[MicrosoftDataSchool] 51일차 - Azure Spark, Azure Databricks, DeltaLake
Microsoft Data School 3기

Azure Spark
대량의 데이터에 대한 빅 데이터 분석 애플리케이션의 성능을 향상시키기 위해 메모리 내 처리를 지원하는 병렬
처리 프레임워크를 제공
(이전의 hadoob은 하드 기반의 방식으로 속도가 느렸음)
- 대화형 데이터 분석
- 스트리밍 분석(Kafka, Flume 등)
- 기계 학습
구성요소
- Spark SQL 및 DataFrames
- 스트리밍
- Mlib
- GraphX
- Spark Core API
Spark SQL Overview

구조화된 데이터를 processing하는 분산 SQL query 엔진
Spark Structured Streaming Overview
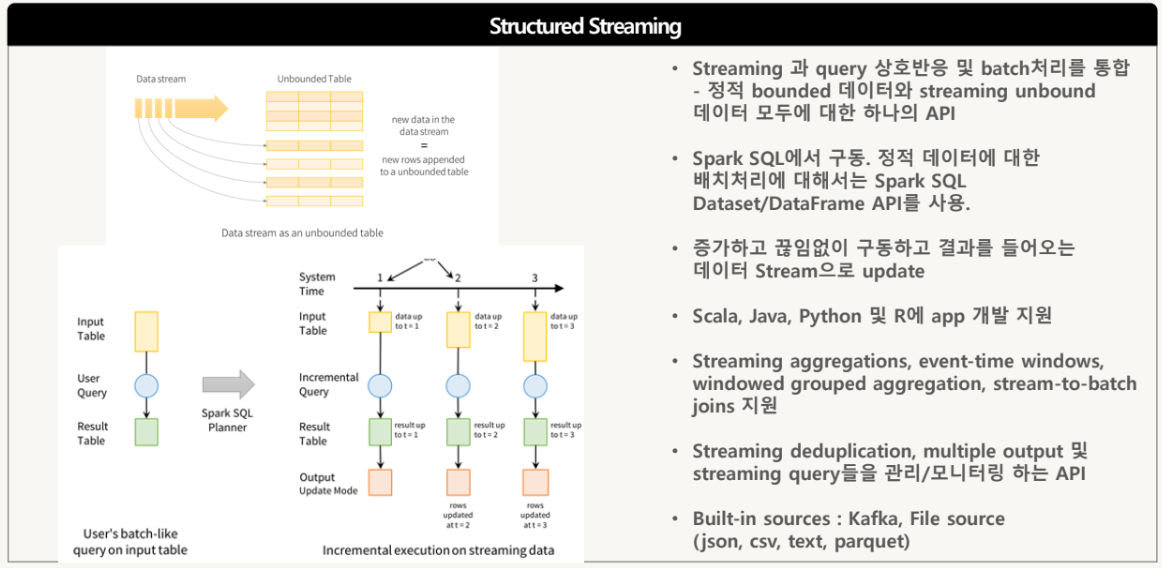
장애가 나거나 재시작해도 데이터 손실 없이 복원
중복 없이 딱 한 번 처리되는 것을 보장
Spark GraphX Overview

graph와 graph-parallel computation에 대한 API들의 Set
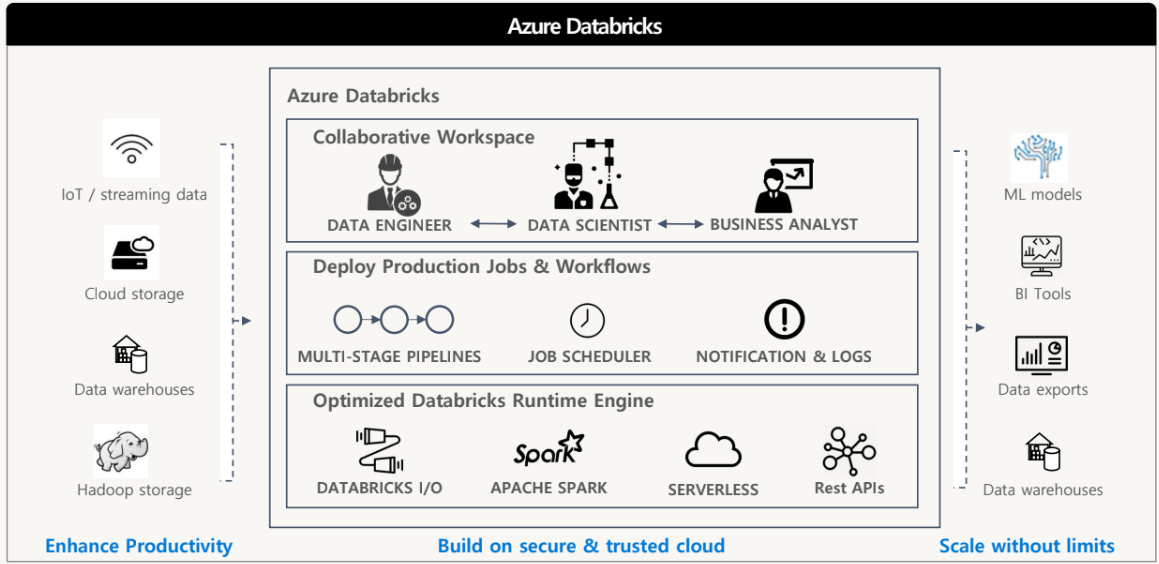
Azure Databricks
MS Azure 클라우드 플랫폼에 최적화된 Apache Spark 기반 분석 플랫폼
ML모델구성, BI Tool 연계, 데이터 추출 및 DW 구성을 수행
사용예
Collaborative workspace
- 관련자들대상 협업공간
- 대화형 검증 + 동시 작업 + 시각화 + Dashboard 제공
Deploy Production Jobs & Workflows
- Production Job과 workflow를 배포할 편리한 도구를 구성
- Job Scheduler를 통해 production pipeline에 스케줄별 job 수행을 진행하고 notebook workflow를 통해 다중구조 pipeline을 처리하며 alert 설정 및 audit log를 통한 모니털이 및 문제해결 진행
Optimized Databricks Runtime Engine
- Databricks I/O Module을 통하여 처리속도 및 클라우드 spark성능향상
- Severless Infra
Core Artifacts
- Clusters, Workspace, Libraries, Jobs, Notebooks
- Workspace에서 관련리소스를 관리하고 Notebbok으로 개발한 spark app을 cluster에서 구동
- Job으로 spark code를 제출하여 정기수행하고 libraries를 통하여 notebook에 외부코드 도입처리
General Spark Cluster Architecture
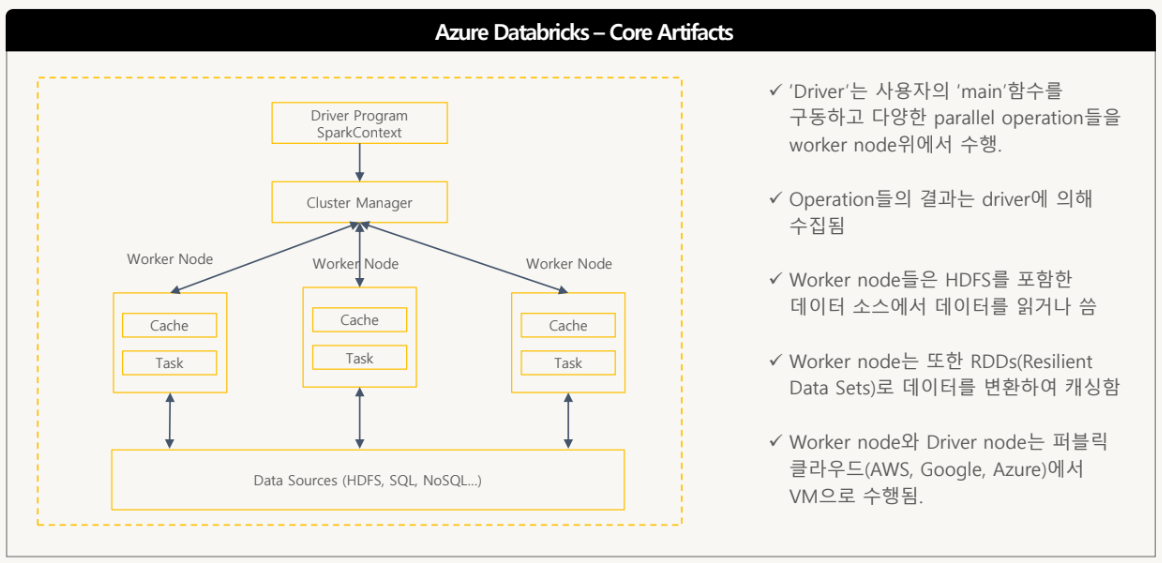
- Driver, node Cluster Manager, Worker node 및 Data sources로 구성
- Driver node는 worker node위에서 operation들을 수행
- Worker node는 HDFS 를 포함한 데이터 소스에서 데이터 read/write 수행
Clusters: Auto Scaling & Auto Termination
- Cluster 생성시에 Auto Scaling 및 Auto Termination에 대한 설정 가능
- 클러스터 관리를 단순화하고 낭비를 제거하여 비용감소의 효과
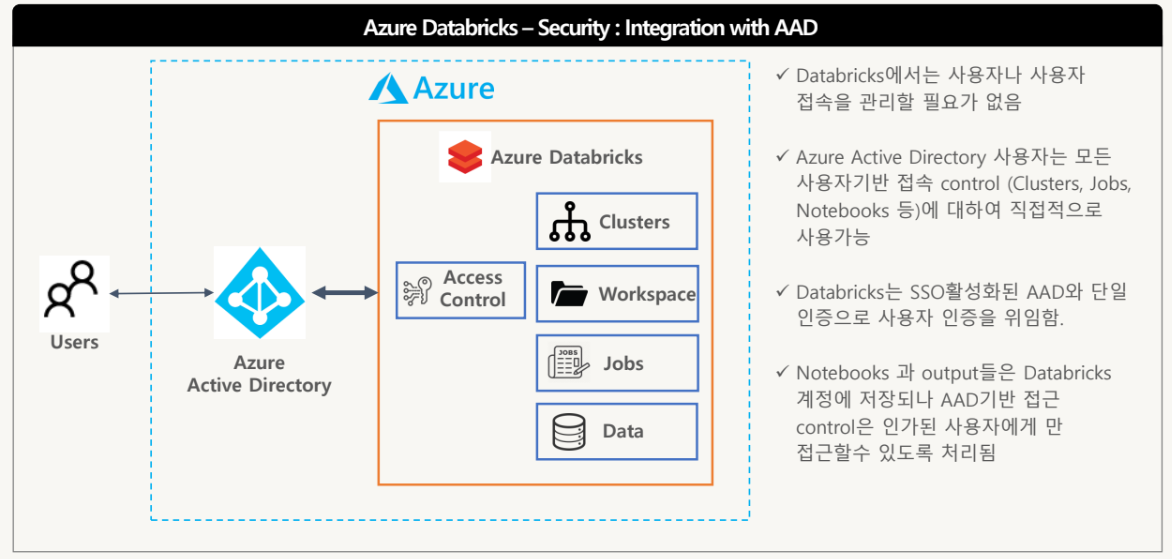
Security: Integration with AAD
Azure Active Directory와 통합되어 AAD의 일반사용자로 간주되어 보안성 확보
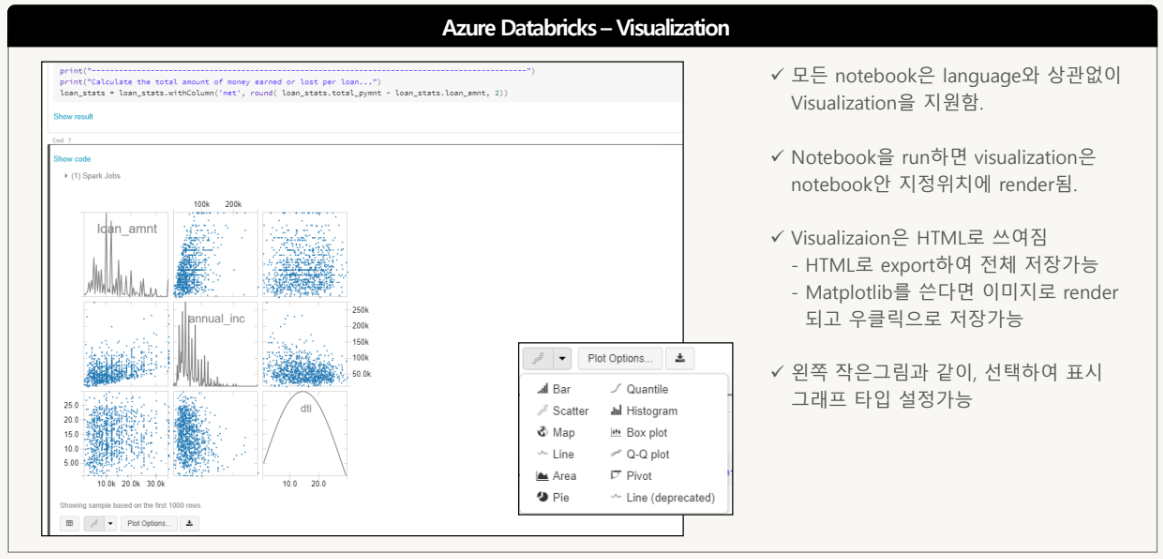
Visualization
Azure Databricks는 여러가지 시각화 방법 제공
Databases & Tables
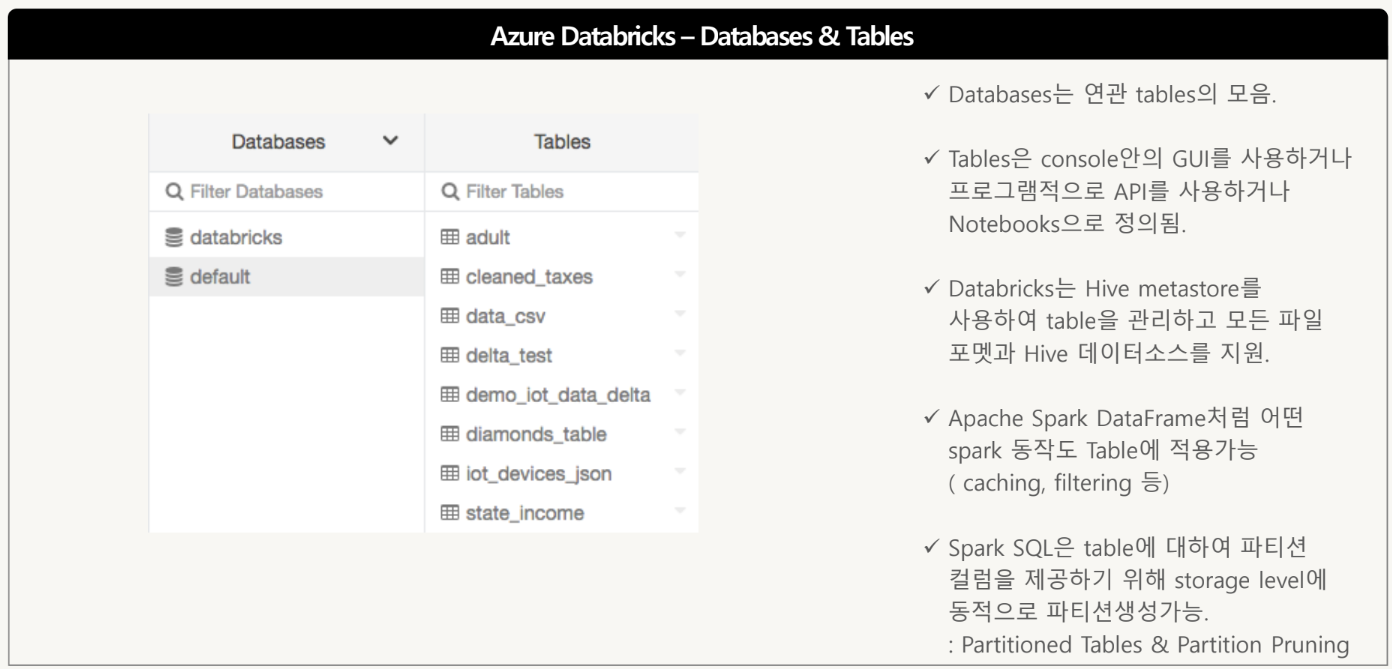
- Tables는 Spakr SQL/Spark language API들에서 사용되어 query되고 구조화된 Data를 활용가능케함
- Databases는 Table들의 집합
CLI & Rest API
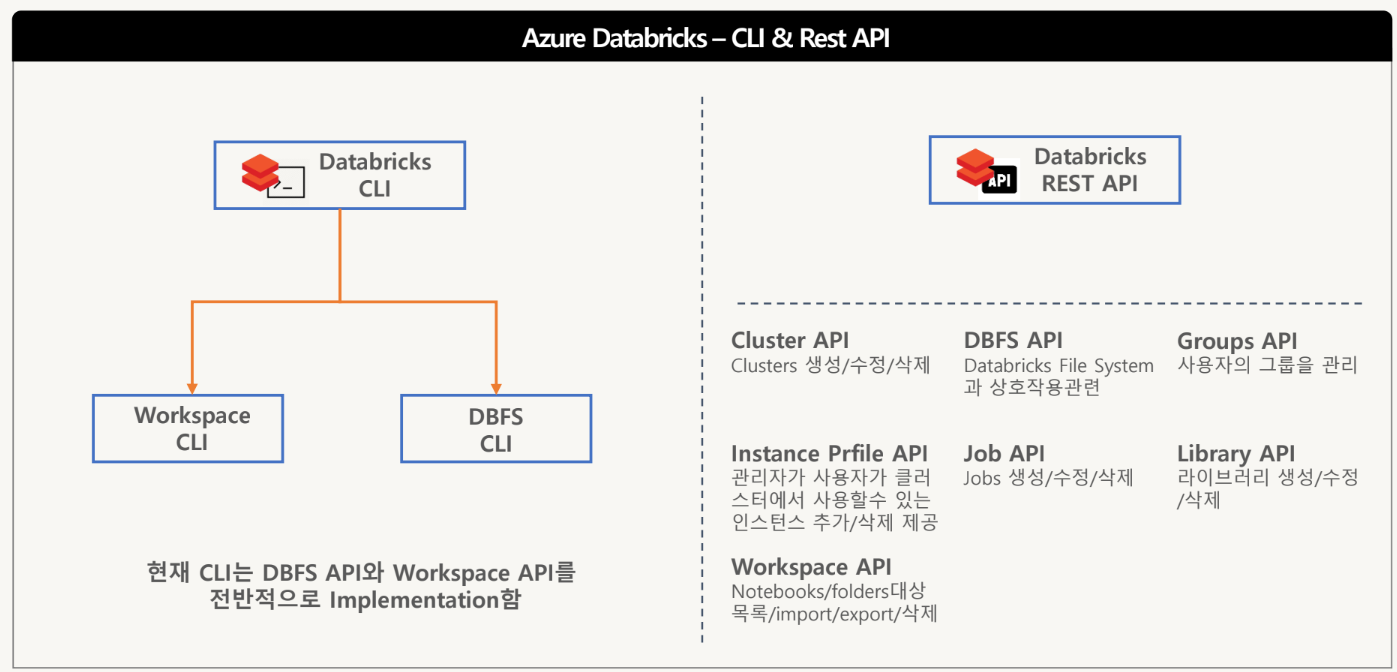
- CLI는 Databricks Rest API의 위에 빌드된 사용하기 쉬운 인터페이스
- Rest API로 Cluster, DBFS, Groups, Instance profile, Job, Library 및 Workspace API가 제공
Advantages of a Unified Platform

- 개발자 생산성 향상
- 동일추상화 공유
- 다양한 형태의 pipeline 사용 및 다른엔진간 이동최소화로 성능향상
Azure Databricks Delta
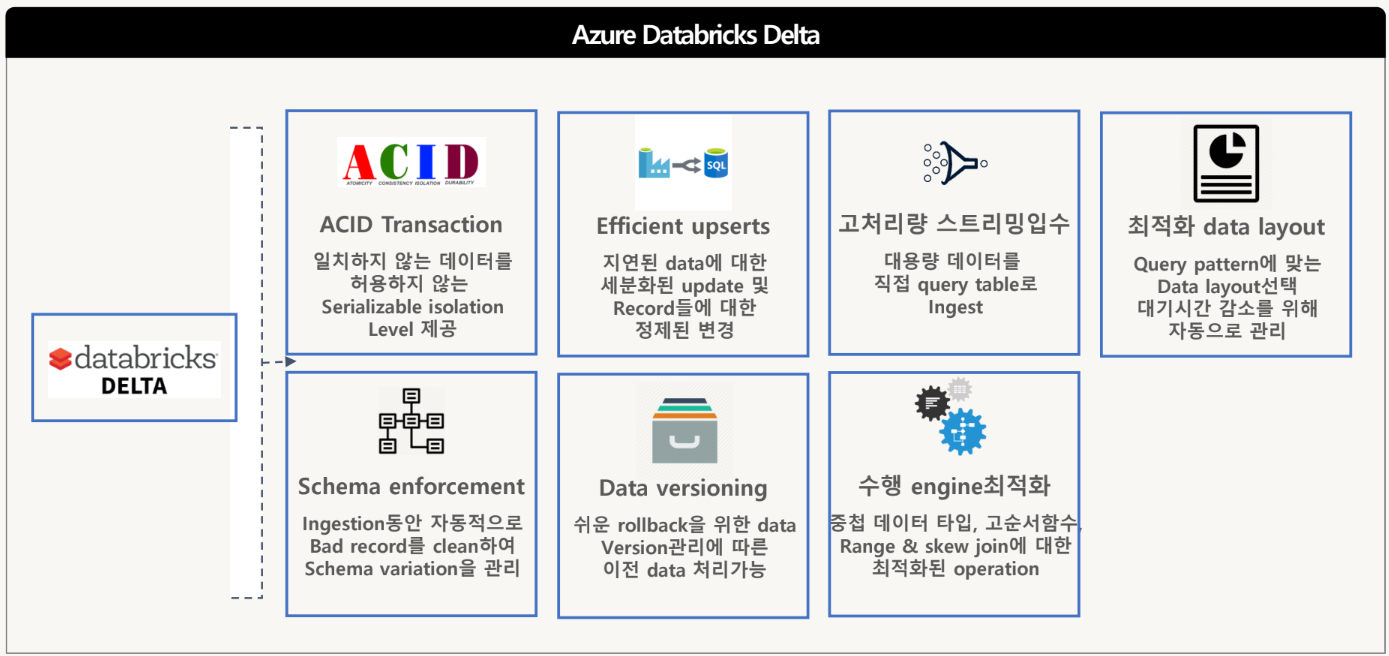
- Apache Spark 기반의 차세대 통합 분석엔진
- Delta는 ACID transaction, 최적화 layout, indexes 제공
- batch, streaming ingests, 빠른 interactive query, ML 대상 data pipeline을 만드는 향상된 수행엔진 제공
엔터프라이즈 보안
- Azure Entra ID
- 역할 기반 액세스 제어(RBAC)
- Enterprise Service Level Agreement(서비스 수준 약정)
Azure Databricks 주요 개념 정리
- 작업 영역: Databricks 자산에 액세스하기 위한 환경
- 노트북: 실행 가능한 코드, 시각화 및 설명 텍스트를 포함하는 대화형 문서. 다양한 언어 지원
- 클러스터(컴퓨트): 계산 엔진
- 작업: 자동화된 작업을 예약하고 실행하는 데 사용. 워크플로 및 주기적 데이터 처리 작업을 자동화
- Databricks Runtime: Apche Spark의 성능을 최적화한 버전
- Delta Lake: 데이터레이크에 안정성과 확장성을 제공하는 오픈 소스 스토리지 계층
- Databricks SQL: Azure Databricks 내의 데이터에 대해 SQL 쿼리를 수행하는 방법 제공
- MLflow: 엔드투엔드 기계 학습 수명 주기를 관리하기 위한 오픈 소스 플랫폼(실험 추적, 모델 관리 및 배포 기능)
실습
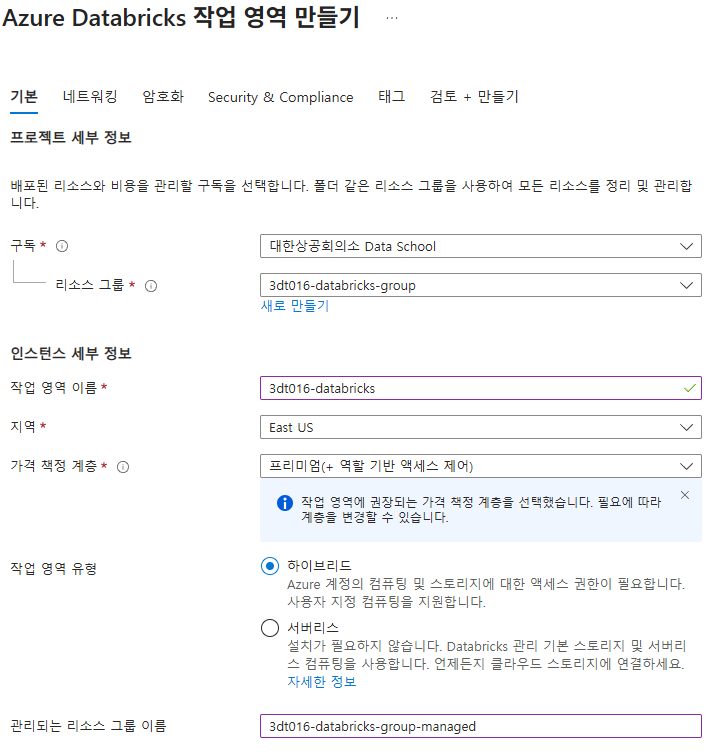
Azure Databricks 작업 영역 만들기

클러스터 및 Notebook 만들기
클러스터 생성
실습에서는 컴퓨팅 리소스 최소화를 위해 단일 노드 클러스터를 생성하지만, 프로덕션 환경에서는 보통 여러 워커 노드로 구성된 클러스터를 생성
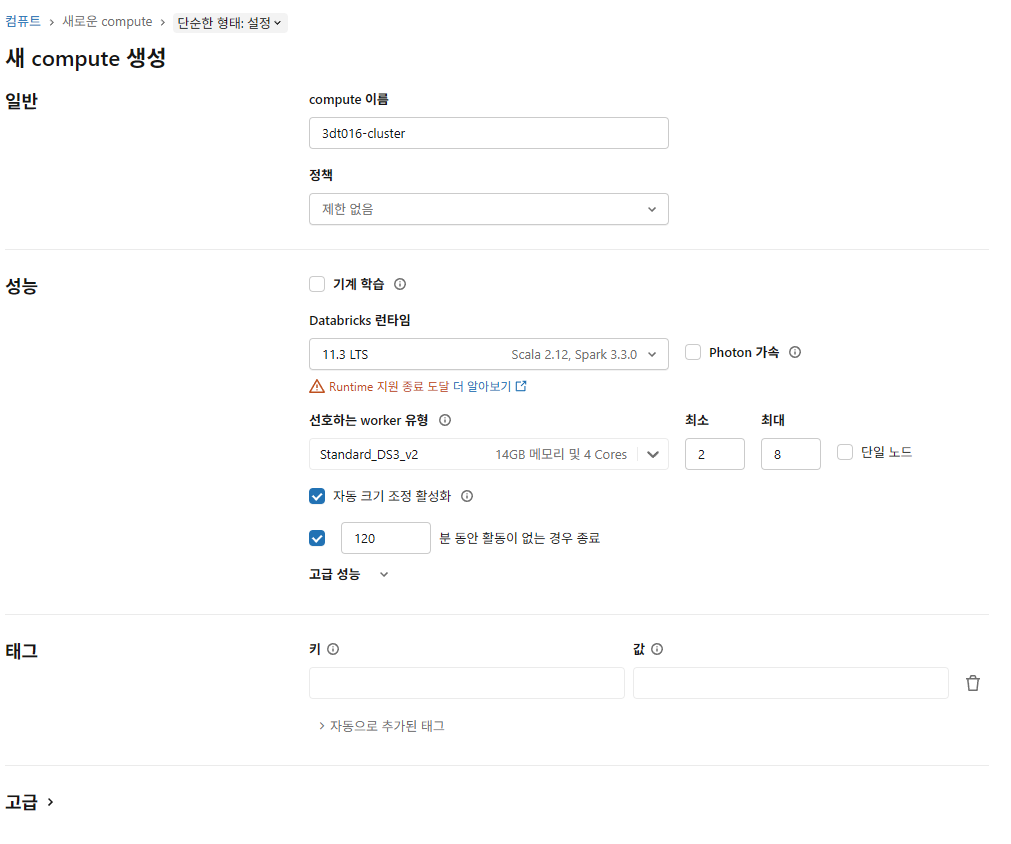
- 포톤 가속: 좀 더 빠르게 수행 가능하지만, 비용이 나감
- 런타임: 11.3 데이터브릭스에서 지원하는 버전 명시
- worker유형: spark 등 지원되는게 깔려있는 vm 미리 설정
- 최소최대: auto scaling.
