Title : Masked Autoencoders Are Scalable Vision Learners
Date : 19 Dec 2021
Keywords : Autoencoder, Self-Supervised, Vision Transformer, Asymmetric architecture
Abstract
본 논문은 두가지 간단한 디자인을 통해서 ImageNet-1K 데이터만을 이용한 학습에서 높은 정확도(87.8%)를 달성했습니다. 첫번째는 비대칭 Encdoer-Decoder구조이며 두번째는 높은 비율(75%)로 input 이미지를 마스킹하는 것입니다. 비대칭적 구조로 Decoder가 Encoder에 비해서 상대적으로 작은 scale이며, input의 대부분을 마스킹 했기 때문에 적은 메모리 사용량으로 학습을 가속할 수 있으며, scale을 변경하기 쉬워서 높은 capacity의 모델을 학습할 수 있습니다. 자세한 내용은 방법론에서 다루겠습니다.

Intro
NLP에서 가장 성공적인 모델을 꼽으라면 단연 GPT와 BERT입니다. 두 모델은 다른 구조를 가지고 있지만 본 논문에서는 두 모델이 데이터의 일부를 지우고 지워진 부분을 예측하기 위해서 학습하는 같은 개념을 가지고 있다고 하며 이를 masked auto encoding이라고 합니다. 또한 이렇게 데이터의 일부분을 지우고 예측하는 것을 Denoising Autoencoder와 유사하다고 합니다.
하지만 BERT의 학습 방법을 Computer Vision(이하 CV)에 적용했을 때 그 성능이 주목할 만큼 좋지는 않았습니다. 여기서 논문이 해결하고자하는 질문이 나옵니다.
What makes masked autoencoding different between vision and language?
본 논문에서는 총 3가지의 이유로 차이가 생긴다고 했습니다.
- NLP와 CV에서 주로 사용하는 모델의 구조(Attention VS CNN)가 근본적으로 다르다.
- Text가 Image에 비해서 정보의 밀도가 높다.
- Autoencoder의 디코더가 Text와 Image에서 수행하는 역할이 다르다.
1번의 경우 ViT 모델의 등장 이후로 CV의 많은 분야에서 Transformer 구조를 채택했기 때문에 NLP와 CV간의 모델 구조의 차이점이 많이 사라졌습니다. 하지만 2번과 3번은 Text와 Image의 데이터 특성이 다르기 때문에 발생합니다. Text의 경우 단어 하나하나가 모두 Semantic 정보를 가지고 있지만 Image의 경우 pixel하나가 가지고 있는 semantic 정보는 많지 않습니다.
예를 들어서 Text에서 단어 하나를 지우고 이를 예측하려면 문장 전체의 맥락과 문장을 이루고 있는 단어들의 의미를 잘 이해해야 하지만 Image에서 pixel하나를 지우고 예측한다고 하면 단순히 근처 픽셀들의 평균값을 넣어도 훌륭한 예측이 됩니다. -> 이미지는 공간적 중복성이 높은 정보를 가지고 있다.
본 논문에서는 위 문제점들을 해결하기 위해서 2가지 방법을 제시합니다.
1. 높은 비율(75% 이상)으로 mask를 적용해서 패치들간의 공간적 중복성을 제거한다.
2. 비대칭적 구조를 가진 encoder-decoder 구조를 통해서 계산 효율성을 높여서 scale을 크게 키운다.
Masked AutoEncoder(이하 MAE)는 입력 이미지를 높은 비율로 mask 하기 때문에 실제 계산에서는 이미지의 일부(25%)만 사용해서 비교적 큰 모델을 특징 추출기로 사용해도 메모리 사용량이 높지 않다. 또한 인코더에 비해서 작은 디코더를 사용해서 계산량을 줄였다.
결과적으로 MAE는 ViT-Large/Huge 모델을 ImageNet-1K 데이터만 사용해서 87.8% 라는 높은 성능을 보여주였고 다른 task로의 전이학습에서도 SOTA에 준하는 성능을 보여주어서 일반화도 잘되는 좋은 이미지 분류 모델임을 증명했습니다. 본 논문의 큰 기여점으로 자가 지도학습(ImageNet 1K 데이터사용)을 통해서 지도학습보다 높은 성능을 내주었으며, 모델의 scale을 키울수록 높은 성능이 나오는 것을 확인해서 NLP에서의 자기 지도학습과 결이 같은 모습을 보여주었다.
