한 단점은 곧 장기 의존성 문제(Long-term dependencies)가 발생할 수 있다. 또한, 활성화 함수로 사용되는 함수의 특성으로 역전파 과정에서 기울기 소실이나 폭주가 발생할 수 있다.
장단기 메모리는 이러한 단점을 해결하기 위해 등장했다. 순환 신경망과 비슷한 구조를 가지지만, 메모리 셀(Memory Cell)과 게이트(Gate) 구조를 도입해 장기 의존성 문제와 기울기 소실 문제를 해결한다.
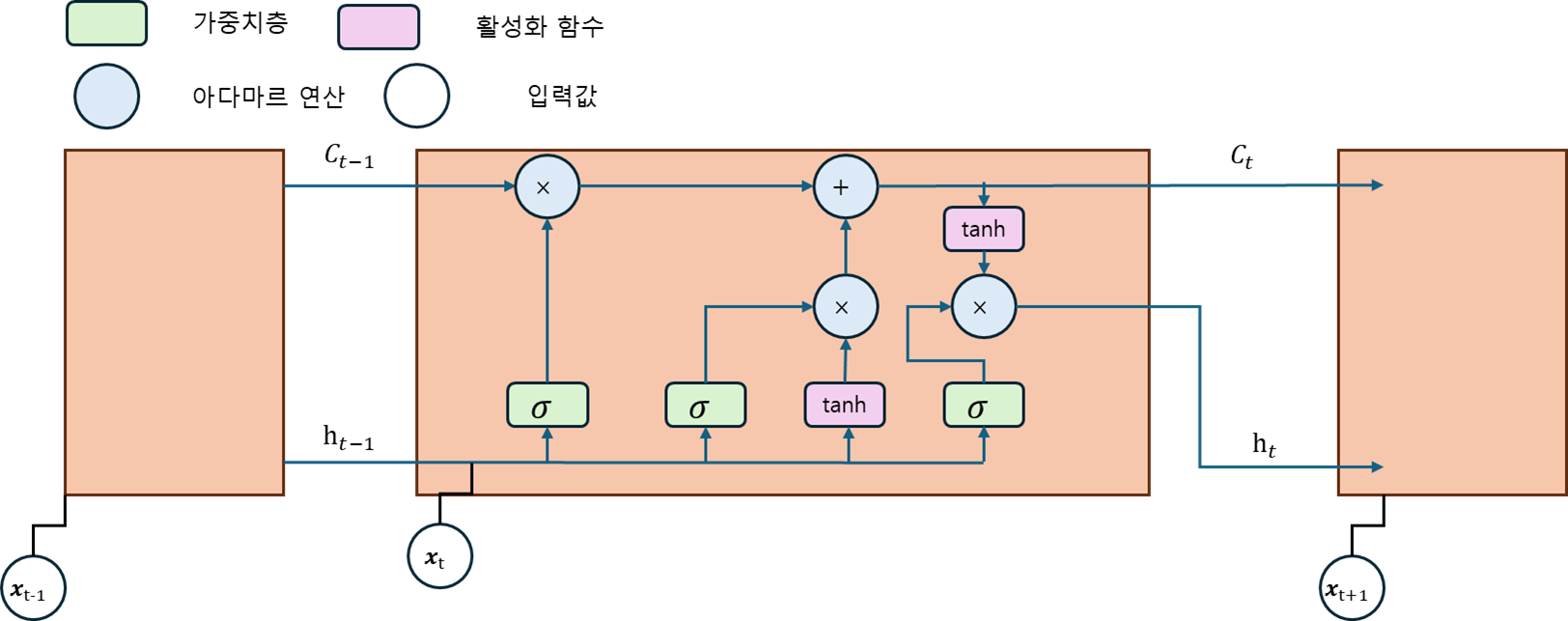
위 그림은 장단기 메모리의 구조를 보여준다. 장단기 메모리는 셀 상태(Cell state)와 망각 게이트(Forget gate), 기억 게이트(Input gate), 출력 게이트(Output gate)로 정보의 흐름을 제어한다.
셀 상태는 정보를 저장하고 유지하는 메모리 역할을 하며 출력 게이트와 망각 게이트에 의해 제어된다.
망각 게이트는 장단기 메모리에서 이전 셀 상태에서 어떠한 정보를 삭제할지 결정하는 역할을 한다.