- DBU: 예상 가격 단위
워크스페이스
- git 폴더를 통해 협업 가능
카탈로그
- 카탈로그 = 데이터 + 권한 + 조직 단위를 묶는 최상위 레벨
노트북
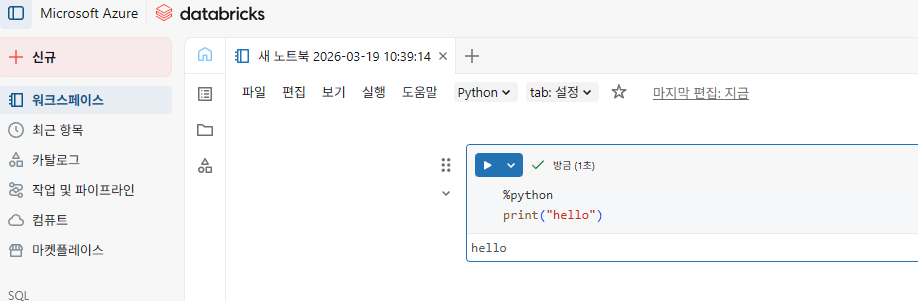
매직커맨드 %를 사용해서 하나의 노트북에서 다양한 언어를 사용해서 코딩 가능
- %python
- %scala
- %sql
- %r
DBC
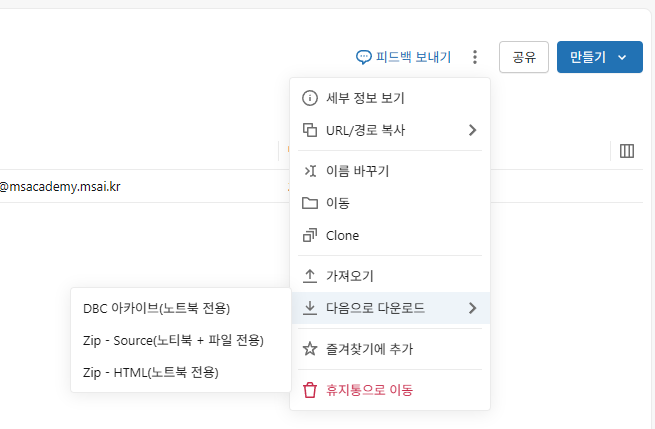
dbc파일을 공유해서 워크스페이스를 공유할 수 있다.
Databricks에서 쿼리 사용
1부: 데이터 탐색
- 1단계: 사이드바 탐색에서 카탈로그 를 선택
- 2단계: 카탈로그 선택기에서 생성한 datbricks 이름으로 생성되어 있는 카탈로그를 선택
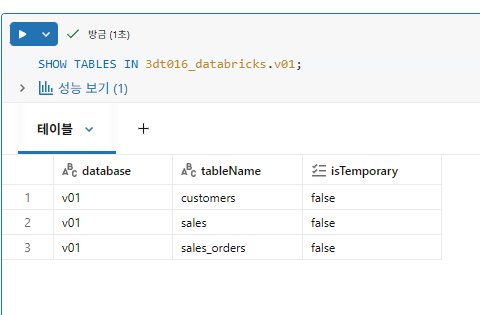
- 3단계: v01 스키마를 생성 후 강사에게 제공받은 데이터로 다음 세 개의 테이블을 생성
- customers
- sales
- sales_orders
스키마 만들기

스키마 만들기 선택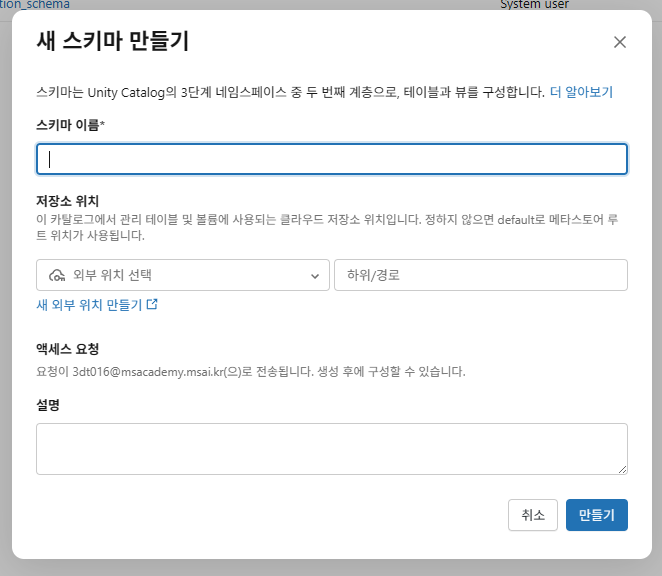
테이블 생성
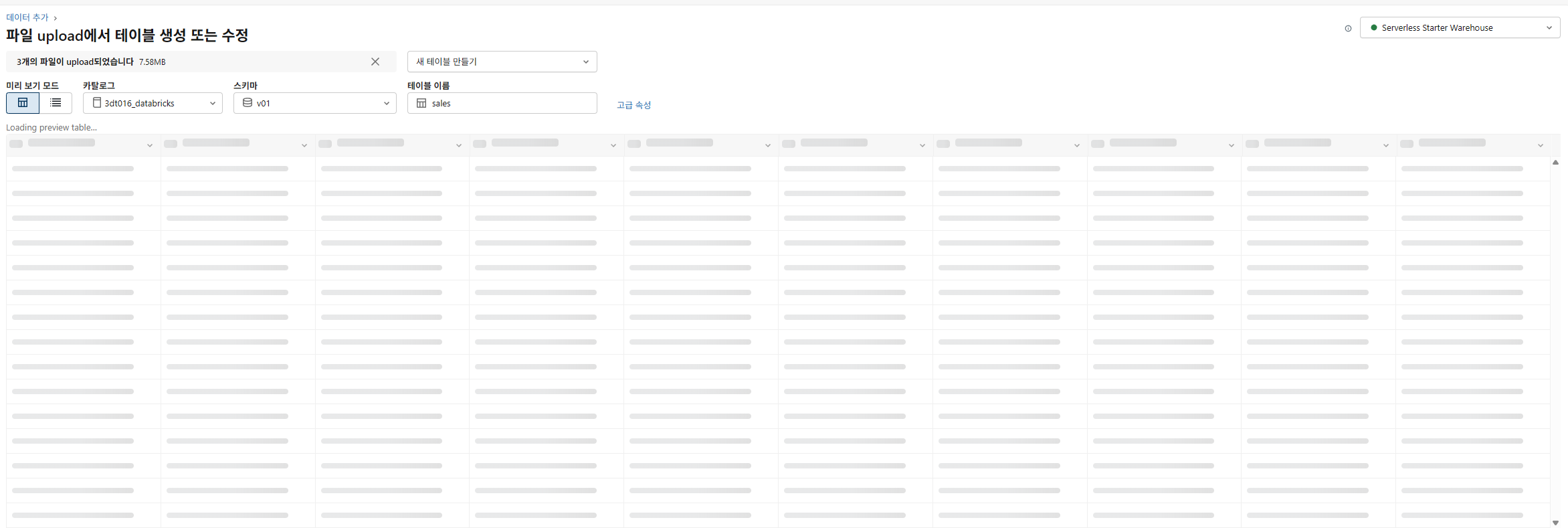
이후 우하단의 만들기 클릭
2부: SQL 개발을 위한 노트북 사용
노트북을 열면 실행 중인 컴퓨팅 클러스터에 연결되어 있는지 확인
- 이는 Serverless Databricks SQL 웨어하우스이어야 함
- SQL 웨어하우스는 SQL 워크로드 최적화를 위해 특별히 설계
- Serverless는 Databricks에서 성능 대비 최고의 가격을 제공하지만 규제 요구 사항에 따라 비서버리스 컴퓨팅 옵션을 사용해야 하는 경우 Databricks는 Databricks SQL 웨어하우스의 Pro 버전을 제공
- Pro Databricks SQL 웨어하우스는 기업용으로 준비되어 있으며 확장성 있는 성능을 최적화했지만 Databricks Serverless 컴퓨팅과 동일한 시작 속도 또는 확장성을 제공하지 않음
Serverless Starter Warehouse
노트북 우상단에서 설정 가능
간단하게 테스트를 빠르게 할 때 사용
셀 코드 유형 변경
혹은 각 인라인마다 매직커맨드 사용 %
3부: 노트북에서 셀 포커스 모드 사용
포커스 모드를 사용하면 결과 패널이 화면의 절반을 차지하는 확장된 셀을 사용

시각화
결과 섹션에서 + 버튼을 누르고 시각화 선택
Databricks Assistant 사용

Databricks SQL에서 Delta Lake 기능 사용
1부: 테이블 생성 및 데이터 추가
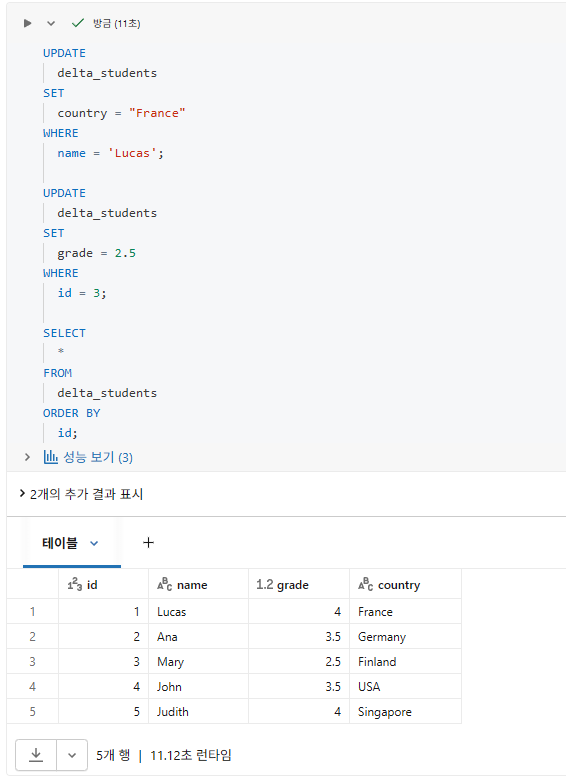
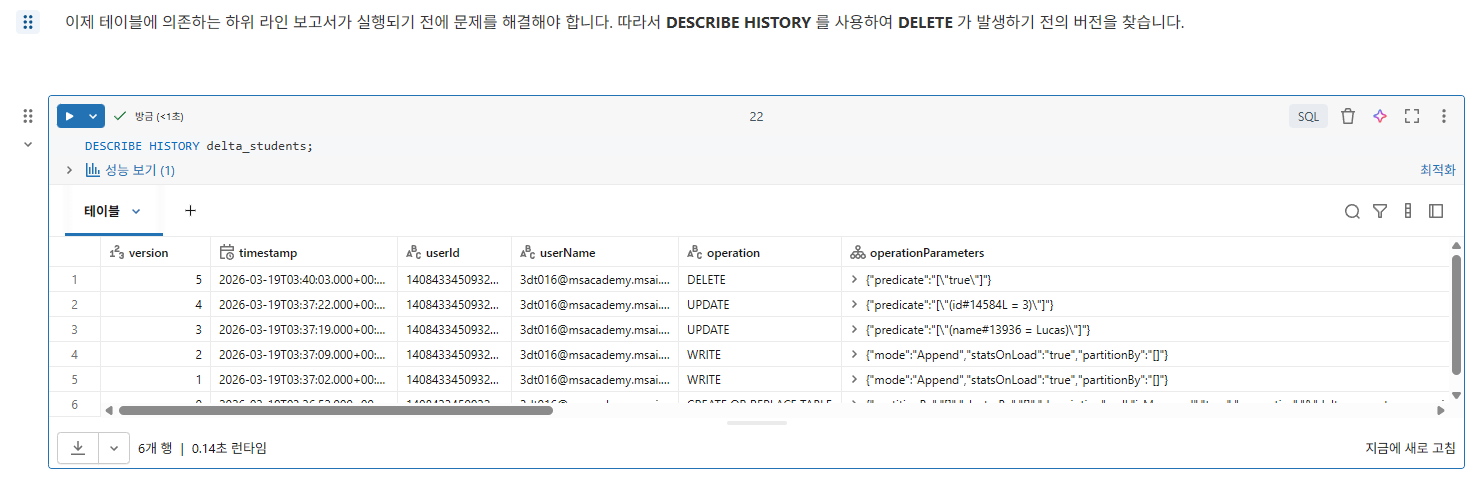
2부: DESCRIBE HISTORY 및 VERSION AS OF
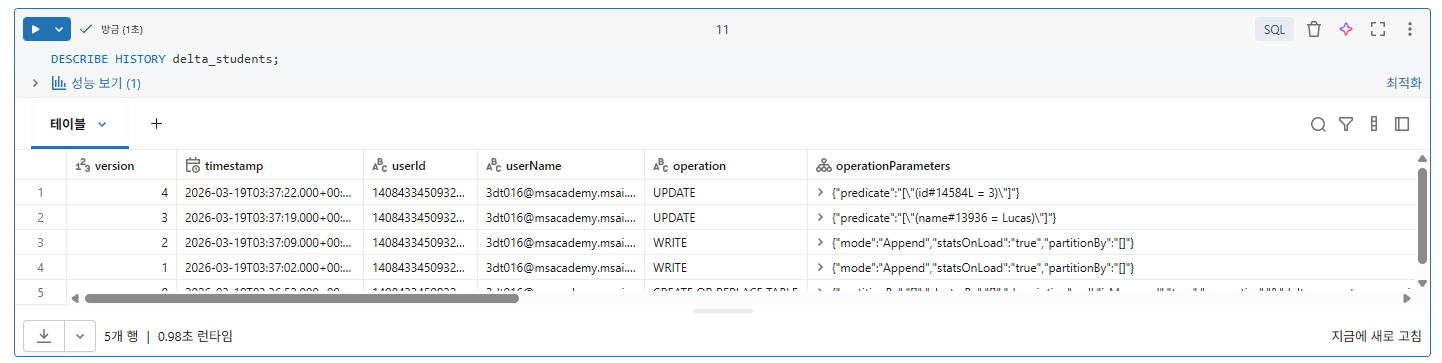
VERSION AS OF 를 사용하여 기록 테이블에서 주어진 버전의 데이터가 어떻게 보였는지 볼 수 있음
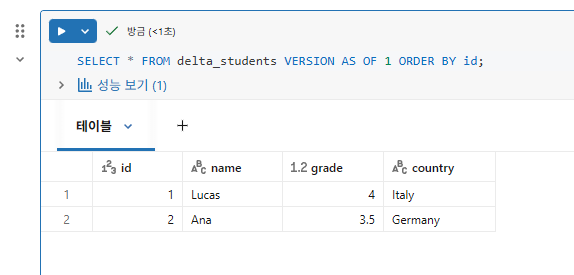
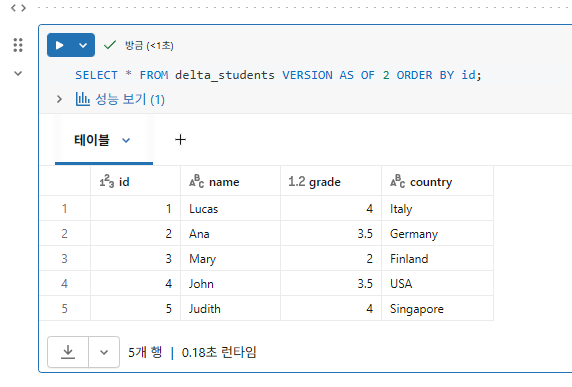
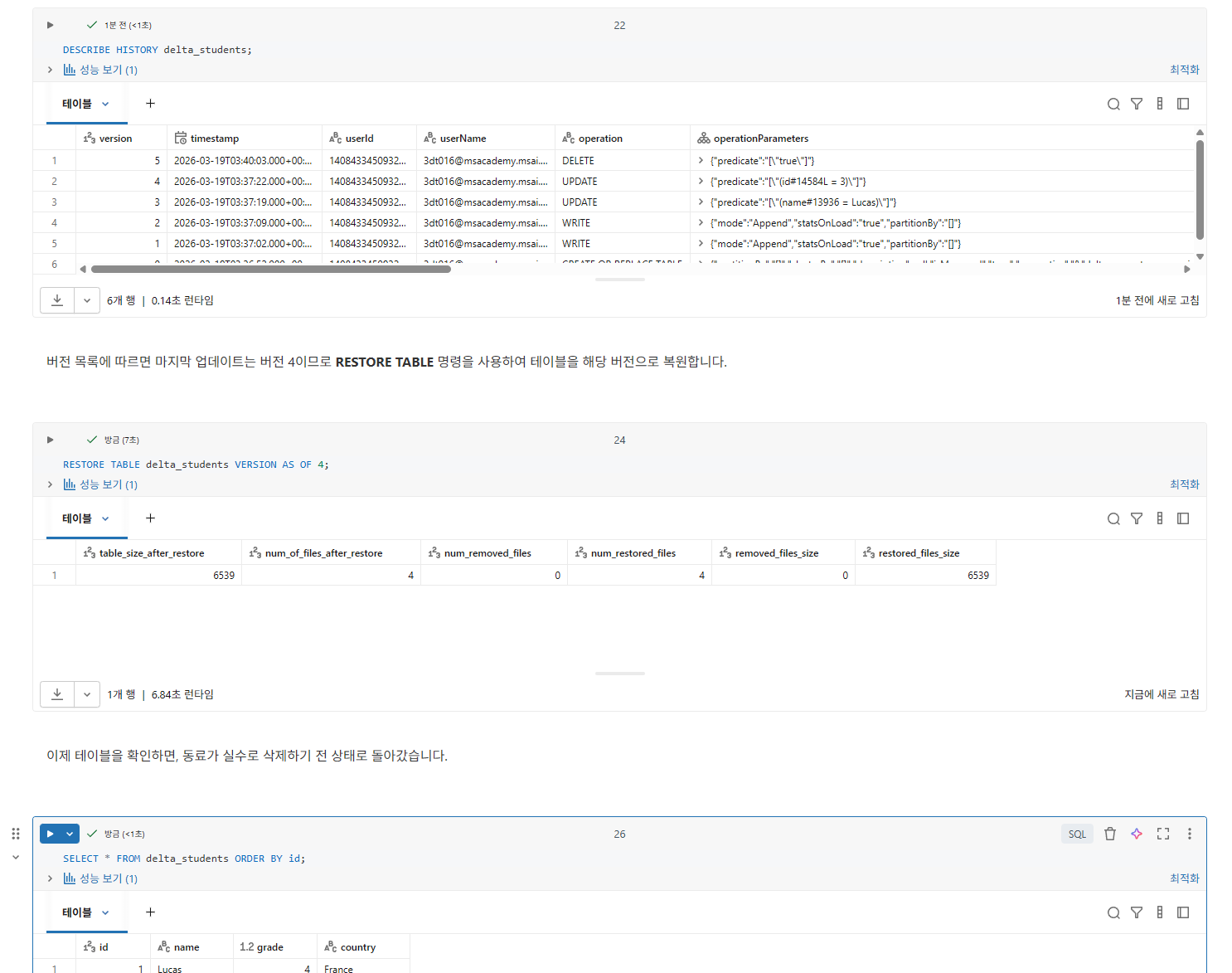
3부: 테이블 복원
테이블을 실수로 삭제했다 가정
AI-BI Dashboards
1부: 새 대시보드 만들기
- 측면 탐색 창에서 대시보드로 이동합니다.
