인공지능 분야에서 시계열 분석과 거대 언어 모델(LLM)은 각자의 영역에서 괄목할 만한 발전을 이루어왔다.
하지만 숫자 데이터의 패턴을 읽는 능력과 인간의 언어를 이해하는 능력은 오랫동안 별개의 길을 걸어왔다. 이 두 강력한 AI를 어떻게 하면 하나로 합쳐 시너지를 낼 수 있을까?
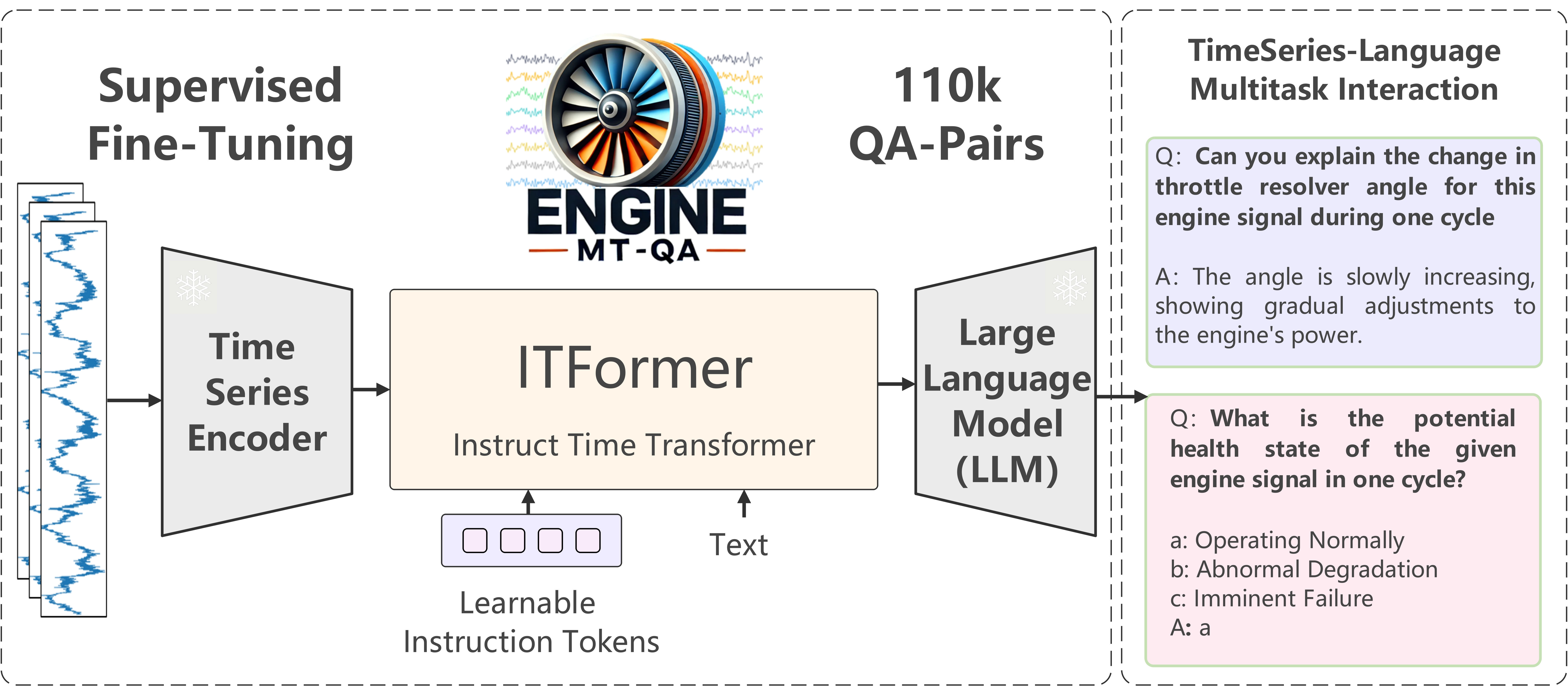
최근 2025 ICML에 공개된 ITFormer 논문은 이 질문에 대한 매우 실용적인 방법론을 제시한다.
연구진은 시계열 인코더와 LLM을 '고정(frozen)'시킨 채, 그 사이를 잇는 'Adapter'만으로 두 Modality를 연결하는 새로운 아키텍처를 제안했다.
