[MicrosoftDataSchool] 50일차 - Azure ML 트리기반 알고리즘. 특성선택, SVM, 로지스틱 회귀
Microsoft Data School 3기

실습 - 트리기반 알고리즘
Azure ML Studio 제공 회귀 알고리즘
Poisson Regression
푸아송 분포를 이용하여 만든 회귀 알고리즘
- 푸아송 분포: 단위 시간 내에 특정 사건이 몇회 발생할 것인지를 나타내는 이산 확률 분포
- 단위 당 특정 사건이 발생할 횟수를 예측함(양의 정숫값)
- 예시: 일주일 고객센터 문의 수, 하루 교통사고 발생 건수 예측
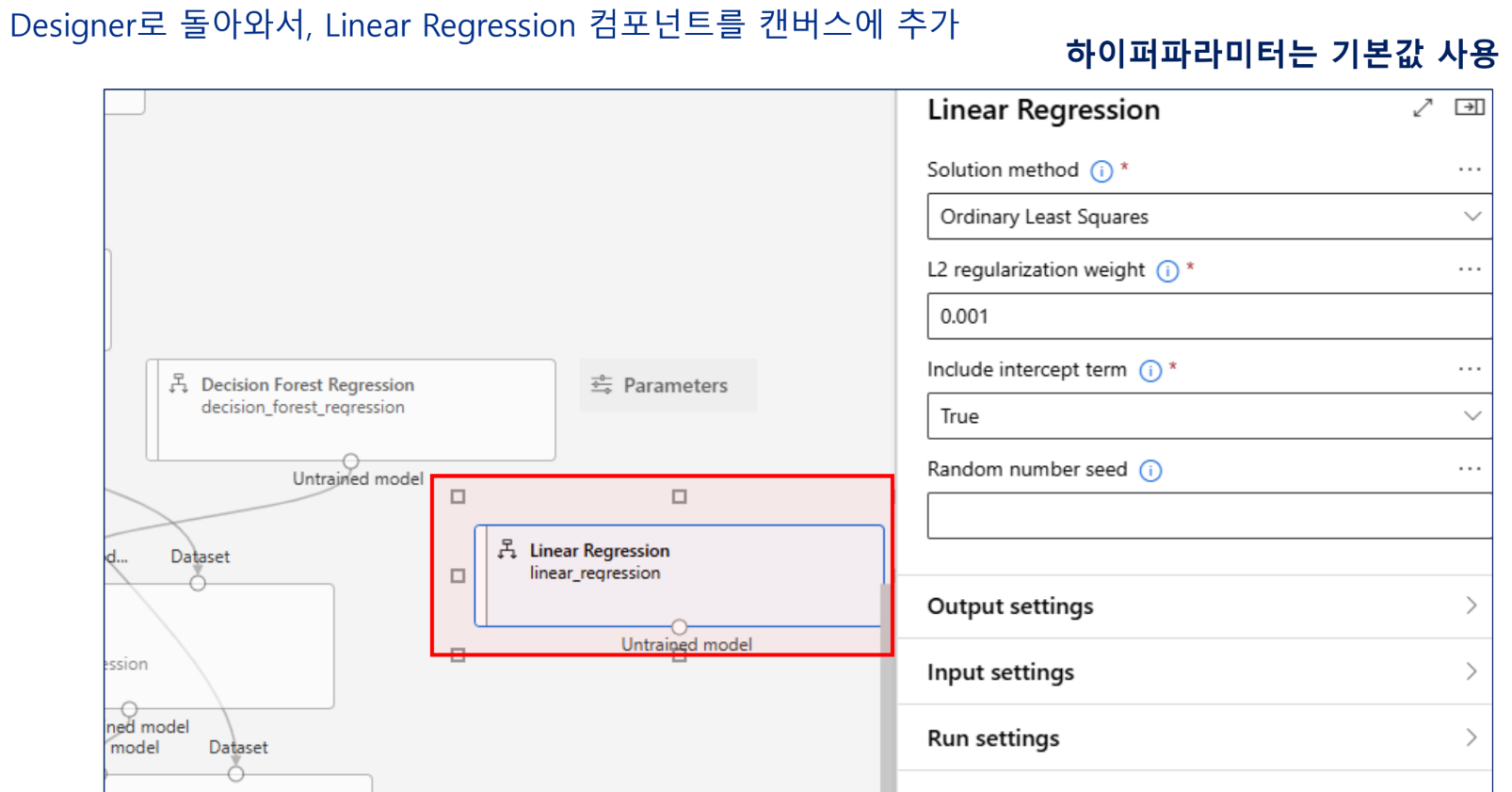
Linear Regression
- 선형회귀식을 이용하여 예측하는 회귀 알고리즘
- 독립변수(feature)과 종속변수(label)와의 선형적인 관계 예측
- 복잡하지 않은 선형 관계를 가질때 유용
Neural Network Regression
- 인공신경망을 활용한 회귀 알고리즘
- 선형 회귀로 모델링하기 어려운 복잡한 문제에 적용
- 인공신경망 모델 특성 상 모델링에 시간이 많이 걸림
Decision Forest Regression
- 의사결정나무 알고리즘을 이용한 회귀 알고리즘
- 메모리 효율적인 알고리즘으로 높은 성능을 보임
Boosted Decision Tree Regression
- 의사결정나무 기반 회귀 알고리즘
- 결정나무를 순차적으로 강화하여 학습하는 모델
- 단순 의사결정나무 회귀 알고리즘에 비해 메모리 사용량이 높지만 정확도는 향상됨
Fast Forest Quantile Regression
- 의사결정나무를 이용하여 범위나 분포를 예측하는 회귀 알고리즘
- 1/4 , 2/4, 3/4 등 사분위수 위치의 값을 빠르게 예측
- 예시 : 가격, 온도 등의 분포를 예측할 때 주로 사용됨
회귀나무
CART (Classification And Regression Tree)
- 분류 문제와 회귀 문제에 모두 사용될 수 있는 나무(Tree) 기반 알고리즘
- 범주 예측과 수치 예측 모두에 사용 가능함을 의미함
- 회귀에 사용될 경우 불순도(gini index)가 아닌 실측값과 예측값의 오차를 이용함
의사결정나무 회귀
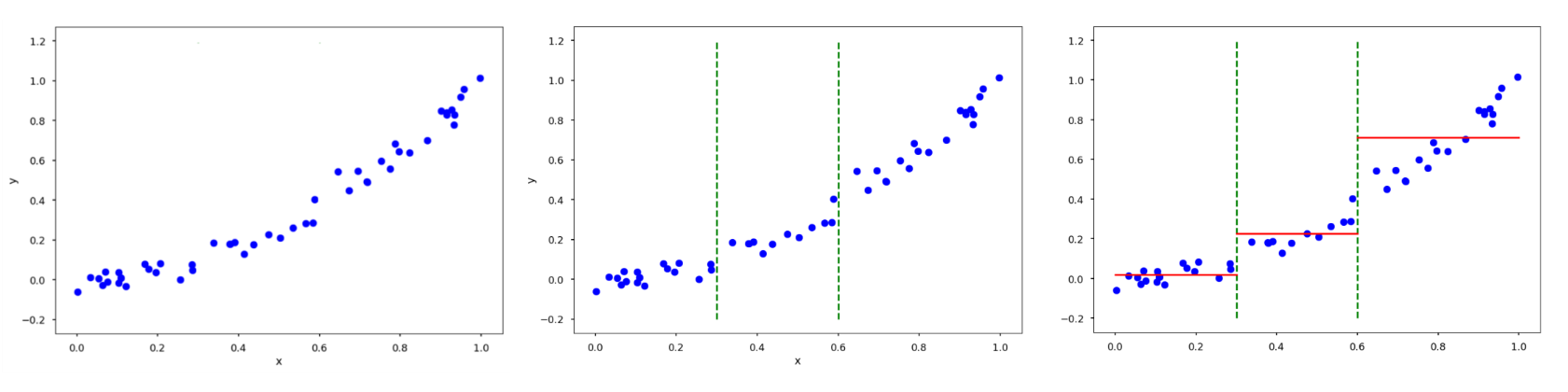
