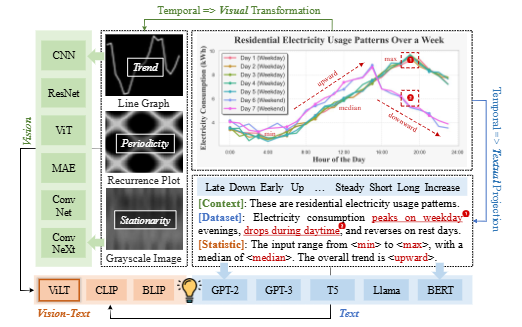
시계열 데이터는 금융, 기후, 에너지 등 다양한 분야에서 예측의 근간이 되지만, ARIMA와 같은 전통적인 모델은 복잡한 비선형 패턴을 포착하는 데 어려움이 있다.
RNN이나 트랜스포머 기반의 딥러닝 모델들이 이러한 한계를 개선했지만, 이들 역시 여러 도메인에 걸쳐 일반화하거나 데이터가 부족한 few-shot 및 zero-shot 환경에 적응하는 데는 여전히 어려움을 겪고 있다.
이러한 문제를 극복하기 위해, 연구자들은 예측 정확도를 높일 수 있는 보완적인 정보를 제공하는 텍스트나 이미지 같은 추가적인 modality로 시계열 예측을 보강하는 데 주목하고 있다.
1. 기존 멀티모달 접근법의 한계
시계열을 다른 단일 모달리티와 결합하려는 시도들은 각각 명확한 한계를 보였다.
-
Text-Augmented 모델
텍스트는 데이터셋 통계나 문맥적 설명을 통해 예측에 중요한 의미론적 정보를 제공한다. Time-LLM과 같은 모델들은 시계열을 텍스트로 변환하여 LLM의 뛰어난 추론 능력을 활용한다. 하지만 이 접근법은 두 가지 문제에 직면한다.-
연속적인 시계열과 이산적인 텍스트 사이의 모달리티 격차로 인해 정보 손실이 발생
-
사전 훈련된 언어 모델은 세밀한 시간적 패턴을 포착하는 데 최적화되어 있지 않음
-
- Vision-Augmented 모델
시계열을 라인 그래프나 이미지로 변환하면 CNN, ViT와 같은 모델이 데이터에 내재된 공간적 패턴을 활용할 수 있다.
시계열과 비전 데이터는 모두 연속적이고 구조적 유사성을 공유하여 사전 훈련된 비전 모델이 시간적 계층을 효과적으로 인코딩할 수 있다. 하지만 이 방법들은 의미론적 해석이 어려워 도메인 특화 지식을 통합하는 데 한계가 있다.
2. 저자의 의도
-
텍스트의 '의미'와 이미지의 '패턴'을 모두 활용하기 위해, 사전 훈련된 VLM을 이용해 시계열, 비전, 텍스트 3가지를 통합하는 것
-
외부 데이터 없이 오직 원본 시계열만으로 필요한 텍스트와 이미지를 내부에서 직접 생성(자가-증강)하여 활용하는 강력한 프레임워크를 만드는 것
-
특히 데이터가 부족한 few-shot 및 zero-shot 환경에서의 예측 성능을 극대화하는 것
-> 단순히 vision과 language 능력을 갖춘 것이 아니라, 훈련 초기부터 이미지와 텍스트 사이의 연관 관계를 학습하여 '사전 정렬(pre-aligned)'되어 있다는 점
3. Time-VLM: 시계열, 비전, 텍스트를 통합하는 프레임워크
이 연구는 텍스트와 비전 모달리티를 시계열과 함께 통합하려는 시도가 아직 부족하다는 문제의식에서 출발한다.
이를 해결하기 위해 사전 훈련된 비전-언어 모델(VLM)을 활용하여 시계열, 시각, 텍스트 정보를 통합하는 새로운 프레임워크인 Time-VLM을 제안한다.
Time-VLM은 다음 세 가지 핵심 구성 요소를 통해 작동한다.
-
Retrieval-Augmented Learner (RAL)
-> 원시 시계열 데이터에서 시간적 특징을 추출- 작동 방식: 입력 시계열을 패치(patch) 단위로 처리하고, memory bank와 multi-head self-attention을 통해 패치 임베딩을 정제한다.
- 목표: 시간적 표현을 보존하고 장기 의존성 모델링을 강화하여 안정적인 예측을 할 수 있도록 한다.
