랜덤 포레스트
랜덤 포레스트는 결정트리의 과적합의 단점을 회피할 수 있는 방법이다.
기본적인 구조는 조금씩 다른 여러 결정 트리의 묶음이다.
랜덤 포레스트는 각 트리는 비교적 예측을 잘 할 수 있지만 일부 데이터에 과대적합하는 경향을 가진다는데 기초한다.
서로 다른 방향으로 과대적합된 트리를 많이 만들고 그 결과를 평균냄으로써 과대적합된 양을 줄일 수 있다.
각각의 트리는 타깃 예측을 잘 해야하고 다른 트리와는 구별되어야 한다.
랜덤 포레스트는 이름에서 알 수 있듯이 트리들이 달라지도록 트리 생성 시 무작위성을 주입한다.
bootstrap sample
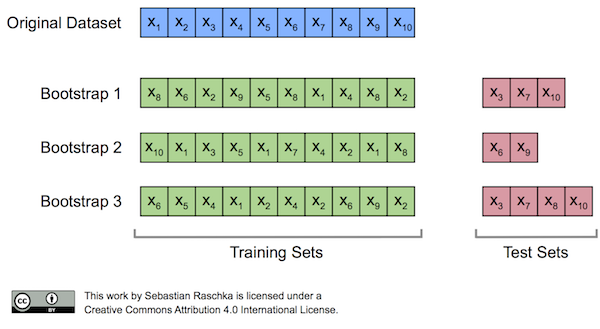
트리를 만들기 위해 먼저 데이터의 부트스트랩 샘플(bootstrap sample)을 생성한다.
다시말해 n개의 데이터 포인트 중에서 무작위 데이터를 n 횟수만큼 반복 추출한다.
(중복 추출될 수 있음)
이 데이터셋은 원래 데이터셋 크기와 같지만, 어떤 데이터 포인트는 누락될 수 있고, 어떤 데이터 포인트는 중복되어 들어 있을 수 있다.
100개의 샘플중 어떤 샘플 하나가 선택되지 않은 확률을 100번 반복할 때 한번도 선택되지 않을 확률
결정트리와 다르게 각 노드에서 전체 특성을 대상으로 최선의 테스트를 찾는 것이 아니고, 알고리즘이 각 노드에서 후보 특성을 무작위로 선택한 후 이 후보들 중에서 최선의 테스트를 찾는다. 후보 특성을 고르는 것은 매 노드마다 반복되므로 트리의 각 노드는 다른 후보 특성들을 사용하여 테스트를 만든다.
부트스트랩 샘플링은 랜덤 포레스트의 트리가 조금씩 다른 데이터셋을 이용해 만들어지도록 한다. 또한 각 노드에서 특성의 일부만 사용하기 때문에 트리의 각 분기는 각기 다른 특성 부분집합을 사용한다. 두 메커니즘이 합쳐져 랜덤 포레스트의 모든 트리가 서로 달라지도록 한다.
max_features
max_features를 1로 설정하면 트리의 분기는 테스트할 특성을 고를 필요가 없게 되며 선택한 특성의 임계값을 찾기만 하면 된다. 결국 max_features 값을 크게 하면 랜덤 포레스트의 트리들은 매우 비슷해지고 가장 두드러진 특성을 이용해 데이터에 잘 맞춰질 것이다. max_features를 낮추면 랜덤 포레스트 트리들은 많이 달라지고 각 트리는 데이터에 맞추기 위해 깊이가 깊어지게 된다.
랜덤 포레스트의 예측
랜덤 포레스트로 예측을 할 때는 먼저 알고리즘이 모델에 있는 모든 트리의 예측을 만들고, 회귀의 경우는 예측들의 평균으로 최종 예측을 만들고, 분류의 경우 약한 투표전략을 사용하는데 각 알고리즘이 가능성 있는 출력 레이블의 확률을 제공함으로써 간접적인 예측을 한다.
트리들이 예측한 확률을 평균내어 가장 높은 확률을 가진 클래스가 예측값이 된다.
랜덤 포레스트의 장단점
랜덤 포레스트의 random_state를 지정하지 않으면 전혀 다른 모델이 만들어진다.
랜덤 포레스트는 텍스트 데이터와 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않는다. 이런 데이터는 선형모델이 더 적합하다.
랜덤 포레스트는 매우 큰 데이터셋에서도 잘 작동하며, 훈련은 여러 CPU 코어로 간단하게 병렬화 할 수 있다. 하지만 랜덤 포레스트는 선형 모델보다 많은 메모리를 사용하며 훈련과 예측이 느리다. 속도와 메모리 사용에 제약이 있는 어플리케이션이라면 선형 모델이 적합하다.
중요 매개변수는 n_estimators, max_features이고 max_depth같은 사전 가지치기 옵션이 있다. n_estmators는 클수록 좋다. 더 많은 트리를 평균하면 과대적합을 줄여 더 안정적인 모델을 만든다. 하지만 이로인해 더 많은 메모리와 긴 훈련 시간으로 이어진다.