- 의사결정나무 알고리즘을 회귀 분석에 적용 한모델
- 입력변수의 영역을 여러 구간으로 나누고, 각 구간에 대해 고정된 값을 예측하는 방식으로 동작
- 이를 통해 비선형적인 데이터에 대해서도 유연한 예측 가능
나무의 노드
- 루트노드 : 전체 데이터 세트를 포함하는 최상위 노드
- 내부노드 : 특정 기준에 따라 데이터를 두 개의 하위 노드로 나누는 노드
- 리프노드 : 더 이상 나눌 수 없는 최종 노드. 노드의 값이 예측 값이 됨
분할 기준
- 각 노드에서 최적의 분할 기준을 찾기 위해 손실함수 사용
- 손실함수(MSE, MAE 등)를 최소화 하는 분할 선택
- MSE(평균제곱오차)의 개념이 일반적으로 사용되며, 각 분할된 구간 내의 데이터 포인트와 평균 간의 오차를 계산하여 최소화 하는 방향으로 분할 수행
예시
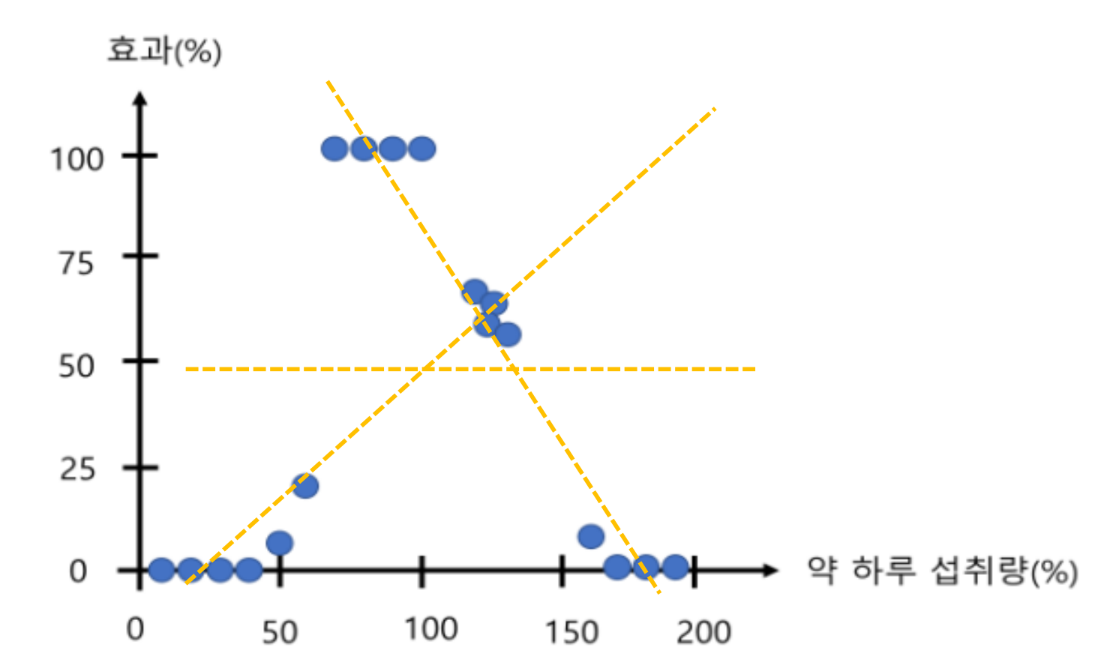
모든 데이터에 대해 각 데이터 포인트들을 각 지역 평균과의 차이를 통해 RSS 계산
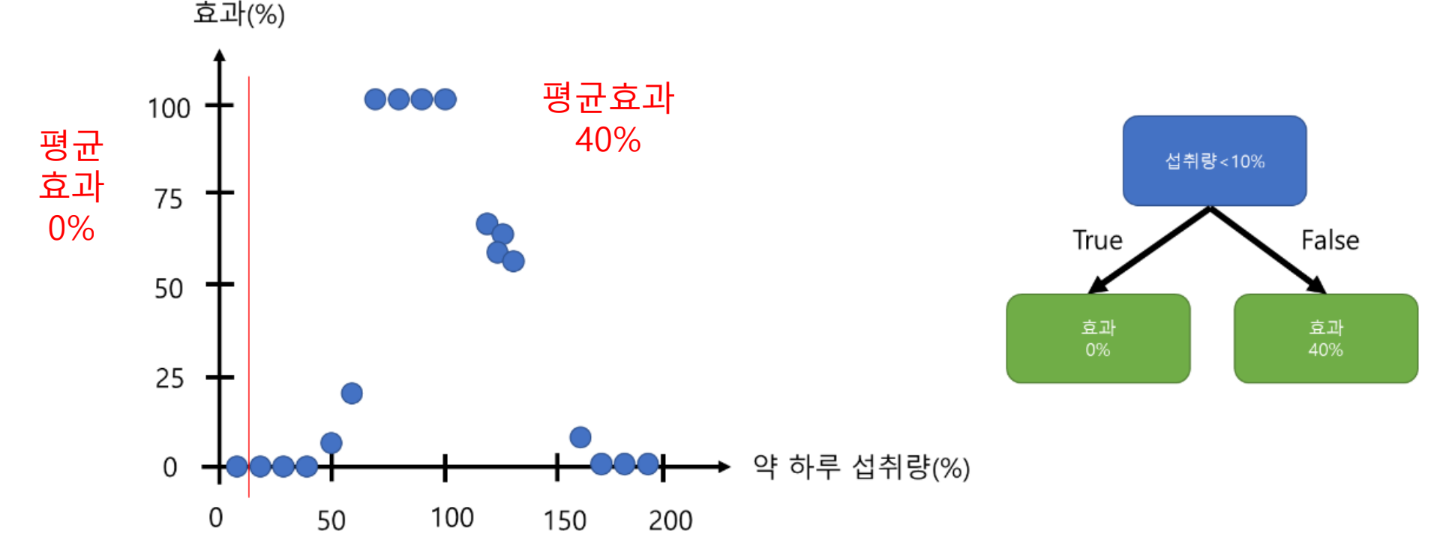
분할 기준2
잔차제곱합 (RSS, Residual Sum of Squre)
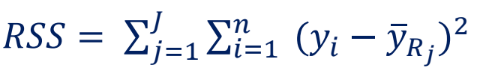
- 특정 지역(Region) 내에 있는 데이터들의 평균과 데이터의 차이의 제곱합
- 모든 데이터로부터 손실(RSS)을 계산하여 이를 최소화 하는 방향으로 학습함
예시
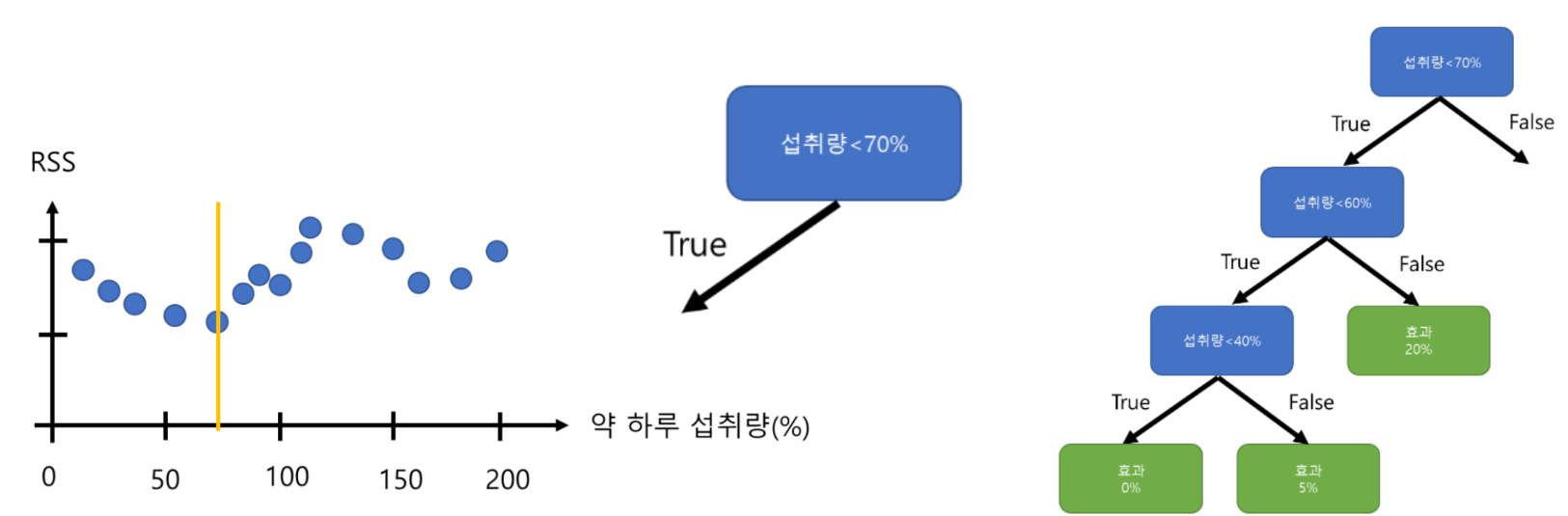
- 모든 데이터에 대해 각 데이터 포인트들을 각 지역 평균과의 차이를 통해 RSS 계산
- 최소의 RSS를 갖는 변수값을 기준으로 산점도를 분할 후 트리의 노드 생성
실습
이전과 같은 방식으로 진행되기때문에 자세한 진행방법은 생략
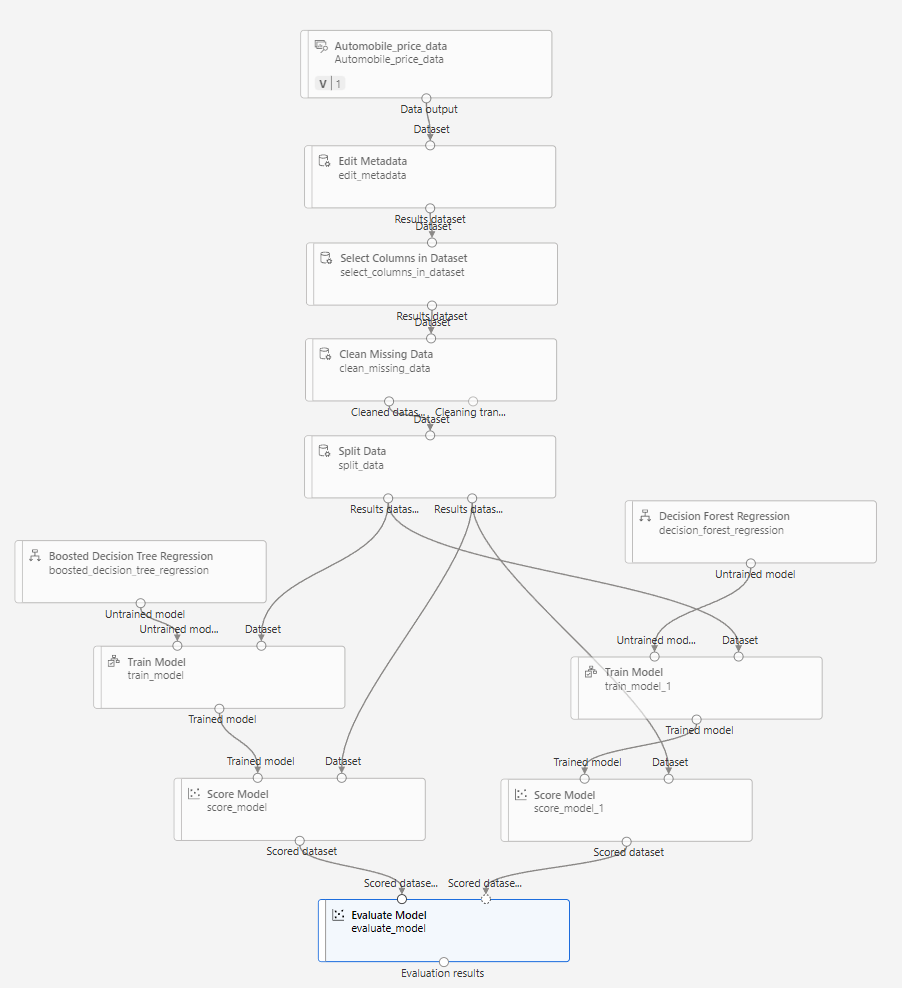
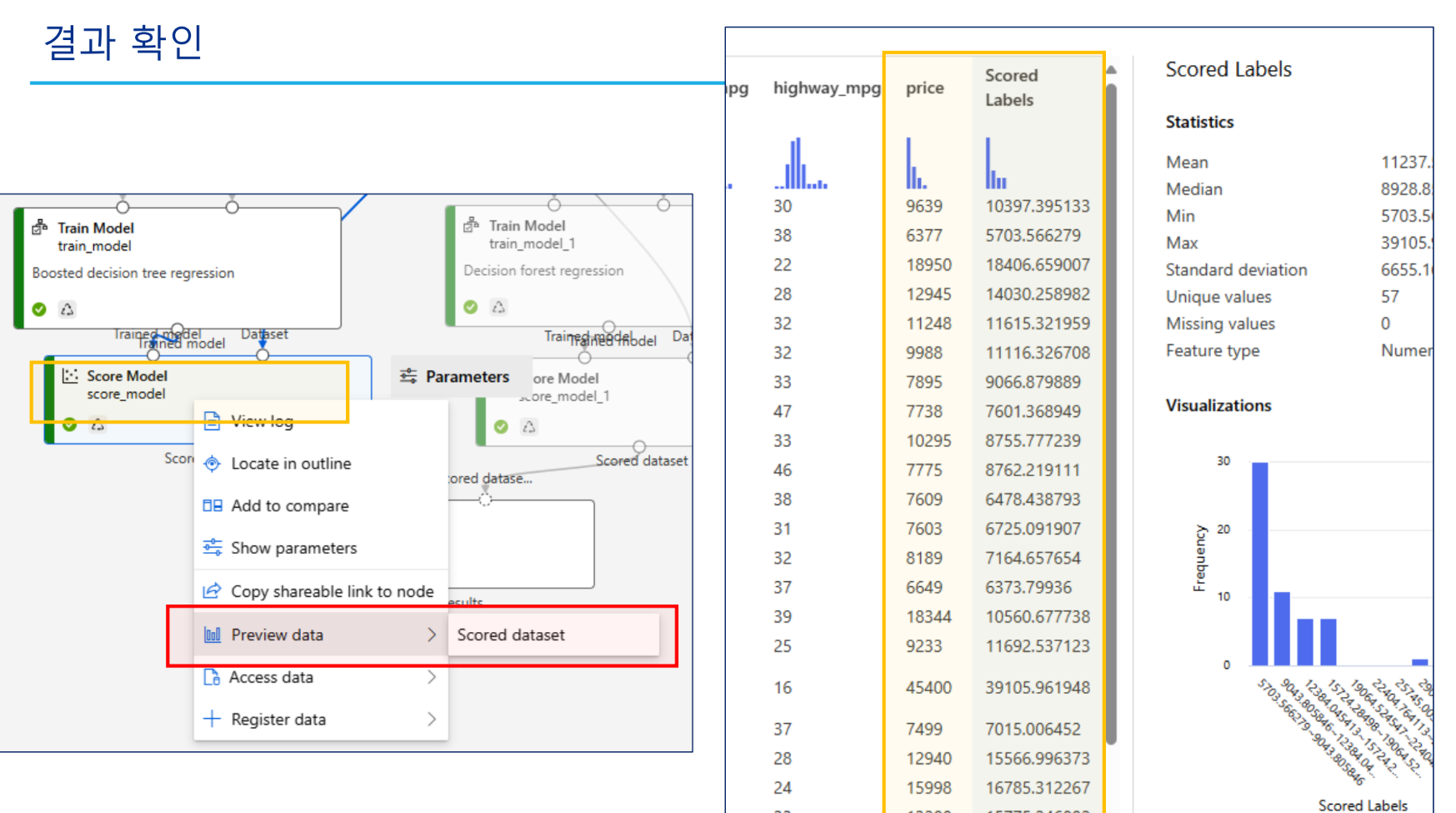
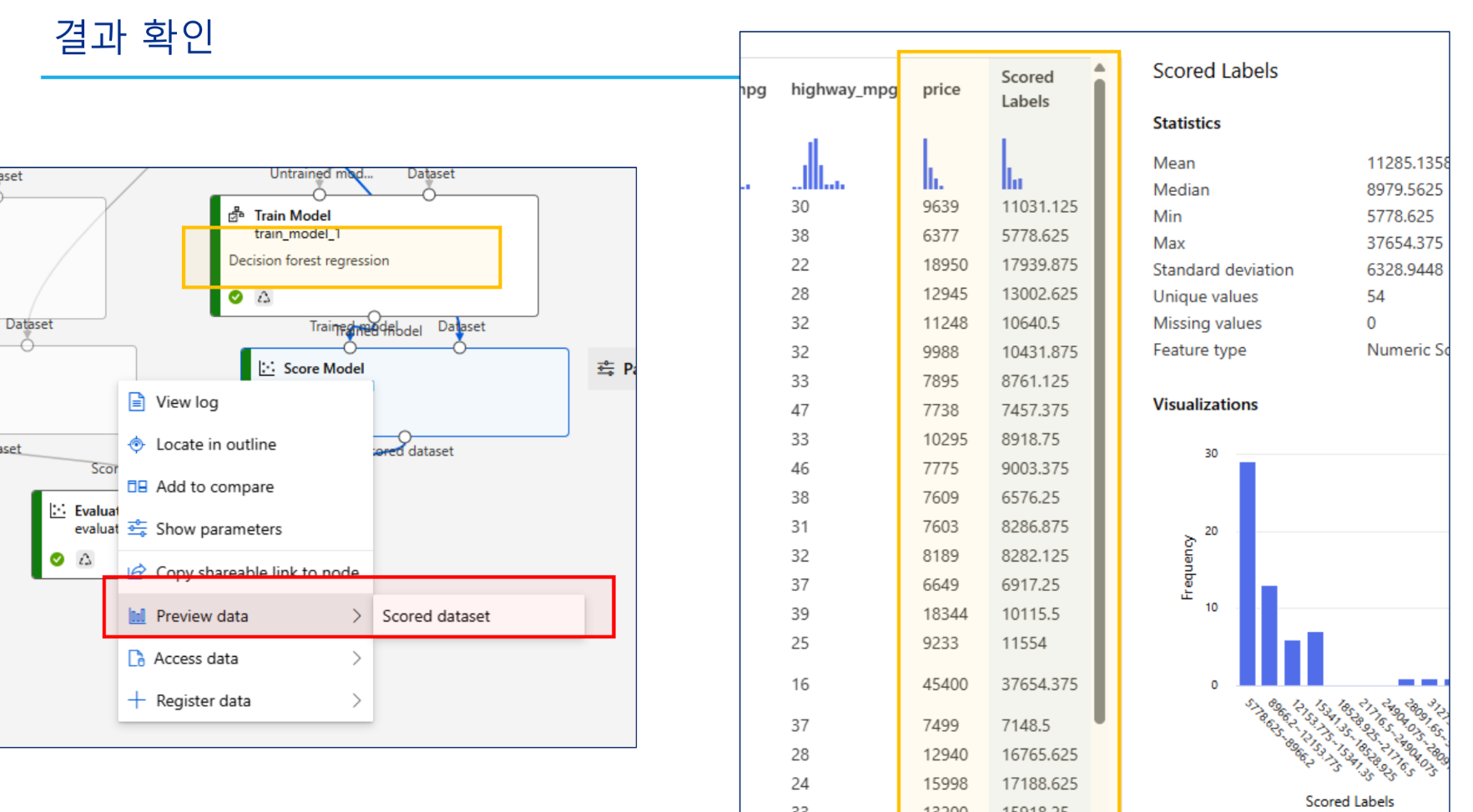
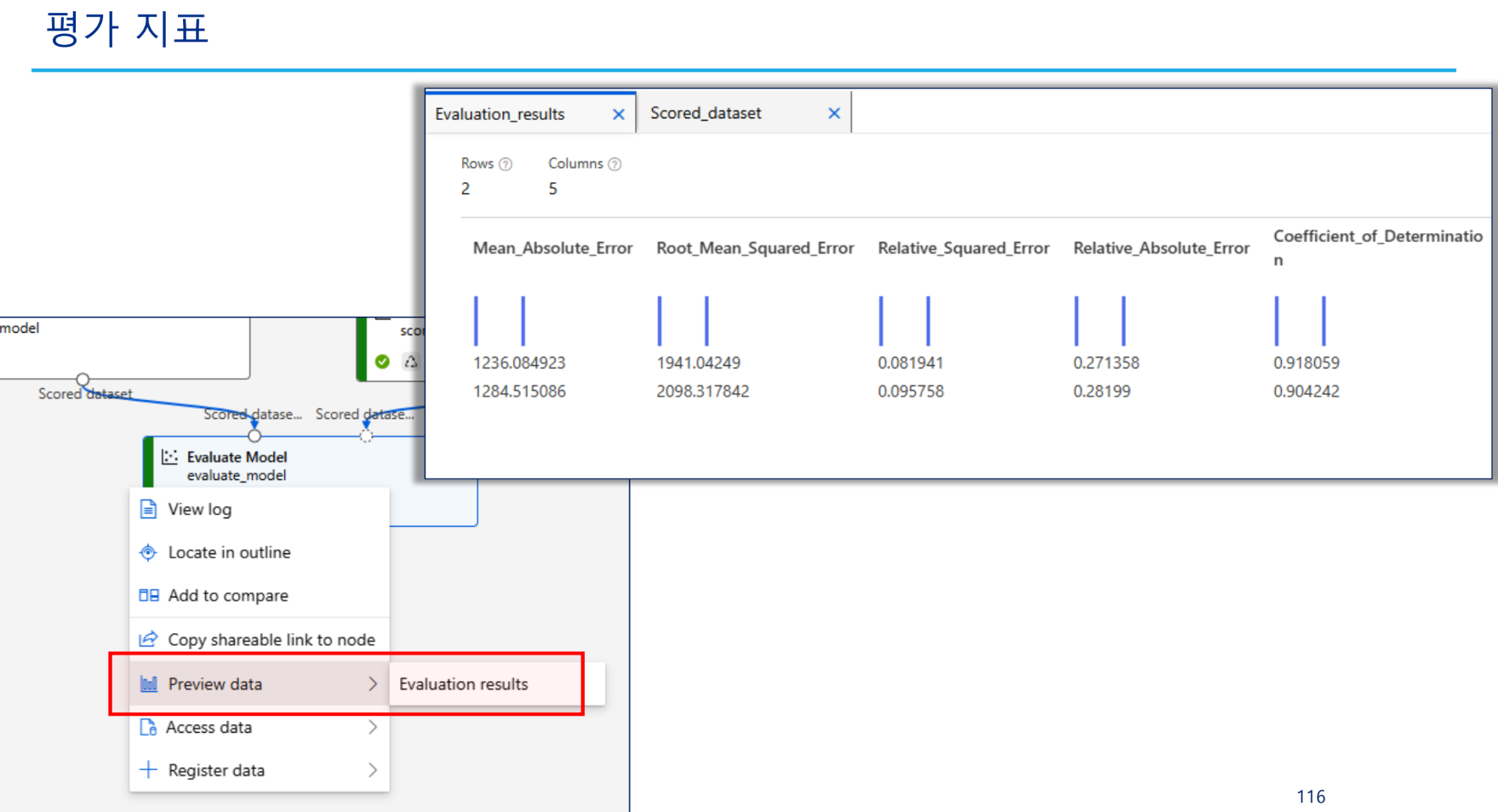
추가실습 - 세 개 이상 알고리즘 비교
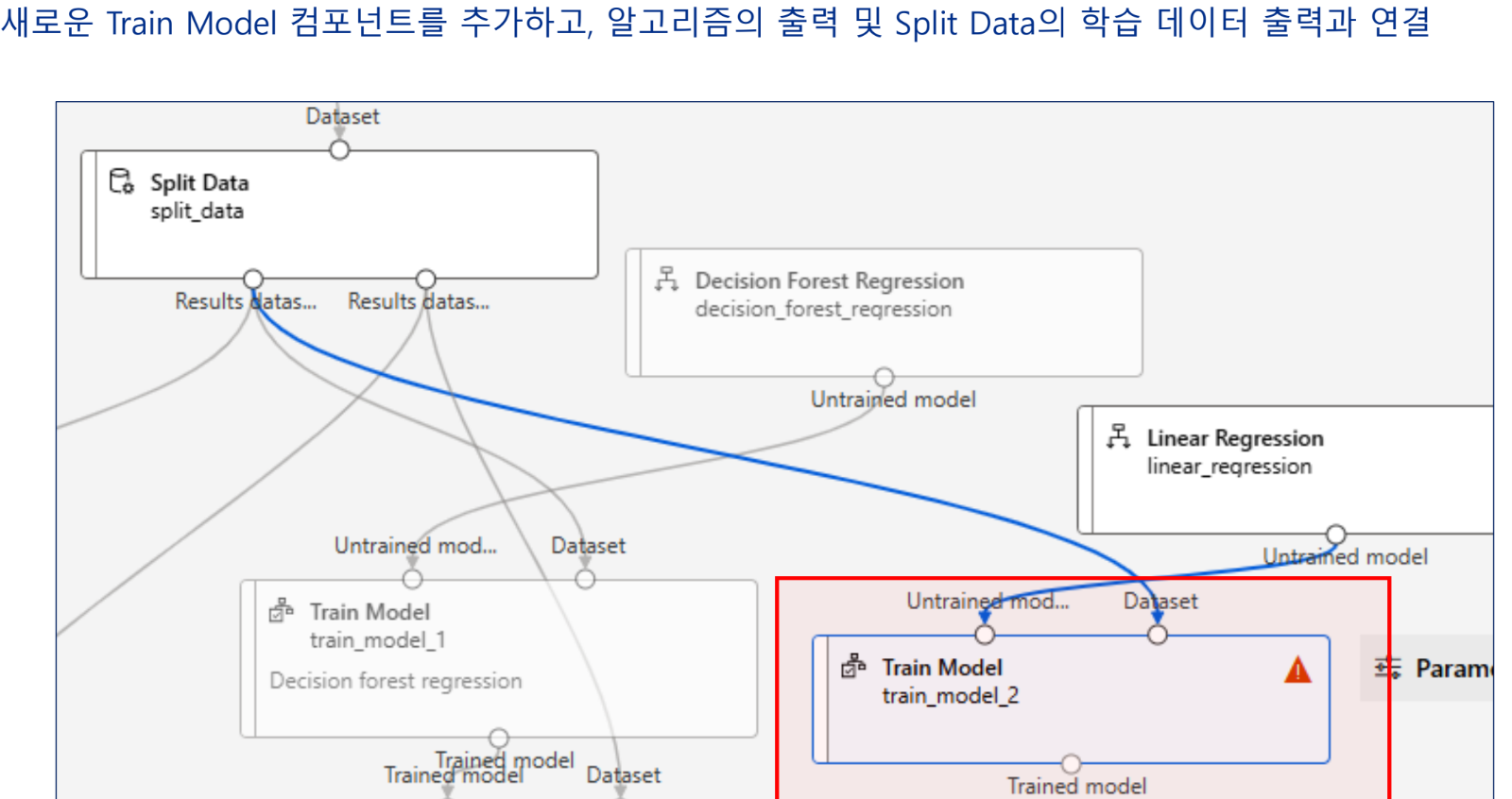
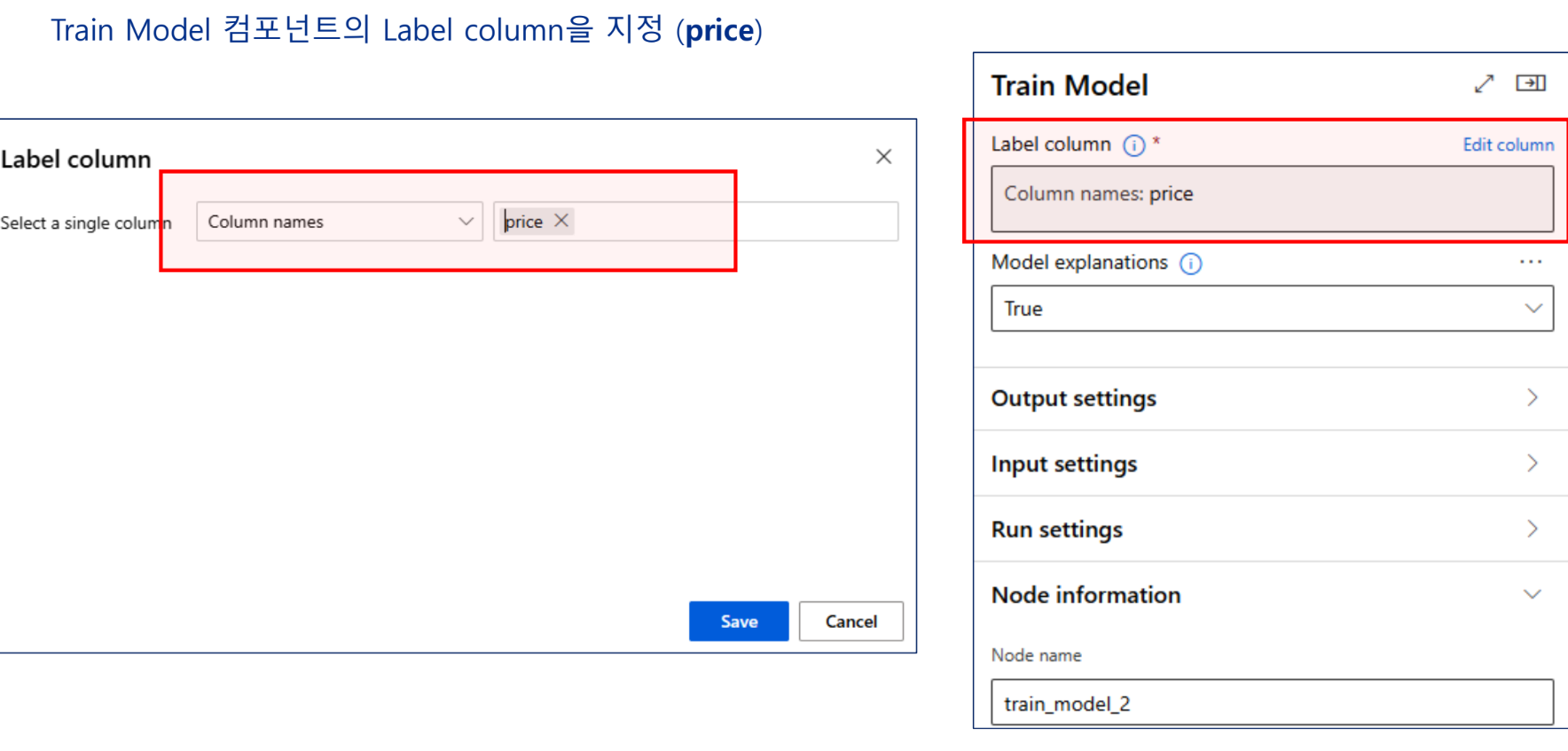