-
Vision-Augmented Learner (VAL)
-> 시계열 데이터를 3채널 이미지로 변환한다.- 작동 방식: 다중 스케일 컨볼루션, 주파수 및 주기성 인코딩을 통해 이미지를 생성한다. 생성된 이미지는 동결된(frozen) VLM 비전 인코더에 의해 처리되어 계층적인 시각 특징으로 변환된다.
- 목표: 데이터의 세밀한 디테일과 높은 수준의 시간적 패턴을 모두 포착한다.
-
Text-Augmented Learner (TAL)
-> 입력 시계열에 대한 문맥적 텍스트 프롬프트를 생성한다.- 작동 방식: 데이터의 통계적 특징(평균, 분산, 추세 등), 도메인 특화 문맥(예: 전력 소비 패턴), 그리고 생성된 이미지에 대한 설명을 포함하는 텍스트를 만든다. 이 프롬프트는 동결된(frozen) VLM 텍스트 인코더를 통해 텍스트 임베딩으로 변환된다.
- 목표: 예측에 필요한 의미론적, 문맥적 정보를 제공한다.
- 작동 방식: 데이터의 통계적 특징(평균, 분산, 추세 등), 도메인 특화 문맥(예: 전력 소비 패턴), 그리고 생성된 이미지에 대한 설명을 포함하는 텍스트를 만든다. 이 프롬프트는 동결된(frozen) VLM 텍스트 인코더를 통해 텍스트 임베딩으로 변환된다.
이 모듈들은 VLM과 협력하여 멀티모달 임베딩을 생성하고, 이는 최종 예측을 위해 시간적 특징과 결합된다.
1) Retrieval-Augmented Learner (RAL)
→ 원본 시계열 데이터에서 과거의 유사한 패턴(지역 메모리)과 현재 데이터의 전체적인 문맥(전역 메모리)을 모두 추출하여 풍부한 시간적 특징을 만드는 것을 목표로 한다. 이 과정은 크게 두 단계로 이루어진다.
1단계: Patch Embedding
입력된 시계열 데이터를 모델이 처리할 수 있는 단위인 'patch'로 만들고 벡터로 변환하는 과정.
- 패치 분할: 입력 시계열(
xenc)을 일정한 길이(pl)와 간격(st)으로 잘라 여러 개의 겹치는 패치로 나눈다. - 벡터 변환: 각 패치를 선형 계층에 통과시켜 차원의 벡터로 변환(임베딩)한다.
- 위치 정보 추가: 시간적 순서를 잃지 않도록 각 패치 벡터에 positional embedding을 더해준다.
이 단계를 거치면 원본 시계열 데이터는 패치 벡터의 시퀀스(Ep)로 변환된다.
2단계: 검색-증강 메모리 (Retrieval-Augmented Memory)
과거 데이터가 저장된 Memory Bank를 활용하여 현재 데이터의 특징을 더욱 풍부하게 만든다. 이 과정은 지역 메모리와 전역 메모리로 나뉜다.
(1) 지역 메모리 (Local Memory): 과거에서 유사한 패턴 찾기
현재 데이터와 가장 관련이 깊은 과거 패턴을 찾아 그 정보를 활용한다.
- 유사도 계산: 현재 패치(
P)와 메모리 뱅크(M)에 저장된 과거 패치들 간의 코사인 유사도를 계산한다.P: 현재 입력된 패치 임베딩 벡터M: 메모리 뱅크에 저장된 과거 패치들의 벡터- 위 수식은 행렬 곱을 통해 모든 현재-과거 패치 쌍 간의 유사도 점수를 계산한다.
- 특징 추출: 계산된 유사도 점수를 바탕으로 가장 유사한 상위 k개의 과거 패치를 선택하고, 이를 2계층 MLP(Multi-Layer Perceptron)에 통과시켜 지역 메모리 특징 ()을 추출한다.
topk(): 가장 유사한 k개의 과거 패치를 선택하는 연산MLP(): 선택된 패치들로부터 유의미한 정보를 압축하여 추출
(2) 전역 메모리 (Global Memory): 현재 데이터의 전체 문맥 파악
현재 입력된 패치 시퀀스 내의 장기적인 관계와 전체적인 문맥을 파악한다.
- 셀프 어텐션 적용: 현재 패치 시퀀스(
P)에 Multi-Head Self-Attention을 적용하여 패치들 간의 상호 연관성을 계산하고 문맥이 반영된 표현을 얻는다.Q, K, V: 각각 쿼리, 키, 밸류로, 입력P를 선형 변환하여 얻어진다. 이 메커니즘은 시퀀스 내에서 어떤 패치가 다른 패치에 더 중요한지 가중치를 계산한다.
