compute 편집
- 다룰 데이터가 클 수록 노드 수 늘리기
- 빠르게 대용량 작업을 해야 할 때 워커노드 자동 확장 자체보단 고정으로 노드 수를 늘리는게 당장 속도에는 좋음
DataEngineering
쿼리문에 익숙하면 SparkSQL, 그게 아니라면 Pyspark를 사용하는 것이 보통임
SparkSQL
DataFrame API를 사용하여 Spark SQL의 기본 개념을 설명
1. SQL 쿼리 실행
2. 테이블에서 DataFrame 생성
3. DataFrame 변환을 사용하여 동일한 쿼리 작성
4. DataFrame 액션을 사용하여 계산 트리거
5. DataFrame과 SQL 간 변환
- SparkSession:
sql,table - DataFrame:
- 변환:
select,where,orderBy - 액션:
show,count,take - 기타 방법:
printSchema,schema,createOrReplaceTempView
다중 인터페이스
Spark SQL은 다중 인터페이스를 갖춘 구조화된 데이터 처리를 위한 모듈
Spark SQL은 두 가지 방법으로 상호 작용 가능
1. SQL 쿼리 실행
1. DataFrame API 사용
1. SQL 쿼리 실행
%sql
SELECT name, price
FROM products
WHERE price < 200
ORDER BY price2. Dataframe API 사용
display(spark
.table("products")
.select("name", "price")
.where("price < 200")
.orderBy("price")
)참고: . 입력 후 ctrl + space 하면 사용 가능한 메소드 제시됨
쿼리 실행
위와 같이 입력하면 Spark SQL 엔진은 Spark 클러스터에서 최적화하고 실행하는 데 사용되는 것과 동일한 쿼리 계획을 생성
참고
- 복원력 있는 분산 데이터셋(RDD)은 Spark 클러스터에서 처리되는 데이터셋의 저수준 표현
- 초기 버전의 Spark에서는 RDD를 직접 조작하는 코드를 작성해야 했음
- 최신 버전의 Spark에서는 더 높은 수준의 DataFrame API를 사용해야 함
- Spark는 이를 자동으로 저수준 RDD 작업으로 컴파일
Spark API Documentation
Scala API와 Python API가 가장 일반적으로 사용
- scala 문서는 일반적으로 더 포괄적이고 Python 문서는 더 많은 코드 예제를 포함하는 경향
- 최근에는 Python이 대세
- Scala API에서는
org.apache.spark.sql - Python API에서는
pyspark.sql
SparkSession
SparkSession 클래스는 DataFrame API를 사용하는 Spark의 모든 기능에 대한 단일 진입점
Databricks 노트북에서는 SparkSession이 자동으로 생성되어 spark라는 변수에 저장
%python
spark
DataFrame 변수에 저장
SparkSession의 table 메서드를 사용하여 products 테이블에서 DataFrame을 생성했었음. 이 DataFrame을 products_df 변수에 저장
%python
products_df = spark.table("products")SparkSession 메서드
| 메서드 | 설명 |
|---|---|
| sql | 주어진 쿼리의 결과를 나타내는 DataFrame을 반환합니다. |
| table | 지정된 테이블을 DataFrame으로 반환합니다. |
| read | DataFrame으로 데이터를 읽는 데 사용할 수 있는 DataFrameReader를 반환합니다. |
| range | 시작부터 끝까지(제외) 범위에 있는 요소를 포함하는 열과 단계 값 및 파티션 개수를 가진 DataFrame을 생성합니다. |
| createDataFrame | 주로 테스트용으로 사용되는 튜플 목록에서 DataFrame을 생성합니다. |
SparkSession 메서드로 SQL 실행도 가능
result_df = spark.sql("""
SELECT name, price
FROM products
WHERE price < 200
ORDER BY price
""")
display(result_df)DataFrames
DataFrame API의 메서드를 사용하여 쿼리를 표현하면 결과가 DataFrame으로 반환
DataFrame은 명명된 열로 그룹화된 데이터의 분산된 컬렉션
budget_df = (spark
.table("products")
.select("name", "price")
.where("price < 200")
.orderBy("price")
)display를 사용하여 데이터프레임의 결과 출력 가능
display(budget_df)스키마는 데이터프레임의 열 이름과 유형을 정의
schema 속성을 사용하여 데이터프레임의 스키마에 액세스
budget_df.schemaOut[17]: StructType([StructField('name', StringType(), True), StructField('price', DoubleType(), True)])printSchema() 메서드를 사용하여 이 스키마의 더 나은 출력을 확인
budget_df.printSchema()root
|-- name: string (nullable = true)
|-- price: double (nullable = true)
변환
budget_df를 생성할 때 select, where, orderBy와 같은 일련의 DataFrame 변환 메서드를 사용했음
- 변환은 DataFrame에서 동작하고 DataFrame을 반환하므로, 변환 메서드를 연결하여 새로운 DataFrame을 생성 가능
- 하지만 이러한 연산은 단독으로 실행될 수 없음 → 변환 메서드는 지연 평가되기 때문
- 다음 셀을 실행해도 계산이 트리거되지 않음
(products_df
.select("name", "price")
.where("price < 200")
.orderBy("price"))동작
반대로 DataFrame 동작은 계산을 트리거하는 메서드
show 동작은 다음 셀에서 변환을 실행하도록 함
(products_df
.select("name", "price")
.where("price < 200")
.orderBy("price")
.show())+--------------------+-----+
| name|price|
+--------------------+-----+
|Standard Foam Pillow| 59.0|
| King Foam Pillow| 79.0|
|Standard Down Pillow|119.0|
| King Down Pillow|159.0|
+--------------------+-----+DataFrame 작업 메서드
| 메서드 | 설명 |
|---|---|
| show | DataFrame의 상위 n개 행을 표 형식으로 표시합니다. |
| count | DataFrame의 행 수를 반환합니다. |
| describe, summary | 숫자 및 문자열 열에 대한 기본 통계를 계산합니다. |
| first, head | 첫 번째 행을 반환합니다. |
| collect | 이 DataFrame의 모든 행을 포함하는 배열을 반환합니다. |
| take | DataFrame의 처음 n개 행을 포함하는 배열을 반환합니다. |
DataFrame과 SQL 간 변환
createOrReplaceTempView는 DataFrame을 기반으로 임시 뷰를 생성
임시 뷰의 수명은 DataFrame을 생성하는 데 사용된 SparkSession에 연결
budget_df.createOrReplaceTempView("budget")
display(spark.sql("SELECT * FROM budget"))Spark SQL 실습
작업
events테이블에서 DataFrame 생성- DataFrame 표시 및 스키마 검사
macOS이벤트 필터링 및 정렬에 변환 적용- 결과 개수 계산 및 처음 5개 행 가져오기
- SQL 쿼리를 사용하여 동일한 DataFrame 생성
메서드
- SparkSession:
sql,table - DataFrame 변환:
select,where,orderBy - DataFrame 작업:
select,count,take - 기타 DataFrame 메서드:
printSchema,schema,createOrReplaceTempView
1. events 테이블에서 DataFrame 생성
- SparkSession을 사용하여
events테이블에서 DataFrame을 생성합니다.
# TODO
events_df = (spark
.table("events")
)2. DataFrame 표시 및 스키마 검사
- 위의 메서드를 사용하여 DataFrame 내용과 스키마를 검사합니다.
