[MicrosoftDataSchool] 48일차 - Azure Machine Learning(분류MLD 로켓발사, 회귀MLD 자전거렌탈, 군집MLD 프로야구 데이터)
Microsoft Data School 3기

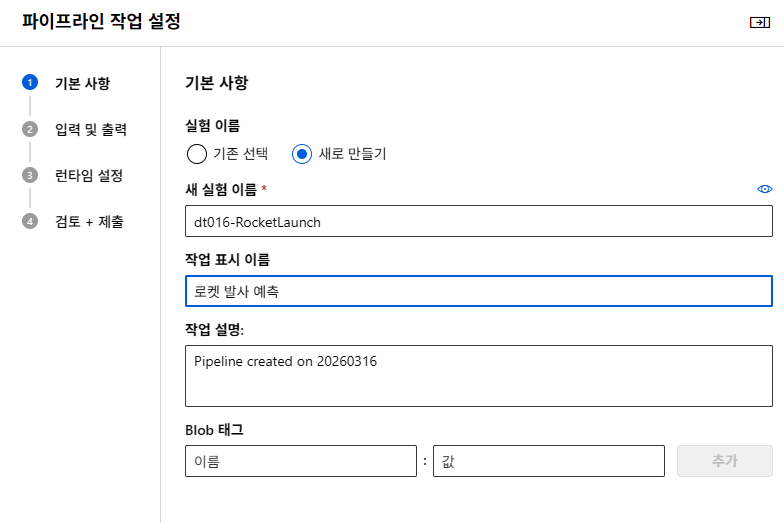
실습 이어서 - 분류 MLD 로켓발사
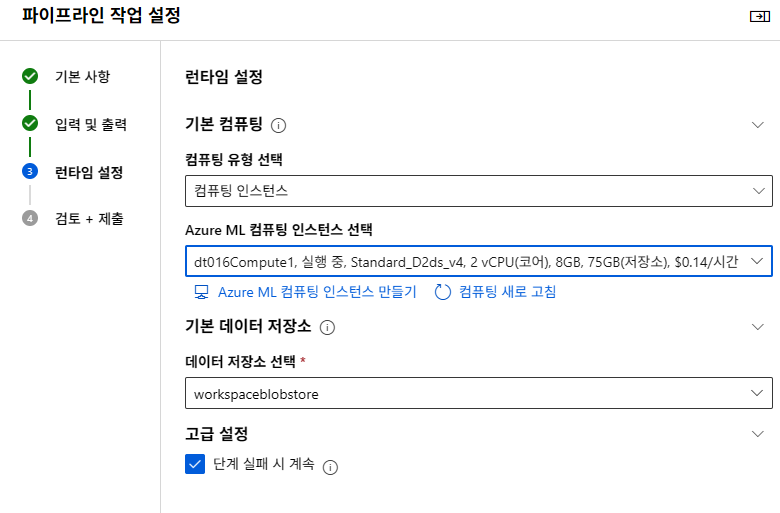
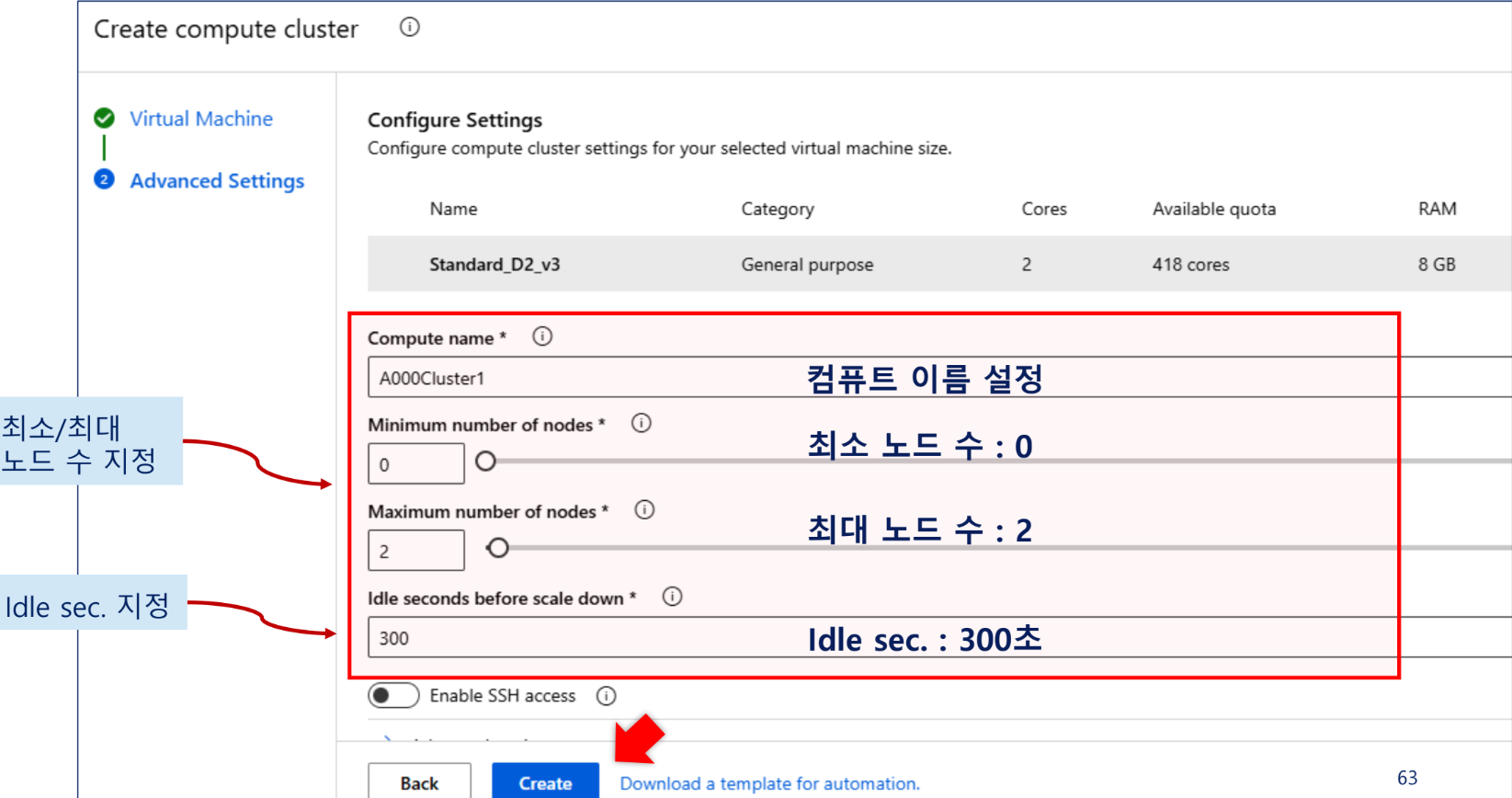
컴퓨트 대상 설정
머신러닝을 실행할 수 있는 컴퓨팅 자원
오프 -> 온을 빠르게 실행하기 위한 설정이다.
트래픽이 적을 때 비용을 아낄 수 있다. 자동 스케일링이 적용됨
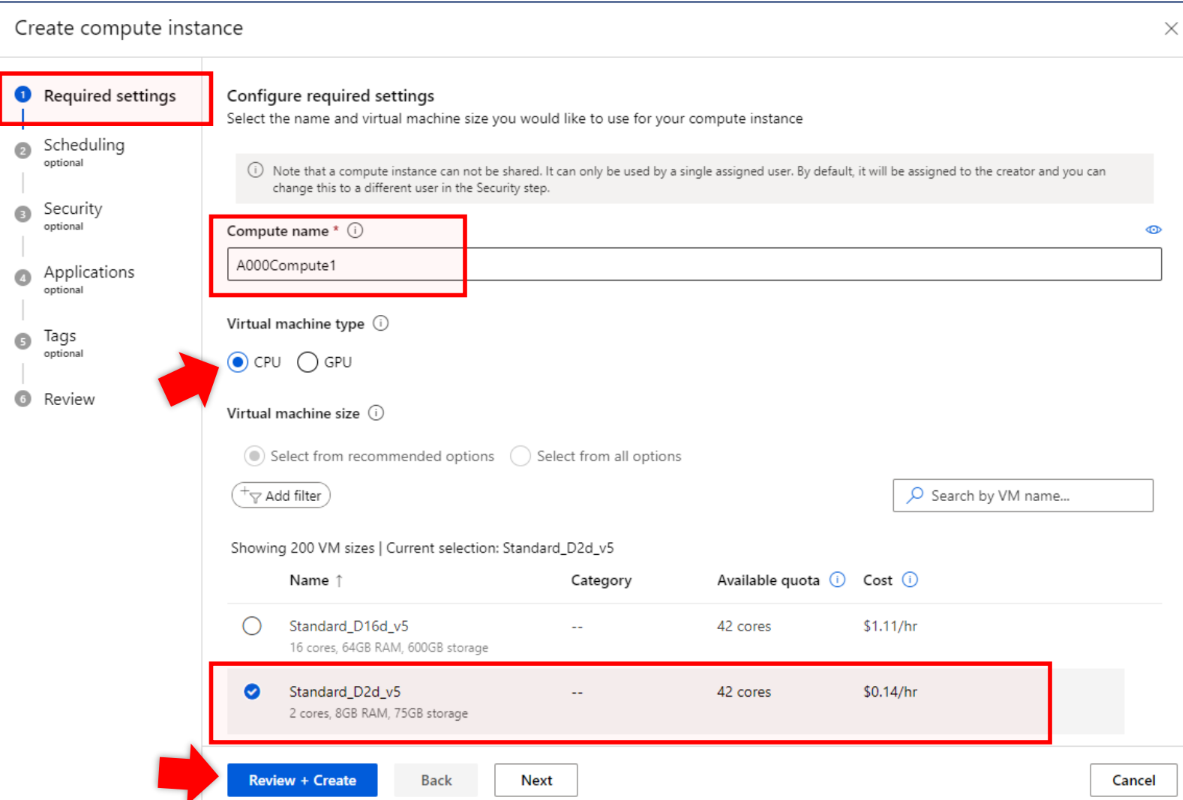
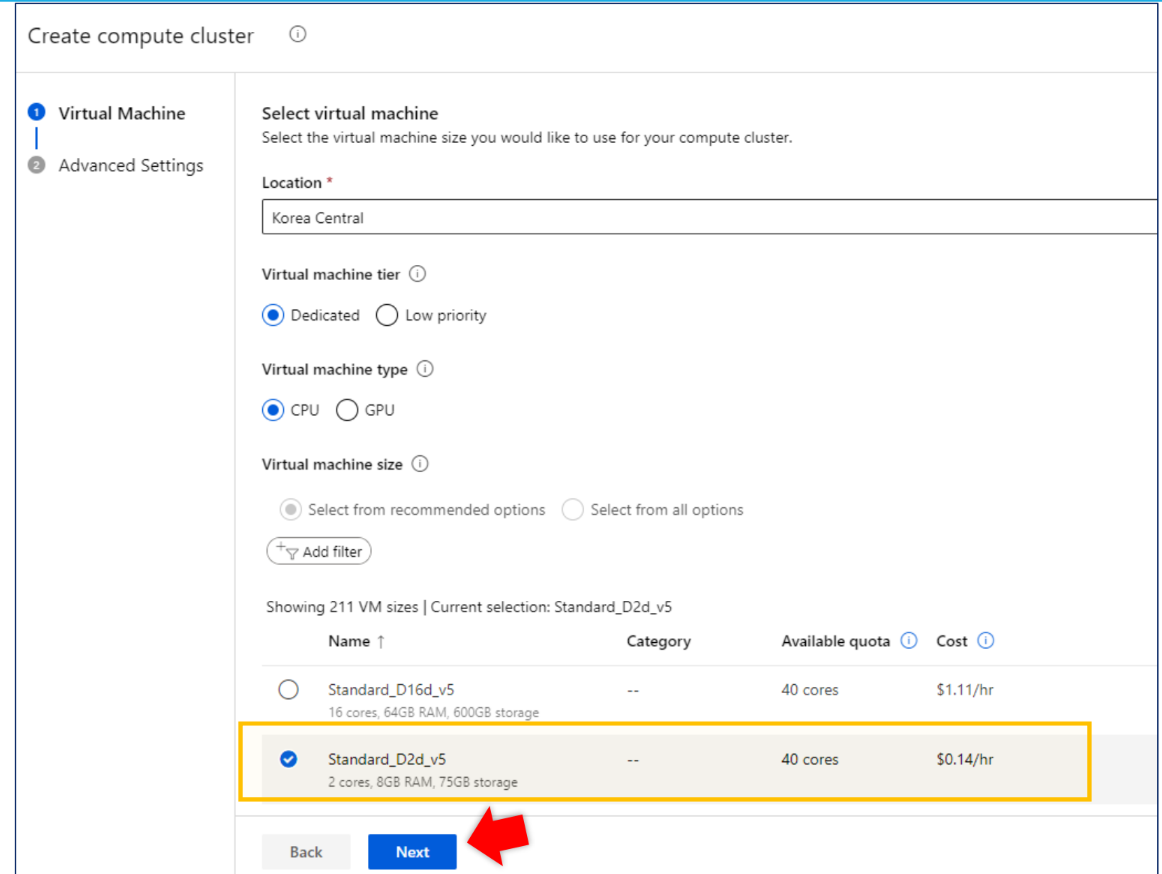
현재는 없는 옵션이라 비슷한 다른걸 사용했다. 2~4코어정도면 상관없다고 하셨다.

유후상태되기까지 걸리는 시간 수정하기

이름을 선택한다
우측의 일정의 편집 버튼을 눌러 수정한다
디자이너 시작
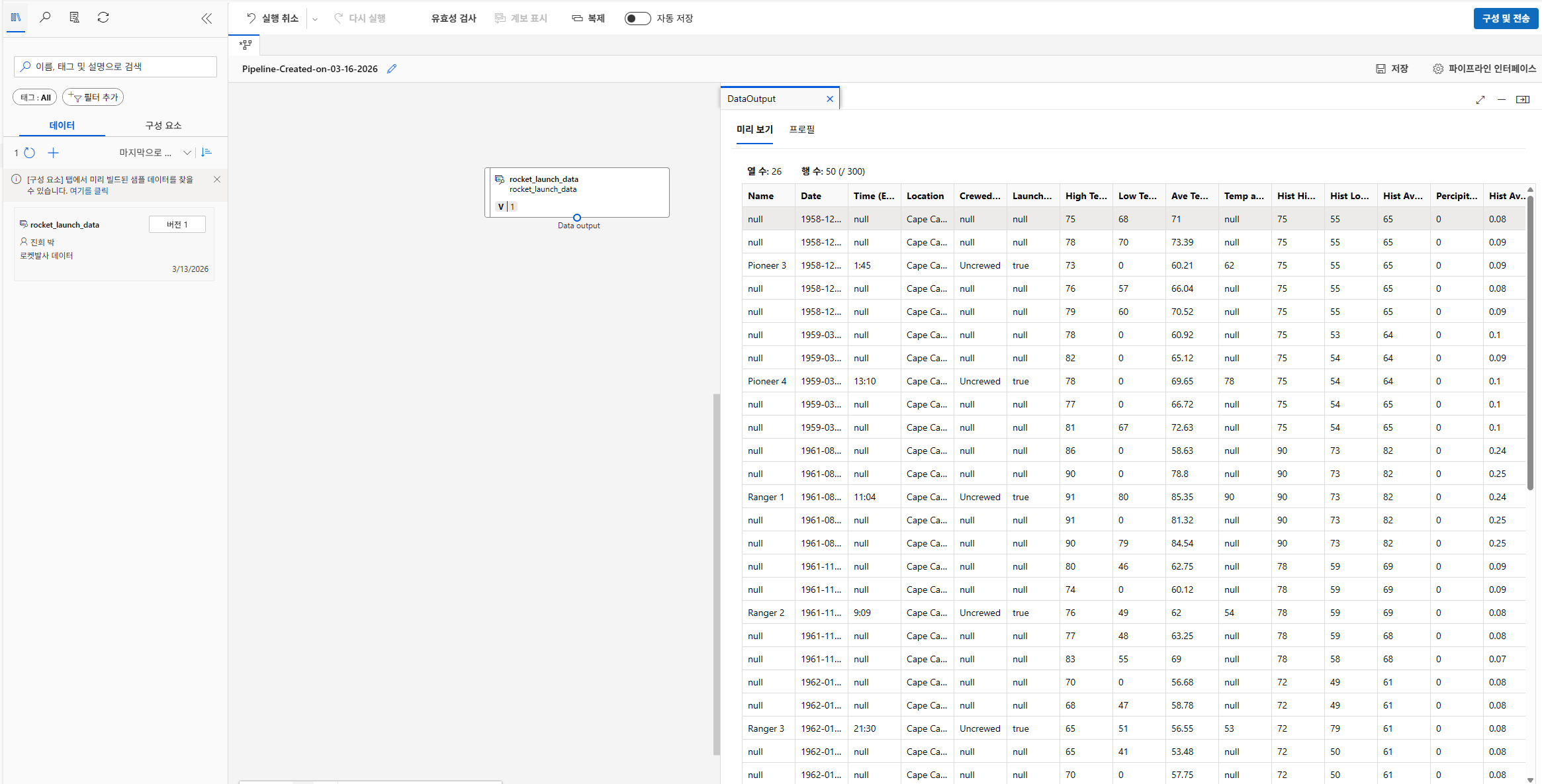
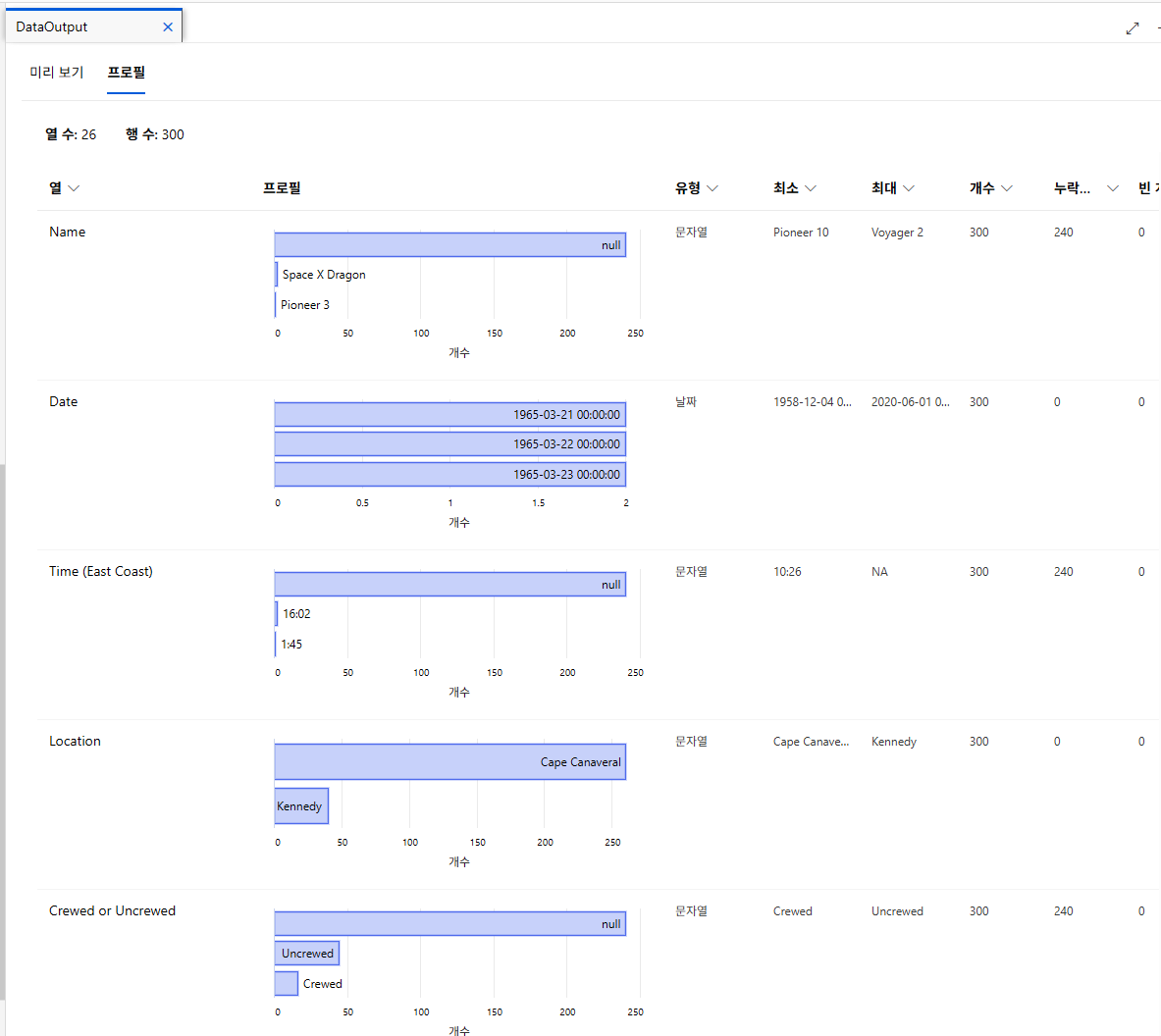
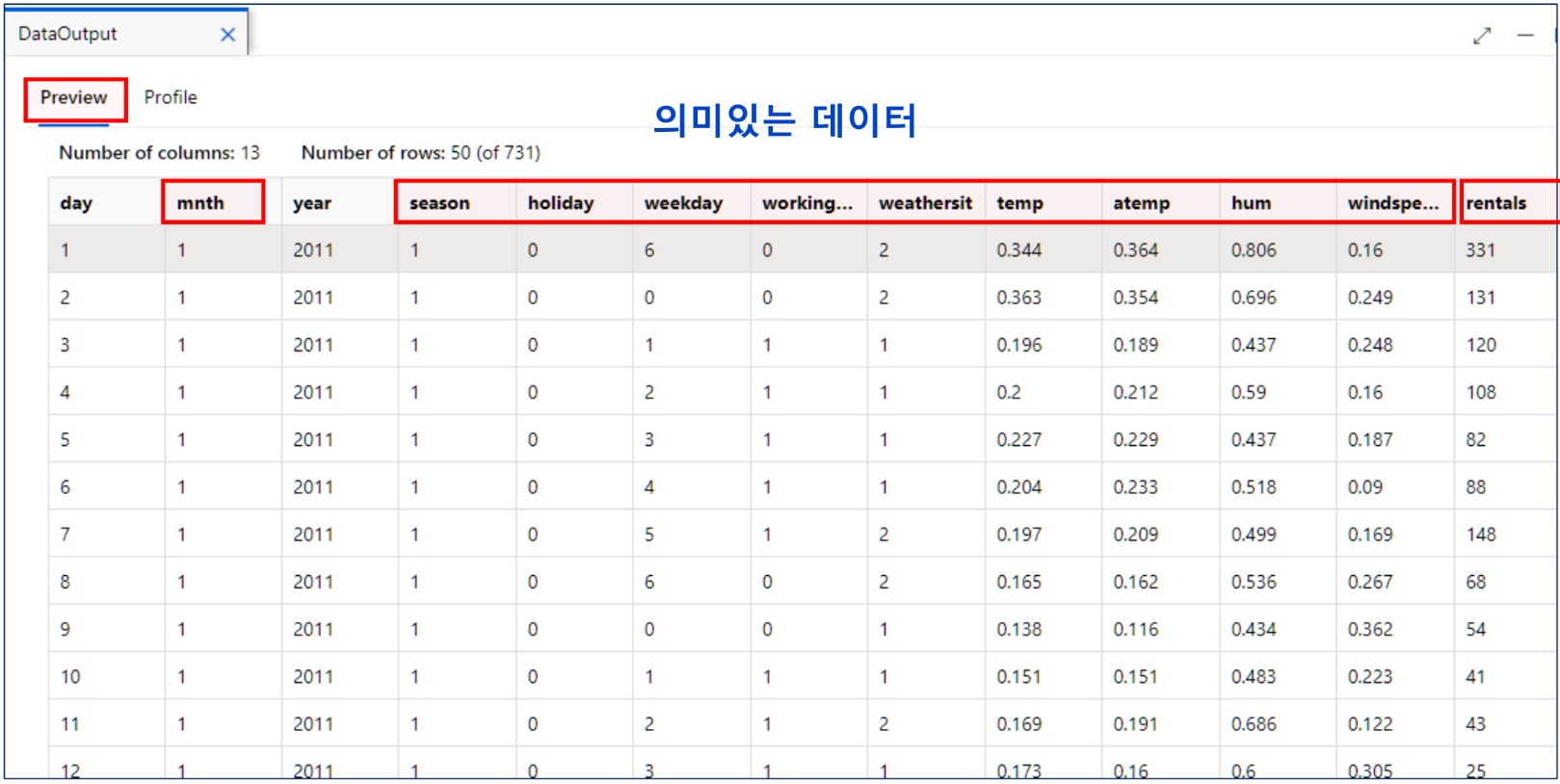
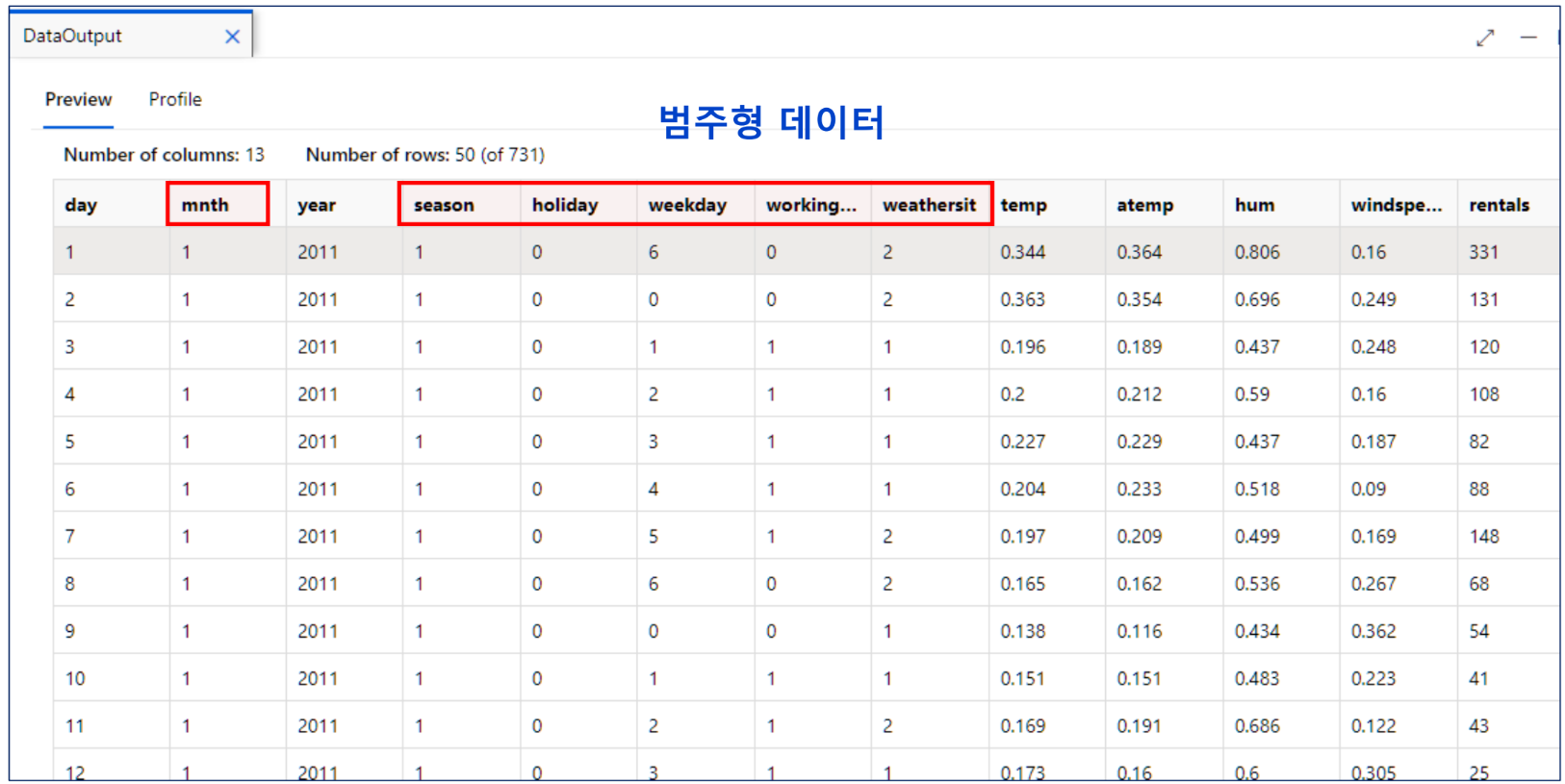
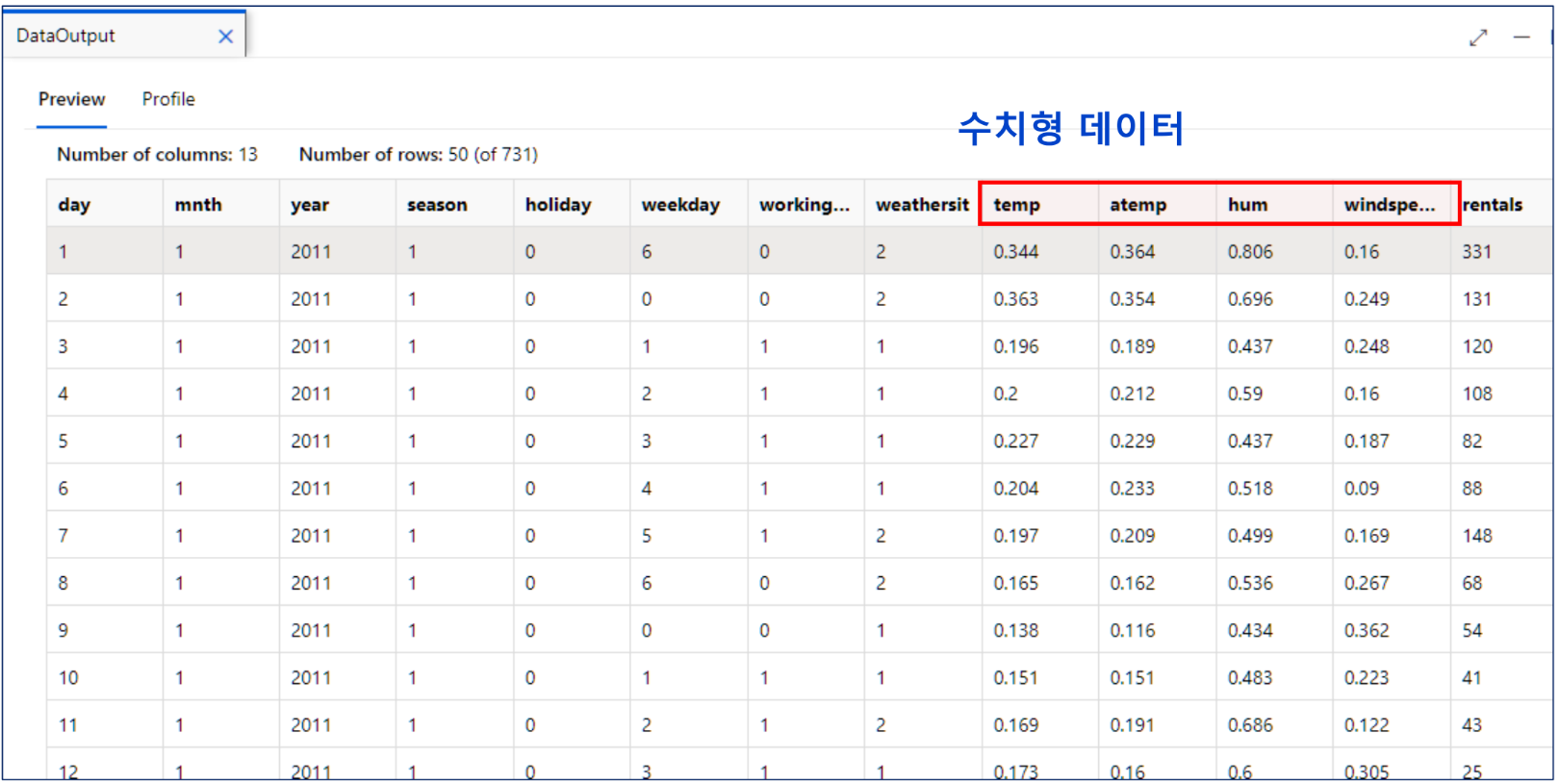
데이터 아웃풋- 미리 보기
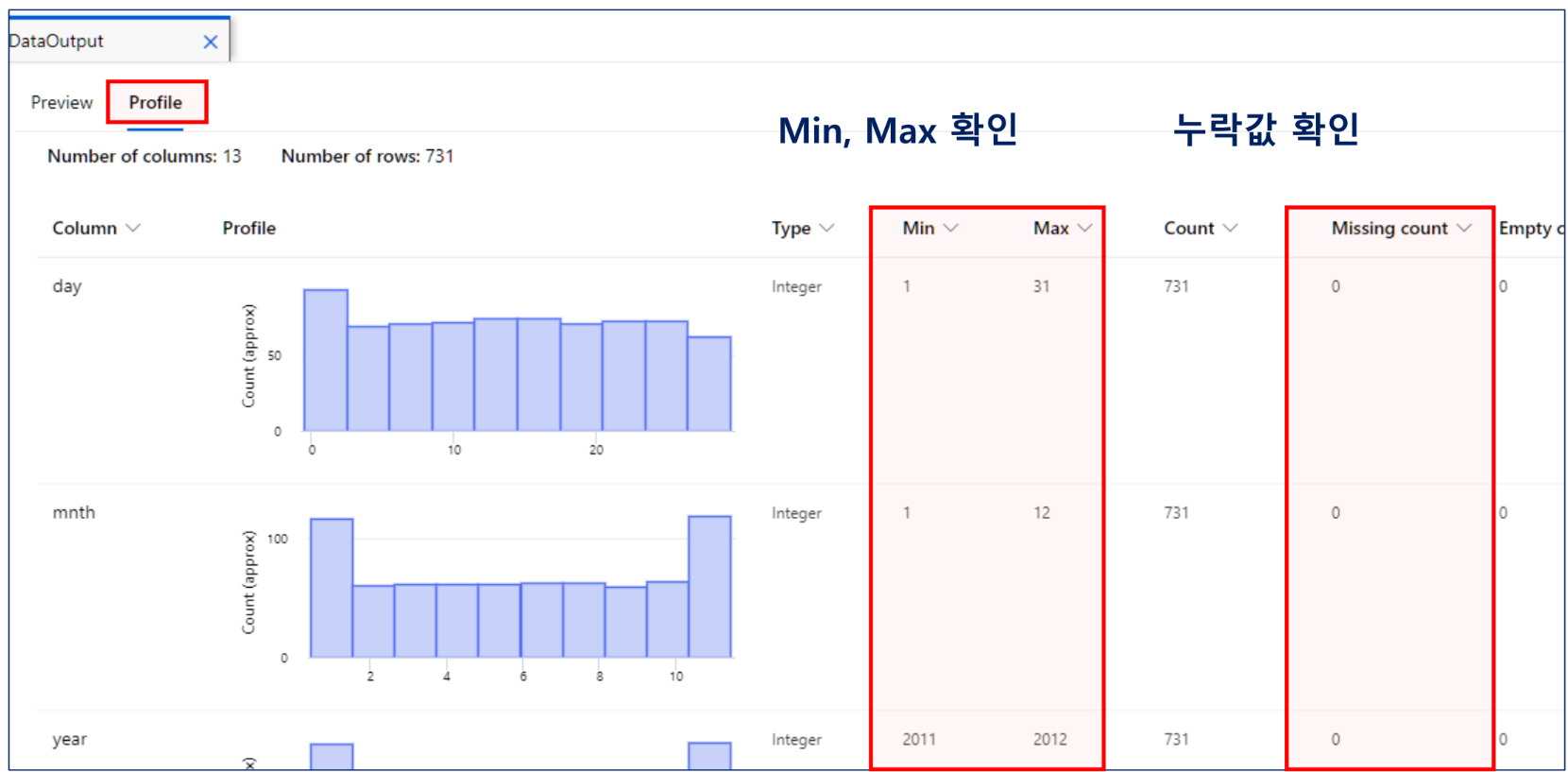
데이터 아웃풋- 프로필
데이터 정리