본 리뷰에서는 ITFormer가 어떻게 파편화된 시계열 task를 '질의응답(QA)'이라는 하나의 패러다임으로 통합했는지, 그리고 그 핵심 설계와 실험 결과를 정리해보겠다.
기존 방식: 예측, 분류, 이상 탐지 등 각 작업마다 별도의 모델을 만들어야 했음. 이는 비효율적이고 확장성이 떨어짐.
저자의 의도: 이 모든 개별 작업을 "자연어 질의응답(QA)"이라는 단 하나의 통일된 프레임워크로 묶어버리려는 것. 사용자가 자연어로 질문만 하면, AI가 알아서 과업을 파악하고 분석하여 자연어로 답하게 함으로써, 어떤 종류의 시계열 문제든 처리할 수 있는 "만능 AI"의 기반을 만들고자 함.
시계열 데이터 T와 질문 q를 입력받아 답변 a를 출력하는 통합된 함수 f를 학습하는 과정
1) 모델의 구성 요소
효과적인 모델링을 위해 함수 f는 여러 단계로 나뉩니다.
- 인코딩 (Encoding)
- 시계열 인코더 (): 먼저, 시계열 데이터 T를 잠재적 표현(latent representation) 으로 압축
- 언어 인코더 (): 동시에, 자연어 질문 q를 의미적 표현(semantic representation) 으로 변환
- 시계열 인코더 (): 먼저, 시계열 데이터 T를 잠재적 표현(latent representation) 으로 압축
- 융합 (Fusion)
- 상호작용 메커니즘 (): 위에서 얻은 두 표현 을 상호작용 메커니즘을 통해 결합하여 하나의 융합된 표현 을 만듦
- 상호작용 메커니즘 (): 위에서 얻은 두 표현 을 상호작용 메커니즘을 통해 결합하여 하나의 융합된 표현 을 만듦
- 디코딩 (Decoding)
- 디코더 (): 마지막으로, 융합된 표현 을 원래 질문 q의 맥락과 함께 고려하여 최종 답변 a를 생성
- 여기서 디코더 는 와 텍스트 질문(q)을 모두 활용해 답을 만들어내는 함수
- 디코더 (): 마지막으로, 융합된 표현 을 원래 질문 q의 맥락과 함께 고려하여 최종 답변 a를 생성
ITFormer는 종류가 다른 시계열 데이터와 텍스트 데이터를 정렬(alignment)할 때 발생하는 문제들과 계산 효율성 문제를 해결하기 위해 설계되었습니다.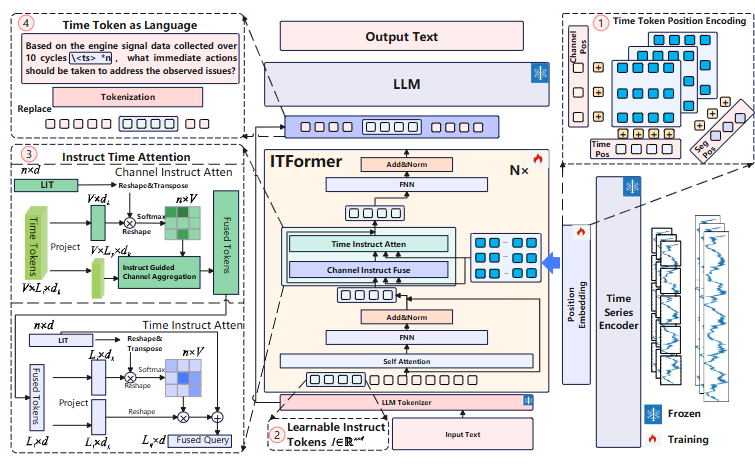
1. Time Token Position Encoding (TPE)
→ 숫자만 나열된 시계열 데이터에 "이 데이터는 언제, 어떤 종류의, 어느 구간의 값이야" 라는 구조적 주소를 명시적으로 부여
- : 시계열 인코더가 데이터를 최초로 처리하여 특징을 추출한 값
- 예를 들어, 특정 시계열 조각은 다음과 같이 표현하고 인코더는 이를 토큰화된 잠재 표현으로 바꿈
- 시간 순서 (): 데이터가 시간적으로 몇 번째 순서인지
→ 데이터의 시간적 순서를 알려주기 위해 사인(sinusoidal) 함수를 이용해 위치 정보를 추가. 각 시간 단계에 대한 순서 정보를 담음 - 채널 정보 (): 데이터가 어떤 종류의 센서값인지
