
Delta Lake 고급 기능
참고: Scalar는 java 기반이다
Delta Lake는 Parquet 기반이며, 로그는 json
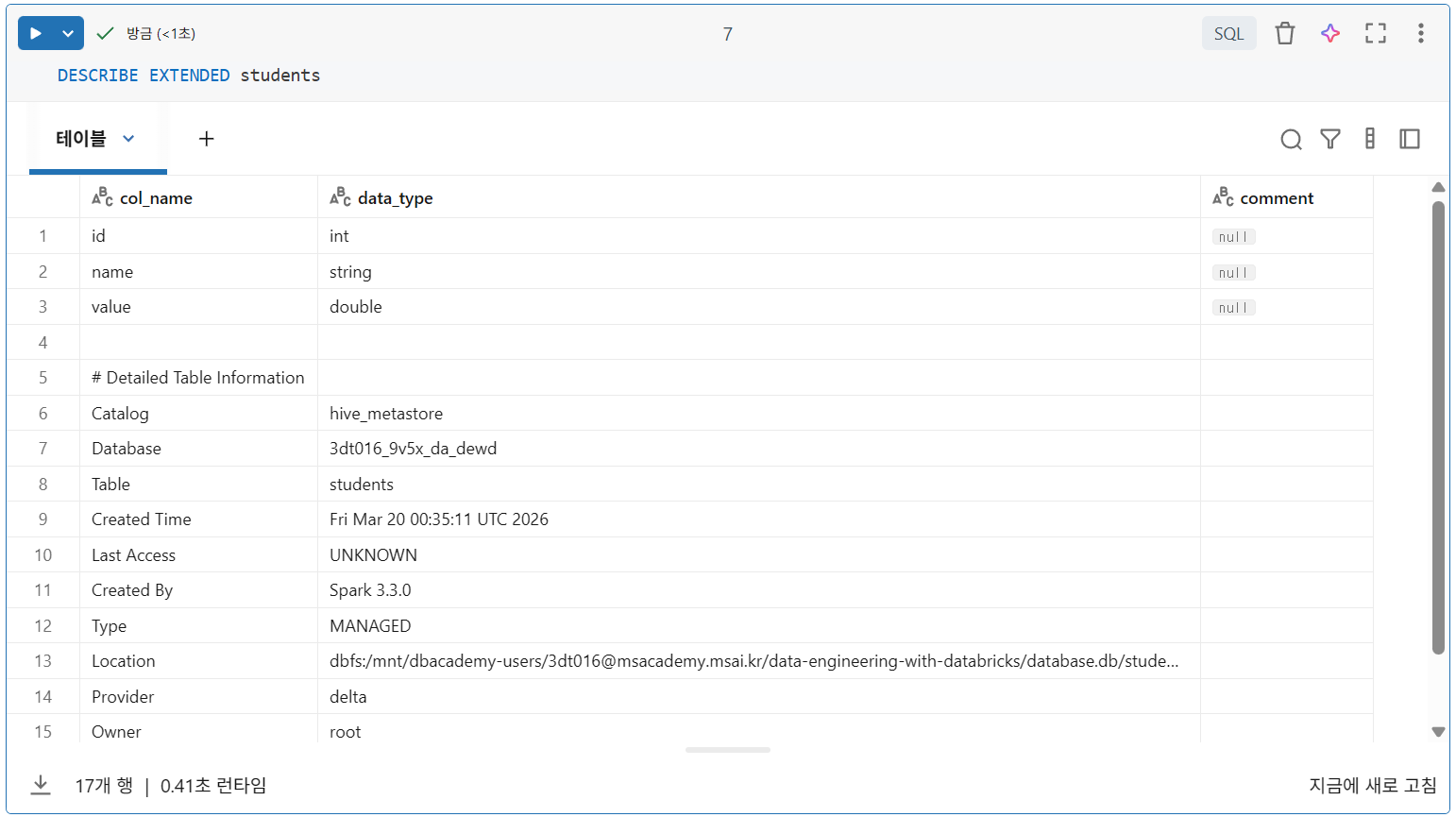
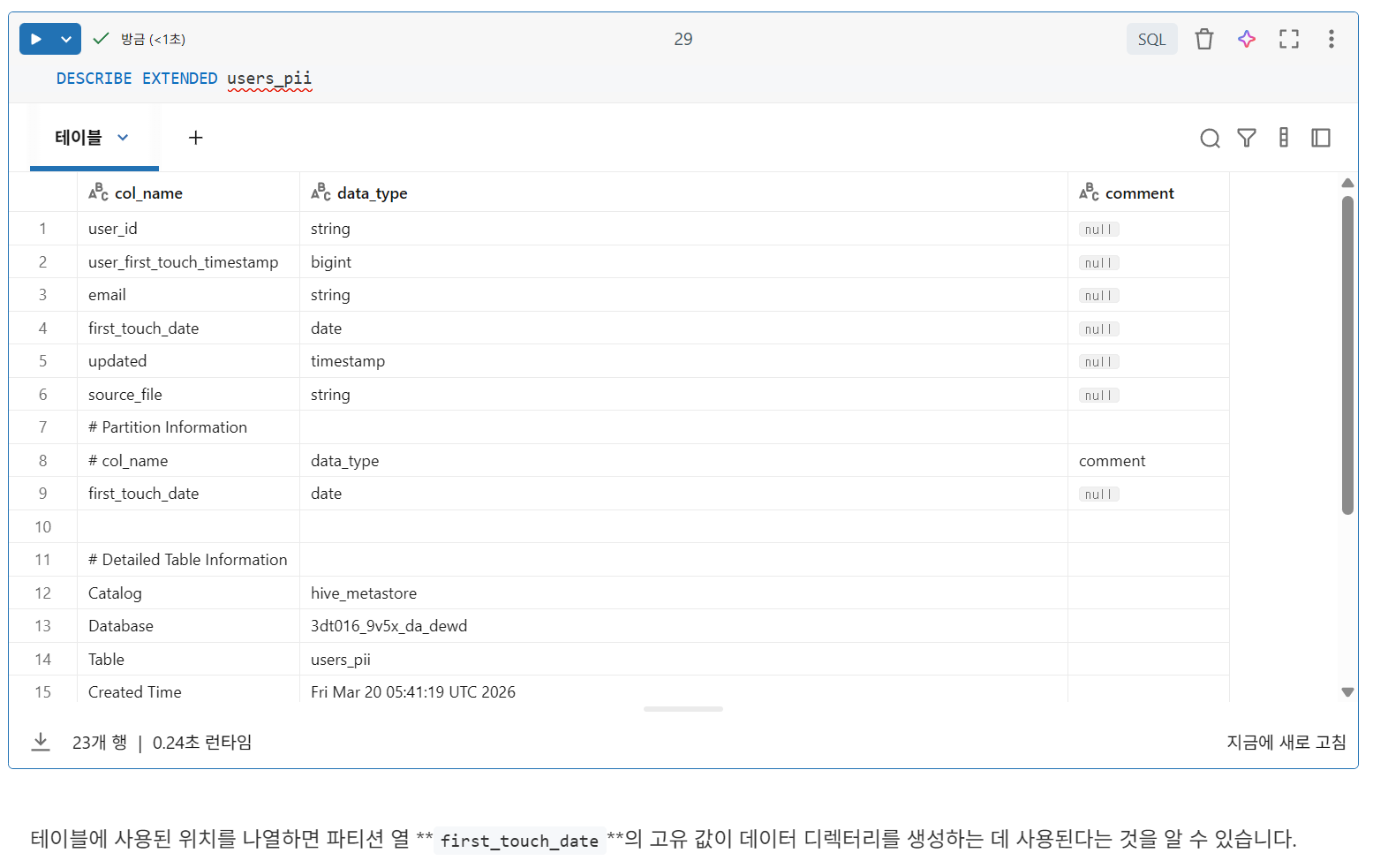
테이블 메타데이터 탐색
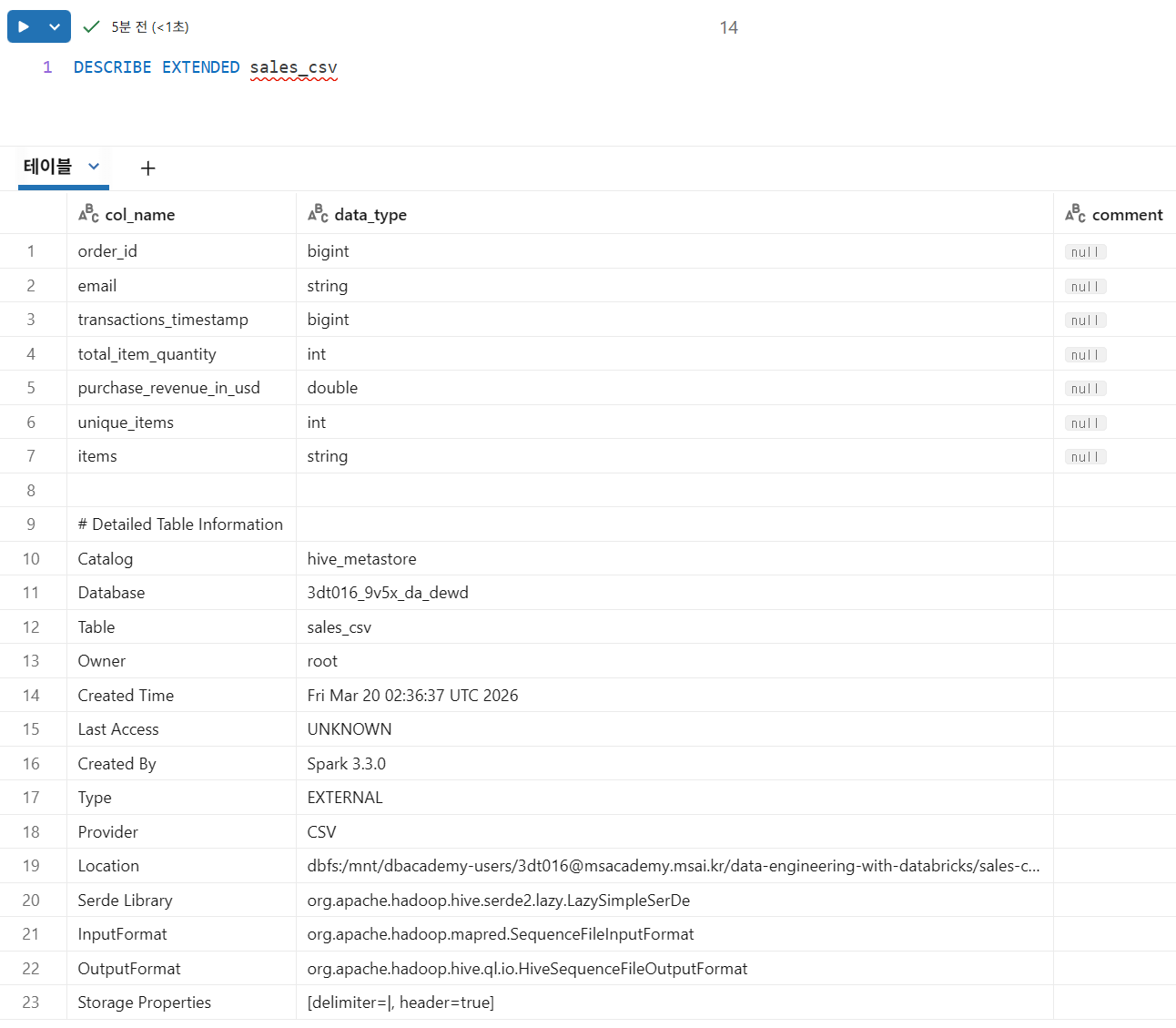
DESCRIBE EXTENDED 테이블명
DESCRIBE DETAIL 테이블명
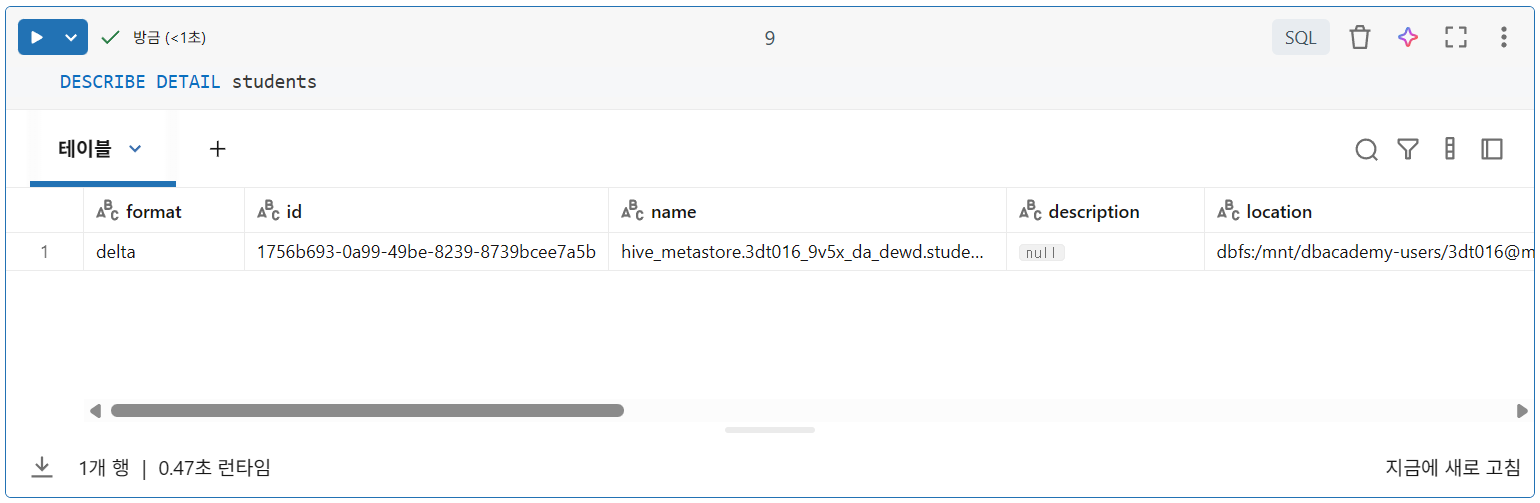
location필드: Delta Lake 테이블이 실제로 클라우드 객체 스토리지에 저장된 파일 모음으로 백업됨을 알 수 있음
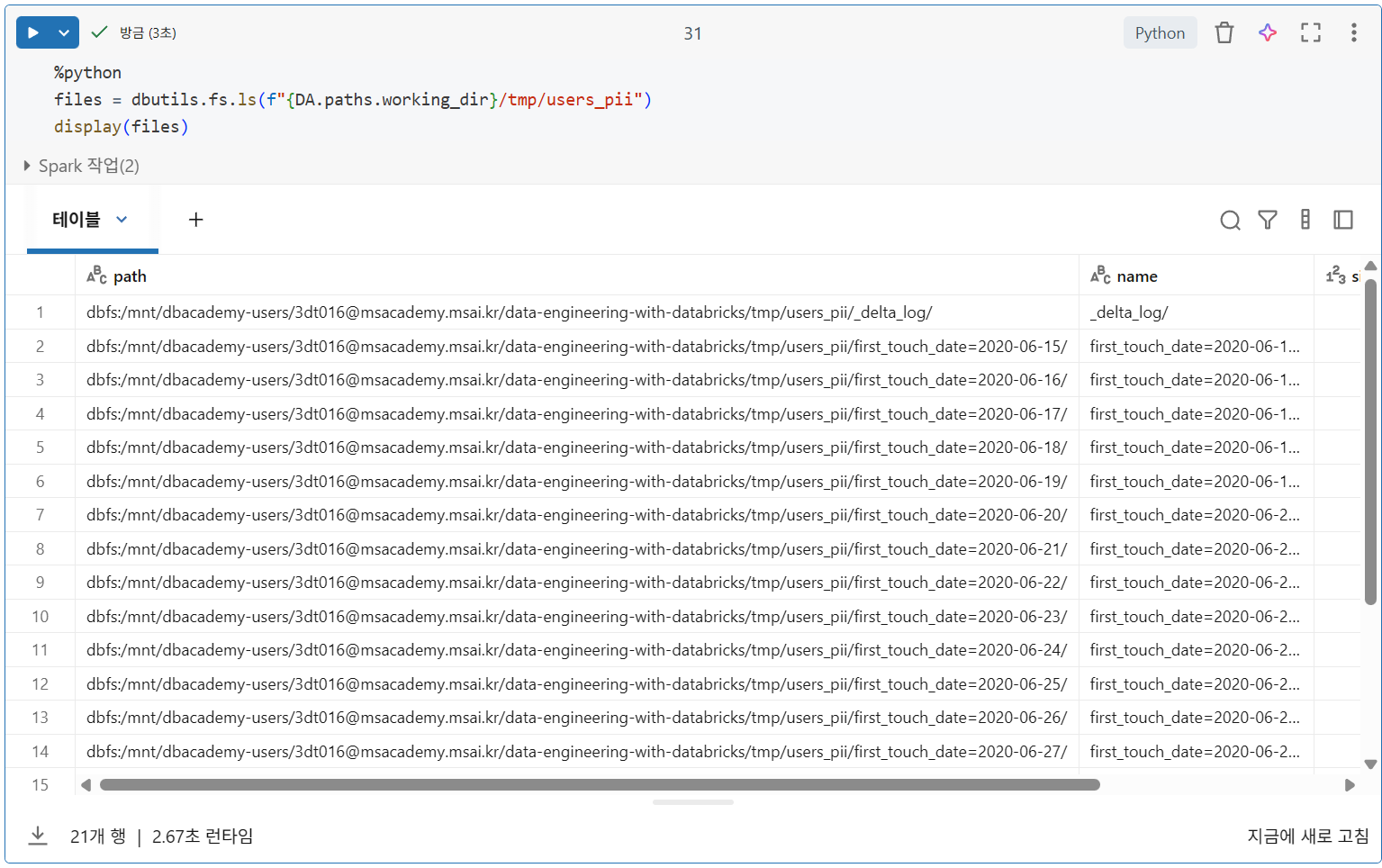
Delta Lake 파일
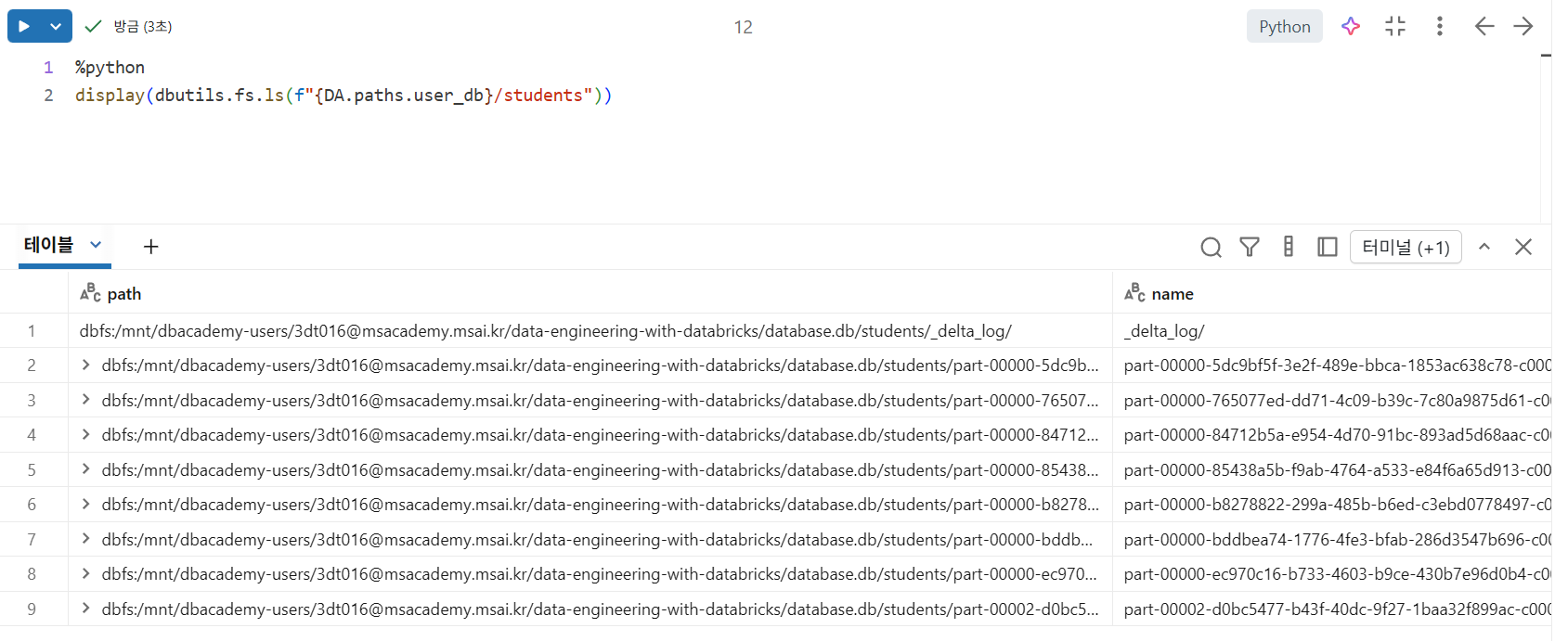
- 디렉토리에는 여러
Parquet 데이터 파일+_delta_log디렉토리 존재
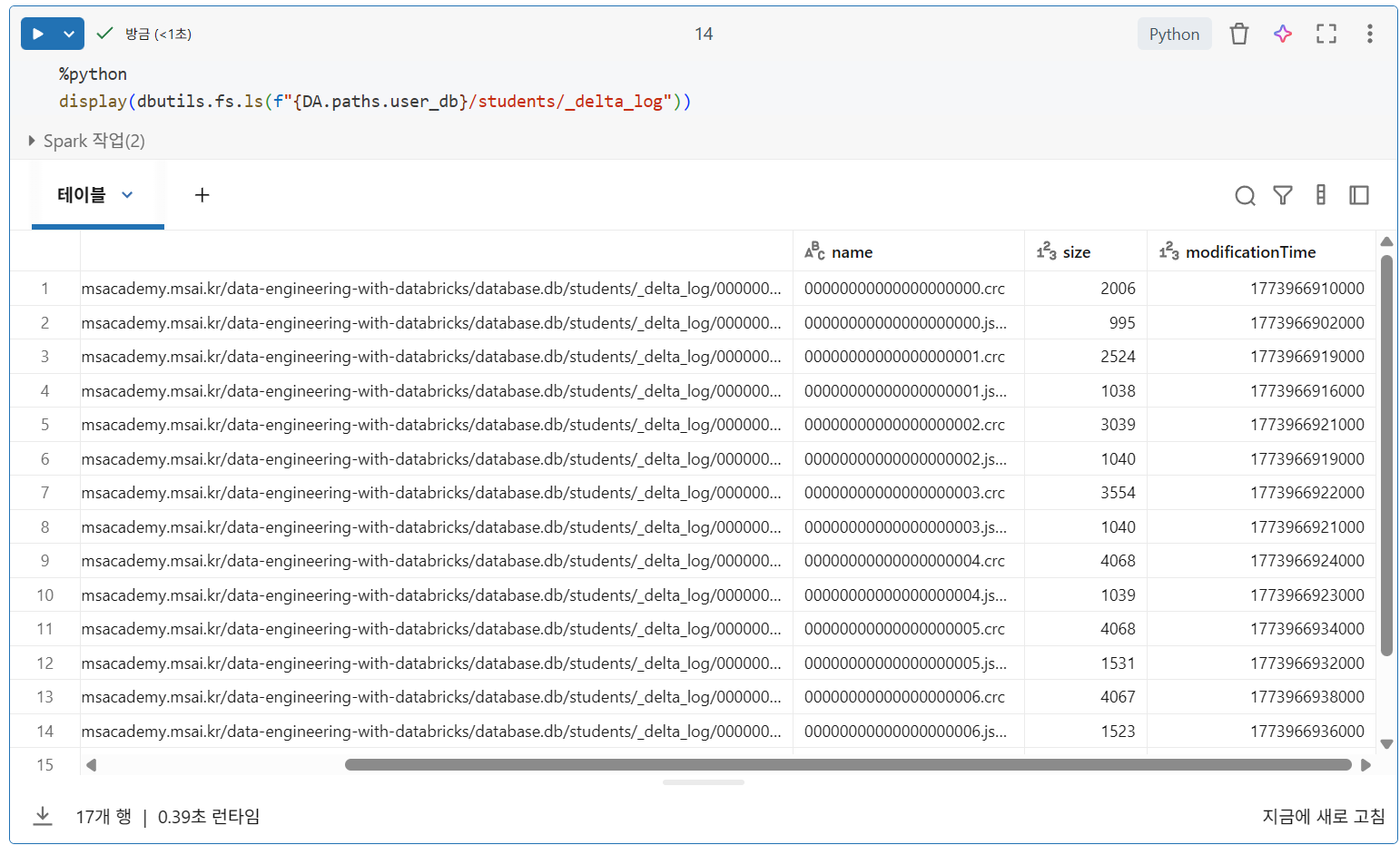
- 각 트랜잭션은 Delta Lake 트랜잭션 로그에 새로운 JSON 파일을 기록
- Delta Lake는 인덱스가 0개
데이터 파일 추론
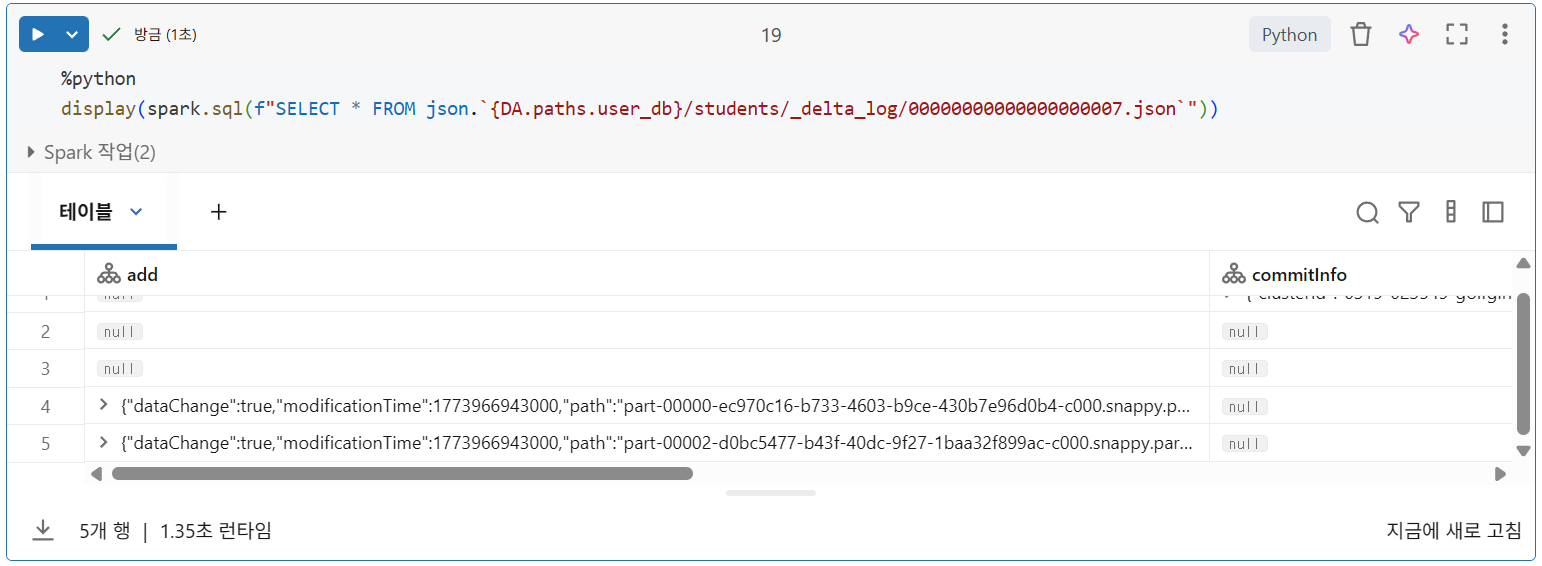
- Delta Lake는 변경된 데이터가 포함된 파일을 덮어쓰거나 즉시 삭제하지 않고 트랜잭션 로그를 사용하여 현재 버전 테이블에서 파일이 유효한지 여부를 나타냄
작은 파일 압축 및 인덱싱
OPTIMIZE 테이블명 ZORDER BY 필드
- 파일이 최적의 크기(테이블 크기에 따라 조정됨)로 결합
- 레코드를 결합하고 결과를 다시 작성하여 기존 데이터 파일을 대체
- 실행할 때 사용자는 선택적으로
ZORDER인덱싱을 위해 하나 또는 여러 개의 필드를 지정- 제공된 필드를 필터링할 때 데이터 파일 내에서 유사한 값을 가진 데이터를 함께 배치하여 데이터 검색 속도를 높임
Delta Lake 트랜잭션 검토
DESCRIBE HISTORY
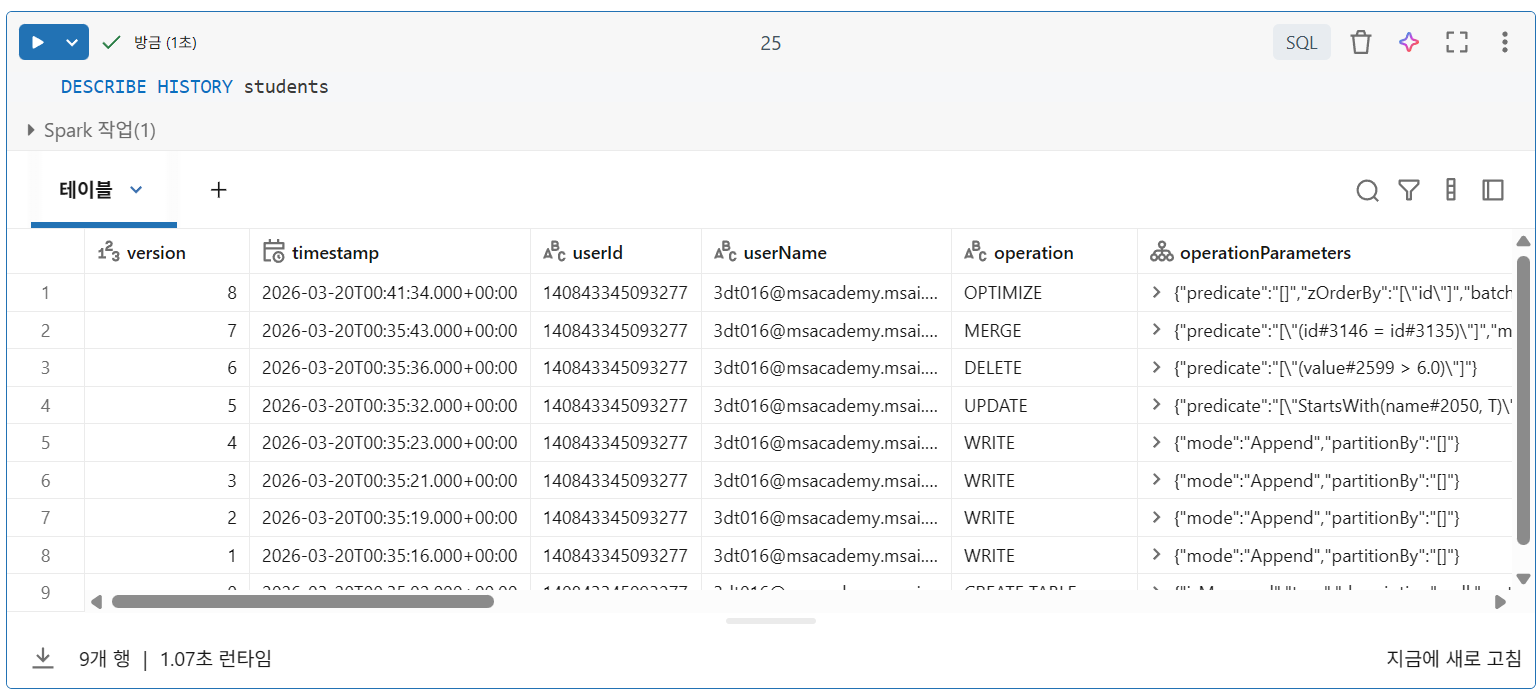
- 이 파일들로 테이블의 이전 버전 쿼리 가능
- 시간 이동 쿼리는 정수 버전 또는 타임스탬프를 지정하여 수행 가능
- 대부분의 경우는 타임스탬프 이용
VERSION AS OF