Methodology
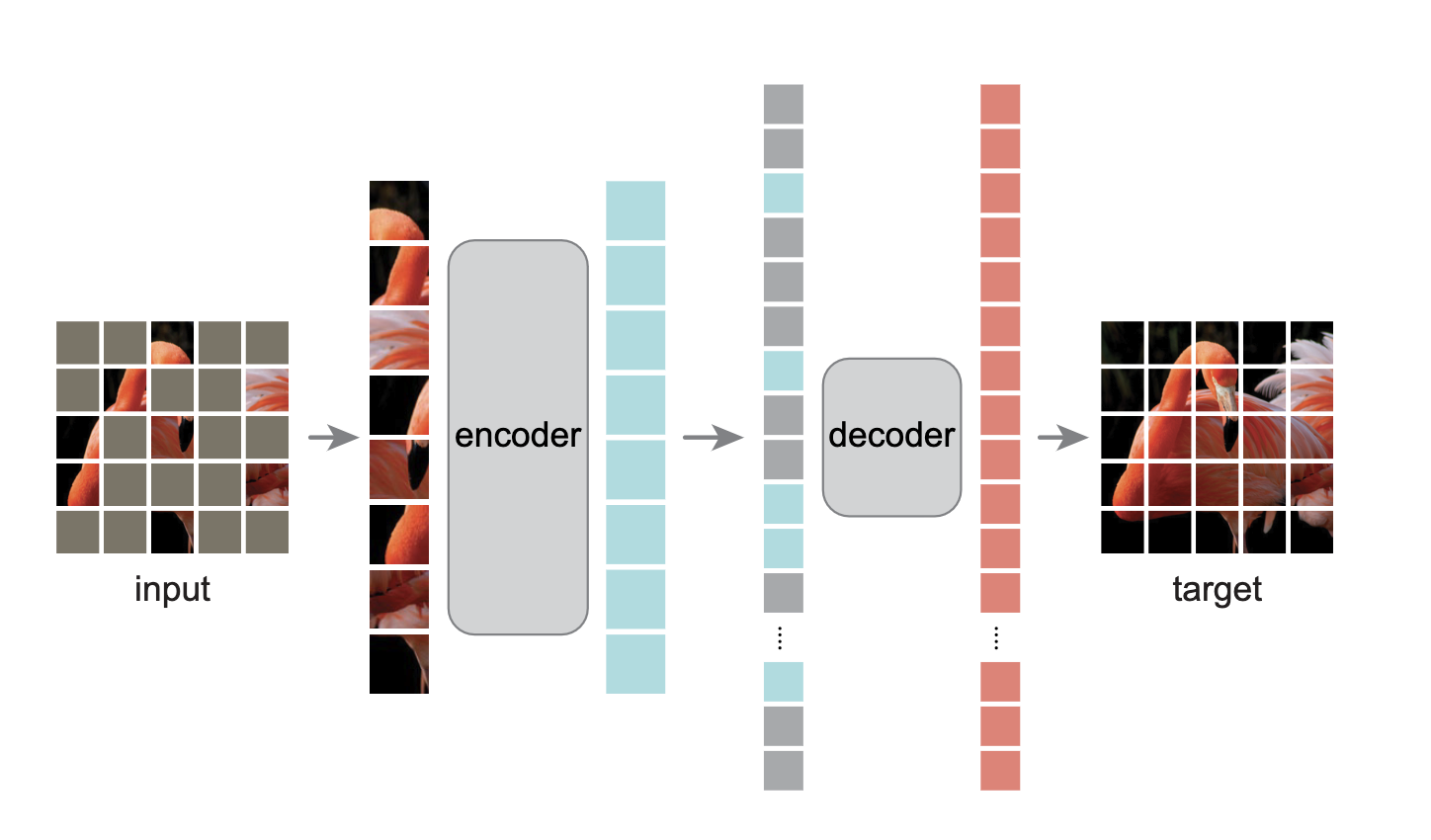
MAE 는 기존의 autoencoder와 마찬가지로 인코더가 입력 이미지를 latent representation으로 만들고 디코더가 이를 이용해서 입력 이미지를 생성합니다. 하지만 비대칭적 구조를 채택해서 인코더가 입력 이미지의 일부분(mask된 부분을 제외한 이미지)만 latent representation으로 만들고 인코더에 비해서 경량화된 디코더를 사용해서 입력 이미지를 재구성합니다.