→ 각 채널(V개)이 갖는 고유한 의미를 구별하기 위해 학습 가능한 임베딩을 추가 - 세그먼트 정보 (): 데이터가 어떤 기간에 속하는지
→ 여러 시계열 조각 ()이 입력되었을 때, 각 토큰이 어떤 조각에 속하는지 명확히 구별하기 위해 회전 인코딩(rotary encoding)을 적용
먼저 시계열 데이터 T를 시계열 인코더 로 처리한 뒤, 여기에 위 세 가지 위치 인코딩 값을 더함
2. Learnable Instruct Tokens (LIT)
→ 사용자의 긴 자연어 질문에서 "그래서 진짜 원하는 게 뭐야?" 라는 핵심 의도만 추출하여 간결한 '명령어'로 만듦
LIT의 작동 방식
- Prepending
먼저, 학습 가능한 명령어 토큰 I를 사용자의 실제 질문 토큰 q의 맨 앞에 붙임. 이렇게 합쳐진 질문가 만들어짐 - Self-Attention
합쳐진 를 Self-Attention 메커니즘에 통과시킴. 이 과정에서 모델은 전체 질문(q)의 맥락을 파악하고, 그 핵심 의도를 I에 요약하여 써넣음 - Extraction
이제 핵심 의도가 모두 요약된 만을 에서 다시 추출함. 원래의 긴 질문 q 부분은 버려짐
3. Instruct Time Attention (ITA)
→ 방대한 시계열 데이터 속에서 사용자의 질문과 관련된 결정적인 정보만 추출하는 것을 목표로 함
-
WHAT?: 어떤 종류(채널)의 데이터를 봐야 하는가?
-
WHEN?: 어떤 시점(시간)의 데이터를 봐야 하는가?
Channel Instruct Fusing → Time Instruct Attention의 2단계 필터링 과정을 거침
-
Channel Instruct Fusing
→ 질문과 관련 없는 데이터 채널을 걸러내고, 의미 있는 채널의 정보만을 하나로 압축-
입력 (Inputs)
- : 질문의 핵심 의도가 담긴 명령어 토큰
- : 전체 시계열 데이터. 3차원 형태(
시간 × 채널 × 특징)로, 모든 시간대의 모든 센서(채널) 정보를 담음
-
출력 (Output)
- : 각 채널의 데이터를 '중요도(어텐션 가중치)'에 따라 섞어서 질문에 가장 유용한 단일 정보로 만드는, 가중 평균(weighted average)
- : 각 채널의 데이터를 '중요도(어텐션 가중치)'에 따라 섞어서 질문에 가장 유용한 단일 정보로 만드는, 가중 평균(weighted average)
-
-
Time Instruct Attention
→ 1단계에서 정제된 데이터 스트림을 가지고, 질문과 관련된 결정적인 시간대를 찾아내는 것-
입력 (Inputs)
- : 동일한 명령어 토큰
- : 1단계에서 채널이 압축된 2차원 시계열 데이터
-
출력 (Output)
- :Q와 K를 비교하여 계산된 시간대별 중요도 점수를 바탕으로, 모든 시간대의 정보(Value)를 하나의 최종 정보로 융합
-
4. Time Token as Language (TAL)
이전 단계에서 최종적으로 융합된 시계열 표현 을 하나의 단어 뭉치처럼 다룸. 그리고 이 "단어" 뭉치를 원래의 자연어 질문 안에 미리 정해둔 빈칸(placeholder)에 삽입