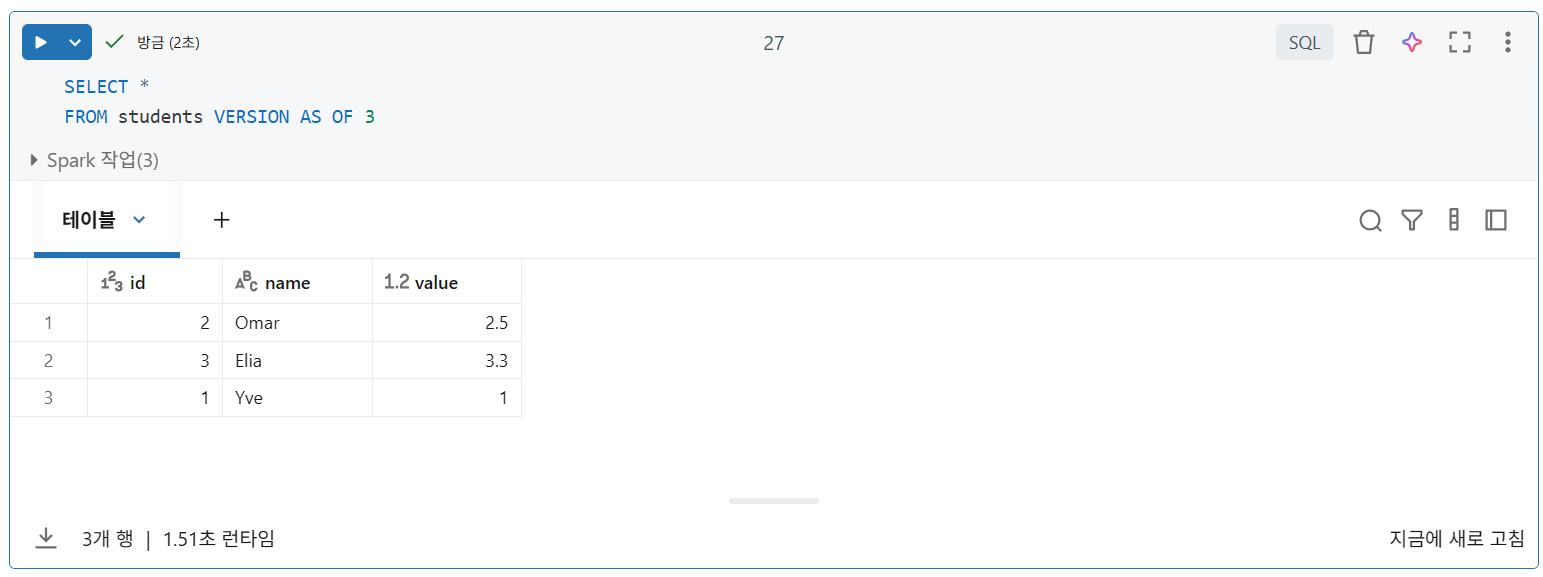
- time travel에서 중요한 점은 현재 버전에 대한 트랜잭션을 취소하여 테이블의 이전 상태를 재생성하는 것이 아니라, 지정된 버전에서 유효하다고 표시된 모든 데이터 파일을 쿼리하는 것
Rollback Versions
DELETE FROM절을 사용했을 때, num_affected_rows 가 -1이라면 전체 데이터 디렉터리가 삭제되었음을 의미
RESTORE TABLE 테이블명 TO VERSION AS OF 버전
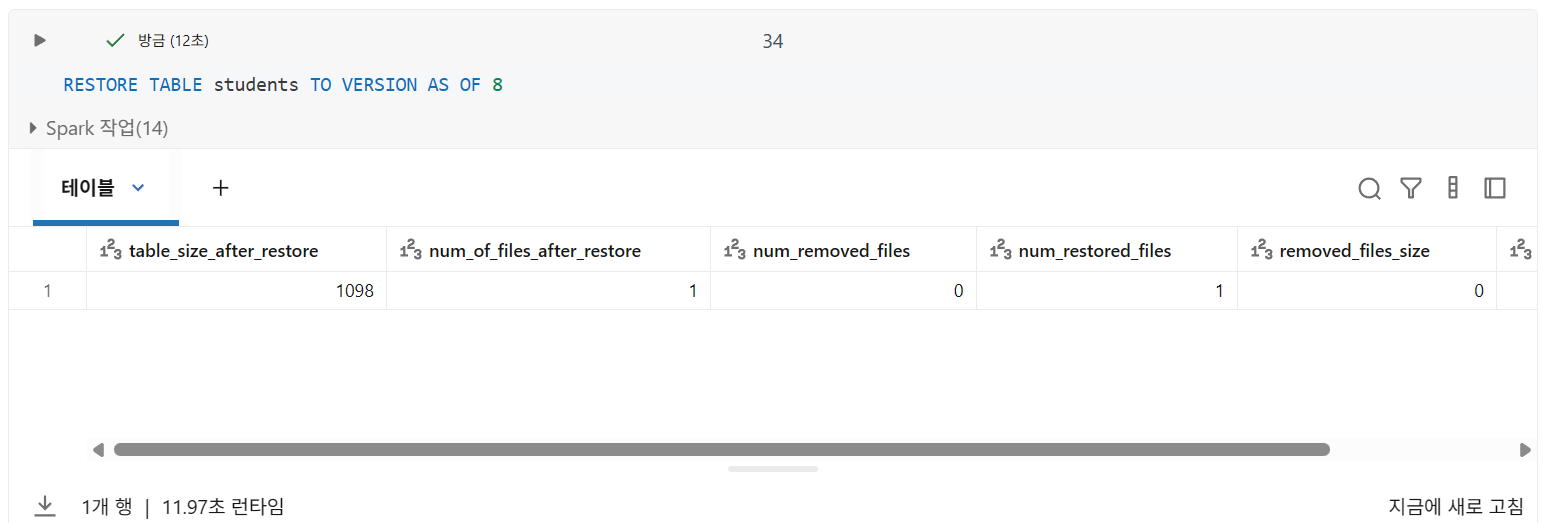
RESTORE명령은 트랜잭션으로 기록됨
오래된 파일 정리
- Databricks는 Delta Lake 테이블의 오래된 파일을 자동으로 정리
- 오래된 데이터 파일을 수동으로 삭제하려면 VACUUM 작업을 사용
- 0 HOURS 보존 기간을 설정하여 실행하면 현재 버전만 유지
- Delta Lake는 일반적으로 7일보다 짧은 기간은 블락하므로, 이를 disable 해야함
- 중요한 데이터 세트에 VACUUM은 파괴적일 수 있으므로 보존 기간을 활성화하는게 바람직
- 데이터 파일의 조기 삭제 방지 체크 해제
SET spark.databricks.delta.retentionDurationCheck.enabled = false; - VACCUM 명령 로깅 활성화
SET spark.databricks.delta.vacuum.logging.enabled = true; - DRY RUN 버전의 vacuum 사용하여 삭제할 모든 레코드 출력(옵션)
VACUUM 테이블 RETAIN 시간 hours [DRY RUN]
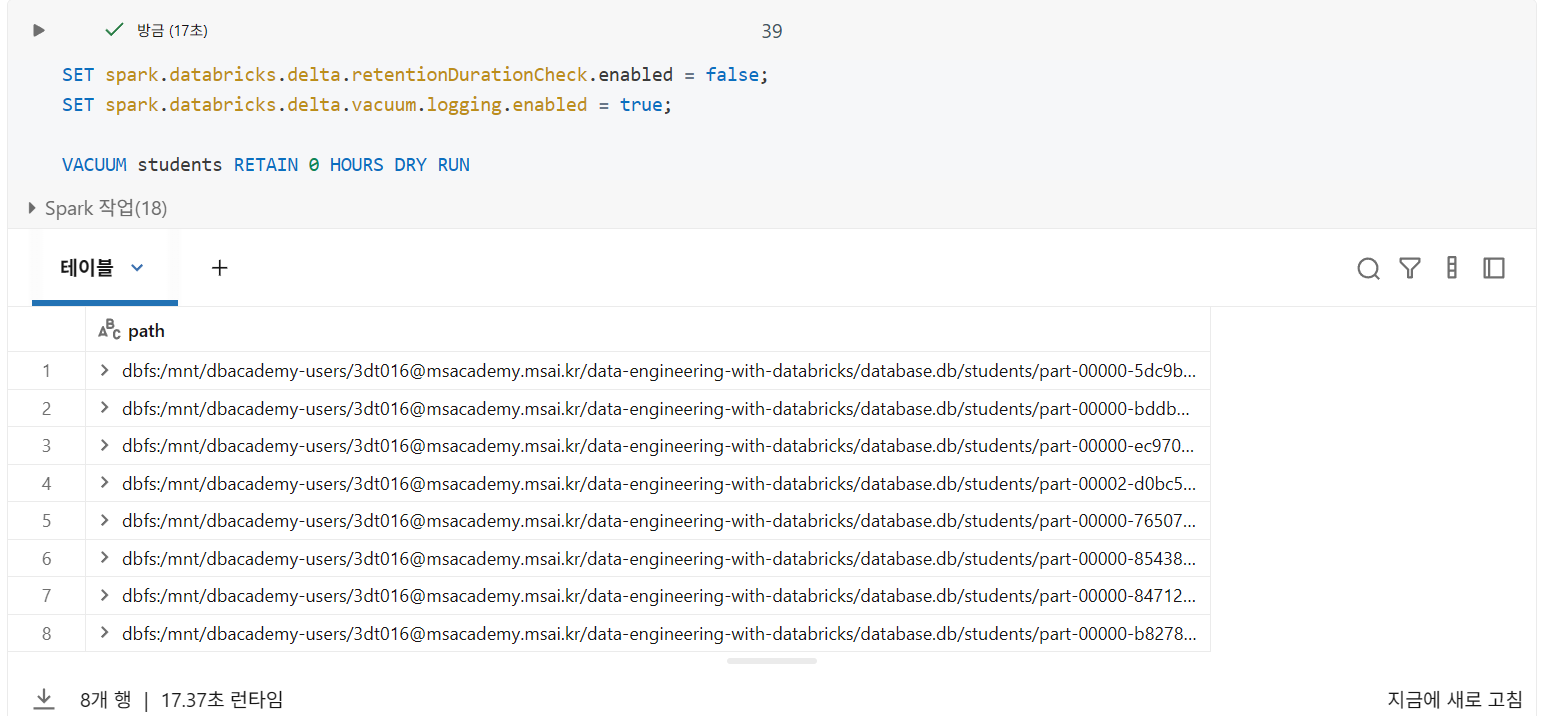
- VACUUM을 실행하고 위의 10개 파일을 삭제하면, 해당 파일이 구현되어야 하는 테이블 버전에 대한 액세스가 영구적으로 제거
- 실제로 제거하려면 DRY RUN을 빼고 실행
- 테이블 디렉터리를 확인하여 파일 제거 확인
64-51c506a239db/image.png)
델타 캐시
델타 캐시는 현재 세션에서 쿼리된 파일의 복사본을 현재 활성 클러스터에 배포된 스토리지 볼륨에 저장하므로 이전 테이블 버전에 일시적으로 액세스할 수 있습니다(단, 시스템은 이러한 동작을 예상하도록 설계되어서는 안 됩니다).
클러스터를 다시 시작하면 캐시된 데이터 파일이 영구적으로 삭제됩니다.
