통계 기반 데이터 활용 개요
머신러닝의 베이스는 기본적으로 통계
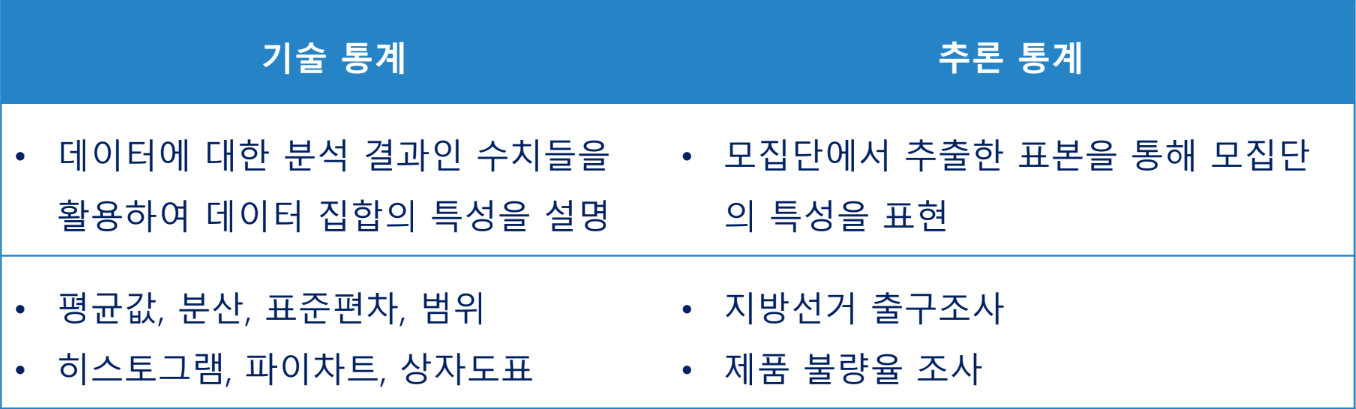
데이터와 통계
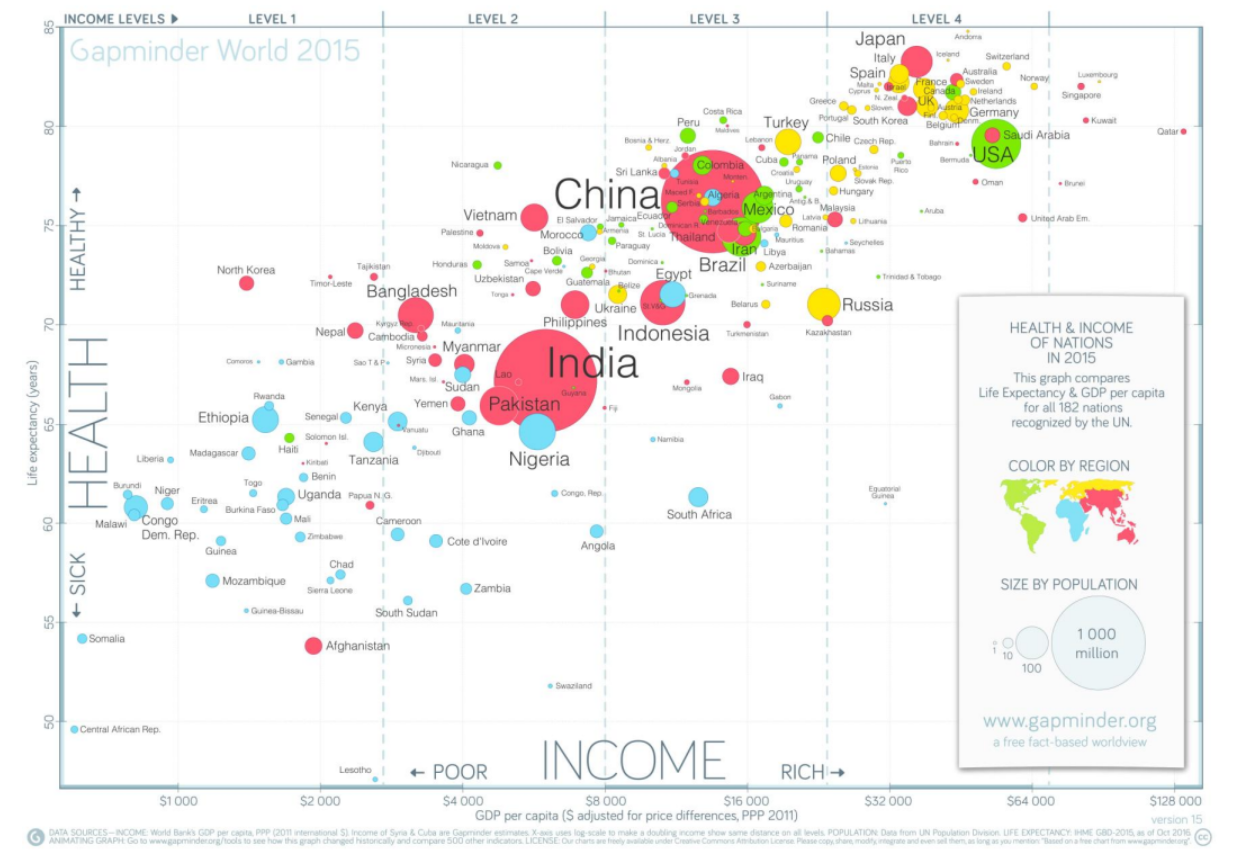
- 이 시각화를 테이블로 다시 바꾸면 4가지 컬럼이 존재할 것(키값 제외)
- Income, Health, Region, 거품크기
- 부정본능: 비관적인 사고를 함(세상이 나빠지고 있다)
머신러닝 개요
- 주어진 데이터 속에서 규칙을 학습(규칙적인 패턴을 발견)
- 학습한 규칙을 기반으로 새로운 데이터에 대한 결과 예측
- 분류, 회귀..
머신러닝 절차
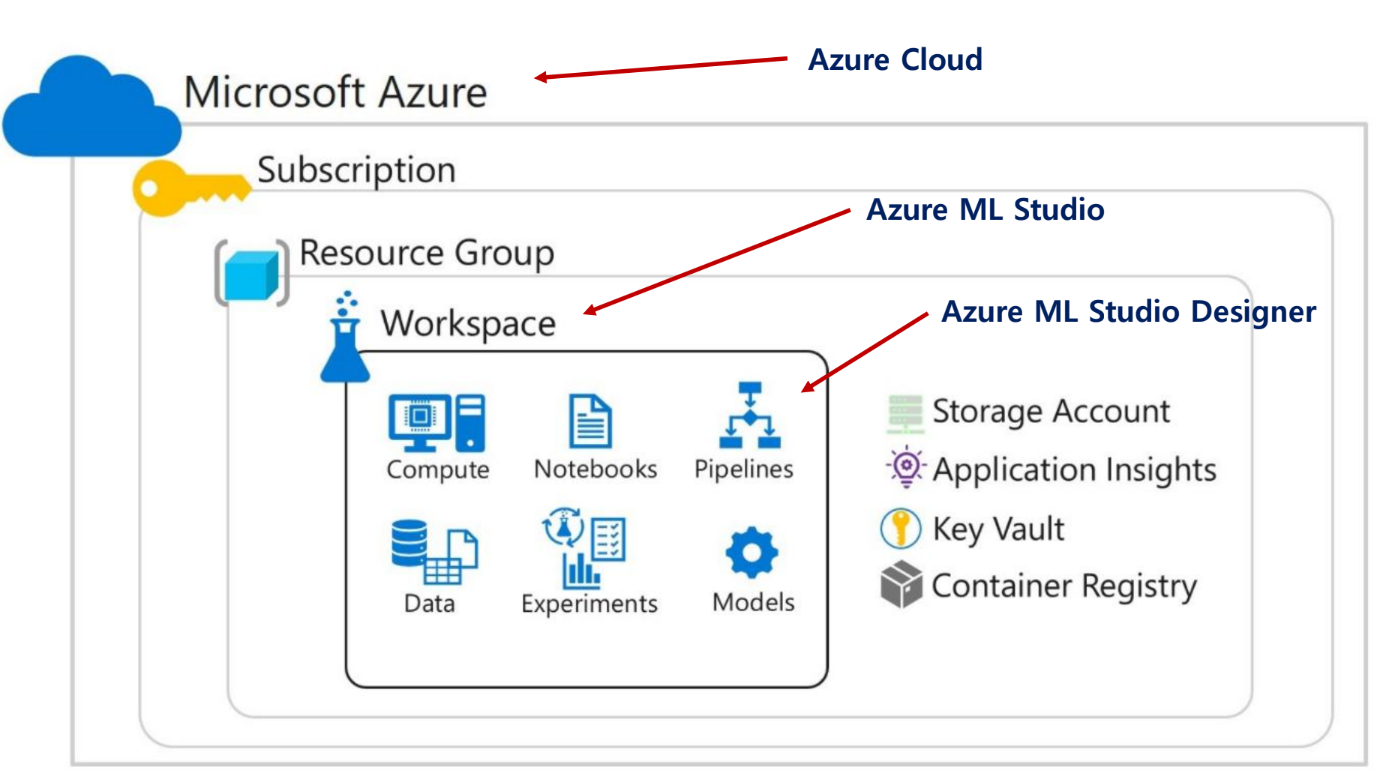
Azure Machine Learning
해외에서 원룸을 스튜디오라고 한다고. 한 공간에 모든 게 있는걸 스튜디오라고 한다.
자동으로 Blob Storage에 연결 가능하다.
구성 단계
이번 실습에서는 python 코딩이 아닌, Pipelines를 이용하여 로우 코딩한다.
Azure Machine Learning
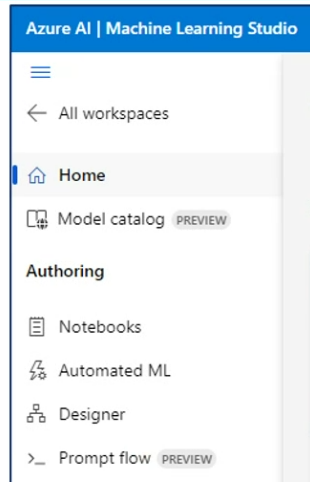
- Designer 탭에서 Pipeline 사용
- Automated ML을 사용하면 좋은 결과를 주지만, 비용이 매우 비싸다.
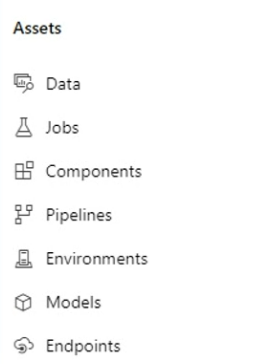
- Jobs: 실행 상황, 실행 결과 확인 가능한 터미널창 같은 개념
- Models: 모델 등록
- Endpoints: 배포 후 활용 가능한 엔드포인트
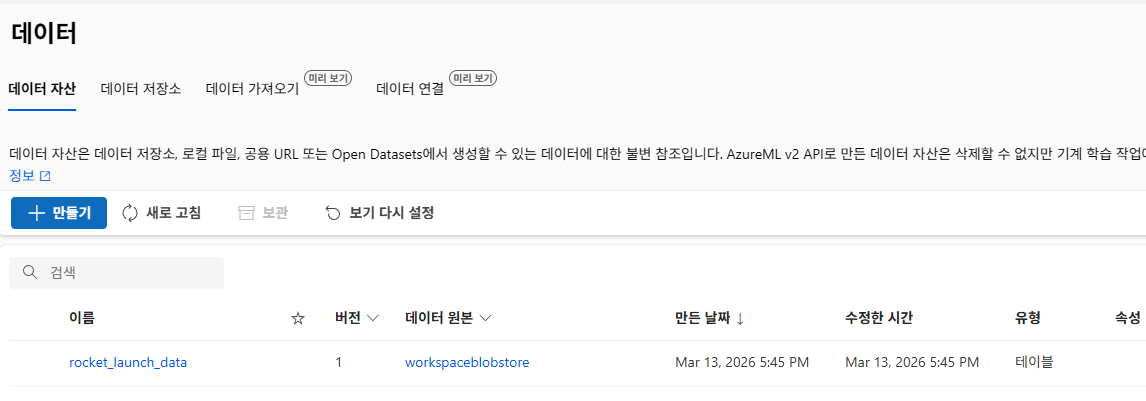
데이터 등록
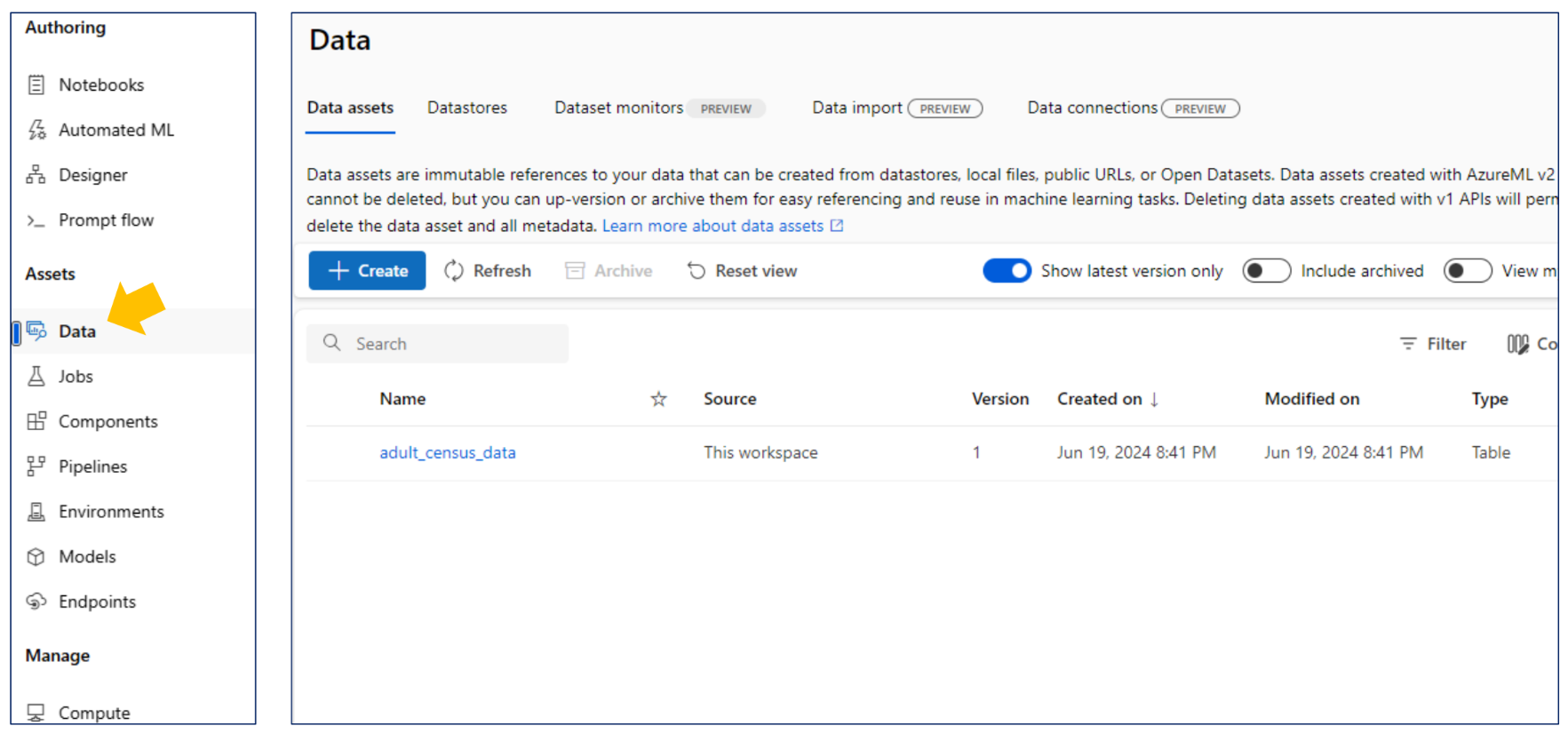
컴퓨트
앞의 데이터들은 반드시 컴퓨트를 통해 실행되어야 함
VM 선택 가능
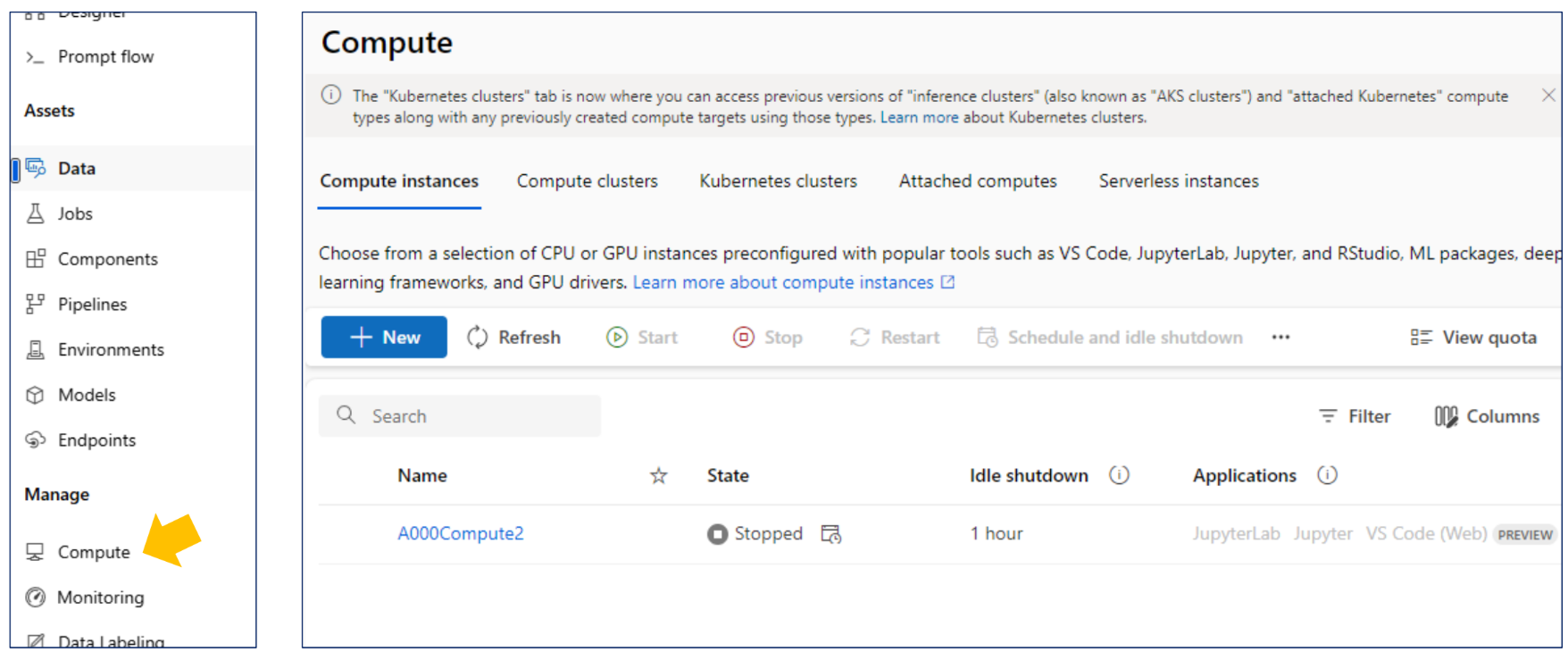
항상 Job을 던지기 전엔 실행상태로 바뀌어야 하니 유의하자
전체 할당 가능 코어수는 공유되므로, 한 사람이 100코어 써버리면 같은 구독의 다른사람이 못 쓸 수 있으니 주의하자.
Desinger
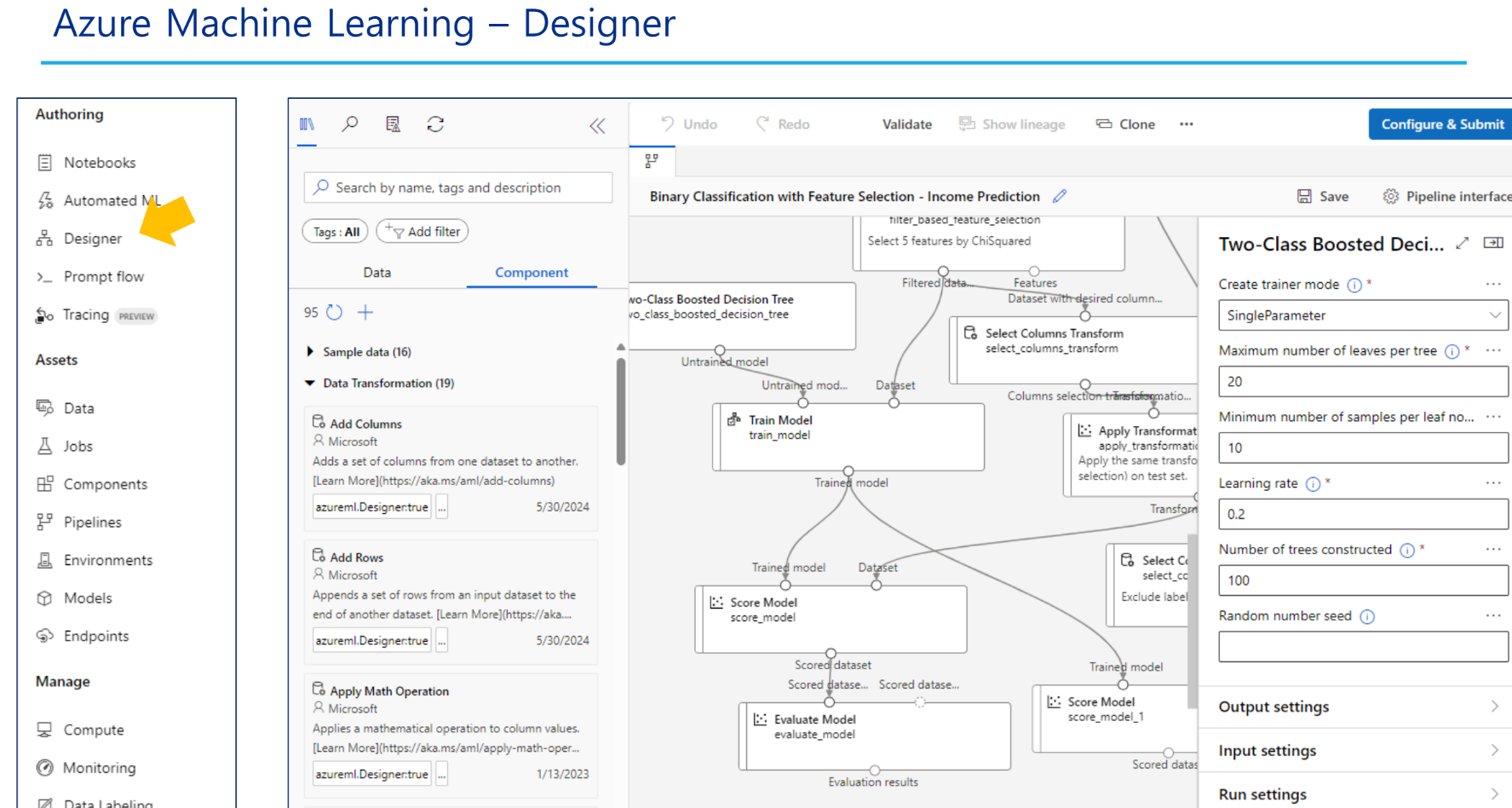
Pipelines로 구현할 수 있다. 함수를 만들어서 연결하는 것이 일반적이다. 함수끼리 입출력을 연결해주는 행위가 메인이다.
지도학습의 범주에서 학습시킬때는 [모델 + 데이터셋 + 레이블]이 필요하다. (설정은 오른쪽 탭 확인)
*레이블: 맞혀야하는 컬럼
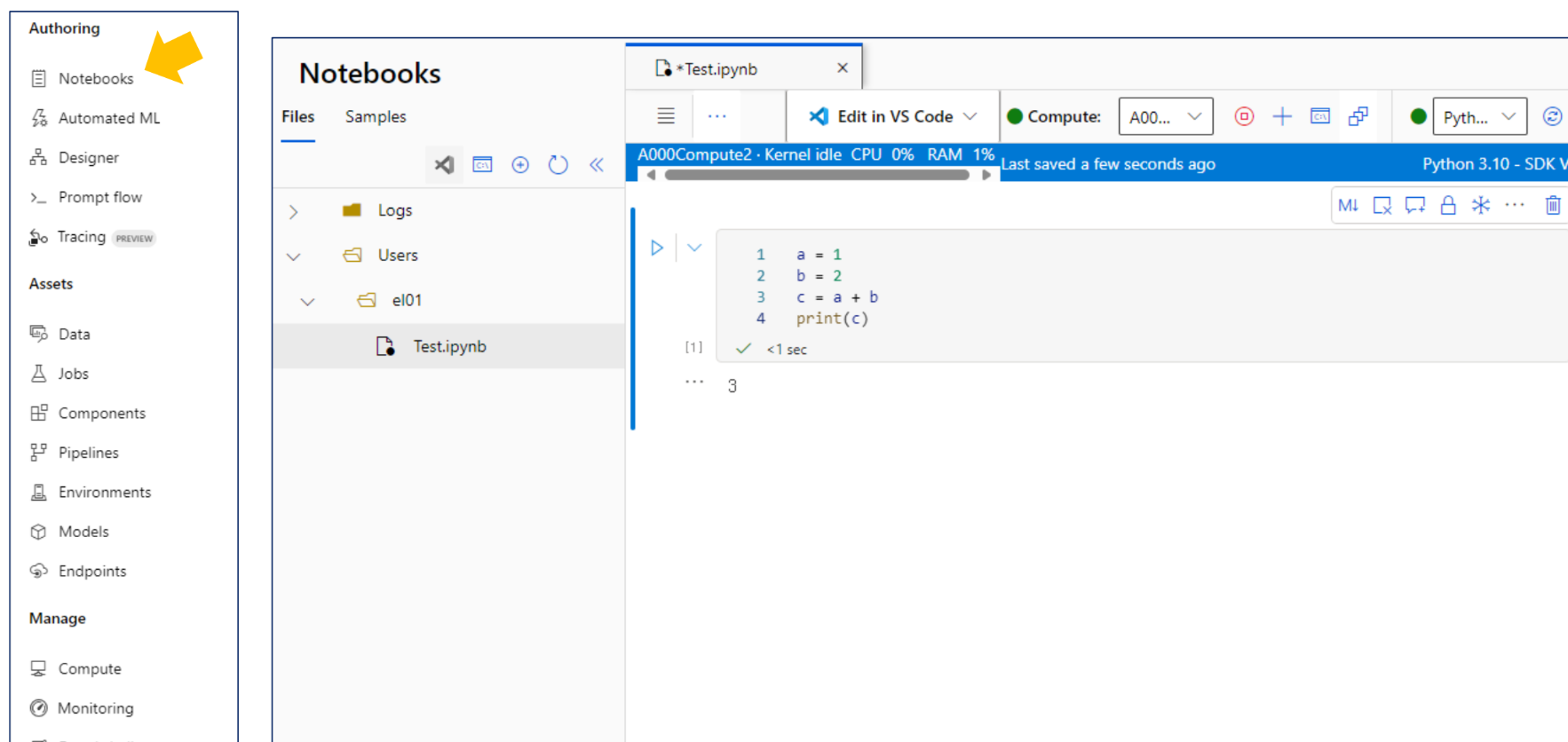
Notebooks
Jobs
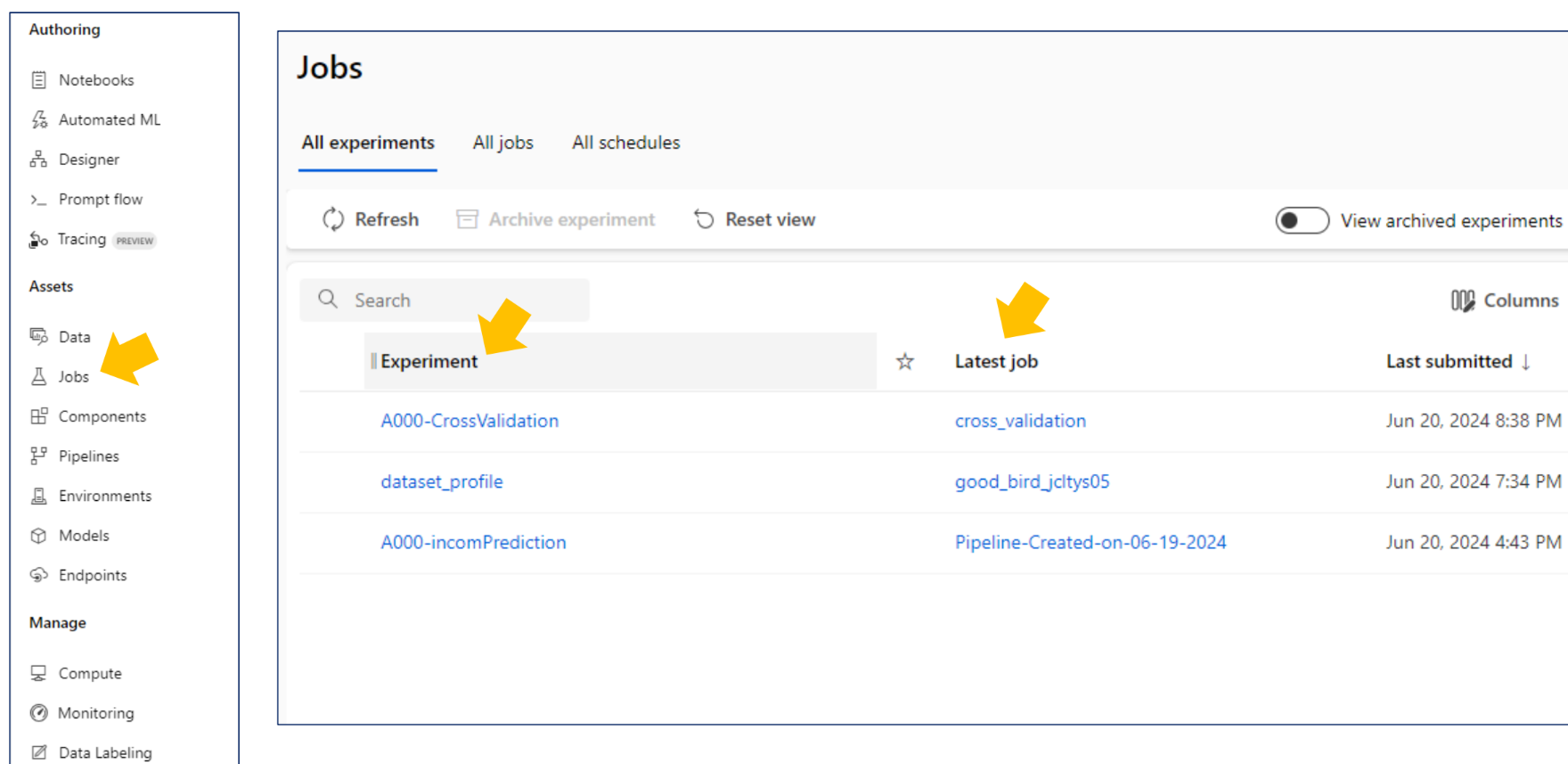
현재 실행중인 작업을 확인할 수 있는 터미널 창의 개념
코드 하나에 실험 하나로 생각하면 된다.
- Job:한 번 실행한 결과 터미널
- Experiment: 카테고리
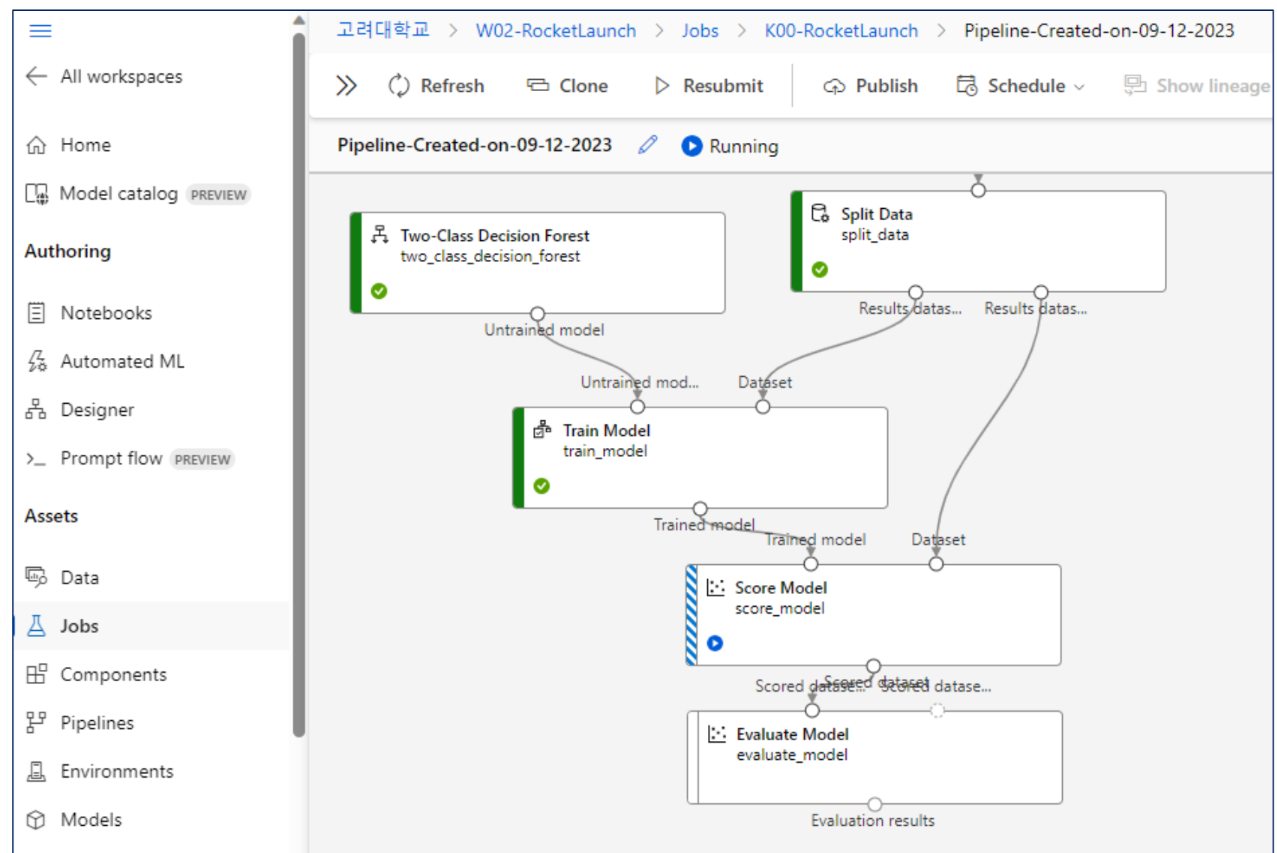
초록색은 실행완료. 빗금이 쳐진 부분은 실행중인 부분.
