
실습 이어서(군집 MLD 프로야구선수)
분할적 군집 - K-means Clustering(초기화)
K-means 군집화는 초기 centroid의 위치에 따라 군집 결과가 달라질 수 있다.
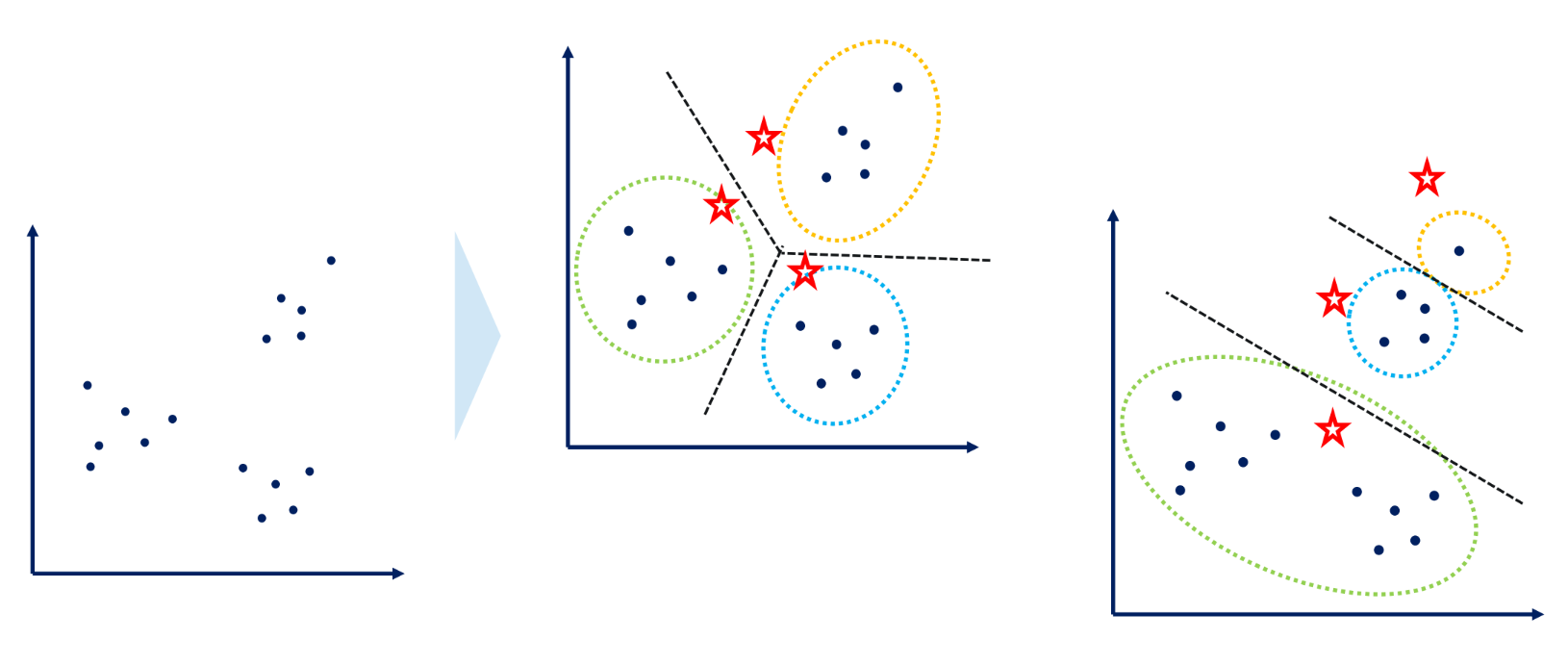
우측은 좋은 군집이 아니다.
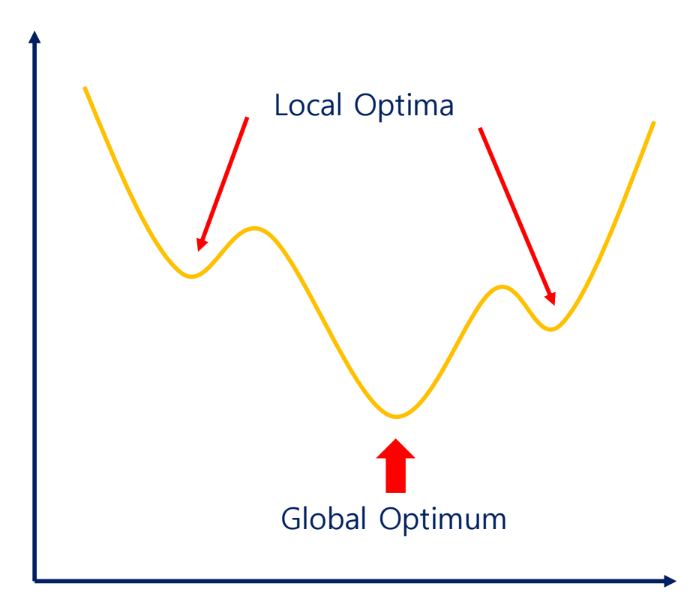
초깃값에 따라 local optima에 빠질 수 있음
Random seed
가장 많이 사용되는 초기화 방법
- 임의의 초기화 점을 선택함
- 초깃값에 따라 좋지 않은 군집 결과 생성 가능
K-means++
초기 centroid들이 최대한 서로 멀리 떨어지도록 선택
- 첫번째 centroid 랜덤 선택
- 나머지 centroid는 기존 centroid와 먼 점으로 선택
- 단순히 유클리드 거리로 가장 먼 거리의 점을 centroid로 고른다.
→ Random seed보다 빠르게 수렴
분할적 군집 - K-means Clustering(군집 수 결정)
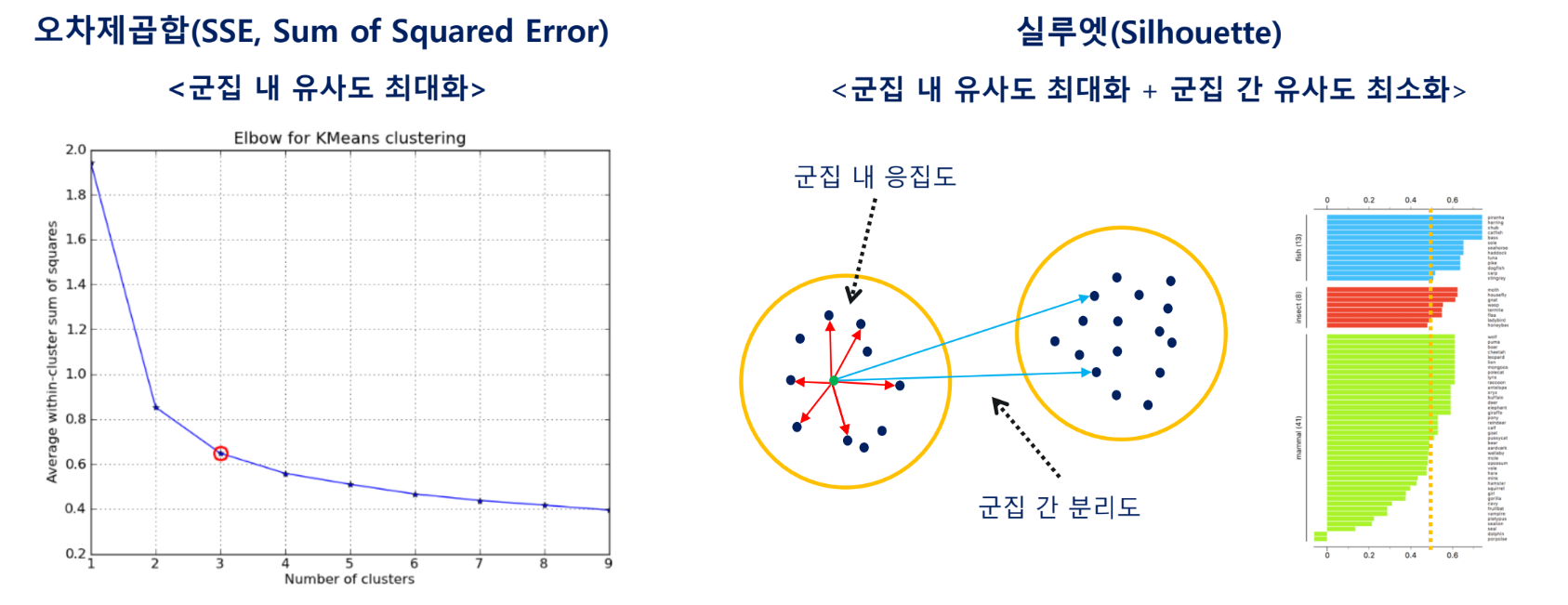
적당한 수의 의미있는 군집을 표현하는 K 결정 필요
K-means의 군집화 결과를 판단하는 방법: SSE, 실루엣
오차제곱합
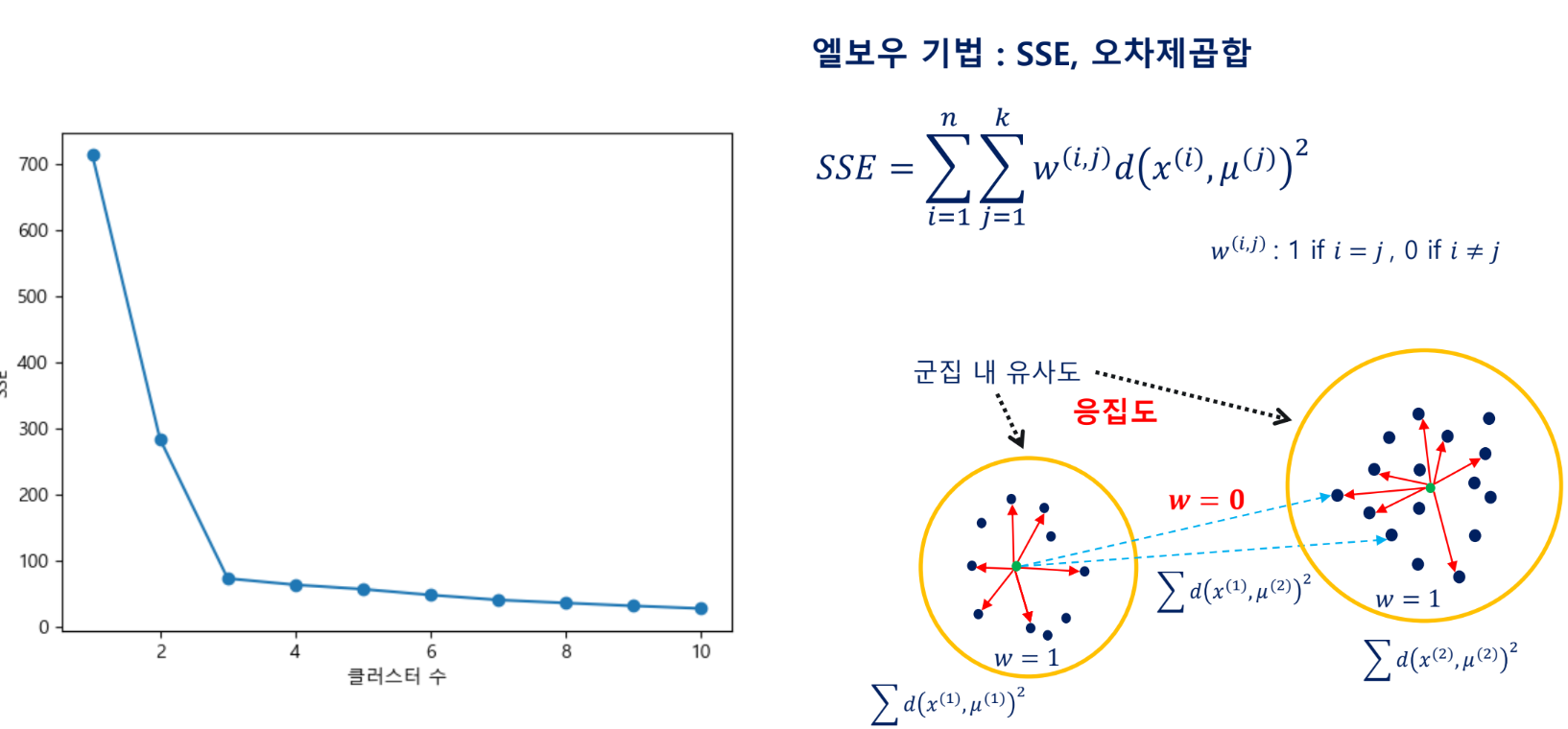
거리의 제곱을 해서 제곱합. 이걸 n으로 나누면 이제 MSE가 됨
실루엣
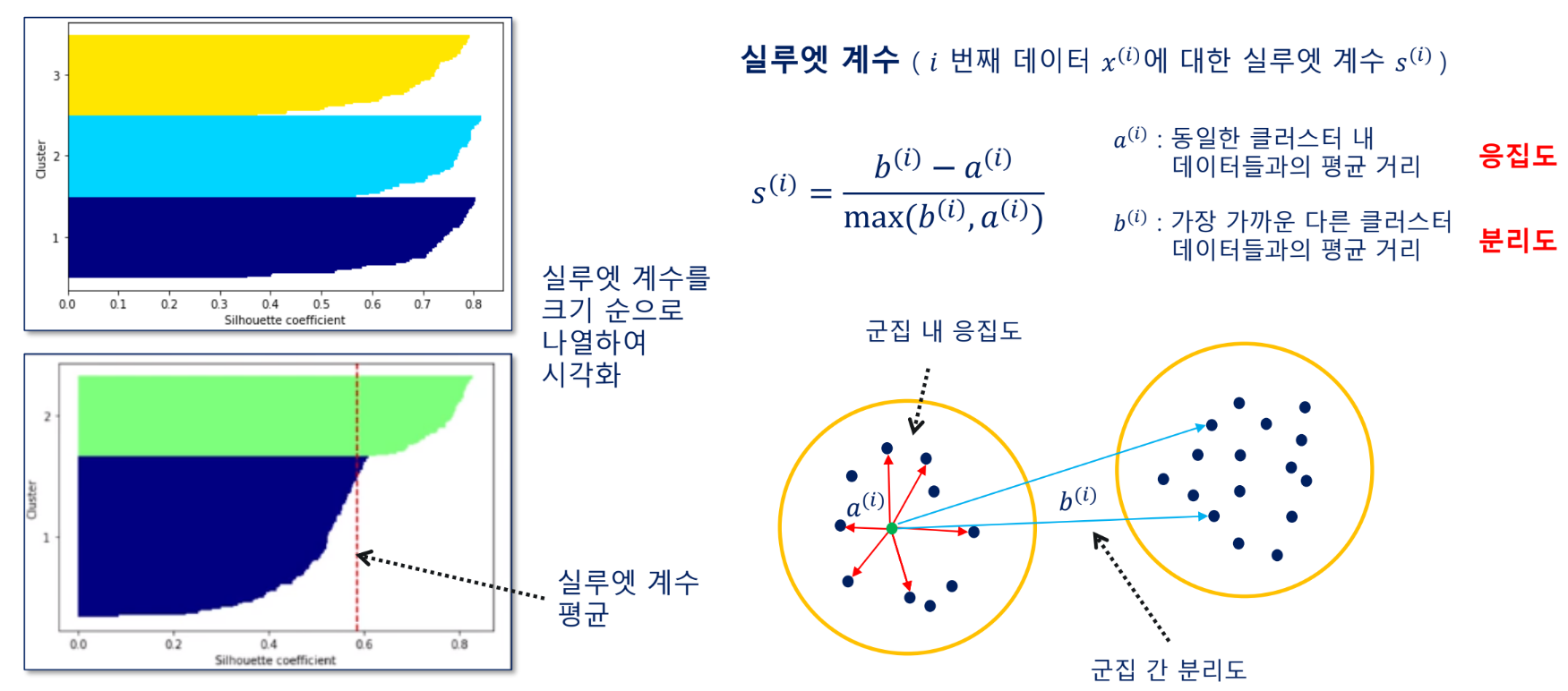
좌측 실루엣차트에서 통통해야 좋은 군집
데이터 수집/이해
KBO 에서 과거 선수들의 기록에 대한 기초적인 데이터 제공
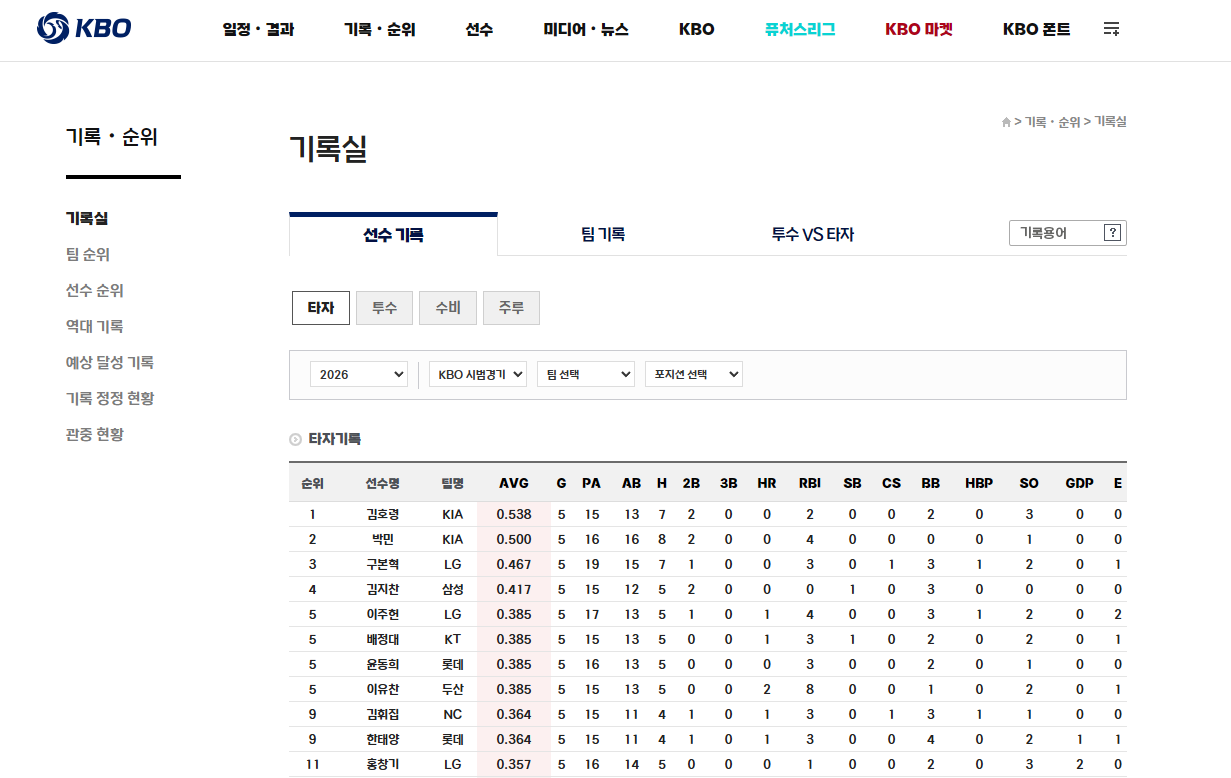
KBO
데이터 다운로드 등의 기능을 제공하지 않으므로, 잘 긁어서 복붙해야 한다
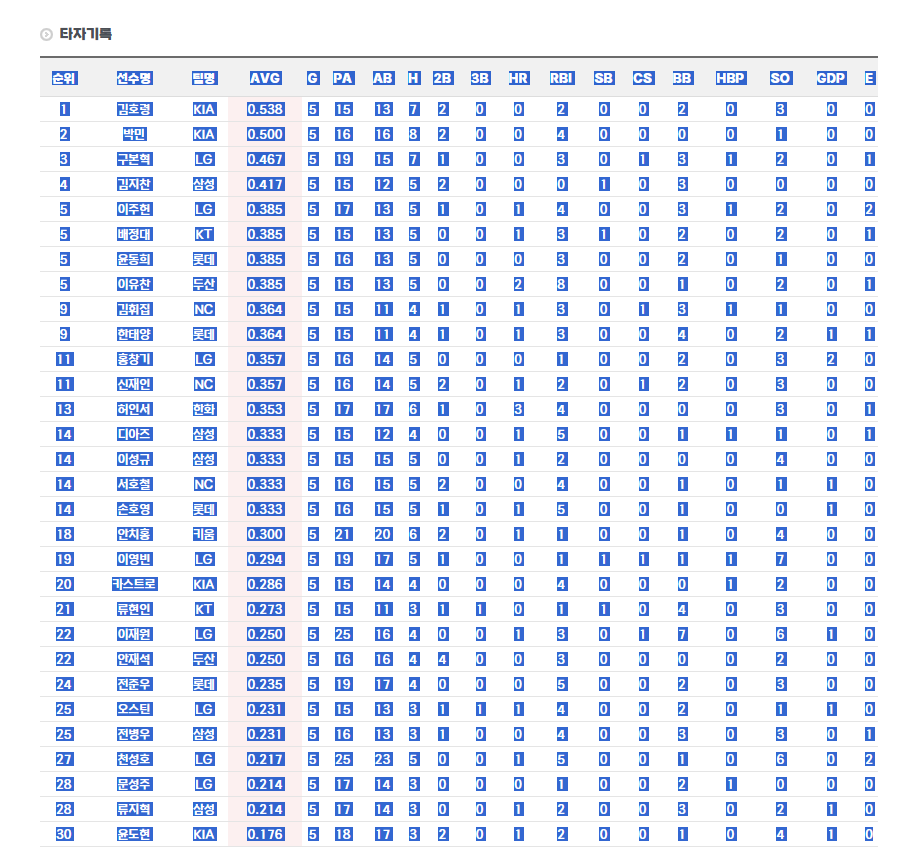
컬럼명까지 잘 긁자
다만 Web Scraping한 데이터를 상업용으로 사용하면 법적 분쟁이 발생할 수 있으니 주의하자.
데이터 일관성 문제
연도에 따라 제공 데이터 종류가 달랐다.
2002년부터 SB(도루), CS(도루실패) 기록이 '주루기록'으로 이동함
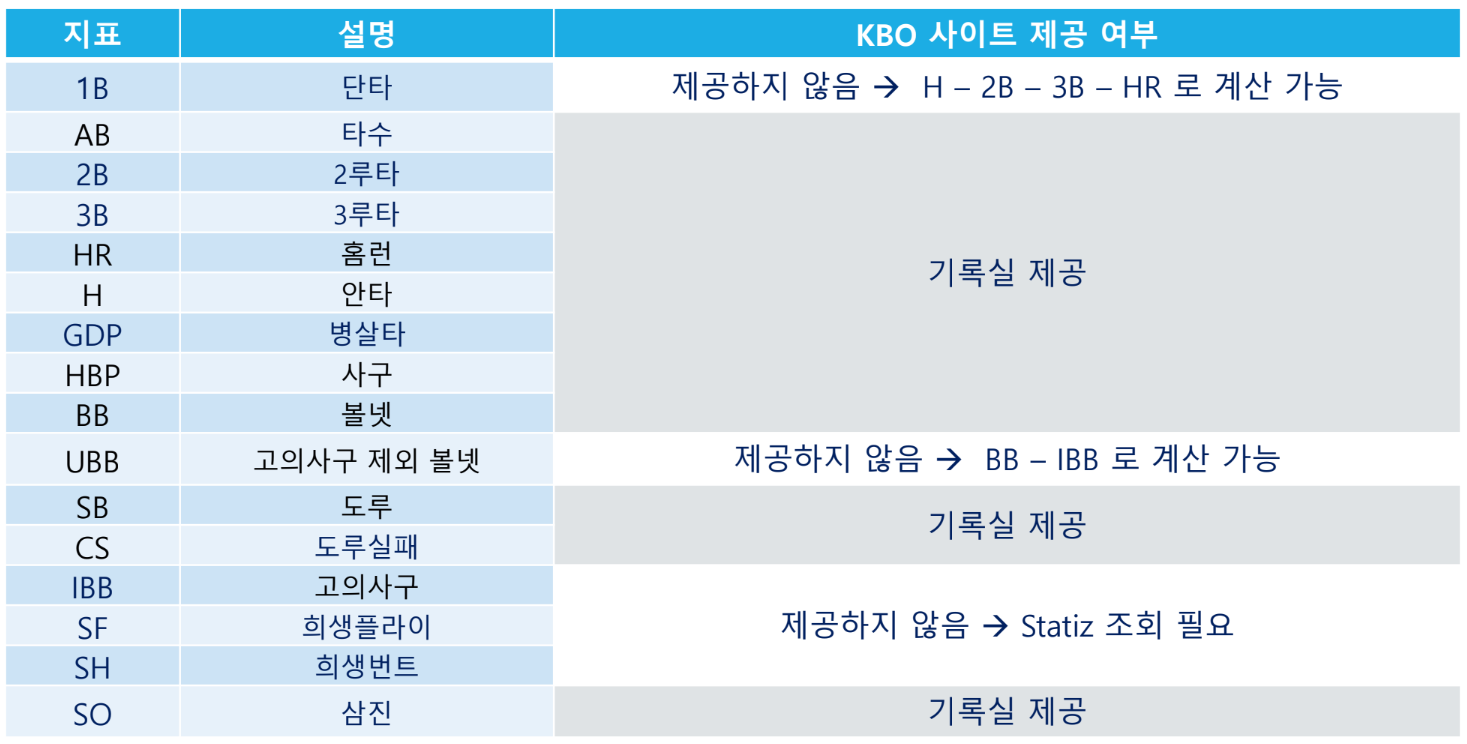
데이터 정리
스크래핑한 데이터를 csv 파일로 만들어야 한다.
