1. 서론
1) 개요 및 문제의식
본 논문은 시계열 분석(Time Series Analysis, TSA)의 현주소와 그 한계를 명확히 짚고, 멀티모달(multimodal) 접근을 통해 이를 극복하고자 하는 시도이다. 특히 기존의 시계열 예측 모델들이 수치 기반 단일 모달(unimodal) 입력에 의존해온 구조적 한계를 지적하며, 실제 전문가들이 사용하는 외생적(exogenous) 텍스트 정보—정책 보고서, 뉴스, 현장 관측 보고 등—를 효과적으로 통합하는 필요성을 강조한다.
기존 연구에서 대규모 언어 모델(LLM)을 시계열 예측에 접목하려는 시도는 있었지만, 대부분은 시계열 수치 정보를 텍스트로 표현한 내생적(endogenous) 설명 수준에 머물러 있어 실제 외부 맥락을 반영한 예측에는 한계가 있었다.
2) 기존 데이터셋의 한계 분석
본 논문은 특히 멀티모달 시계열 연구가 더딘 이유를 고품질 데이터셋의 부재로 진단하며, 기존 데이터셋들이 다음과 같은 문제를 공통적으로 안고 있다고 지적한다.
-
좁은 도메인 적용성: 대부분 금융/주가 예측 중심으로 편중되어, 다양한 실제 도메인(예: 보건, 농업, 에너지 등)을 반영하지 못함.
-
Coarse Alignment: 단순한 도메인 일치 기준으로 텍스트-시계열 데이터를 연결, 의미적 연관성이 부족.
-
데이터 오염 (Contamination)
- 보고서 내 미래 예측 정보로 인한 정보 누출(Leakage) 문제.
- 최신 LLM의 학습 범위 내에 포함된 테스트셋으로 인한 성능 과대평가 가능성.
이러한 지적은 단순한 문제제기를 넘어, 향후 멀티모달 시계열 연구의 신뢰성과 일반화 가능성을 위협하는 요소로도 해석될 수 있다.
3) Main contribution: Time-MMD & MM-TSFlib
이러한 문제 인식에 기반하여, 저자들은 두 가지 핵심 결과물을 제안한다.
Time-MMD: 최초의 범용 멀티모달 시계열 데이터셋
- 도메인 다양성: 경제, 보건, 농업 등 9개 도메인을 포괄.
- Fine-grained Alignment: 도메인 전문가에 의해 수집 및 정제된 텍스트-수치 데이터 페어링.
- 데이터 신뢰성 확보: 미래 정보 제거, 최신 시점(2024년 5월) 기준으로 수집되어 LLM 데이터 누출 방지.
MM-TSFlib: 멀티모달 시계열 예측을 위한 라이브러리
- 다양한 시계열 예측 모델에 LLM 계열 텍스트 인코더를 손쉽게 통합할 수 있는 엔드투엔드 파이프라인 제공.
- 연구자의 빠른 실험/확장/탐색을 위한 고도화된 인터페이스 제공.
2. Time-MMD 구축
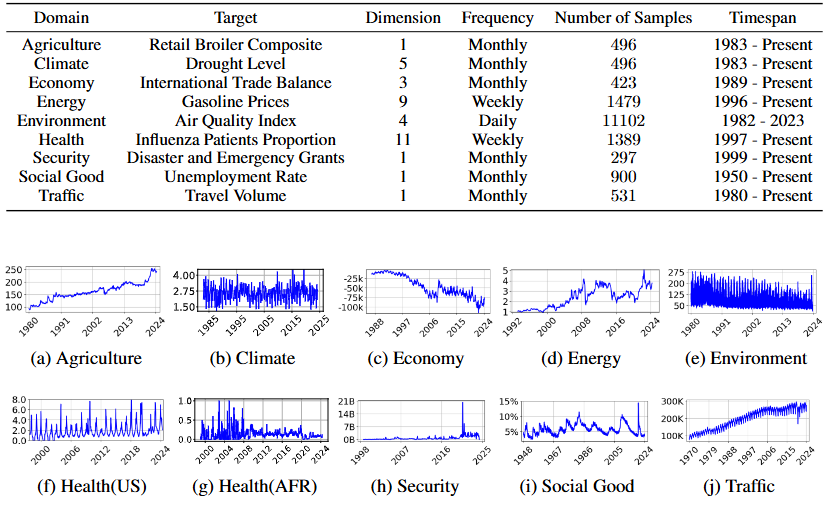
1) Challenges
Time-MMD 데이터셋은 단순한 멀티모달 데이터를 넘어, 실제 예측 문제에 사용할 수 있는 고신뢰도 시계열-텍스트 페어링을 지향한다. 이를 위해 다음의 세 가지 주요 기술적 과제를 해결해야 했다.