- 대시보드 만들기를 선택합니다.
- 결과 화면 상단에서 대시보드 이름을 클릭하고 소매 대시보드로 변경합니다.
이미 대시보드가 있는 경우 대시보드를 가져오는 옵션도 있습니다. 기존 대시보드는 모두 플랫폼의 이 영역에서 찾을 수 있습니다. 플랫폼 전반에 걸쳐 여러 가지 빠른 생성 도구가 있는데, 다른 하위 메뉴에서 대시보드를 만들기 위한 옵션 중 하나로 대시보드를 제공합니다.
2부: 데이터 추가
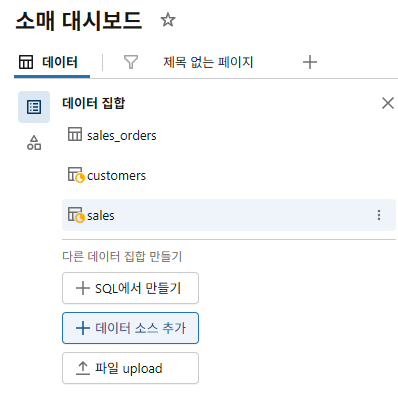
새로운 대시보드를 사용하려면 먼저 대시보드를 데이터에 연결해야 함
대시보드 화면 상단에는 캔버스와 데이터라는 두 개의 탭
- 캔버스: 캔버스 탭을 사용하면 사용자가 시각화를 만들고 대시보드를 구성
- 시각화, 텍스트 상자, 필터
- 데이터: 데이터대시보드에서 사용할 데이터 세트를 정의. UI나 API를 사용하여 데이터 세트를 공유하거나 가져오거나 내보낼 때 대시보드와 함께 데이터 세트가 번들로 제공.
- 카탈로그를 사용하면 작업 공간에서 액세스할 수 있는 카탈로그, 스키마 및 테이블을 탐색할 수 있습니다.
- 어시스턴트는 자연어로 플랫폼에 쿼리를 보내 객체를 발견하거나 쿼리 작성에 대한 인사이트나 도움을 얻을 수 있는 AI 기반 인터페이스를 제공합니다.
- 데이터 세트는 대시보드에 사용된 모든 데이터 세트와 쿼리 목록을 보여줍니다. 사용 가능한 테이블 목록에서 선택하거나 SQL 쿼리에서 만든 여러 데이터 세트를 단일 대시보드에서 사용할 수 있습니다.
다음 단계에서는 이 예제 대시보드에 테이블을 추가하는 과정을 안내합니다.
- 데이터 세트 목록 탭을 선택하고 + 테이블 선택 버튼을 클릭합니다.
- 결과로 나타나는 팝업에서
sales를 검색하세요. - sales를 클릭하여 데이터 세트로 추가한 다음 확인 버튼을 선택합니다. 데이터 세트 목록에 표시되는지 확인하세요.
customers테이블을 추가하려면 이 단계를 반복하세요.
각 테이블은 쿼리 편집 패널에서 자동으로 채워진 SELECT * 쿼리 문으로 목록에 추가됩니다. SQL 쿼리를 수정하여 데이터 세트를 변경할 수 있습니다.
3부: 시각화 추가
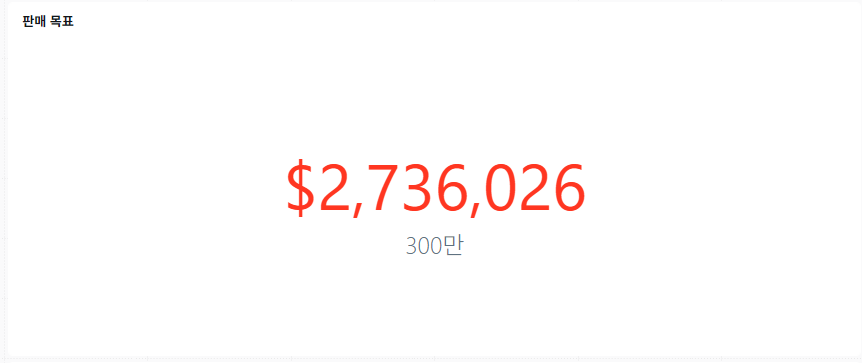
시각화 1: 카운터
대시보드에 추가할 첫 번째 비주얼리제이션은 매출 목표인 300만 달러 대비 현재 매출을 표시하는 카운터 비주얼리제이션입니다.
-
데이터 탭에서 + SQL에서 만들기 옵션을 선택합니다.
-
다음 쿼리를 쿼리 편집 공간에 입력하세요:
SELECT sum(total_price) AS Total_Sales, 3000000 AS Sales_Goal FROM xxxxx.v01.sales;
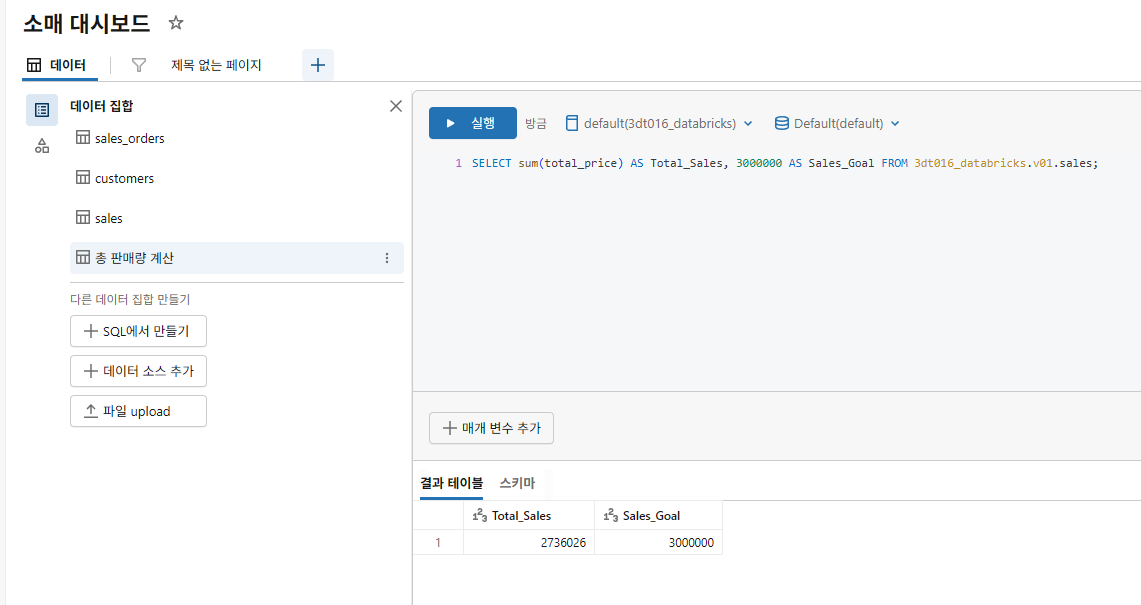
-
실행을 클릭하여 쿼리를 실행합니다.
-
데이터 세트 목록에서 쿼리를 마우스 오른쪽 버튼으로 클릭하고 이름 바꾸기를 선택하여 쿼리 이름을 총 판매량 계산으로 변경합니다.
-
캔버스 탭으로 돌아갑니다.
-
화면 하단에는 객체 이동, 시각화 추가, 텍스트 상자 추가, 필터 추가를 위한 도구 모음이 있습니다. 시각화 추가를 선택합니다.
-
화면의 어느 곳으로든 커서를 옮기고 클릭하여 시각화를 캔버스에 추가합니다.
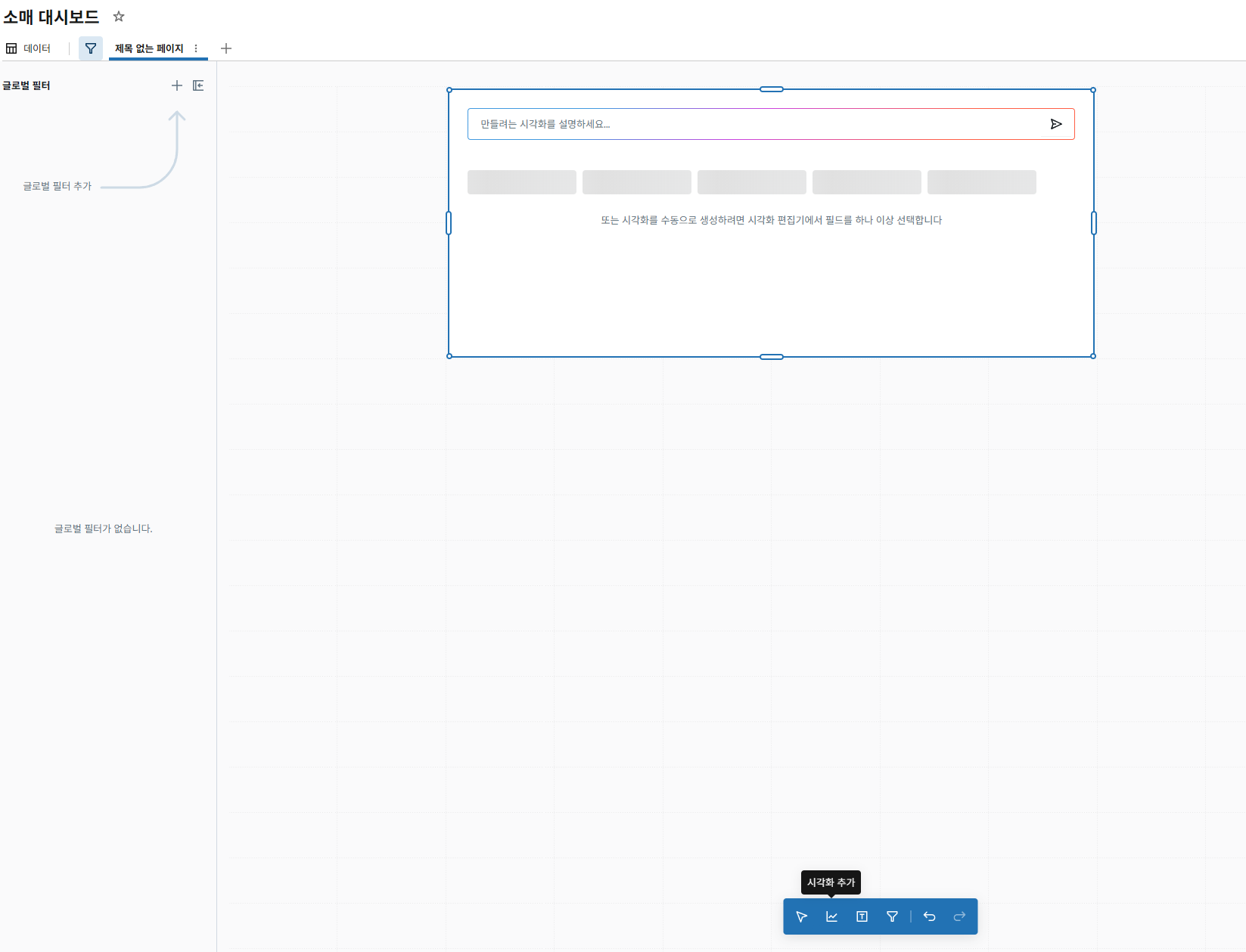
-
오른쪽의 구성 패널에서 설정에 대해 다음 선택을 하세요:
- 데이터 세트: 총 판매량 계산
- 시각화: 카운터
- 제목: 체크된
- 시각화에서 위젯 제목을 클릭합니다.
- 판매 목표로 바꾸세요.
- 값: Total_Sales
- *비교 Sales_Goal
-
이제 Total_Sales을 클릭하고 드롭다운에서 형식을 선택합니다. 그런 다음 사용자 지정을 클릭합니다. 다음 조정을 하세요:
- 유형: 통화($)
- 약어: 없음
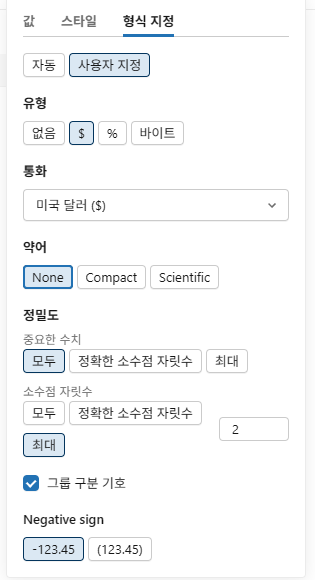
-
스타일 섹션에서 조건부 스타일 옆에 있는 + 를 클릭합니다. 다음 설정으로 구성하세요.
- Value <= Target인 경우
- 그런 다음 (색상: 빨간색)
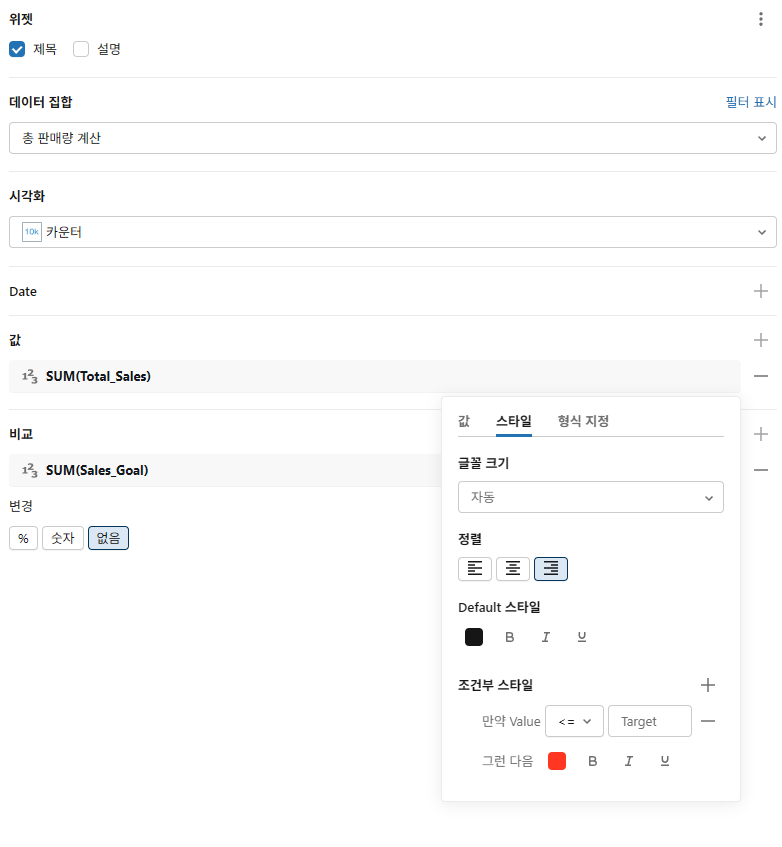
정말 간단한 시각화이지만, 대시보드에서 시각화를 사용하는 방법을 체험할 수 있게 해줍니다. 시각화 상자의 가장자리를 드래그하거나, 시각화 상자 위에서 클릭하고 드래그하면 시각화의 위치와 크기를 조정할 수 있습니다.
시각화 2: 콤보 차트
다음으로, 3개월 동안의 총 판매 가격과 판매 횟수에 대한 정보가 포함된 콤보 차트인 다른 시각화를 추가해 보겠습니다.
- 데이터 탭에서 + SQL에서 만들기 옵션을 선택합니다.
- 다음 쿼리를 쿼리 편집 공간에 입력하고 실행하세요.
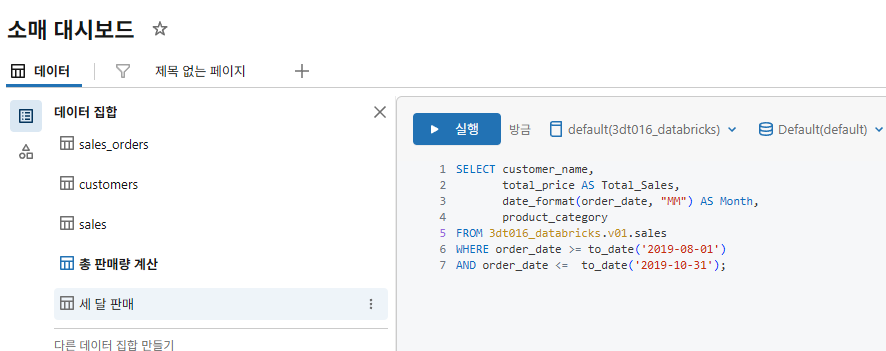
SELECT customer_name,
total_price AS Total_Sales,
date_format(order_date, "MM") AS Month,
product_category
FROM xxxxx.v01.sales
WHERE order_date >= to_date('2019-08-01')
AND order_date <= to_date('2019-10-31');-
쿼리 이름을 세 달 판매로 변경하세요.
-
캔버스 탭으로 돌아갑니다.
-
캔버스 하단의 메뉴에서 시각화 추가를 선택하고 캔버스를 클릭하여 시각화를 추가합니다.
-
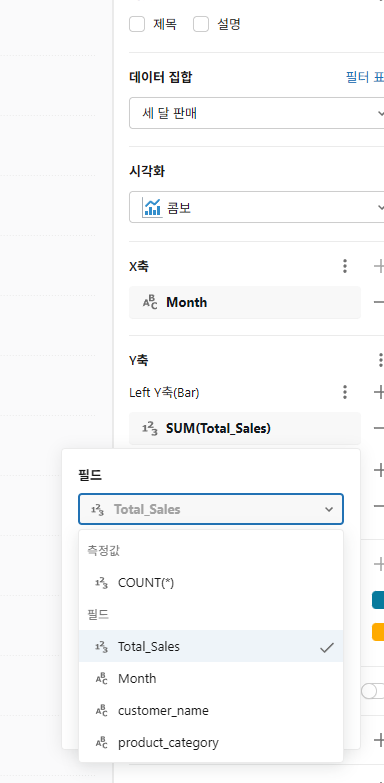
오른쪽의 구성 패널에서 설정에 대해 다음 선택을 하세요.
- 데이터 세트: 세 달 판매
- 시각화: 콤보
- X축: 월
- Y축:
- 왼쪽 Y축(막대): Total_Sales
- 표시 이름: 총 판매 금액
- 오른쪽 Y축(선): Total_Sales
- 오른쪽 Y축(선) 을 COUNT로 변경합니다.
- 표시 이름: 판매 주문 수
- 왼쪽 Y축(막대): Total_Sales
7. Y축 옆에 있는 케밥 메뉴 아이콘을 선택하고 이중 축 사용을 클릭합니다.
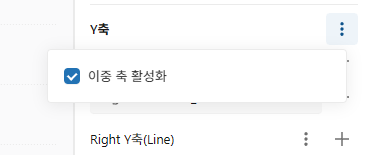
이중 축을 활성화하면 두 가지 다른 척도에서 데이터의 변화를 볼 수 있습니다. 8월과 10월의 매출 건수는 낮았지만 금액은 높은 것을 알 수 있습니다. 9월에는 그 반대의 상황입니다.
- 왼쪽 Y축 옆에 있는 케밥 메뉴 아이콘을 선택하세요.
- 유형을 통화($) 로 변경합니다.
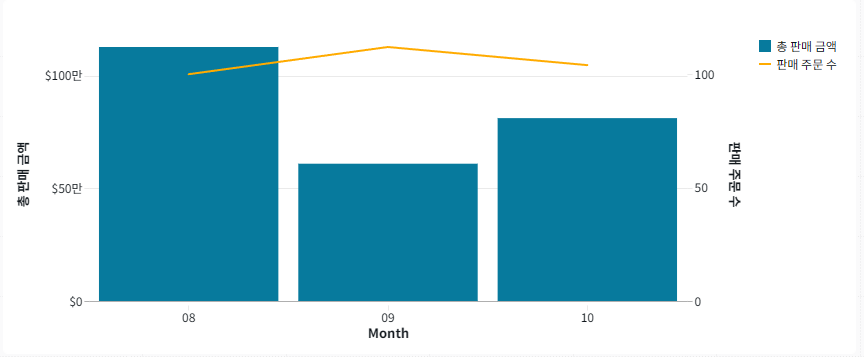
축 제목은 차트 시리즈의 표시 이름에 따라 자동으로 조정됩니다. 시리즈 이름 옆에 있는 색상 블록을 선택하여 시리즈의 색상을 조정할 수도 있습니다.
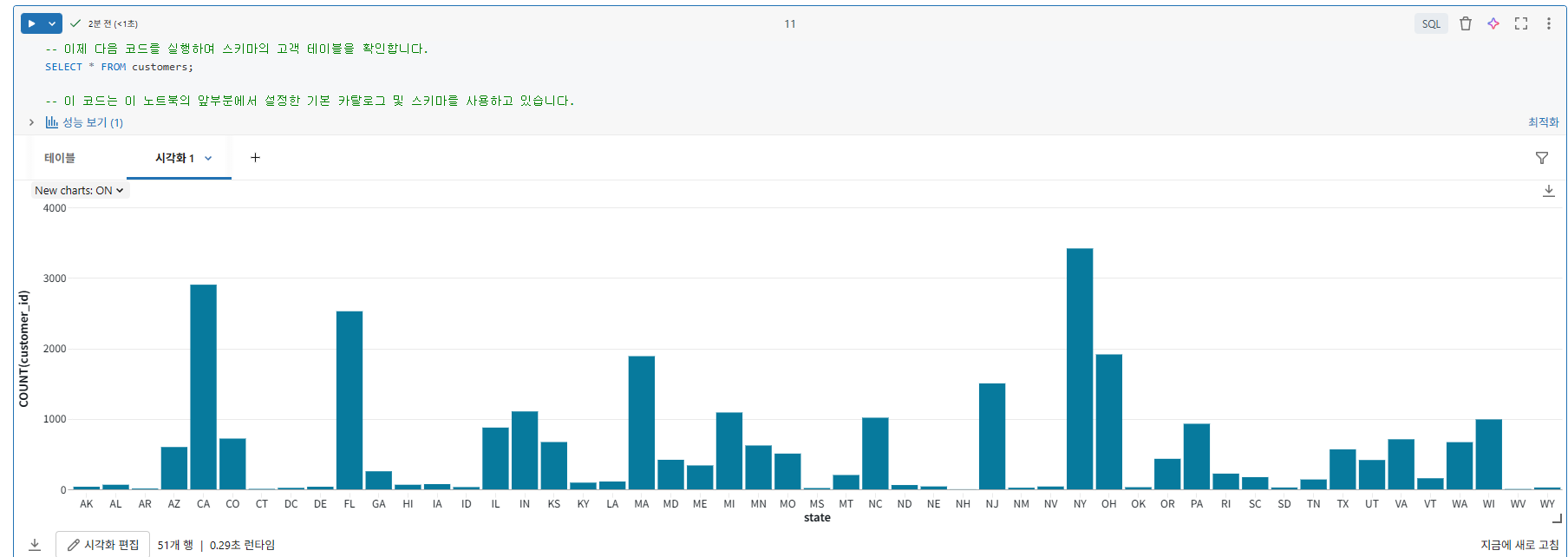
시각화 3: Databricks Assistant를 사용한 막대형 차트
대시보드를 작성할 때 Databricks Assistant에 자연어 프롬프트를 제공하면 요청에 따라 차트가 자동 생성됩니다. Databricks Assistant를 사용하면 대시보드의 데이터 탭에 정의된 모든 데이터 세트를 기반으로 차트를 작성할 수 있습니다. 함께 시도해 봅시다.