- 특징 추출: 어텐션을 거친 패치 벡터들을 시간 축에 대해 평균을 내어(각 차원(열)별로 평균을 계산) 전역 메모리 특징()을 얻는다.-> 문맥화된 모든 패치 벡터들을 평균내는 이유..?
전체 시퀀스가 가진 핵심적인 특징이나 long-range dependencies을 하나의 대표 벡터로 압축하고 요약하기 위해
(3) 최종 fusion
과거의 유사 패턴 정보와 현재의 전체 문맥 정보를 결합한다.
- 메모리 fusion: 지역 메모리와 전역 메모리를 element-wise addition으로 합쳐 최종적인 시간적 특징 표현인 를 생성한다.
→ 원본 시계열 데이터에 과거의 정보와 현재의 문맥 정보가 모두 풍부하게 담긴 고차원적 특징
2) Vision-Augmented Learner (VAL)
VAL 모듈의 목표는 1차원의 시계열 데이터를 VLM이 잘 이해할 수 있는 2차원의 정보성 있는 이미지로 변환하는 것이다.
B: 배치 크기 (Batch size)
L: 시계열 길이 (Sequence Length)
D: 변수 개수 (Number of Variables)
1단계: 정보 보강 - 주파수 및 주기성 인코딩
원본 시계열 데이터에서 보이지 않는 중요한 정보인 주파수와 주기성을 명시적으로 추가하여 특징을 풍부하게 만드는 과정이다.
입력 형태: B x L x D (원본 시계열)
출력 형태: B x L x D x Channels_augmented (정보가 보강된 텐서)
(1) 주파수 인코딩 (Frequency Encoding)
시계열 데이터가 어떤 진동수(frequency) 성분들로 이루어져 있는지 분석한다. 예를 들어, 하루 주기의 큰 흐름(저주파)과 시간별 미세한 변동(고주파)을 분리해내는 것과 같습으며 이를 위해 고속 푸리에 변환(FFT)을 사용한다.
- : 시간 에서의 시계열 값
- : 전체 시계열의 길이(sequence length)
- : 주파수 인덱스(frequency index)
→ 시간 순서로 나열된 데이터()를 주파수 성분별로 분해하여, 어떤 주파수가 얼마나 강하게 나타나는지에 대한 정보(스펙트럼 정보)를 추출한다.
(2) 주기성 인코딩 (Periodicity Encoding)
데이터가 가진 주기적인 패턴(하루, 일주일)을 모델이 쉽게 인지할 수 있도록 사인(sin), 코사인(cos) 함수를 이용해 시간의 위치 정보를 인코딩한다.
- : 현재 시간 단계(time step)
- : 데이터의 주요 주기(periodicity)를 나타내는 하이퍼파라미터이다. 예를 들어, 시간별 데이터라면 하루 주기인 24가 될 수 있다.
→ 시간의 흐름에 따라 반복되는 고유한 값을 생성하여, 모델이 '지금이 주기의 어느 지점인지'를 알 수 있게 돕는다.
2단계: 특징 추출 - 다중 스케일 컨볼루션
입력 형태: B x L x D x Channels_augmented (정보 보강 텐서)
출력 형태: B x C x H_feat x W_feat (특징 맵 텐서)
정보가 보강된 시계열 데이터에서 이미지의 특징을 뽑아내듯, 계층적인 패턴을 추출한다. 1D 컨볼루션으로 짧은 구간의 지역적 패턴을 포착한 뒤, 2D 컨볼루션으로 더 넓은 범위의 전역적, 구조적 패턴을 추출한다.
3단계: 이미지 생성 - 보간 및 정규화
입력 형태: B x C x H_feat x W_feat (특징 맵 텐서)
출력 형태: B x C x H x W (최종 이미지 텐서)
(1) 이미지 보간 (Image Interpolation)
특징 맵을 지정된 이미지 크기(예: 64x64 픽셀)로 부드럽게 확대하거나 축소한다. 이때 쌍선형 보간법(bilinear interpolation)을 사용한다.
- : 생성될 이미지의 위치의 픽셀 값
- (, ): 위치 주변의 가장 가까운 4개 픽셀의 값
- : 거리에 따라 계산된 4개 픽셀의 가중치
→ 새로운 픽셀 값을 주변 4개 픽셀 값의 가중치 합으로 계산하여, 이미지의 깨짐 없이 자연스러운 크기 조정을 가능하게 한다.