# TODO
events_df.printSchema()3. macOS 이벤트 필터링 및 정렬에 변환 적용
device가macOS인 행 필터링event_timestamp로 행 정렬
# TODO
mac_df = (events_df
.where("device = 'macOS'")
.orderBy("event_timestamp")
)4. 결과 개수를 세고 처음 5개 행 가져오기
- DataFrame 액션을 사용하여 행 개수를 세고 가져오기
# TODO
num_rows = mac_df.count()
rows = mac_df.take(5)5. SQL 쿼리를 사용하여 동일한 DataFrame 생성
- SparkSession을 사용하여
events테이블에 SQL 쿼리 실행 - SQL 명령을 사용하여 이전에 사용한 것과 동일한 필터 및 정렬 쿼리 작성
# TODO
mac_sql_df = spark.sql(
"""
SELECT * FROM events WHERE device = 'macOS' ORDER BY event_timestamp
"""
)
display(mac_sql_df)DataFrame & Column
목표
- 열 생성
- 열 부분 집합 생성
- 열 추가 또는 교체
- 행 부분 집합 생성
- 행 정렬
- DataFrame:
select,selectExpr,drop,withColumn,withColumnRenamed,filter,distinct,limit,sort - Column:
alias,isin,cast,isNotNull,desc,operators
열 표현식
from pyspark.sql.functions import col
print(events_df.device)
print(events_df["device"])
print(col("device"))Column<'device'>
Column<'device'>
Column<'device'>Scala는 DataFrame의 기존 열을 기반으로 새 열을 생성하는 추가 구문을 지원
%scala
$"device"res0: org.apache.spark.sql.ColumnName = device열 연산자 및 메서드
| 메서드 | 설명 |
|---|---|
| *, + , <, >= | 수학 및 비교 연산자 |
| ==, != | 같음 및 같지 않음 테스트(Scala 연산자는 === 및 =!=입니다) |
| alias | 열에 별칭을 지정합니다 |
| cast, astype | 열을 다른 데이터 유형으로 변환합니다 |
| isNull, isNotNull, isNan | null인지, null이 아닌지, NaN인지 |
| asc, desc | 열의 오름차순/내림차순 정렬 표현식을 반환합니다 |
col("ecommerce.purchase_revenue_in_usd") + col("ecommerce.total_item_quantity")
col("event_timestamp").desc()
(col("ecommerce.purchase_revenue_in_usd") * 100).cast("int")Out[10]: Column<'CAST((ecommerce.purchase_revenue_in_usd * 100) AS INT)'>실제 사용
rev_df = (events_df
.filter(col("ecommerce.purchase_revenue_in_usd").isNotNull())
.withColumn("purchase_revenue", (col("ecommerce.purchase_revenue_in_usd") * 100).cast("int"))
.withColumn("avg_purchase_revenue", col("ecommerce.purchase_revenue_in_usd") / col("ecommerce.total_item_quantity"))
.sort(col("avg_purchase_revenue").desc())
)
display(rev_df)DataFrame 변환 메서드
| 메서드 | 설명 |
|---|---|
select | 각 요소에 대해 주어진 표현식을 계산하여 새 DataFrame을 반환합니다. |
drop | 열을 삭제한 새 DataFrame을 반환합니다. |
withColumnRenamed | 열 이름이 변경된 새 DataFrame을 반환합니다. |
withColumn | 열을 추가하거나 이름이 같은 기존 열을 대체하여 새 DataFrame을 반환합니다. |
filter, where | 주어진 조건을 사용하여 행을 필터링합니다. |
sort, orderBy | 주어진 표현식으로 정렬된 새 DataFrame을 반환합니다. |
dropDuplicates, distinct | 중복 행을 제거한 새 DataFrame을 반환합니다. |
limit | 처음 n개 행을 가져와 새 DataFrame을 반환합니다. |
groupBy | 지정된 열을 사용하여 DataFrame을 그룹화하여 해당 열에 대한 집계를 실행할 수 있습니다. |
열 부분 집합
DataFrame 변환을 사용하여 열 부분 집합 만들기
select()
열 목록 또는 열 기반 표현식을 선택
devices_df = events_df.select("user_id", "device")
display(devices_df)from pyspark.sql.functions import col
locations_df = events_df.select(
"user_id",
col("geo.city").alias("city"),
col("geo.state").alias("state")
)
display(locations_df)selectExpr()
SQL 표현식 목록을 선택
apple_df = events_df.selectExpr("user_id", "device in ('macOS', 'iOS') as apple_user")
display(apple_df)drop()
주어진 열을 삭제한 후 새 DataFrame을 반환.
문자열 또는 Column 객체로 지정됨.
문자열을 사용하여 여러 열을 지정.
anonymous_df = events_df.drop("user_id", "geo", "device")
display(anonymous_df)no_sales_df = events_df.drop(col("ecommerce"))
display(no_sales_df)열 추가 또는 바꾸기
DataFrame 변환을 사용하여 열을 추가하거나 바꿈
withColumn()
같은 이름의 열을 추가하거나 기존 열을 대체하여 새 DataFrame을 반환
mobile_df = events_df.withColumn("mobile", col("device").isin("iOS", "Android"))
display(mobile_df)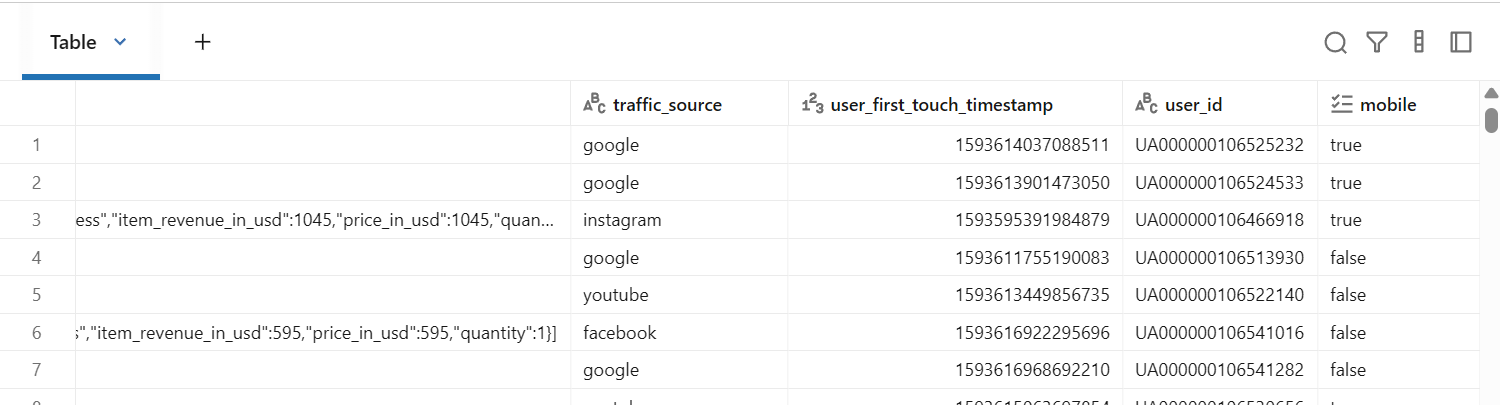
purchase_quantity_df = events_df.withColumn("purchase_quantity", col("ecommerce.total_item_quantity").cast("int"))
purchase_quantity_df.printSchema()
withColumnRenamed()
열 이름이 변경된 새 DataFrame을 반환
location_df = events_df.withColumnRenamed("geo", "location")
display(location_df)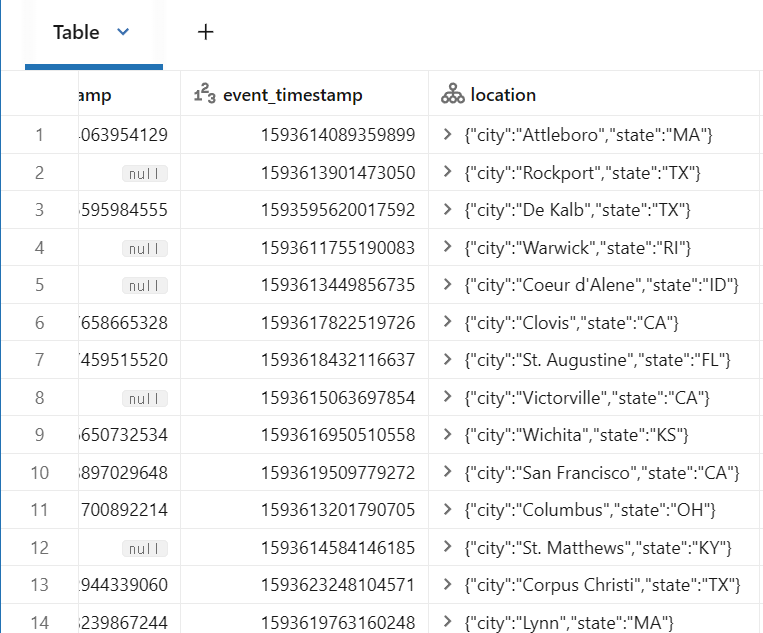
행 부분 집합
DataFrame 변환을 사용하여 행 부분 집합을 만듦
filter()
주어진 SQL 표현식 또는 열 기반 조건을 사용하여 행을 필터링합니다.