- 희소한 텍스트 소스
- 수치 데이터는 구조화된 포맷으로 제공되는 반면, 텍스트 정보는 뉴스, 보고서 등 다양한 채널에 비정형적이고 분산된 형태로 존재한다.
- 따라서 고품질 소스의 탐색, 수집 자동화, 시점 일치 등에 높은 리소스가 소요된다.
- 노이즈와 편향이 많은 텍스트 정보
- 전문가의 의견, 불확실한 전망, 중복 기사 등으로 인해 데이터 오염 위험이 존재하며, LLM 기반의 전처리 및 분리 작업이 필수적이다.
- 정확한 시간 정렬(Synchronization)
- 시계열 분석에서 예측 가능성을 확보하기 위해 텍스트가 유효한 기간과 수치 데이터의 관측 지점을 정확히 동기화해야 하며, 이는 단순한 수집 이상의 정제된 설계가 필요하다.
2) 해결 전략
저자들은 이러한 문제를 해결하기 위해 LLM 기반의 반자동 처리 기법과 도메인 전문 지식을 통합한 정밀 파이프라인을 설계하였다.
1단계: 수치 시계열 데이터 구축
- 도메인별 신뢰도 있는 출처 선정 (정부 기관, 공공 통계 등).
- 예측이 의미 있는 핵심 변수 선정 (예: 감염자 수, 농산물 가격, GDP 변화 등).
- 시계열 빈도 유지 및 결측 제거, 원 데이터의 통계적 특성을 훼손하지 않도록 보존.
2단계: 텍스트 데이터 수집 및 정제
- 텍스트 수집 이중화 전략
- 정확성 확보: 도메인 전문가가 직접 선택한 주요 보고서 시리즈.
- 커버리지 확보: 설계된 키워드 기반의 웹 크롤링 (Google API 사용).
- LLM 기반 텍스트 전처리 (LLaMA3-70B)
- 필터링: 주제와 관련 없는 문단 제거.
- 정보 분리: ‘사실’ vs ‘예측’ 정보 분리 → 데이터 누출 방지.
- 요약: 긴 보고서를 요약해 사용성과 토큰 효율성 향상.
3단계: 텍스트-수치 정렬
- 모든 데이터에 이진 타임스탬프(start date / end date) 부여.
- 이는 향후 다양한 시계열 예측 task에서 유연한 윈도우 설정과 fine-tuning이 가능하도록 설계됨.
3) 정량적∙정성적 검증
- 소스 융합의 유효성
-
보고서만 사용 → 정보는 정확하나 범위가 협소.
-
뉴스만 사용 → 정보는 풍부하나 중복/무관 정보 존재.
→ 결합 전략이 최적: 높은 커버리지와 정확성 동시에 확보.
-
- LLM 처리 효과
- 워드 클라우드 및 토큰 분포 분석 결과, 전처리 후 무관 키워드 제거됨.
- 텍스트 길이 평균 65% 감소 → 효율적인 학습 가능.
- 공정성 확보 노력
- 지역 편향을 막기 위해 보건 도메인에서 아프리카 등 비서구권 데이터 포함.
- 재현 가능성과 개방성:
- 모든 텍스트는 출처(URL), 생성 시점, 도메인 정보 등의 메타데이터 포함.
- 공개 라이선스 기반으로 연구자들에게 제공 예정.
3. Multimodal Time-Series Forecasting Library: MM-TSFlib
Time-MMD 데이터셋의 잠재적 이점을 보여주기 위해, 시계열 예측(TSF)이라는 기본적인 분석 작업에 초점을 맞춘다.
연구의 목표는 기존의 수치 데이터만 사용하는 단일 모드(unimodal) 모델들을 텍스트 데이터까지 함께 활용하는 다중 모드(multimodal) 모델로 확장하는 것이다.
이를 위해, 연구팀은 다중 모드 시계열 예측 문제를 수학적으로 정의하고, 이를 해결하기 위한 라이브러리인 MM-TSFlib을 제안한다.