각 카드를 오른쪽 마우스로 클릭하면 입출력을 확인할 수 있다.
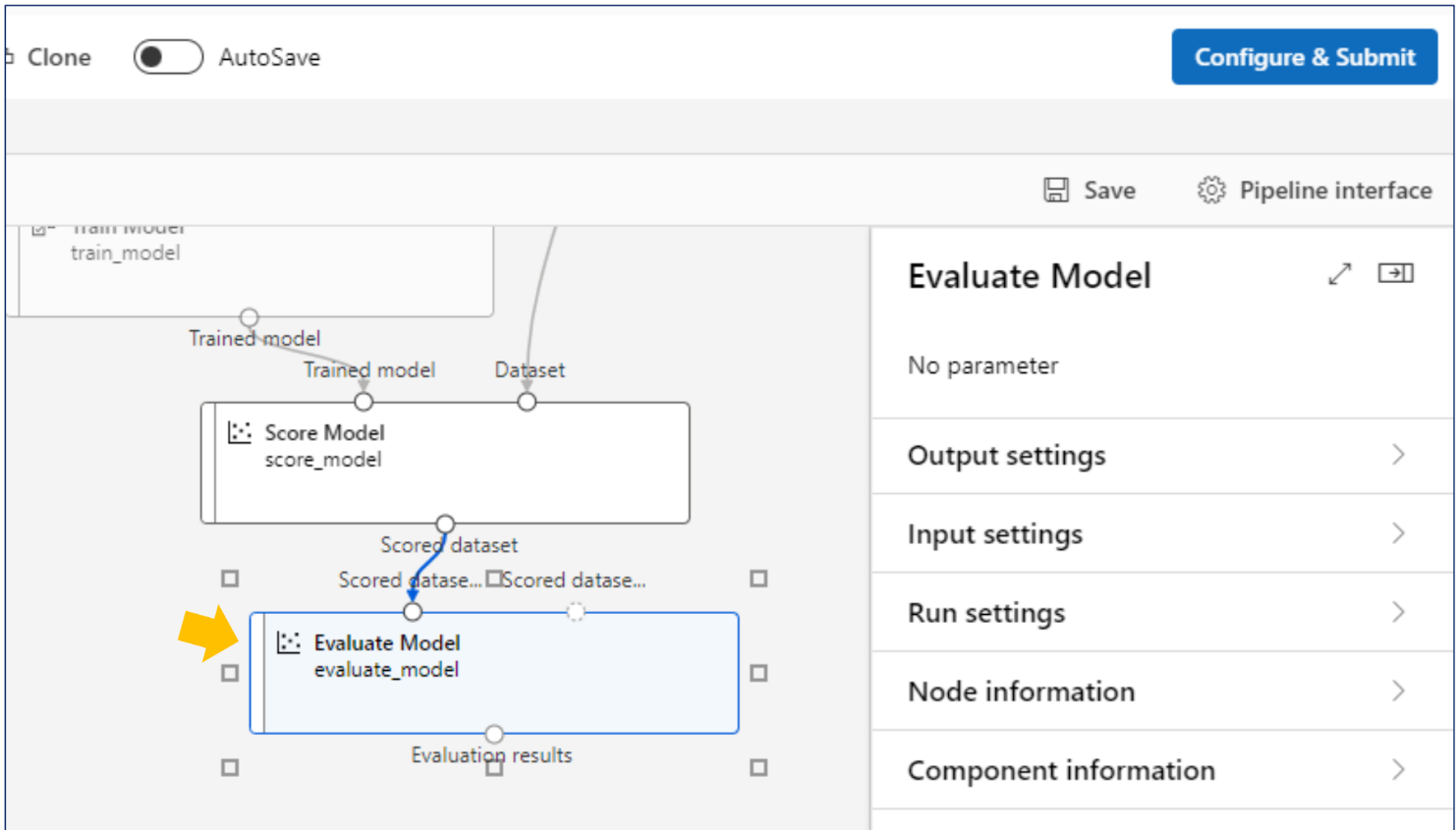
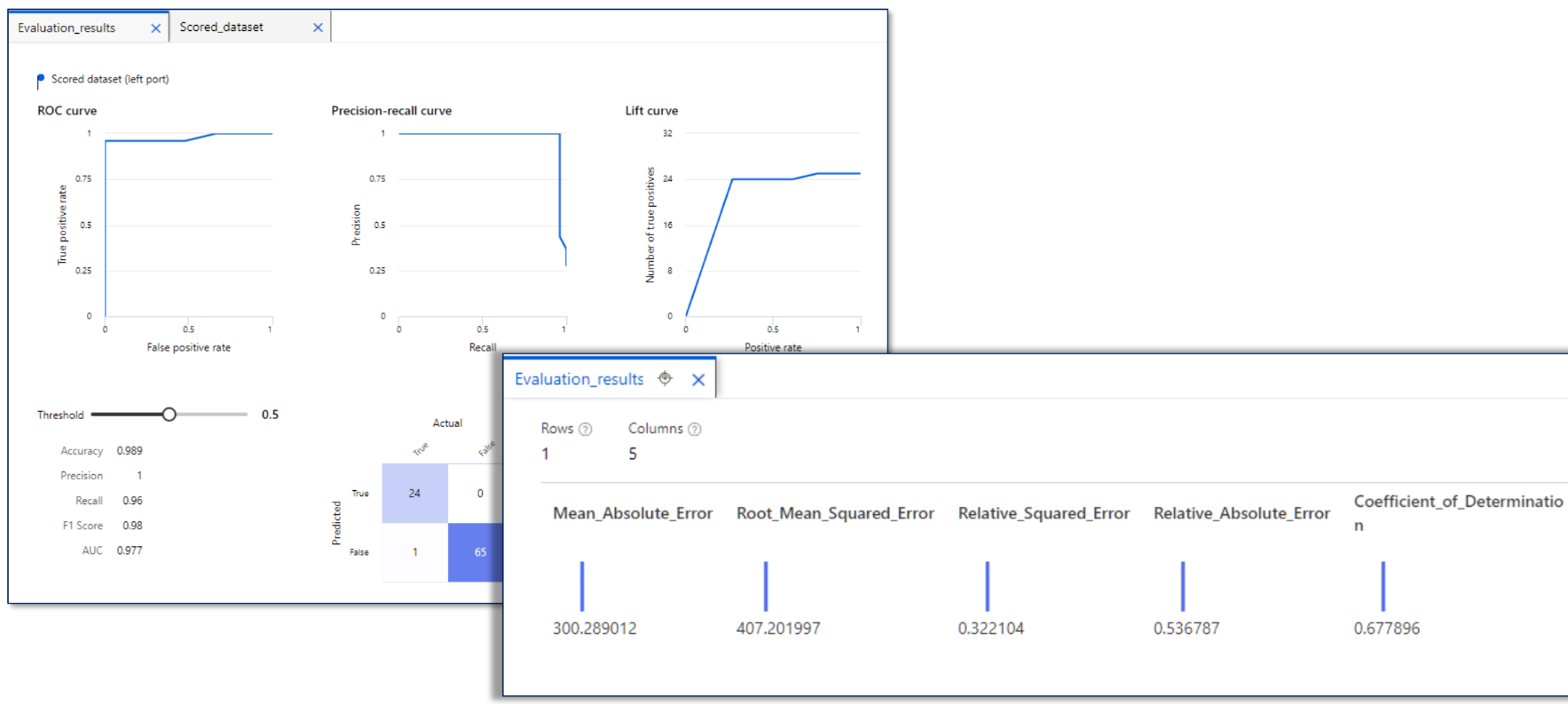
results 확인을 즉, Jobs에서 할 수 있다.(Evaluation results 참고)
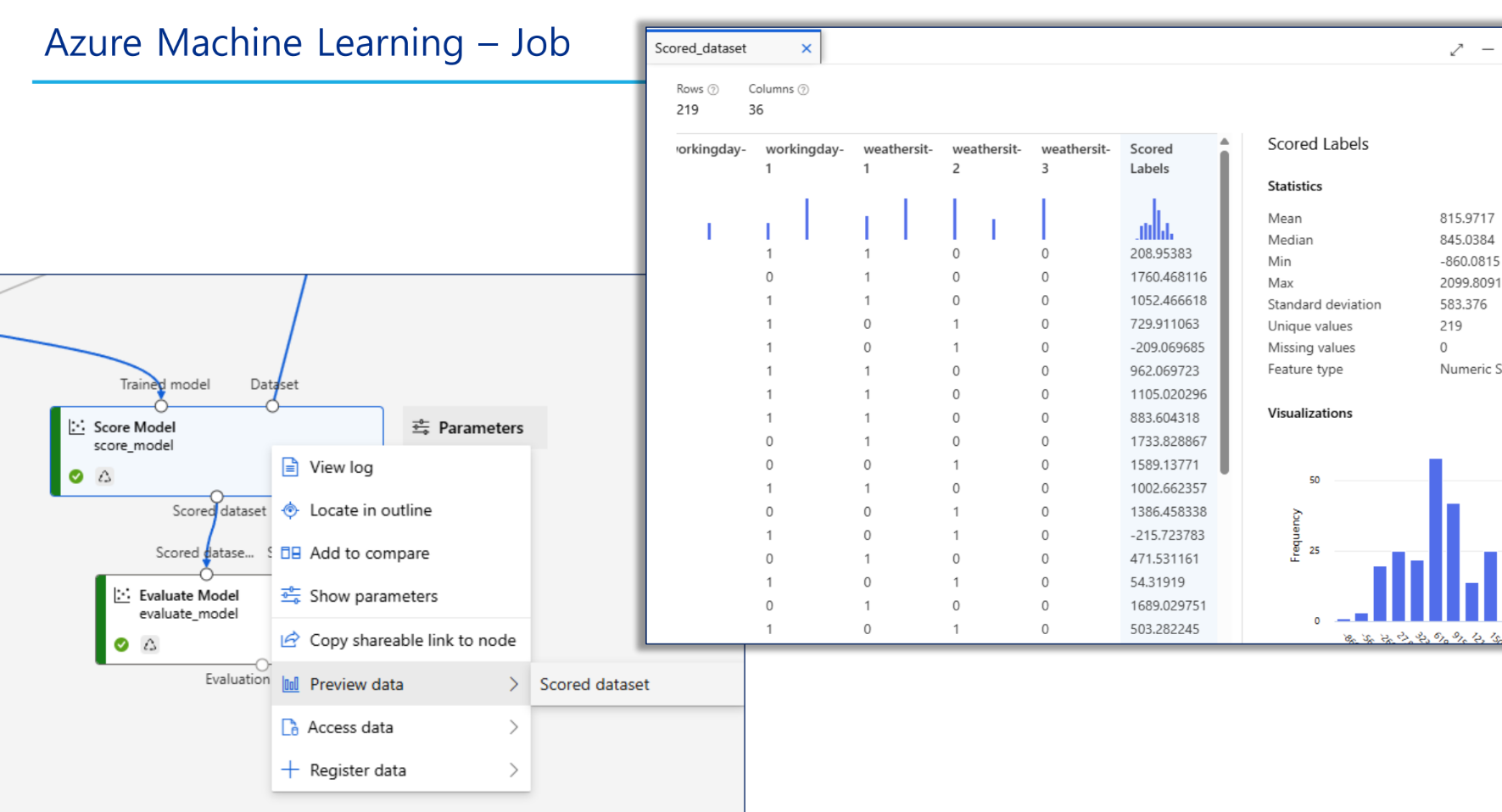
배포 및 유추
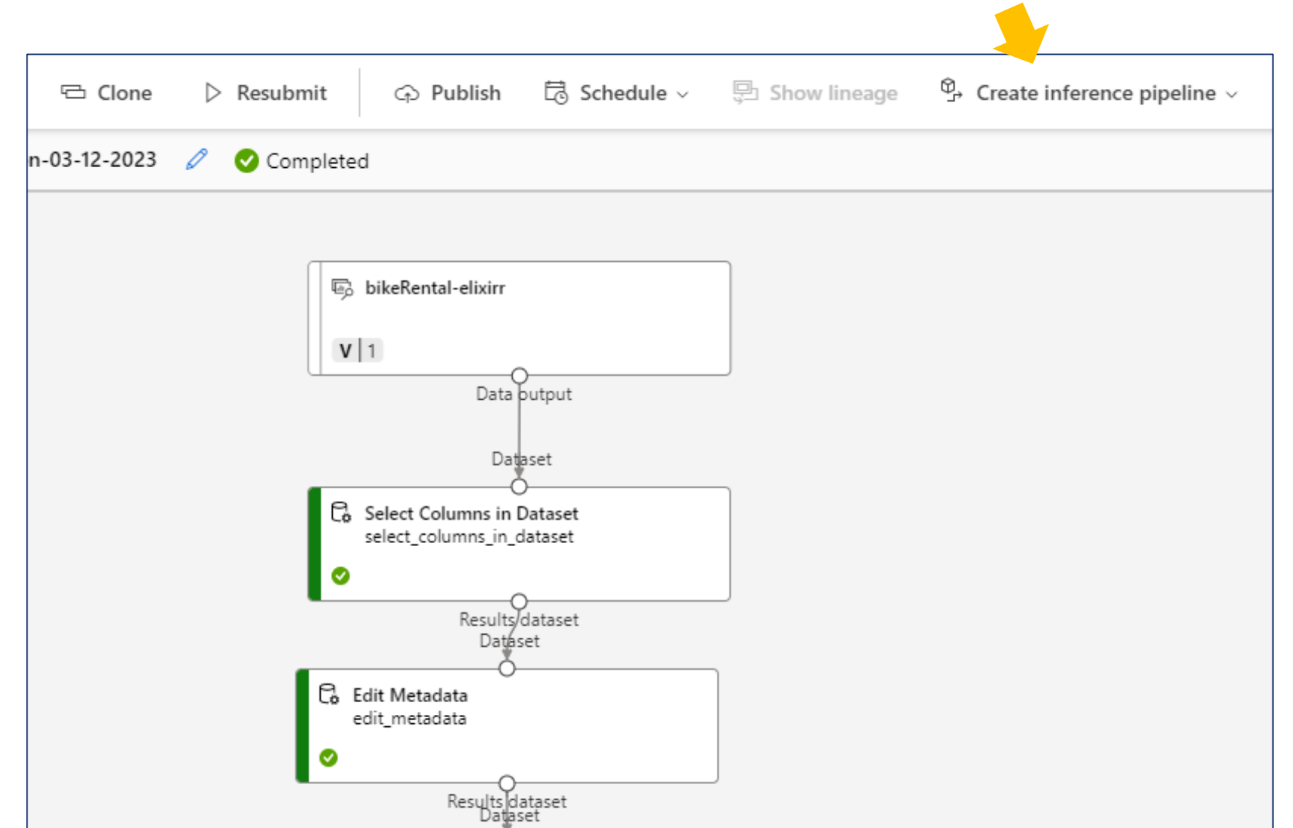
학습 처리 후에는 이제 모델 데이터와 Transforming 데이터만 있으면 유추 가능. Inference Data 탭을 통해 새로운 유추 파일을 제공
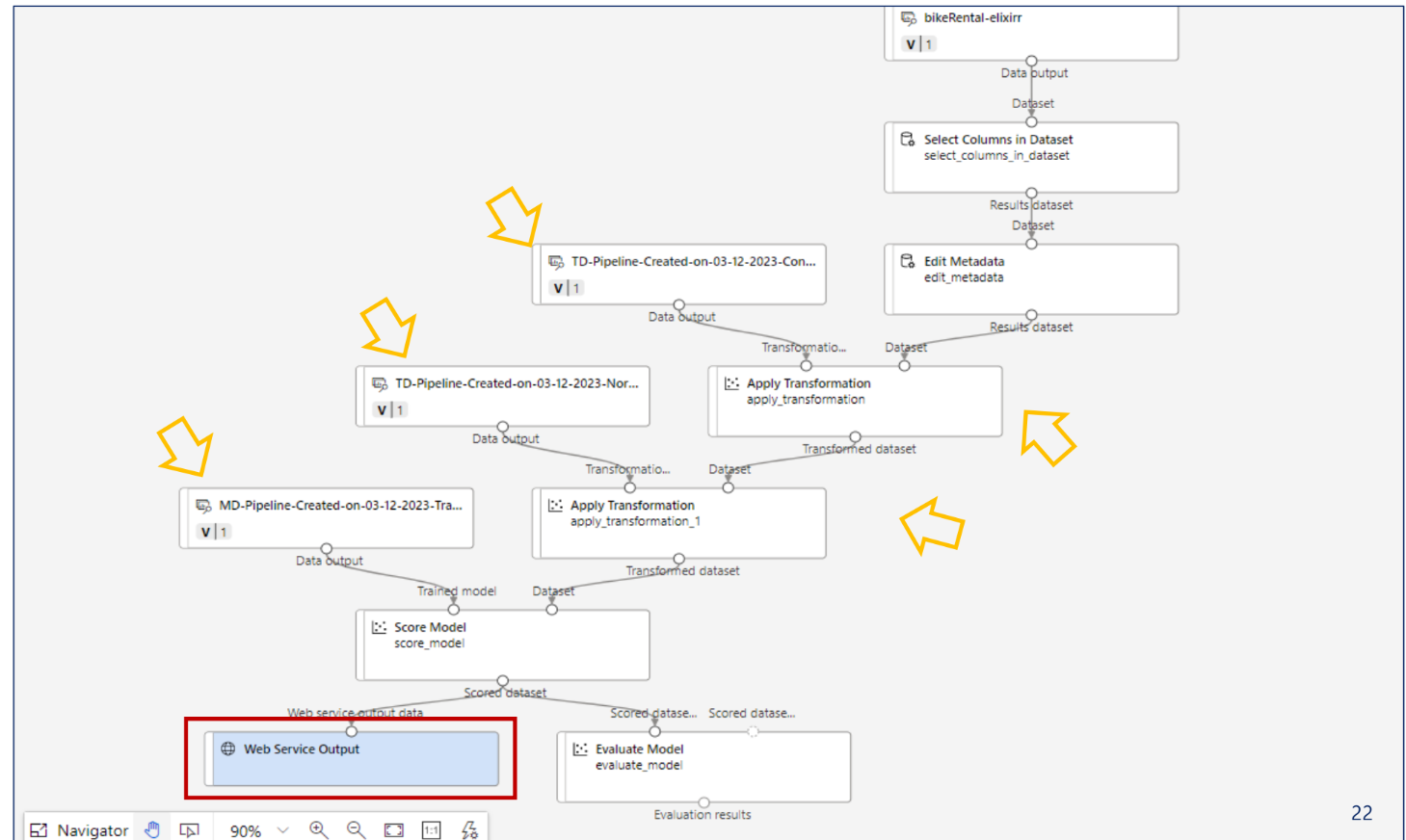
이런식으로 자동으로 유추 파이프라인을 제공한다.
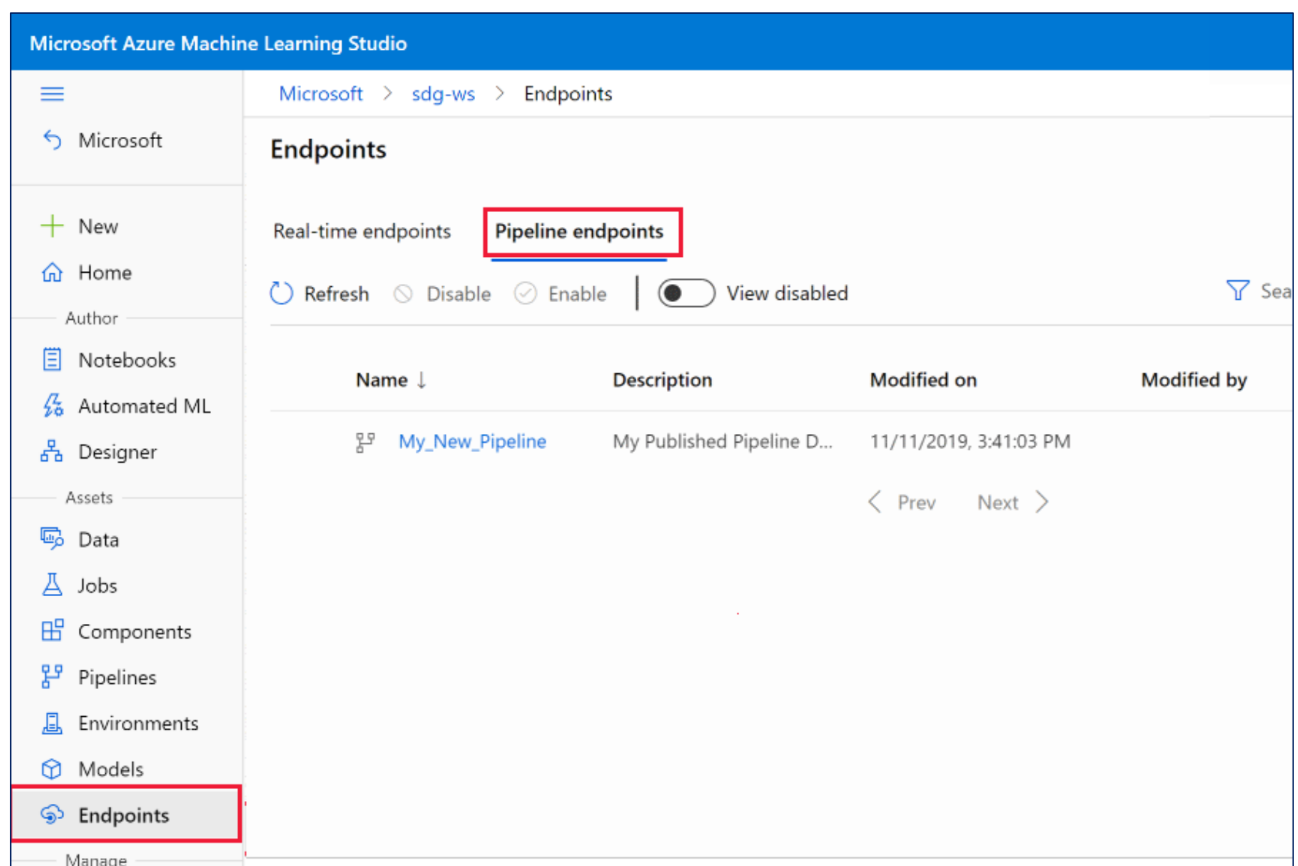
Endpoints로 배포하여 REST API로 사용 가능
Azure Machine Learning - Designer: 데이터 수집 및 이해
1. 데이터 업로드
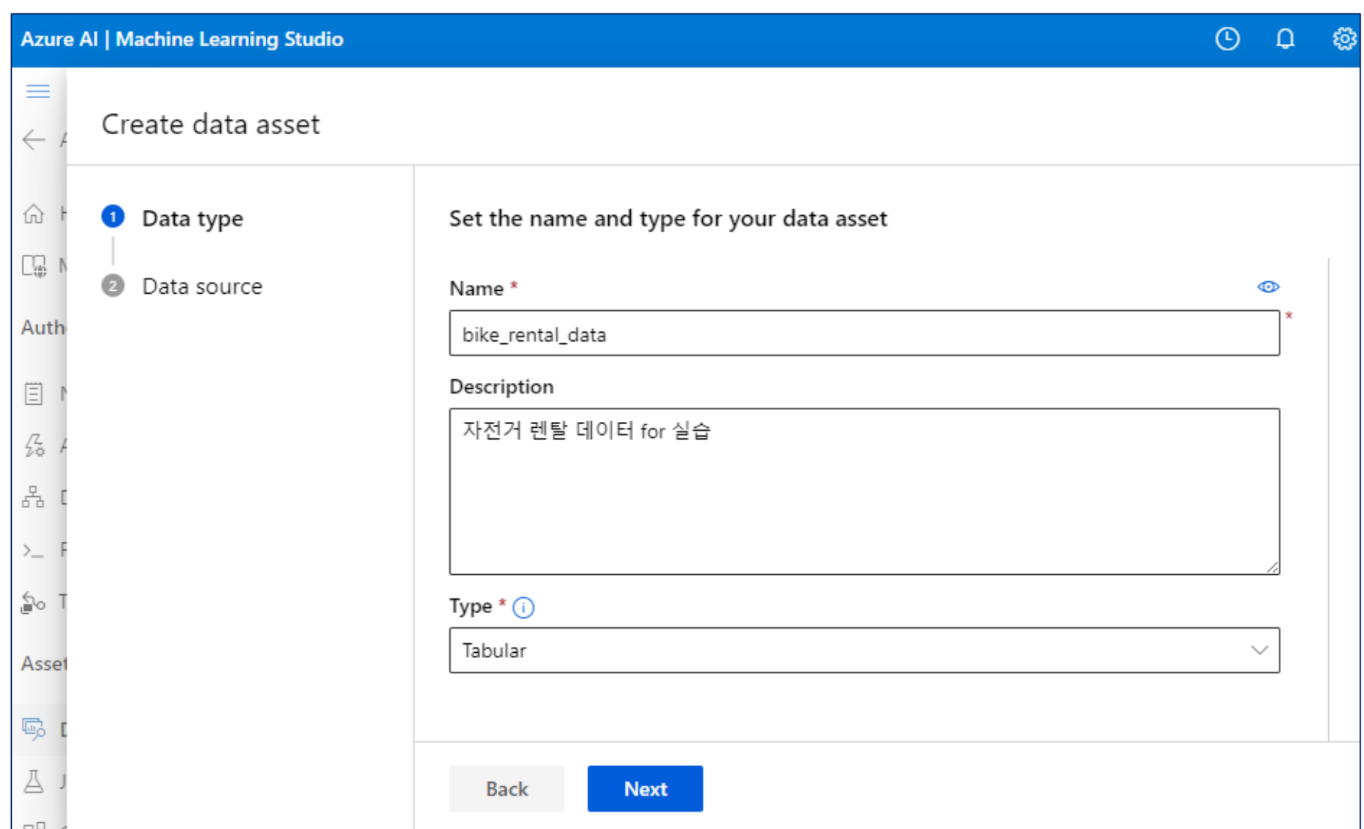
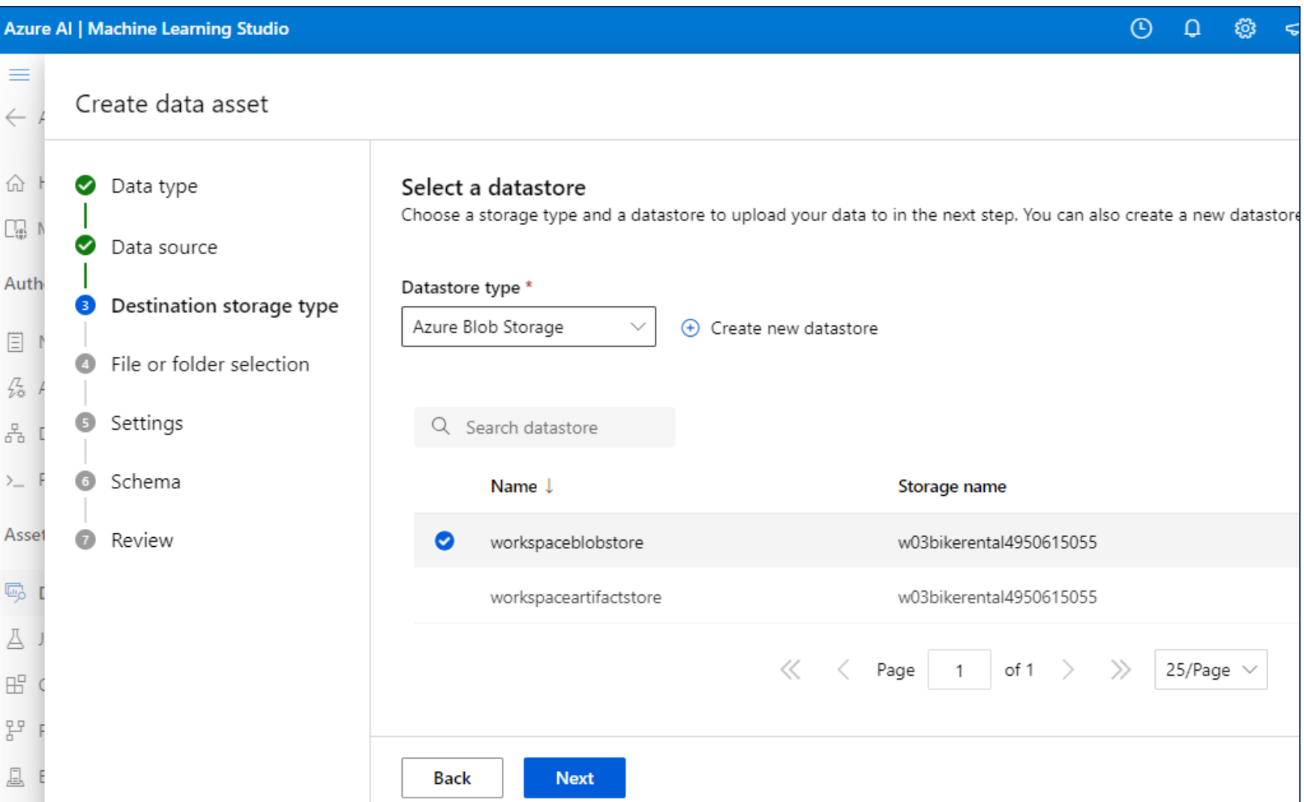
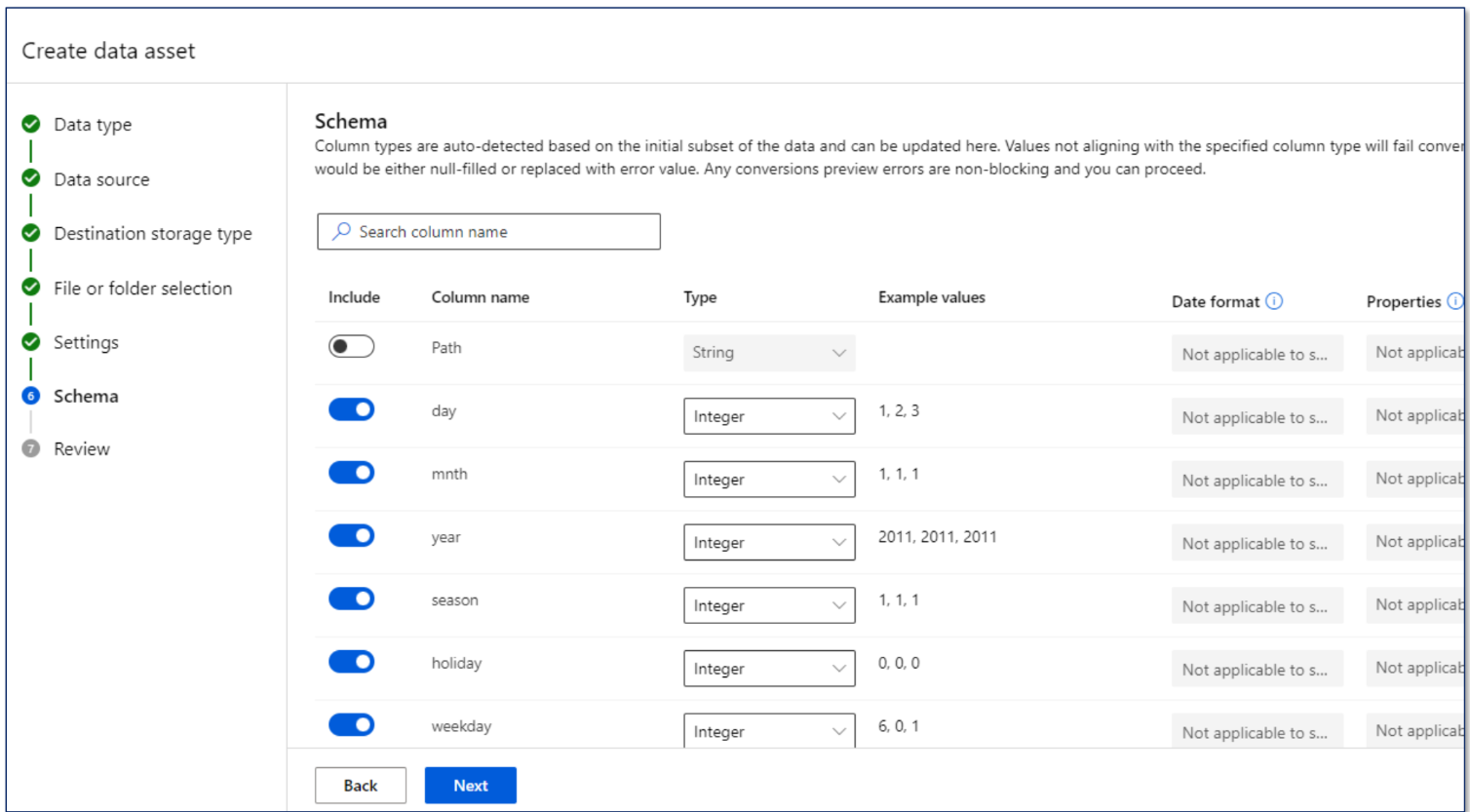
사용할 스키마, 컬럼 설정도 가능
2. 데이터 사용(로딩)
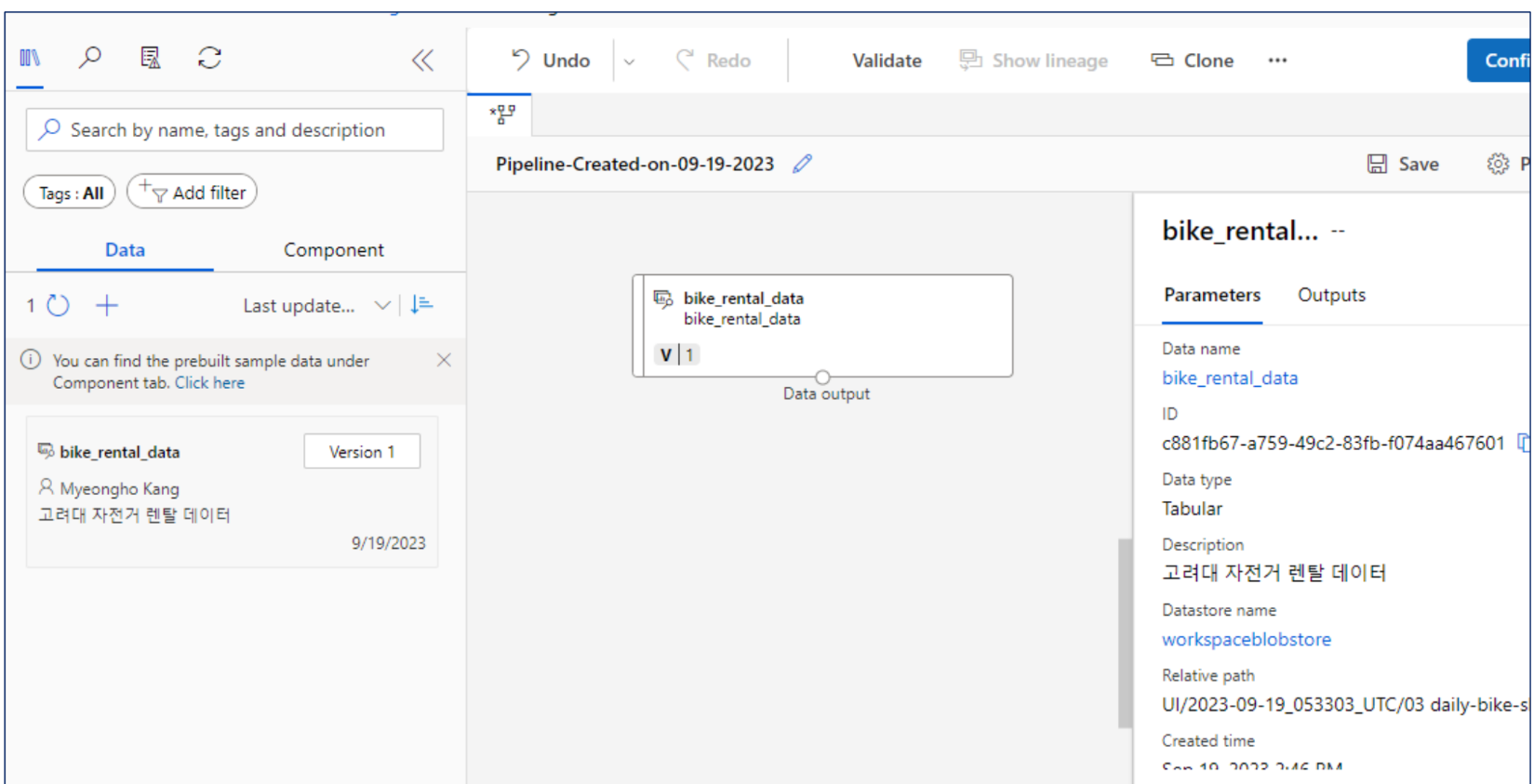
좌측의 데이터에서 우측의 캔버스로 이동시켜 로딩한다.
