
ETL: Extract-Transform-Load
데이터의 최종 목적은 sink
Azure Data Factory는 보고서를 작성하는데 기초되는 데이터의 반복적 적재에 사용
Azure Data Factory 개요 정리
Azure Data Factory는 다양한 데이터 소스에서 데이터를 수집하고, 필요한 형태로 이동·변환·적재하는 데이터 통합 서비스이다. 이번 정리는 ADF의 개념, ETL/ELT 배경, 핵심 구성 요소, 그리고 Blob Storage의 CSV 데이터를 SQL Database로 복사하는 기본 실습 흐름까지 한 번에 정리한 내용이다.
1. 데이터와 AI 시대
-
데이터 기반 의사결정 중요성 증가함
-
기업은 데이터로부터 비즈니스 인사이트 도출 필요함
-
데이터 활용 목적:
- 고객 성향 분석
- 사회·경제 변화 분석
- 비즈니스 전략 수립
데이터를 수집하고 저장하는 것만으로는 충분하지 않고, 분석에 적합한 형태로 가공한 뒤 실제 의사결정에 연결해야 가치가 생긴다. 자료에서도 수집/변환/저장 → 데이터 분석 → 비즈니스 인사이트 도출 흐름으로 설명한다.
2. 데이터 정의 및 유형
데이터 정의
| 구분 | 설명 |
|---|---|
| 위키백과 | 양, 품질, 사실, 통계 등의 형태로 된 의미의 단위 |
| 옥스포드 컴퓨터 용어 사전 | 프로그램을 운용할 수 있는 형태로 기호화·숫자화한 자료 |
| 네이버 사전 | 이론을 세우는 데 기초가 되는 사실 또는 바탕 자료 |
| 옥스포드 대사전 | 추론과 추정의 근거를 이루는 사실 |
데이터 유형
| 유형 | 설명 |
|---|---|
| 정성적 데이터 | 언어, 문자 등 비정형 데이터 |
| 정량적 데이터 | 숫자, 도형, 기호 등 정형 데이터 |
| 암묵지 | 학습, 체험 등으로 개인이 습득한 무형 지식 |
| 형식지 | 문서화되어 전달·공유가 가능한 지식 |
정형 데이터는 저장·검색·분석에 유리하고, 비정형 데이터는 활용 가치가 크지만 전처리와 통합이 더 어렵다.
3. 데이터와 정보: DIKW 구조
DIKW 개념
| 단계 | 설명 |
|---|---|
| Data | 관찰을 통해 수집된 원시 데이터 |
| Information | 정제·가공되어 의미가 부여된 데이터 |
| Knowledge | 연결된 정보 패턴을 이해하여 내재화한 결과 |
| Wisdom | 근본 원리에 대한 깊은 이해를 바탕으로 한 의사결정 |
예시
| 단계 | 예시 |
|---|---|
| Data | A마트 식빵 100원, B마트 식빵 200원 |
| Information | A마트가 B마트보다 식빵이 더 쌈 |
| Knowledge | 식빵은 A마트에서 사는 것이 좋음 |
| Wisdom | 다른 식료품도 A마트가 더 저렴할 가능성이 높음 |
즉, 데이터는 그 자체로 끝나지 않고, 가공과 해석을 거쳐 정보·지식·지혜로 발전해야 실제 비즈니스 가치가 된다.
4. OLTP와 OLAP
| 구분 | OLTP | OLAP |
|---|---|---|
| 목적 | 실시간 데이터 처리 | 데이터 분석 및 의사결정 |
| 데이터 형태 | 원시 데이터 | 정제·집계된 데이터 |
| 구조 | 정규화된 스키마 중심 | 분석 친화적 구조 |
| 특징 | 거래 시스템 중심 | 다차원 분석 및 리포트 중심 |
OLTP는 운영계 시스템이고, OLAP는 분석계 시스템이다. ADF는 주로 운영계의 데이터를 분석계 저장소로 이동시키는 역할과 맞닿아 있다.
5. ADF, AML, BI의 역할
| 단계 | 도구 | 역할 |
|---|---|---|
| 수집·정제·결합 | Azure Data Factory | ETL/ELT, 데이터 파이프라인 구축 |
| 분석·모델링 | Azure Machine Learning | EDA, Feature Engineering, 모델 학습·예측 |
| 시각화·의사결정 | Power BI | 리포트, 대시보드, 결과 공유 |
ADF는 데이터를 준비하는 계층이고, AML은 패턴을 학습하는 계층이며, Power BI는 결과를 보여주는 계층이라고 보면 이해가 쉽다.
6. 데이터 수집·저장 시 고려사항
| 항목 | 설명 |
|---|---|
| 파일 포맷 | 형식 변환이 필요한지 확인해야 함 |
| 질의 처리 | 쿼리 성능 및 실행 계획 확인 필요함 |
| JSON 구조 | 스키마 변경 필요 여부 점검해야 함 |
| 결측치 | 누락 데이터 처리 기준 필요함 |
| 보안 | 민감 데이터 보호 방안 필요함 |
| 중복 데이터 | 여러 소스 통합 시 중복 제거 필요함 |
| 비용·인력 | 운영·이관에 드는 비용 고려해야 함 |
자료에서는 이 과정을 복잡성, 정합성, 무결성, 보안성 문제로 정리한다.
7. 데이터로부터 가치를 얻는 데 장애가 되는 요인
- 데이터 사일로: 부서, 시스템별로 데이터가 분리되어 있어 통합·분석이 어려움
- 이기종 데이터 형식: 정형·비정형 데이터를 모두 다뤄야 해 관리 복잡성 증가함
- 솔루션 복잡성: 여러 도구를 병행 운영하면 유지보수 부담 커짐
- 멀티 클라우드 환경: 클라우드별 API와 접근 방식이 달라 관리 비용 증가함
- 급증하는 운영 비용: 인프라, 도구, 인력 비용이 누적되어 전체 TCO 상승함
핵심은 “데이터를 한곳에 통합하고, 권한 있는 사용자가 쉽게 활용할 수 있어야 한다”는 점이다.