1. KBO Scraping 하여 csv 만들기
2. 한글 컬럼명 → 영문화
3. 컬럼 추가
- SF, SH, IBB 컬럼: Statiz 데이터로 채움
- 1B 컬럼: 계산하여 채울 예정
- Year 컬럼: 해당 연도로 채움
- YrPlayer 컬럼: 선수 이름의 연도 별 구분
- Sabermetrics 컬럼들: TB, OBP, SLG, OPS, ISO, SECA, TA, RC, RC/27, wOBA, XR 컬럼
컬럼을 새로 추가하는 과정을 Machine Learning Designer에서도 할 수 있음
Sabermetrics 계산 및 데이터 병합
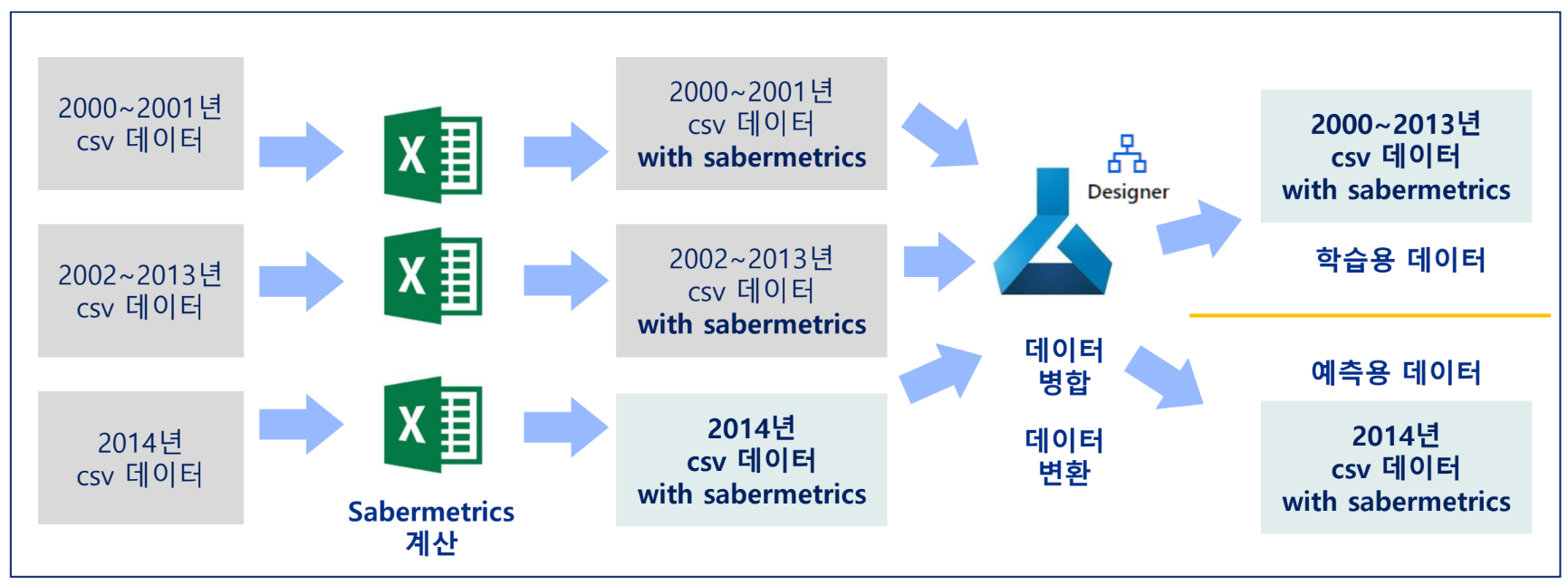
데이터 ML에 업로드

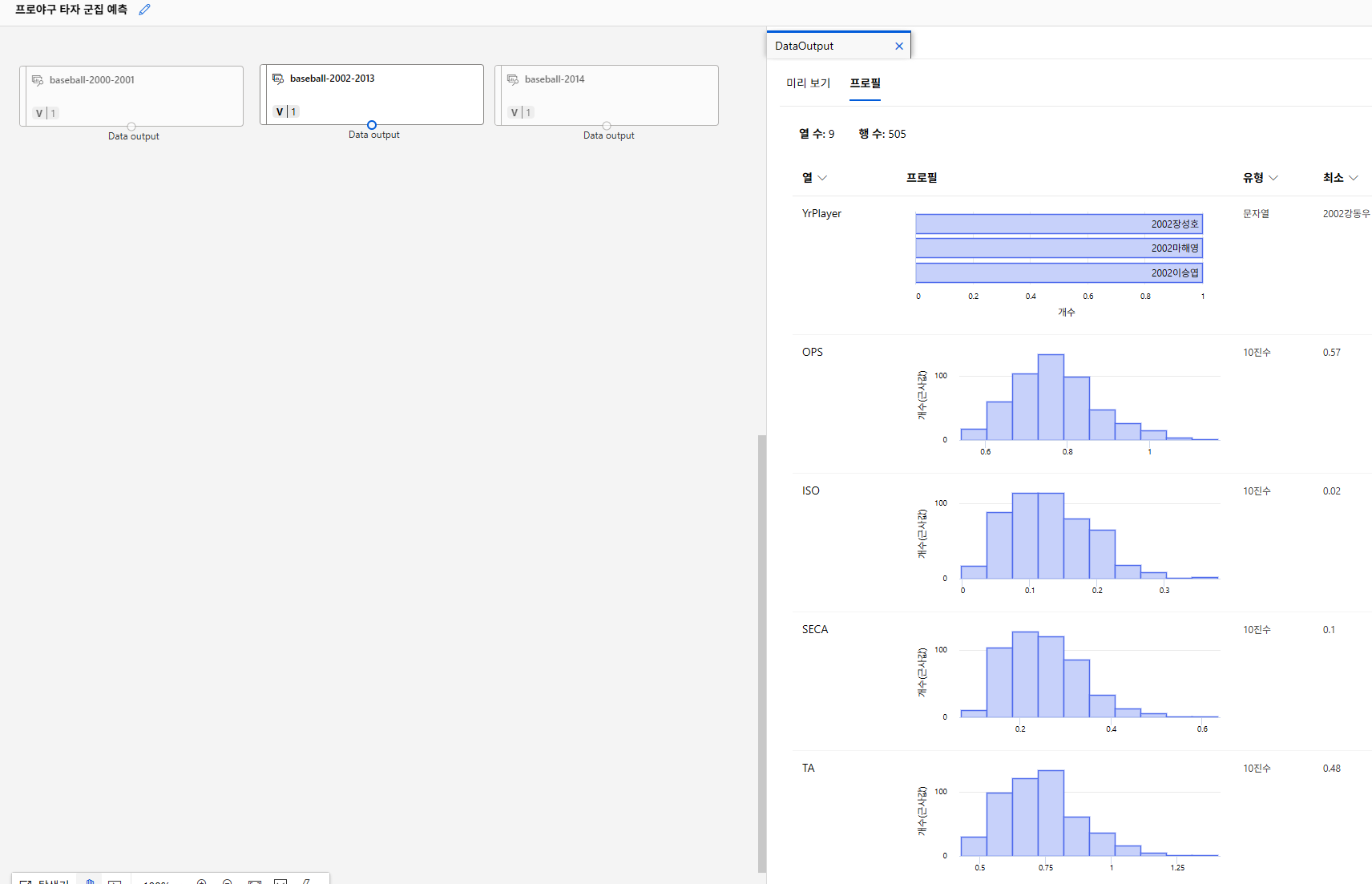
대부분의 컬럼이 양의 왜도를 보이며, 각 컬럼의 범위가 다름
데이터 준비
데이터 병합(merge)
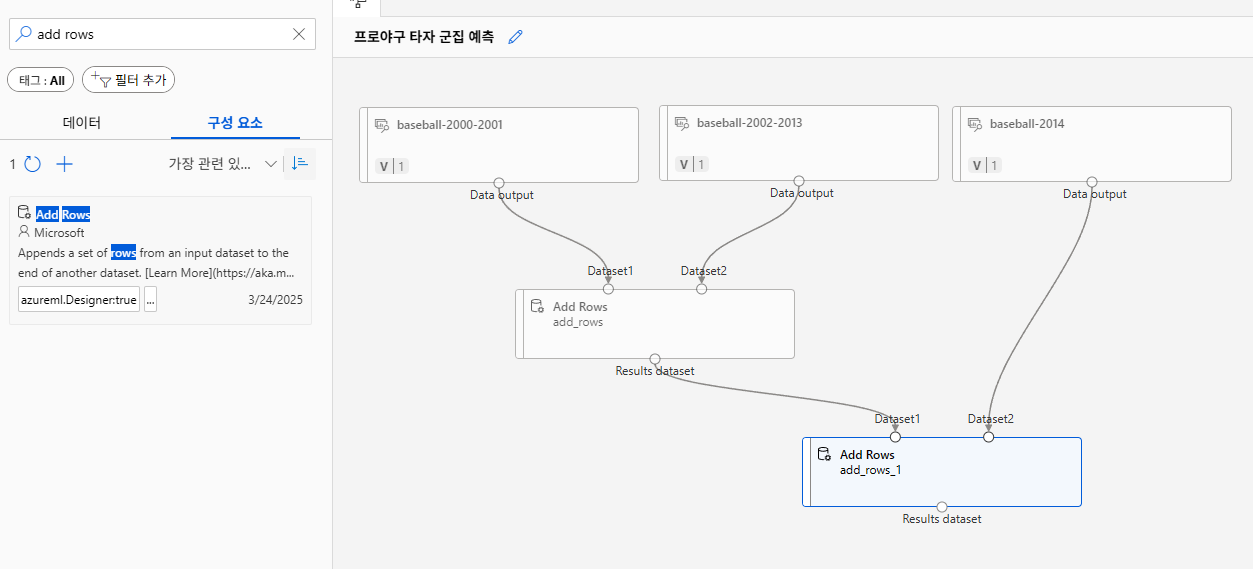
수치 데이터 표준화
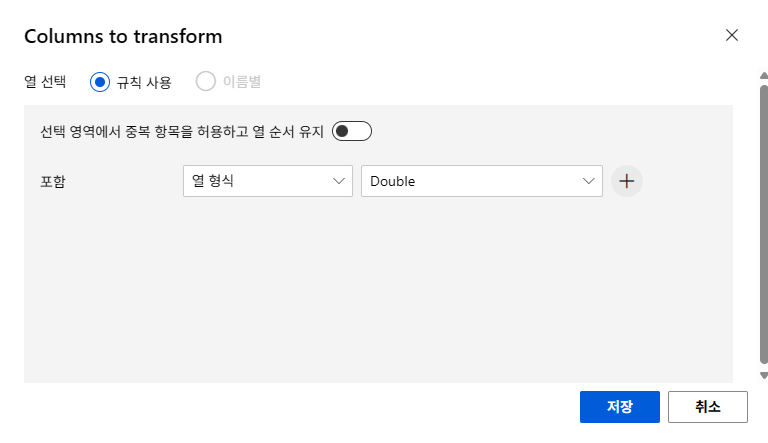
주성분 분석(PCA)
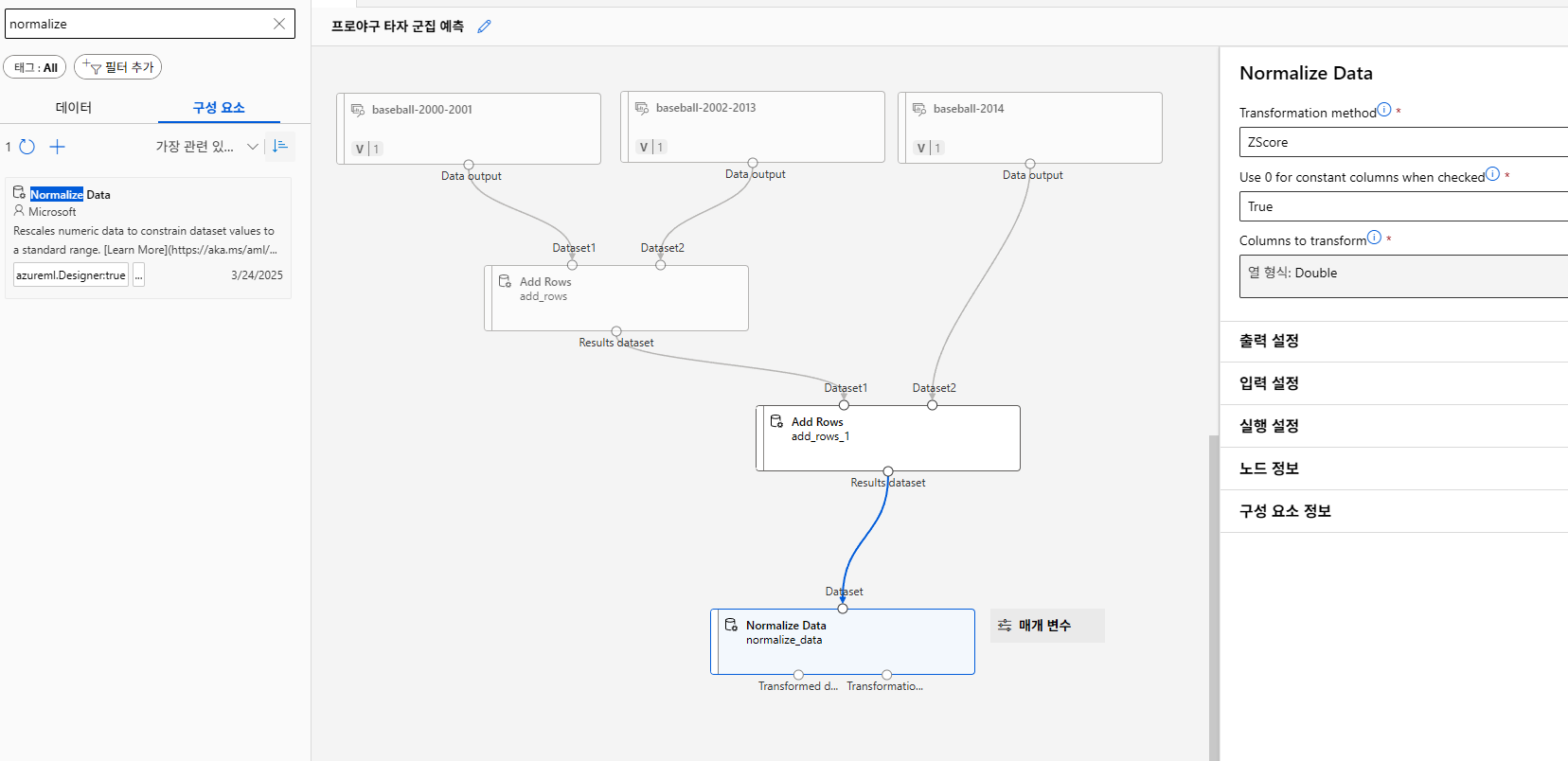
주성분을 기존 feature의 수만큼 찾은 후 몇 개의 차원으로 축소할지 결정
5단계
- 표준화
- 공분산 행렬 계산
- 주성분 계산
- Feature Vector 생성
- 데이터 조정
python 코드 이용
MLD에서는 주성분 분석이 지원되지 않으므로, python 스크립트로 처리한다

주의가 뜬건 직전에 설명이 아닌, 노드 이름에 "PCA 주성분 8개 찾기"를 썼기 때문이다. 설명에 쓰도록 하고, 새로고침하면 문제는 사라진다.
노드 이름은 수정하면 오류 발생할 수 있어서 그냥 두고 주로 코멘트작업만 한다고 하셨다.

주성분 확인
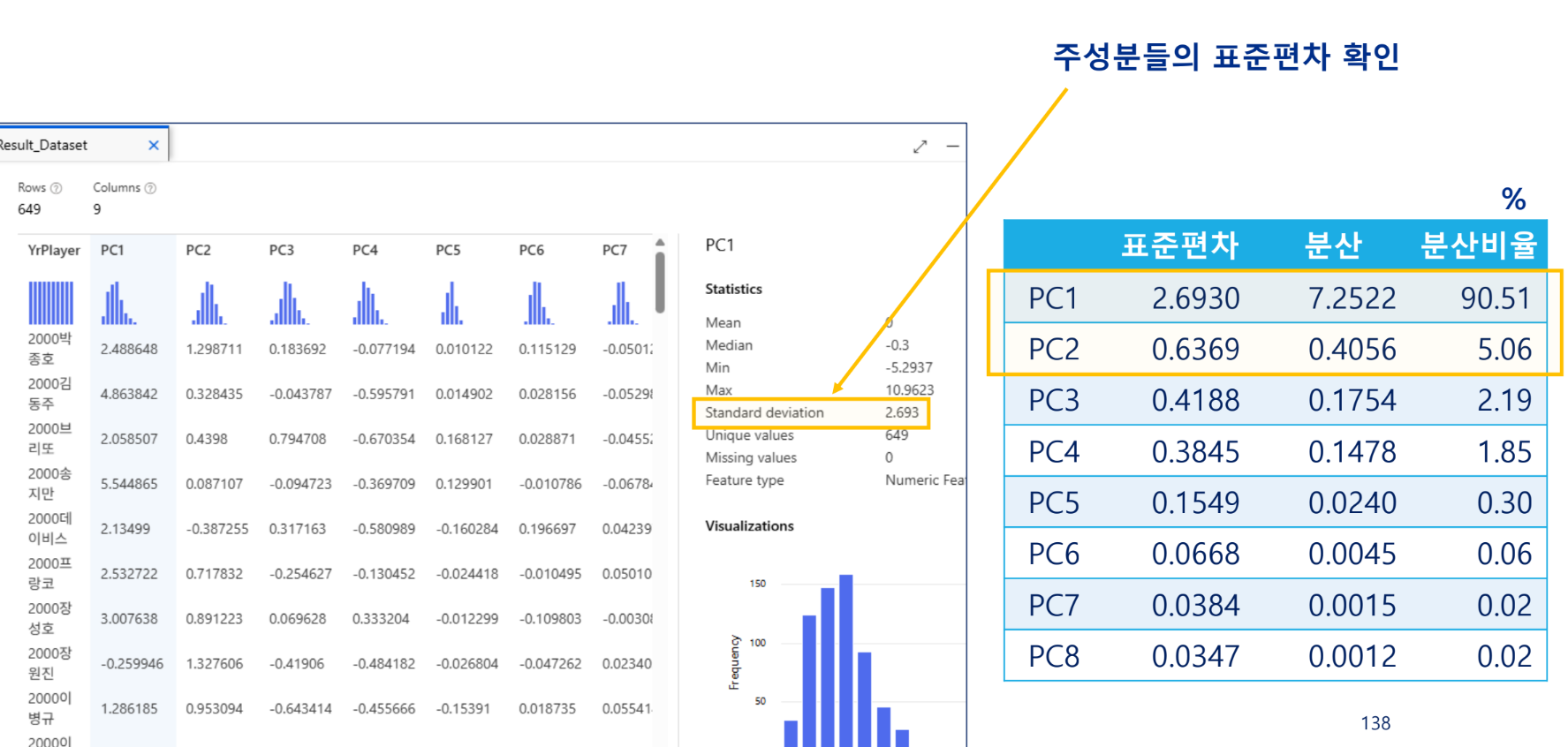
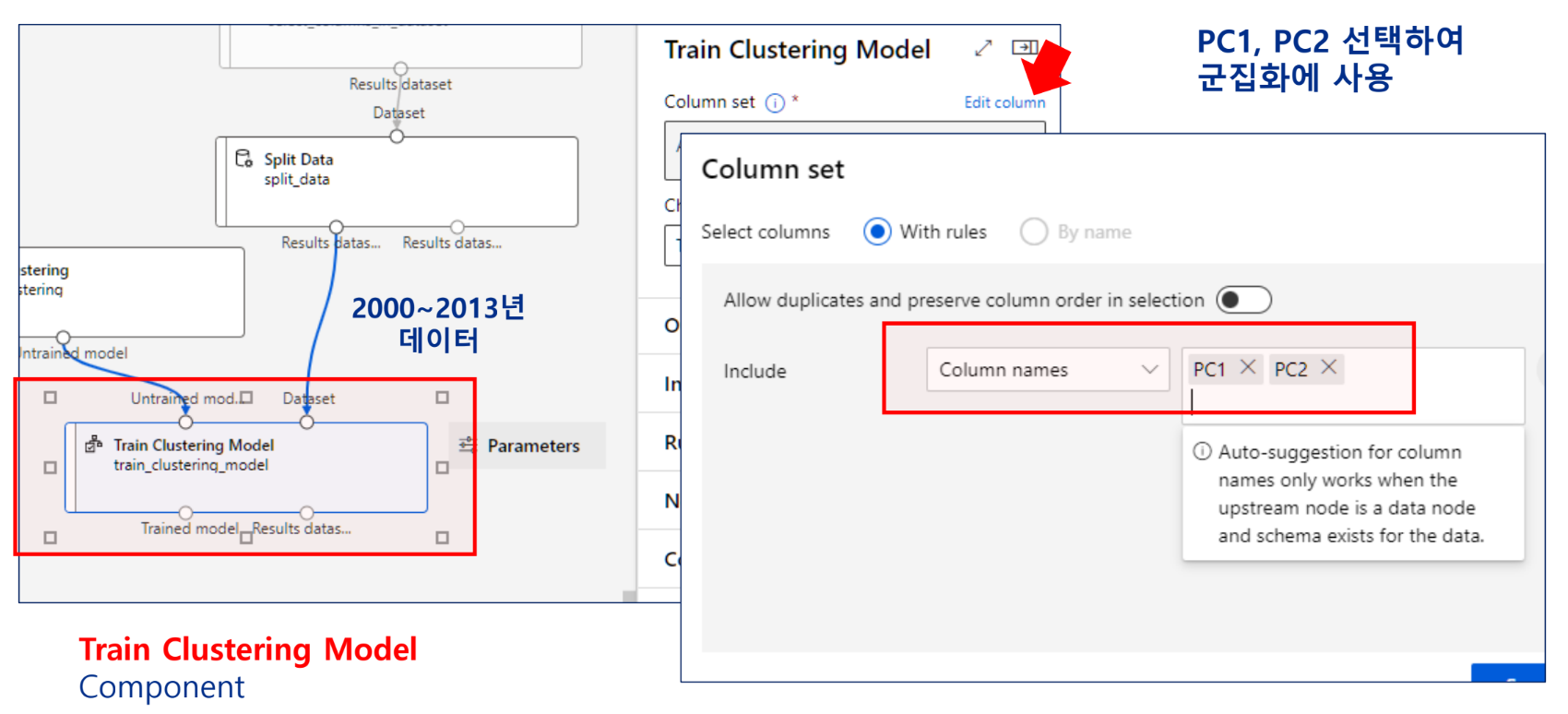
주성분 선택
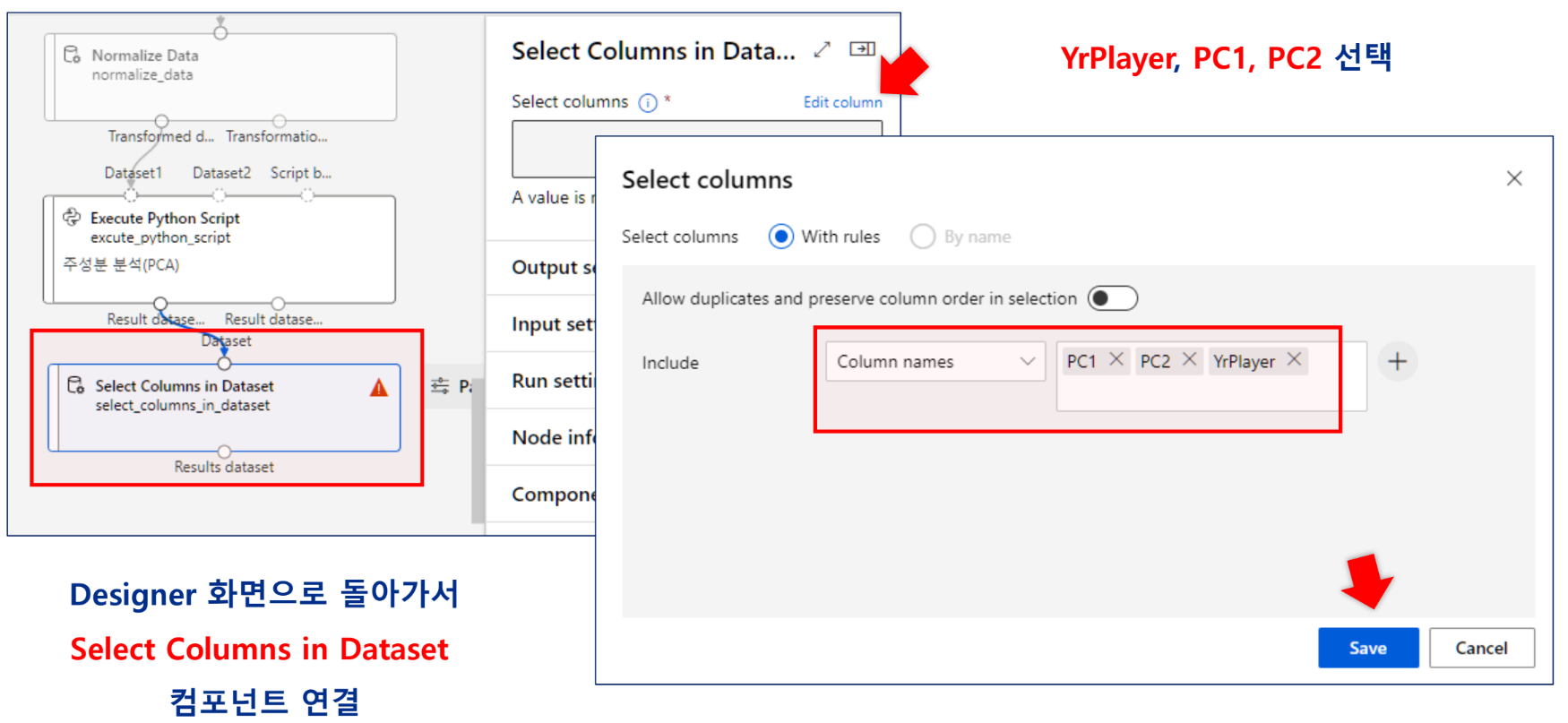
데이터 분리
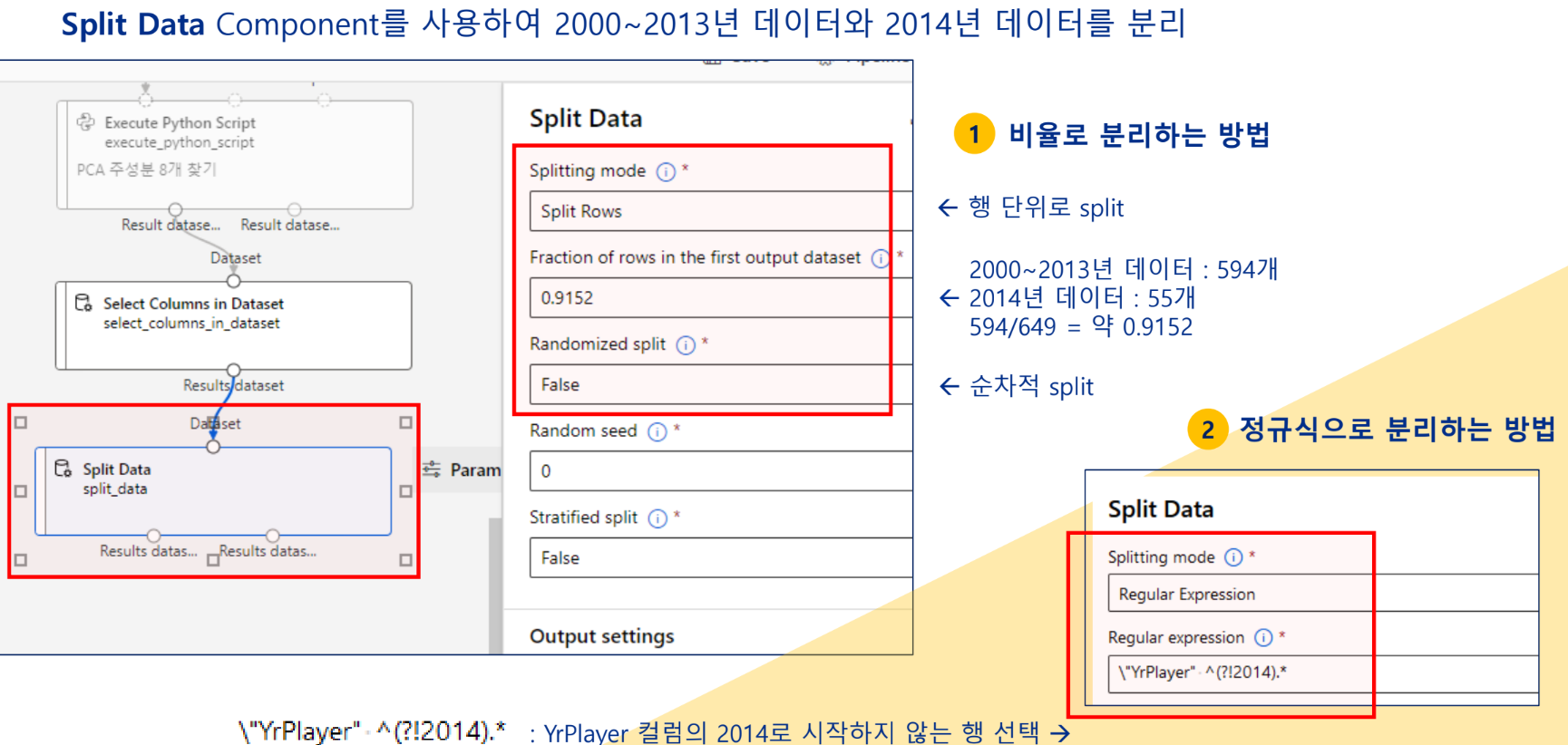