3. EDA
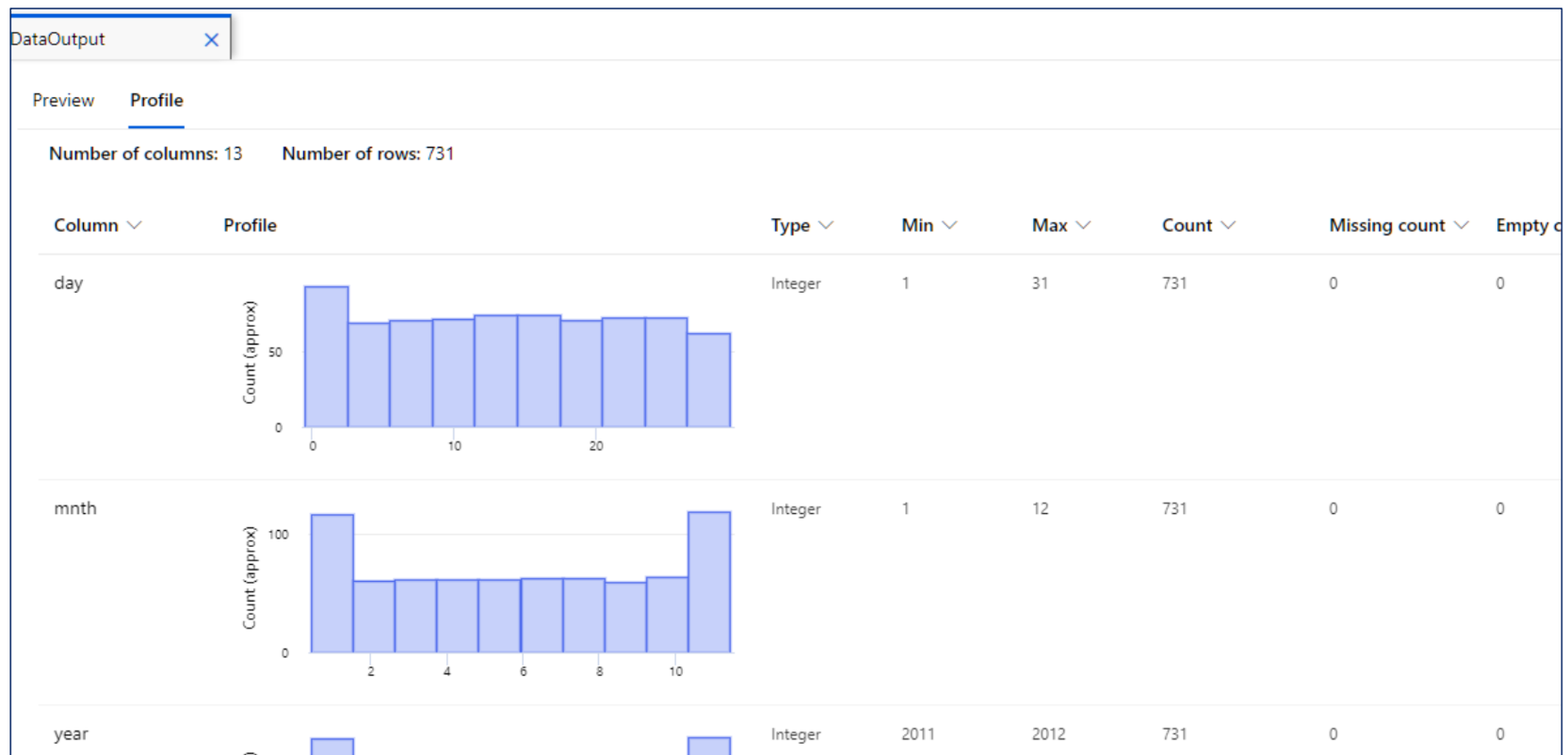
자동으로 EDA 확인도 가능하다
Azure Machine Learning - Designer: 데이터 준비
정규화 지원(전처리)
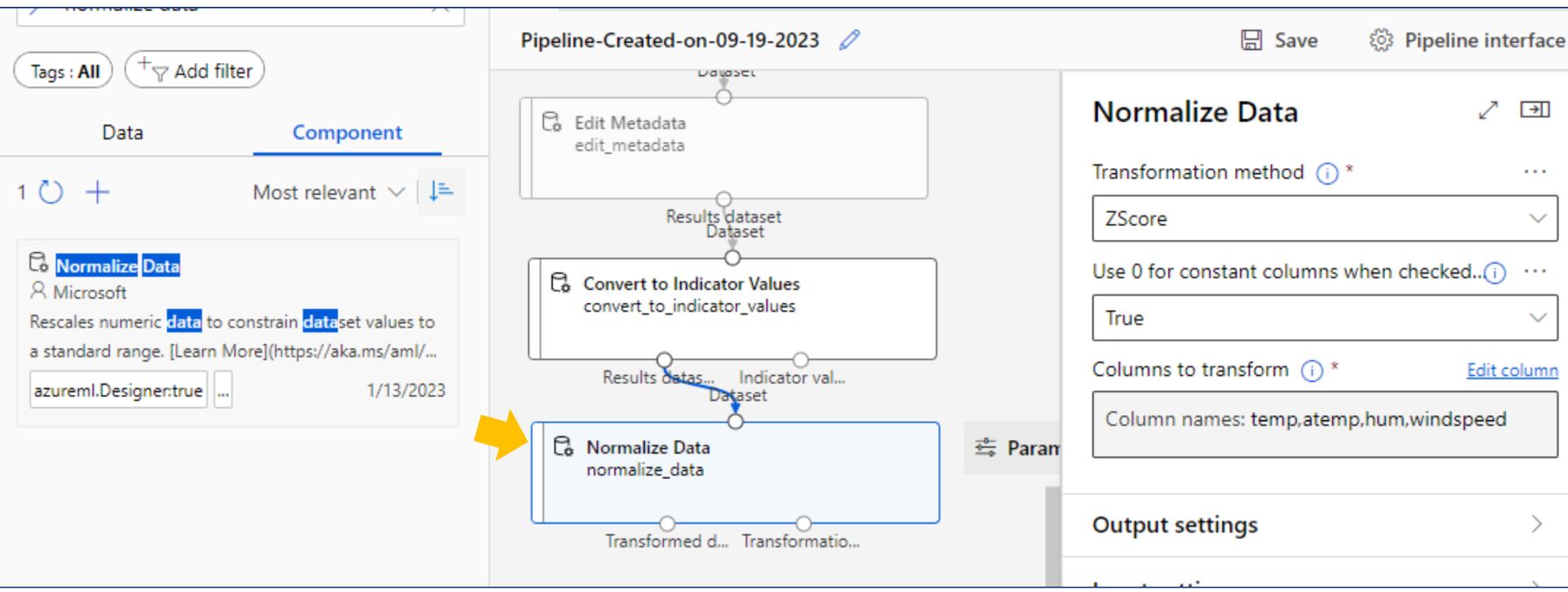
데이터 형변환
일반 데이터인지, 범주형 데이터인지 변경 가능
메타데이터 변경 함수 지원
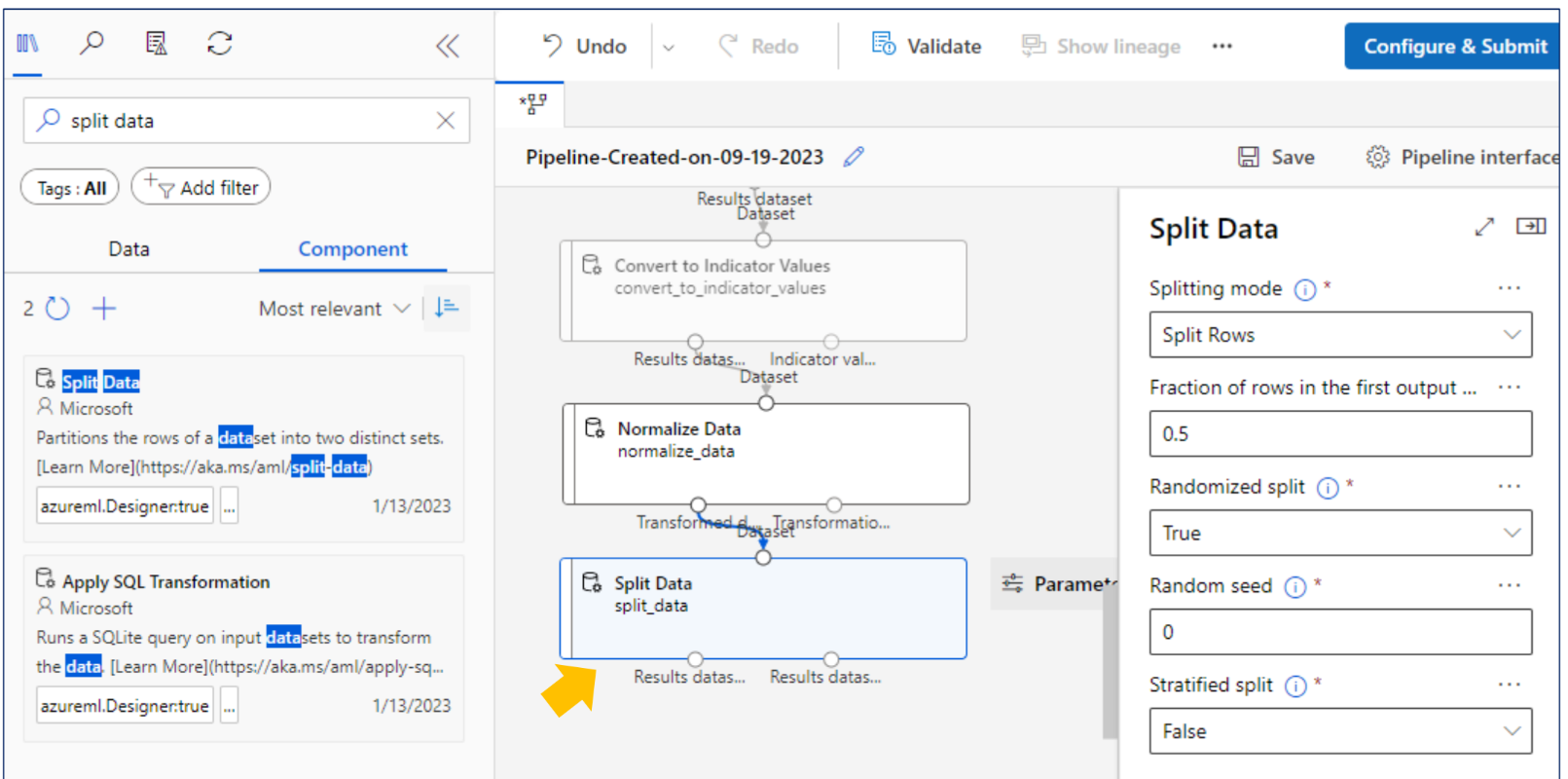
Split Data
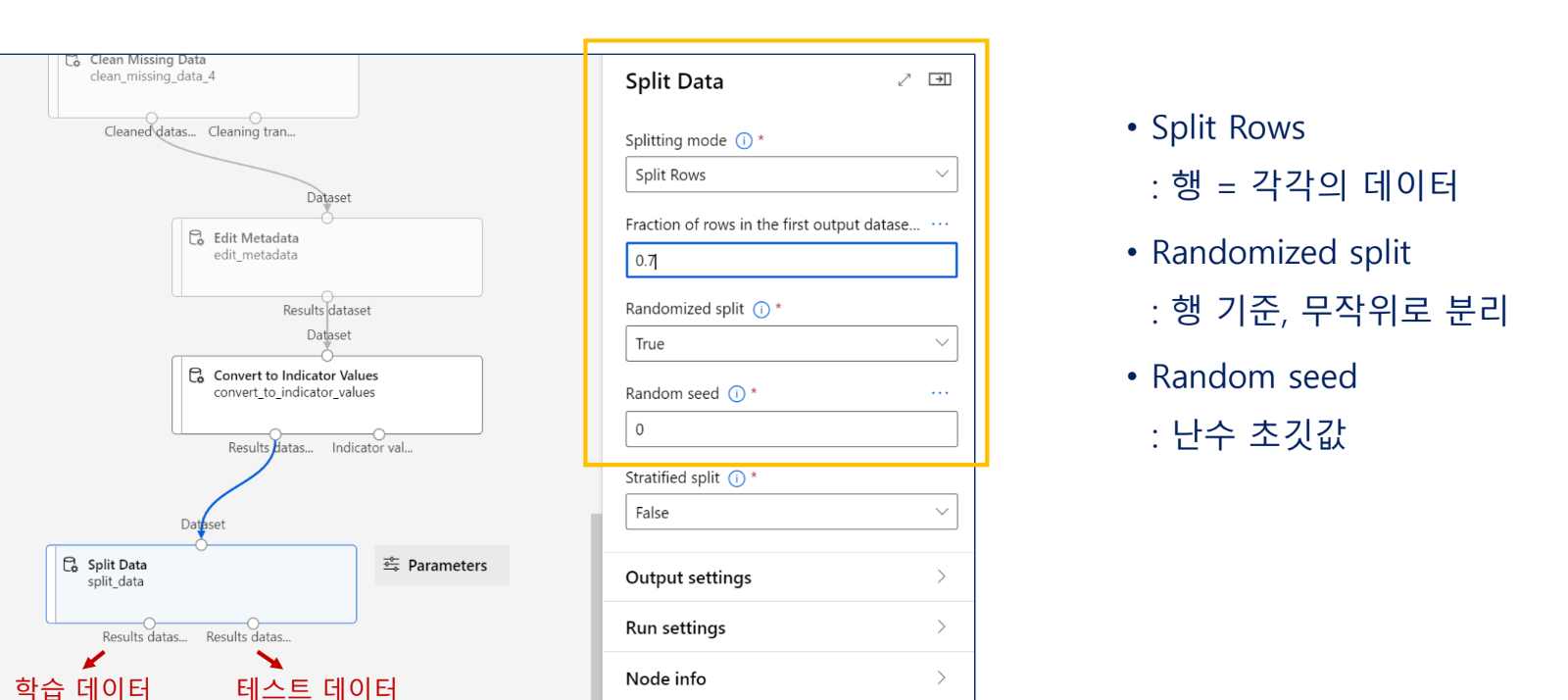
학습용 데이터를 쪼개서 활용 -> 3:7 또는 2:8 로 더 큰 양은 학습용으로, 작은 용으로는 검증할 때 보통 사용
모델 데이터를 평가할 땐 깨끗한 데이터를 사용해야 함(학습용 데이터로 오염되어서는 안됨)
그러므로 학습용/검증용으로 나누는 기능도 지원
이때 Random SubSampling 이 필요하다. (예: 대학생 1~4학년 설문조사 해두고 검증은 1학년걸로만 할 수는 없으니까)
Azure Machine Learning - Designer: 데이터 모델링
= 데이터 피팅
이 단계에서 모델링 알고리즘 선택, 모델 학습을 한다
모델을 돌릴 때는 VM을 만들어 실행 상태로 설정해줘야 한다.
2코어 혹은 4코어로 충분히 가능하고 가성비있으므로 추천
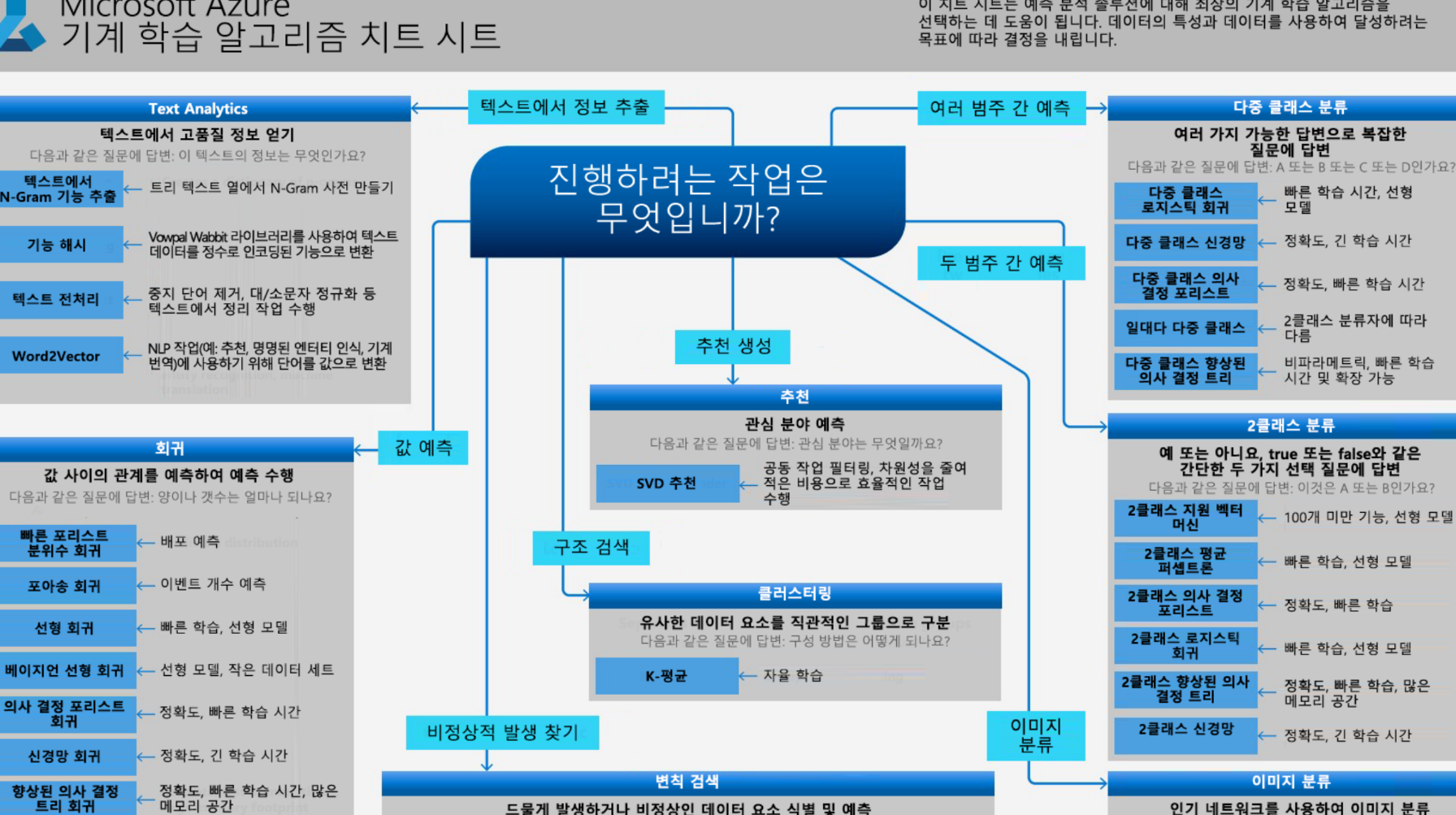
Microsoft Azure 기계 학습 알고리즘 치트 시트
- 대부분의 관련 알고리즘을 제공하지만, 없는 경우도 있음
실제 모델 알고리즘 설정
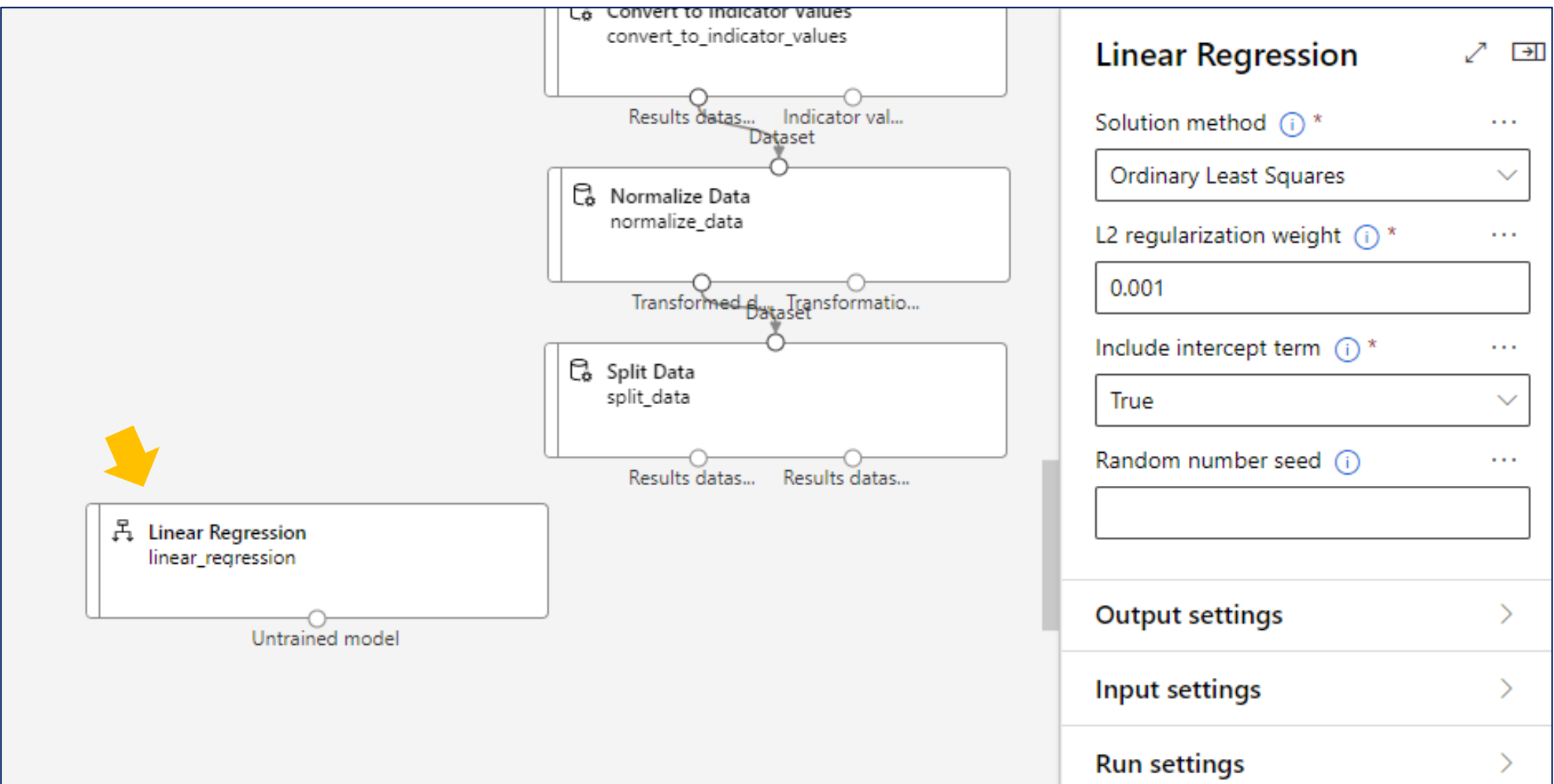
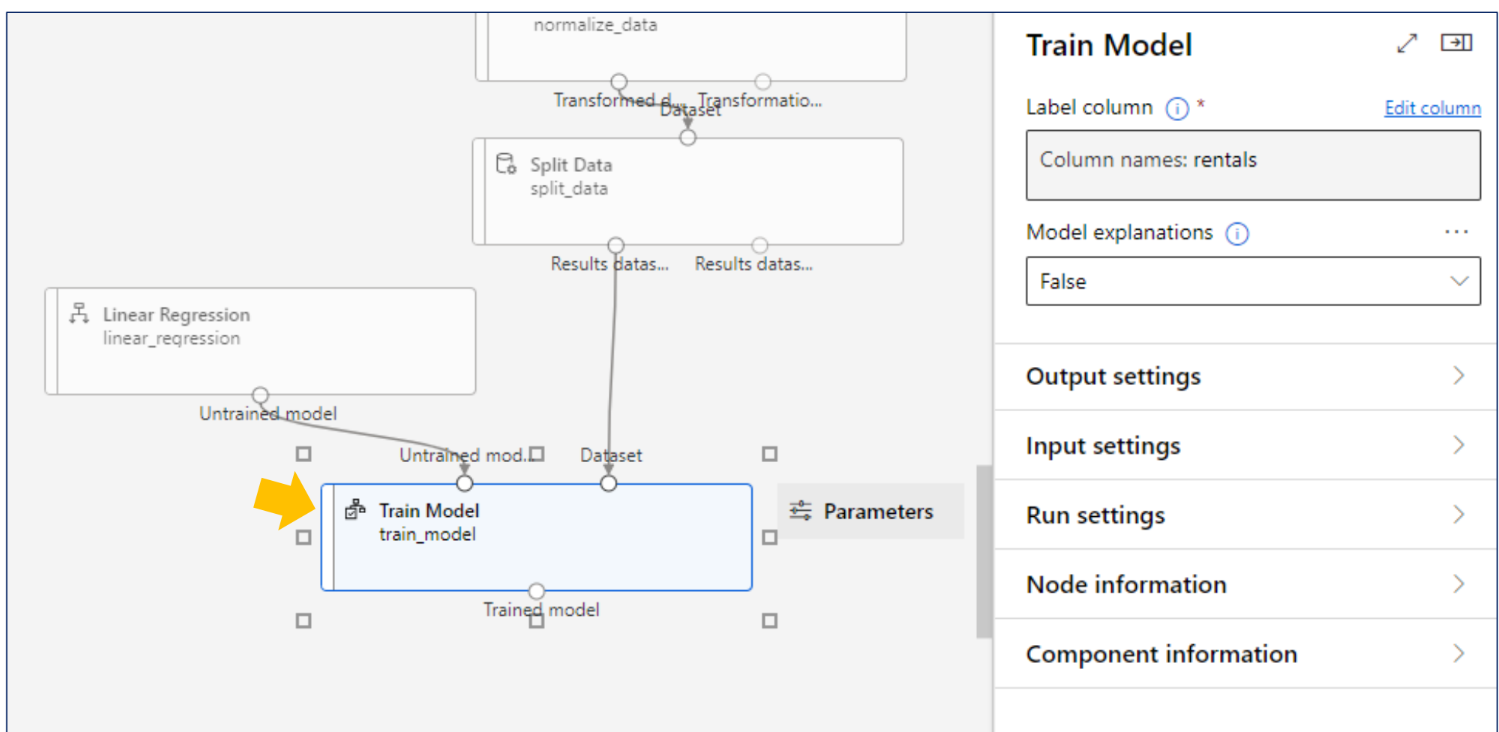
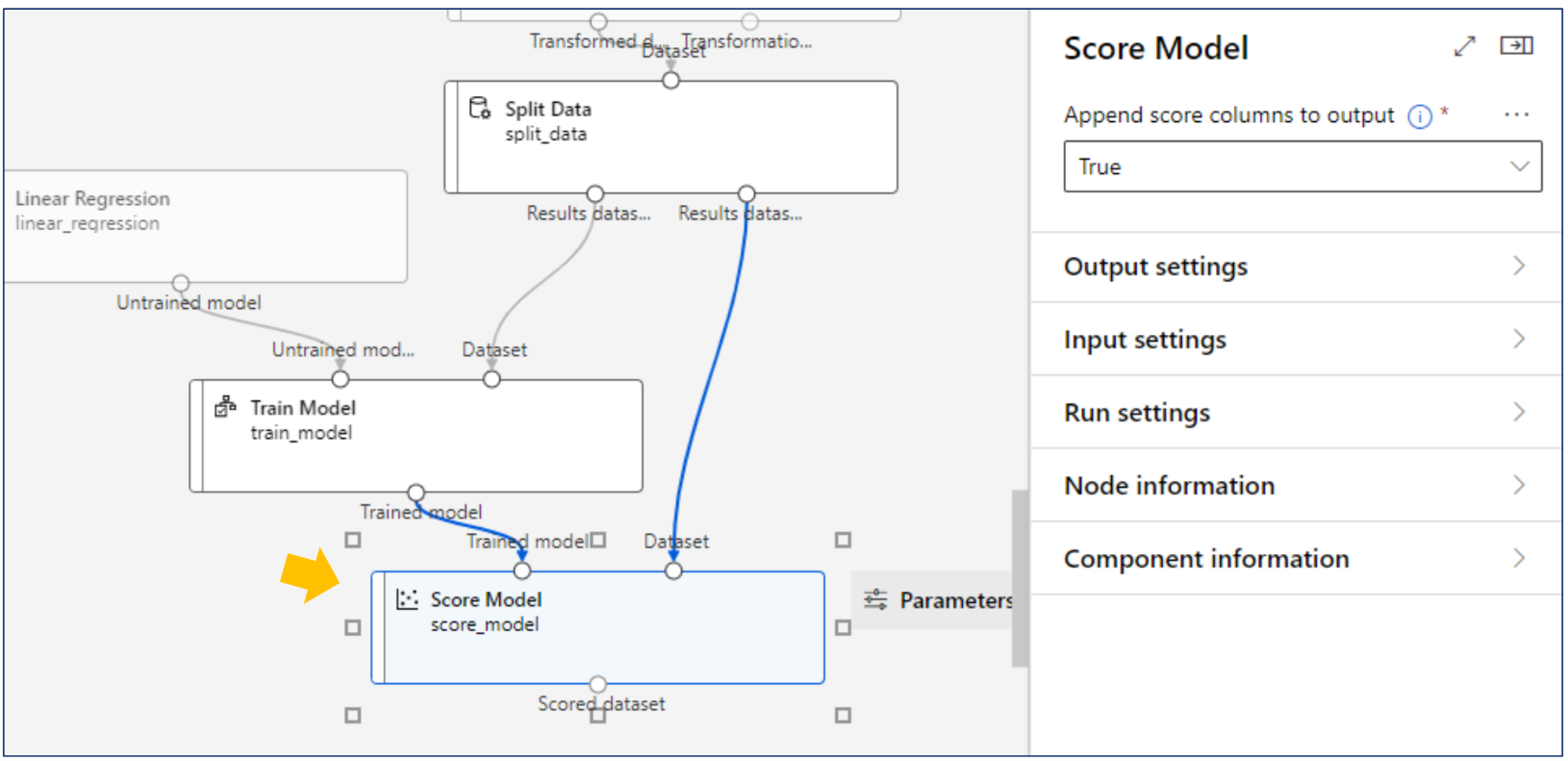
Azure Machine Learning - Desinger: 평가
통계
- 기술 통계
- 확률과 분포
- 추정과 가설 검정
- 상관분석
용어 및 개념
모집단과 표본
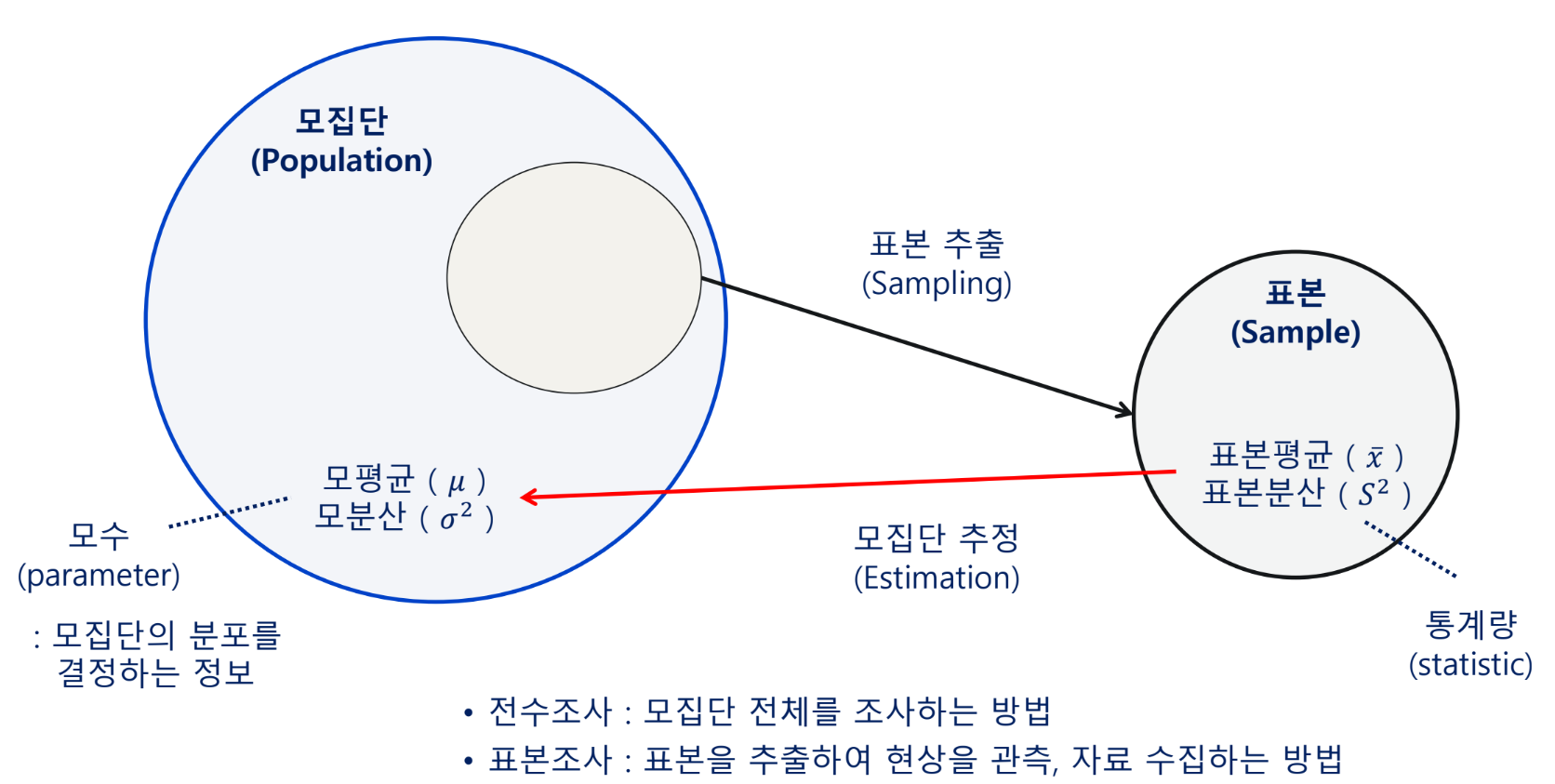
표본의 추출
데이터 자체가 표본이다.