별칭: where
purchases_df = events_df.filter("ecommerce.total_item_quantity > 0")
display(purchases_df)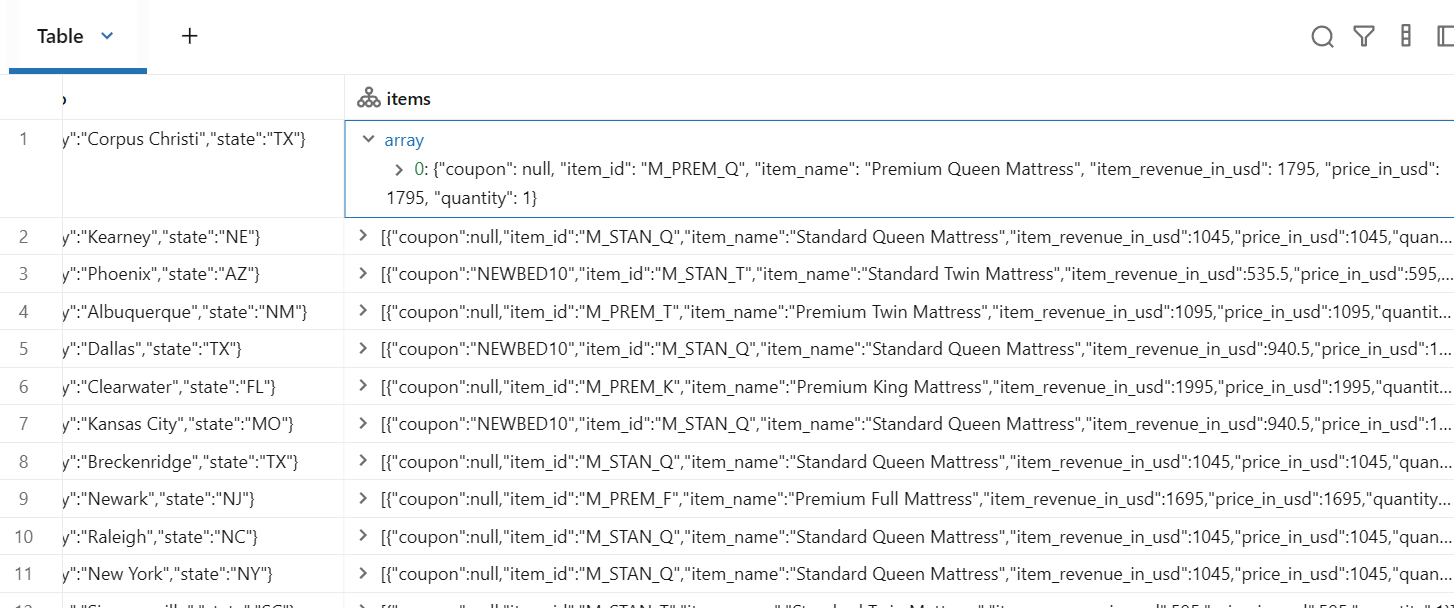
revenue_df = events_df.filter(col("ecommerce.purchase_revenue_in_usd").isNotNull())
display(revenue_df)
android_df = events_df.filter((col("traffic_source") != "direct") & (col("device") == "Android"))
display(android_df)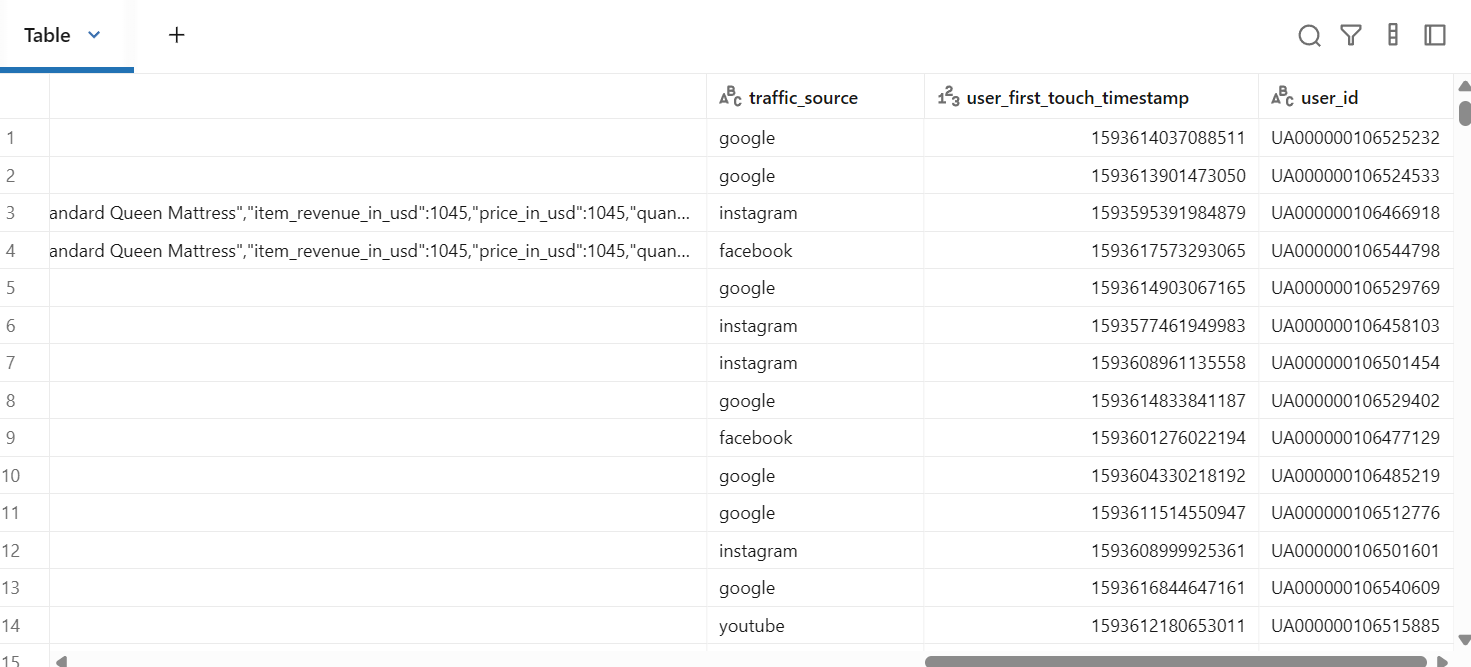
dropDuplicates()
중복 행을 제거한 새 DataFrame을 반환합니다. 선택적으로 일부 열만 고려합니다.