8. 가치 창출을 위한 데이터 환경 구축 요건
| 요소 | 설명 |
|---|---|
| 통합 데이터 허브 | 모든 데이터를 한 곳에 통합하고 다양한 형식을 지원해야 함 |
| 데이터 통합 | 원천 데이터를 ETL/ELT 방식으로 추출·변환·적재해야 함 |
| Self-Service Access | 사용자가 필요한 데이터를 손쉽게 조회·활용할 수 있어야 함 |
| Right & Responsibility | 데이터 품질 책임과 활용 책임을 분리해 관리해야 함 |
ADF는 이 중에서도 특히 데이터 통합을 담당하는 대표 도구로 볼 수 있다.
9. ETL과 ELT
ETL
- Extract: 원천 시스템에서 데이터 추출함
- Transform: 중간 단계에서 정제, 표준화, 집계 수행함
- Load: 대상 시스템에 적재함
ELT
- Extract: 원천 시스템에서 데이터 추출함
- Load: 우선 대상 시스템에 원시 데이터 적재함
- Transform: 대상 시스템 내부에서 SQL, Spark 등으로 변환함
ETL vs ELT 비교
| 구분 | ETL | ELT |
|---|---|---|
| 처리 순서 | 추출 → 변환 → 적재 | 추출 → 적재 → 변환 |
| 변환 위치 | 외부 시스템 | 대상 시스템 내부 |
| 실행 시간 | 잦은 데이터 이동으로 상대적으로 느림 | 병렬 처리 활용 가능해 빠름 |
| 장점 | 정제된 상태로 적재 가능 | 대용량 처리와 클라우드 환경에 유리 |
| 유연성 | 정해진 파이프라인 중심 | SQL/Spark로 유연하게 가공 가능 |
| 적합 환경 | 전통적인 DWH | 고성능 DWH, 레이크하우스 |
| 활용 예시 | 금융기관 정기 보고서 | 로그, 센서, ML 분석용 데이터 |
최근에는 대용량 비정형·반정형 데이터가 늘어나면서 ELT 방식이 더 자주 활용된다고 설명한다.
10. CDC(Change Data Capture)
CDC 개념
CDC는 데이터 소스에서 발생한 변경 사항만 감지해 추출하고 반영하는 방식이다.
CDC 처리 흐름
| 단계 | 설명 |
|---|---|
| Detect | Insert, Update, Delete 같은 변경 이벤트 감지 |
| Capture | 변경 내용을 추출해 전달 가능한 형태로 준비 |
| Apply | 변경분만 대상 시스템에 반영해 동기화 유지 |
CDC 특징
| 항목 | 설명 |
|---|---|
| 주요 목적 | 전체 재처리 없이 최신 상태 유지 |
| 처리 방식 | 실시간 또는 Near Real-Time |
| 주요 기술 | DB 로그, 트리거, 타임스탬프 비교, Debezium 등 |
| 장점 | 대용량 효율 처리, 실시간 분석 가능 |
| 활용 예시 | 실시간 대시보드, 복제 시스템, 이벤트 기반 아키텍처 |
즉, CDC는 ETL/ELT의 배치 처리 한계를 보완하는 실시간 데이터 처리 방식이다.
11. 데이터 파이프라인
데이터 파이프라인 정의
데이터 파이프라인은 원천 시스템에서 분석·활용 시스템까지 이어지는 전체 데이터 흐름을 자동화하는 구조다. 수집, 처리, 저장, 전달 전 단계를 연결한다.
데이터 파이프라인 단계
| 단계 | 설명 |
|---|---|
| Ingest | 파일, DB, API, IoT 등에서 데이터 수집 |
| Process | 정제, 필터링, 변환, 결측치 처리, 집계 |
| Store | 데이터 웨어하우스, 데이터 레이크 등에 저장 |
| Deliver | 대시보드, 분석 시스템, 모델링 시스템 등에 전달 |
데이터 파이프라인 특징
- 자동화: 반복 작업을 자동 실행함
- 연속성: 흐름이 단계별로 끊기지 않음
- 확장성: 병렬 처리 및 클라우드 인프라 활용 가능함
- 신뢰성: 재처리, 오류 감지, 모니터링 가능함
- 실시간성: 스트리밍 처리도 가능함
12. 데이터 파이프라인 구성 요소
| 구성 요소 | 설명 |
|---|---|
| Data Source | 데이터베이스, 파일 시스템, API, 로그 등 원천 위치 |
| Extract | 소스에서 데이터를 읽어오는 단계 |
| Transform | 필터링, 조인, 포맷 변경, 집계 등 가공 단계 |
| Load | 대상(데이터 웨어하우스, 데이터레이크, NoSQL DB) 시스템에 저장하는 단계 |
| Orchestration | 전체 흐름 제어, 조건 분기, 재시도, 트리거 관리 |
| Monitoring & Alert | 성공/실패 감시, 알림, 로깅, 성능 분석 |
| Execution Environment | 정의된 파이프라인을 실제 실행하는 컴퓨팅 환경 |
ADF에서는 이 Execution Environment를 Integration Runtime이라고 부른다.
13. 오케스트레이션과 트랜스포메이션
| 구분 | 구성 요소 | 설명 |
|---|---|---|
| 오케스트레이션 | 워크플로우 | 작업 순서와 흐름 정의 |
| 트리거 | 일정·이벤트·수동 실행 조건 설정 | |
| 조건 분기 및 반복 | 조건에 따른 분기와 루프 제어 | |
| 에러 처리 및 알림 | 실패 시 재시도, 로그, 알림 수행 | |
| 트랜스포메이션 | Extract | 데이터 추출 |
| Transform | 데이터 가공 | |
| Load | 데이터 적재 | |
| 사용자 정의 로직 | 커스텀 처리 코드 실행 |
ADF는 특히 오케스트레이션에 강점이 있고, 복잡한 변환은 외부 컴퓨팅 서비스와 함께 사용하는 구조가 자주 등장한다.