입력 게이트는 새로운 정보를 어떤 부분에 추가할지 결정하는 역할을 하며 현재 입력과 이전 셀 상태를 입력으로 받아 어떤 정보를 추가할지 결정한다.
출력 게이트는 셀 상태의 정보 중 어떤 부분을 출력할지 결정하는 역할을 한다.
이제 장단기 메모리 신경망 내에서 셀 상태와 게이트가 어떻게 동작하는지 자세히 알아보자.
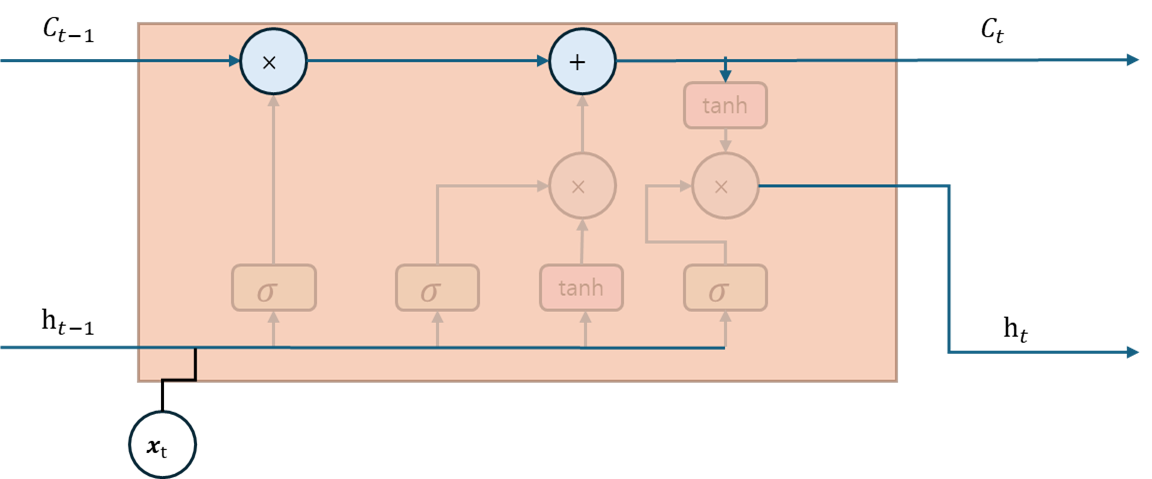
위 그림은 장단기 메모리 셀 상태의 연산 괒어을 보여준다. 메모리 셀은 순환 신경망의 은닉 상태와 유사하게 현재 시점의 입력과 이전 시점의 은닉 상태를 기반으로 정보를 계산하고 저장하는 역할을 한다. 하지만 순환 신경망에서 은닉 상태는 출력값을 계산하는 데 사용되지만, 장단기 메모리의 메모리 셀은 출력값 계산에 직접 사용되지 않는다.
대신 장단기 메모리는 망각 게이트, 입력 게이트, 출력 게이트를 통해 어떤 정보를 버릴지, 어떤 정보를 기억할지, 어떤 정보를 출력할지를 결정하는 추가적인 연산이 존재한다.
세 가지 게이트는 모두 시그모이드 함수를 활성화 함수로 채택하는데, 각각 게이트의 출력값이 0과 1사이로 매핑되므로, 얼마나 많은 정보를 게이트에서 통과시킬지 결정하게 된다.
예를 들어, 망각 게이트가 1을 출력하면, 이전 시점의 기억 상태가 완전히 유지되며 0이 출력되면 이전 시점의 기억 상태는 현재 시점의 기억 상태에 전혀 반영되지 않는다.
망각 게이트는 현재 시점의 입력과 이전 시점의 은닉 상태를 입력으로 받아 시그모이드 함수를 거친 값과 메모리 셀을 곱한 값으로 이전 시점의 메모리 셀을 업데이트하며, 어떤 정보를 유지할 것인지 망각할 것인지를 결정한다.
두번째는 기억 게이트로, 현재 시점의 입력과 이전 시점의 은닉 상태를 입력으로 받아 시그모이드 함수와 하이퍼볼릭 탄젠트 함수를 거친 값의 곱으로 새로운 기억 값을 계산한다. 결국 -1과 1사이의 값으로 출력되는데, 어떤 정보를 얼마나 추가할지 결정하게 된다.