- 확률적 표본 추출
- 동일한 확률 하에 표본을 추출하는 방법
- 무작위 표본 추출: 난수표 등을 따라 모집단에서 표본을 기계적으로 추출
- 체계적 표본 추출: 모집단에서 특정한 규칙으로 표본을 추출하는 방법
- 층화 표본 추출: 모집단을 특정 특성에 따라 여러 하위 집단으로 구분한 후, 집단의 규모에 비례하도록 추출
- 예) 한국 전국에 대해서, 서울, 경기만 추출하면 안됨
- 비확률적 표본 추출
- 조사자가 자의로 표본을 추출하거나 조사 대상이 자발적으로 표본에 참여
기술 통계
데이터를 설명하는 방법
중심경향성 측정
중심경향성(Central Tedency)
- 표본 내의 원소들의 중심을 나타내는 지표
- 평균, 중앙값, 최빈값..
평균(Mean)
→ 평균을 의미
- 장점: 데이터를 통합하여 하나의 대표값으로 표현
- 단점: 이상치에 민감하여 극단적인 값에 영향을 받음
- 연속적이고 정규 분포를 따르는 데이터에서 대표값을 구할 때 유용
중앙값(Median)
- 표본 내의 원소들을 정렬했을 때 중앙에 위치한 값
- 장점: 이상치의 영향을 덜 받음
- 단점: 표본의 크기가 클 경우 정렬에 많은 시간 소요
- 비대칭적이거나 이상치가 있을 때 사용
최빈값(Mode)
- 표본에서 가장 자주 나타나는 값
- 장점: 표본의 원소들의 빈도 분포를 잘 나타냄
- 단점: 표본 내의 최빈값이 존재하지 않을 수 있음. 복수 개의 최빈값 존재 가능
- 범주형 데이터에서 빈도가 가장 높은 값을 찾을 때 유용
가중평균(Weighted Mean)
- 표본의 원소들의 값에 가중치를 부여하여 계산한 평균
- 모든 원소들의 값이 동일한 중요도를 가지지 않을 때 사용
조화평균(Harmonic Mean)
- 원소들의 값들의 역수의 평균을 다시 역수로 변환하여 계산
- 주로 비율이나 속도 데이터에서 사용
- ex) 240km를 갈 때 60km/h, 올 때 40km/h로 다녀오면 평균은 5km/h가 아닌, 480/100 = 4.8km/h이다.
속력은 비율이기 때문에 조화평균으로 구해야 한다. →
산포도 측정
산포도(Measure of Dispersion)
- 데이터의 변동성을 파악하는데 중요한 역할
범위(Range)
- 표본 집합에서 가장 큰값과 가장 작은 값의 차이
- 극단값에 민감함
분산(Variance)
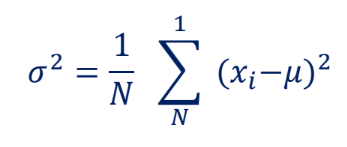
- 데이터 값들이 평균에서 얼마나 떨어져 있는지를 나타냄
- (각 데이터 값 - 평균)^2 의 평균
표준편차(Standard Deviation)
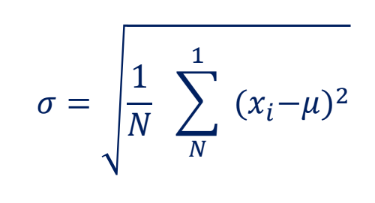
- 분산의 제곱근
- 데이터가 평균에서 얼마나 떨어져 있는지에 대한 표준적인 거리
사분위수 범위(Interquartile Range, IQR)
- 데이터의 중앙 50%가 포함된 범위로, Q3(3사분위수)와 Q1(1사분위수)의 차이
- 극단값의 영향을 덜 받음
왜도와 첨도
- 통계에서 데이터의 분포의 특성을 설명하는 지표
왜도(Skewness)
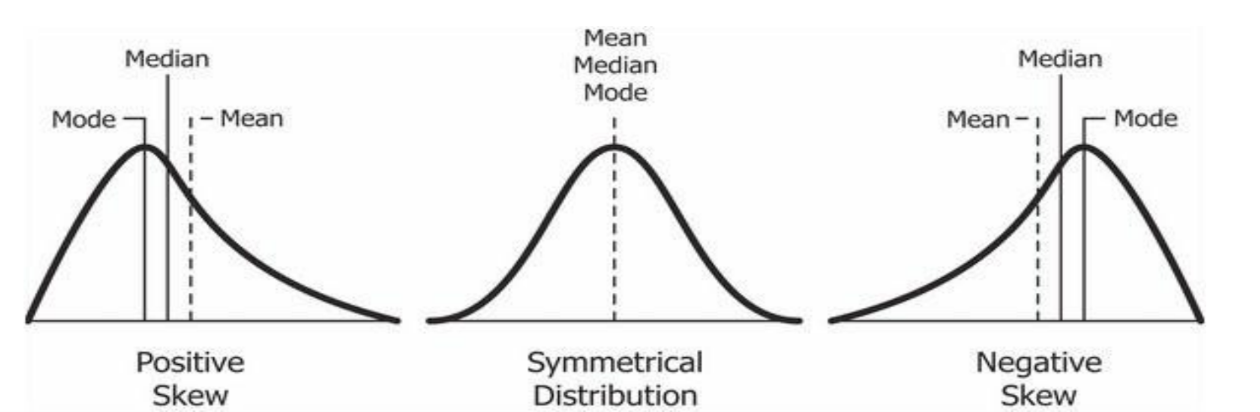
- 분포의 비대칭성을 측정하는 지표
- 양의 왜도
- 분포의 꼬리가 오른쪽(양의 방향) 으로 길게 늘어져 있는 경우
- 평균이 중앙값보다 큼
- 음의 왜도
- 분포의 꼬리가 왼쪽(음의 방향)으로 길게 늘어져 있는 경우
- 평균이 중앙값보다 작음
첨도(Kurtosis)
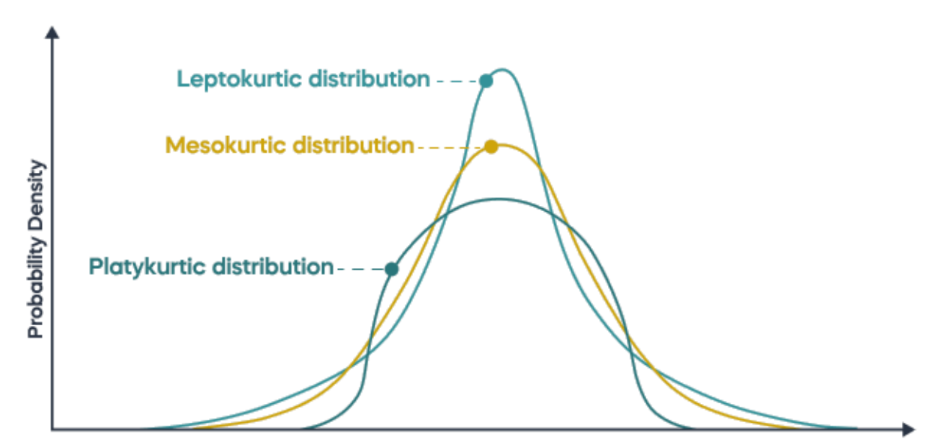
- 분포의 뾰족함과 꼬리의 두꺼움을 측정하는 지표
- 양의 첨도(Leptokurtic): (Kurtosis > 3)
- 정규 분포보다 뾰족하고 꼬리가 두꺼운 분포
- 극단적인 값(이상치)이 더 자주 발생함
- 음의 첨도(Platykurtic): (Kurtosis < 3)
- 정규 분포보다 평평하고 꼬리가 얇은 분포
- 극단적인 값이 덜 발생
확률과 분포
확률
- 표본 공간(Sample Space): 실험을 통해 나타날 수 있는 모든 결과들의 집합
- 사건: 표본공간에 있는 일부 원소들로 이루어진 부분 집합
- 확률: 특정사건이 일어날 가능성을 나타내는 척도로 0~1
- 확률 함수: 사건이 발생할 확률을 나타내는 함수
- 규칙
- 덧셈 법칙:
P(A∪B) = P(A) + P(B) - P(A∩B) - 곱셈 법칙: 두 사건이 독립사건일 때
P(A∩B) = P(A) × P(B)
- 덧셈 법칙:
확률 변수와 확률 분포
- 확률 변수(Random Variable)
- 특정 값이 나타날 가능성이 확률적으로 주어지는 변수
- 표본 공간의 각 표본점에 실수 값을 대응시키는 함수 역할
- 이산 확률 변수와 연속 확률변수로 구분
- 특정 값이 나타날 가능성이 확률적으로 주어지는 변수
표본점(Sample Point)
- 모집단에서 무작위로 뽑은 하나의 표본
확률 표본(Random Sample)
- 모든 표본점들이 동일한 괄률로 추출된다는 조건 하에서 추출된 표본
확률 변수
이산형 확률변수(Discrete random variable)
- 0이 아닌 확률 값을 갖는 값이 셀 수 있는 경우의 확률 변수
- 주사위를 굴렸을 때 나오는 눈의 수, 동전 던지기의 결과
- 확률질량함수(Probability Mass Function) : 이산형 확률변수의 확률함수
- 이항분포, 기하분포, 포아송분포
연속형 확률분포(Continuous random variable)
- 가능한 값이 실수의 어느 특정 구간 전체에 해당하는 확률 변수
- 연속적인 값을 가짐
- 특정 시간 동안의 온도, 사람의 키
- 확률밀도함수(Probability Density Function): 연속형 확률변수의 확률함수
- 정규분포, 균일분포, t-분포, 카이제곱분포
확률 분포
- 확률 변수가 가질 수 있는 값들과 그 값들이 발생할 확률을 나타내는 함수, 표, 그래프
이산 확률 분포(Discrete Probability Distribution)
- 확률 변수가 취할 수 있는 값이 유한하거나 셀 수 있는 경우
- 확률질량함수(PMF)로 표현
베르누이 분포
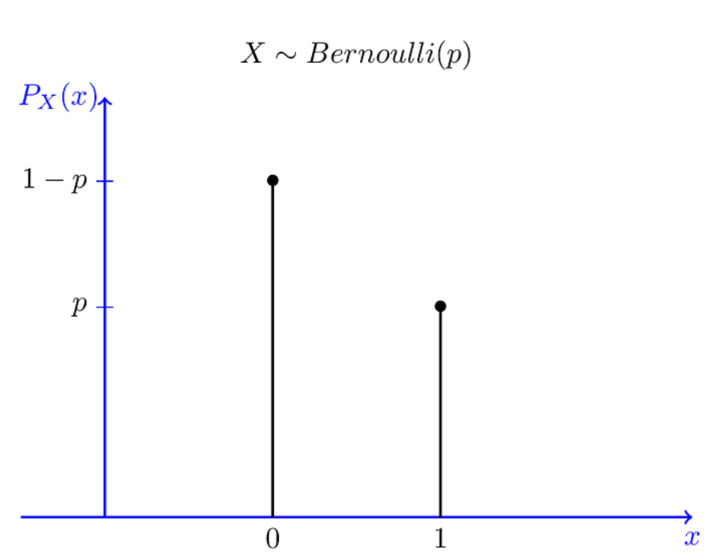
- 두 가지 결과(성공, 실패)가 있는 단일 시행의 확률분포
- 확률변수 X: 성공1 실패0
- 기대값: E(X) = p
- 동전 던지기, 제품 검수
이항 분포
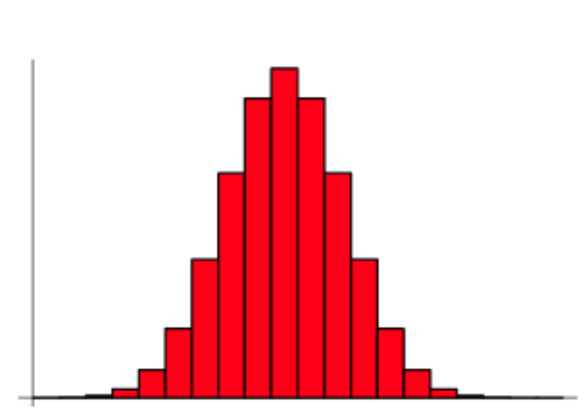
- 일정한 횟수의 독립적인 베르누이 시행에서 성공의 횟수를 나타내는 분포
- 확률 변수 X: n번의 독립적인 시행 중 성공 횟수
- 기대값: E(X) = np
- 분산: Var(X) = np(1-p)
- 동전 여러번 던지기: 20번 던져서 앞면이 나오는 횟수
푸아송 분포
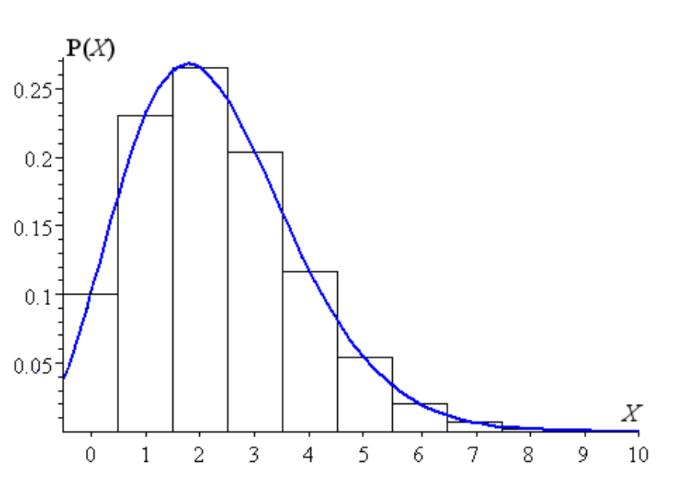
- 단위 시간(단위 공간)에서 특정 사건의 발생 빈도를 나타내는 분포
- 드물게 발생하는 사건의 빈도를 모델링할 경우 사용
- 확률변수 X: 일정한 시간에서 발생하는 사건의 횟수
- 콜센터: 1시간 동안 걸려오는 전화의 수, 특정 도로에서 1시간 동안 발생하는 교통사고 수
연속 확률 분포(Continuous Probability Distribution)
- 확률 변수가 취할 수 있는 값이 연속적인 경우
- 확률 밀도 함수(PDF) 로 표현
- 정규 분포, 지수 분포, 카이제곱 분포
정규 분포(Normal Distribution)
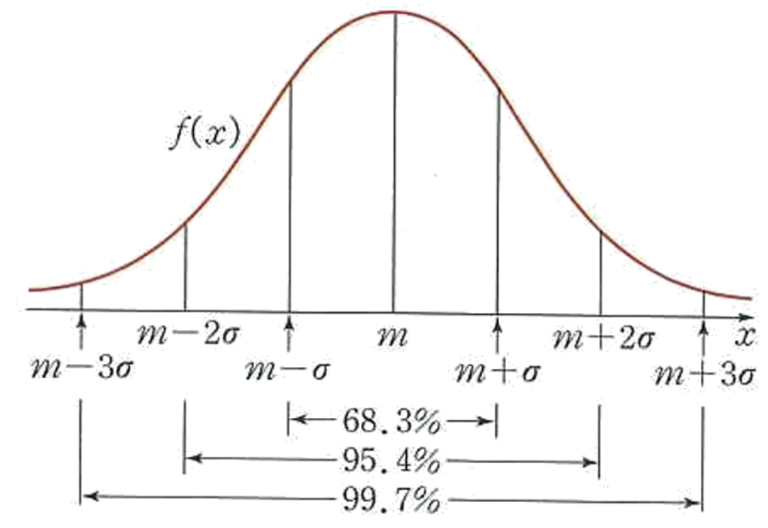
- 데이터를 표준편차로 나눔
- 종 모양의 대칭 분포로, 자연 현상에서 많이 나타나는 일반적인 분포
- 평균을 중심으로 대칭
- 성인의 키 분포, 대규모 시험의 성적 분포
지수 분포(Exponential Distribution)
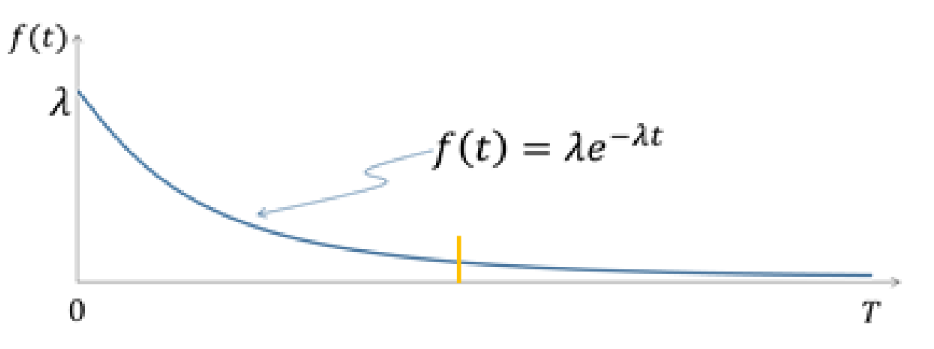
람다: 발생율, T: 시간
- 포아송 분포의 확장판: 포아송 과정에서 시간 간격을 모델링하는데 사용
- 사건 간의 시간 간격에 대한 분포
- 콜센터 대기 시간: 다음 전화가 걸려올 때까지의 시간
카이제곱 분포(Chi-Square Distribution)
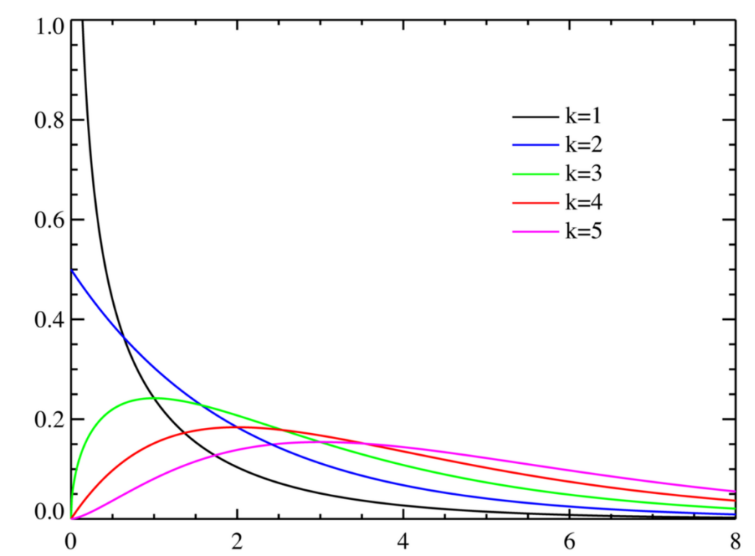
- 정규 분포를 따르는 독립적인 변수들의 제곱의 합의 분포
- 모집단의 분산을 추정할 때 주로 사용
- 적합도 검정: 관찰된 데이터가 기대 분포와 일치하는지 검정, 분산 분석: 여러 집단의 분산을 비교
추정과 가설검정
추론
- 표본을 활용하여 모집단의 특성을 추측
- 모집단 전체를 조사할 수 없을 경우 사용
추론의 방법
모수의 추정
- 미지수인, 모집단의 모수에 대한 추측 또는 추측값을 정확도와 함께 제시
모수에 대한 가설검정
- 모집단의 모수에 대한 여러 가설들이 적합한지 여부를 표본으로부터 판단
추정
점추정(Point Estimation)
- 모집단의 모수를 단일 값으로 추정
- 대푯값: 표본평균, 표본분산
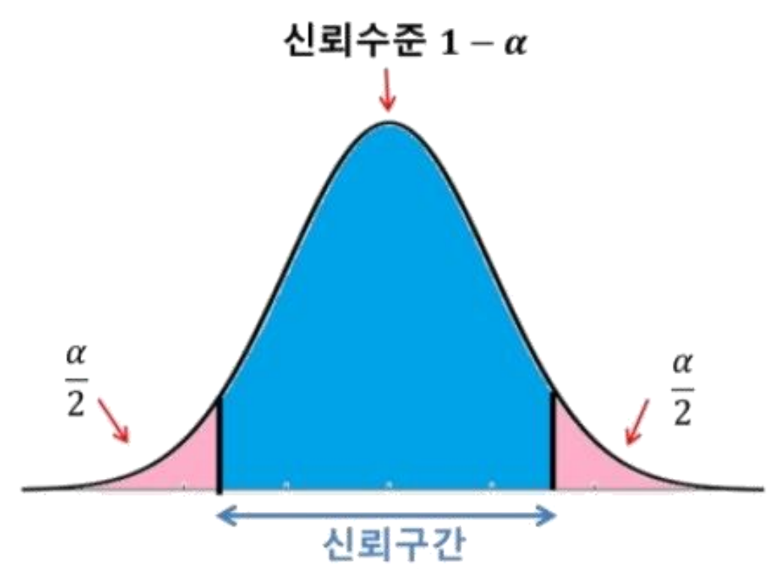
구간추정(Interval Estimation)
- 모집단의 모수를 포함할 것으로 예상되는 구간을 제시
- 구성: 신뢰구간(Confidence Interval)과 신뢰수준(Confidence Level)으로 구성
- 신뢰구간: 모수가 포함될 것으로 예상되는 범위
- 신뢰수준: 모수가 해당 구간에 포함될 확률
- 90%, 95%, 99%가 자주 사용됨
- 알파값은 모수가 신뢰구간에 포함되지 않을 확률
가설 검정

- 어떤 추측이나 주장, 가설에 대해 타당성을 조사하는 작업
- 표본 통계량으로 모수 추정시, 추정한 모수값이나 확률분포 등이 타당한지 평가하는 통계적 추론 방법
- 귀무가설(Null Hypothesis, H0): 버릴 것으로 예상하는 가설
- 대립가설(Alternative Hypothesis, H1): 실제 주장 또는 증명하려는 가설
H0이 기각되면 H1이 채택됨
예시: 진통제 개발
귀무가설/대립가설 수립 :
• 귀무가설 H0 : 새로운 진통제의 효과가 기존 진통제와 차이가 없다.
• 대립가설 H1 : 새로운 진통제가 기존 진통제보다 더 효과적이다.