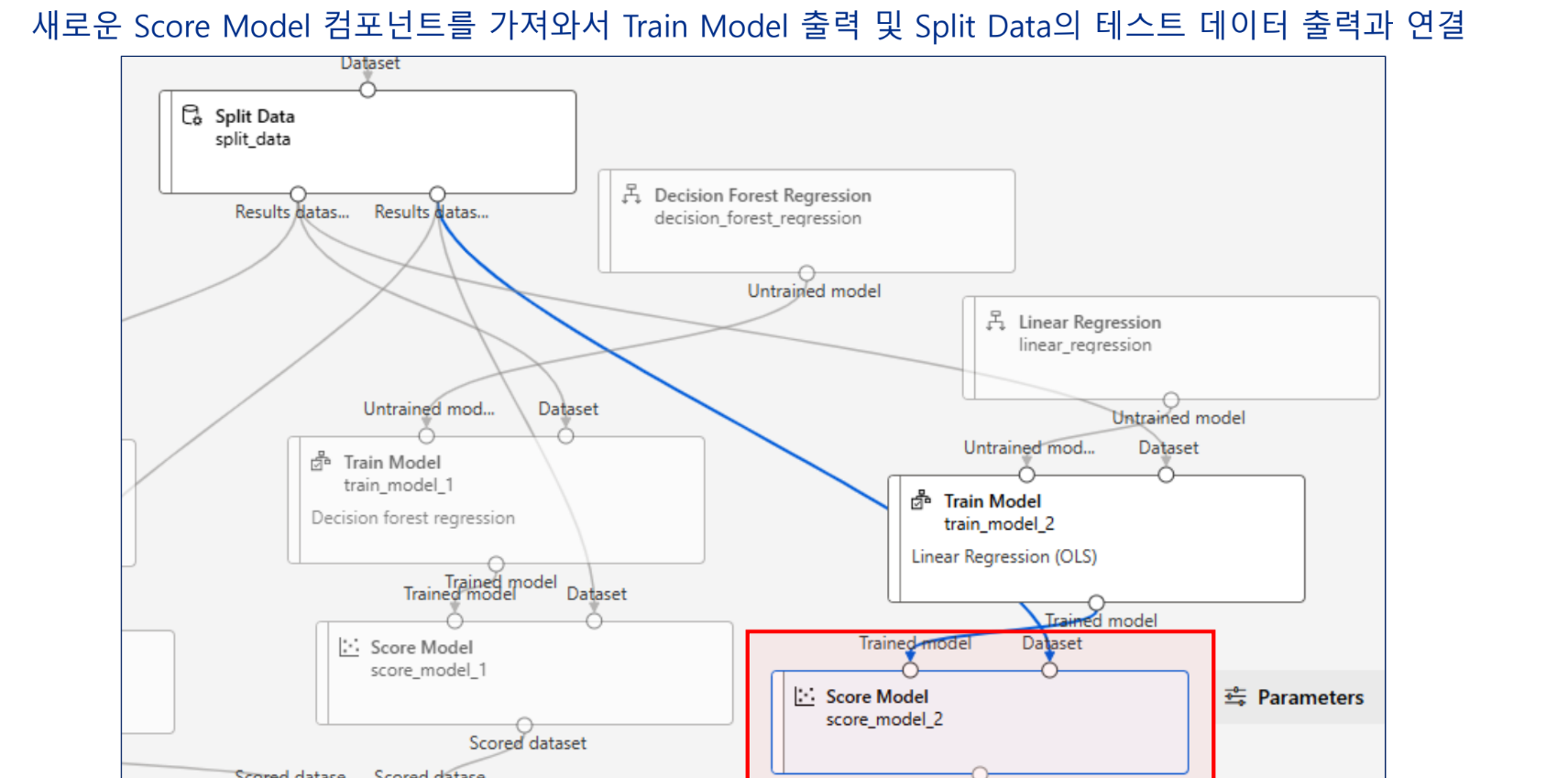
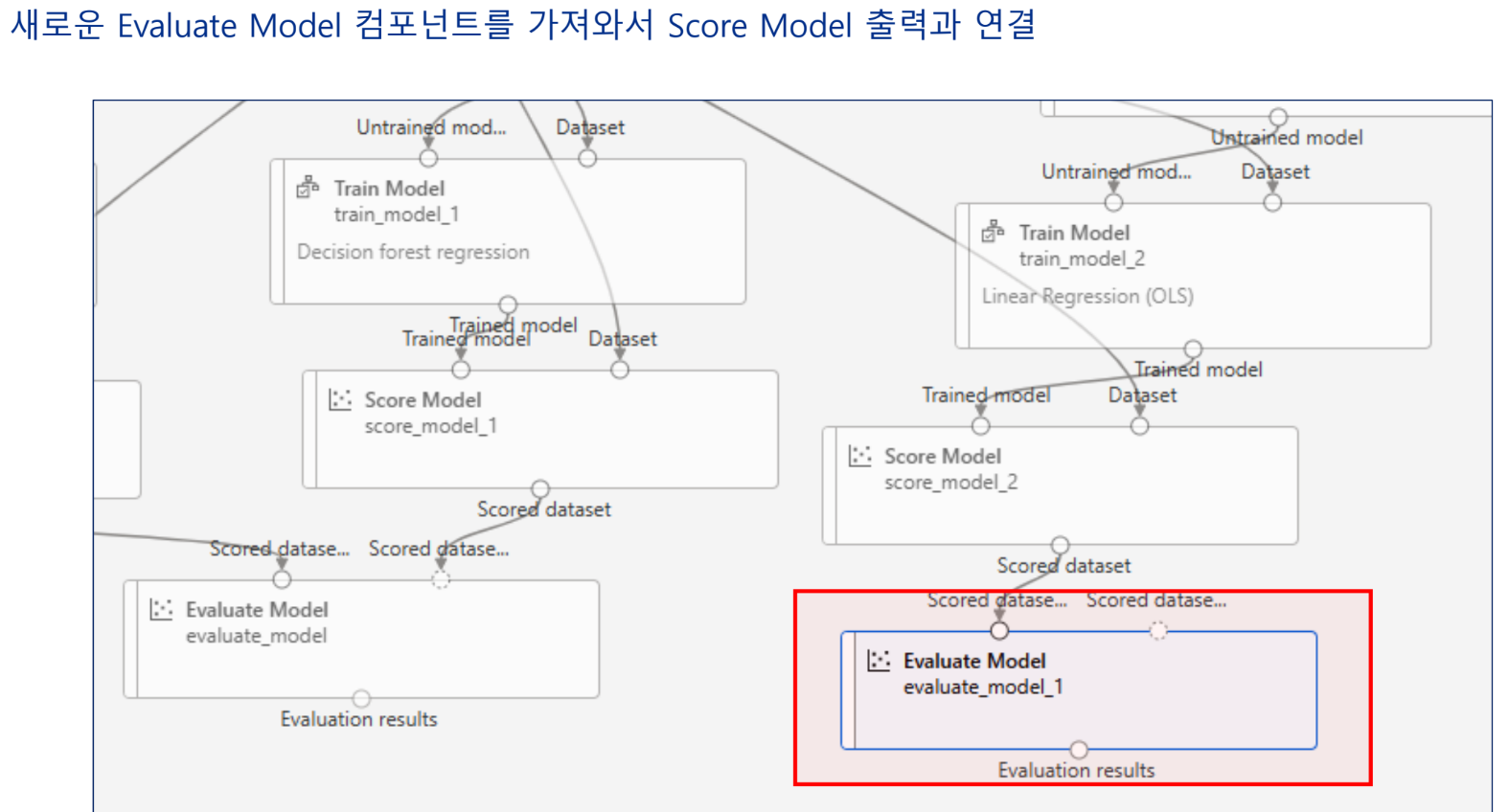
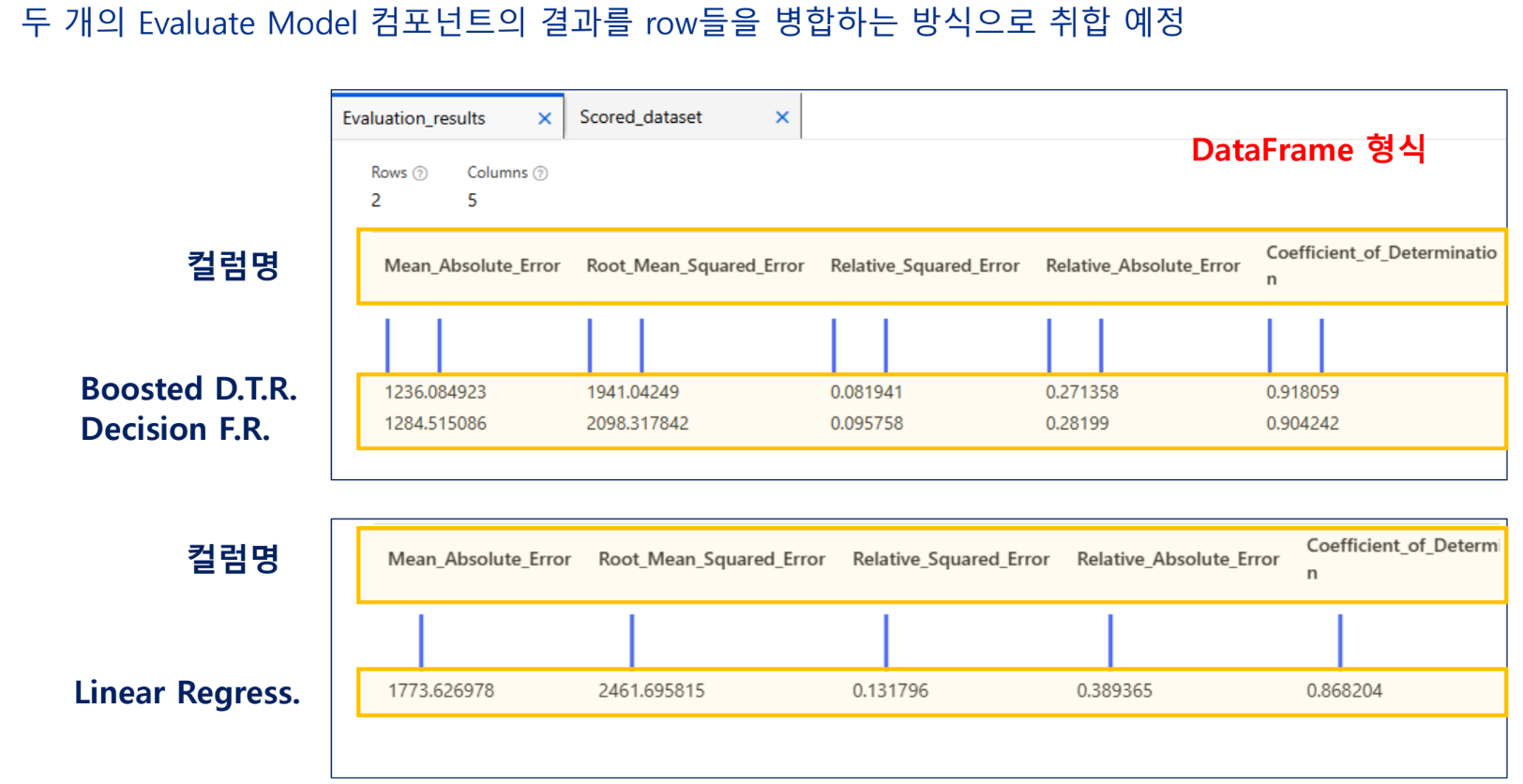
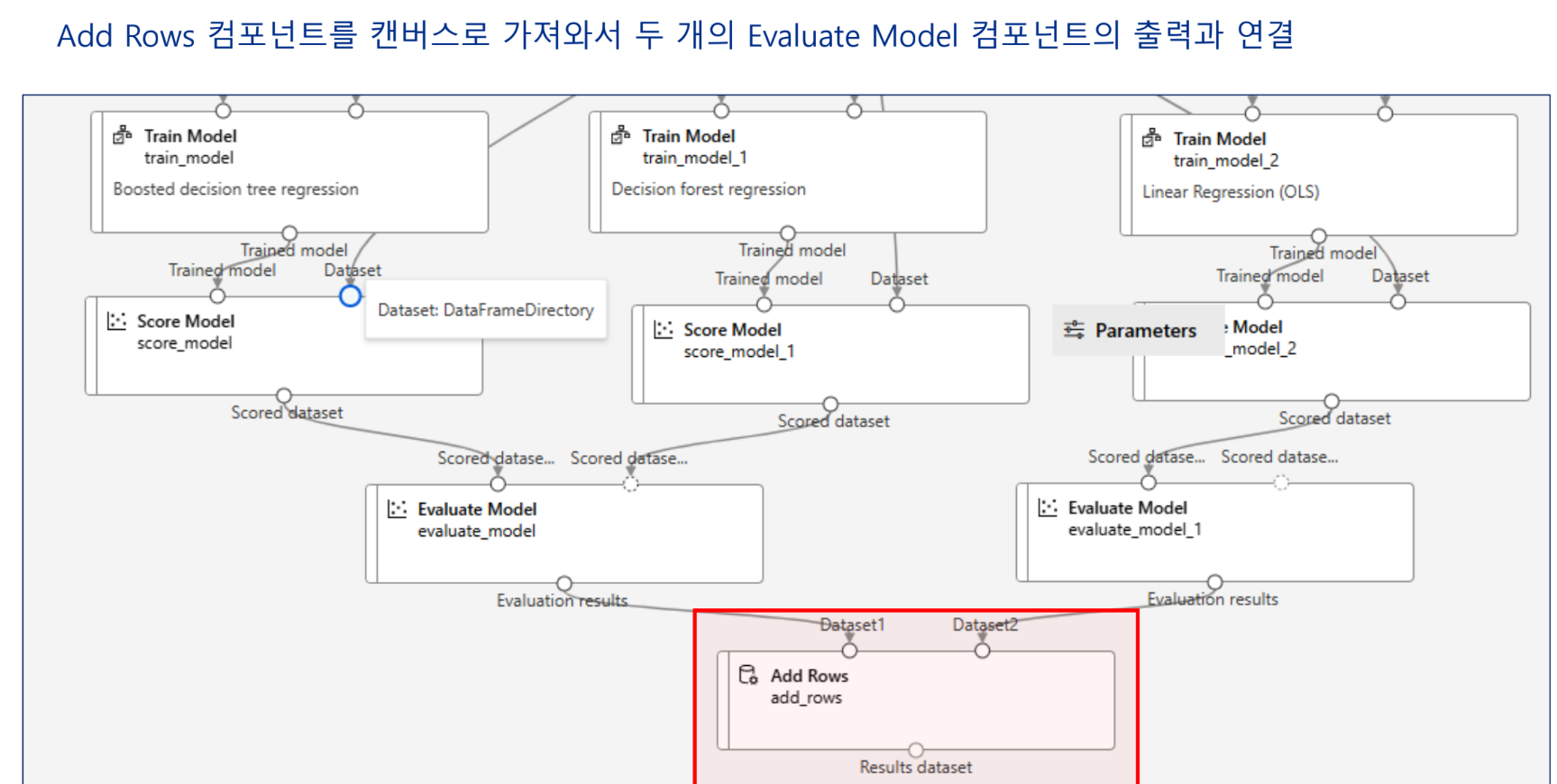
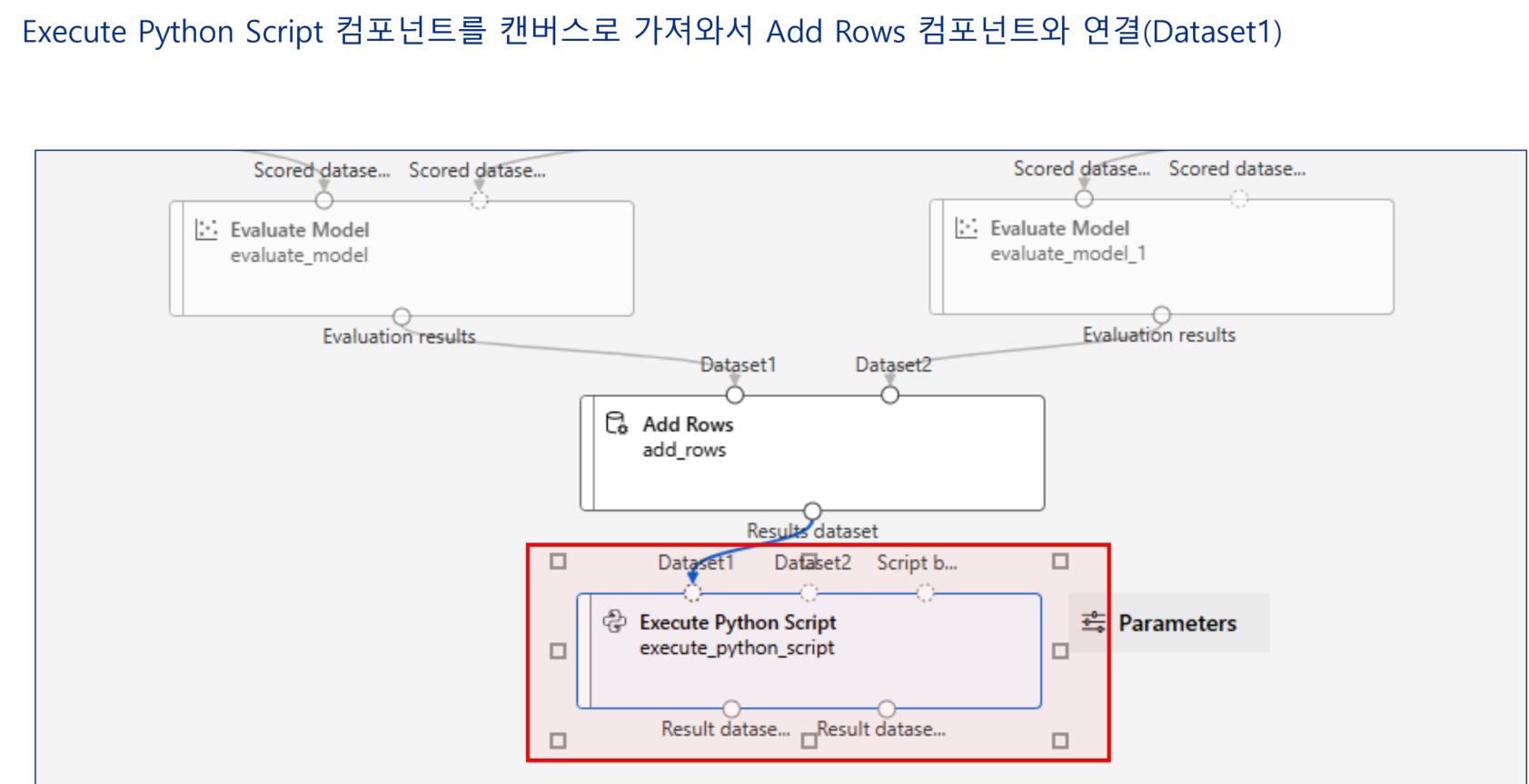
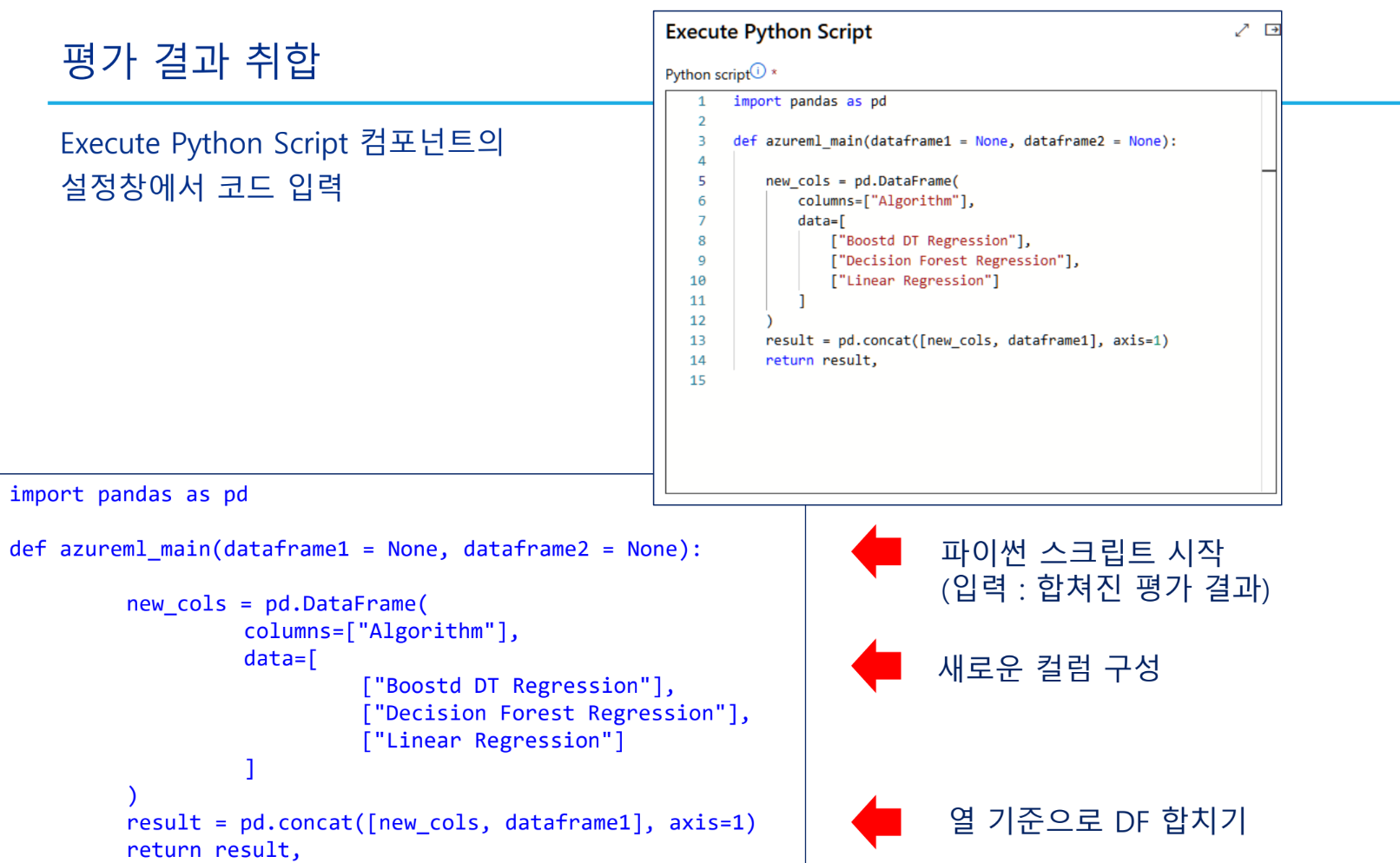
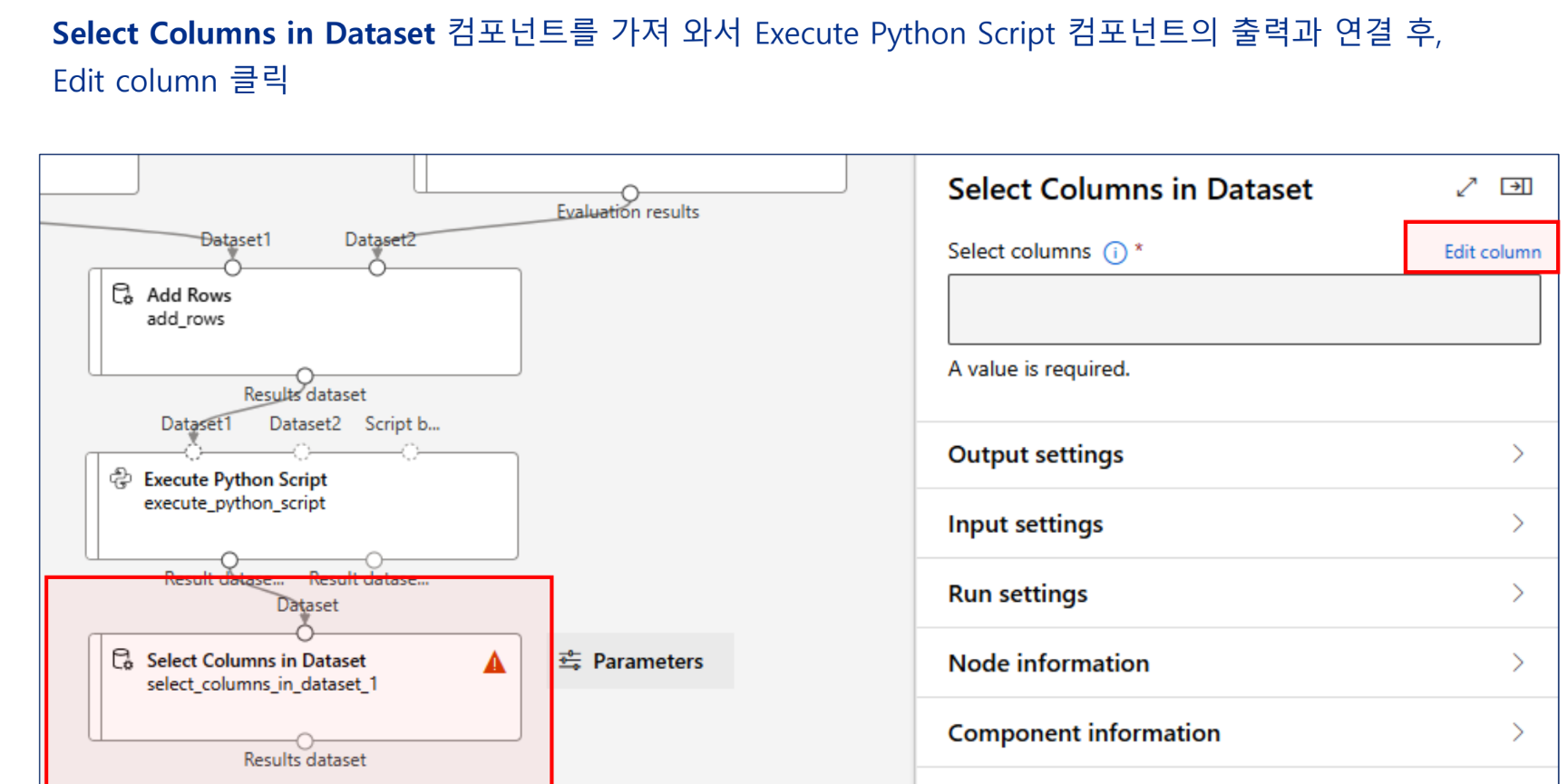
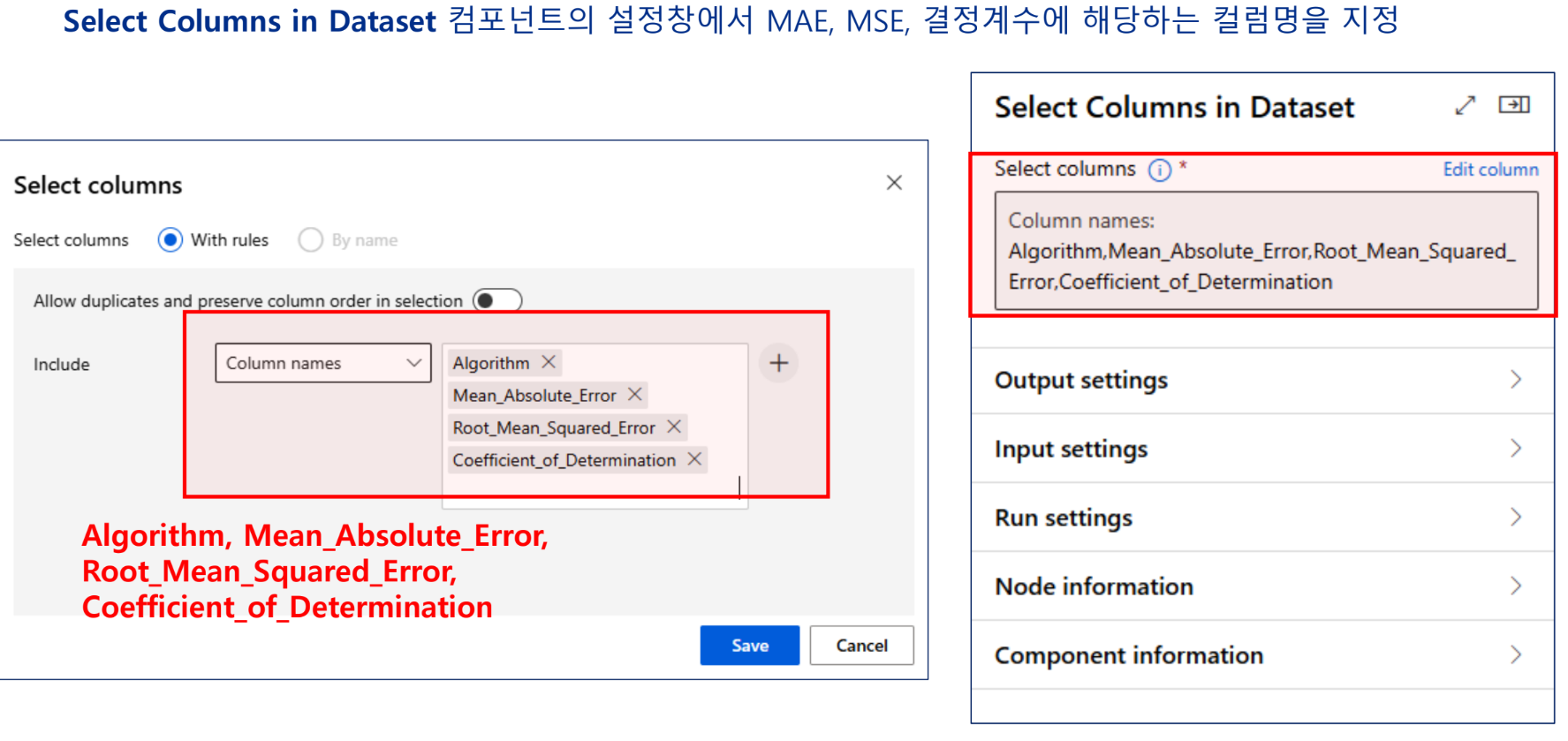
실습 - 특성 선택 기법을 활용한 개인 수입 예측 모델 구현
앙상블 기법
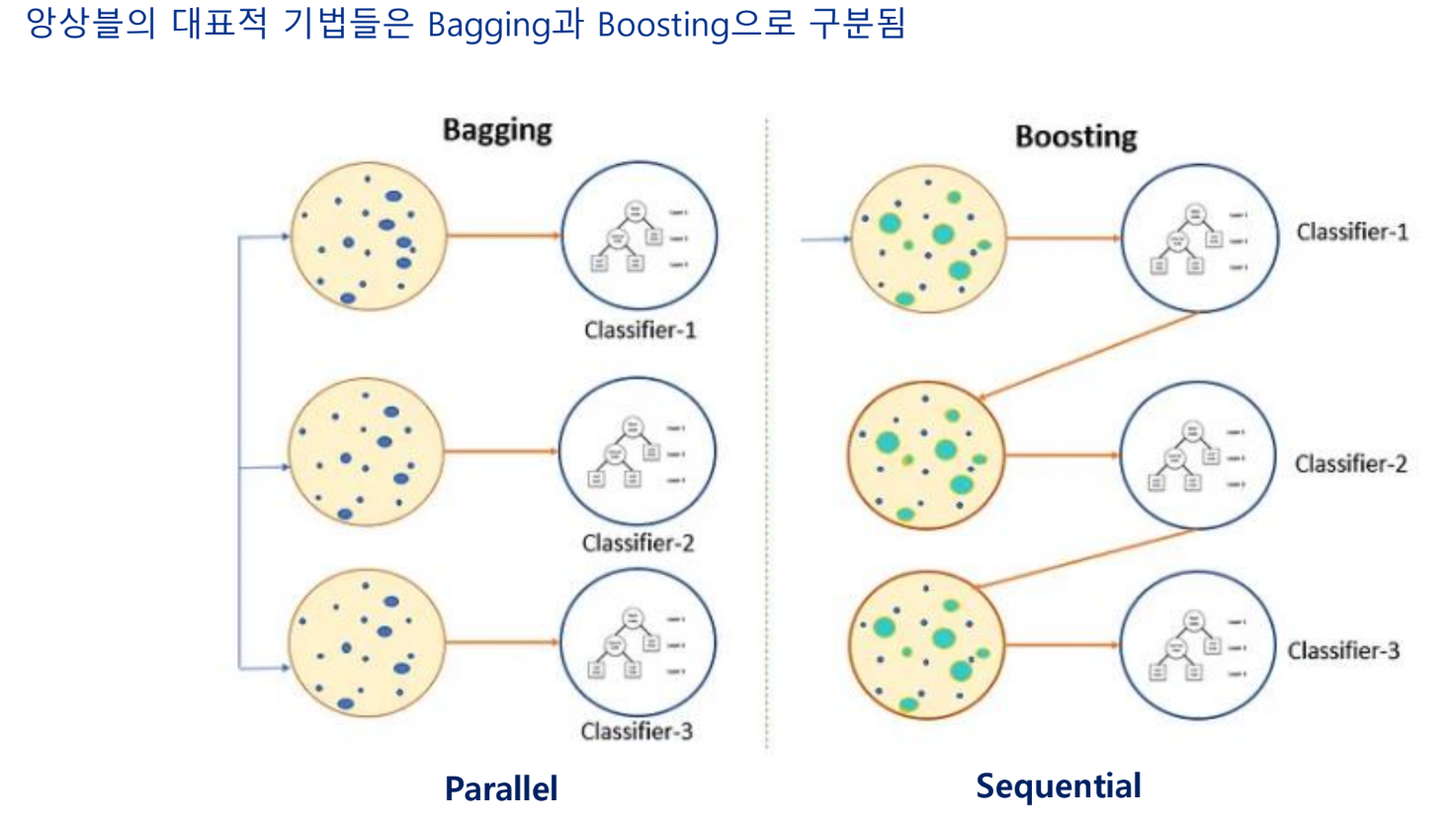
sequential은 메모리를 더 많이 사용하지만, 성능은 좋다
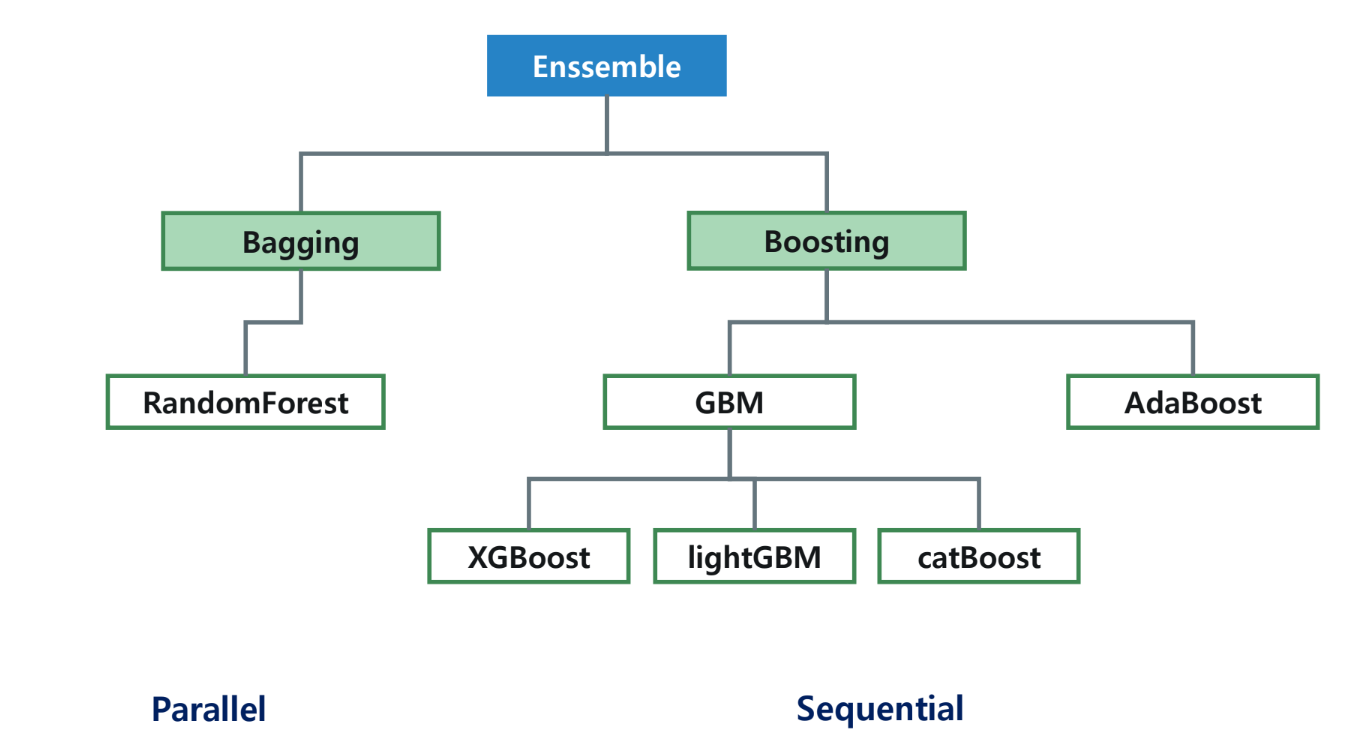
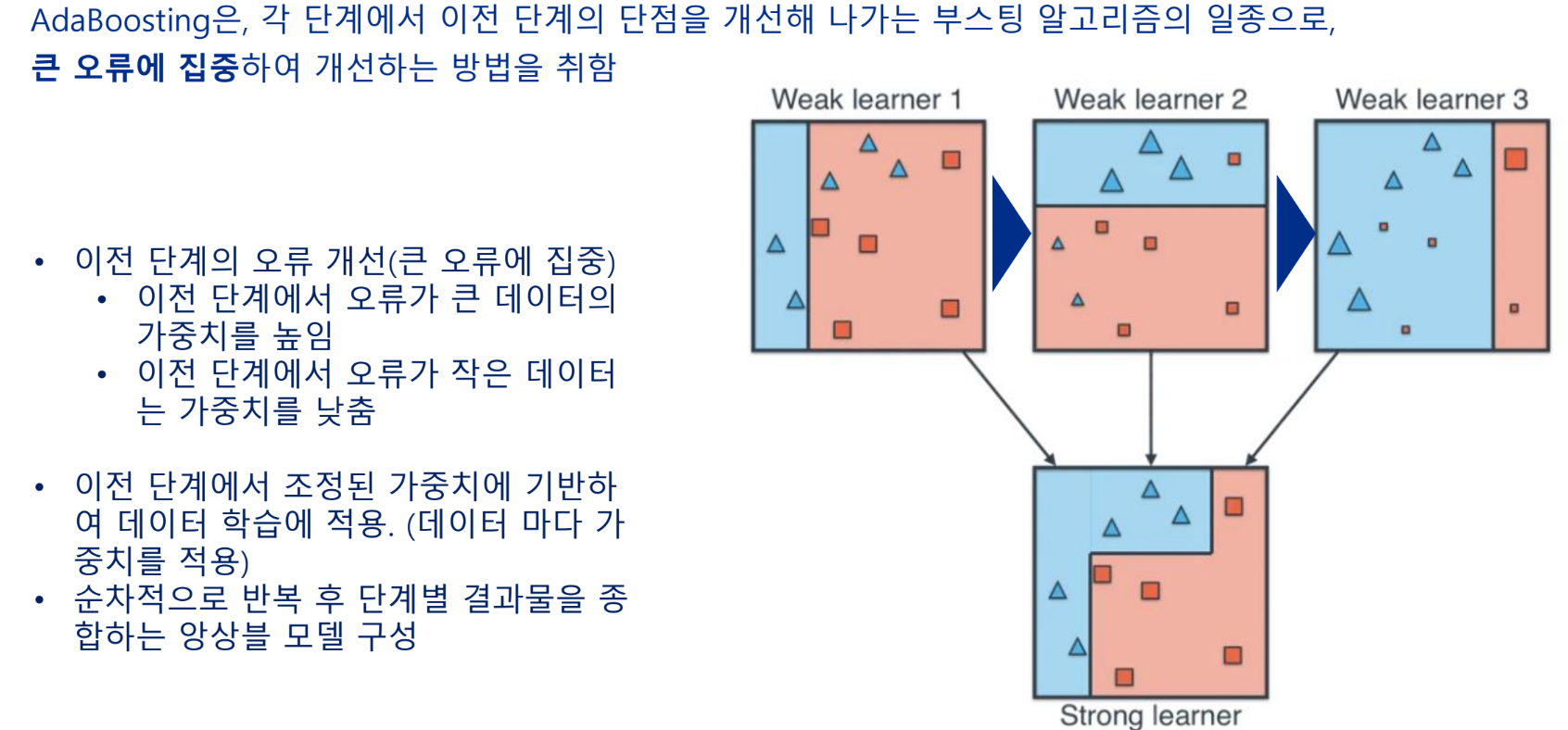
부스팅 알고리즘
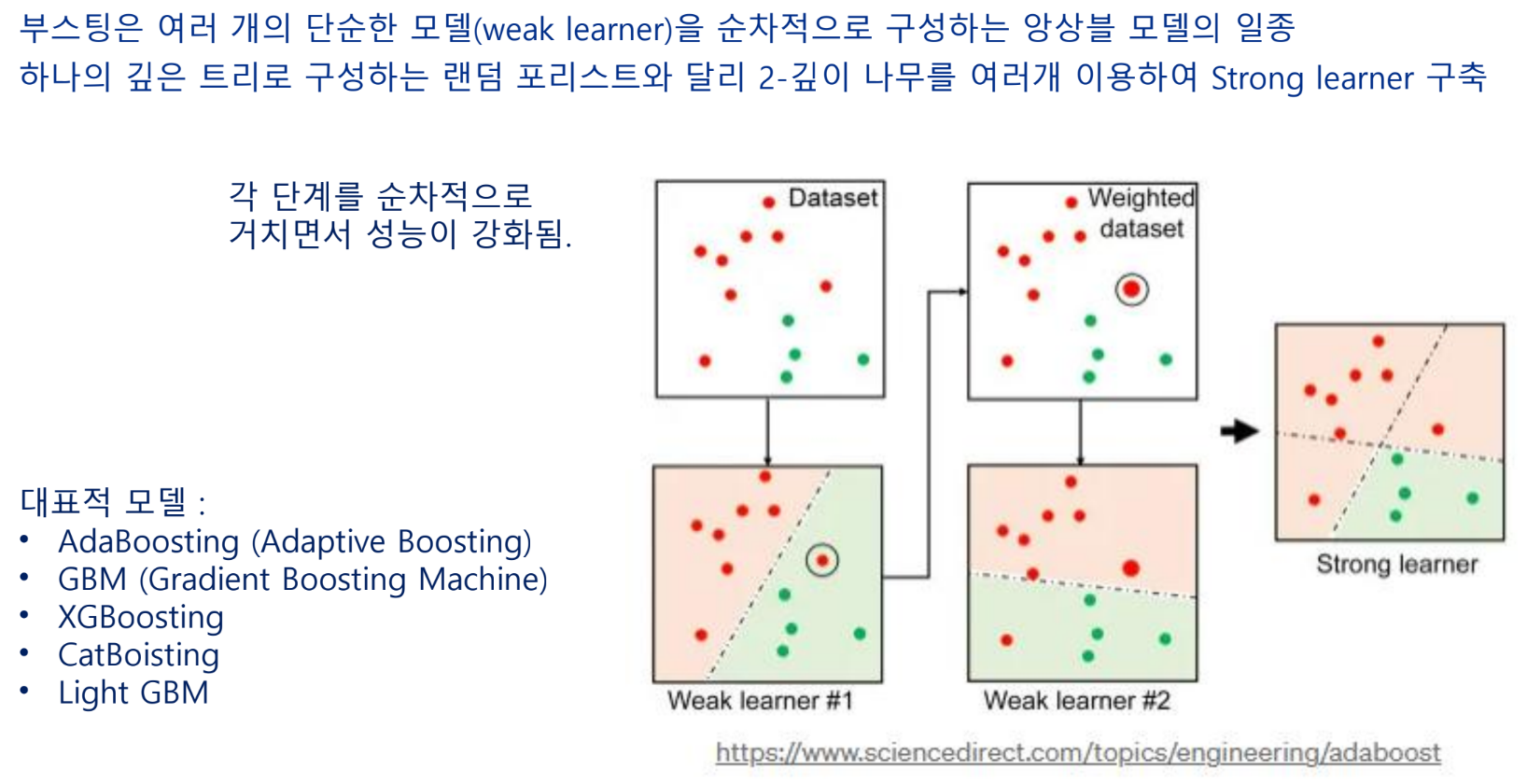
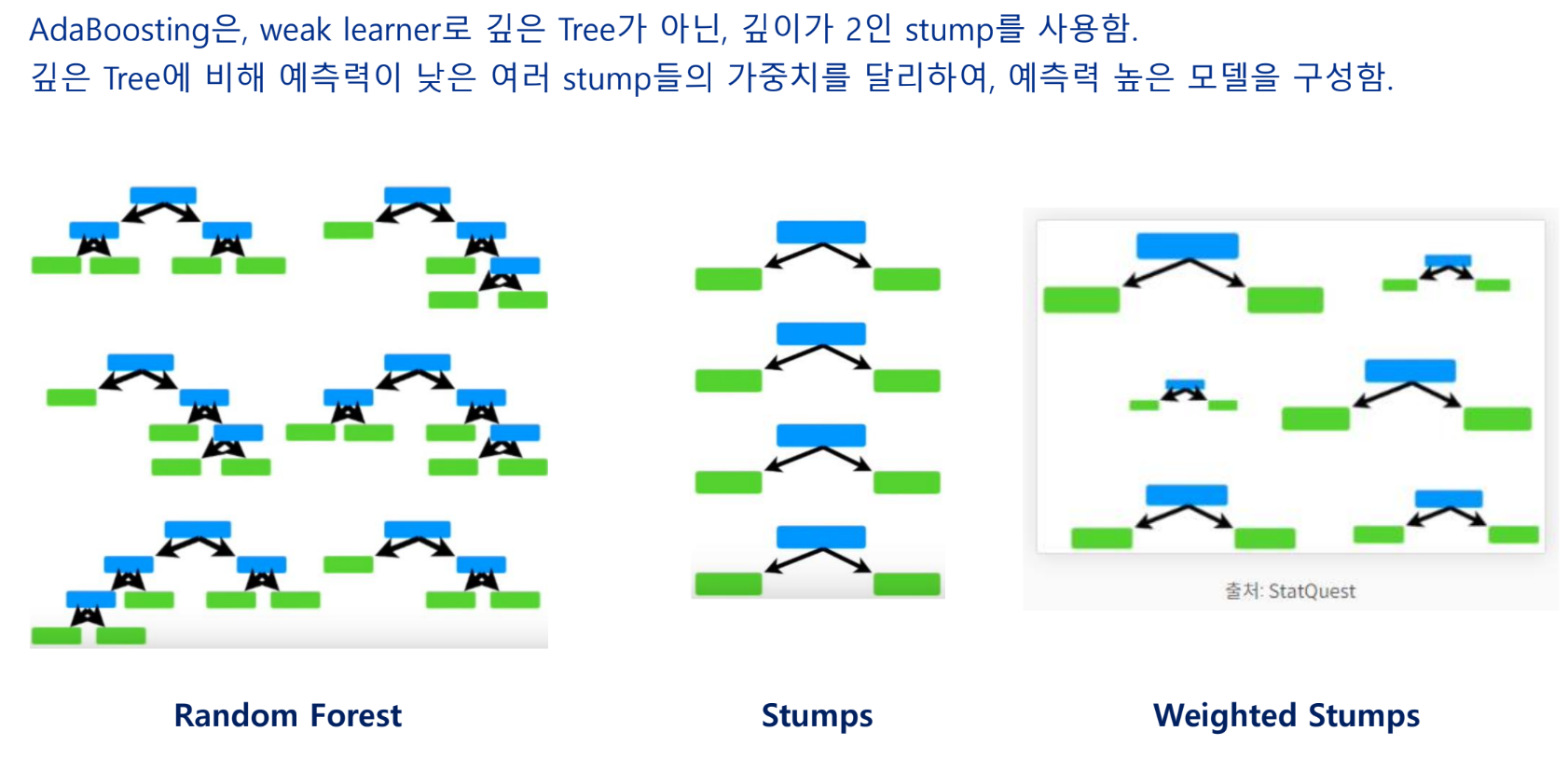
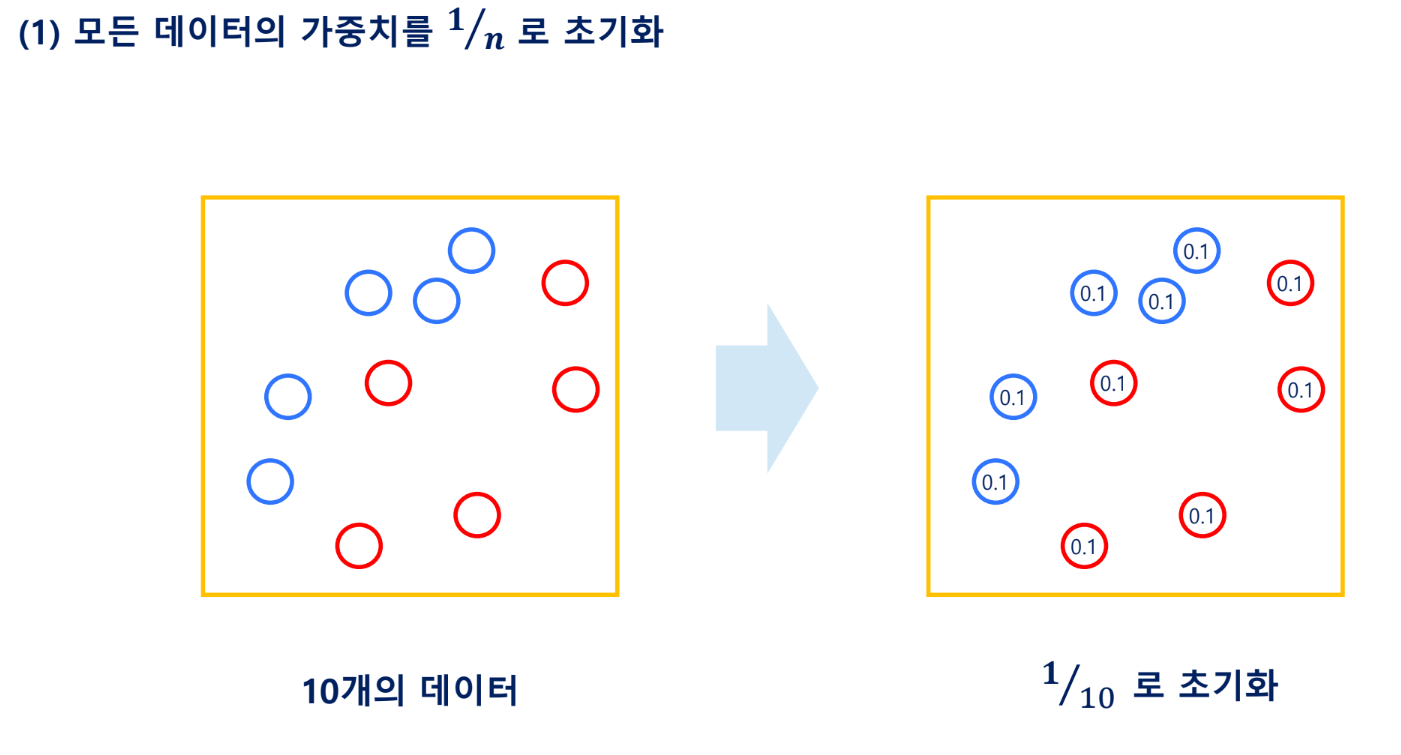
AdaBoosting

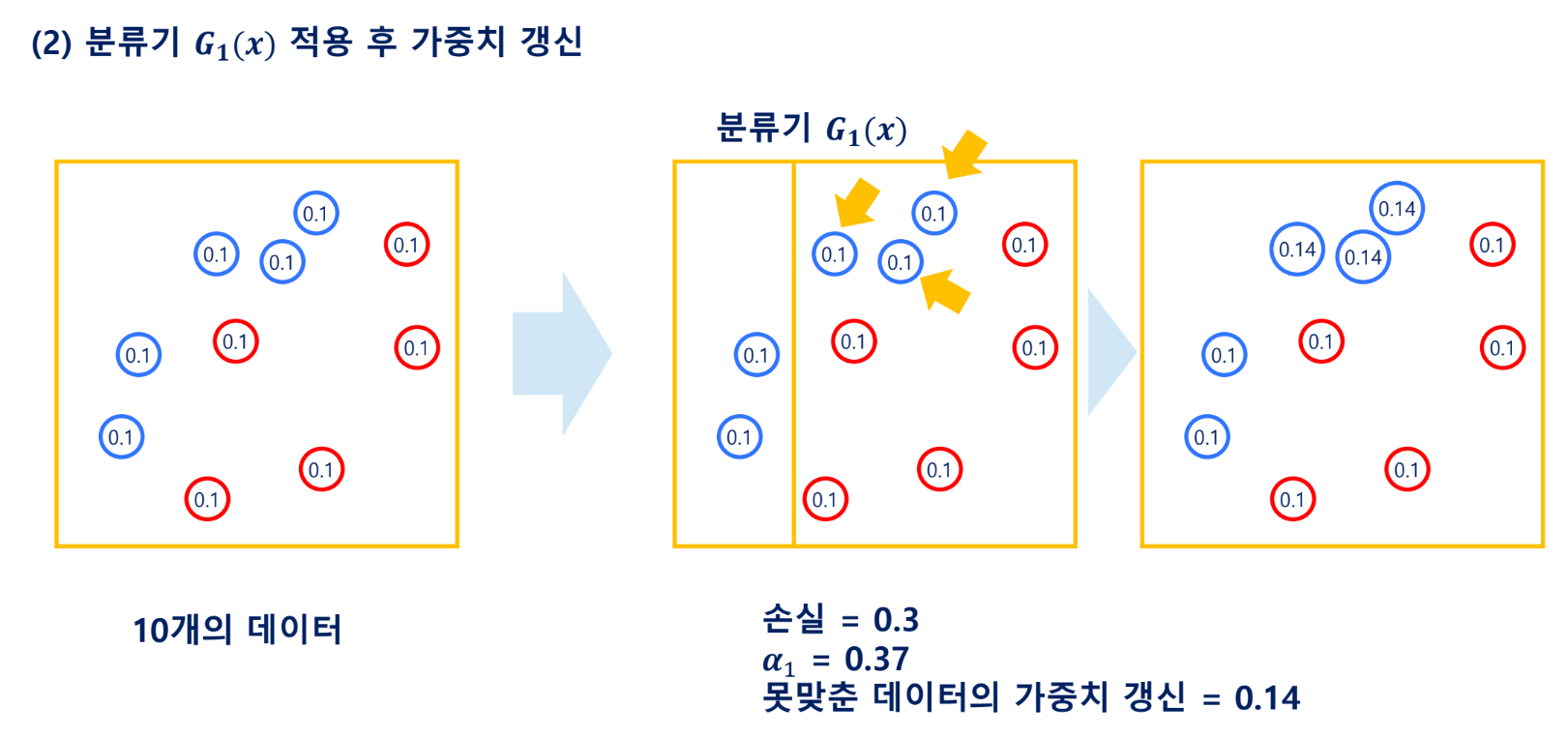
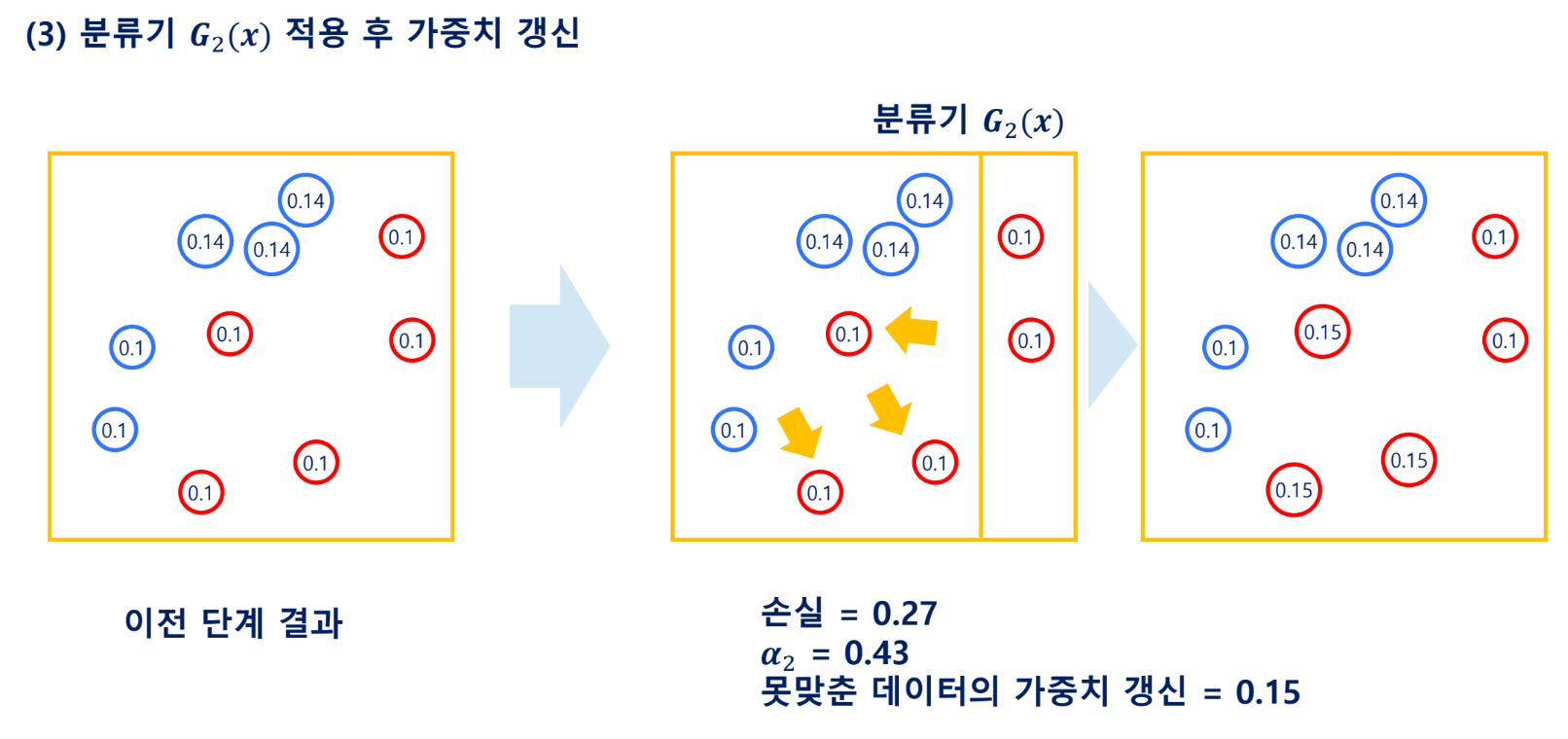
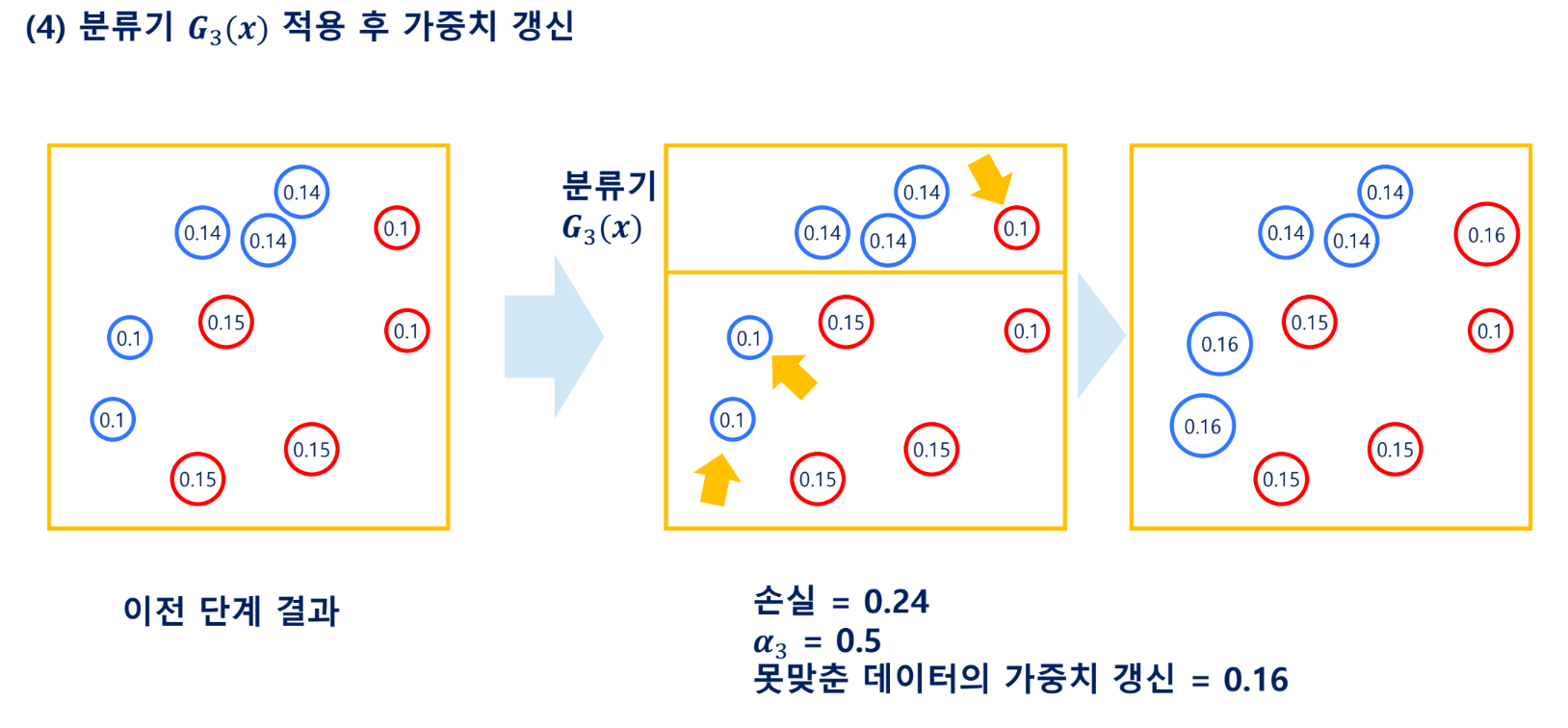
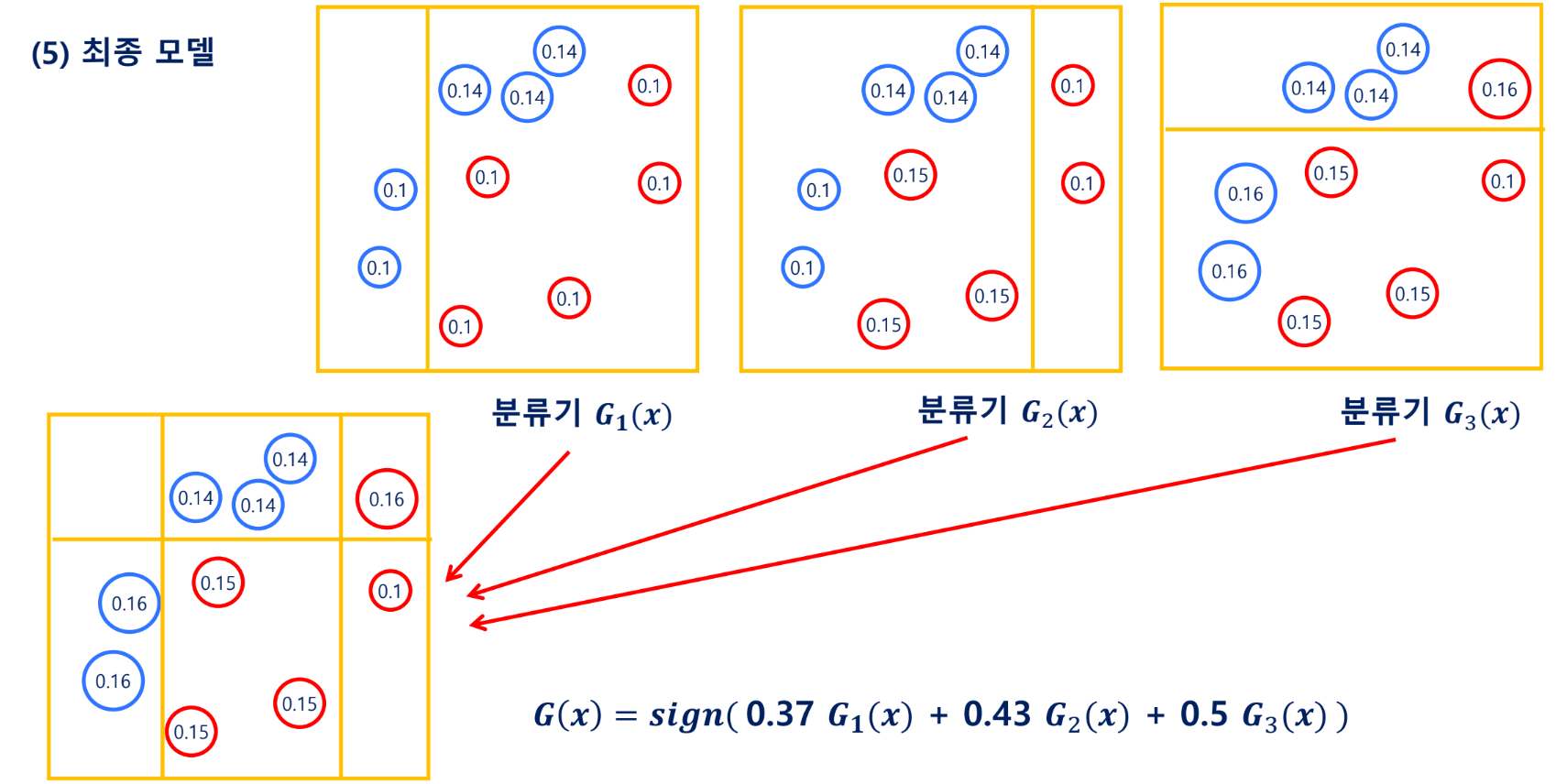
Gradient Boosting Machine(GBM)
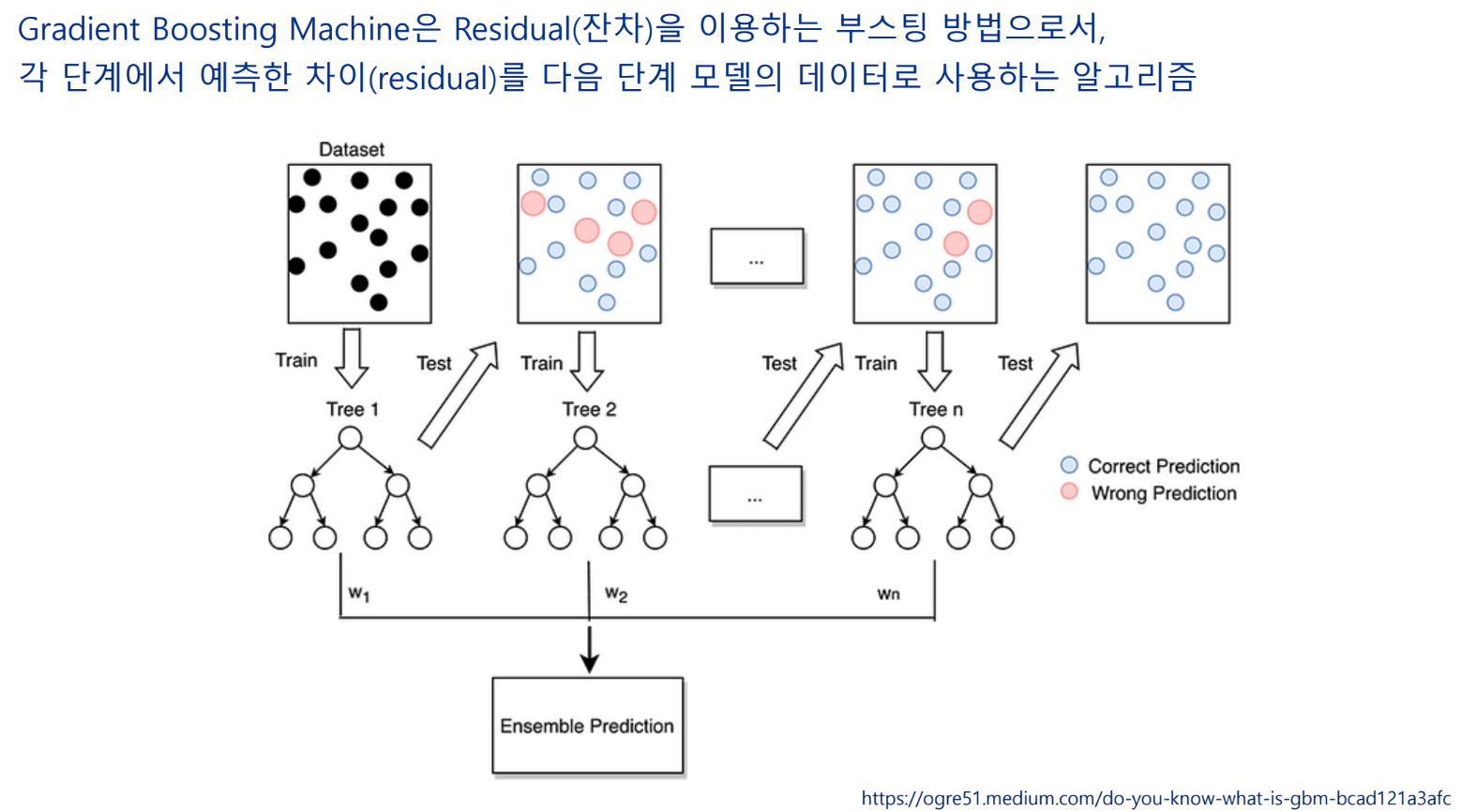
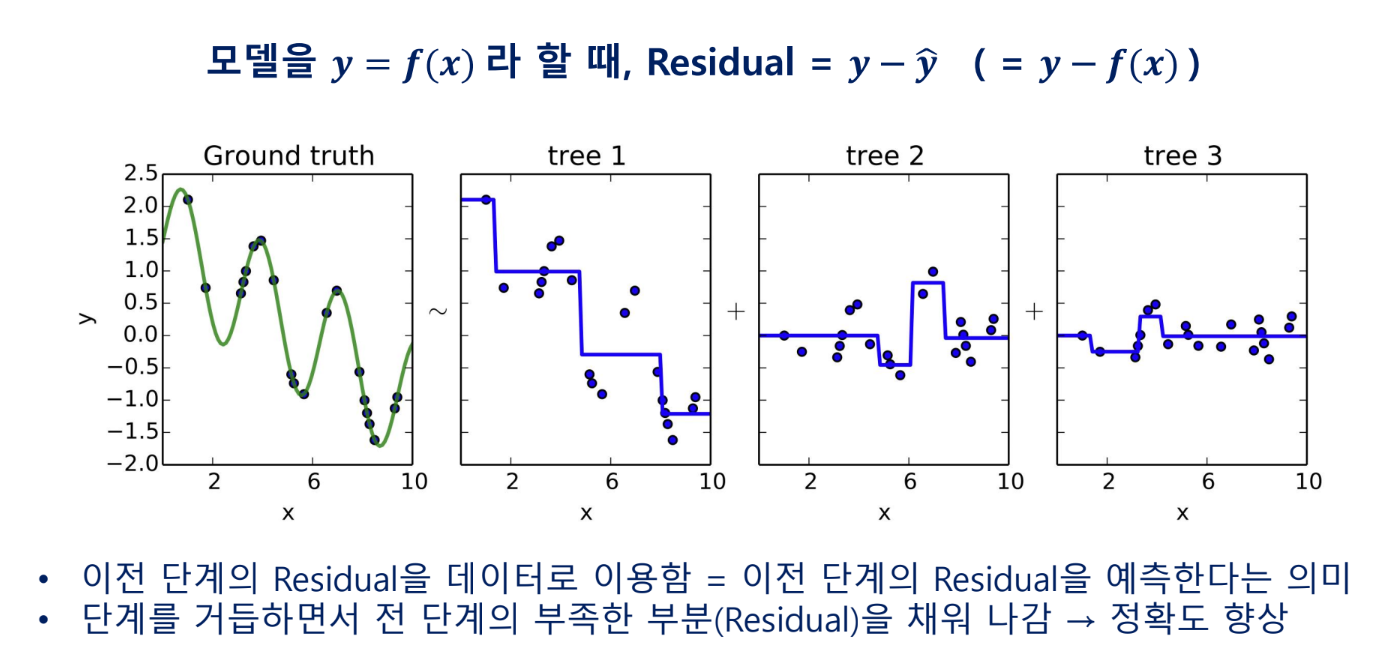
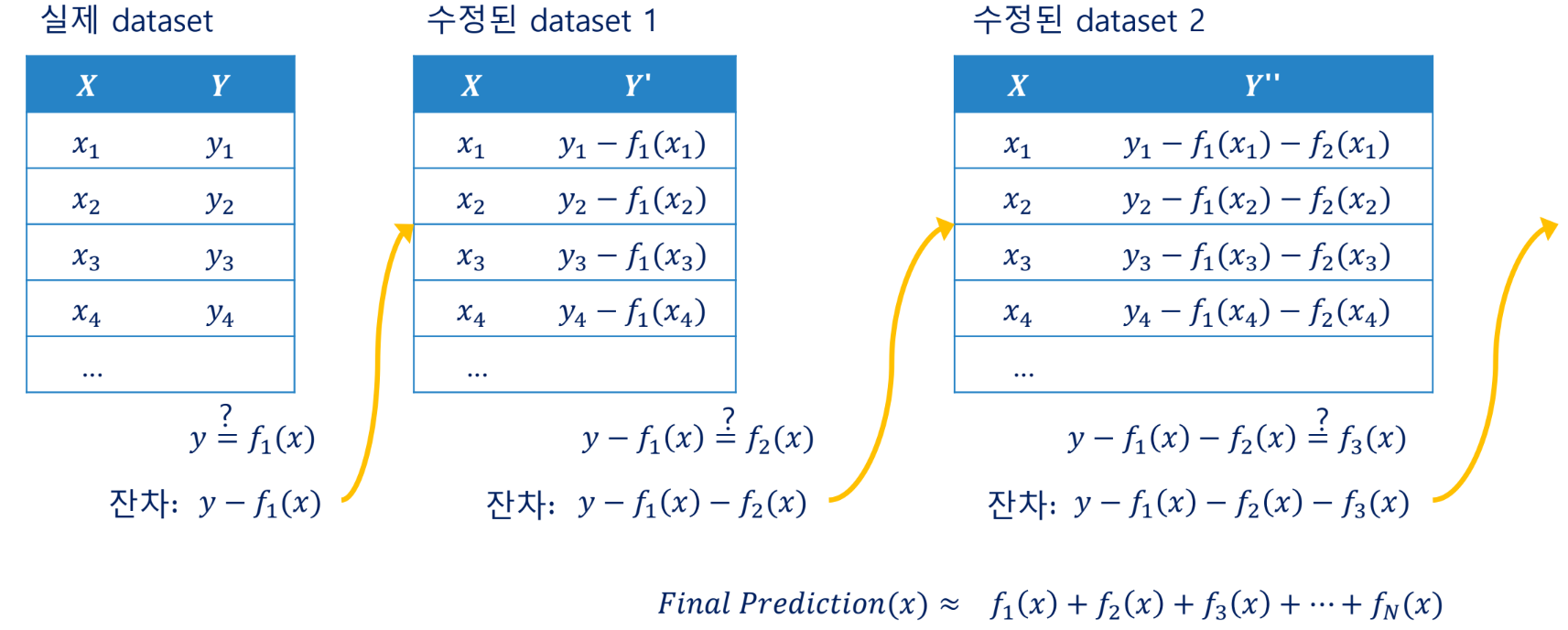
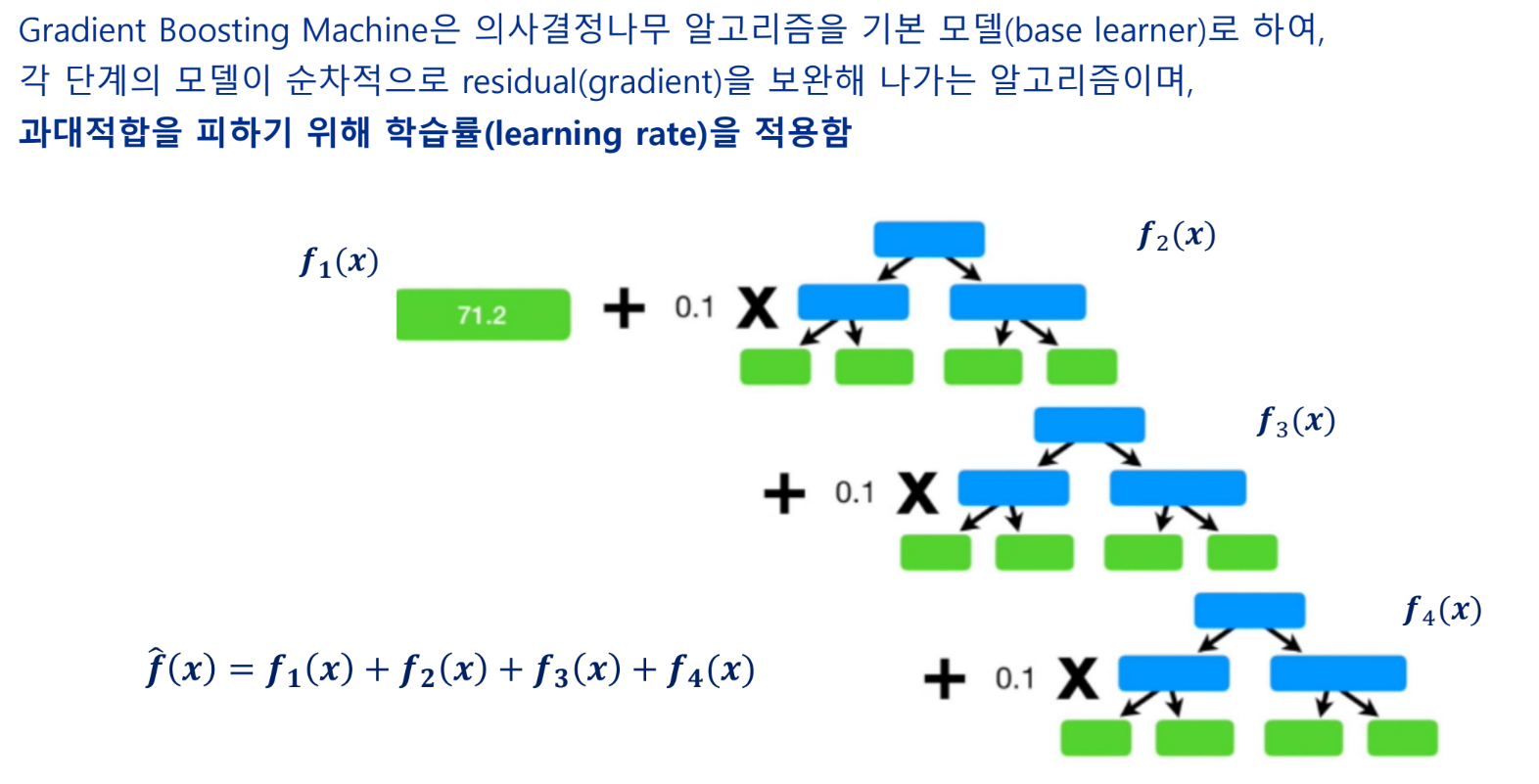
특성 선택
- 특성 중 모델 학습에 가장 유용한 특성을 선택함
- 수집한 데이터에서 가장 좋은 성능을 보이는, 데이터의 부분집합을 찾아냄
- Garbage in Garbage out
- 쓰레기 데이터가 많으면 쓰레기가 나온다.