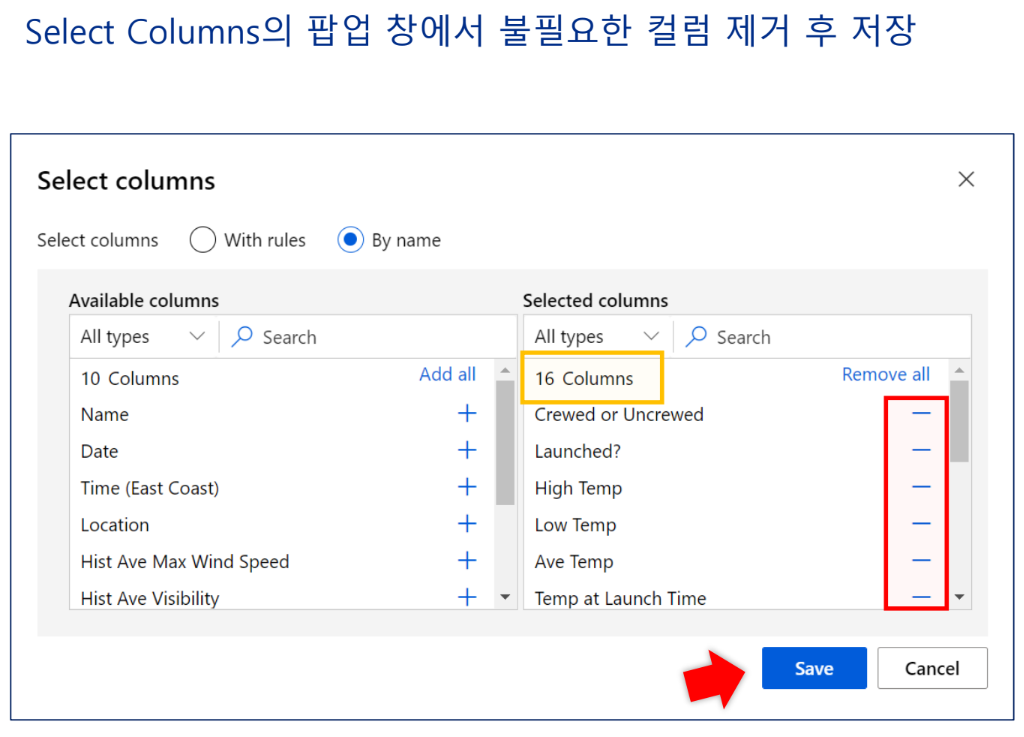
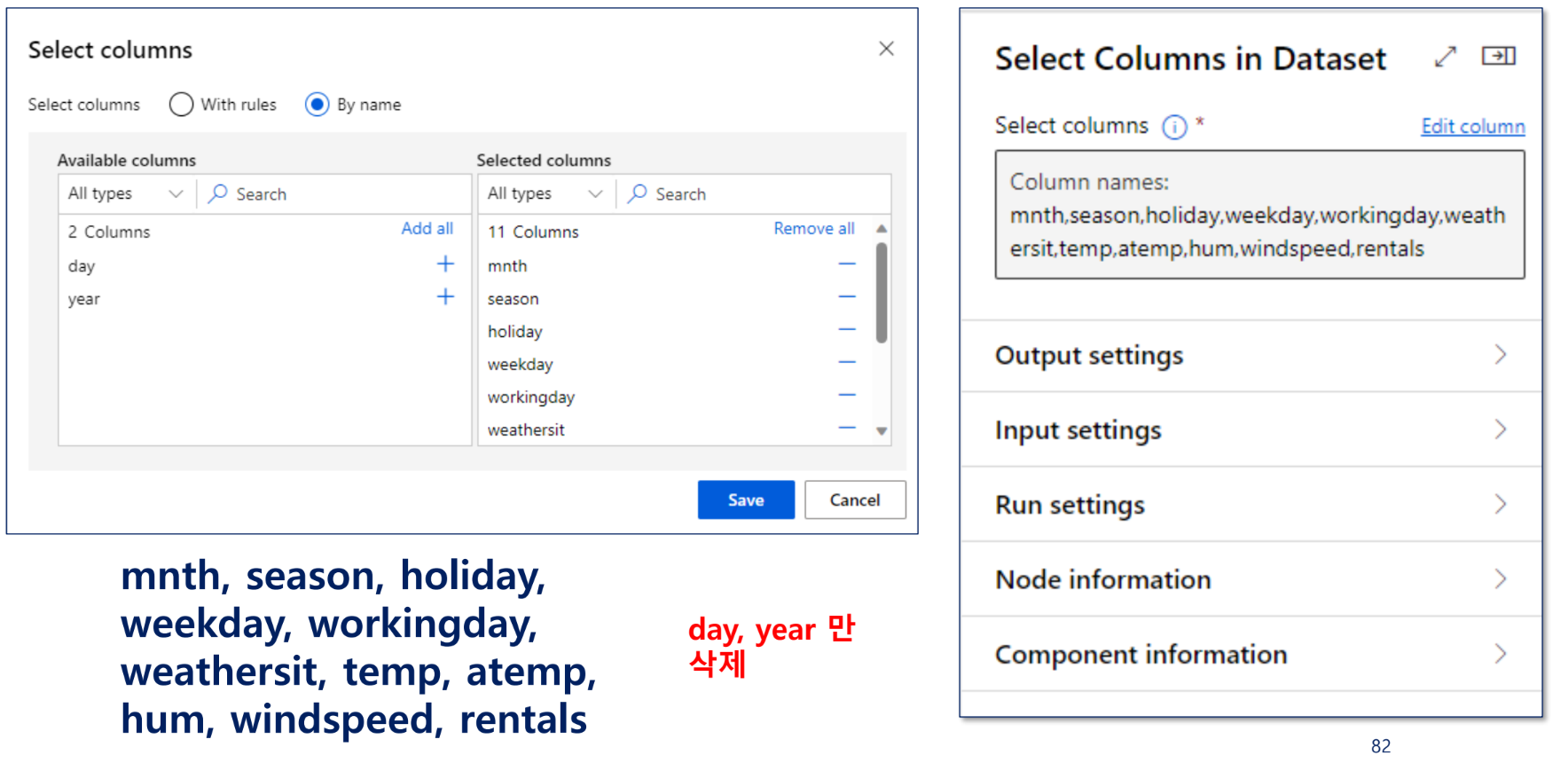
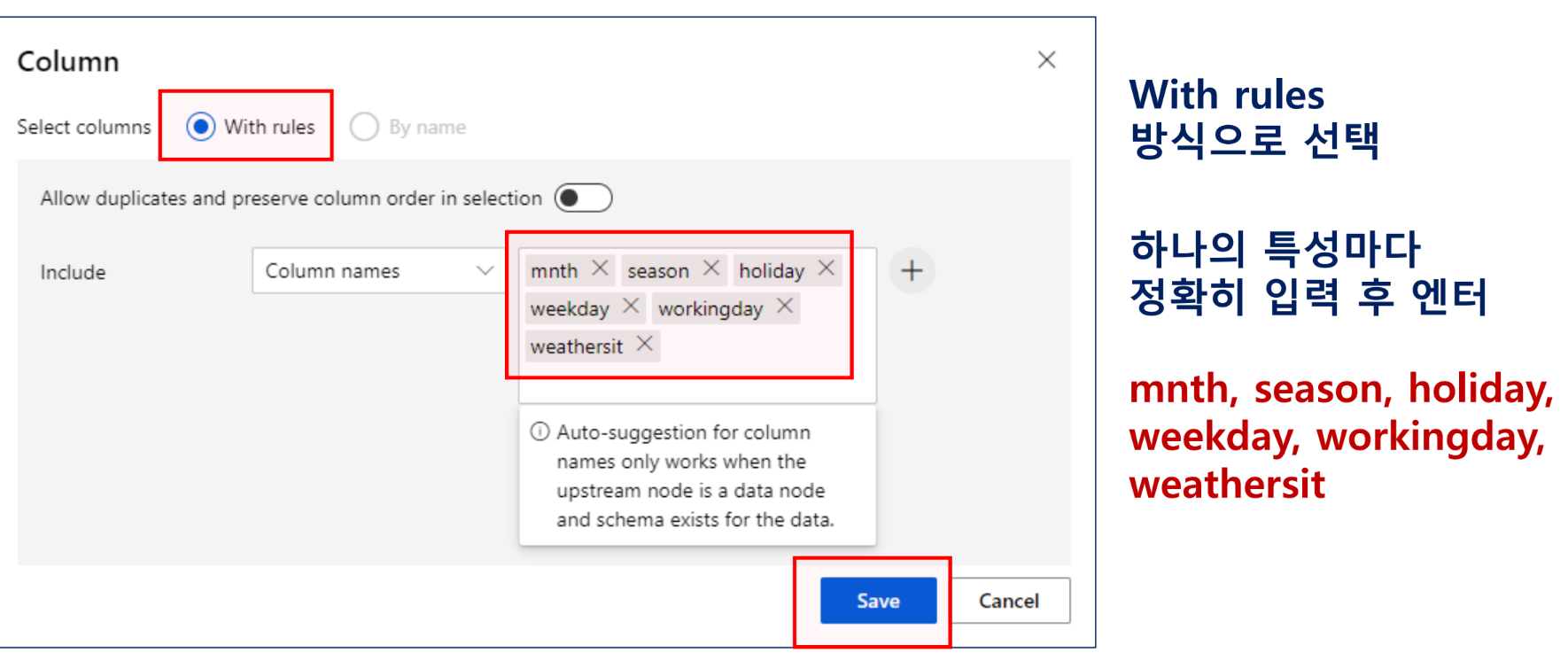
1) 필요한 컬럼 선택
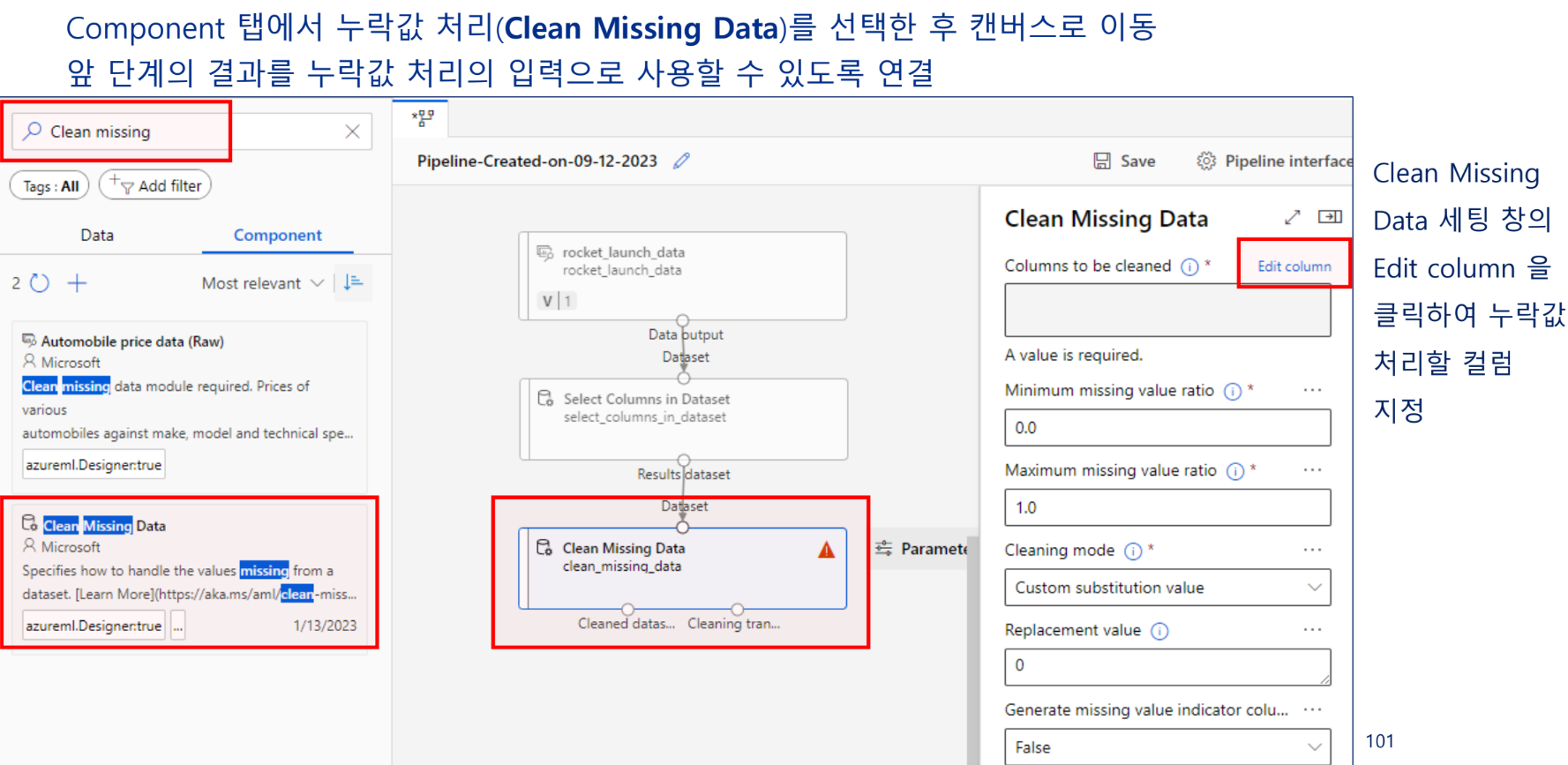
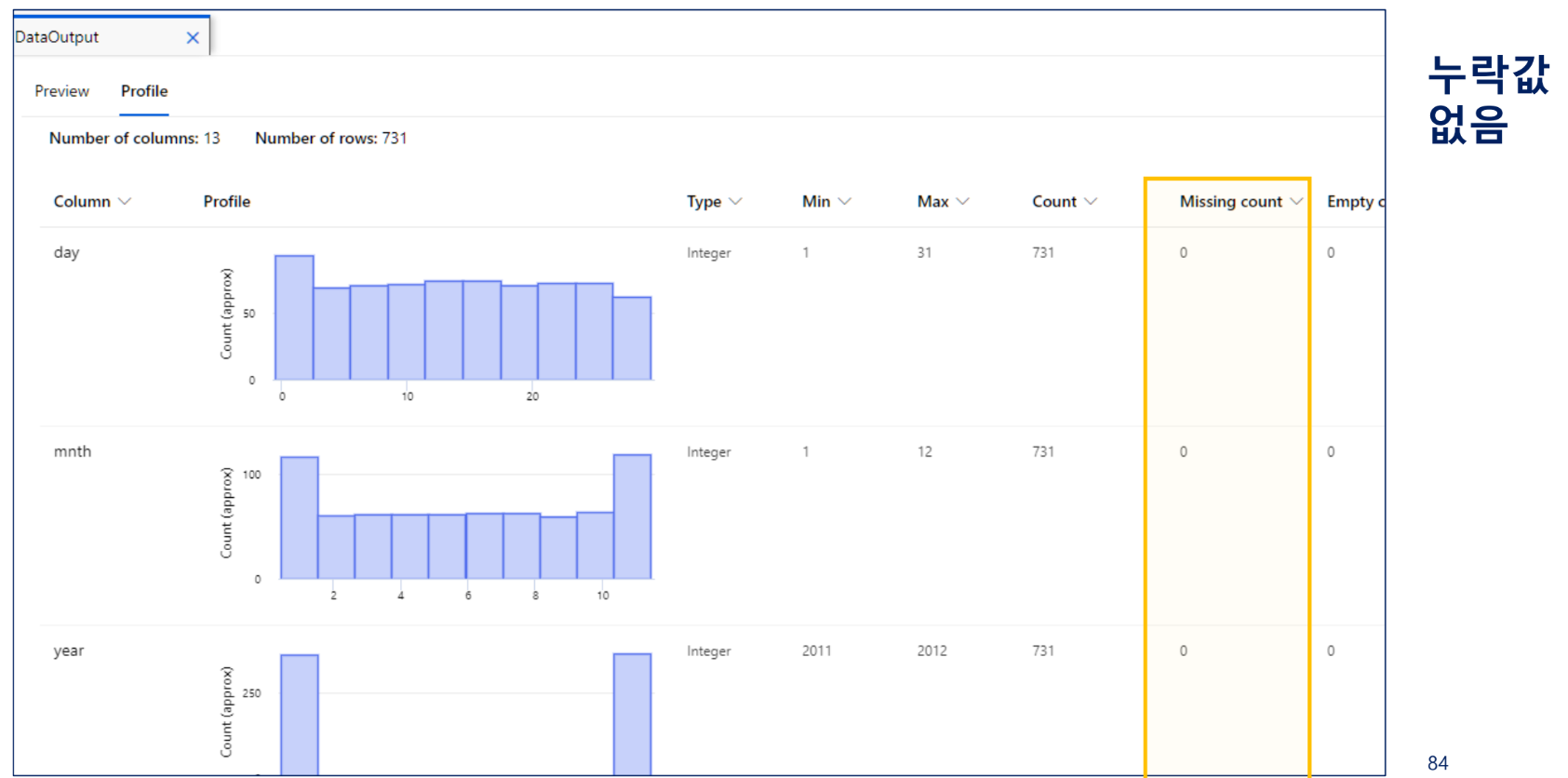
2) 누락값 처리
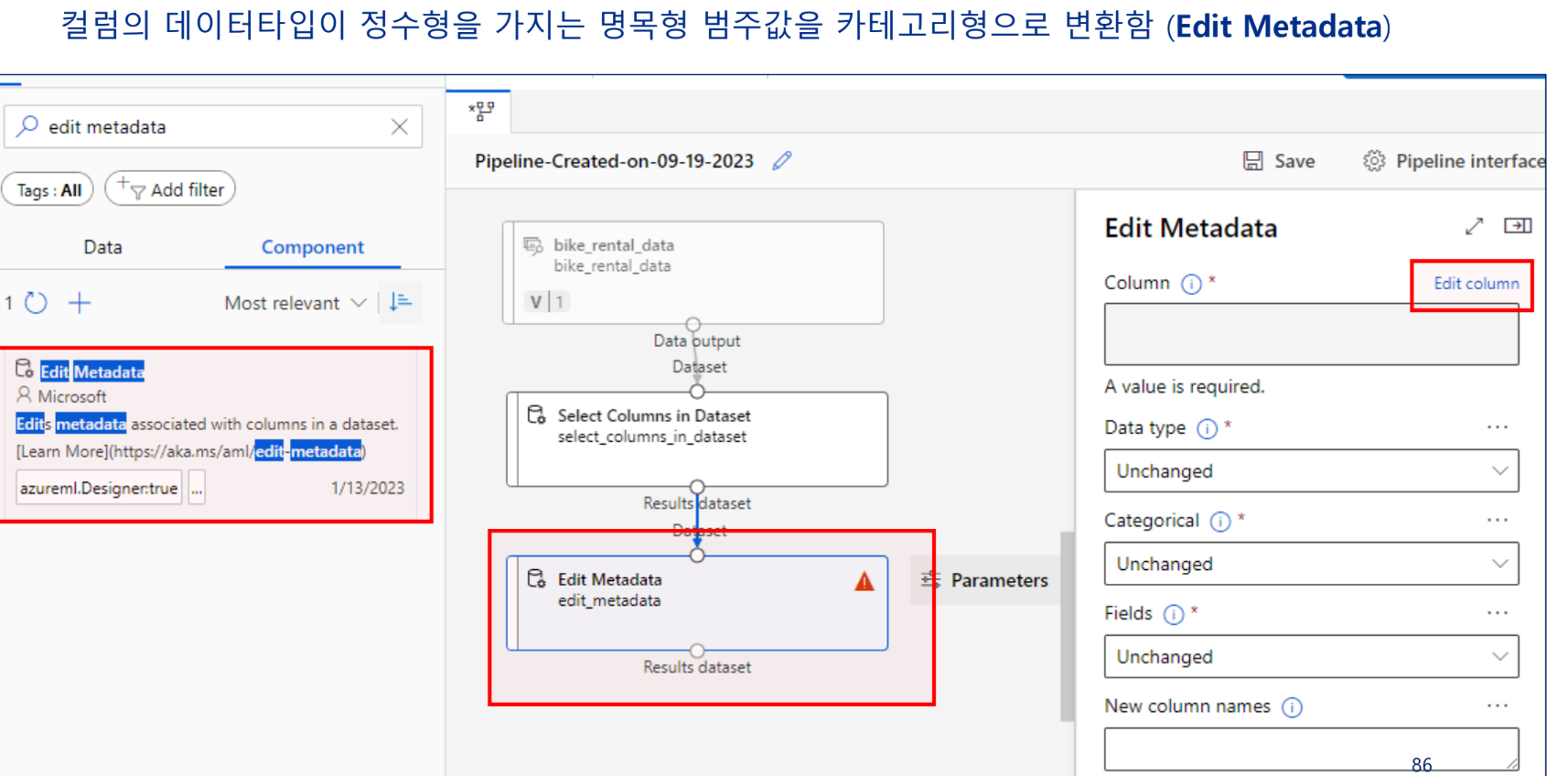
3) 데이터 타입 변환 작업
이 순서가 일반적
특성 선택
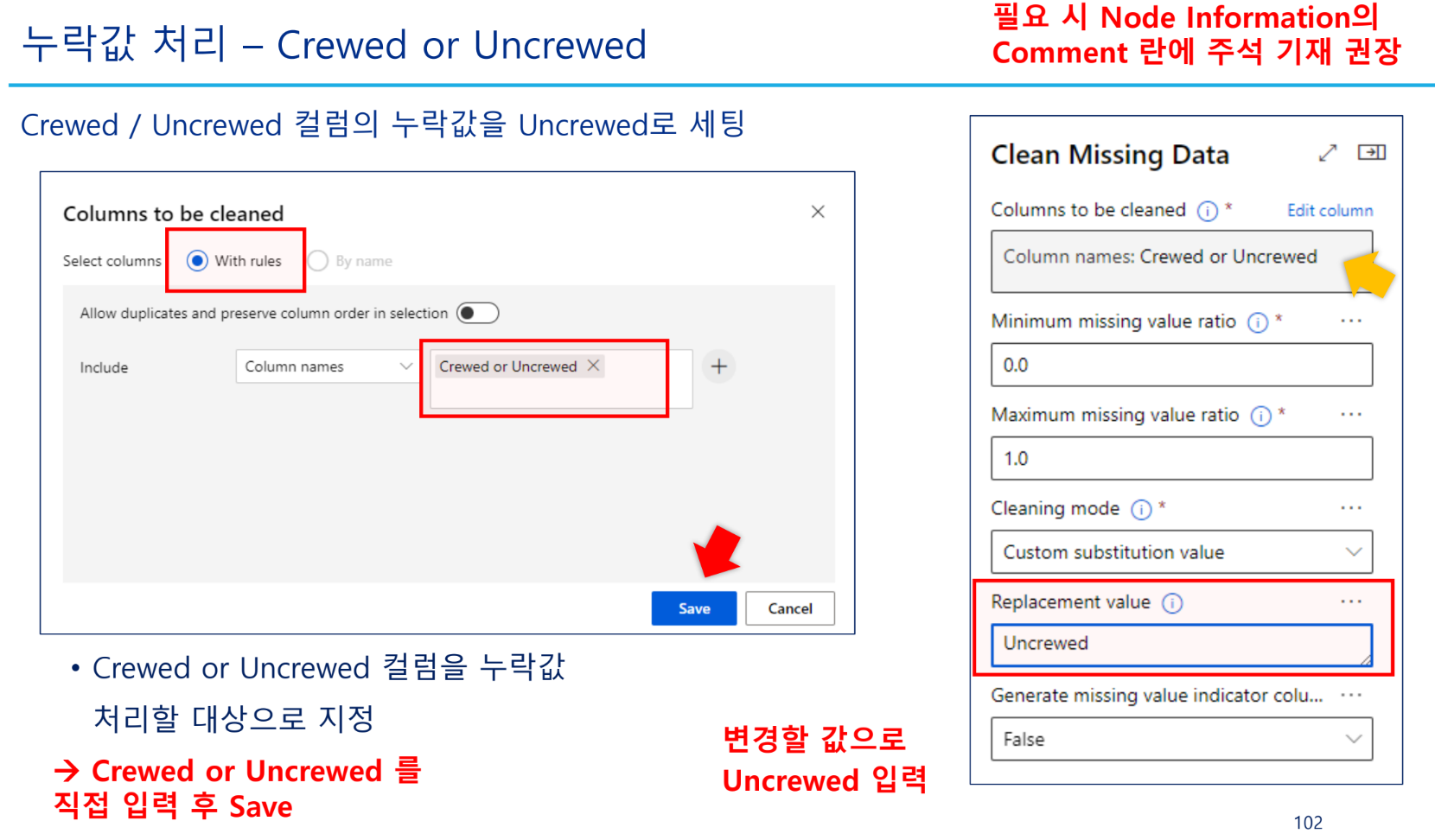
누락값 처리
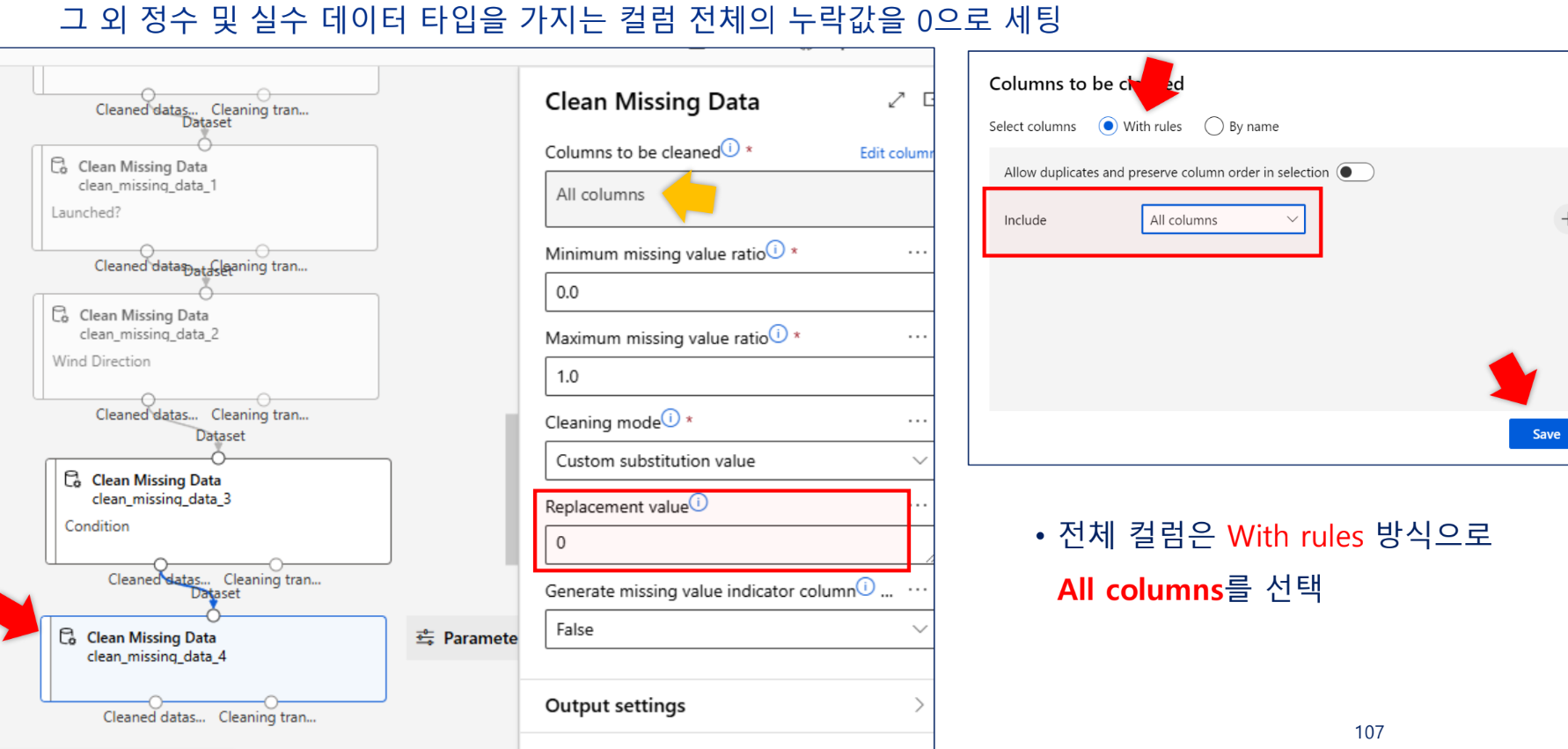
정수 및 실수 데이터 타입 가지는 컬럼 전체 누락값 0으로 세팅하기
데이터 변환
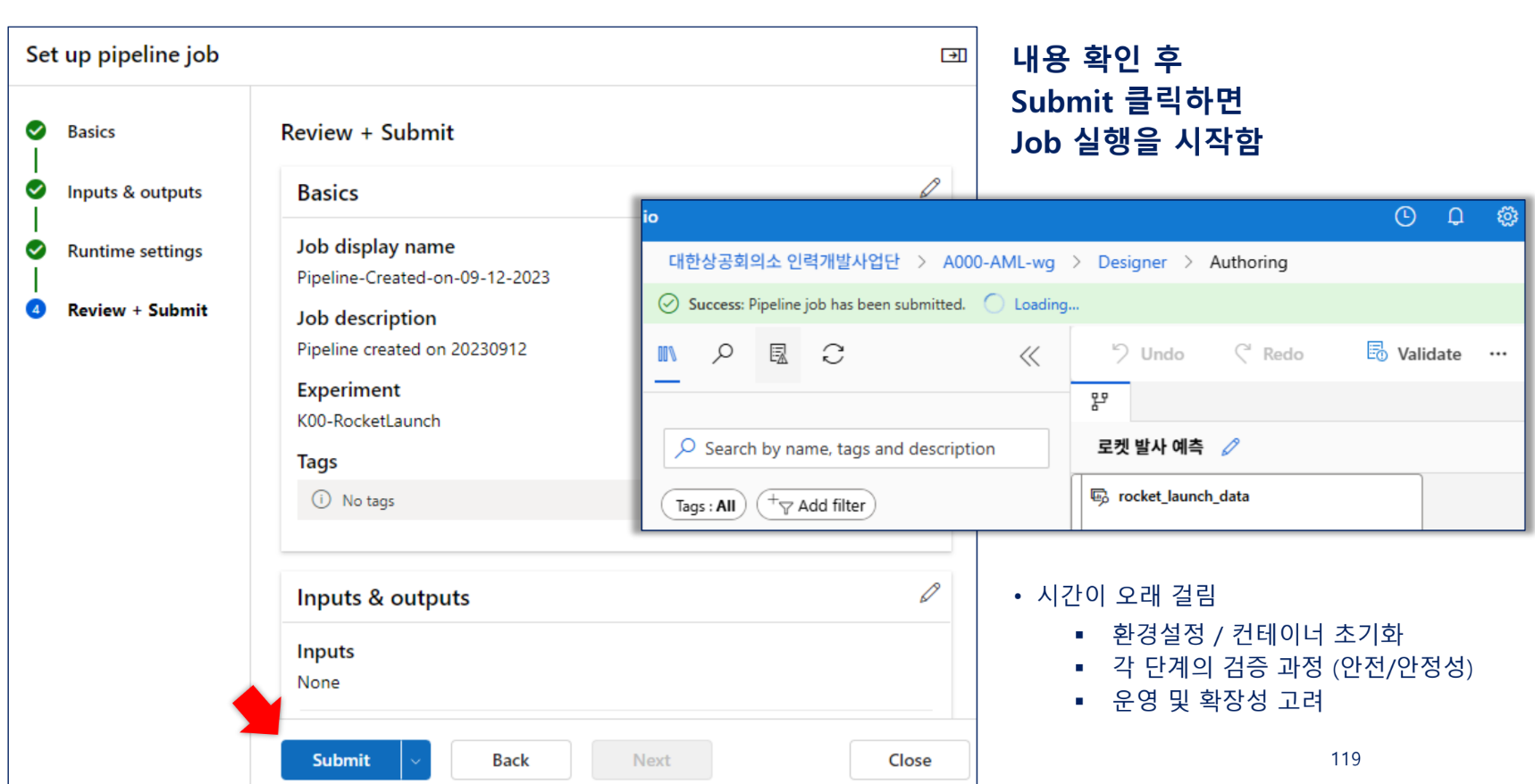
구성 및 내보내기(중간 점검)
인스턴스 설정
jobs 확인
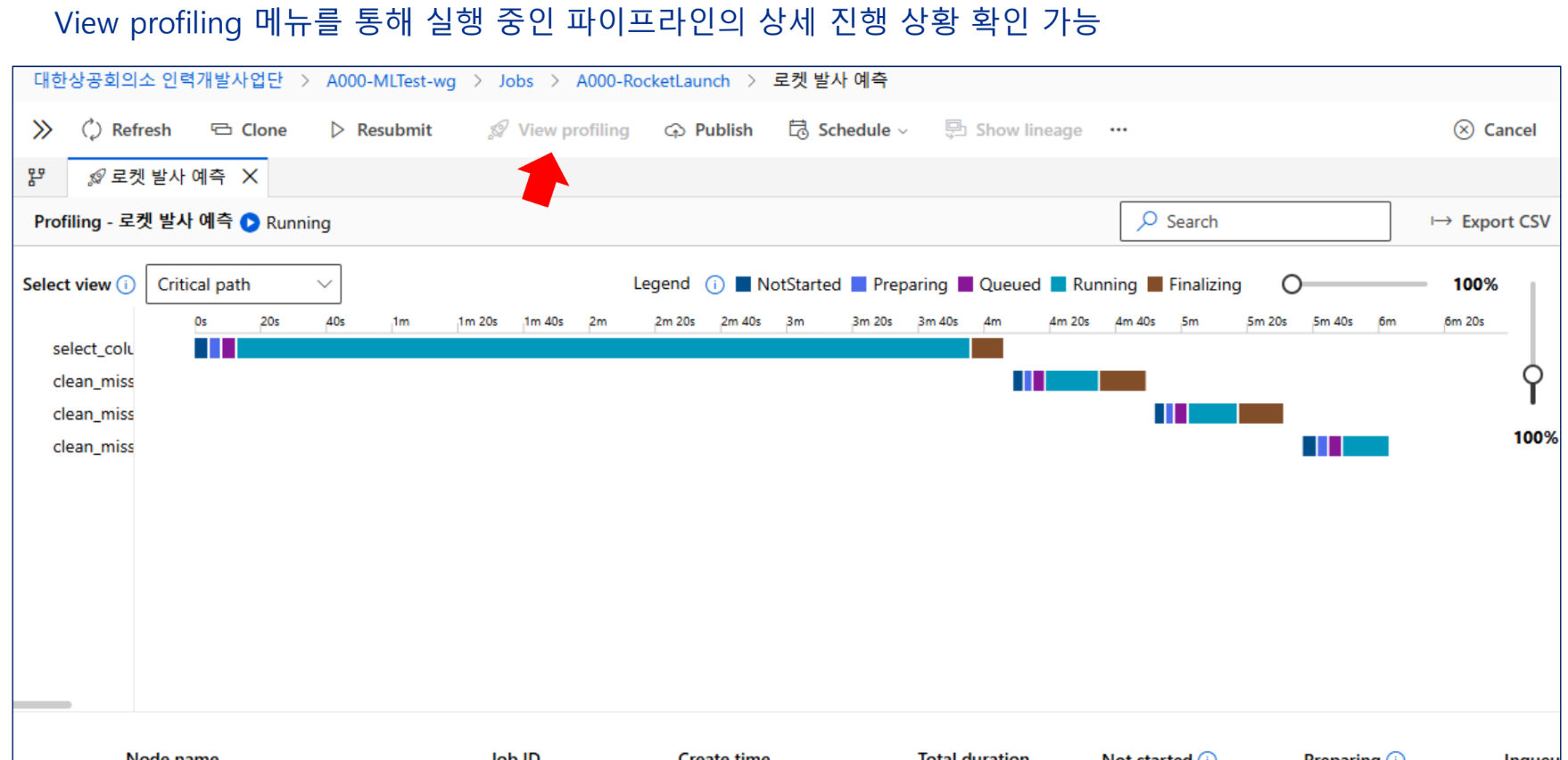
view profiling
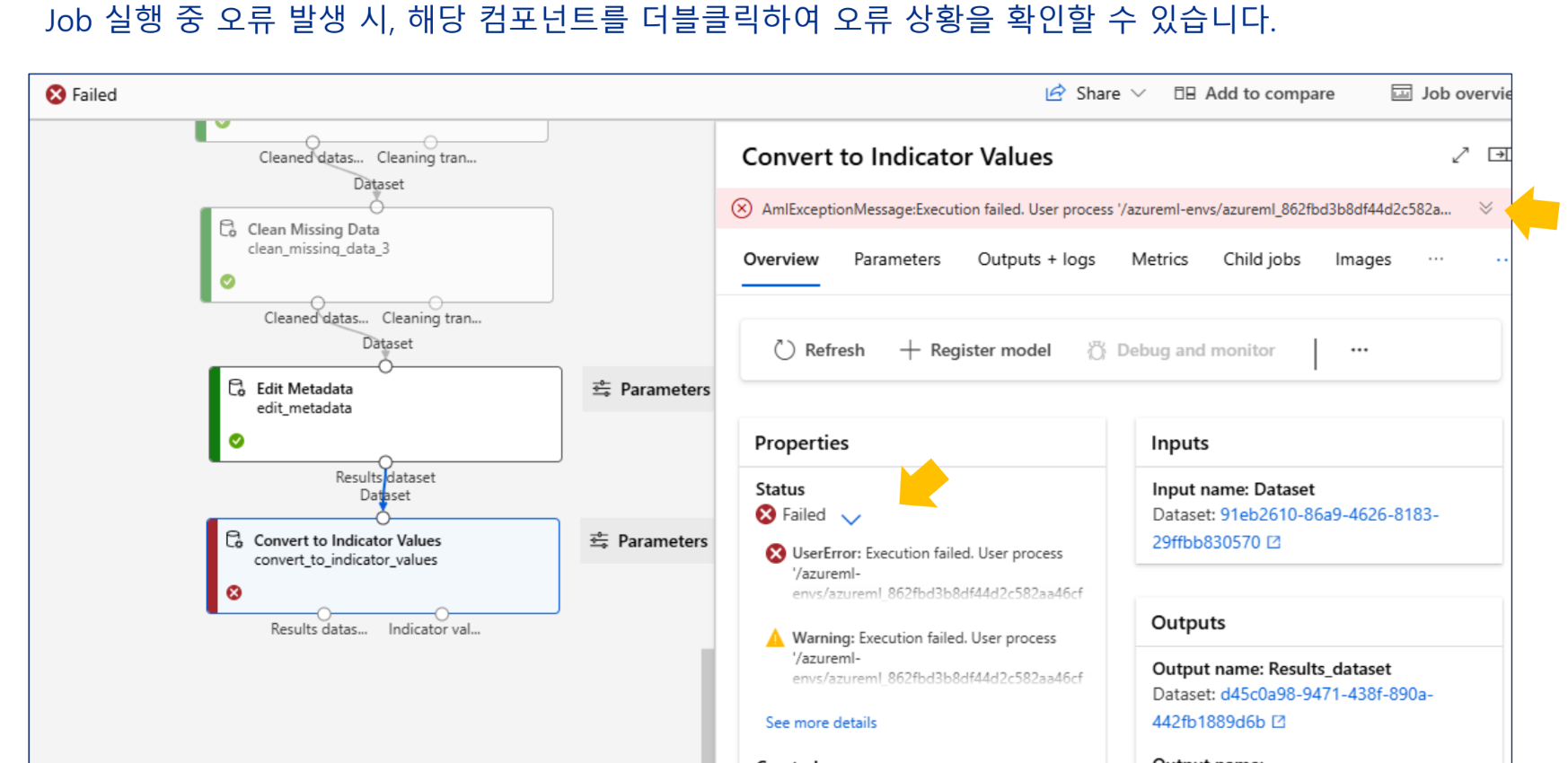
오류 발생시
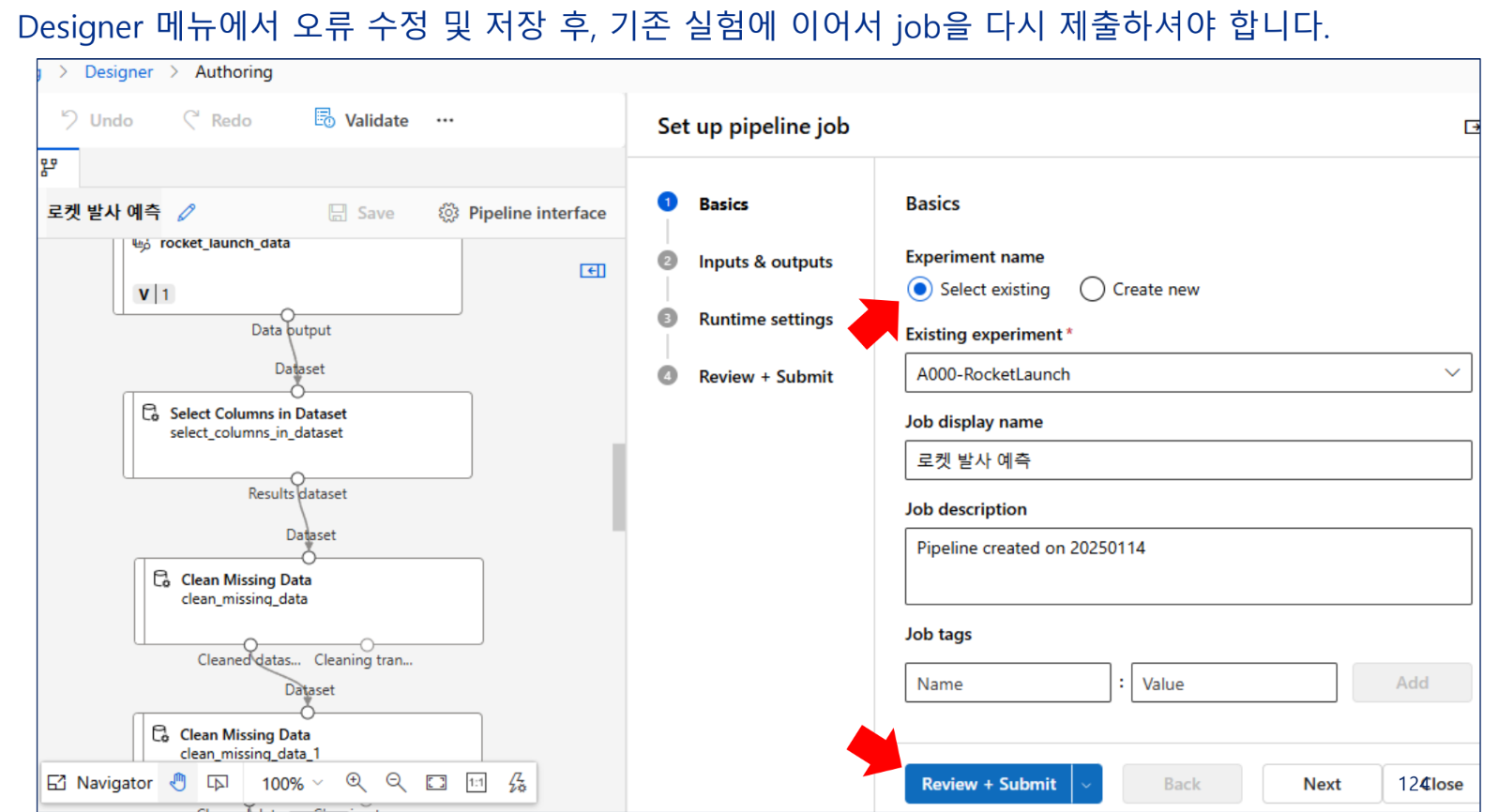
결과 관찰
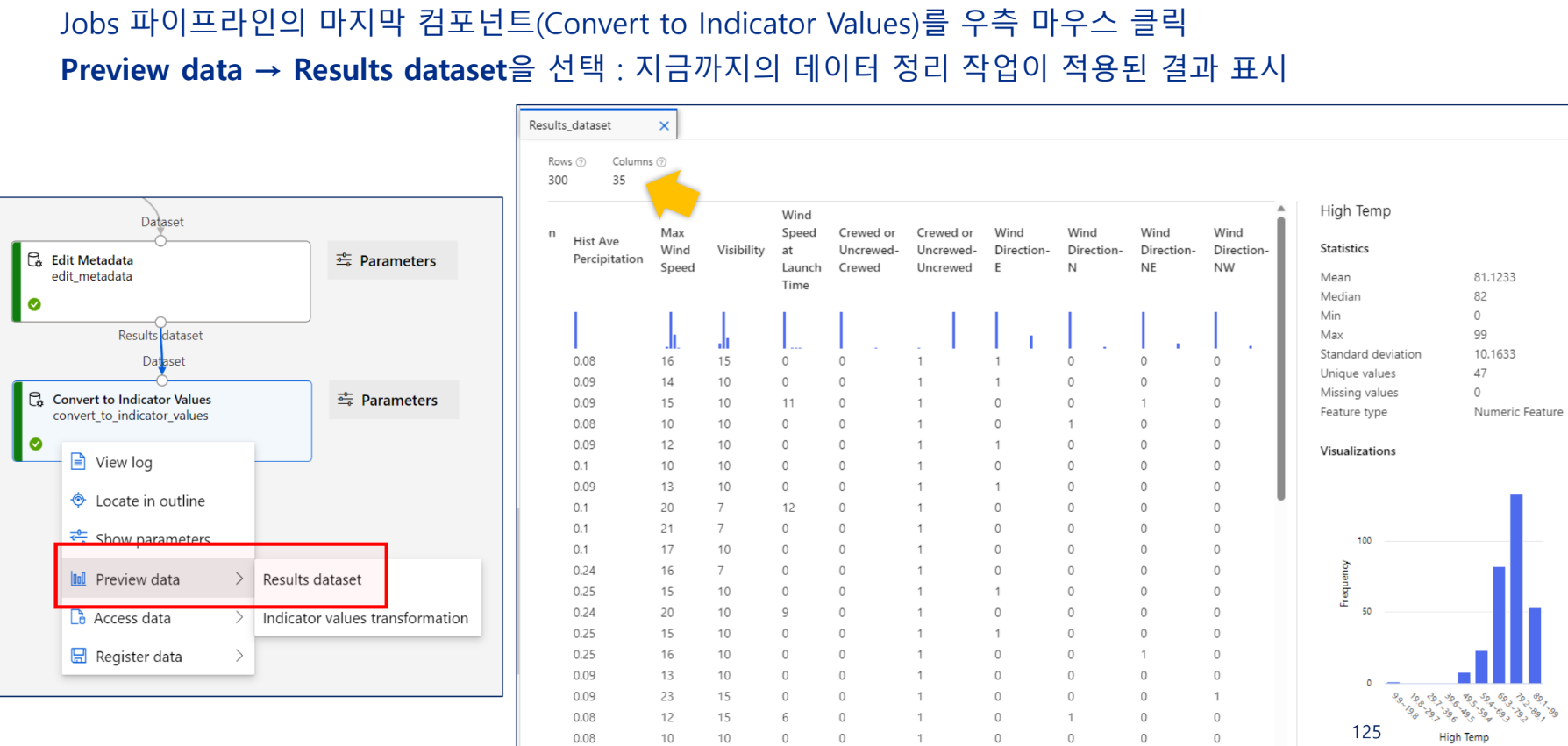
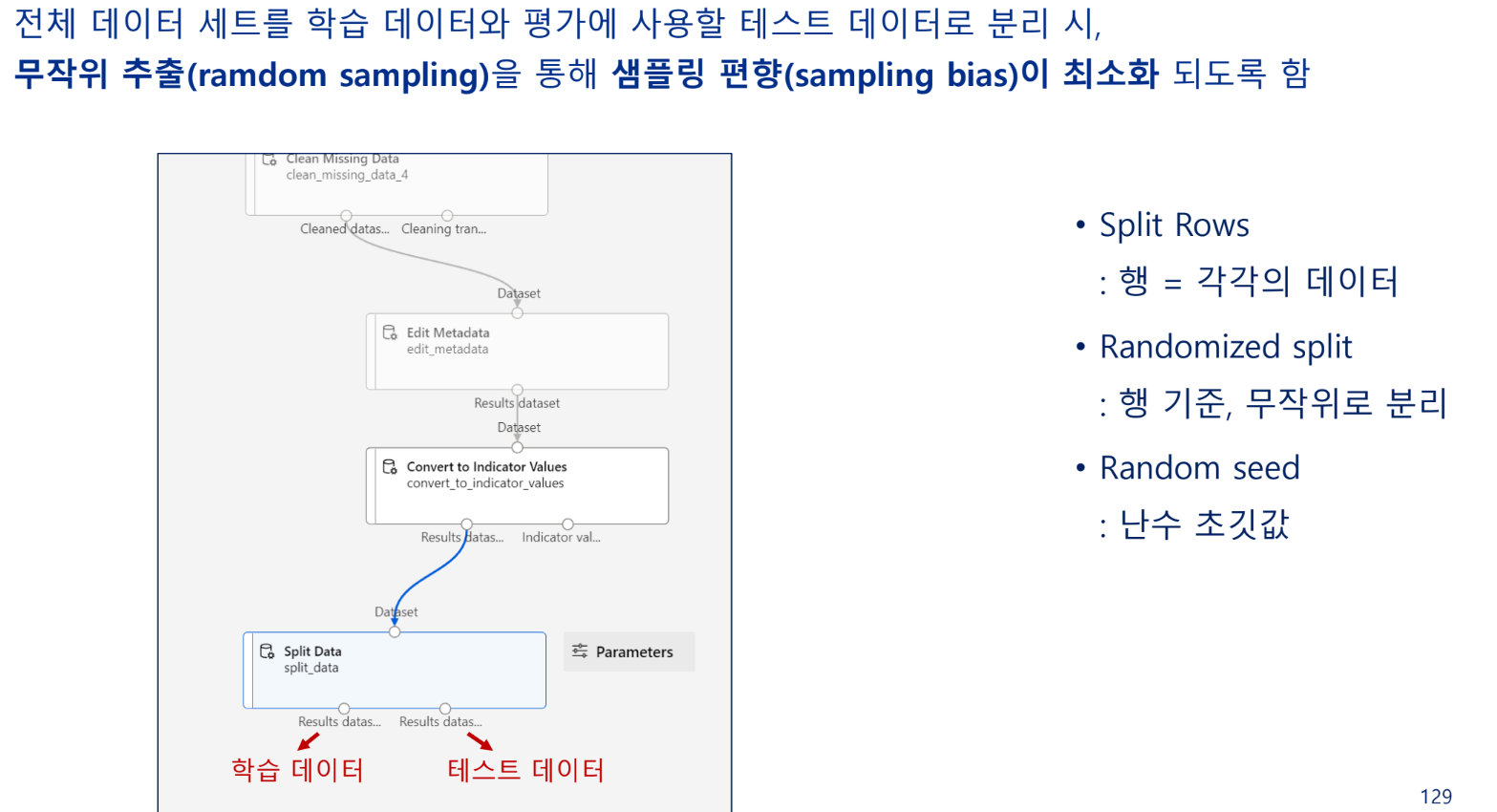
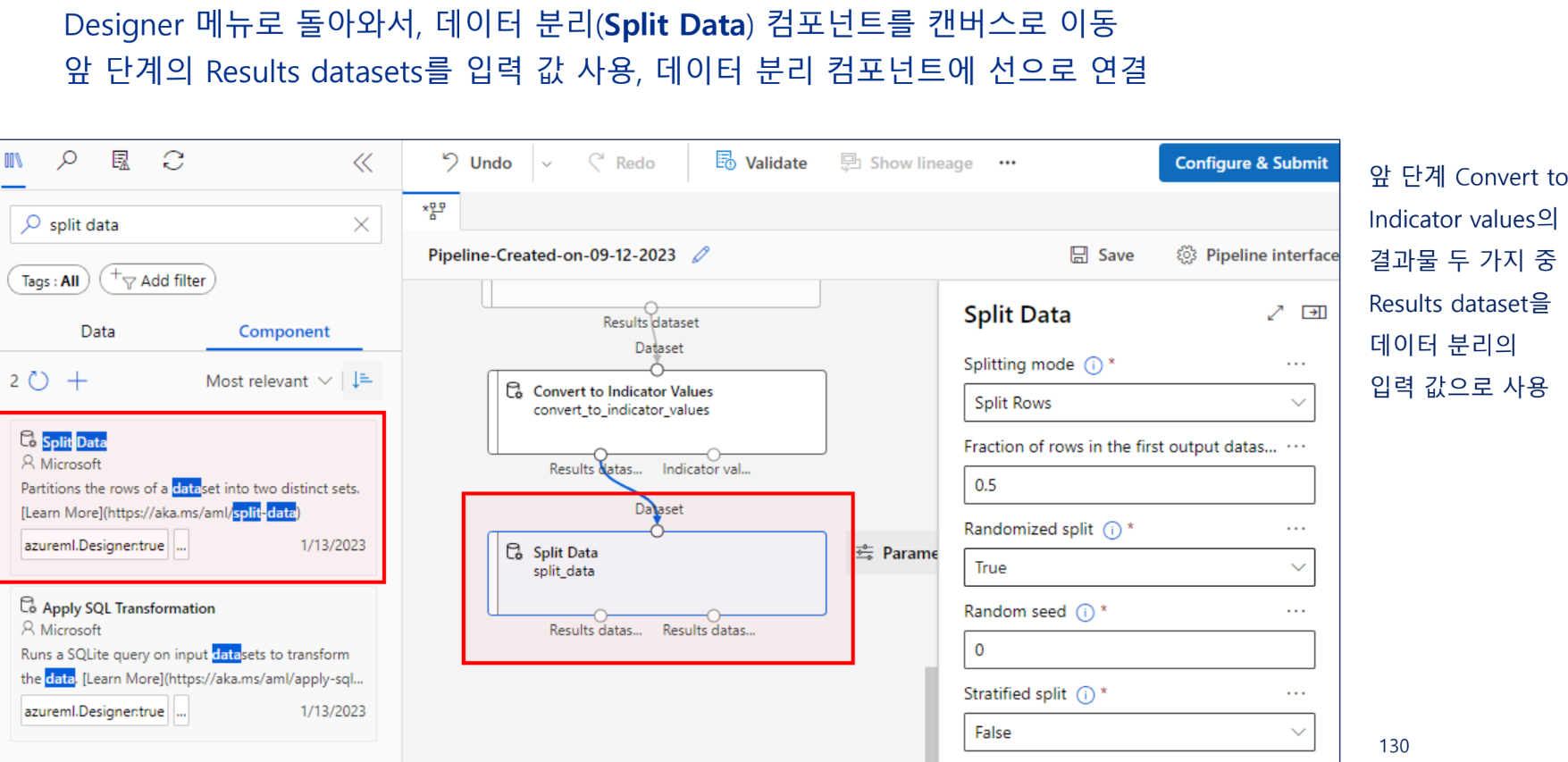
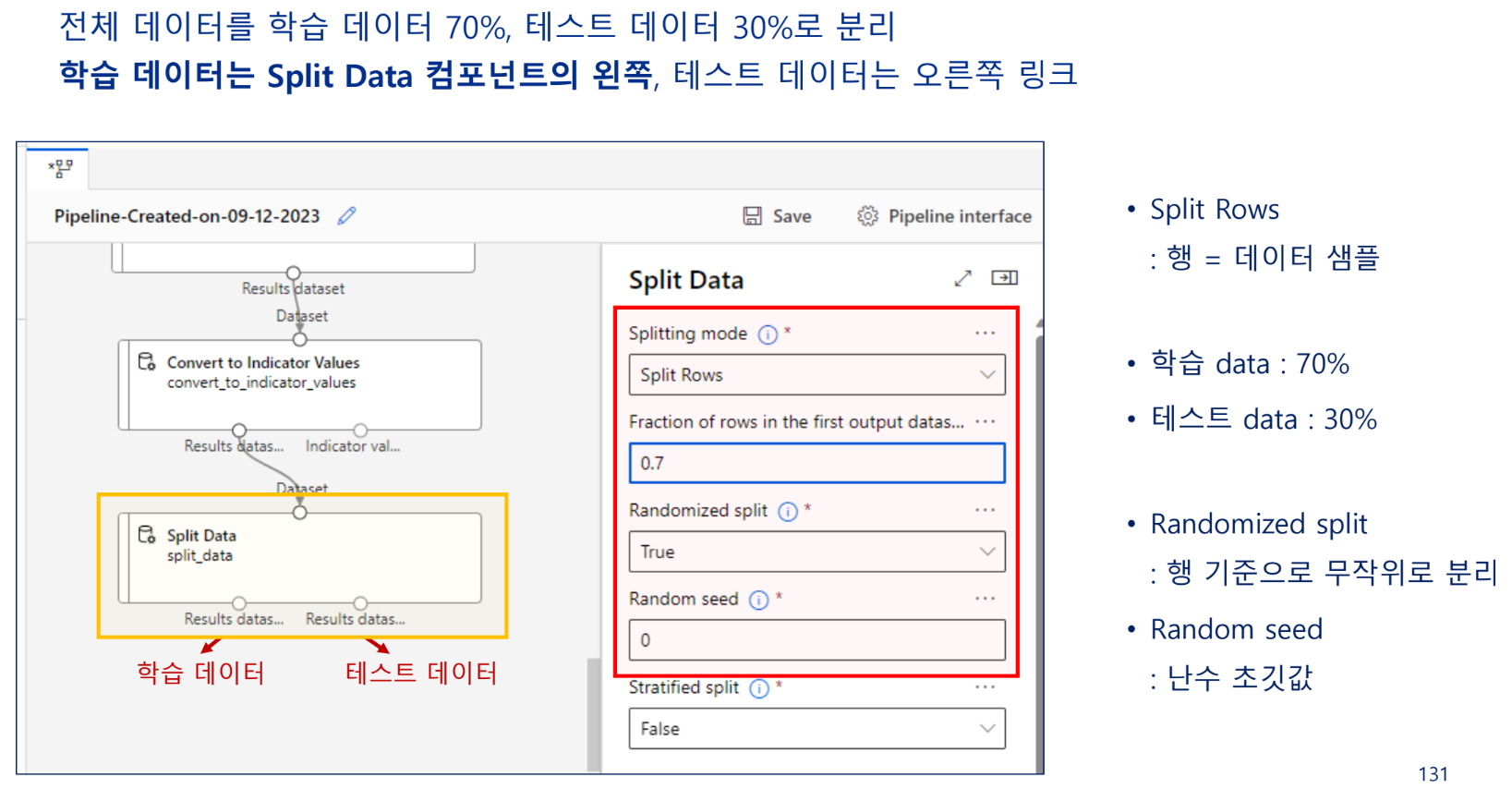