14. Execution Environment
| 도구/플랫폼 | 실행 환경 명칭 | 설명 |
|---|---|---|
| Azure Data Factory | Integration Runtime | 컴퓨팅/실행 엔진(Azure/Self-Hosted/SSIS) |
| AWS Glue | Job Worker / Spark Environment | Spark 기반 실행 환경 |
| Apache Airflow | Worker / Executor | DAG를 실제로 실행하는 프로세스 |
| Google Dataflow | Worker / Runner | 파이프라인을 실행하는 관리형 워커 노드 |
| Talend | Job Server | Talend Job 실행 환경 |
파이프라인이 “무엇을 할지”를 정의한다면, Execution Environment는 “어디서 어떻게 실행할지”를 담당한다.
- Azure Integration Runtime: 클라우드상
- Self-Hosted: 로컬환경상
15. Azure Data Factory 구성 요소
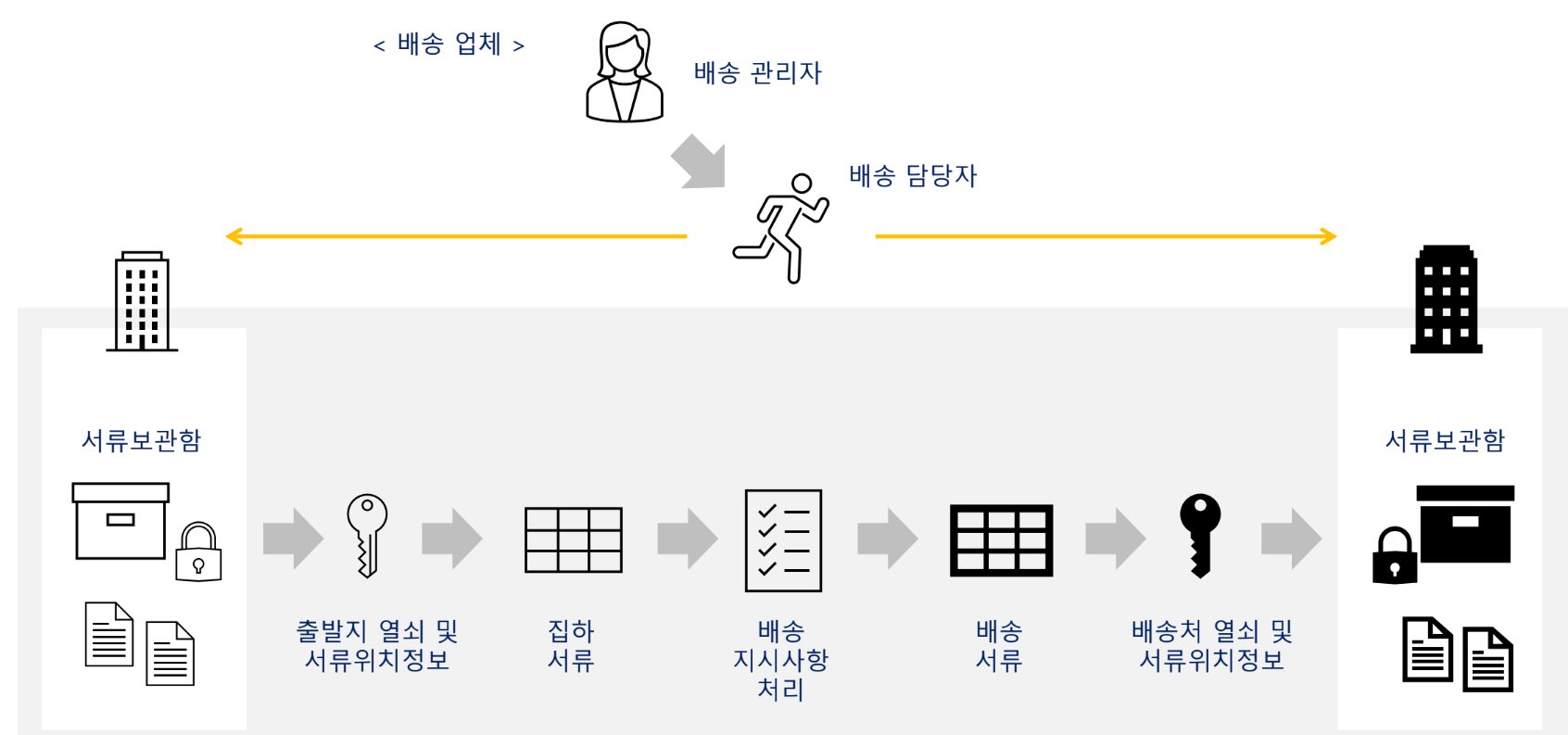
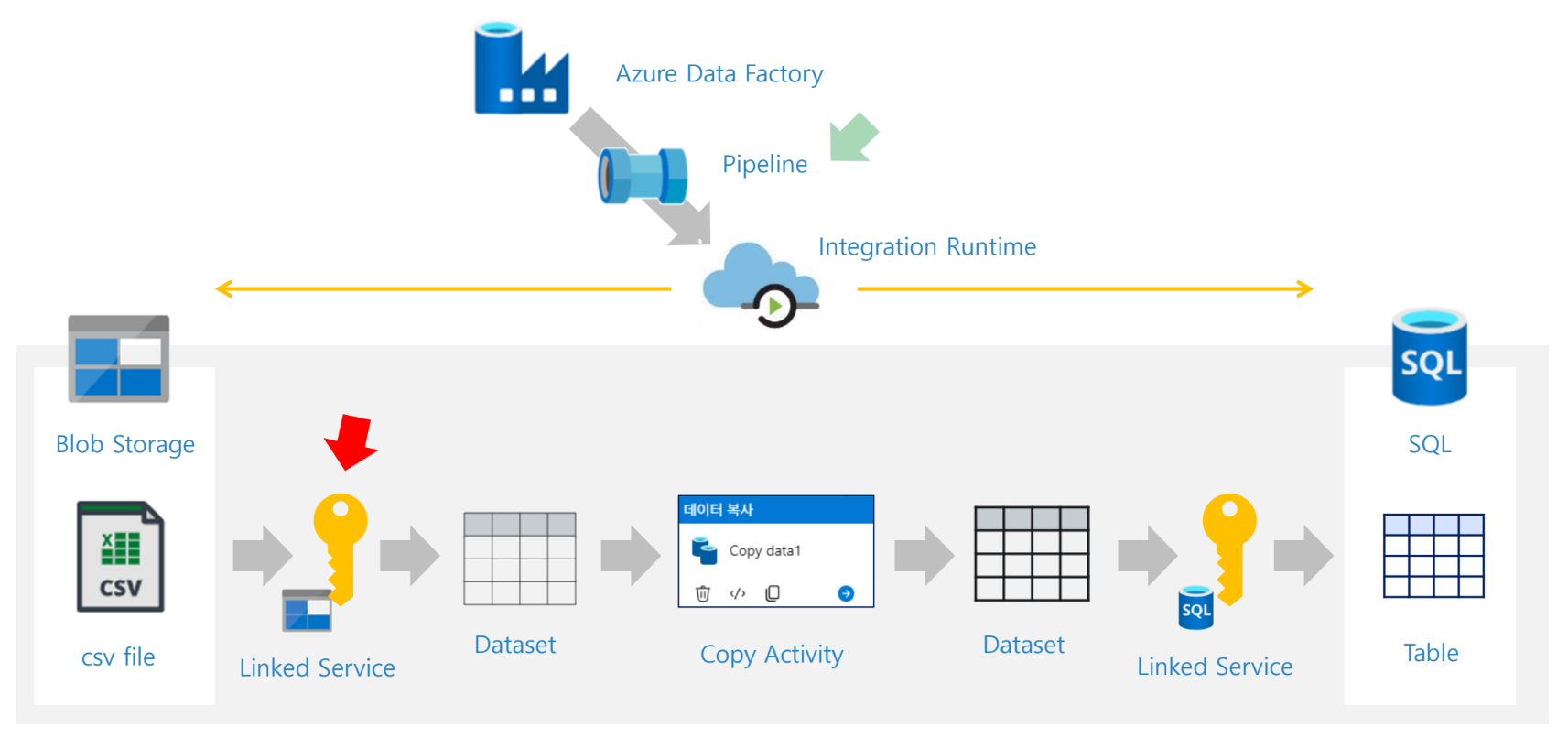
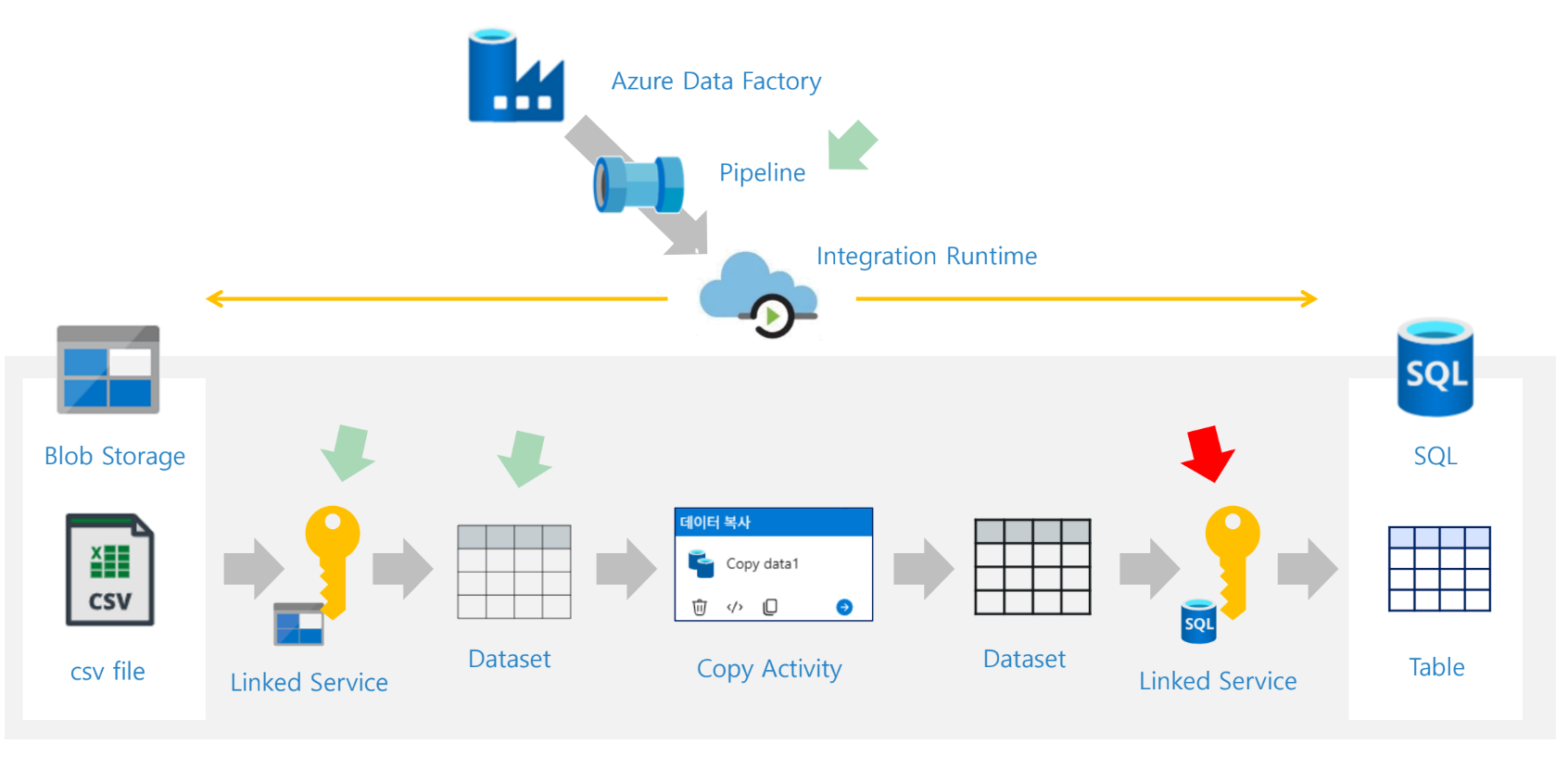
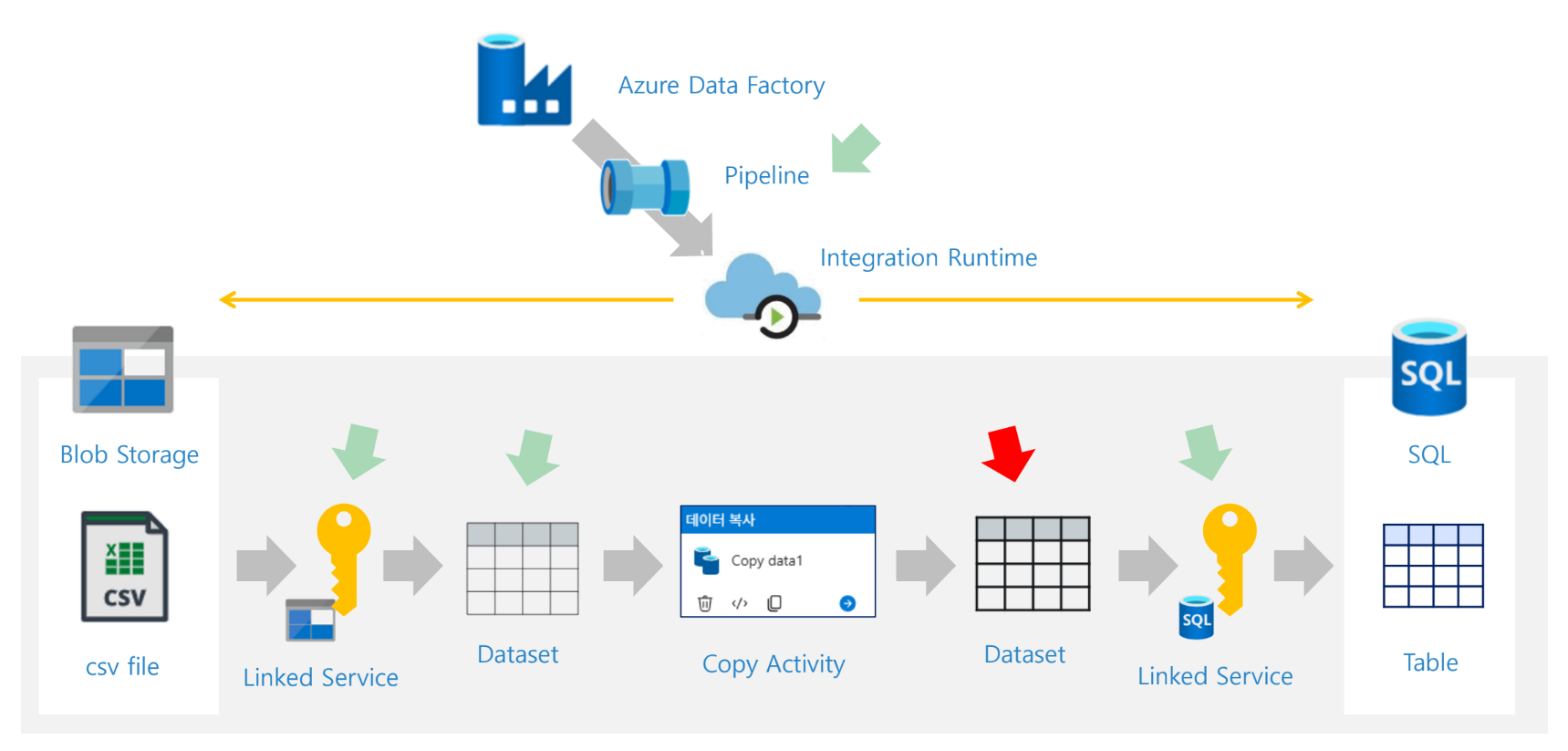
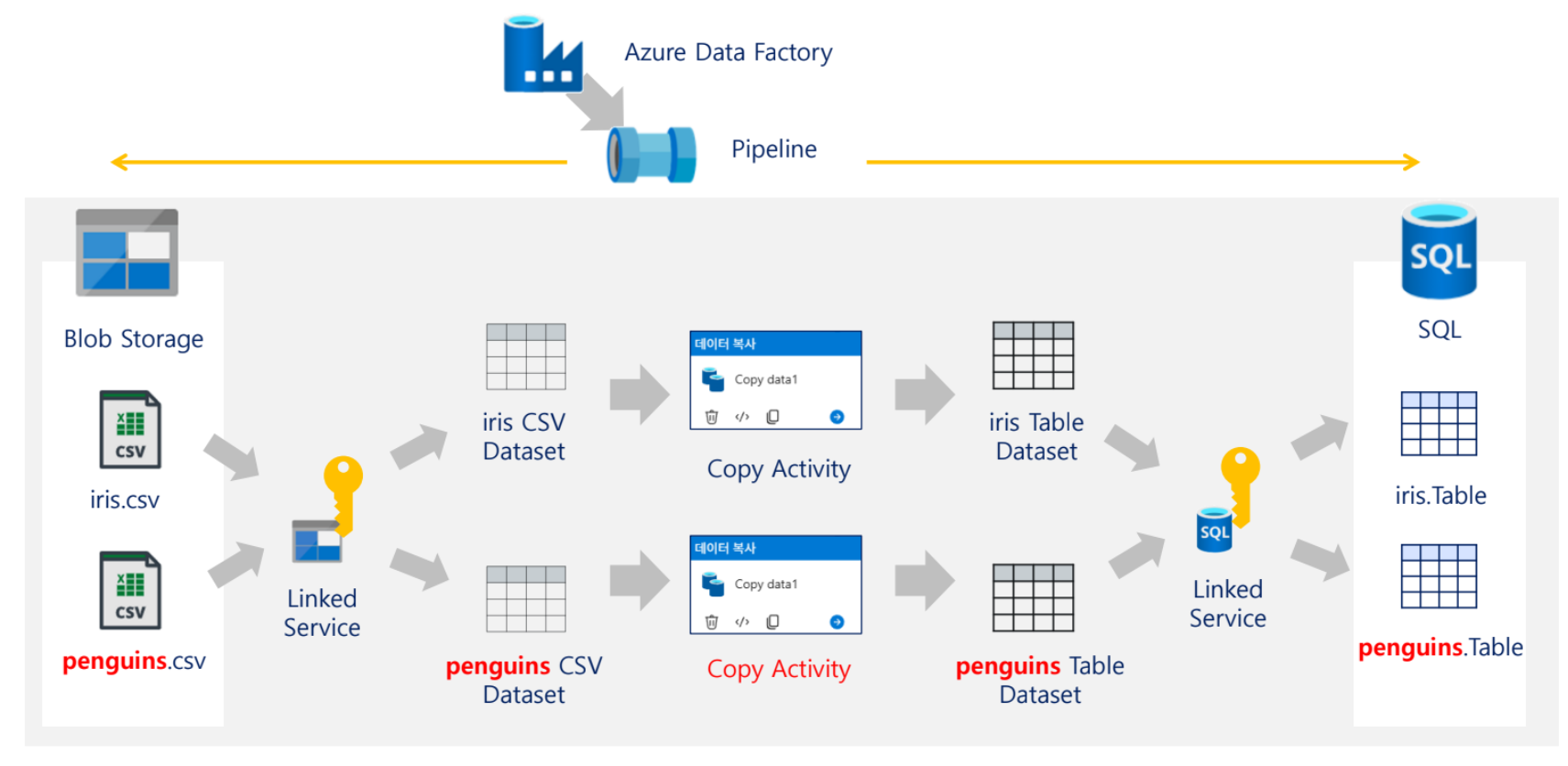