다음 단계를 완료하세요.
-
캔버스 하단의 메뉴에서 시각화 추가를 선택하고 캔버스를 클릭하여 시각화를 추가합니다.
-
위젯 상단의 텍스트 필드에 다음 프롬프트를 입력하세요:
product_category를 x축에, total_sales 평균을 y축에 나타내는 막대형 차트를 만듭니다.
-
Enter 키를 누르거나 제출을 클릭하여 응답을 생성하세요. 도우미가 시각화를 제공하는 데 시간이 걸릴 수 있습니다.
-
제공된 설명과 일치하는 막대형 차트가 표시됩니다. 시각화가 귀하의 요구 사항을 충족하는지 확인하려면 수락하기 를 클릭하세요.
시각화가 설명과 일치하지 않거나 만들고 싶었던 시각화 종류와 일치하지 않는 경우 응답을 거부하거나 다시 생성할 수 있습니다. 수락한 후에 차트 구성을 조정할 수도 있습니다. 시각화의 색상을 변경해보세요.
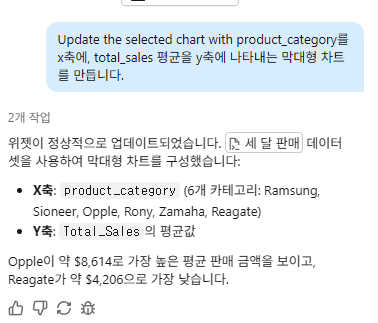
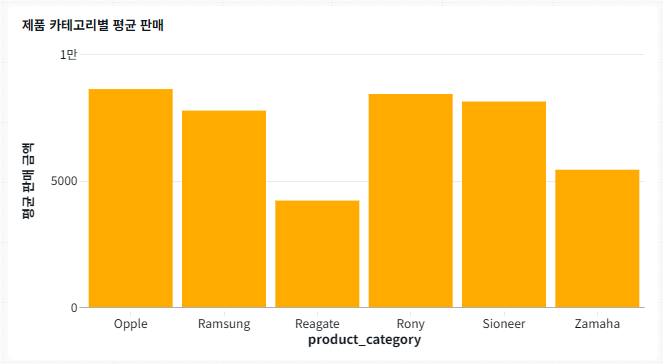
시각화 4: 산점도
판매 값이 주문 날짜에 따라 어떻게 달라지는지 이해하기 위해 산점도라는 차트를 하나 더 만들어 보겠습니다. 이 산점도를 만들려면 다음 단계를 완료하세요.
-
캔버스 하단의 메뉴에서 시각화 추가를 선택하고 캔버스를 클릭하여 시각화를 추가합니다.
-
오른쪽의 구성 패널에서 설정에 대해 다음 선택을 하세요.
- 데이터세트: 판매
- 시각화: 산점도
- X축: order_date
- 스케일 유형: 연속
- 변환: DAILY
- Y축: total_price
- 척도 유형: 범주형
- 변환: SUM
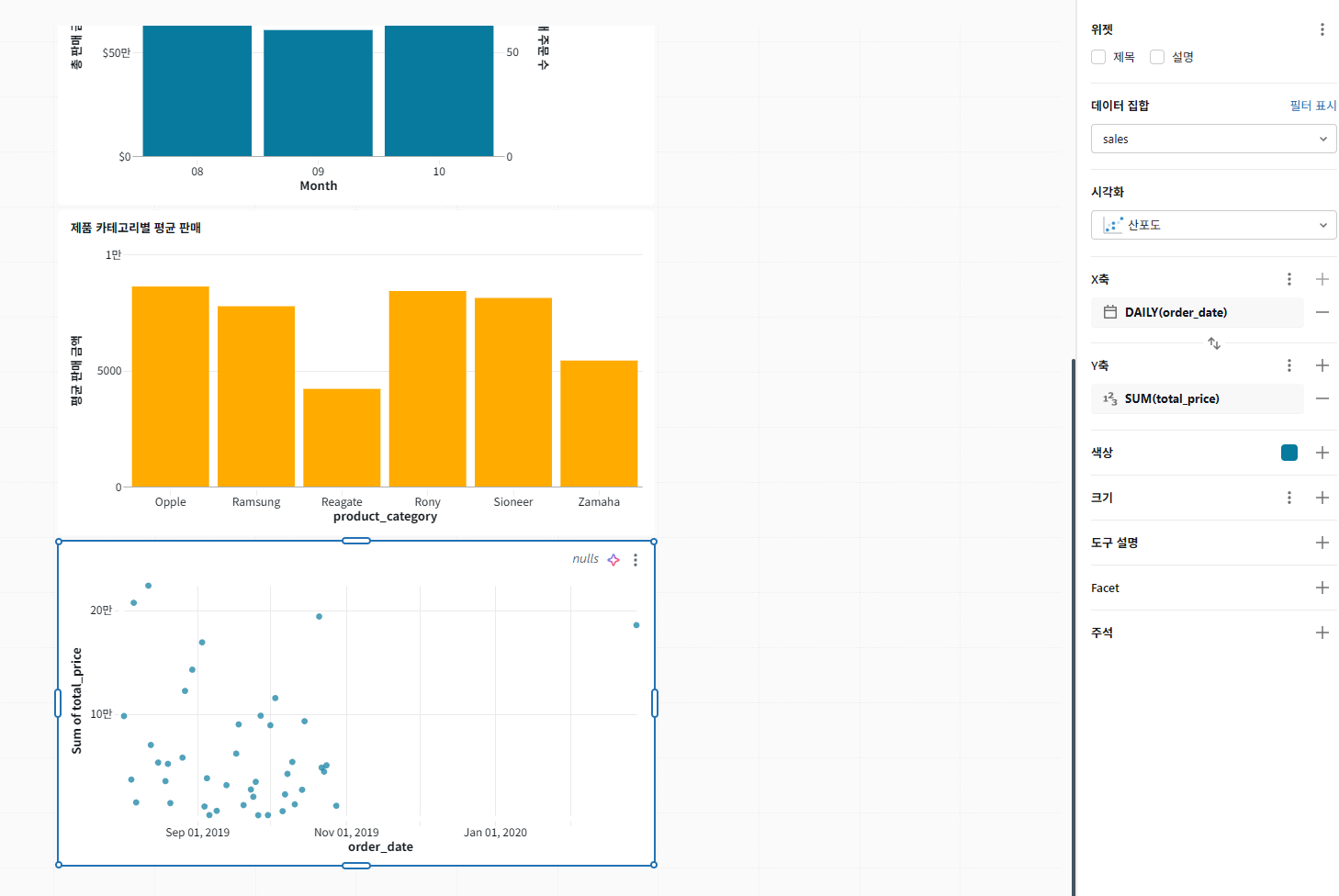
텍스트 상자 추가
캔버스에 대시보드의 이름과 텍스트 설명을 위한 공간을 추가해 보겠습니다. 캔버스에 새로운 위젯을 추가하면 다른 위젯도 자동으로 해당 위치에 맞춰 이동합니다. 마우스를 사용하여 위젯을 이동하고 크기를 조정할 수 있습니다. 위젯을 삭제하려면 위젯을 선택한 다음 Delete 키보드 키를 누르세요. 각 위젯의 오른쪽 상단에 있는 케밥 메뉴 아이콘을 사용하여 위젯을 조작할 수도 있습니다.
대시보드에 텍스트 상자를 추가하려면 다음 단계를 완료하세요.
-
텍스트 상자 추가 아이콘을 클릭하십시오. 위젯을 캔버스 맨 위로 드래그합니다.
-
유형:
# Retail organization참고: 텍스트 상자는 마크다운을 사용합니다. 포함된 텍스트의
#문자는 소매 조직 이 레벨 1 제목임을 나타냅니다. 기본 마크다운 구문에 대한 자세한 내용은 이 마크다운 가이드 를 참조하세요.
4부: 게시 및 공유
대시보드가 완성되면 다른 사람들과 공유하려면 게시해야 합니다.
게시된 대시보드는 워크스페이스의 다른 사용자와 공유할 수 있으며, 어카운트 수준에서 등록된 사용자와도 공유할 수 있습니다. 즉, 워크스페이스 액세스 또는 컴퓨트 리소스가 할당되지 않았더라도 Databricks 어카운트에 등록된 사용자에게 대시보드 액세스 권한이 부여될 수 있습니다.
대시보드를 게시할 때 기본 설정은 자격 증명 포함입니다. 게시된 대시보드에 자격 증명을 포함하면 대시보드 뷰어가 자격 증명을 사용하여 데이터에 액세스하고 이를 지원하는 쿼리를 실행할 수 있습니다. 자격 증명을 포함하지 않도록 선택하면 대시보드 뷰어는 자체 자격 증명을 사용하여 필요한 데이터와 컴퓨트에 액세스합니다. 시청자가 대시보드를 구동하는 기본 SQL 웨어하우스에 액세스할 수 없거나 기반 데이터에 액세스할 수 없는 경우 시각화는 렌더링되지 않습니다.
대시보드를 게시하려면 다음 단계를 완료하세요.
- 대시보드 오른쪽 상단에 있는 게시 를 클릭하세요. 게시 대화 상자에서 설정과 참고 사항을 읽어보세요.
- 대화 상자의 오른쪽 하단에 있는 게시 를 클릭합니다. 그러면 공유 대화 상자가 열립니다. 열리지 않으면 대시보드 상단의 게시 옆에 있는 공유를 선택하면 됩니다.
- 텍스트 필드를 사용하여 개별 사용자를 검색하거나 관리자 또는 모든 워크스페이스 사용자와 같이 미리 구성된 그룹과 대시보드를 공유할 수 있습니다. 이 창에서 관리 가능 또는 편집 가능과 같은 레벨별 권한을 부여할 수 있습니다. 권한에 대한 자세한 내용은 대시보드 ACL 을 참조하세요.
- 공유 대화 상자 하단에서 보기 액세스를 제어합니다. 이 설정을 사용하면 모든 어카운트 사용자와 쉽게 공유할 수 있습니다.
공유 설정에서 조직의 모든 사람이 볼 수 있음을 드롭다운 메뉴에서 선택합니다. 그런 다음 공유 대화 상자를 닫습니다.
대시보드 상단에 있는 드롭다운을 사용하여 대시보드의 초안 버전과 게시된 버전 간에 전환합니다.
참고: 초안 대시보드를 편집할 경우, 게시된 대시보드를 보는 사람은 다시 게시하기 전까지 변경 사항을 볼 수 없습니다. 게시된 대시보드에는 새로운 데이터가 도착하면 업데이트할 수 있는 쿼리를 기반으로 구축된 시각화가 포함되어 있습니다. 대시보드는 다시 게시하지 않고도 새로운 데이터로 자동으로 업데이트됩니다.
5부: 대화형 기능: 필드 필터
랩에서 만든 대시보드는 보고에 유용하며, 사용자는 이를 사용하여 최신 소매 판매 수치에 대한 최신 정보를 얻을 수 있습니다. 하지만 사용자에게는 데이터를 더 자세히 탐색할 수 있는 제어 기능이 없습니다. 예를 들어, 사용자가 특정 기간의 데이터를 보고 싶다면 대시보드 작성자에게 연락하여 변경 사항을 요청해야 합니다.
뷰어가 필드나 매개변수 값을 기준으로 특정 데이터를 필터링할 수 있도록 하는 사용자 컨트롤을 만들 수 있습니다. 필터는 대시보드 뷰가 특정 필드를 필터링하거나 데이터 세트 매개변수를 설정하여 결과를 좁힐 수 있는 위젯입니다.
필터는 하나 이상의 데이터세트의 필드에 적용될 수 있습니다. 필드에 필터를 사용하면 사용자는 데이터의 특정 값이나 값 범위에 집중할 수 있습니다. 필터는 선택한 데이터세트를 기반으로 작성된 모든 시각화에 적용됩니다.
대시보드에 필터를 추가하려면 다음 단계를 완료하세요.
대시보드에서 벗어난 경우 다시 대시보드로 돌아가세요.
- **대시보드** 메뉴에서 **소유자** 옵션을 선택하고 본인이 만들거나 소유한 대시보드만 보기를 필터링합니다. -
게시된 버전을 보고 있는 경우 대시보드의 초안 버전 보기로 전환하세요.
-
캔버스 하단 근처에 있는 도구 모음에서 필터 아이콘을 클릭합니다.
-
위젯을 대시보드 상단에 배치하세요. 텍스트 상자 아래에 추가하는 것도 좋습니다. 대시보드의 위젯을 재배치하여 원하는 대로 구성할 수 있습니다.
-
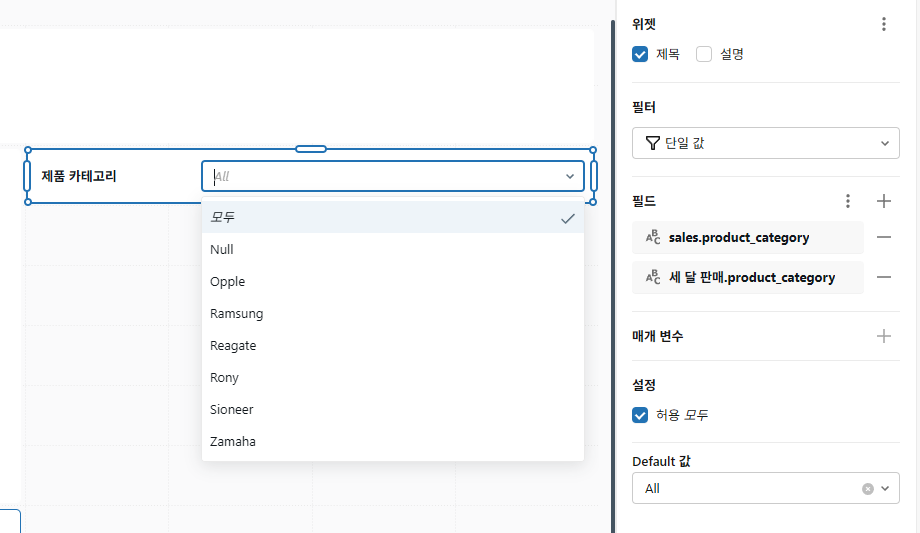
필터 위젯을 선택하면 화면 오른쪽에 필터 구성 패널이 나타납니다.
-
다음 설정을 적용합니다:
- 필터: 단일 값
- 필드:
- sales.product_category
- Three Month Sales.product_category
체크박스를 사용하여 제목을 활성화하세요.
위젯의 제목을 더블클릭하여 제품 카테고리로 변경합니다.
필터 위젯의 드롭다운을 사용하여 필터를 테스트하세요.
참고: 필터는 필터 구성 패널에서 선택한 각 데이터 세트에 적용됩니다. 선택한 모든 데이터 세트는 product_category에 대해 동일한 범위의 값을 공유합니다. 대시보드 뷰어는 대시보드에서 필터링할 데이터를 선택할 때 해당 목록에서 선택할 수 있습니다.
매개변수를 사용하여 대화형 대시보드를 만들 수도 있습니다. 매개변수를 사용하면 사용자는 런타임에 데이터 세트 쿼리에 값을 대체하여 시각화를 사용자 정의할 수 있습니다. 이는 이 과정의 범위를 벗어나는 내용이므로, 자세한 내용은 대시보드 매개변수란 무엇인가요? 를 참조하세요.
게시된 버전에 새 필터가 반영되도록 대시보드를 편집한 후에는 다시 게시해야 합니다.
데이터 분석 종합 실습
1부: 대시보드에 새로운 데이터셋 추가
이제 소매 조직 대시보드에 또 다른 테이블을 데이터셋으로 추가하여 더 많은 데이터를 준비할 시간입니다.
사이드바 메뉴에서 대시보드를 클릭하여 대시보드 목록 페이지로 이동합니다. 기본적으로 이 페이지는 소유한 대시보드 목록을 표시합니다.
04 수업에서 만든 대시보드를 열기 위해 Retail Dashboard를 클릭합니다. 대시보드의 마지막으로 게시된 버전이 열립니다.
페이지 상단 근처의 드롭다운을 사용하여 초안 대시보드에 액세스합니다.
데이터 탭을 클릭합니다.
새 테이블을 추가하려면 테이블 선택을 클릭합니다.
사용자 스키마에서 sales_orders 테이블을 찾고 데이터셋으로 추가합니다.
2부: 다른 시각화 만들기
파이 차트
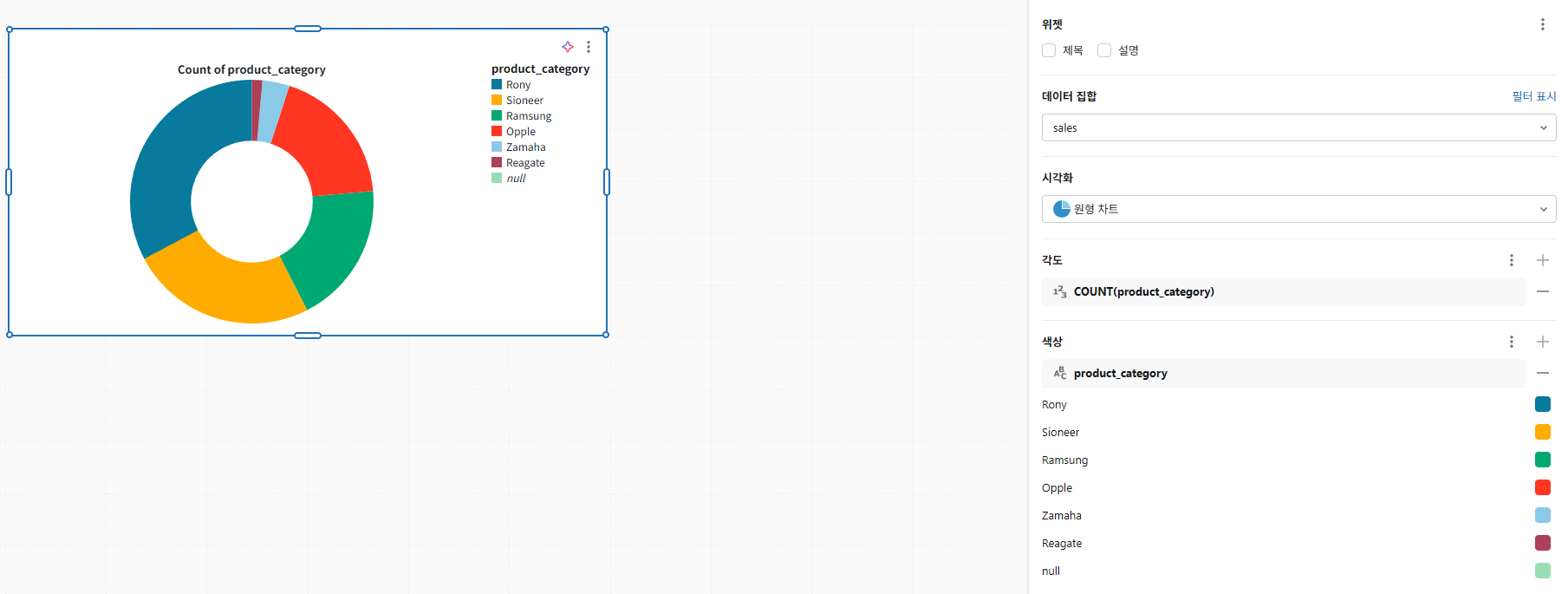
각 제품 카테고리에서 판매되는 비율을 보여주는 파이 차트를 만들어 보겠습니다.
다음을 완료하십시오:
-
캔버스 탭을 클릭합니다.
-
캔버스에 시각화 위젯을 추가합니다.
-
다음 구성 설정을 적용합니다:
- 데이터 세트: sales
- 시각화: 파이
- 각도: product_category. COUNT 변환을 적용합니다.
- 색상/그룹화 기준: product_category
3부: SQL query를 사용하여 데이터셋 추가
다음 두 차트에는 두 개의 다른 테이블에서 데이터가 필요합니다. 데이터 탭의 query 편집기에서 JOIN을 사용하여 모든 필요한 값을 포함하는 데이터셋을 만들 수 있습니다. 데이터셋은 공통 테이블 표현식과 조인을 사용하여 생성할 수 있습니다.
데이터셋 1: 로열티 세그먼트별 판매
이 query는 고객 및 판매 테이블의 데이터를 조인하는 데이터셋을 생성합니다. 고객의 지출 금액을 로열티 프로그램 상태와 연결합니다.
다음 단계를 완료하여 이 데이터셋을 생성합니다.
데이터 탭을 query합니다.
SQL에서 생성을 query합니다.
새 데이터셋의 제목을 더블 클릭하고 기본 이름인 제목 없음을 로열티 세그먼트별 판매로 바꿉니다.
다음 query를 편집기에 붙여넣습니다.
SELECT
product_category,
loyalty_segment,
total_price
FROM
<catalog.schema.table>
-- 판매 테이블 사용
JOIN <catalog.schema.table>
-- 고객 테이블 사용
on sales.customer_id = customers.customer_id-
query를 실행하기 전에 주석에 표시된 대로 <catalog.schema.table>을 적절한 테이블 이름으로 바꿉니다.
-
query를 실행합니다.
데이터셋 2: 일별 판매 및 주문
이 query는 구매가 이루어진 월의 날짜, 해당 날짜의 총 판매액 및 해당 그룹의 주문 수를 보여주는 데이터셋을 생성합니다. 판매 및 판매 주문 테이블에서 데이터를 가져옵니다.
다음 데이터셋을 추가하려면 다음 단계를 완료합니다.
SQL에서 생성을 클릭합니다.
새 데이터셋의 제목을 더블 클릭하고 기본 이름인 제목 없음을 일별 판매 및 주문으로 바꿉니다.
다음 query를 편집기에 붙여넣습니다.