Spark SQL
Spark SQL 을 사용하여 파일에서 직접 데이터 추출
Databricks에서 Spark SQL을 사용하여 파일에서 직접 데이터를 추출하는 방법
- Spark SQL을 사용하여 데이터 파일을 직접 쿼리
- 레이어 뷰 및 CTE를 사용하여 데이터 파일을 더 쉽게 참조
- text 및 binaryFile 메서드를 사용하여 원시 파일 내용을 검토
- 다양한 파일 형식에서 이 옵션을 지원하지만, Parquet 및 JSON과 같은 자체 설명적 데이터 형식에 가장 유용
데이터 개요(Kafka)
이 예제에서는 JSON 파일로 작성된 원시 Kafka 데이터 샘플을 사용
각 파일에는 5초 간격 동안 사용된 모든 레코드가 포함되어 있으며, 전체 Kafka 스키마와 함께 다중 레코드 JSON 파일로 저장
| field | type | description |
|---|---|---|
| key | BINARY | user_id 필드는 키로 사용됩니다. 세션/쿠키 정보에 해당하는 고유한 영숫자 필드입니다. |
| value | BINARY | JSON으로 전송되는 전체 데이터 페이로드(나중에 설명)입니다. |
| topic | STRING | Kafka 서비스는 여러 토픽을 호스팅하지만, clickstream 토픽의 레코드만 여기에 포함됩니다. |
| partition | INTEGER | 현재 Kafka 구현에서는 2개의 파티션(0과 1)만 사용합니다. |
| offset | LONG | 각 파티션에 대해 단조롭게 증가하는 고유한 값입니다. |
| 타임스탬프 | LONG | 이 타임스탬프는 에포크 이후 밀리초 단위로 기록되며, 프로듀서가 파티션에 레코드를 추가하는 시간을 나타냅니다. |
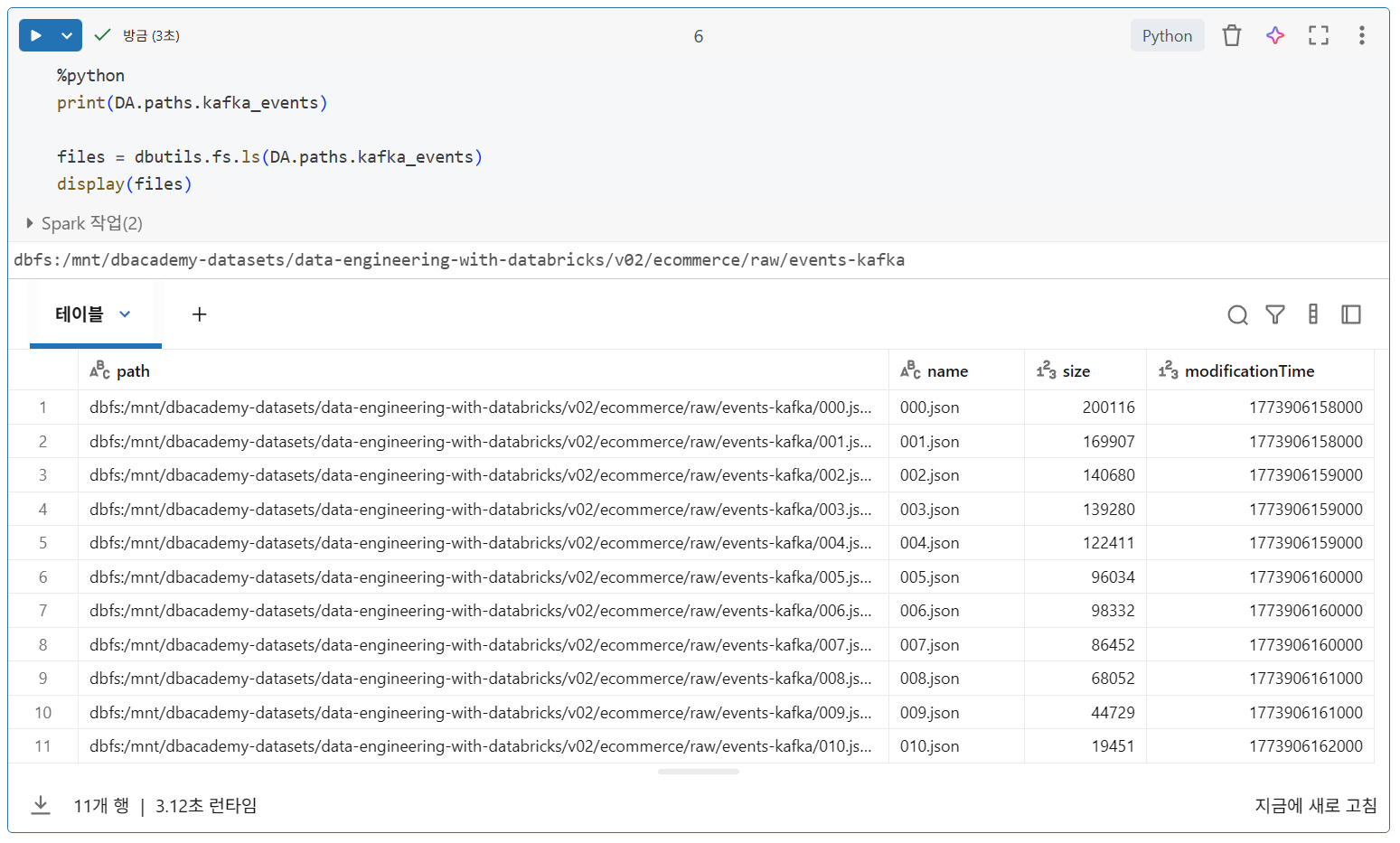
- DBFS 루트에 기록된 데이터의 상대 파일 경로를 사용
- 대부분의 워크플로에서는 사용자가 외부 클라우드 스토리지 위치의 데이터에 액세스
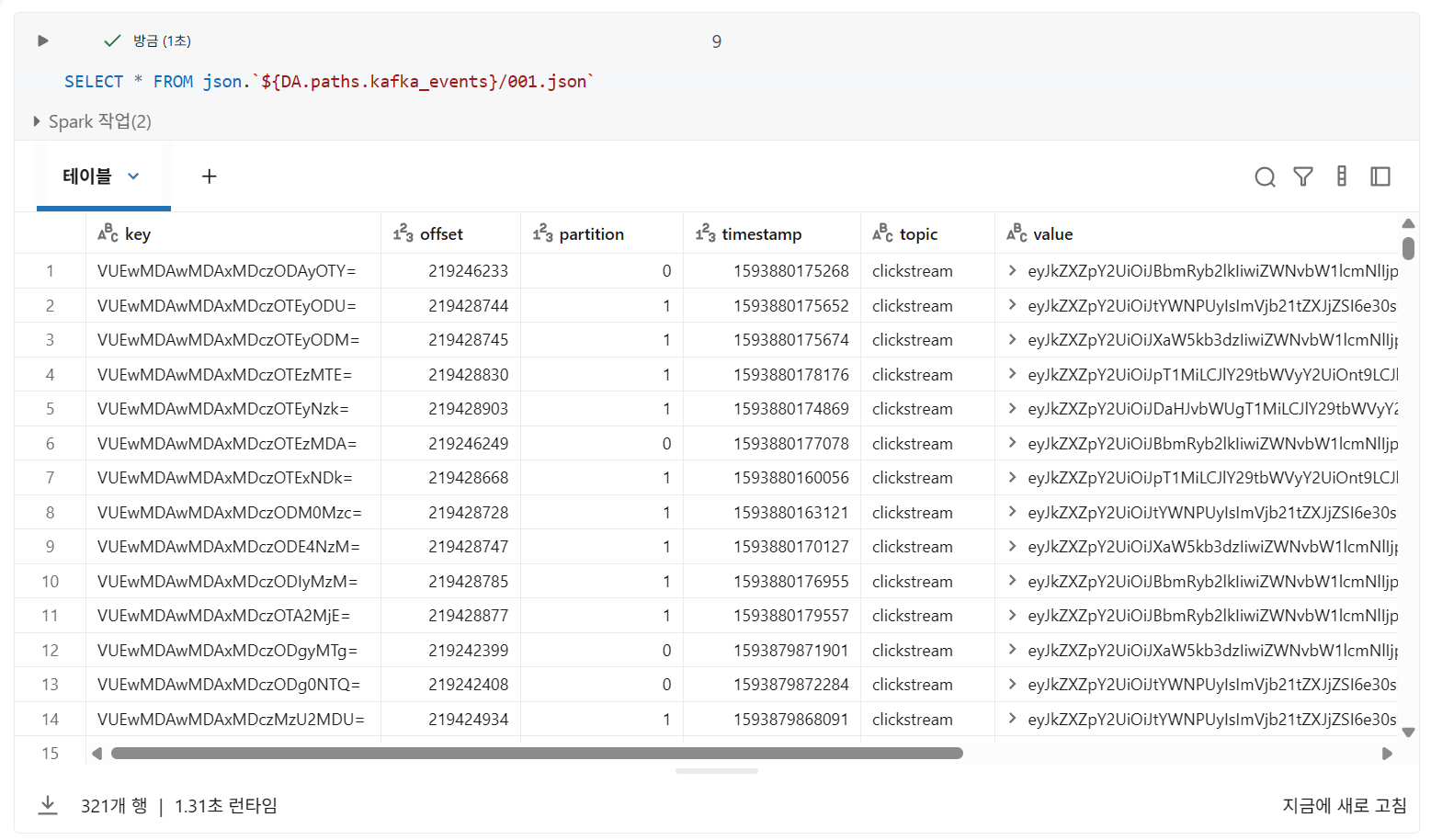
단일 파일 쿼리
SELECT * FROM file_format.`/path/to/file`
- 경로를 작은따옴표가 아닌 백틱(')으로 묶어야 함
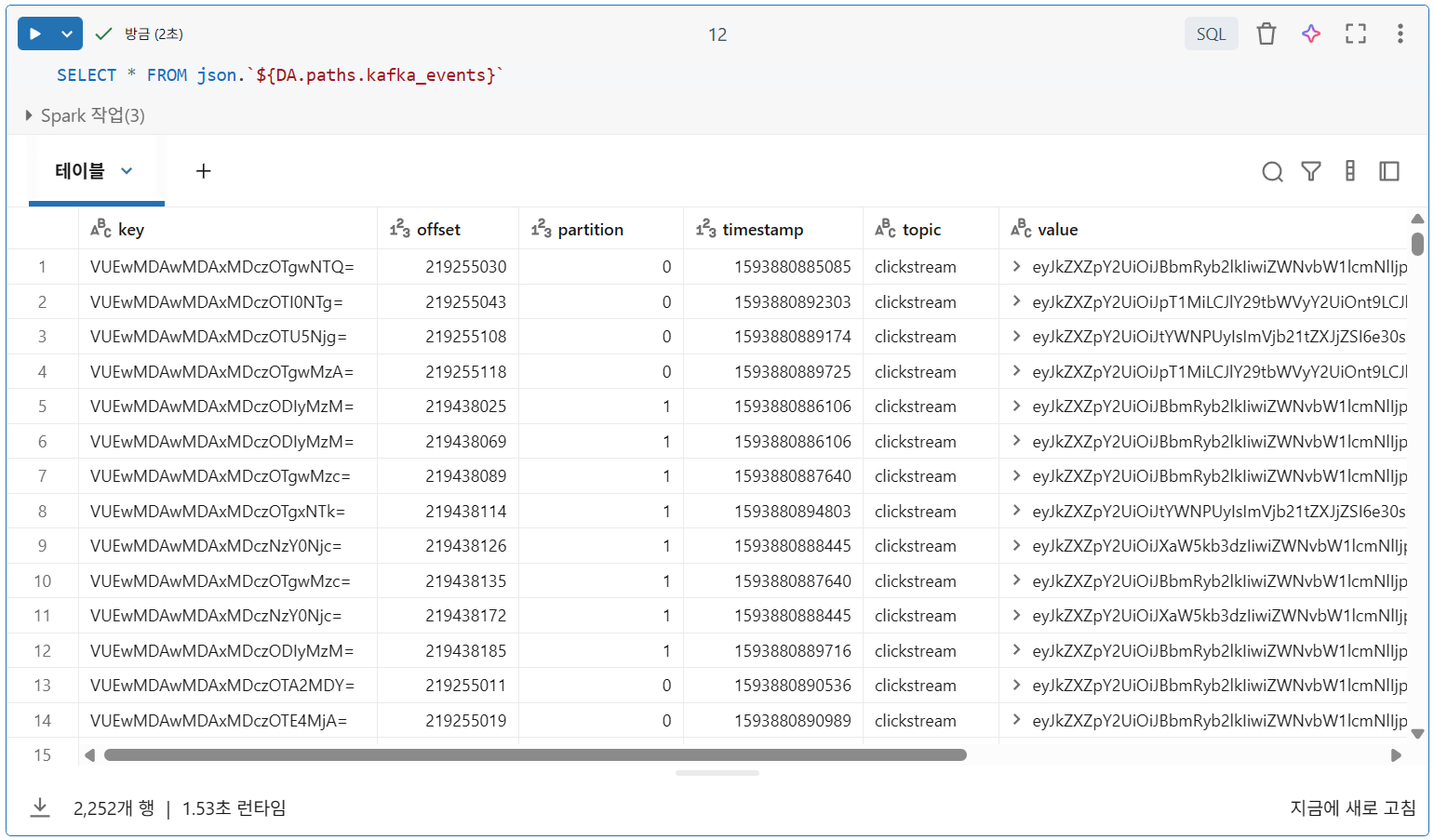
파일 디렉터리 쿼리
SELECT * FROM file_format.`${DA.paths.kafka_events}`
- 디렉토리에 있는 모든 파일의 형식과 스키마가 동일하다고 가정할 경우, 개별 파일 대신 디렉터리 경로를 지정하여 모든 파일을 동시에 쿼리 가능
외부 소스 옵션 제공
- Spark SQL을 사용하여 외부 소스에서 데이터를 추출하는 옵션을 구성
- 다양한 파일 형식에 대해 외부 데이터 소스에 대한 테이블을 생성
- 외부 소스에 대해 정의된 테이블을 쿼리할 때의 기본 동작을 설명
- 외부 데이터 소스는 아직 Delta Lake 형식으로 저장되지 않으므로 Lakehouse에 최적화되지 않지만, 이 기법은 다양한 외부 시스템에서 데이터를 추출하는 데 도움
직접 쿼리가 작동하지 않는 경우
- CSV 파일은 가장 일반적인 파일 형식 중 하나이지만, 이러한 파일에 대한 직접 쿼리를 실행해도 원하는 결과를 얻는 경우는 드물다.
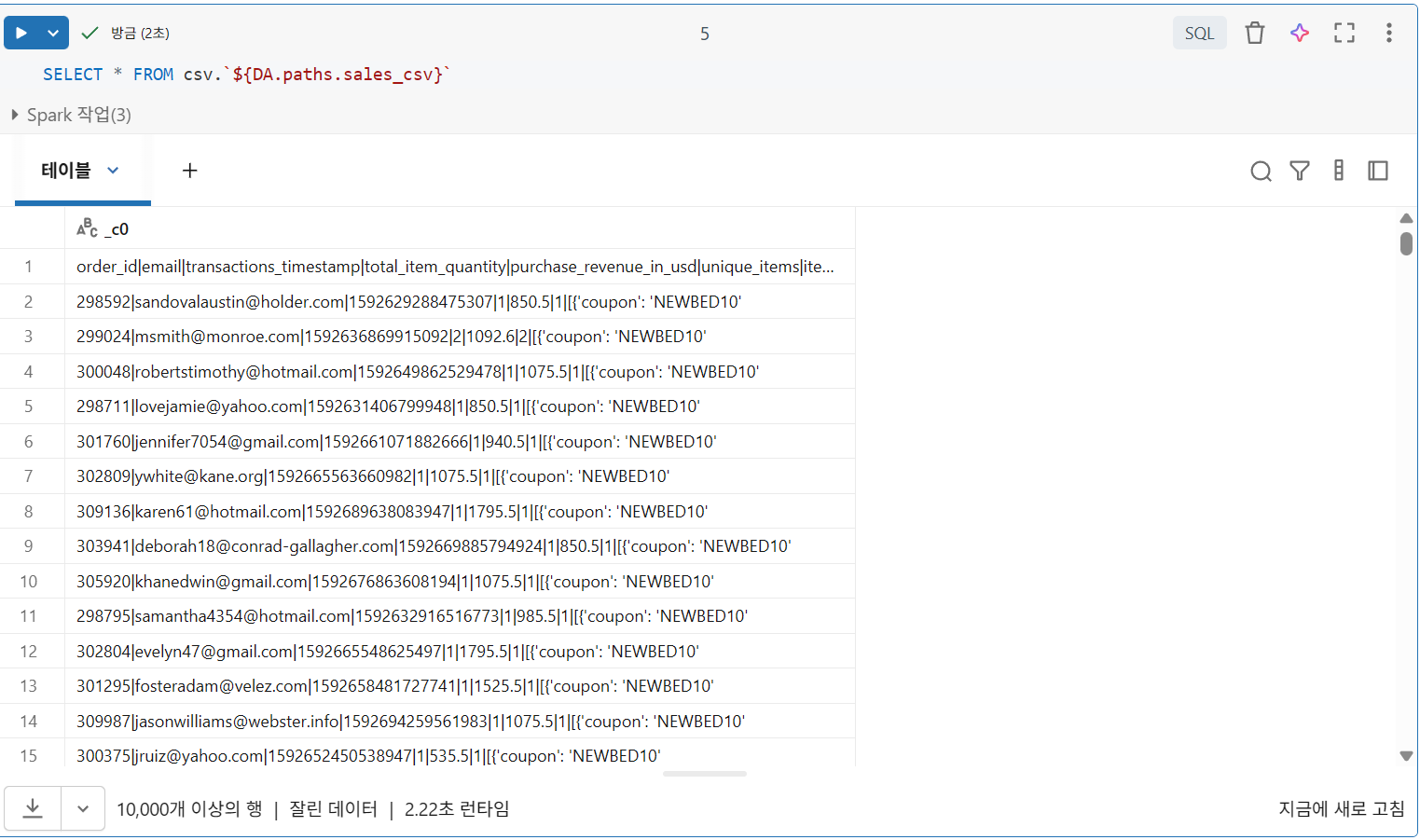
컬럼 분리가 되어있지 않음
읽기 옵션을 사용하여 외부 데이터에 테이블 등록
- Spark는 기본 설정을 사용하여 일부 자체 설명적 데이터 소스를 효율적으로 추출하지만, 많은 형식에서는 스키마 선언이나 기타 옵션이 필요
- 옵션은 키는 따옴표 없이, 값은 따옴표로 묶어 전달
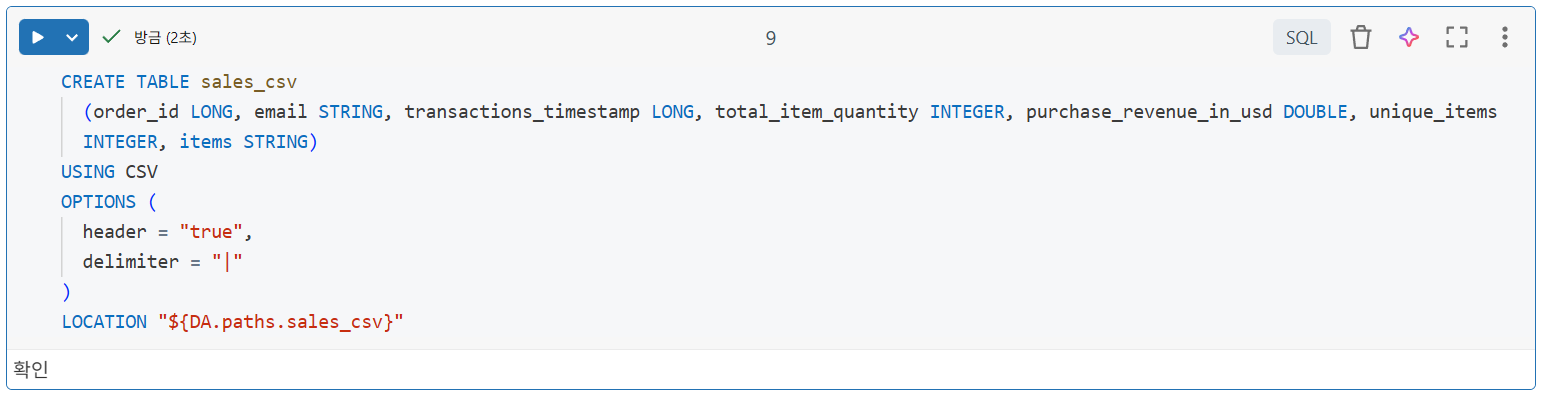
CREATE TABLE 테이블 (col_name1 col_type1, ...)
USING 파일형식
OPTIONS (
header = "val1",
delimiter = "val2",
key = "value",
...