(2) 정규화 (Normalization)
이미지의 픽셀 값을 VLM이 처리하기 쉬운 0~255 범위로 변환하며 이를 위해
최소-최대 정규화를 사용한다.
- : 정규화 이전의 이미지 픽셀 값
- : 각각 이미지 전체의 최소, 최대 픽셀 값
- : 분모가 0이 되는 것을 방지하기 위한 아주 작은 값(10−5).
→ 이미지의 모든 픽셀 값을 0과 1 사이로 압축한 뒤, 255를 곱해 표준 이미지의 픽셀 범위에 맞춘다. 이는 VLM 비전 인코더의 입력 형식과 일치시켜 성능을 보장하는 중요한 단계이다.
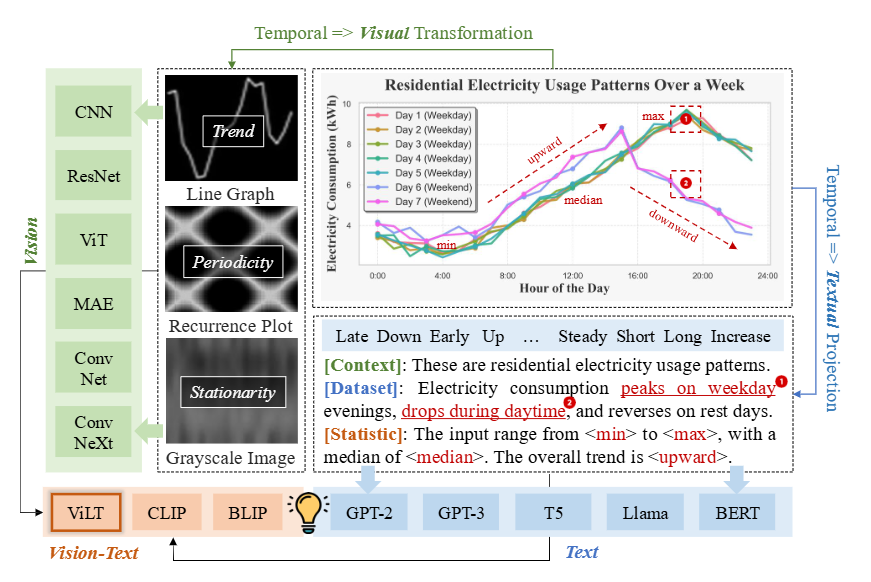
3) Text-Augmented Learner (TAL)
시계열 데이터를 VLM의 텍스트 인코더가 이해할 수 있도록 상세한 설명문(텍스트 프롬프트)으로 만드는 것으로 이 과정은 dual-path를 통해 유연하게 작동한다.
1단계: 동적 생성 경로: 데이터를 보고 실시간으로 설명문 만들기
이 경로는 일반적인 예측 작업에 사용되며, 입력된 시계열 데이터로부터 직접 정보를 추출해 설명문을 자동으로 생성한다.
(1) 정보 추출
- 통계적 속성 (Statistical Properties)
- 값의 범위: 데이터의 최솟값(min)과 최댓값(max)
- 중심 경향성: 데이터의 중앙값(median)
- 전반적인 추세: 데이터가 전반적으로 상승세인지, 하락세인지 등의 방향성
- 문맥 정보 (Contextual Information)
- 작업 정보: 예측에 사용될 과거 데이터의 길이(input window)와 예측할 미래 구간의 길이(forecasting horizon)
- 주기성 정보: 데이터가 가진 주기(예: 하루, 일주일)에 대한 설명
- 도메인 정보: 데이터셋의 종류나 특징 (예: 주거용 전력 사용량 패턴)
(2) 프롬프트 구성
- 예시 프롬프트
[Task]: Forecast the next {pred_len} steps based on the past {seq_len} steps.
[Domain]: This is residential electricity consumption data. It peaks at noon and drops in the evening.
[Statistics]: Input ranges from {min} to {max}, with a median of {median}. Overall, the trend is {increasing/decreasing}.
2단계: 사전 정의 경로: 전문가 지식 활용하기
의료나 금융 분석처럼 특수한 전문 지식이 필요한 경우, 미리 작성된 전문가의 설명문을 활용할 수 있다. 이 사전 정의된 텍스트는 동적으로 생성된 프롬프트와 결합되어, 모델이 더 깊은 문맥을 이해하도록 돕는다.