1) Problem Formulation
단일 모드(Unimodal) TSF
-> 수치 시계열 데이터를 입력받아 미래의 수치 값을 예측한다.
-
입력 데이터 (X)
- 과거의 특정 기간 동안 관찰된 수치 데이터를 의미한다.
- 은 lookback window의 길이로, 모델이 예측을 위해 과거 데이터를 얼마만큼 참고할지를 나타냅니다 (예: 과거 30일치 데이터). 이 값은 주로 해당 분야의 전문가가 결정한다.
- 은 각 시점에서의 feature dimension으로, 동시에 관찰하는 수치 데이터의 종류를 의미한다 (주가, 거래량 등 2가지 특징).
- 따라서 입력 는 개의 시간 단계와 개의 특징으로 구성된 행렬( )로 표현된다.
-
출력 데이터 (Y)
- 모델이 예측하려는 미래의 특정 기간 동안의 수치 데이터를 의미합니다.
- 는 예측 기간 (horizon window)의 길이로, 모델이 미래를 얼마만큼 예측할지를 나타낸다 (예: 향후 7일).
- 은 각 미래 시점에서 예측하려는 target dimension이다.
- 따라서 출력 는 개의 시간 단계와 개의 목표값으로 구성된 행렬( )로 표현된다.
다중 모드(Multimodal) TSF
-> 기존의 수치 데이터( )에 더해 텍스트 시계열 데이터( )를 추가로 입력받는다.
- 추가된 입력 데이터 ( )
- 수치 데이터 외에 텍스트 시계열 데이터를 추가적인 입력으로 고려합니다.
- 는 텍스트 데이터의 lookback window 길이로, 수치 데이터의 길이 과는 독립적입니다.
- 는 텍스트의 특징 차원을 의미합니다 ( 텍스트를 벡터로 변환했을 때의 크기).
- 실제 텍스트 데이터는 길이가 제각각이라 특징 차원이 일정하지 않을 수 있다.
2) 해결책: MM-TSFlib
-
멀티모달 통합 프레임워크
-
독립적 모델링: 수치 데이터는 기존 TSF 모델이, 텍스트 데이터는 LLM(대규모 언어 모델)이 각각 독립적으로 처리한다.
-
결합: 두 모델의 출력은 '학습 가능한 선형 가중치 메커니즘'을 통해 결합되어 최종 예측을 생성한다.
-
효율성: 계산 비용을 줄이기 위해 LLM의 파라미터는 고정(freeze)하고, 추가된 일부 레이어(프로젝션 레이어)만 학습시킨다. 또한, 길이가 제각각인 텍스트 데이터 문제를 해결하기 위해 pooling layer를 사용한다.
-
-
MM-TSFlib 라이브러리
-
호환성: BERT, GPT-2, Llama-2, Llama-3 등 7개의 오픈소스 언어 모델을 통해 20개 이상의 기존 TSF 모델의 다중 모드 확장을 지원한다.
-
사용성: Time-MMD 데이터셋과 함께 쉽게 사용할 수 있도록 설계되었으며, 기존 모델들의 다중 모드 확장성을 평가하는 파일럿 툴킷 역할을 한다.