)
LOCATION = path지정할 부분
- 열 이름 및 유형
- 파일 형식
- 필드를 구분하는 데 사용되는 구분 기호
- 헤더 존재 여부
- 이 데이터가 저장된 경로
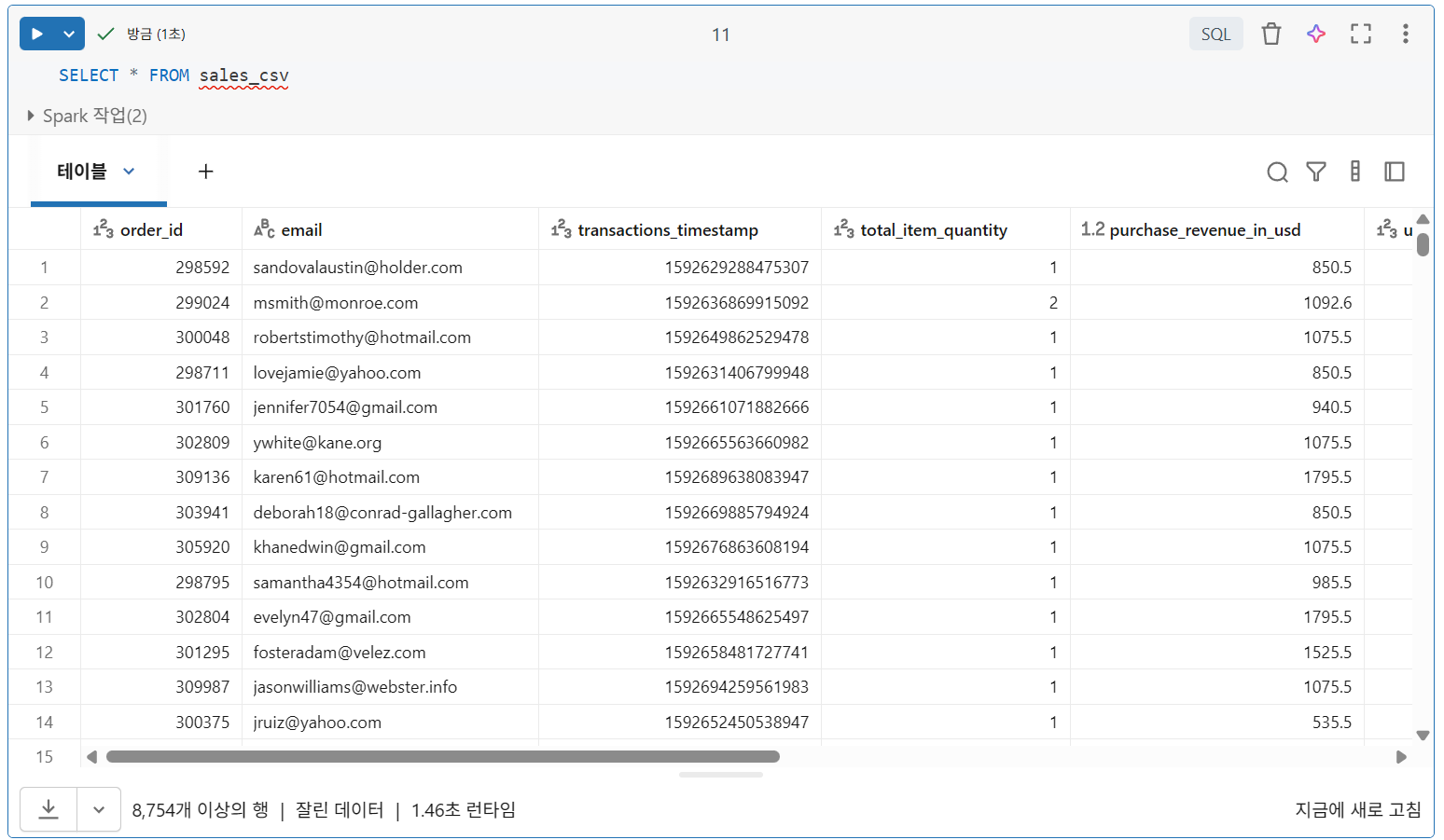
참고: CSV를 데이터 소스로 사용하는 경우, 소스 디렉터리에 추가 데이터 파일이 추가되더라도 열 순서가 변경되지 않도록 해야 함. 이 데이터 형식은 스키마를 엄격하게 적용하지 않으므로 Spark는 테이블 선언 시 지정된 순서대로 열을 로드하고 열 이름과 데이터 유형을 적용
외부 데이터 소스를 사용한 테이블의 한계
- 외부 데이터 소스에 대한 테이블이나 쿼리를 정의할 때 Delta Lake 및 Lakehouse와 관련된 성능 보장을 기대할 수 없음
- Delta Lake 테이블은 항상 최신 버전의 소스 데이터를 쿼리하도록 보장하지만, 다른 데이터 소스에 등록된 테이블은 이전에 캐시된 버전을 나타낼 수 있음
- 외부 데이터 소스는 Spark에 이 데이터를 새로 고침하도록 구성되어 있지 않음
수동 캐시 새로고침
REFRESH TABLE 테이블명
- 테이블을 새로 고치면 캐시가 무효화되므로 원래 데이터 소스를 다시 스캔하고 모든 데이터를 메모리로 다시 가져와야 함
SQL 데이터베이스에서 데이터 추출
- 참고: SQLite는 로컬 파일을 사용하여 데이터베이스를 저장하며 포트, 사용자 이름 또는 비밀번호를 요구하지 않음
- 경고: JDBC 서버의 백엔드 구성은 이 노트북을 단일 노드 클러스터에서 실행한다고 가정. 여러 워커가 있는 클러스터에서 실행하는 경우, 실행기에서 실행 중인 클라이언트는 드라이버에 연결할 수 없음
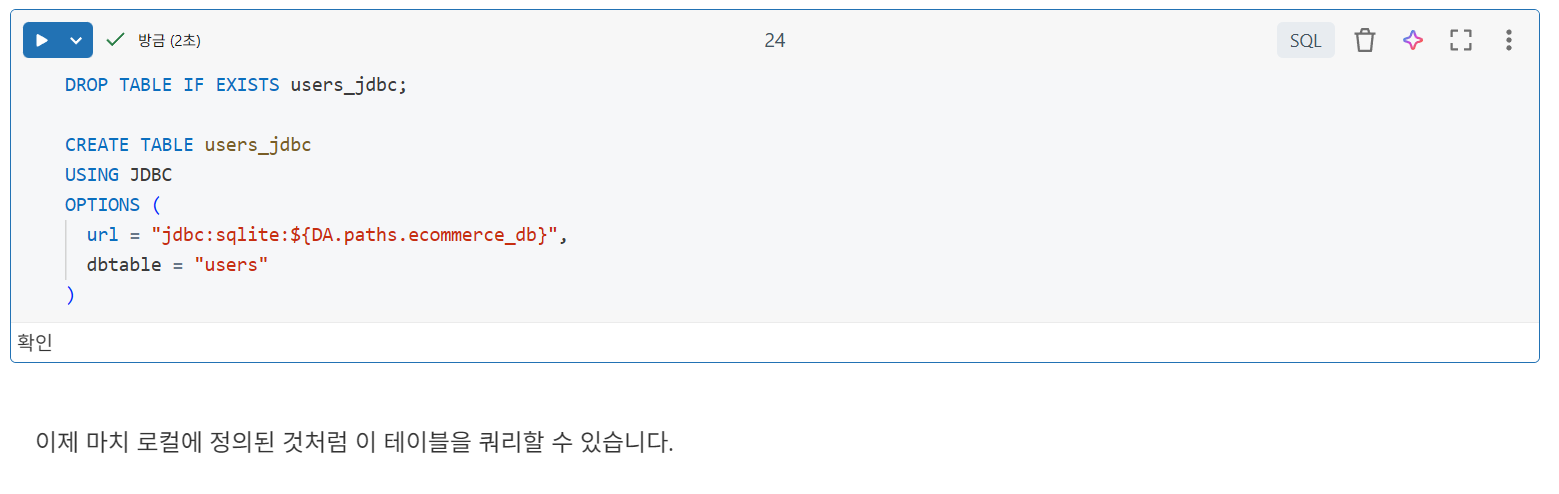
CREATE TABLE
USING JDBC
OPTIONS (
url = "jdbc:{databaseServerType}://{jdbcHostname}:{jdbcPort}",
dbtable = "{jdbcDatabase}.table",
user = "{jdbcUsername}",
password = "{jdbcPassword}"
)
- 테이블 메타데이터 확인시 외부 시스템에서 스키마 정보 캡처 확인 가능
- 저장소 속성(연결과 관련된 사용자 이름, 비밀번호)는 자동으로 삭제
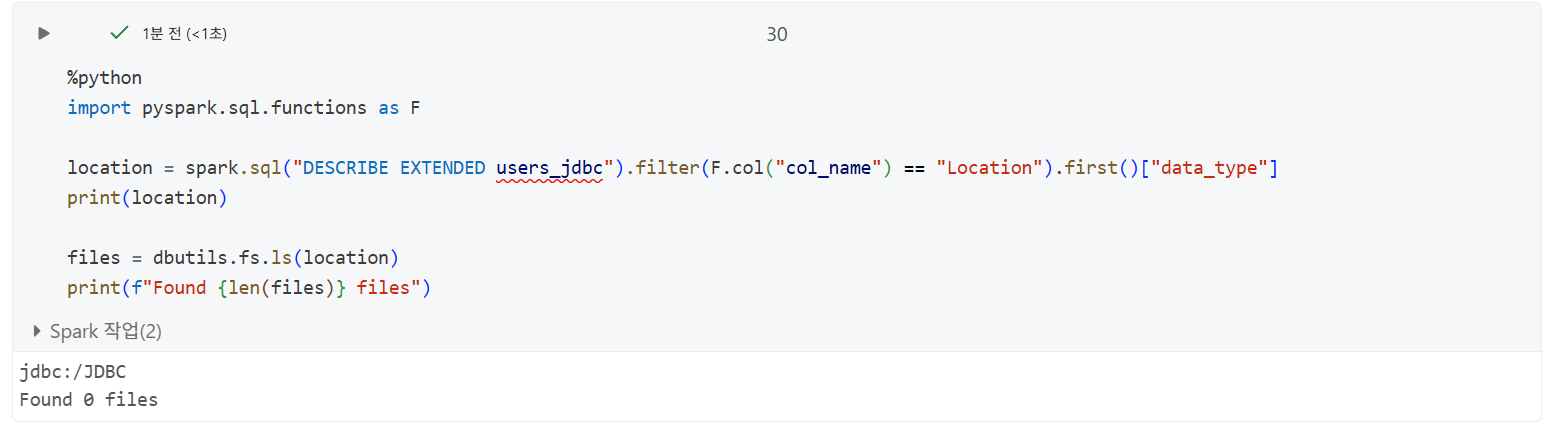
- 지정된 위치의 콘텐츠 나열 시 로컬에 데이터가 저장되지 않음 확인 가능
-
데이터웨어하우스와 같은 일부 SQL 시스템에는 사용자 지정 드라이버가 존재
-
Spark는 다양한 외부 데이터베이스와 서로 다르게 상호 작용하지만, 두 가지 기본적인 접근 방식은 다음과 같음
1. 전체 소스 테이블을 Databricks로 이동한 다음 현재 활성 클러스터에서 로직을 실행
2. 쿼리를 외부 SQL 데이터베이스로 푸시하고 결과만 Databricks로 다시 전송 -
두 경우 모두 외부 SQL 데이터베이스에서 매우 큰 데이터 세트를 사용하면 다음과 같은 이유로 상당한 오버헤드가 발생
1. 공용 인터넷을 통해 모든 데이터를 이동하는 데 따른 네트워크 전송 지연 시간
2. 빅데이터 쿼리에 최적화되지 않은 소스 시스템에서 쿼리 로직을 실행
델타 테이블 생성
- CTAS 문을 사용하여 Delta Lake 테이블 생성
- 기존 뷰 또는 테이블에서 새 테이블 생성
- 추가 메타데이터로 로드된 데이터 보강
- 생성된 열과 설명 주석을 사용하여 테이블 스키마 선언
- 데이터 위치, 품질 적용 및 파티셔닝을 제어하는 고급 옵션 설정
- 외부 데이터 소스에서 데이터를 추출한 후, Databricks 플랫폼의 모든 이점을 최대한 활용할 수 있도록 Lakehouse에 데이터를 로드
- 일반적으로 초기 테이블은 대부분 원시 데이터 버전을 나타내고 유효성 검사 및 보강은 이후 단계에서 수행하는 것이 좋음
- 이 패턴을 사용하면 데이터 유형이나 열 이름이 예상과 일치하지 않더라도 데이터가 삭제되지 않으므로 프로그래밍 방식이나 수동 작업을 통해 부분적으로 손상되었거나 유효하지 않은 상태의 데이터를 복구 가능
SELECT 로 테이블 생성(CTAS)
CREATE TABLE AS SELECT 문은 입력 쿼리에서 검색된 데이터를 사용하여 델타 테이블을 생성하고 채움
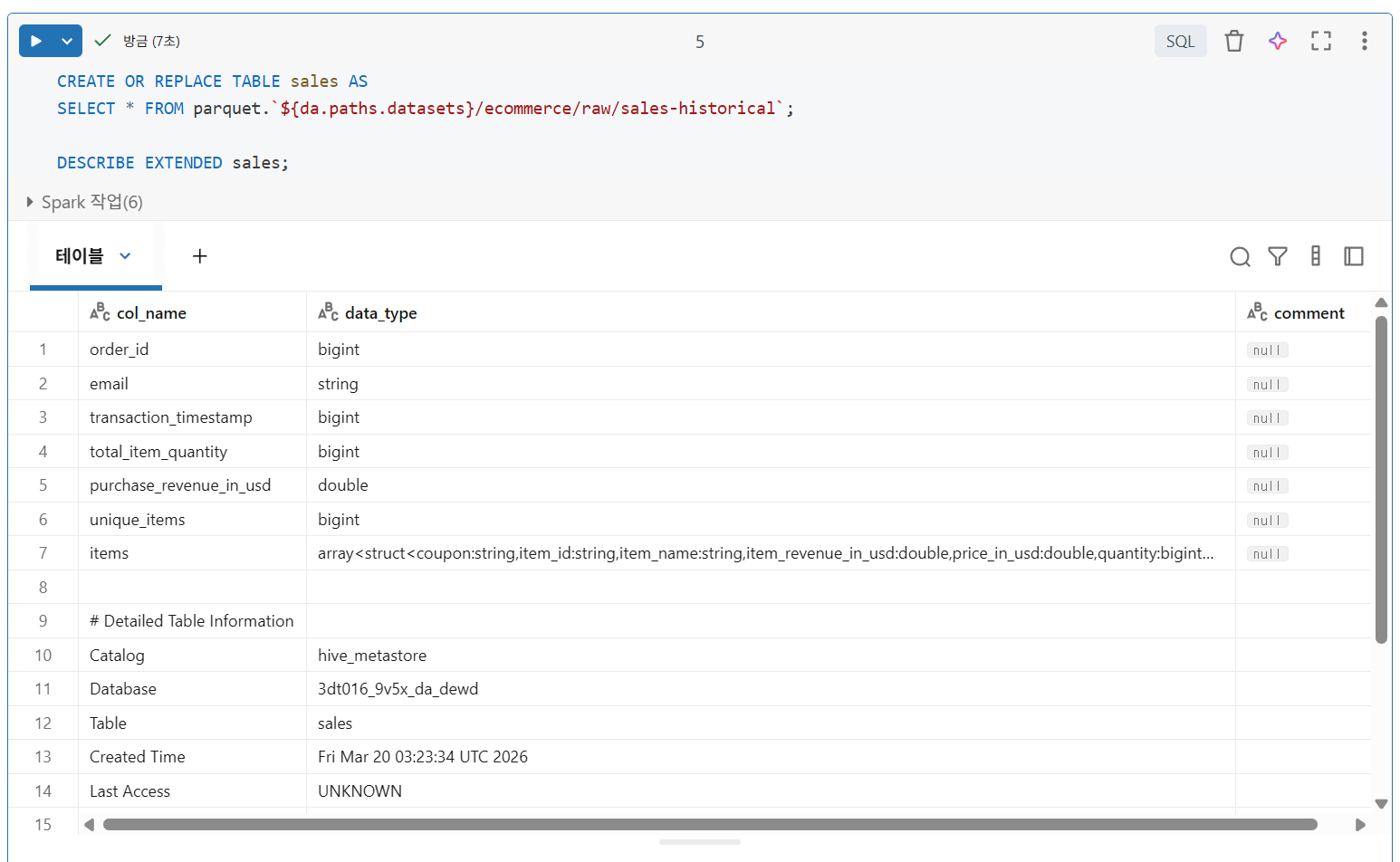