3단계: VLM 인코딩
두 경로를 통해 완성된 최종 텍스트 프롬프트는 동결된(frozen) VLM 텍스트 인코더에 입력된다.
- 출력: 텍스트 인코더는 이 설명문을 contextual embedding이라는 벡터로 변환한다.
→ 이 벡터는 시계열 데이터의 의미론적, 문맥적 정보를 압축하여 담고 있으며, 이후 시각적 특징(VAL) 및 시간적 특징(RAL)과 결합되어 예측 정확도를 높이는 데 사용된다.
Multimodal Fusion with VLMs
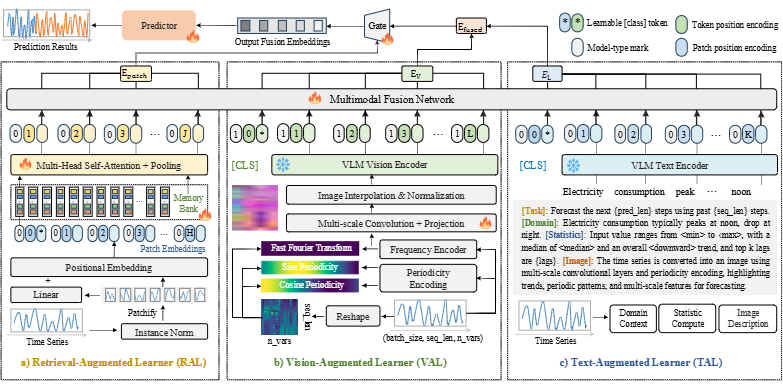
1단계: 멀티모달 임베딩 추출
- VAL에서 생성된 이미지와 TAL에서 생성된 텍스트를 frozen VLM에 입력한다. VLM은 이 두 정보를 내부적으로 처리하여, 이미지와 텍스트의 의미가 통합된 멀티모달 임베딩( )을 출력한다.
→ 이 임베딩은 시계열 데이터에 대한 시각적 패턴과 문맥적 설명을 모두 함축한 고차원의 벡터이다.
2단계: 시간적 특징 융합
RAL에서 추출된 순수한 시간적 특징( )과 1단계에서 얻은 멀티모달 특징( )을 결합하는 단계
(1) 교차-모달 어텐션: "서로 다른 정보의 연관성 계산"
→ 시간적 특징이 멀티모달 특징의 어떤 부분에 더 주목해야 할지 학습하는 과정
- Query (Q): 시간적 특징( )이 "질문" 역할
- Key/Value (K/V): 멀티모달 특징( )이 "참조할 정보" 역할
→ "시간적 특징(Q)을 기준으로 봤을 때, 멀티모달 특징(K)의 어떤 부분이 가장 연관성이 높을까?"를 계산한다. 그 연관성(가중치)에 따라 멀티모달 특징(V)에서 중요한 정보만 가져와 새로운 특징( )을 만든다.
(2) Gate fusion: "최적의 정보 조합 비율 결정"
→ 어텐션을 거친 정보와 원본 멀티모달 정보를 어떤 비율로 섞을지 동적으로 결정하는 과정
- Gate 계산: 먼저, 시간적 특징과 멀티모달 특징을 모두 고려하여 0과 1 사이의 값을 가지는 게이트
G를 계산한다.
- 최종 fusion: 이 게이트
G값을 '조절 밸브'처럼 사용하여 두 특징을 섞는다.G가 1에 가까우면 어텐션을 거친 특징( )을 더 많이 반영G가 0에 가까우면 원본 멀티모달 특징()을 더 많이 반영
(3) 최종 예측
→ 모든 정보가 풍부하게 담긴 최종 융합 임베딩 ( )을 미세 조정된 predictor에 입력하여 예측한다.
최적화(Optimization) 과정
모델의 학습 목표는 예측값( )이 실제 미래 값( )과 최대한 가까워지도록 만드는 것
이를 위해 Mean Squared Error (MSE)를 손실 함수로 사용하여 모델의 오차를 계산하고, 이 오차를 최소화하는 방향으로 모델을 훈련시킨다.
- : 전체 손실(Loss) 값
- : 예측하고자 하는 미래 구간의 총 길이(Horizon)
- : 모델이 예측한
h번째 미래 시점의 값 - : 실제
h번째 미래 시점의 값(Ground-Truth)
Lightweight Fine-Tuning
Time-VLM의 가장 중요한 최적화 전략은 사전 훈련된 거대 VLM의 대부분을 동결(frozen)시키는 것이다. 즉, 수십억 개의 파라미터를 가진 VLM의 가중치는 훈련 중에 전혀 업데이트되지 않는다.