유의수준 결정 :
• 유의수준을 0.05로 설정
(5%의 확률로 귀무가설이 참인데도 불구하고 기각할 가능성을 허용함)
검정 통계량 계산 :
• 임상 실험을 통해 두 그룹의 환자들을 각각 새로운 진통제와 기존 진통제 투약
• 각 그룹에서 진통 정도를 수치화한 데이터 수집
• 두 그룹의 평균 진통 수치를 비교하여 검정 통계량(예: t-검정) 계산
기각/채택 결정 :
• P-value 계산 : 검정 통계량을 바탕으로 P-value를 계산
• P-value : 귀무가설 하에서 관측된 데이터가 발생할 확률 (H0을 지지하는 값)
결정 :
• P-value가 유의수준 0.05보다 작으면 귀무가설 기각 (효과 있다)
• 그렇지 않으면 귀무가설 채택 (효과 없다)
오류
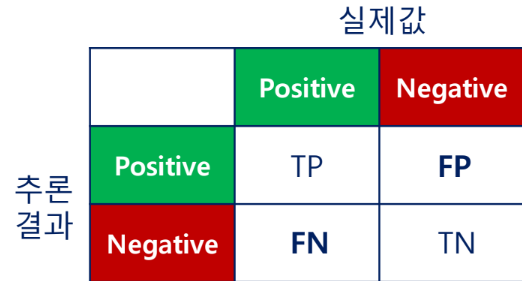
1종 오류
- 귀무가설이 참인데도 불구하고 이를 기각하는 오류
- 잘못된 긍정 결과 초래
2종 오류
- 대립가설이 참인데도 불구하고 귀무가설을 기각하지 않는 오류
- 잘못된 부정 결과 초래
가설 검정 방법
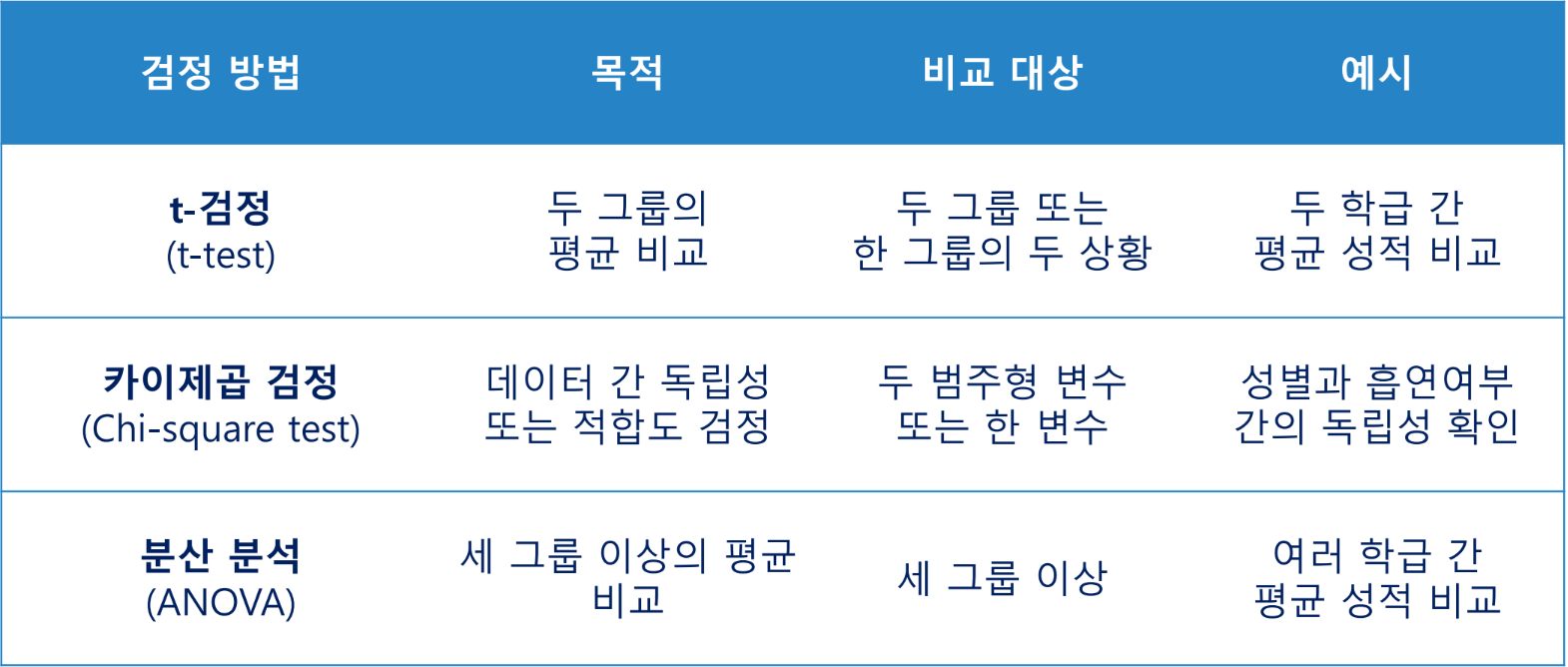
t-검정
두 그룹 간의 평균의 차이가 유의미한지 확인하고자 할 때 주로 사용
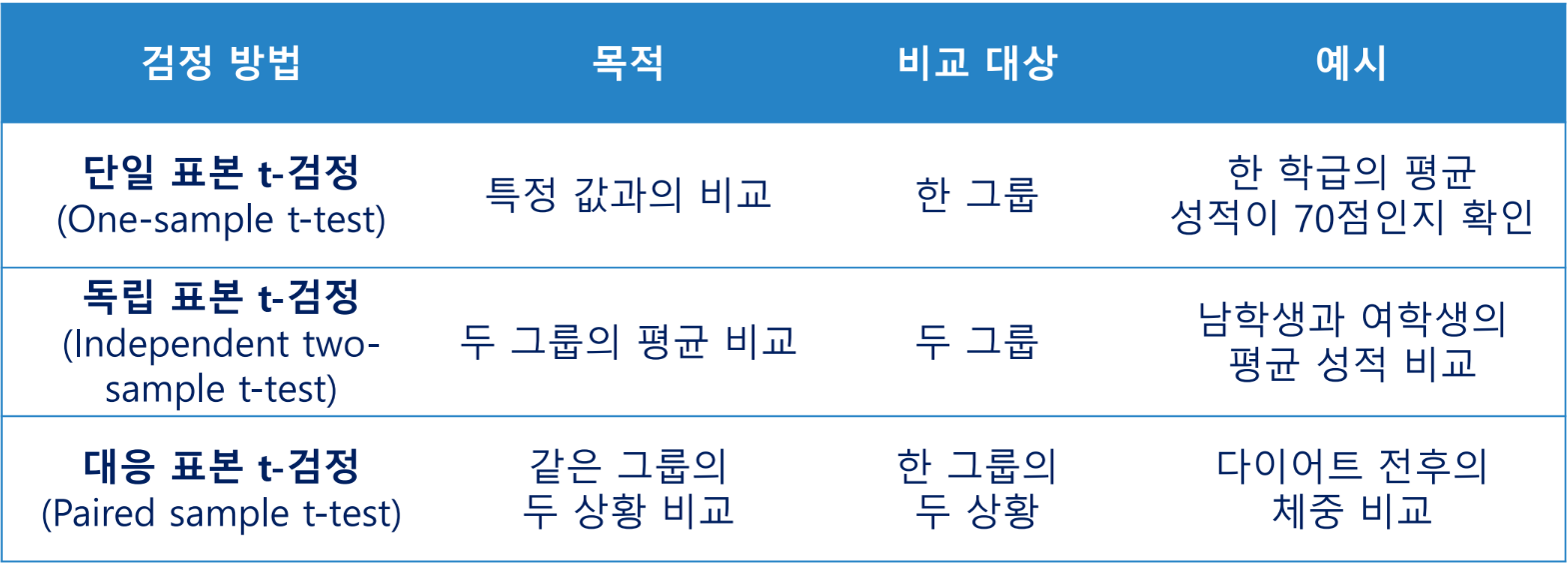
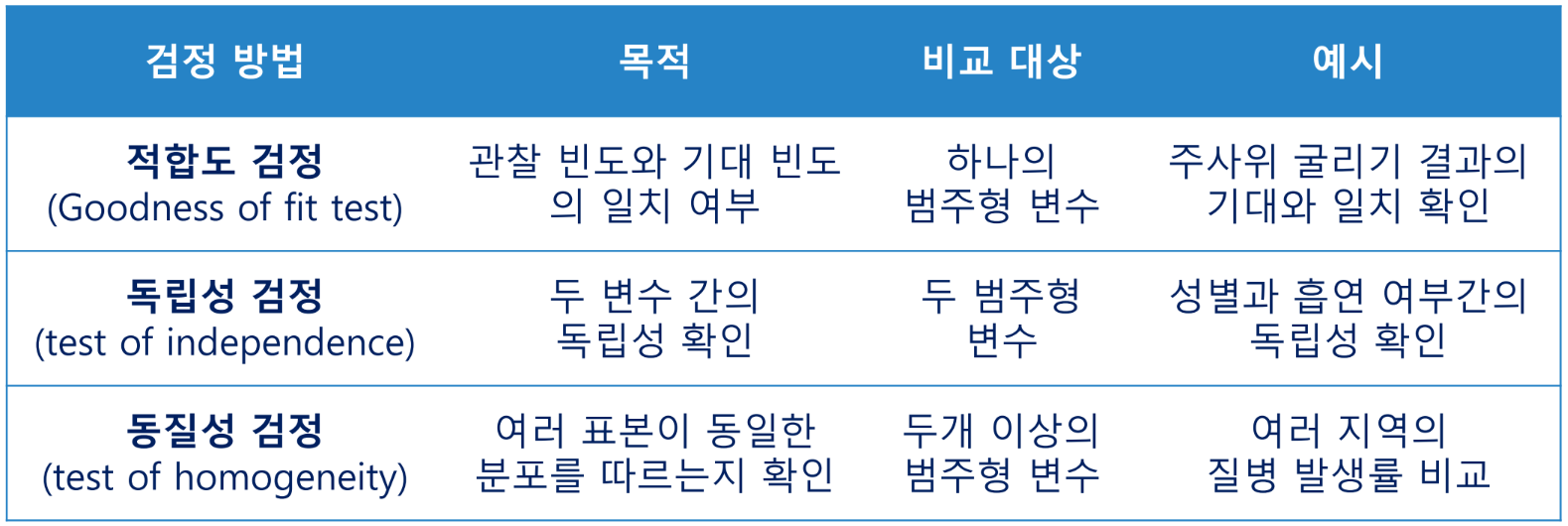
카이제곱 검정
범주형 데이터에서 기대 빈도와 관찰된 빈도 간의 차이를 확인할 때 사용
두 범주형 데이터에서 변수 간 독립성 여부를 검정할 때 사용
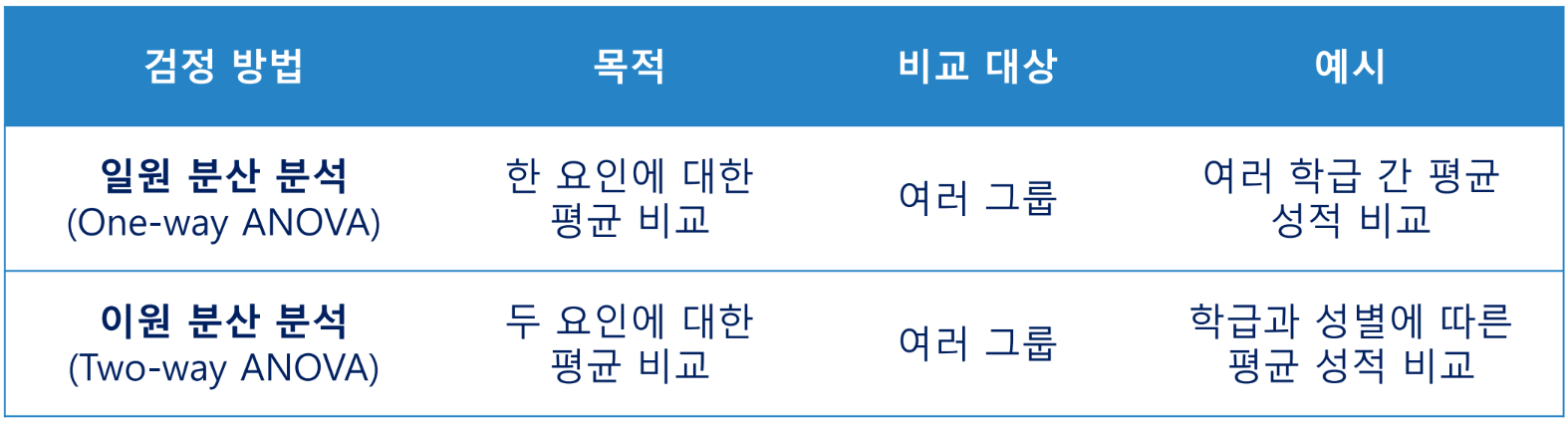
분산 분석
Analysis of Variance(ANOVA)
3개 이상의 집단에 대한 평균 차이를 검증하는 분석
상관 분석
- 두 분석 간의 관계를 정략적으로 평가하는 통계 기법
- 하나의 변수가 변할 때 다른 변수가 어떻게 변하는지 파악할 수 있음
상관계수(Correlation Coefficient)
- 두 변수 간의 관계의 강도와 방향을 나타내는 수치
상관관계의 방향
- 양의 상관관계: 한 변수가 증가할 때 다른 변수도 증가하는 경향
- 음의 상관관계: 한 변수가 증가할 때 다른 변수는 감소하는 경향
상관관계의 강도
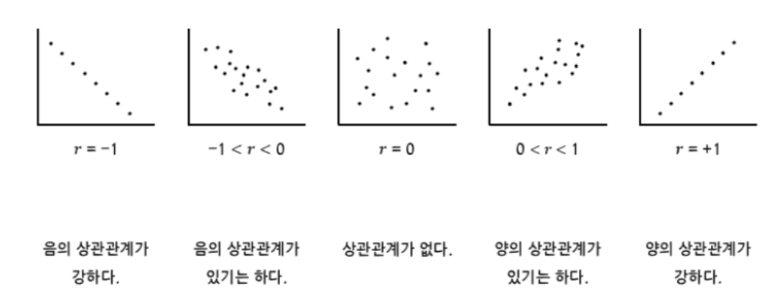
- 강한 상관관계: |상관계수| ≥ 0.7
- 중간 상관관계: 0.3 ≤ |상관계수| < 0.7
- 약한 상관관계: |상관계수| < 0.3
피어슨 상관계수(Pearson Correlation Coefficient)
- 측정 대상: 연속형 변수 간의 선형 관계를 측정
- 두 변수의 공분산을 각 변수의 표준편차로 나누어 계산
- 두 변수가 얼마나 함께 변하는지를 표준편차를 통해 정규화
- 해석
- r = 1: 완전한 양의 상관관계
- r = -1: 완전한 음의 상관관계
- r = 0: 상관관계 없음
- 장점: 데이터의 선형 관계를 직접적으로 반영, 해석 직관적
- 단점: 두 변수 간의 관계가 비선형 관계일 경우 이를 제대로 반영 X