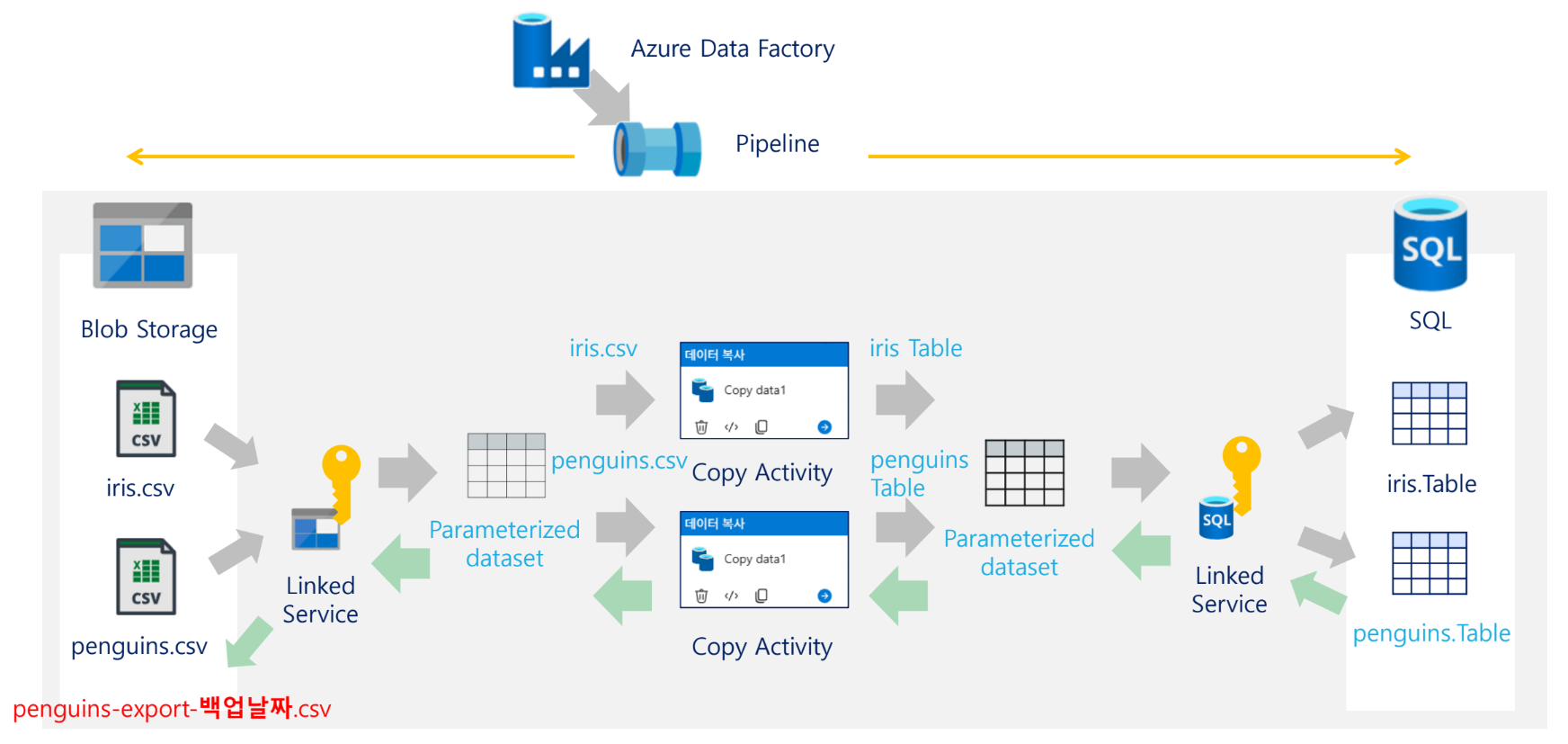
자료에서는 ADF를 배송 시스템에 비유한다. 출발지 서류보관함에서 서류를 집하해 처리한 뒤 목적지 서류보관함에 전달하는 흐름으로 설명한다. 이 비유에서 파이프라인은 전체 배송 계획, 액티비티는 개별 운송 작업, 데이터셋은 다루는 서류 묶음, 링크드 서비스는 출발지·도착지 정보, Integration Runtime은 실제 배송을 수행하는 엔진에 해당한다.