-
4. Experiments for Multimodal TSF
1) 실험 설정
실험 구성
- 도메인: Time-MMD의 9개 전 도메인
- 예측 기간: 단기부터 장기까지 다양한 Horizon Window 설정
- 모델: Transformer/MLP 계열 포함 12개 고급 단일 모드 TSF 모델
- 텍스트 모델: 특별한 언급 없을 경우 GPT-2 Small 사용
- 평가지표: 평균 제곱 오차 (MSE) – 낮을수록 성능 우수
비교 실험
- 각 TSF 모델에 대해
- 단일 모드 (Unimodal): 수치 시계열만 입력
- 다중 모드 (Multimodal): 수치 + 텍스트 시계열 입력
- 동일 설정하에서 두 버전을 비교 분석
2) 실험 결과
(1) 다중 모드 TSF의 성능 향상
-
결과
- 95% 이상의 실험에서 다중 모드 모델이 단일 모드보다 우수
- 평균 MSE 15% 이상 감소, 일부 텍스트 풍부 도메인에서는 최대 40% 감소
- 성능 향상이 모델 전반에서 일관됨
-
특이 케이스
- Informer 모델은 단일 모드에서는 성능이 낮았지만, 멀티모드 전환 후 큰 향상
→ 장거리 의존성에 강한 아키텍처가 텍스트 신호로부터 더 많은 정보 획득 가능
- Informer 모델은 단일 모드에서는 성능이 낮았지만, 멀티모드 전환 후 큰 향상
(2) Time-MMD 데이터셋 품질 검증
- 정량적 신뢰성
- iTransformer, PatchTST 등 최신 SOTA 단일 모드 모델이 강력한 성능 유지
→ 수치 시계열 데이터의 정제된 품질 입증
- iTransformer, PatchTST 등 최신 SOTA 단일 모드 모델이 강력한 성능 유지
- 텍스트 신호의 기여도
- 멀티모드 모델이 꾸준히 성능 향상
→ 텍스트 시계열 역시 예측 정보로서 유용함을 입증
- 멀티모드 모델이 꾸준히 성능 향상
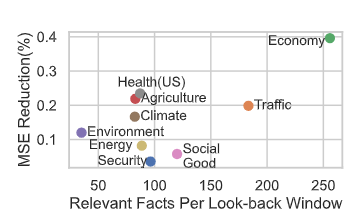
(3) 도메인별 성능 차이
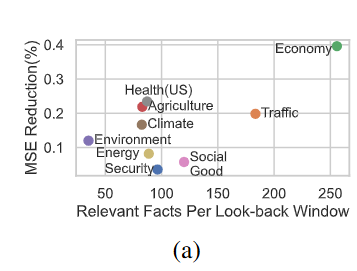
-
도메인 내 텍스트 사실 수(fact count)와 MSE 개선 간 양의 선형 상관관계를 보임
- 예: 기후/건강/교육 도메인은 텍스트 활용 이득이 큼
-
예외 도메인
- 보안(Security) 도메인은 본질적 예측 불확실성이 커서 텍스트 기반 예측 성능 낮음
(4) 예측 기간(horizon) 크기 영향
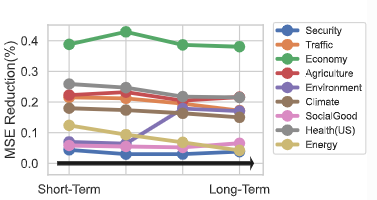
- 단기부터 장기까지 다양한 예측 기간에서 다중 모드 성능 일관되게 우수
→ 멀티모달 TSF는 다양한 시간적 예측 요구에도 강건함
(5) 텍스트 모델링 전략 비교
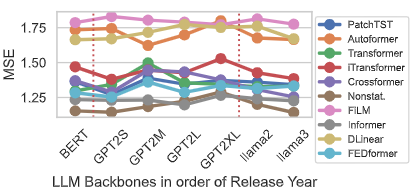
- LLM 성능 분석
- GPT2 Small ~ XL, BERT, LLaMA 시리즈 간 성능 큰 차이 없음
- GPT-2 파라미터 수 증가가 성능 향상으로 직결되지 않음
- LLaMA-3-8B vs BERT 간 성능 유사
- 가능한 해석
- 현재 프레임워크가 LLM의 전체 능력 활용 미흡
- 일반 목적 LLM이 TSF에 직접적으로 최적화되어 있지 않음
- 작은 LLM (예: BERT)은 학습이 더 효율적일 수 있음
- 대안 모델:
- Doc2Vec 사용 → 효과적이나 BERT보다는 낮은 성능
- → 단순한 임베딩 방식도 유효하지만, 성능 극대화에는 한계
5. Potential Future Works
1) 멀티모달 결측치 채우기 (Imputation)
- 문제
센서 고장이나 시스템 문제 때문에 중간중간 데이터가 비는 경우가 많다. 이걸 그냥 두면 예측이나 분석이 잘 안 된다.
- 지금까지의 한계
대부분은 앞뒤 숫자 값만 보고 비어 있는 걸 때우는데, 이러면 중요한 문맥 정보(예: 사고나 날씨 같은 텍스트)가 무시된다.
- Time-MMD를 활용하면?
예를 들어 교통량 데이터가 비었을 때, “사고가 났다”는 보고서가 같이 있다면 그 시점은 값이 낮았을 가능성이 크다. 이런 식으로 텍스트 정보를 함께 쓰면 훨씬 정확하게 비어 있는 값을 채울 수 있다.
또는 일부러 숫자 데이터를 지우고, 텍스트만 보고 복원하는 실험도 가능할것으로 보인다.