대신, Time-VLM을 위해 새롭게 추가된, 작고 가벼운(lightweight) 부분들만 학습(미세 조정)한다. 훈련되는 부분은 다음과 같다.
- RAL 모듈: 원본 시계열을 패치로 만들고, 메모리 뱅크와 어텐션을 통해 시간적 특징을 추출하는 부분.
- VAL 모듈: 시계열을 이미지로 변환하기 위해 주파수/주기성 정보를 인코딩하고, 다중 스케일 CNN을 처리하는 부분.
- Prediction Head: 최종적으로 fusion된 특징들을 바탕으로 예측값을 생성하는 게이트 네트워크와 선형 계층 부분.
Experiments
데이터셋 및 평가지표
- 데이터셋: 에너지(ETTh1, ETTh2, ETTm1, ETTm2), 날씨, 전력(ECL), 교통 등 다양한 도메인의 7가지 데이터셋에서 장기 예측 성능을 평가했다. 단기 예측 성능은 M4 벤치마크를 사용하여 측정했다.
- 평가지표: 성능은 MAE와 MSE를 사용하여 측정했다.
비교 모델 (Baselines)
| 분류 | 모델명 |
|---|---|
| 기본/선형 | DLinear |
| Transformer 기반 | Autoformer, FEDformer, Informer, Reformer, PatchTST, TimeNet, ETSFormer, Stationary, LightTS |
| LLM 기반 | GPT4TS, Time-LLM |
구현 세부사항
- 공정성: 공정한 비교를 위해 모든 비교 모델들은 통일된 평가 파이프라인 하에서 동일한 구성으로 평가되었다.
- 백본 모델: 기본 비전-언어 백본으로는 ViLT가 사용되었으며, CLIP과 BLIP-2 또한 지원된다.
- 훈련 환경: 모든 모델은 Adam 옵티마이저, 배치 크기 32, 최대 10 에포크(조기 종료 포함)로 훈련되었으며, 실험은 Nvidia RTX A6000 GPU에서 실행되었다.
Forecasting 결과
Table 1 & 2: Few-shot Forecasting
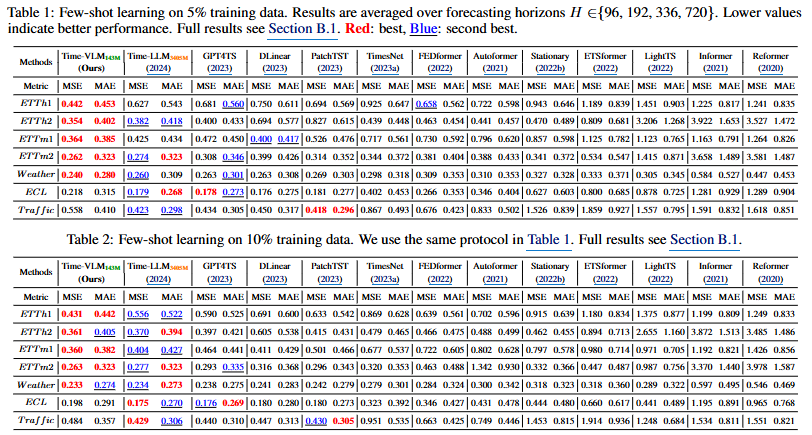 → 훈련 데이터의 5% 또는 10%만 사용했을 때의 장기 예측 성능을 보여준다.
→ 훈련 데이터의 5% 또는 10%만 사용했을 때의 장기 예측 성능을 보여준다.
- Time-VLM은 거의 모든 데이터셋에서 다른 모든 비교 모델들(TimeLLM, GPT4TS, PatchTST 등)을 압도적으로 능가하는 성능을 기록했다. 데이터가 극히 적은 상황에서 사전 훈련된 VLM의 지식을 활용하는 멀티모달 접근법이 매우 효과적이다.
Table 3: Zero-shot Forecasting
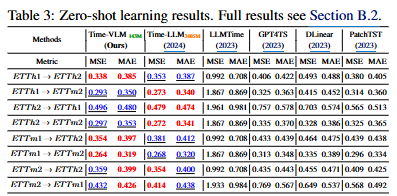 → 한 데이터셋(소스 도메인)에서 학습한 뒤, 추가 학습 없이 다른 데이터셋(타겟 도메인)을 예측하는 교차 도메인 성능을 평가한다.