ADF 핵심 구성 요소
- Linked Service는 저장의 추상화
Pipeline과 Activity 관계
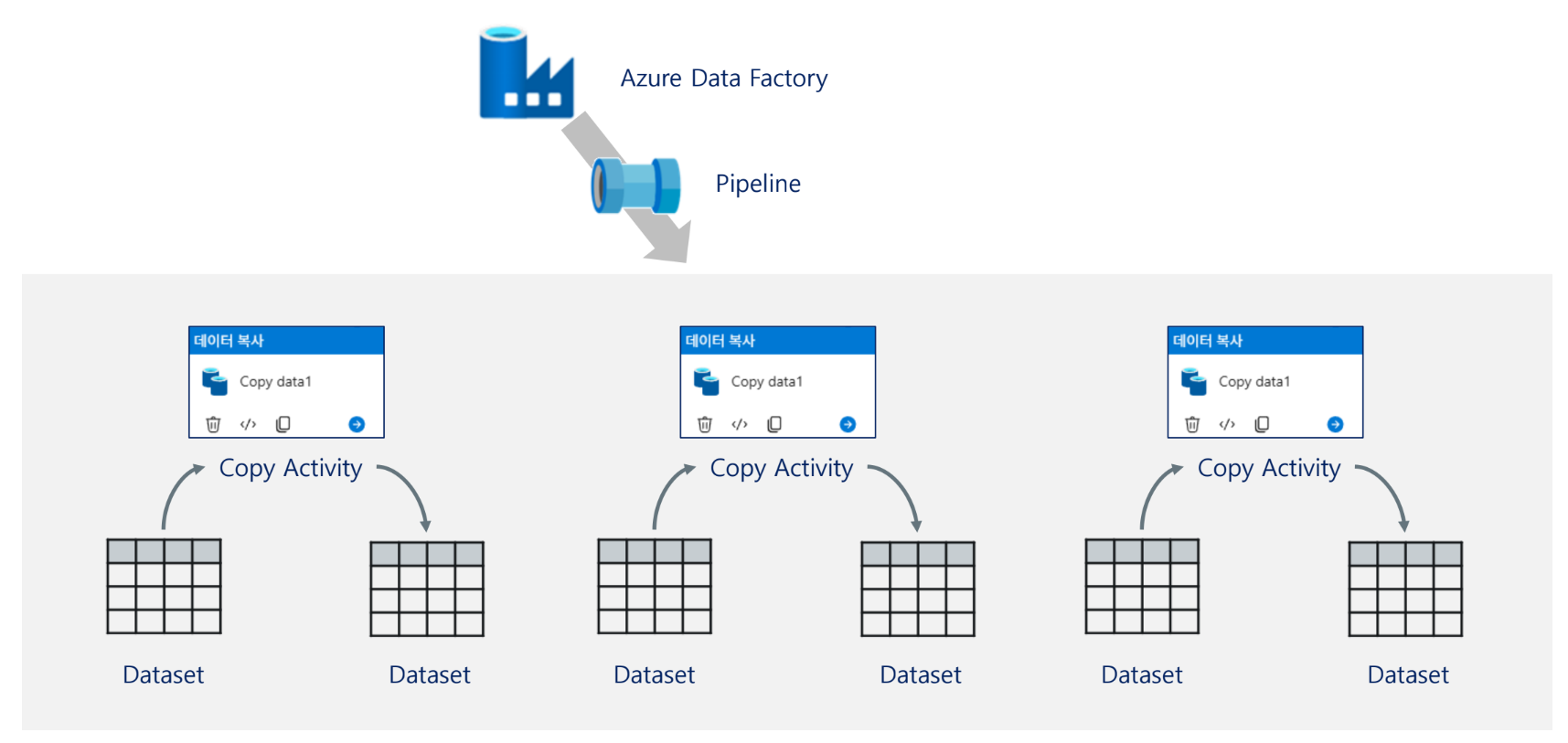
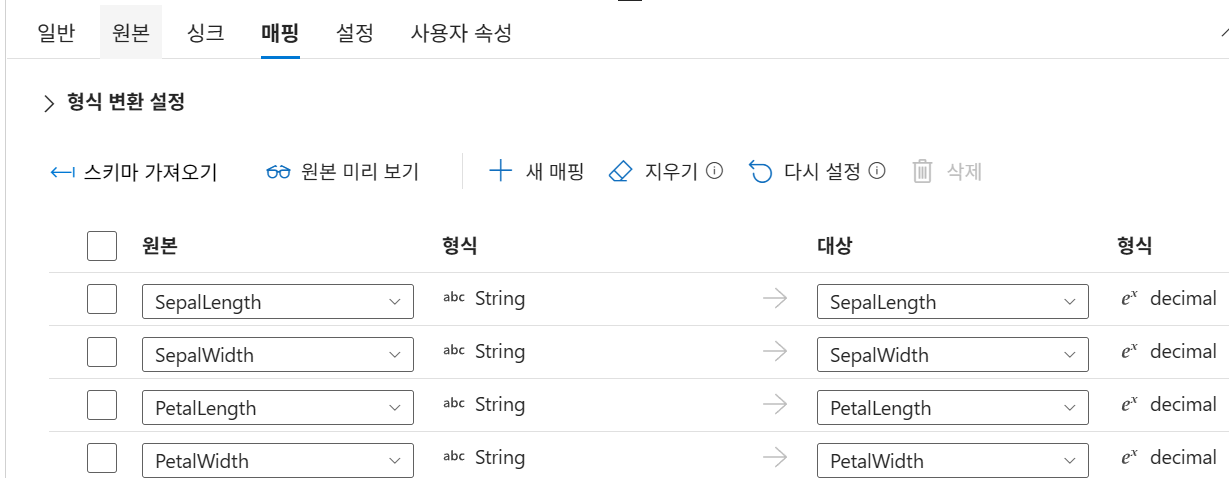
- 그림에서는 Activity 중 Copy를 예시로 듬