- 키와 몸무게의 관계
스피어만 상관계수(Spearman's Rank Correlation Coefficient)
- 측정 대상: 순위형 변수 간의 관계 측정(비선형 관계일 경우에도 가능)
- 각 변수의 순위를 매긴 후, 그 순위들 간의 상관계수를 계산함
- 해석
- r = 1: 완전한 양의 상관관계
- r = -1: 완전한 음의 상관관계
- r = 0: 상관관계 없음
- 장점: 비선형 관계와 이상치에 민감하지 않음
- 단점: 데이터의 순위 정보만 사용하여 정보 손실이 발생할 수 있음
- 학생 성적 순위와 스포츠 성적 순위 간의 관계
켄달의 타우(Kendall's Tau, Kendall's Rank Correlation Coefficient)
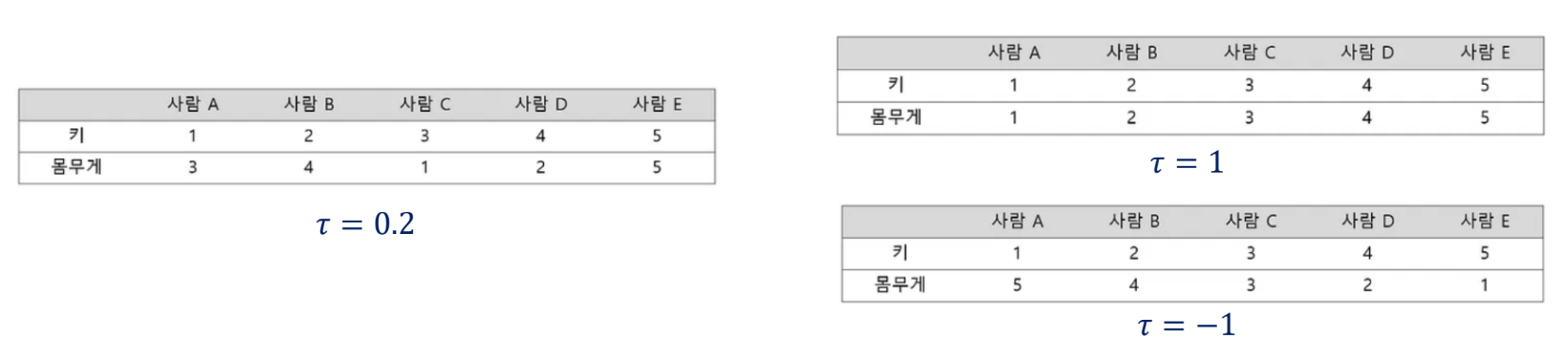
- 측정 대상: 변수의 순서 간의 상관성을 측정
- 순위 쌍 간의 일치와 불일치를 비교하여 상관관계를 계산
- 해석: 피어슨 상관계수와 동일
- 장점: 순위 정보에 기반하여 비선형 관계도 잘 반영
- 단점: 계산이 복잡하며, 해석이 어려울 수 있음
- 직무 수행 순위와 승진 순위 간의 관계
머신 러닝
데이터에 기반하여 규칙을 파악하고, 이 규칙에 따라 새로운 입력값의 결과를 예측
- 주어진 데이터를 가장 잘 표현할 수 있는 선형 방정식(y = ax + b) 찾기
- 사용자가 좋아요를 누른 작품들을 바탕으로 사용자가 좋아하는 영화의 유형 파악, 새로운 영화를 좋아할지 예측
- 유사한 특성을 가진 데이터를 하나의 그룹으로 구분, 그룹에 속해 있다는 정보가 없음. 주어진 데이터 자체의 특징으로부터 규칙 파악
- 개별 그룹의 평균 지점 산출 -> 개별 데이터와 각 그룹 평균 사이의 거리를 계산 -> 가장 거리가 가까운 평균의 그룹으로 지정
머신러닝 유형
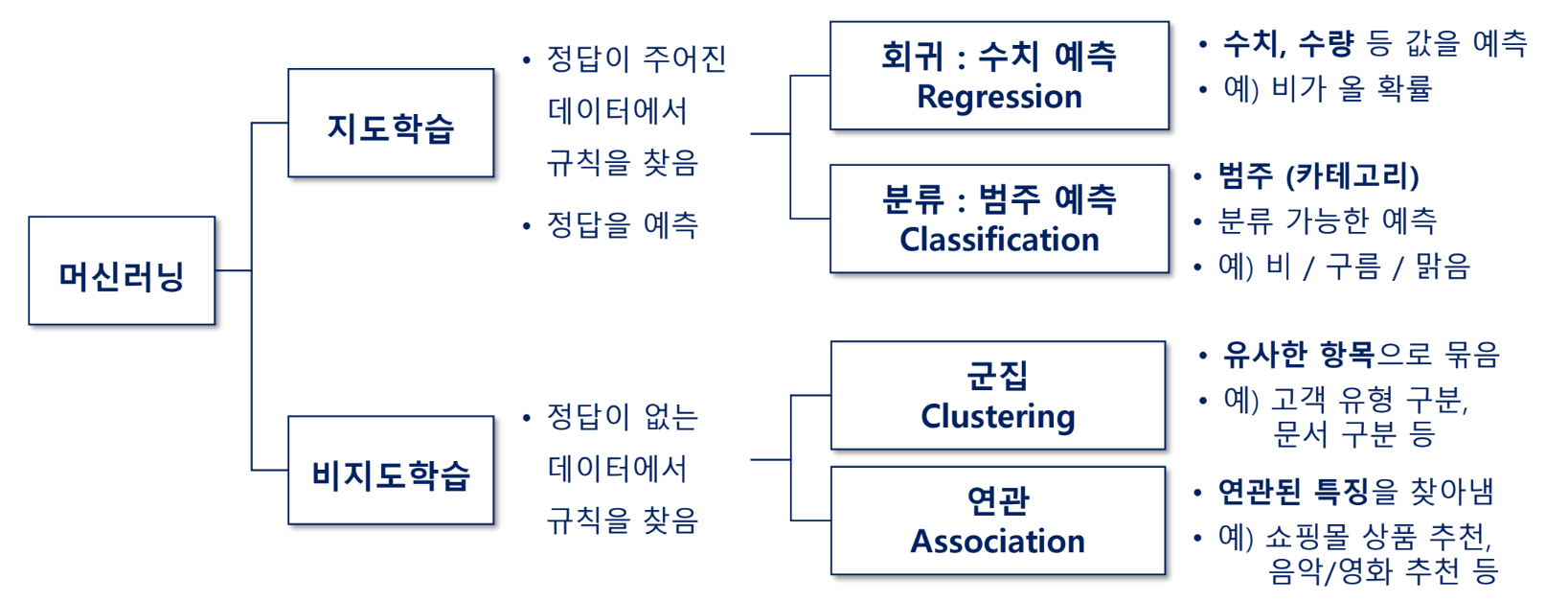
지도학습
분류
- 주어진 데이터를 모델에 적용한 후 범주 중 하나의 값으로 분류하여 예측
- 2진 분류와 다중 클래스 분류로 구분

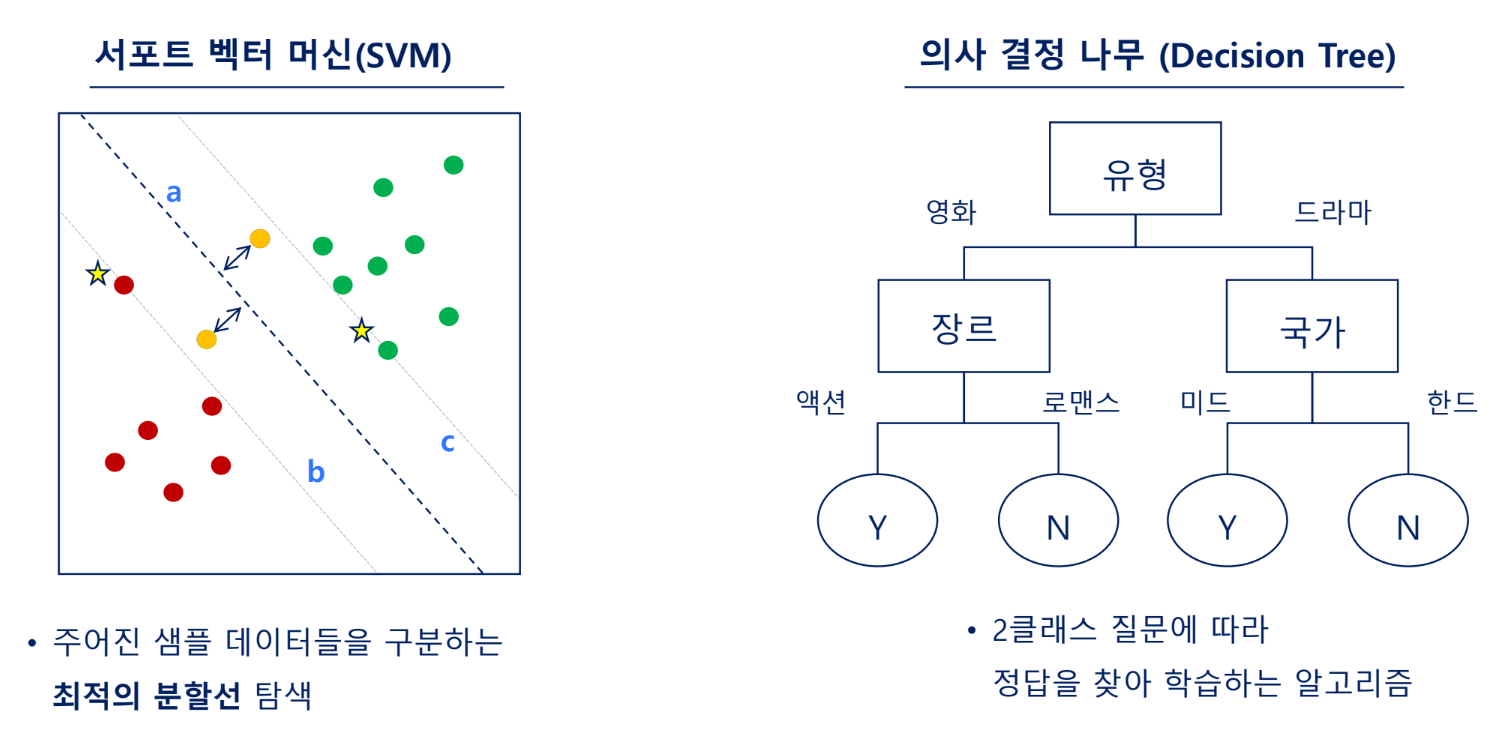
머신러닝 용어 및 단계
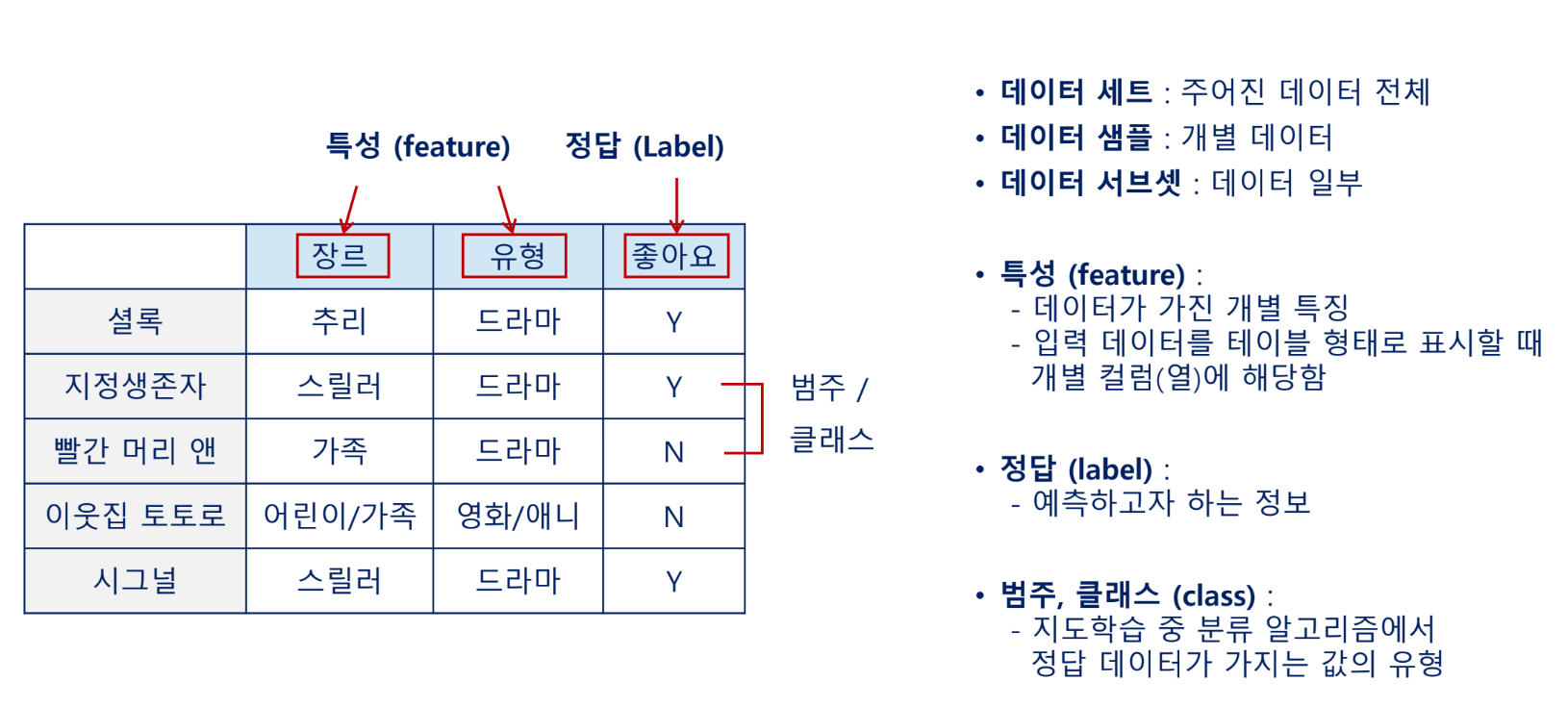
알고리즘: 의사 결정 나무
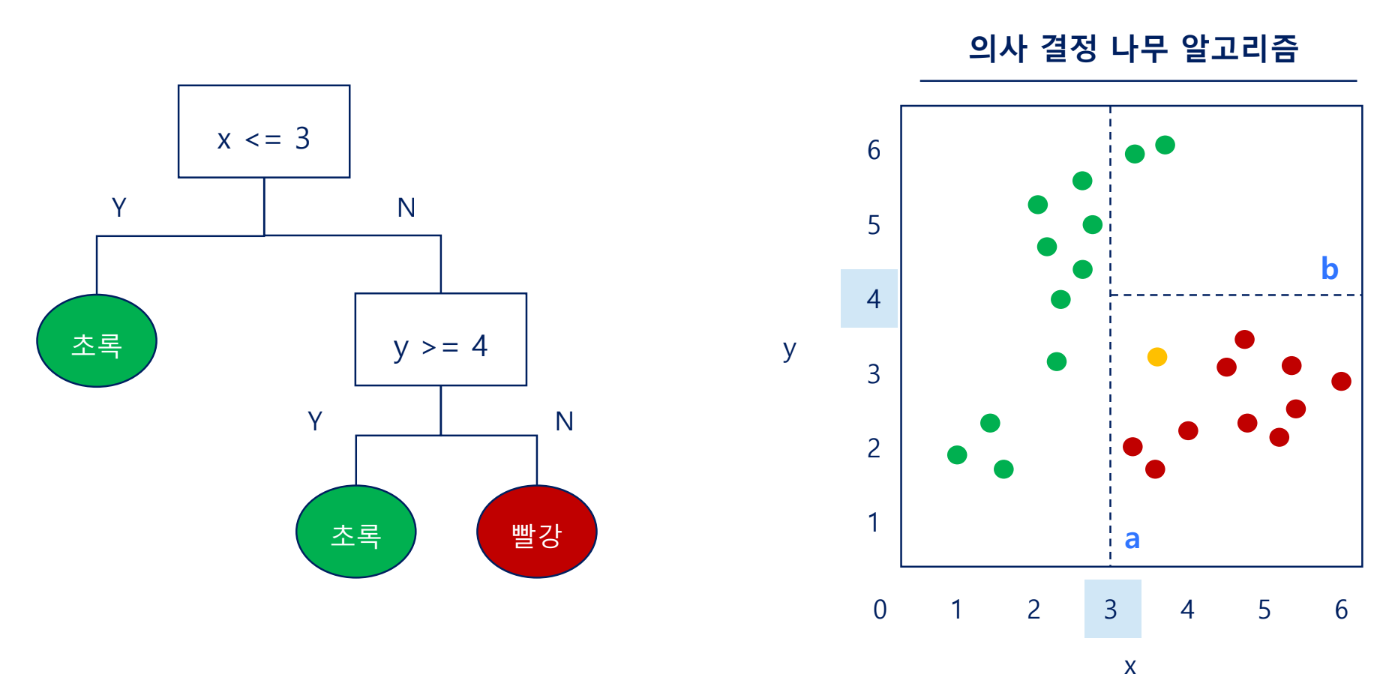
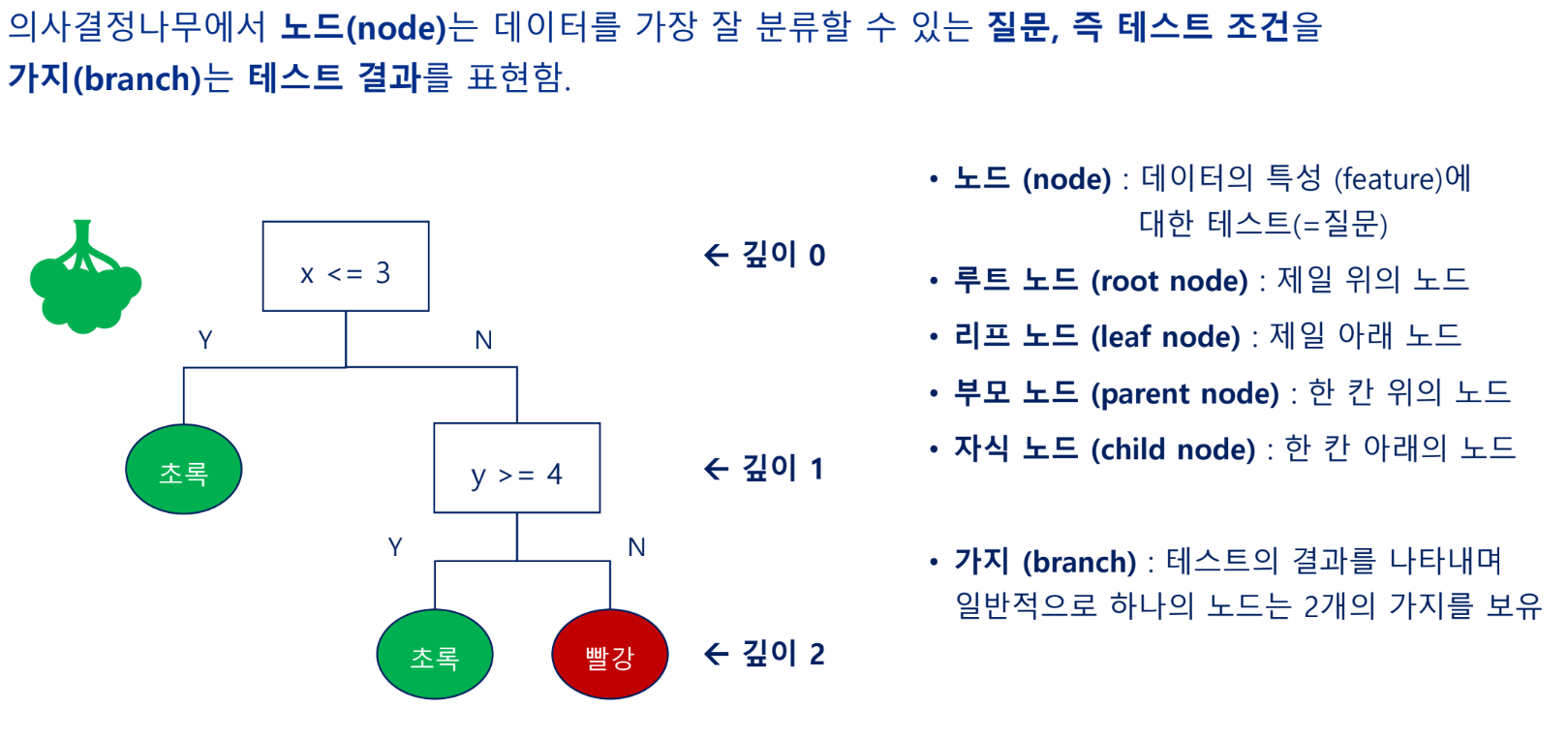
불순도
- 데이터를 가장 잘 분류할 수 있는 테스트조건(질문)을 찾아내는 방법
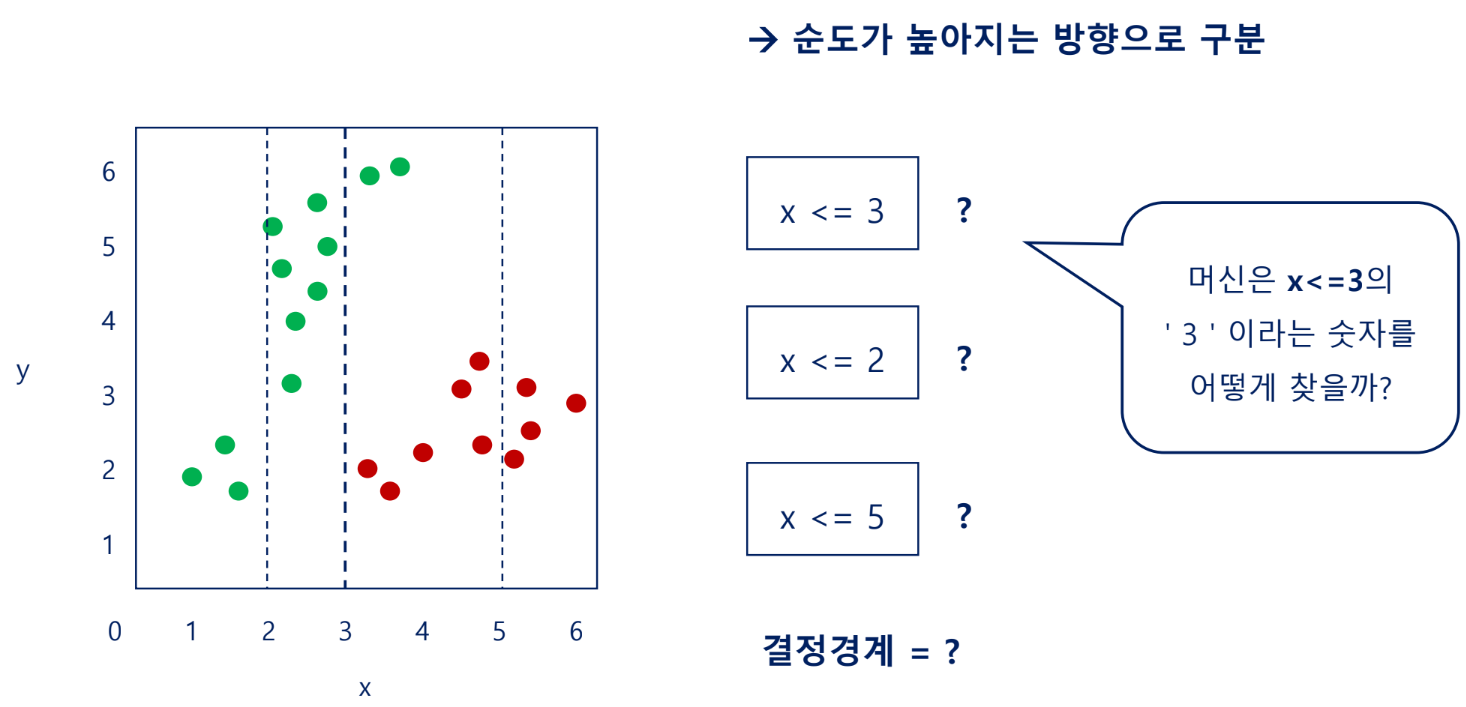
- 한 종류의 데이터만 포함되어있다면 불순도가 낮음
- 여러 종류의 데이터가 포함되어 있다면 불순도가 높음
불순도가 높음 → 결과 예측 어려움
불순도가 낮음 → 결과 예측 용이
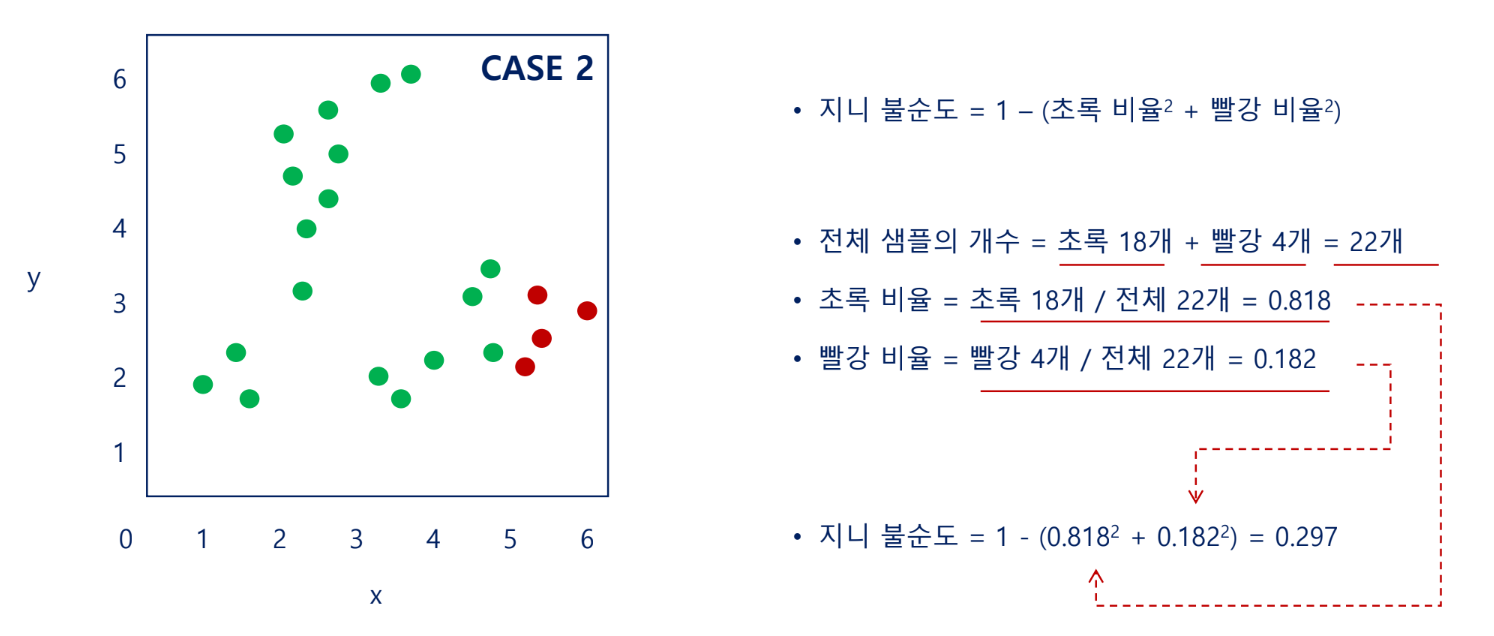
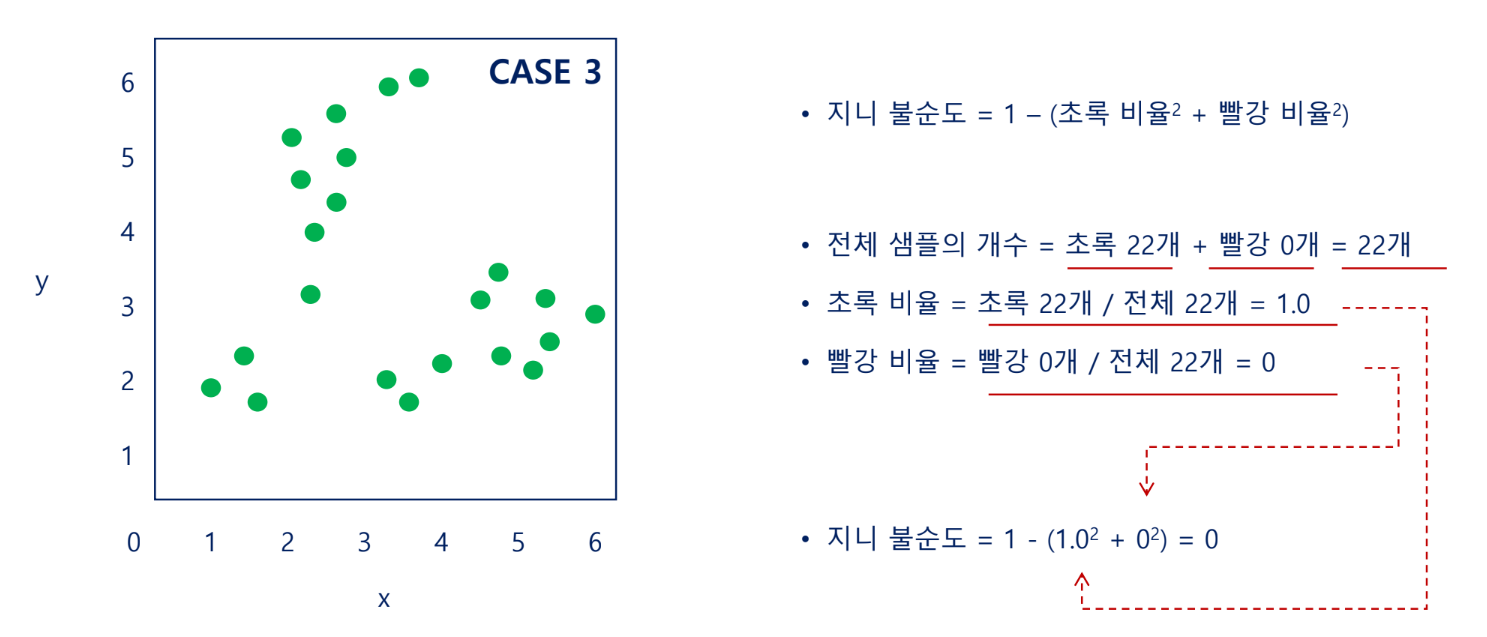
지니 불순도(Gini impurity)