→ 한 데이터셋(소스 도메인)에서 학습한 뒤, 추가 학습 없이 다른 데이터셋(타겟 도메인)을 예측하는 교차 도메인 성능을 평가한다.
- Time-VLM은 더 적은 파라미터를 사용함에도 불구하고 SOTA 모델인 TimeLLM과 대등하거나 더 우수한 성능을 보였다. 예를 들어,
ETTh1 → ETTh2전이 환경에서 TimeLLM보다 오차(MSE)가 4.2% 낮았다. 이는 Time-VLM의 강력한 일반화 및 지식 전이 능력을 보여준다.
Table 4: Short-term Forecasting
 → M4 벤치마크 데이터셋에서의 단기 예측 성능을 SMAPE, MASE, OWA 지표로 평가했다.
→ M4 벤치마크 데이터셋에서의 단기 예측 성능을 SMAPE, MASE, OWA 지표로 평가했다.
- Time-VLM은 모든 지표에서 꾸준히 SOTA 모델들을 능가했다. 2위 모델인 Time-LLM보다도 더 적은 계산 자원으로 더 높은 성능을 달성했으며, 이는 멀티모달 지식이 단기 예측에도 유용함을 시사한다.
Table 5: Long-term Forecasting
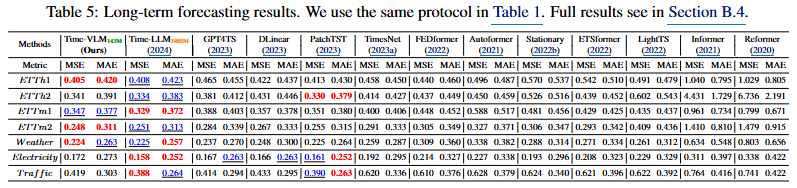 → 전체 훈련 데이터를 사용했을 때의 일반적인 장기 예측 성능을 보여준다.
→ 전체 훈련 데이터를 사용했을 때의 일반적인 장기 예측 성능을 보여준다.
- Time-VLM은 SOTA 모델들과 경쟁력 있는 성능을 달성했다. 일부 데이터셋에서는 TimeLLM보다 약간 낮은 성능을 보이기도 했지만 , TimeLLM(3405M)의 약 1/20 수준인 143M 파라미터만으로 이러한 결과를 달성하여 압도적인 효율성을 보였다.
Ablation Studies: 각 모듈의 기여도 평가
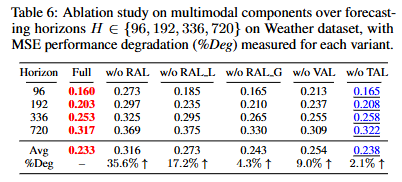
-
RAL이 가장 중요: RAL을 제거했을 때 오차(MSE)가 35.6%나 급증하였다.. 특히 RAL의 지역 메모리(Local)와 전역 메모리(Global)는 각각 17.2%, 4.3%의 성능 기여도를 보여, 계층적 메모리 설계가 효과적이었음을 확인할 수 있다.
-
VAL도 필수적: VAL을 제거하자 오차가 9.0% 증가했다. 이는 시계열을 이미지로 변환하여 시각적 패턴을 분석하는 것이 성능에 큰 도움이 됨을 의미한다.
-
TAL의 영향은 제한적: 반면, TAL을 제거했을 때 오차는 2.1% 증가하는 데 그쳤다. 저자들은 그 이유를 현재 사용된 VLM(ViLT)이 텍스트보다 이미지 특징을 훨씬 많이 사용하기 때문이라고 보인다. (전체 156개 토큰 중 텍스트 토큰은 11개뿐). 즉, TAL은 유용한 문맥을 제공하지만 현재 VLM 구조에서는 그 영향력이 제한적이다.