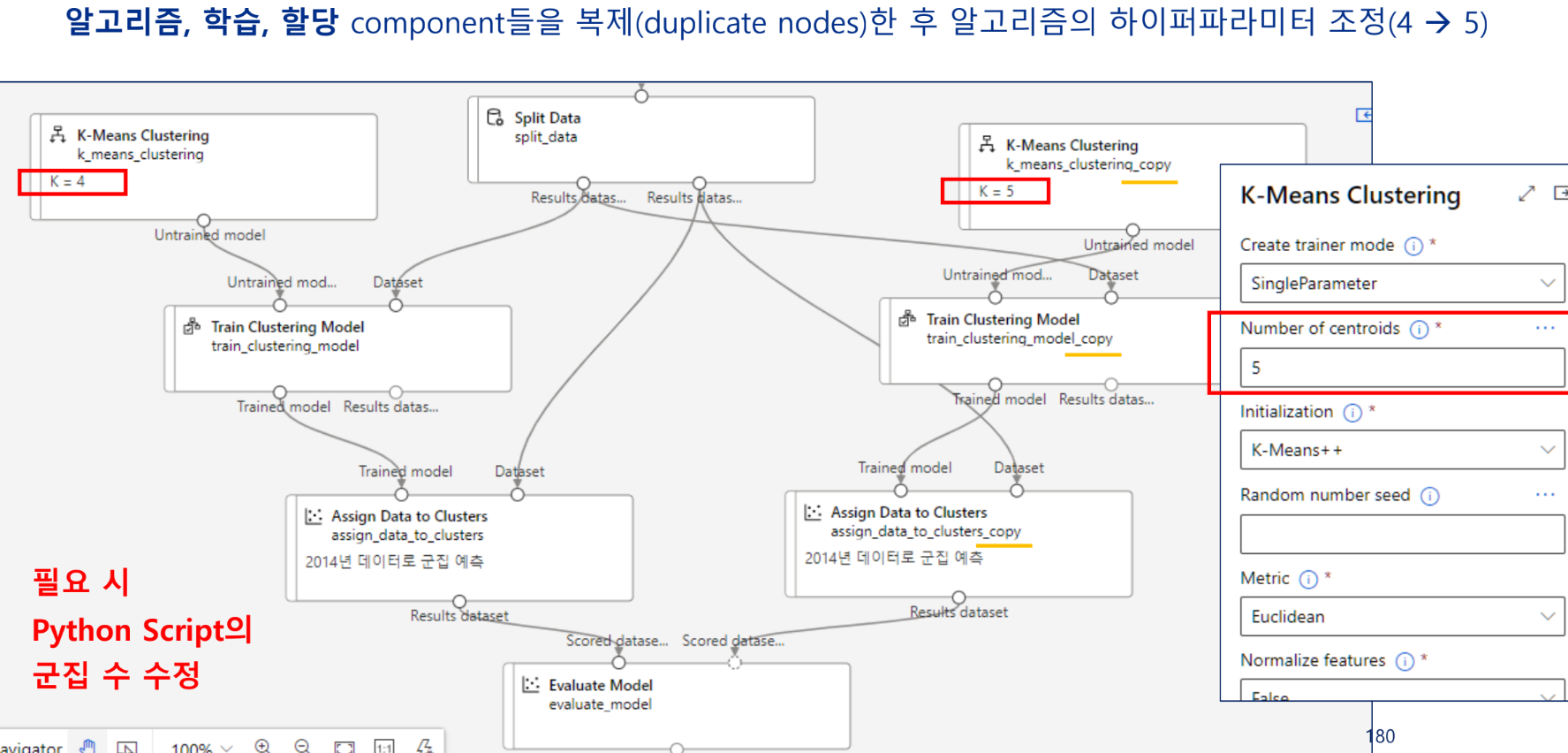
알고리즘 및 하이퍼 파라미터
K-means 알고리즘 선택
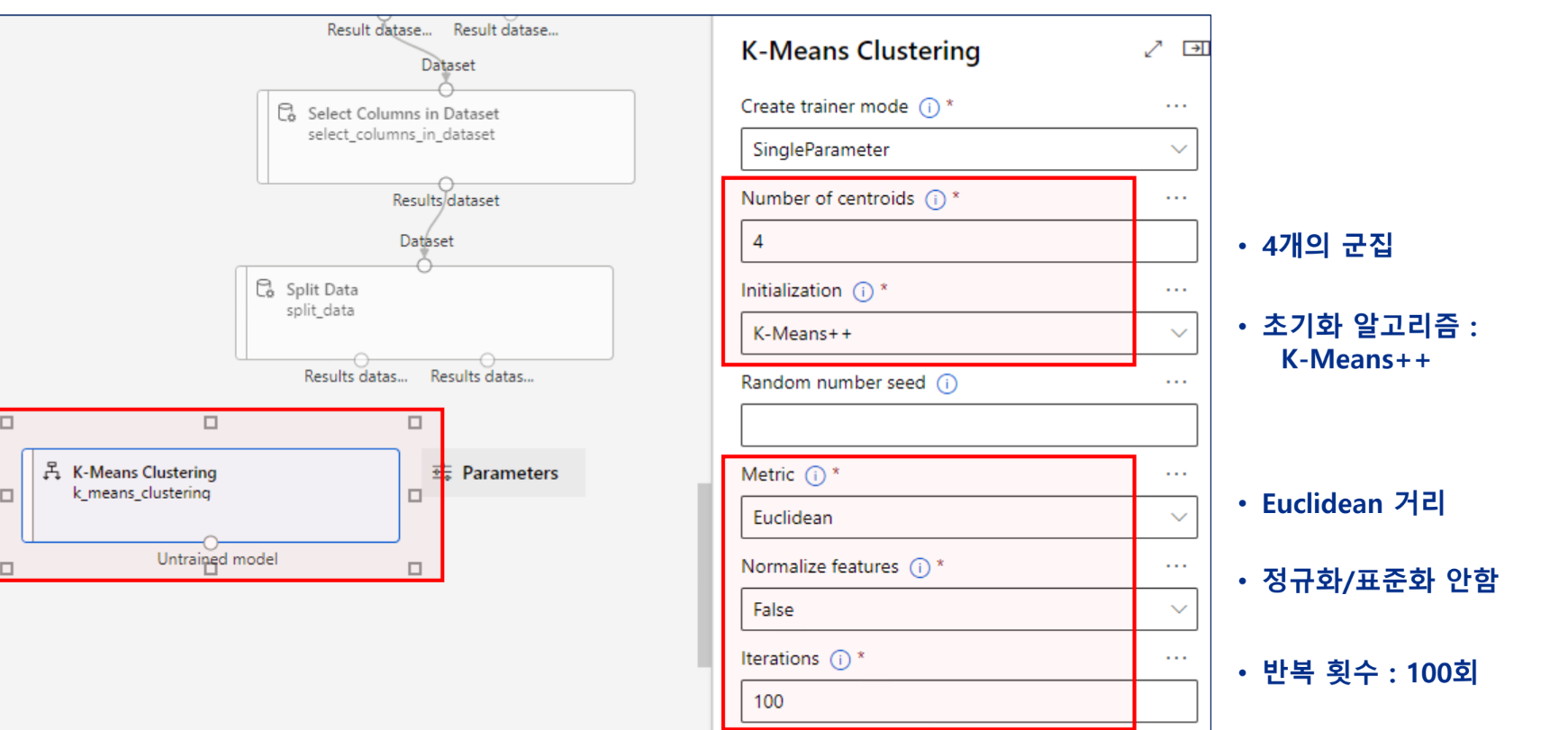
모델 학습
모델 테스트(예측)
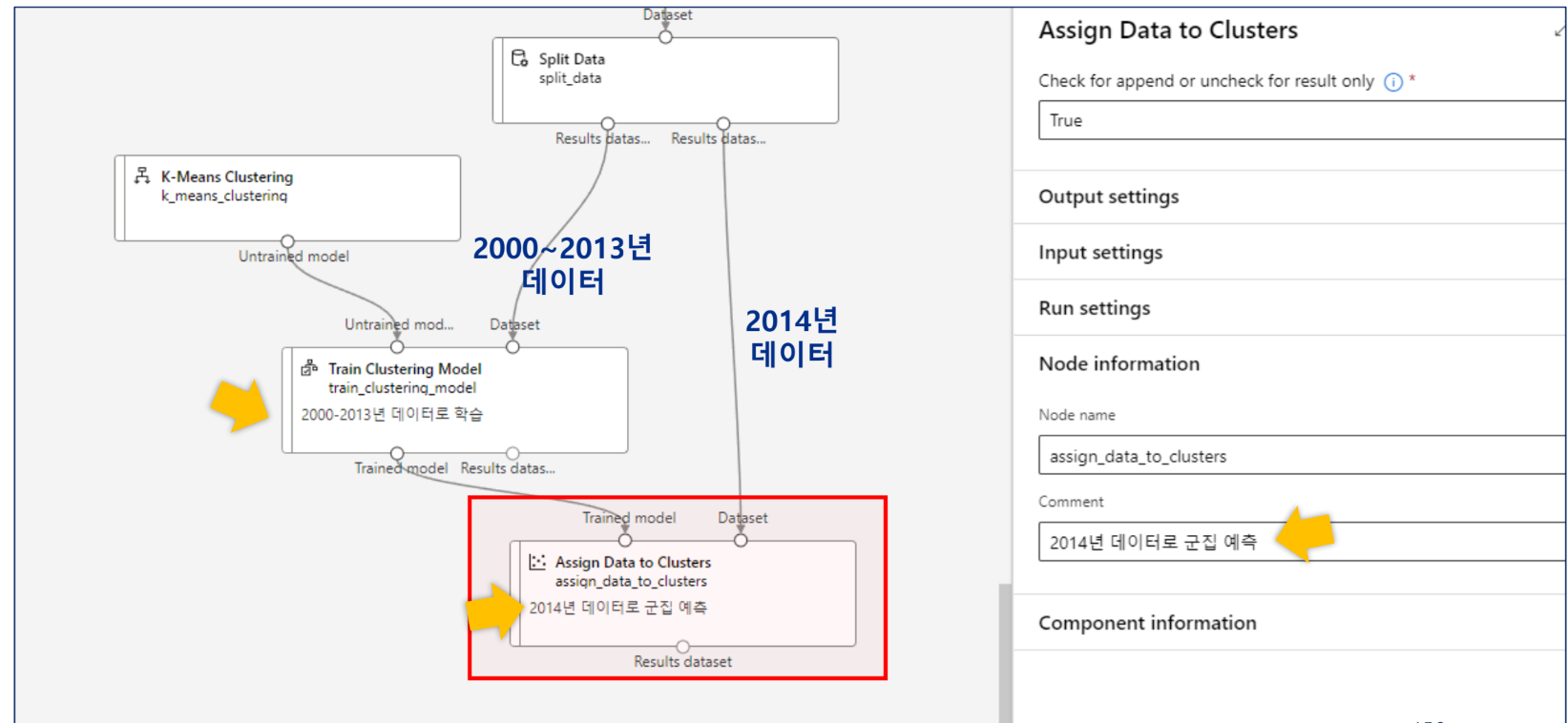
Train -> 기존 데이터를
Assign -> 신규 데이터를
Assign은 유추 파이프라인 구축 시 사용한다.
모델 평가
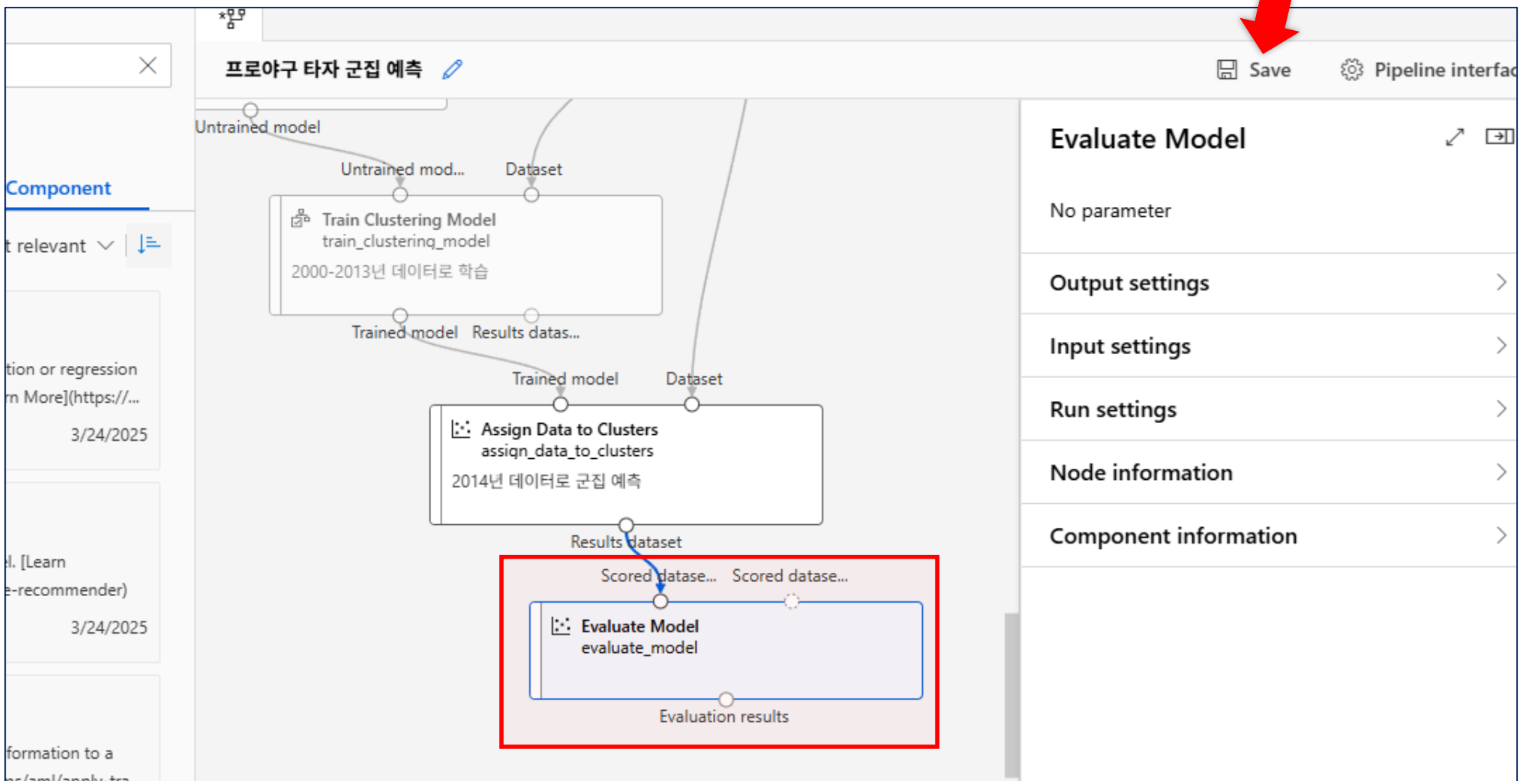
evaluate는 지도/비지도에 모두 쓰인다.
군집 결과 확인
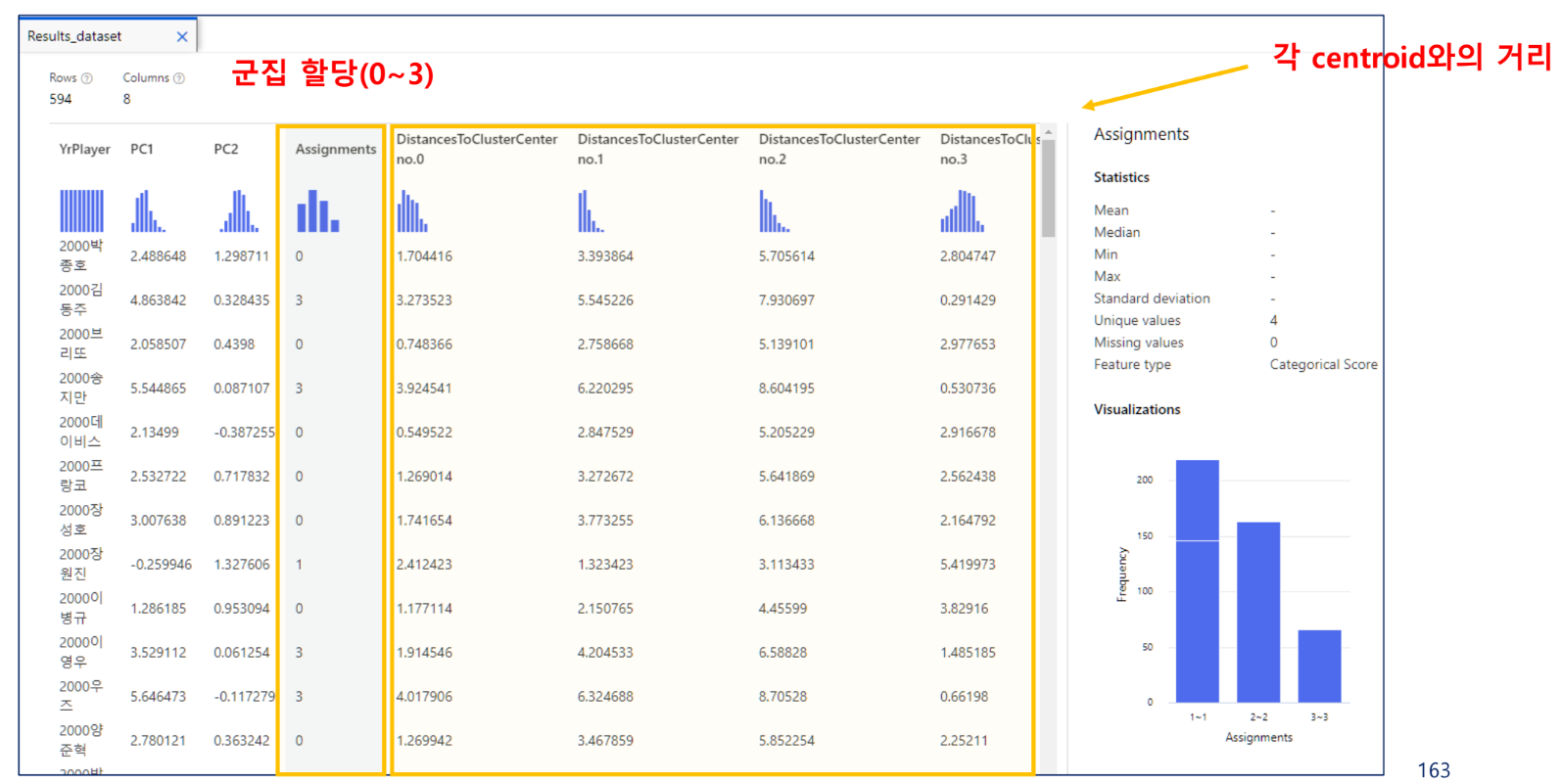
군집 예측 결과 확인
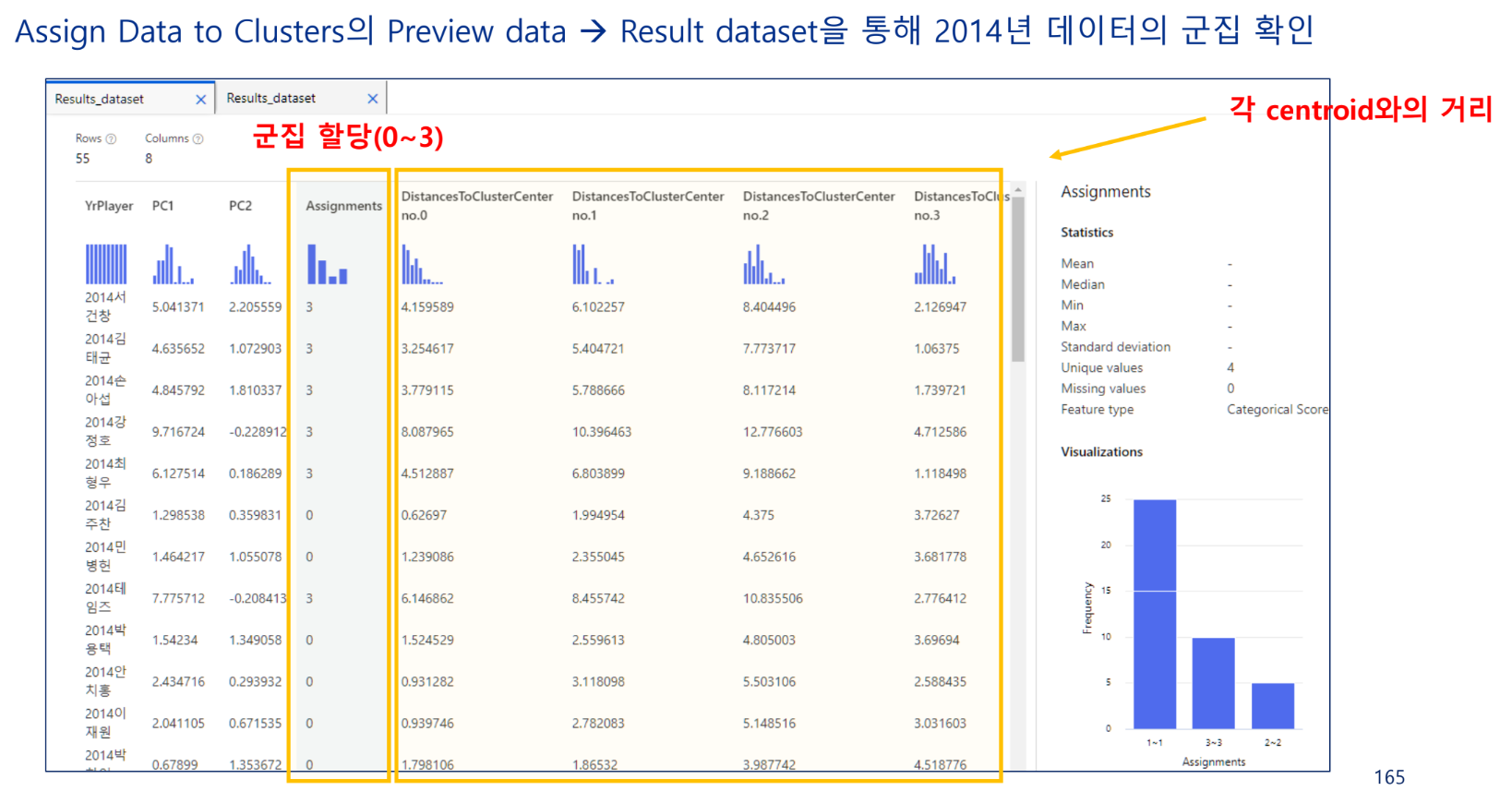
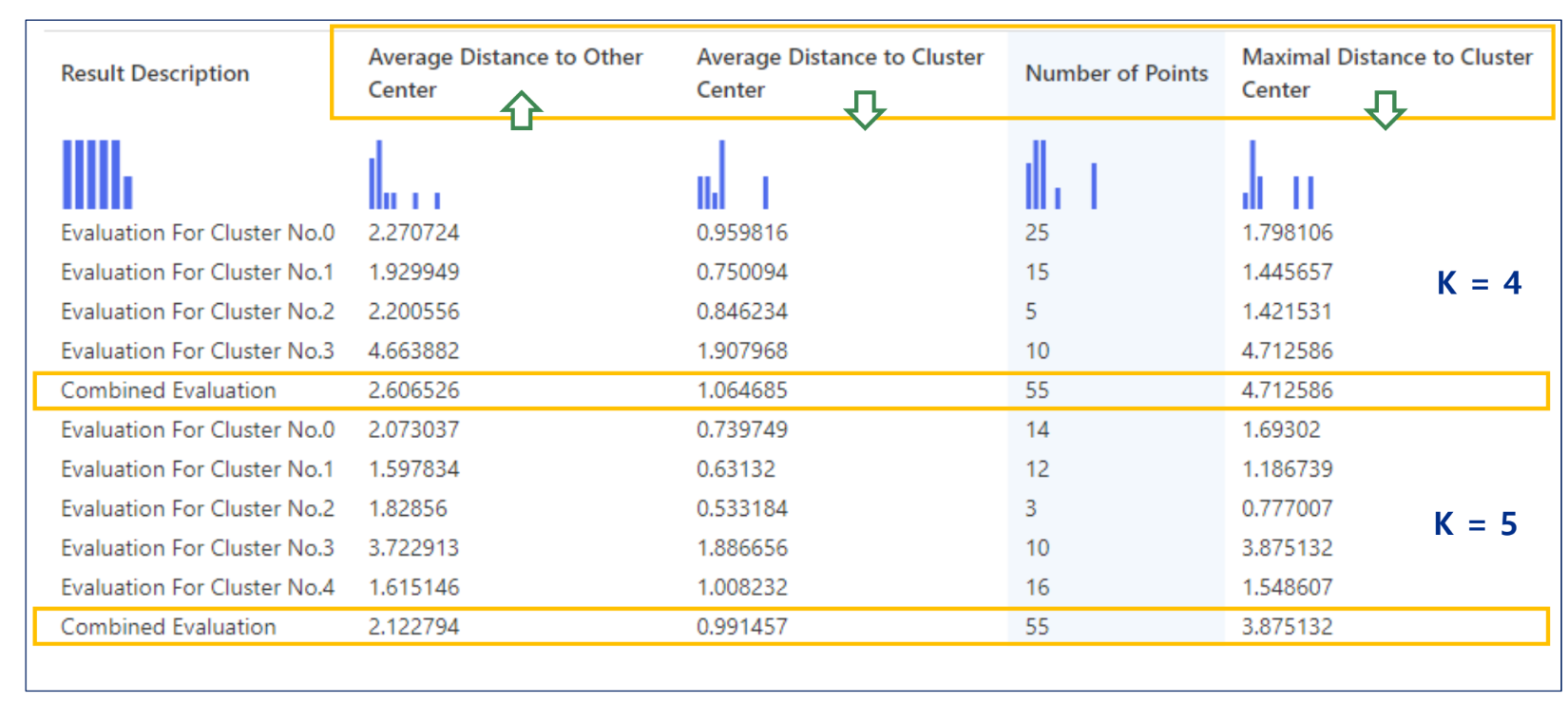
클러스터를 4개를 만들라 했기 때문에 DistancesToClusterCenter은 4개가 존재
군집 모델 평가 결과 확인
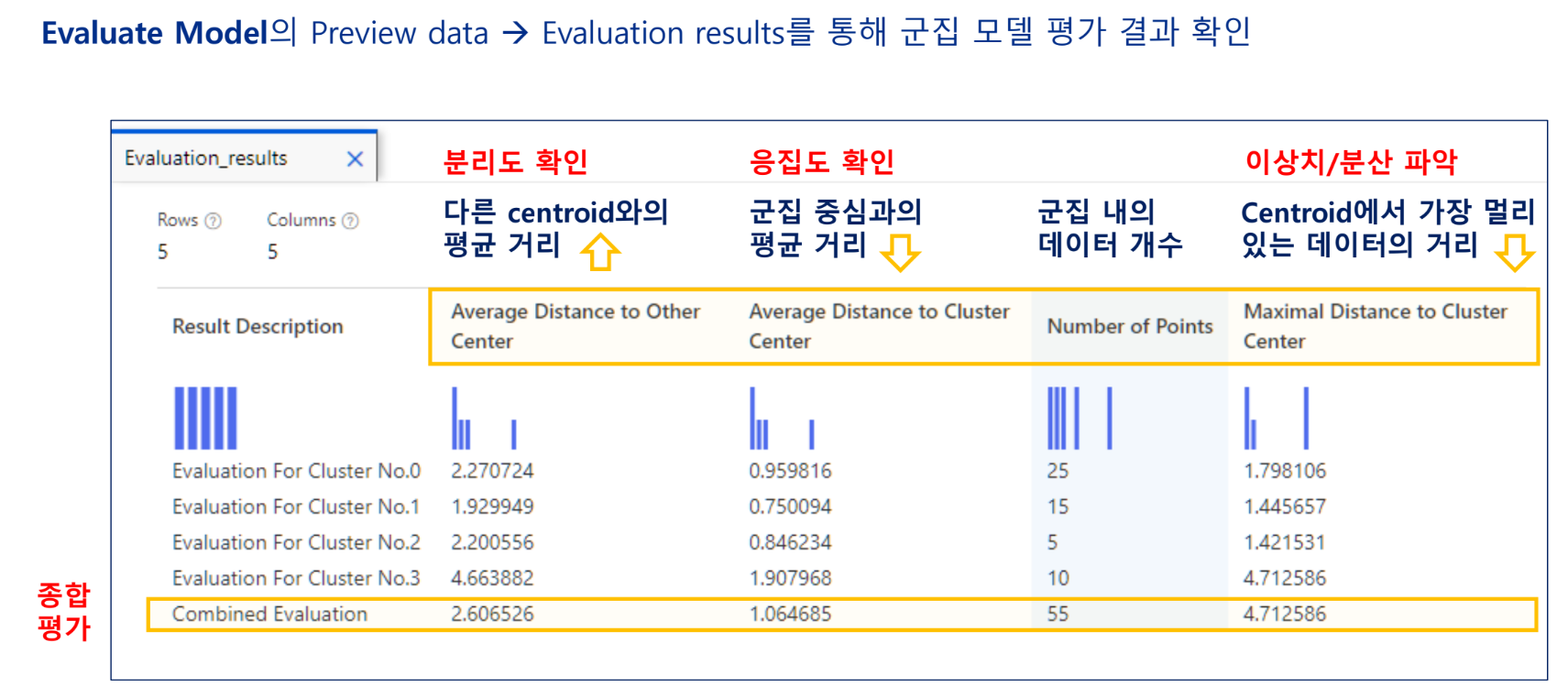
Average Distance to Other Center: 클수록 좋음
Average Distance to Cluster Center:작을수록 좋음
추가 실습 - 산점도 및 실루엣
군집화 결과 병합
python script
#산점도
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from azureml.core import Run
def azureml_main(dataframe1 = None, dataframe2 = None):
df = dataframe1.copy()
colors = ['blue', 'red', 'green', 'purple'] # 군집색상 정의 (K = 4)
cluster_names = [f'Cluster {i}' for i in range(4)] # 군집이름
plt.figure(figsize=(10, 8)) # 시각화 시작
for cluster in range(4): # 군집별 산점도 그리기