- CTAS 명령문은 쿼리 결과에서 스키마 정보를 자동으로 유추하며, 수동 스키마 선언은 지원X
- CTAS 명령문은 Parquet 파일 및 테이블과 같이 스키마가 잘 정의된 소스에서 외부 데이터를 수집하는 데 유용
- CTAS 명령문은 추가 파일 옵션 지정도 지원X
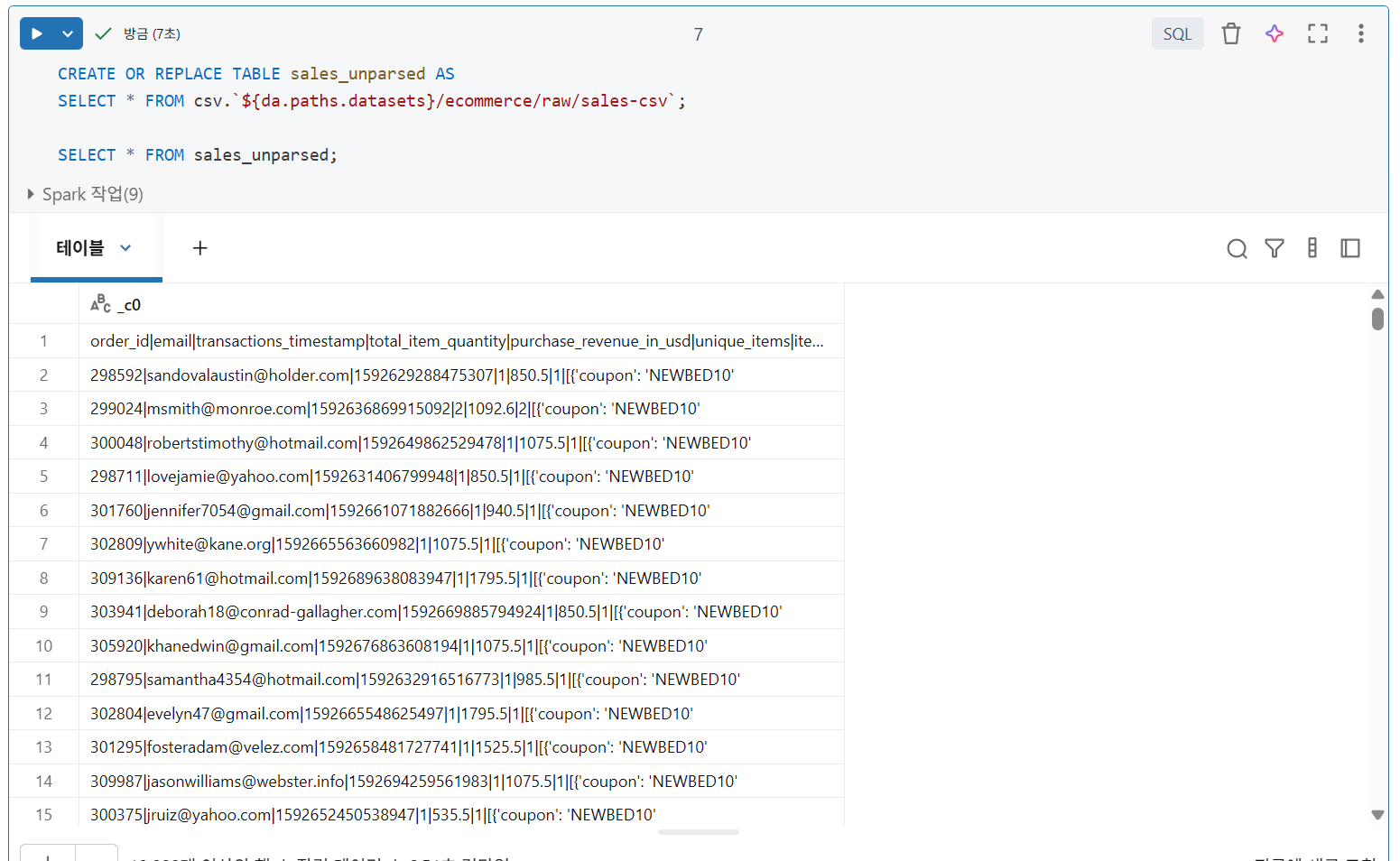
- 이 데이터를 Delta Lake 테이블에 올바르게 수집하려면 옵션을 지정할 수 있는 파일 참조를 사용
- 임시 뷰에 옵션을 지정한 다음, 이 임시 뷰를 CTAS 명령문의 소스로 사용하여 Delta 테이블을 성공적으로 등록 가능
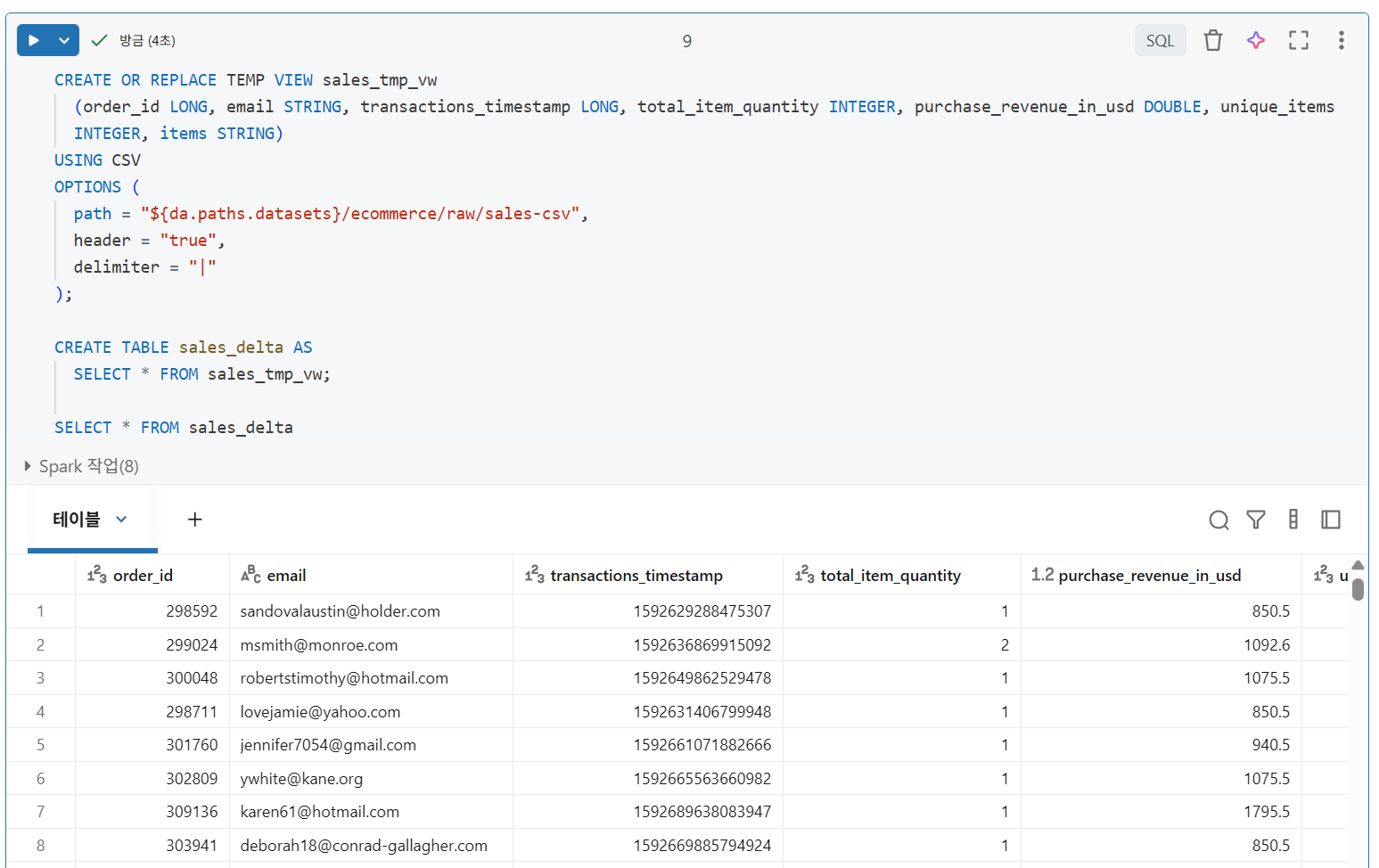
기존 테이블의 열 필터링 및 이름 바꾸기
-
열 이름을 변경하거나 대상 테이블에서 열을 제외하는 것과 같은 간단한 변환은 테이블 생성 중에 쉽게 수행
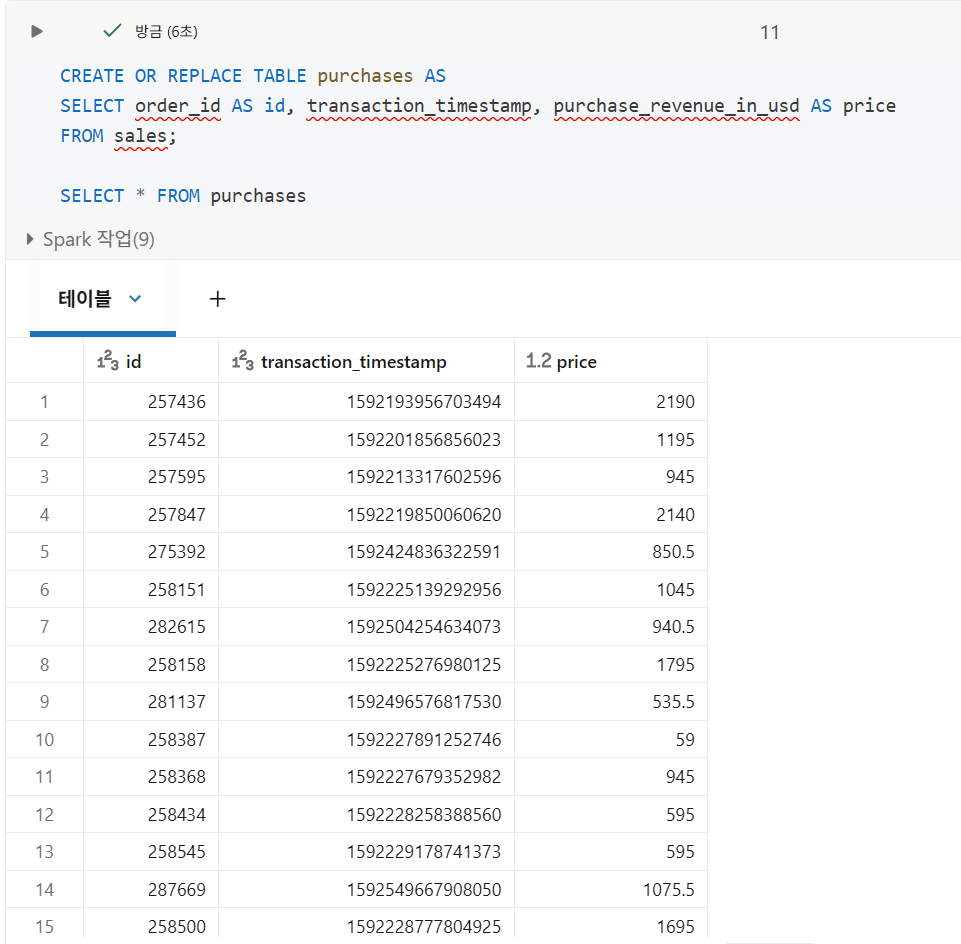
-
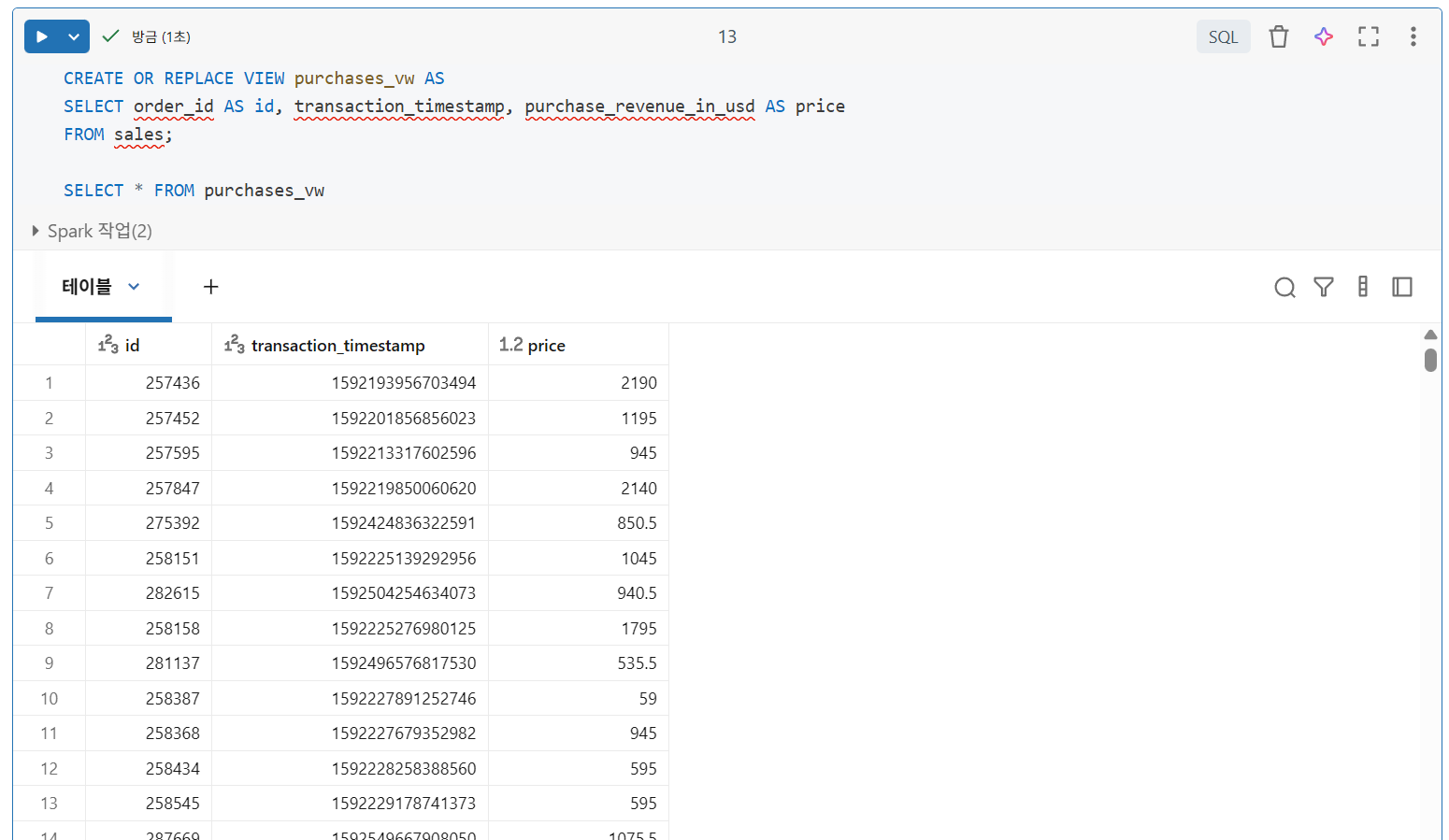
뷰도 동일하게 사용 가능
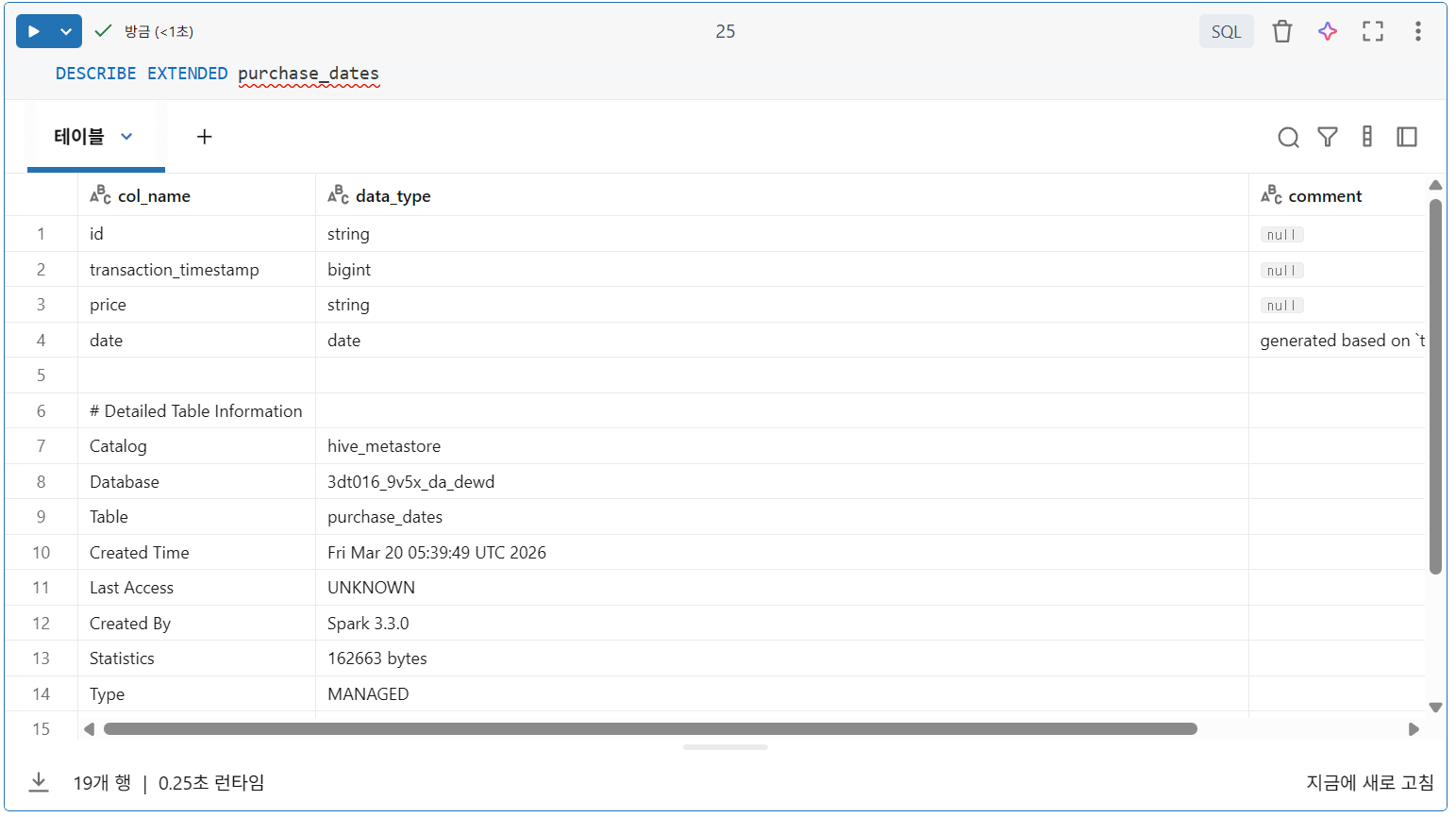
생성된 열로 스키마 선언
- 열 이름 및 유형 지정
- 날짜를 계산하기 위해 생성된 열 추가
- 생성된 열에 대한 설명적인 열 주석 제공
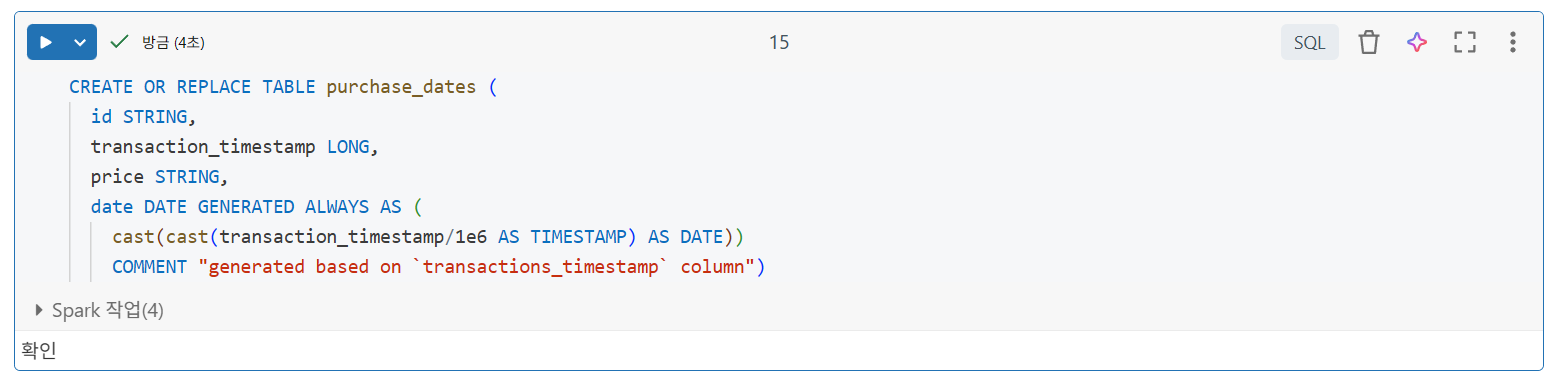
date는 생성된 열이므로,date열에 값을 제공하지 않고purchase_dates에 값을 입력하면 Delta Lake에서 자동으로 계산
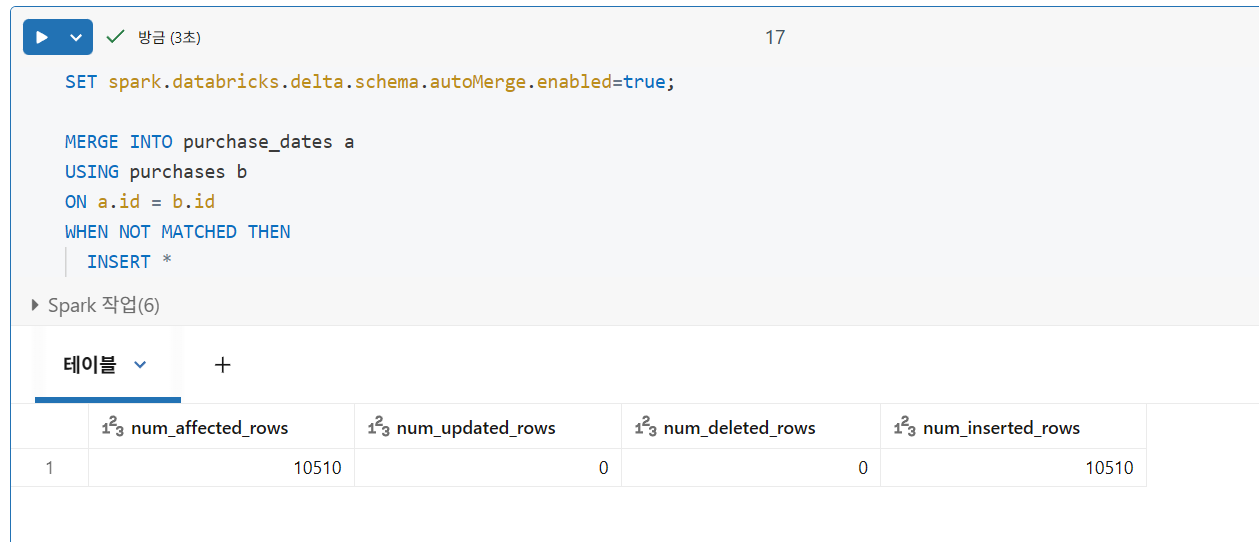
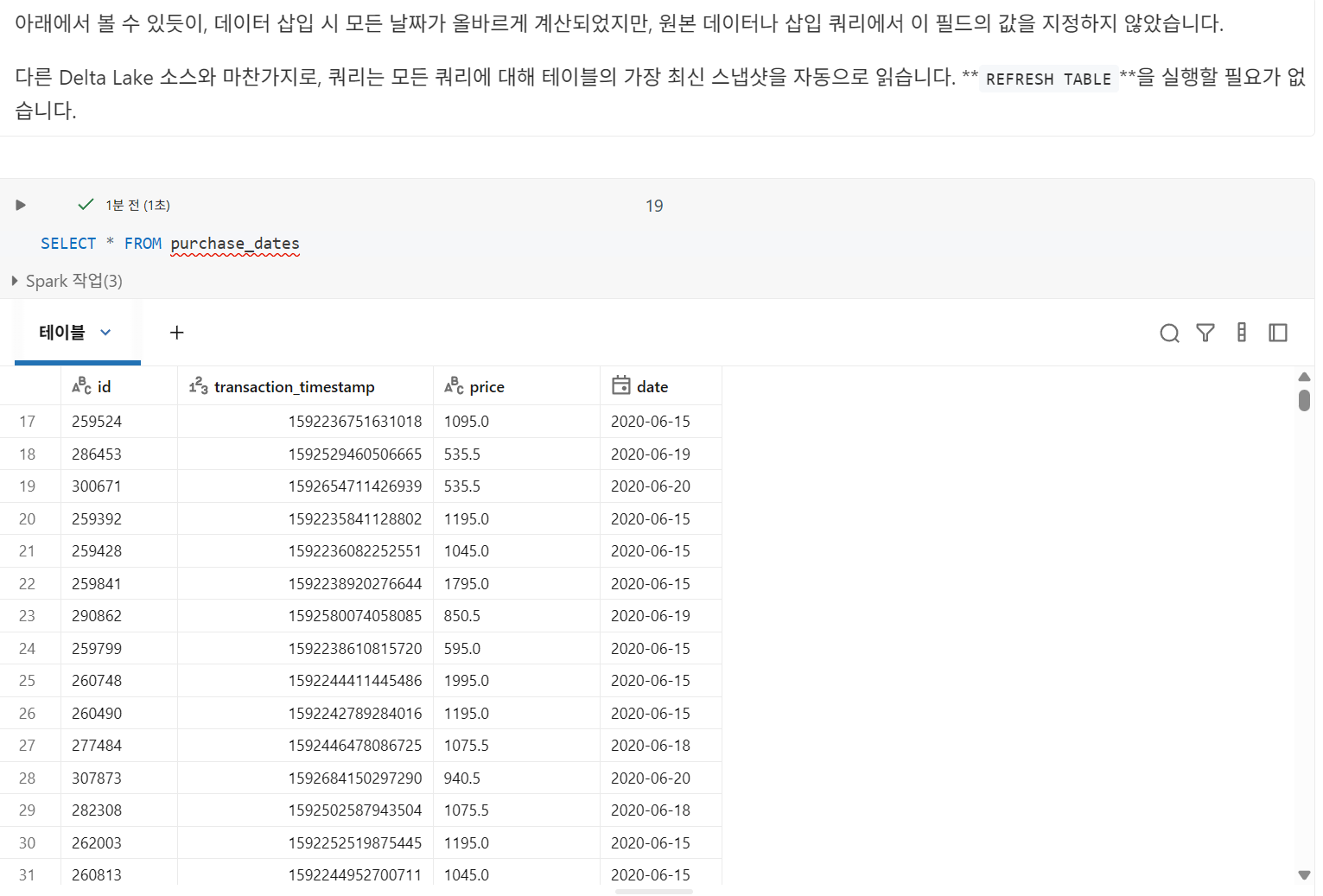
테이블에 삽입할 때 생성될 필드가 포함된 경우, 제공된 값이 생성된 열을 정의하는 데 사용된 로직에서 도출되는 값과 정확히 일치하지 않으면 삽입 작업이 실패
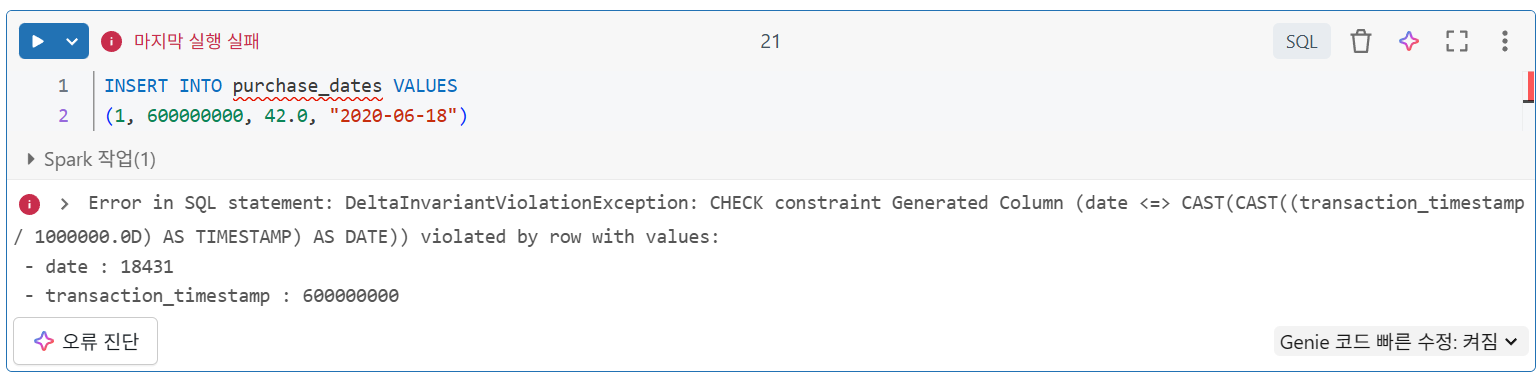
테이블 제약 조건 추가
- 위의 오류 메시지는 CHECK 제약 조건과 관련이 있습니다. 생성된 열은 CHECK 제약 조건의 특수 구현
- Delta Lake는 쓰기 시 스키마를 적용하므로 Databricks는 표준 SQL 제약 조건 관리 절을 지원하여 테이블에 추가되는 데이터의 품질과 무결성을 보장
- Databricks는 현재 두 가지 유형의 제약 조건을 지원
- NOT NULL 제약 조건
- CHECK 제약 조건
- 테이블 제약 조건은 TBLPROPERTIES 필드에 표시

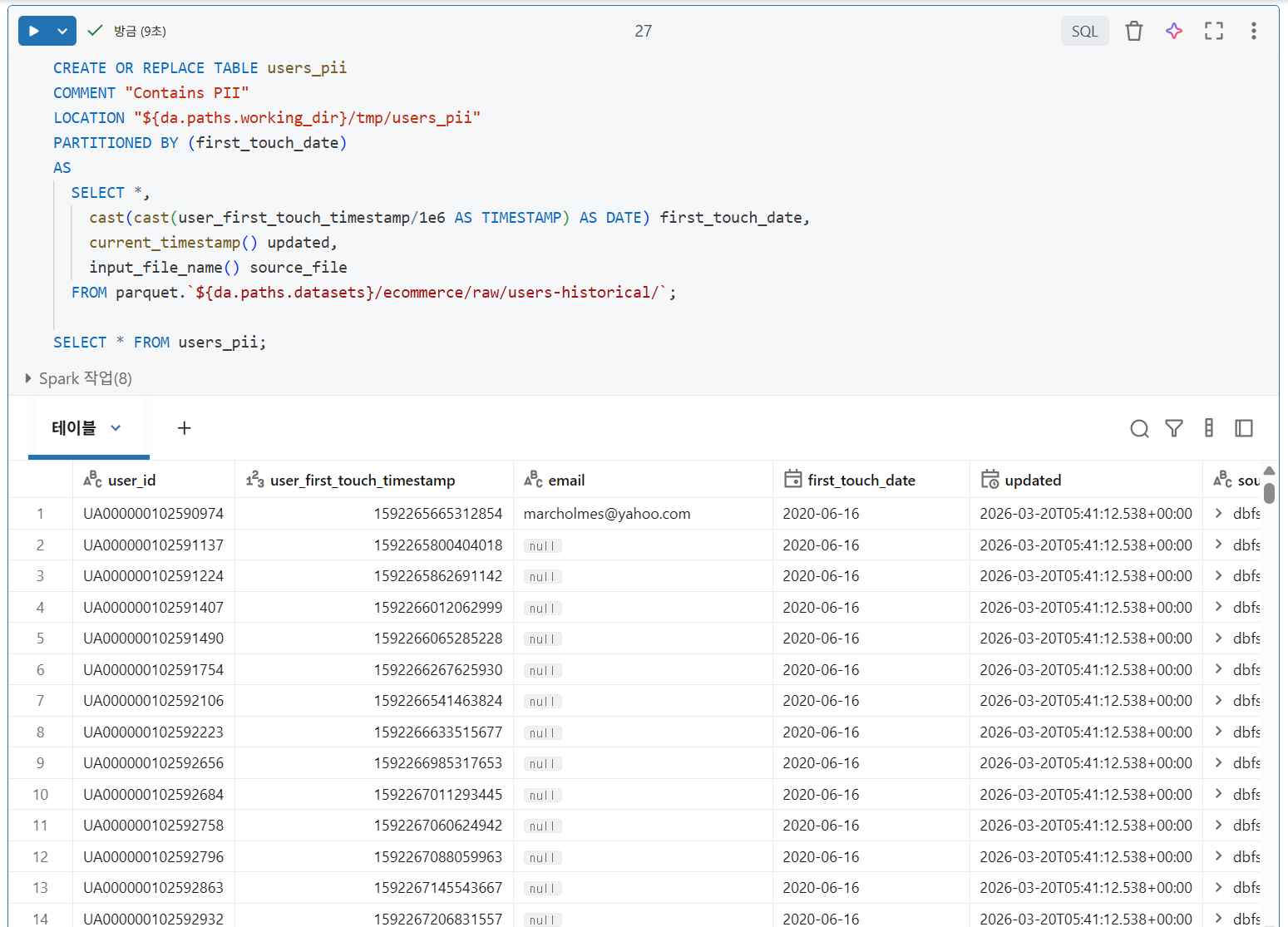
추가 옵션 및 메타데이터로 테이블 강화
여러 추가 구성 및 메타데이터를 포함하도록 CTAS 문을 개선하는 방법
- SELECT 절은 파일 수집에 유용한 두 가지 내장 Spark SQL 명령을 활용
- current_timestamp()는 로직이 실행될 때의 타임스탬프를 기록
- input_file_name()은 테이블의 각 레코드에 대한 소스 데이터 파일을 기록
- CREATE TABLE 절에는 여러 옵션이 포함
- 테이블 내용을 더 쉽게 검색할 수 있도록 COMMENT
- 관리형 테이블이 아닌 외부 테이블이 생성
- 테이블은 날짜 열로 PARTITIONED BY
- 즉, 각 날짜의 데이터는 대상 저장소 위치의 자체 디렉터리에 저장
- 파티셔닝은 데이터 파일을 물리적으로 분리하기 때문에, 이 방식은 작은 파일 문제를 야기하고 파일 압축 및 효율적인 데이터 건너뛰기를 방해 가능
- Delta Lake를 사용할 때는 대부분의 사용 사례에서 기본적으로 파티셔닝되지 않은 테이블을 사용하는 것이 가장 좋음
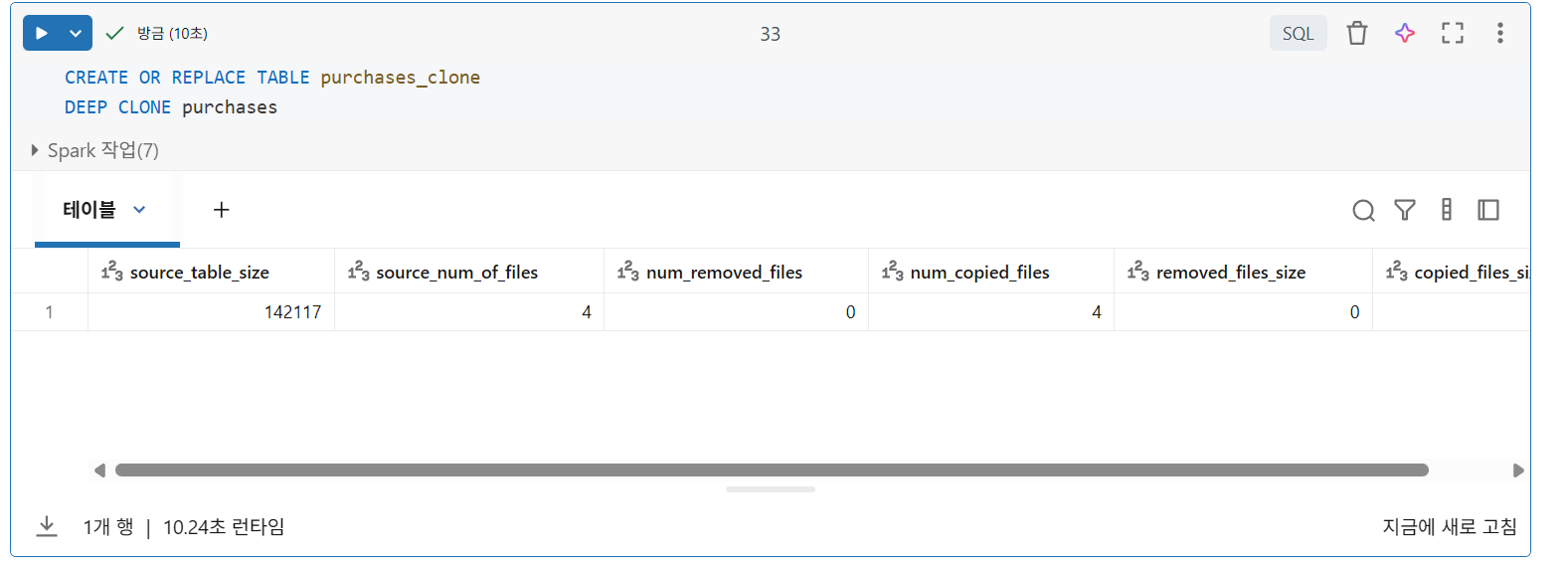
Delta Lake 테이블 복제
- 딥 클로닝: 소스 테이블의 데이터와 메타데이터를 타겟 테이블로 완전히 복사
- 증분 방식 수행
- 얕은 복제: 델타 트랜잭션 로그만 복사 → 데이터 이동 X
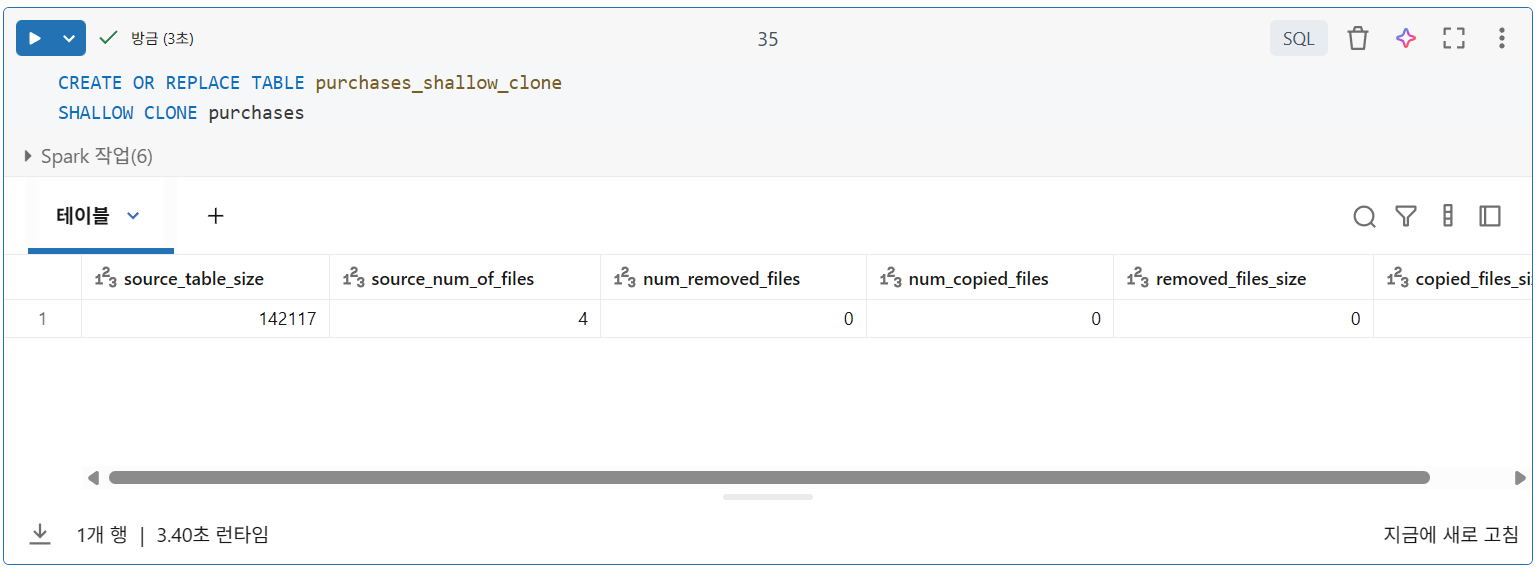
두 경우 모두 복제된 테이블에 적용된 데이터 수정 사항은 원본과 별도로 추적 및 저장
델타 테이블에 쓰기
델타 레이크 테이블은 클라우드 객체 스토리지의 데이터 파일로 지원되는 테이블에 ACID 호환 업데이트를 제공