마지막 출력 게이트는 현재 시점의 입력과 이전 시점의 은닉 상태, 그리고 새로 업데이트된 메모리 셀을 입력으로 받아 현재 시점의 출력값을 계산한다.
이제 다시 망각 게이트 연산부터 살펴보자.
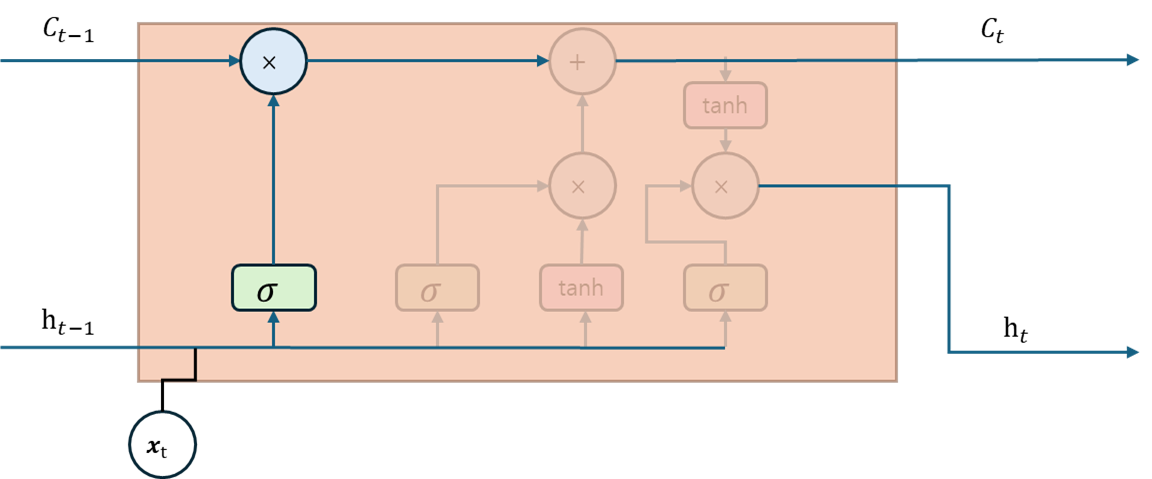
망각 게이트는 이전 시점의 은닉 상태 과 현재 시점의 입력값 를 통해 연산을 수행하며 수식은 아래와 같다.
여기서 와 은 입력갑소가 은닉 상태를 위한 가중치를 의미하며, 는 망각 게이트의 편향을 의미한다, 망각 게이트는 두 가중치로 망각 게이트의 출력값을 최적화하며, 메모리 셀을 계산하기 위한 가중치로 사용된다. 다음은 기억 게이트 계산 방법을 보자.
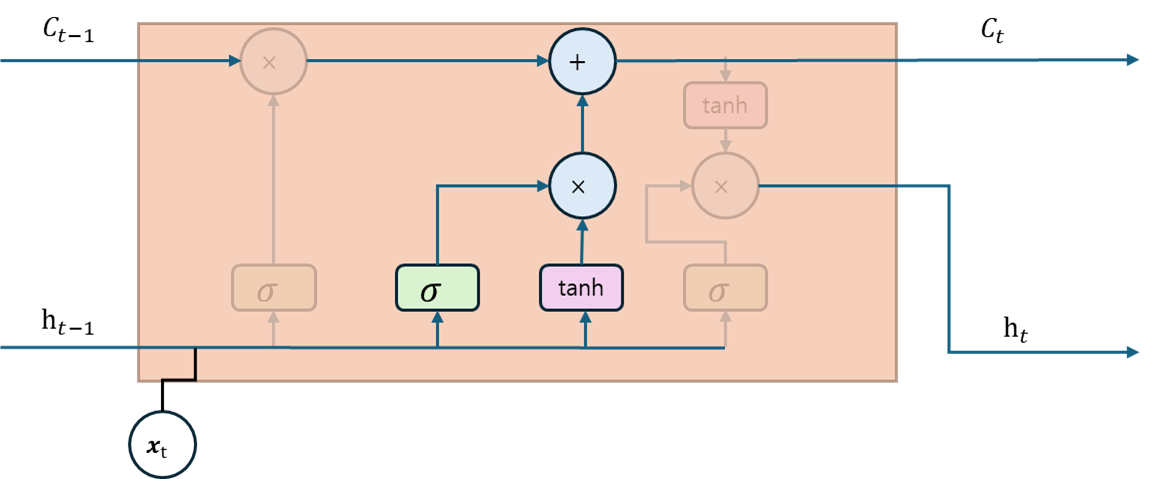
기억 게이트는 와 로 구성되어 있으며 망각 게이트와 동일한 연산으로 계산된다. 는 활성화 함수로 하이퍼볼릭 탄젠트를 사용하며, 는 시그모이드를 사용한다. 가 -1에서 1사이의 값을 가지므로, 새로운 은닉 상태를 계산하기 위해 이 은닉 상태를 얼마나 기억할지 제어하기가 어렵다. 그러므로, 값으로 새로운 은닉 상태의 기억을 제어한다. 는 [0,1] 의 값을 가지므로 현재 시점에서 얼마나 많은 정보를 기억할지 결정하는 가중치 역할을 한다.