Maksing
많은 Vision Transformer 모델이 그러하듯 겹치지 않게 격자로 이미지를 나누고 Linear projection하는 Patch Embedding으로 입력 이미지를 패치로 만들어줍니다. 이후 패치의 집합에서 부분집합을 샘플링 해주고 선택되지 않은 패치들은 mask해줍니다. 샘플링 방식은 균등 분포를 따르는데 논문에서는 이를 random sampling(이하 랜덤 샘플링) 이라고 합니다. 높은 비율로 masking하는 랜덤 샘플링은 중복성(redundancy)를 제거해서 인접한 패치를 보고 문제를 쉽게 해결할 수 없게 만듭니다. 균등 분포 이외의 분포를 사용하게 되면 중앙 부분만 높게 샘플링 되는 등의 bias가 생길 수 있기 때문에 균등 분포를 사용했다고 밝혔습니다.
MAE encoder
ViT를 인코더로 사용했으며 위에서 설명했듯이 입력 이미지는 Patch Embedding을 거쳐서 패치로 변환되며 이 패치들중 일부만 선택되어 인코더의 입력값으로 사용됩니다. Mask된 패치들은 일련의 과정에서 사용되지 않기 때문에 제거해서 메모리 효율성을 높였습니다.
MAE decoder
디코더는 인코더와 마찬가지로 Transformer block으로 이루어져 있지만 인코더 보다는 가벼운 구조를 채택합니다. 위 그림과 같이 디코더는 인코딩된 패치들과 mask된 패치 모두를 입력값으로 받게 됩니다. 이 때 mask된 패치에도 positional embedding을 더해주게 됩니다. 이렇게 하지 않으면 mask된 패치가 이미지에서 어느 위치에 있는지 나타내는 정보가 없기 때문에 디코더가 작동하지 않게 됩니다.
디코더는 pre-training 단계에서 입력 이미지를 latent representation으로 부터 복원하기 위해서 사용되며 실제로 이미지 분류에는 인코더의 latent representation만 사용됩니다. 따라서 디코더는 인코더의 구조와는 별개로 사용이 가능하다는 것을 의미합니다. 본 논문에서는 굉장히 가볍고 얕은 구조를 사용했습니다.
인코더의 경우 입력 이미지의 25%만 연산하기 때문에 계산량이 적지만 디코더의 경우 모든 패치에 대해서 연산을 하기 때문에 인코더와 같은 구조(깊이와 넓이)를 채택하게 되면 계산량이 한번에 너무 커지게 됩니다.
Reconstruction target
MAE는 mask된 패치의 pixel값을 예측합니다. 따라서 디코더의 출력값은 입력 이미지의 크기와 형태로 reshape 됩니다. 또한 BERT와 마찬가지로 mask되었던 패치들의 예측에 대해서만 MSE Loss 를 적용합니다.
저자들은 원본 이미지를 그대로 복원하는 것 보다는 mean, std를 이용해서 정규화된 입력값을 복원하는 것이 성능 향상에 기여한다고 밝혔습니다.
Experiments
MAE의 기본 구조자체가 워낙 간단해서 방법론에 대한 설명은 길지 않았습니다. 본 논문에서도 1페이지 정도로 모든 설명을 마쳤습니다. 본 논문에서 제시하는 방법론은 CV에서 기존의 분류 모델을 학습시키는 그것보다는 NLP와 비슷하기 때문에 다양한 실험을 통해서 제시하는 방법론을 구체화 했습니다.