INSERT OVERWRITE를 사용하여 데이터 테이블 덮어쓰기INSERT INTO를 사용하여 테이블에 추가MERGE INTO를 사용하여 테이블에 추가, 업데이트 및 삭제COPY INTO를 사용하여 테이블에 데이터를 증분 방식으로 수집
완전 덮어쓰기
- 덮어쓰기를 사용하면 테이블의 모든 데이터를 원자적으로 바꾸는게 가능
- 테이블 덮어쓰기는 디렉터리를 재귀적으로 나열하거나 파일을 삭제할 필요가 없으므로 훨씬 빠름
- 테이블의 이전 버전이 여전히 존재하므로 시간 여행을 사용하여 이전 데이터를 쉽게 검색
- 원자적 연산 → 테이블을 삭제하는 동안에도 동시 쿼리에서 테이블을 읽을 수 있음
- ACID 트랜잭션 보장으로 인해 테이블 덮어쓰기가 실패하더라도 테이블은 이전 상태로 유지
1. CREATE OR REPLACE TABLE(CRAS)
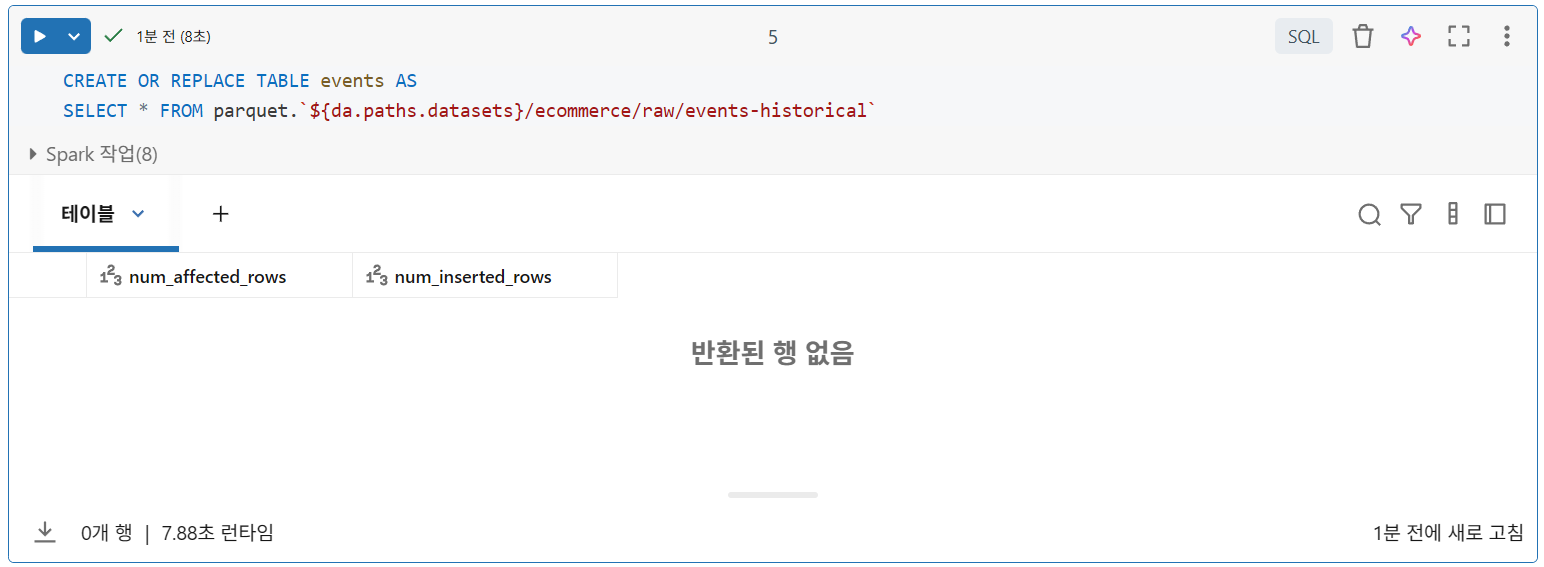
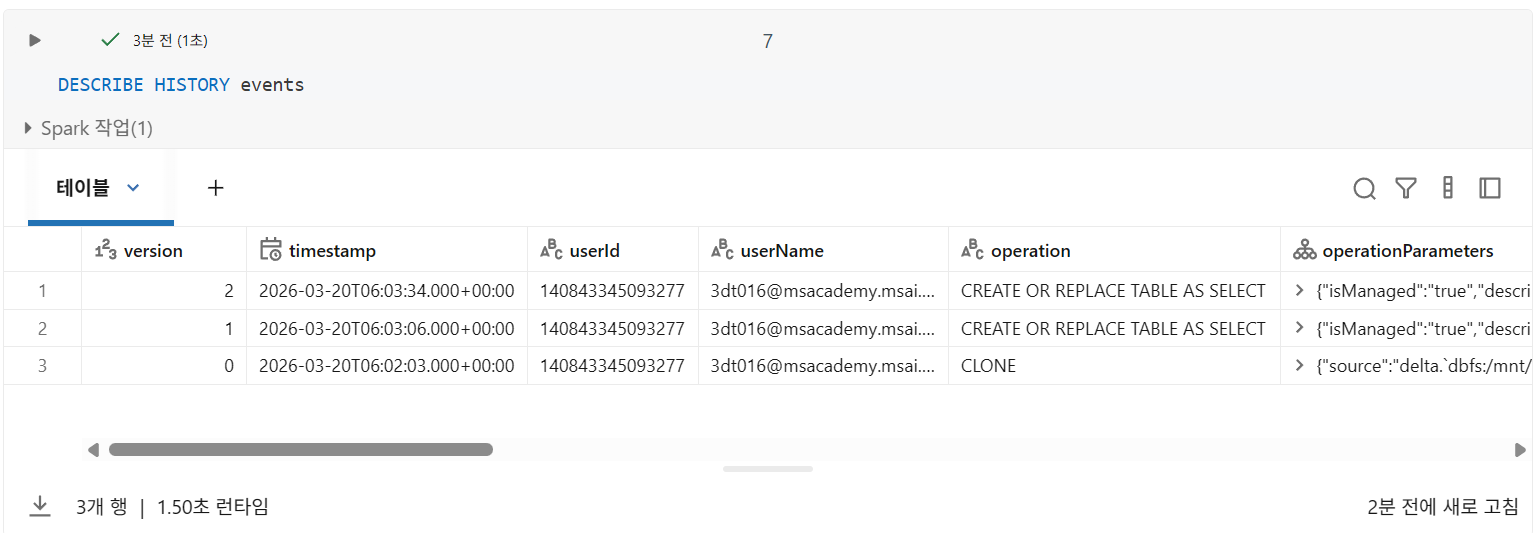
(오류가 발생한 줄 알고 CRAS를 두 번 실행함을 유의)
2. INSERT OVERWRITE
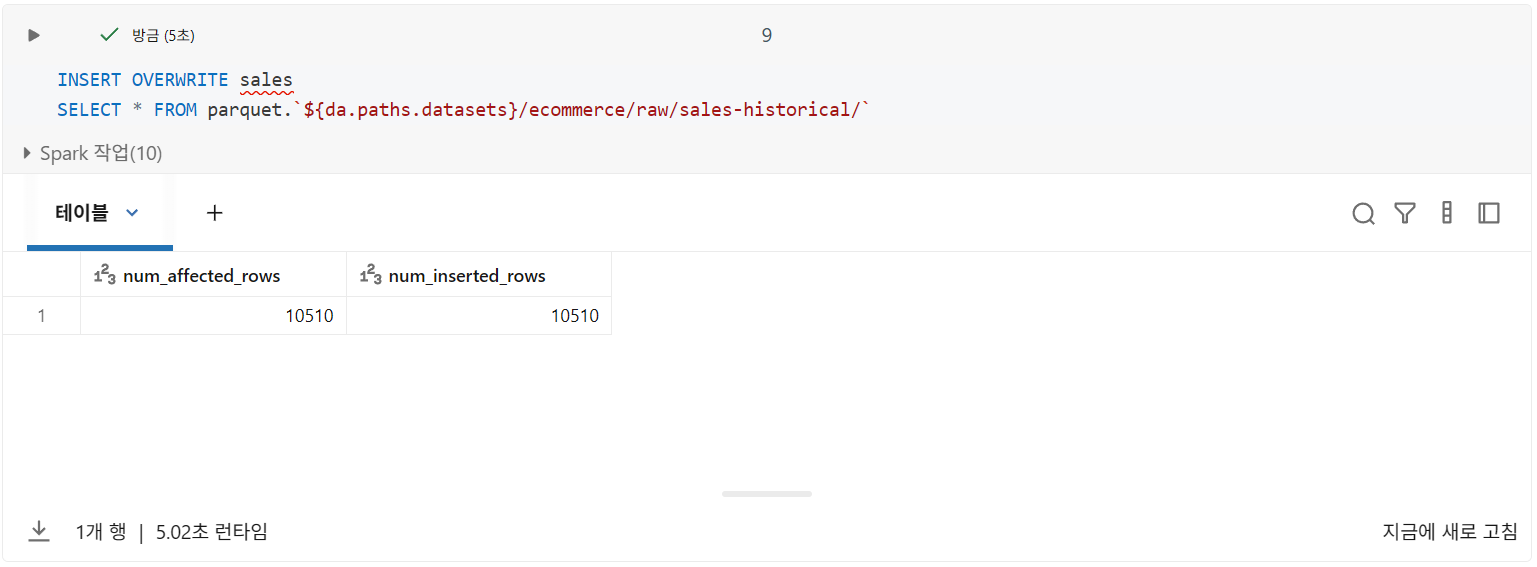
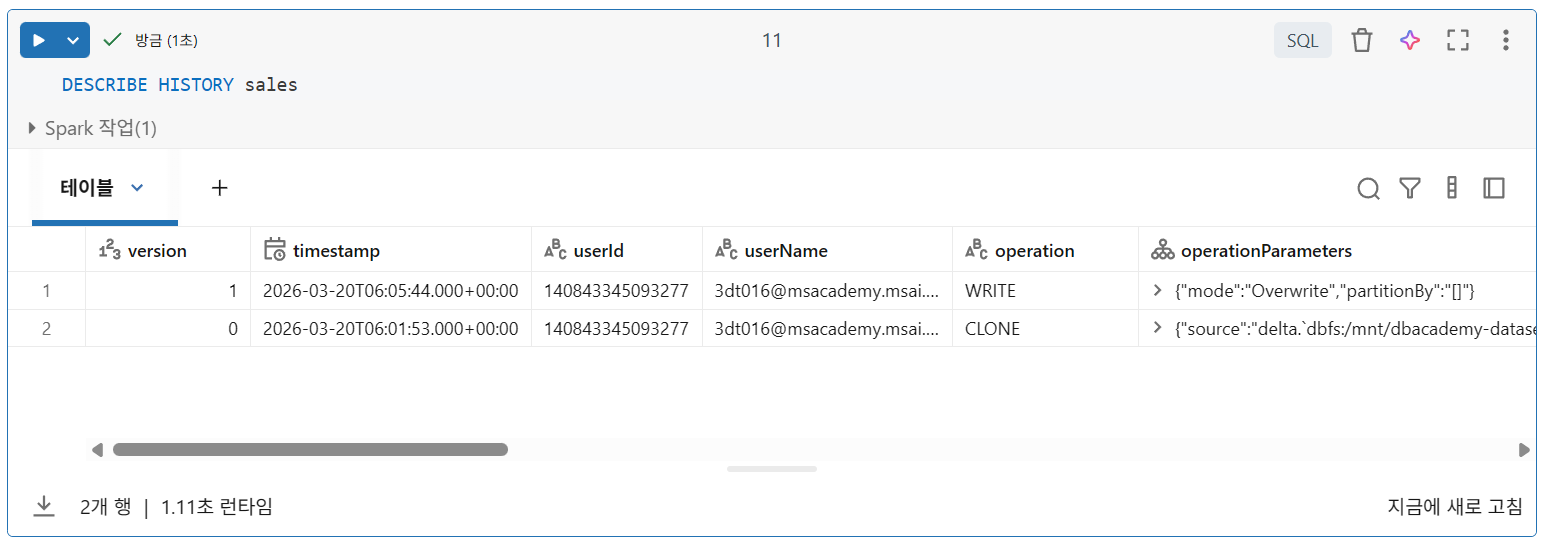
대상 테이블의 데이터가 쿼리의 데이터로 대체
INSERT OVERWRITE:
- 기존 테이블만 덮어쓸 수 있으며, CRAS 문처럼 새 테이블을 생성할 수 없음
- 현재 테이블 스키마와 일치하는 새 레코드로만 덮어쓸 수 있음
- 따라서 다운스트림 소비자를 방해하지 않고 기존 테이블을 덮어쓸 수 있는 "더 안전한" 기법
- 개별 파티션을 덮어쓸 수 있음
CRAS와 차이점
- Delta Lake가 스키마 온 쓰기(schema on write)를 적용하는 방식과 관련
- CRAS 문을 사용하면 대상 테이블의 내용을 완전히 재정의할 수 있지만, 스키마를 변경하려고 하면 (선택적인 설정을 제공하지 않는 한) INSERT OVERWRITE가 실패
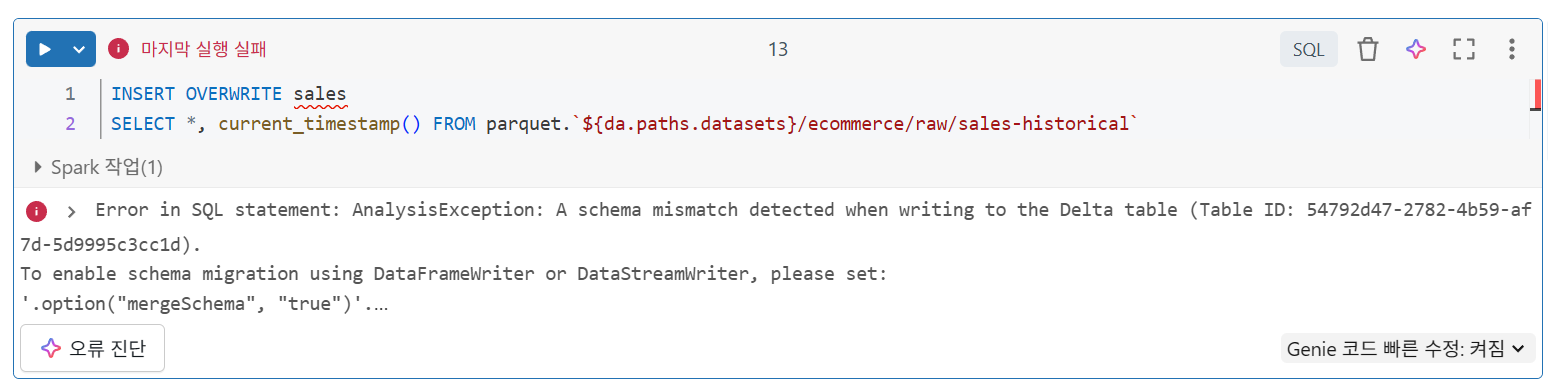
행추가
INSERT INTO를 사용하여 기존 델타 테이블에 새로운 행을 원자적으로 추가- 기존 테이블에 증분 업데이트를 적용할 수 있으므로 매번 덮어쓰는 것보다 훨씬 효율적
- INSERT INTO에는 동일한 레코드를 여러 번 삽입하는 것을 방지하는 기본 제공 기능이 없음
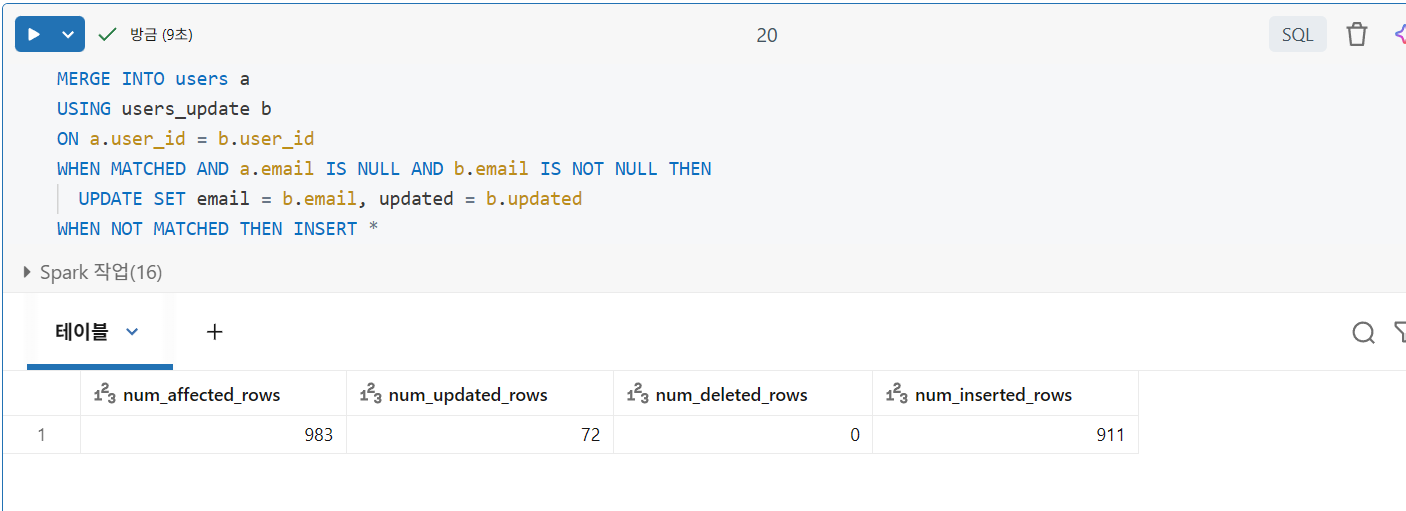
업데이트 병합
MERGE INTO target a
USING source b
ON {merge_condition}
WHEN MATCHED THEN {matched_action}
WHEN NOT MATCHED THEN {not_matched_action}- 업데이트, 삽입 및 삭제가 단일 트랜잭션으로 완료
- 일치하는 필드 외에도 여러 조건을 추가 가능
- 사용자 지정 로직을 구현하기 위한 광범위한 옵션을 제공
중복 제거를 위한 삽입 전용 병합
- 동일한 MERGE 구문을 사용하지만 WHEN NOT MATCHED 절만 제공
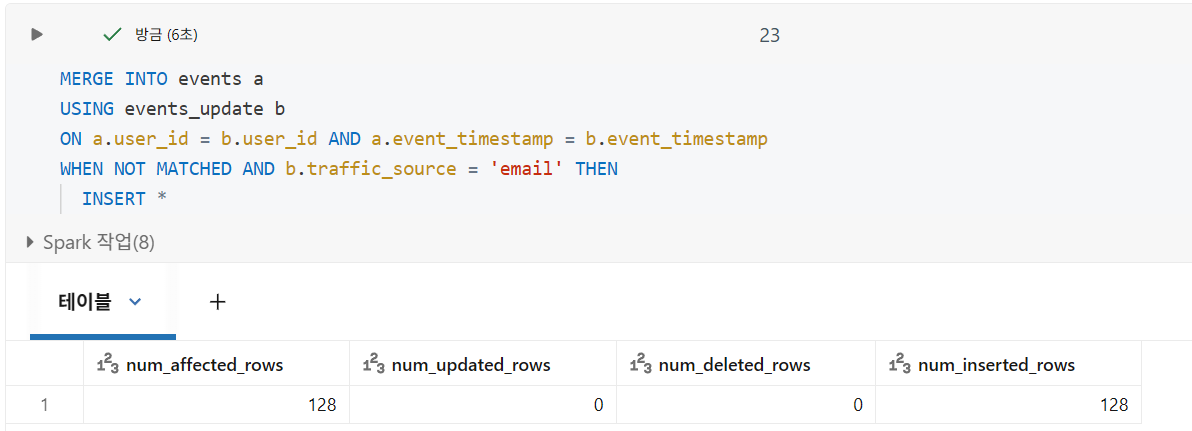
증분 로드
COPY INTO는 SQL 엔지니어에게 외부 시스템에서 데이터를 증분 방식으로 수집할 수 있는 멱등 옵션을 제공
- 데이터 스키마는 일관성이 있어야 함
- 중복 레코드는 제외되거나 다운스트림에서 처리되어야 함
- 예측 가능하게 증가하는 데이터의 경우 전체 테이블 스캔보다 훨씬 저렴
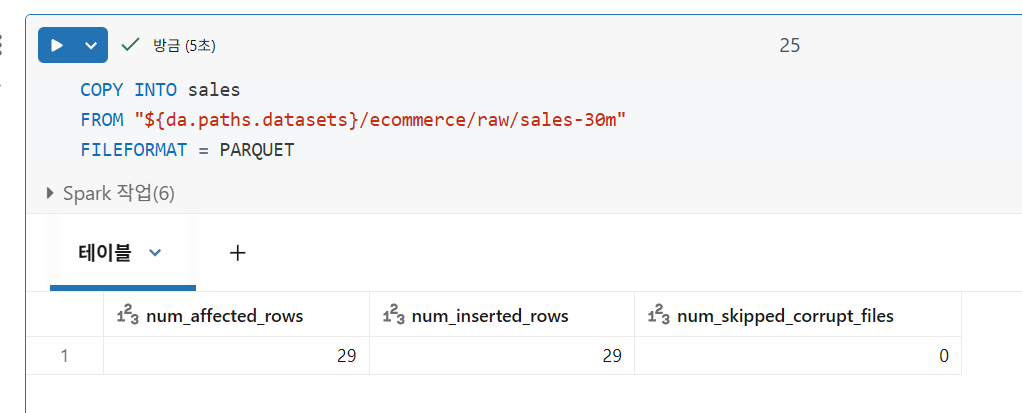
데이터 추출 및 로드(개인 실습)
데이터 개요
JSON 파일로 작성된 원시 Kafka 데이터 샘플을 사용합니다.
각 파일에는 5초 간격 동안 사용된 모든 레코드가 포함되어 있으며, 전체 Kafka 스키마와 함께 다중 레코드 JSON 파일로 저장됩니다.
테이블 스키마는 다음과 같습니다.
| field | type | description |
|---|---|---|
| key | BINARY | user_id 필드는 키로 사용됩니다. 세션/쿠키 정보에 해당하는 고유한 영숫자 필드입니다. |
| offset | LONG | 각 파티션에 대해 단조롭게 증가하는 고유한 값입니다. |
| partition | INTEGER | 현재 Kafka 구현에서는 2개의 파티션(0과 1)만 사용합니다. |