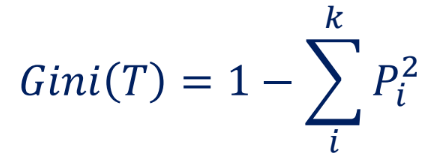
각 범주(=클래스)의 비율을 제곱해서 더한 후 1에서 뺀 값으로 계산함
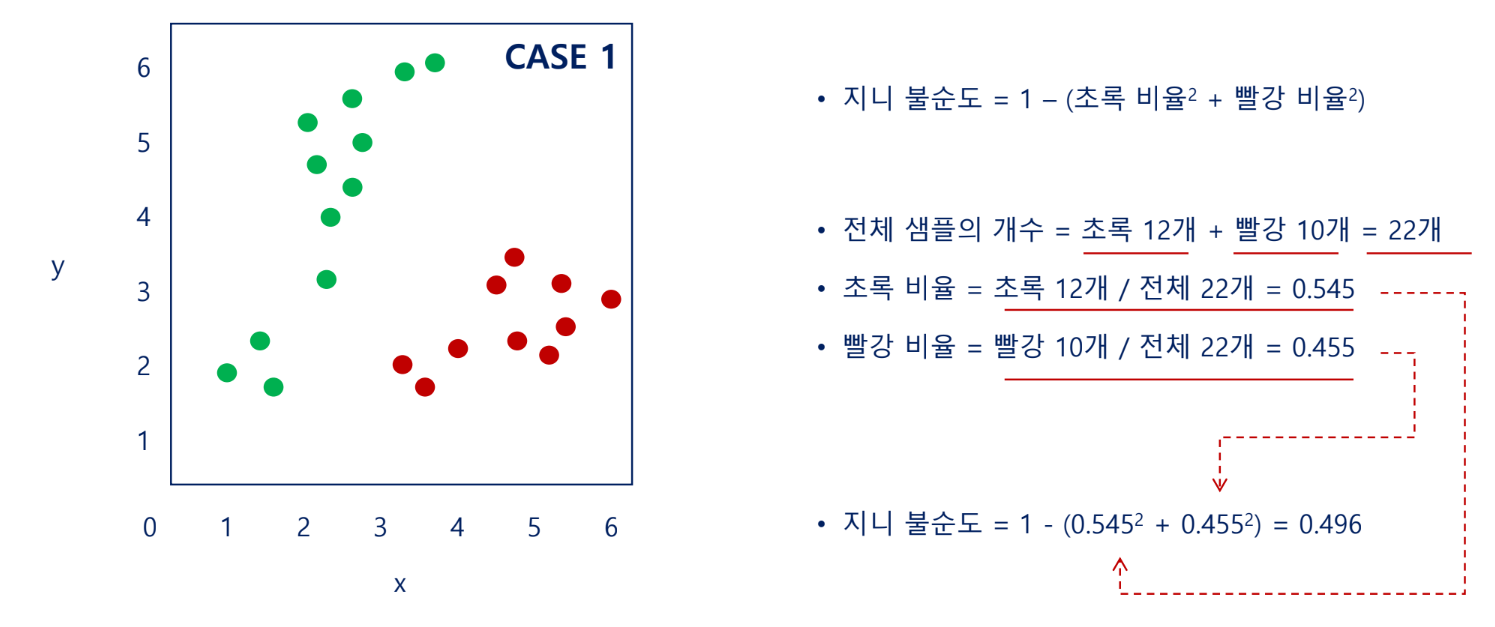
불순도가 낮을 때
규칙 생성
- 각 노드의 조건은 순도가 높도록 정한다. 즉, 영향력이 높은 질문(영향력 높은 독립변수)부터 시작함
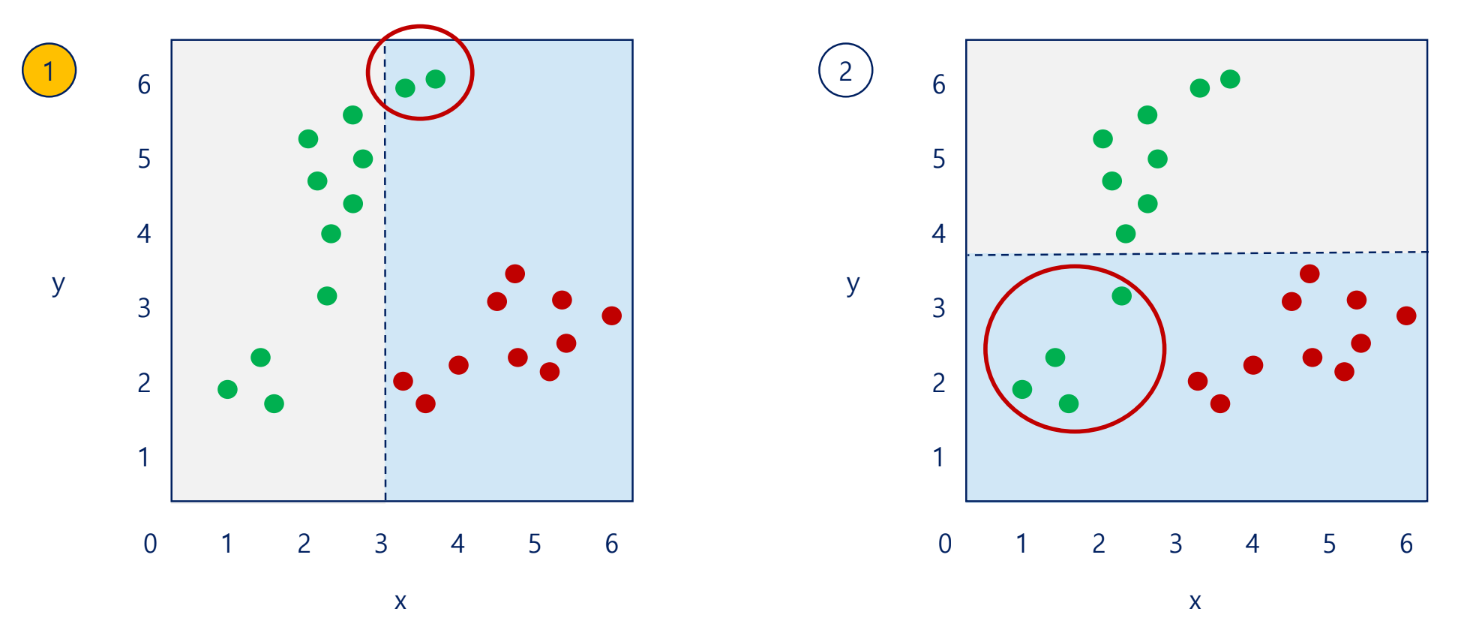
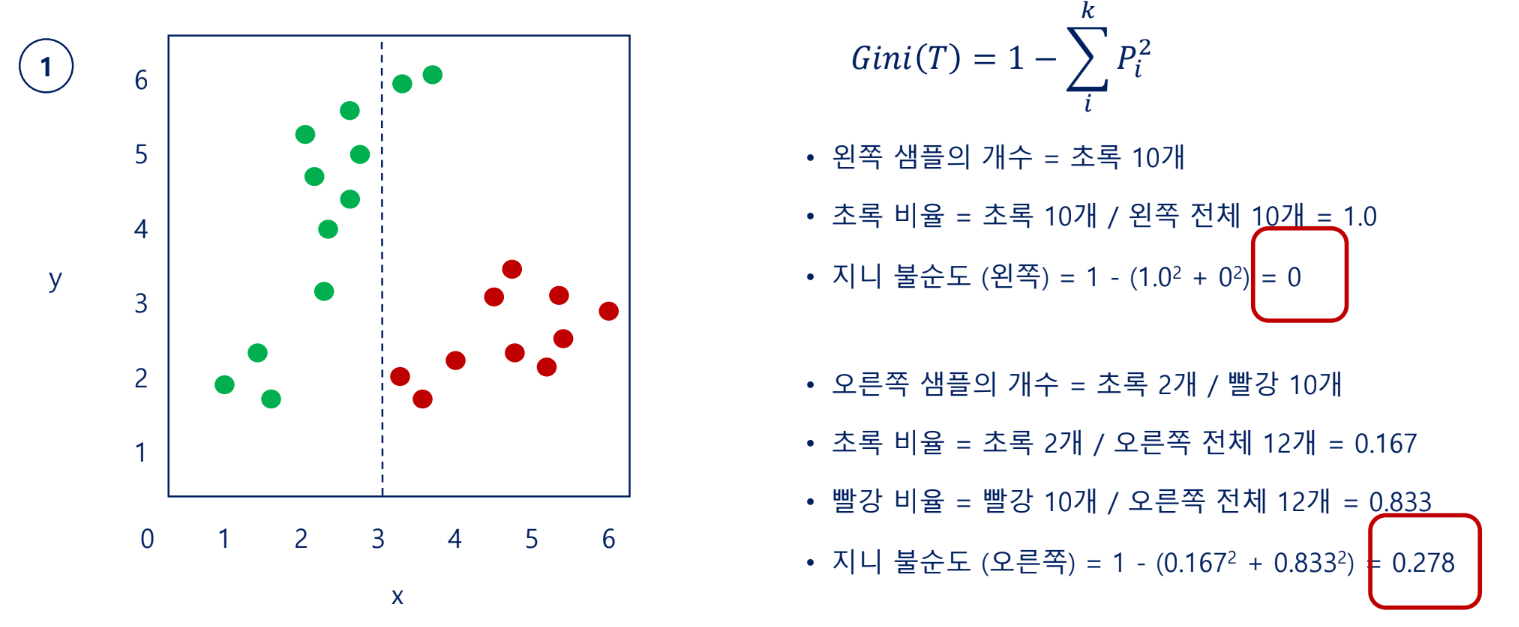
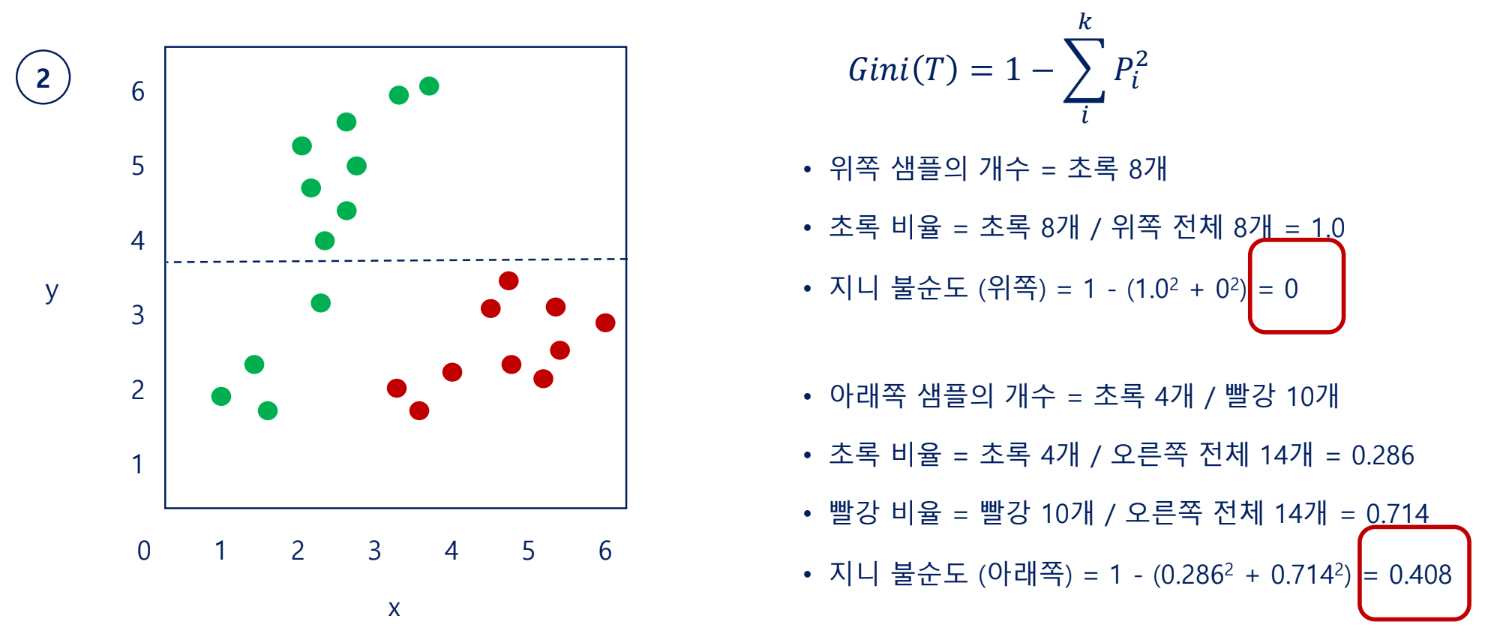
→1번처럼 x축부터가 순도가 높음
시각화
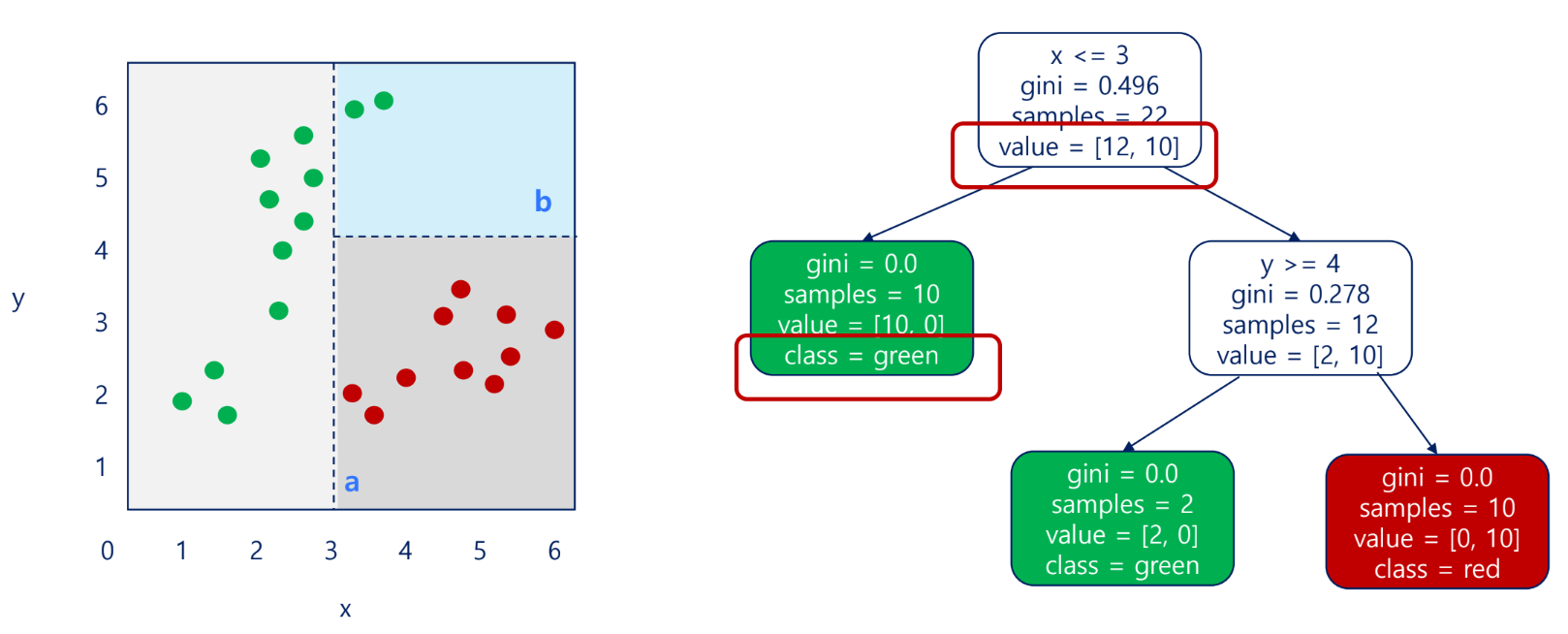
테스트 조건, 불순도, 노드에 속한 총 샘플 수, 각 범주 별 샘플 수, 범주 등
과대적합
의사결정나무는 깊이의 제한이 없으면 주어진 데이터에 과대적합 되기 쉬움
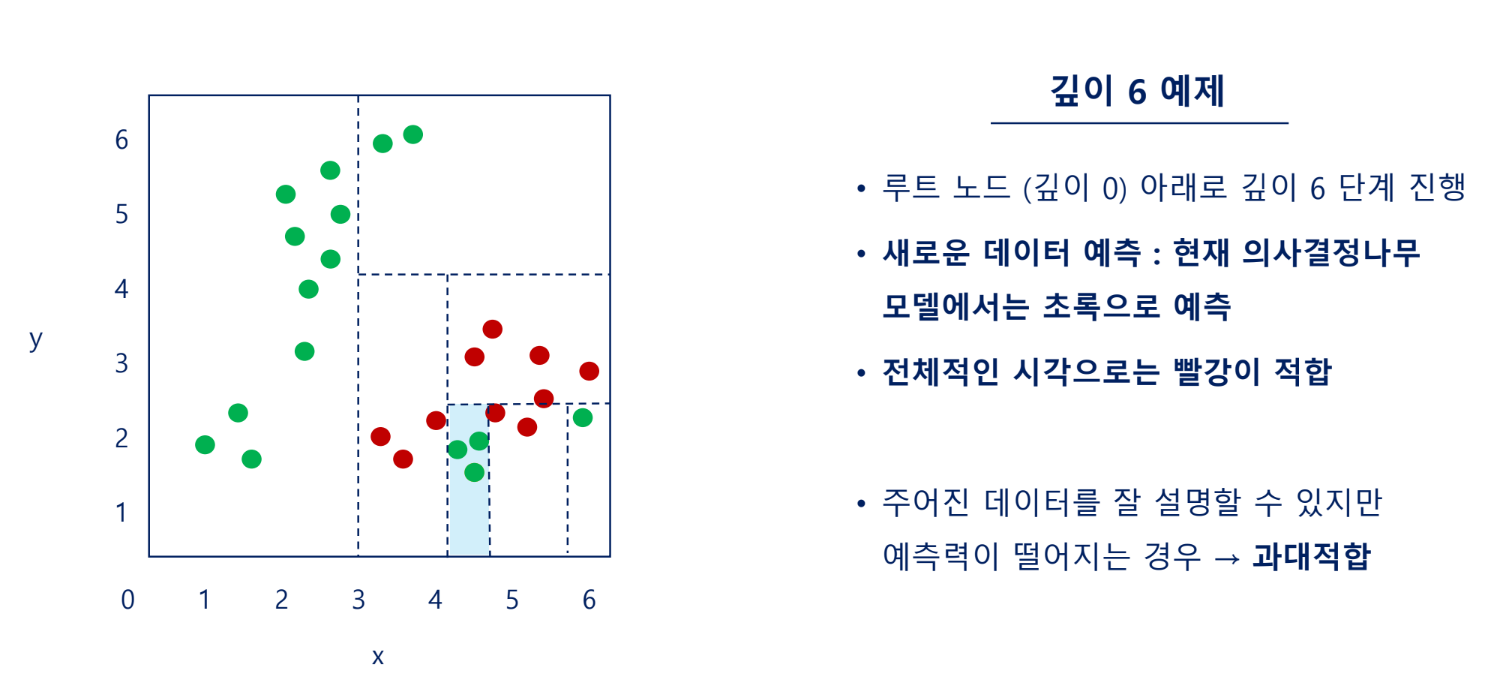
그러므로 최대 깊이(Max Depth)를 설정하여 과대적합을 방지함
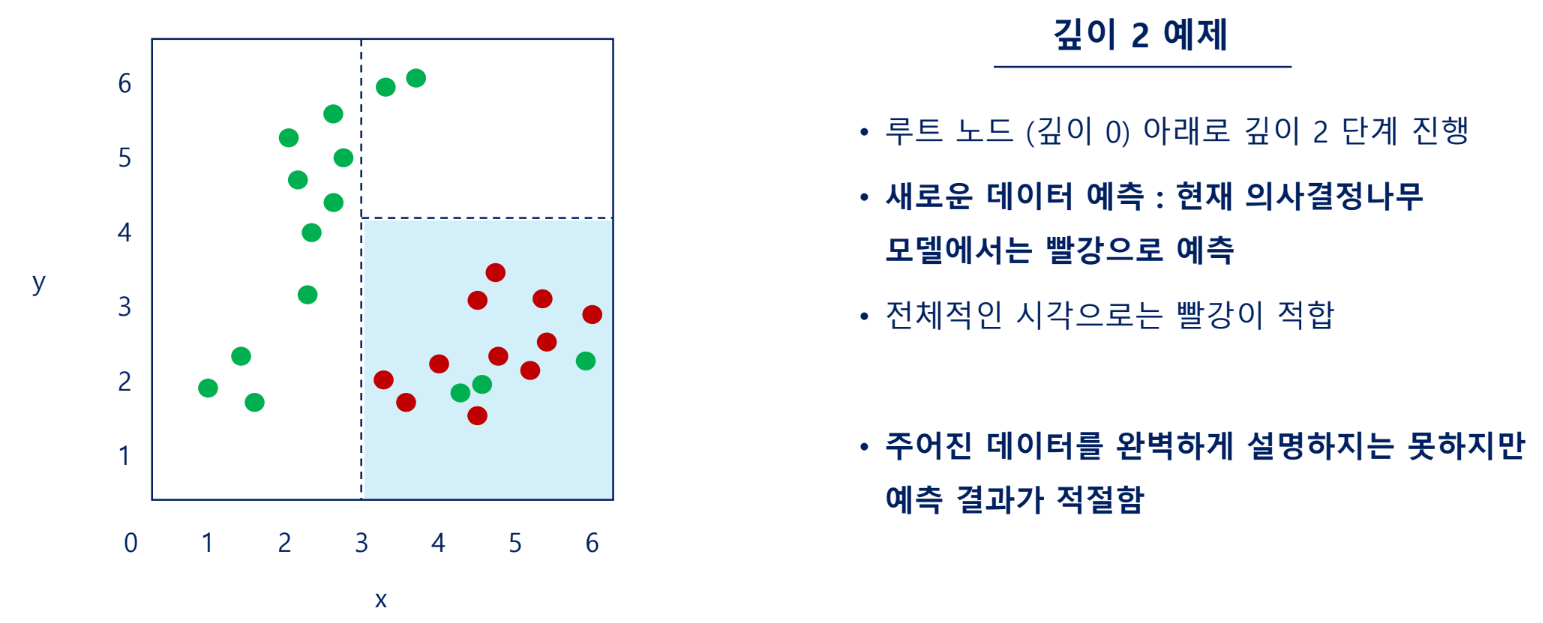
예측 확률
분류 모델은 주어진 데이터 샘플을 활용하여 특정 범주에 속할 확률을 추정할 수 있음
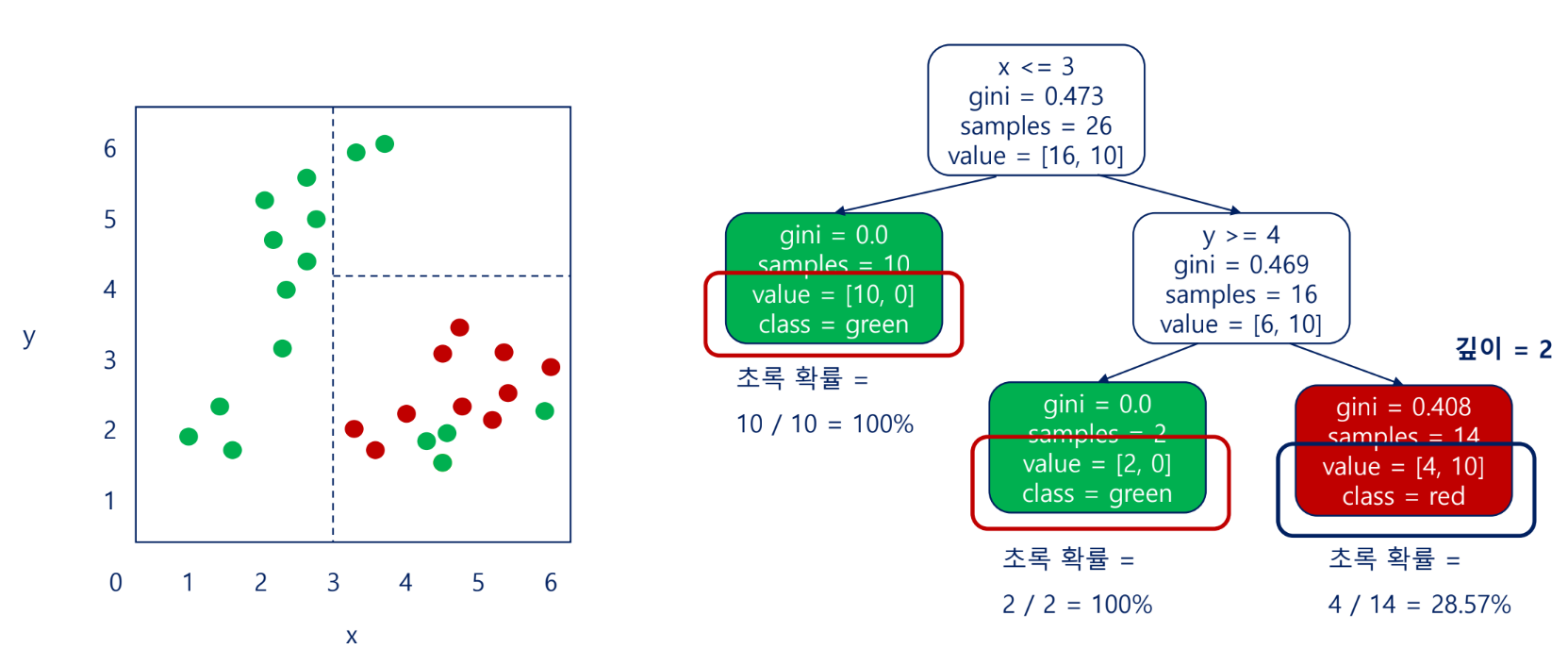
임계치
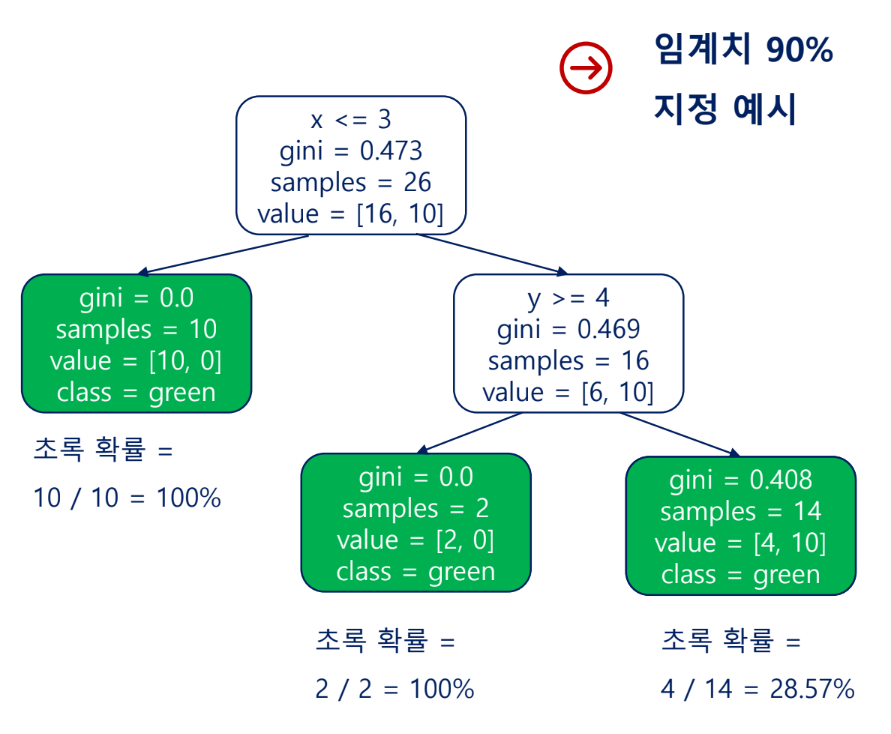
임계치를 90%로 지정한 경우, 초록일 확률이 28.57%임에도 초록으로 판단됨
모델링 알고리즘 결정
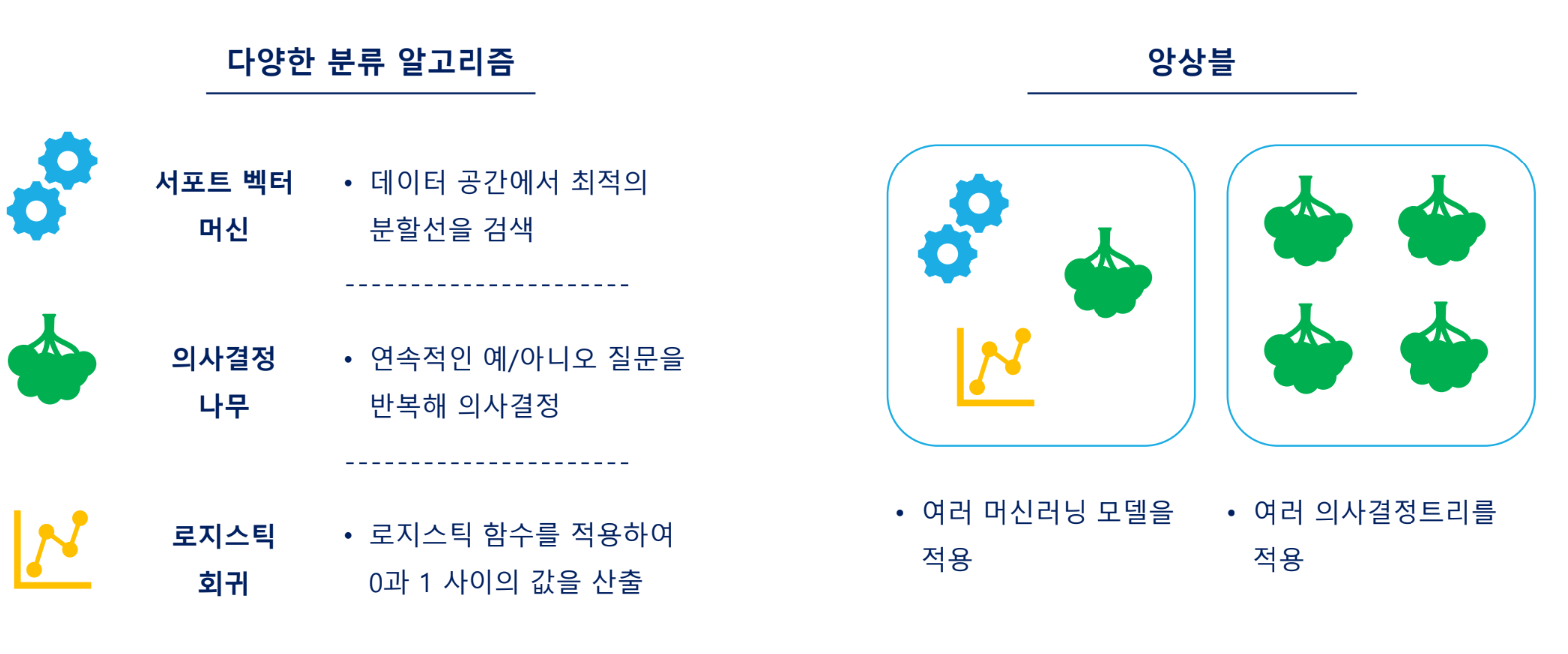
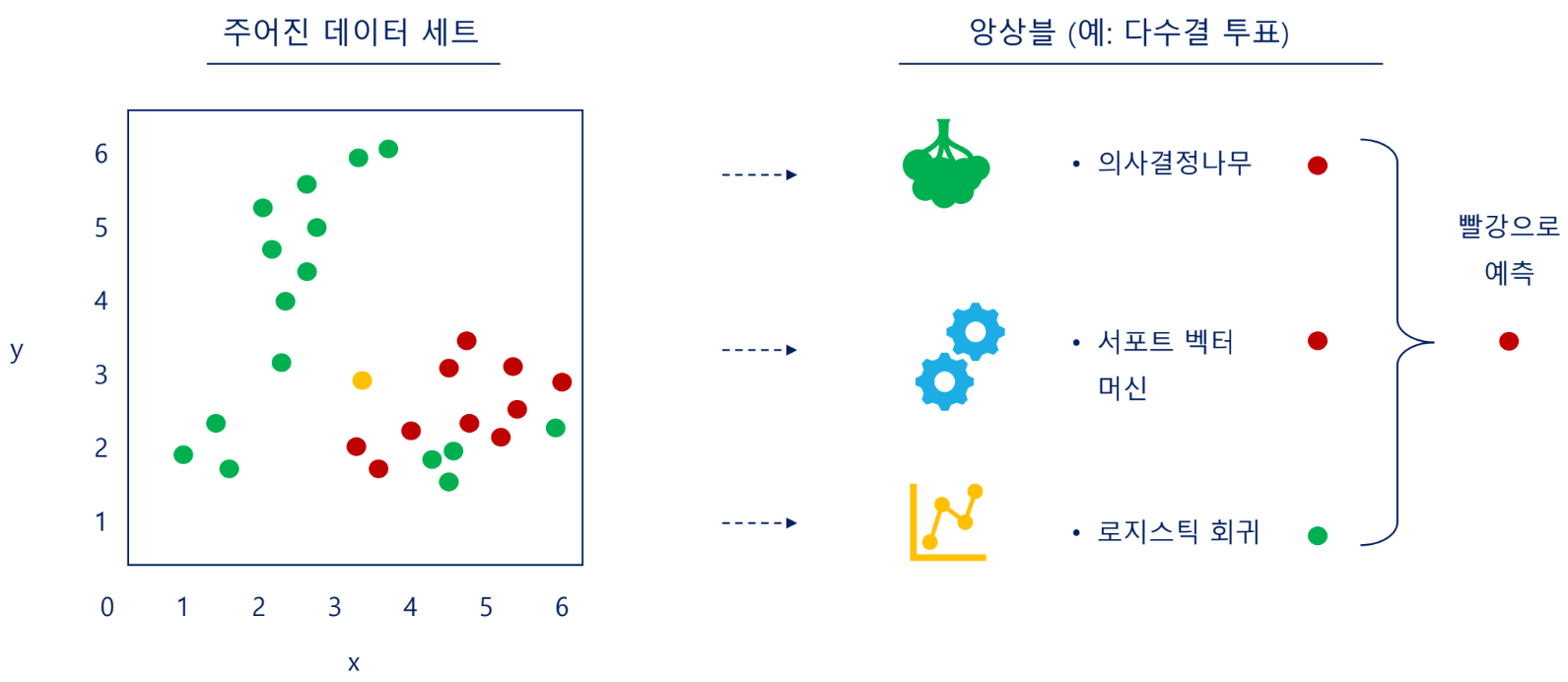
알고리즘: 앙상블(Ensemble learning)
단일 모델이 아닌 여러 모델을 사용하여 예측하는 것을 앙상블 기법이라고 함
다양한 모델을 사용하여 과대적합 감소 효과 있음
알고리즘: 랜덤 포레스트(Random Forest)
데이터 세트에서 여러 번의 데이터 서브셋을 추출, 의사결정나무를 각각 적용
간단하지만 강력한 ML 알고리즘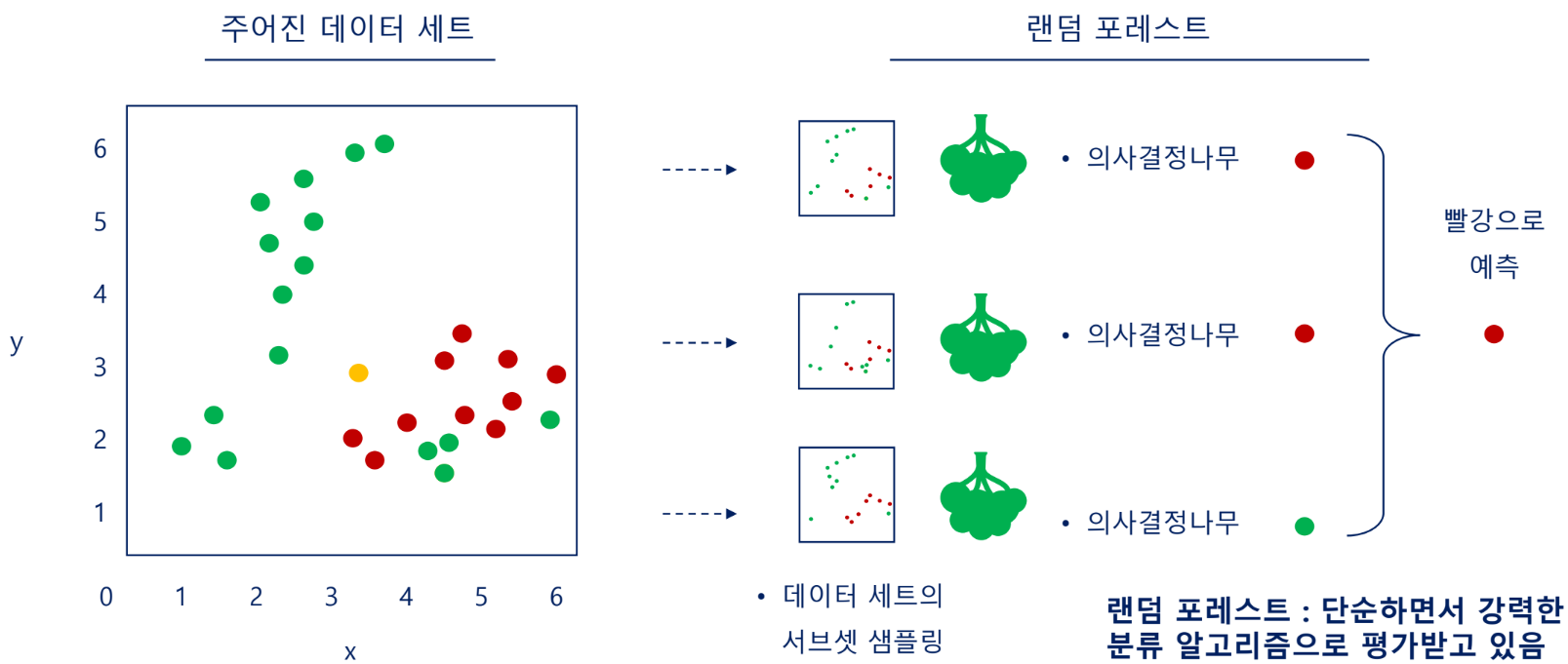
배깅 vs 페이스팅
- 배깅: 샘플링 시 중복을 허용
- 페이스팅: 샘플링 시 중복 비허용
하이퍼 파라미터
모델링할 때 사용자가 직접 조정 및 세팅하는 값
- 의사결정나무의 깊이 지정
- 샘플링 방식
실습 개요
데이터 수집
- 미국 해양 대기청(NOAA)
- 웨더 언더그라운드
- NASA
데이터의 이해
- 각 변수의 의미, 형식, 빈 공간 등 불필요한 컬럼 확인
- 각 컬럼 데이터의 분포, 평균 등 통계 정보 확인
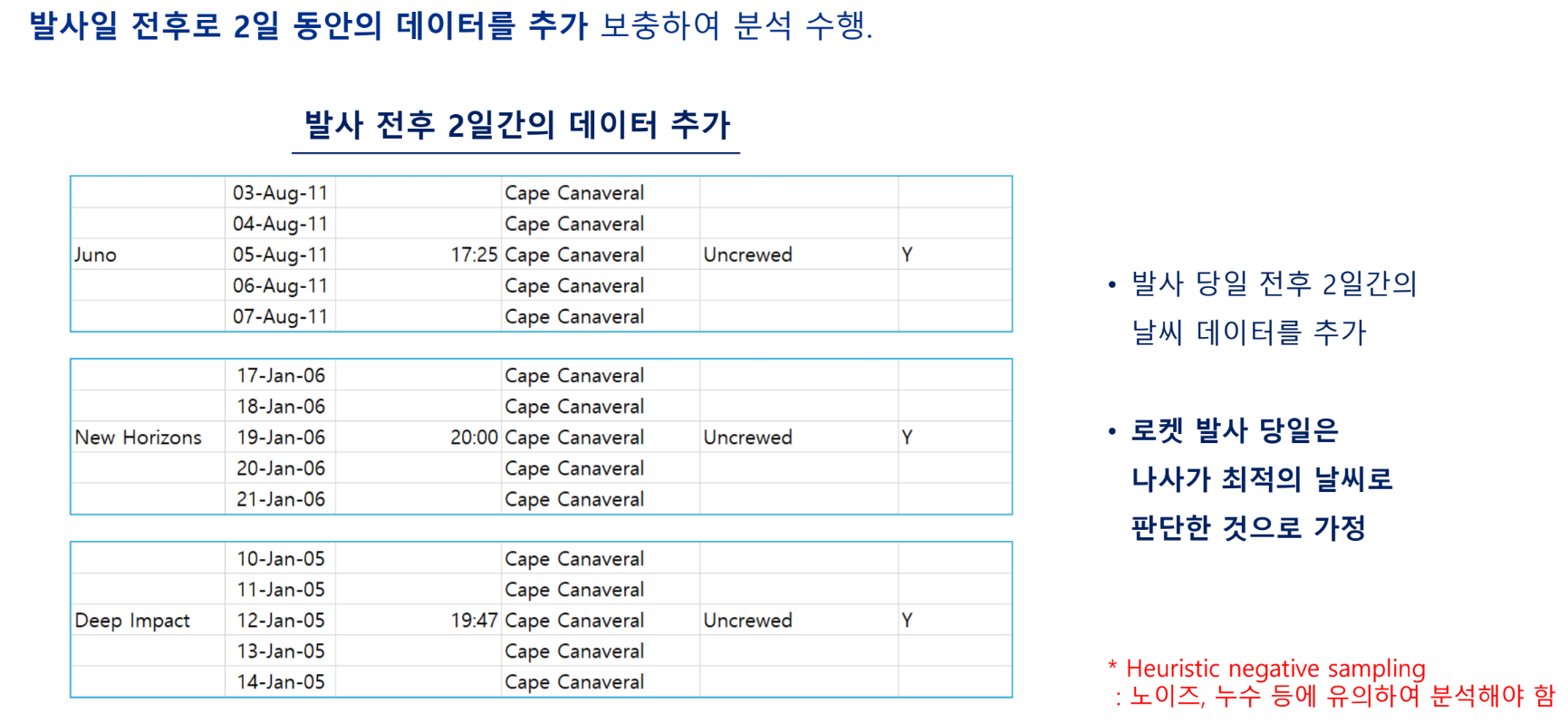

데이터 정리
- 누락 데이터 보충(컬럼 제외, 결측치 처리)
- 올바른 데이터 형태로 변경

데이터의 종류
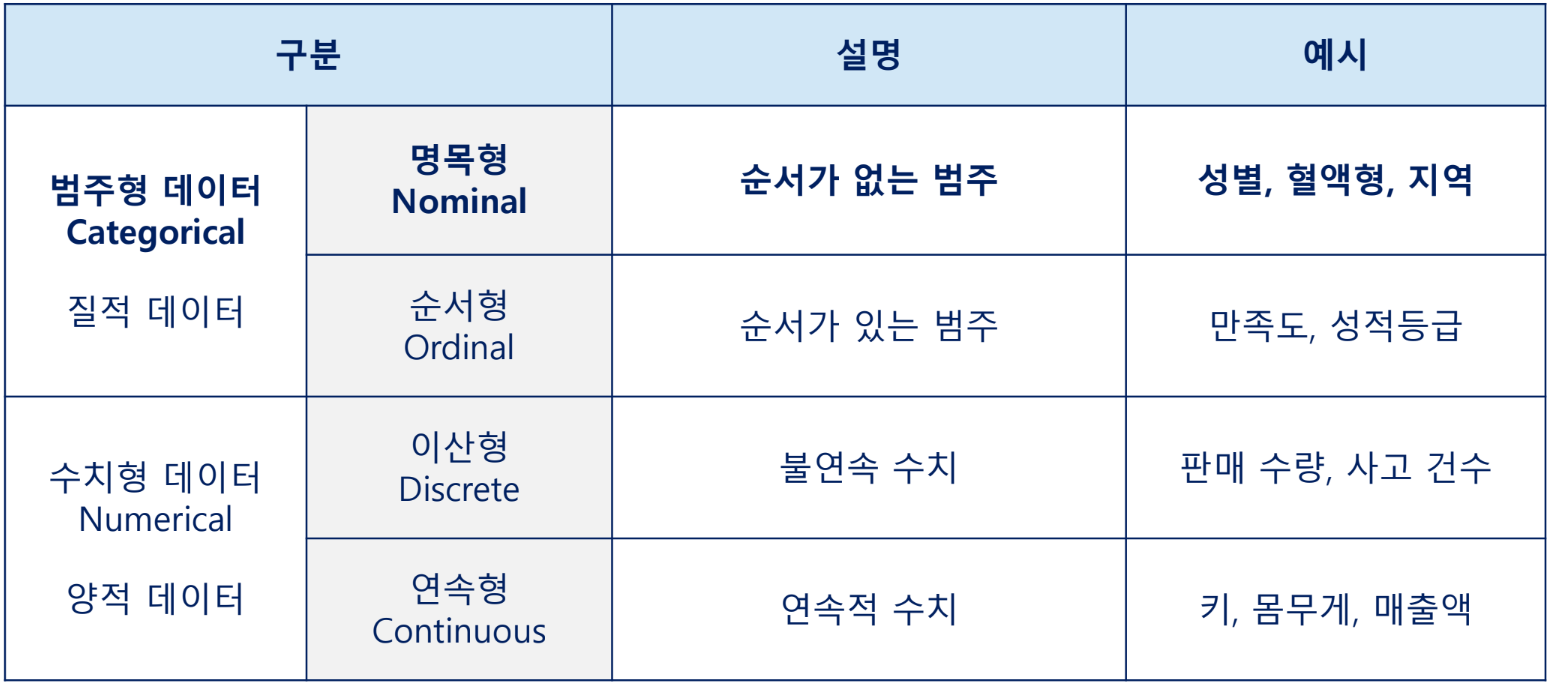
데이터 형식 변경