실험에 사용한 모델은 ViT-Large 16이며 비교에 사용한 방법론은 ViT논문에서 제시했던 scratch 방식이 아닌 DeiT입니다. 제가 중요하다고 생각하는 실험의 결과와 주관적 해석은 아래와 같습니다.
여기부터는 부족한 저의 의견이 많이 있습니다. 적당히 걸러서 읽어주시길 바랍니다.
Masking ratio
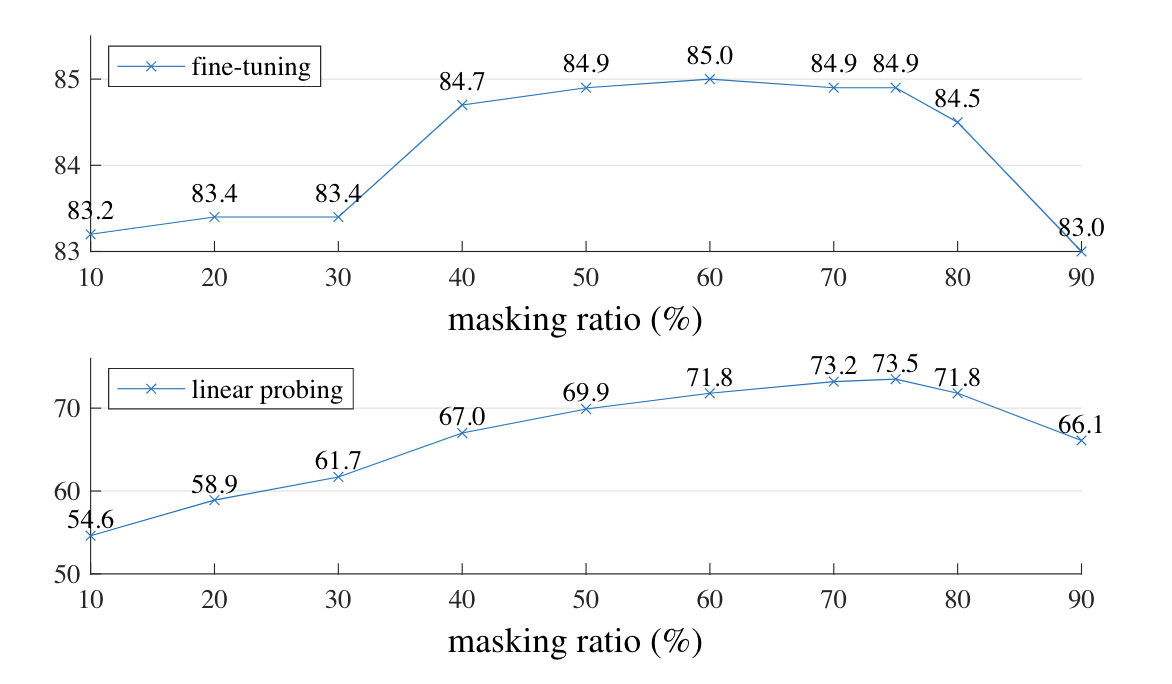
본 논문에서는 Masking 비율을 찾기위해서 10~90%까지 비율을 바꾸면서 실험을 했습니다. 위 그래프를 보면 40~80% 구간에서 높은 성능이 나오는 것을 확인할 수 있으며, 저자들은 높은 비율의 masking이 spatial redundancy를 줄여서 더 높은 일반화 성능을 얻을 수 있다고 기술했습니다.
하지만 실제 10% mask의 결과도 DeiT에서 제시하는 82.5% 보다 높은것을 확인할 수 있습니다. Linear probing 방식에서는 mask 비율 10~75% 구간에서 성능이 선형적으로 상승하지만 fine-tuning에서는 이미 10%에서도 충분히 높은 수치입니다. 따라서 높은 masking 비율보다 더 크리티컬하게 작용하는 무언가가 있다는 사실을 내포하고 있을 수 있다고 생각합니다.
인코더에 비해서 굉장히 작은 디코더를 사용했기 때문에 mask 비율이 높을 때 좋은 성능이 나온것은 아닌가 생각합니다. 인코더와 비슷한 크기의 디코더를 사용하고 mask비율을 조정하면서 실험을 해보면 굉장히 큰 컴퓨팅 파워가 필요하겠지만 어떤 결과가 나올지 궁금합니다.