cluster_data = df[df['Assignments'] == cluster]
plt.scatter(
cluster_data['PC1'], cluster_data['PC2'],
c=colors[cluster], label=cluster_names[cluster], alpha=0.7, s=100
)
plt.title('Cluster Analysis: PC1 vs PC2', fontsize=15)
plt.xlabel('Principal Component 1 (PC1)', fontsize=12)
plt.ylabel('Principal Component 2 (PC2)', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(fontsize=10)
plt.axis('equal') # 가로축과 세로축의 스케일 맞춤
img_file = "cluster_scatter_plot.png"
plt.savefig(img_file)
plt.close()
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
return dataframe1,#실루엣
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.metrics import silhouette_samples, silhouette_score
from azureml.core import Run
def azureml_main(dataframe1 = None, dataframe2 = None):
df = dataframe1.copy()
X = df[['PC1', 'PC2']].values # 주성분 값을 사용
cluster_labels = df['Assignments'].values # 군집 레이블
silhouette_avg = silhouette_score(X, cluster_labels) # 실루엣 점수 계산
sample_silhouette_values = silhouette_samples(X, cluster_labels)
fig, ax = plt.subplots(figsize=(10, 8)) # 시각화 설정
y_lower = 0 # 군집 간 간격 기준
colors = ['blue', 'red', 'green', 'purple'] # (K = 4)
for i in range(4): # i번째 군집에 속한 샘플 별 실루엣 값 표시
ith_cluster_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_values.sort()
size_cluster_i = ith_cluster_values.shape[0]
y_upper = y_lower + size_cluster_i
ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_values,
facecolor=colors[i], edgecolor=colors[i], alpha=0.7,
label=f'Cluster {i} ({size_cluster_i})')
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, f'Cluster {i}') # 군집 레이블
y_lower = y_upper # 군집 간 간격 = 0
# 전체 평균 실루엣 점수 표시
ax.axvline(x=silhouette_avg, color="red", linestyle="--",
label=f'Avg Silhouette: {silhouette_avg:.3f}')
ax.set_title('Silhouette Analysis for Clustering', fontsize=15)
ax.set_xlabel('Silhouette Coefficient Values', fontsize=12)
ax.set_ylabel('Cluster', fontsize=12)
ax.set_xlim([-0.1, 1]) # x 축 제한 설정
ax.set_ylim([0, y_lower]) # y 축 제한 설정
ax.set_yticks([]) # y축 눈금 제거
plt.legend(loc='lower right')
plt.tight_layout()
img_file = "silhouette_plot.png" # 그래프를 파일로 저장
plt.savefig(img_file)
plt.close()