최종적으로 메모리 셀은 망각 게이트와 기억 게이트의 정보로 현재 시점의 메모리 셀 값을 계산한다. 그 수식은 아래와 같다.
는 망각 게이트 출력값이며, 은 이전 시점의 메모리 셀 값을 나타낸다. 이 값의 원소별 곱셈 연산을 의미하는 아다마르 곱(Hadamard Product, : 두 행렬의 각 성분끼리 곱하는 연산)을 수행하면 현재 시점의 메모리 셀 값이 계산된다.
메모리 셀이 계산되었다면, 마지막으로 어떤 정보를 출력할지 결정해야한다.
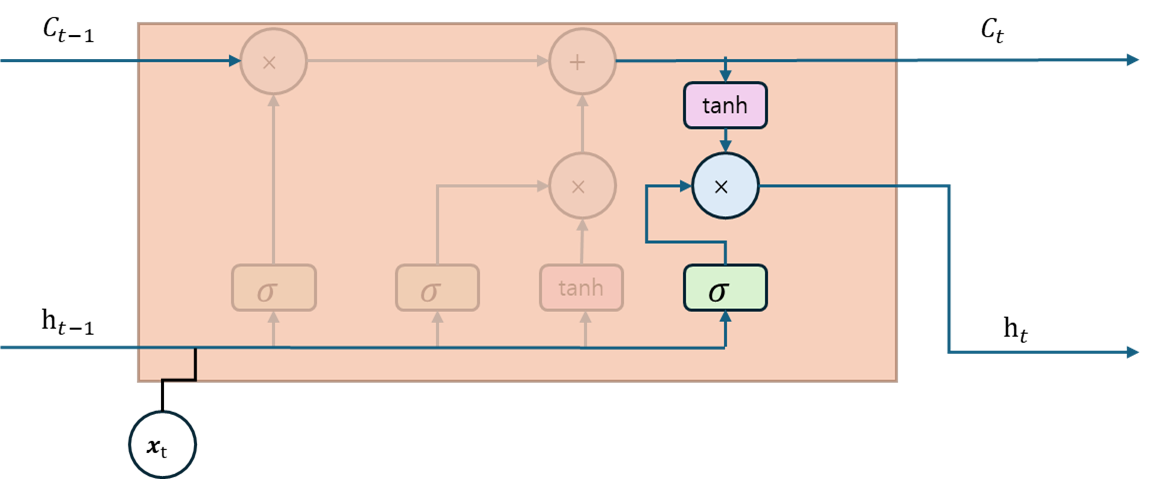
출력 게이트는 현재 시점의 은닉 상태를 제어한다, 수식은 망각 게이트에서 사용된 수식과 동일하다. 출력 게이트를 다시 현재 메모리 셀과 연산하면 새로운 은닉 상태를 갱신하는데 아래는 그 수식이다.
현재 시점의 은닉 상태는 출력 게이트와 하이퍼볼릭 탄젠트를 적용한 메모리 셀 값으로 계산된다. 두 값을 아다마르 곱 연산을 하면 최종저긍로 현재 시점의 은닉 상태가 이전 시점의 은닉 상태에서 얼마나 영향을 받는지 계산하게 되고, 이러한 방법으로 LSTM은 현재 은닉 상태에서 이전 은닉 상태의 정보의 중요도를 제어할 수 있다.
실습
본 실습에선 문장에 대해 부정/긍정 분류를 수행하는 모델을 만들어보자.