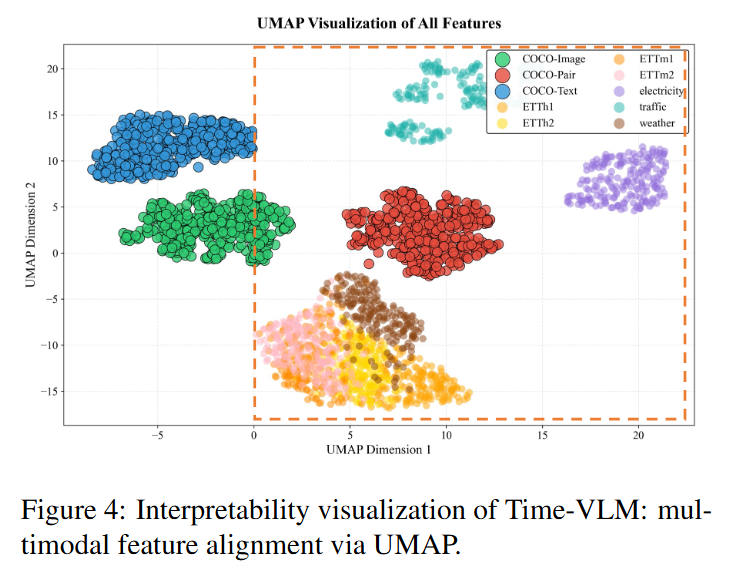
Interpretability Analysis
서로 다른 종류의 데이터(자연 이미지, 텍스트, 시계열)가 VLM에 의해 어떻게 표현되는지를 하나의 2D 공간에 점으로 찍어 분포를 확인
- 비교 대상
- COCO-Image: VLM의 사전 훈련 데이터(MSCOCO)에서 이미지 정보만 추출한 것.
- COCO-Text: 동일한 데이터에서 텍스트 정보만 추출한 것.
- COCO-Pair: 이미지와 텍스트가 짝을 이룬 멀티모달 정보.
- Time-VLM의 시계열: Time-VLM이 시계열 데이터를 변환한 멀티모달 정보.
분석 결과
1. 단일 모달 정보는 '섬'처럼 고립되었다 .
- COCO-Image와 COCO-Text의 점들은 시계열 데이터의 점들과 전혀 섞이지 않고, 각각 멀리 떨어진 별개의 군집(클러스터)을 형성했다.
→ 모달리티 간에 명확한 격차(gap)가 존재
2. 멀티모달 정보가 '다리' 역할을 했다.
- COCO-Pair의 점들은 시계열 데이터의 점들(ETT, Traffic 등)과 가장 많이 겹쳤으며, 심지어 그 중심부에 위치했다.
→ 텍스트의 의미론적 정보가 이미지의 시각적 패턴과 시계열의 시간적 패턴을 연결해주는 핵심적인 '가교' 역할을 한다.
4. 생각정리
장점 (Advantages)
-
뛰어난 저데이터 성능: 훈련 데이터의 5% 또는 10%만 사용하는 few-shot 환경과, 처음 보는 데이터셋을 예측하는 zero-shot 환경에서 기존 SOTA 모델들을 압도하는 성능을 보인다.
-
높은 계산 효율성: SOTA 모델인 Time-LLM 파라미터 개수의 약 1/20 수준(143M vs 3405M)만으로도 대등하거나 더 나은 성능을 달성했다. 또한 메모리 사용량이 훨씬 적어 대용량 데이터셋에서도 안정적으로 작동한다.
-
최초의 3-모달리티 통합: 시계열, 비전, 텍스트의 3가지 정보를 하나의 프레임워크로 통합한 최초의 모델이다. 이를 통해 각 모달리티의 단점을 보완하고 강점을 극대화한다.
-
Self-augumented 능력: 외부의 이미지나 텍스트 없이 오직 원본 시계열 데이터만으로 필요한 시각/텍스트 표현을 내부적으로 생성하여 활용한다. 이는 보조 데이터가 없는 실제 환경에서도 모델이 강건하게 작동하도록 만든다.
한계점 (Limitations)
-
제한적인 텍스트 활용: 텍스트 정보를 제공하는 TAL 모듈의 성능 향상 기여도가 2.1%로 미미했다. 이는 현재 VLM이 시계열 관련 텍스트를 이해하는 능력이 제한적이기 때문이다.
-
Full-shot 성능의 한계: 데이터가 적은 환경에서는 최고 성능을 보이지만, 전체 데이터를 모두 사용하는 환경에서는 일부 특정 데이터셋(ECL, Traffic 등)에 한해 특화된 단일 모달 모델보다 약간 성능이 뒤처지는 경우가 있었다.
-
불규칙한 패턴에 대한 취약성: Traffic 데이터셋처럼 갑작스러운 변화가 많거나 변동성이 큰 불규칙한 패턴을 모델링하는 데는 어려움을 보였다.
-
경량 디바이스 배포의 어려움: LLM 기반 모델보다는 훨씬 효율적이지만, 리소스가 제한된 소형 기기에 배포하기에는 여전히 무겁다.