별칭: distinct
display(events_df.distinct())distinct_users_df = events_df.dropDuplicates(["user_id"])
display(distinct_users_df)limit()
처음 n개 행을 가져와 새 DataFrame을 반환
limit_df = events_df.limit(100)
display(limit_df)
행 정렬
sort()
주어진 열 또는 표현식을 기준으로 정렬된 새 DataFrame을 반환
별칭: orderBy
increase_timestamps_df = events_df.sort("event_timestamp")
display(increase_timestamps_df)decrease_timestamp_df = events_df.sort(col("event_timestamp").desc())
display(decrease_timestamp_df)increase_sessions_df = events_df.orderBy(["user_first_touch_timestamp", "event_timestamp"])
display(increase_sessions_df)decrease_sessions_df = events_df.sort(col("user_first_touch_timestamp").desc(), col("event_timestamp"))
display(decrease_sessions_df)구매 수익 실습
작업
- 각 이벤트의 구매 수익 추출
- 수익이 null이 아닌 이벤트 필터링
- 수익이 있는 이벤트 유형 확인
- 불필요한 열 삭제
메서드
- DataFrame:
select,drop,withColumn,filter,dropDuplicates - Column:
isNotNull
events_df = spark.table("events")
display(events_df)
from pyspark.sql.functions import col
# 각 이벤트에 대한 구매 수익을 추출
revenue_df = events_df.withColumn("revenue", col("ecommerce.purchase_revenue_in_usd"))
display(revenue_df)
# 매출이 null이 아닌 이벤트 필터링
purchases_df = revenue_df.filter(col("revenue").isNotNull())
display(purchases_df)
# 수익이 발생한 이벤트 유형 확인
distinct_df = purchases_df.dropDuplicates(["event_name"])
display(distinct_df)
# 불필요한 열 삭제
final_df = purchases_df.drop("event_name")
display(final_df)
# 불필요한 열 삭제를 제외한 모든 단계 한 번에 실행
final_df = (events_df
.withColumn("revenue", col("ecommerce.purchase_revenue_in_usd"))
.filter(col("revenue").isNotNull())
.drop("event_name")
)
display(final_df)집계
목표
- 지정된 열을 기준으로 데이터 그룹화
- 그룹화된 데이터 메서드를 적용하여 데이터 집계
- 내장 함수를 적용하여 데이터 집계
메서드
df = spark.table("events")
display(df)Grouping data
groupBy
DataFrame의 groupBy 메서드를 사용하여 그룹화된 데이터 객체를 생성
이 그룹화된 데이터 객체는 Scala에서는 RelationalGroupedDataset, Python에서는 GroupedData라고 함
df = spark.read.format('csv').option('header', 'true').load('path/to/data.csv')df.groupBy("event_name")# 여러개도 가능
df.groupBy("geo.state", "geo.city")그룹화된 데이터 메서드
GroupedData 객체에서 다양한 집계 메서드를 사용할 수 있습니다.
| 메서드 | 설명 |
|---|---|
| agg | 일련의 집계 열을 지정하여 집계를 계산합니다. |
| avg | 각 그룹의 각 숫자 열에 대한 평균값을 계산합니다. |
| count | 각 그룹의 행 수를 센다. |
| max | 각 그룹의 각 숫자 열에 대한 최대값을 계산합니다. |
| mean | 각 그룹의 각 숫자 열에 대한 평균값을 계산합니다. |
| min | 각 그룹의 각 숫자 열에 대한 최소값을 계산합니다. |
| pivot | 현재 DataFrame의 열을 피벗(행의 값을 열로 바꾸기)하고 지정된 집계를 수행합니다. |
| sum | 각 그룹의 각 숫자 열에 대한 합계를 계산합니다. |
event_counts_df = df.groupBy("event_name").count()
display(event_counts_df)avg_state_purchases_df = df.groupBy("geo.state").avg("ecommerce.purchase_revenue_in_usd")
display(avg_state_purchases_df)city_purchase_quantities_df = df.groupBy("geo.state", "geo.city").sum("ecommerce.total_item_quantity", "ecommerce.purchase_revenue_in_usd")
display(city_purchase_quantities_df)내장 함수
DataFrame 및 Column 변환 메서드 외에도 Spark의 내장 SQL 함수 모듈
Scala에서는 org.apache.spark.sql.functions이고, Python에서는 pyspark.sql.functions
집계 함수
| 메서드 | 설명 |
|---|---|
| approx_count_distinct | 그룹 내 고유 항목의 대략적인 개수를 반환합니다. |
| avg | 그룹 내 값의 평균을 반환합니다. |
| collect_list | 중복된 객체 목록을 반환합니다. |
| corr | 두 숫자형 열의 상관계수를 반환합니다. |
| max | 각 그룹의 각 숫자 열에 대한 최댓값을 계산합니다. |
| mean | 각 그룹의 각 숫자 열에 대한 평균값을 계산합니다. |
| stddev_samp | 그룹 내 표현식의 표본 표준 편차를 반환합니다. |
| sumDistinct | 표현식 내 고유 값의 합계를 반환합니다. |
| var_pop | 그룹 내 값의 모분산을 반환합니다. |
그룹화된 데이터 메서드 agg를 사용하여 내장 집계 함수를 적용
이렇게 하면 결과 열에 alias와 같은 다른 변환을 적용 가능
from pyspark.sql.functions import sum
state_purchases_df = df.groupBy("geo.state").agg(sum("ecommerce.total_item_quantity").alias("total_purchases"))
display(state_purchases_df)그룹화된 데이터에 여러 집계 함수 적용
from pyspark.sql.functions import avg, approx_count_distinct
state_aggregates_df = (df
.groupBy("geo.state")
.agg(avg("ecommerce.total_item_quantity").alias("avg_quantity"),
approx_count_distinct("user_id").alias("distinct_users"))
) #큰 데이터에서는 count 후 distinct 시 부하 발생. 그럴 때 사용(보통 빅데이터에서는 정확한 값을 요구치 않기 떄문)
display(state_aggregates_df)수학 함수
| 메서드 | 설명 |
|---|---|
| ceil | 주어진 열의 상한값을 계산합니다. |
| cos | 주어진 값의 코사인을 계산합니다. |
| log | 주어진 값의 자연 로그를 계산합니다. |
| round | HALF_UP 반올림 모드를 사용하여 e 열의 값을 소수점 이하 0자리로 반올림하여 반환합니다. |
| sqrt | 지정된 부동 소수점 값의 제곱근을 계산합니다. |
from pyspark.sql.functions import cos, sqrt
display(spark.range(10) # Create a DataFrame with a single column called "id" with a range of integer values
.withColumn("sqrt", sqrt("id"))
.withColumn("cos", cos("id"))
)가장 높은 총 수익 실습
- 트래픽 소스별 매출 집계
- 총 매출 기준 상위 3개 트래픽 소스 가져오기
- 매출 열을 소수점 둘째 자리까지 정리
메서드
# df 생성
from pyspark.sql.functions import col
# Purchase events logged on the BedBricks website
df = (spark.table("events")
.withColumn("revenue", col("ecommerce.purchase_revenue_in_usd"))
.filter(col("revenue").isNotNull())
.drop("event_name")
)
display(df)
# 트래픽 소스별 총 수익
from pyspark.sql.functions import sum, avg, round, col
traffic_df = (df
.groupBy("traffic_source")
.agg(
round(sum("revenue"), 1).alias("total_rev"),
avg("revenue").alias("avg_rev")
)
)
display(traffic_df)
# 총 수익 기준 상위 3개 트래픽 소스 가져오기
from pyspark.sql.functions import desc
top_traffic_df = traffic_df.orderBy(desc("total_rev")).limit(3)
display(top_traffic_df)
# 매출 열의 소수점 이하 두자리까지 제한
final_df = (top_traffic_df
.withColumn("avg_rev", (col("avg_rev") * 100).cast("long") / 100)
.withColumn("total_rev", (col("total_rev") * 100).cast("long") / 100)
)
display(final_df)
# 내장 수학 함수를 사용하여 재작성
bonus_df = (top_traffic_df
.withColumn("avg_rev", round(col("avg_rev"), 2))
.withColumn("total_rev", round(col("total_rev"), 2))
)
display(bonus_df)
# 한 번에 체이닝으로 처리
chain_df = (df
.groupBy("traffic_source")
.agg(
round(sum("revenue"), 2).alias("total_rev"),
round(avg("revenue"), 2).alias("avg_rev")
)
.orderBy(col("total_rev").desc()).limit(3)
)
display(chain_df)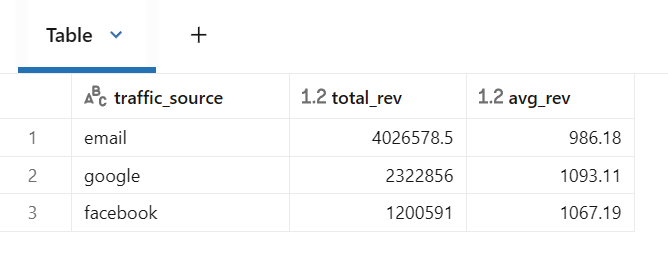
Reader & Writer
목표
- CSV 파일에서 읽기
- JSON 파일에서 읽기
- DataFrame을 파일에 쓰기
- DataFrame을 테이블에 쓰기
- DataFrame을 Delta 테이블에 쓰기
방법
- DataFrameReader:
csv,json,option,schema - DataFrameWriter:
mode,option,parquet,format,saveAsTable - 구조체 유형:
toDDL
Spark 유형
- 유형:
ArrayType,DoubleType,IntegerType,LongType,StringType,StructType,StructField
DataFrameReader
외부 저장소 시스템에서 DataFrame을 로드하는 데 사용되는 인터페이스
spark.read.parquet("path/to/files")
DataFrameReader는 SparkSession 속성인 read를 통해 액세스 가능.