우선 클래스는 아래와 같이 작성하자.
import torch
import numpy as np
from torch import nn, optim
from konlpy.tag import Okt
from collections import Counter
from torch.utils.data import DataLoader, TensorDataset
from gensim.models import Word2Vec
class SentenceClassifier(nn.Module):
def __init__(self, n_vocab, hidden_dim, embedding_dim, n_layers, dropout=0.5, bidirectional=True, model_type="lstm"):
super().__init__()
self.embedding = nn.Embedding(num_embeddings=n_vocab, embedding_dim=embedding_dim, padding_idx=0)
if model_type == "rnn":
self.model = nn.RNN(input_size=embedding_dim, hidden_size=hidden_dim, num_layers=n_layers,
dropout=dropout, batch_first=True, bidirectional=bidirectional)
elif model_type == "lstm":
self.model = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, num_layers=n_layers,
dropout=dropout, batch_first=True, bidirectional=bidirectional)
if bidirectional:
self.classifier = nn.Linear(hidden_dim*2, 1)
else:
self.classifier = nn.Linear(hidden_dim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, inputs):
embeddings = self.embedding(inputs)
outputs, _ = self.model(embeddings)
last_output = outputs[:, -1, :]
last_output = self.dropout(last_output)
logits = self.classifier(last_output)
return logits
SentenceClassifier 클래스는 임베딩 층을 구성할 때 사용하는 단어 사전 크기(n_vocab)와 순환 신경망 클래스와 장단기 메모리 클래스에서 사용하는 매개변수를 입력으로 전달받는다. 또한, 모델 종류를 매개변수로 받아 어떤 방법을 사용할지 설정한다.
순방향 메서드에선 입력받은 정수 인코딩을 임베딩 계층에 통과시켜 임베딩 값을 얻는다. 그리고 얻은 임베딩 값을 모델에 입력하고 출력값을 얻는다.
이제 데이터세트를 불러오는 부분을 살펴보자.
corpus = Korpora.load('nsmc')
corpus_df = pd.DataFrame(corpus.test)
train = corpus_df.sample(frac=0.9, random_state=42)
test = corpus_df.drop(train.index)
print(train.head(5).to_markdown())
print("Training data size : ", len(train))
print("Test data size : ", len(test))
학습은 네이버 영화 리뷰 텍스트 데이터셋을 사용하며 정상적으로 학습 데이터와 테스트 데이터가 분리되었다면 아래와 같이 출력될 것이다.
| | text | label |
|------:|:-----------------------------------------------------|--------:|
| 33553 | 모든 편견을 날려 버리는 가슴 따뜻한 영화. 로버트 드 니로, 필립 세이모어 호프만 영원하라. | 1 |
| 9427 | 무한 리메이크의 소재. 감독의 역량은 항상 그 자리에... | 0 |
| 199 | 신날 것 없는 애니. | 0 |
| 12447 | 잔잔 격동 | 1 |
| 39489 | 오랜만에 찾은 주말의 명화의 보석 | 1 |
Training data size : 45000
Test data size : 5000
이제 토큰화 및 단어 사전을 구축할 차례다.
def build_vocab(corpus, n_vocab, special_tokens):
counter = Counter()
for tokens in corpus:
counter.update(tokens)
vocab = special_tokens
for token, count in counter.most_common(n_vocab):
vocab.append(token)
return vocab
tokenizer = Okt()
train_tokens = [tokenizer.morphs(text) for text in train.text]
test_tokens = [tokenizer.morphs(text) for text in test.text]
vocab = build_vocab(train_tokens, n_vocab=5000, special_tokens=["", ""])
token_to_id = {token: idx for idx, token in enumerate(vocab)}
id_to_token = {idx: token for idx, token in enumerate(vocab)}
Okt 토크나이저를 활용하여 토큰화를 하고 단어 사전을 구축하는 부분이다. 문장의 길이를 맞추기 위해 토큰을 추가한다. 다음은 토큰을 정수 인코딩하고 패딩하는 차례이다.