- Garbage data
- 모델이 예측하는데 관련 없는 데이터 (예측값(Label)과 무관한 데이터)
- 비슷한 특성이 중복되는 데이터
- 필요한 특성(컬럼, 독립변수)만으로 모델 학습
- 필요한 특성들 만을 사용하여 모델링해야 올바른 예측 결과를 기대할 수 있음
- 모델의 빠른 학습과 성능 향상을 기대할 수 있음
- 처리할 데이터의 양이 축소되어, 최소의 리소스 사용이 가능
- 종류
- Filter Methods
- Wrapper Methods
- Embedded Methods
Filter Methods
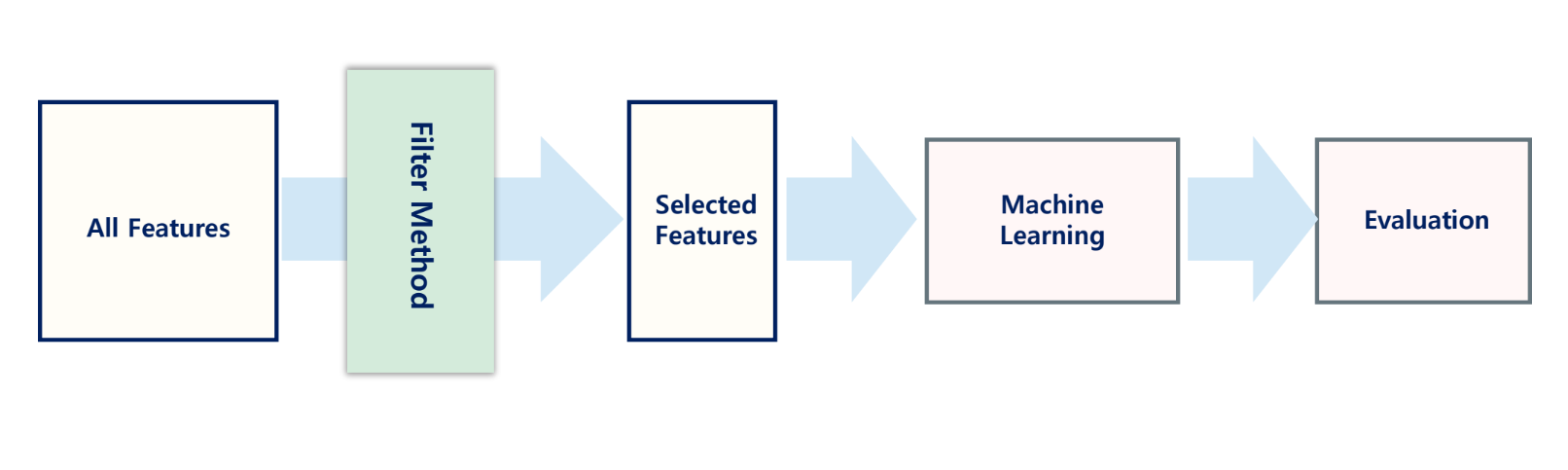
- 전처리 과정(모델 학습 이전 과정)에서 특성 선택
- 통계적 방법을 통해 각 특성들의 관련성을 계산하여 특성 선택
- 피어슨 상관분석, 카이제곱 검정 등을 방법으로 상관관계를 파악하여 선택함
- 카이제곱 검정(Chi-square test)
- 범주형 데이터에서 기대 빈도와 관찰된 빈도 간의 차이를 확인할 때 사용
- 두 범주형 데이터에서 변수 간 독립성 여부를 검정할 때 사용
- 카이제곱 검정(Chi-square test)
Wrapper Methods
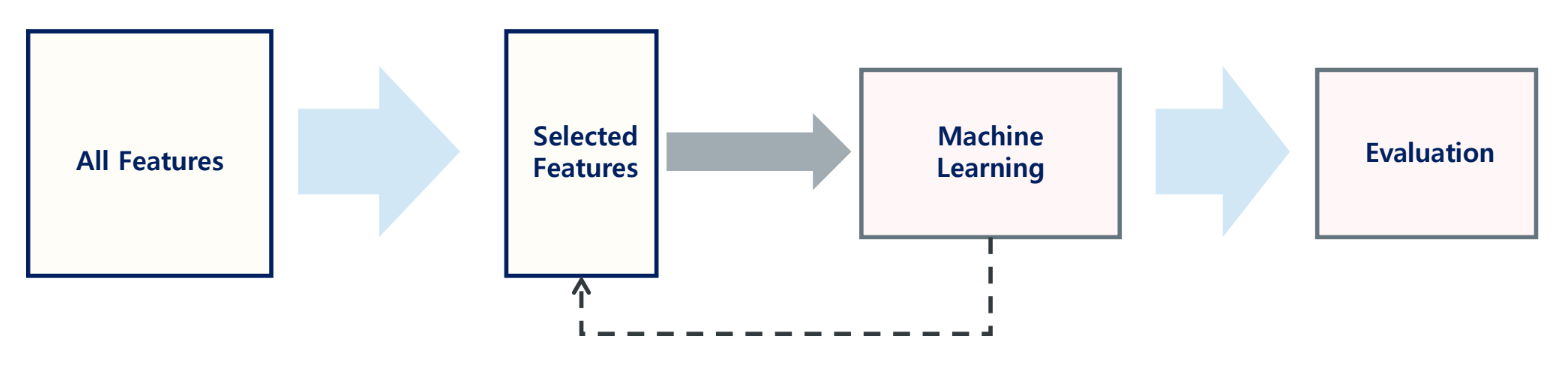
- 모델 학습 및 검증을 반복하여 특성 선택
- 특성들의 다양한 조합으로 모델의 학습을 진행하며, 성능 지표를 바탕으로 특성 조합 구성
- 최적의 특성 조합을 찾는 방법으로
Forward Selection,Backward Elimination등이 있음
Embedded Methods
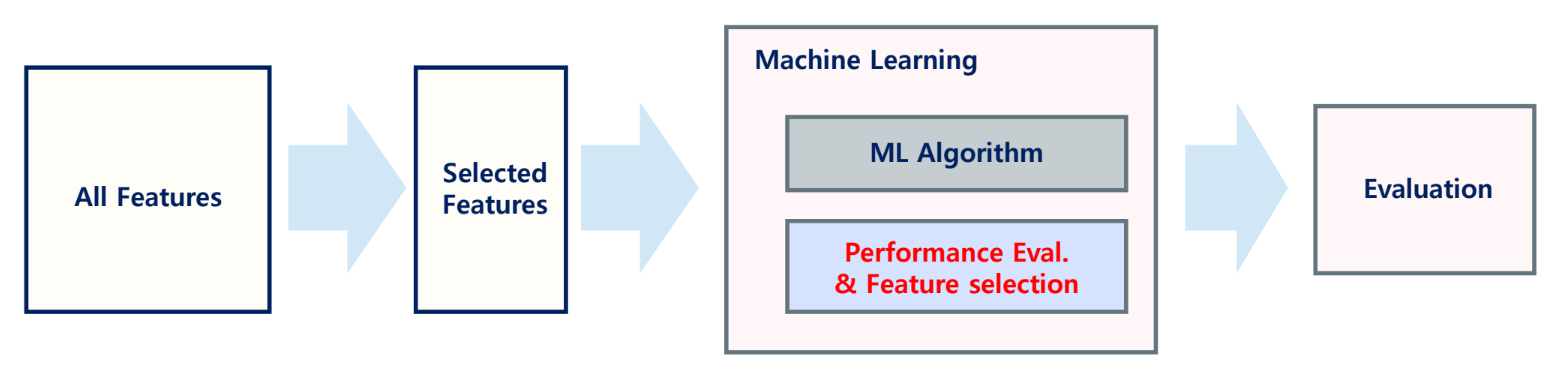
- 모델 자체에 포함된 특성 선택 기능을 이용하는 방법
- 학습 알고리즘 내에서 특성들의 영향력을 축소하는 방식으로 특성 선택
- LASSO, Ridge 등의 기법이 대표적임
Azure ML 파이프라인 클론

파이프라인에 들어가서 상단의 복제를 누르면 된다.
특성 선택
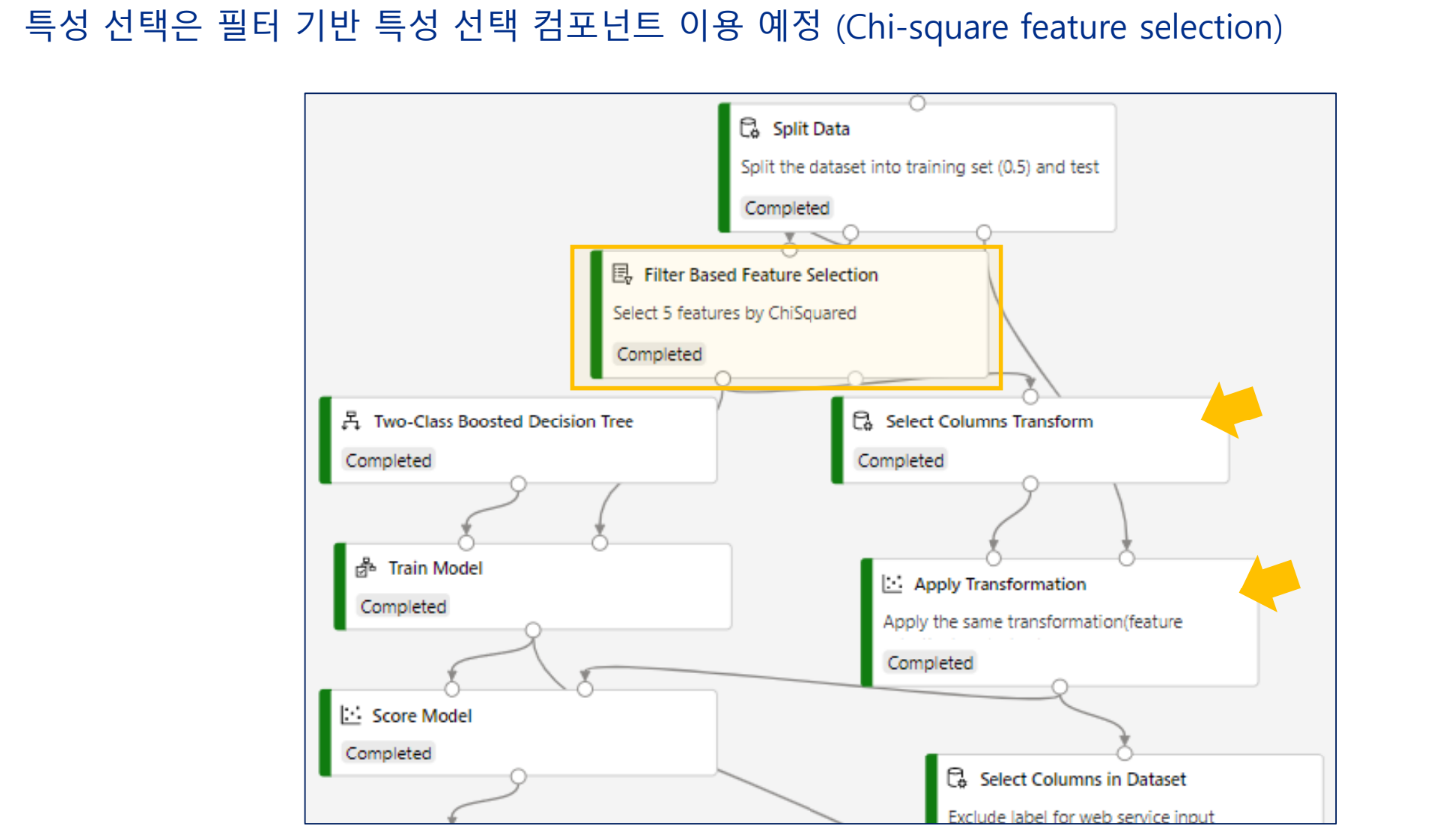
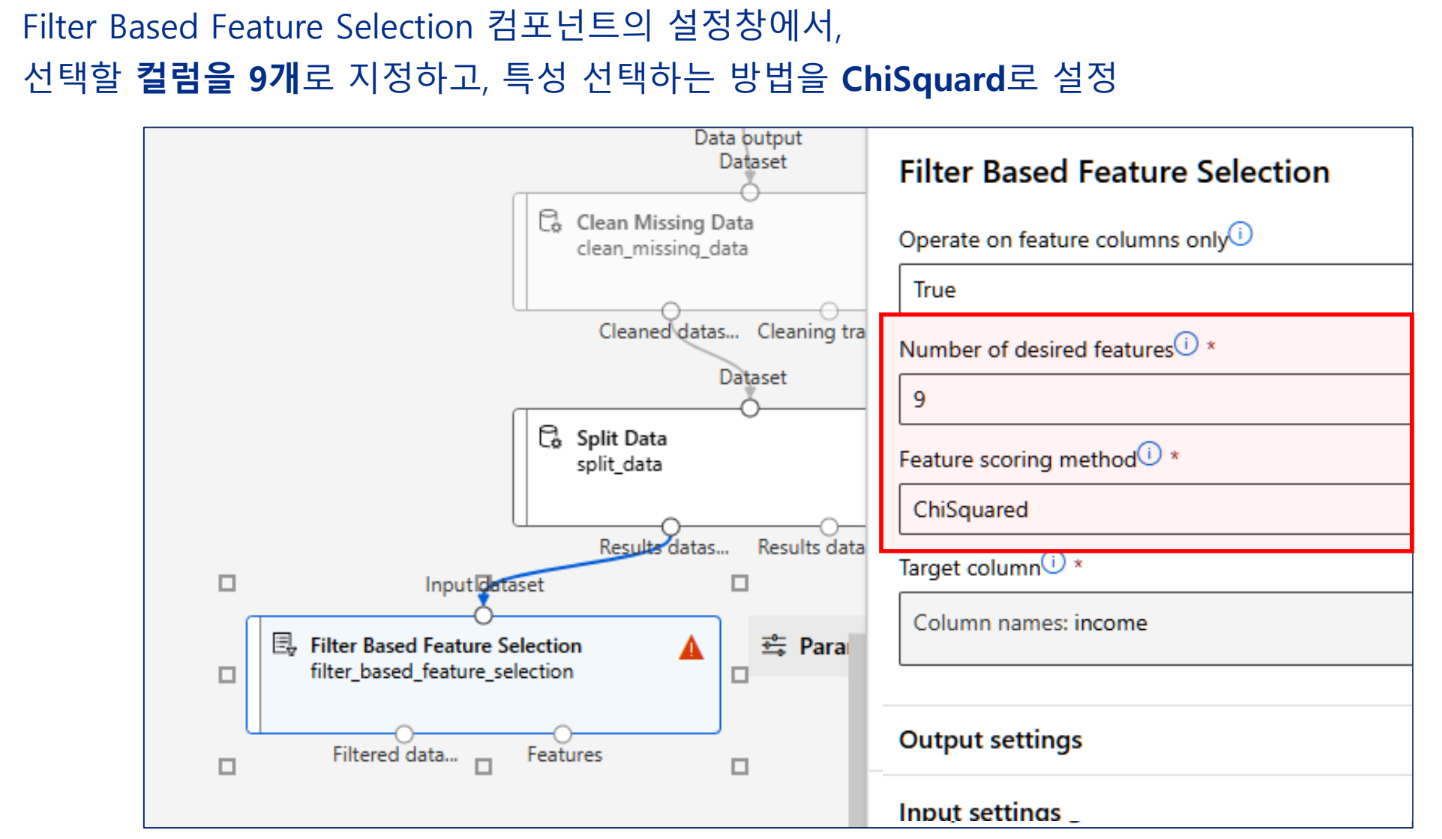
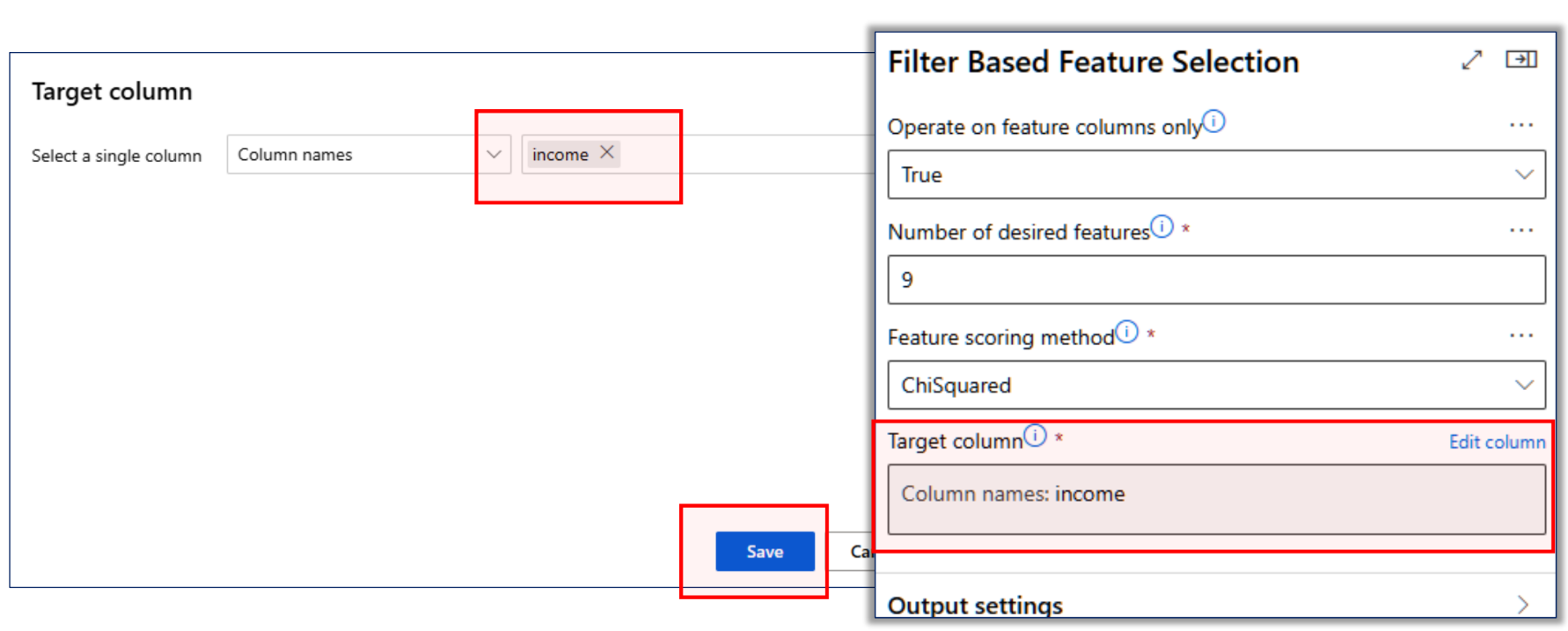
모델링 알고리즘 선택
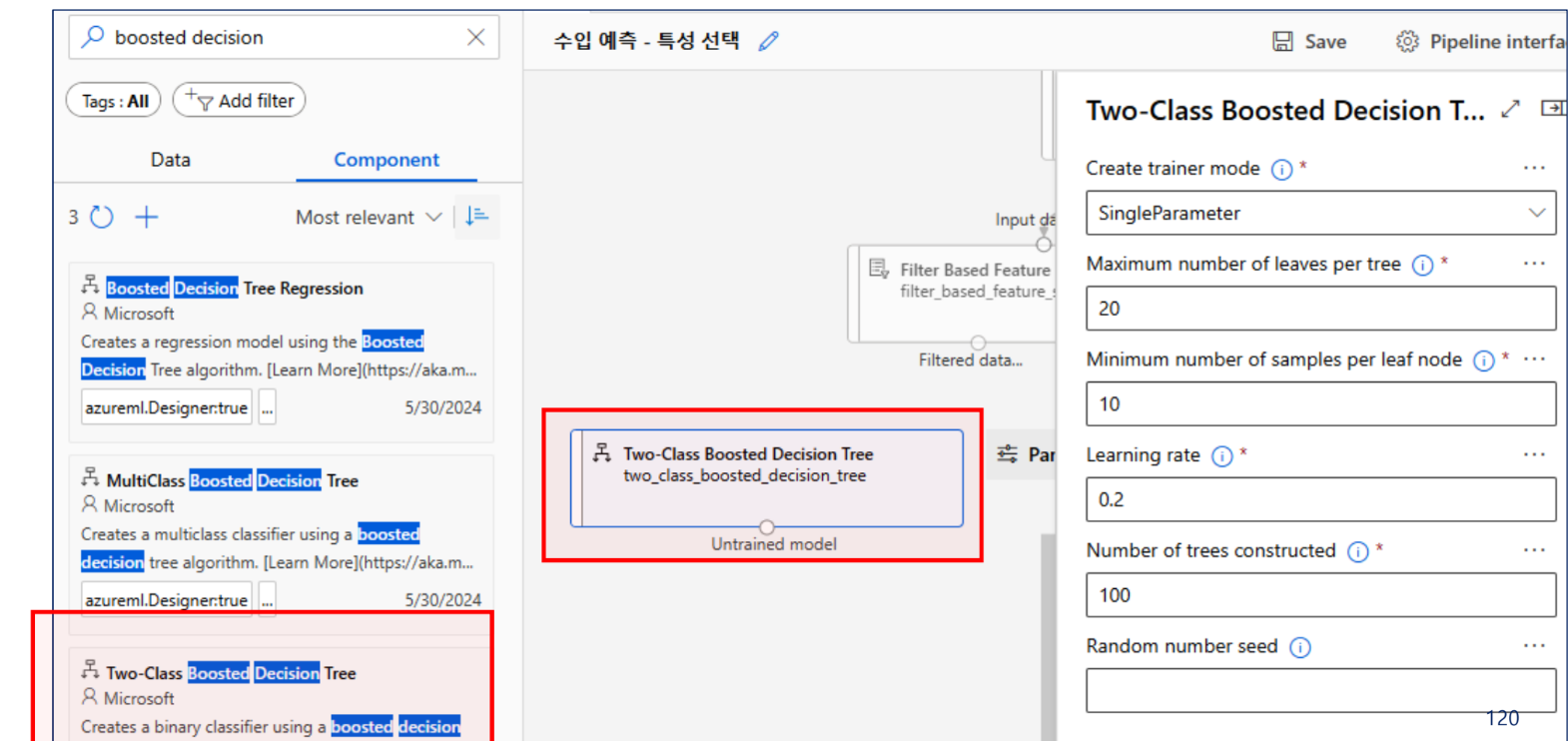
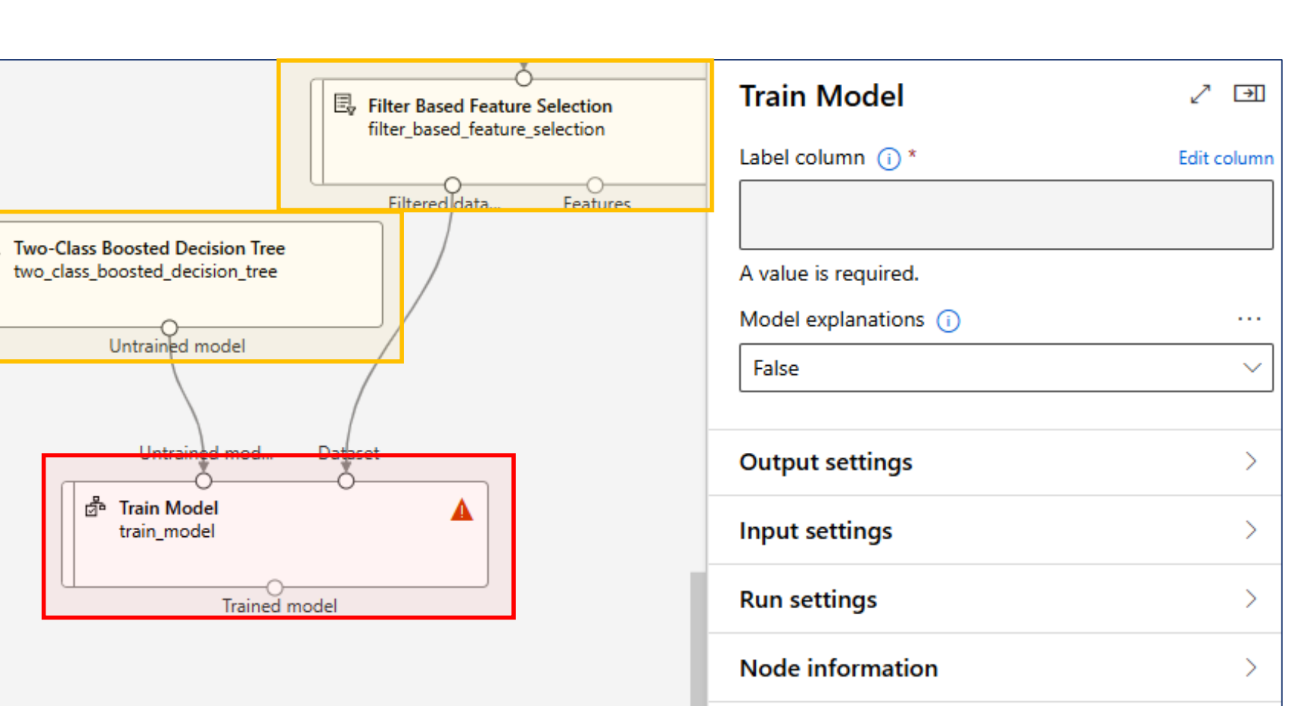
모델 학습
모델 테스트
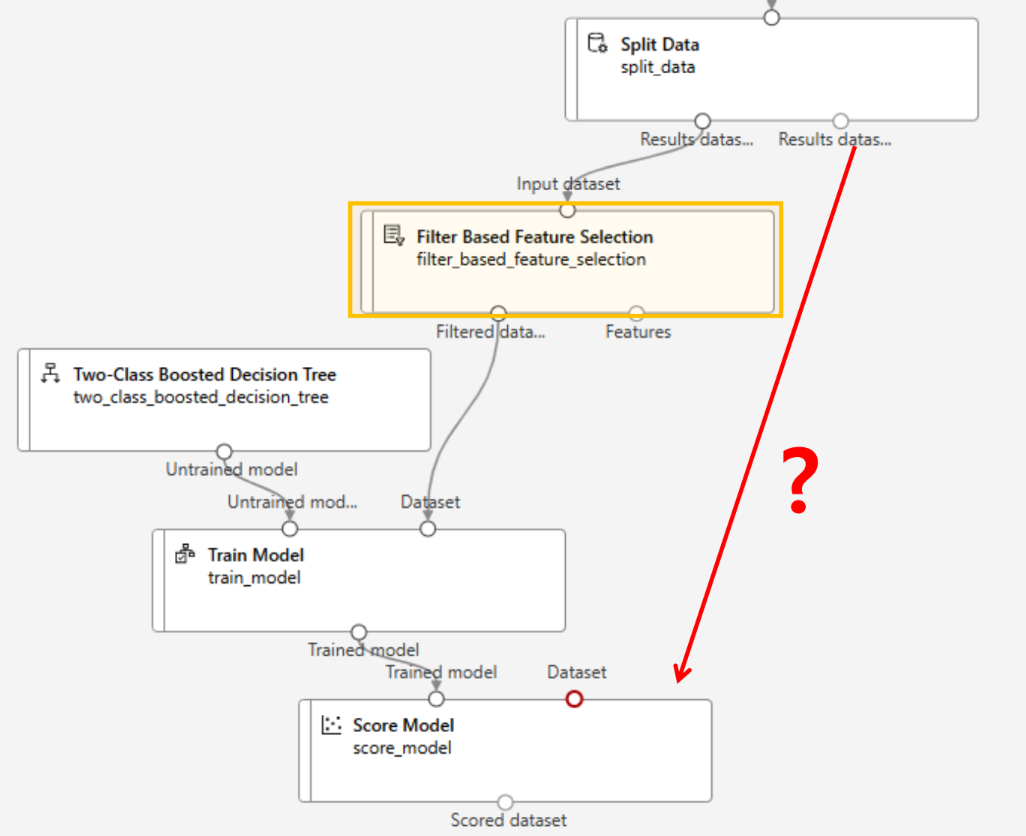
이렇게 하면 안됨 ↑
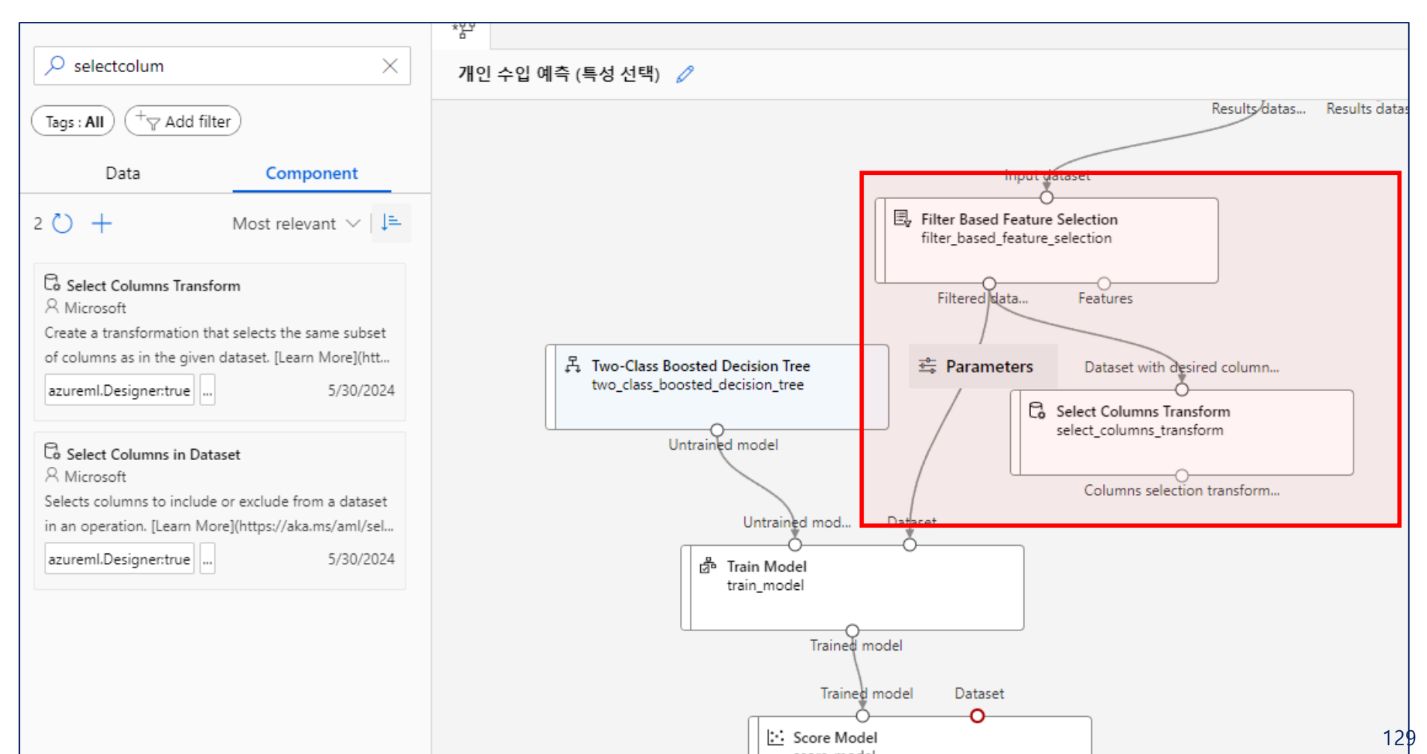
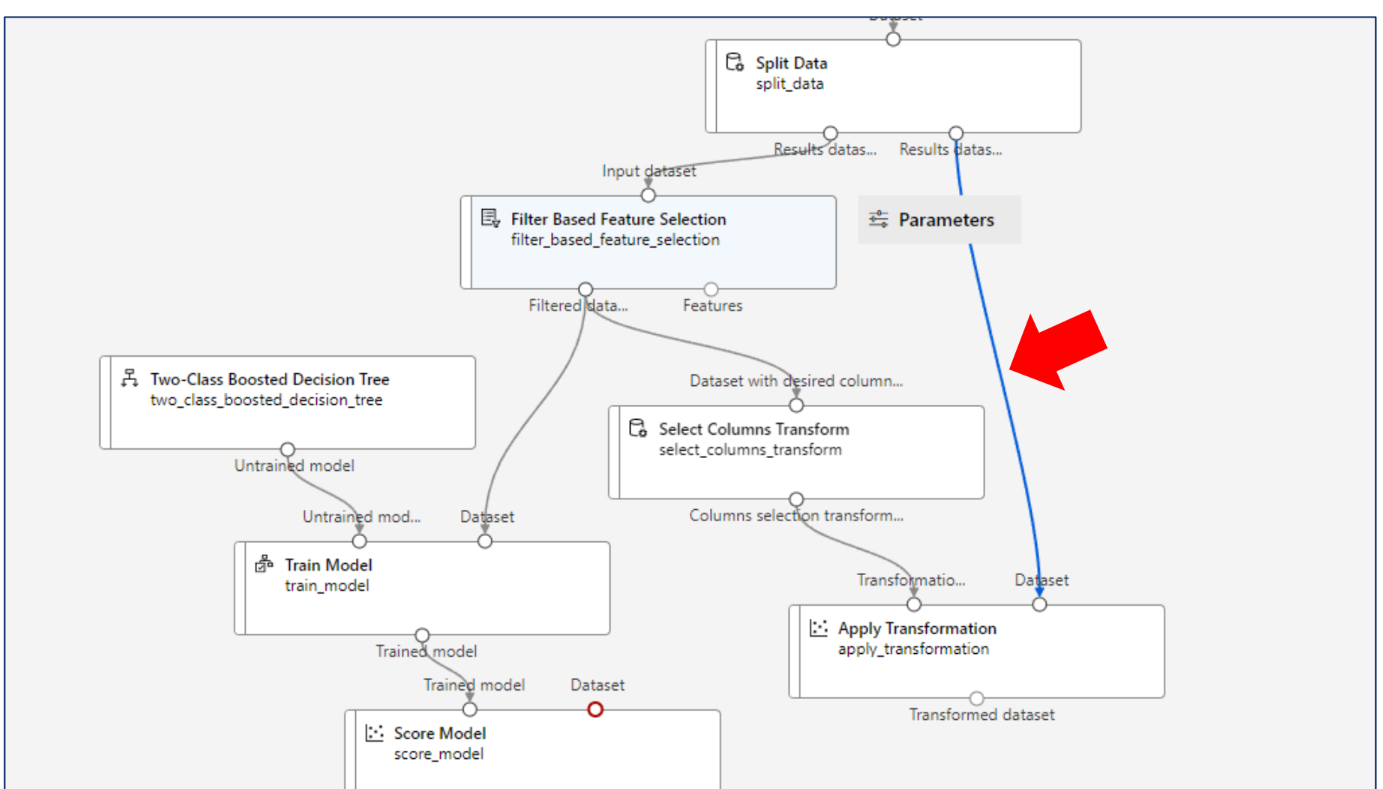
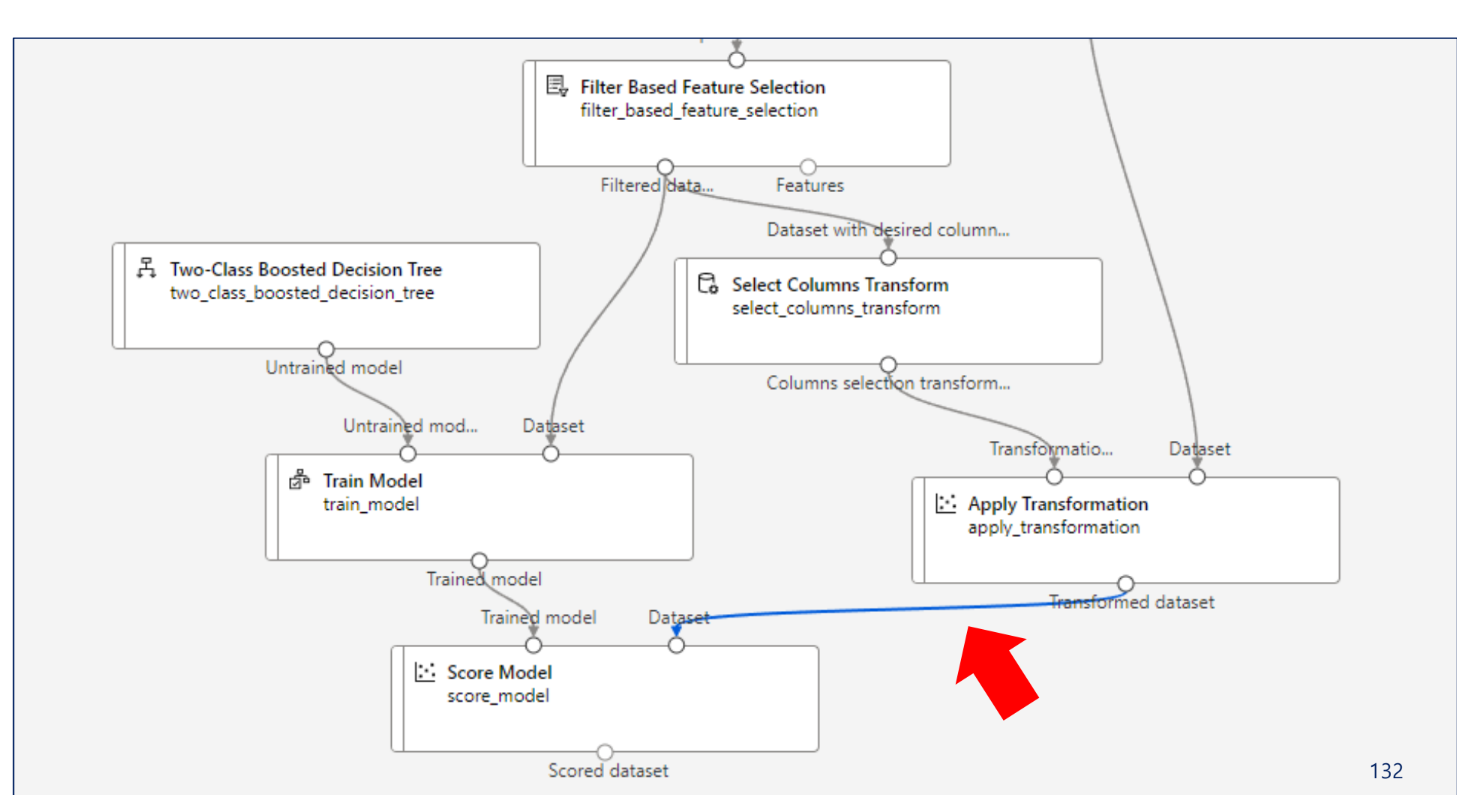
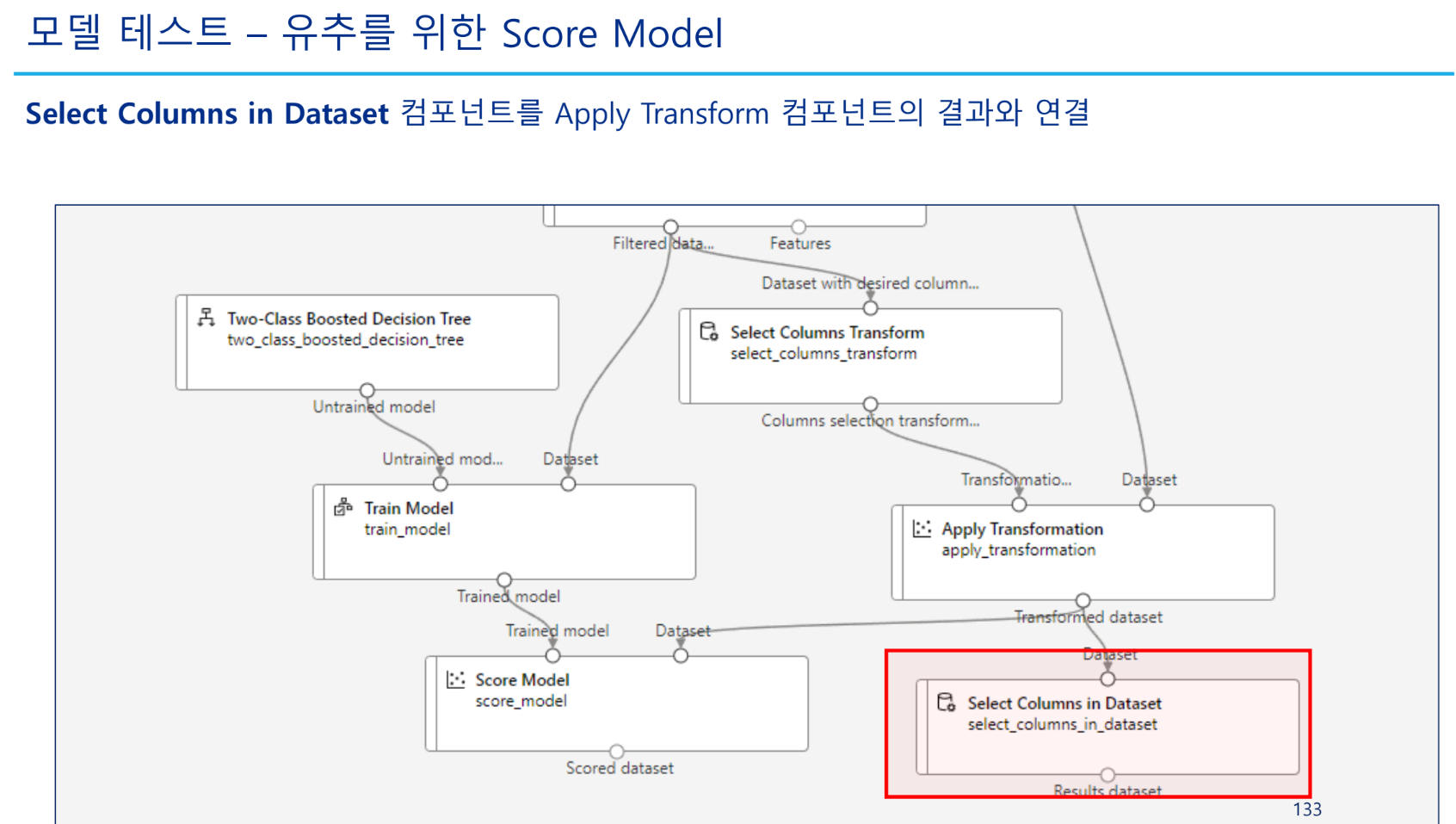
왼쪽은 훈련, 오른쪽은 예측을 위한 파이프라인
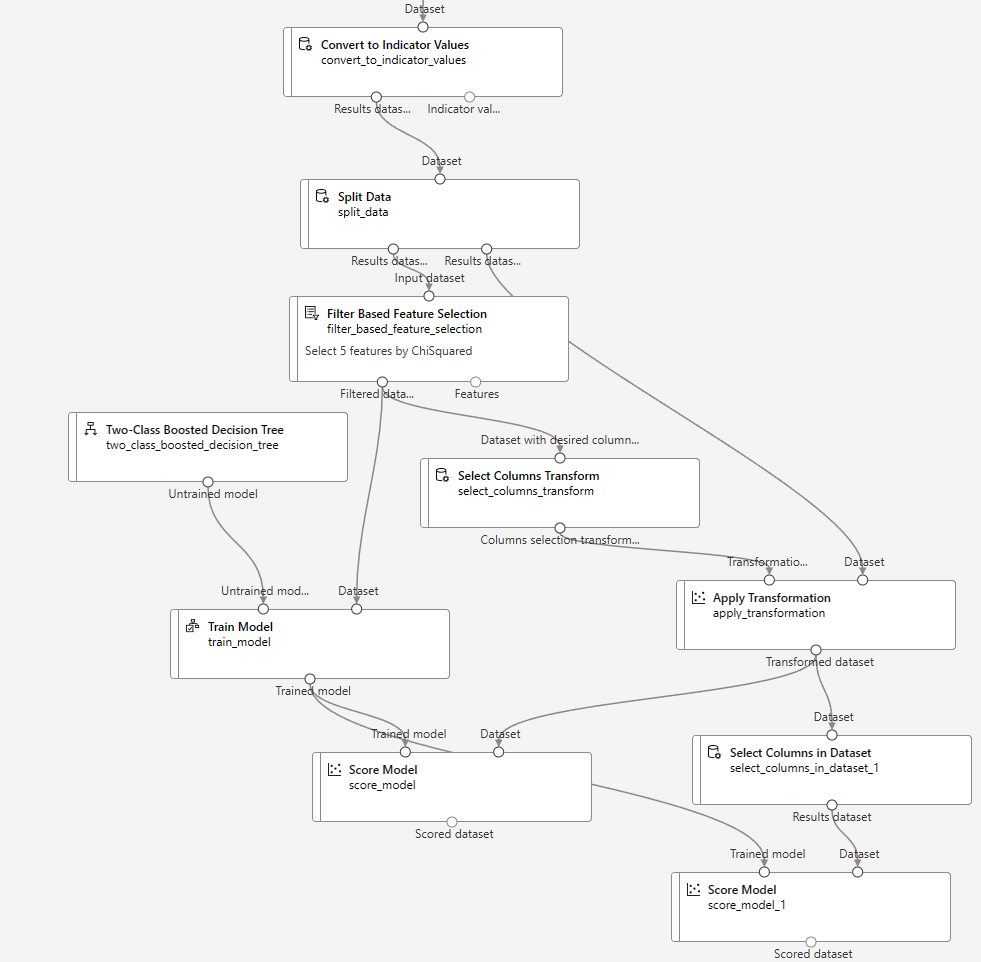
결과
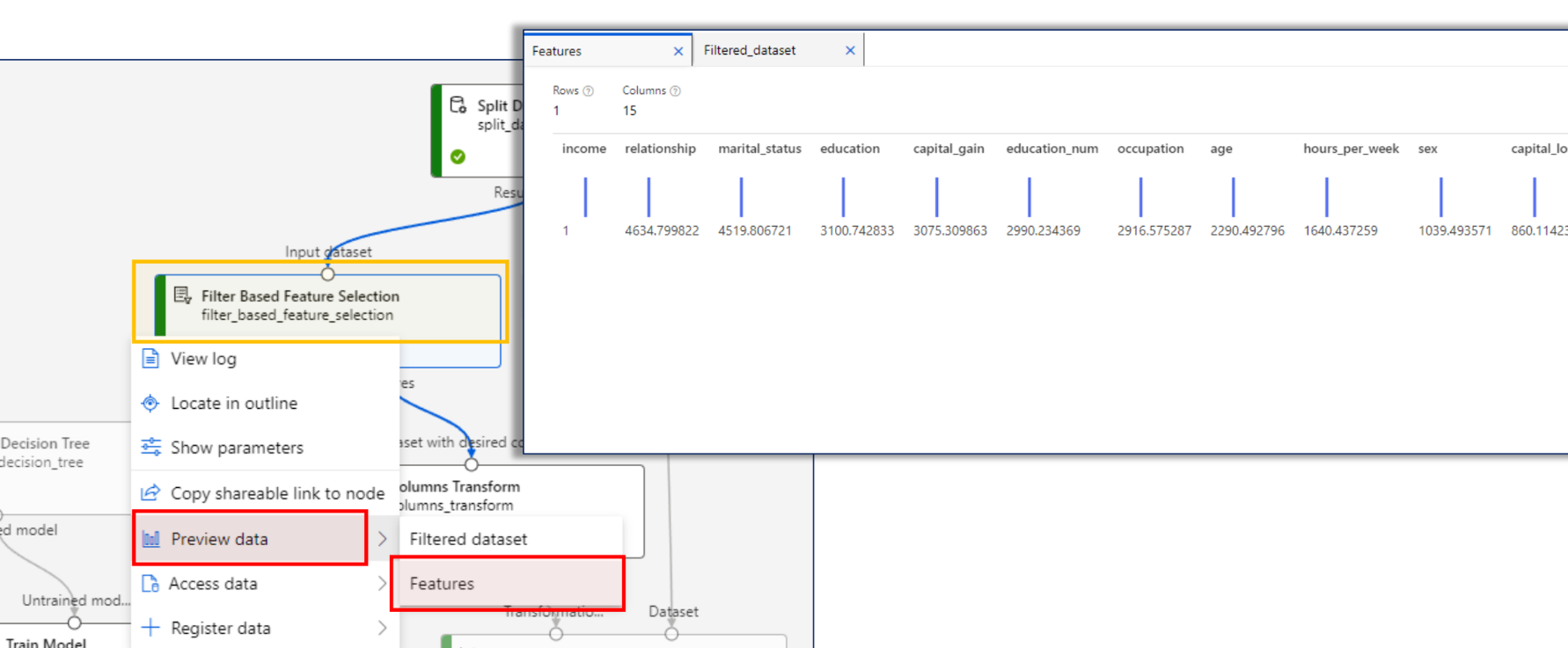
features 확인
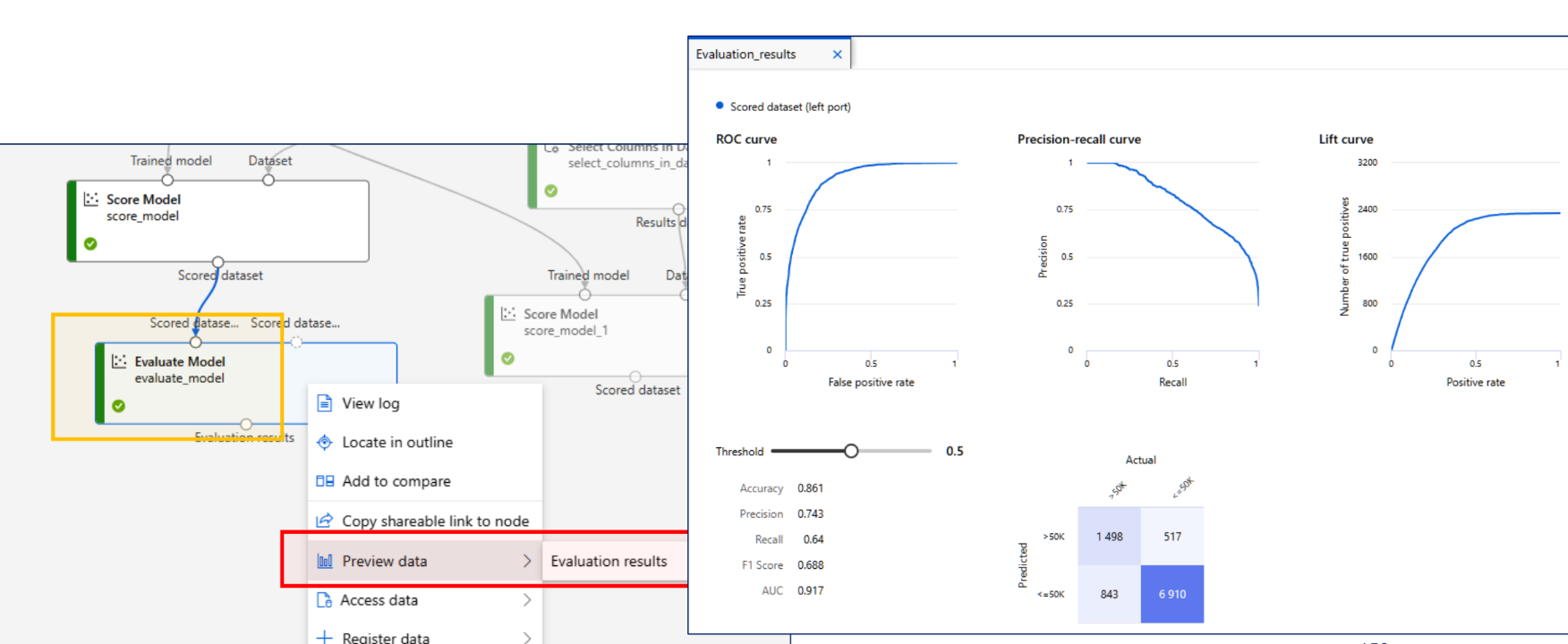
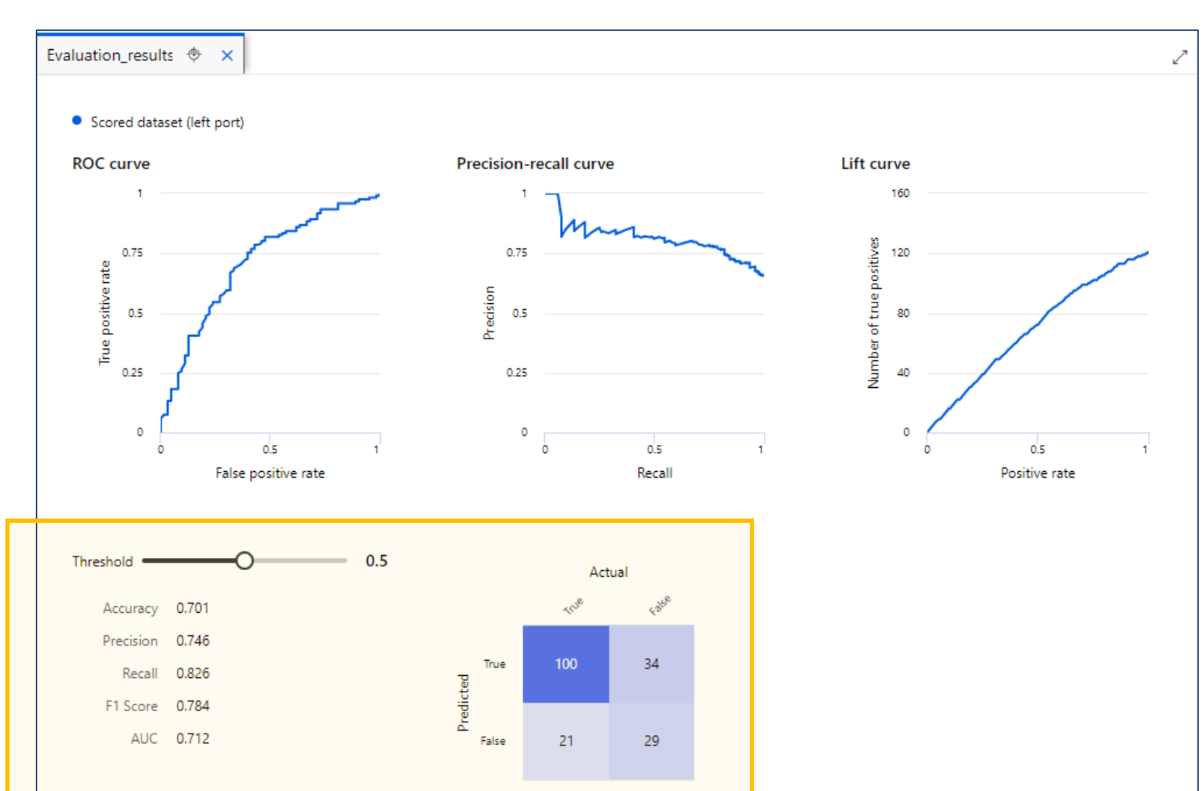
모델 테스트 결과
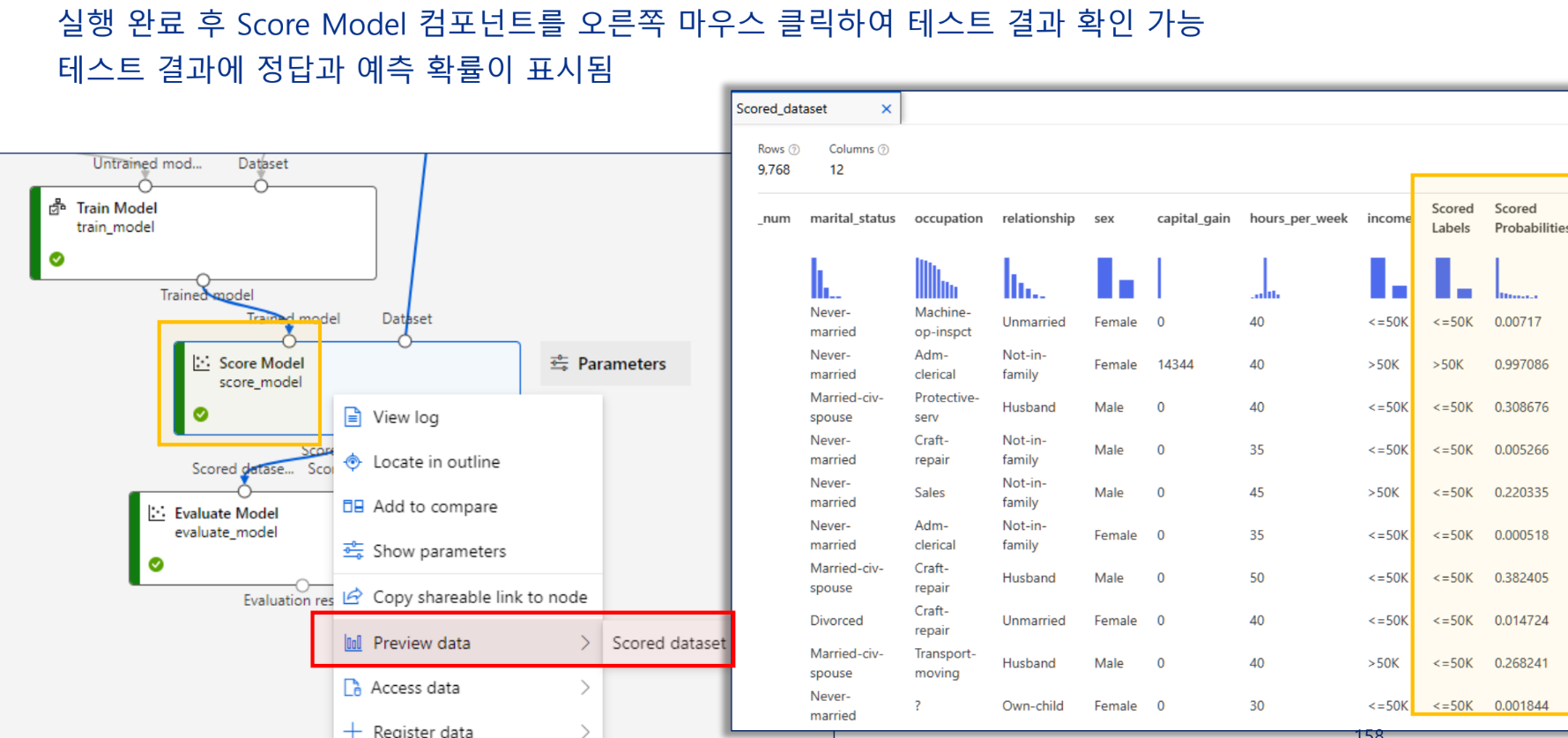
모델 평가 결과
실습 - 신용 위험 예측 모델 구현
알고리즘 - SVM
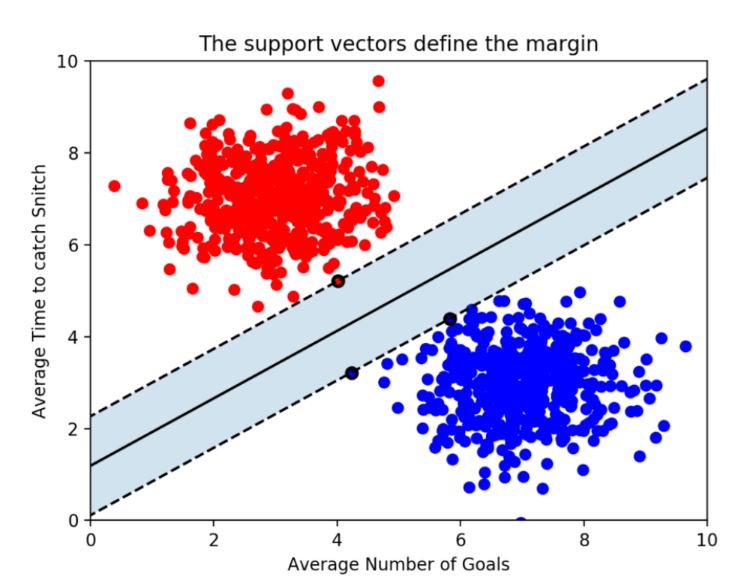
- SVM(Support Vector Machine)
- 데이터를 두 개의 클래스 또는 여러 클래스 중 하나로 나누는 최적의 초평면(hyperplane)을 찾는 알고리즘
- 목표 : 두 클래스 간의 경계 정의