CSV 파일에서 읽기
DataFrameReader의 csv 메서드와 다음 옵션을 사용하여 CSV에서 읽기:
Tab separator, use first line as header, infer schema
users_df = (spark
.read
.option("sep", "\t")
.option("header", True)
.option("inferSchema", True)
.csv(DA.paths.users_csv)
)
users_df.printSchema()Spark의 Python API를 사용하면 DataFrameReader 옵션을 csv 메서드의 매개변수로 지정 가능
users_df = (spark
.read
.csv(DA.paths.users_csv, sep="\t", header=True, inferSchema=True)
)
users_df.printSchema()열 이름과 데이터 유형을 사용하여 StructType을 생성하여 스키마를 수동으로 정의
from pyspark.sql.types import LongType, StringType, StructType, StructField
user_defined_schema = StructType([
StructField("user_id", StringType(), True),
StructField("user_first_touch_timestamp", LongType(), True),
StructField("email", StringType(), True)
])users_df = (spark
.read
.option("sep", "\t")
.option("header", True)
.schema(user_defined_schema)
.csv(DA.paths.users_csv)
)또는 데이터 정의 언어(DDL) 구문을 사용하여 스키마를 정의
ddl_schema = "user_id string, user_first_touch_timestamp long, email string"
users_df = (spark
.read
.option("sep", "\t")
.option("header", True)
.schema(ddl_schema)
.csv(DA.paths.users_csv)
)JSON 파일에서 읽기
DataFrameReader의 json 메서드와 infer schema 옵션을 사용하여 JSON에서 읽기
events_df = (spark
.read
.option("inferSchema", True)
.json(DA.paths.events_json)
)
events_df.printSchema()스키마 이름과 데이터 유형을 사용하여 StructType을 생성하여 데이터를 더 빠르게 읽기
from pyspark.sql.types import ArrayType, DoubleType, IntegerType, LongType, StringType, StructType, StructField
user_defined_schema = StructType([
StructField("device", StringType(), True),
StructField("ecommerce", StructType([
StructField("purchaseRevenue", DoubleType(), True),
StructField("total_item_quantity", LongType(), True),
StructField("unique_items", LongType(), True)
]), True),
StructField("event_name", StringType(), True),
StructField("event_previous_timestamp", LongType(), True),
StructField("event_timestamp", LongType(), True),
StructField("geo", StructType([
StructField("city", StringType(), True),
StructField("state", StringType(), True)
]), True),
StructField("items", ArrayType(
StructType([
StructField("coupon", StringType(), True),
StructField("item_id", StringType(), True),
StructField("item_name", StringType(), True),
StructField("item_revenue_in_usd", DoubleType(), True),
StructField("price_in_usd", DoubleType(), True),
StructField("quantity", LongType(), True)
])
), True),
StructField("traffic_source", StringType(), True),
StructField("user_first_touch_timestamp", LongType(), True),
StructField("user_id", StringType(), True)
])
events_df = (spark
.read
.schema(user_defined_schema)
.json(DA.paths.events_json)
)스칼라의 StructType 메서드인 toDDL을 사용하면 DDL 형식의 문자열을 자동으로 생성 가능
이 기능은 CSV 및 JSON 데이터를 처리하기 위해 DDL 형식의 문자열을 가져와야 하지만 문자열을 직접 작성하거나 스키마의 StructType 변형을 원하지 않을 때 편리
Python에서는 이 기능을 사용할 수 없지만, 노트북의 기능을 통해 두 언어를 모두 사용 가능
spark.conf.set("com.whatever.your_scope.events_path", DA.paths.events_json)Python 노트북에서 Scala 셀을 생성하여 데이터를 삽입하고 DDL 형식의 스키마를 생성
%scala
// Step 2 - config에서 값을 끌어오거나 복사하여 붙여넣습니다.
val eventsJsonPath = spark.conf.get("com.whatever.your_scope.events_path")
// Step 3 - JSON을 읽지만 스키마를 추론하게 합니다.
val eventsSchema = spark.read
.option("inferSchema", true)
.json(eventsJsonPath)
.schema.toDDL
// Step 4 - 스키마를 print하고, 선택한 후 복사합니다.
println("="*80)
println(eventsSchema)
println("="*80)# Step 5 - 위의 스키마를 붙여넣고 여기에서 볼 수 있듯이 변수에 할당합니다.
events_schema = "`device` STRING,`ecommerce` STRUCT<`purchase_revenue_in_usd`: DOUBLE, `total_item_quantity`: BIGINT, `unique_items`: BIGINT>,`event_name` STRING,`event_previous_timestamp` BIGINT,`event_timestamp` BIGINT,`geo` STRUCT<`city`: STRING, `state`: STRING>,`items` ARRAY<STRUCT<`coupon`: STRING, `item_id`: STRING, `item_name`: STRING, `item_revenue_in_usd`: DOUBLE, `price_in_usd`: DOUBLE, `quantity`: BIGINT>>,`traffic_source` STRING,`user_first_touch_timestamp` BIGINT,`user_id` STRING"
# Step 6 - 새로운 DDL 형식 문자열을 사용하여 JSON 데이터를 읽습니다.
events_df = (spark.read
.schema(events_schema)
.json(DA.paths.events_json))
display(events_df)경고: 운영 환경에서는 이 트릭 사용X
스키마 추론은 스키마를 추론하기 위해 소스 데이터 세트를 모두 읽어야 하므로 매우 느릴 수 있음
파일에 DataFrame 쓰기
ataFrameWriter의 parquet 메서드와 다음 구성을 사용하여 users_df를 parquet에 쓰기:
Snappy compression, overwrite mode
users_output_dir = DA.paths.working_dir + "/users.parquet"
(users_df
.write
.option("compression", "snappy")
.mode("overwrite")
.parquet(users_output_dir)
)display(
dbutils.fs.ls(users_output_dir)
)DataFrameReader와 마찬가지로 Spark의 Python API를 사용하면 parquet 메서드의 매개변수로 DataFrameWriter 옵션을 지정
(users_df
.write
.parquet(users_output_dir, compression="snappy", mode="overwrite")
)테이블에 DataFrame 쓰기
DataFrameWriter 메서드인 saveAsTable`을 사용하여 테이블에 events_df를 쓰기
![]() 이 메서드는 DataFrame 메서드인
이 메서드는 DataFrame 메서드인 createOrReplaceTempView로 생성되는 로컬 뷰와 달리 전역 테이블을 생성
events_df.write.mode("overwrite").saveAsTable("events")print(DA.schema_name)Delta Lake
거의 모든 경우, 특히 Databricks 작업 공간에서 데이터를 참조할 경우 Delta Lake 형식을 사용하는 것이 가장 좋음
Delta Lake는 Spark와 함께 작동하여 데이터 레이크의 안정성을 높이도록 설계된 오픈 소스 기술
Delta Lake의 주요 기능
- ACID 트랜잭션
- 확장 가능한 메타데이터 처리
- 통합 스트리밍 및 일괄 처리
- 시간 이동(데이터 버전 관리)
- 스키마 적용 및 진화
- 감사 기록
- Parquet 형식
- Apache Spark API와 호환
델타 테이블에 결과 쓰기
DataFrameWriter의 save 메서드와 다음 구성을 사용하여 events_df를 작성합니다. 델타 형식 및 덮어쓰기 모드.
events_output_path = DA.paths.working_dir + "/delta/events"
(events_df
.write
.format("delta")
.mode("overwrite")
.save(events_output_path)
)데이터수집 실습
제품 데이터가 포함된 CSV 파일을 읽어옵니다.