이 과정을 통해 시계열 데이터에서 추출된 의미 가 자연어 질문의 문맥 구조 안으로 통합
- Placeholder Replacement
- Answer Generation → LLM의 디코더 사용
2) 훈련 과정
ITFormer는 생성된 답변과 실제 정답 간의 교차 엔트로피 손실을 최소화하는 SFT을 통해 훈련
ITFormer의 파라미터만 업데이트되며, 시계열 인코더 와 LLM (예: 7B 파라미터)는 고정된 상태로 유지. 시계열 인코더 는 다변량 시계열 데이터 에서 시계열 임베딩 를 추출
Alignment Training
전체 파라미터의 약 0.07%에 해당하는 정렬 모듈 만 업데이트되며, 이는 를 쿼리 임베딩 = 의 의미 공간으로 투영하여 융합된 표현을 형성
그 후 고정된 LLM 디코더 는 최종 답변 를 생성
훈련은 다음의 교차 엔트로피 손실을 최소화함 → 여기서 오직 만 업데이트
3) 저자가 제시한 EngineMT-QA 데이터셋
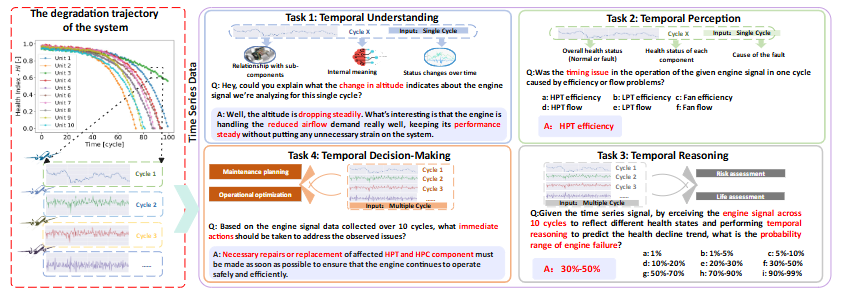
- 기반: 실제 항공기 엔진의 운행 및 고장 데이터를 담고 있는 N-CMAPSS를 기반으로 제작
- 규모: 총 11,000개의 시계열 데이터와 질문-답변 쌍으로 구성된 대규모 데이터셋
- 목표: AI가 단순 분석을 넘어, 실제 산업 현장에서 필요한 복합적인 능력을 갖추었는지 종합적으로 평가하는 것
4가지 기준
- 이해 (Understanding)
- 질문 예시: "센서 A와 센서 B는 어떤 관계가 있어? 왜 A가 올라갈 때 B는 내려가?"
- 평가 항목: 센서 데이터 간의 관계 및 변화의 의미를 해석하는 능력.
- 인식 (Perception)
- 질문 예시: "현재 엔진의 상태는 정상이야, 아니면 결함이 있어? 원인이 뭐야?"
- 평가 항목: 데이터의 상태를 파악하고, 문제의 원인을 진단하는 능력.
- 추론 (Reasoning)
- 질문 예시: "엔진 성능이 나빠지고 있는 것 같은데, 앞으로 어떻게 될까? 잔여 수명은 얼마나 남았어?"
- 평가 항목: 데이터의 추세를 분석하여 미래를 예측하는 능력.
- 의사결정 (Decision-Making)
- 질문 예시: "엔진 부품을 지금 당장 수리해야 할까, 아니면 나중에 해도 될까?"
- 평가 항목: 분석과 추론을 바탕으로 최적의 행동을 결정하는 능력.
평가 방식
-
서술형 문제 (이해, 의사결정): 답변이 정해져 있지 않으므로, 생성된 문장이 얼마나 논리적이고 풍부한지를 BLEU, Rouge-L 점수로 평가
-
객관식 문제 (인식, 추론): 답변이 정해져 있으므로, 정확도(Accuracy)와 F1 점수로 모델이 정답을 맞혔는지 평가
실험 결과
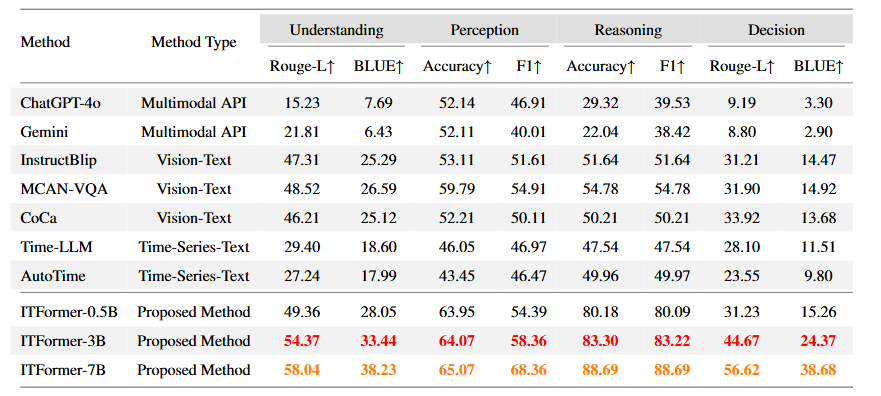
-
자체 제작한 EngineMT-QA 데이터셋의 4가지 모든 작업(이해, 인식, 추론, 의사결정)에서 ITFormer-7B 모델이 모든 평가 지표 1위를 차지함.