def pad_sequences(sequences, max_length, pad_value):
result = list()
for sequence in sequences:
sequence = sequence[:max_length]
pad_length = max_length - len(sequence)
padded_sequence = sequence + [pad_value] * pad_length
result.append(padded_sequence)
return np.asarray(result)
unk_id = token_to_id[""]
train_ids = [[token_to_id.get(token, unk_id) for token in text] for text in train_tokens]
test_ids = [[token_to_id.get(token, unk_id) for token in text] for text in test_tokens]
max_length = 32
pad_id = token_to_id[""]
train_ids = pad_sequences(train_ids, max_length, pad_id)
test_ids = pad_sequences(test_ids, max_length, pad_id)
이때 max_length는 입력 텍스트의 길이를 고려하여 입력 행렬이 적절한 크기를 갖게끔 설정하여야 한다. 그리고 pad_sequence는 크기를 조절하는 함수의 역할을 한다. 이제 파이토치 데이터로더에 적용하자.
train_ids = torch.tensor(train_ids, device=device)
test_ids = torch.tensor(test_ids, device=device)
train_labels = torch.tensor(train.label.values, dtype=torch.float32, device=device)
test_labels = torch.tensor(test.label.values, dtype=torch.float32, device=device)
train_dataset = TensorDataset(train_ids, train_labels)
test_dataset = TensorDataset(test_ids, test_labels)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)
이제 손실 함수와 최적화 함수를 정의하자.
n_vocab = len(token_to_id)
hidden_dim = 64
embedding_dim = 128
n_layers = 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
classifier = SentenceClassifier(n_vocab=n_vocab, hidden_dim=hidden_dim, embedding_dim=embedding_dim,
n_layers=n_layers, dropout=0.5, bidirectional=True, model_type="lstm").to(device)
criterion = nn.BCEWithLogitsLoss().to(device)
optimizer = optim.RMSprop(classifier.parameters(), lr=0.001)
은닉 상태의 크기는 64로, 임베딩 벡터의 크기는 128로 적용하고 신경망을 두 개의 층으로 구성한다.
이번 예제에선 긍/부정 이진 분류므로, 이진 교차 엔트로피 함수를 적용한다. BCEWithLogitsLoss는 BCELoss와 Sigmoid 클래스가 결합된 형태다. 최적 함수는 RMSProp (Root Mean Square Propagation)을 적용한다. RMSProp는 모든 기울기를 누적하지 않고, 지수 가중 이동 평균을 사용해 학습률을 조절한다. 즉, 기울기 제곱 값의 평균이 작아지면 학습률을 증가시키고, 그 반대의 경우 학습률을 감소시켜 Local Minima에 빠지는 것을 방지한다.
이제 마지막으로 모델 학습 및 테스트를 수행해보자.
def train(model, datasets, criterion, optimizer, device, interval):
model.train()
losses = list()
for step, (input_ids, labels) in enumerate(datasets):
input_ids = input_ids.to(device)
labels = labels.to(device).unsqueeze(1)
logits = model(input_ids)
loss = criterion(logits, labels)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % interval == 0:
print(f"Step {step}, Loss: {loss.item():.4f}")
def test (model, datasets, criterion, device):
model.eval()
losses = list()
corrects = list()
for step, (input_ids, labels) in enumerate(datasets):
input_ids = input_ids.to(device)
labels = labels.to(device).unsqueeze(1)
logits = model(input_ids)
loss = criterion(logits, labels)
losses.append(loss.item())
yhat = torch.sigmoid(logits)>.5
corrects.extend(torch.eq(yhat, labels).cpu().tolist())
print(f"Val Loss: {np.mean(losses):.4f}, Accuracy: {np.mean(corrects):.4f}")
epochs = 5
interval = 500
for epoch in range(epochs):
print(f"Epoch {epoch+1}")
train(classifier, train_loader, criterion, optimizer, device, interval)
test(classifier, test_loader, criterion, device)
token_to_embedding = dict()
embedding_matrix = classifier.embedding.weight.detach().cpu().numpy()
for word, emb in zip(vocab, embedding_matrix):
token_to_embedding[word] = emb
token = vocab[1000]
print(token, token_to_embedding[token])
def predict_text(text, model, tokenizer, token_to_id, max_length, pad_id, device):
model.eval()
tokens = tokenizer.morphs(text)
ids = [token_to_id.get(t, token_to_id[""]) for t in tokens][:max_length]
ids += [pad_id] * (max_length - len(ids))
x = torch.tensor([ids], dtype=torch.long, device=device)
with torch.no_grad():
logit = model(x).item()
prob = torch.sigmoid(torch.tensor(logit)).item()
label = "긍정" if prob > 0.5 else "부정"
return label, prob
print(predict_text("정말 감동적인 영화였어요", classifier, tokenizer, token_to_id, max_length, pad_id, device))
print(predict_text("너무 지루하고 별로였다", classifier, tokenizer, token_to_id, max_length, pad_id, device))
에포크마다 검증 손실과 검증 정확도를 확인하며 모델이 새로운 데이터를 얼마나 잘 예측하는지 확인하는 기능이 추가되었으며, 마지막엔 임의의 문장으로 긍/부정 이진 분류 성능을 평가해보자. 출력은 다음과 같다.