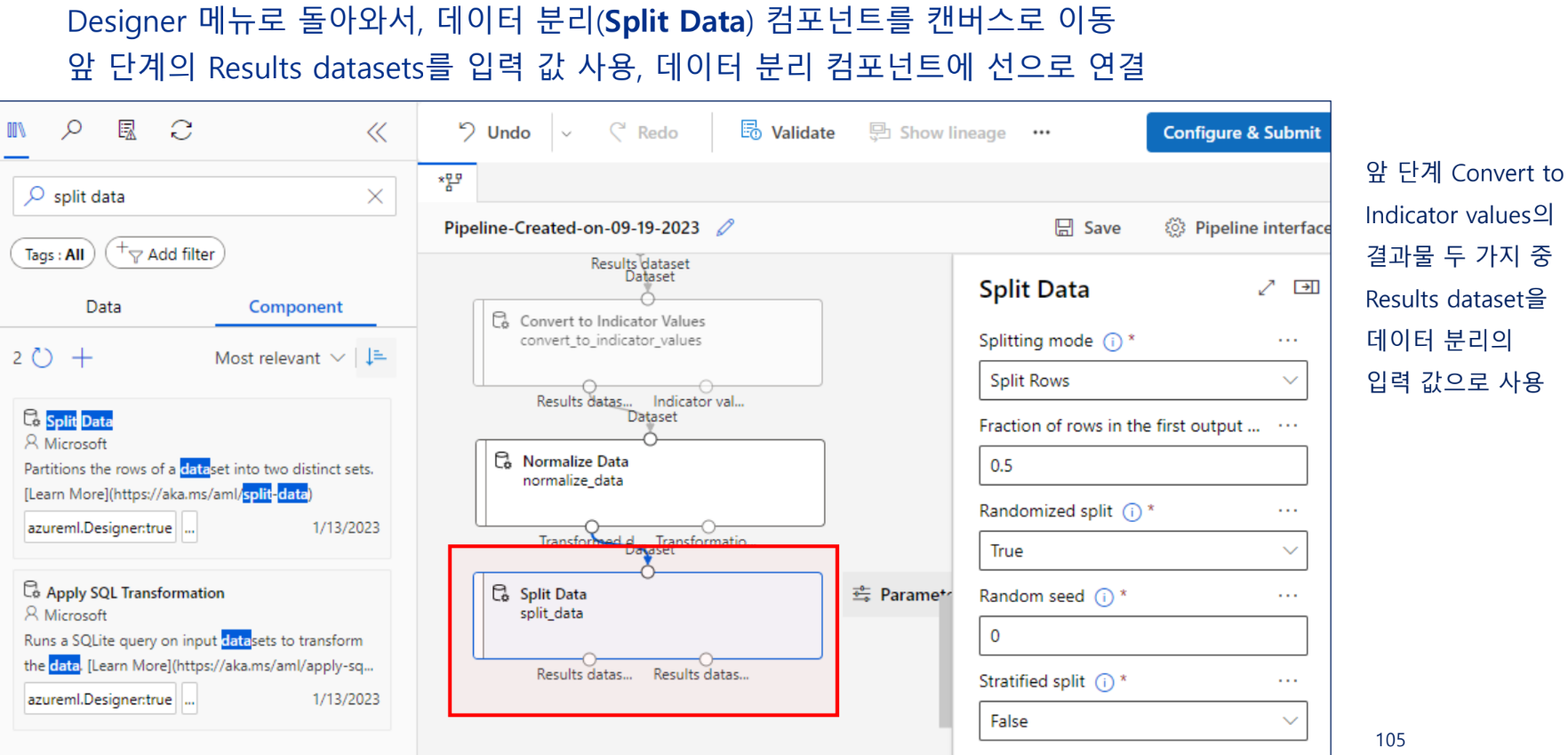
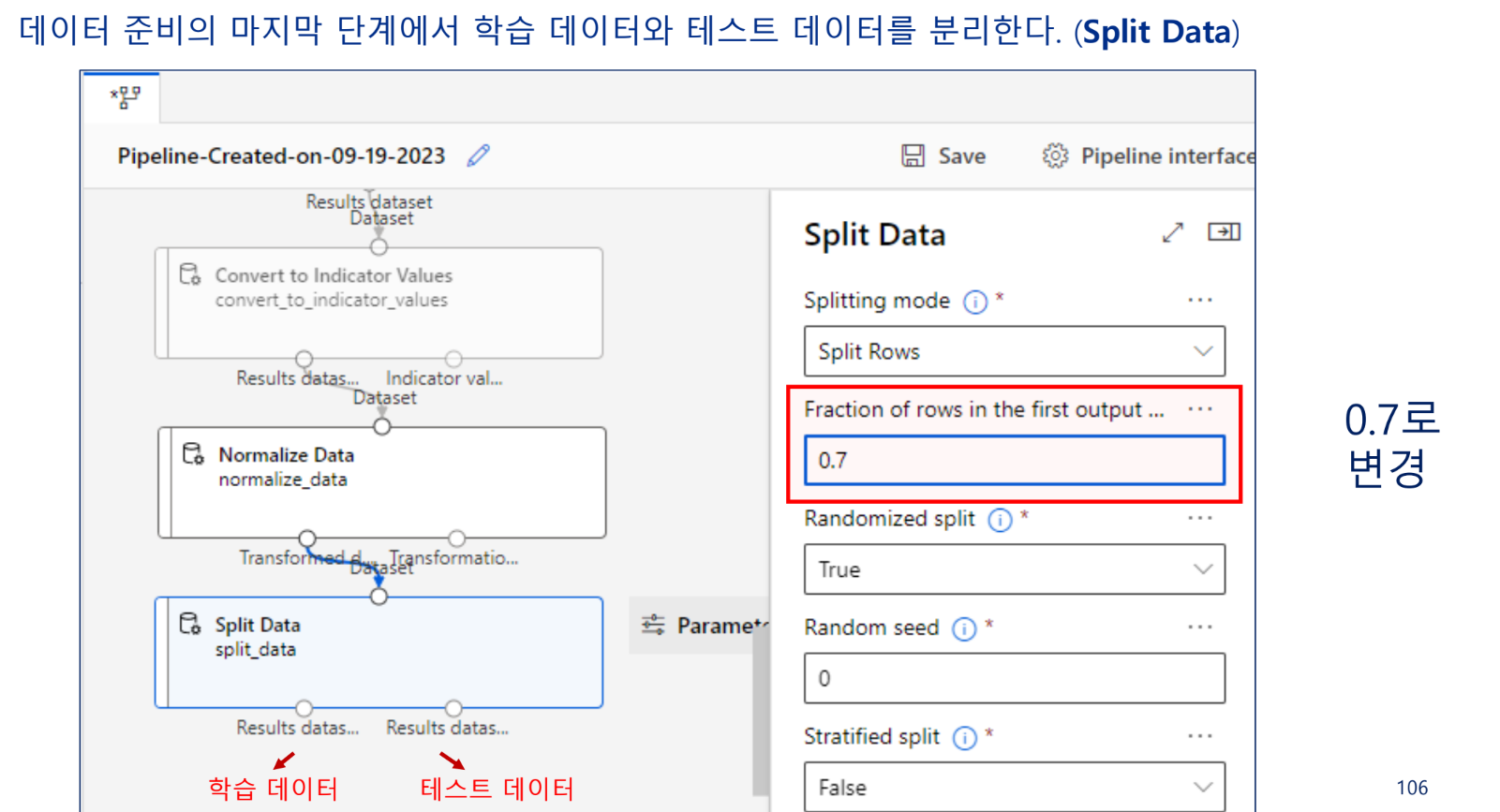
데이터 분리
학습 데이터와 테스트 데이터 분리
모델링 알고리즘 선택
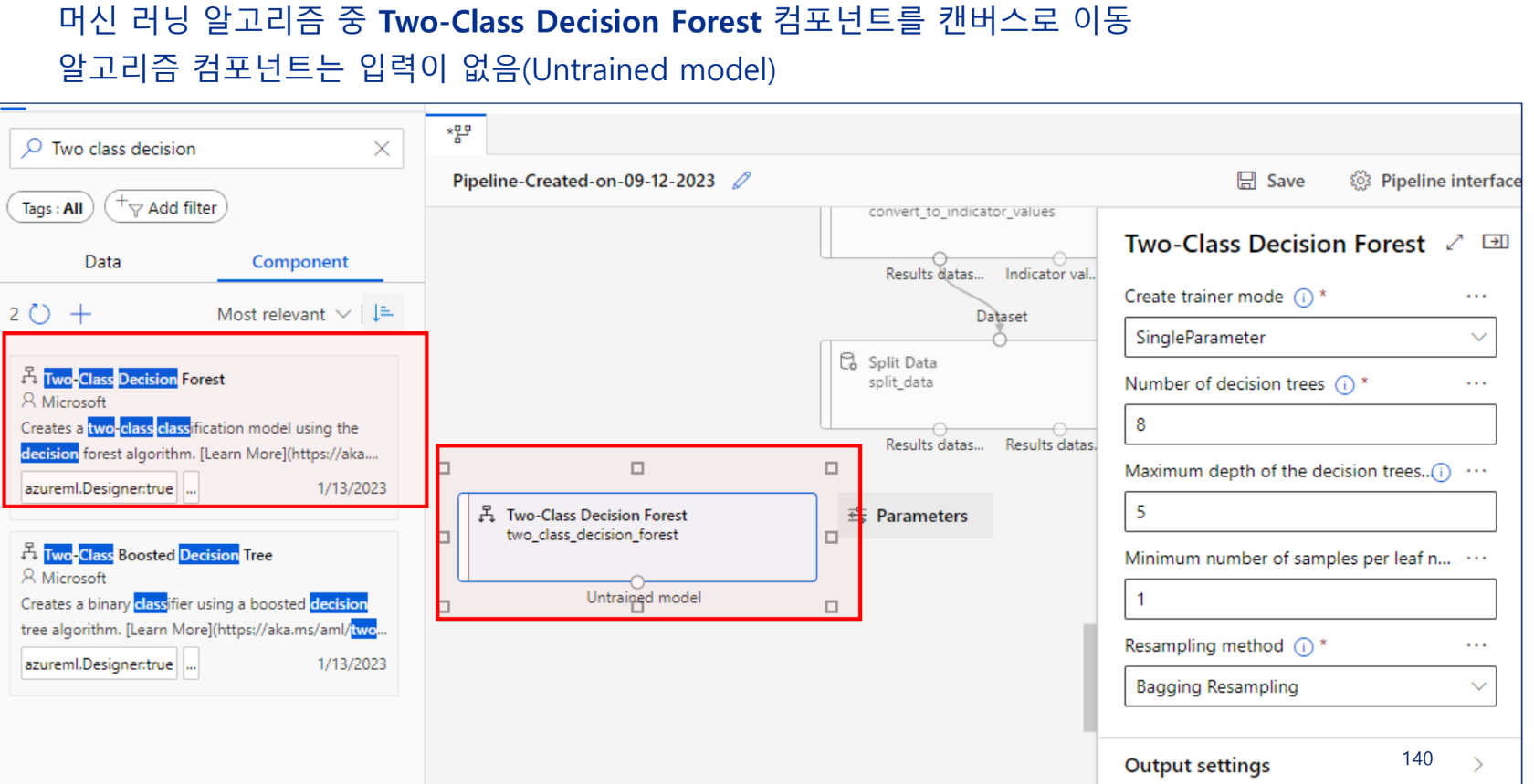
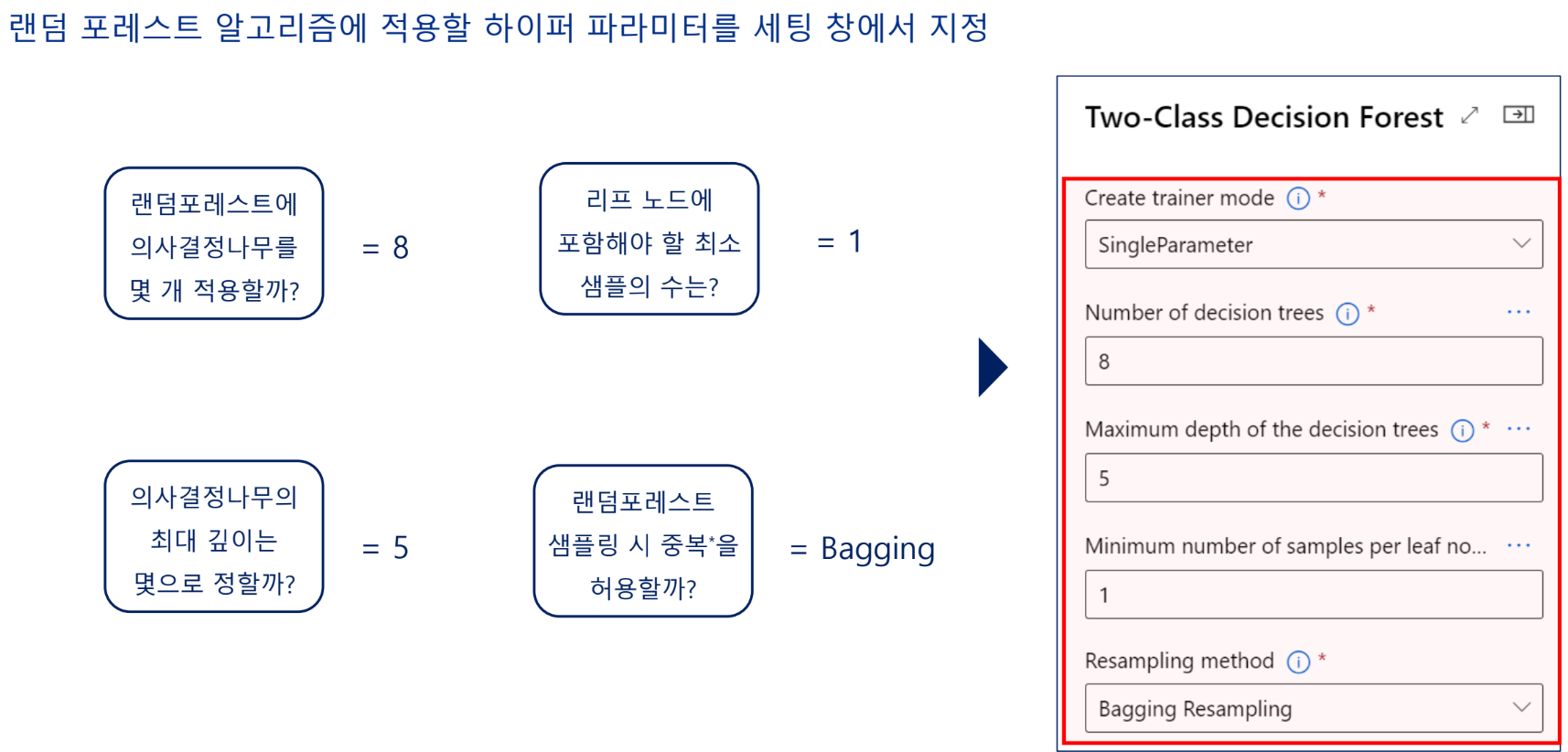
모델 학습(훈련)
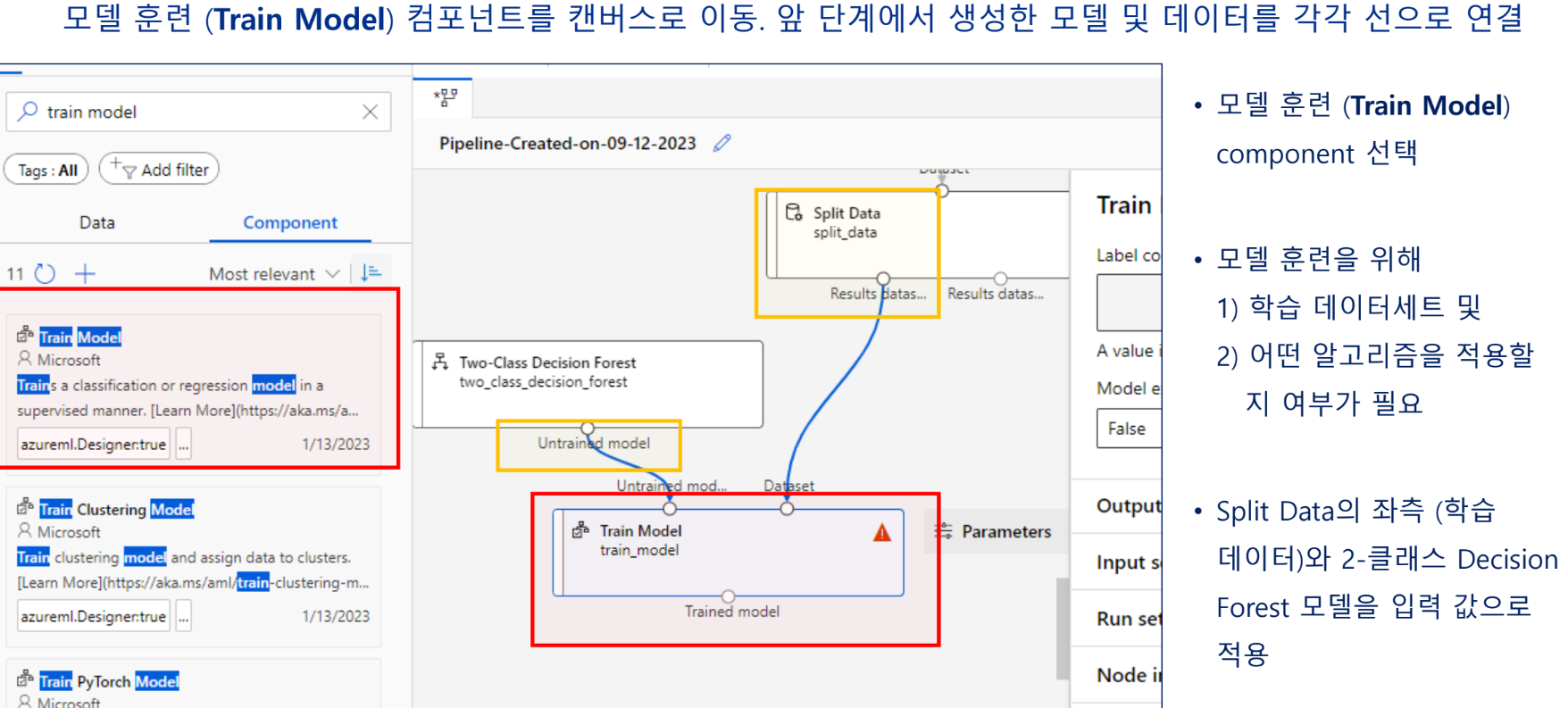
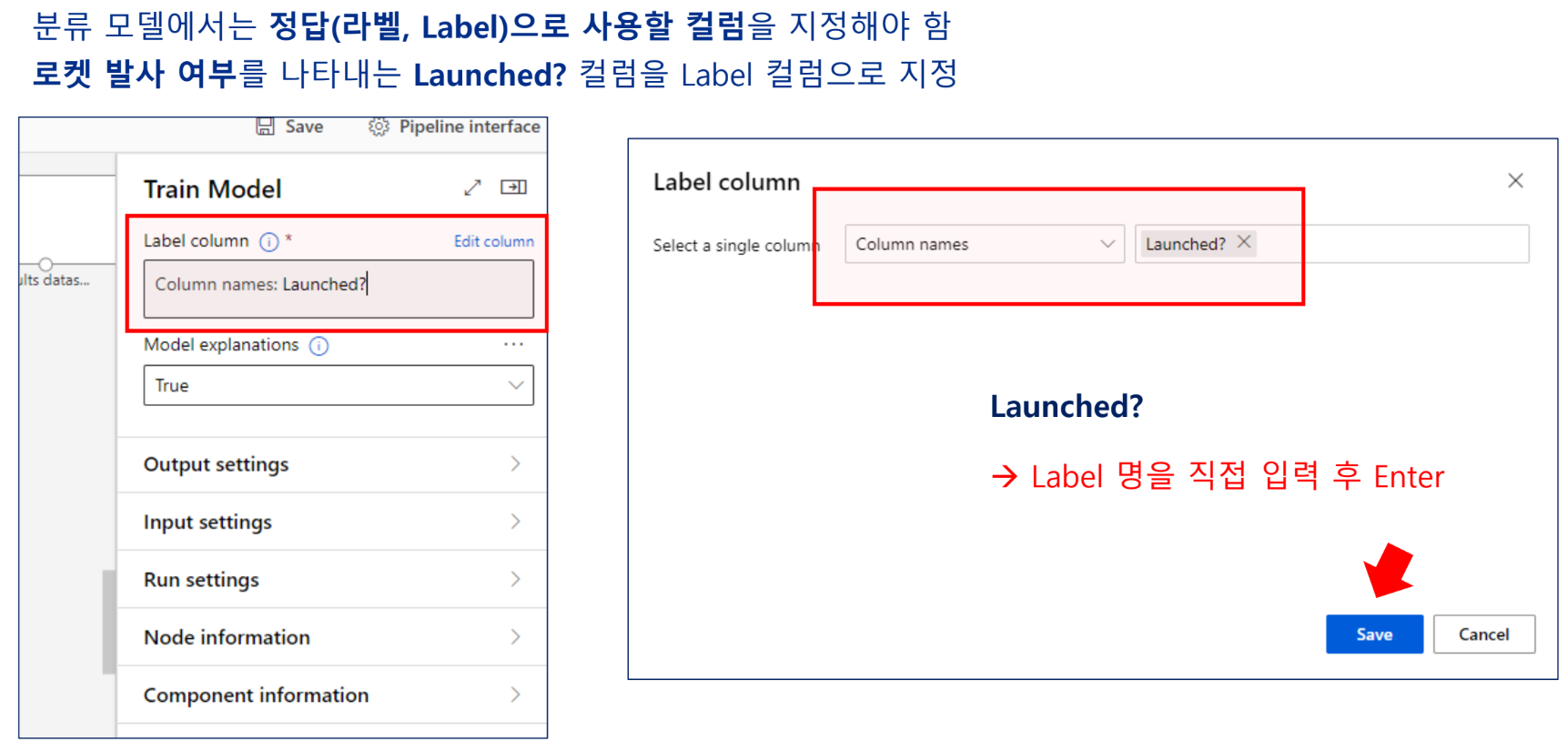
모델 테스트
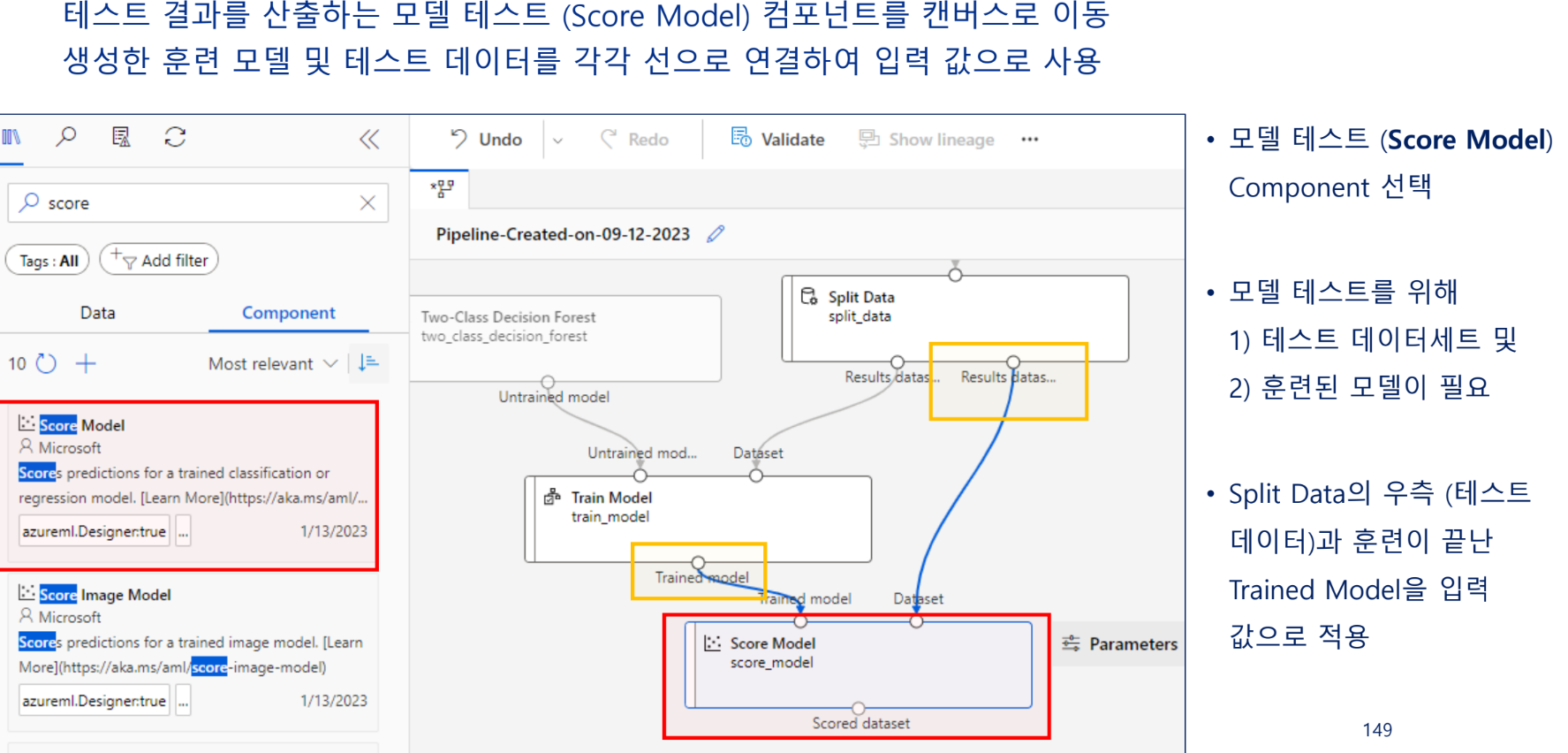
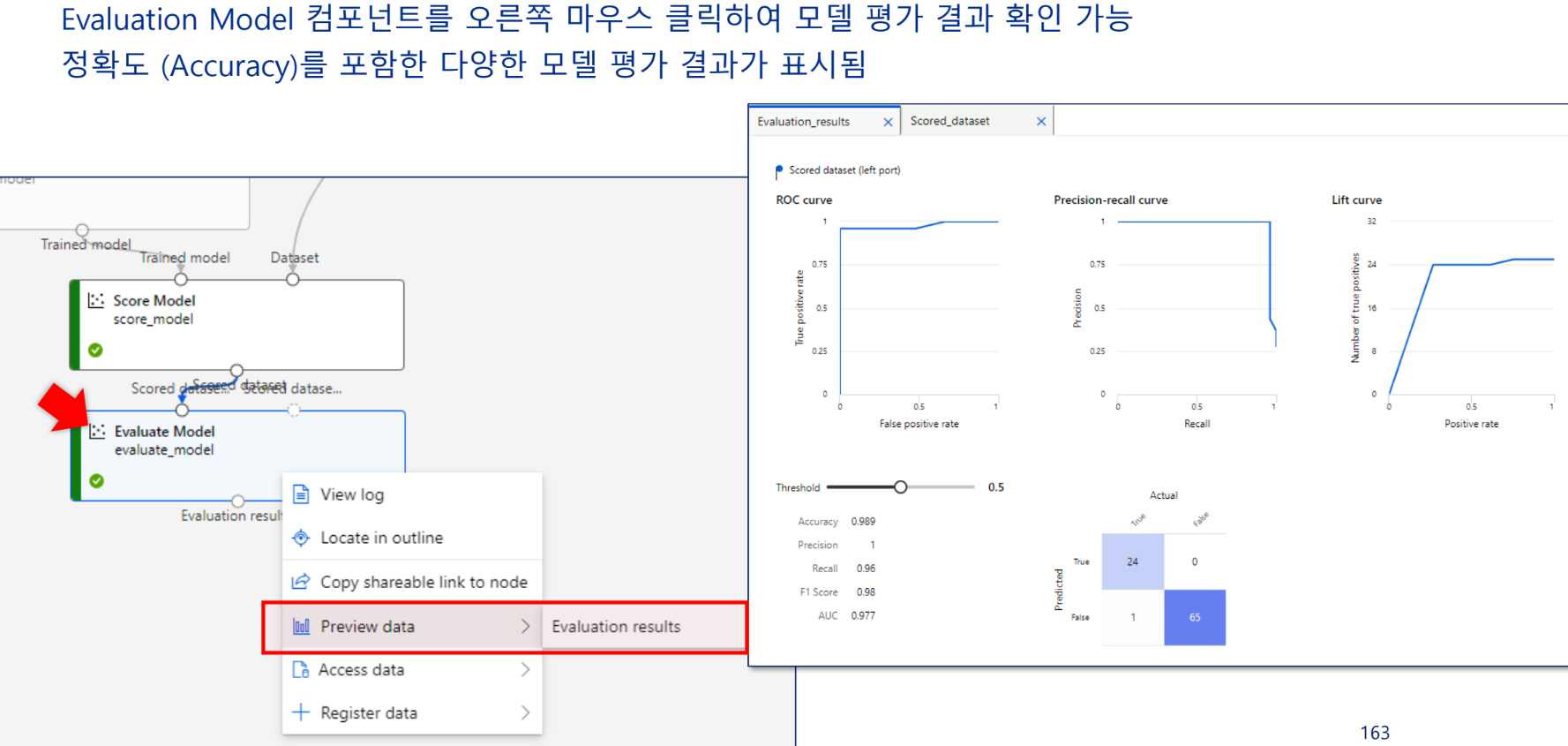
모델링 결과 평가
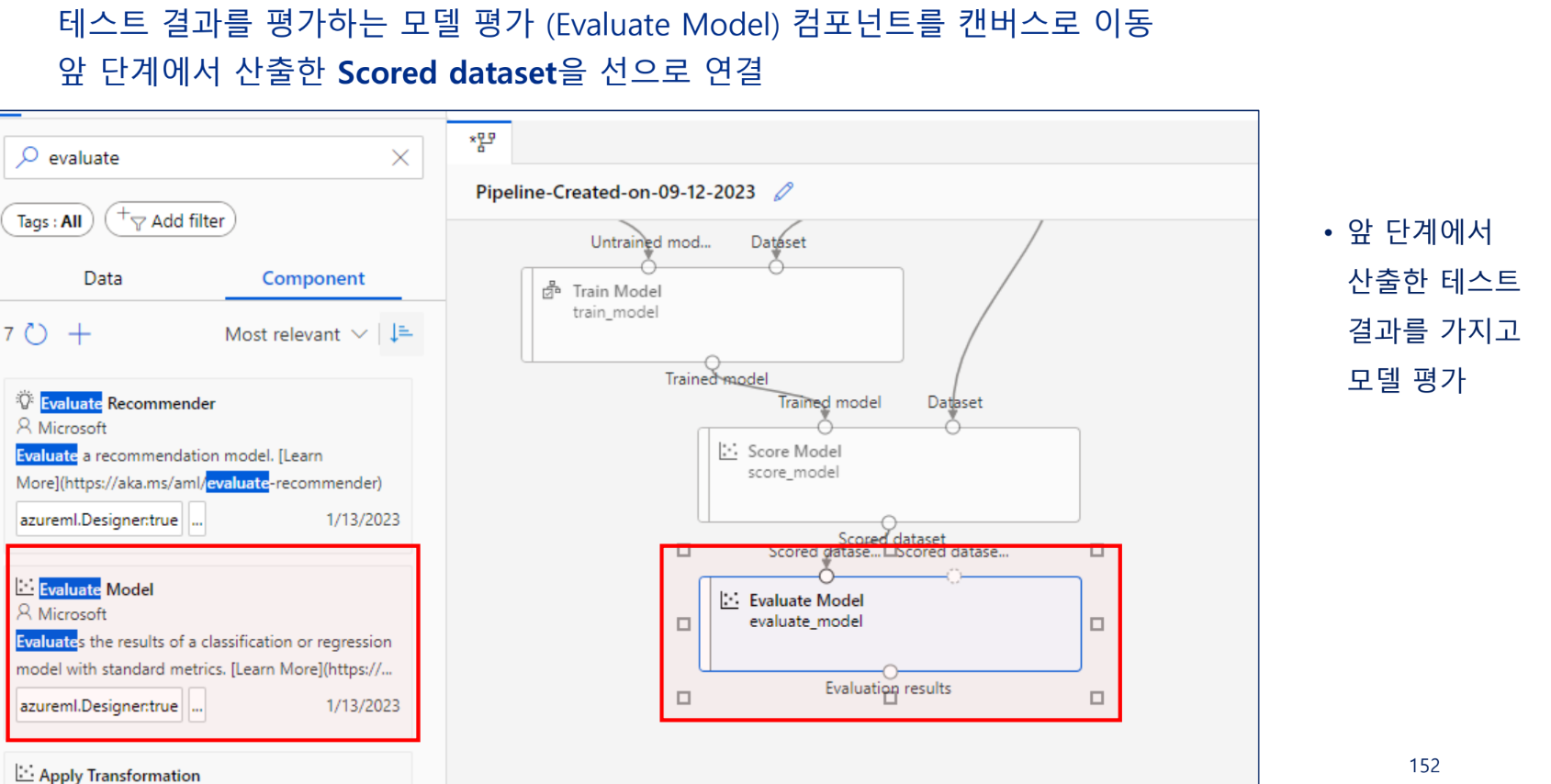
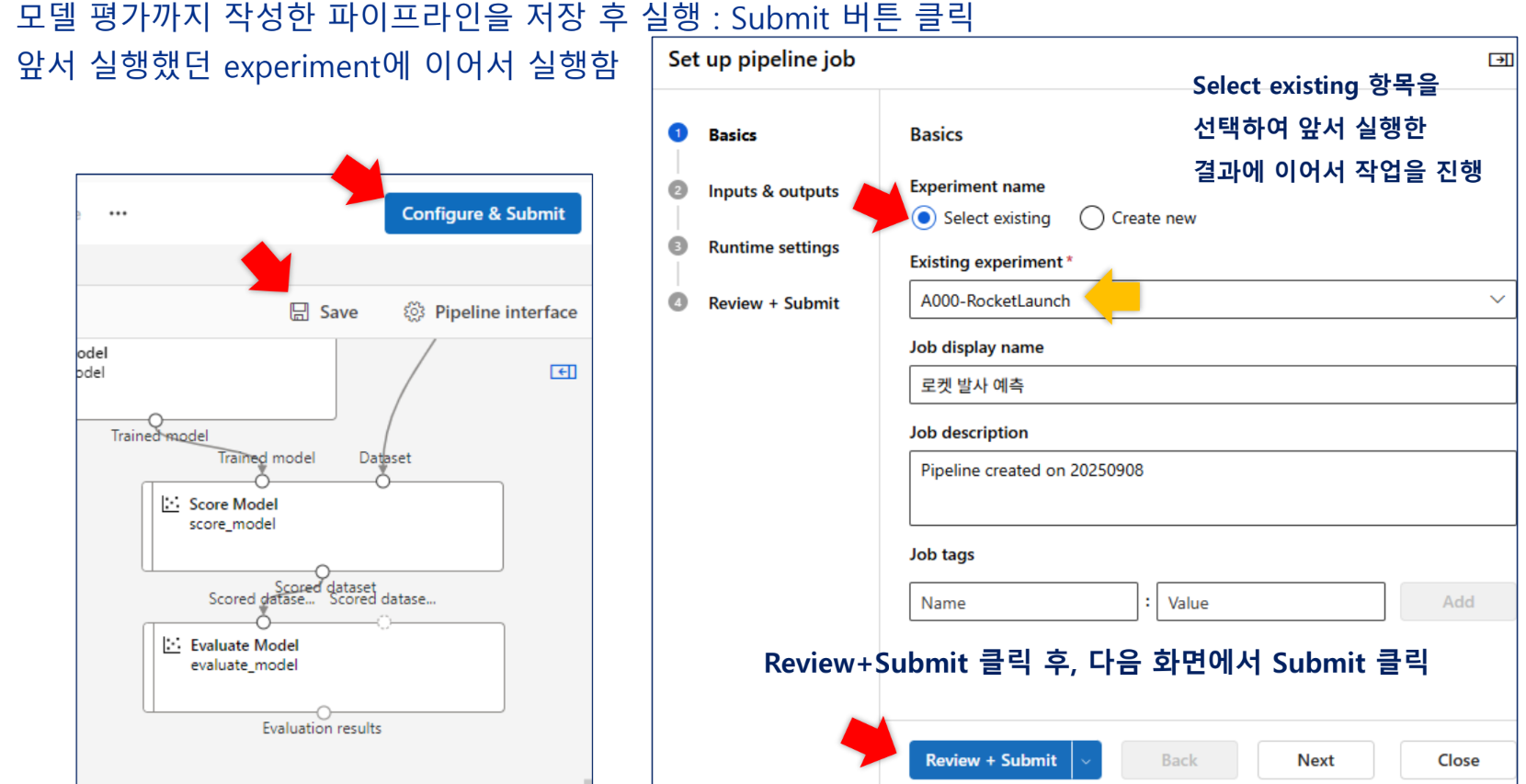
실행 후 결과 확인
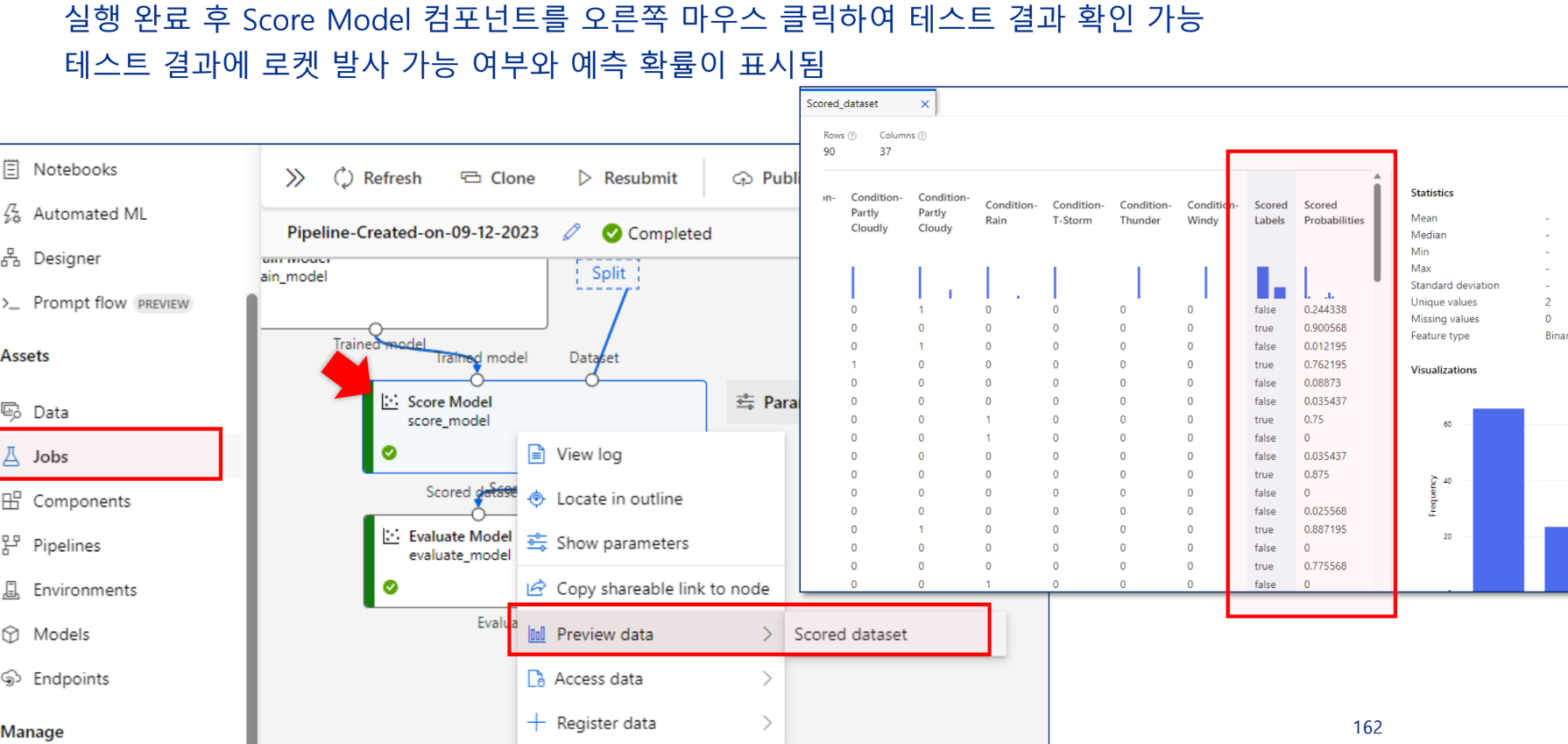
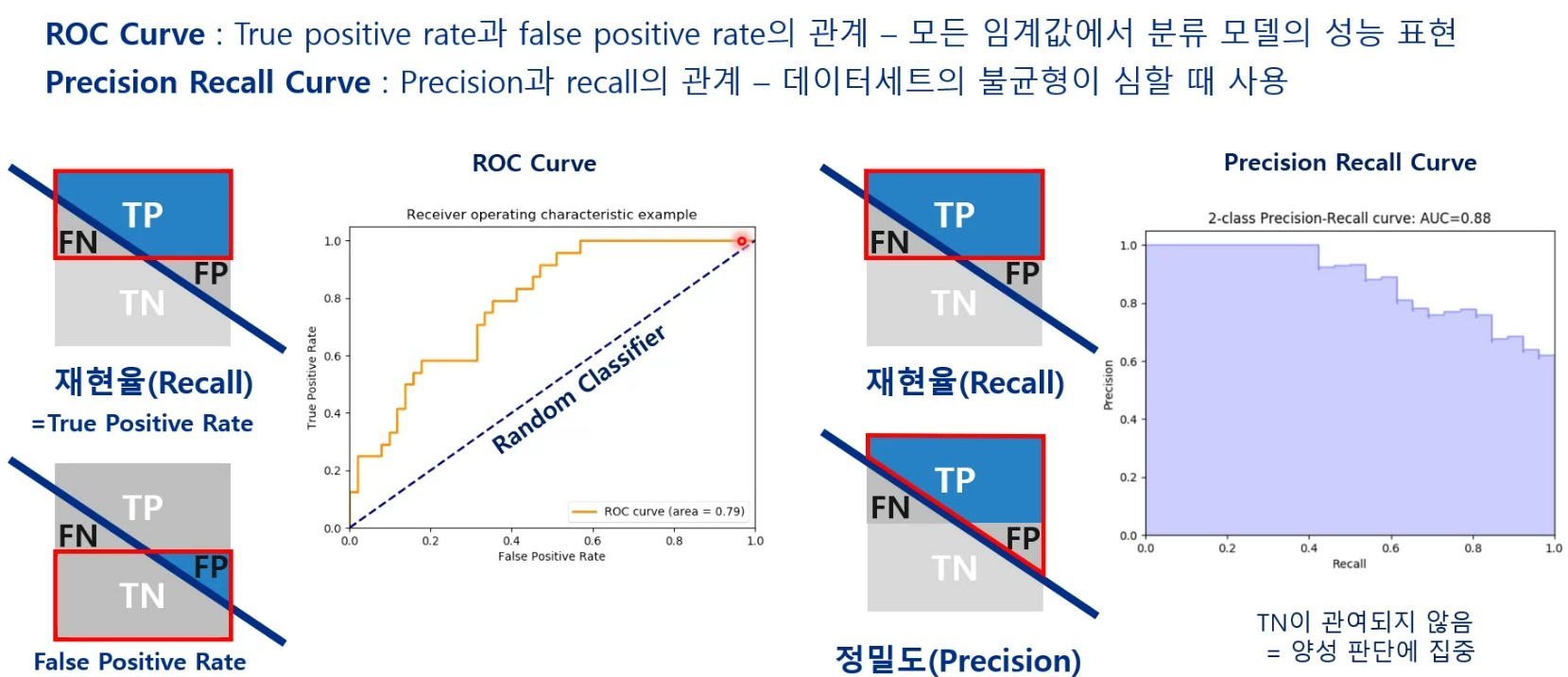
random classifier에 roc curve에 가까울수록 재현율이 높아 좋은것임
데이터셋의 불균형이 심할 떈 precision recall curve가 더 나음
실습 - 회귀 MLD 자전거 렌탈
문제 정의 - 환경 및 상황 분석
날씨, 계절, 휴일/평일이 영향을 줌
모델링 유형
수치, 수량 등 값을 예측하는 회귀: 수치 예측이 적합
날씨, 계절과 휴무일 여부에 따라 자전거 렌탈 수요 변동
↓
자전거 수요량은 특정 조건에서 수치형 데이터를 예상 → 회귀에 해당
↓