WITH sales_data AS (
SELECT
date_format(order_date, "dd") AS day,
SUM(total_price) AS total_sales
FROM <catalog.schema.table> -- 판매 테이블 사용
GROUP BY day
),
orders_data AS (
SELECT
CASE
WHEN try_cast(sales_orders.order_datetime AS BIGINT) IS NOT NULL
THEN DAY(FROM_UNIXTIME(sales_orders.order_datetime))
ELSE NULL
END as day,
COUNT(order_number) AS total_orders
FROM <catalog.schema.table> -- 판매 주문 테이블 사용
GROUP BY day
)
SELECT
cast(s.day as INT),
s.total_sales,
o.total_orders
FROM sales_data s
JOIN orders_data o ON s.day = o.day
ORDER BY s.day;-
query를 실행하기 전에 주석에 표시된 대로 <catalog.schema.table>을 적절한 테이블 이름으로 바꿉니다.
-
query를 실행합니다.
4부: 추가 시각화 생성
이제 새로운 데이터 세트를 사용하여 새로운 시각화를 생성해 보겠습니다.
히트맵 시각화
히트맵은 특정 이벤트의 발생 패턴을 이해하는 데 도움이 됩니다. 생성할 히트맵은 고객의 할당된 로열티 세그먼트와 제품 카테고리별로 나뉘어진 데이터를 보여줍니다. 차트의 색상은 각 카테고리에서 지출된 총 금액을 나타냅니다.
히트맵을 생성하려면 다음 단계를 완료하십시오:
-
Canvas 탭을 클릭합니다.
-
캔버스에 시각화 위젯을 추가합니다.
-
다음 구성 설정을 적용합니다:
- 데이터 세트: 로열티 세그먼트별 판매
- 시각화: 히트맵
- X 축: product_category
- Y 축: loyalty_segment
- 색상 기준: SUM(total_price)
-
대시보드에서 위젯의 크기를 조정하고 배치합니다.
-
이 위젯의 기본 크기는 모든 제품 카테고리를 표시하기에 너무 작습니다. 위젯의 가장자리에 마우스를 올리고 차트의 크기를 조정합니다. 차트의 다른 영역에 마우스를 올려 손 아이콘을 표시한 다음 클릭하여 캔버스에서 차트를 이동합니다.
좋습니다! 이 데이터의 경우 로열티 세그먼트 3의 고객이 가장 많은 금액을 지출하는 것으로 보입니다. 제품 카테고리 Reagate 및 Zamaha의 경우 로열티 세그먼트가 느리게 반응하고 고객 지출과 관련이 없는 것으로 보입니다.
이중 축 선 차트
이중 축 선 차트는 이중 축 막대 차트와 마찬가지로 다른 척도에서 관련된 양을 비교하는 데 유용합니다. 생성할 차트는 판매 수익과 주문 수를 추적합니다. 데이터는 판매가 발생한 월의 날짜별로 그룹화됩니다. 이는 월 전체에 걸쳐 고객의 지출 패턴을 추적하는 데 유용할 수 있습니다.
이중 축 선 차트를 생성하려면 다음을 완료하십시오:
-
캔버스에 시각화 위젯을 추가합니다.
-
다음 구성 설정을 적용합니다:
- 데이터 세트: 일별 판매 및 주문
- 시각화: 선
- X 축: 일 (변환을 없음으로 설정)
- Y 축: SUM(total_sales)
- Y 축: SUM(total_orders)
기본 차트가 생성되지만 각 척도에 대한 양을 표시하려면 이중 축을 활성화해야 합니다.
-
Y 축 오른쪽의 케밥을 클릭합니다. 그런 다음 이중 축 사용 확인란을 클릭하여 활성화합니다.
-
대시보드에서 위젯의 크기를 조정하고 배치합니다.
5부: 필터 편집 및 재게시
이제 추가 시각화를 완료했으므로 추가 시간이 있으면 대시보드를 추가 텍스트 설명 및 차트의 대체 색상으로 사용자 지정할 수 있습니다. 완료되면 필터에 다른 선택 필드를 추가하여 사용할 때 추가 차트에 영향을 미치도록 해야 합니다.
필터 편집
필터를 편집하려면 다음 단계를 사용하십시오:
- 대시보드에서 필터를 선택합니다.
- 구성 패널에서 필드 옆의 +를 선택합니다.
- sales by loyalty segment.product_category 필드를 추가합니다.
대시보드 재게시
나가기 전에 추가 사용자가 완성된 대시보드를 볼 수 있도록 대시보드를 재게시하는 것을 기억하십시오.
게시를 클릭하여 수정된 대시보드의 공유 가능한 복사본을 만듭니다.
전환기를 사용하여 게시된 대시보드를 봅니다.
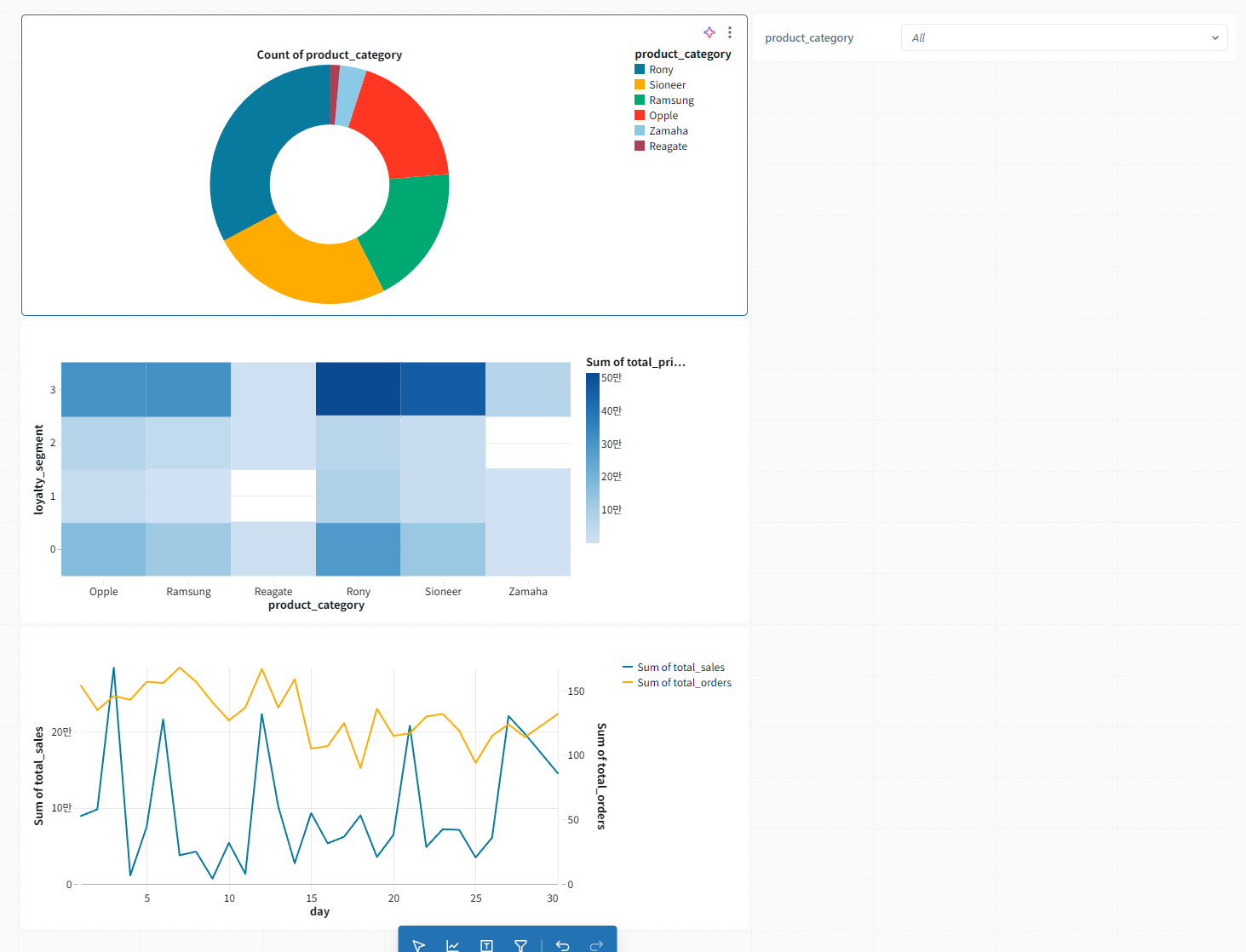
Azure Databricks 인프라
Databricks 인프라 및 플랫폼
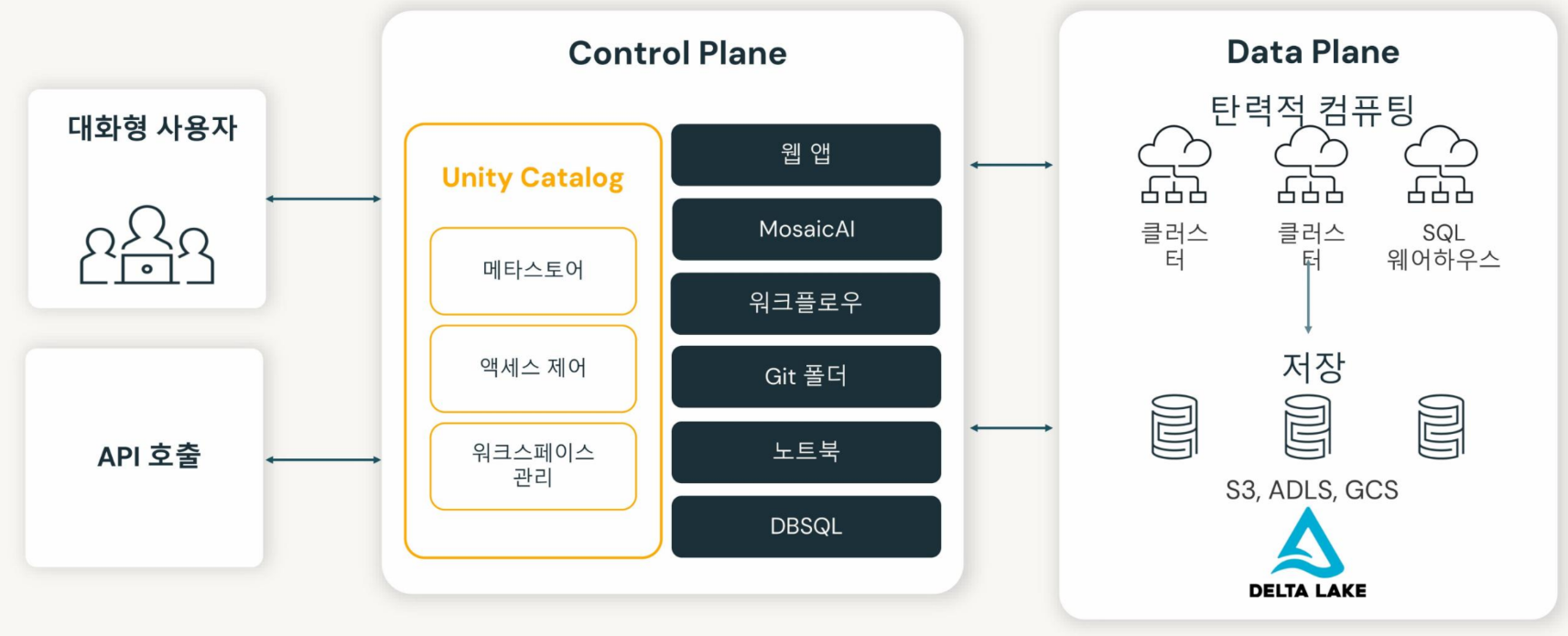
Databricks 컴퓨트 종류
런타임
표준
Apache Spakr와 여러 다른 구성 요소와 업데이트를 통해 최적화된 빅데이터 분석 환경을 제공
머신러닝
TensorFlow, keras, PyTorch, XGBoost 등 인기 있는 머신 러닝 라이브러리 추가
특화된 컴퓨팅
SQL웨어하우스
최고의 가격 대비 성능을 위한 내장 최적화 기능을 통해 SQL BI 워크로드 최적화를 위해 특별히 설계
서버리스 플랫폼
사용자가 쿼리를 실행하면 즉시 할당되지 않은 풀에서 자원을 가져와서 활용
비용 저렴
단점: 안정적이지 못한 경우도 존재
- 주로 테스트 용도로 간단하게 사용
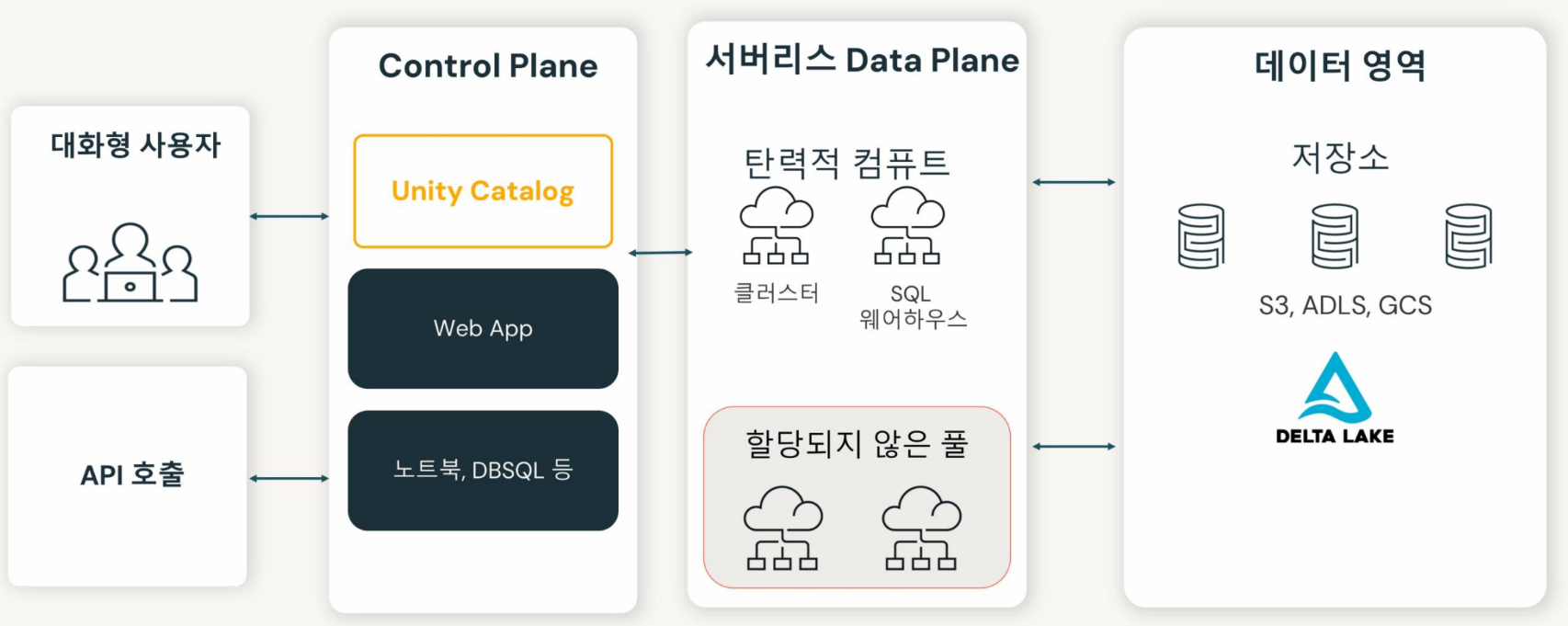
Databricks 구조
클라우드에서만 사용 가능하며, 온프레미스로 불가능
저장 및 거버넌스
- 저장은 클라우드 데이터 스토리지(AWS, Azure, GCP)
- Unity Catalog 권한 세팅 가능