- 초평면 : 데이터를 나누는 경계 (2차원 공간에서는 선, 3차원 공간에서는 평면)
- 지원 벡터(Support Vector) : 각 클래스에서 경계에 가장 가까운 데이터 포인트들
- 지원벡터들은 초평면을 정의하는 데 사용
- 마진(Margin) : 두 클래스 간의 거리 (마진을 최대화하는 것이 SVM의 목표)
- 마진이 클수록 모델의 일반화 능력 높음
- 위 그래프에서는 파란색 부분이 마진
초평면 찾기
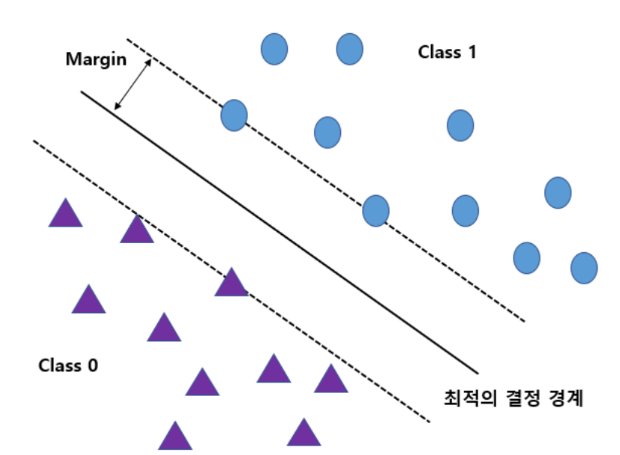
초평면에서 가장 가까운 지원 벡터들과의 거리를 최대화하도록 찾음
- 수학적 표현 :
- wx + b vs 0 , w는 가중치 벡터, b는 편향(bias)
- class 1 : wx + b > 0 , class 0 : wx + b < 0
아웃라이어의 허용 여부
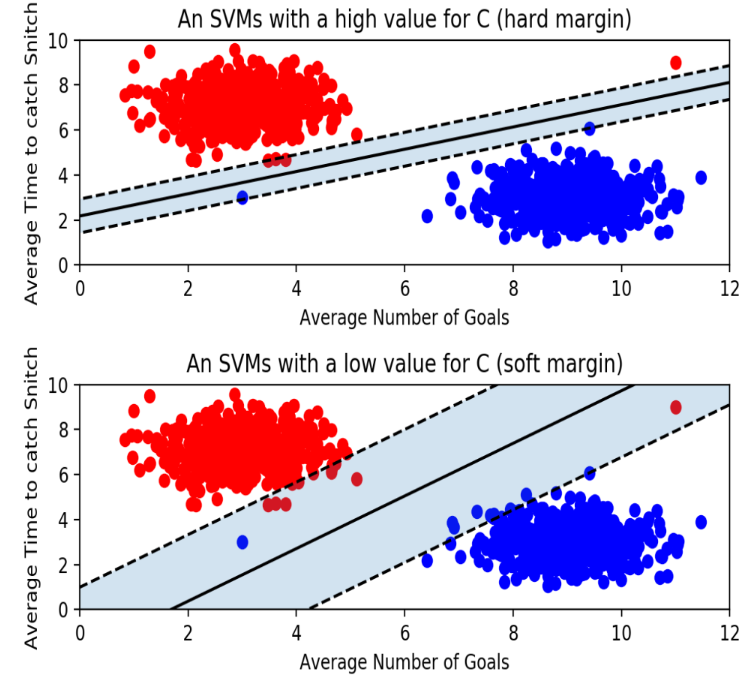
하드 마진
- 데이터가 완벽하게 분리 되도록 함
- 모든 데이터 포인트가 초평면으로부터 일정 거리 이상 떨어져 있어야 함
- 마진의 폭이 줄어들 수 있으며, 과적합 문제 야기 가능
소프트 마진
- 일부 데이터 포인트가 초평면에 가까이 있거나 초평면을 넘을 수 있음
- 실제 데이터는 완벽하게 분리되지 않는 경우가 많기 때문에 소프트 마진이 실용적
- 마진이 커지는 반면, 과소적합 문제 우려
규제
SVM 알고리즘은 과대적합이 쉬운 알고리즘
- 적절한 규제(regularization)를 통하여 과대적합 최소화 필요
- SVM에서는 규제 파라미터 (C) 를 활용, 마진 폭(하드마진, 소프트마진)을 조절하여 과대적합을 줄임
- 참고 : C = 1/λ
정규화(feature Scaling)
- SVM 알고리즘은 변수 간 스케일 차이에 민감하게 동작함
- 따라서, SVM 적용 전에 데이터의 정규화가 필수적인 알고리즘 중 하나임.
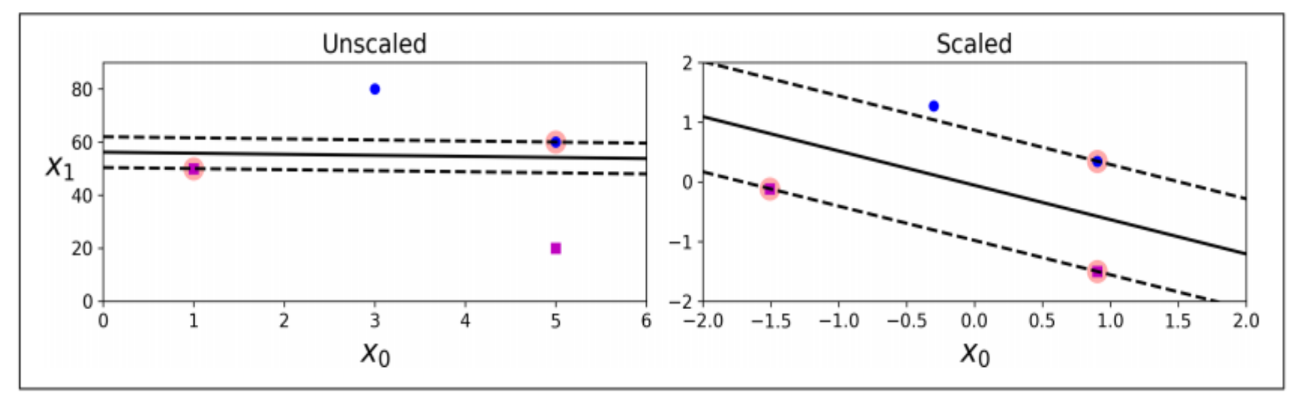
- Unscaled 차트의 데이터는 x1의 스케일이 x0 보다 크며, SVM이 수치적 비율에 따라 결정 경계 구성
- Scaled 차트는 두 변수의 스케일을 맞춰 주어, 비율에 따라 더 여유로운 마진의 결정 경계를 구성함
커널 트릭
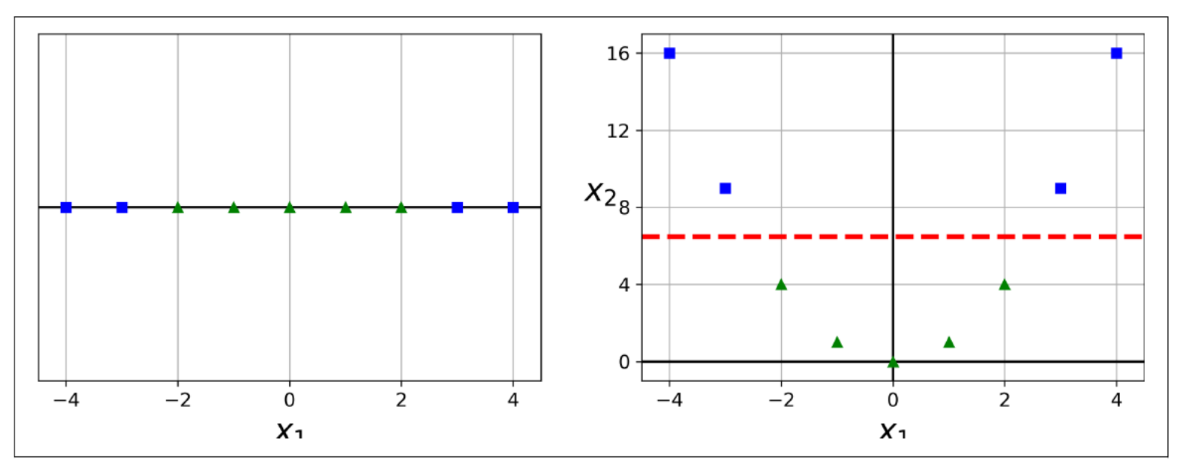
- 직선으로 구분할 수 없는 데이터 세트의 경우에 사용되는 변환 방법
- 비선형 데이터의 처리 :
- 데이터가 선형적으로 구분되지 않는 경우, SVM은 커널 트릭을 사용하여 데이터를 고차원 공간으로 변환하고, 변환된 공간에서 데이터를 선형적으로 분리
- 커널 종류: 선형 커널, 다항 커널, RBF(가우시안) 커널 등
정규화
Min-Max 정규화
- 정의 : 데이터를 0과 1사이로 변환하는 정규화 방법
- 공식 :
- 장점 : 알고리즘이 특정 속성에 대해 편향되지 않도록 함
- 단점 : 이상치에 매우 민감함 (이상치가 있으면 데이터 범위가 왜곡될 수 있음)
Max Abs 정규화
- 정의 : 데이터의 절대 최대값을 기준으로, 데이터를 (-1~1)의 범위로 변환하는 방법
- 공식 :
- 장점 : 데이터의 중심을 유지하면서 크기만 조정할 수 있음
- 양수와 음수가 섞여 있는 데이터에 유용함
- 단점 : 절댓값 최대치에 민감 (여전히 이상치가 문제될 수 있음)
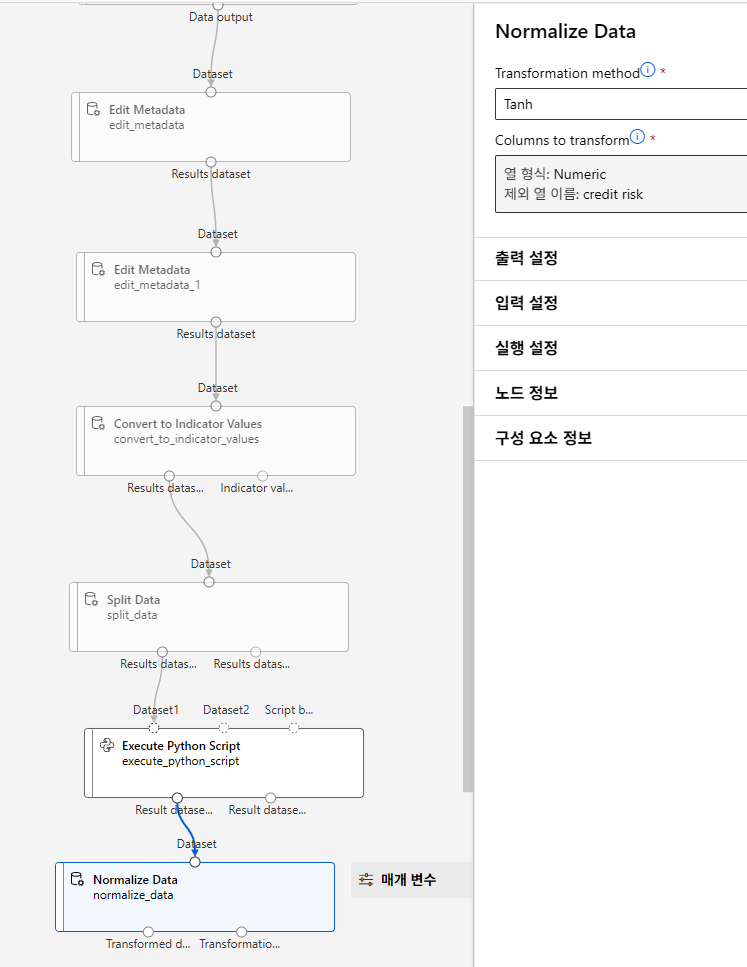
Tanh 정규화
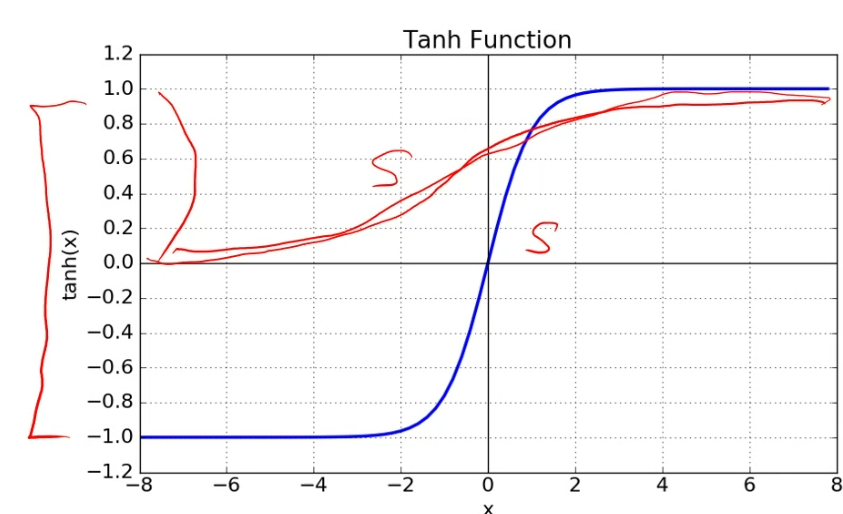
빨간 선은 Sigmoid 함수로, 범위가 0~1이기 때문에 Tanh가 더 넓은 폭 포함 가능
- 정의 : 하이퍼볼릭 탄젠트(tanh) 함수를 이용하여 데이터를 정규화 하는 방법
- 적용 : 데이터 표준화 후 tanh 함수를 적용하여 값을 [-1, 1] 범위로 변환
- 장점 :
- 데이터의 분포가 중간값을 중심으로 대칭적이지 않을 때 유용