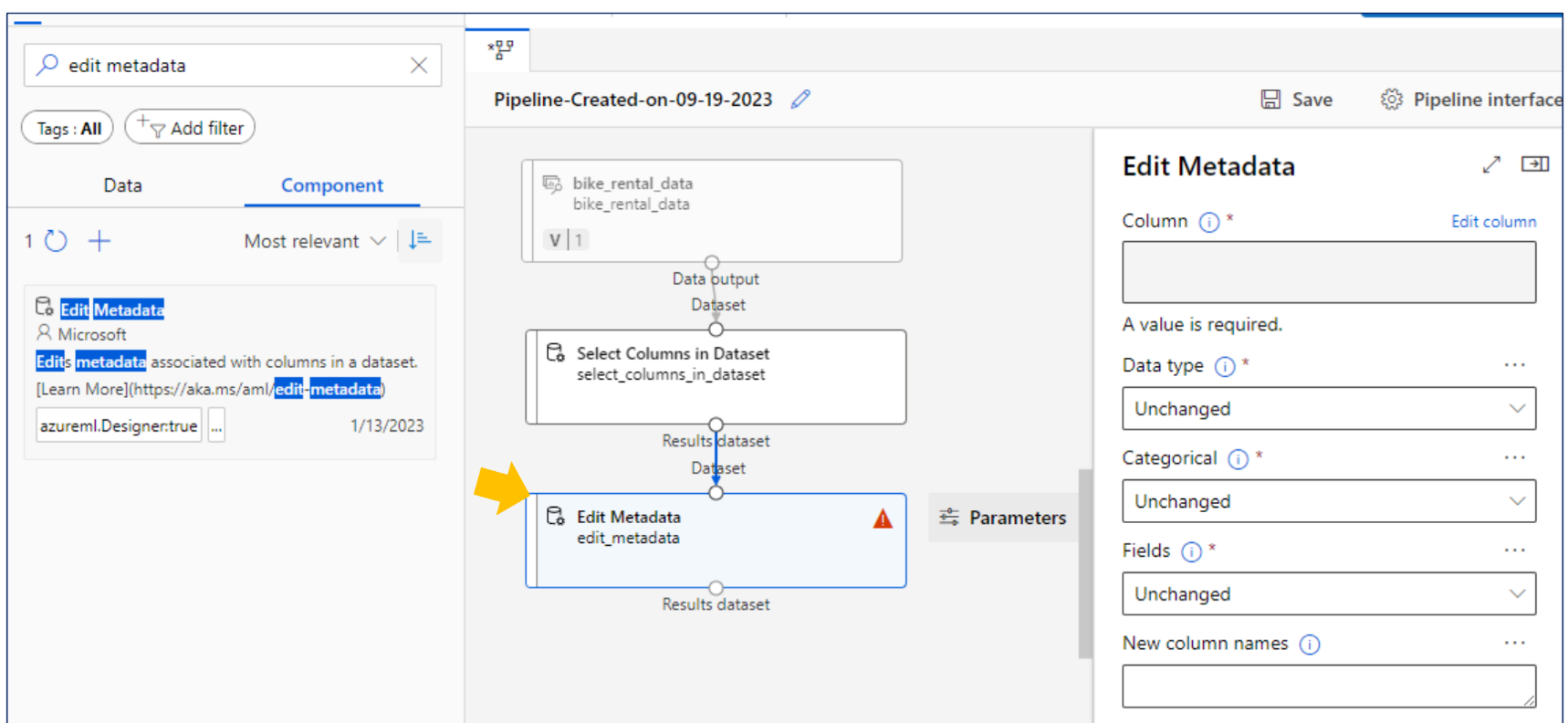
edit metadata

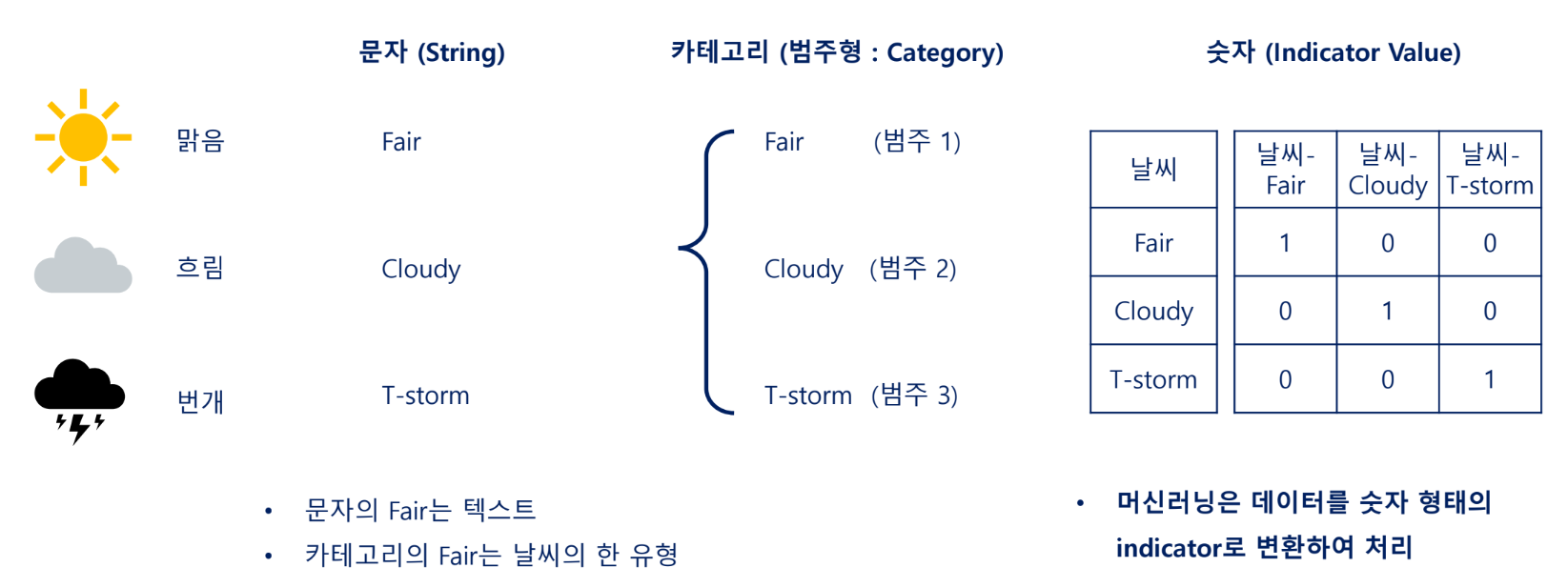
범주형 문자(열) → 카테고리 → 숫자
one - hot encoding
데이터 분리
데이터 세트
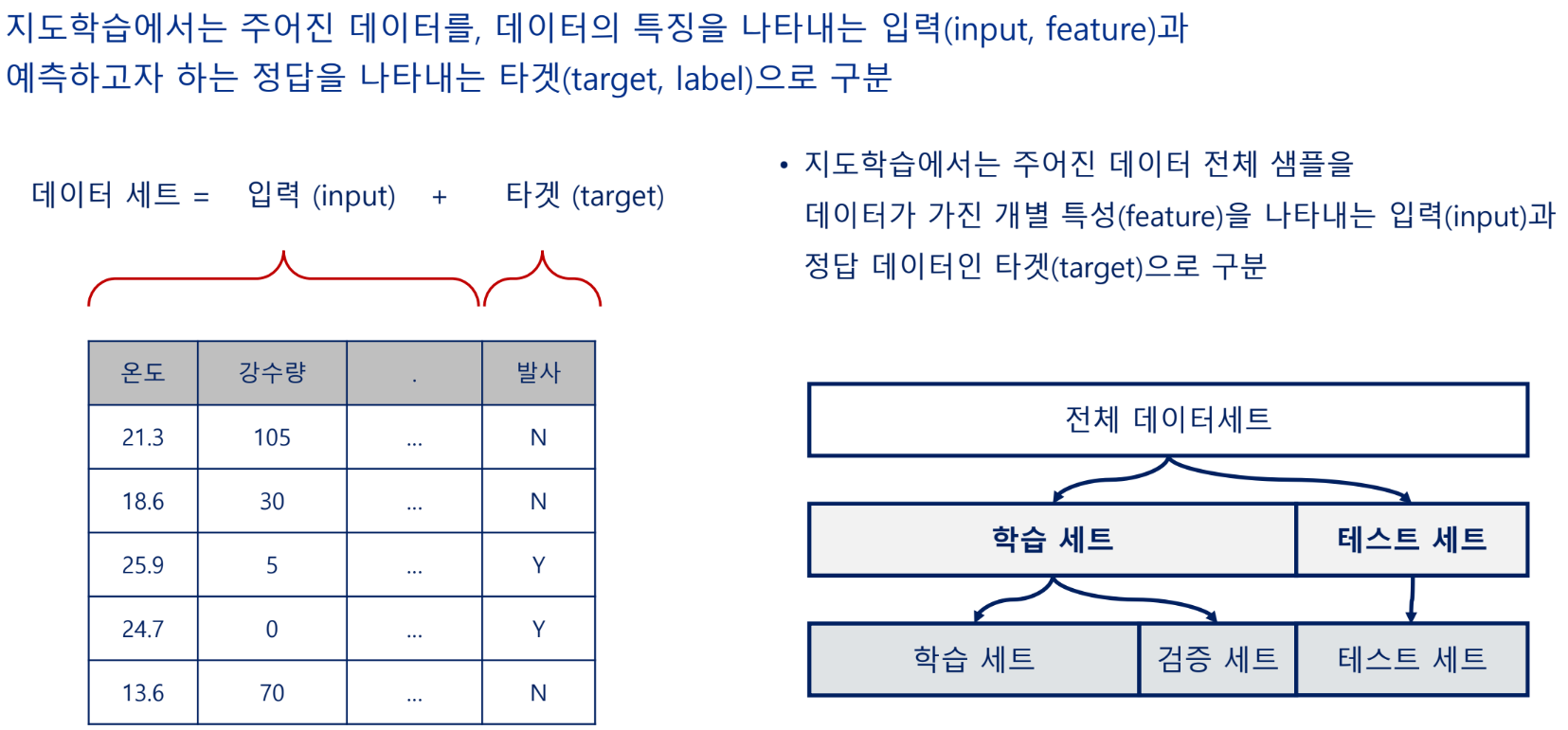
학습 데이터와 테스트 데이터 분리
무작위 추출을 통해 샘플링 편향이 최소화 되도록 함
모델링/평가
모델링 유형 결정
발사 or 연기 2가지 유형 예측이므로 분류 유형으로 결정
모델 학습(훈련)
데이터에서 규칙을 찾는 과정을 의미
2-클래스 랜덤 포레스트 모델에 적용하여 훈련
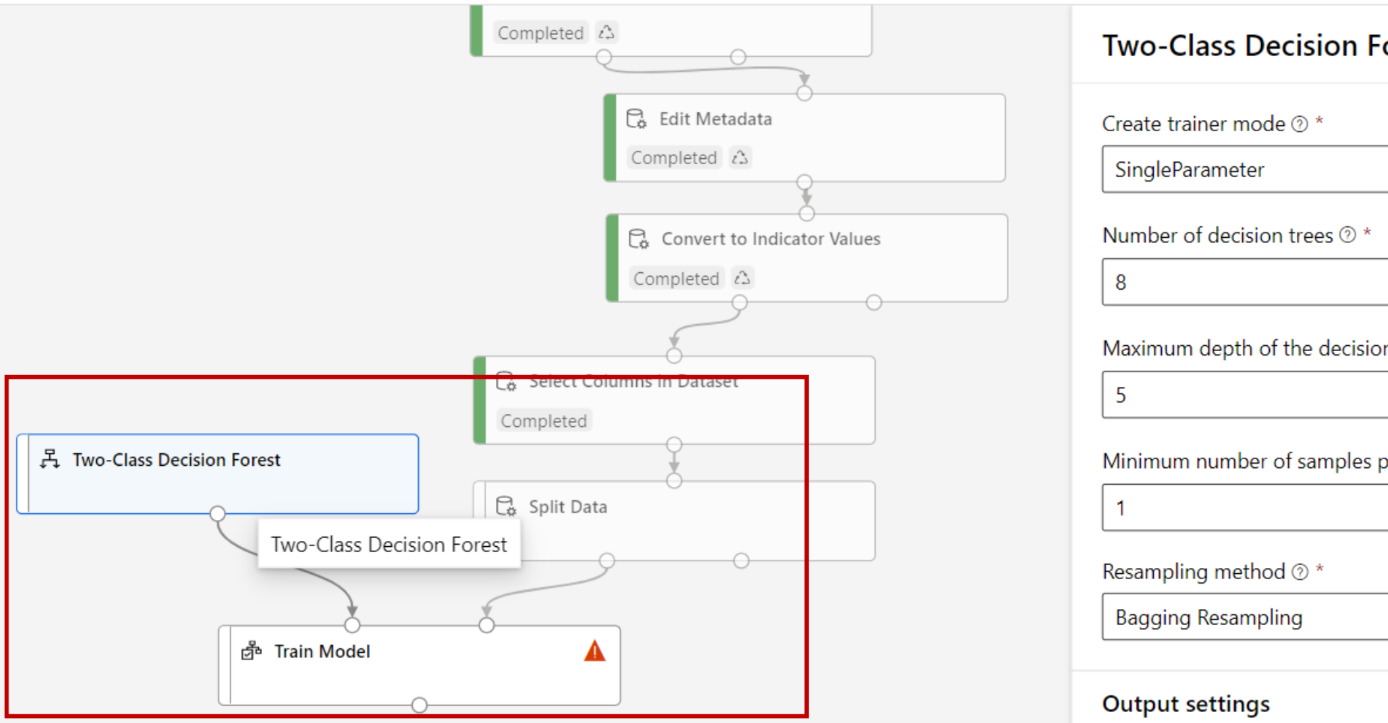
하이퍼 파라미터 지정

테스트
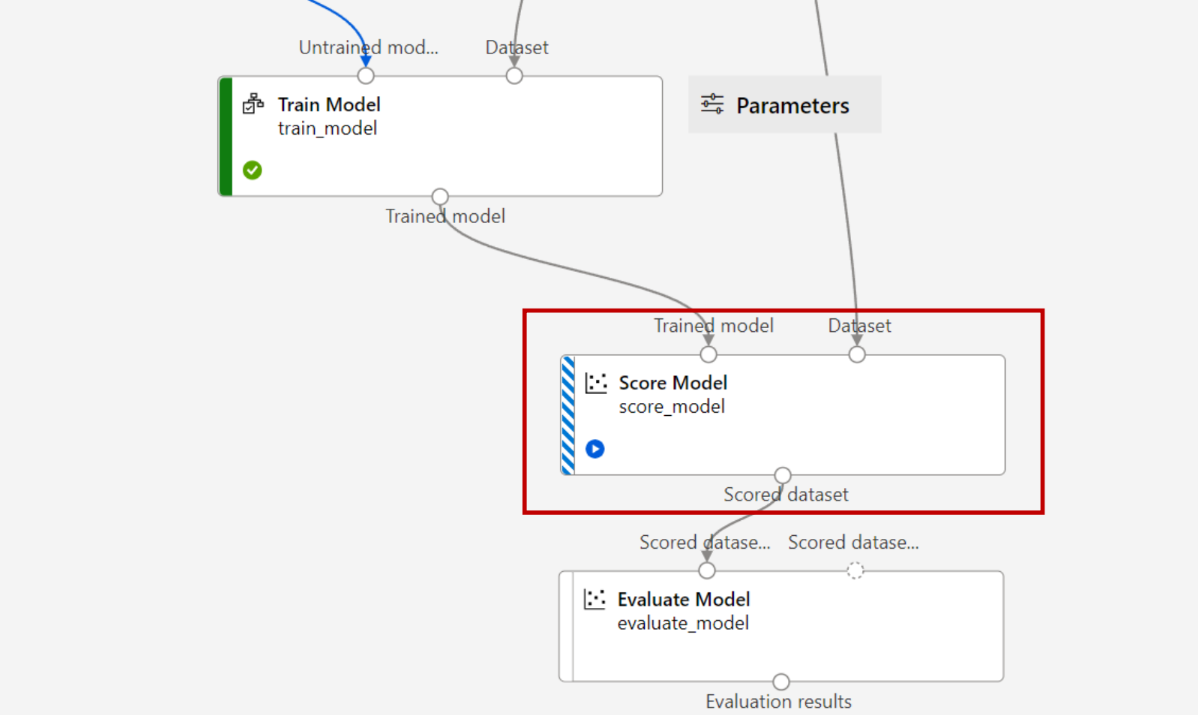
결과 평가
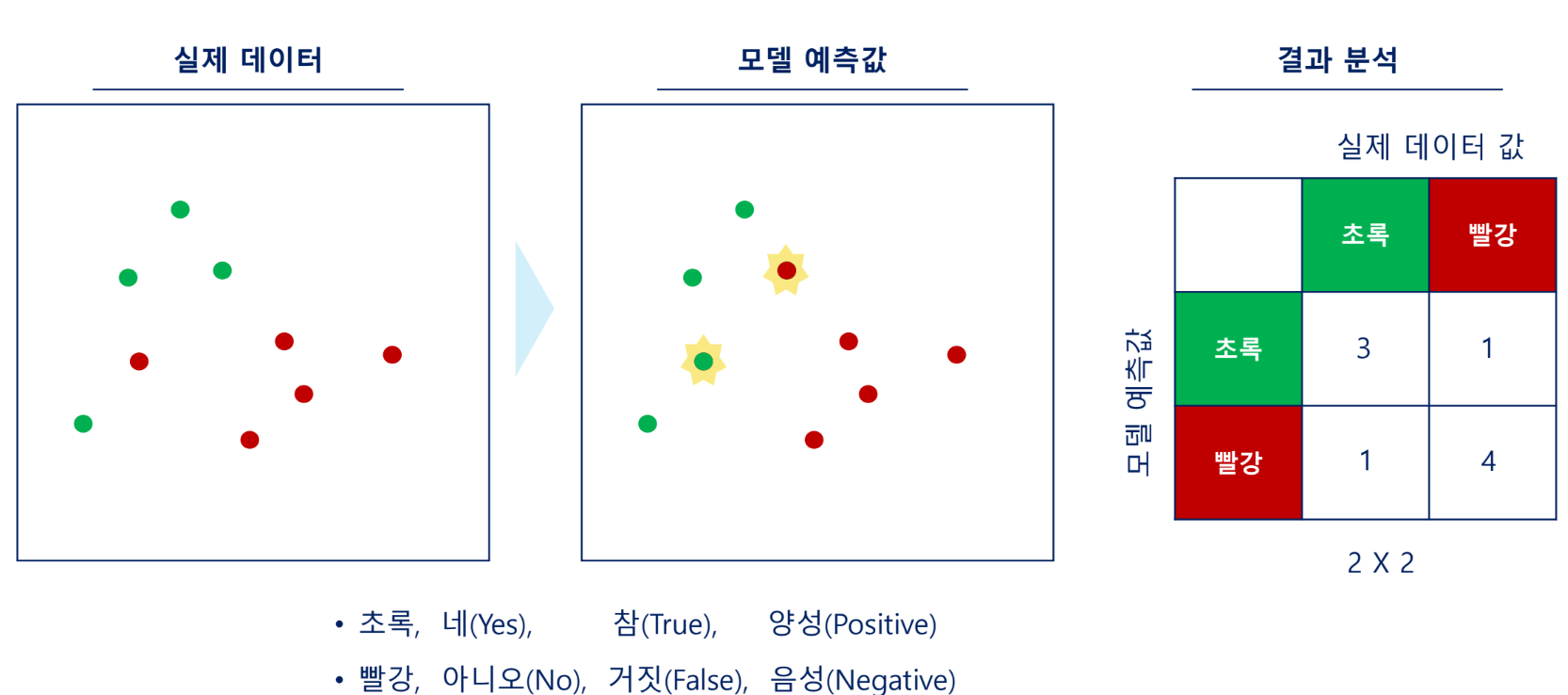
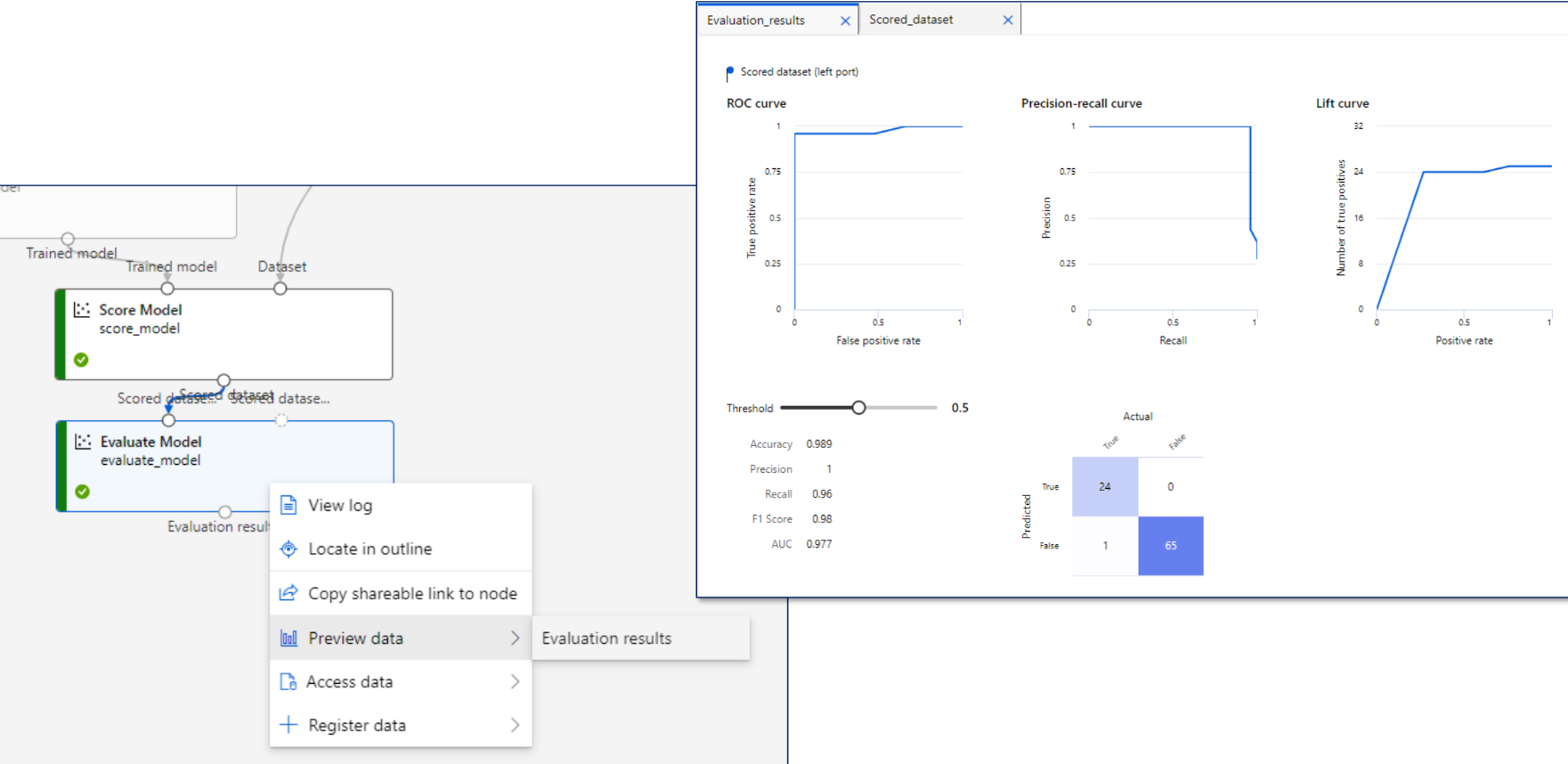
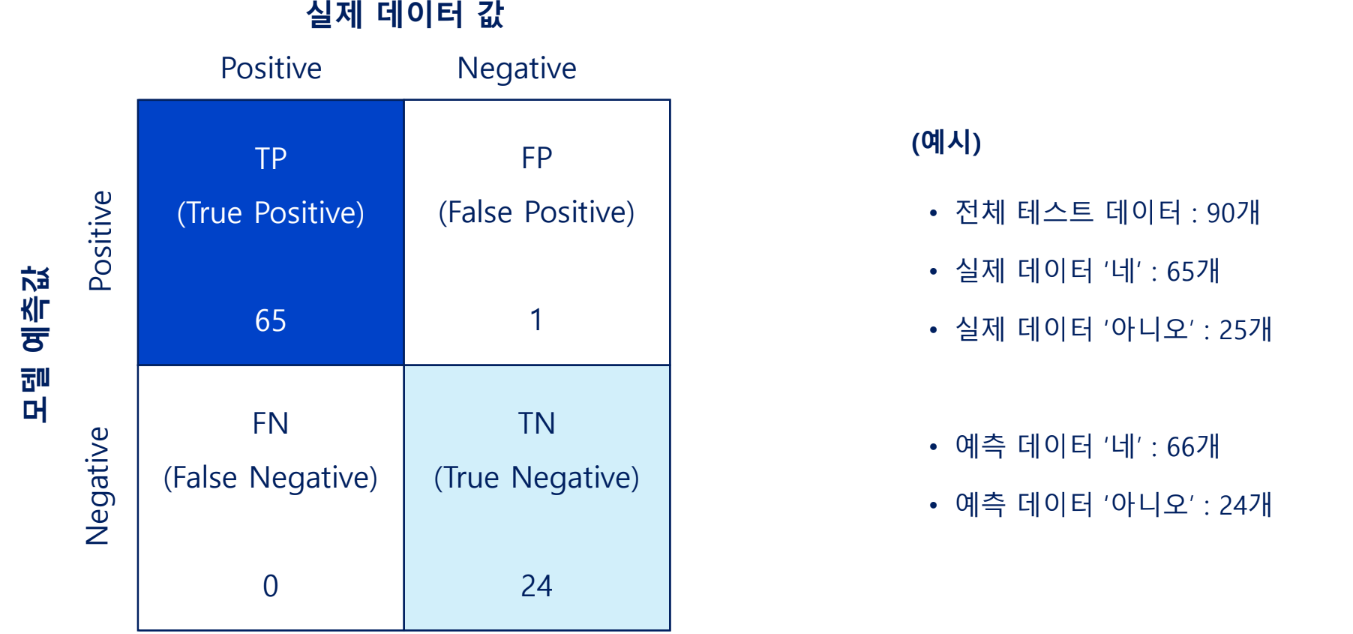
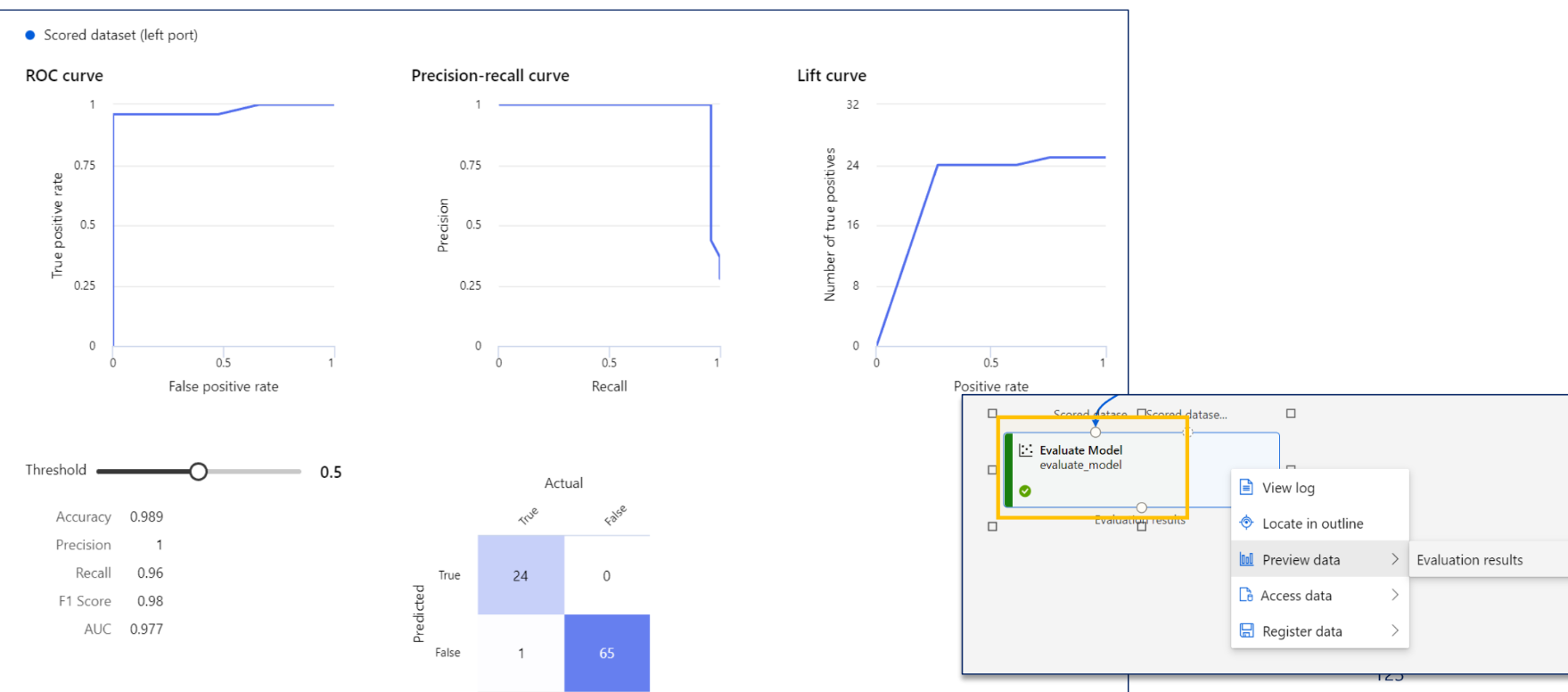
오차 행렬(Confusion Matrix)
이진 분류의 예측 오류가 얼마인지, 어떠한 유형의 예측 오류가 있는지 확인 가능한 지표
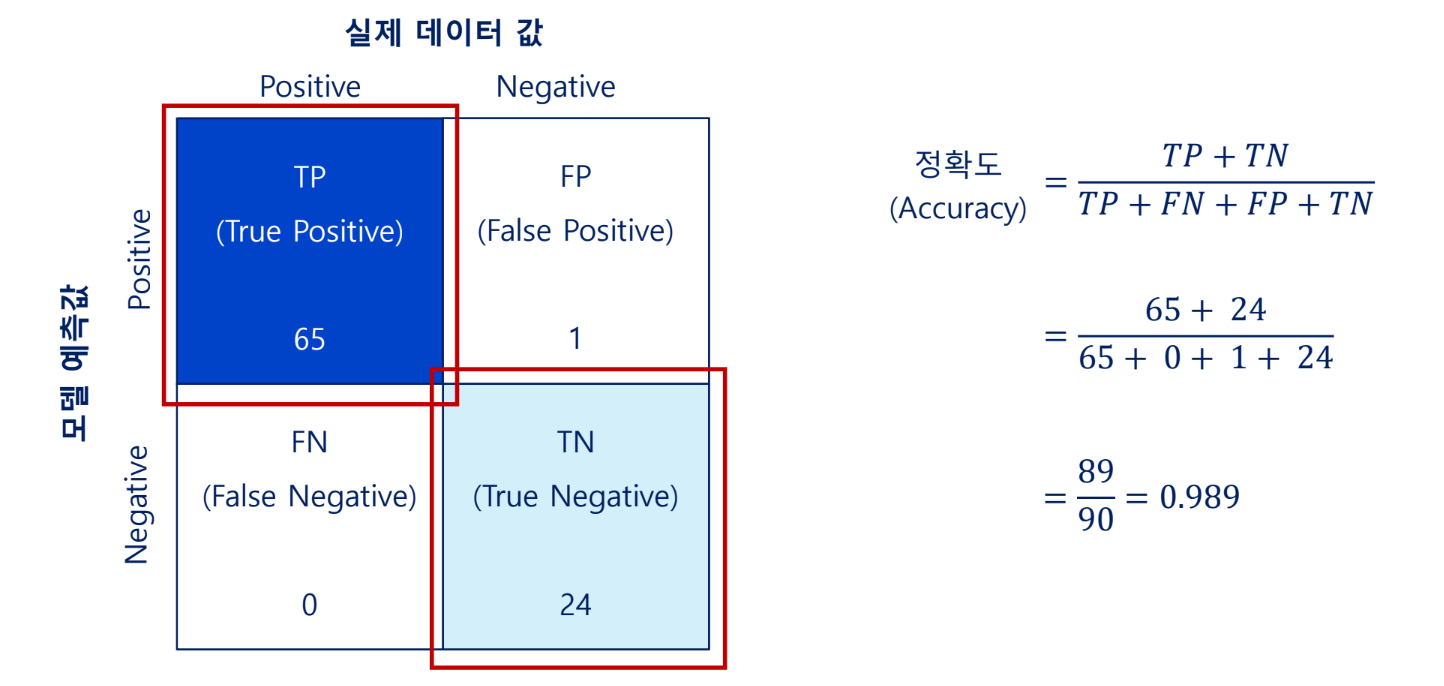
정확도
모든 결과 중 모델이 맞춘 비율
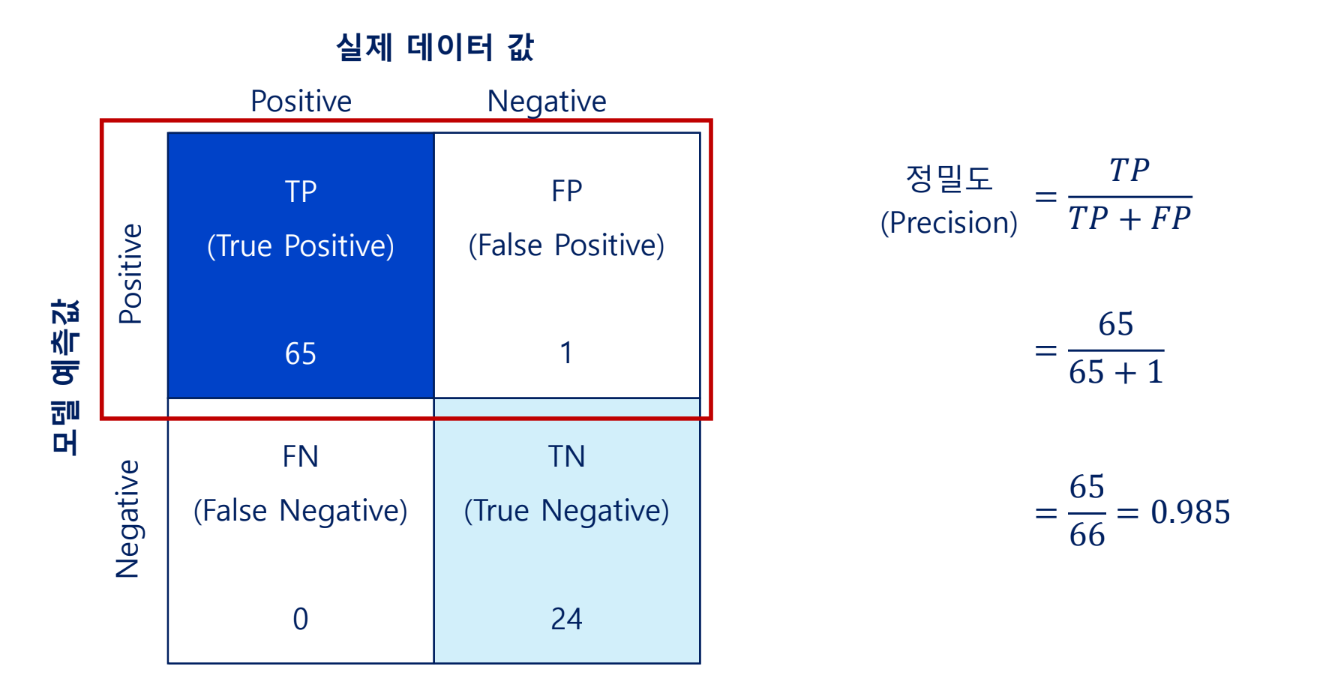
정밀도
모델이 Positive로 예측한 값 중 실제로 Positive인 비율
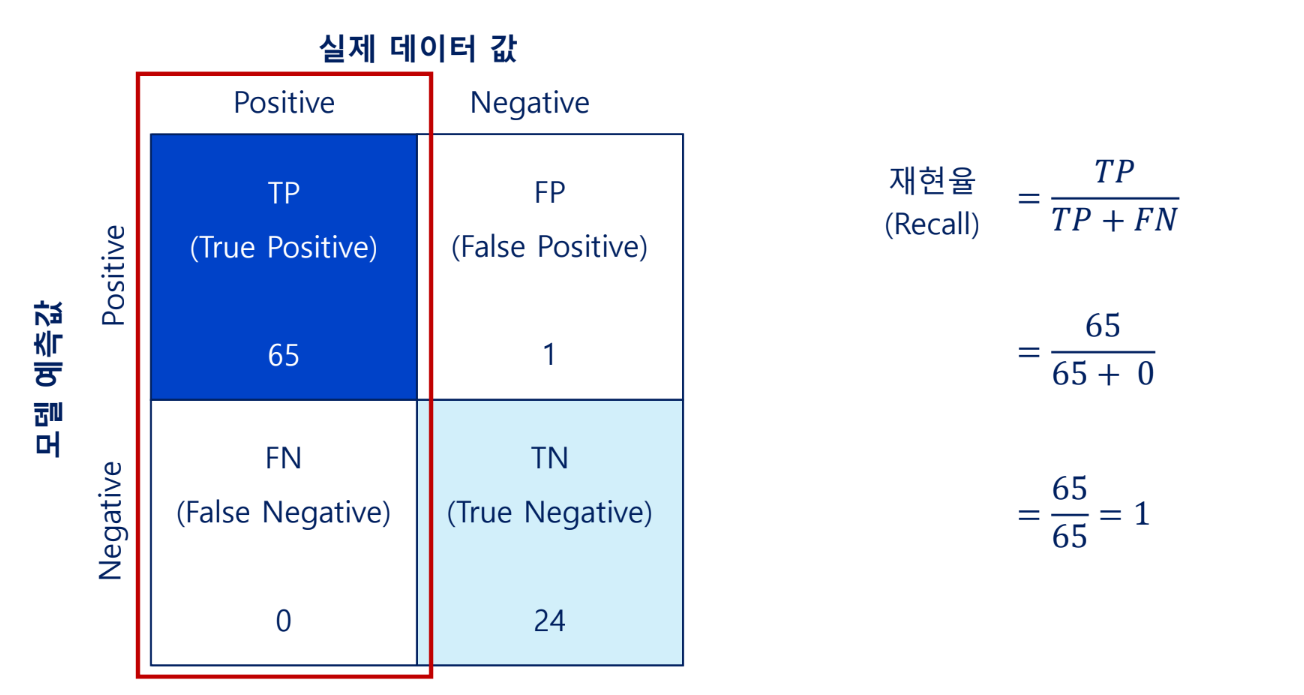
재현율
실제 Positive인 데이터 중 모델이 맞춘 비율

Azure ML Evaluate
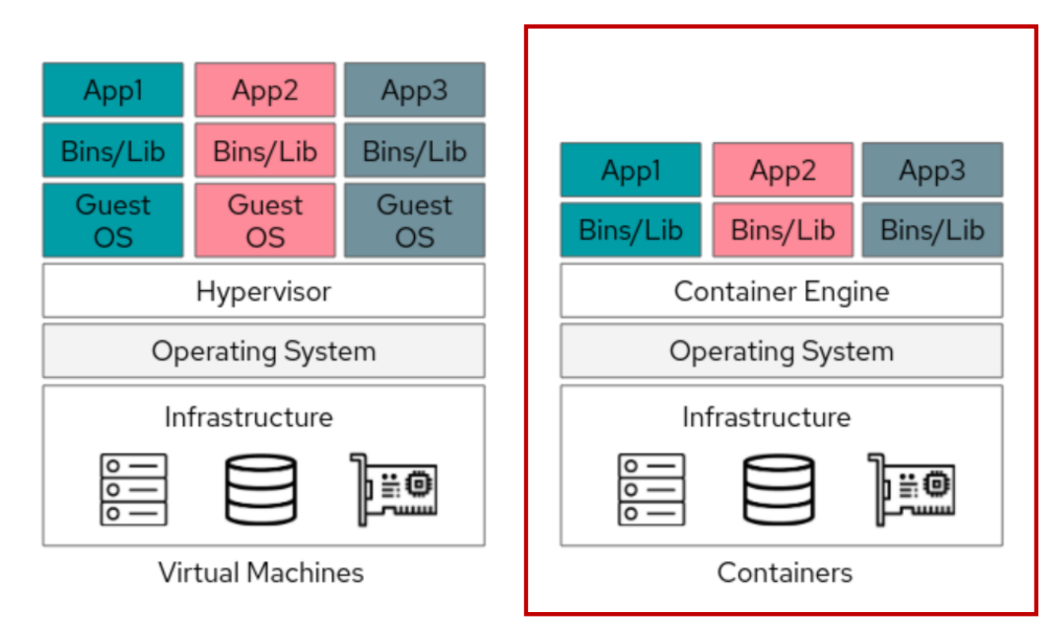
클라우드
VM보단 컨테이너가 더 가벼워 자주 사용
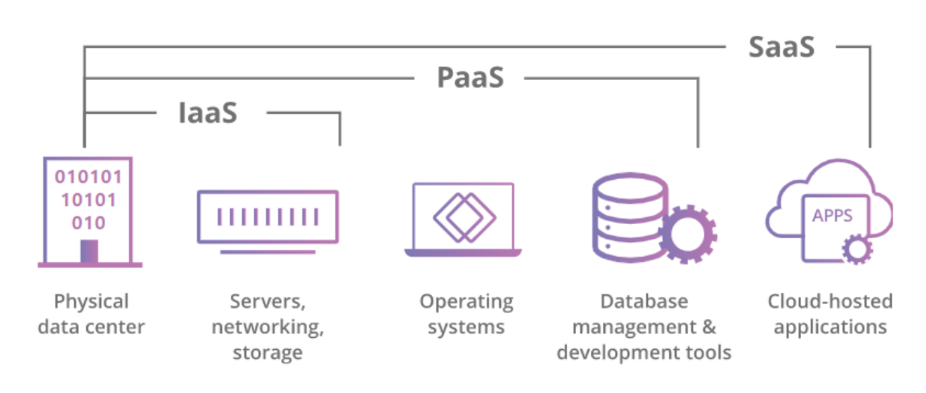
MS Azure 클라우드
리소스그룹으로 관리
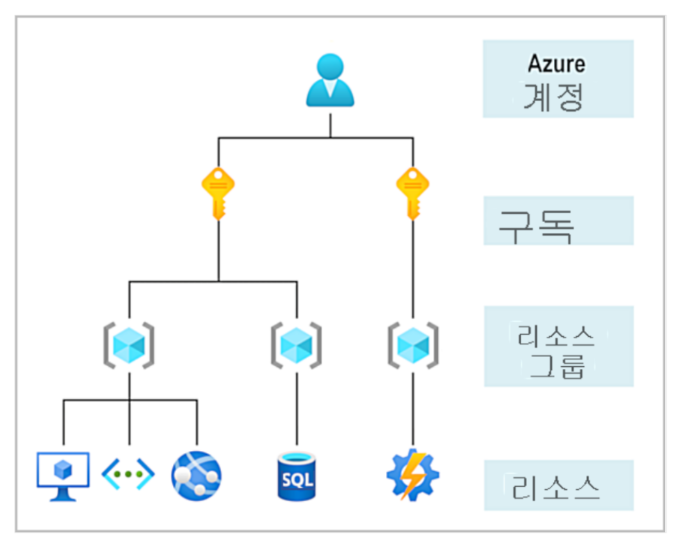
클라우드 AI/머신러닝 서비스
- 머신러닝 모델 개발 도구 제공 서비스: Machine Learning Studio (바닥부터 개발)
- 학습 완료된 머신러닝 모델 제공 서비스: Custom Vision Service
실습
1. 리소스 생성
리소스그룹과 Azure ML 생성
2. Azure ML Studio에 데이터세트 등록

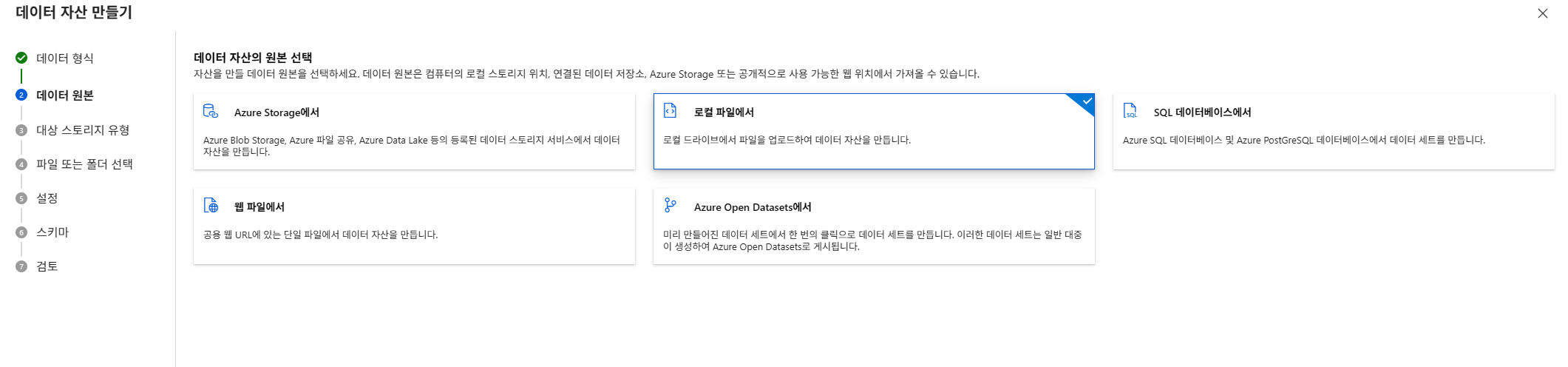
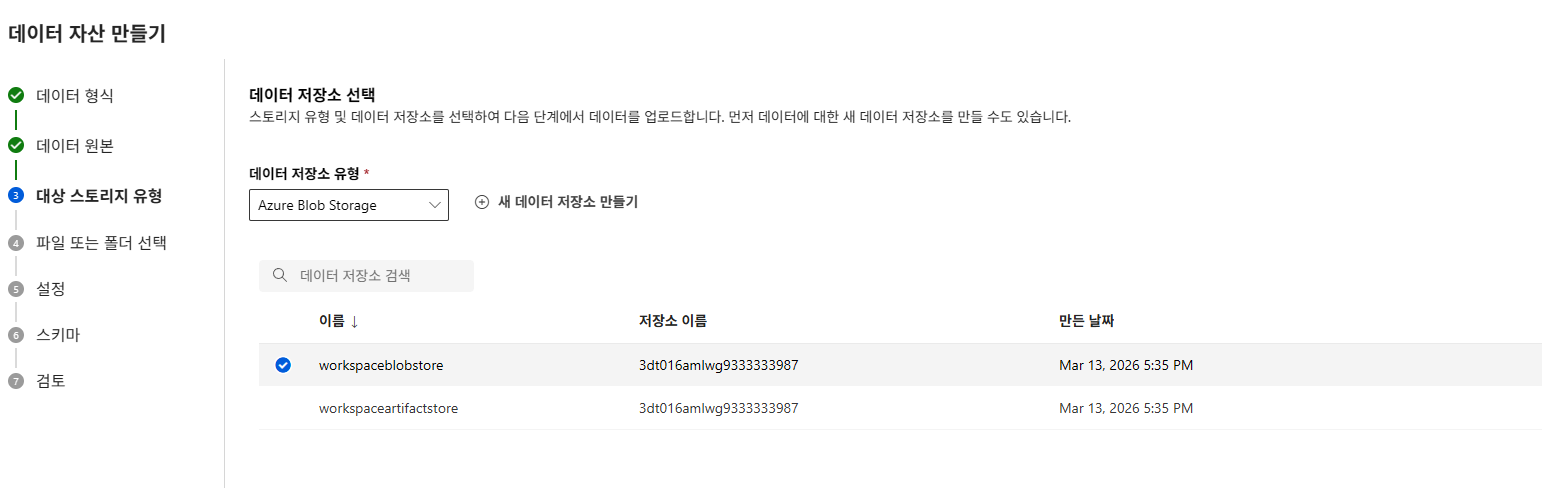
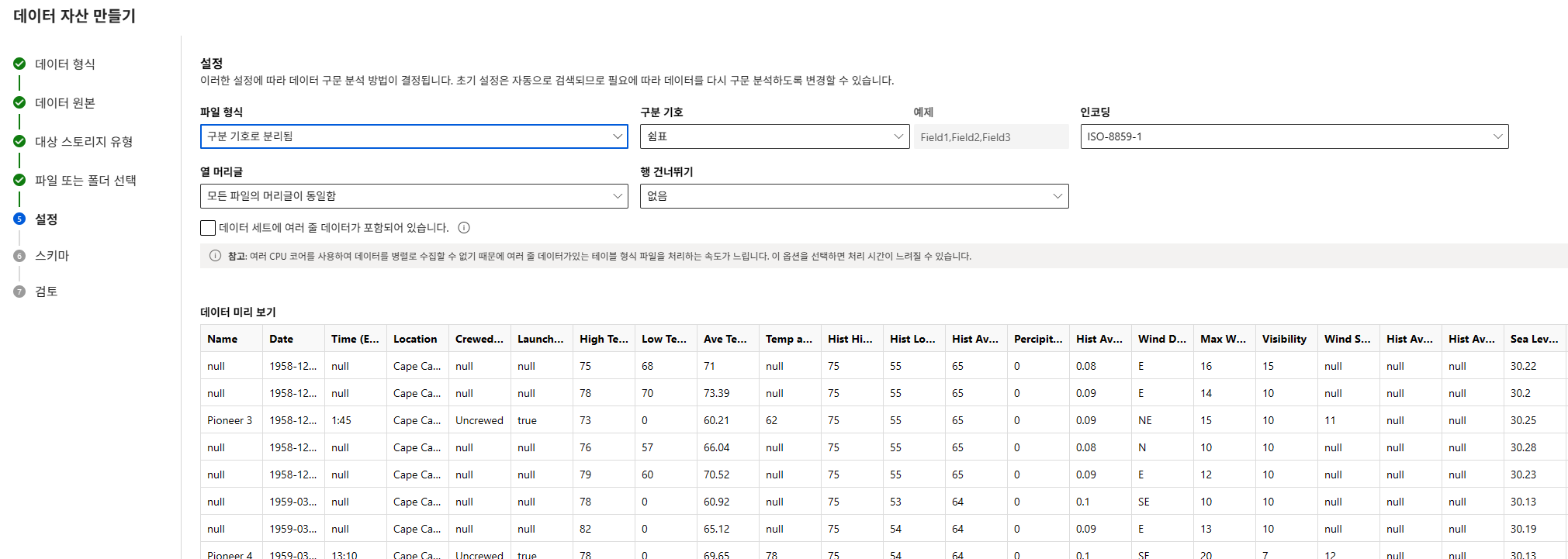
데이터타입 설정
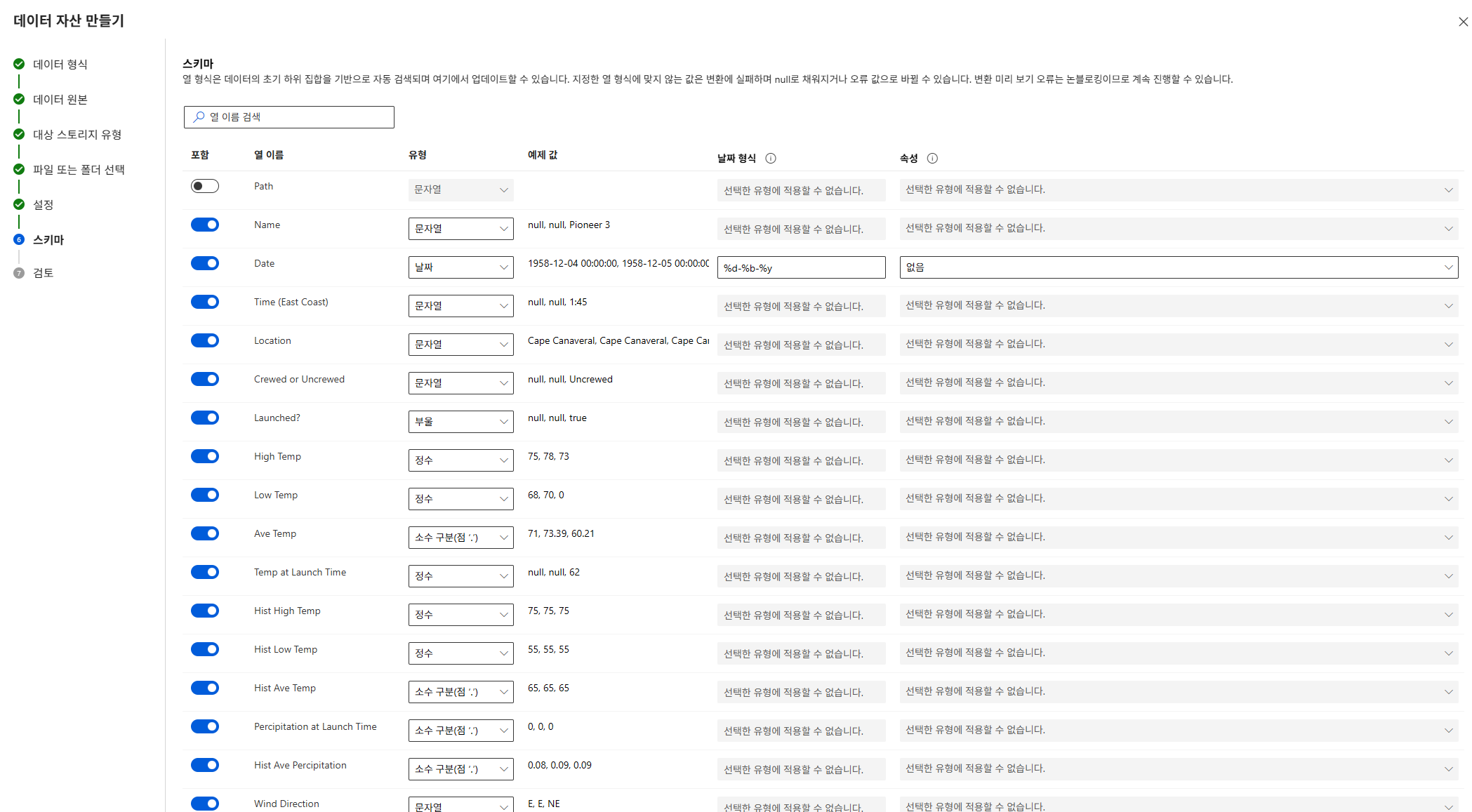
온도 관련 컬럼 데이터 타입을 정수에서 실수로 변경