회귀에서도 여러 조건을 고려 → 다중 회귀회귀 알고리즘 이해
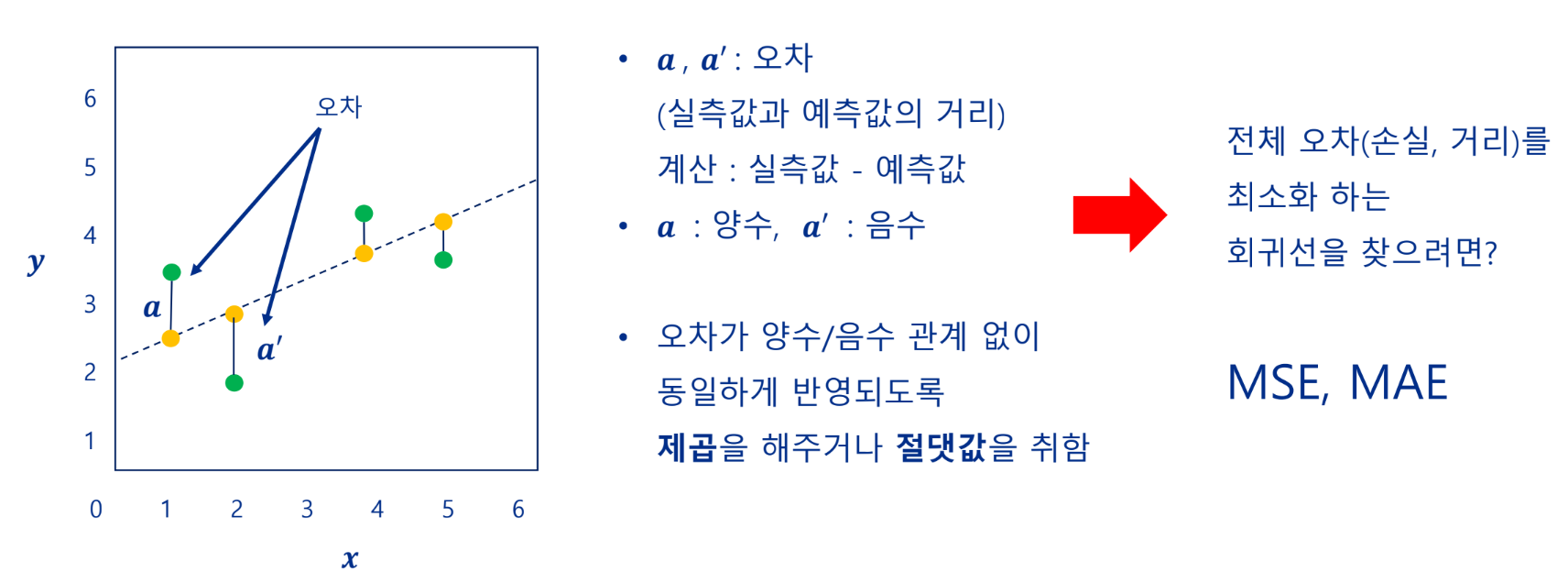
예측한 선으로 오차가 회귀(regression)하도록 만들어진 모델
선형 회귀
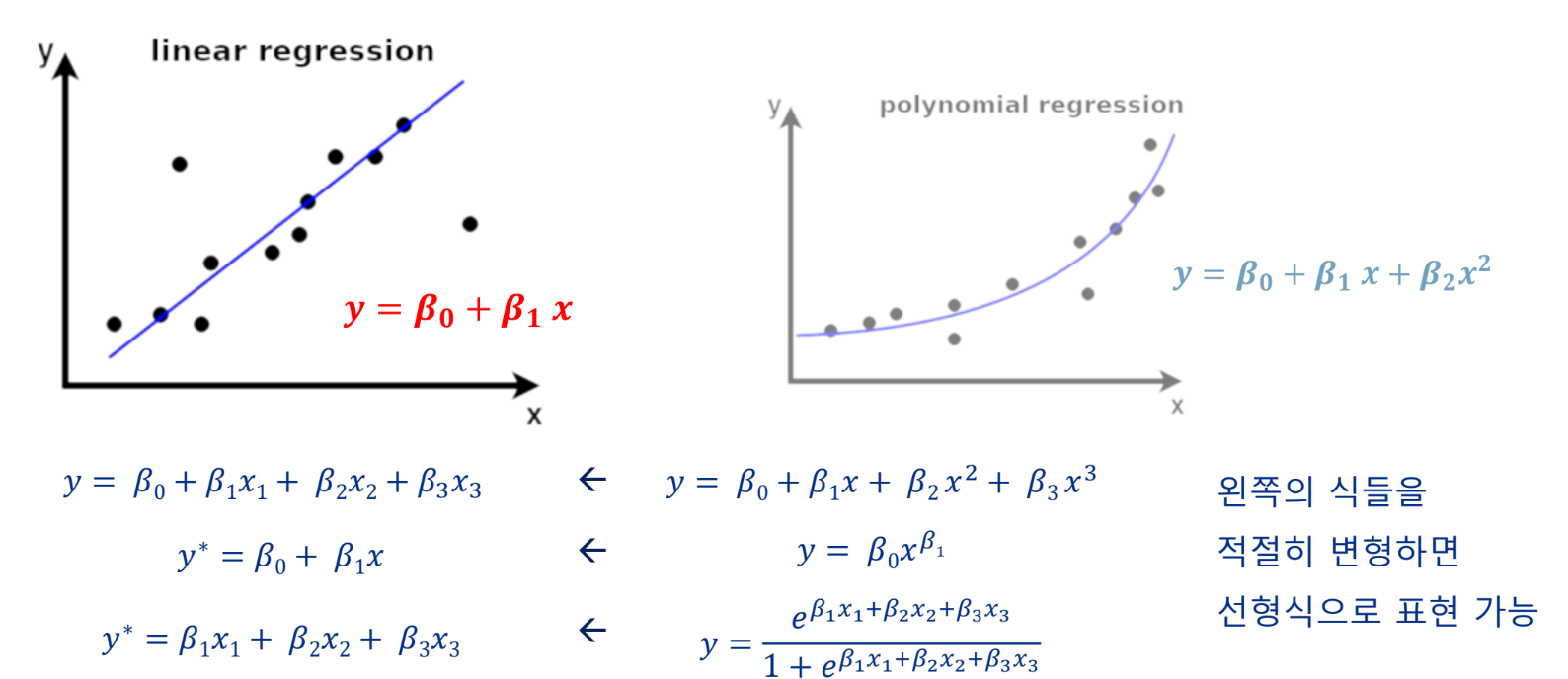
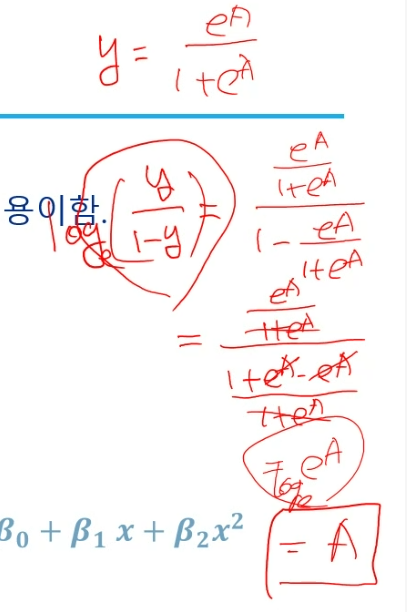
선형으로 바꿀 때 보통 로그를 취한다
선형 모델은 회귀 계수를 선형 결합으로 표현 가능한 모델을 의미
독립변수와 종속변수의 관계를 선형 관계로 모델링
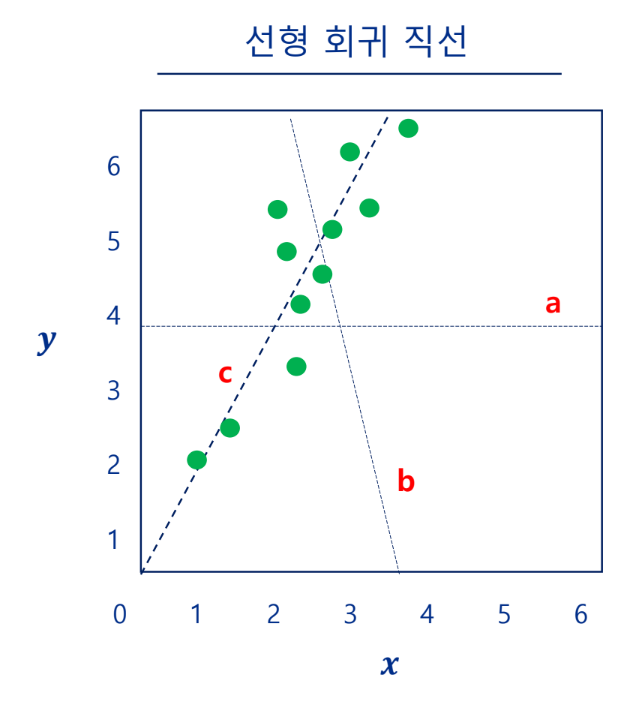
단순 선형 회귀
독립변수 x로부터 종속변수 y를 예측하는 알고리즘
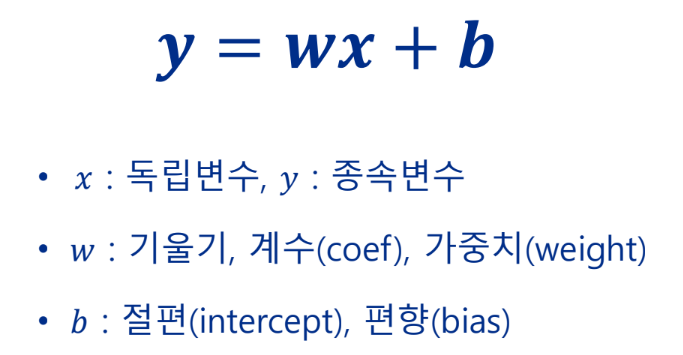
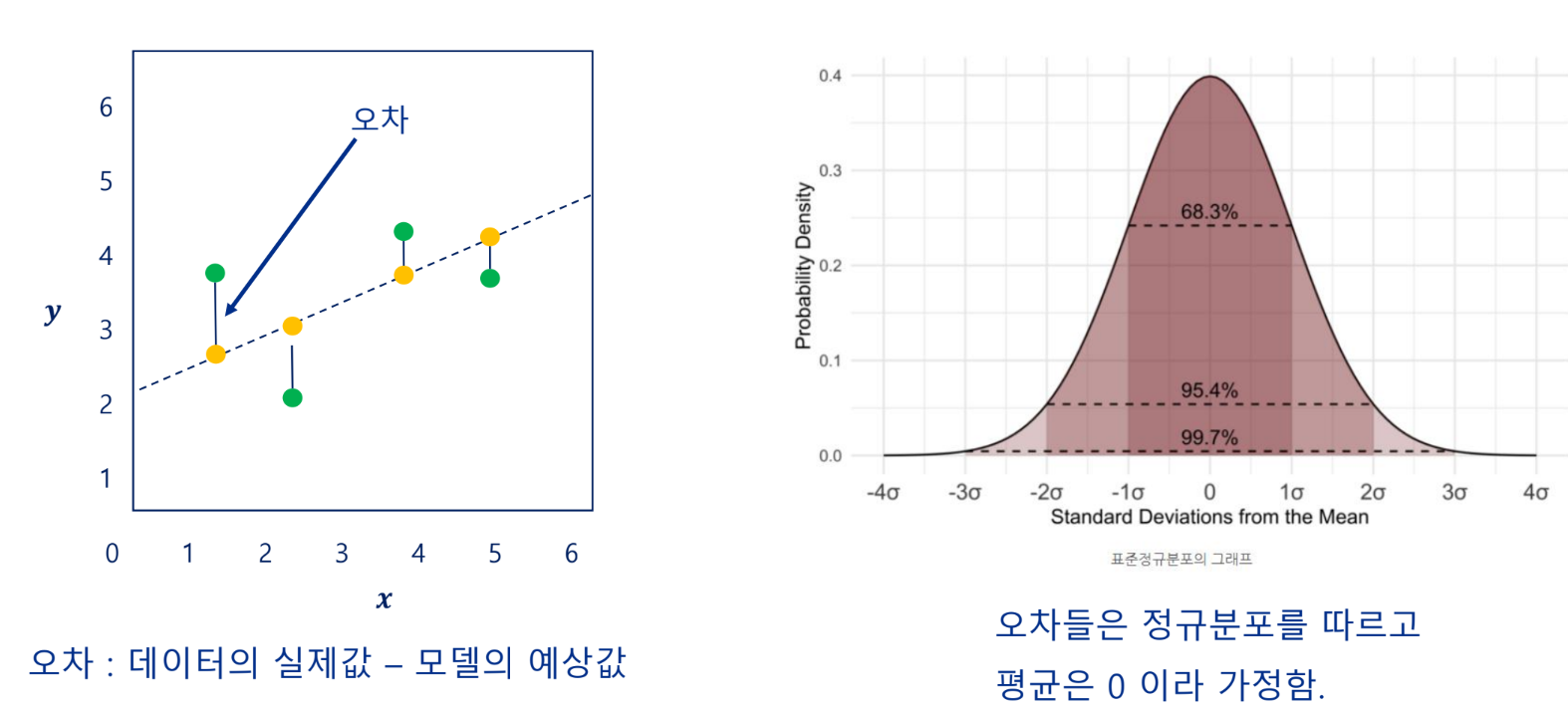
오차
선형 회귀 모델의 목표: 오차를 최소화할 수 있는 기울기와 절편 찾기
실측값과 예측값의 거리
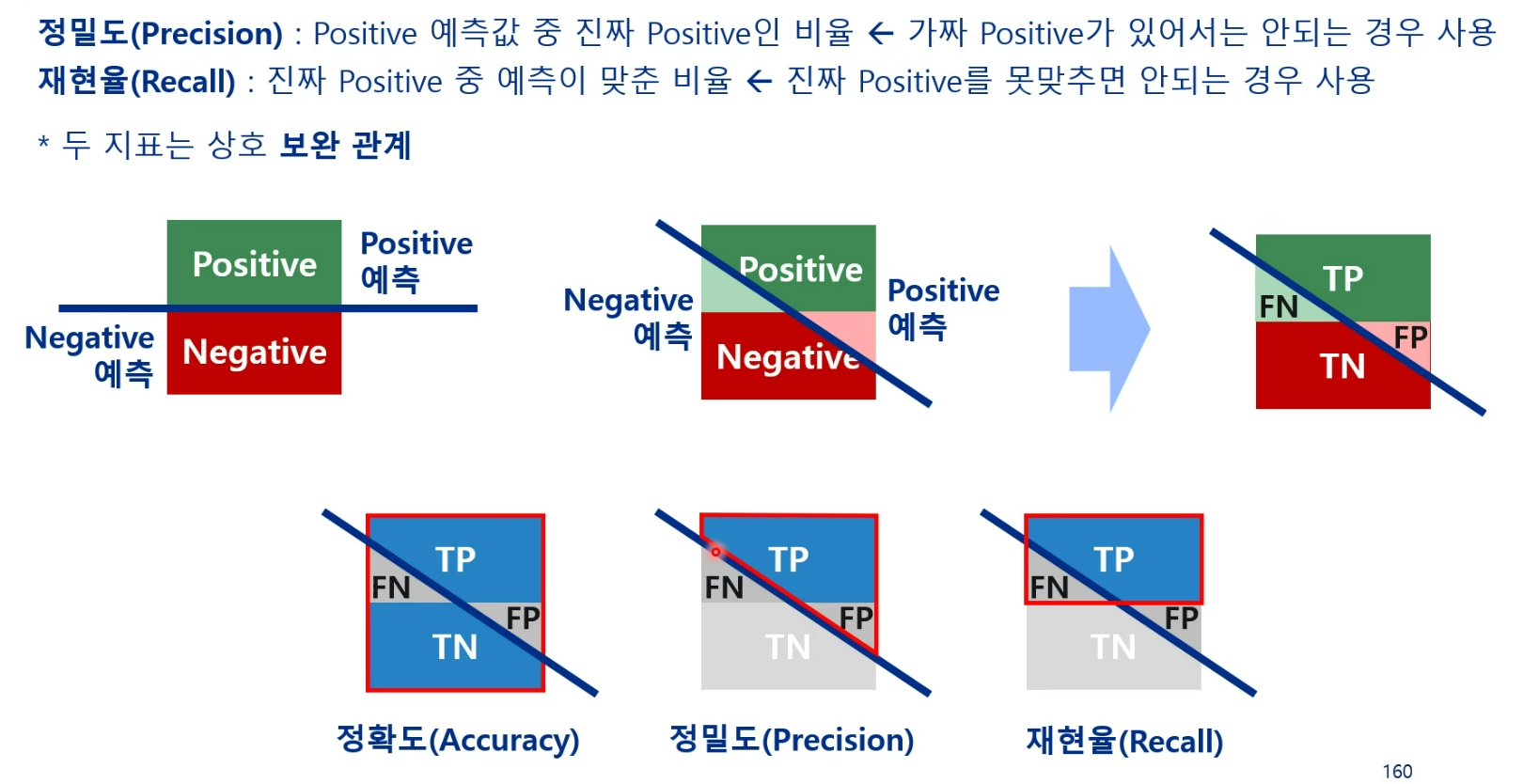
비용함수 - MAE(Mean Absolute Error)
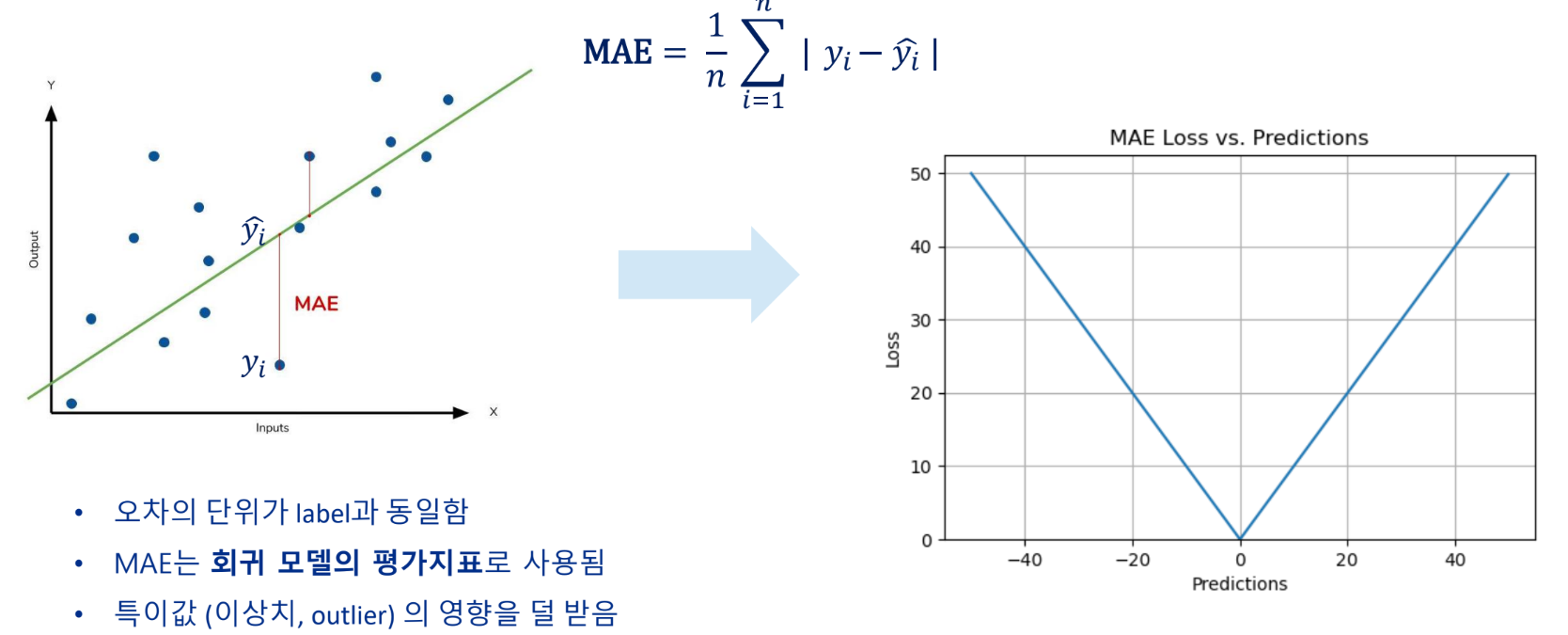
오차의 절대값을 평균한 값(L1 Loss)
MAE 가 0에 가까울수록 예측값이 실측값과 가까움
비용함수 - MSE(Mean Squared Error)
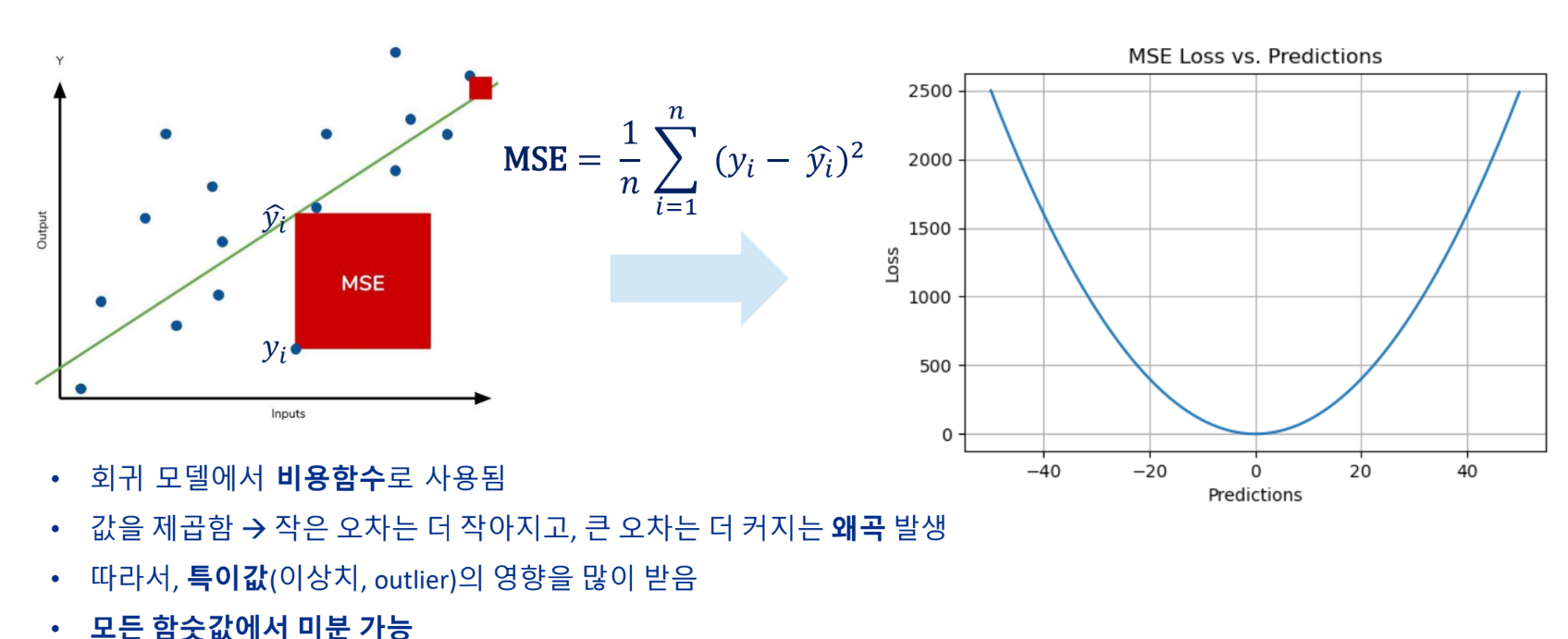
오차의 제곱을 평균한 값(L2 Loss)
MSE가 0에 가까울수록 예측값이 실측값에 가까움. 예측값과 실측값 차이를 한 변으로 하는 정사각형 면적의 평균과 같음
보통 MSE를 주로 사용한다.