- 이상치의 영향을 적게 받음
- 중심값 분석에 용이함
- 단점 :
- 계산이 상대적으로 복잡함
- 사전에 데이터를 표준화 해야 함
비용 민감 학습(Cost-sensitive Learning)
잘못된 예측의 비용(Cost)이 동일하지 않을때 사용함. 복제 등과 같은 방법으로 비용에 민감한 데이터의 비중을 높여서, 모델이 더 신중하게 예측하도록 조정함
샘플링 기법
데이터 불균형 문제를 해결하기 위한 방법으로, 소수의 클래스의 데이터를 오버샘플링하여 소수 클래스에 대한 예측 성능을 향상시킴
비용 민감 로지스틱 회귀
로지스틱 회귀 모델을 이용하여 클래스 별 다른 가중치를 부여하는 방식
임계값 이동
예측의 임계값을 조정하여 고위험 클래스를 더 쉽게 예측할 수 있도록 함
실험 설계
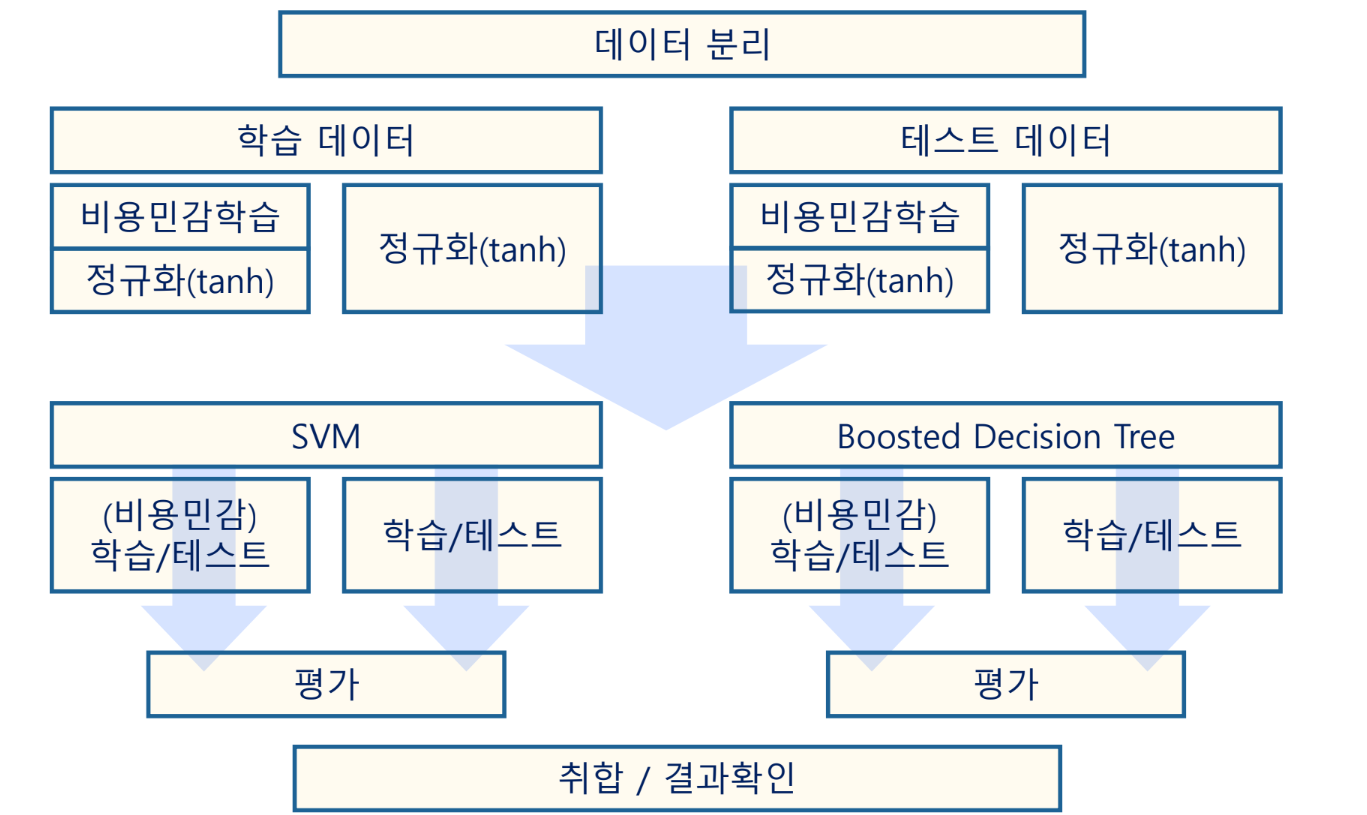
비용 민감 학습에서 중요한 칼럼의 값을 뻥튀기 해준다
데이터 수집
데이터 준비
컬럼명 추가
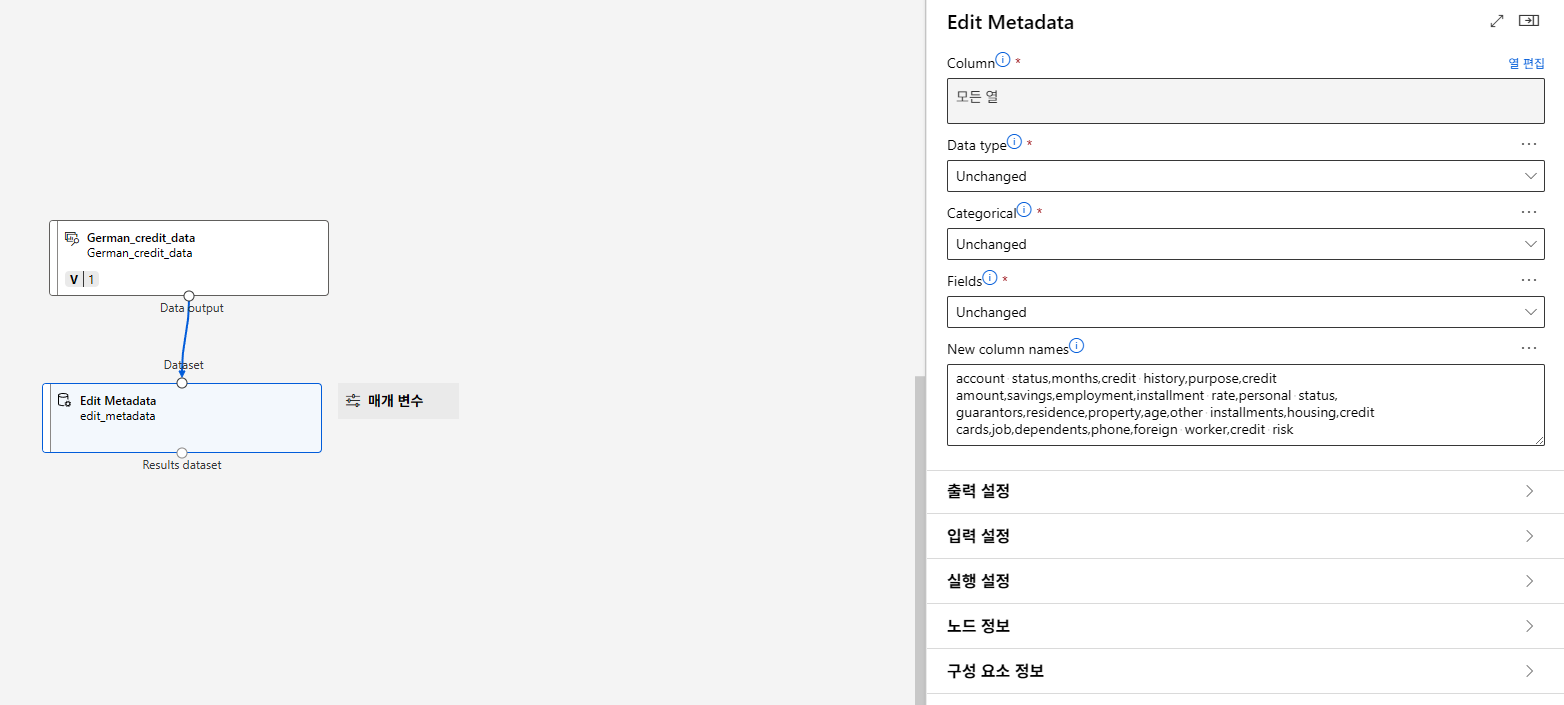
데이터 변환(범주형)
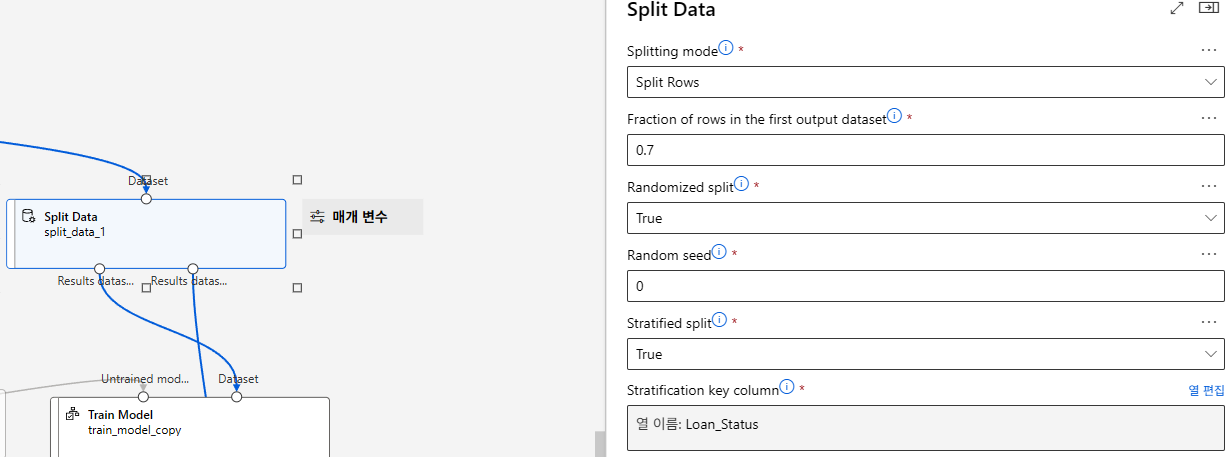
데이터 분리
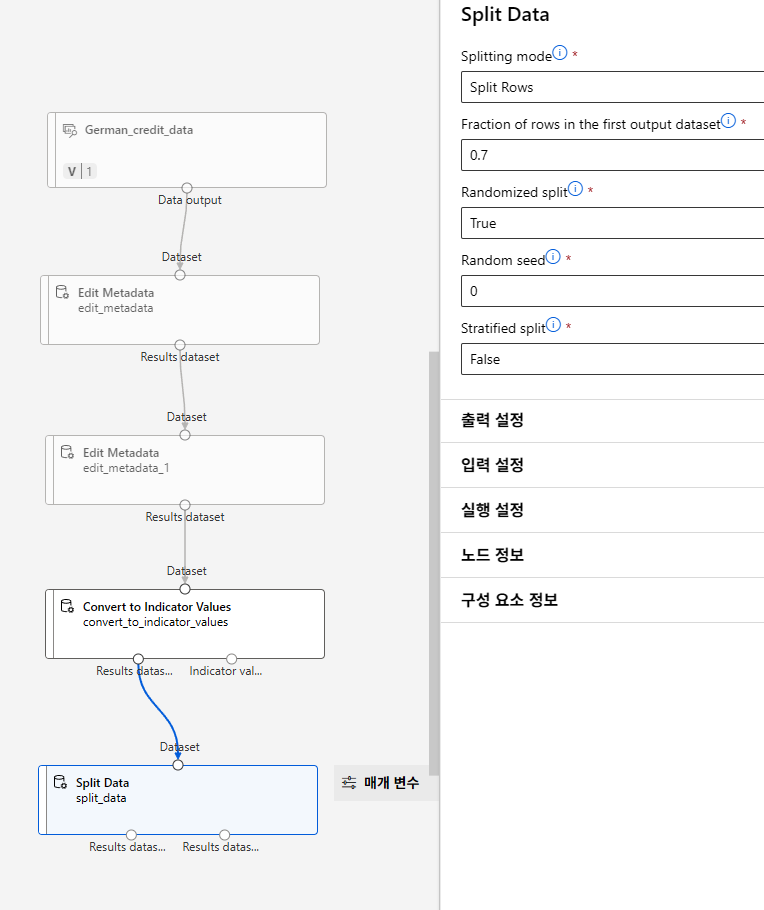
데이터 복제(위험도 비용 고려)
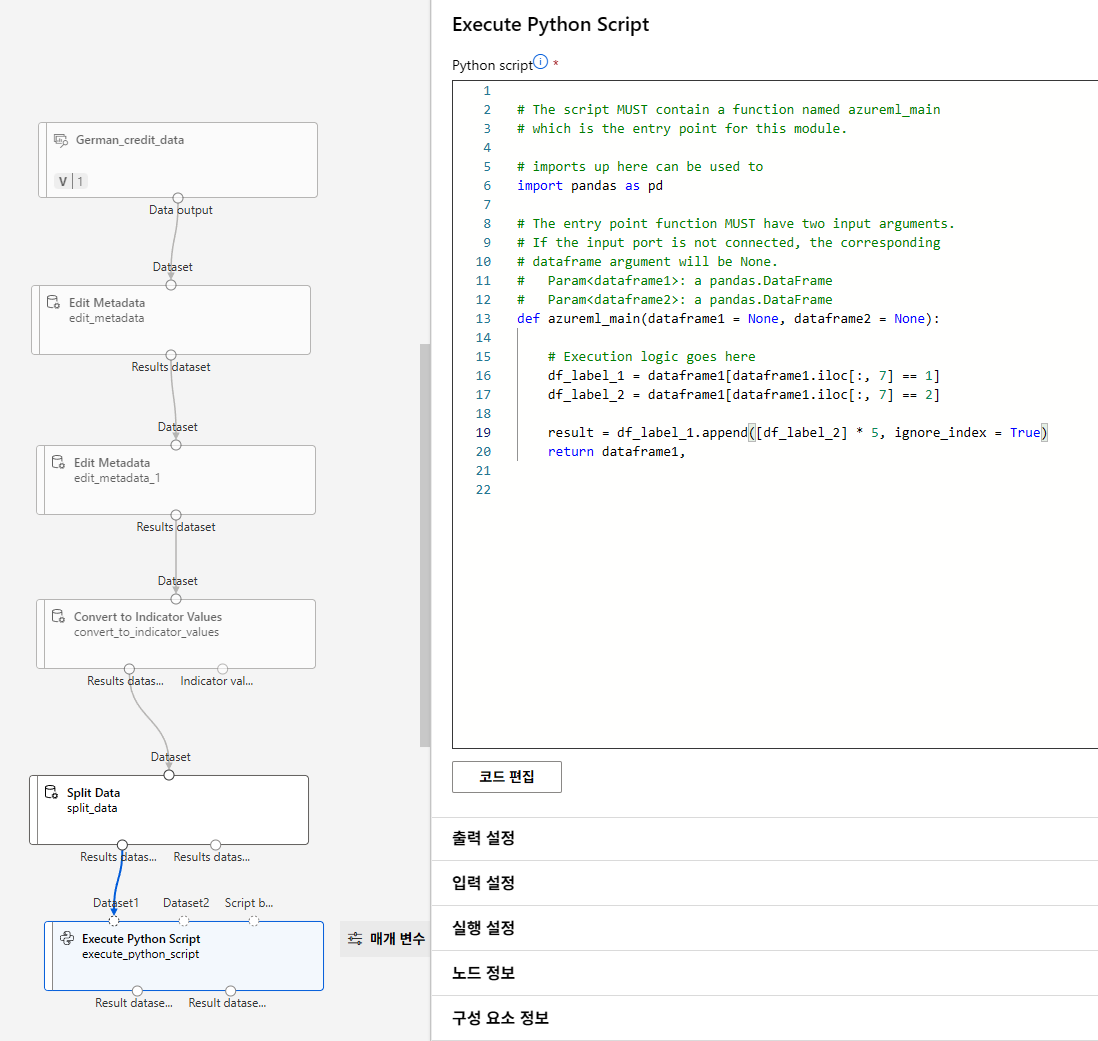
테스트용
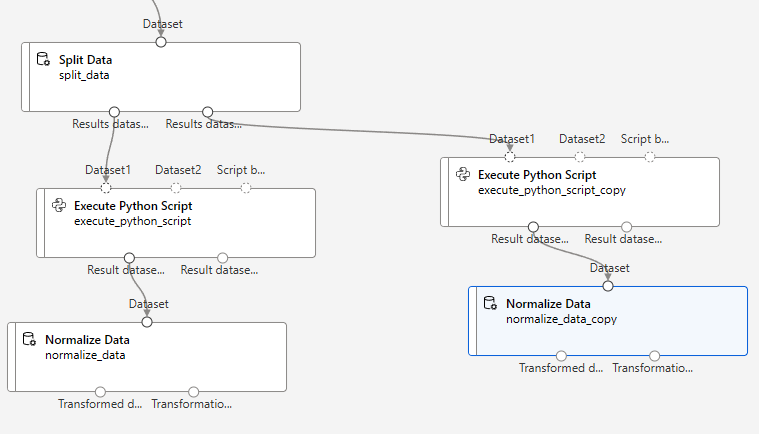
오른쪽(왼쪽을 복붙)
정규화
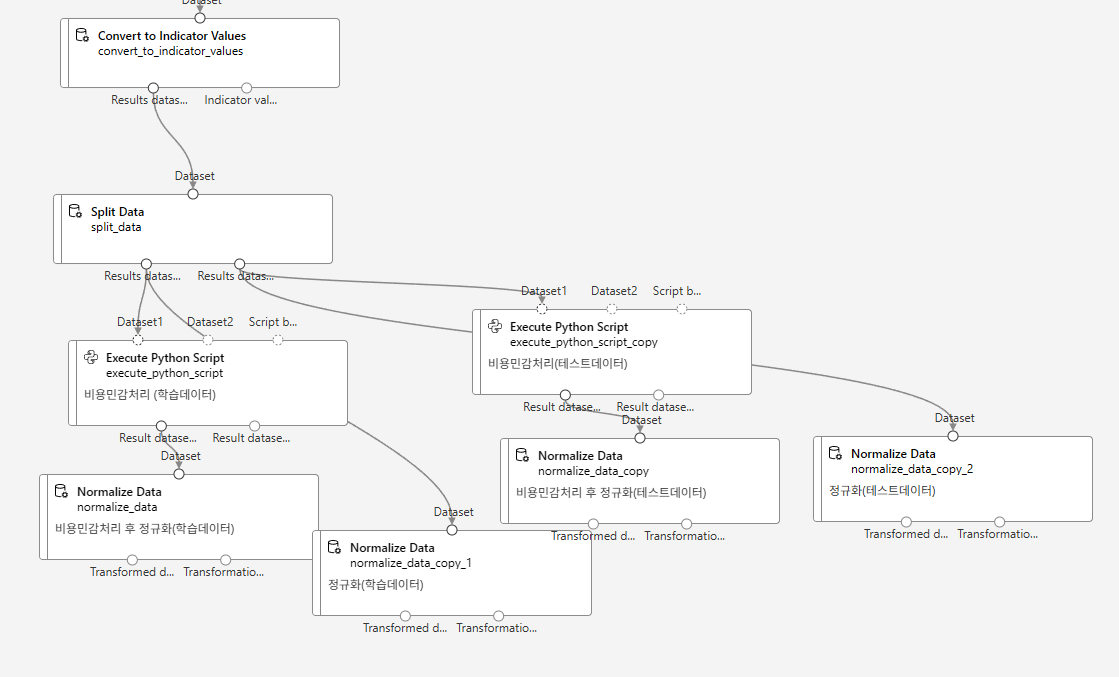
모델링/평가
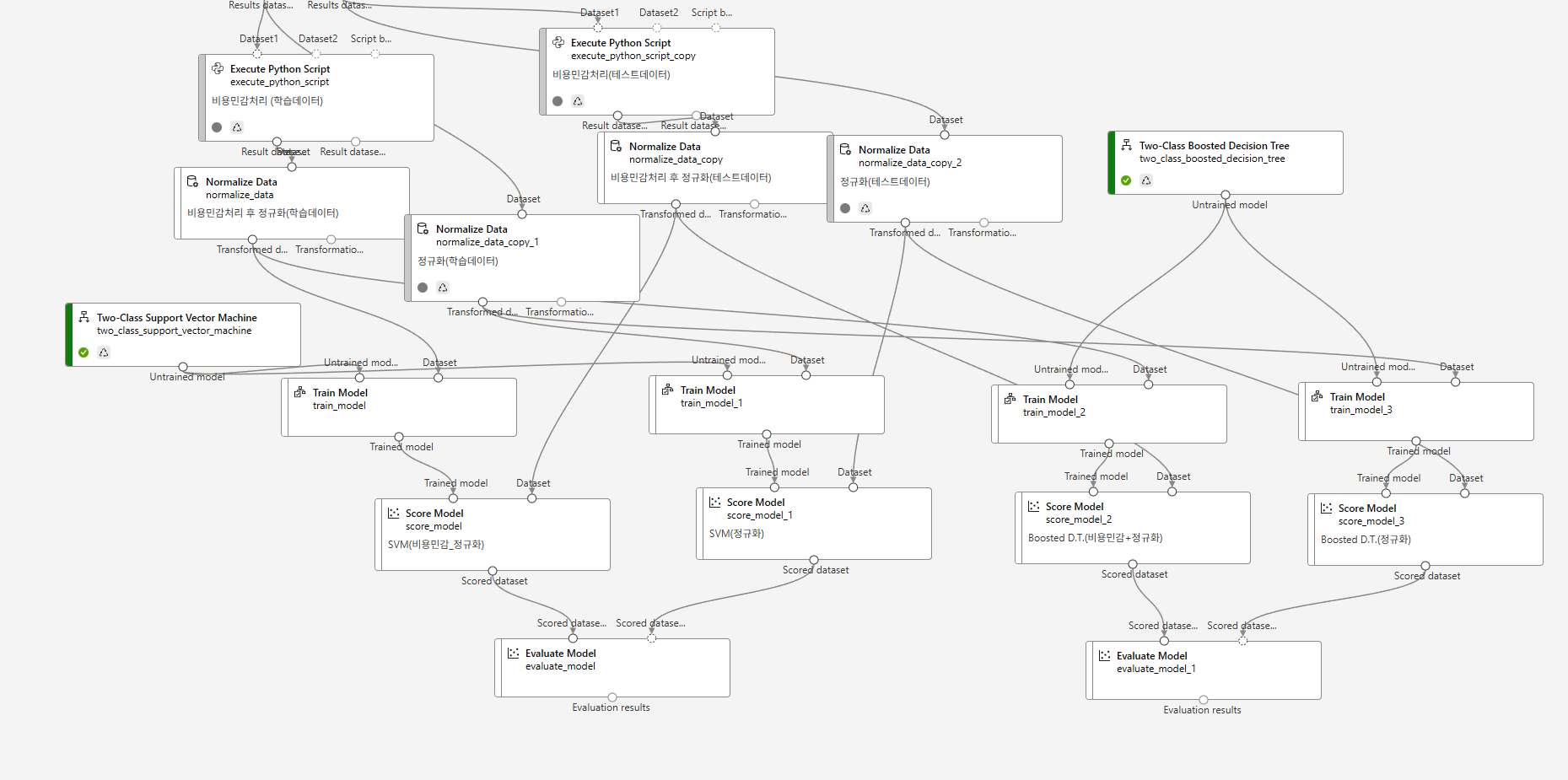
결과
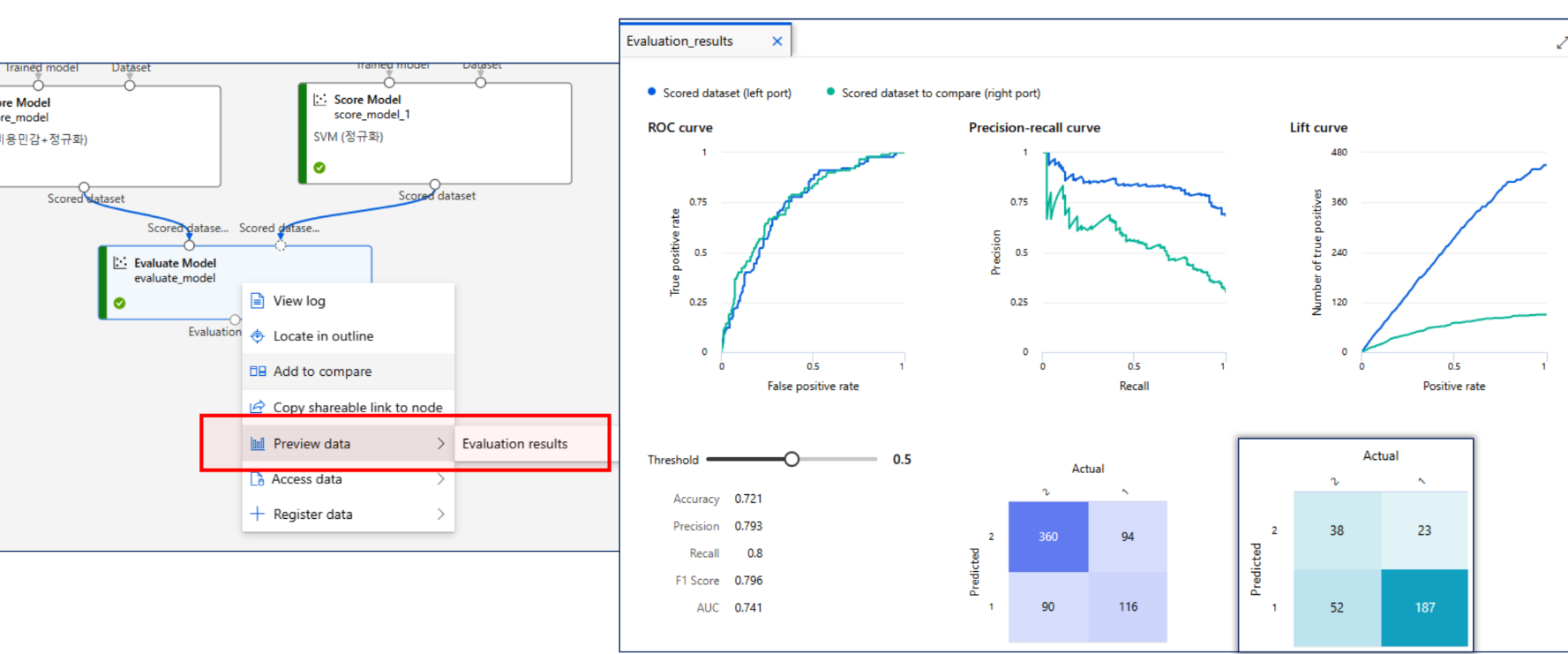
민감처리한쪽이 PR Curve에서 좋아보임. 이유는 불균형한 데이터였기 때문
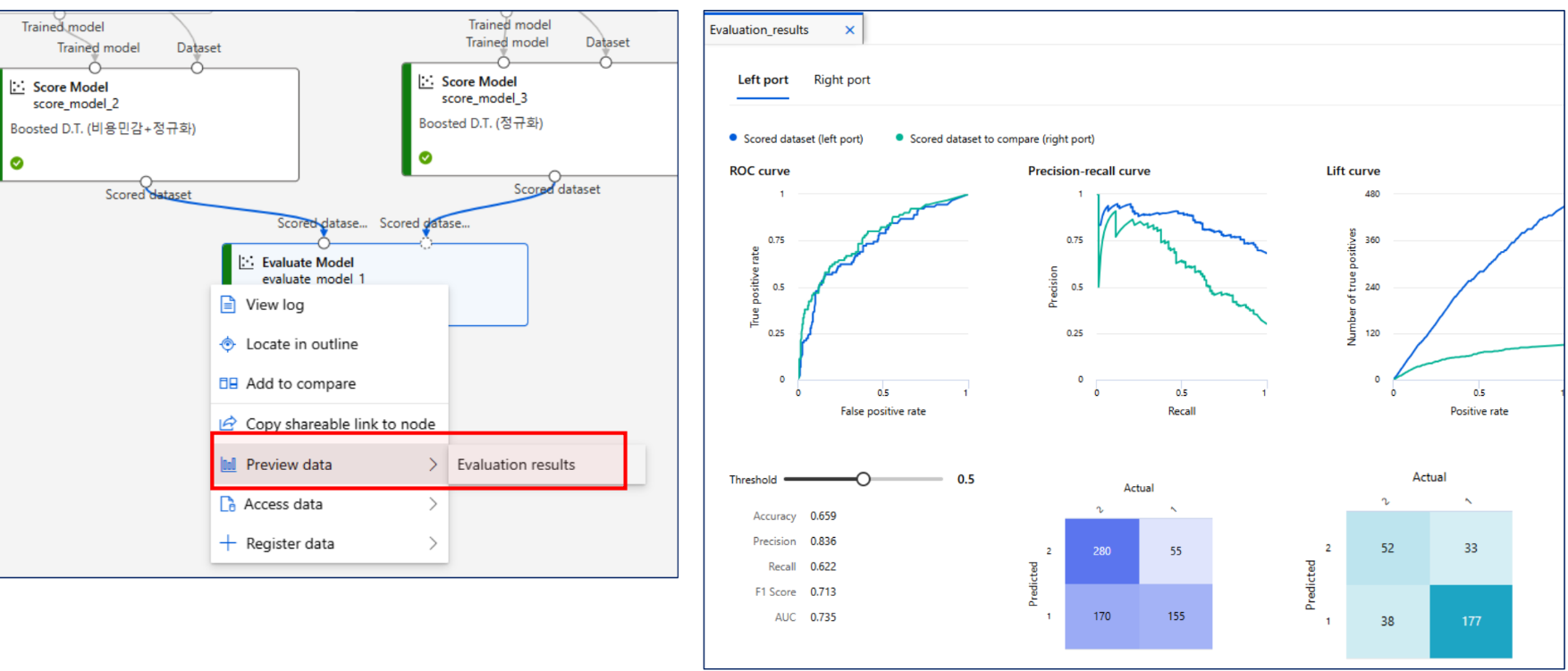
취합
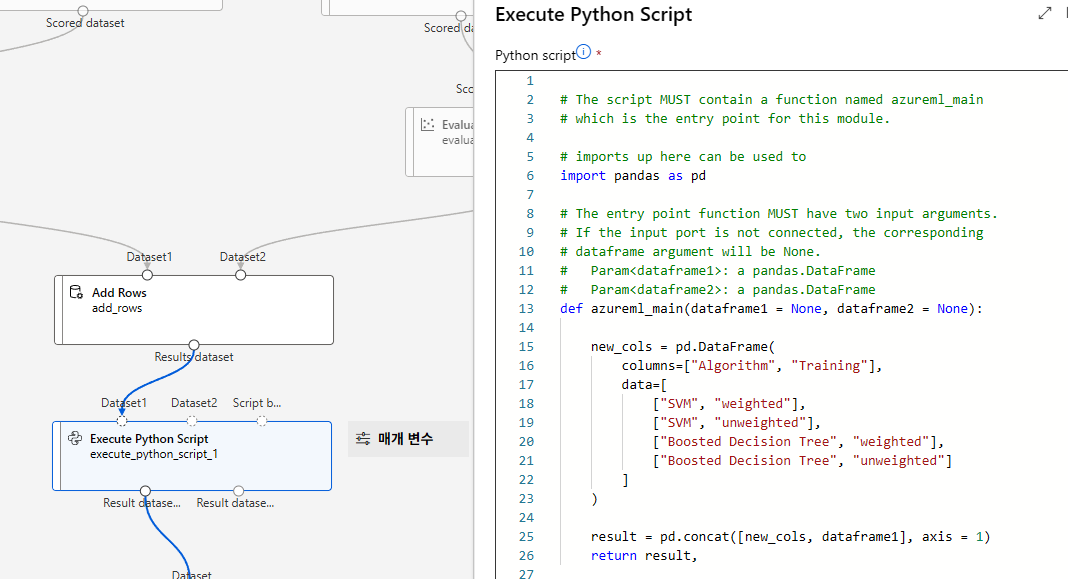
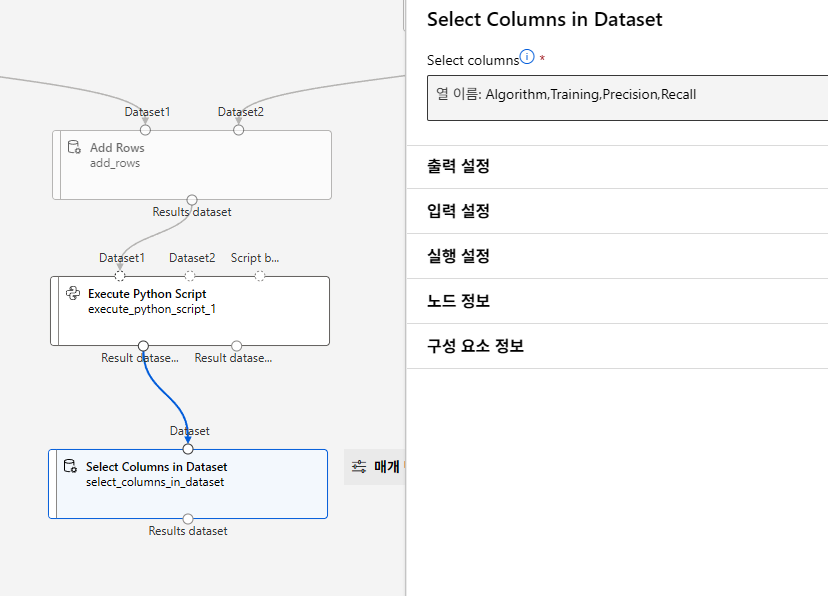
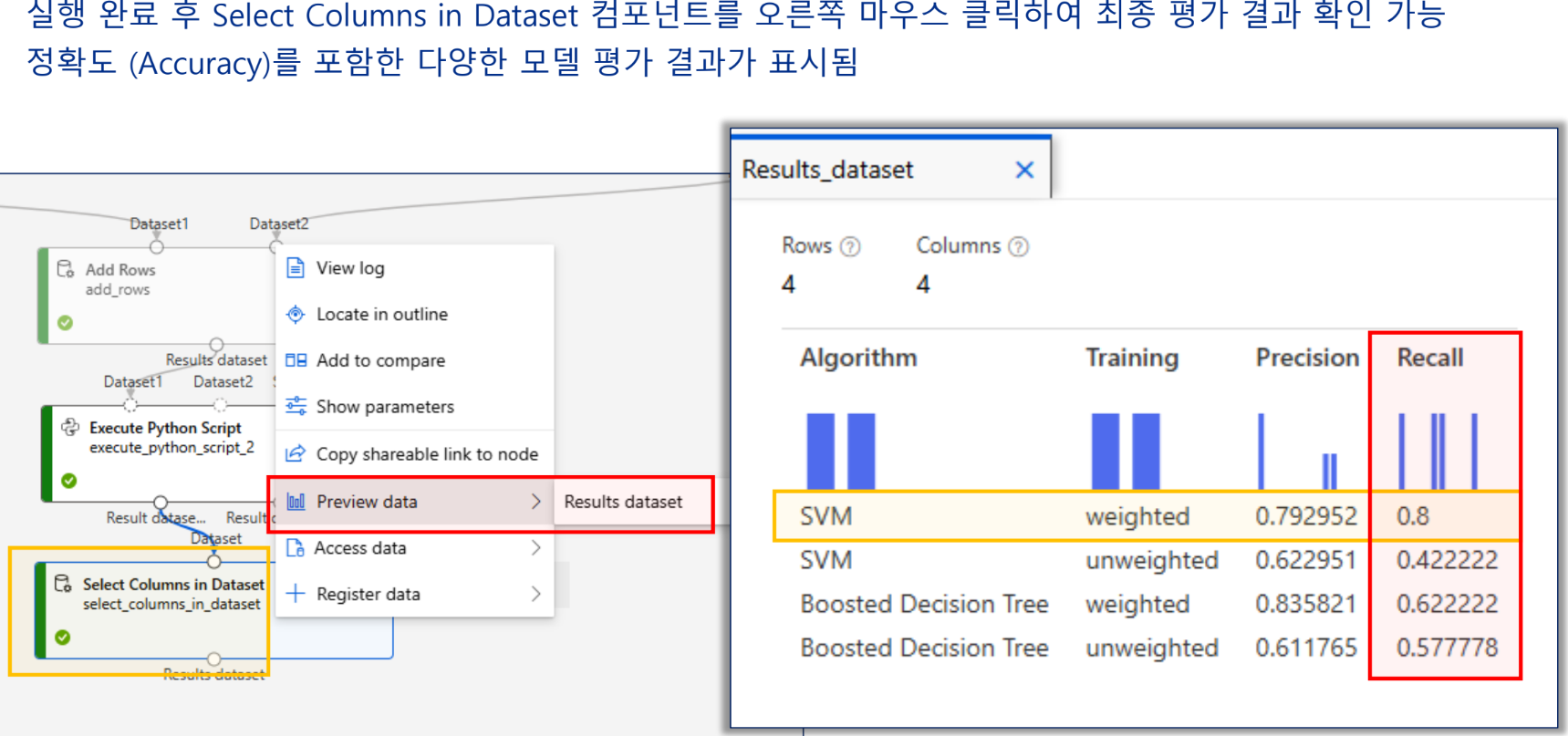
실습 - 로지스틱 회귀 알고리즘을 이용한 고객 대출 자격 예측 모델 구현
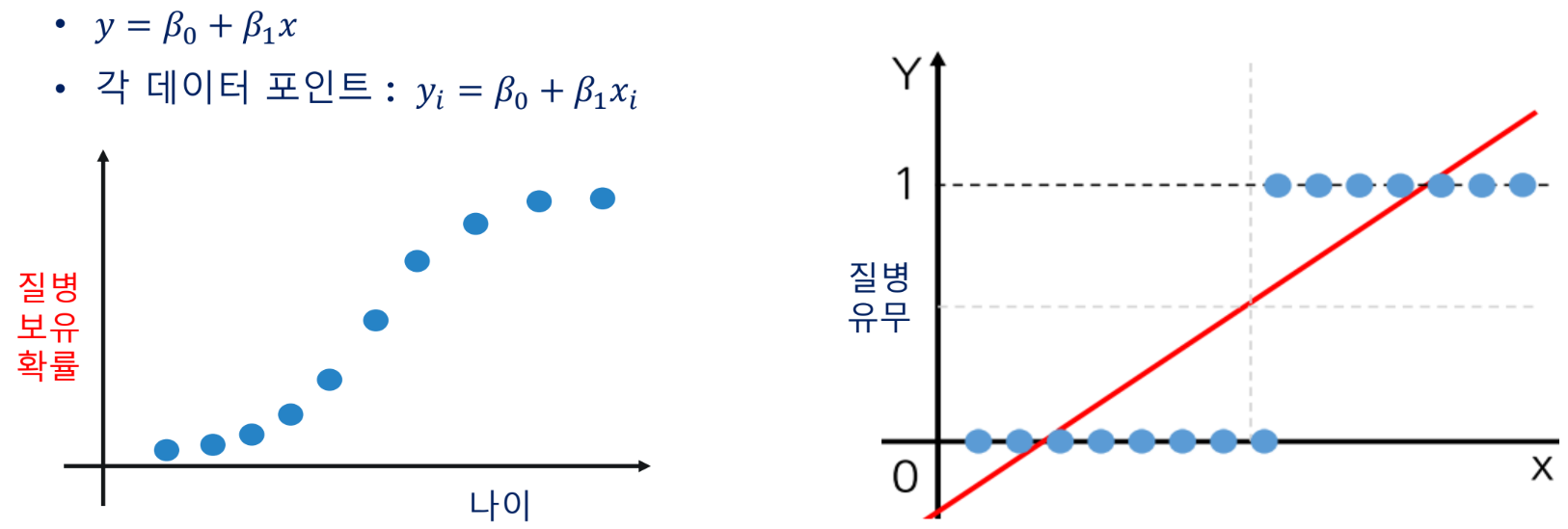
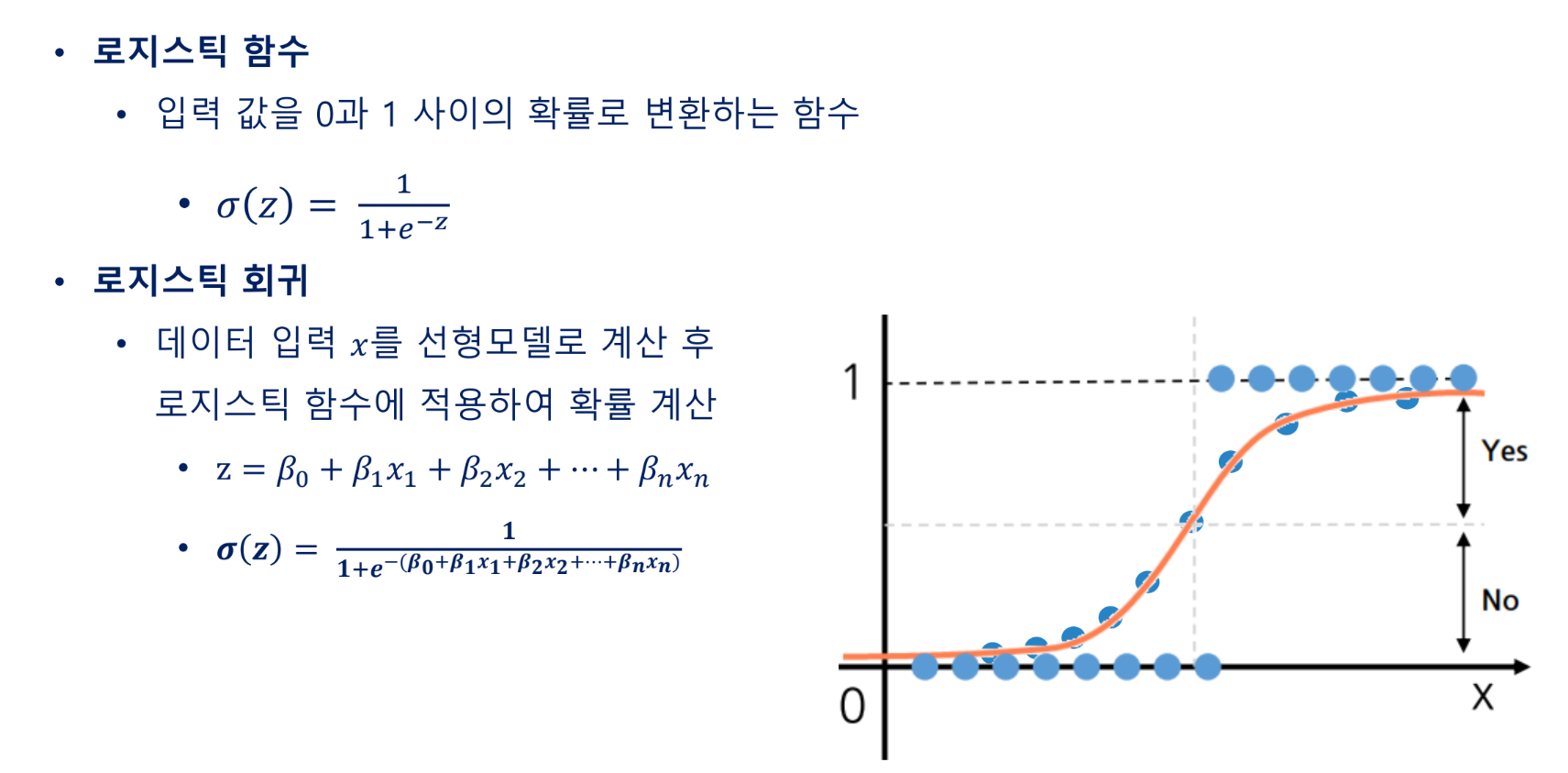
로지스틱 회귀
- 종속 변수가 이진(0 또는 1)인 경우에 사용되는 회귀 분석 기법
- 예시) 환자의 질병 유무(있다/없다), 이메일의 스팸 여부(스팸/스팸아님)
- 회귀식
오즈비
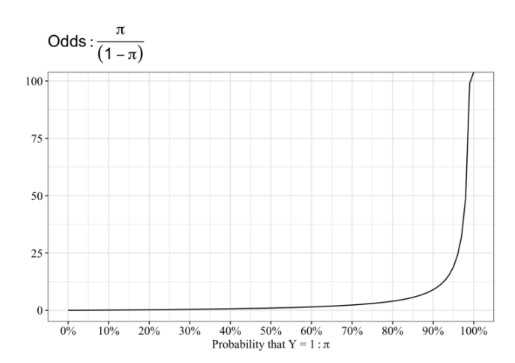
- 실패 대비 성공 확률의 비율
- 성공 확률을 p 로, 실패 확률을 1 − p 로 정의할 때,
Odds = p/(1 − p) , p = Odds/ 1 + Odds
로짓변환
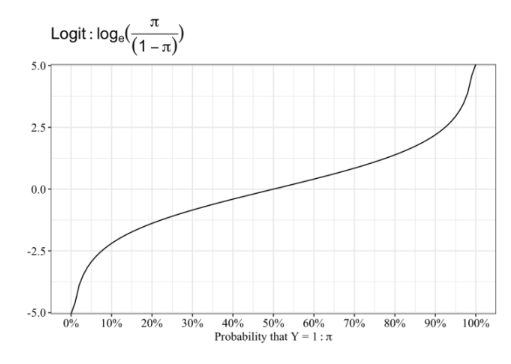
- 0~Odds에 자연로그를 취하여 다루기 쉬운 형태로 변환함
로짓변환의 역함수
y = Logit p 로 치환하여 역함수로 표현
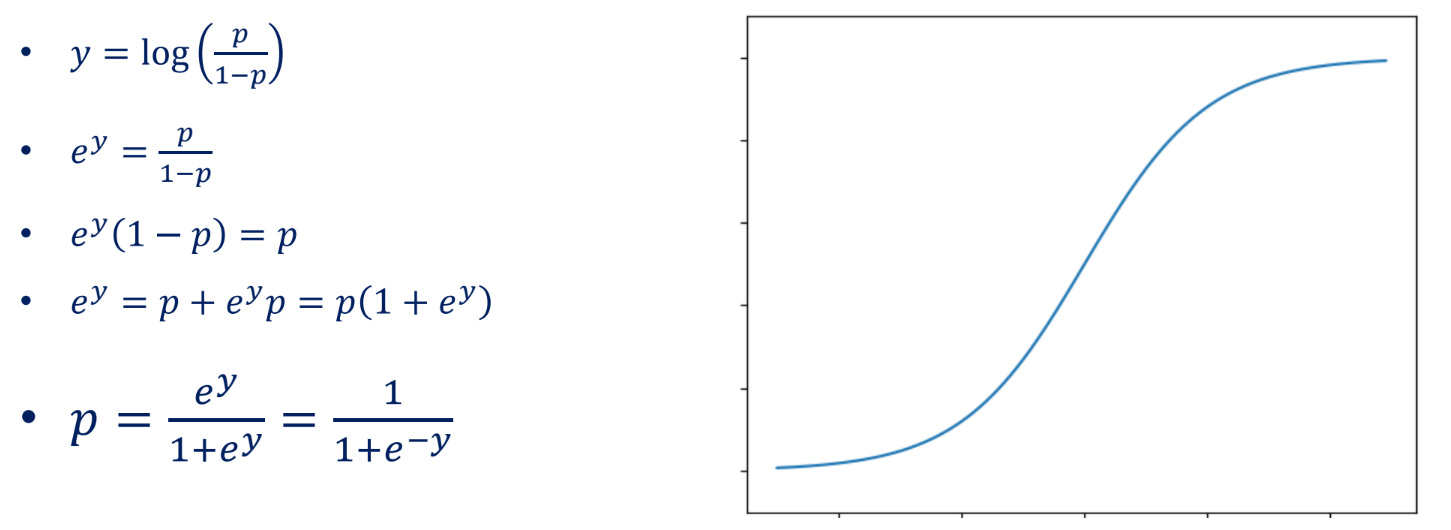
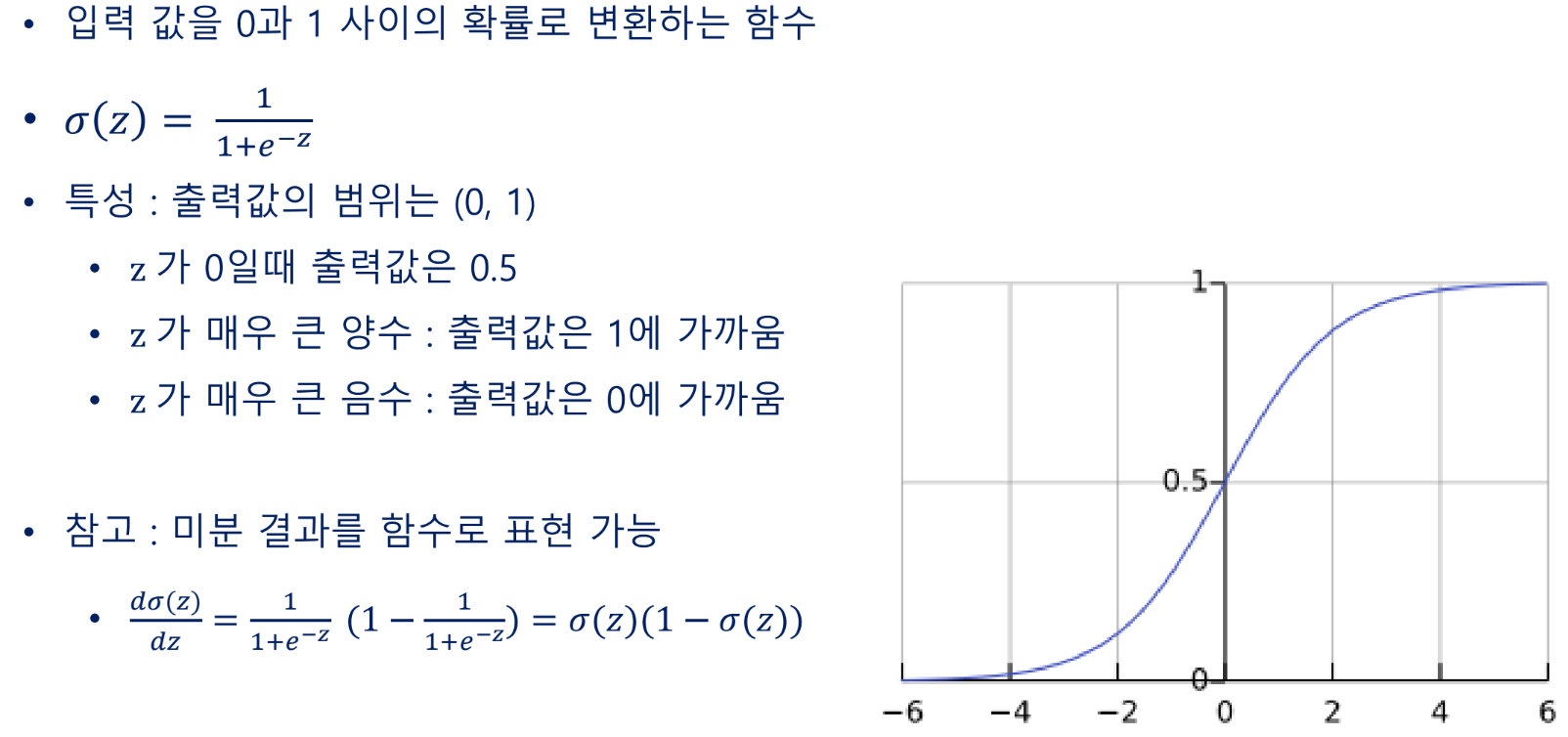
시그모이드 함수
샘플링 방법
층화 추출(Stratified Sampling)
- 모집단을 여러 하위 집단(층)으로 나눈 다음 각 층에서 표본을 무작위로 추출
- 모집단이 이질적일 경우 특성을 더 잘 반영하기 위해 사용함
AzureML 결과
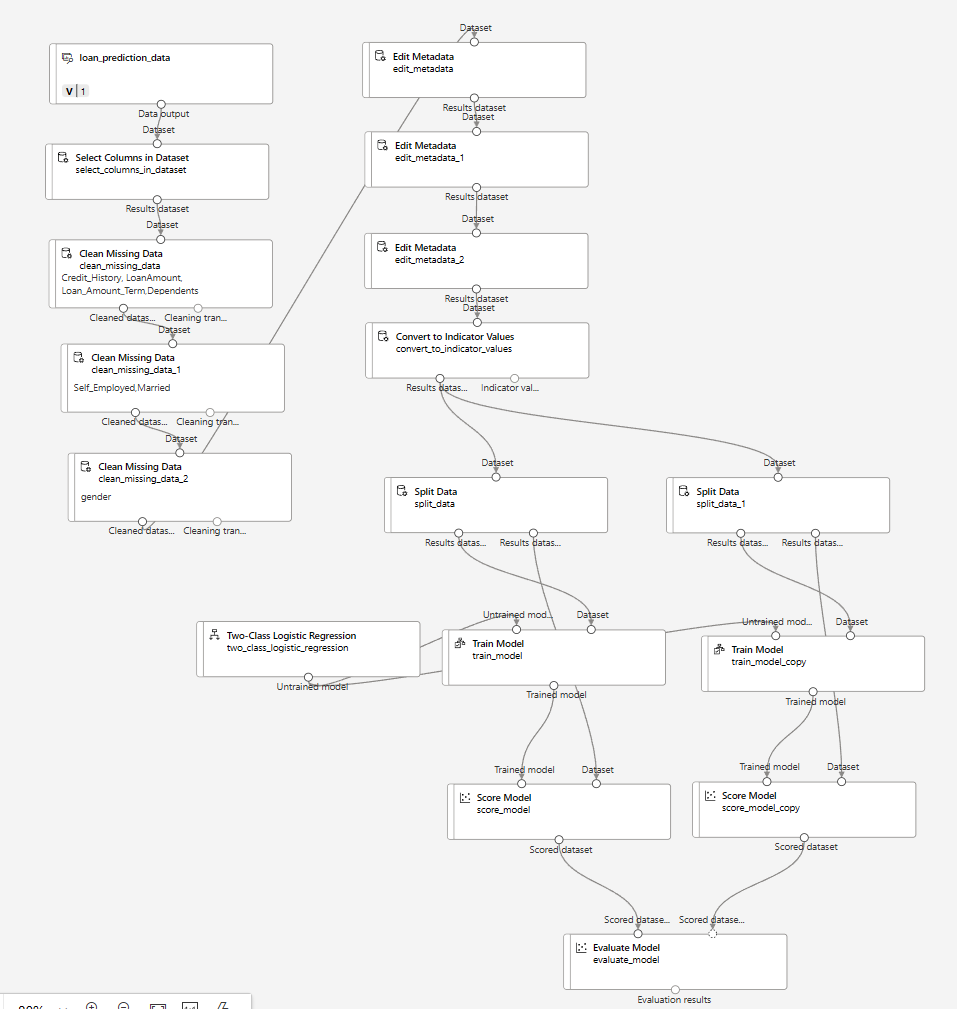
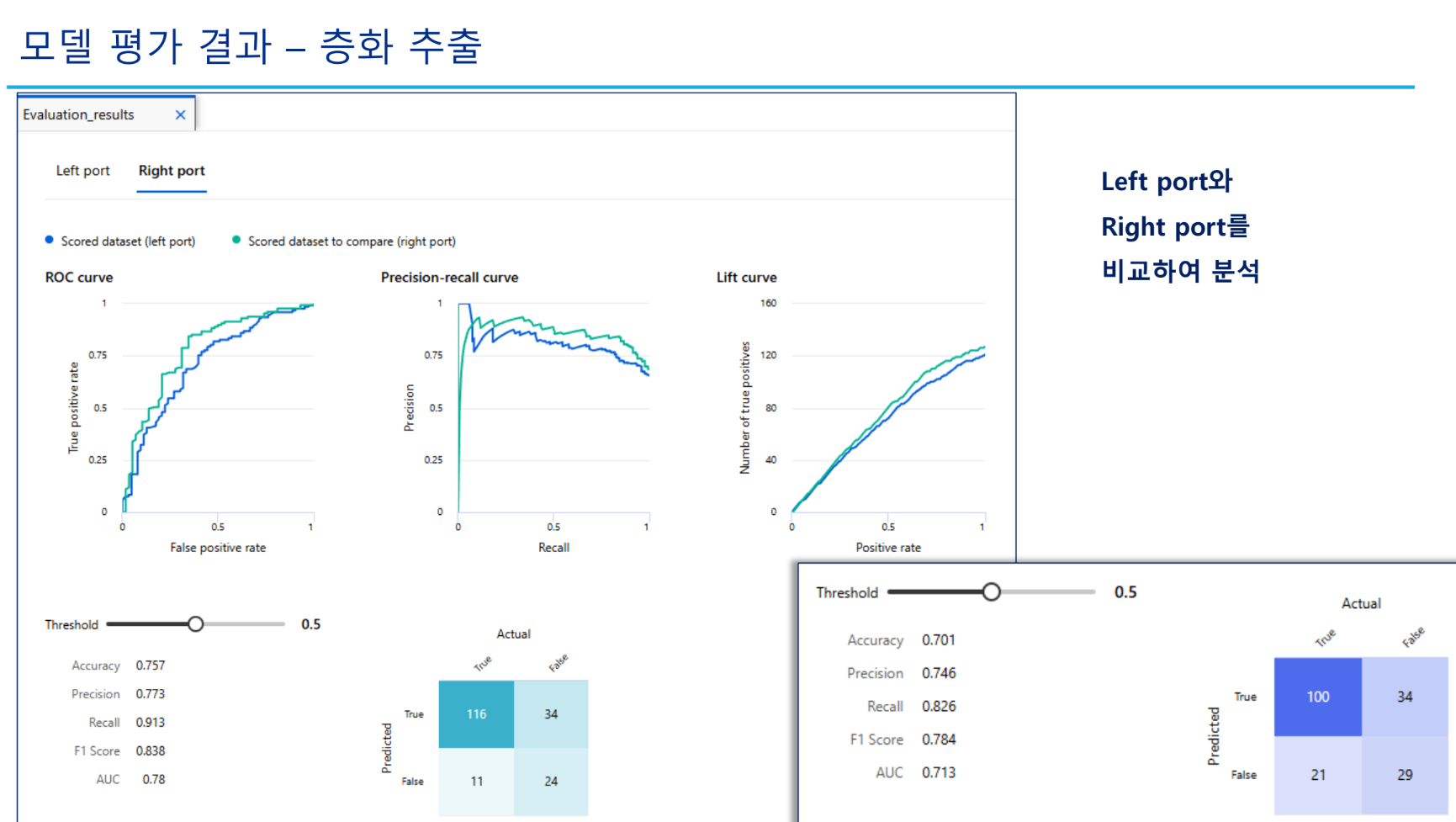