-
뛰어난 확장성 및 효율성: 모델 크기가 클수록 성능이 좋아졌으며(7B > 3B > 0.5B), 가장 작은 ITFormer-0.5B 모델조차도 다른 강력한 모델들(Time-LLM, InstructBlip 등)을 능가함.
-
경쟁 모델의 한계
- ChatGPT-4o, Gemini: 이와 같은 범용 API는 전문성이 부족하여 모든 작업에서 매우 낮은 점수를 기록.
- Time-LLM 등: 시계열 전문 모델들은 의사결정과 같은 글짓기(생성) 능력이 부족.
- InstructBlip 등: 비전 모델을 개조한 경우, 성능이 불안정.
4) 제거 연구 (Ablation Study)
모델의 최적 설정 찾기
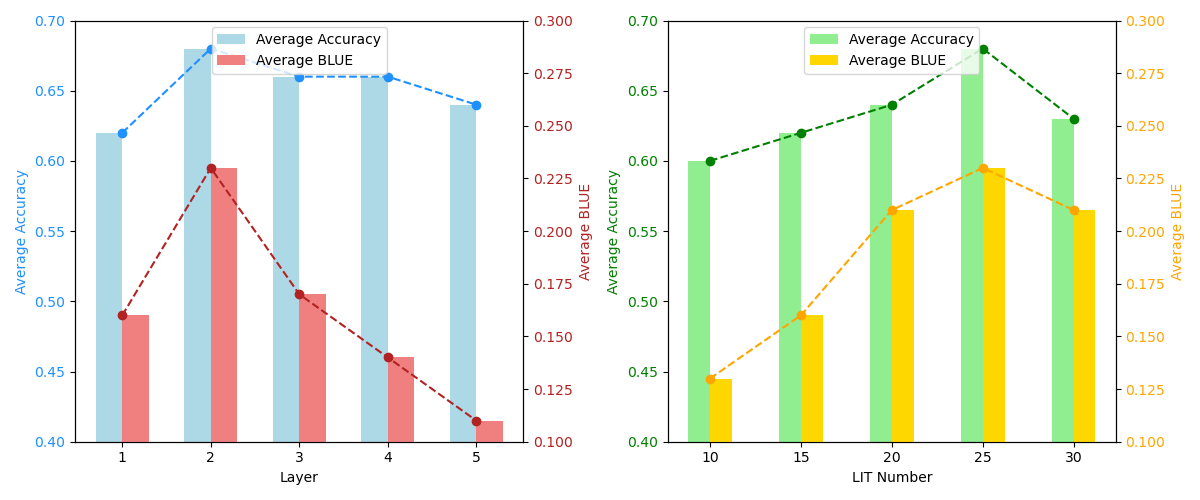
- ITFormer 레이어 수: 모델을 너무 깊게 쌓는다고 무조건 좋은 것은 아님. 2개의 레이어를 사용했을 때 효율과 성능의 균형이 가장 좋았음.
- LIT 토큰 길이: 질문을 요약하는 명령어 토큰(LIT)의 개수는 너무 적어도, 너무 많아도 안 됐음. 25개를 사용했을 때 가장 이상적인 성능을 보임.