다중 선형 회귀
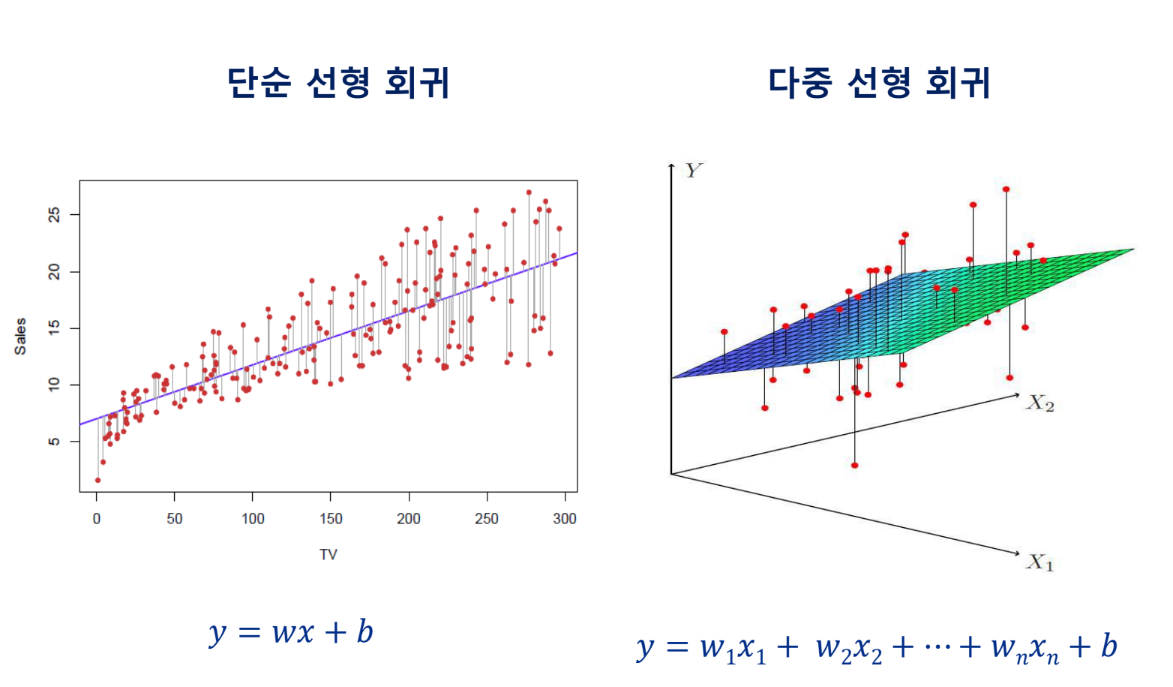
하나의 결과를 여러 원인으로 설명할 수 있음
독립변수 중 종속변수를 설명하는데 필요한 변수만 모델에 포함시켜야 함
1) 전진선택법(forward Selection)
독립 변수를 하나씩 추가하면서 모델을 만들고 결과 확인
빠름. 다만 처음 선택한 변수들이 영향이 크지 않은 변수일 가능성 있음
2) 후진제거법(backward Elimination)
데이터에 있는 모든 독립 변수를 사용해 모델을 만들고 하나씩 제거한 후 결과 확인
데이터 수집/이해
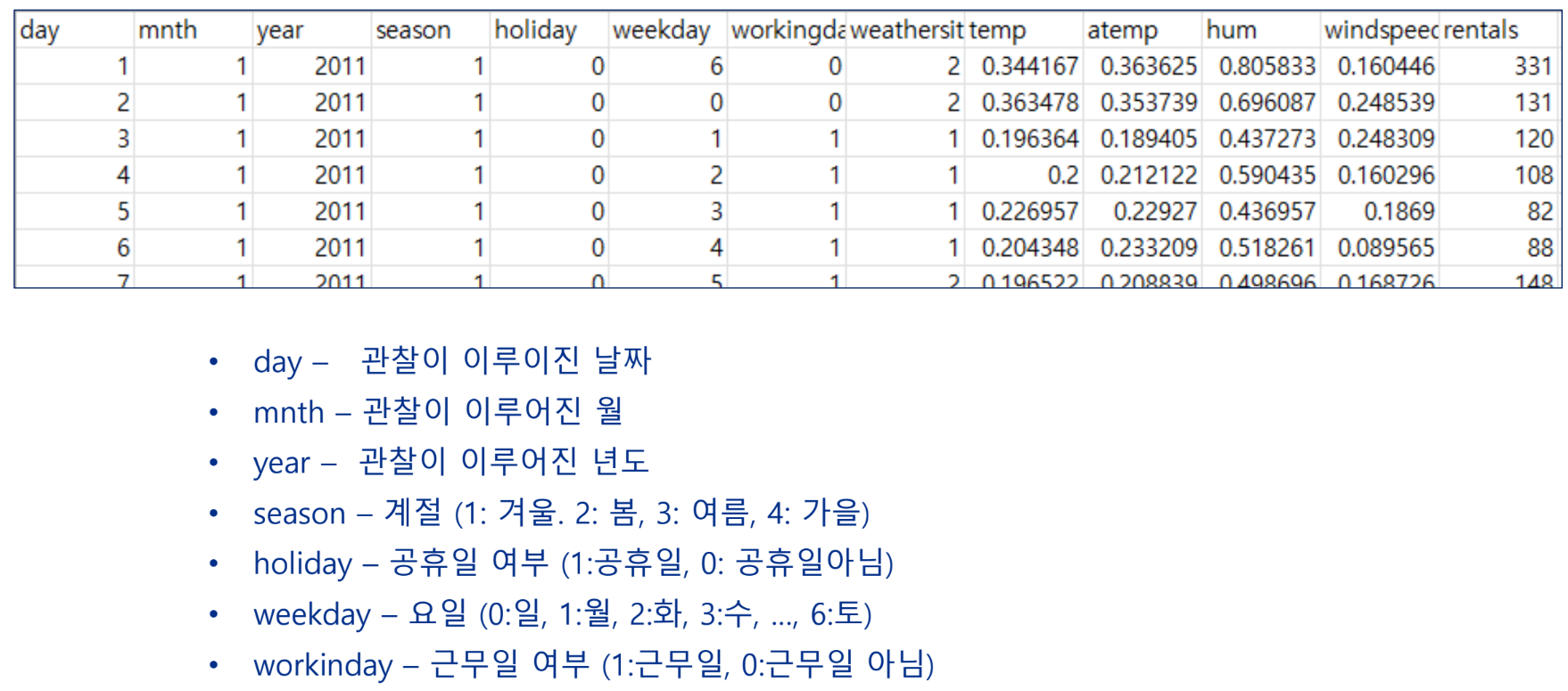
자전거 렌탈 데이터 수집
UCI에서 제공하는 데이터에 기반하여 자전거 렌탈 수요 예측을 위한 모델 구현

데이터 준비
데이터 세트 등록
Compute Cluster 생성
머신러닝 디자이너 - 파이프라인 생성
데이터세트
파이썬 스크립트 처리
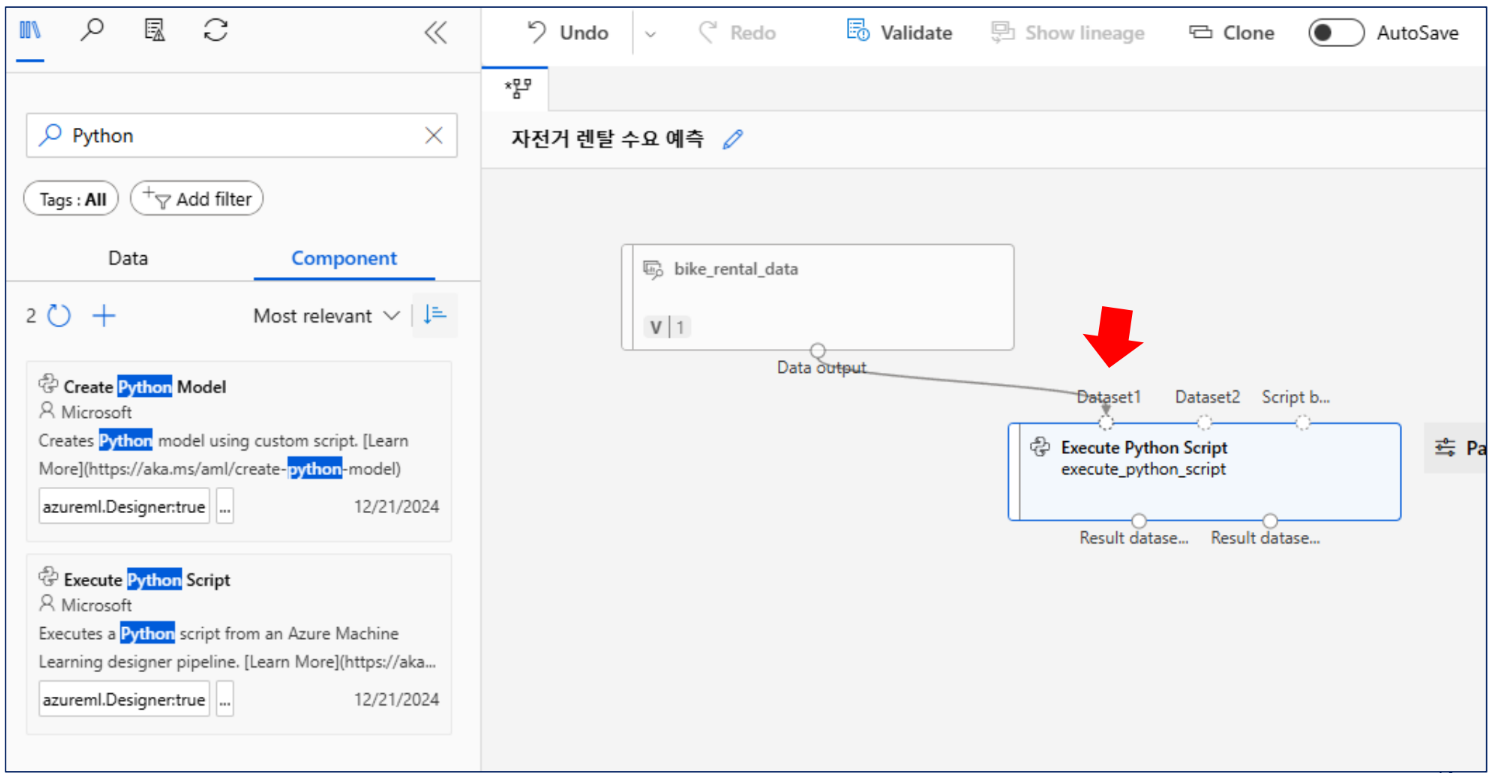
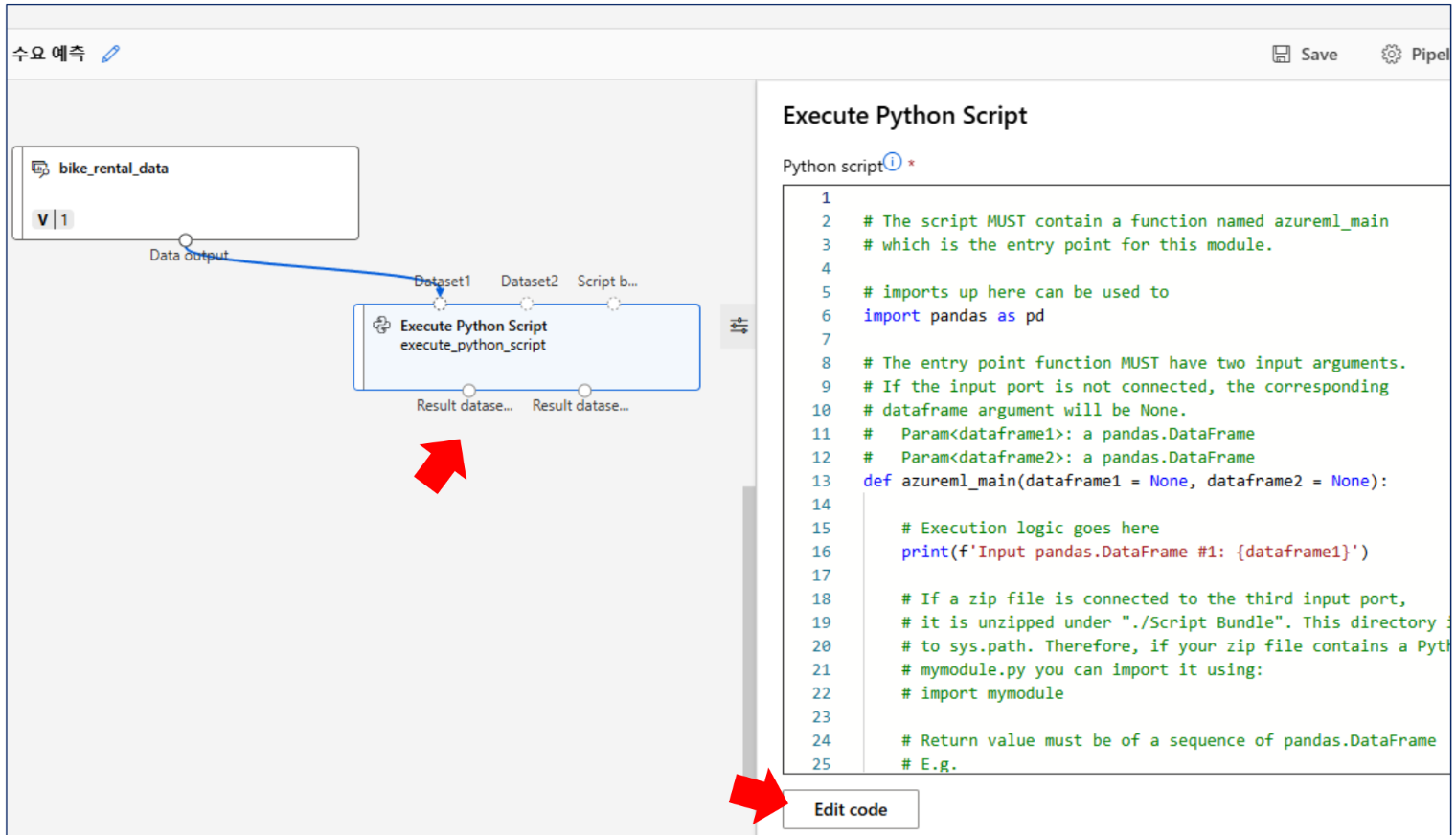
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from azureml.core import Run
def azureml_main(dataframe1 = None, dataframe2 = None):
plt.figure(figsize=(10,8))
corr_matrix = dataframe1.corr()
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap="coolwarm")
plt.title("Heatmap")
img_file = "heatmap.png"
plt.savefig(img_file)
plt.close()
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
return dataframe1,검토 및 실행
Cluster node 확장에 시간이 소요됨
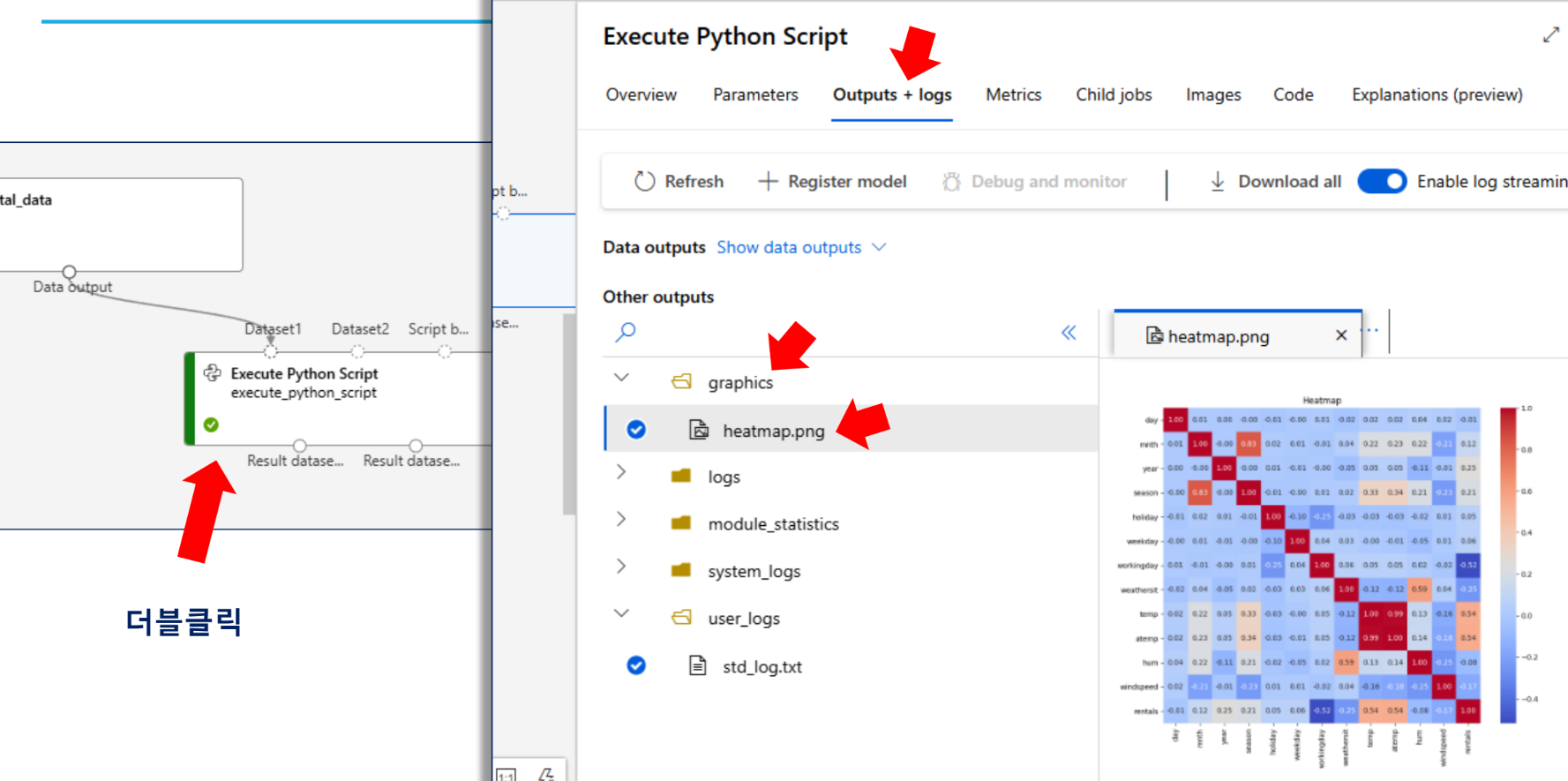
atemp와 temp끼리 상관관계가 높음 -> 원래는 둘 중 하나 빼줘야 함
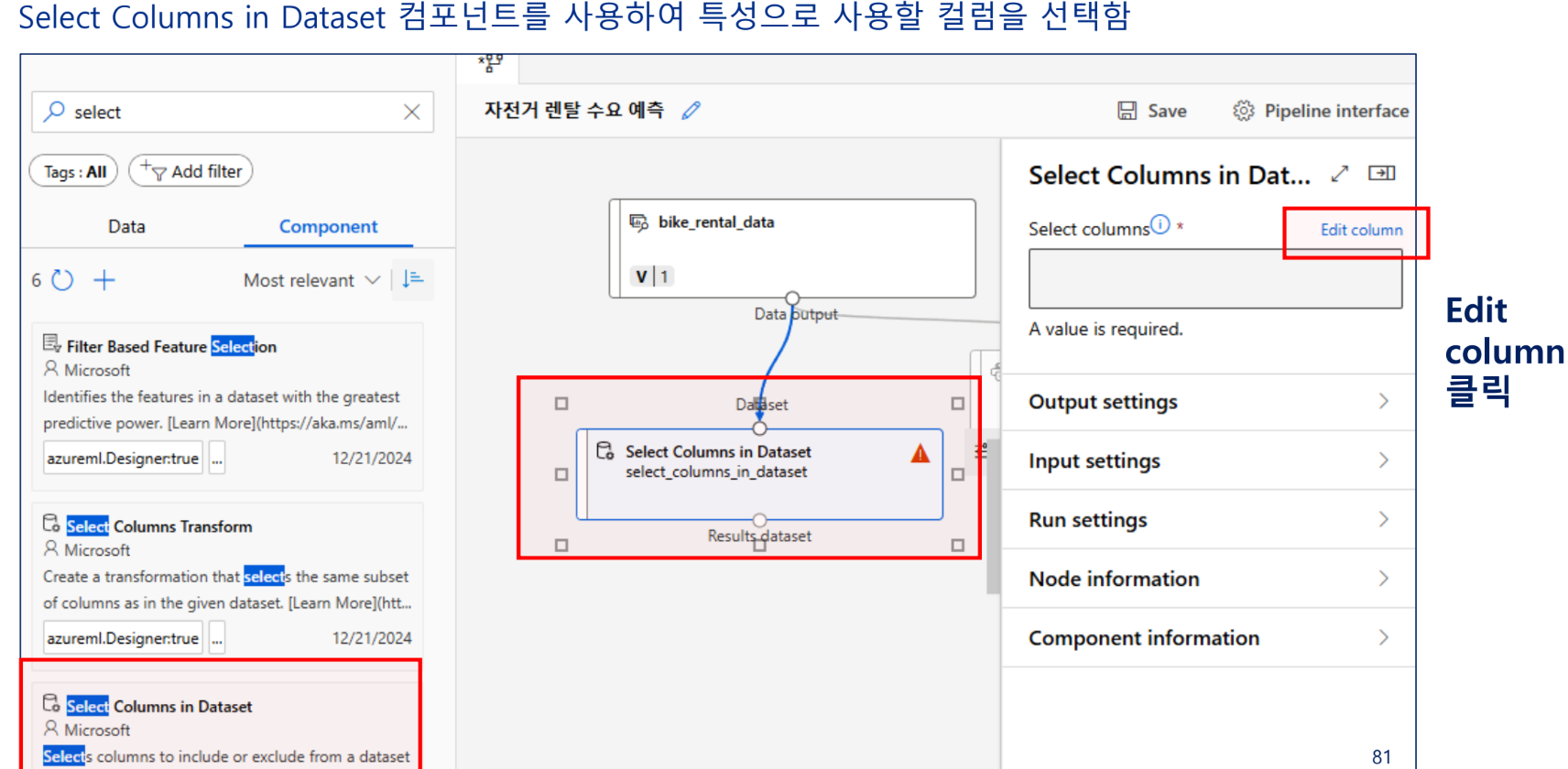
특성 선택
특성으로 사용할 열 선택
누락값 처리
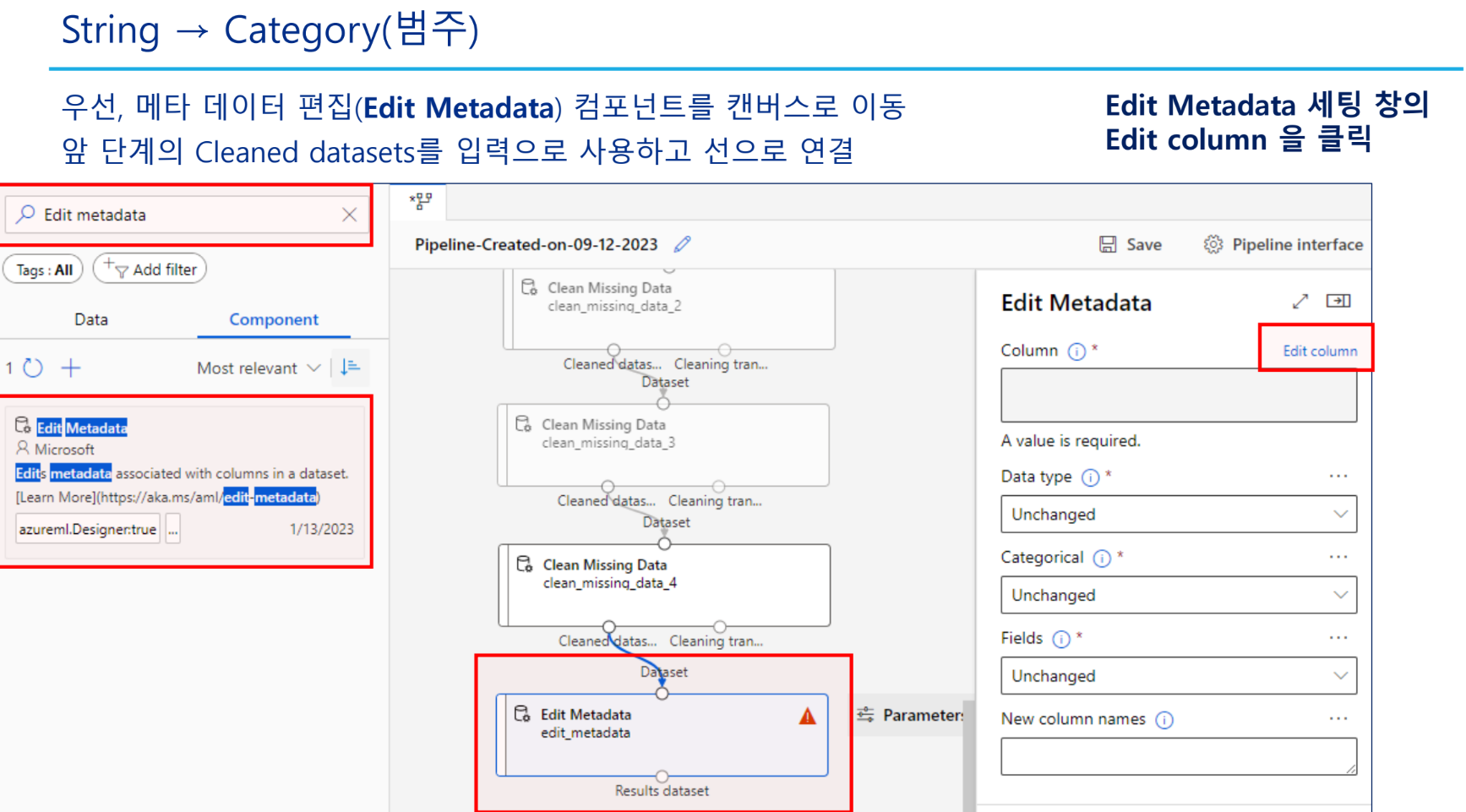
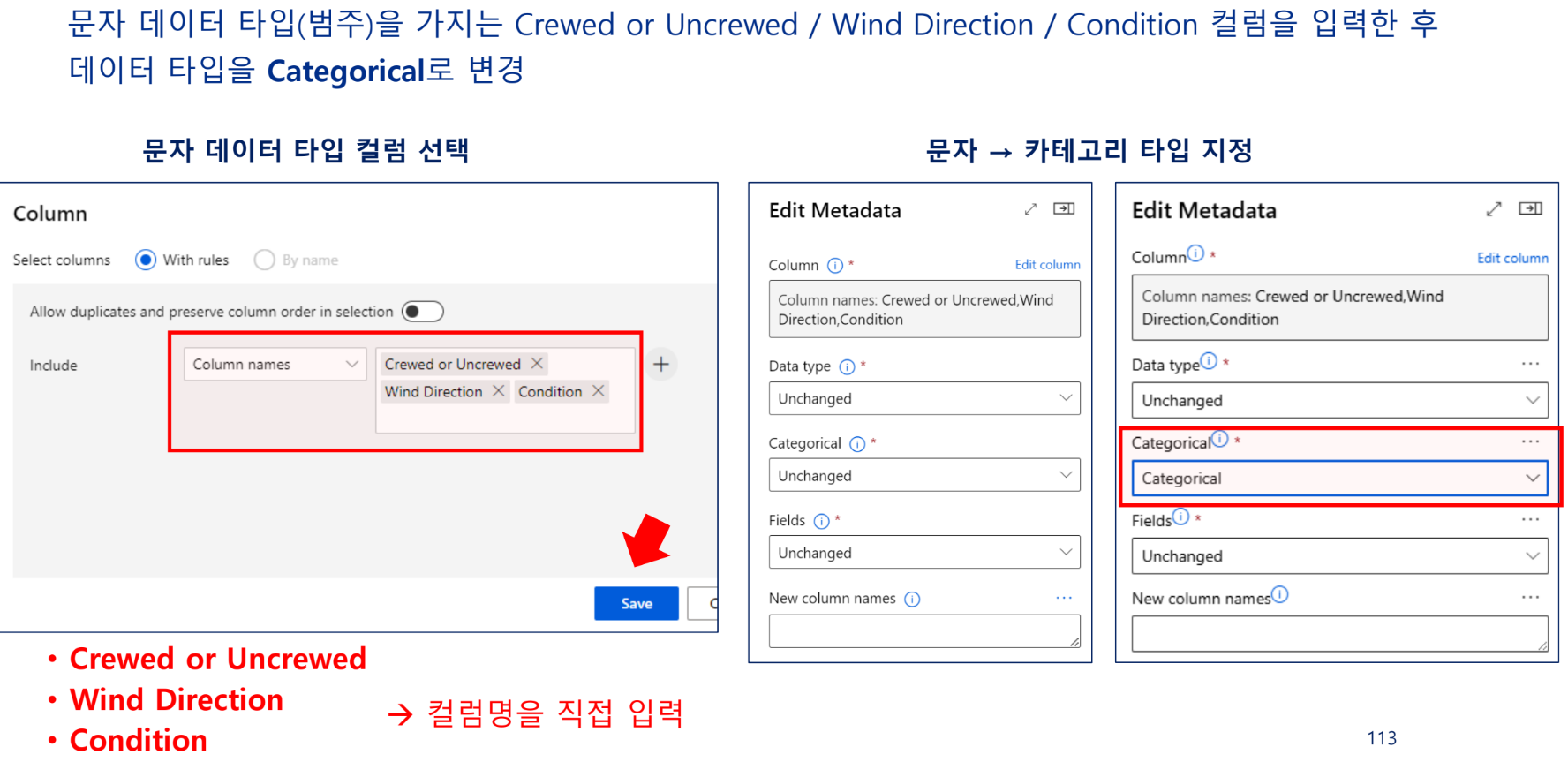
범주형 데이터 변환
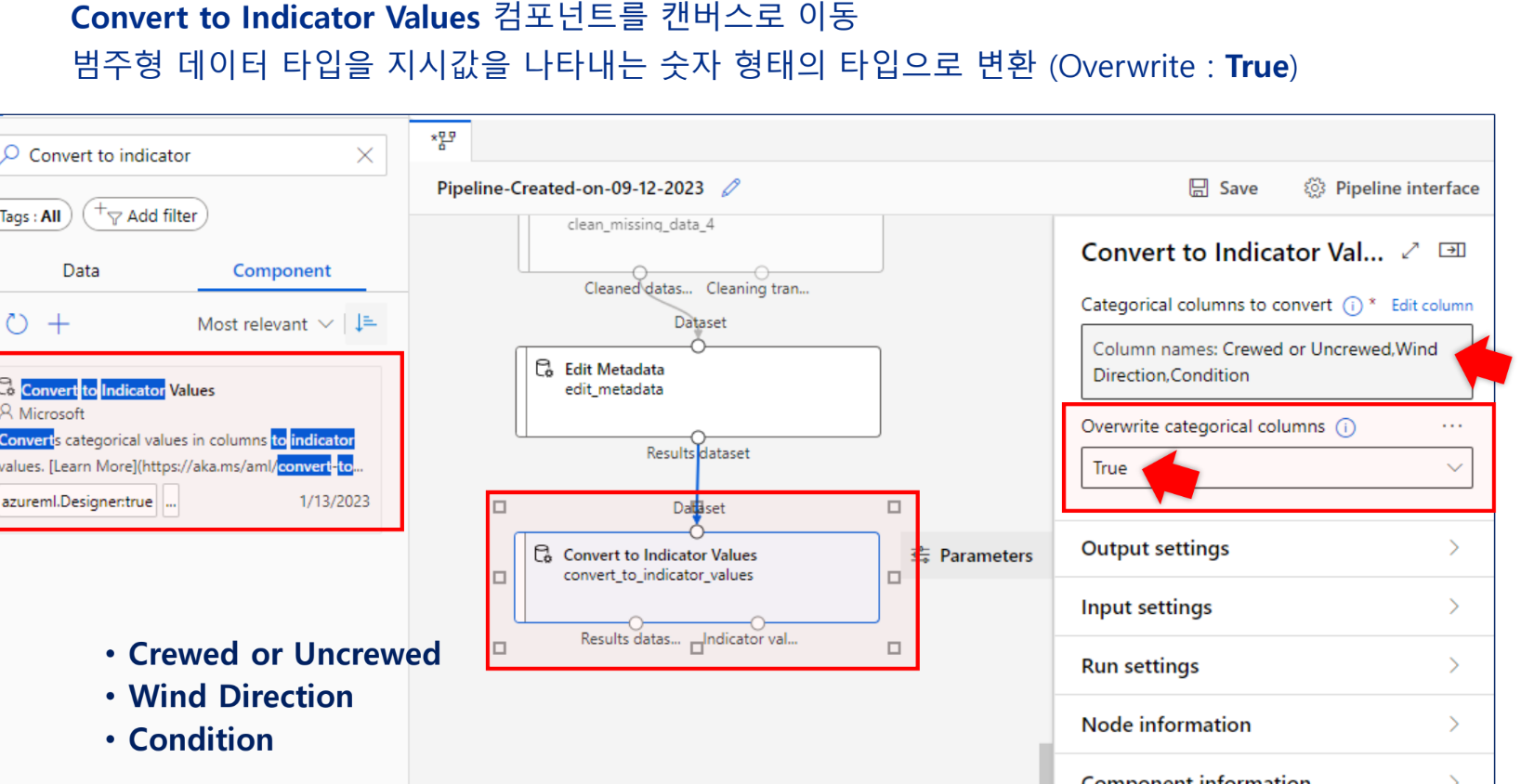
정수형 범주값 → 카테고리형
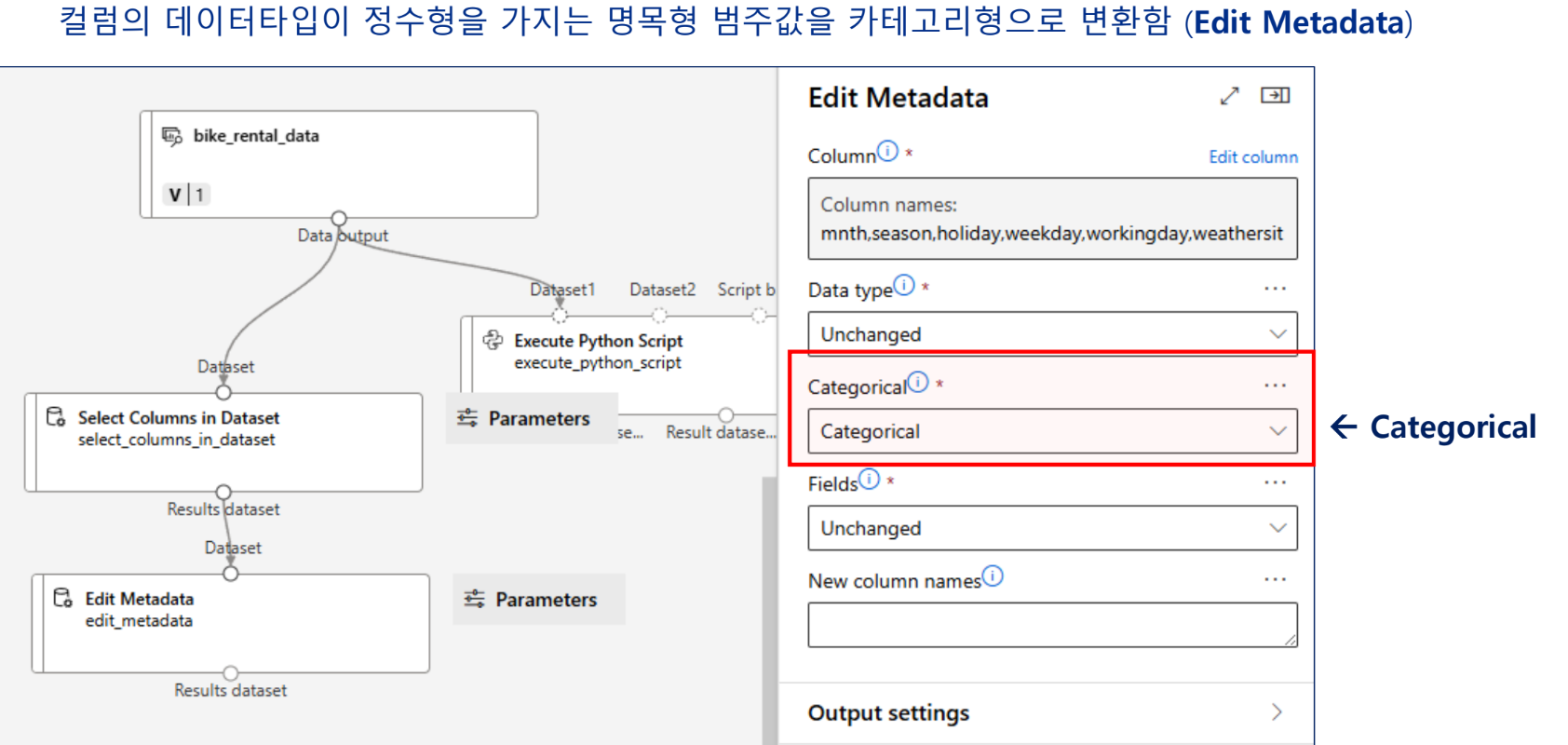
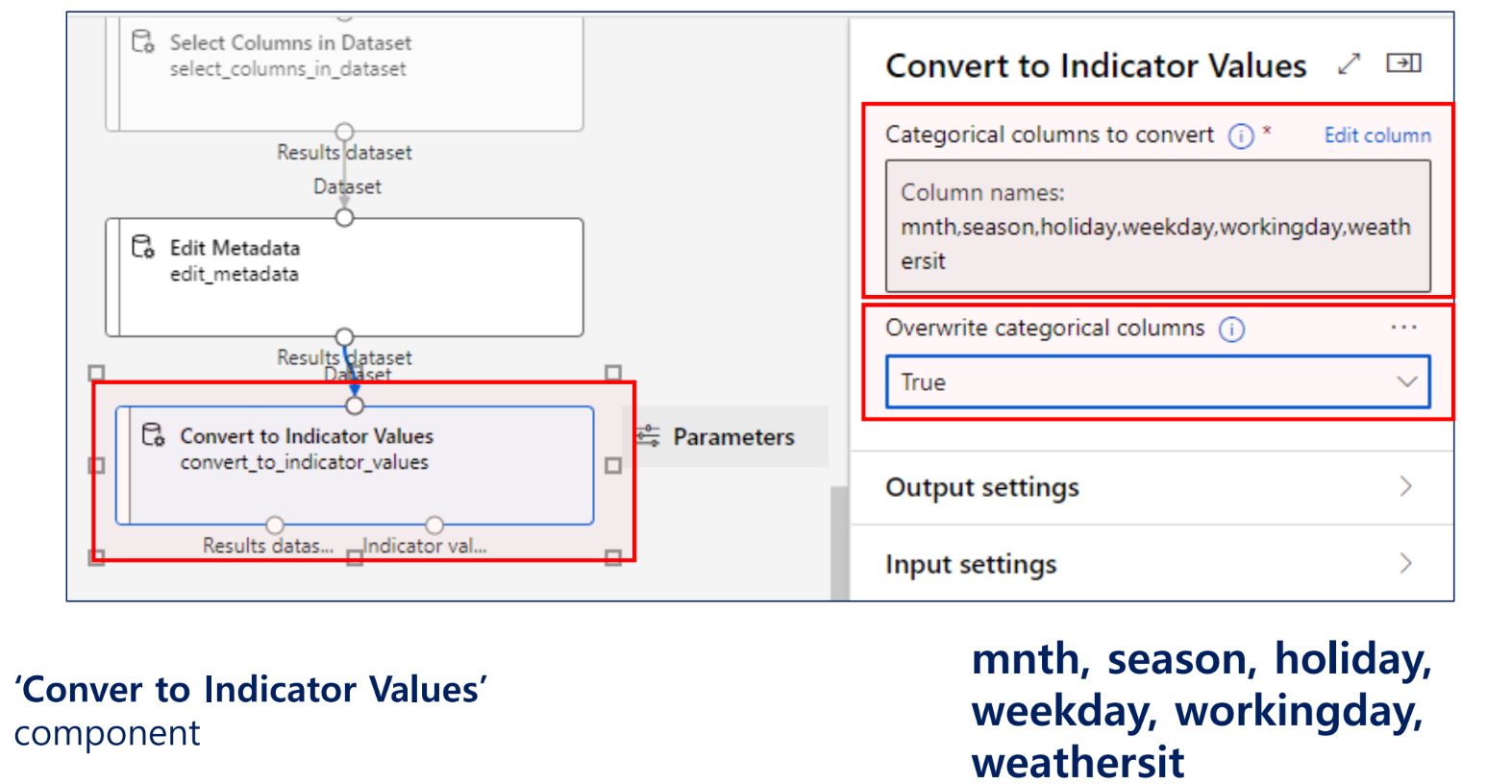
카테고리형 컬럼에 지시값 할당
표준화와 정규화