run = Run.get_context(allow_offline=True) # 파일 업로드
run.upload_file(f"graphics/{img_file}", img_file)
return dataframe1,
결과 확인
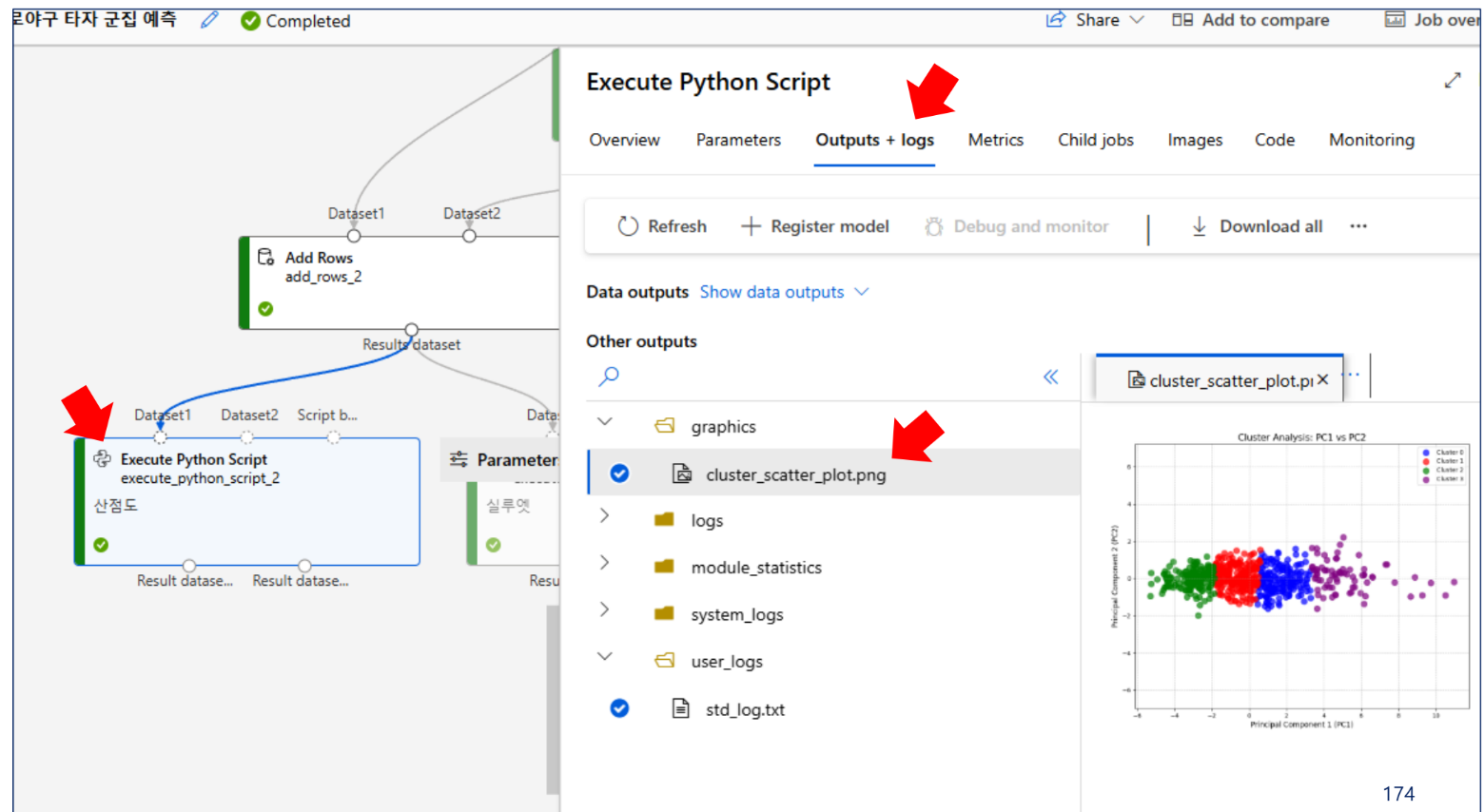
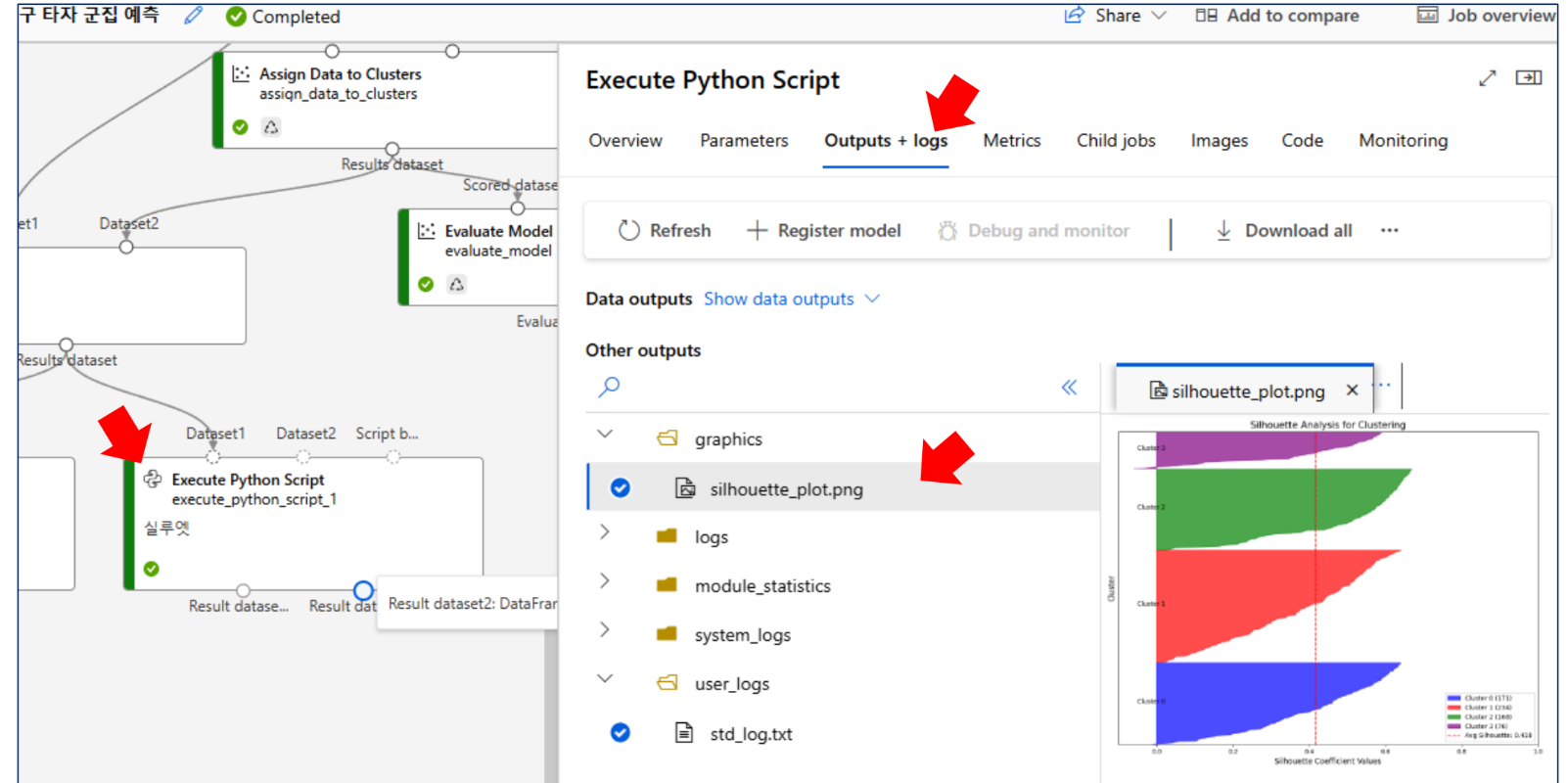
추가 실습: 군집 모델 평가 - K = 4, 5 비교
분류 MLD: Random Forest 알고리즘을 이용한 개인 수입 예측 모델 구현 실습
배경 및 모델링 목표
미국의 인구조사(census) 데이터를 분석하여 개인의 연간 소득을 예측할 수 있는 모델 구현
이진 분류 모델을 통해 연간 소득 5만 달러를 기준으로 개인 구분
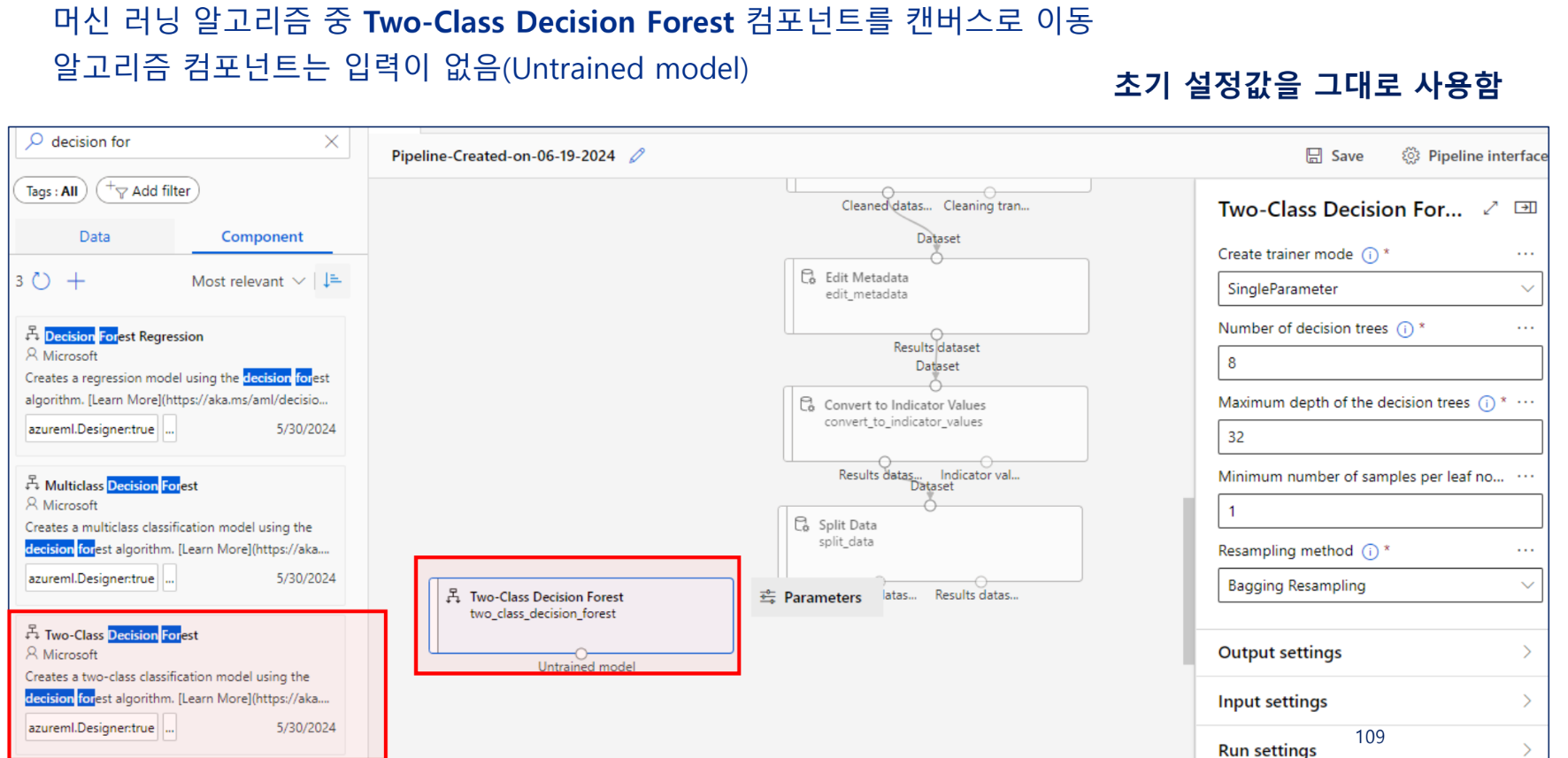
알고리즘 - Random Forest
데이터 세트에서 여러 번의 데이터 서브셋을 추출, 의사결정나무를 각각 적용
하이퍼 파라미터
- 의사결정나무의 최대 깊이
- 의사결정나무의 개수
- 샘플링 시 중복 허용 여부
- 리프 노드에 포함할 최소 샘플 수
실습 준비
데이터 수집
Kaggle의 Adult Census Income 데이터세트 이용
데이터세트 등록
로컬데이터 등록으로 업로드
컴퓨트 대상 설정
앞선 실습에서 사용한 컴퓨팅 인스턴스 이용
데이터 수집/이해
데이터 세트 가져오기
데이터의 이해
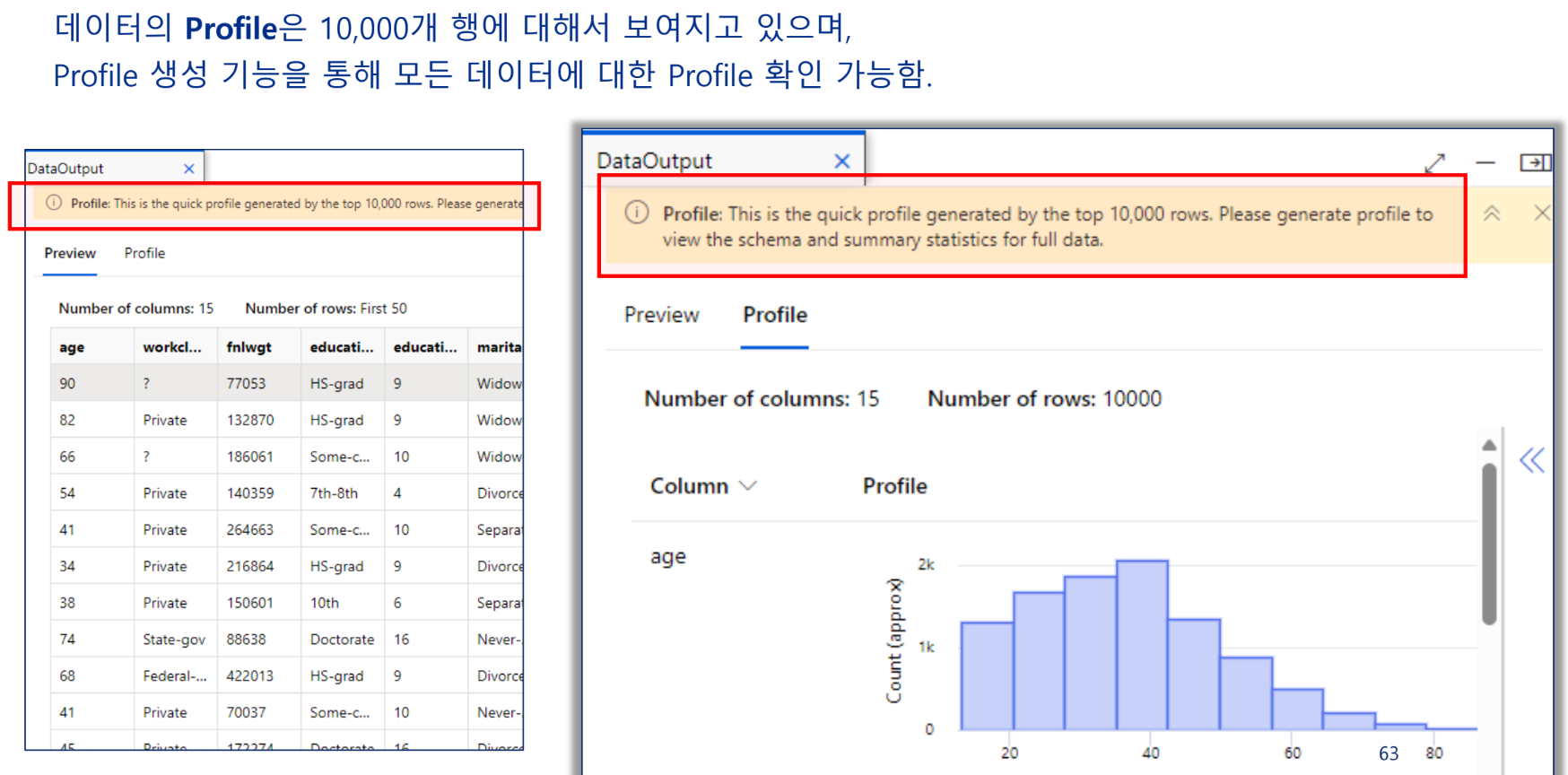
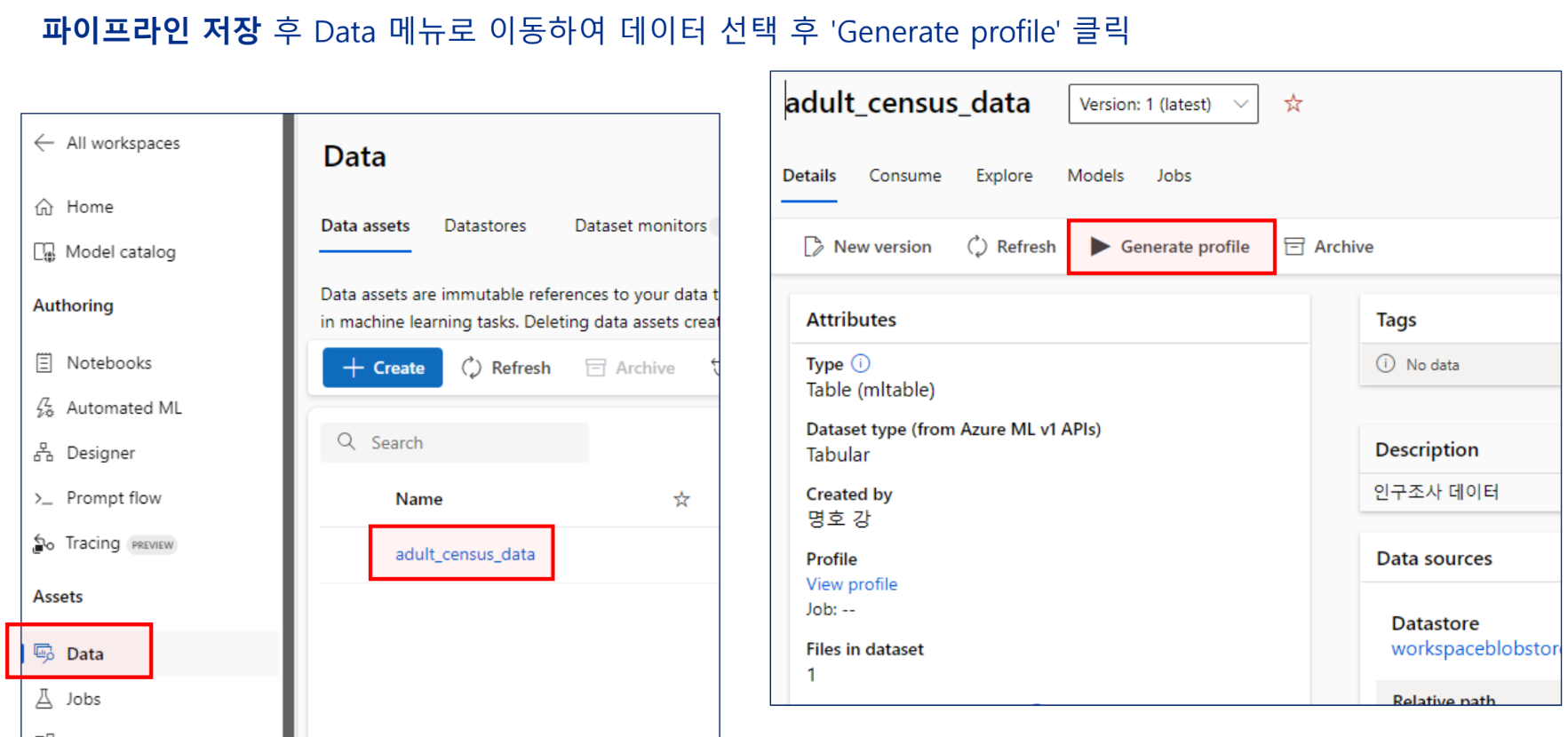
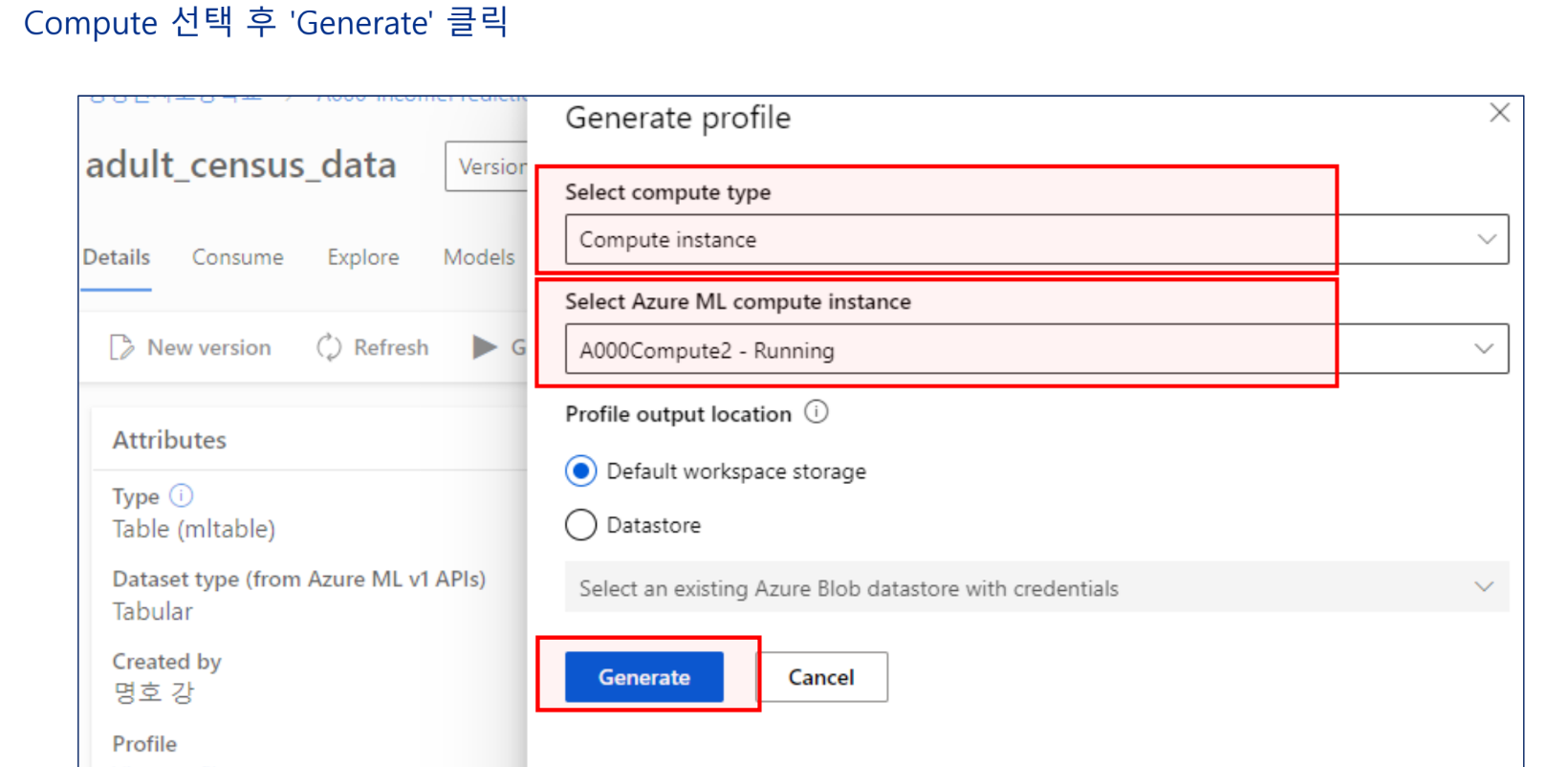
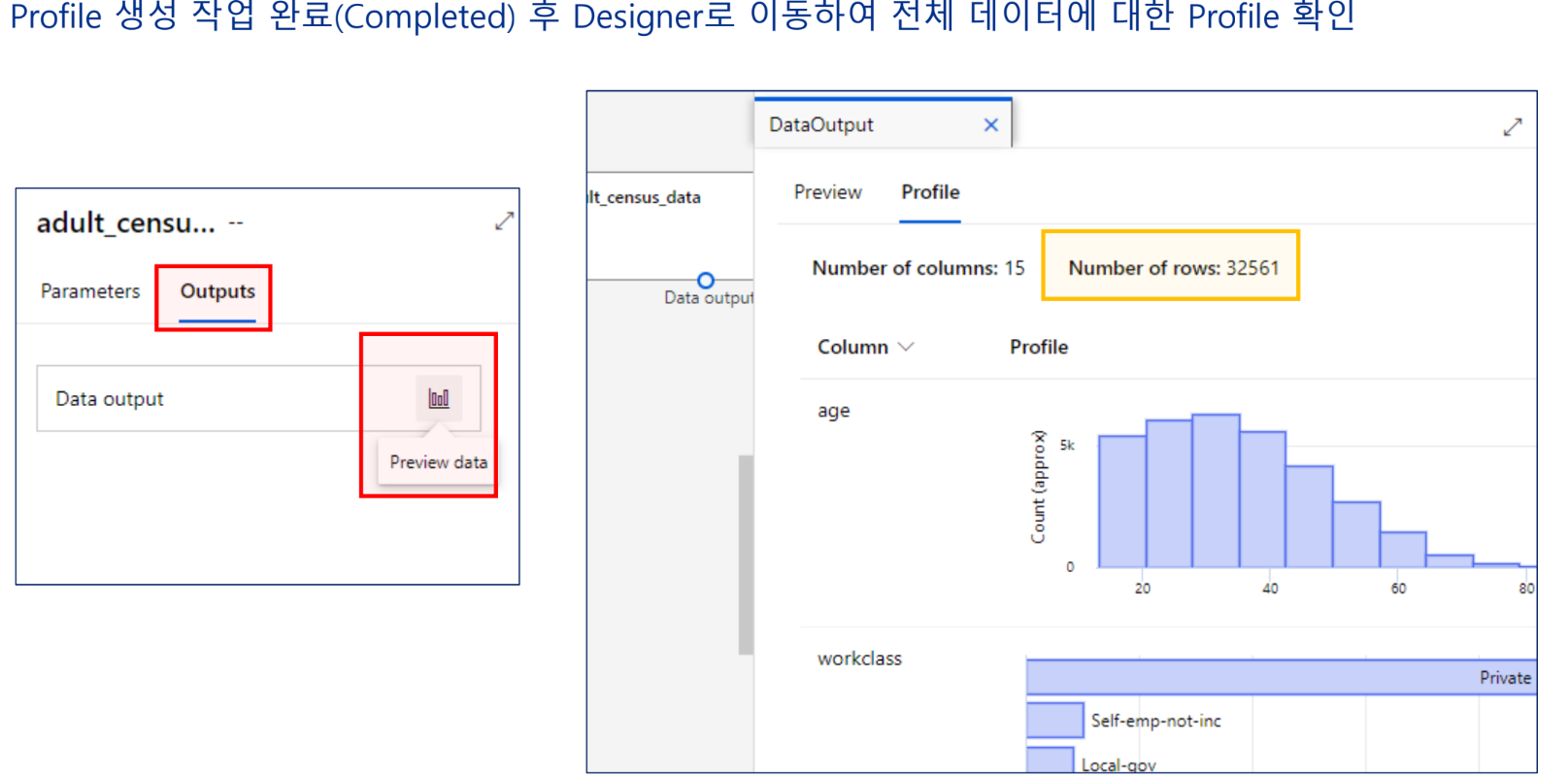
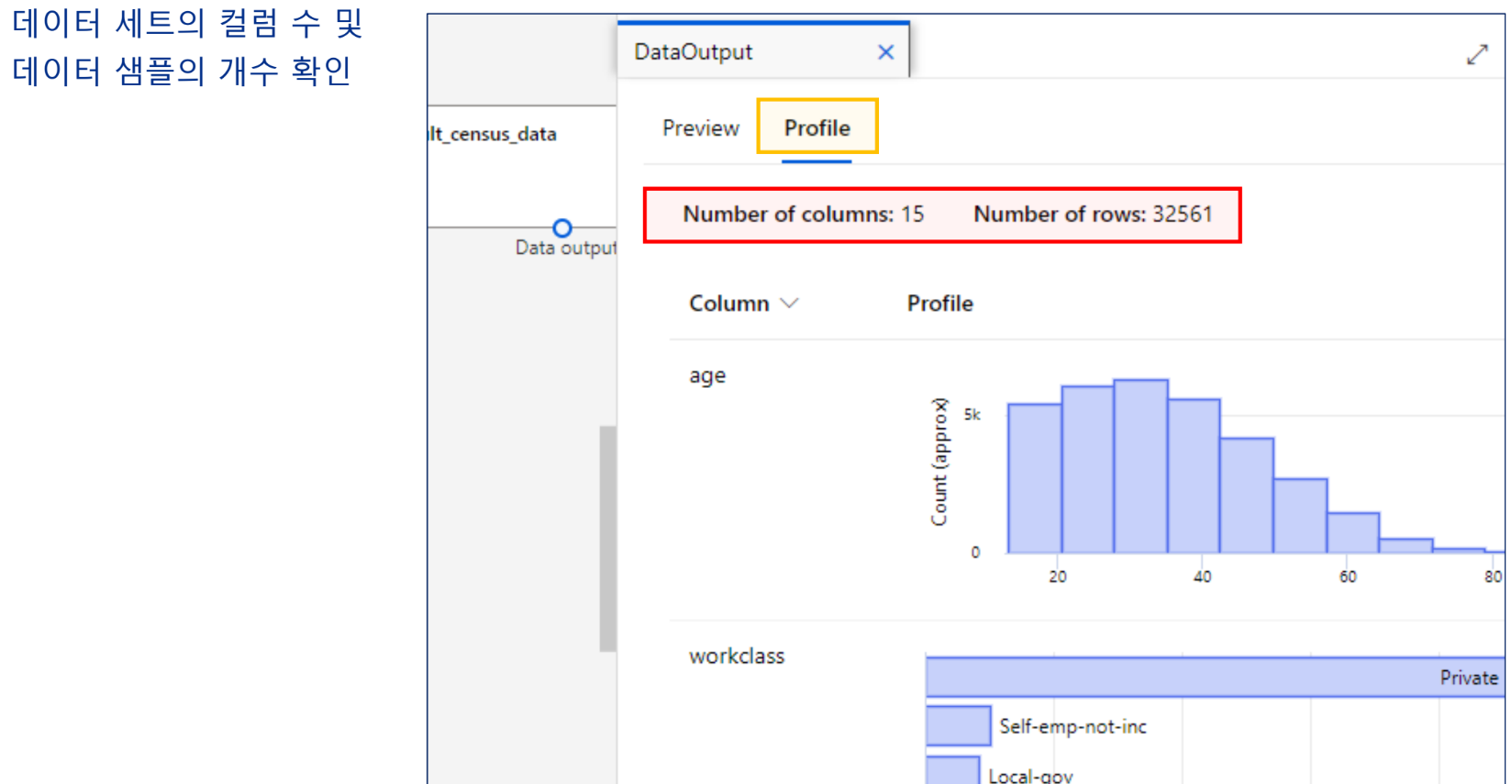
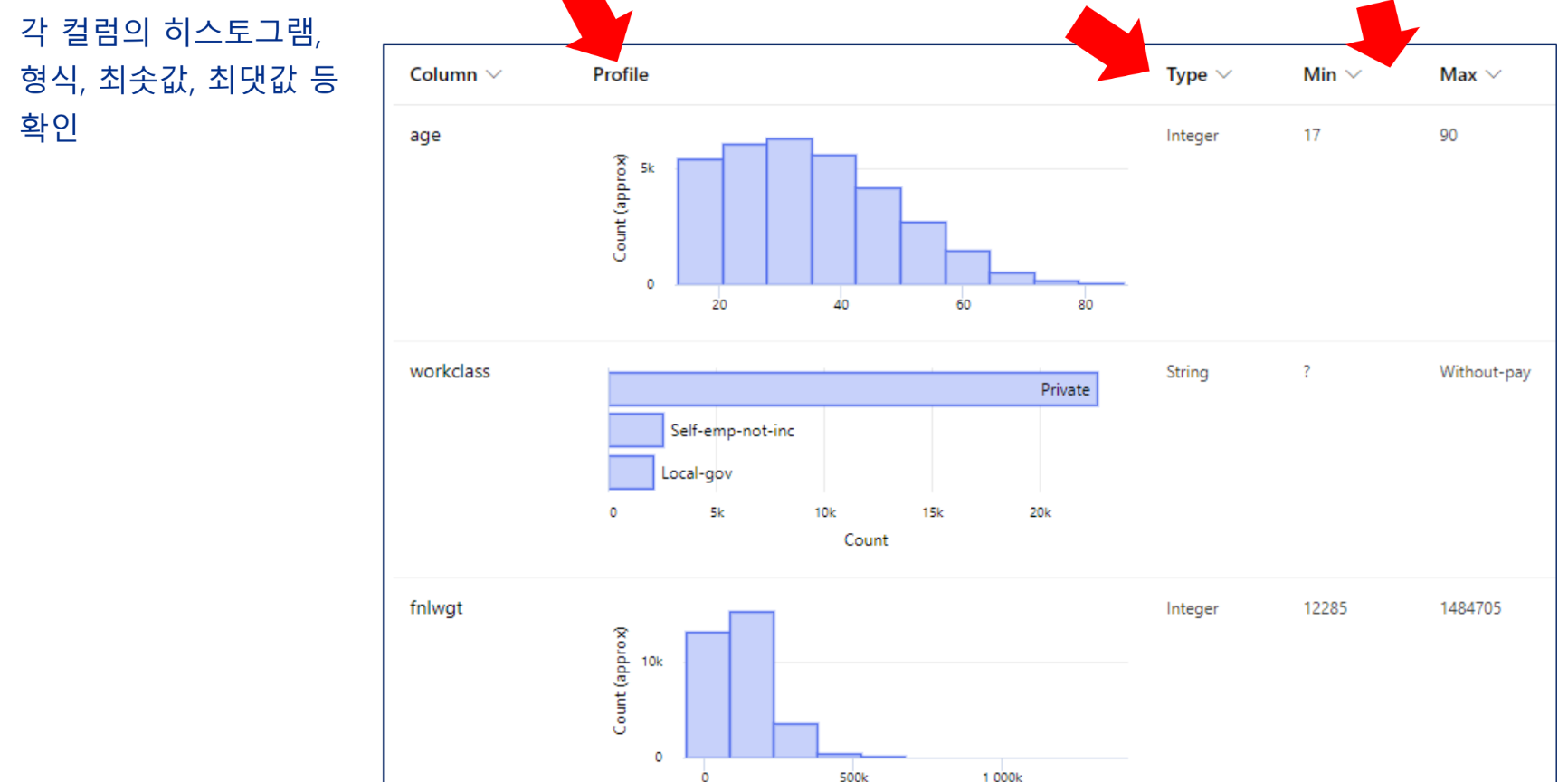
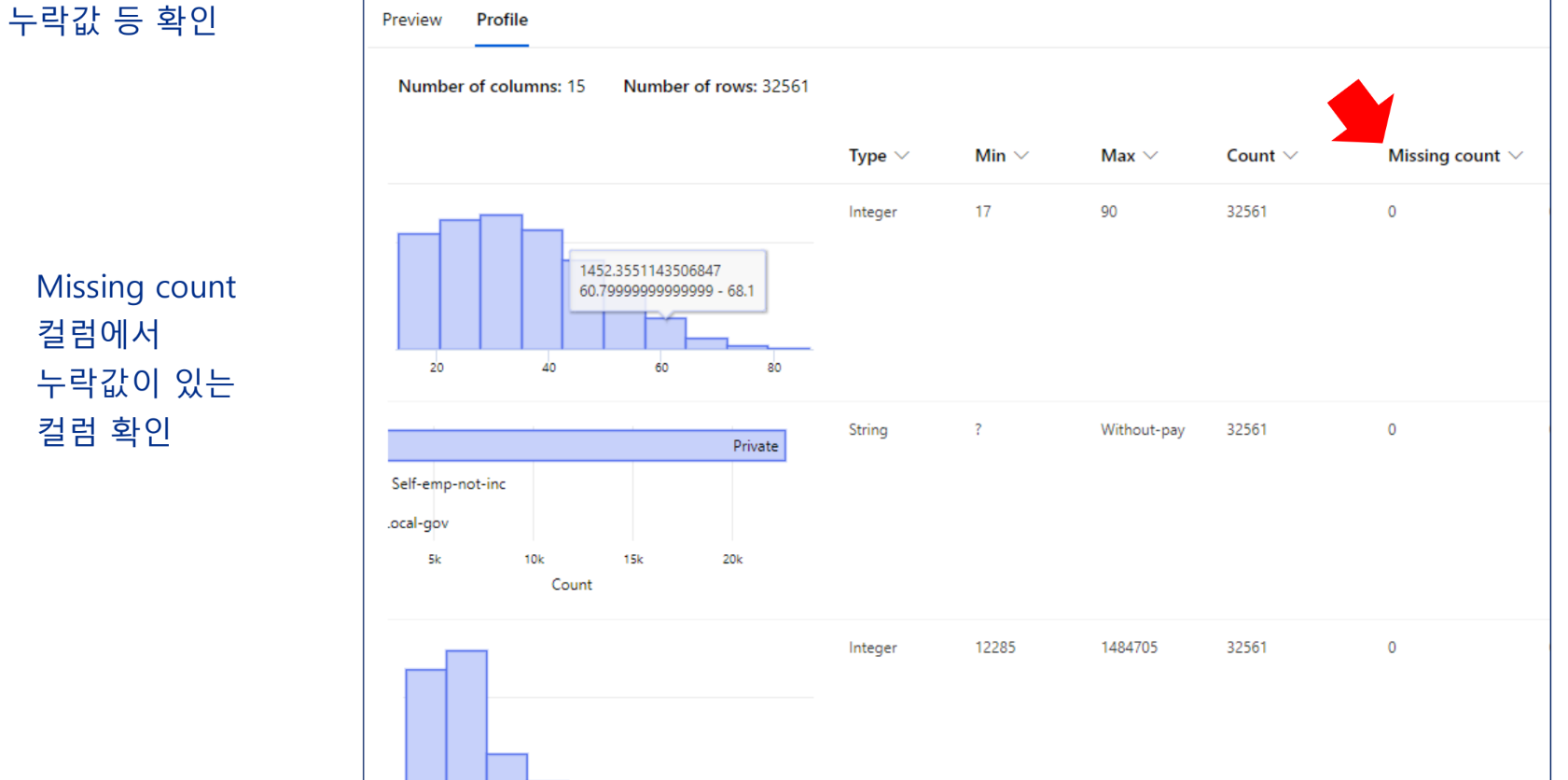
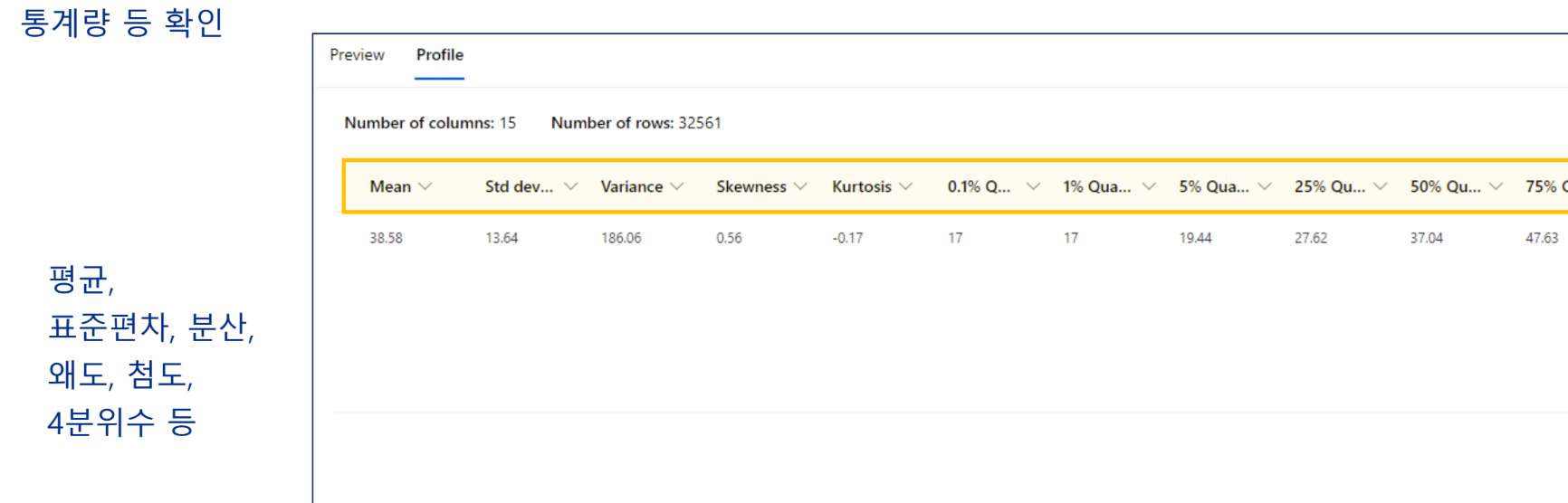
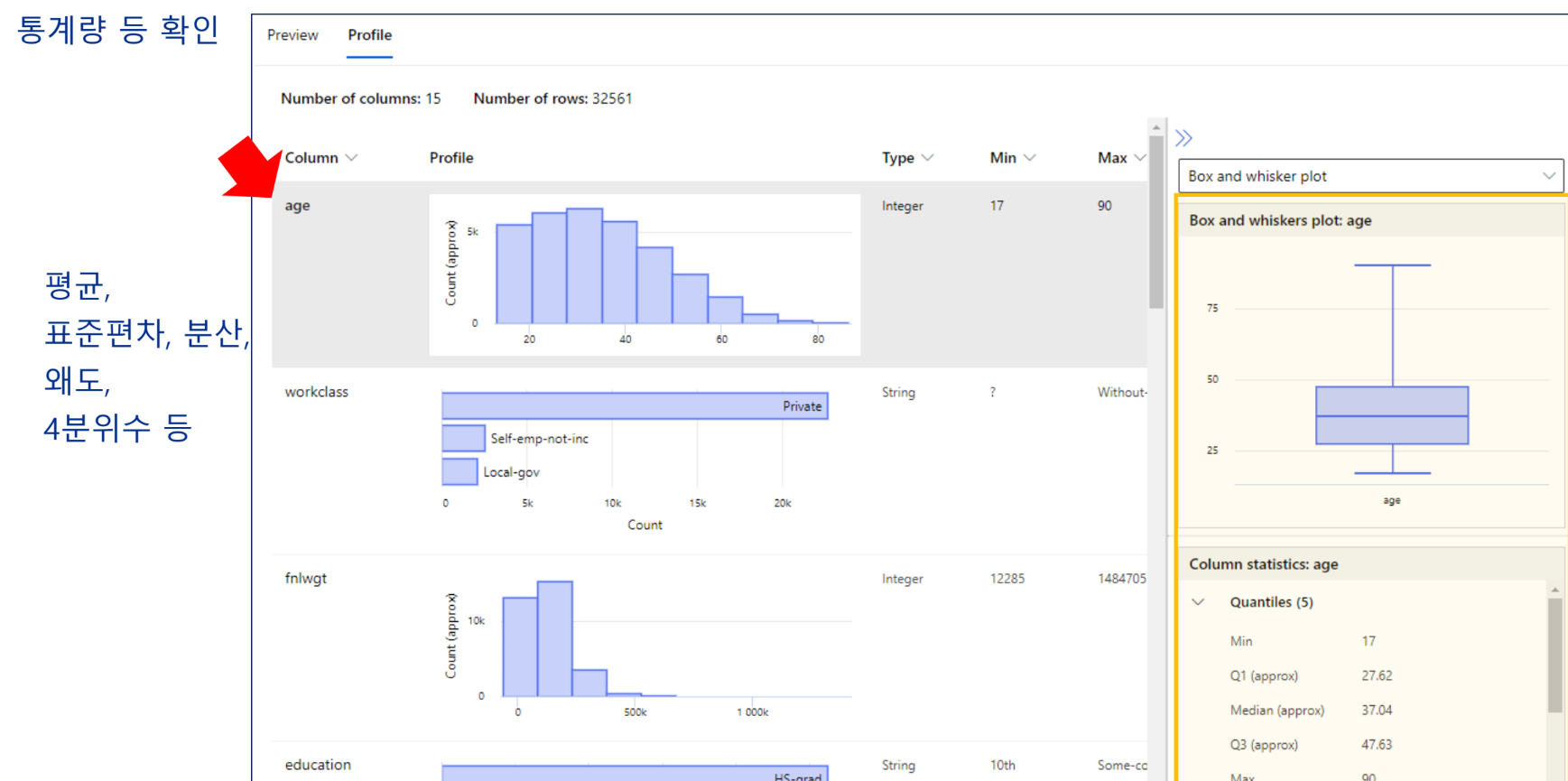