| timestamp | LONG | 이 타임스탬프는 에포크 이후 밀리초 단위로 기록되며, 프로듀서가 파티션에 레코드를 추가하는 시간을 나타냅니다. |
| topic | STRING | Kafka 서비스는 여러 토픽을 호스팅하지만, clickstream 토픽의 레코드만 여기에 포함됩니다. |
| value | BINARY | 전체 데이터 페이로드(나중에 설명)이며, JSON 형식으로 전송됩니다. |
JSON 파일에서 원시 이벤트 추출
이 데이터를 Delta에 제대로 로드하려면 먼저 올바른 스키마를 사용하여 JSON 데이터를 추출해야 합니다.
아래 제공된 파일 경로에 있는 JSON 파일에 대한 외부 테이블을 생성합니다. 이 테이블의 이름을 events_json으로 지정하고 위의 스키마를 선언합니다.
CREATE TABLE IF NOT EXISTS events_json
(key BINARY, offset LONG, partition INTEGER, timestamp LONG, topic STRING, value BINARY)
USING JSON
OPTIONS (
path = '${da.paths.datasets}/ecommerce/raw/events-kafka/'
)델타 테이블에 원시 이벤트 삽입
동일한 스키마를 사용하여 events_raw라는 이름의 빈 관리형 델타 테이블을 생성합니다.
CREATE TABLE events_raw
(key BINARY, offset LONG, partition INTEGER, timestamp LONG, topic STRING, value BINARY)추출된 데이터와 Delta 테이블이 준비되면 events_json 테이블의 JSON 레코드를 새 events_raw Delta 테이블에 삽입합니다.
INSERT INTO events_raw
select * from events_json쿼리에서 델타 테이블 생성
새로운 이벤트 데이터 외에도, 나중에 사용할 제품 세부 정보를 제공하는 작은 조회 테이블도 로드해 보겠습니다.
CTAS 문을 사용하여 아래에 제공된 Parquet 디렉터리에서 데이터를 추출하는 item_lookup이라는 관리형 델타 테이블을 생성합니다.
CREATE TABLE item_lookup AS
SELECT * FROM parquet.`${da.paths.datasets}/ecommerce/raw/item-lookup`데이터 정리
- 데이터세트 요약 및 null 동작 설명
- 중복 항목 검색 및 제거
- 예상 개수, 누락된 값 및 중복 레코드에 대한 데이터세트 검증
- 일반적인 변환을 적용하여 데이터 정리 및 변환
데이터 검사
- 특정 열이나 표현식을 계산할 때
count(col)은NULL값을 건너뜀 - 하지만
count(*)는 총 행 수(NULL값만 있는 행 포함)를 계산하는 특별한 경우 - NULL 값을 계산하려면
count_if함수 또는WHERE절을 사용하여 값이IS NULL인 레코드를 필터링하는 조건을 제공
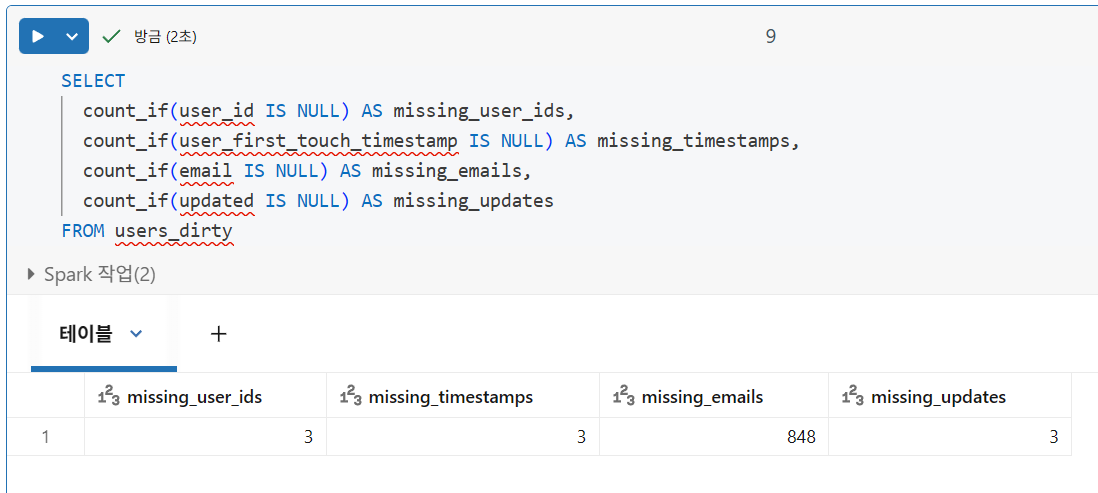
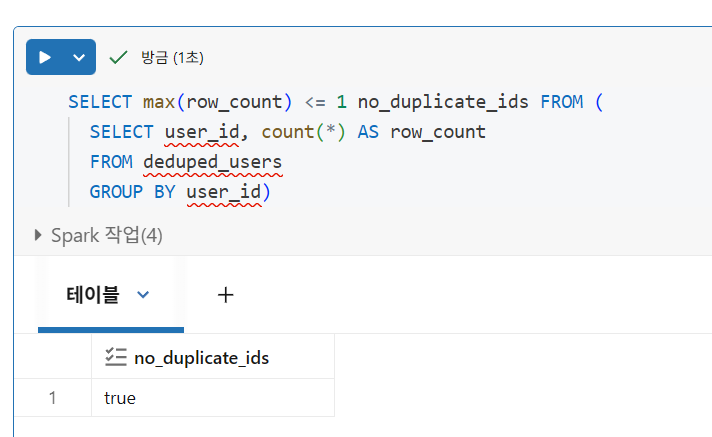
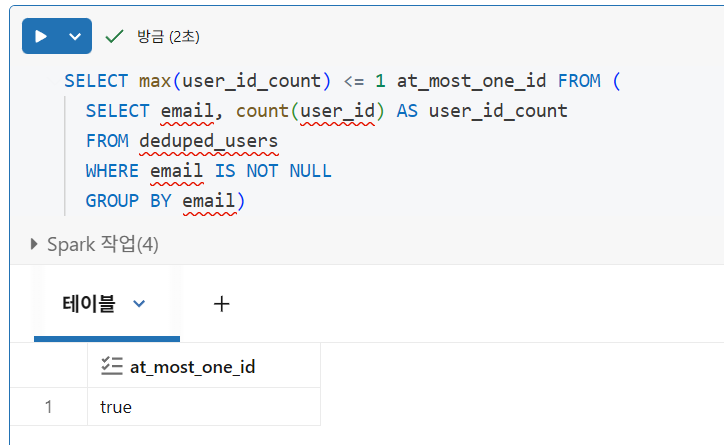
고유 레코드
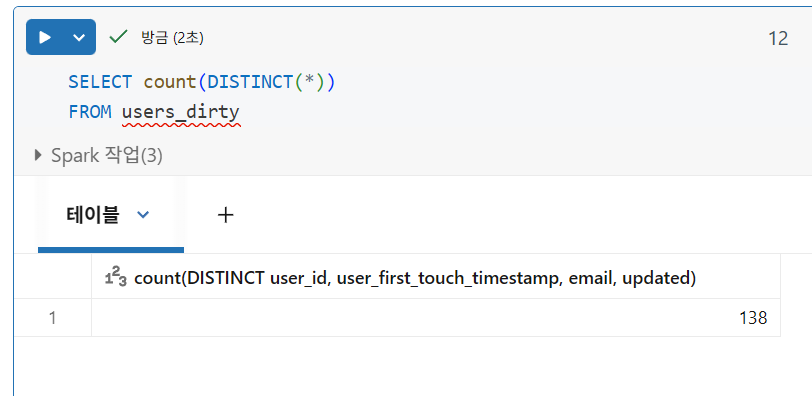
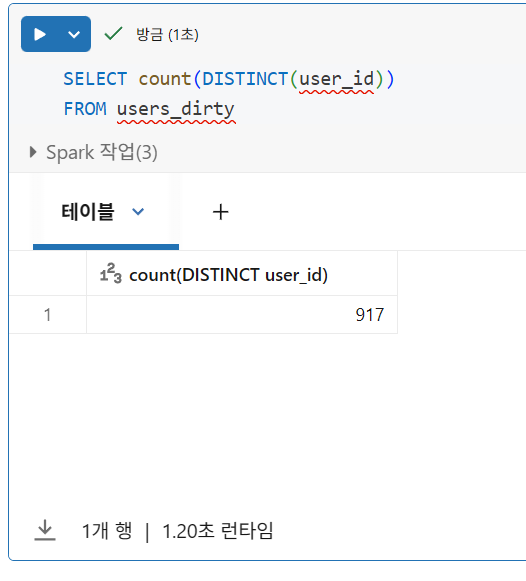
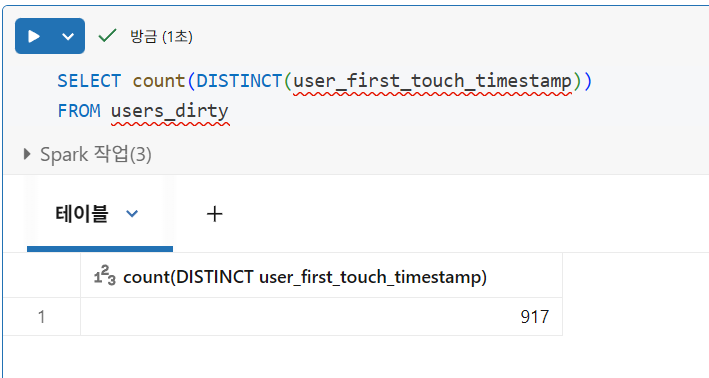
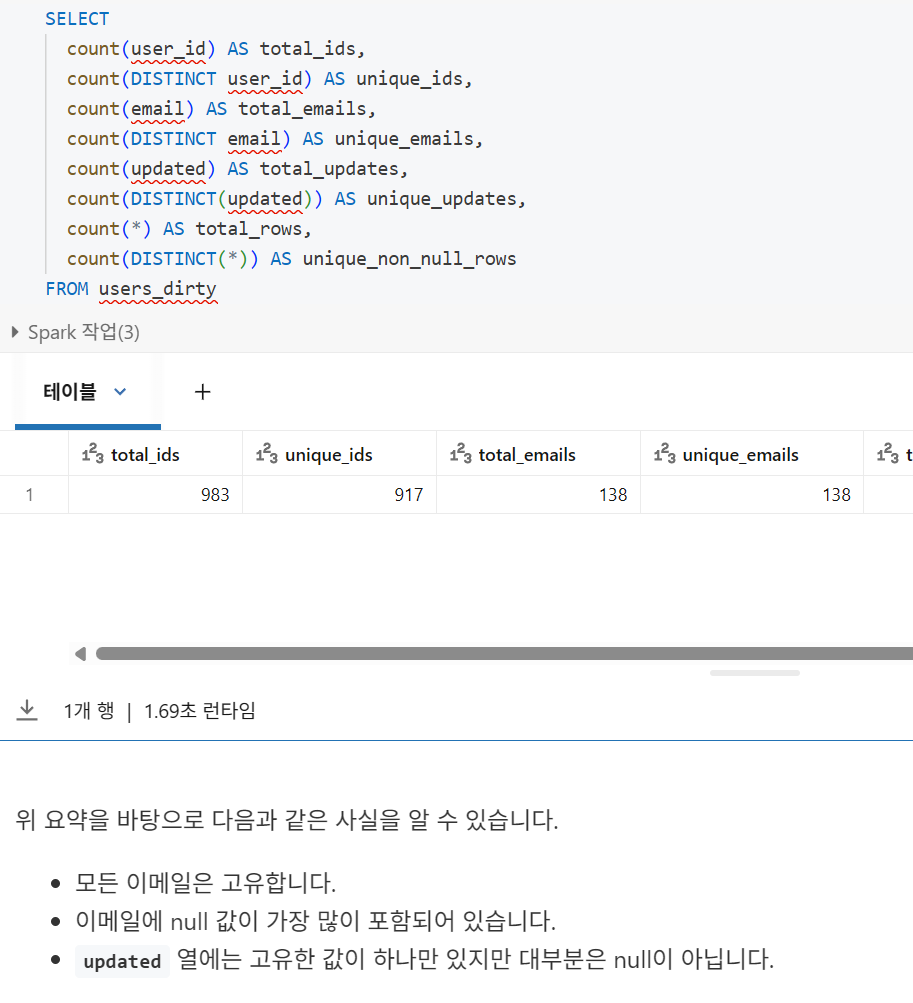
중복 행 제거
- Spark는 열의 값을 세거나 필드의 고유 값을 세는 동안 null 값을 건너뛰지만, DISTINCT 쿼리에서는 null이 있는 행을 제외하지 않음
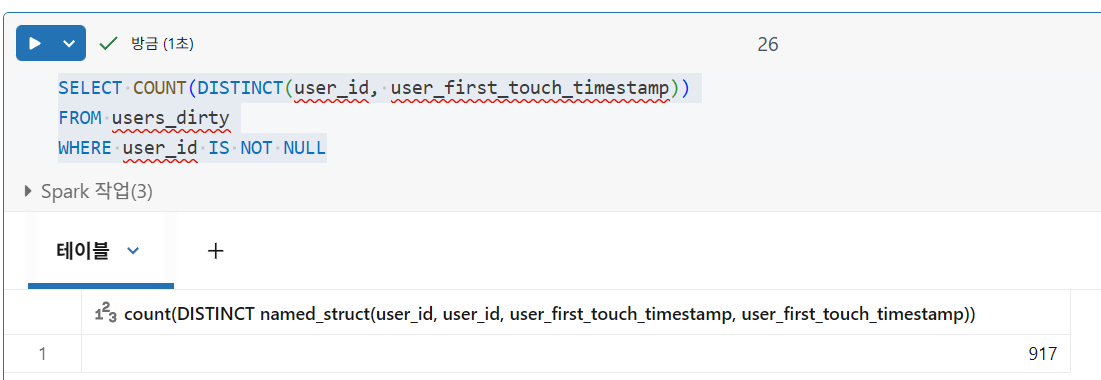
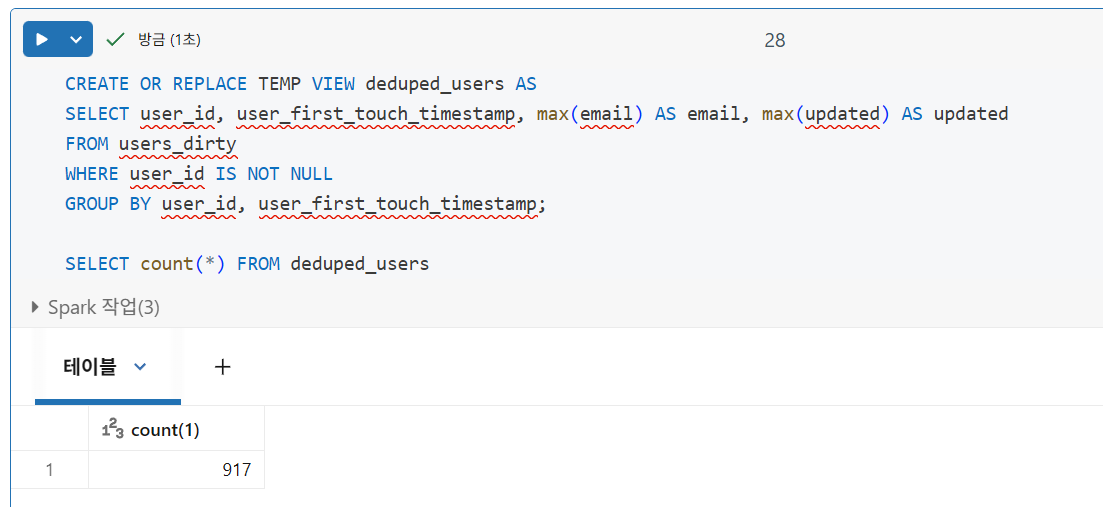
아래 코드는 GROUP BY를 사용하여 user_id와 user_first_touch_timestamp를 기준으로 중복 레코드를 제거합니다.
max() 집계 함수는 email 열에 사용되어 여러 레코드가 있는 경우 null이 아닌 이메일을 캡처하는 방편으로 사용됩니다. 이 배치에서는 모든 updated 값이 동일했지만, 이 값을 그룹화 결과에 유지하려면 집계 함수를 사용해야 합니다.