Decoder design

디코더의 디자인에 따라서 Fine-tuning과 Linear probing의 성능이 차이를 보입니다. 위 표에서 알 수 있듯이 디코더의 깊이가 깊어질수록 linear probing의 성능은 올라가지만 Fine-tuning의 성능은 큰 차이를 보이지 않습니다. 극단적으로 디코더의 깊이가 1일때와 8일때의 fine-tuning 성능도 차이를 보이지 않습니다.
본 논문에서는 이렇게 차이가 발생하는 이유를 인코더의 마지막 부분과 디코더가 recognition보다 reconstruction에 집중하기 때문이라고 해석했습니다. 따라서 디코더가 깊을수록 latent representation이 더 추상적인 수준(논문에서는 abstract level이라고 표현)으로 올라가기 때문에 linear probing에서 높은 성능이 나오지만, fine-tuning시에는 인코더의 마지막 부분이 recognition task에 더 집중하도록 조정되기 때문에 성능에 큰 차이가 없다고 합니다.
MAE가 만들어내는 latent representation을 이용해서 contrasive learning이나 DINO에서 적용했던 distillation을 이용한 학습을 적용해 보면 어떤 결과가 나올지 궁금해지기도 합니다.
깊이가 큰 차이를 만들어내지 않듯이 dimenstion 또한 128과 1024가 큰 차이를 만들지 않기 때문에(오히려 감소) 512라는 상대적으로 작은 차원을 디코더에 적용한것을 알 수 있습니다.
기타
MAE는 위에서 설명했다 싶이 mask토큰을 제거하고 입력값으로 mask되지 않은 토큰만을 이용합니다. mask 토큰을 입력값으로 넣으면 오히려 성능을 떨어지고(linear probing -14%) 계산량만 늘어났다고 합니다.
패치별로 정규화된 값을 예측하게 하면 성능이 더 올라간다고 합니다. 이러한 방법이 지역적인 contrast를 올린다고 해석했습니다. 또한 PCA를 패치별로 적용해보았는데 이 경우에는 성능이 떨어진다고 합니다.
BEiT에서 적용되었던 token을 예측하는 방식을 적용했다고 합니다. MAE는 pixel을 예측하는 방식인데 DALLE pre-trained dVAE를 토크나이저로 이용해서 token 예측방식을 적용하니 fine-tunig에서는 성능이 아주 약간 올랐지만 linear probing에서는 성능이 떨어졌다고 합니다. 더 직관적인 pixel 방식이 났다고 주장합니다.
MAE는 데이터 증강기법을 적용하지 않는게 더 높은 성능이 나온다고 합니다. 기존 contrastive learning등의 연구에서는 다양한 증강기법을 적용했는데 비해서 특이한 결과인것 같습니다. 높은 비율로 mask를 적용한다는 것 자체가 강력한 데이터 증강기법이 사용된것이며 랜덤 샘플링은 이터레이션마다 다른 패치를 mask하기 때문에 추가적인 증강기법이 유의미하지 않다고 합니다.
결론/생각
NLP 에서 주로 사용되고 성공적인 결과를 가져왔던 Masked token prediction 방식을 이미지에 적용하기 위해서 Autoencoder 방식을 채택했다. 결과로 비교적 간단한 구조에 적은 자원을 사용하고도 기존의 지도학습 방식보다 높은 성능을 얻을 수 있었다. 본 논문에서 가장 중요하다고 생각하는 점은 높은 mask 비율을 적용해서 spatial redundancy를 줄여서 모델이 각 patch 들의 semantic 정보를 학습하게 한 것이라고 생각합니다. FAIR에서 나왔던 DINO논문에서도 small crop과 large crop을 이용해서 이미지의 일부만을 보게하는 학습방식을 사용했었는데 본 논문에서 적용했던 방식과 비교하면 MAE의 방식이 더 직관적이어서 이해하기 쉬웠던 것 같습니다. 더 자세한 내용은 코드리뷰에서 다뤄보겠습니다.