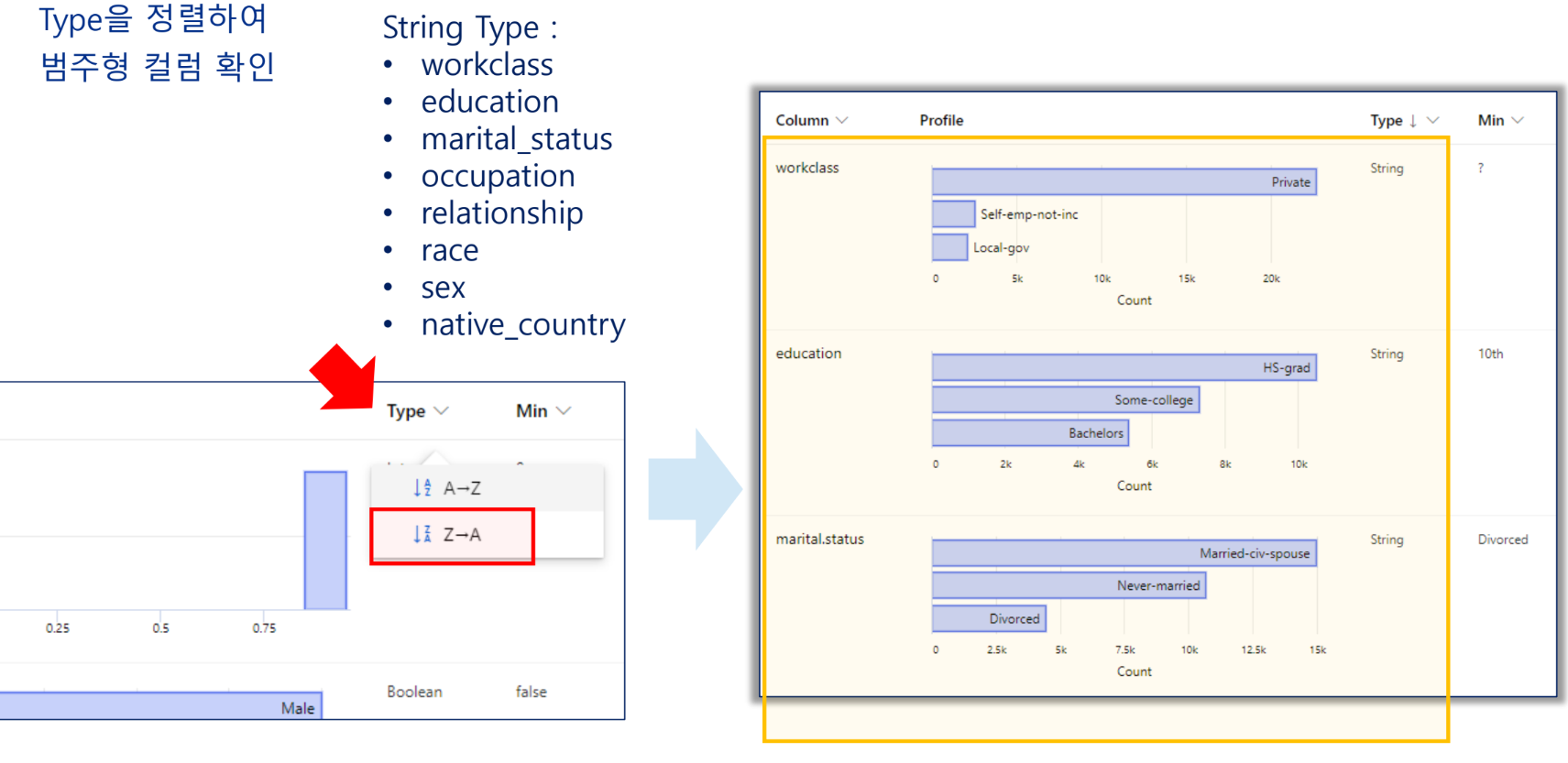
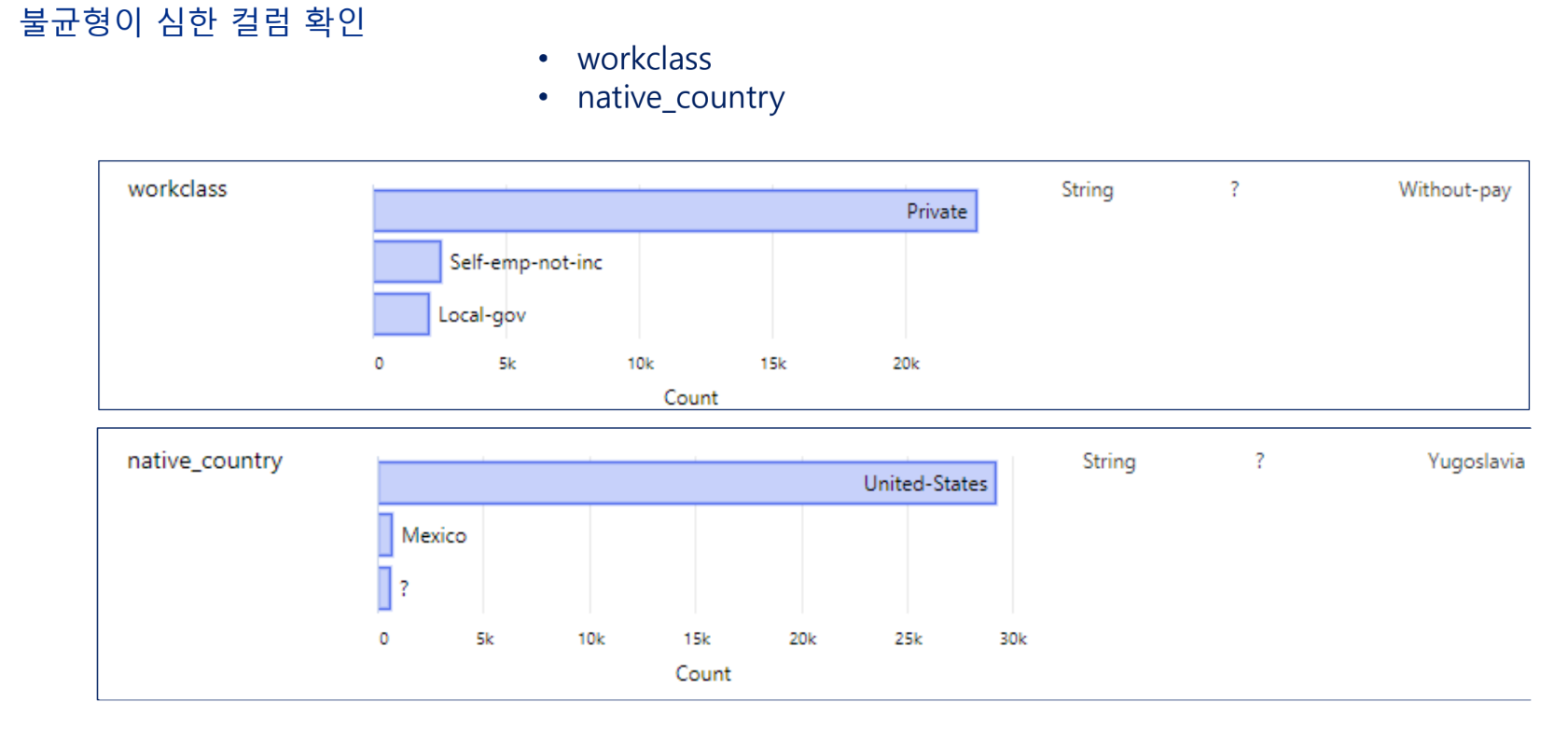
데이터 준비
특성 선택
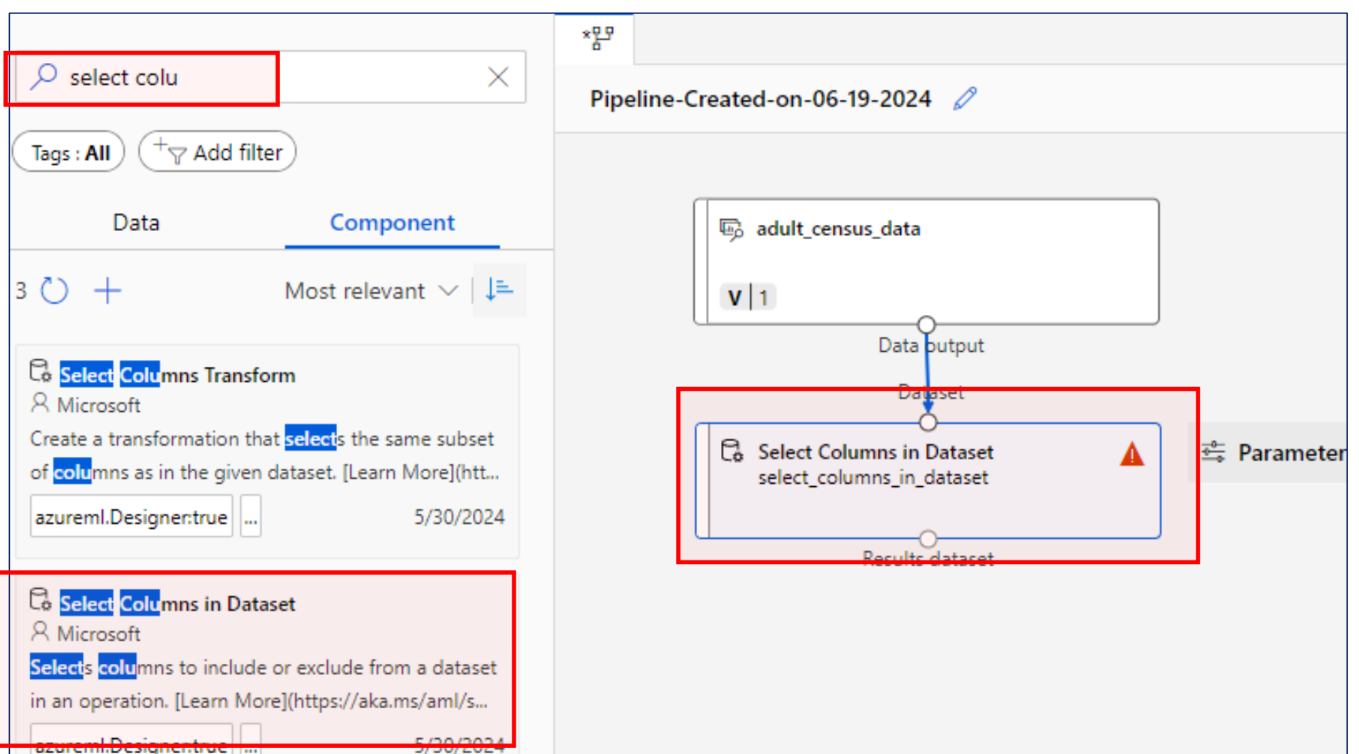
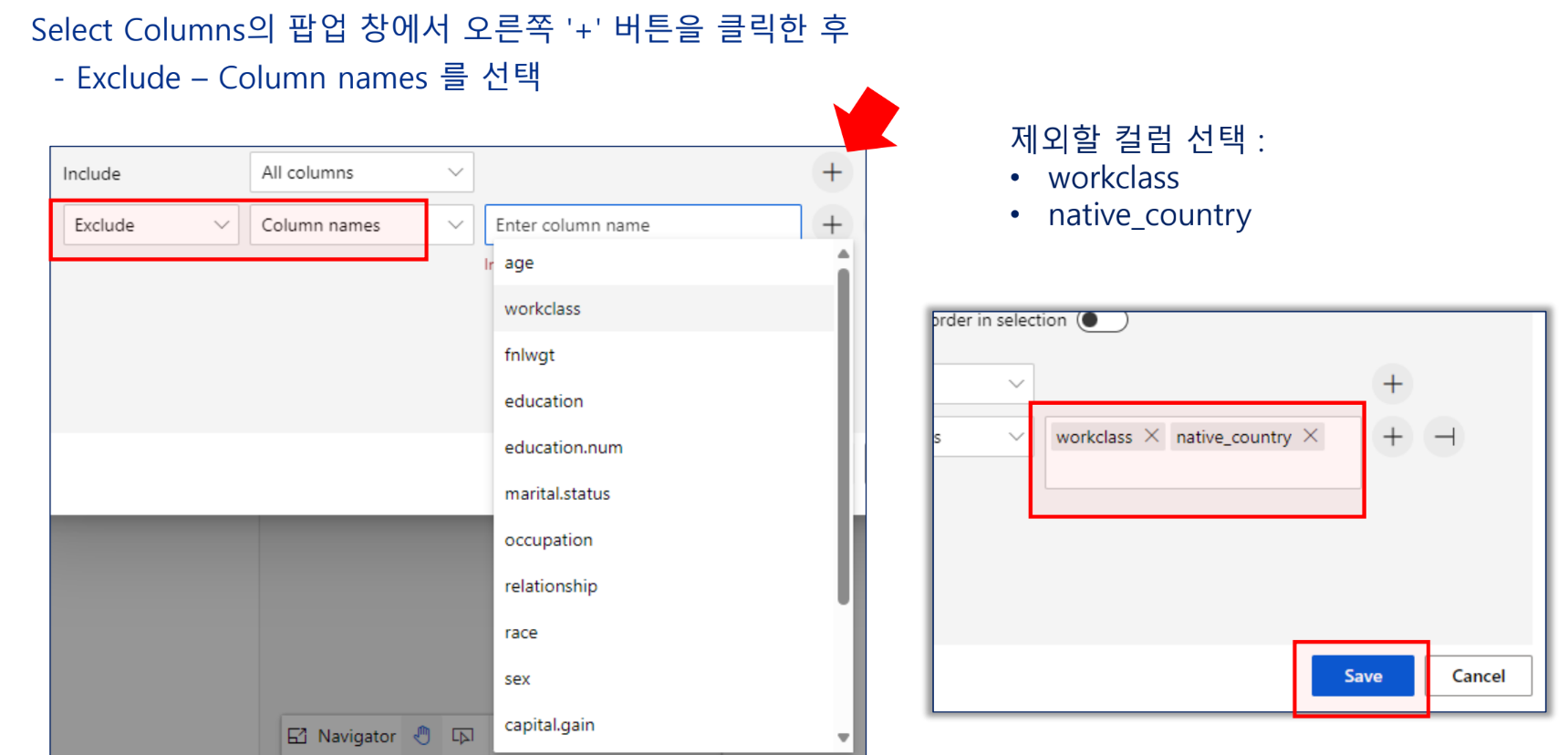
Include All 한 뒤에 하는 것을 주의

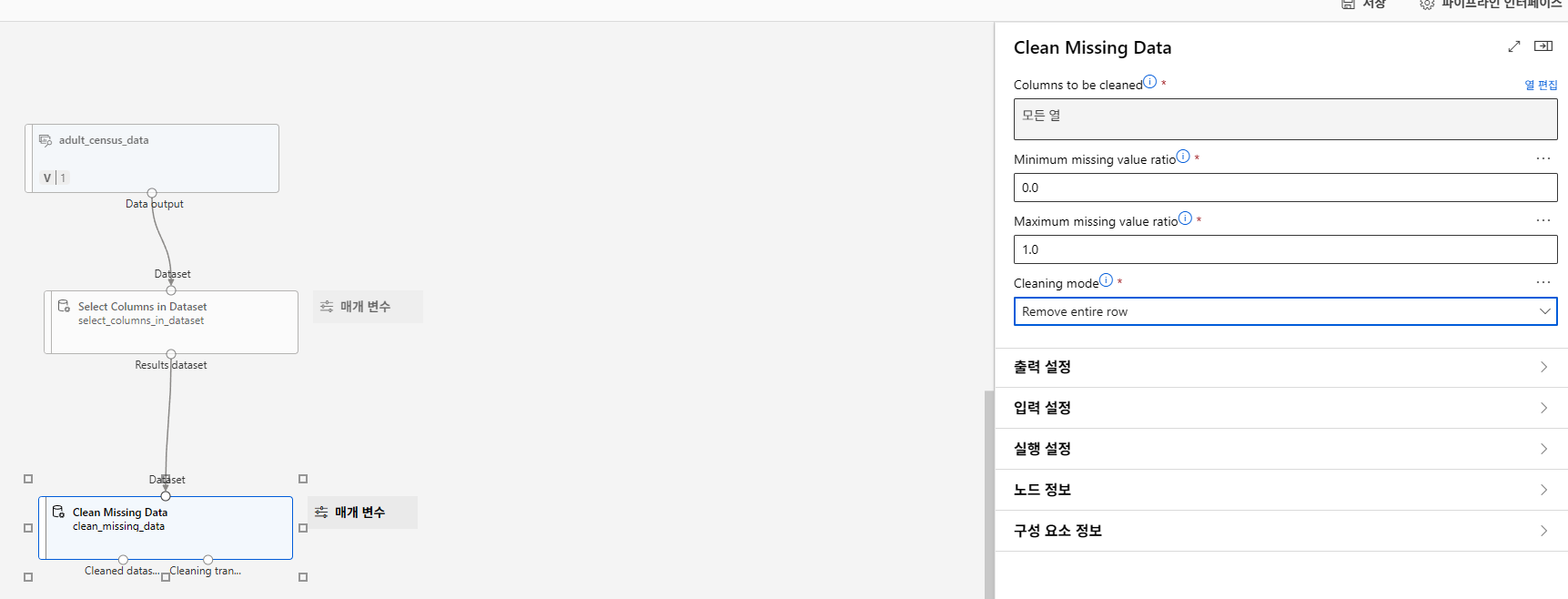
누락값 처리
데이터 변환
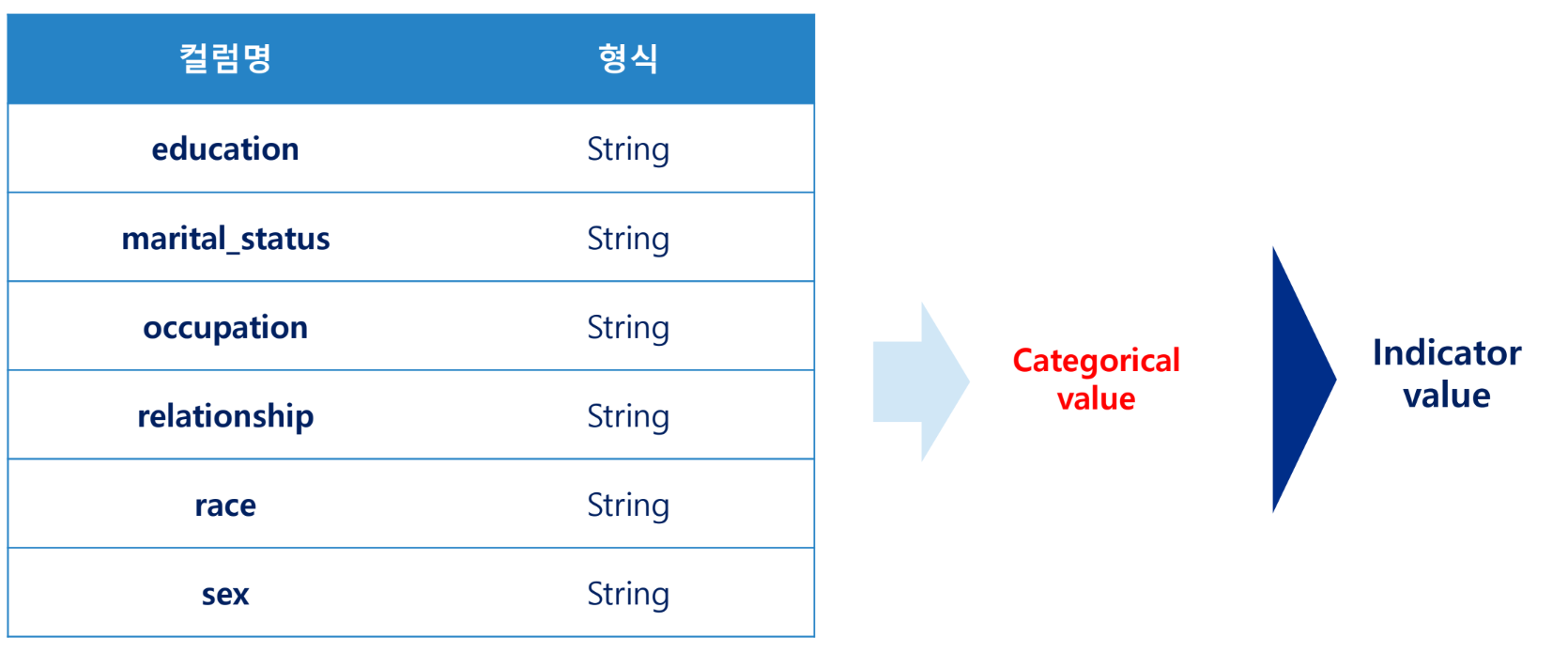
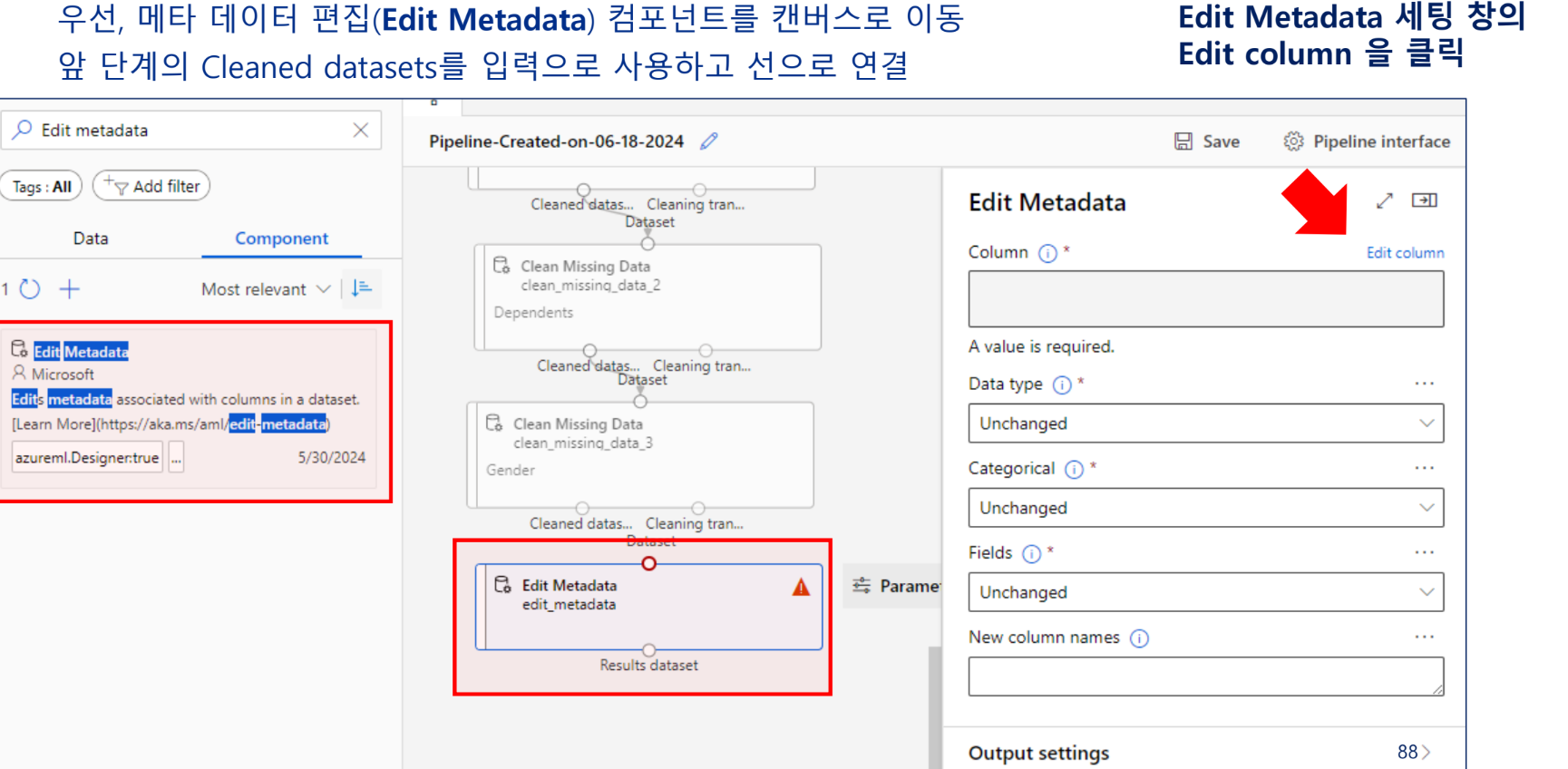
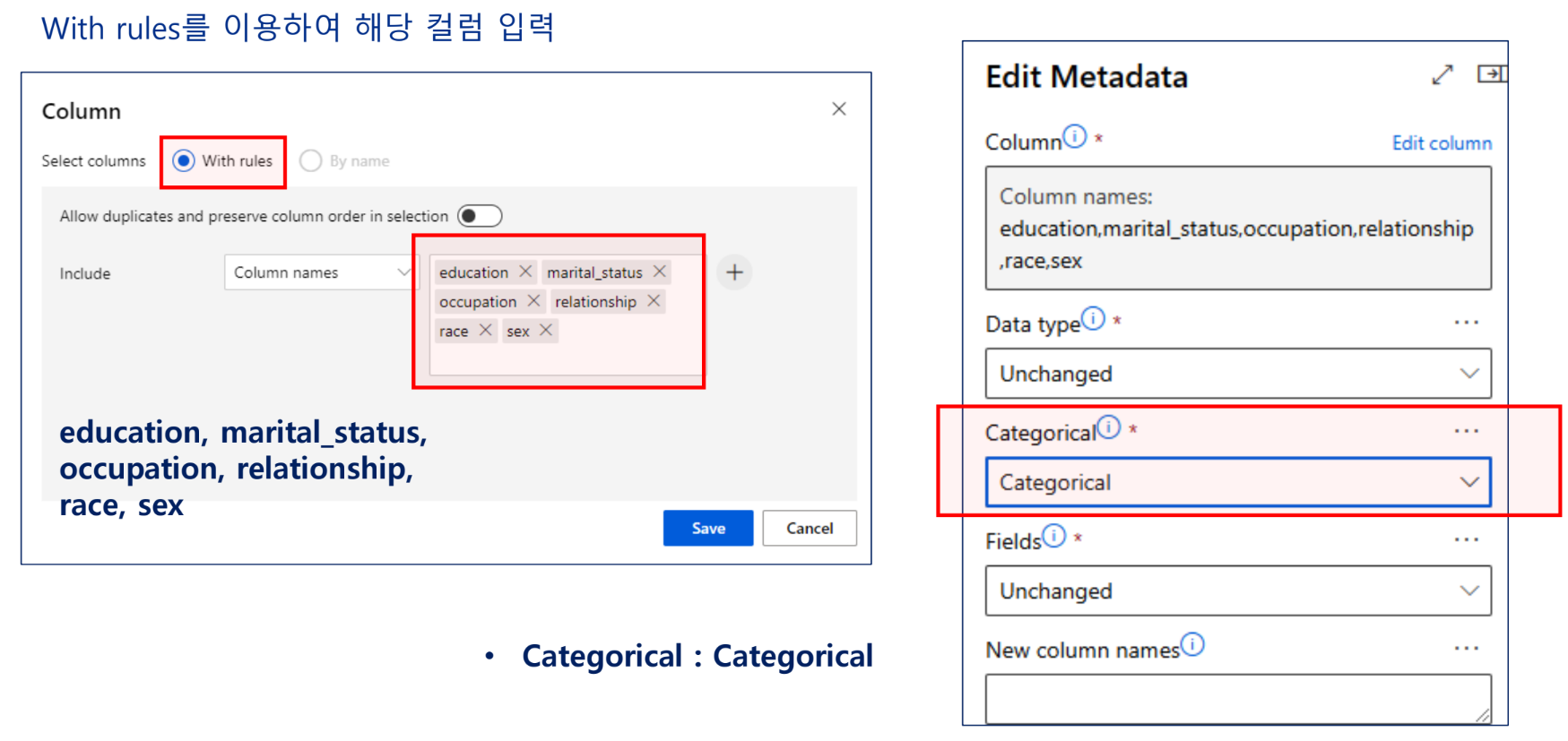
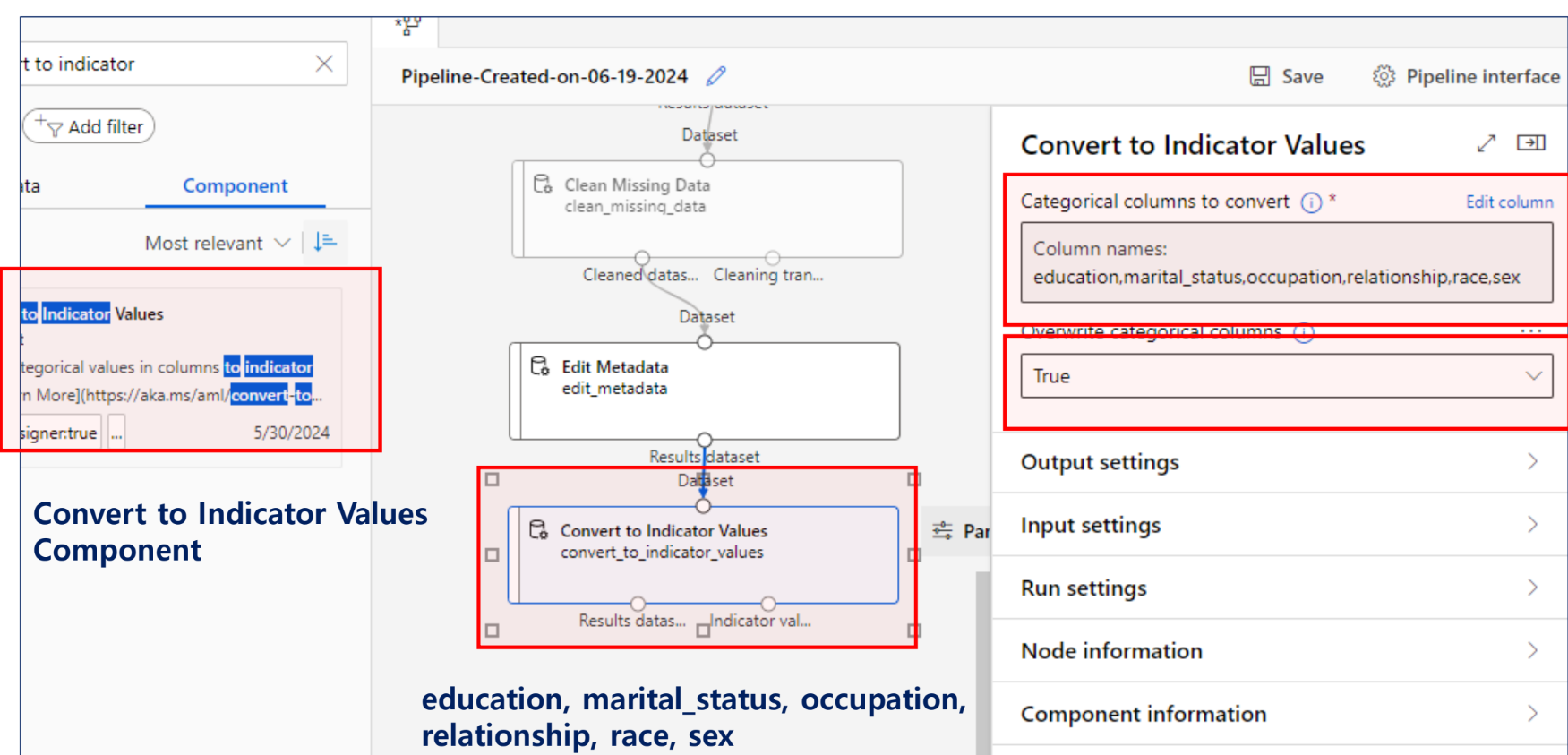
String → Category → Indicator value
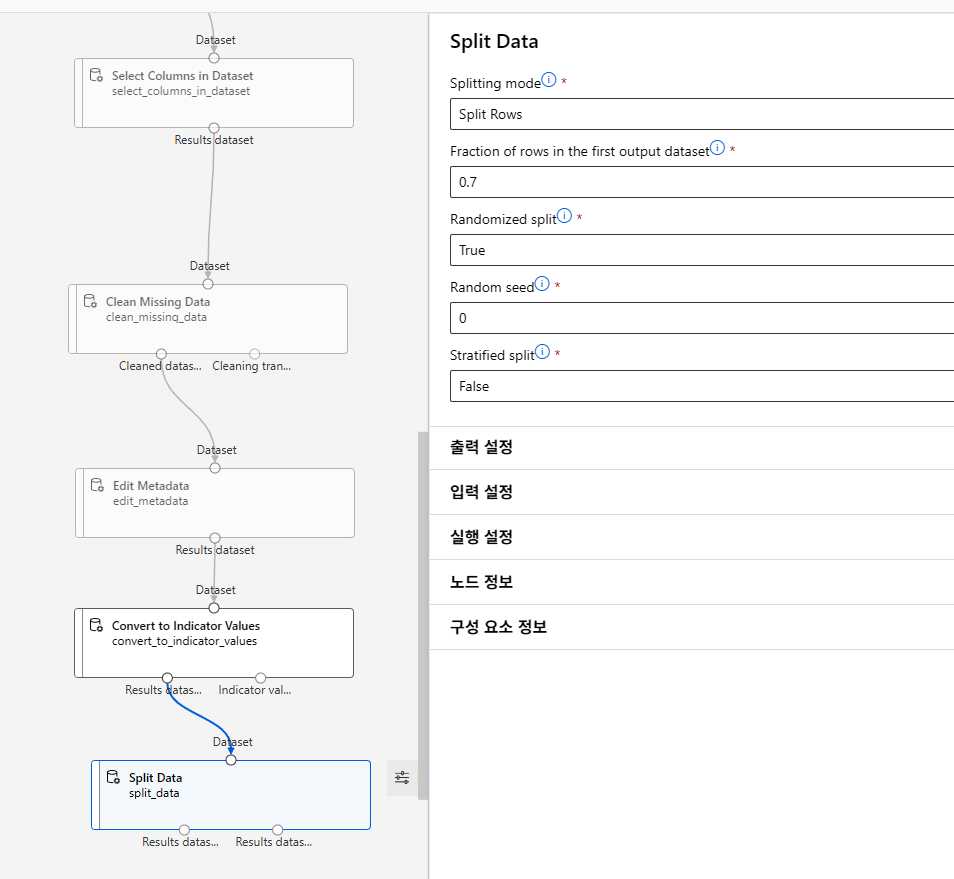
데이터 분리
학습 데이터와 테스트 데이터로 분리
모델링/평가
모델링 알고리즘 선택
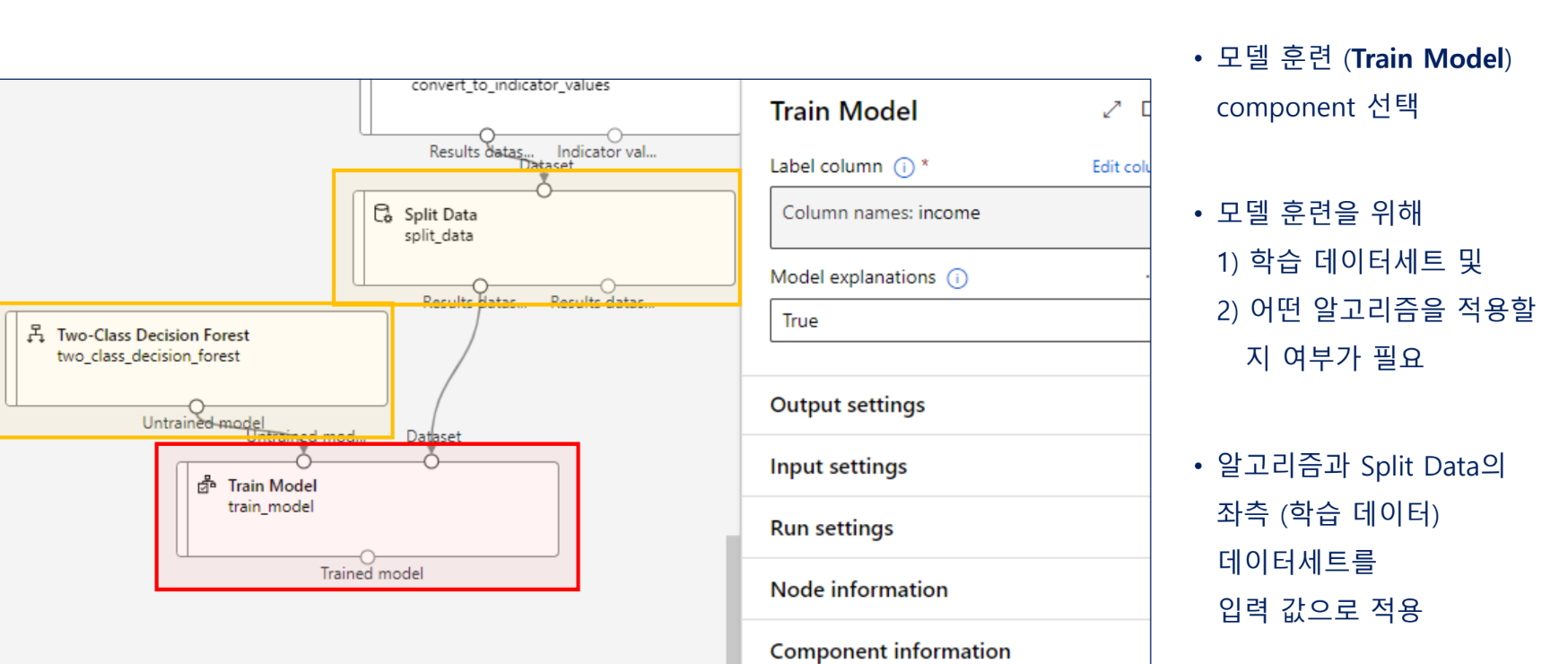
모델 학습(훈련)
모델 테스트
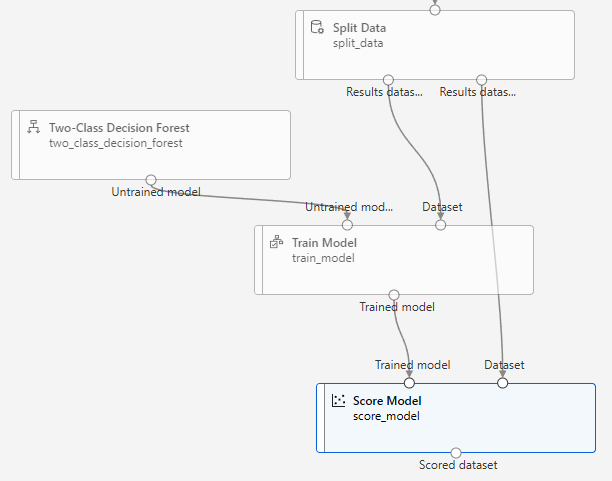
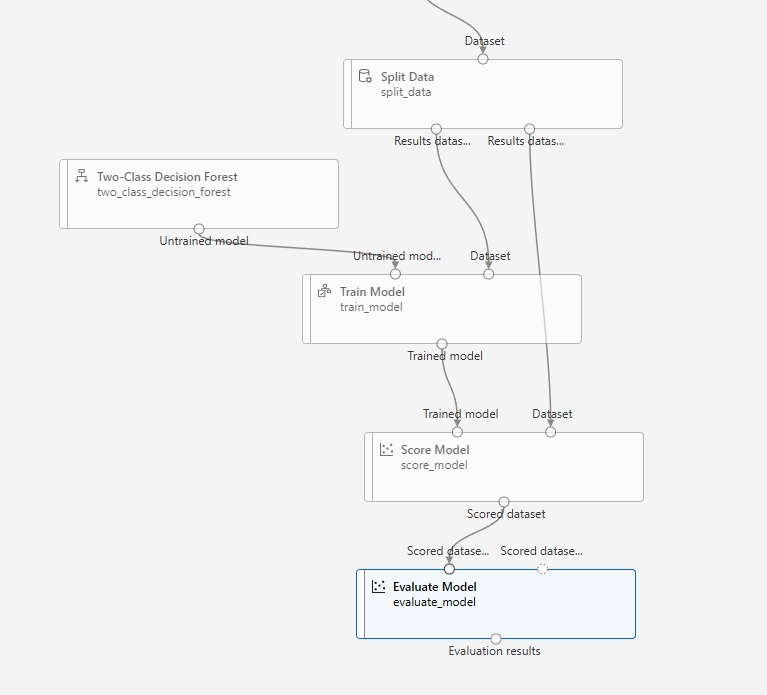
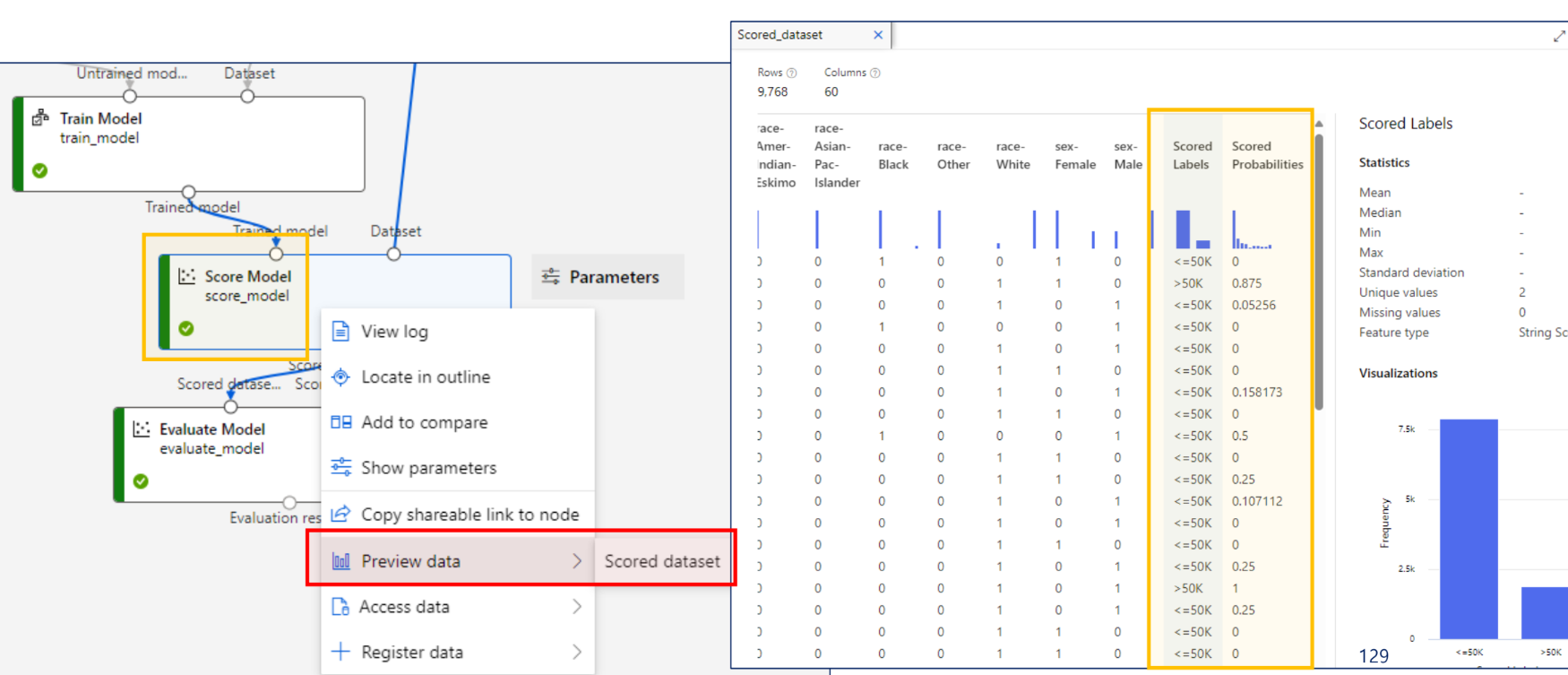
모델 평가(테스트 결과 평가)
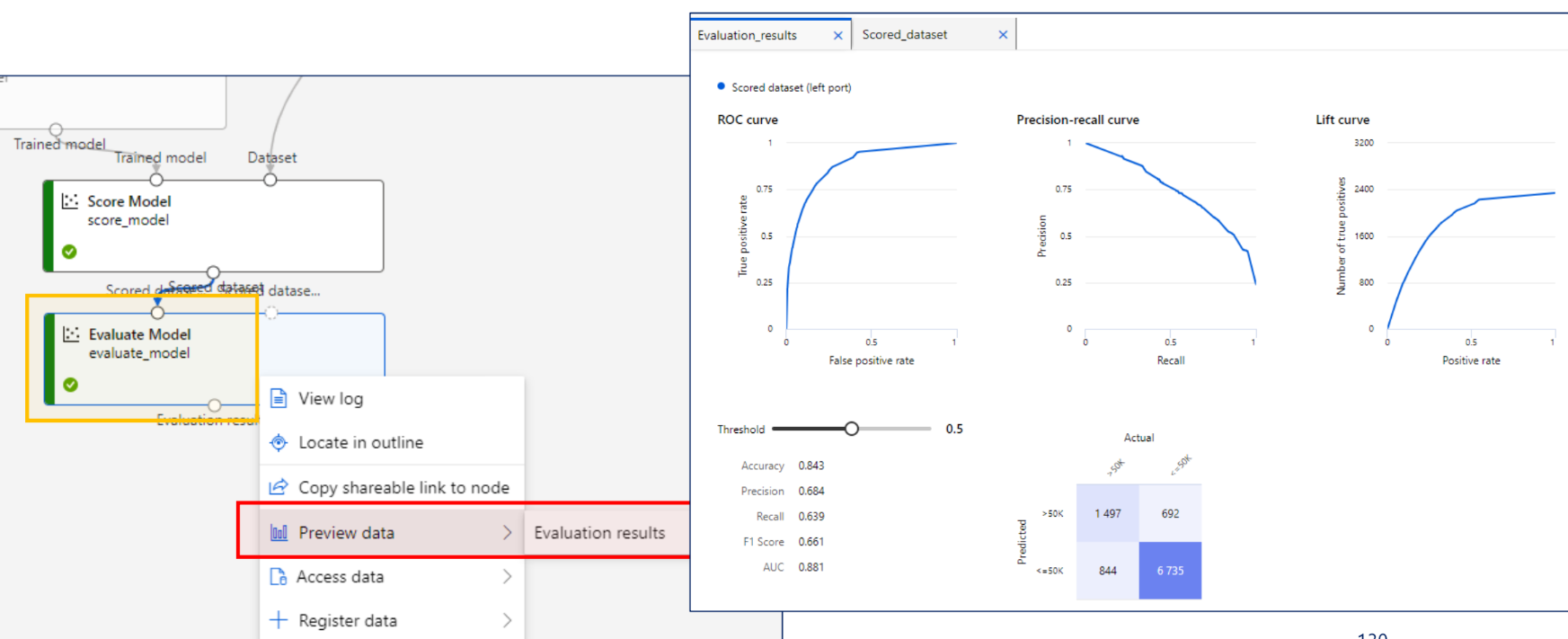
임계값(Threshold): 특정 확률 이상의 예측값을 Positive로 예측
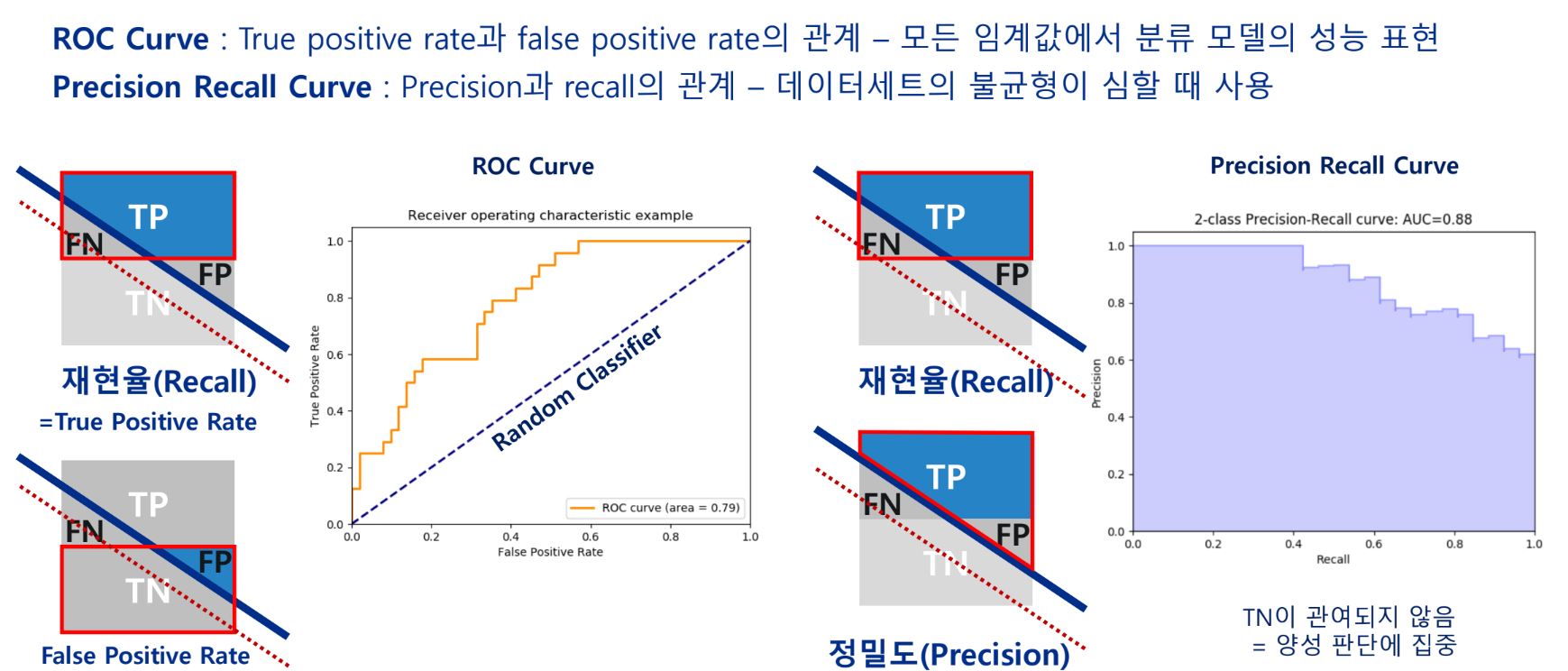
데이터가 불균형할땐 True Negative가 관여하지 않는 지표가 중요
실습: 회귀MLD 자동차가격예측 선형회귀
데이터 수집
UCI Repository의 Automobile 데이터세트 이용
데이터세트 등록
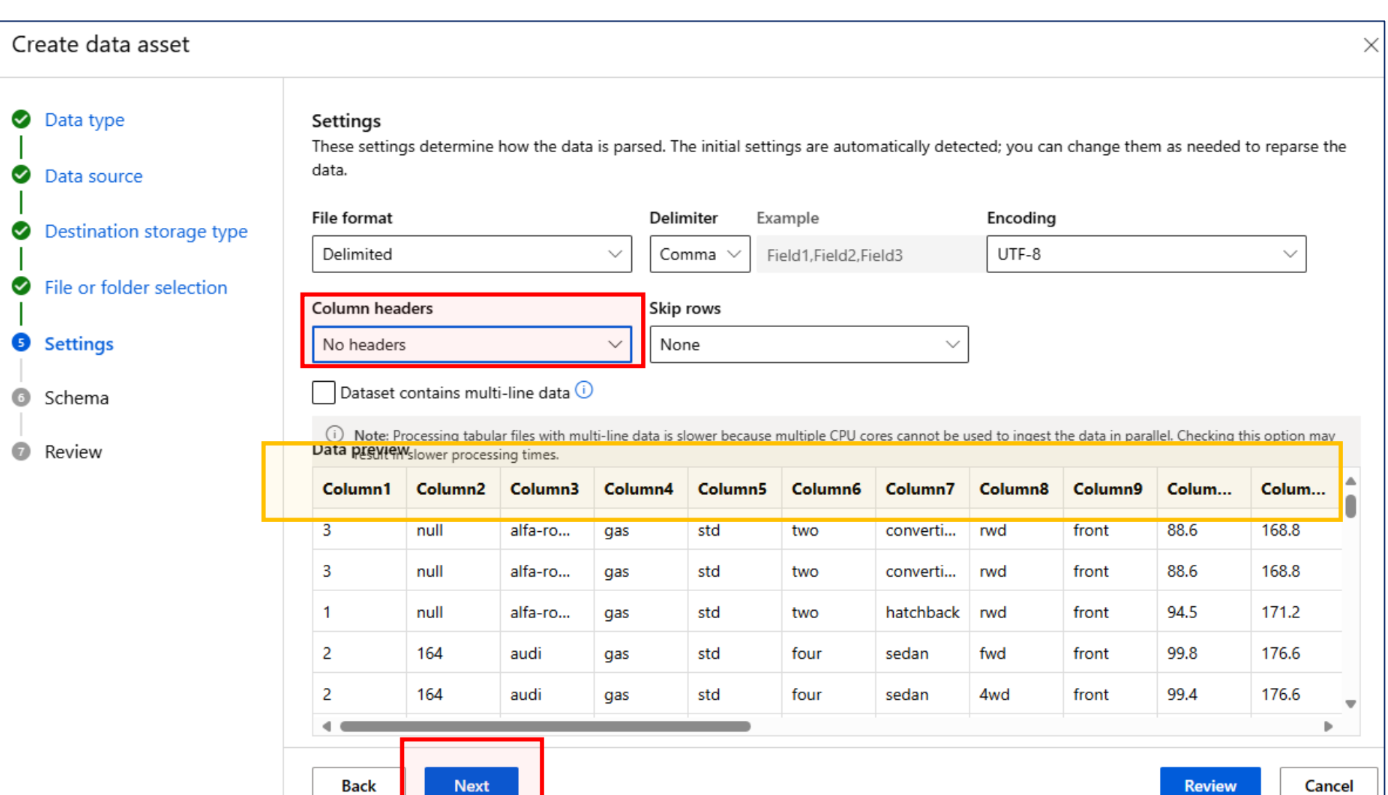
데이터 이해
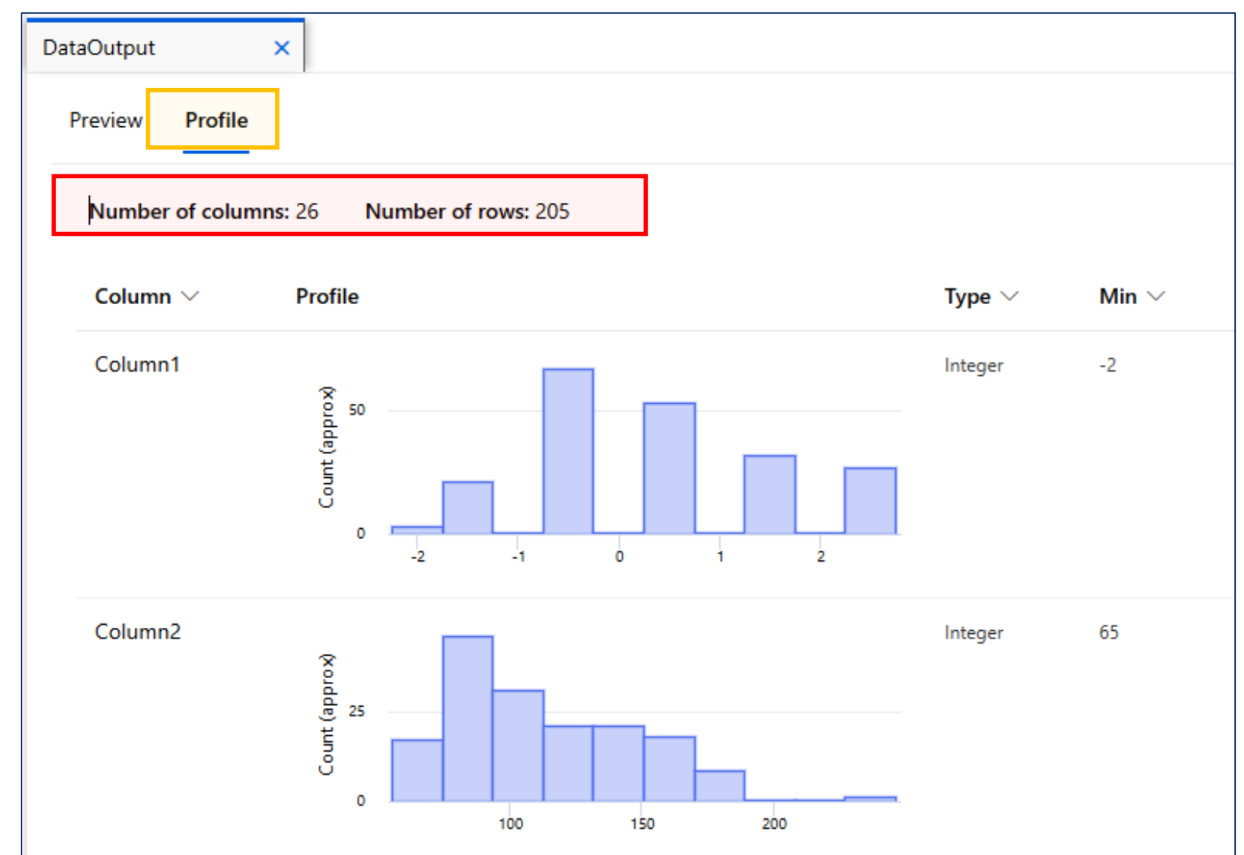
양의 왜도 상태.