데이터셋 검증
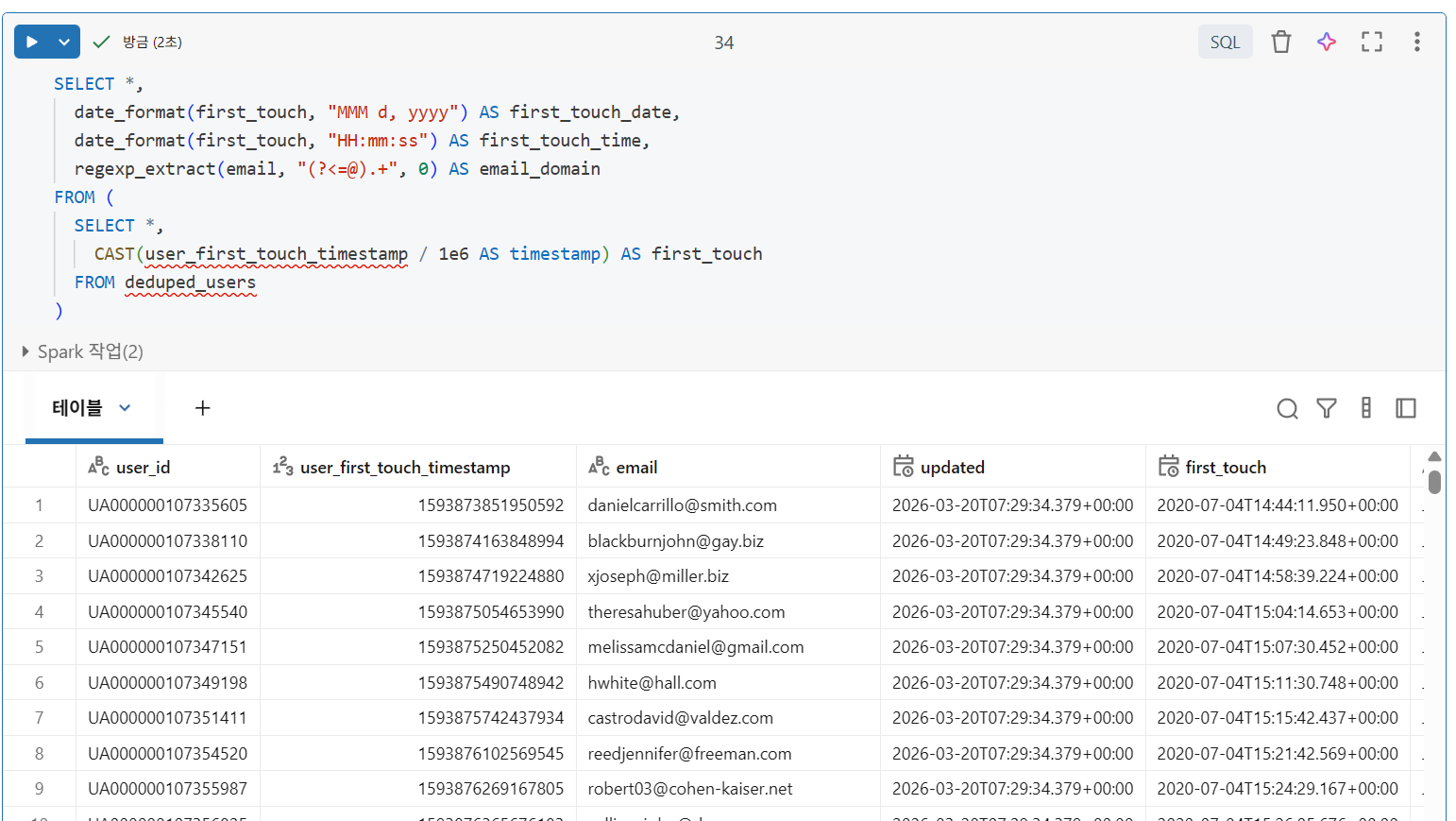
날짜 및 정규 표현식
아래 코드:
user_first_touch_timestamp를 올바른 크기 조정 및 유효한 타임스탬프로 변환합니다.- 이 타임스탬프에 대한 캘린더 데이터와 시계 시간을 사람이 읽을 수 있는 형식으로 추출합니다.
regexp_extract를 사용하여 정규 표현식을 사용하여 이메일 열에서 도메인을 추출합니다.
고급 SQL 변환
.및:구문을 사용하여 중첩된 데이터를 쿼리- JSON 작업
- 배열 및 구조체를 평면화하고 압축 해제
- 조인 및 집합 연산자를 사용하여 데이터 세트를 결합
- 피벗 테이블을 사용하여 데이터 형태를 변경
- 고차 함수를 사용하여 배열 작업을 수행
JSON 데이터와 상호 작용
- 대부분의 경우 Kafka 데이터는 이진 인코딩된 JSON 값
아래에서 key와 value를 문자열로 변환하여 사람이 읽을 수 있는 형식으로 표시
CREATE OR REPLACE TEMP VIEW events_strings AS
SELECT string(key), string(value)
FROM events_raw;
SELECT * FROM events_strings
- 중첩된 데이터 구조를 탐색하려면
:구문을 사용
SELECT value:device, value:geo:city
FROM events_strings- Spark SQL은 JSON 객체를 구조체 타입(중첩된 속성을 가진 네이티브 Spark 타입)으로 파싱하는 기능도 제공
- 하지만
from_json함수에는 스키마가 필요 - 현재 데이터의 스키마를 도출하기 위해 먼저 null 필드가 없는 JSON 값을 반환하는 쿼리를 실행
SELECT value
FROM events_strings
WHERE value:event_name = "finalize"
ORDER BY key
LIMIT 1- Spark SQL에는 예제에서 JSON 스키마를 도출하는
schema_of_json함수도 존재 - 여기서는 예제 JSON을 복사하여 함수에 붙여넣고
from_json함수에 연결하여value필드를 구조체 타입으로 변환
CREATE OR REPLACE TEMP VIEW parsed_events AS
SELECT from_json(value, schema_of_json('{"device":"Linux","ecommerce":{"purchase_revenue_in_usd":1075.5,"total_item_quantity":1,"unique_items":1},"event_name":"finalize","event_previous_timestamp":1593879231210816,"event_timestamp":1593879335779563,"geo":{"city":"Houston","state":"TX"},"items":[{"coupon":"NEWBED10","item_id":"M_STAN_K","item_name":"Standard King Mattress","item_revenue_in_usd":1075.5,"price_in_usd":1195.0,"quantity":1}],"traffic_source":"email","user_first_touch_timestamp":1593454417513109,"user_id":"UA000000106116176"}')) AS json
FROM events_strings;
SELECT * FROM parsed_events- JSON 문자열이 구조체 타입으로 압축 해제되면 Spark는 필드를 열로 평면화하는
*(별표) 압축 해제를 지원
CREATE OR REPLACE TEMP VIEW new_events_final AS
SELECT json.*
FROM parsed_events;
SELECT * FROM new_events_final데이터 구조 살펴보기
구조체는 .으로 접근
SELECT ecommerce.purchase_revenue_in_usd
FROM events
WHERE ecommerce.purchase_revenue_in_usd IS NOT NULL배열 작업
size로 각 행의 배열 요소 개수를 계산
SELECT user_id, event_timestamp, event_name, items
FROM events
WHERE size(items) > 2배열 분해
explode 함수를 사용하면 배열의 각 요소를 별도의 행에 배치 가능
SELECT user_id, event_timestamp, event_name, explode(items) AS item
FROM events
WHERE size(items) > 2Collect Arrays
collect_set 함수는 배열 내의 필드를 포함하여 필드에 대한 고유한 값을 수집할 수 있습니다.
flatten 함수는 여러 배열을 하나의 배열로 결합할 수 있도록 합니다.
array_distinct 함수는 배열에서 중복 요소를 제거합니다.
SELECT user_id,
collect_set(event_name) AS event_history,
array_distinct(flatten(collect_set(items.item_id))) AS cart_history
FROM events
GROUP BY user_idJoin Tables
Spark SQL은 표준 조인 연산(inner, outer, left, right, anti, cross, semi)을 지원
CREATE OR REPLACE VIEW sales_enriched AS
SELECT *
FROM (
SELECT *, explode(items) AS item
FROM sales) a
INNER JOIN item_lookup b
ON a.item.item_id = b.item_id;
SELECT * FROM sales_enrichedSet Operators
Spark SQL은 UNION, MINUS, INTERSECT 집합 연산자를 지원합니다.
UNION은 두 쿼리의 집합을 반환합니다.
SELECT * FROM events
UNION
SELECT * FROM new_events_finalINTERSECT는 두 관계에서 모두 발견된 모든 행을 반환합니다.
SELECT * FROM events
INTERSECT
SELECT * FROM new_events_finalMINUS는 한 데이터세트에서는 발견되지만 다른 데이터세트에서는 발견되지 않은 모든 행을 반환
피벗 테이블
PIVOT 절은 데이터 관점에서 사용됩니다. 특정 열 값을 기준으로 집계된 값을 얻을 수 있으며, 이 값은 SELECT` 절에서 사용되는 여러 열로 변환됩니다. PIVOT` 절은 테이블 이름이나 하위 쿼리 뒤에 지정할 수 있습니다.
SELECT * FROM (): 괄호 안의 SELECT` 문은 이 테이블의 입력입니다.
PIVOT: 절의 첫 번째 인수는 집계 함수와 집계할 열입니다. 그런 다음 FOR 하위 절에서 피벗 열을 지정합니다. IN` 연산자는 피벗 열 값을 포함합니다.
평면화된 데이터 형식은 대시보드 작성에 유용할 뿐만 아니라, 추론이나 예측을 위한 머신 러닝 알고리즘 적용에도 유용합니다.
CREATE OR REPLACE TABLE transactions AS
SELECT * FROM (
SELECT
email,
order_id,
transaction_timestamp,
total_item_quantity,
purchase_revenue_in_usd,
unique_items,
item.item_id AS item_id,
item.quantity AS quantity
FROM sales_enriched
) PIVOT (
sum(quantity) FOR item_id in (
'P_FOAM_K',
'M_STAN_Q',
'P_FOAM_S',
'M_PREM_Q',
'M_STAN_F',
'M_STAN_T',
'M_PREM_K',
'M_PREM_F',
'M_STAN_K',
'M_PREM_T',
'P_DOWN_S',
'P_DOWN_K'
)
);
SELECT * FROM transactions고차 함수
Spark SQL의 고차 함수를 사용하면 복잡한 데이터 유형을 직접 처리할 수 있습니다. 계층적 데이터를 처리할 때 레코드는 배열 또는 맵 유형 객체로 저장되는 경우가 많습니다. 고차 함수를 사용하면 원래 구조를 유지하면서 데이터를 변환할 수 있습니다.
고차 함수에는 다음이 포함됩니다.
FILTER는 주어진 람다 함수를 사용하여 배열을 필터링합니다.EXISTS는 배열의 하나 이상의 요소에 대해 명령문이 참인지 여부를 테스트합니다.TRANSFORM은 주어진 람다 함수를 사용하여 배열의 모든 요소를 변환합니다.REDUCE는 두 개의 람다 함수를 사용하여 배열의 요소를 버퍼에 병합하여 단일 값으로 줄이고, 최종 버퍼에 마무리 함수를 적용합니다.
필터
items 열의 모든 레코드에서 킹 사이즈가 아닌 항목을 제거합니다. FILTER` 함수를 사용하여 각 배열에서 해당 값을 제외하는 새 열을 만들 수 있습니다.
FILTER (items, i -> i.item_id LIKE "%K") AS king_items
위 명령문에서:
FILTER: 고차 함수의 이름items: 입력 배열의 이름i: 반복자 변수의 이름. 이 이름을 선택한 다음 람다 함수에서 사용합니다. 배열을 반복하며 각 값을 한 번에 하나씩 함수에 순환합니다.->: 함수의 시작을 나타냅니다.i.item_id LIKE "%K": 이것이 함수입니다. 각 값은 대문자 K로 끝나는지 확인합니다. 대문자 K로 끝나면 새 열인king_items로 필터링됩니다.
생성된 열에 빈 배열이 많이 생성되는 필터를 작성할 수 있습니다. 이 경우, 반환된 열에 비어 있지 않은 배열 값만 표시하기 위해 WHERE 절을 사용하는 것이 유용할 수 있습니다.
SELECT
order_id,
items,
FILTER (items, i -> i.item_id LIKE "%K") AS king_items
FROM salesCREATE OR REPLACE TEMP VIEW king_size_sales AS
SELECT order_id, king_items
FROM (
SELECT
order_id,
FILTER (items, i -> i.item_id LIKE "%K") AS king_items
FROM sales)
WHERE size(king_items) > 0;
SELECT * FROM king_size_salesTransform
내장 함수는 셀 내의 단일 단순 데이터 유형에 대해 작동하도록 설계되었으며, 배열 값을 처리할 수 없습니다. TRANSFORM은 배열의 각 요소에 기존 함수를 적용하려는 경우 특히 유용합니다.
-- get total revenue from king items per order
CREATE OR REPLACE TEMP VIEW king_item_revenues AS
SELECT
order_id,
king_items,
TRANSFORM (
king_items,
k -> CAST(k.item_revenue_in_usd * 100 AS INT)
) AS item_revenues
FROM king_size_sales;
SELECT * FROM king_item_revenues
SQL UDF
- Databricks는 DBR 9.1부터 SQL에 기본적으로 등록된 사용자 정의 함수(UDF)에 대한 지원을 추가
- 사용자 정의 SQL 로직 조합을 데이터베이스에 함수로 등록하여 Databricks에서 SQL을 실행할 수 있는 모든 곳에서 이러한 메서드를 재사용
- SQL UDF 정의 및 등록
- SQL UDF 공유에 사용되는 보안 모델 설명
- SQL 코드에서
CASE/WHEN문 사용- 사용자 지정 제어 흐름을 위해 SQL UDF에서
CASE/WHEN문 활용
CREATE OR REPLACE FUNCTION 이름(변수이름 변수타입)
RETURNS 변수타입
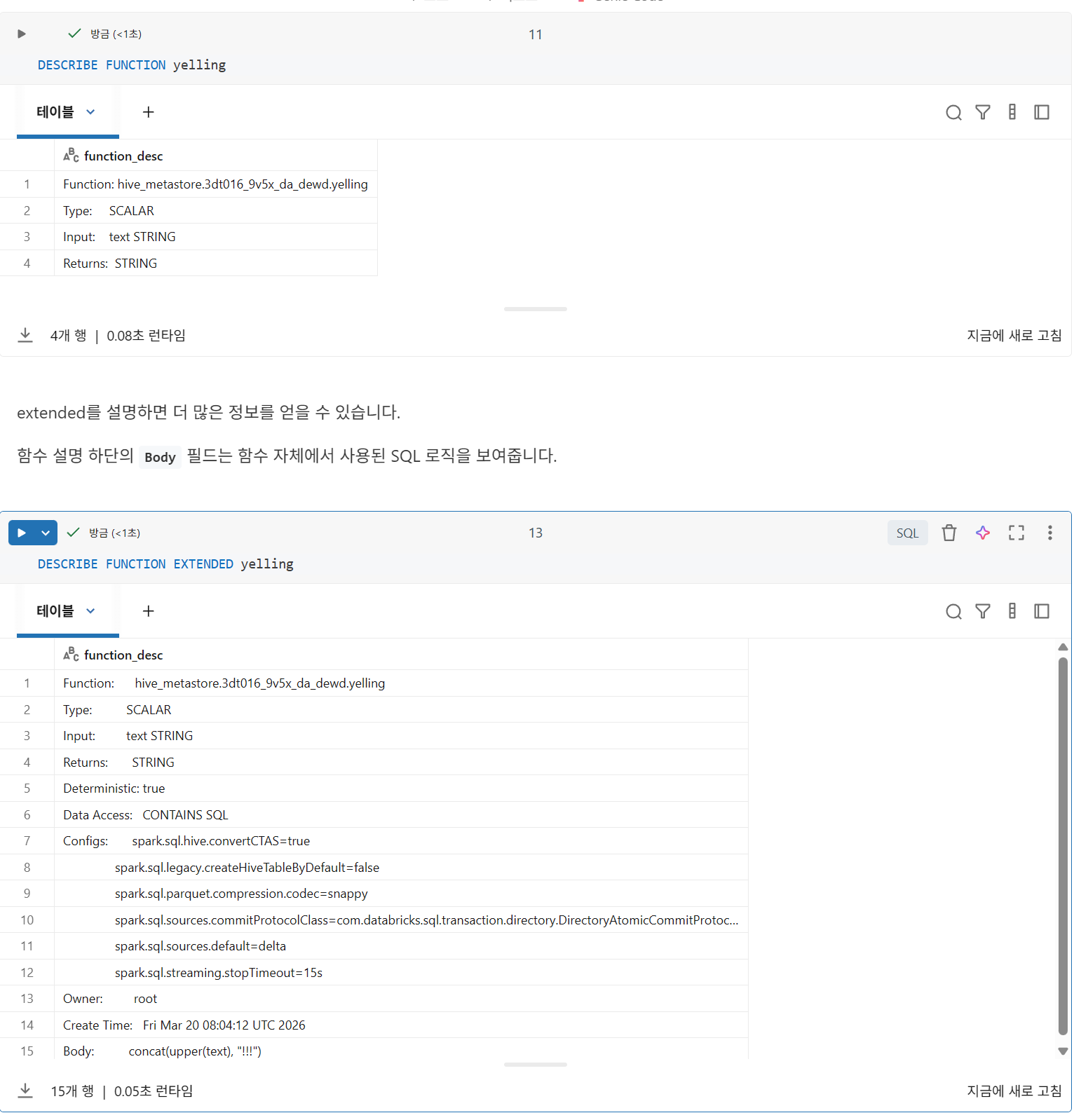
RETURN 반환값CREATE OR REPLACE FUNCTION yelling(text STRING)
RETURNS STRING
RETURN concat(upper(text), "!!!")사용
SELECT yelling(food) FROM foodsSQL UDF의 범위 및 권한
- SQL UDF는 실행 환경(노트북, DBSQL 쿼리, 작업 등) 간에 유지
- SQL UDF는 메타스토어에 객체로 존재하며 데이터베이스, 테이블 또는 뷰와 동일한 테이블 ACL에 의해 관리
- SQL UDF를 사용하려면 사용자에게 해당 함수에 대한 USAGE 및 SELECT 권한이 있어야 함
CASE/WHEN
- 병렬 실행에 최적화
병렬 실행에 최적화간단한 제어 흐름 함수
- SQL UDF를 CASE / WHEN 절 형태의 제어 흐름과 결합하면 SQL 워크로드 내에서 제어 흐름 실행을 최적화 가능
CREATE FUNCTION foods_i_like(food STRING)
RETURNS STRING
RETURN CASE
WHEN food = "beans" THEN "I love beans"
WHEN food = "potatoes" THEN "My favorite vegetable is potatoes"
WHEN food <> "beef" THEN concat("Do you have any good recipes for ", food ,"?")
ELSE concat("I don't eat ", food)
END;데이터 재구성
1. events를 피벗하여 각 사용자의 작업 수를 계산합니다.
event_name 열에 지정된 각 사용자가 특정 이벤트를 수행한 횟수를 집계하려고 합니다. 이를 위해 user_id로 그룹화하고 event_name을 피벗하여 각 이벤트 유형의 개수를 각 열에 표시합니다.
-- TODO
CREATE OR REPLACE VIEW events_pivot AS
SELECT *
FROM (
SELECT user_id as user, event_name
FROM events
)
PIVOT (
COUNT(event_name)
FOR event_name IN ('cart', 'pillows', 'login', 'main', 'careers', 'guest', 'faq', 'down', 'warranty', 'finalize',
'register', 'shipping_info', 'checkout', 'mattresses', 'add_item', 'press', 'email_coupon',
'cc_info', 'foam', 'reviews', 'original', 'delivery', 'premium')
);
SELECT * FROM events_pivot;2. 모든 사용자의 이벤트 수와 거래를 조인합니다.
다음으로, events_pivot과 transactions를 조인하여 clickpaths 테이블을 만듭니다. 이 테이블에는 위에서 만든 events_pivot 테이블과 동일한 이벤트 이름 열이 있어야 하며, 그 뒤에 transactions 테이블의 열이 있어야 합니다
-- TODO
CREATE OR REPLACE VIEW clickpaths AS
SELECT
ep.*,
t.*
FROM events_pivot ep
INNER JOIN transactions t
ON ep.user = t.user_id구매한 제품 유형 플래그 지정
여기서는 고차 함수 EXISTS를 sales 테이블의 데이터와 함께 사용하여 구매한 품목이 매트리스인지 베개인지를 나타내는 부울 열 mattress와 pillow를 생성합니다.
예를 들어, items 열의 item_name이 문자열 "Mattress"로 끝나는 경우, mattress의 열 값은 true이고 pillow의 값은 false여야 합니다. 다음은 품목과 결과 값의 몇 가지 예입니다.
| items | mattress | pillow |
|---|---|---|
[{..., "item_id": "M_PREM_K", "item_name": "Premium King Mattress", ...}] | true | false |
[{..., "item_id": "P_FOAM_S", "item_name": "Standard Foam Pillow", ...}] | false | true |
[{..., "item_id": "M_STAN_F", "item_name": "Standard Full Mattress", ...}] | true | false |
-- TODO
CREATE OR REPLACE TABLE sales_product_flags AS
SELECT
items,
EXISTS(items, item -> item.item_name LIKE '%Mattress') AS mattress,
EXISTS(items, item -> item.item_name LIKE '%Pillow') AS pillow
FROM sales