Unity Catalog로 데이터와 AI 거버넌스 통합
Mosaic AI
생성적인 및 기존 AI 애플리케이션 개발을 위한 지원
- MLFlow
- AutoML
- Feature Store
- Model Serving
- Vector Search
- AI Playground
- Agent Framework
- Model Training
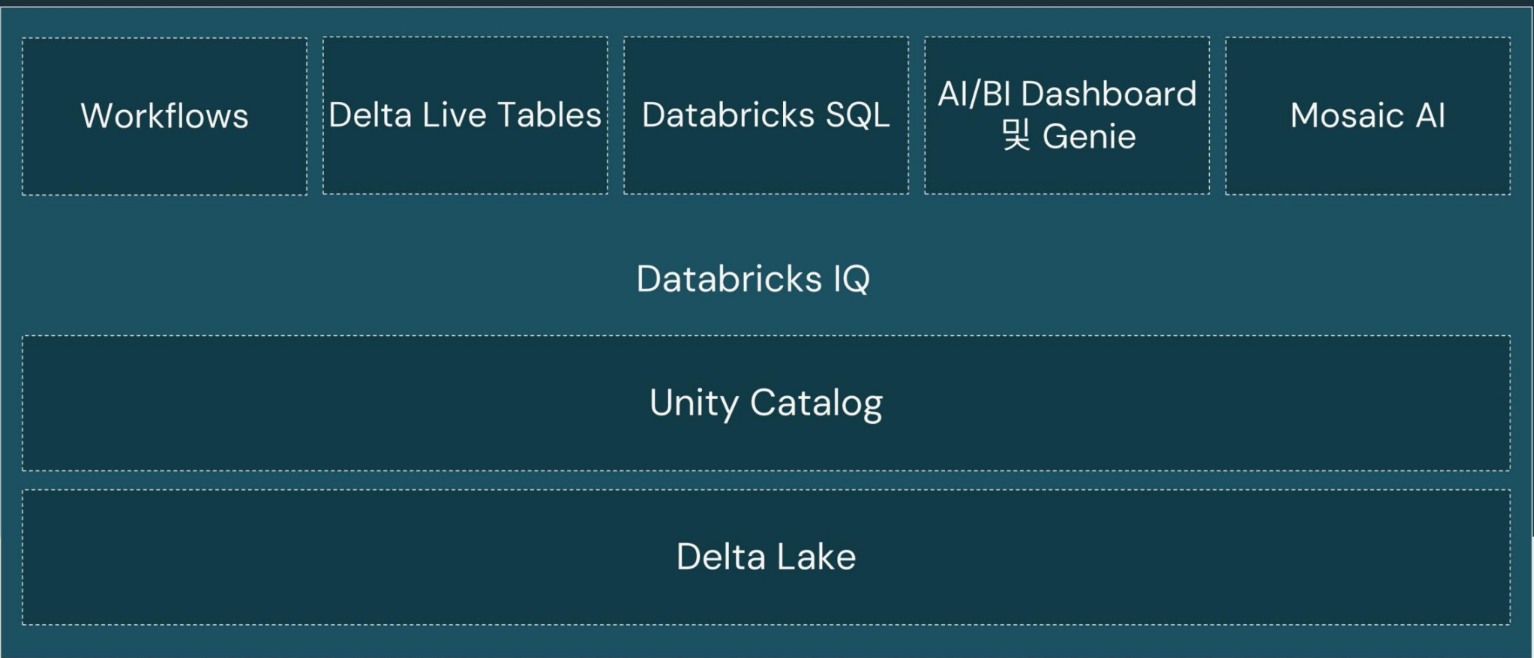
오케스트레이션 및 ETL
Databricks Workflows
제어 흐름 - DLT 파이프라인을 포함하여 플랫폼의 모든 것을 조율
Delta Live Tbles
데이터 흐름 - Delta Lake를 위한 자동화된 데이터 파이프라인
데이터웨어하우징 및 BI
Databricks SQL
Databriks에서 최고 가성비로 데이터 웨어하우징 및 분석을 수행
AI/BI Dashboards
통합된 시각화 및 프레젠테이션 환경
AI/BI Genie
기업 내 고유한 용어를 사용하여 자연어로 데이터 질의
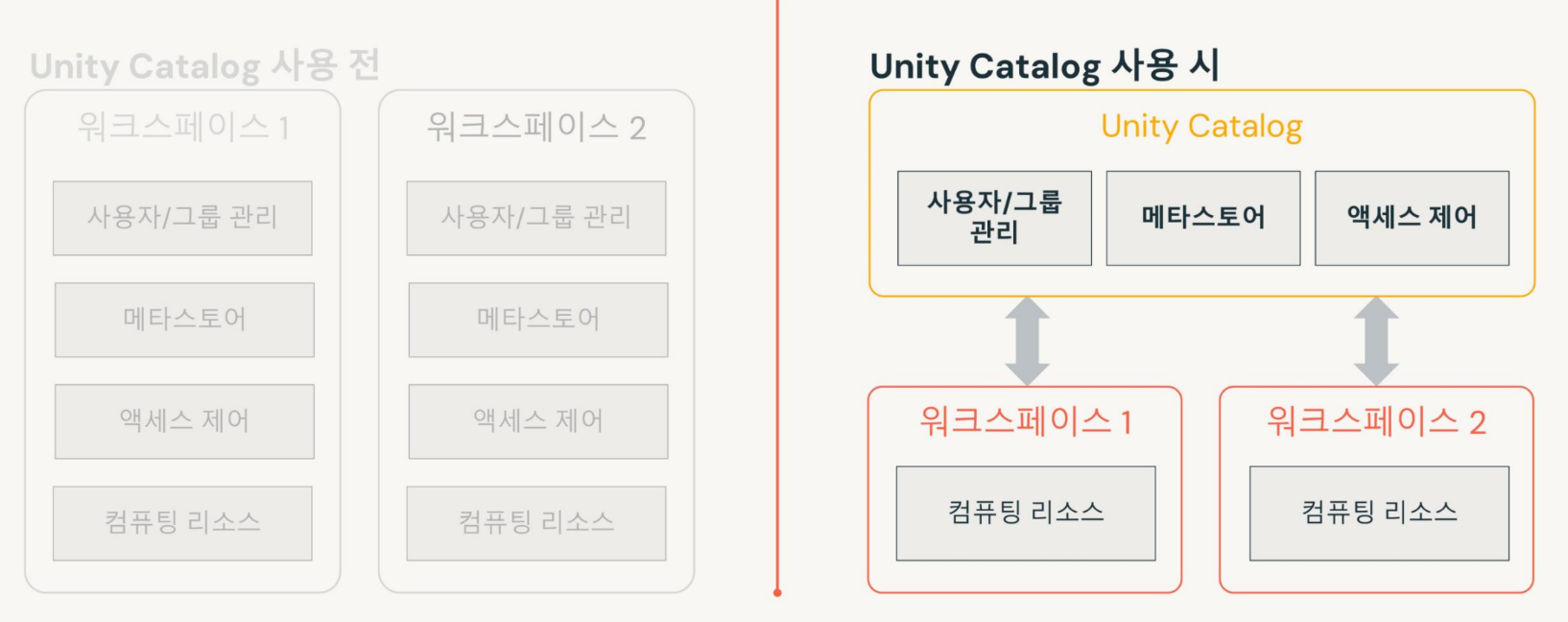
Azure Databricks Unity Catalog
Unity Catalog 사용 전후
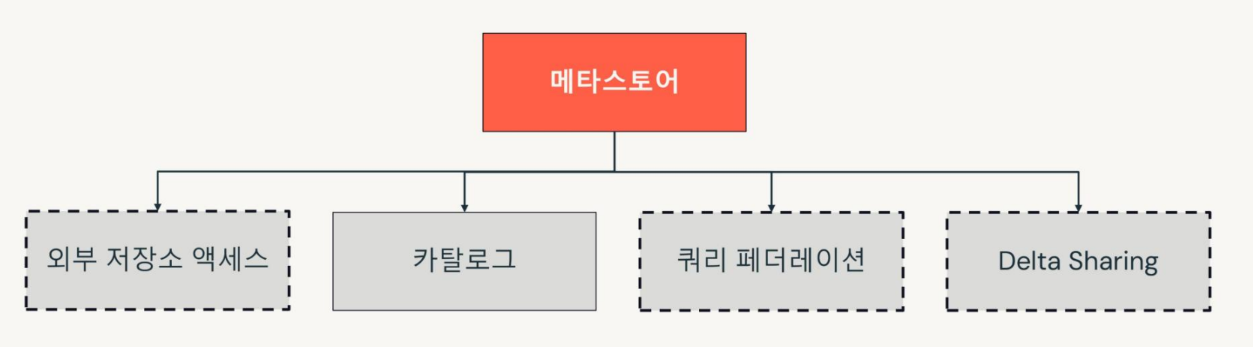
메타스토어
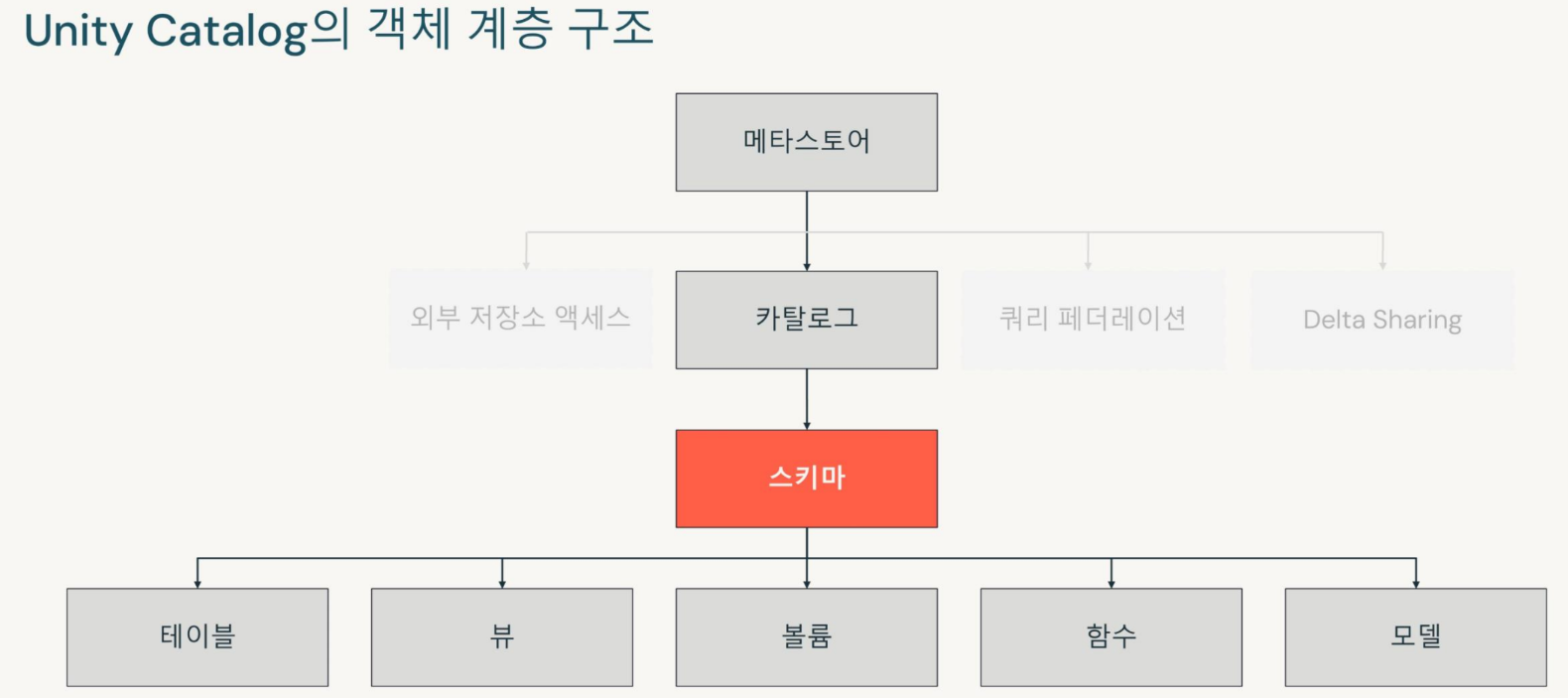
계층구조
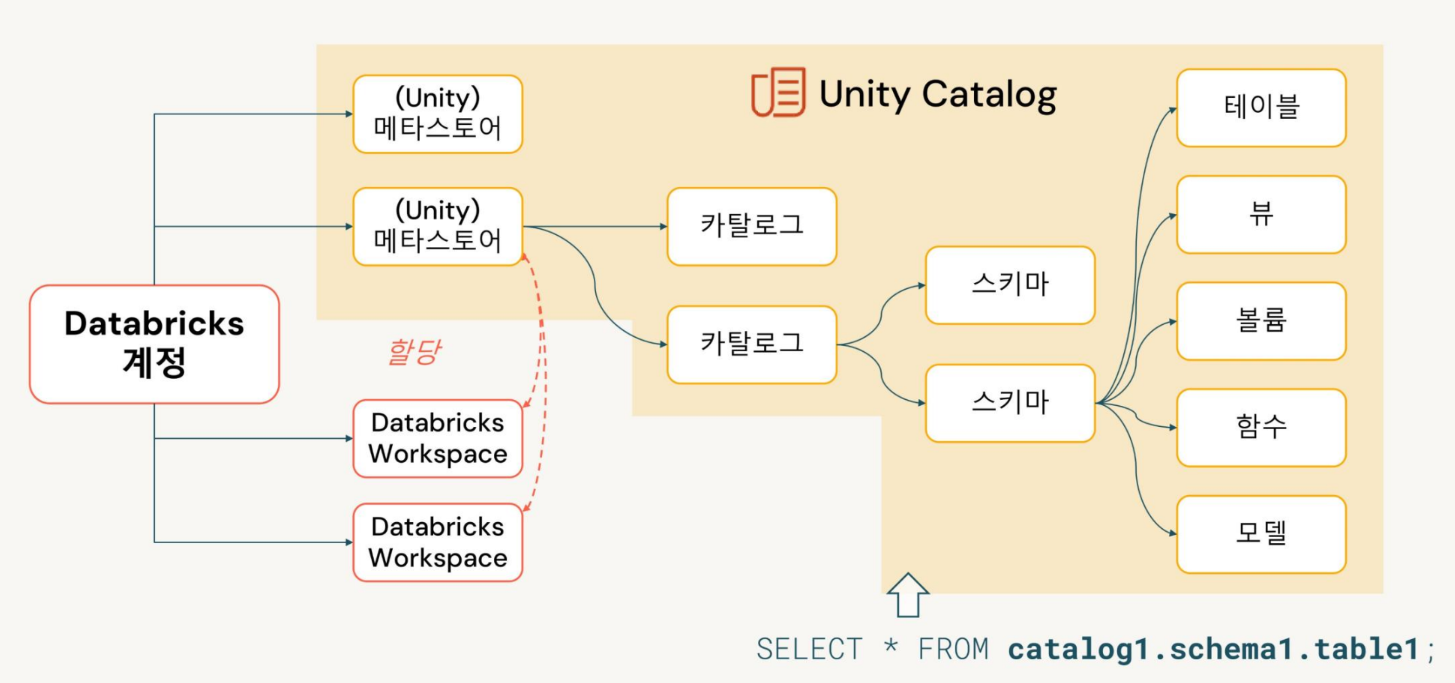
주요 기능
- 통합 네임스페이스: 모든 작업 영역에서 데이터 세트, 파일 및 기계 학습 모델에 대한 단일 네임스페이스 제공
- 세분화된 액세스 제어
- 데이터 계보: 데이터 계보를 캡처하고 표시 → 데이터 흐름을 추적하고 시간에 따른 데이터 변환을 이해하는데 중요
- 중앙화된 메타데이터 관리
- Databricks SQL과 통합
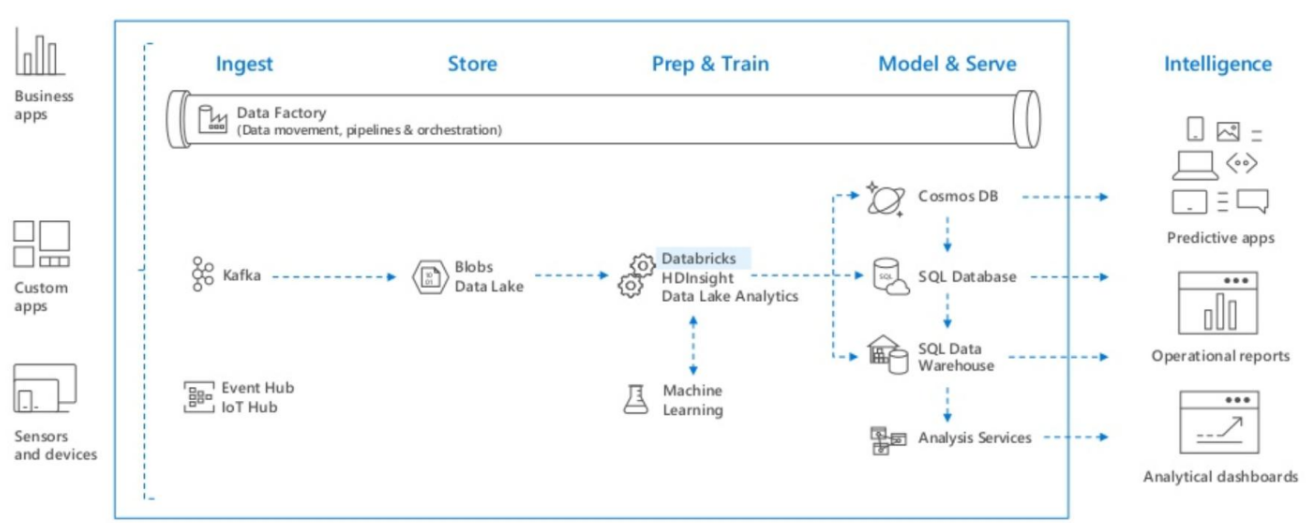
Azure Databricks를 사용하여 데이터 읽기
데이터 원본 액세스 대상
- Data Lake
- Cosmos DB
- Event Hubs
- SQL Database
- SQL Data Warehouse
데이터 읽기
SQL 혹은 DataFrame(Python)을 사용하여 데이터 읽기
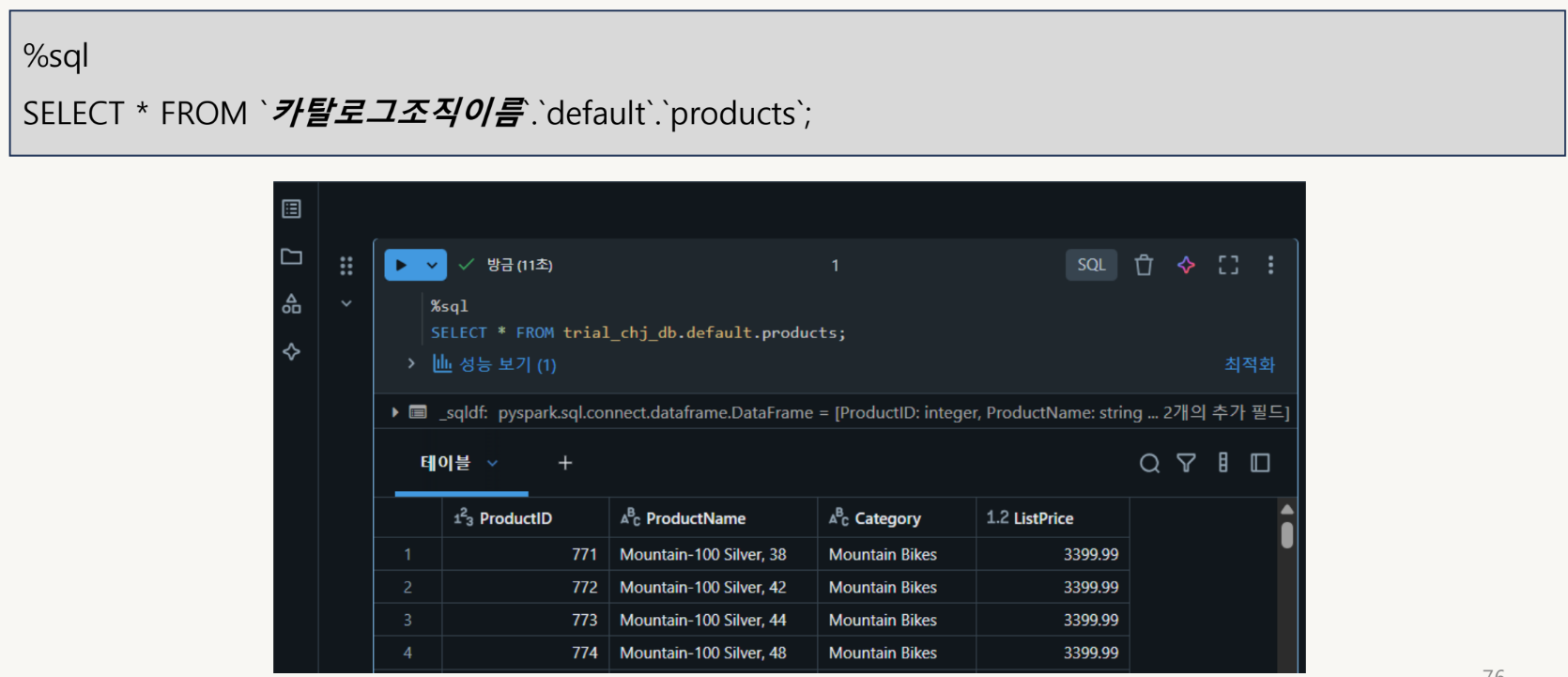
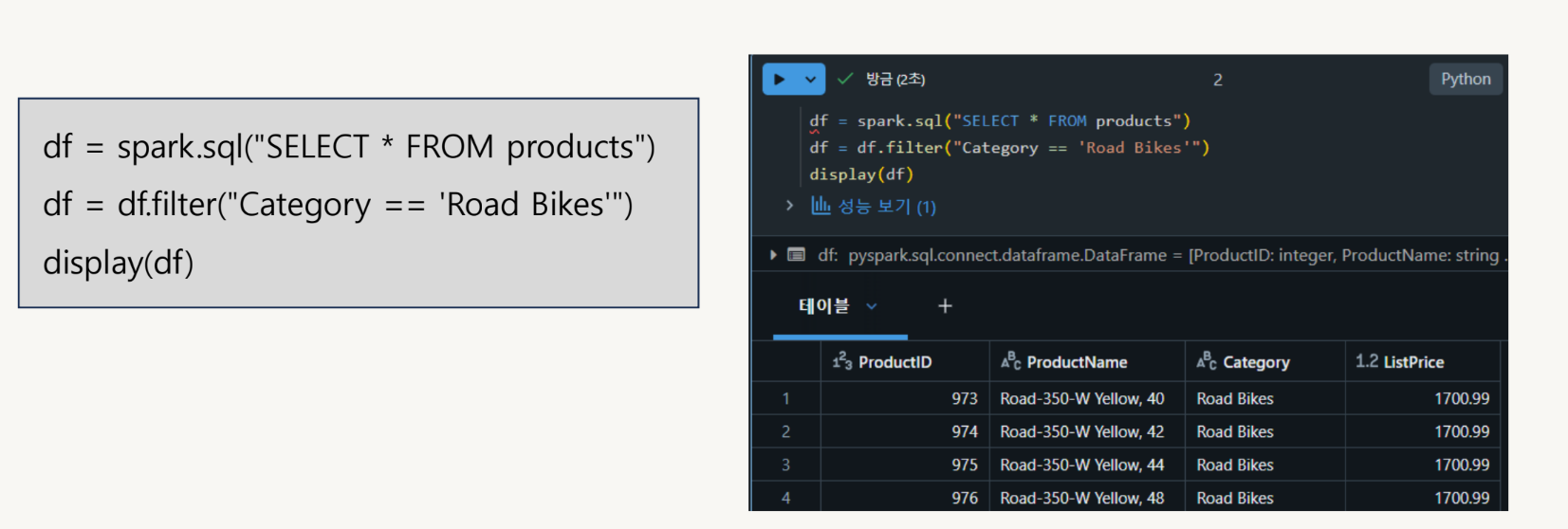
Spark Engine에서의 속도는 둘 다 같다.
Delta Lake로 데이터 관리
클라우드 저장소에 파일을 읽고 쓰기 위한 오픈 소스 프로토콜
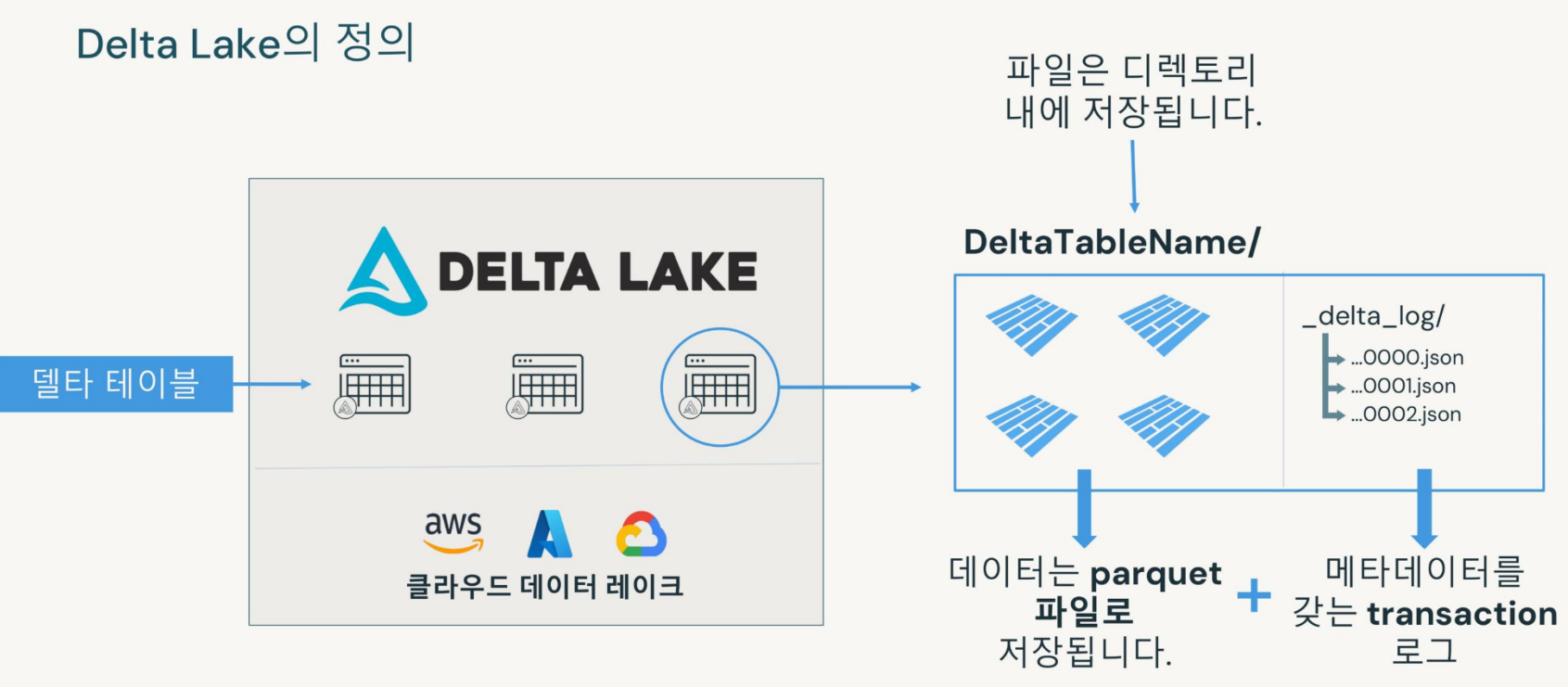
- Delta Lake는 Databricks에서 생성된 테이블의 기본형식
- 테이블 버전 관리 기록은 delta_log의 json에 저장된다.
주요 기능
- ACID 트랜잭션
- DML 작업
- 시간 여행
- 과거 버전 질의
- 스냅샷 격리
- auditing
- 스키마 진화 및 강제
- 데이터 변경에 따라 Delta 테이블의 스키마가 자동으로 조정(ex: string column에 int형이 삽입되면 스키마가 자동 업데이트)
- 강제: Delta 테이블에 입력되는 모든 데이터가 테이블의 정의된 스키마와 일치하는지 확인
데이터 변환 개요

메달리온 아키텍처(Multi Hop)
- 브론즈
- 외부 소스 시스템에서 온 원시 데이터용
- 장기 보관
- 원본 형태(필요한 경우 개인 식별 정보(PII) 를 제거 가능)
- 실버
- 필터, 정제, 조인 및 브론즈 데이터 보강
- 구조를 정의하고 스키마 진화 똔느 강제
- 단일 진실 원천(Single Source of truth)
- 골드
- 바로 사용 가능한 정제된 데이터
- 실버 데이터의 비즈니스 수준 집계일 수 있음
- 사용자 및 애플리케이션에 전달됨
실습
노트북 명령어 추가
%run
- %run 명령어를 사용하여 다른 노트북에서 노트북을 실행할 수 있습니다.
- 실행할 노트북은 상대 경로로 지정됩니다.
- 참조된 노트북은 현재 노트북의 일부인 것처럼 실행되므로 호출하는 노트북에서 임시 뷰 및 기타 로컬 선언을 사용할 수 있습니다.
Databricks Utilities
Databricks 노트북에는 환경 구성 및 상호 작용을 위한 다양한 유틸리티 명령을 제공하는 dbutils 객체가 포함되어 있습니다. dbutils docs
이 과정에서는 Python 셀의 파일 디렉터리를 나열하기 위해 dbutils.fs.ls()를 가끔씩 사용합니다.
path = f"{DA.paths.datasets}"
dbutils.fs.ls(path)display()
셀에서 SQL 쿼리를 실행하면 결과는 항상 렌더링된 표 형식으로 표시됩니다.
Python 셀에서 반환된 표 형식 데이터가 있는 경우, display를 호출하여 동일한 유형의 미리보기를 얻을 수 있습니다.
여기서는 파일 시스템에서 이전 list 명령을 display로 래핑합니다.
display() 명령은 다음과 같은 기능과 제한 사항을 가집니다.
- 결과 미리보기는 1000개 레코드로 제한됩니다.
- 결과 데이터를 CSV로 다운로드할 수 있는 버튼을 제공합니다.
- 플롯 렌더링을 허용합니다.
path = f"{DA.paths.datasets}"
files = dbutils.fs.ls(path)
display(files)델타 테이블 관리
Databricks로 생성된 모든 테이블의 기본 형식은 Delta Lake입니다. Databricks에서 SQL 문을 실행해 본 적이 있다면 이미 Delta Lake를 사용하고 있을 가능성이 높습니다.