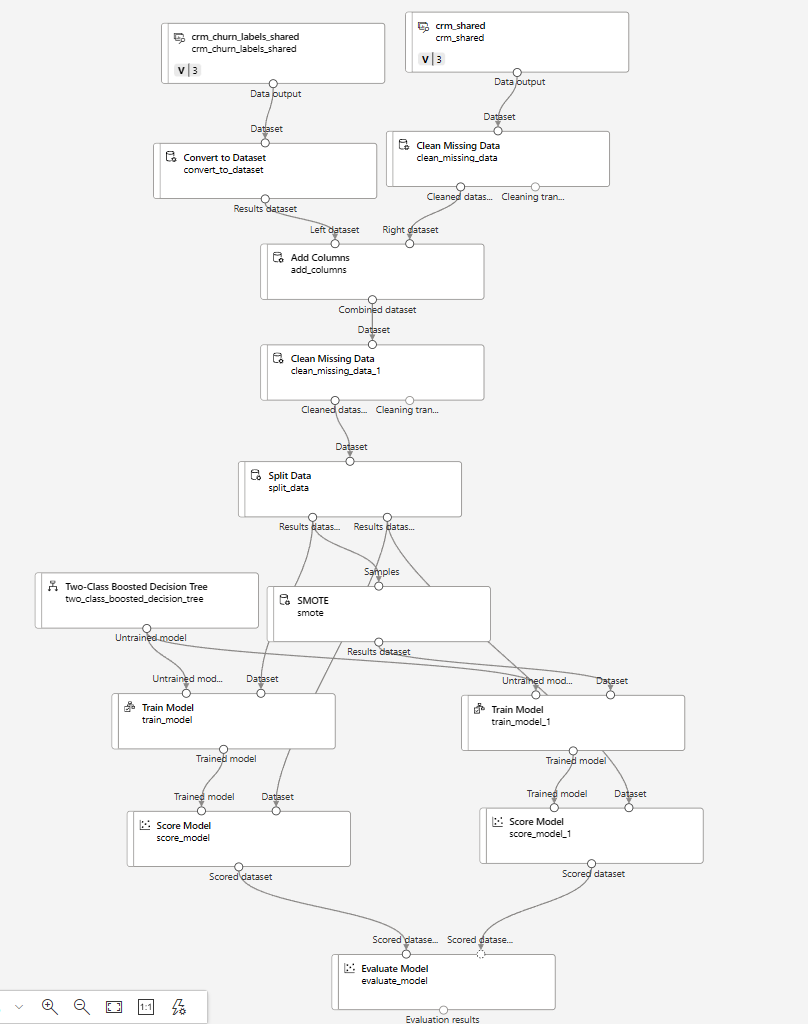
실습-오버샘플링을 이용한 CRM 고객 이탈 예측 모델 구현
오버샘플링
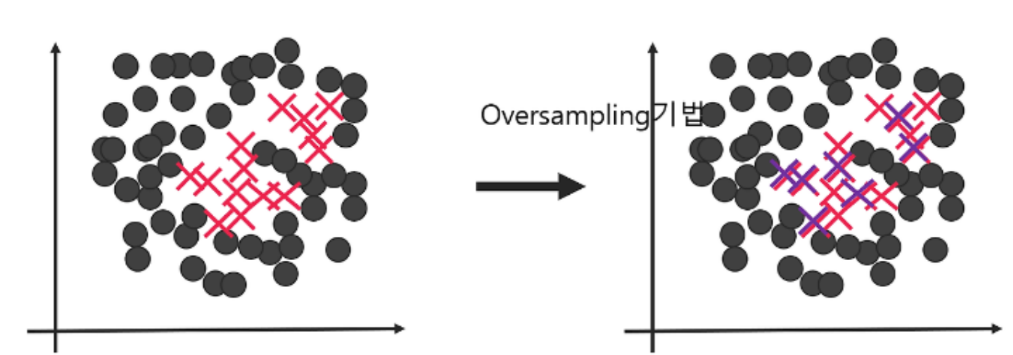
불균형한 데이터 (Imbalanced data)
- 데이터세트의 각 클래스 간 데이터 수가 많이 차이나면, 학습된 모델의 성능에 좋지 않은 영향을 줌
- 분류 모델의 학습 데이터의 클래스 간 비율 차이가 큰 경우, 비율이 높은 쪽으로 분류 결과를 출력하는 경향 있음
오버샘플링 (Over Sampling)
- 불균형한 데이터세트에서 소수 클래스의 데이터를 증가시켜 클래스 간의 불균형을 조정하기 위해 사용되는 기법
랜덤 샘플링 (Random Oversampling)
- 소수 클래스의 기존 데이터를 무작위로 복제하여 샘플 수를 늘리는 방법
- 장점 : 소수 클래스의 샘플 수를 손쉽게 증가시킬 수 있음
- 단점 : 데이터의 다양성을 늘리지 않고 단순 복제하기 때문에 모델이 복제된 샘플에 과적합될 수 있음
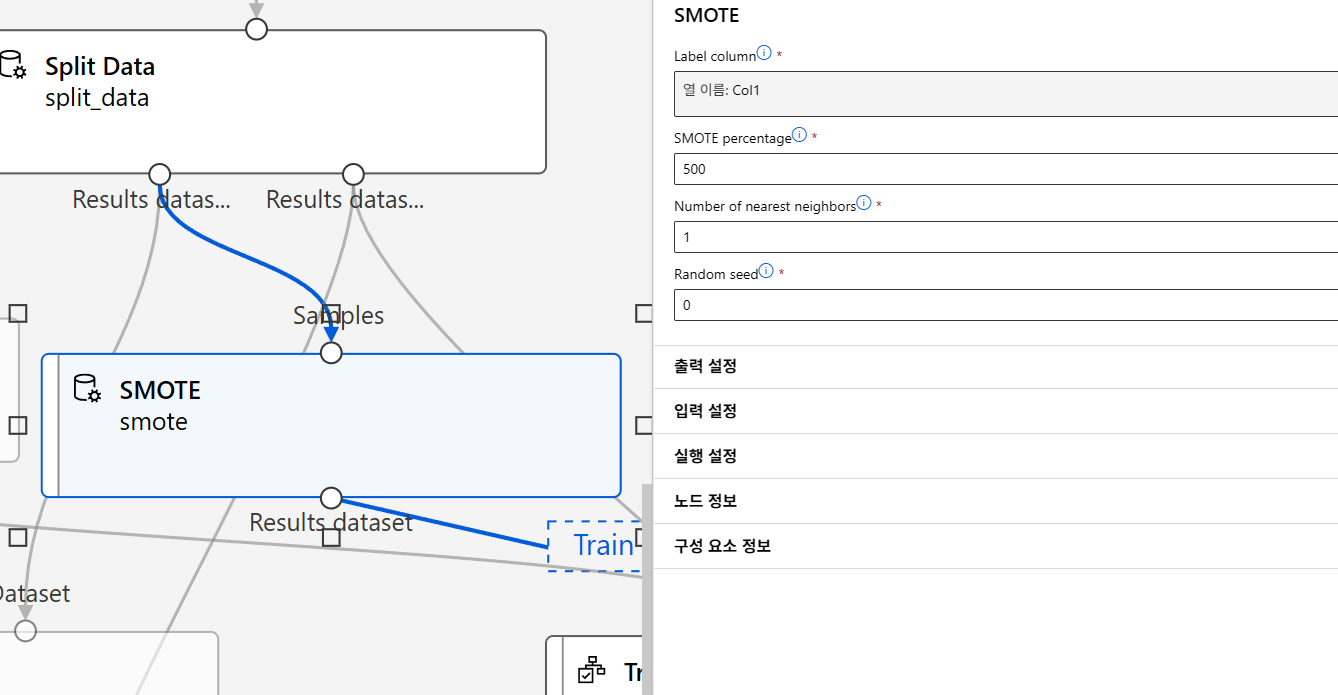
SMOTE (Synthetic Minority Over-sampling Technique)
- 소수 클래스 샘플들을 이용하여 새로운 샘플을 합성하여 생성하는 방법
- 기존 샘플과 그 이웃 샘플들 간의 선형 결합을 통해 새로운 샘플을 만듦
- 장점 :
- 데이터 다양성을 증가시켜 과적합을 줄일 수 있음
- 소수 클래스의 분포를 더 자연스럽게 확장 가능
- 단점:
- 노이즈 데이터가 포함될 수 있습니다.
- 동작 방식 :
- 같은 클래스에 속한 데이터 사이의 거리를, 랜덤한 값으로 내분하는 지점에 새로운 데이터 생성
- 임의의 데이터에서 동일한 클래스에 속한 데이터 중 가장 가까운 K 개의 데이터와의 선분 상에 새로운 데이터 생성

ADASYN (Adaptive Synthetic Sampling Approach for Imbalanced Learning)
- 소수 클래스 샘플의 난이도에 따라 가중치를 다르게 부여하여 새로운 샘플 생성
- 어려운 샘플(근접한 다수 클래스 샘플들이 많은 샘플)을 더 많이 생성하는 접근법
- 장점 :
- 학습이 어려운 샘플을 더 많이 생성하여 모델의 학습 능력을 향상시킴
- 데이터의 균형을 맞추면서도 어려운 샘플에 대해 더 잘 대응함
- 단점 :
- 과적합 위험이 있으며, 노이즈가 포함될 가능성이 높음
- 알고리즘이 복잡하여 실행 시간이 길어질 수 있음
데이터 수집
Azure ML
SMOTE
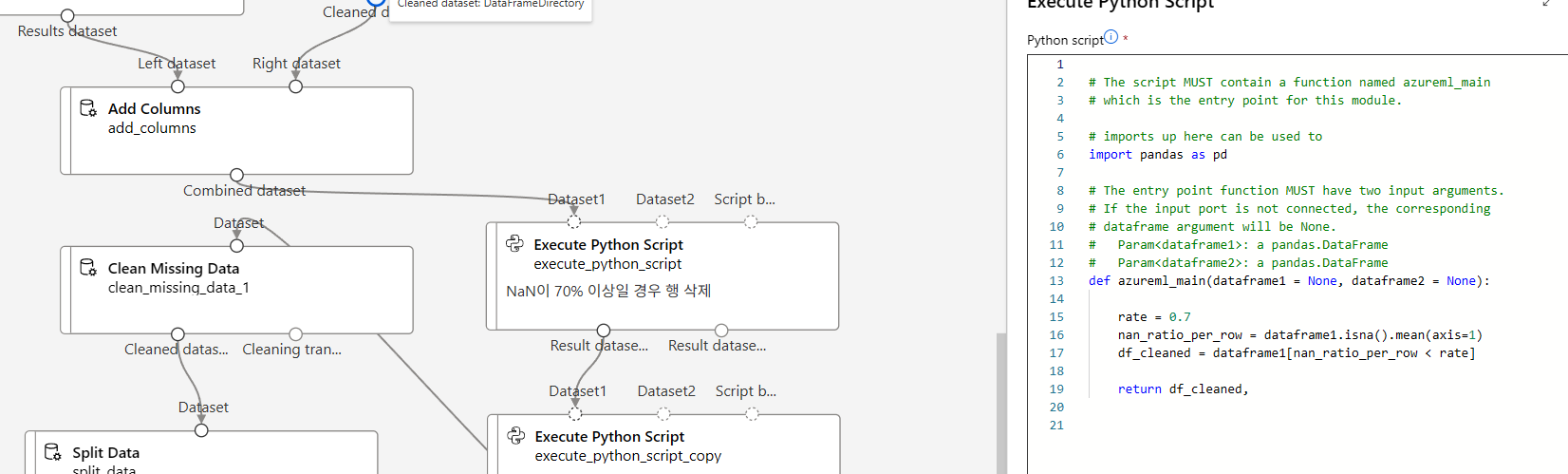
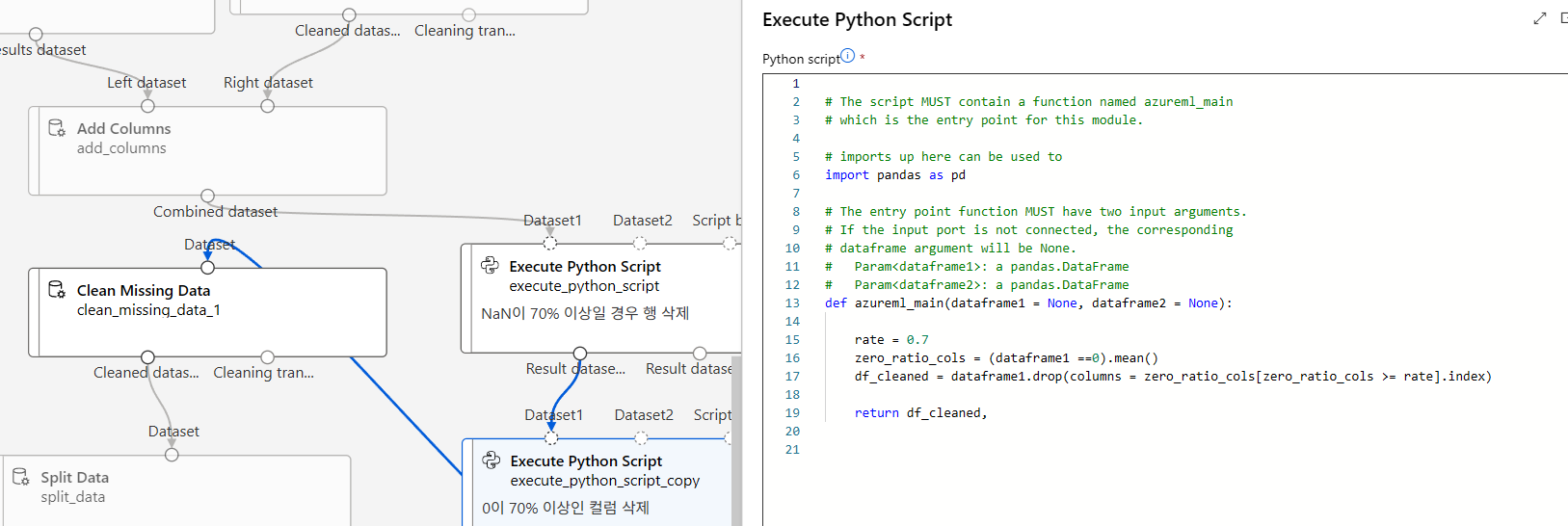
누락값 많은 데이터행/컬럼 제거
실습: 교차 검증을 이용한 개인 수입 예측 모델 구현
교차검증
학습 데이터 세트를 여러 부분으로 나누고 각 부분을 학습과 검증 용도로 번갈아 사용하여 모델을 학습 및 평가하는 방법을 의미함
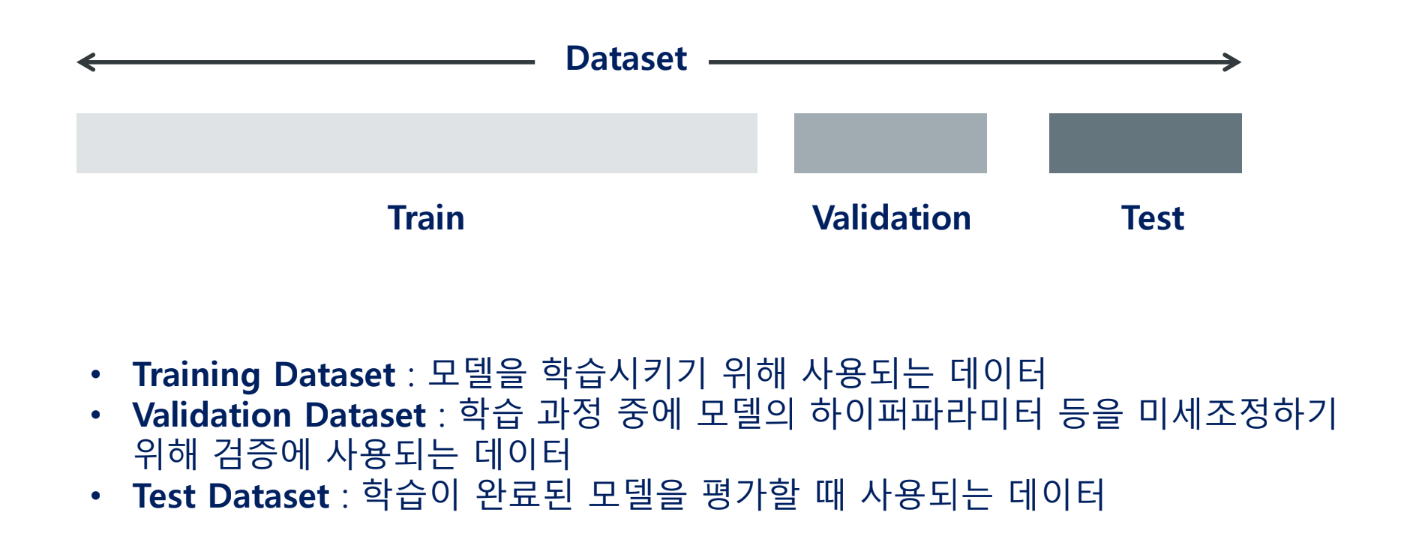
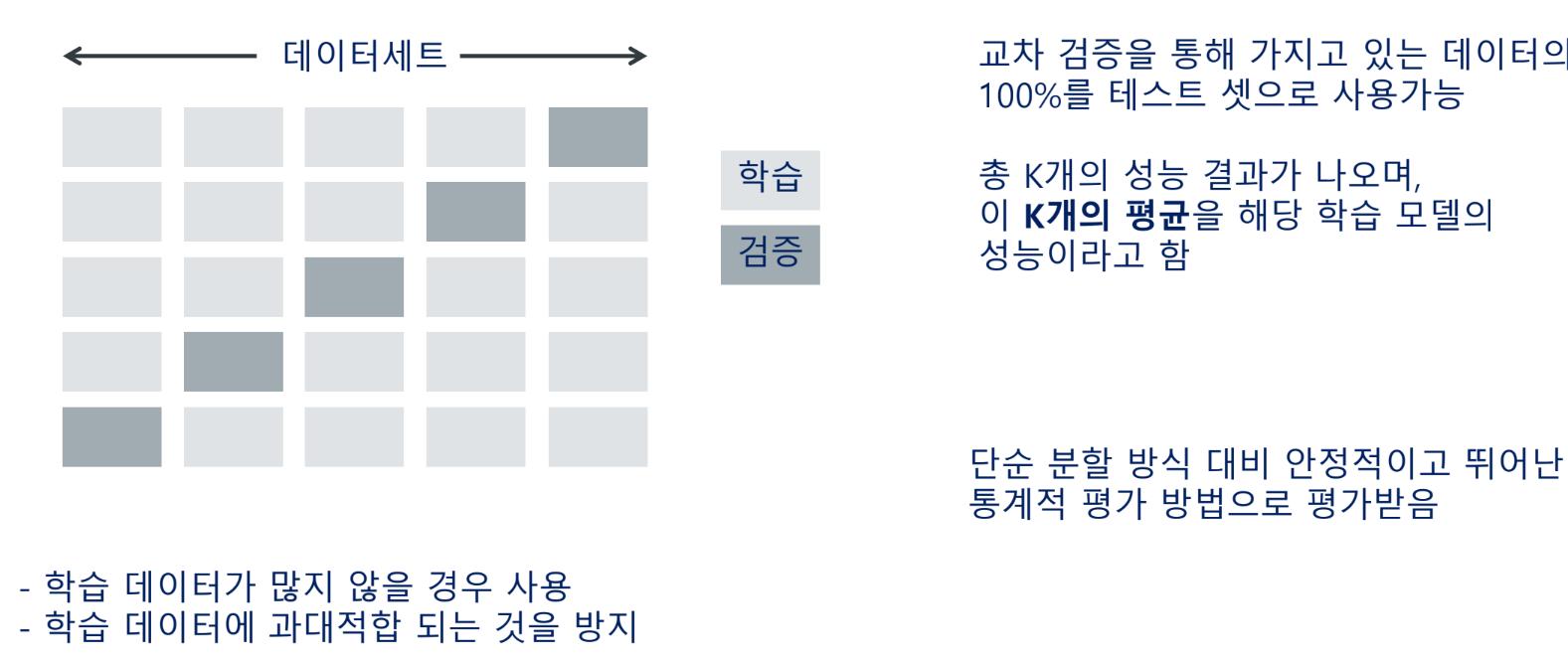
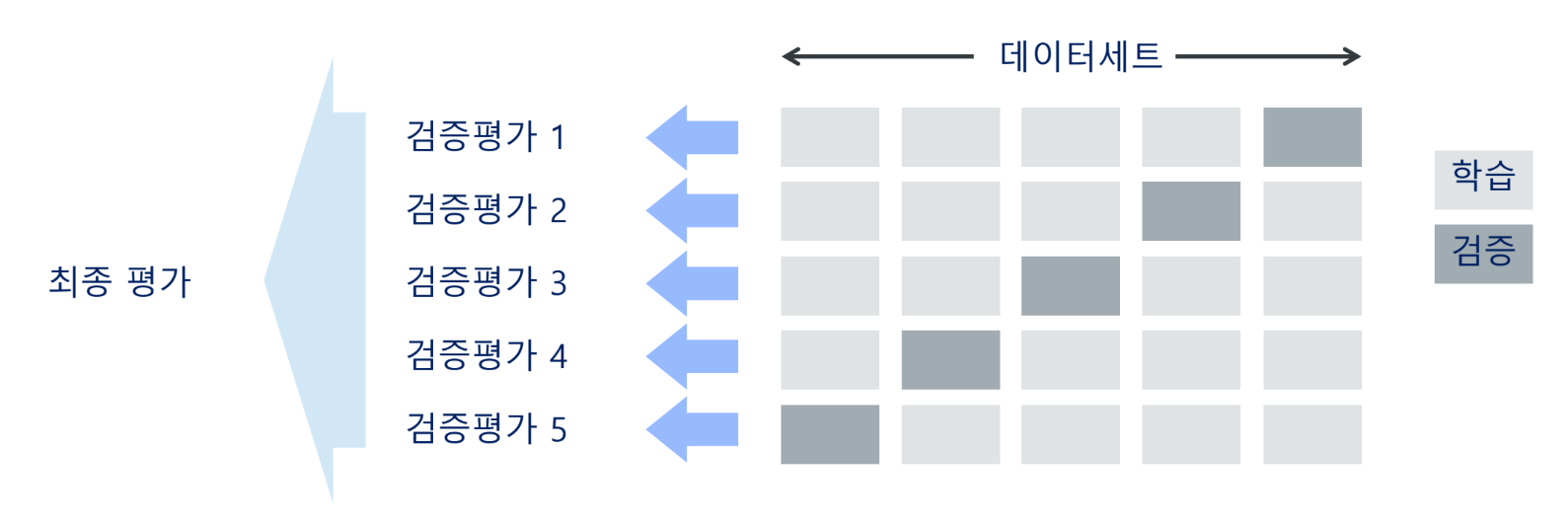
교차 검증을 적용하면 모든 학습 데이터를 학습과 검증에 사용할 수 있으며, 각각의 검증 결과를 평균하여 최종 성능을 평가함
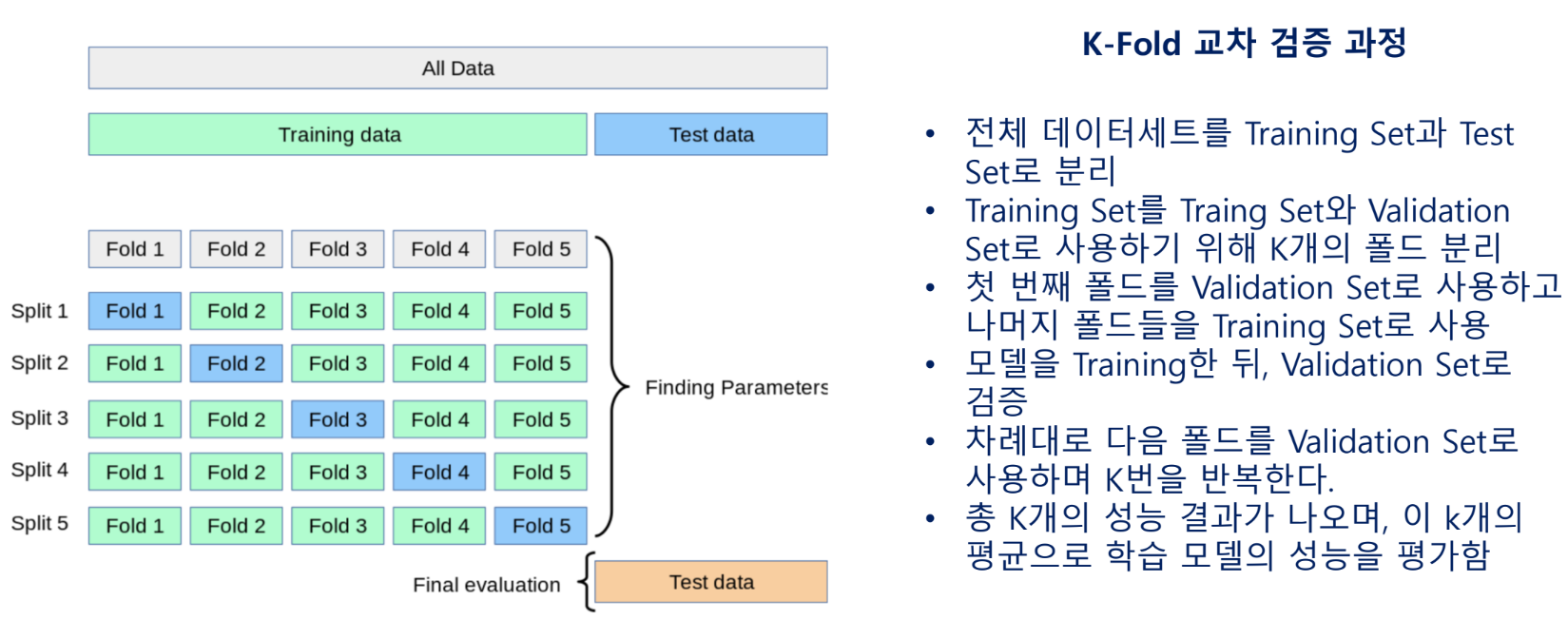
K-Fold 교차 검증
전체 데이터세트를 K개의 폴드로 나누어 각 데이터 폴드를 학습 데이터와 검증 데이터로 번갈아 사용하여, 서로 다른 데이터로 학습한 실험들의 결과를 평균하여 학습 데이터와 모델을 평가하는 방법
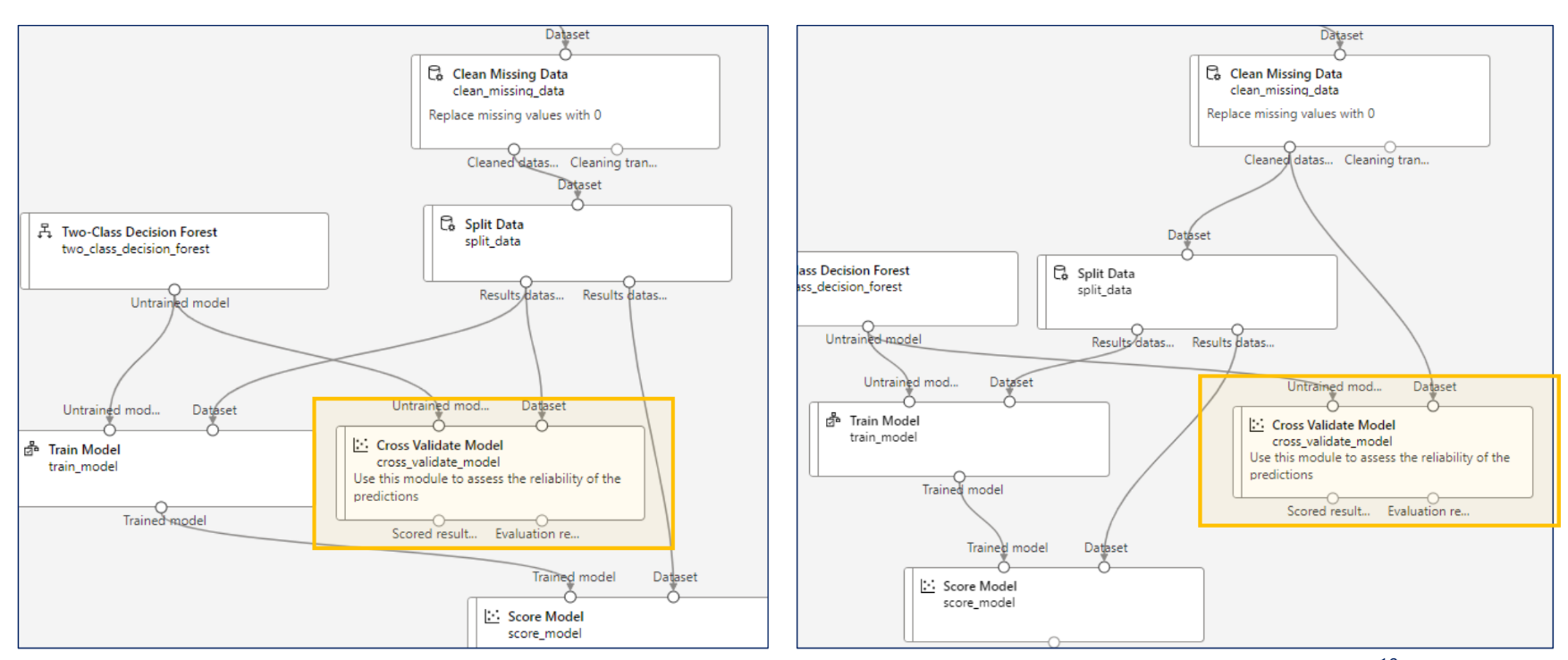
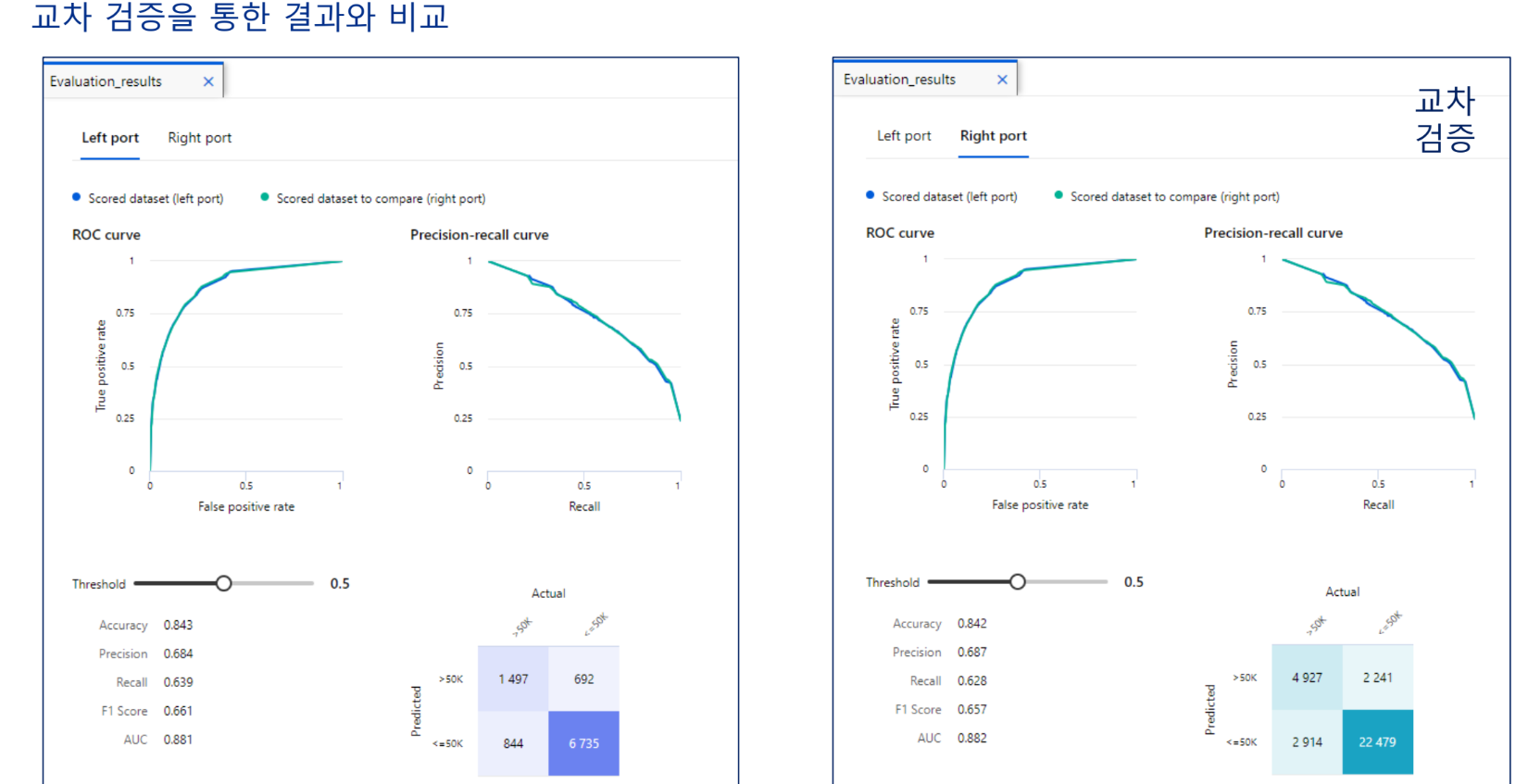
2번째처럼 해야한다.