작업
- 스키마 추론을 사용하여 읽기
- 사용자 정의 스키마를 사용하여 읽기
- 스키마를 DDL 형식 문자열로 사용하여 읽기
- 델타 형식을 사용하여 쓰기
# 스키마 추론을 사용한 읽기
single_product_csv_file_path = f"{DA.paths.products_csv}/part-00000-tid-1663954264736839188-daf30e86-5967-4173-b9ae-d1481d3506db-2367-1-c000.csv"
print(dbutils.fs.head(single_product_csv_file_path))
products_csv_path = DA.paths.products_csv
products_df = spark.read.csv(products_csv_path,
header=True,
inferSchema=True)
products_df.printSchema()
# 사용자 정의 스키마로 읽기
from pyspark.sql.types import DoubleType, StringType, StructField, StructType
user_defined_schema = StructType([
StructField("item_id", StringType(), True),
StructField("name", StringType(), True),
StructField("price", DoubleType())
])
products_df2 = spark.read.csv(products_csv_path,
header=True,
schema=user_defined_schema)
# DDL 형식 문자열로 읽기
ddl_schema = "item_id string, name string, price double"
products_df3 = spark.read.csv(products_csv_path,
header=True,
schema=ddl_schema)
# Delta에 쓰기
products_output_path = DA.paths.working_dir + "/delta/products"
(products_df
.write
.format("delta")
.mode("overwrite")
.save(products_output_path)
)Datetimes
목표
- 타임스탬프로 변환
- 날짜/시간 형식 지정
- 타임스탬프에서 추출
- 날짜/시간으로 변환
- 날짜/시간 조작
Methods
- Column:
cast - Built-In Functions:
date_format,to_date,date_add,year,month,dayofweek,minute,second
from pyspark.sql.functions import col
df = spark.table("events").select("user_id", col("event_timestamp").alias("timestamp"))
display(df)내장 함수: 날짜/시간 함수
| 메서드 | 설명 |
|---|---|
add_months | startDate로부터 numMonths 후의 날짜를 반환합니다. |
current_timestamp | 쿼리 실행 시작 시 현재 타임스탬프를 타임스탬프 열로 반환합니다. |
date_format | 날짜/타임스탬프/문자열을 두 번째 인수로 지정된 날짜 형식의 문자열 값으로 변환합니다. |
dayofweek | 주어진 날짜/타임스탬프/문자열에서 일자를 정수로 추출합니다. |
from_unixtime | 유닉스 시대(1970-01-01 00:00:00 UTC)의 초 수를 현재 시스템 시간대의 해당 시점의 타임스탬프를 yyyy-MM-dd HH:mm:ss 형식으로 나타내는 문자열로 변환합니다. |
minute | 주어진 날짜/타임스탬프/문자열에서 분을 정수로 추출합니다. |
unix_timestamp | 주어진 패턴을 갖는 시간 문자열을 유닉스 타임스탬프(초)로 변환합니다. |
타임스탬프로 변환
cast()
문자열 표현이나 DataType을 사용하여 지정된 다른 데이터 유형으로 열을 변환합니다.
#1e6 = 1,000,000
timestamp_df = df.withColumn("timestamp", (col("timestamp") / 1e6).cast("timestamp"))
display(timestamp_df)from pyspark.sql.types import TimestampType
timestamp_df = df.withColumn("timestamp", (col("timestamp") / 1e6).cast(TimestampType()))
display(timestamp_df)날짜/시간
- CSV/JSON 데이터 소스는 날짜/시간 콘텐츠의 구문 분석 및 형식 지정에 패턴 문자열을 사용
- StringType과 DateType 또는 TimestampType 간의 변환과 관련된 날짜/시간 함수(예:
unix_timestamp,date_format,from_unixtime,to_date,to_timestamp등)
형식 지정 및 구문 분석을 위한 날짜/시간 패턴
Spark는 날짜 및 타임스탬프 구문 분석 및 형식 지정에 패턴 문자를 사용
| 기호 | 의미 | 표현 | 예시 |
|---|---|---|---|
| G | 시대 | 텍스트 | 서기; 기원후 |
| y | 년 | 년 | 2020; 20 |
| D | 일 | 숫자(3) | 189 |
| M/L | 월 | 월 | 7; 07; 7월; 7월 |
| d | 일 | 숫자(3) | 28 |
| Q/q | 분기 | 숫자/텍스트 | 3; 03; 3분기 |
| E | 요일 | 텍스트 | 화; 화요일 |
Spark 3.0 버전에서 날짜 및 타임스탬프 처리 방식이 변경되었으며, 이러한 값을 구문 분석하고 서식을 지정하는 데 사용되는 패턴도 변경됨.
이러한 변경 사항에 대한 설명
날짜 형식 지정
date_format()
날짜/타임스탬프/문자열을 주어진 날짜/시간 패턴으로 형식화된 문자열로 변환합니다.
from pyspark.sql.functions import date_format
formatted_df = (timestamp_df
.withColumn("date string", date_format("timestamp", "MMMM dd, yyyy"))
.withColumn("time string", date_format("timestamp", "HH:mm:ss.SSSSSS"))
)
display(formatted_df)타임스탬프에서 날짜/시간 속성 추출
year
주어진 날짜/타임스탬프/문자열에서 연도를 정수로 추출
유사 메서드: month, dayofweek, minute, second 등
from pyspark.sql.functions import year, month, dayofweek, minute, second
datetime_df = (timestamp_df
.withColumn("year", year(col("timestamp")))
.withColumn("month", month(col("timestamp")))
.withColumn("dayofweek", dayofweek(col("timestamp")))
.withColumn("minute", minute(col("timestamp")))
.withColumn("second", second(col("timestamp")))