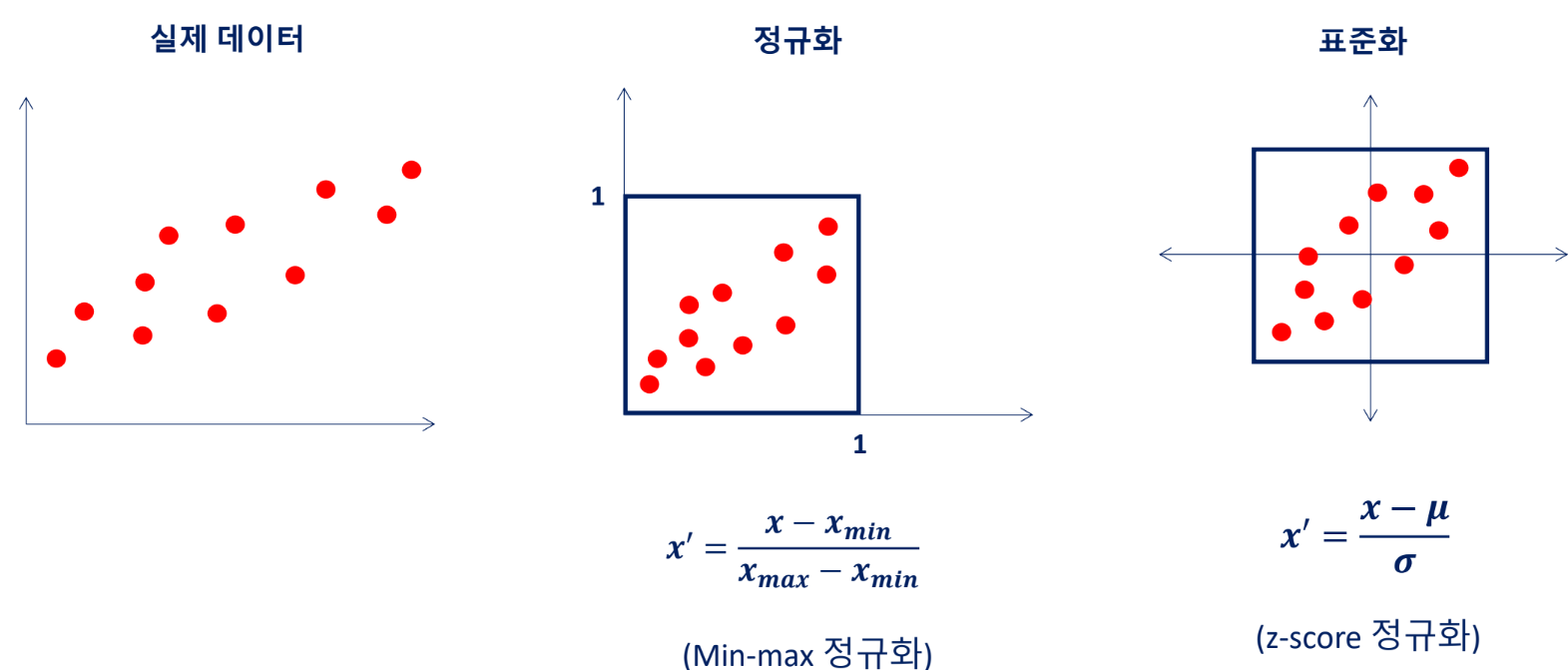
- 의미: 머신러닝 모델에서 사용할 특성들의 값이 비슷한 영향력을 갖도록 변환시킴
- 필요한 이유: 온도, 체감온도, 풍속, 강수량 등은 서로 단위, 분포가 다르므로 정규화 또는 표준화 필요
- 정규화: 특성값들의 범위를 [0, 1] 범위로 변환하여 비슷한 범위로 만들어 줌
- 표준화: 특성값들이 평균 0, 표준편차 1인 정규분포를 이루도록 변환
다중 선형 회귀에 입력되는 여러 특성들의 값의 범위가 차이가 나면, 머신러닝 모델이 잘못된 예측을 할 수 있음
특성의 정규화 및 표준화
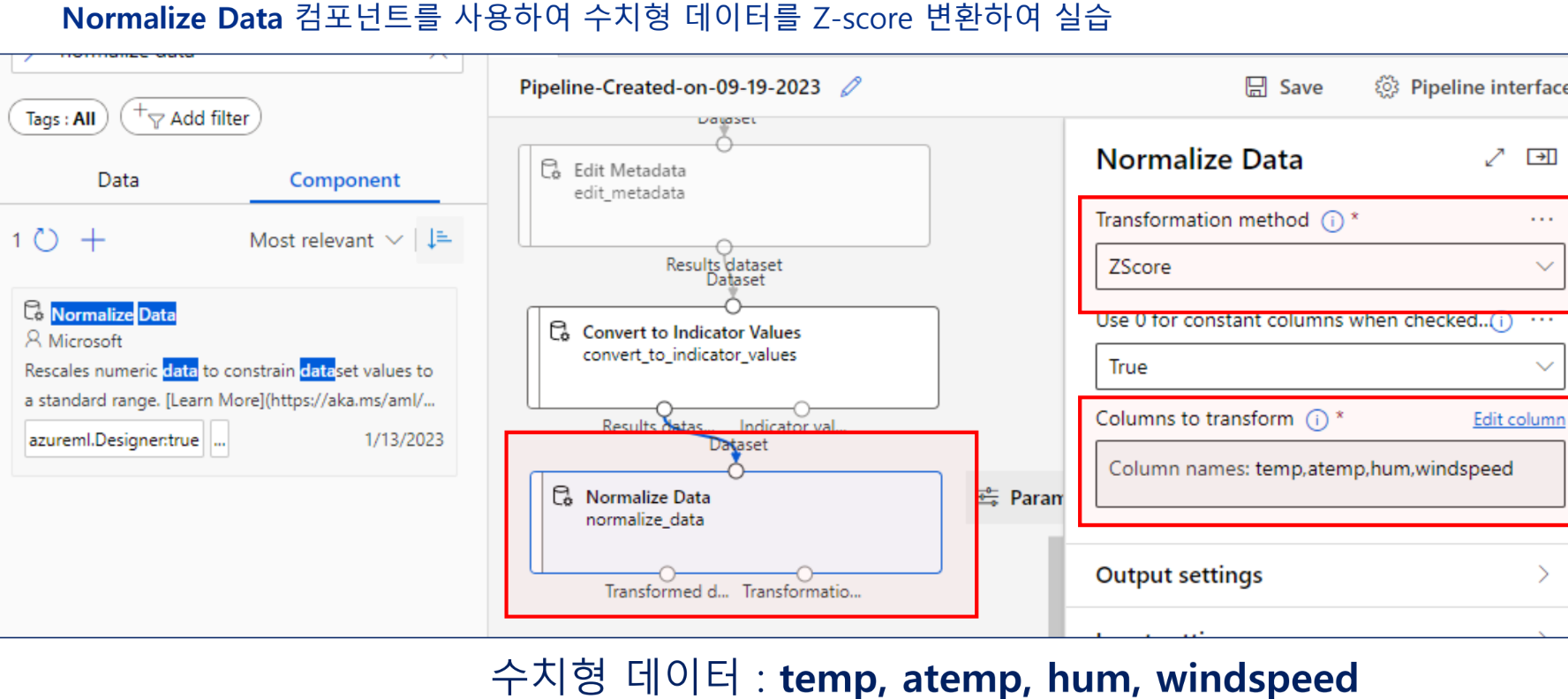
중간 실행 결과 관찰
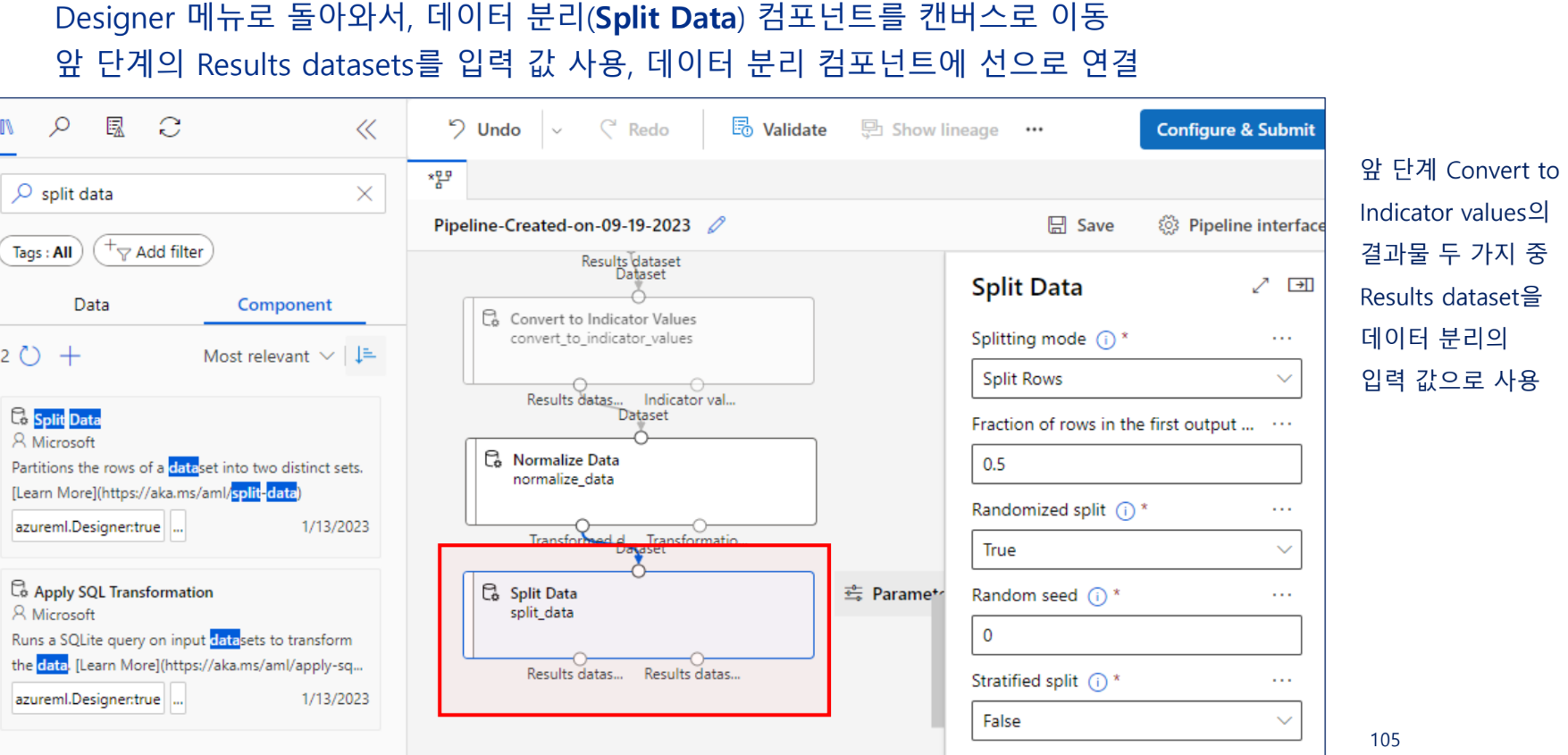
데이터 분리
학습 데이터와 테스트 데이터로 분리
모델링
선형 회귀 모델의 학습 과정
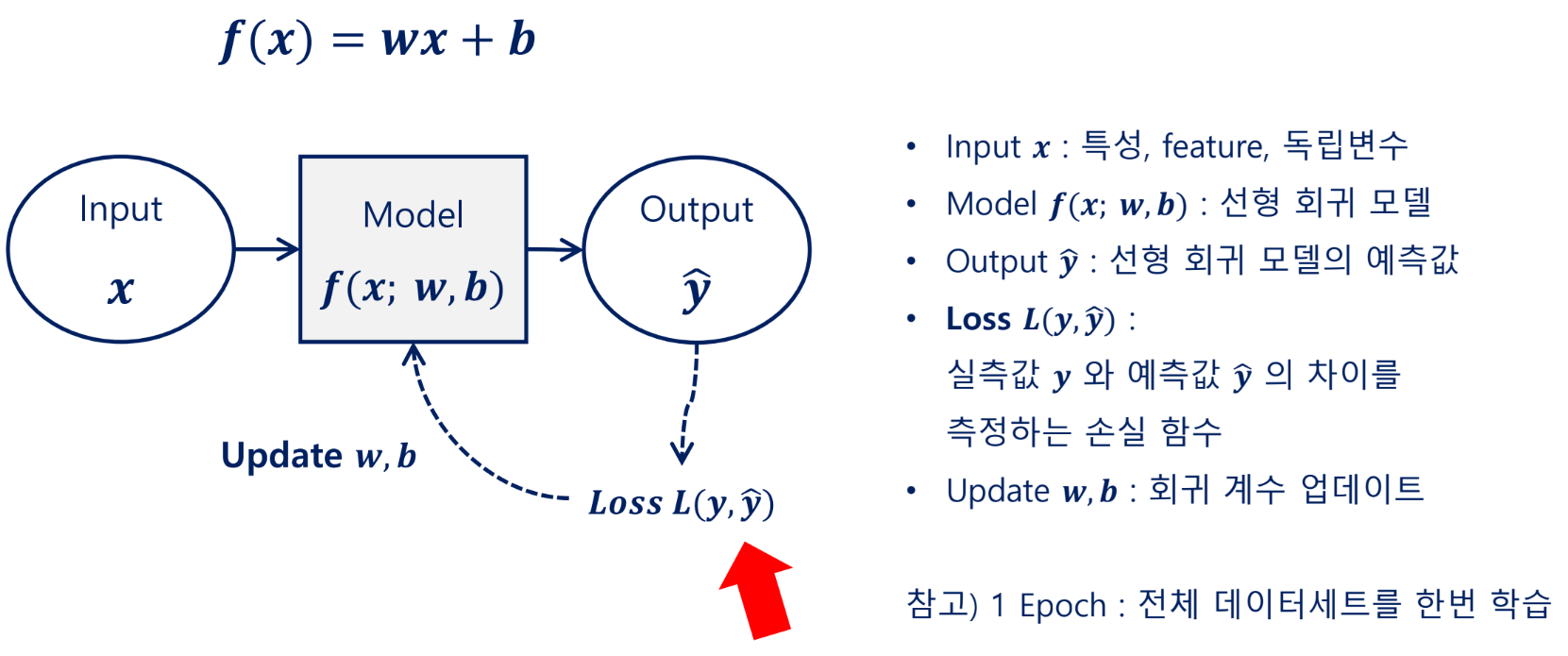
경사하강법
머신러닝 모델은 비용함수를 사용하여 오차를 줄이는 방향으로 학습
경사하강법을 통해 오차가 최소가 되는 방향으로 가중치를 조정해가며 학습
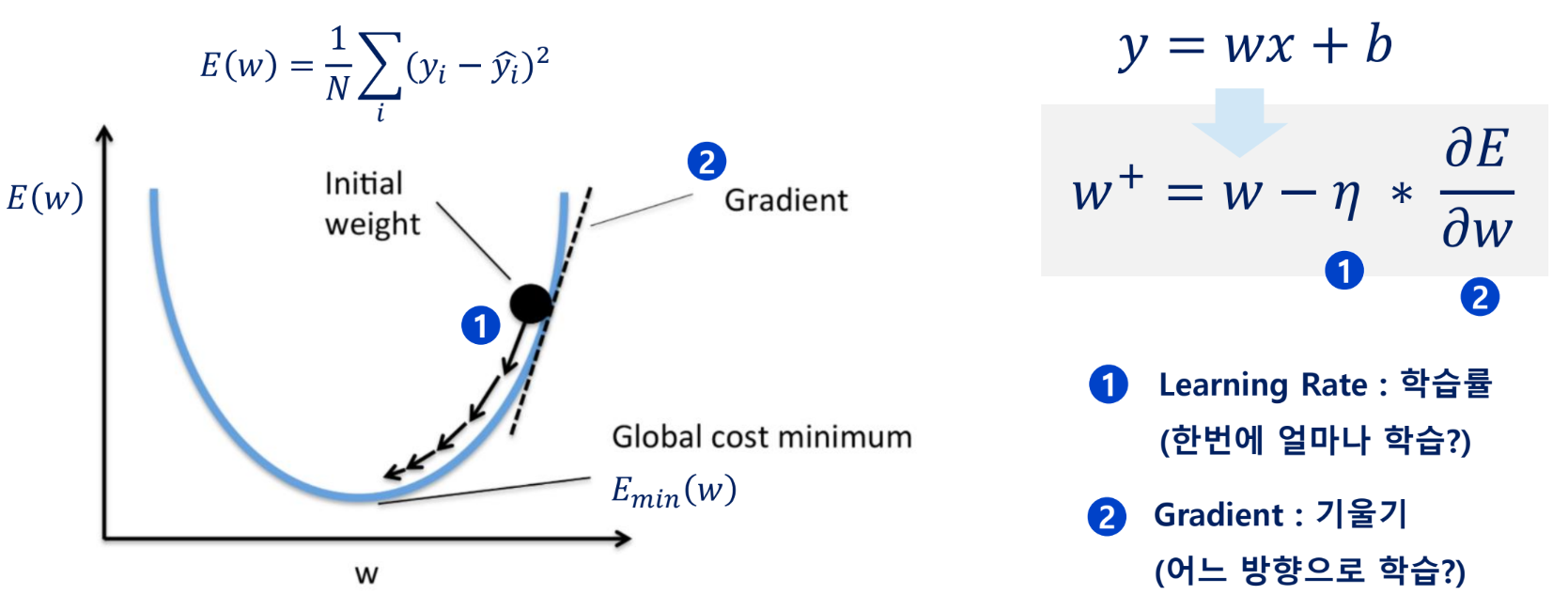
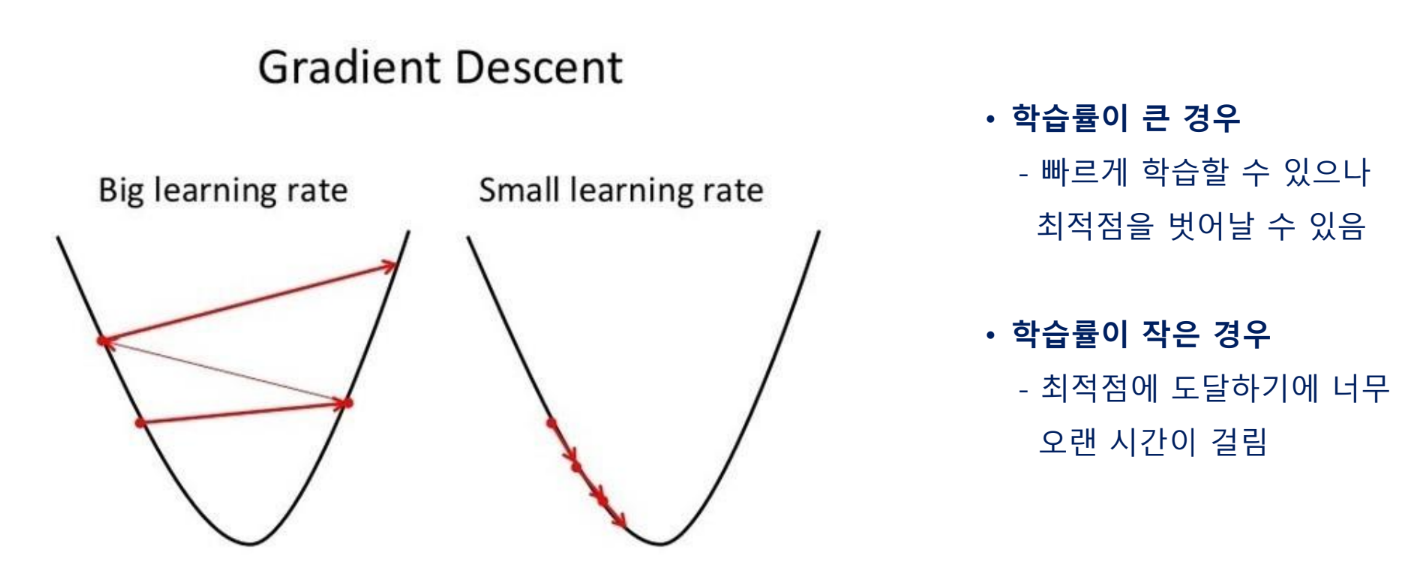
학습률
경사 하강법은 기울기에 학습률(보폭)이라는 스칼라 값을 곱해서 다음 지점을 정함
최적점에 도달하기 위해서 적절한 학습률을 설정하는 것이 중요
수렴(Covergence)
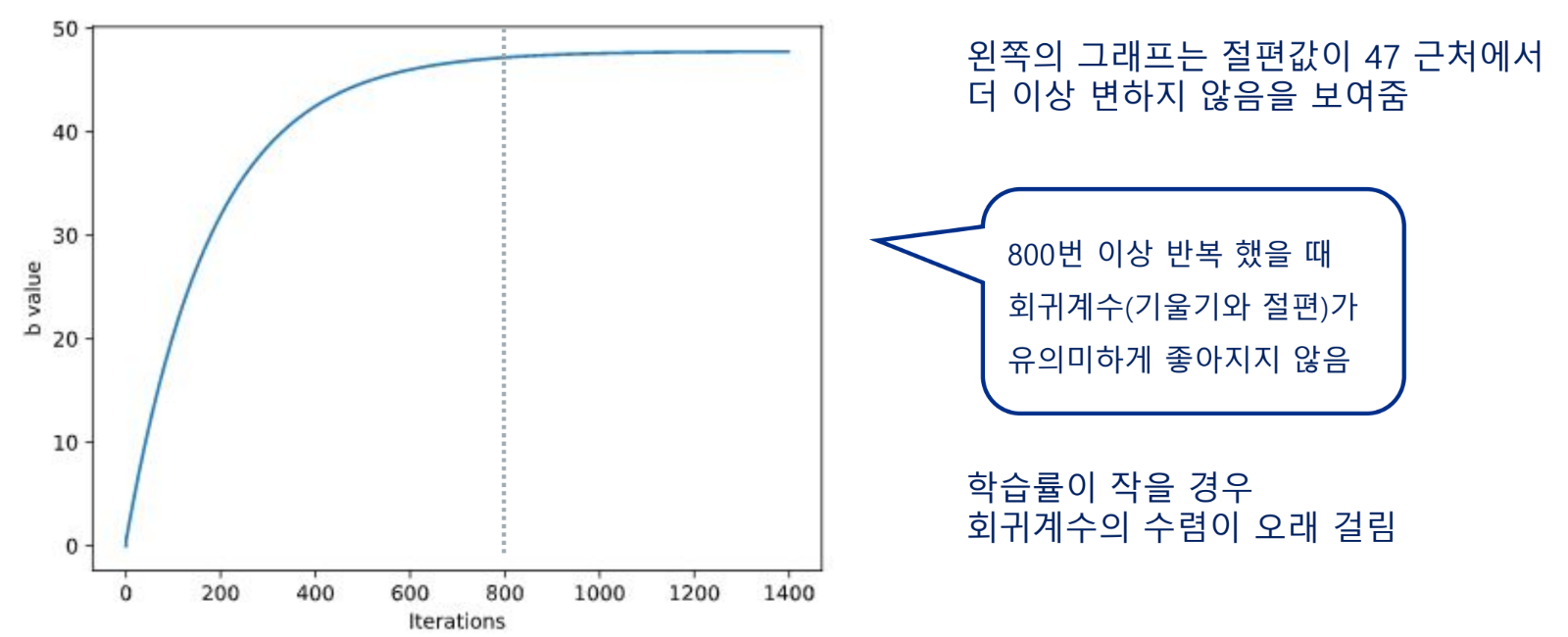
선형 회귀 분석은 비용함수 및 경사하강법 등을 이용하여 회귀계수(기울기와 절편)의 최적값을 찾아 나감
기울기와 절편을 반복하여 update(학습)하면 특정 값으로 수렴함
규제
데이터를 제한할 수는 없음. 결국 제한의 대상은 가중치
원하는 결과: MSE가 가장 작은 값을 가지도록 하는 w1, w2.. 그 점을 찾아내는 것
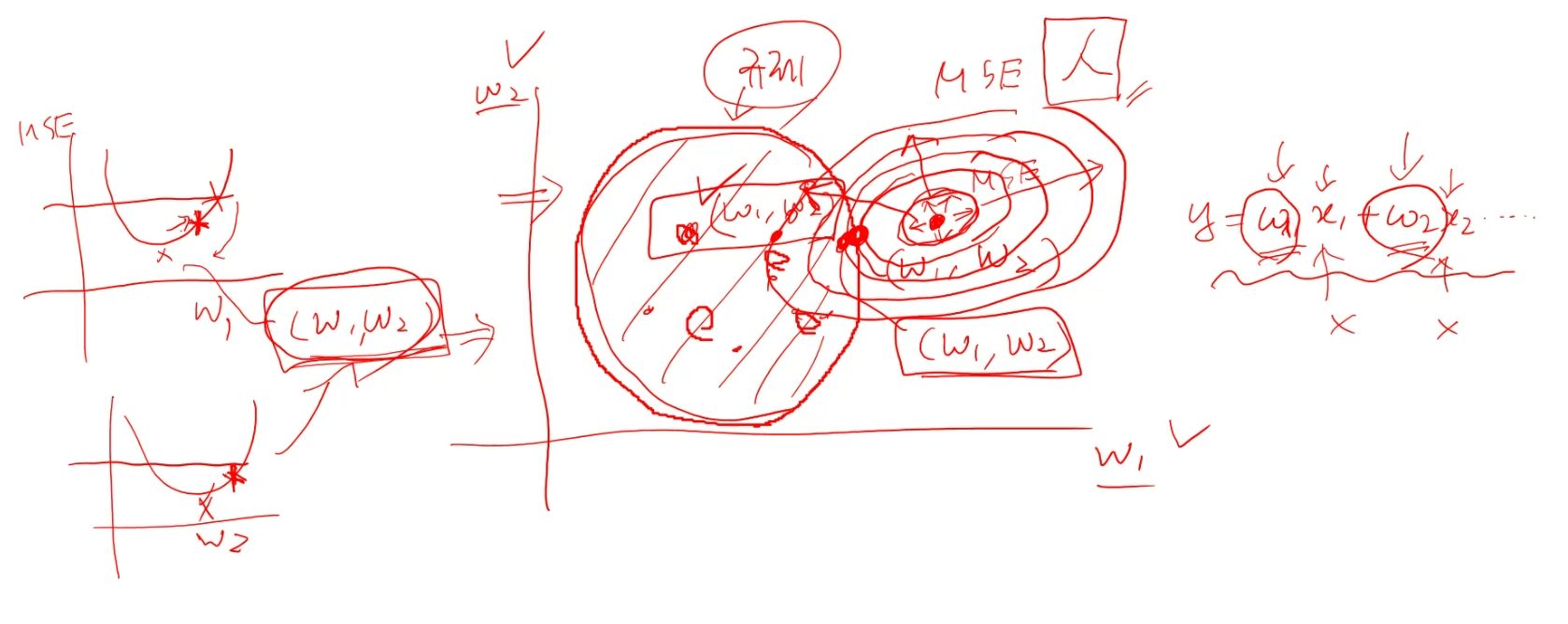
규제와 MSE값이 딱 맞닿는 부분을 보통 사용(우측 MSE의 동심원을 너무 늘리게 되면, MSE의 해에서 멀어짐)
과대적합(overfitting) vs 과소적합(underfitting)
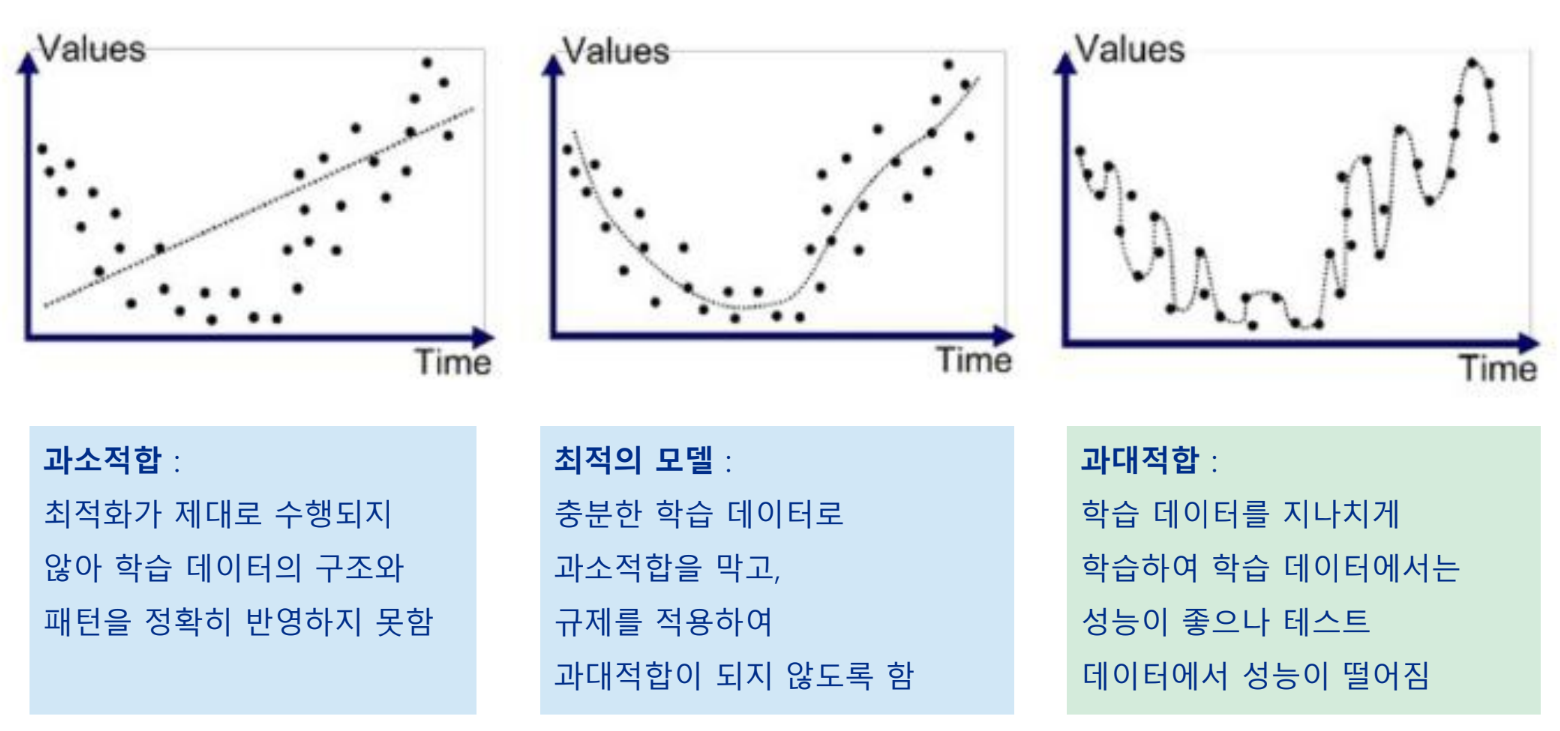
다중 회귀 모델에서의 규제

독립변수가 많아지면 과대적합의 경향이 있음
→ 회귀식의 가중치의 영향력을 제한하여 과대적합 방지
규제의 양
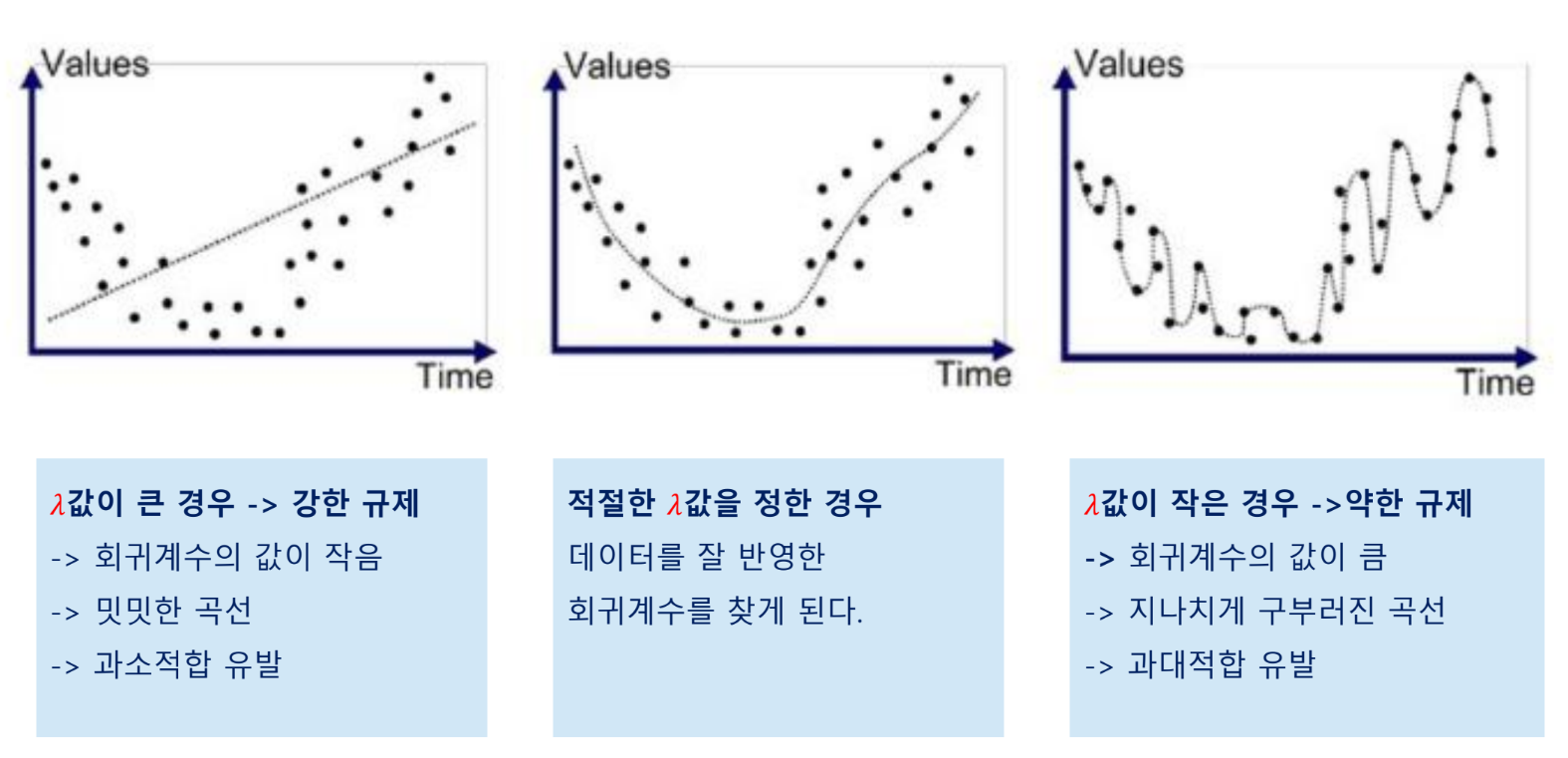
알고리즘 및 하이퍼 파라미터
머신러닝 알고리즘 선택
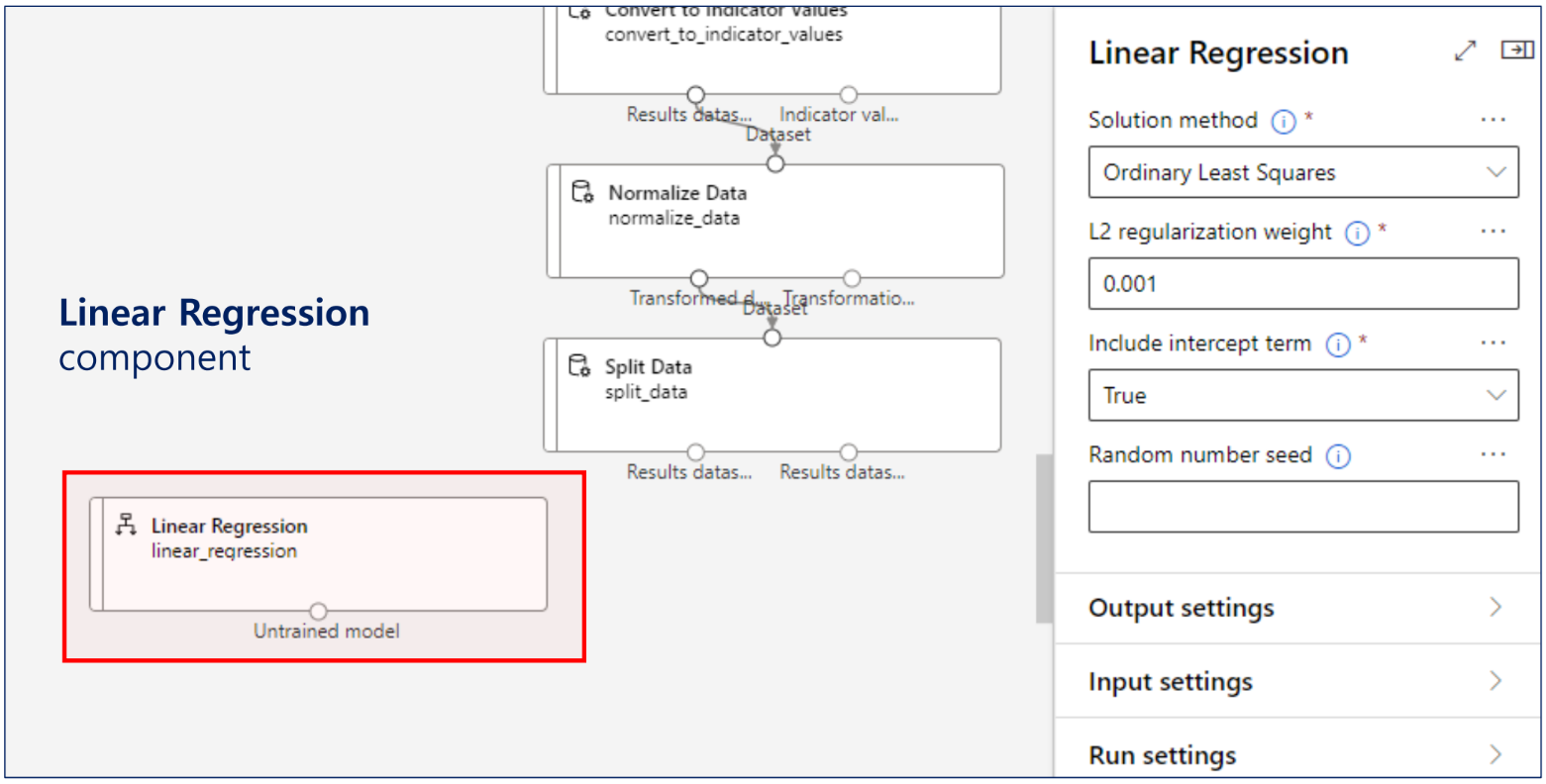
경사하강법 사용

모델 학습
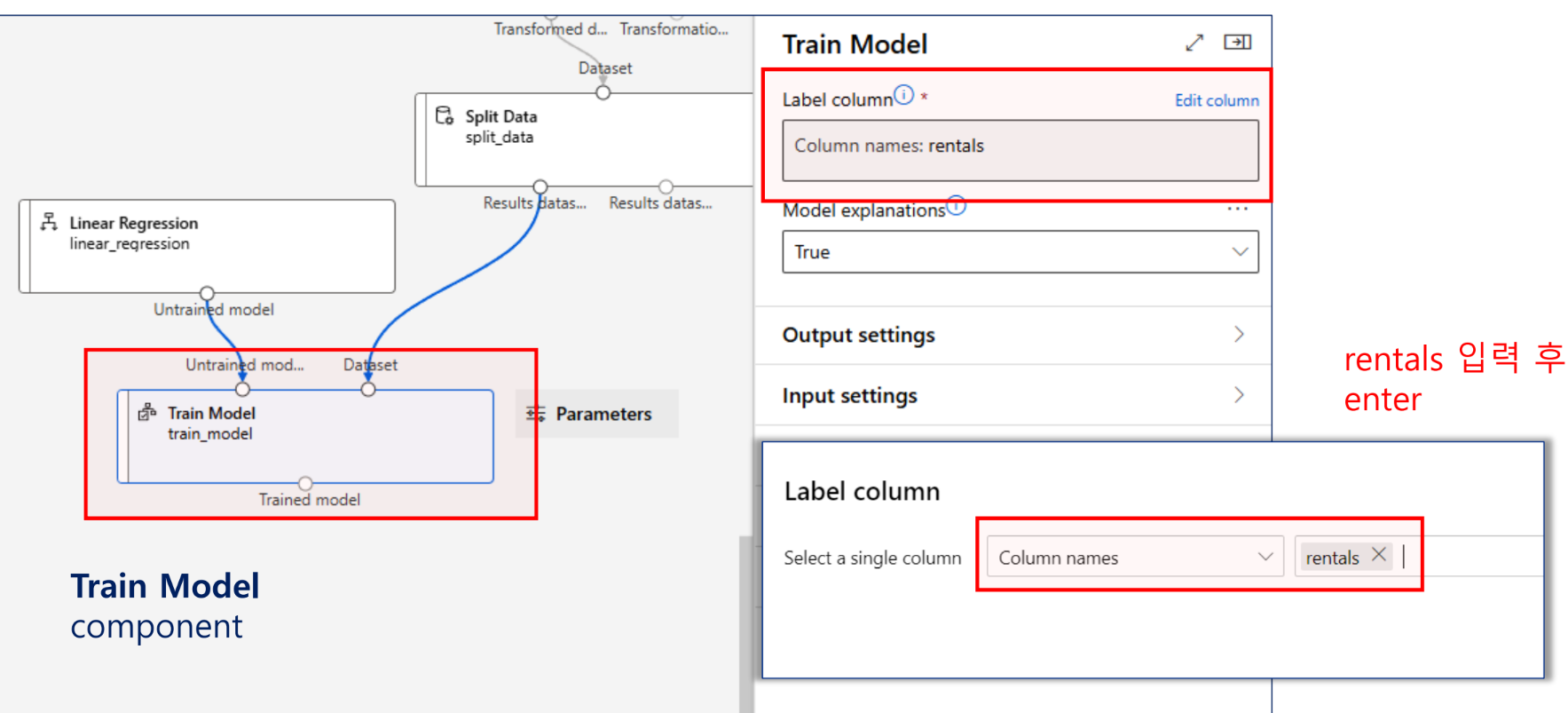
평가
모델 테스트