Creating a Delta Table
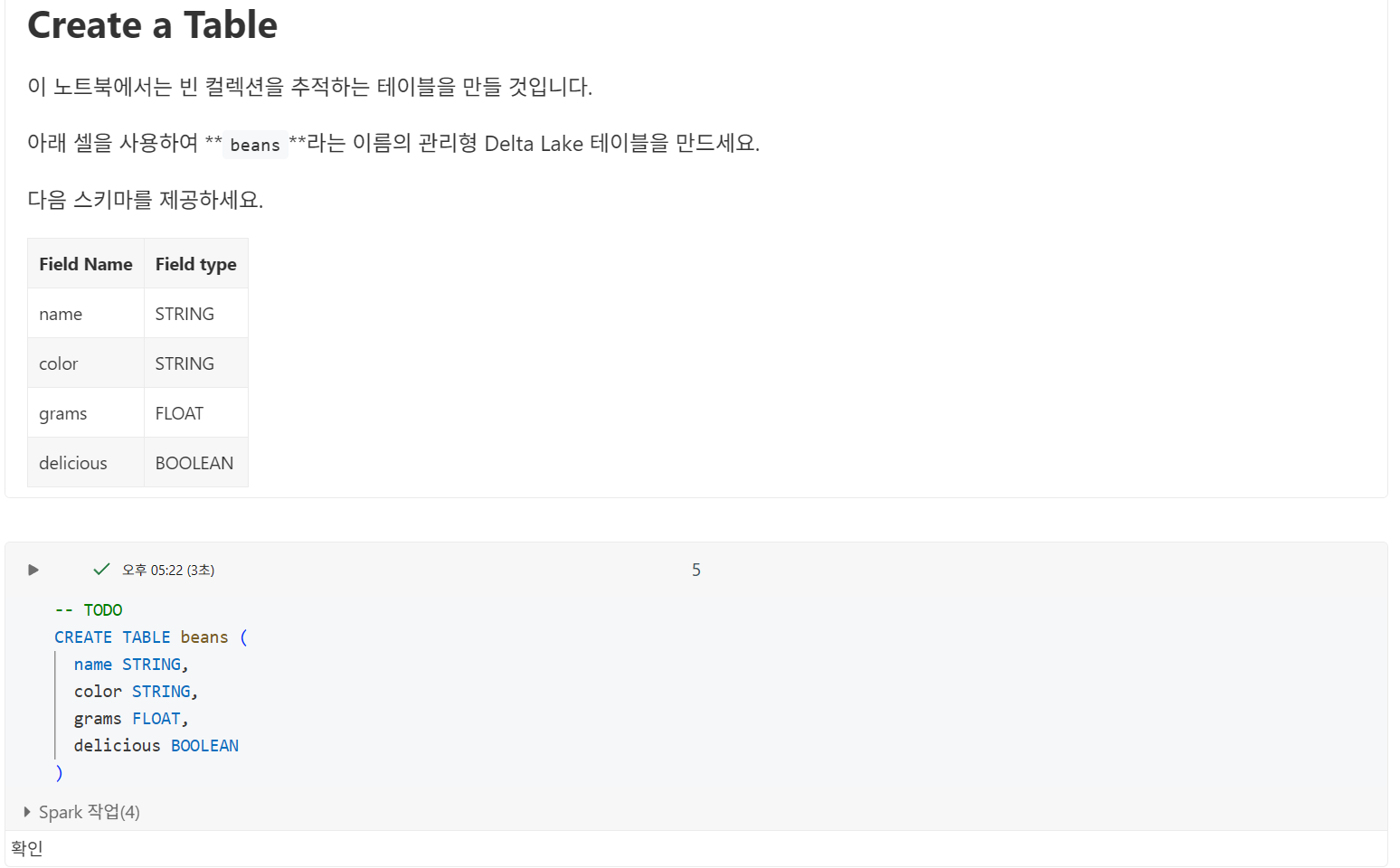
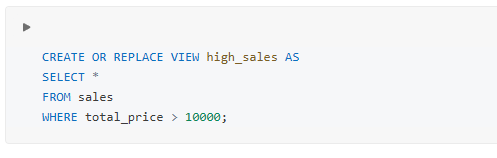
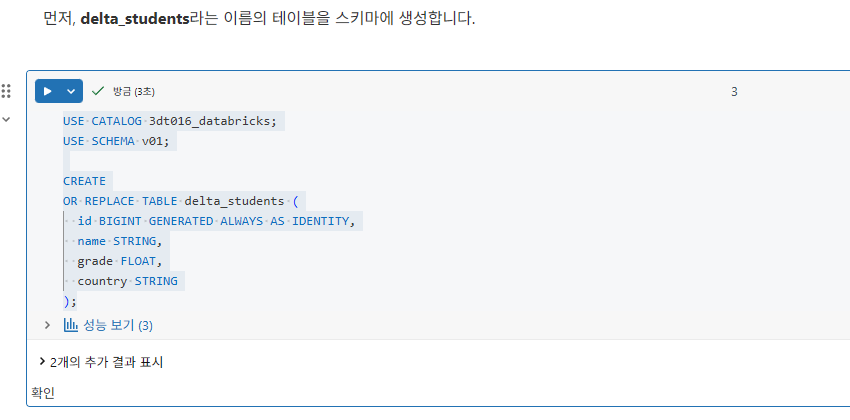
Delta Lake로 테이블을 생성하는 데 필요한 코드는 많지 않습니다. 이 강좌 전반에 걸쳐 Delta Lake 테이블을 생성하는 여러 가지 방법을 살펴보겠습니다. 가장 쉬운 방법 중 하나인 빈 Delta Lake 테이블을 등록하는 것부터 시작해 보겠습니다.
필요한 항목:
CREATE TABLE문- 테이블 이름(아래에서는
students를 사용합니다) - 스키마
참고: Databricks Runtime 8.0 이상에서는 Delta Lake가 기본 형식이므로 USING DELTA가 필요하지 않습니다.


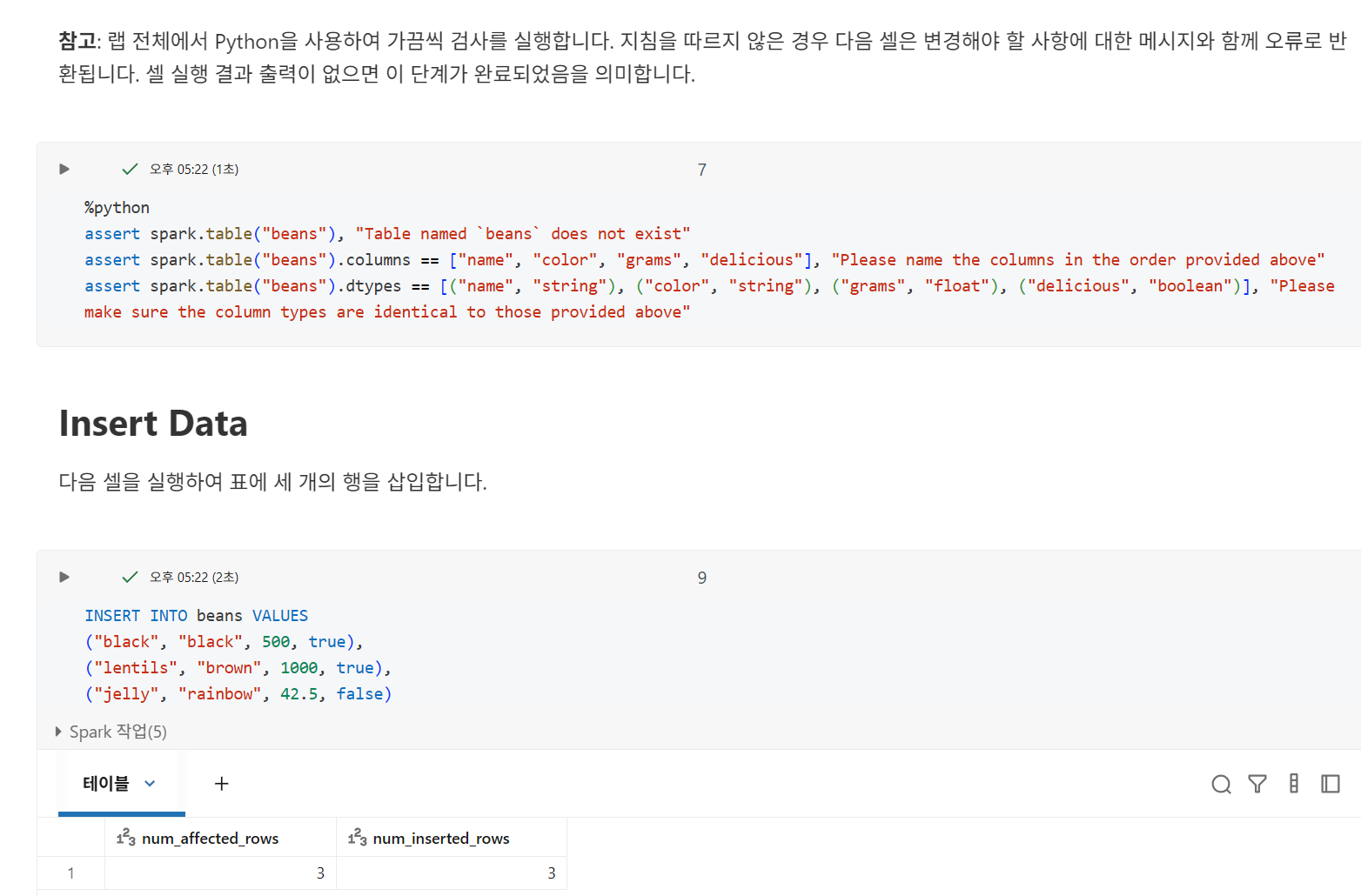
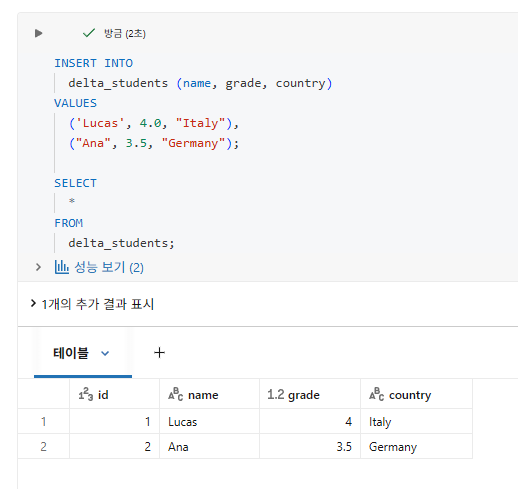
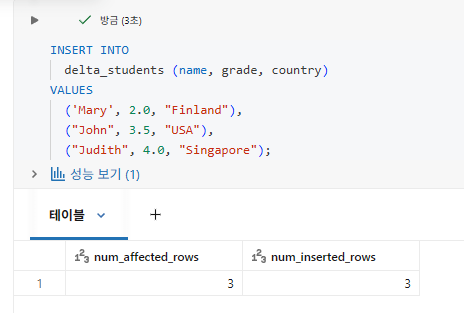
Inserting Data
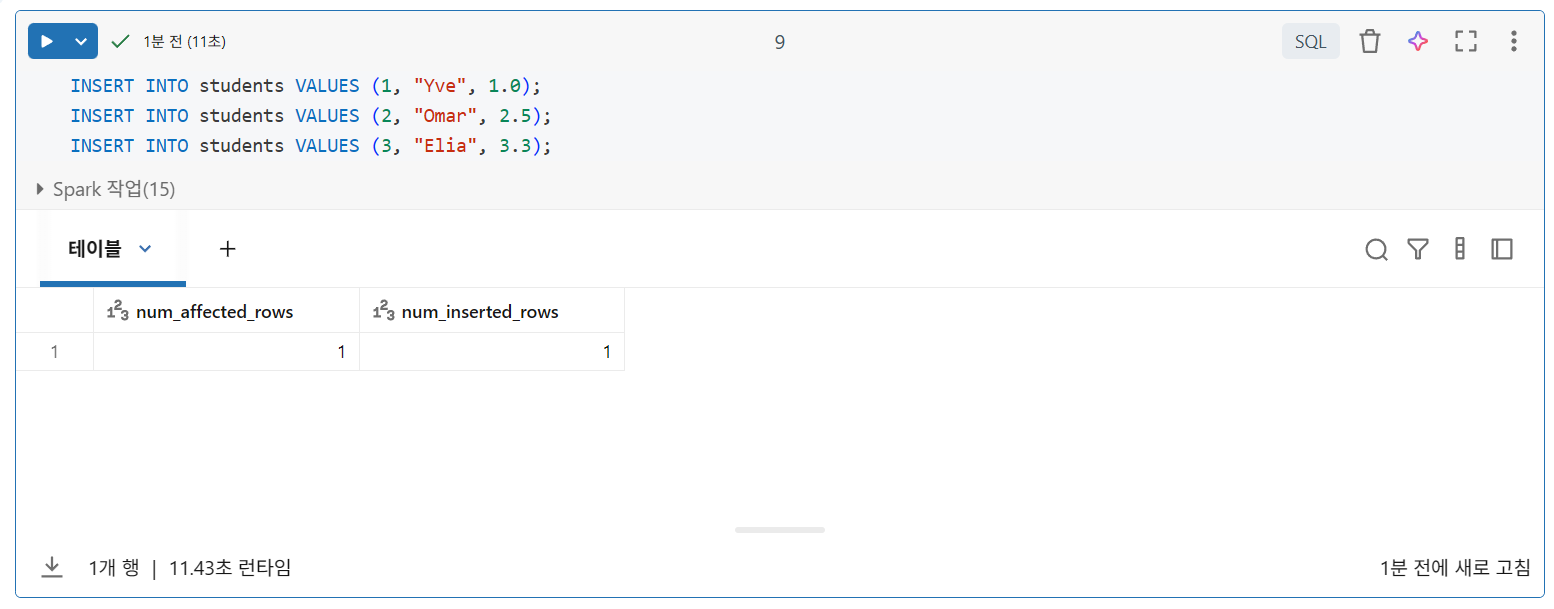
각 문은 자체 ACID 보장을 가진 별도의 트랜잭션으로 처리된다.
가장 자주 사용되는 방법은 단일 트랜잭션에 여러 레코드를 삽입하는 것
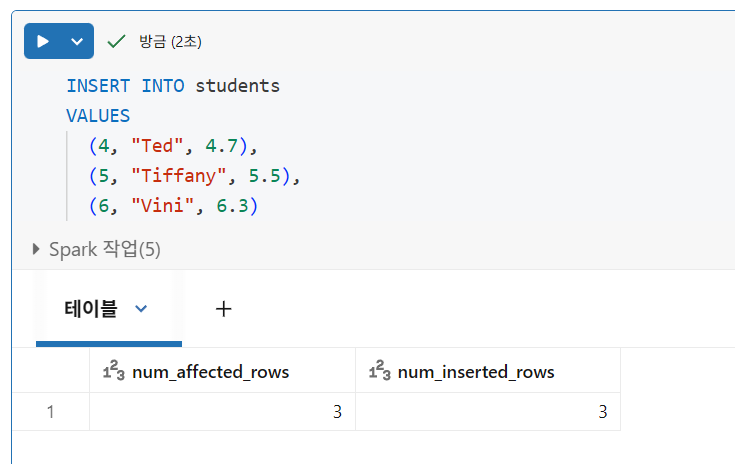
Databricks에는 COMMIT 키워드가 없다. 트랜잭션은 실행되자마자 실행되고, 성공하면 커밋된다.
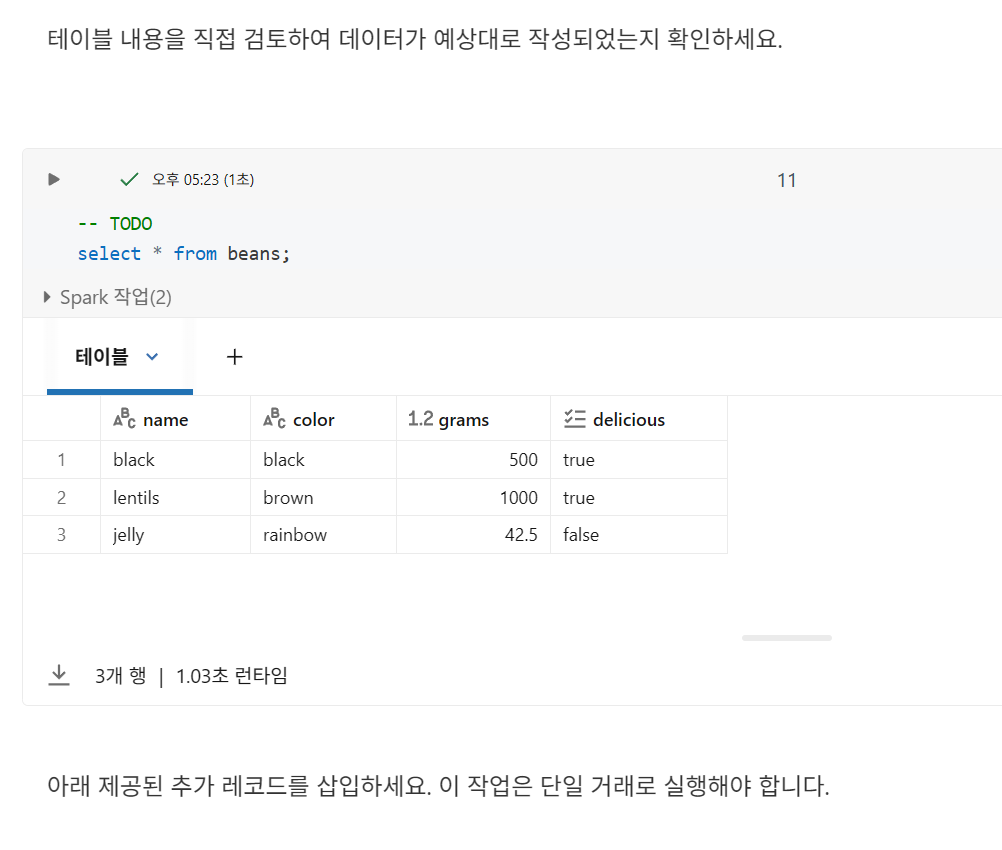
델타 테이블 쿼리
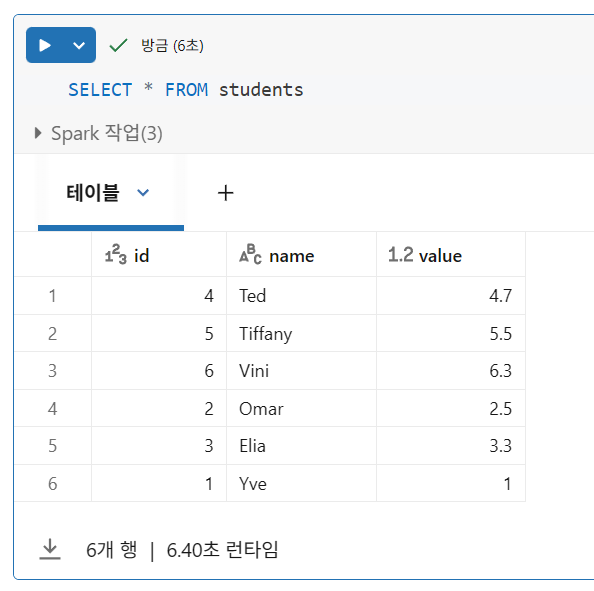
- Delta Lake는 테이블에 대한 모든 읽기가 항상 최신 버전의 테이블을 반환하고, 진행 중인 작업으로 인한 교착 상태가 발생하지 않도록 보장
- 모든 트랜잭션 정보는 데이터 파일과 함께 클라우드 객체 스토리지에 저장되므로 Delta Lake 테이블의 동시 읽기는 클라우드 공급업체의 객체 스토리지 제한에 의해서만 제한
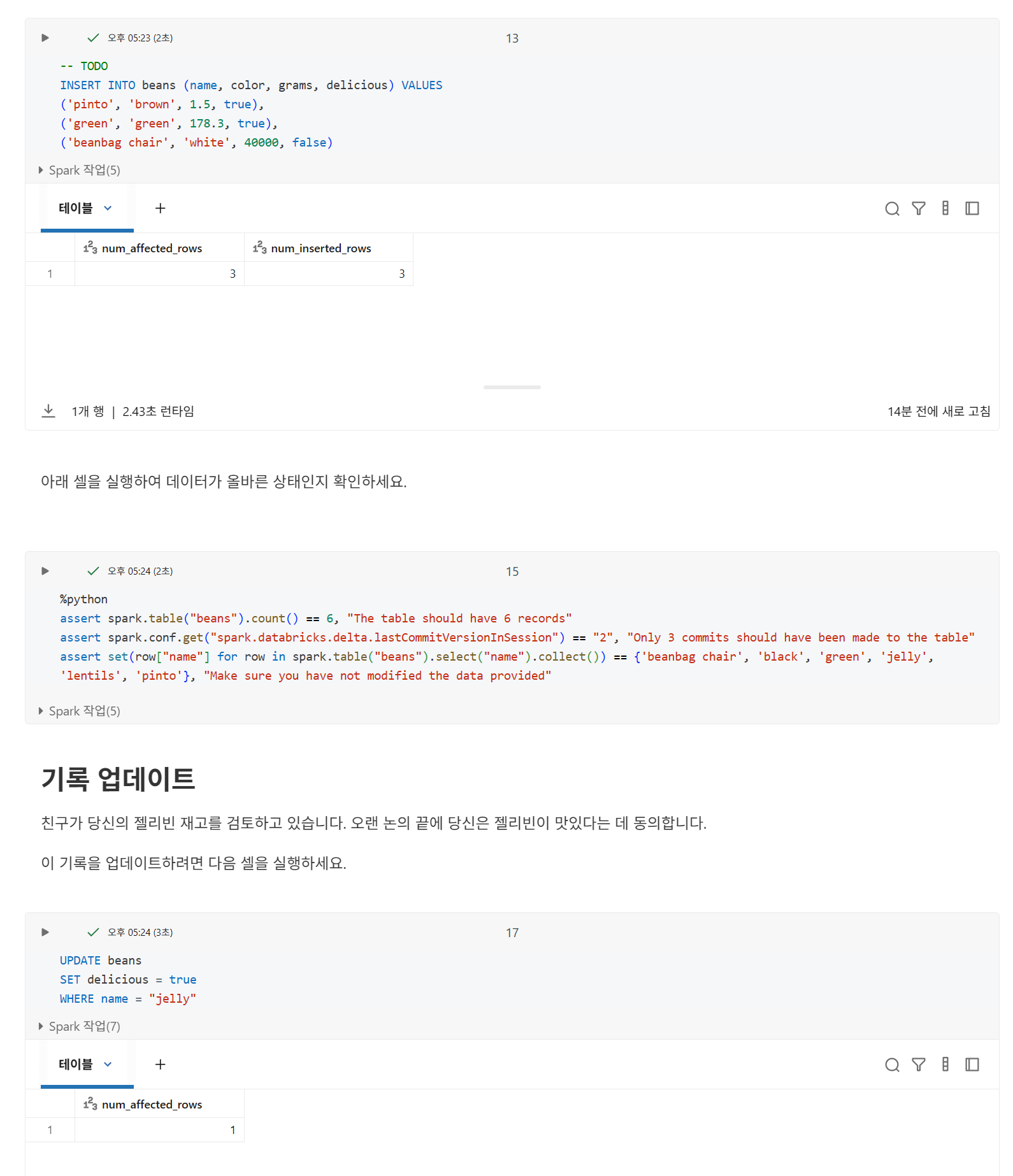
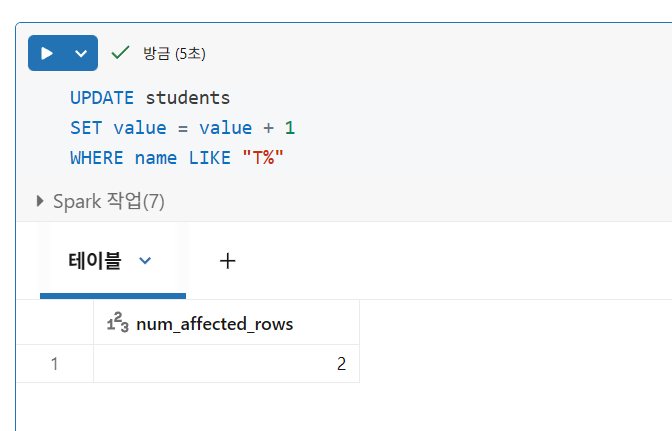
레코드 업데이트
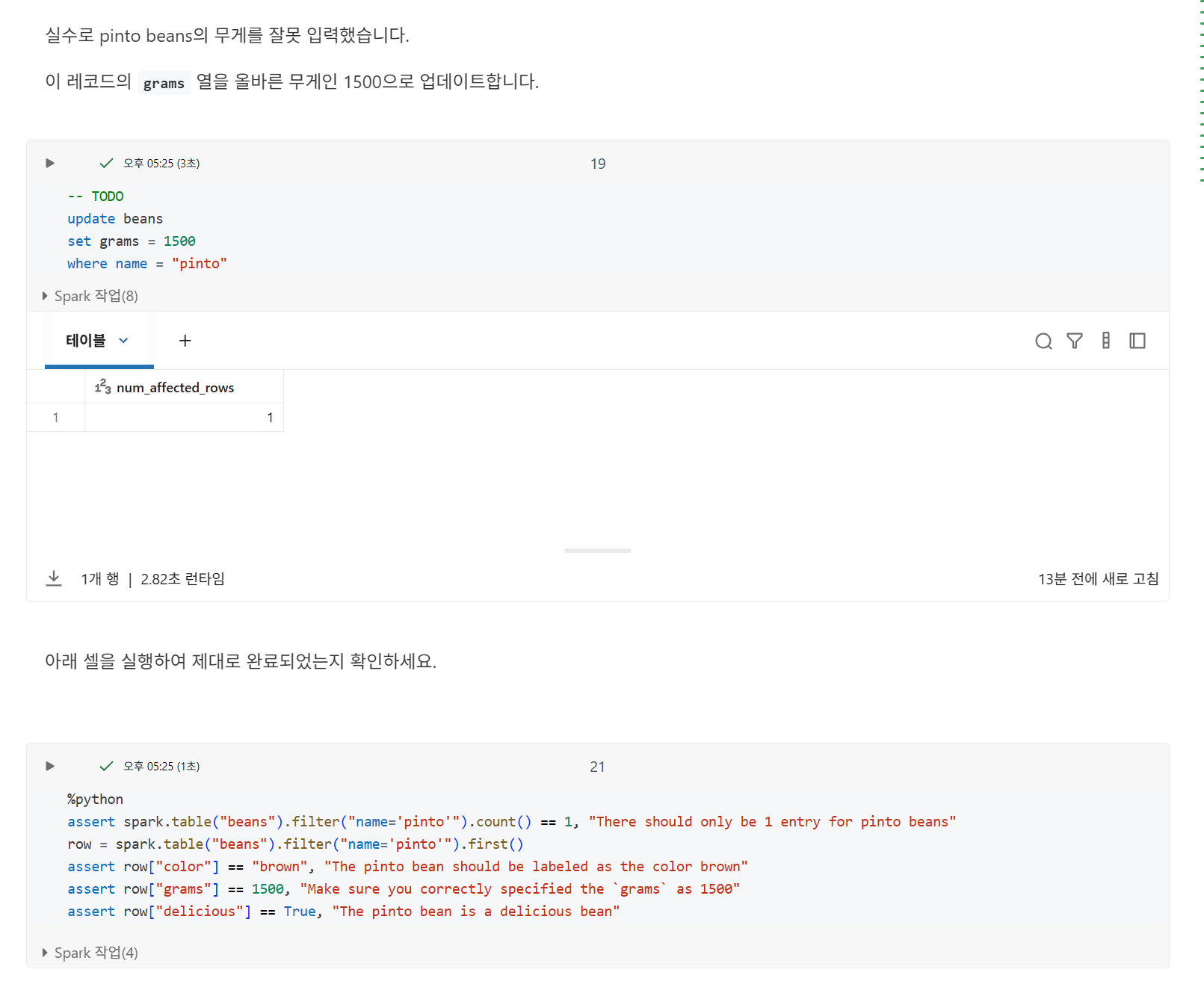
레코드 업데이트는 원자성 보장도 제공합니다. 테이블의 현재 버전에 대한 스냅샷 읽기를 수행하고, WHERE 절과 일치하는 모든 필드를 찾은 다음, 설명된 대로 변경 사항을 적용합니다.