Epoch 1
Step 0, Loss: 0.6860
Step 500, Loss: 0.6931
Step 1000, Loss: 0.6817
Step 1500, Loss: 0.5340
Step 2000, Loss: 0.7110
Step 2500, Loss: 0.3671
Val Loss: 0.5932, Accuracy: 0.7082
Epoch 2
Step 0, Loss: 0.5144
Step 500, Loss: 0.5458
Step 1000, Loss: 0.5058
Step 1500, Loss: 0.4274
Step 2000, Loss: 0.4063
Step 2500, Loss: 0.5099
Val Loss: 0.4886, Accuracy: 0.7738
Epoch 3
Step 0, Loss: 0.3435
Step 500, Loss: 0.3870
Step 1000, Loss: 0.3178
Step 1500, Loss: 0.5622
Step 2000, Loss: 0.4913
Step 2500, Loss: 0.2912
Val Loss: 0.4303, Accuracy: 0.7912
Epoch 4
Step 0, Loss: 0.6430
Step 500, Loss: 0.3344
Step 1000, Loss: 0.4207
Step 1500, Loss: 0.3006
Step 2000, Loss: 0.5826
Step 2500, Loss: 0.3565
Val Loss: 0.4070, Accuracy: 0.8058
Epoch 5
Step 0, Loss: 0.3784
Step 500, Loss: 0.4505
Step 1000, Loss: 0.2106
Step 1500, Loss: 0.3572
Step 2000, Loss: 0.6091
Step 2500, Loss: 0.3601
Val Loss: 0.3988, Accuracy: 0.8120
보고싶다 [ 0.5959505 0.6347596 0.84427357 1.5051677 1.0570676 1.0886965
-1.1399231 0.35316032 -0.24245797 1.1229166 2.1669118 0.1322404
-0.5809564 0.40121886 1.1330917 -0.4224256 0.2827114 -0.16198757
1.126155 -0.46680522 1.1705858 1.7209032 1.5929209 -0.93312347
0.2888782 1.6562216 -0.45801637 1.0992333 -0.49359593 0.7355754
-0.3053184 -0.5929138 1.7842551 0.31071863 -0.70998174 -1.1875554
-0.6621557 -1.4849786 0.393815 1.4581602 1.812 -0.73603684
-0.40945616 0.09571438 0.00532104 1.2021596 -1.5148377 0.9458217
1.650969 -0.1540429 1.0365015 2.1982043 0.54517037 0.17842132
-1.2449061 0.7651252 1.1632944 1.0738548 -1.0399367 1.9176655
-2.0286064 0.6505754 0.2861101 -1.1117821 -0.76069134 0.10909719
0.04771893 0.25451067 0.5640041 -0.622614 -0.6176093 -0.15267019
-2.0108104 -0.10443105 2.066601 0.99914837 1.1948621 1.0809549
0.7909735 -1.5795307 -0.82618093 0.9048154 1.2166215 -1.7926097
-0.6993301 -1.1121578 1.8093185 -0.4311315 -0.9146514 0.6976847
-1.8162047 0.3059477 -0.39086363 -2.0206132 0.40742558 -0.4242684
0.28574178 -0.1519168 -1.2368116 1.1221207 -1.3494716 -0.5482058
-1.3271915 2.0880773 -1.4782076 0.6119747 0.8021806 0.8223128
1.1359428 -1.105575 -0.2755356 1.2998011 0.3945962 -0.36851338
1.0149134 1.0107859 0.45073915 -0.6012719 -0.76531476 -1.1261681
-1.1435729 -0.7073723 0.33121789 -0.16143276 -0.21560344 -1.4802594
0.6507501 -0.30329654]
('긍정', 0.9759194254875183)
('부정', 0.01071464829146862)
최종적인 결과를 보았을 때, 긍정적인 문장에 대해선 긍정을, 부정적인 문장에 대해선 부정을 보임을 알 수 있다.