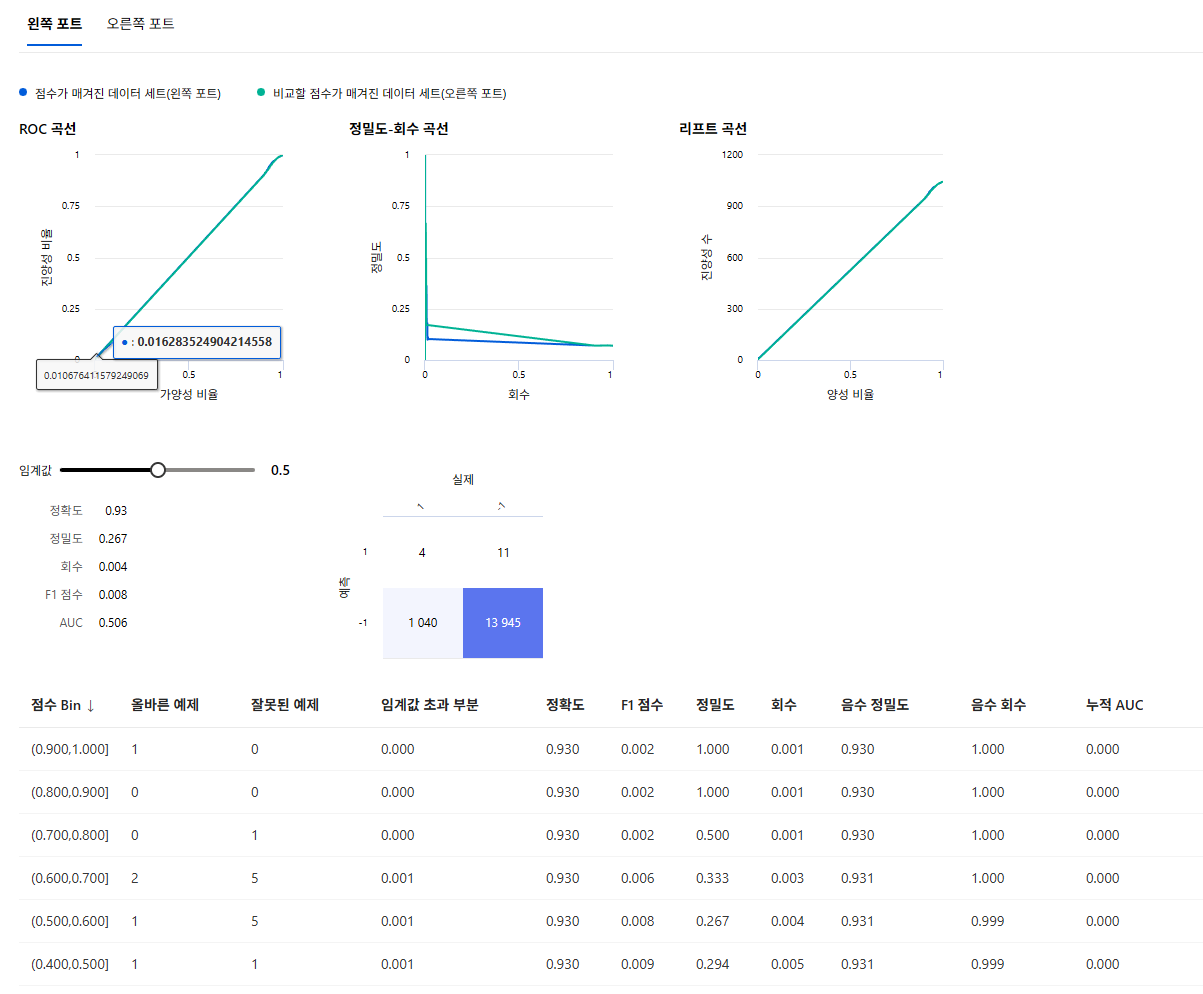
결과
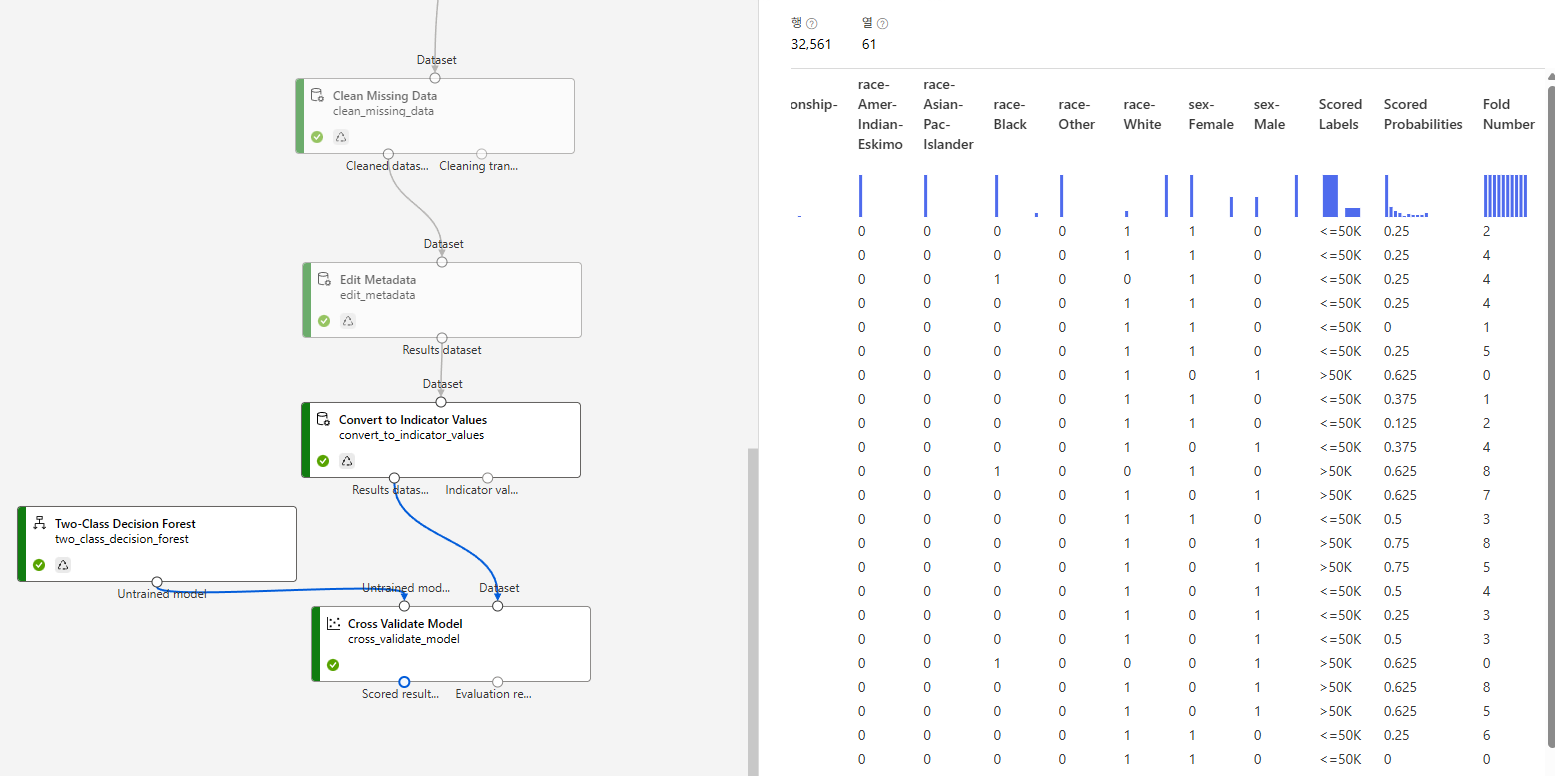
데이터가 많으면 cross validate를 하던, 기존 작업대로 하던 큰 의미는 없다.
데이터가 적을 때 의미 있는 것.
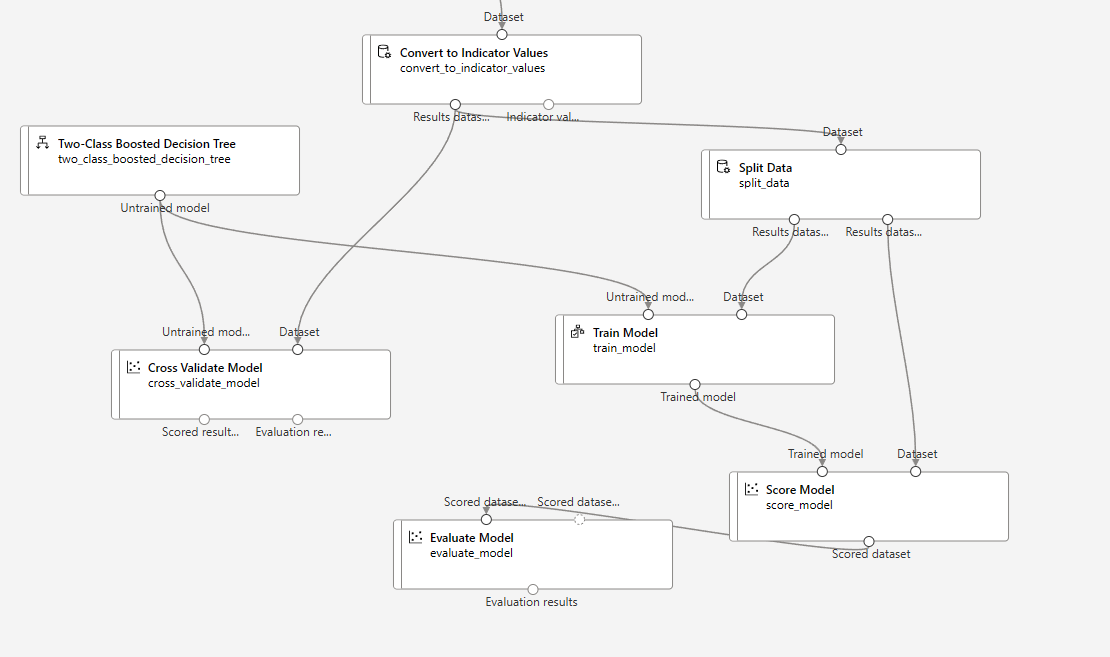
개인실습
버섯이 독버섯인지 아닌지 예측하는 모델이다.
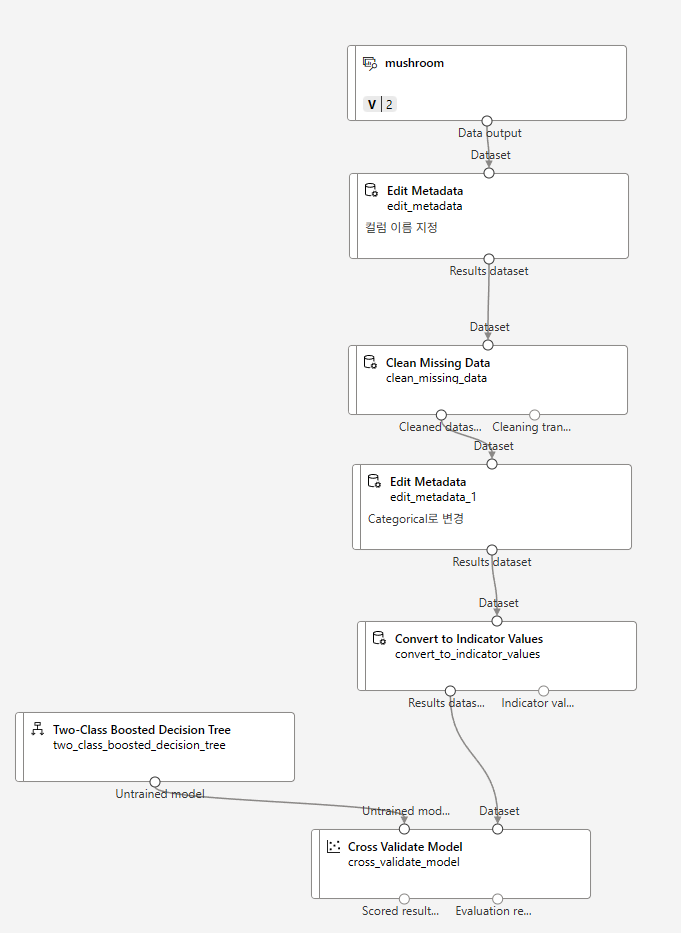
하나의 범주값만 갖는 특성은 데이터 임포트때 컬럼자체를 제외했다.
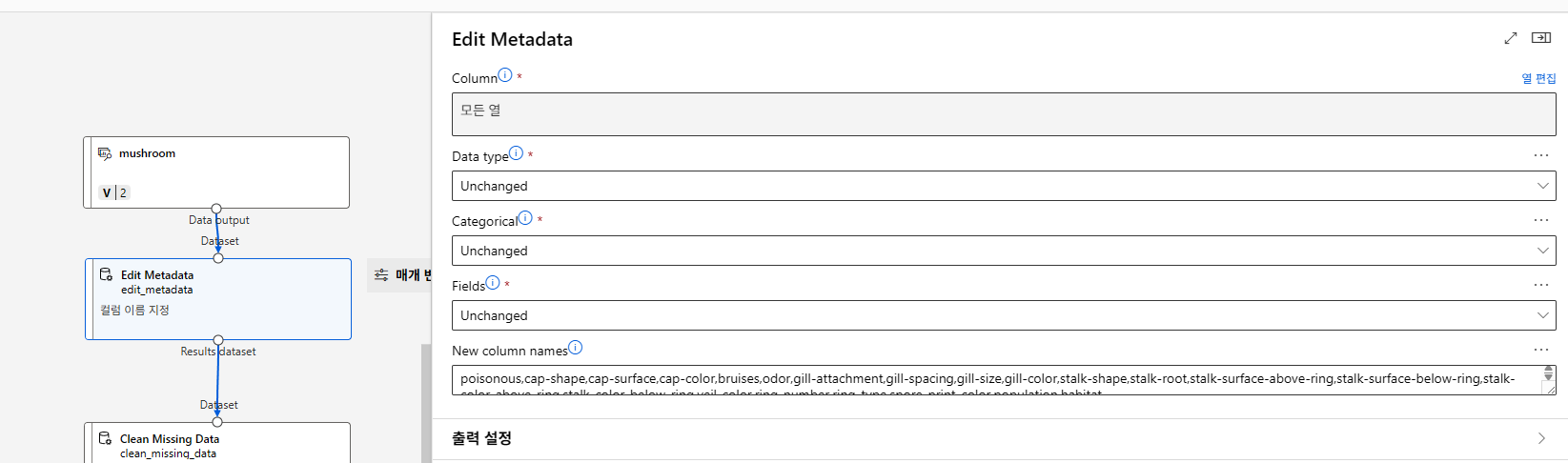
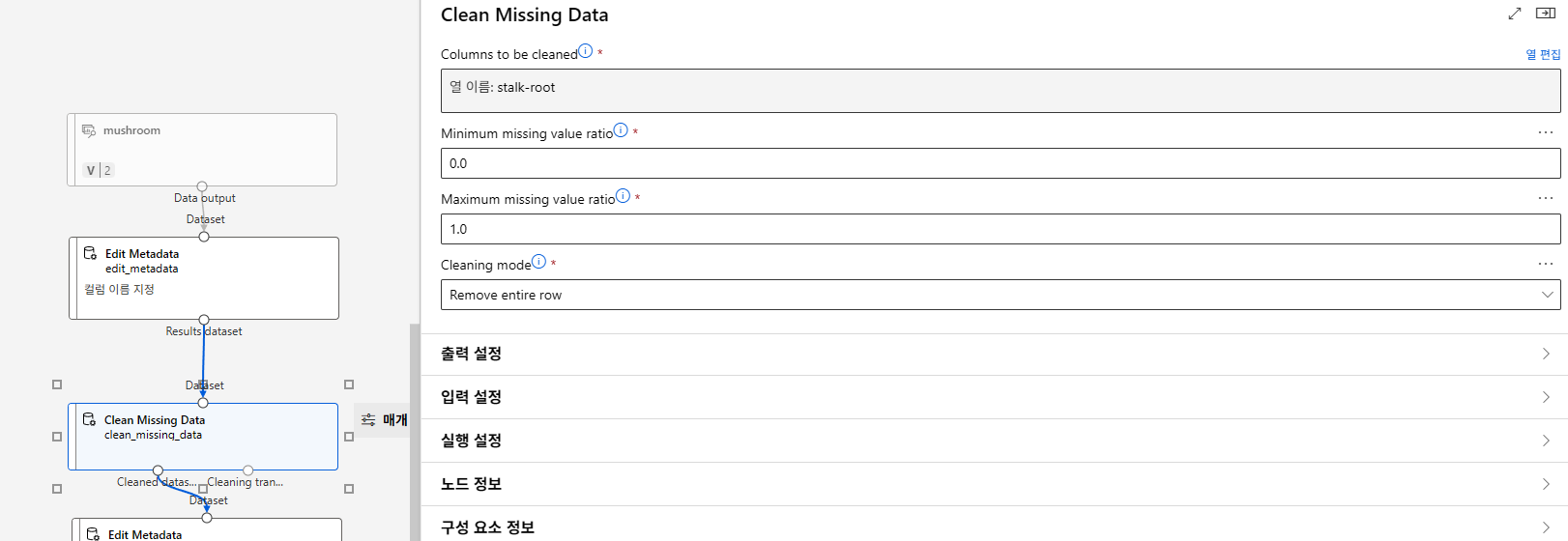
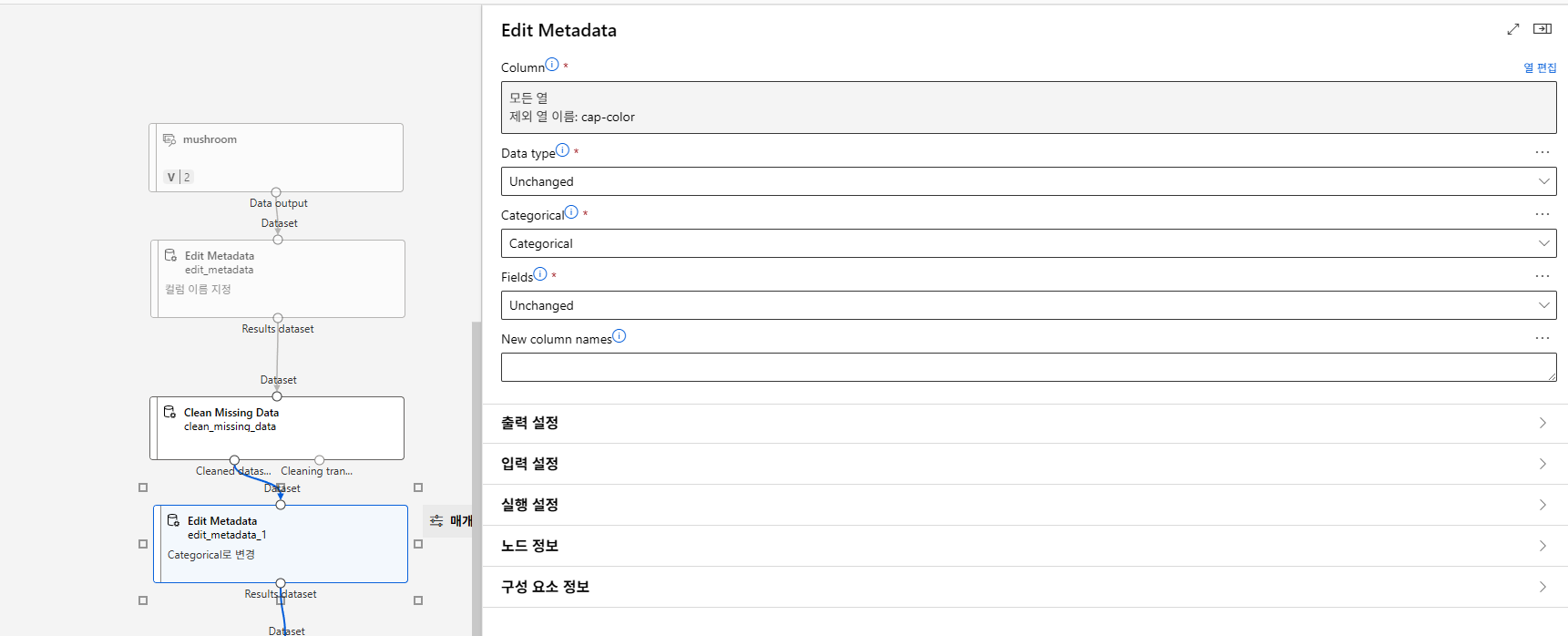
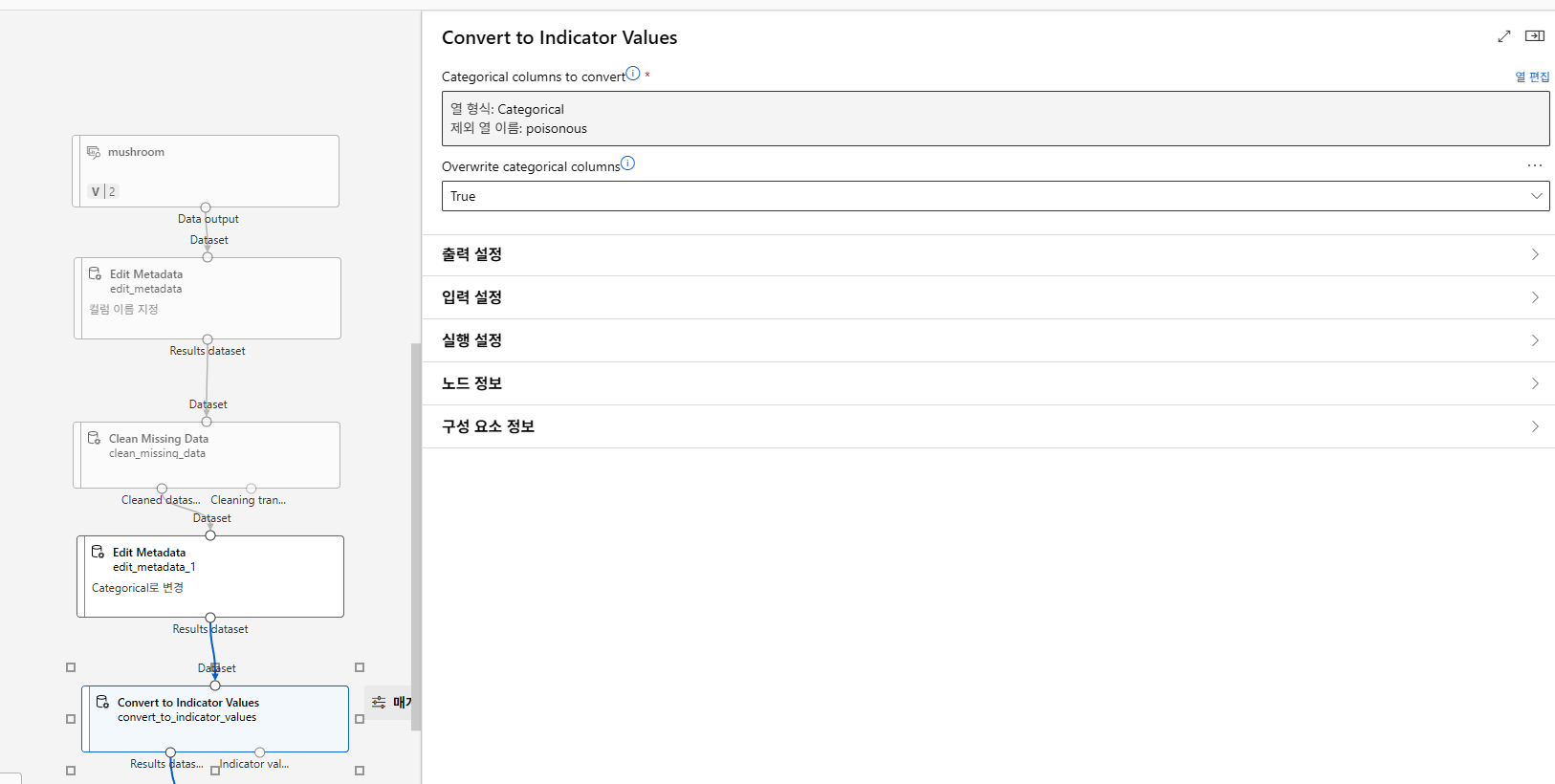
label은 제외하고 indicator value로 바꿔야한다.
그리고 독버섯인지 아닌지를 구분하는것이기 때문에 two_class_boosted_decision_tree 를 사용했다.
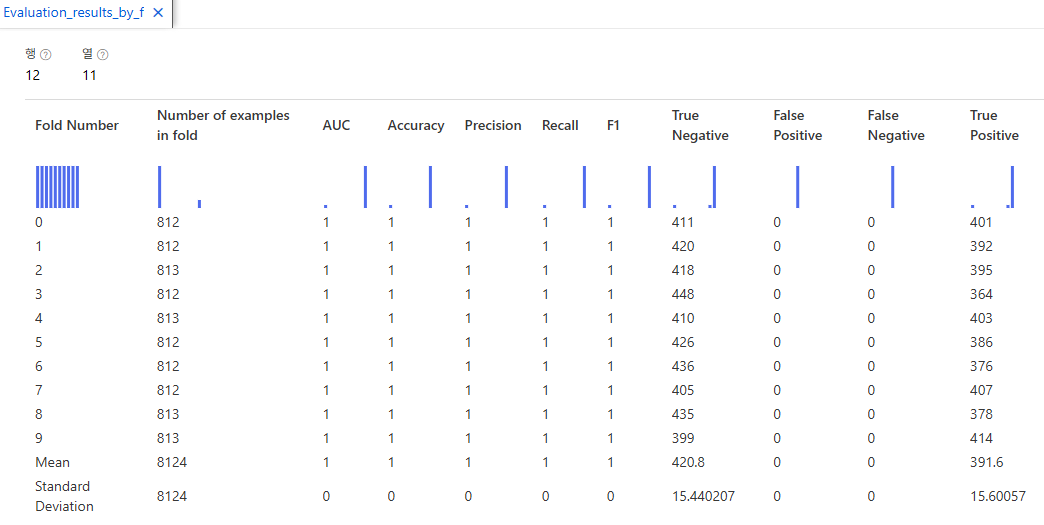
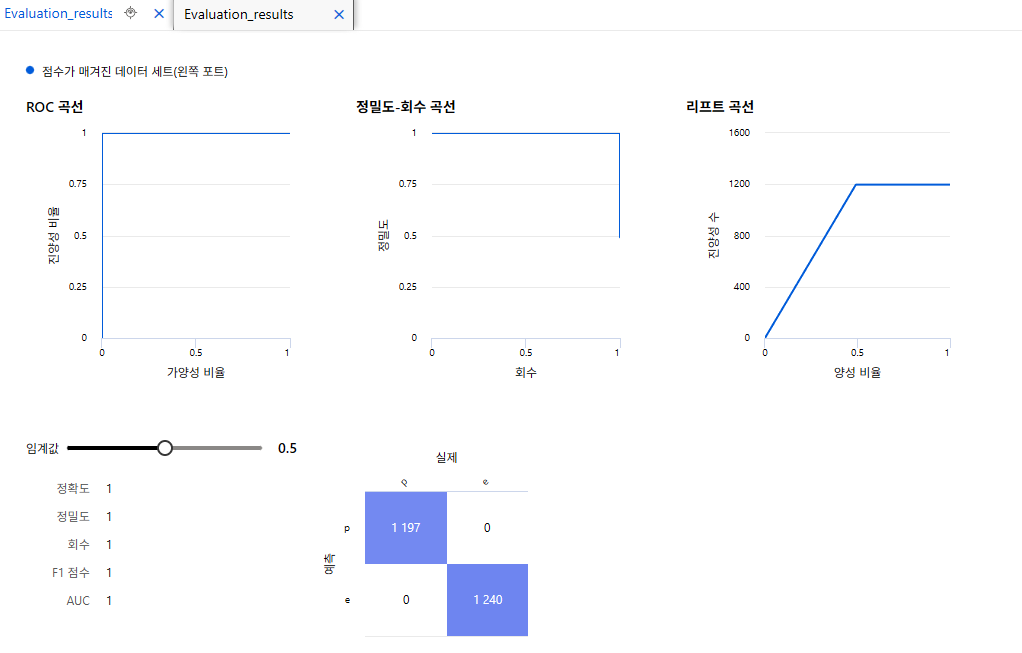
그런데 Cross validate model에서는 roc 등 그래프가 나오지 않아서 다시 해주었다.