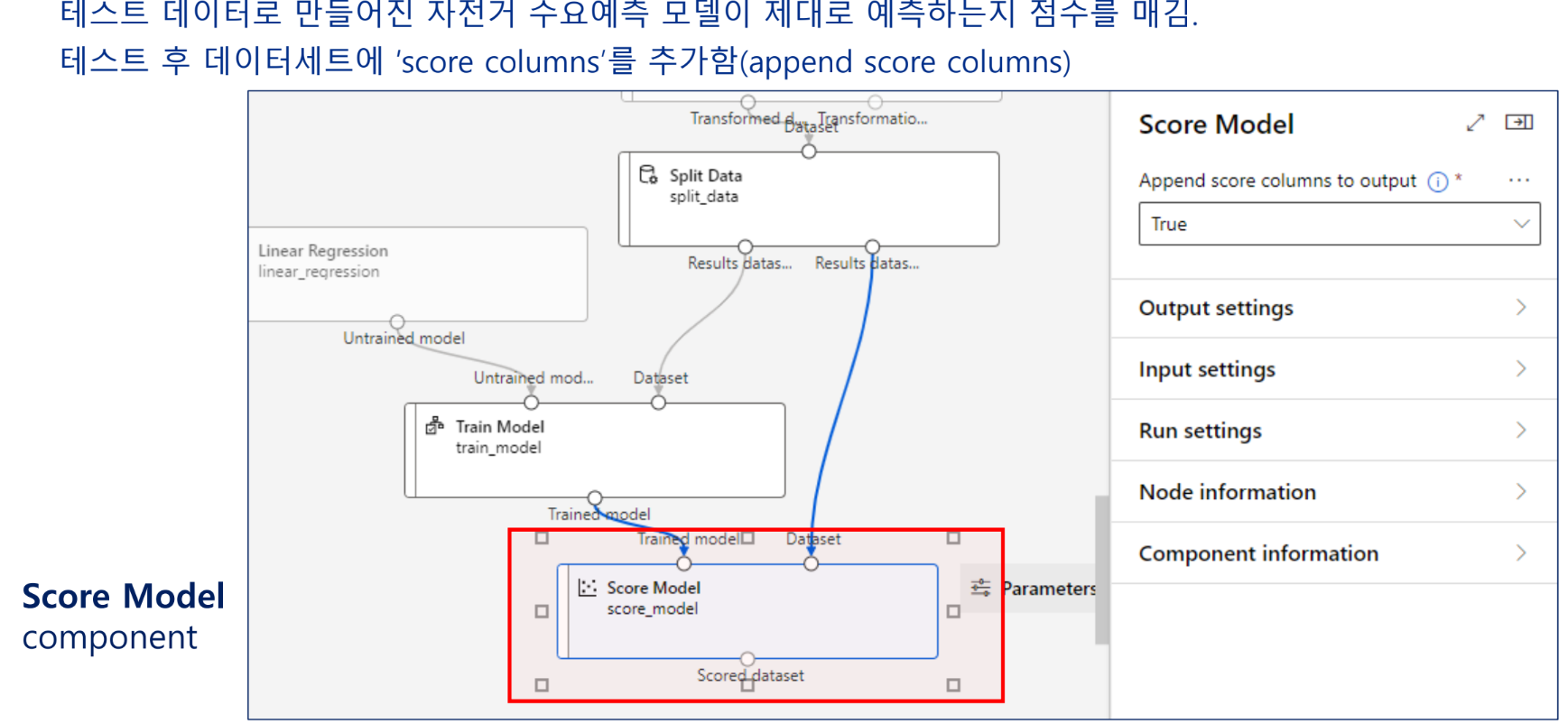
모델 평가
평가 지표
오차(손실)
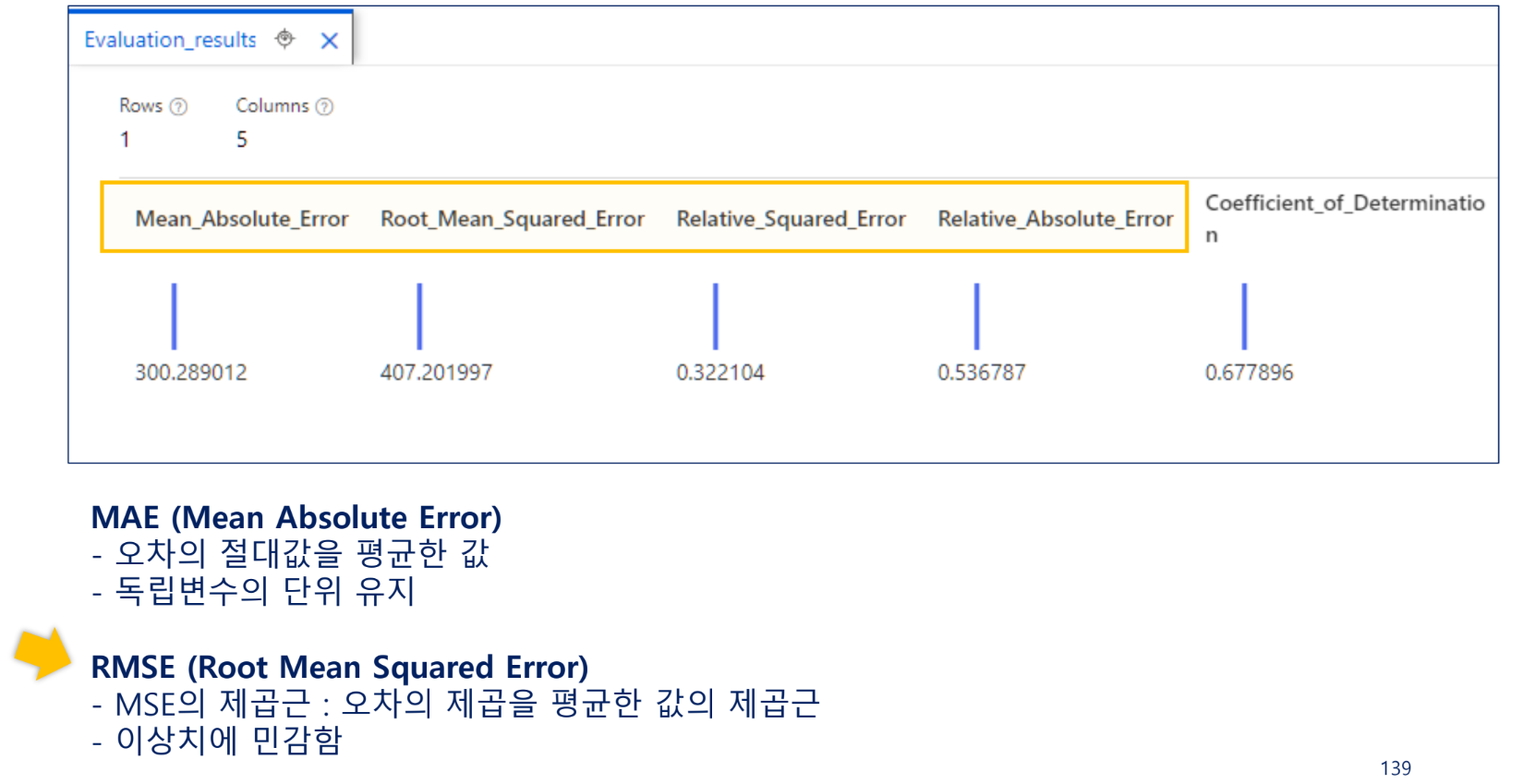
- MAE -> 300대의 자전거를 추가하면 되겠군
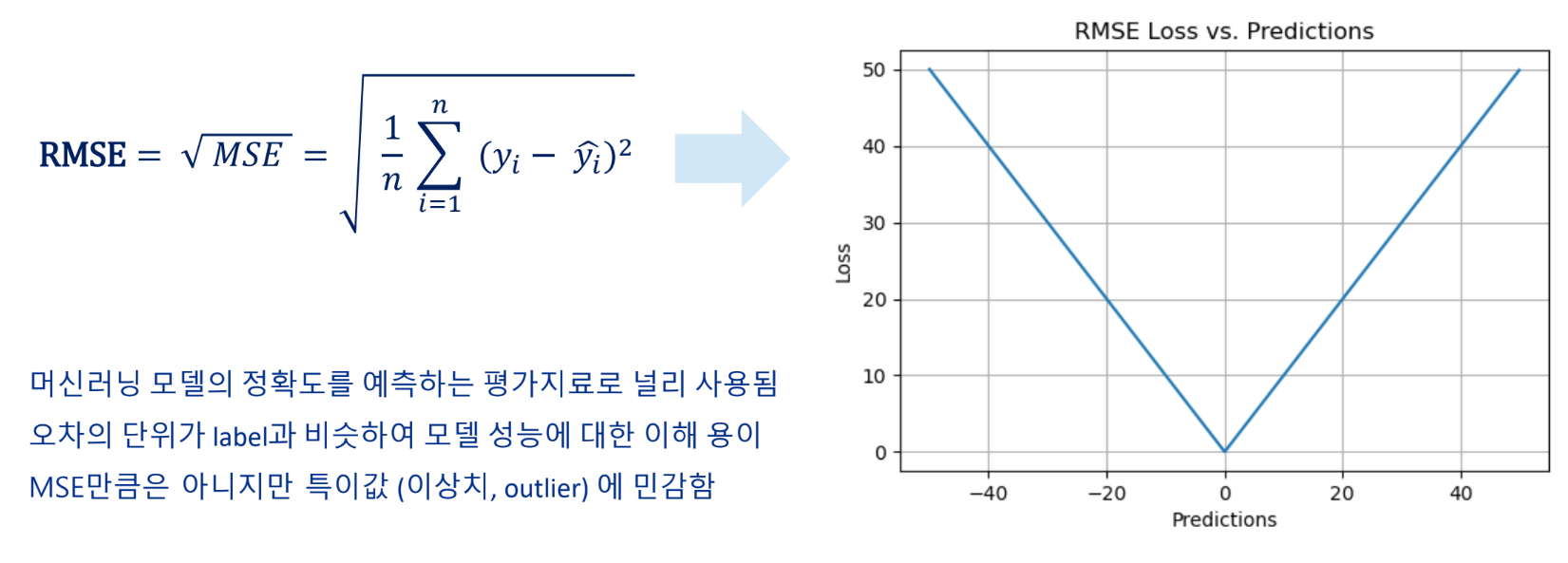
RMSE(Root Mean Squared Error)
MSE에 제곱근을 적용한 값
RMAE가 0에 가까울수록 예측값이 실측값과 가까움
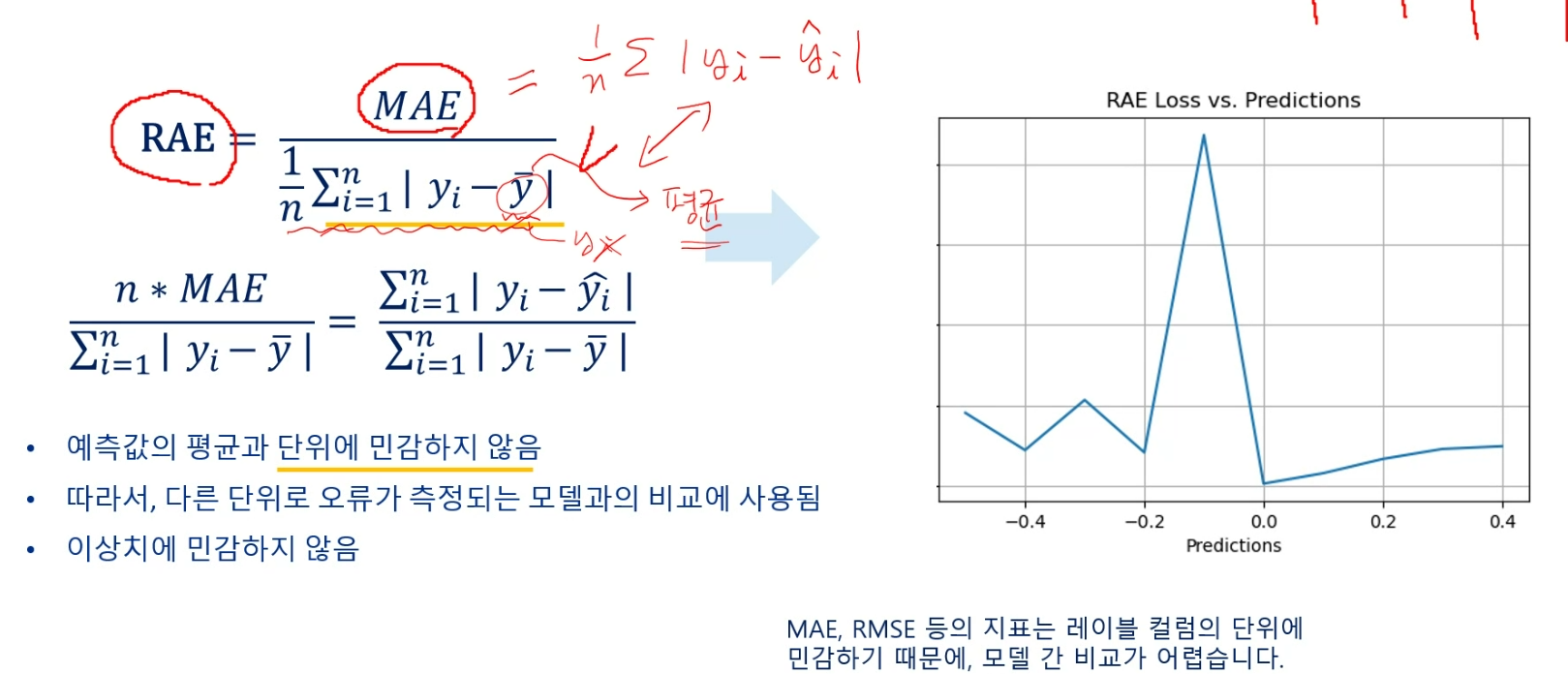
RAE(Relative Absolute Error)
MAE를 실제갑소가 평균값의 절대차의 평균으로 나눈 값
RAE가 0에 가까울수록 예측값이 실측값과 가까움
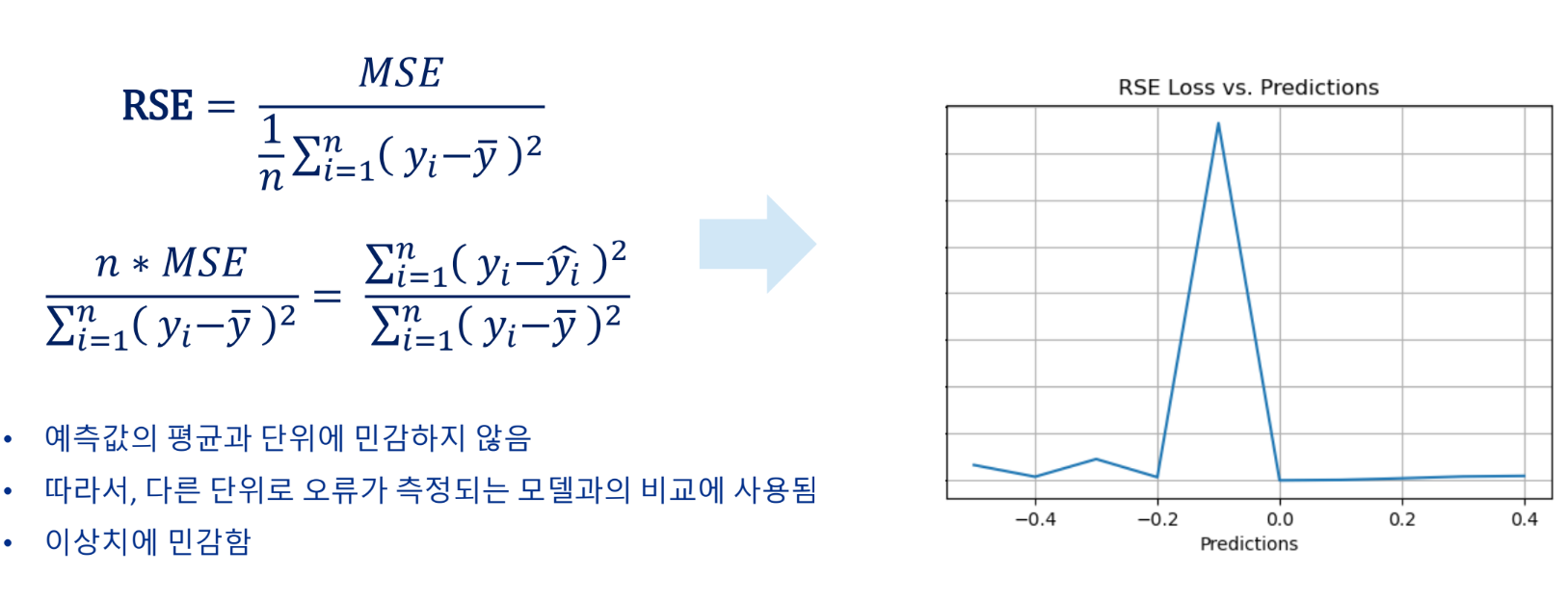
RSE(Relative Squared Error)
MSE를 실제값과 평균값의 차이의 제곱평균으로 나눈 값
RSE가 0에 가까울수록 예측값이 실측갑소가 가까움
R^2 결정계수
모델의 독립변수들이 종속변수를 얼마나 잘 설명하는지 나타내는 지표
- 결정계수: 종속변수의 변동량 중에서 회귀모델로 설명가능한 부분의 비율, 독립변수가 종속변수를 설명하는 정도를 표현하는 지표
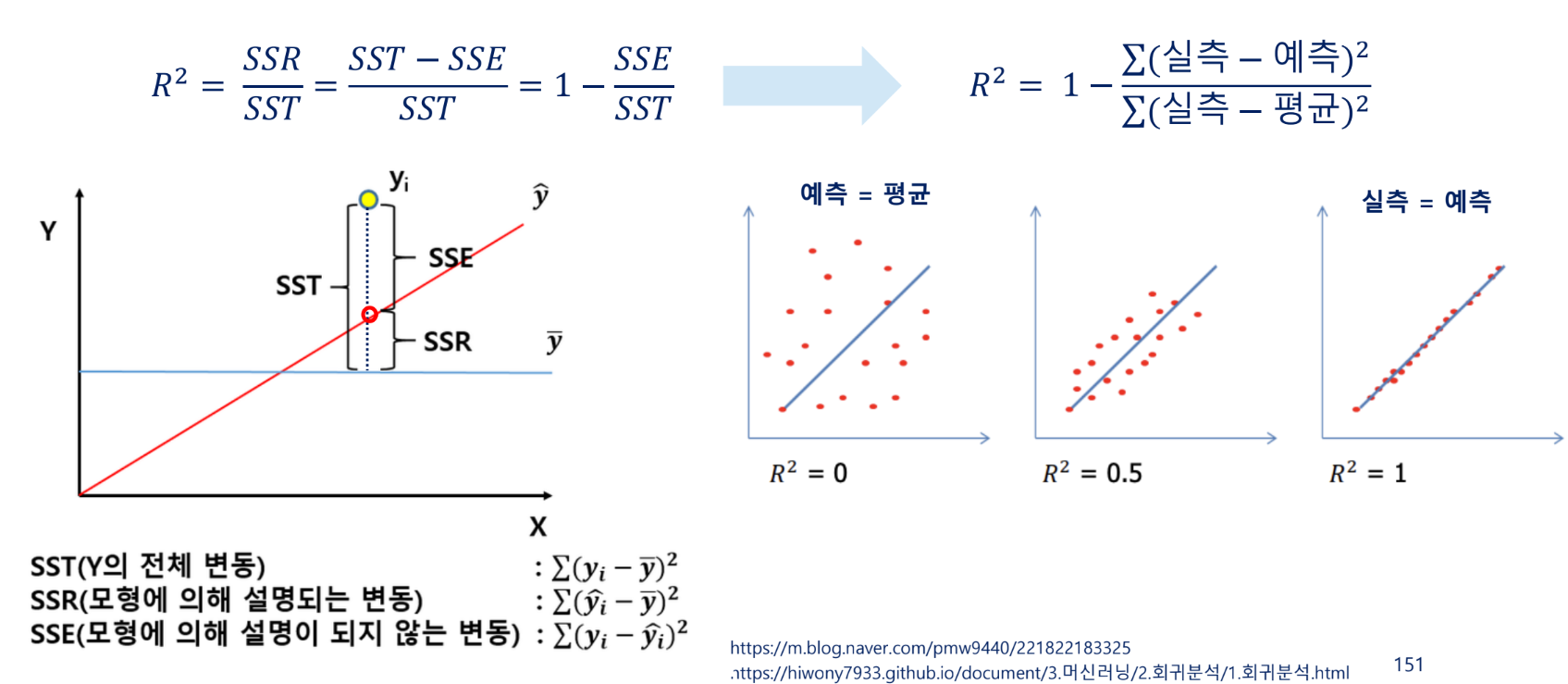
0.7 이상 정도면 잘 설명했다고 이해
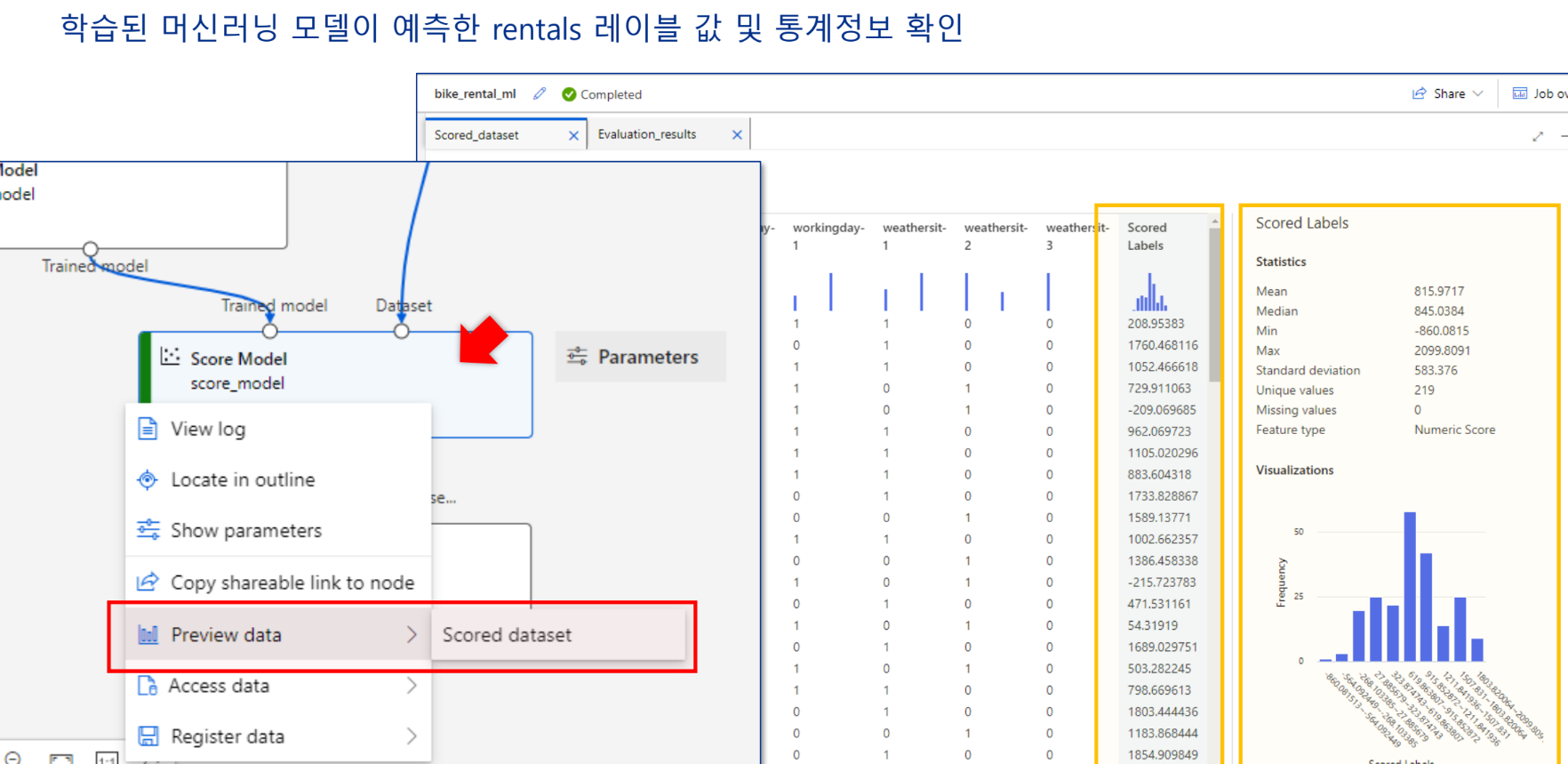
예측 결과 확인
Scored Labels 확인
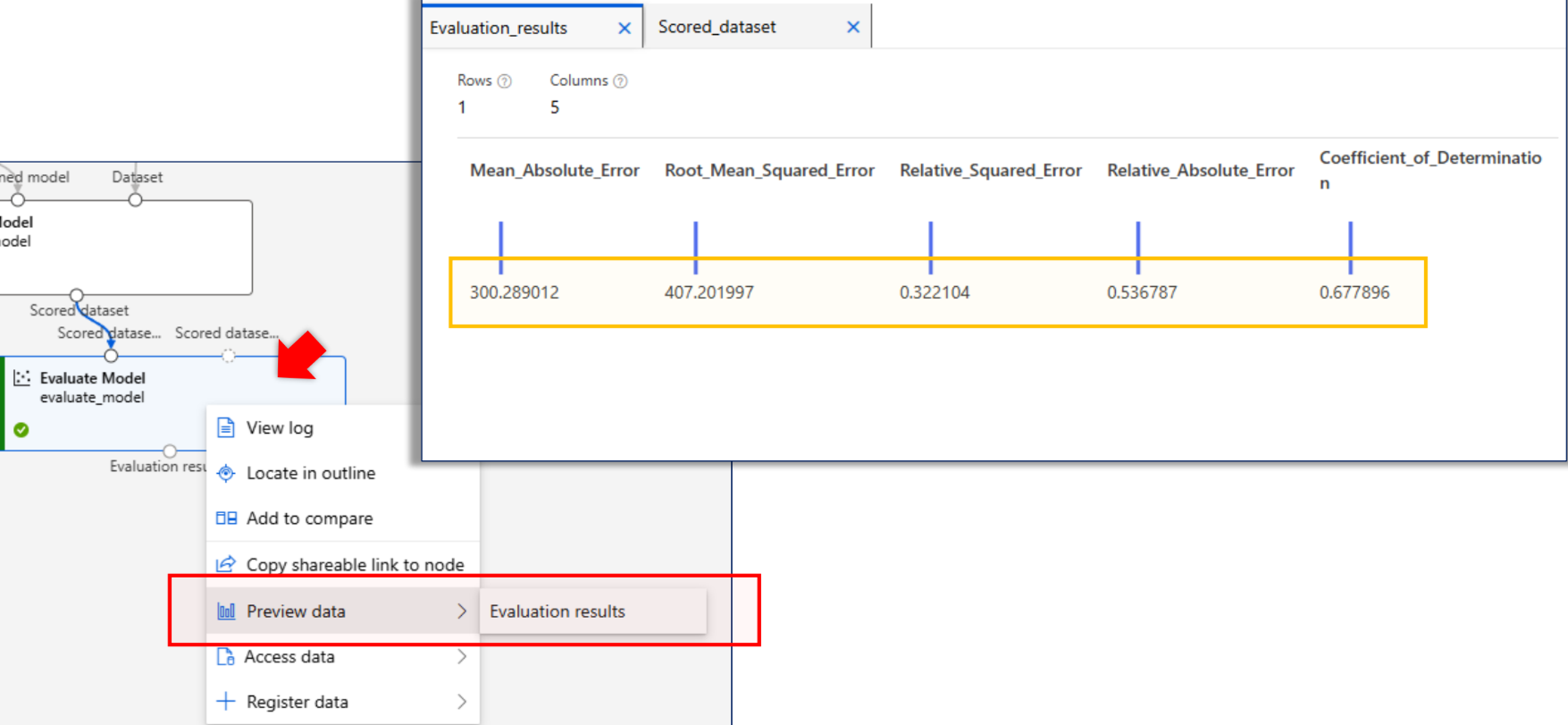
Evaluation results 확인
실습 - 군집 MLD 프로야구 데이터를 활용한 선수능력 측정 모델
"한국 프로야구에서 타자능력의 측정" 논문에 언급된 이론과 실습 진행
K-means 군집 알고리즘 및 PCA(주성분 분석) 차원축소 개념 확인
문제 정의

모델링 유형

비지도 학습의 군집을 이용
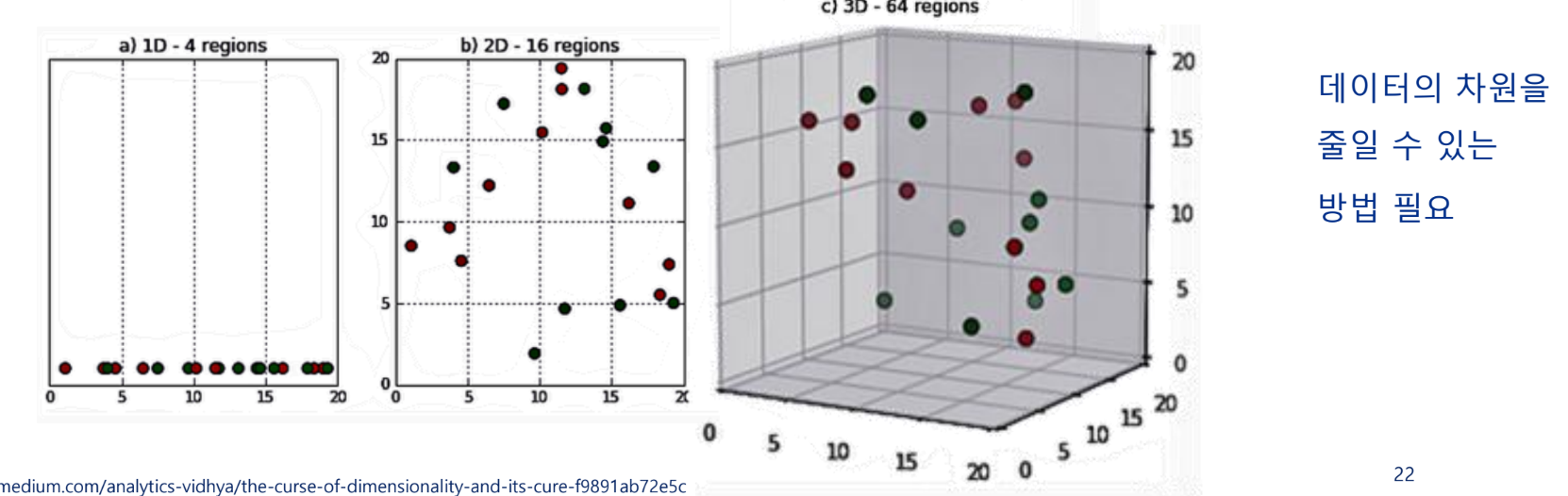
차원의 저주
머신러닝에서 데이터의 차원이 증가하면 차원의 수에 비해 학습데이터의 수가 줄어들면서 발생하는 문제를 의미함
데이터가 희박해짐 → 탐색할 공간이 늘어남 → 저장공간, 처리시간 문제 → 머신러닝 모델에 불필요한 부하
전체 공간에 비해 데이터 개수가 적으면 과대적합의 문제 우려
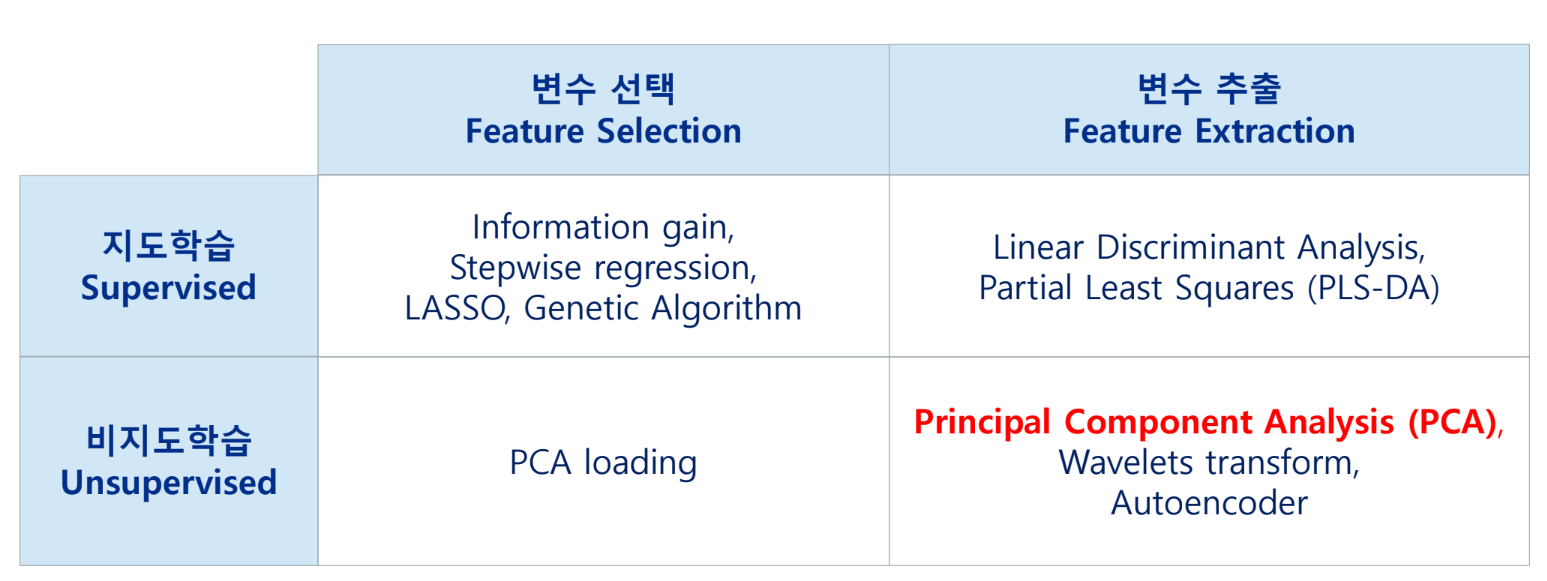
차원 축소
- 데이터의 차원 = 독립변수의 수
- 차원 축소: 변수(feature)의 개수를 줄임 (고차원의 데이터 → 저차원의 데이터)
- 다변량 변수: 일반적으로 상관관계가 많음 = 불필요한 변수가 많을 수 있음
→ 상관관계가 없는 변수들만 남기는 것이 목표

군집화 자체가 목적이면 변수 추출이 더 좋은 결과를 낸다
머신러닝 단계 중 데이터 이해 및 준비 단계에서 적용