Component 분석
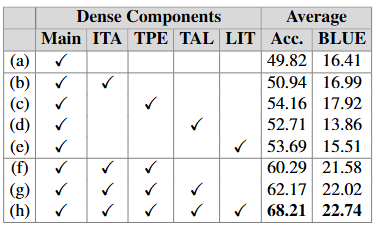
-
TPE, LIT, ITA, TAL이 함께 사용될 때 훨씬 더 강력한 성능을 발휘함
-
ITA + TPE: 특히 두 요소를 결합하자 성능이 크게 향상됨
-> 여기에 TAL(결과를 언어로 변환)을 더하니 정확도가 더욱 향상됨
추가 실험 방법 및 결과
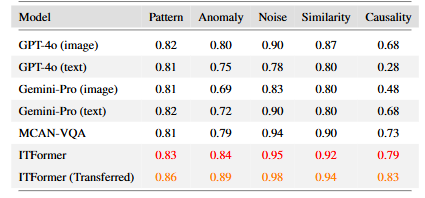
-
테스트 방식: 항공기 엔진과 관련 없는 5가지 일반적인 시계열 문제(패턴 인식, 이상 탐지 등)를 모아놓은 TimeSeriesExam 데이터셋으로 모델을 평가
-
결과 1: 직접 테스트 (Direct Generalization)
- 엔진 데이터 없이 바로 TimeSeriesExam 데이터로 훈련시켜도, ITFormer는 GPT-4o나 Gemini 같은 거대 모델보다 뛰어난 성능을 보임
-
결과 2: 전이 학습 (Transfer Learning)
- 엔진 데이터(EngineMT-QA)로 미리 학습시킨 후 TimeSeriesExam 데이터로 추가 학습시켰더니, 성능이 훨씬 더 좋아짐
5) 생각정리
장점 (Strengths)
-
통합된 프레임워크
예측, 분류 등 각기 다른 시계열 문제를 하나의 자연어 QA 모델로 통합하여, 사용자가 대화하듯 다양한 문제를 해결할 수 있게했다. -
훈련 효율성
이미 검증된 LLM은 그대로 두고, 두 모델을 잇는 Adapter만 훈련시키는 방식으로, 시간과 비용을 절약해 현실적인 적용 가능성을 높였다. -
구조화된 아키텍처
숫자 데이터인 시계열을 LLM이 이해할 수 있는 언어적 맥락으로 변환하는 4단계(TPE, LIT, ITA, TAL) 파이프라인을 통해, 복잡한 문제를 논리적이고 효과적으로 해결했다.
한계 (Limitations)
-
일반화 성능의 불확실성
'항공기 엔진' 데이터 외에 금융, 의료 등 전혀 다른 특성의 시계열 데이터에서도 모델이 효과적으로 작동할지는 아직 검증되지 않았다. -
고품질 데이터셋의 필요
모델을 훈련시키려면 질문과 정답이 있는 대규모 데이터셋이 반드시 필요하다. 이러한 데이터셋이 없는 새로운 분야에 적용하기에는 시간과 비용 문제가 발생할 수 있다. -
설명 가능성 부족
모델이 내놓은 답변에 대해 '왜' 그렇게 판단했는지에 대한 근거를 제시하지 못한다. 이는 AI의 결정을 신뢰해야 하는 중요 산업 분야에서 사용되기 어려운 결정적인 한계로 보인다.
저자의 관점은 이렇지..않을까?
"LLM은 어떻게 방대한 시계열 숫자 데이터 속에서, 자연어 질문에 해당하는 특정 부분을 정확히 찾아내어 분석할 수 있을까?"
"인간 Expert처럼 생각하게 만들자"
-
[의도 1] 텍스트와 시계열을 처음부터 분리하여 처리 → '인식의 병목' 해결
숫자인 시계열 데이터를 섣불리 텍스트 토큰으로 변환하면 정보가 손실된다.
(이에 텍스트 토큰보다는 이미지 캡셔닝을 주로 다른 연구에서도 사용한 사례가 종종보였다.)
저자는 이를 피하기 위해, 시계열은 전용 Encoder로 처리하고 텍스트는 LLM Tokenizer로 처리하여 각 데이터의 특성을 최대한 보존했다. -
[의도 2] 2단계 어텐션(채널 → 시간) 설계 → '인간의 분석 순서' 모방
인간 전문가는 "진동 채널의 초기 10초"를 분석할 때, 다음과 같은 순서로 생각한다.- (채널 선택): 먼저 수많은 센서 데이터 중 '진동' 채널을 찾아낸다.
- (시간 선택): 그 다음, 해당 채널의 데이터 전체에서 '초기 10초' 구간을 찾아 집중한다.
-
[의도 3] Learnable Instruct Tokens (LiT) 도입 → '명령의 의도' 명확하게
"피크 값을 찾아라", "평균을 내라" 등 자주 사용되는 명령어의 '의도'를 더 명확하게 전달하기 위해, 학습 가능한 특별 토큰 LiT를 도입했다.
이는 단순한 텍스트 임베딩보다 훨씬 더 강력하게 모델의 분석 방향을 지시하는 '특수 명령어' 역할을 한다. -
[의도 4] 마지막 출력단에서 LLM을 활용 → '역할 분담'
ITFormer의 역할은 시계열 데이터를 분석하고 핵심 정보를 추출하는 것이다.
하지만 최종적으로 논리적인 문장을 생성하는 것은 LLM이 가장 잘하는 일이다.
이에 ITFormer가 추출한 핵심 정보를 LLM에게 넘겨 출력 결과물의 완성도를 높이고자 했다.