음의 왜도였으면 보험사 망함
데이터 준비
특성 이름 지정
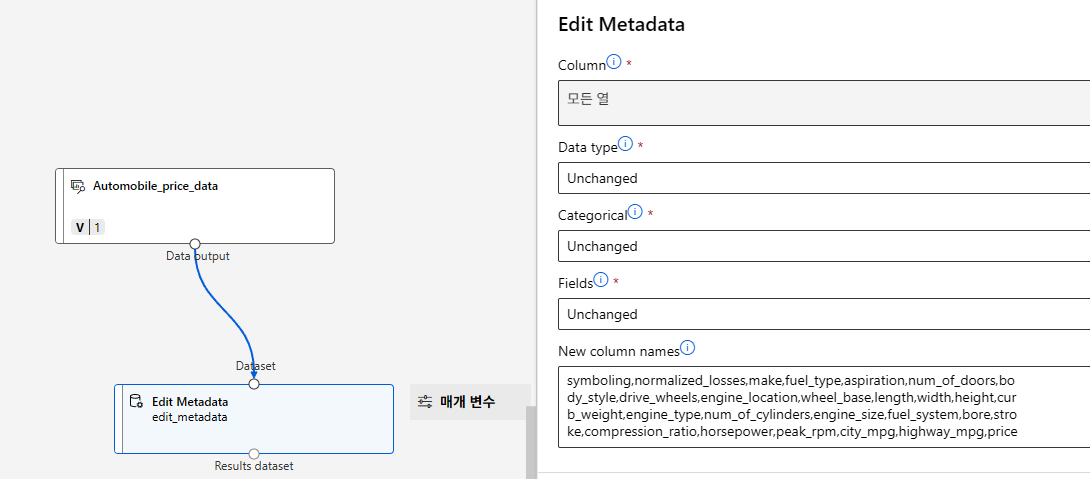
특성 선택
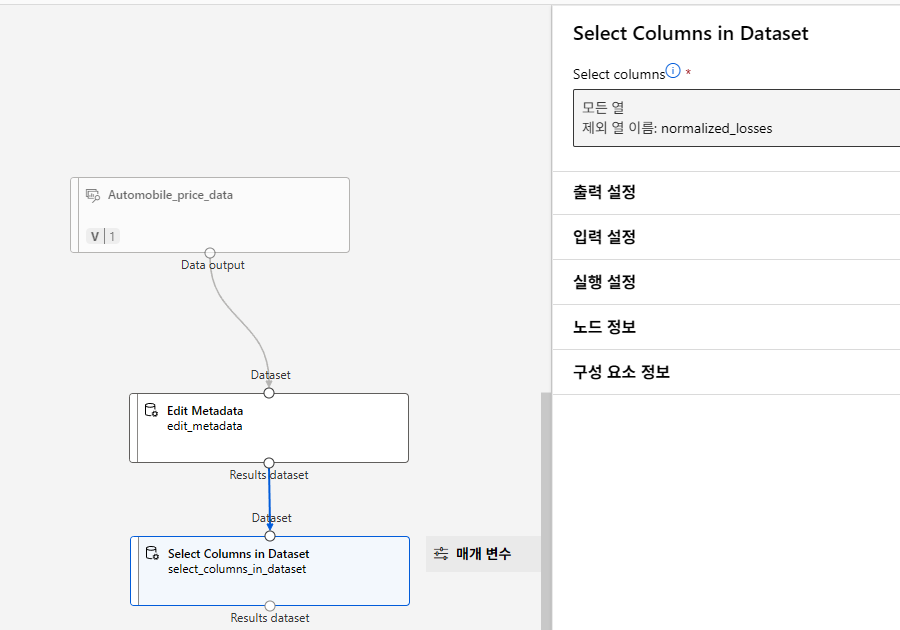
누락값 처리
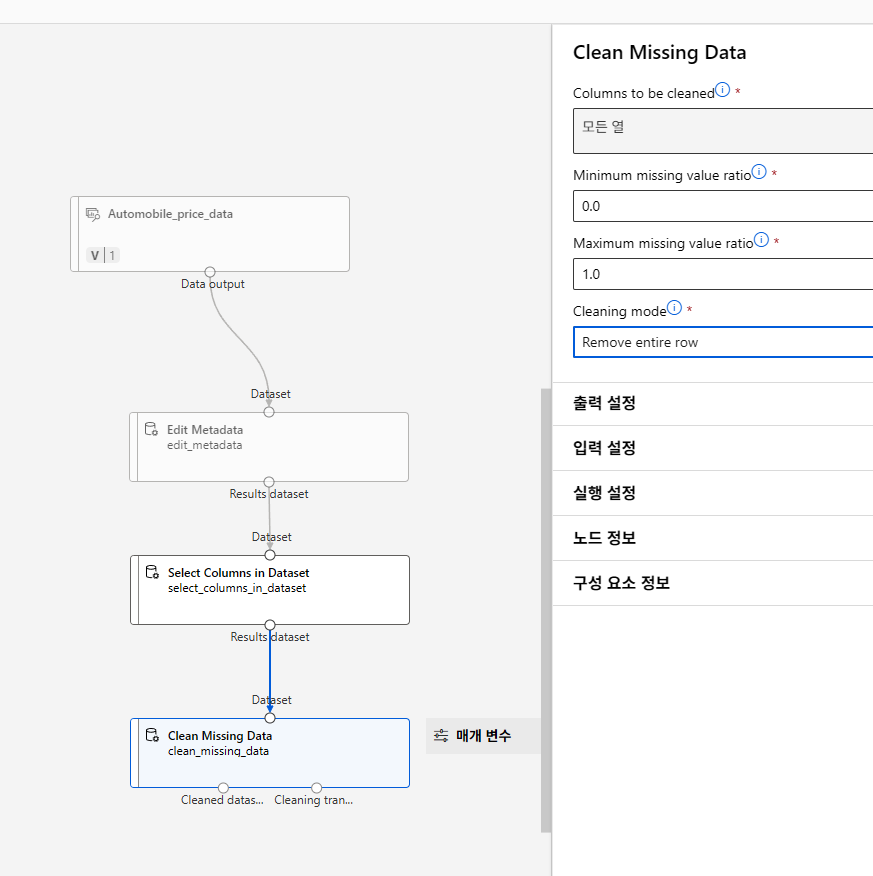
데이터 분리
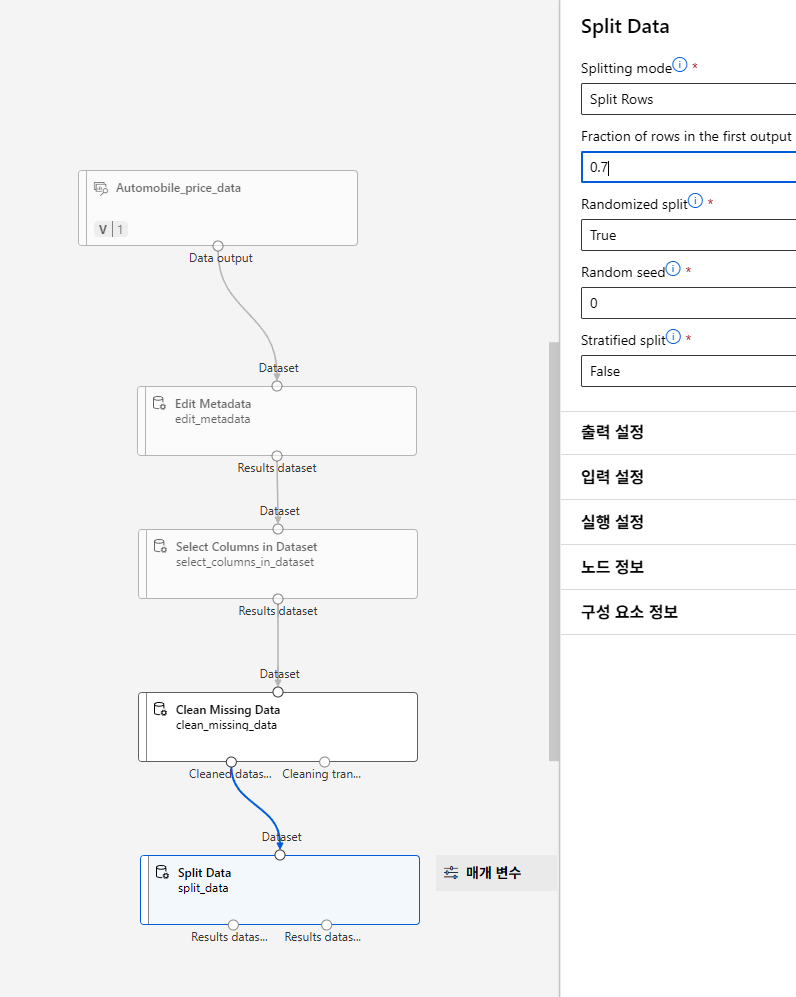
모델링 평가
모델링 알고리즘 선택
Linear Regression
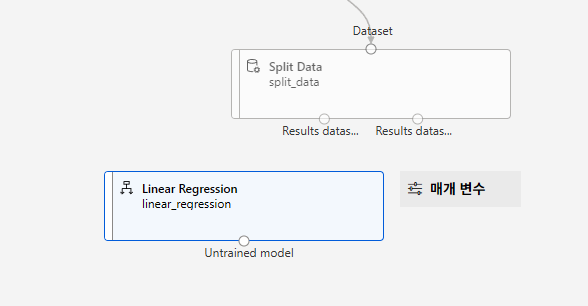
모델 학습
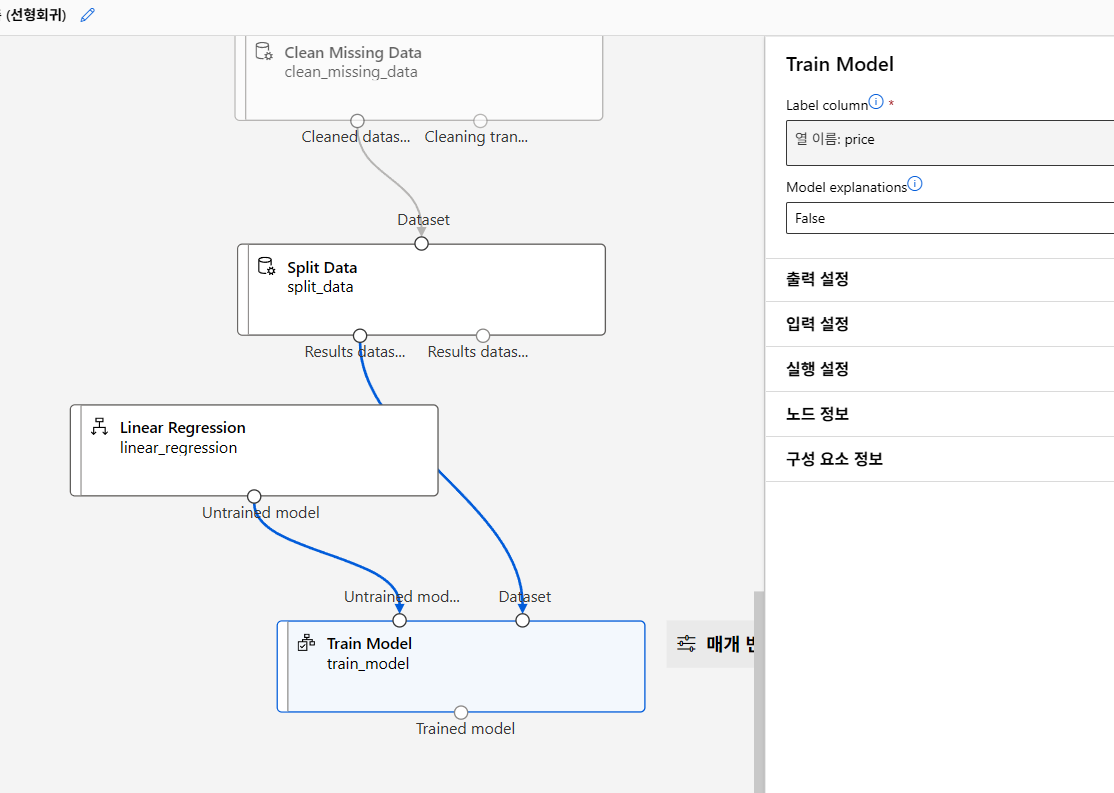
모델 테스트
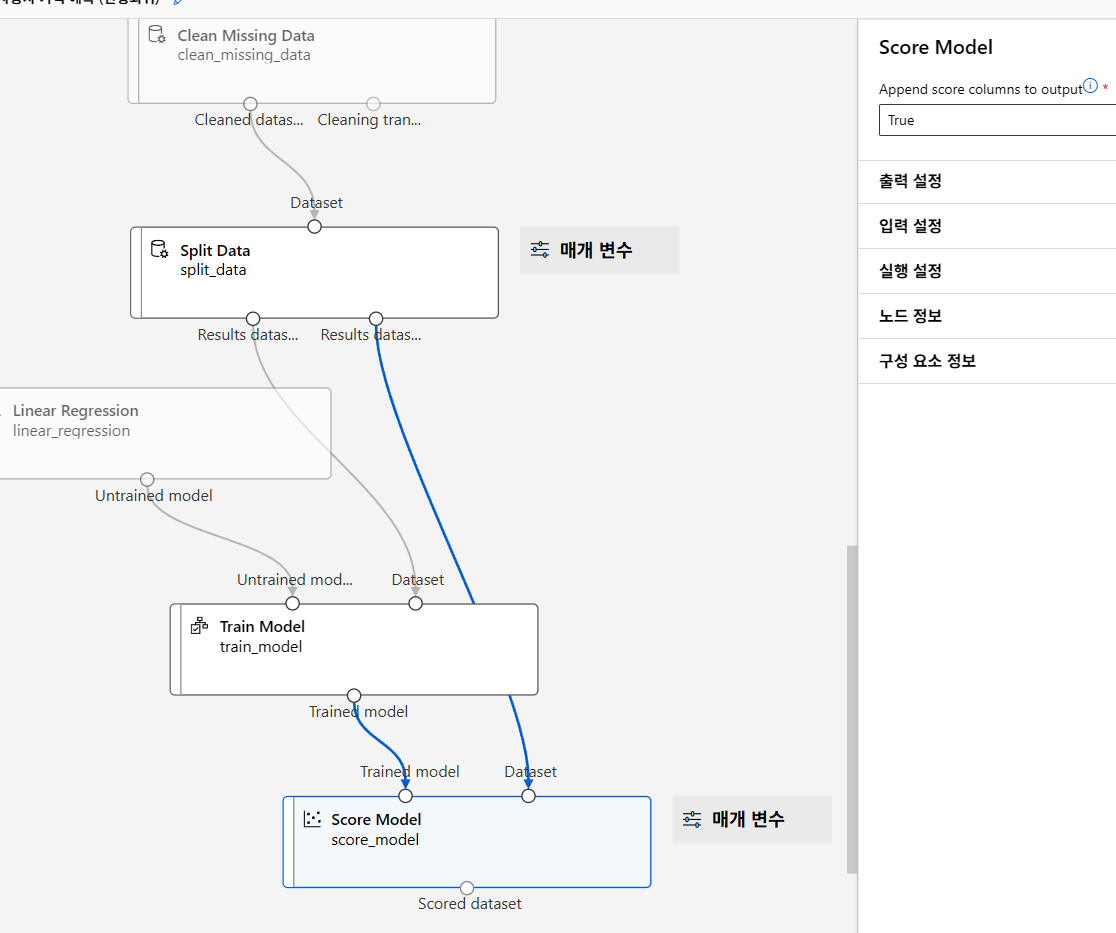
모델 평가
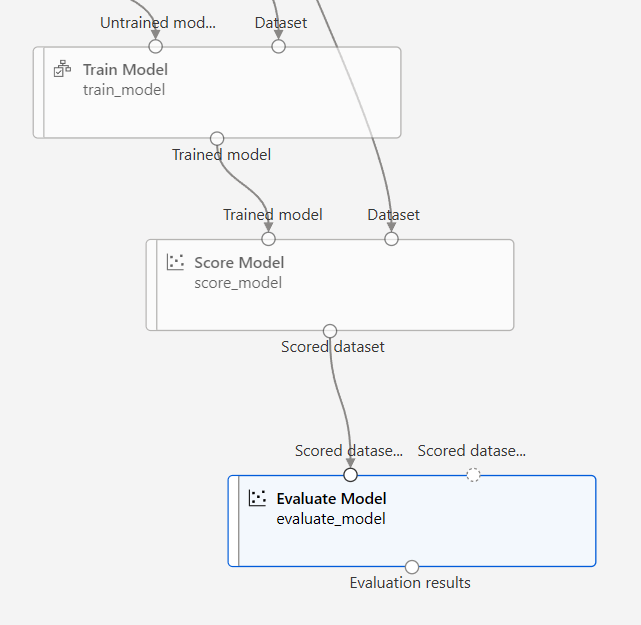
실행 후 결과 확인
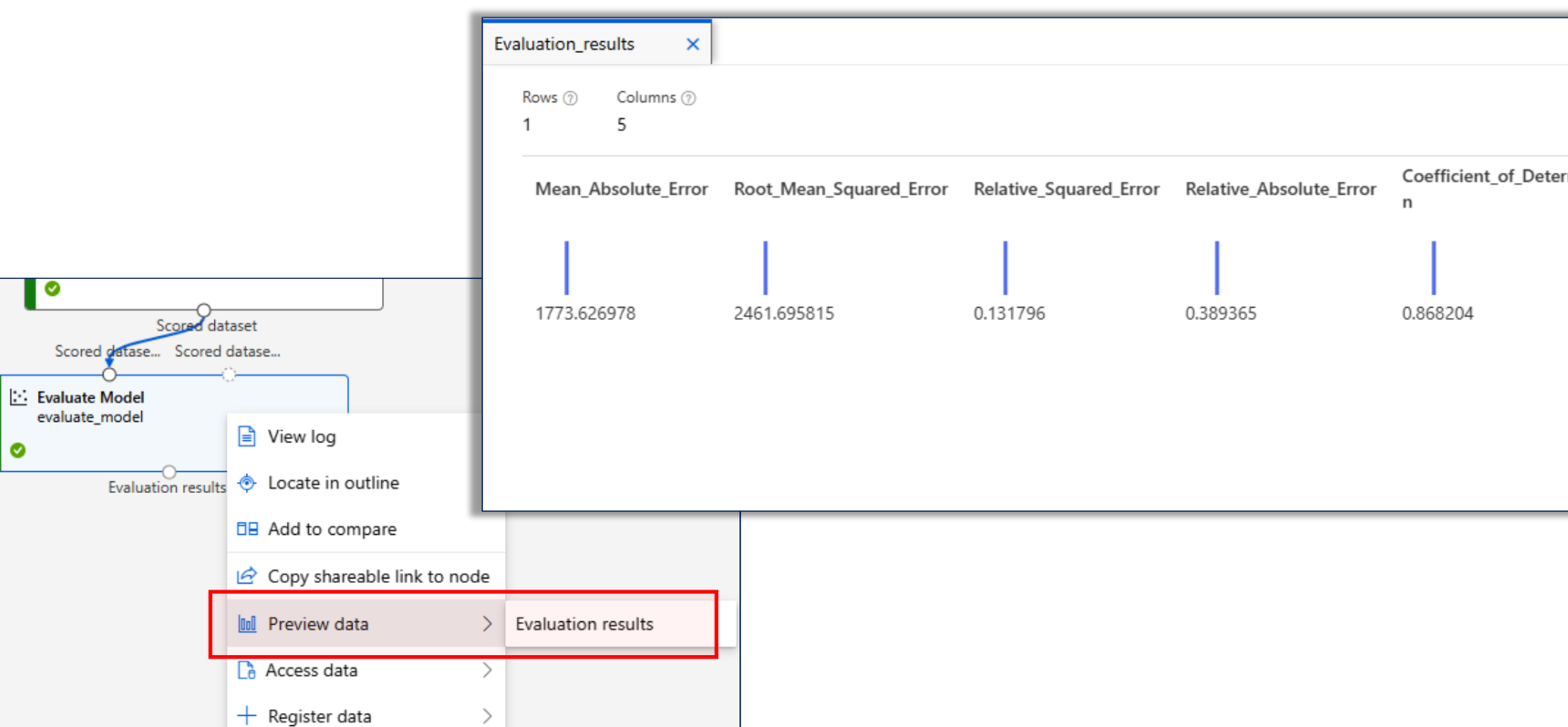
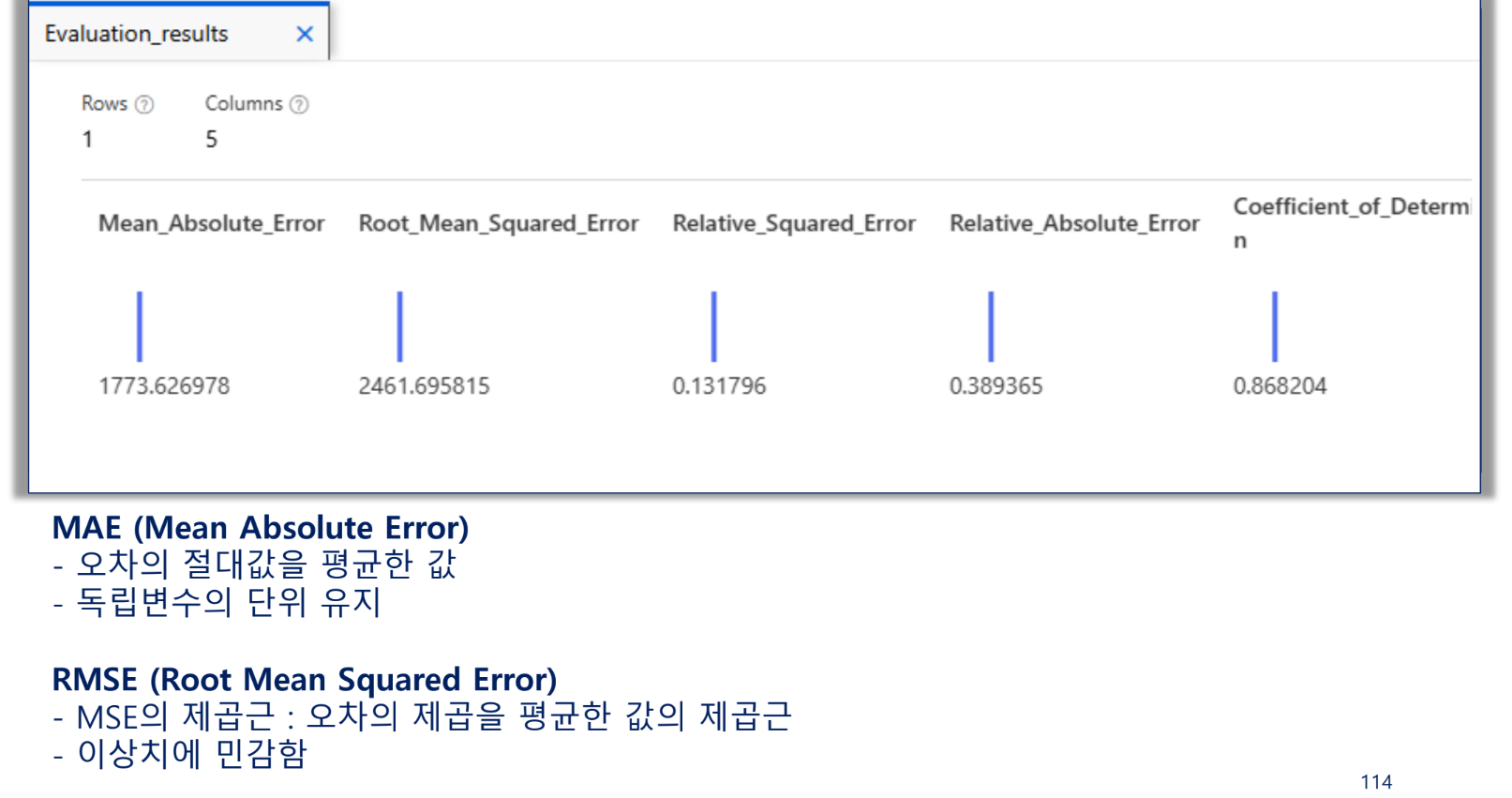
평가 지표 - 오차(손실)
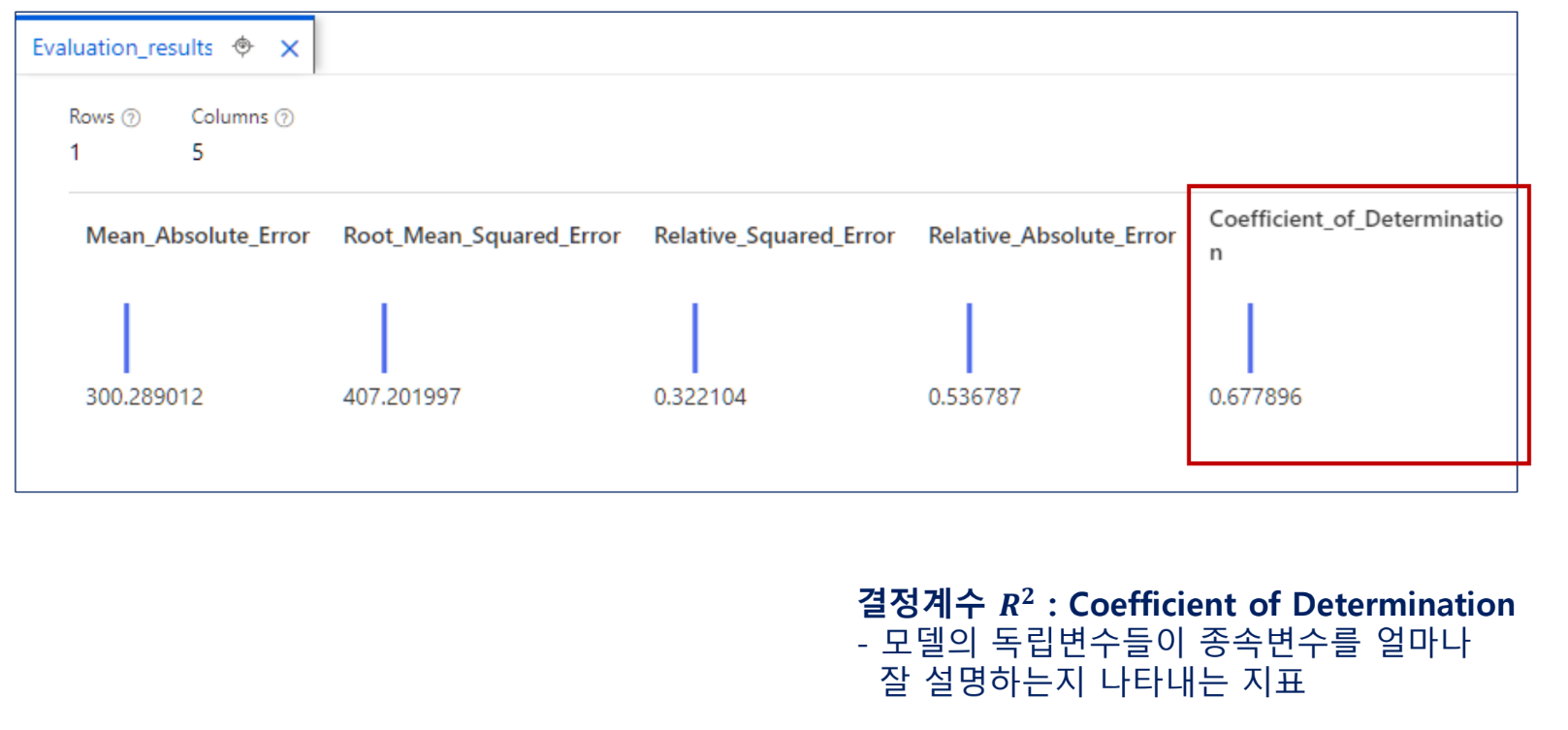
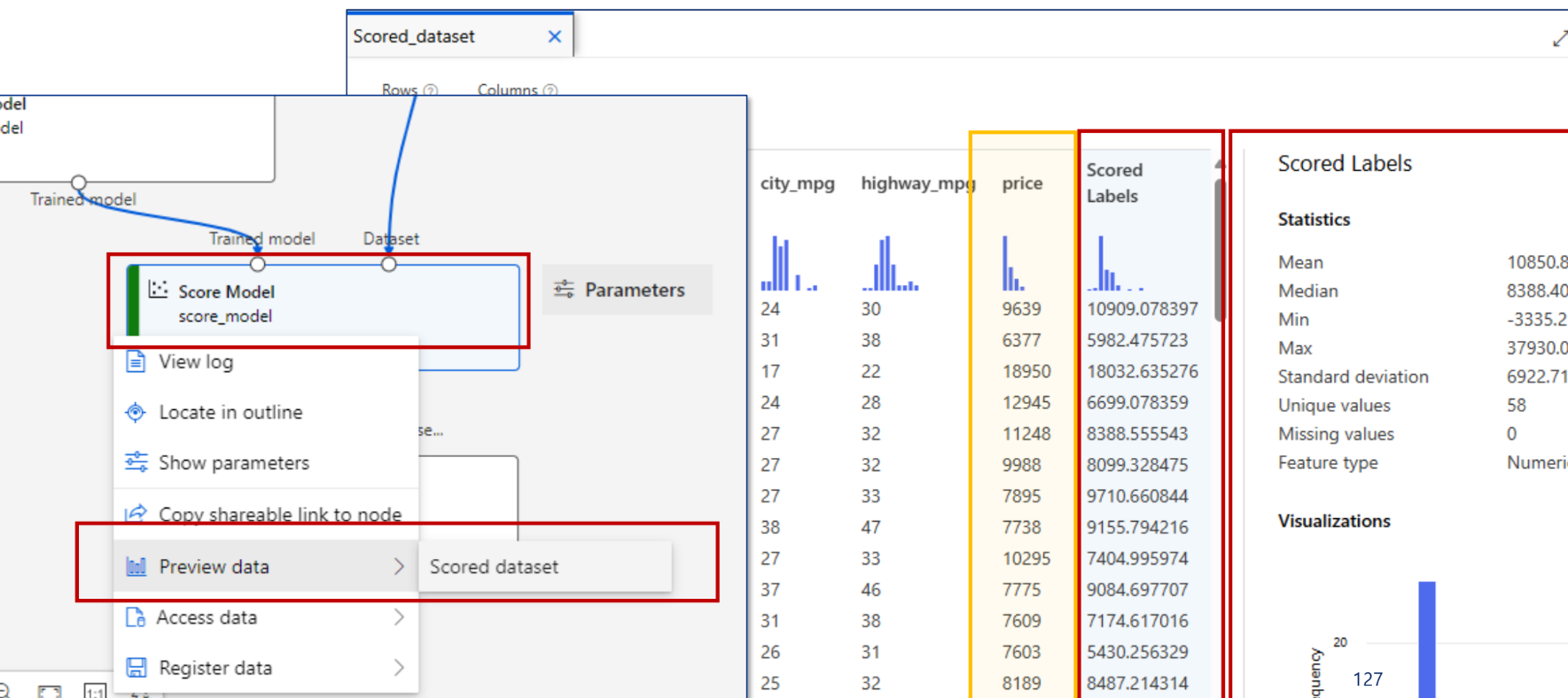
이후에는 조퇴했다.