)
display(datetime_df)날짜로 변환
to_date
규칙을 DateType으로 캐스팅하여 열을 DateType으로 변환
from pyspark.sql.functions import to_date
date_df = timestamp_df.withColumn("date", to_date(col("timestamp")))
display(date_df)날짜/시간 조작
date_add
시작일로부터 주어진 일수 후의 날짜를 반환
from pyspark.sql.functions import date_add
plus_2_df = timestamp_df.withColumn("plus_two_days", date_add(col("timestamp"), 2))
display(plus_2_df)Complex Types
컬렉션 및 문자열 작업을 위한 내장 함수
1. 배열 처리에 컬렉션 함수 적용
2. DataFrames 결합
방법
- DataFrame:
union,unionByName - 내장 함수:
- 집계:
collect_set - 컬렉션:
array_contains,element_at,explode - 문자열:
split
details_df = (df
.withColumn("items", explode("items")) #행변환
.select("email", "items.item_name")
.withColumn("details", split(col("item_name"), " "))
)
display(details_df)문자열 함수
문자열 내장 함수
| 메서드 | 설명 |
|---|---|
| translate | src의 모든 문자를 replaceString의 문자로 변환합니다. |
| regexp_replace | 지정된 문자열 값에서 regexp와 일치하는 모든 부분 문자열을 rep로 바꿉니다. |
| regexp_extract | 지정된 문자열 열에서 Java 정규식과 일치하는 특정 그룹을 추출합니다. |
| ltrim | 지정된 문자열 열에서 선행 공백 문자를 제거합니다. |
| lower | 문자열 열을 소문자로 변환합니다. |
| split | 주어진 패턴과 일치하는 문자열을 중심으로 str을 나눕니다. |
email 열을 구문 분석 → split 함수를 사용하여 도메인을 분할하고 처리
from pyspark.sql.functions import split
display(df.select(split(df.email, '@', 0).alias('email_handle')))컬렉션 함수
배열 내장 함수
| 메서드 | 설명 |
|---|---|
| array_contains | 배열이 null이면 null을 반환하고, 배열에 값이 있으면 true를 반환하고, 그렇지 않으면 false를 반환합니다. |
| element_at | 주어진 인덱스에 있는 배열의 요소를 반환합니다. 배열 요소는 1부터 번호가 매겨집니다. |
| explode | 주어진 배열 또는 맵 열의 각 요소에 대해 새 행을 생성합니다. |
| collect_set | 중복 요소가 제거된 객체 집합을 반환합니다. |
mattress_df = (details_df
.filter(array_contains(col("details"), "Mattress"))
.withColumn("size", element_at(col("details"), 2)))
display(mattress_df)집계 함수
GroupedData에서 배열을 생성하는 데 사용
| 메서드 | 설명 |
|---|---|
| collect_list | 그룹 내의 모든 값으로 구성된 배열을 반환합니다. |
| collect_set | 그룹 내의 모든 고유 값으로 구성된 배열을 반환합니다. |
# 이메일 주소별로 주문된 매트리스 크기 확인
size_df = mattress_df.groupBy("email").agg(collect_set("size").alias("size options"))
display(size_df)Union 및 unionByName
- DataFrame
union메서드는 표준 SQL처럼 위치를 기준으로 열을 확인
두 DataFrame의 스키마가 열 순서를 포함하여 정확히 동일한 경우에만 사용해야 함 - 반면, DataFrame
unionByName메서드는 이름을 기준으로 열을 확인
이는 SQL의 UNION ALL과 동일. - 둘 다 중복 제거 X
# 두 데이터프레임에 union이 적합한 일치하는 스키마가 있는지 확인
mattress_df.schema==size_df.schema #falseunion_count = mattress_df.select("email").union(size_df.select("email")).count()
mattress_count = mattress_df.count()
size_count = size_df.count()
mattress_count + size_count == union_count #trueAdditional Functions
- 내장 함수를 적용하여 새 열에 대한 데이터 생성
- DataFrame NA 함수를 적용하여 Null 값 처리
- DataFrame 조인
메서드
- DataFrame 메서드:
join - DataFrameNaFunctions:
fill,drop - 내장 함수:
- 집계:
collect_set - 컬렉션:
explode - 비집계 및 기타:
col,lit
비집계 함수 및 기타 함수
| 메서드 | 설명 |
|---|---|
| col / column | 주어진 열 이름을 기반으로 열을 반환합니다. |
| lit | 리터럴 값의 열을 생성합니다. |
| isnull | 열이 null이면 true를 반환합니다. |
| rand | [0.0, 1.0]에 균등하게 분포하는 독립적이고 동일 분포(i.i.d.) 샘플을 갖는 난수 열을 생성합니다. |
col 함수를 사용하여 특정 열 선택
gmail_accounts = sales_df.filter(col("email").endswith("gmail.com"))
display(gmail_accounts)lit은 값으로 열을 생성하는데 사용, 열을 추가할 때 유용
모든 행에 똑같은 값을 입력할 때 유용
display(gmail_accounts.select("email", lit(True).alias("gmail user")))DataFrameNaFunctions
DataFrameNaFunctions는 null 값을 처리하는 메서드를 포함하는 DataFrame 하위 모듈
DataFrame의 na 속성에 접근하여 DataFrameNaFunctions의 인스턴스를 가져옴
| 메서드 | 설명 |
|---|---|
| drop | 열의 선택적 하위 집합을 고려하여 null 값이 있는 행을 일부, 전체 또는 지정된 개수만큼 제외하고 새 DataFrame을 반환합니다. |
| fill | 열의 선택적 하위 집합에 대해 null 값을 지정된 값으로 바꿉니다. |
| replace | 열의 선택적 하위 집합을 고려하여 값을 다른 값으로 바꾸고 새 DataFrame을 반환합니다. |
# null/NA 값이 있는 행을 삭제하기 전과 삭제한 후의 행 수 확인
print(sales_df.count())