차원이 줄어들면 원래 데이터가 가진 정보의 일부가 손실됨 → 원래 feature들의 분산 특성을 유지하는 것이 중요
PCA(Principal Component Analysis) 분석
고차원 데이터를 효과적으로 분석하기 위해 대표적 분석 기법
독립변수(features)의 분산을 가장 넓게 표현하는 주성분(새로운 축, PC)를 찾는 작업
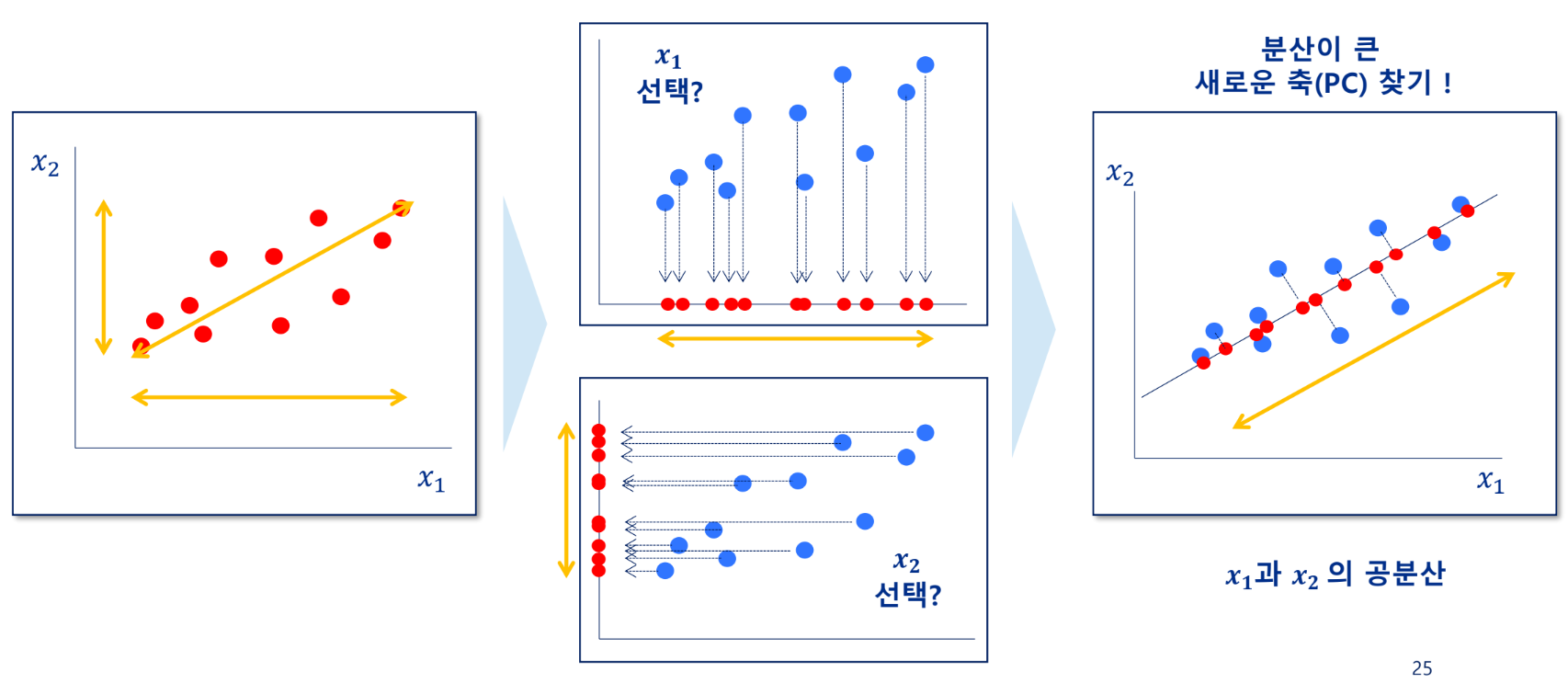
비지도 학습의 대표적인 차원 축소 방법으로, 데이터의 분산을 최대한 보존하는 새로운 축(주성분)을 찾고, 그 축에 데이터를 사영시킴
분산이 큼 = 원래 데이터의 분포를 잘 설명할 수 있음
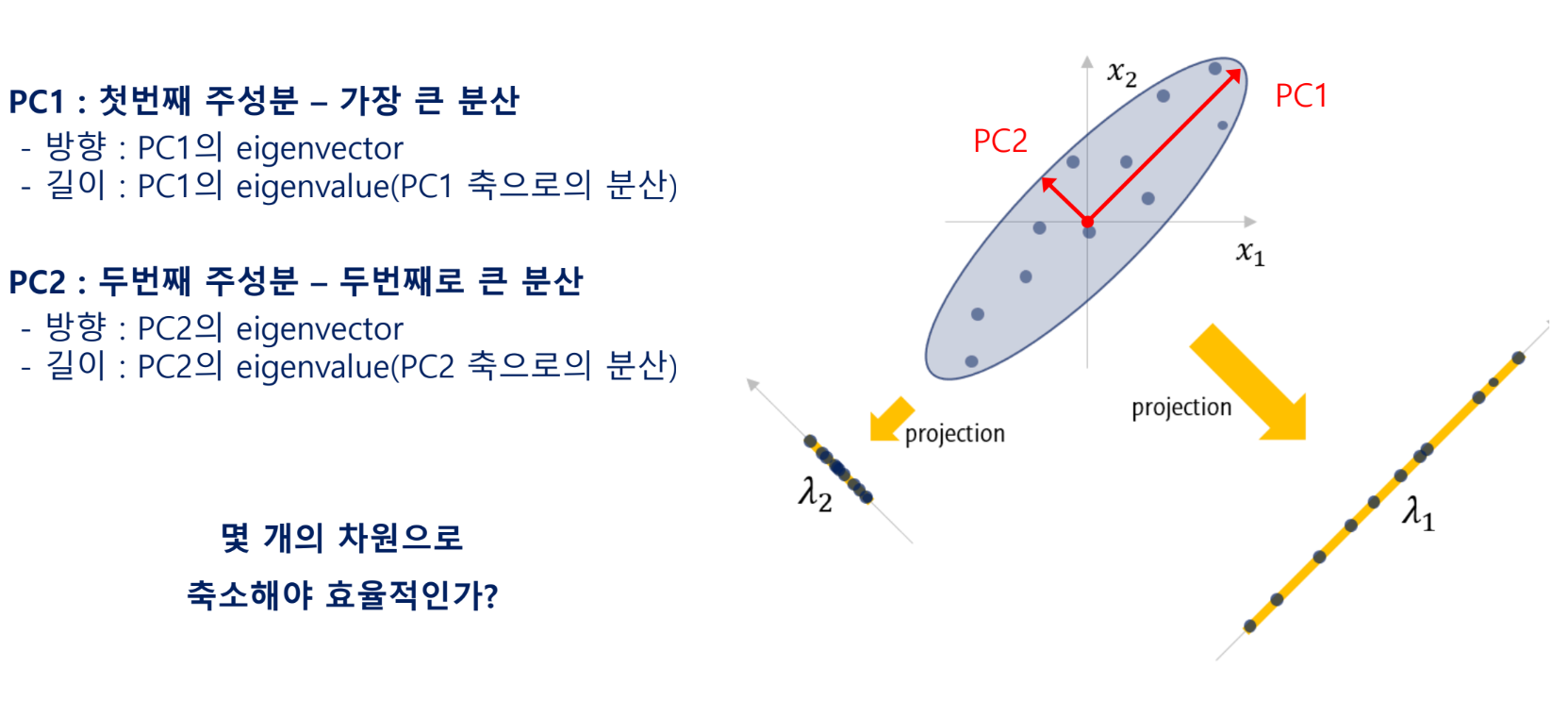
주성분을 기존 feature(변수)의 수만큼 찾은 후 몇 개의 차원으로 축소할 지 결정
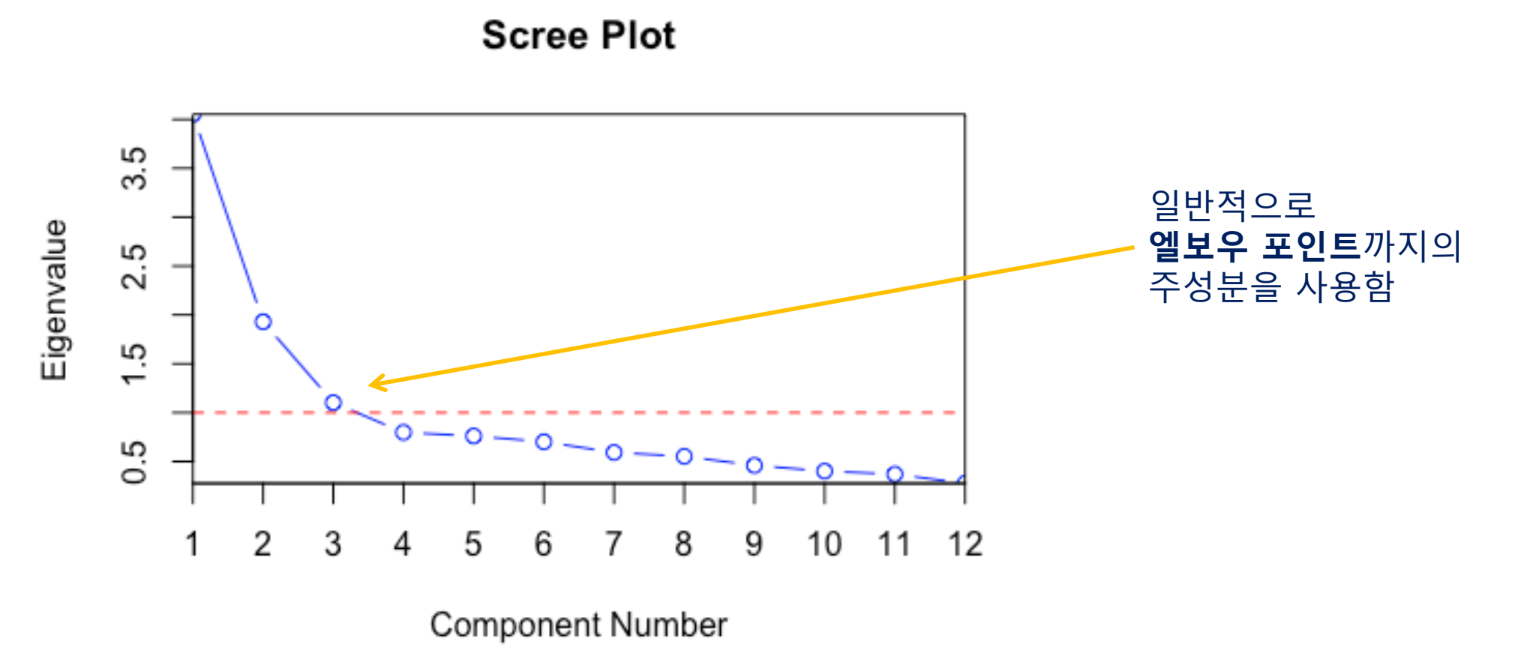
Screen Plot을 사용하여 주성분의 개수를 정할 수 있음
주성분들의 eigenvalue를 그래프로 시각화(각 주성분들이 분산을 설명하는 비율에 대한 그래프)
PCA를 찾는 방법

군집 알고리즘 이해
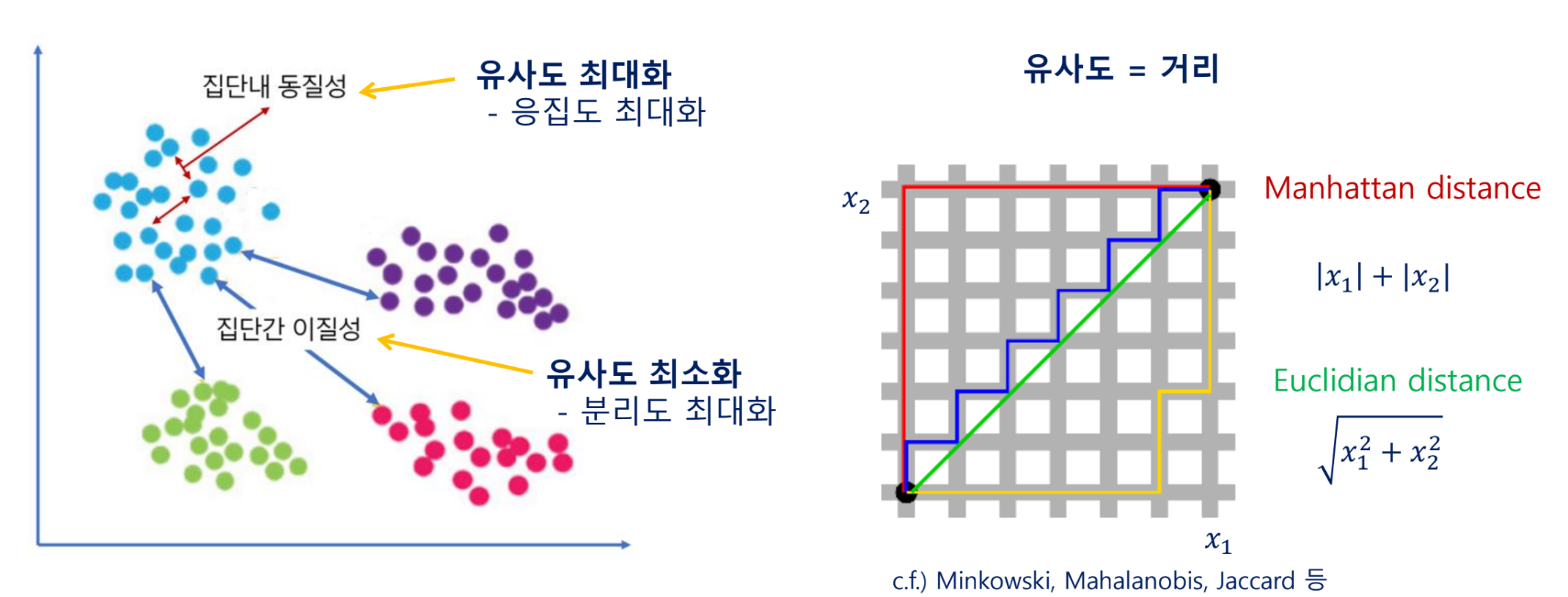
데이터 간의 유사도를 정의하고, 유사도에 따라 군집을 형성하는 알고리즘
군집의 수, 속성이 사전에 알려져 있지 않을 때 주로 사용
유사도는 거리의 개념으로 접근하는 것이 일반적
군집화 알고리즘 종류
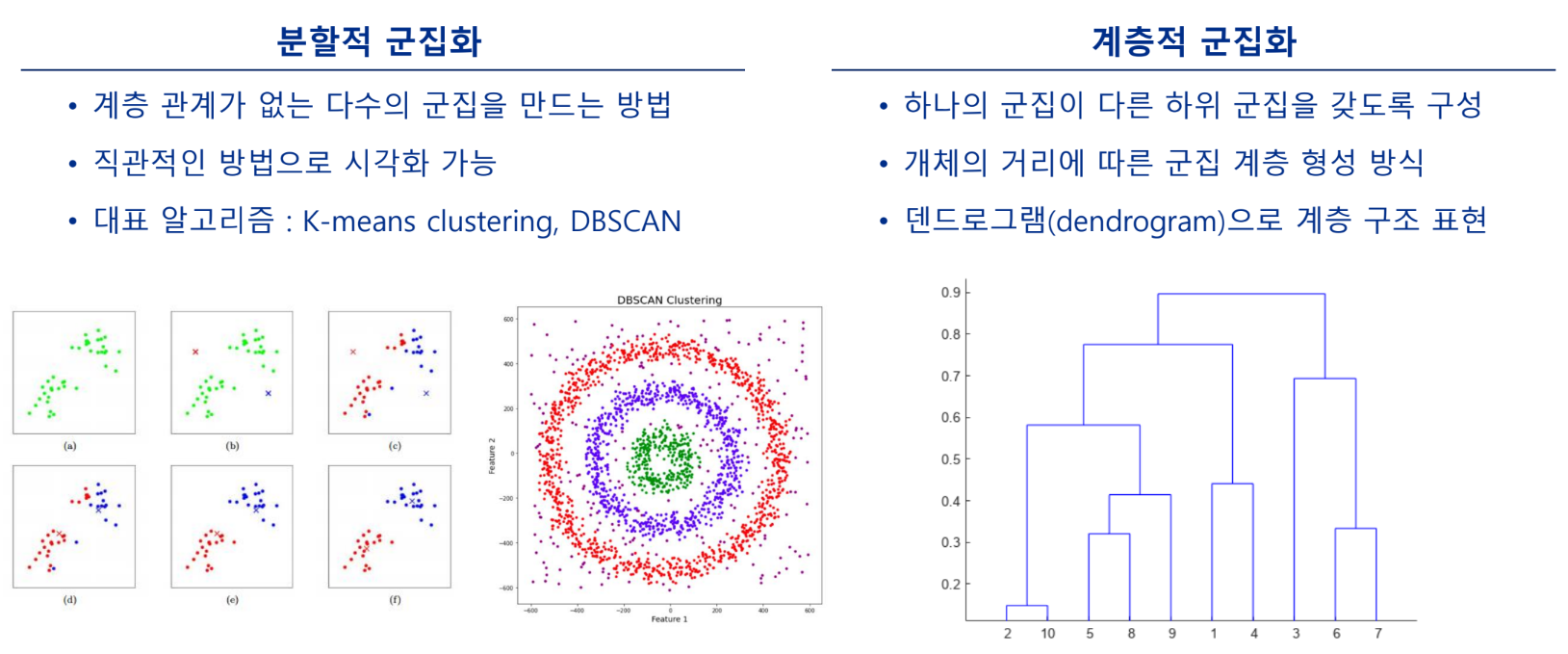
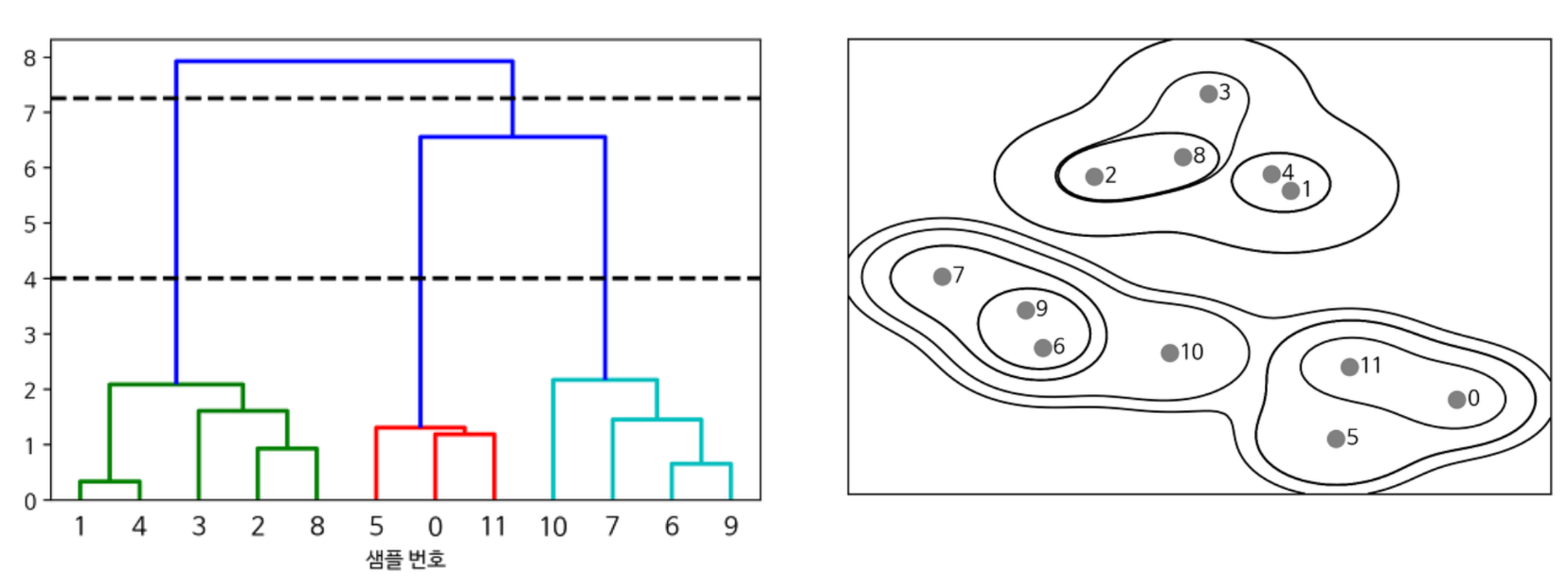
계층적 군집 - H-Clustering
개체 간 거리에 따라 클러스터 계층을 표현하는 방식
비슷한 개체끼리 서로 묶어가며 클러스터를 만들어 가는 방법(덴드로그램 이용)
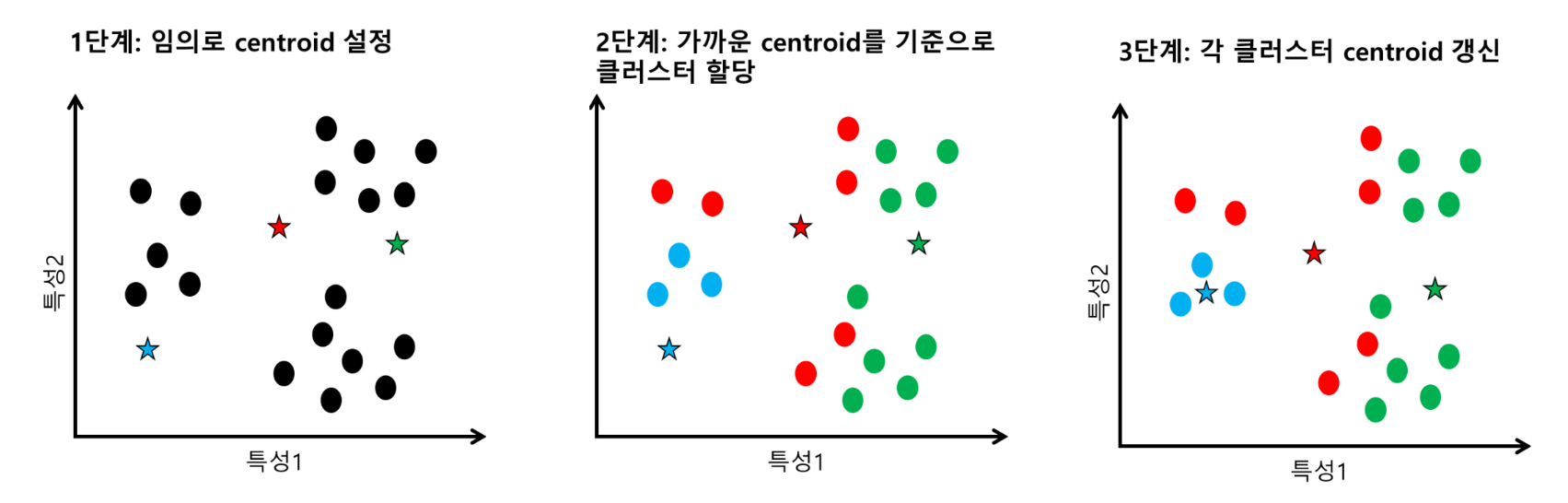
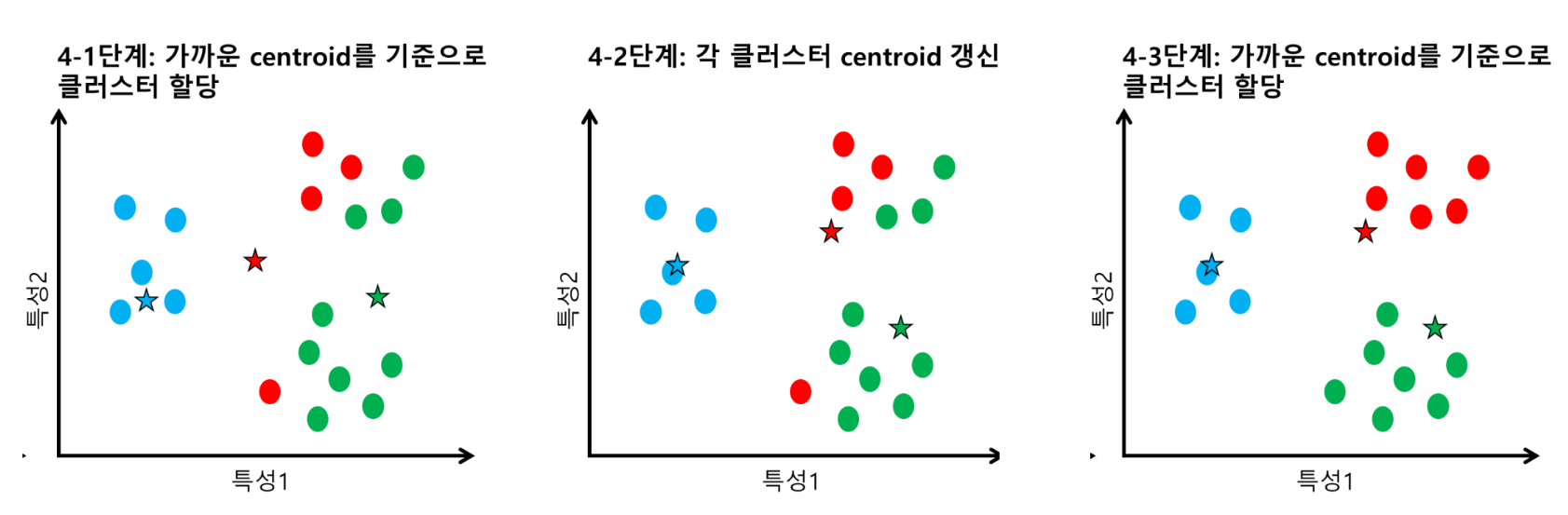
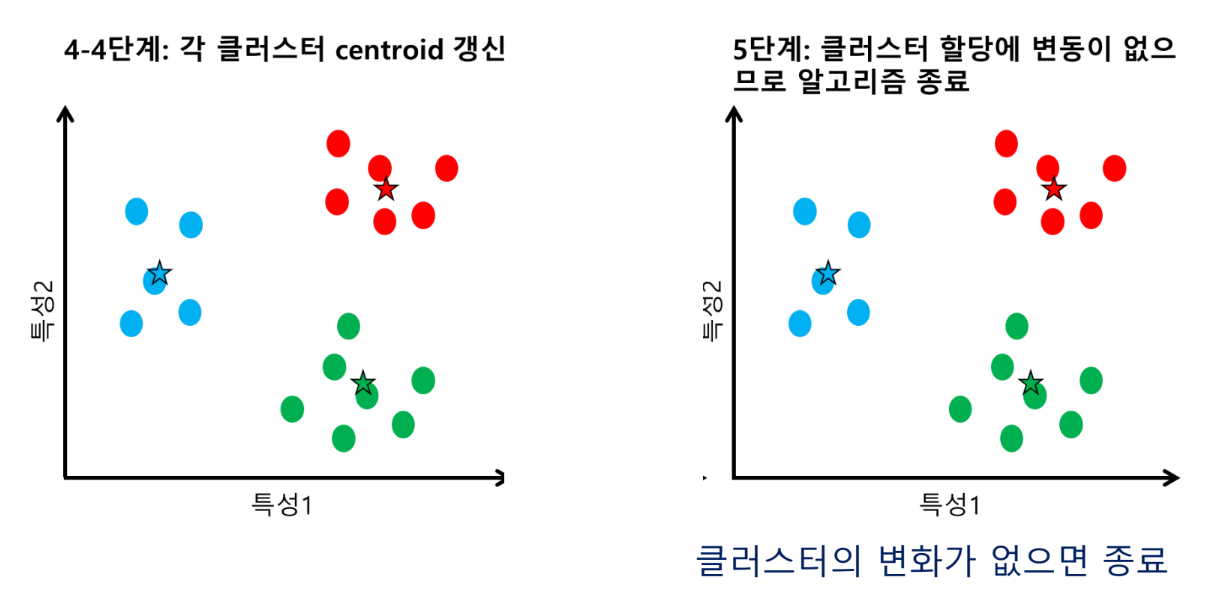
분할적 군집 - K-means Clustering
가장 일반적으로 사용되는 분할적 군집 알고리즘
중심점에 기반한 분할적 군집 알고리즘: 거리의 평균을 적용
클러스터링의 개수(K)를 미리 정하고, 초기 중심점을 설정한 후 알고리즘에 따라 중심점 갱신을 반복함

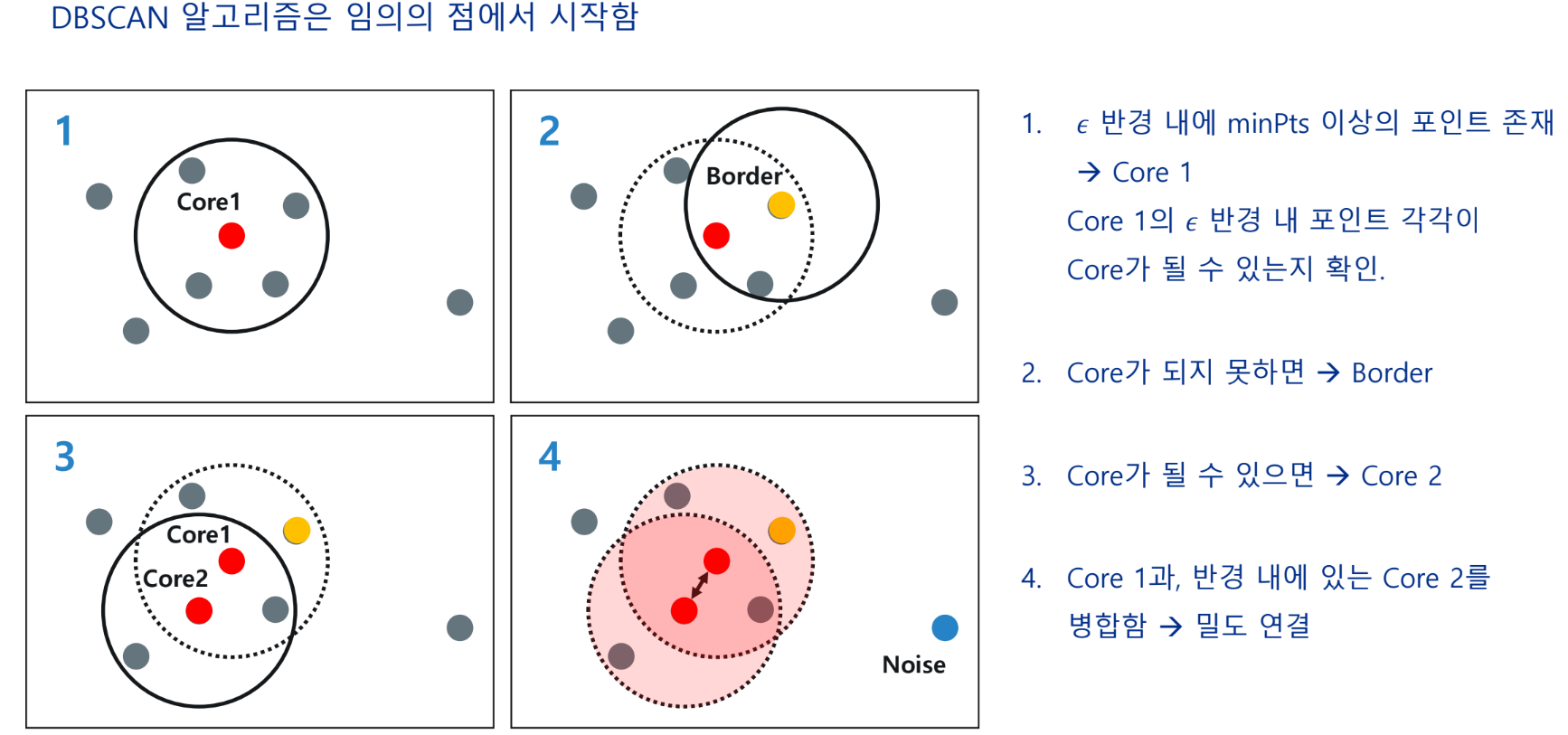
분할적 군집 - DBSCAN Clustering
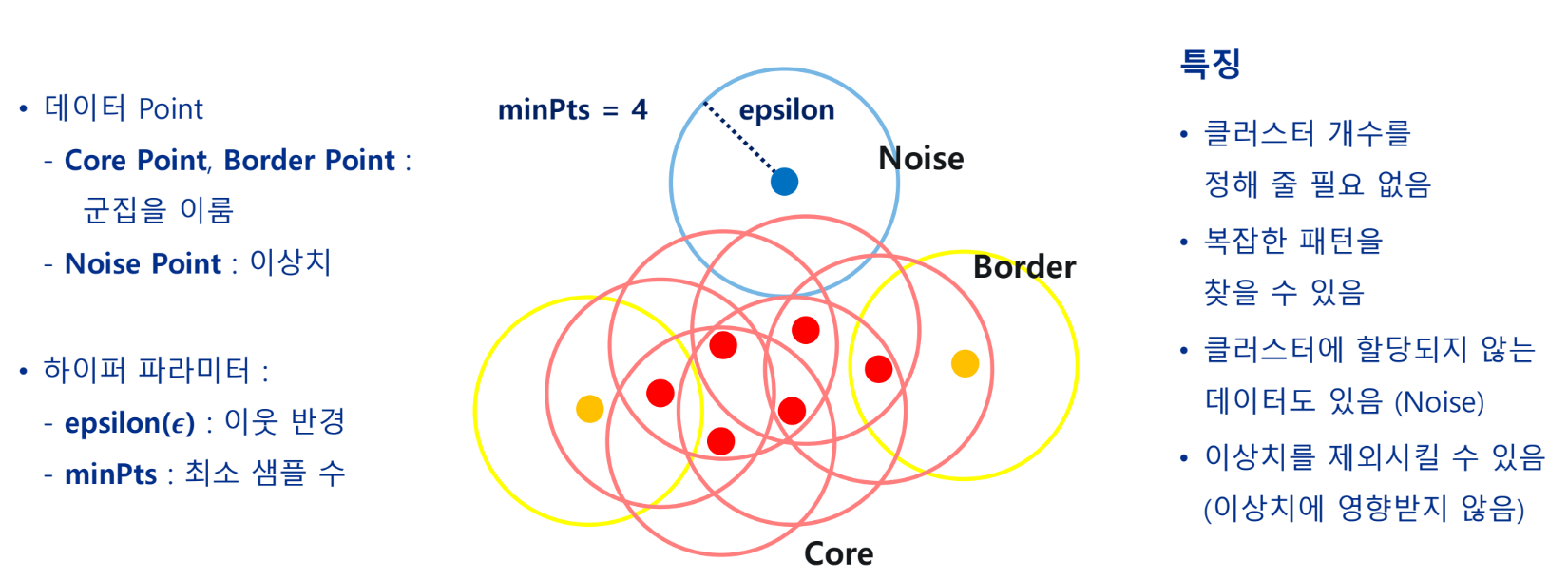
Density-Based Spatial Clustering of Applications with Noise
- 밀도의 개념으로 군집을 형성(높은 밀도)
- 군집 결과를 통해 noise 제거 가능(낮은 밀도)
- 밀도로 연결된 임의의 패턴을 찾음
- 희박한 데이터에 대한 성능 좋지 않음(고차원 데이터에 저성능)