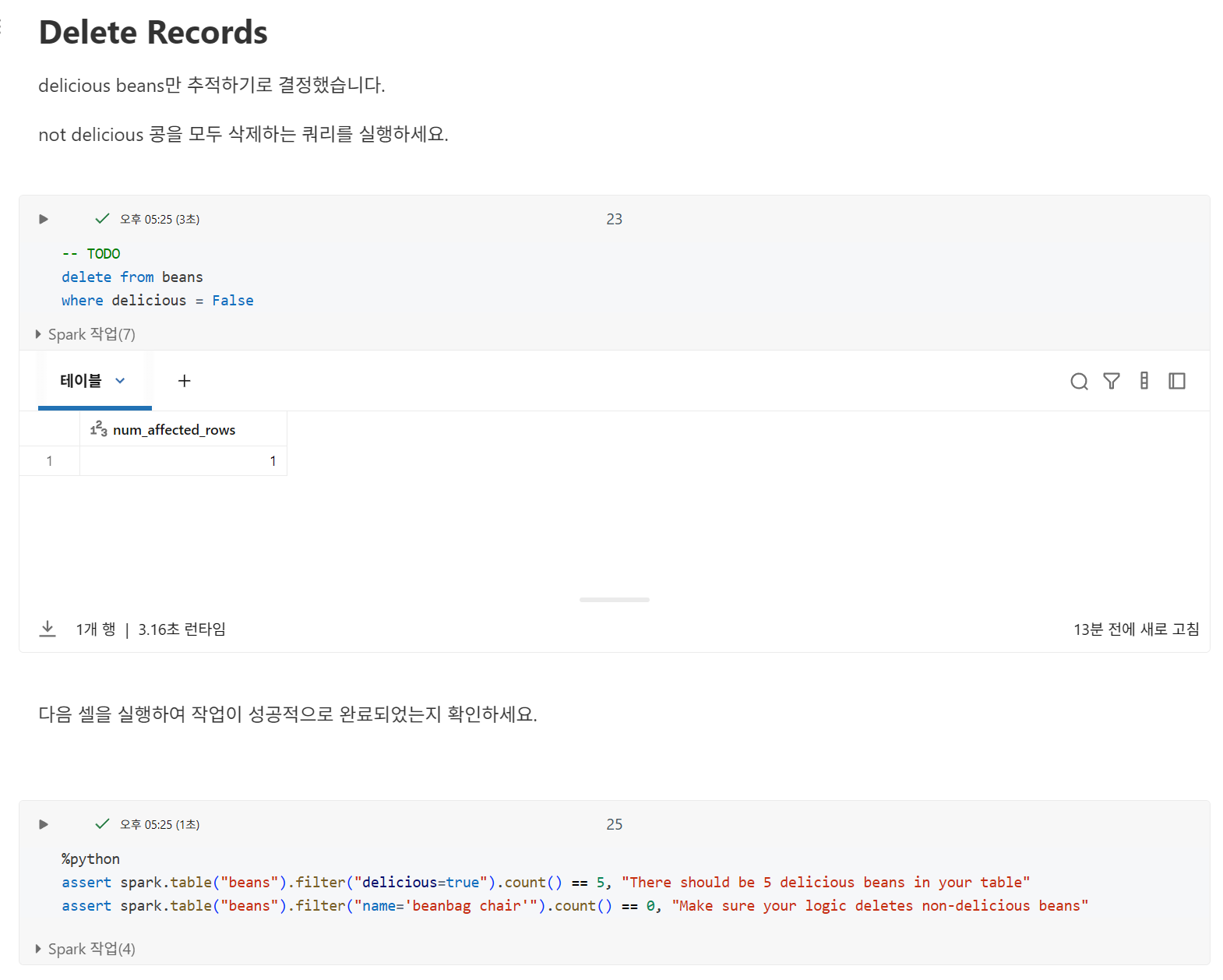
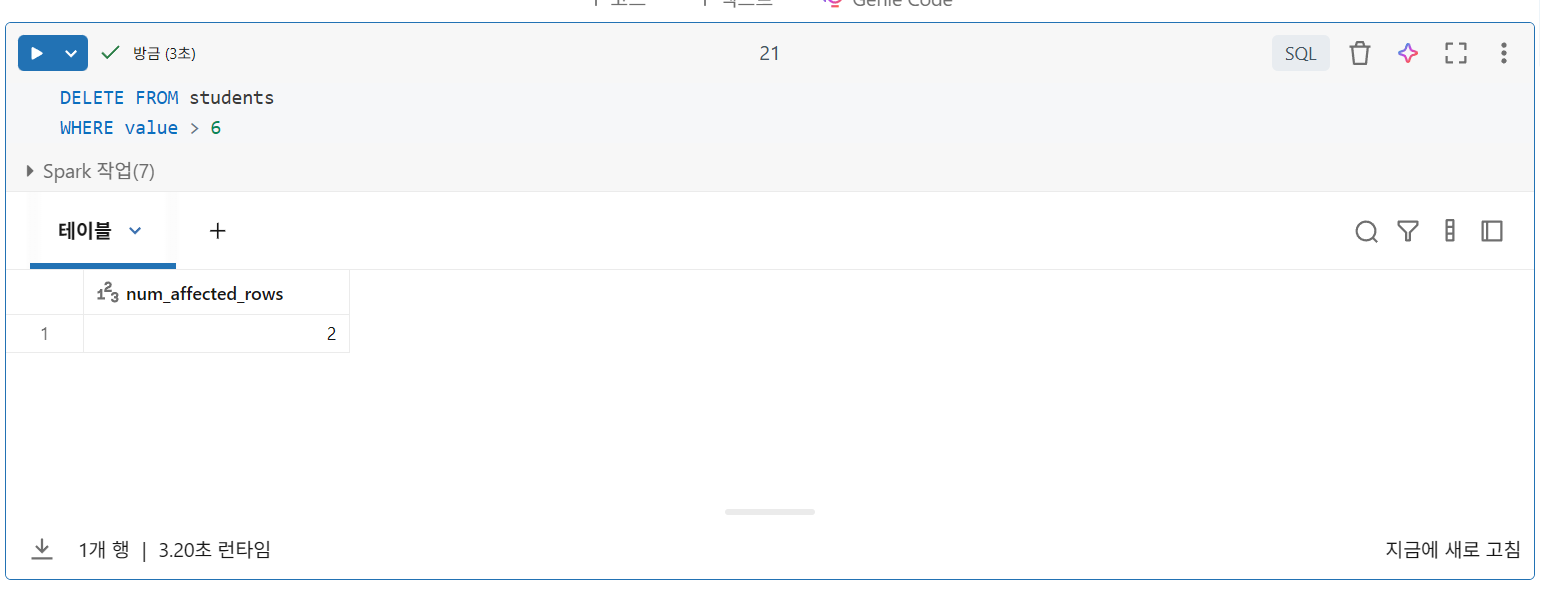
레코드 삭제
삭제는 원자적이므로 데이터 레이크하우스에서 데이터를 제거할 때 부분적으로만 성공할 위험이 없습니다.
DELETE 문은 하나 이상의 레코드를 제거할 수 있지만, 항상 단일 트랜잭션으로 처리됩니다.
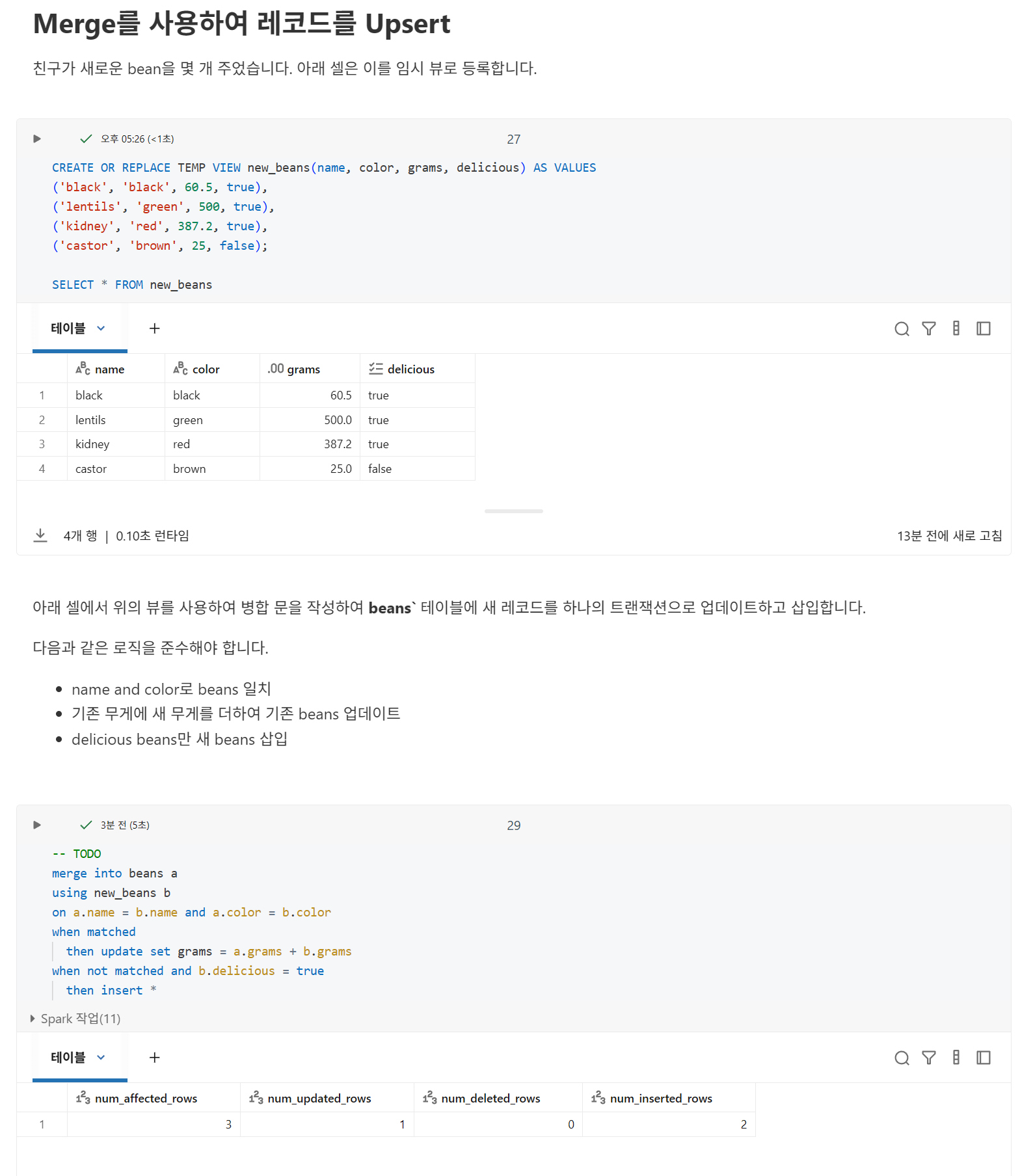
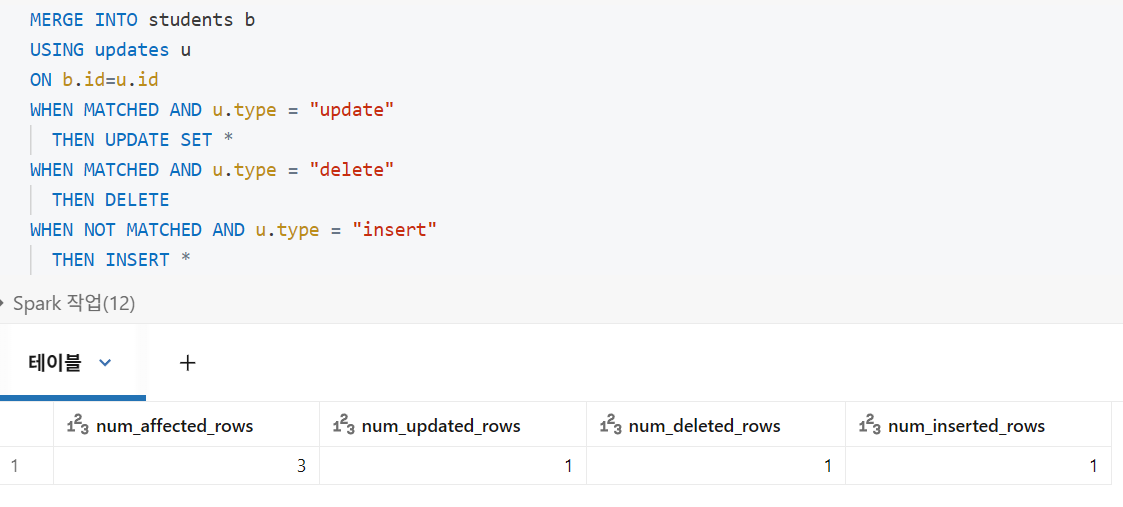
Using Merge
일부 SQL 시스템에는 업데이트, 삽입 및 기타 데이터 조작을 단일 명령으로 실행할 수 있는 upsert라는 개념이 있습니다.
Databricks는 MERGE 키워드를 사용하여 이 작업을 수행합니다.
다음과 같은 임시 뷰를 살펴보겠습니다. 이 뷰에는 변경 데이터 캡처(CDC) 피드에서 출력될 수 있는 4개의 레코드가 포함되어 있습니다.
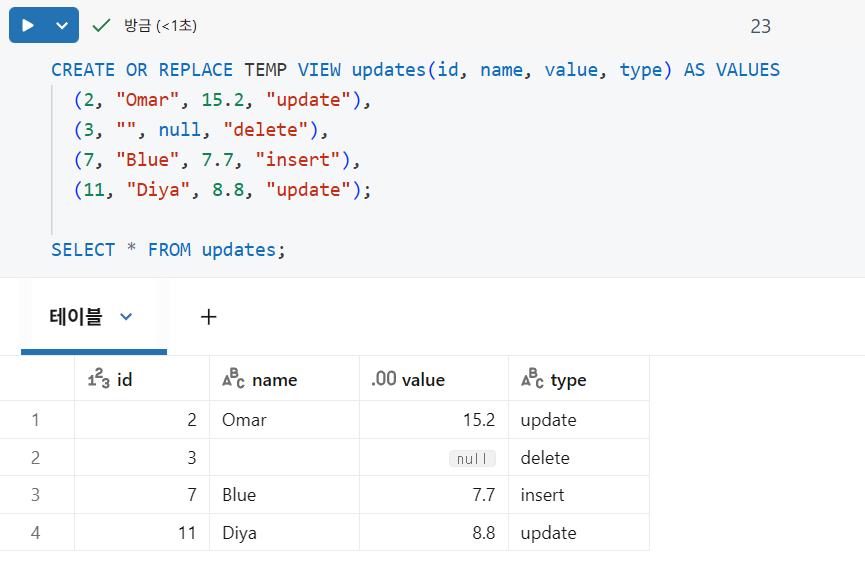
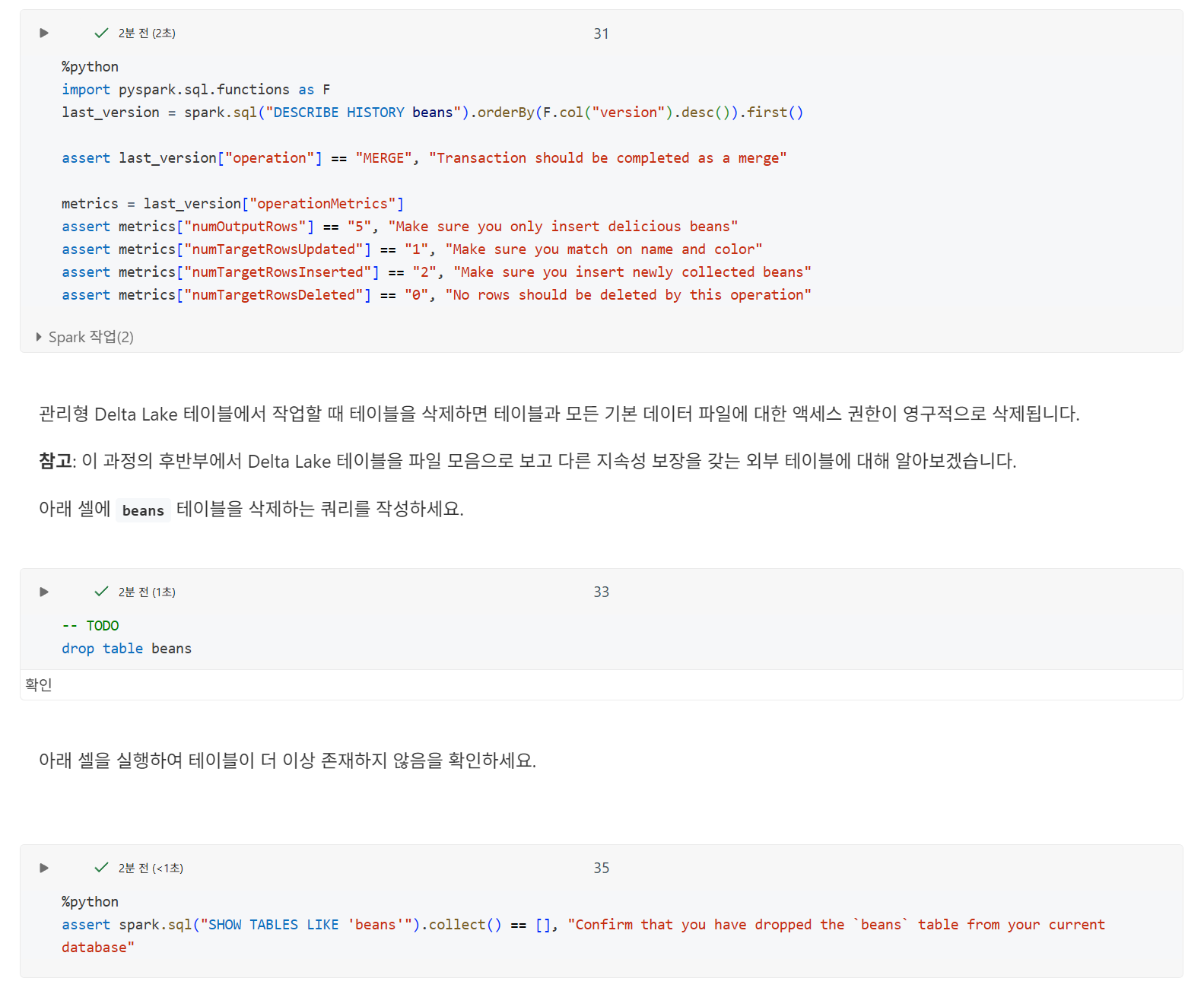
테이블 삭제
대상 테이블에 대한 적절한 권한이 있다면 DROP TABLE 명령을 사용하여 레이크하우스의 데이터를 영구적으로 삭제할 수 있습니다.(테이블 액세스 제어 목록(ACL)과 기본 권한)
Delta Lake를 사용한 테이블 조작