2) 멀티모달 이상 탐지 (Anomaly Detection)
- 문제
시계열에서 이상한 패턴을 빨리 잡아내는 건 중요하다. 시스템 고장, 사기, 건강 이상 등등 다 여기랑 관련된다.
- 지금까지의 한계
숫자만 보고 판단하니까, 진짜 이상한 상황인데 그냥 넘어가는 경우도 있다. 예를 들어 가격은 괜찮은데, 뉴스에서 “시장 조작” 얘기가 나왔다면 그건 이상이다.
- Time-MMD를 활용하면?
숫자 변화만 보는 게 아니라, 그 시점에 어떤 텍스트가 있었는지도 같이 보면 더 정확하게 이상을 잡을 수 있다.
예를 들어 건강 데이터에서 “독감 유행”이란 말이 나왔을 때, 수치가 평소랑 조금만 달라도 그걸 이상으로 간주할 수 있다.
3) 멀티모달 시계열 파운데이션 모델 만들기
- 왜 중요해?
요즘은 GPT나 CLIP 같은 파운데이션 모델이 대세다. 시계열 쪽에도 그런 범용 멀티모달 모델이 필요하며 Time-MMD 같은 데이터셋이 있으면 그게 가능해진다.
- Time-MMD로 뭘 할 수 있냐면..?
- 숫자랑 텍스트를 같이 넣어서 대규모로 학습시키는 모델을 만들 수 있다.
- 예측, 분류, 이상 탐지 같은 다양한 태스크를 한 번에 처리할 수 있는 모델도 만들 수 있다.
- 텍스트 프롬프트로 시계열 분석을 조작할 수 있는 인터페이스도 생각해볼 수 있다.
6. 생각정리
-
기존 흐름
기존 시계열 분석(TSA) 분야가 수치 데이터만 사용하는 단일 모드(Unimodal) 방식에 정체되어 있다. -
파악한 문제
전문가들은 실제 분석에서 뉴스나 보고서 같은 텍스트 정보를 함께 활용하지만, 정작 모델 개발에 필요한 고품질 멀티모달 데이터셋이 없어 연구가 제대로 이루어지지 못하는 '데이터 병목 현상'이 문제의 핵심이라고 생각했다.
→ 시계열 분석의 패러다임을 '수치 중심'에서 '수치와 텍스트를 함께 보는 멀티모달'로 전환의 필요성
장점 (Advantages)
-
문제 정의가 명확하며 구체적인 분석을 제공함
기존 연구의 한계를 단순히 나열하지 않고, ‘좁은 도메인’, ‘정렬 오류’, ‘데이터 오염’이라는 구조적 문제로 명확히 구분하여 제시한다.
-
데이터 구축 방식이 투명하고 재현 가능성이 높음
보고서 및 웹 기반 텍스트를 수집한 뒤, LLM 기반 전처리를 거쳐 정제된 과정을 상세히 공개하여 신뢰도를 높였다.
-
실험 설계가 포괄적이며 일반화 가능성이 높음
12개 모델, 9개 도메인, 1,000회 이상의 반복 실험을 통해 다중 모달 접근의 일관된 우수성을 체계적으로 입증했다.
-
실질적 기여와 확장 가능성을 동시에 확보함
데이터셋(Time-MMD)과 라이브러리(MM-TSFlib)를 공개하여 후속 연구 기반을 마련했으며, 이상 탐지 등 다양한 태스크로의 확장 가능성도 제시했다.
한계점 (Limitations)
-
LLM 활용 방식이 제한적임
대부분의 실험에서 사전 학습된 LLM을 고정하거나 부분적으로만 미세 조정하여, 모델의 잠재력을 충분히 반영하지 못했을 가능성이 존재한다.
-
언어 및 적용 범위가 제한됨
텍스트는 모두 영어로 구성되어 있으며, 적용된 태스크도 시계열 예측에 국한되어 있음. 다른 언어나 문제 유형으로의 확장은 추가 작업이 필요하다.
-
다른 모달리티는 고려되지 않음
현실 세계의 다양한 데이터 유형(이미지, 오디오, 센서 등)은 포함되지 않았으며, 본 논문은 텍스트 + 수치 조합에 한정되어 있다.
-
프레임워크의 완성도가 초기 수준에 머무름
저자 스스로도 MM-TSFlib을 ‘first-cut’으로 명시하고 있으며, 이는 해당 구조가 최적화된 형태가 아니라 출발점에 가깝다는 의미다.