print(sales_df.na.drop().count())# 10510으로 위에서 행 개수가 같으므로 null이 없는 열이 있음
# items.coupon과 같은 열에서 null을 찾기 위해 항목 분리
sales_exploded_df = sales_df.withColumn("items", explode(col("items")))
display(sales_exploded_df.select("items.coupon"))
print(sales_exploded_df.select("items.coupon").count())
print(sales_exploded_df.select("items.coupon").na.drop().count())# 누락된 쿠폰 코드는 **`na.fill`**을 사용하여 채움
display(sales_exploded_df.select("items.coupon").na.fill("NO COUPON"))DataFrame 결합
DataFrame의 join 메서드는 주어진 조인 표현식을 기반으로 두 DataFrame을 결합
"name"이라는 공유 열의 값이 같은 경우를 기준으로 하는 내부 조인(즉, 동등 조인)
df1.join(df2, "name")
"name"과 "age"라는 공유 열의 값이 같은 경우를 기준으로 하는 내부 조인
df1.join(df2, ["name", "age"])
"name"이라는 공유 열의 값이 같은 경우를 기준으로 하는 전체 외부 조인
df1.join(df2, "name", "outer")
명시적 열 표현식을 기준으로 하는 왼쪽 외부 조인
df1.join(df2, df1["customer_name"] == df2["account_name"], "left_outer")
users_df = spark.table("users")
display(users_df)
joined_df = gmail_accounts.join(other=users_df, on='email', how = "inner")
display(joined_df)버려진 장바구니 실습
구매하지 않고 버려진 장바구니 항목을 이메일로 받아보기
- 거래에서 전환된 사용자의 이메일 가져오기
- 사용자 ID로 이메일 병합
- 각 사용자의 장바구니 항목 내역 가져오기
- 이메일로 장바구니 항목 내역 병합
- 장바구니에서 버려진 항목이 있는 이메일 필터링
방법
- DataFrame:
join - 내장 함수:
collect_set,explode,lit - DataFrameNaFunctions:
fill
sales_df = spark.table("sales")
display(sales_df)
users_df = spark.table("users")
display(users_df)
events_df = spark.table("events")
display(events_df)
# 거래에서 전환된 사용자의 이메일 가져오기
from pyspark.sql.functions import *
converted_users_df = sales_df.select("email", lit(True).alias("converted")).distinct()
# 사용자 ID로 이메일을 조인
conversions_df = (users_df.join(converted_users_df, on = "email", how = "leftouter")).filter("email IS NOT NULL").fillna(False)
display(conversions_df)
# 긱 사용자의 장바구니 항목 내역 가져오기
carts_df = (events_df.withColumn("items", explode(col("items")))
.groupBy("user_id")
.agg(collect_set("items.item_id").alias("cart"))
)
display(carts_df)
# 장바구니 항목 내역을 이메일과 연결
email_carts_df = conversions_df.join(carts_df, how = "left", on = "user_id")
display(email_carts_df)
# 장바구니에 버려진 상품이 있는 이메일 필터링
abandoned_carts_df = (email_carts_df.filter("converted == False").filter("cart IS NOT NULL"))
display(abandoned_carts_df)
# 제품별 장바구니 포기 항목 수 표시
abandoned_items_df = (abandoned_carts_df.withColumn("items", explode("cart")).groupBy("items").count())
display(abandoned_items_df)Query Optimization
df = spark.read.table("events")
display(df)논리적 최적화
explain(..)은 쿼리 계획을 출력하며, 선택적으로 지정된 설명 모드에 따라 형식이 지정
from pyspark.sql.functions import col
limit_events_df = (df
.filter(col("event_name") != "reviews")
.filter(col("event_name") != "checkout")
.filter(col("event_name") != "register")
.filter(col("event_name") != "email_coupon")
.filter(col("event_name") != "cc_info")
.filter(col("event_name") != "delivery")
.filter(col("event_name") != "shipping_info")
.filter(col("event_name") != "press")
)
limit_events_df.explain(True)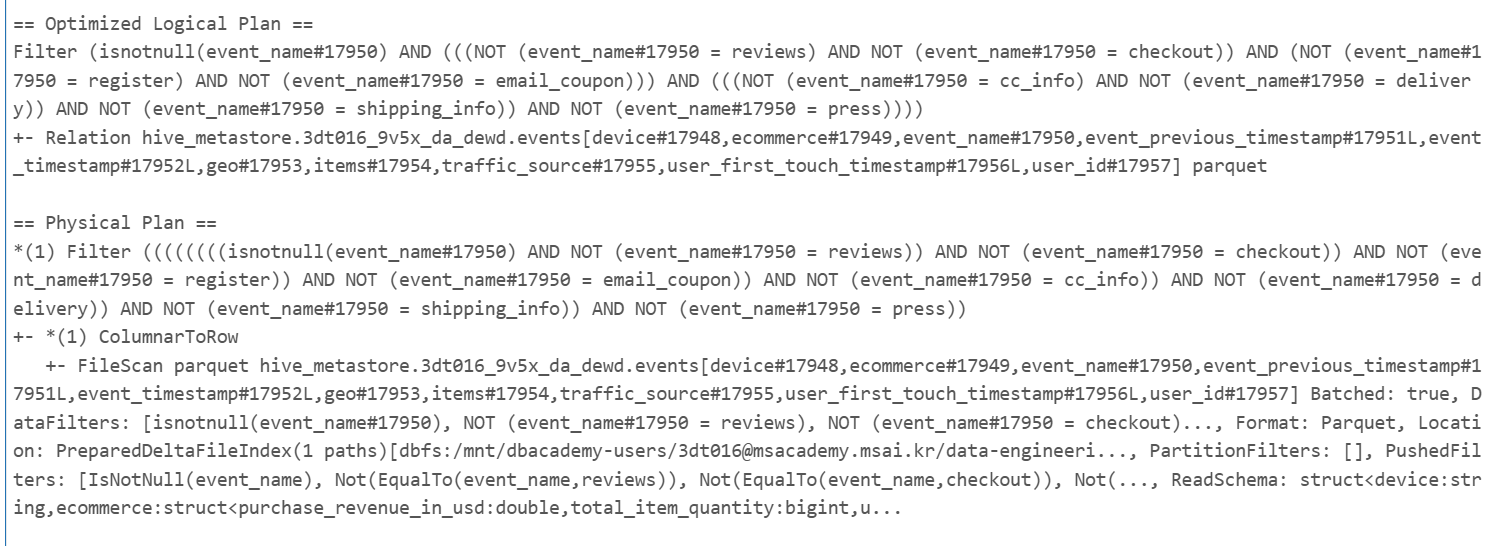
better_df = (df
.filter((col("event_name").isNotNull()) &
(col("event_name") != "reviews") &
(col("event_name") != "checkout") &
(col("event_name") != "register") &
(col("event_name") != "email_coupon") &
(col("event_name") != "cc_info") &
(col("event_name") != "delivery") &
(col("event_name") != "shipping_info") &
(col("event_name") != "press"))
)
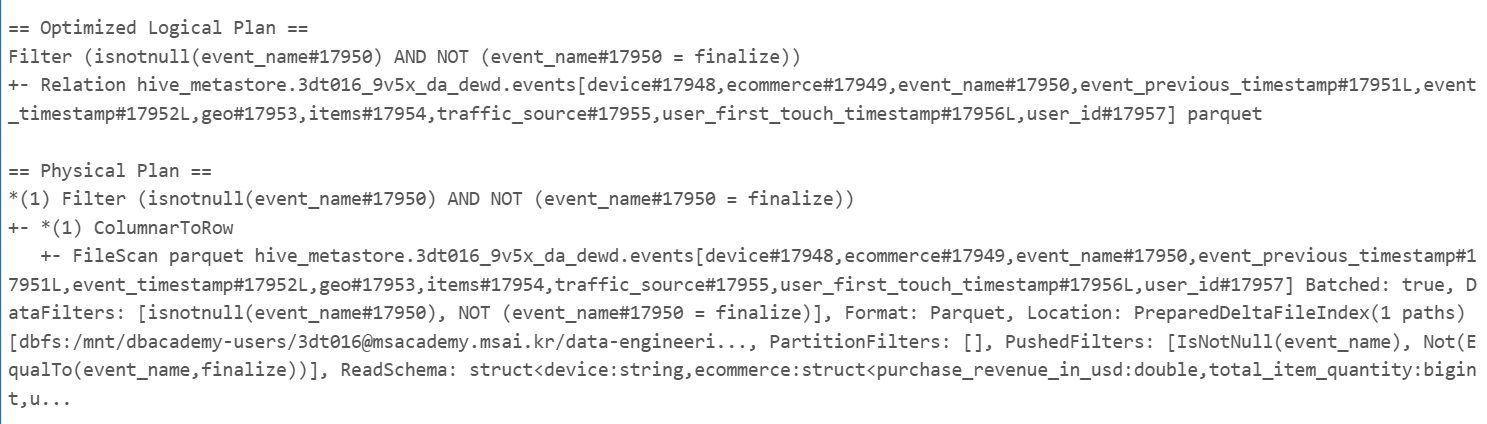
better_df.explain(True)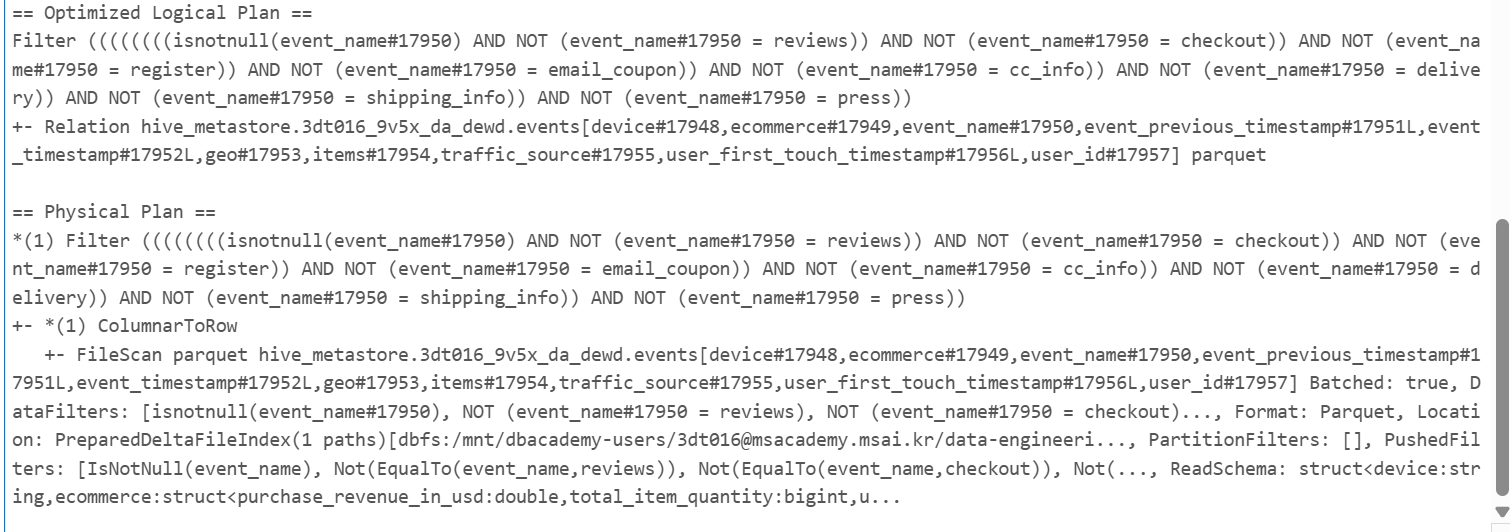
stupid_df = (df
.filter(col("event_name") != "finalize")
.filter(col("event_name") != "finalize")
.filter(col("event_name") != "finalize")
.filter(col("event_name") != "finalize")
.filter(col("event_name") != "finalize")
)
stupid_df.explain(True)