자료의 그림에서는 하나의 Pipeline 아래에 여러 Copy Activity가 들어갈 수 있고, 각 Activity는 입력 Dataset과 출력 Dataset을 가진다. 즉, 파이프라인은 큰 흐름이고 액티비티는 그 안에서 수행되는 세부 작업이다.
(원본 → 싱크)
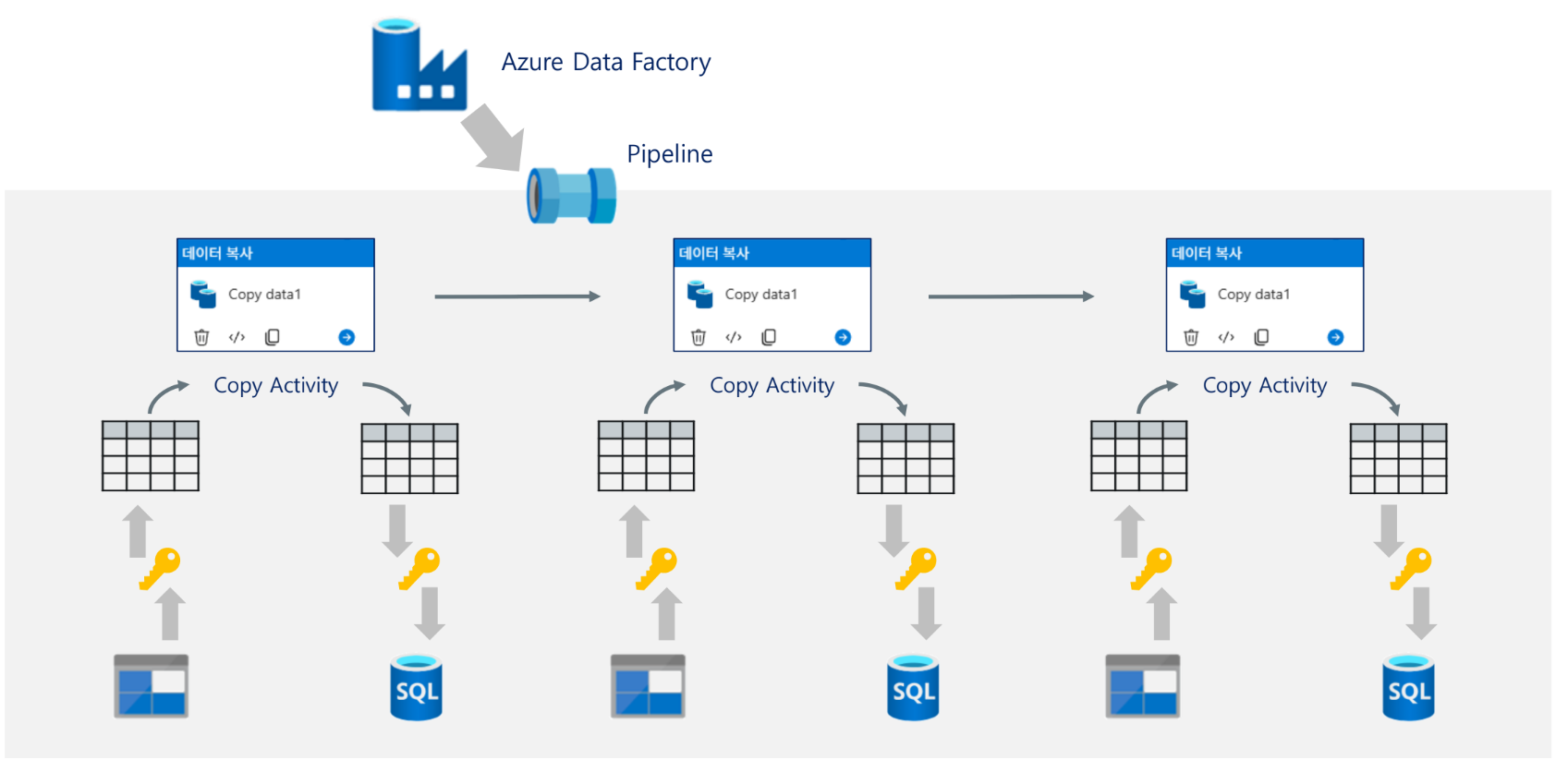
Pipeline과 Linked Service 관계
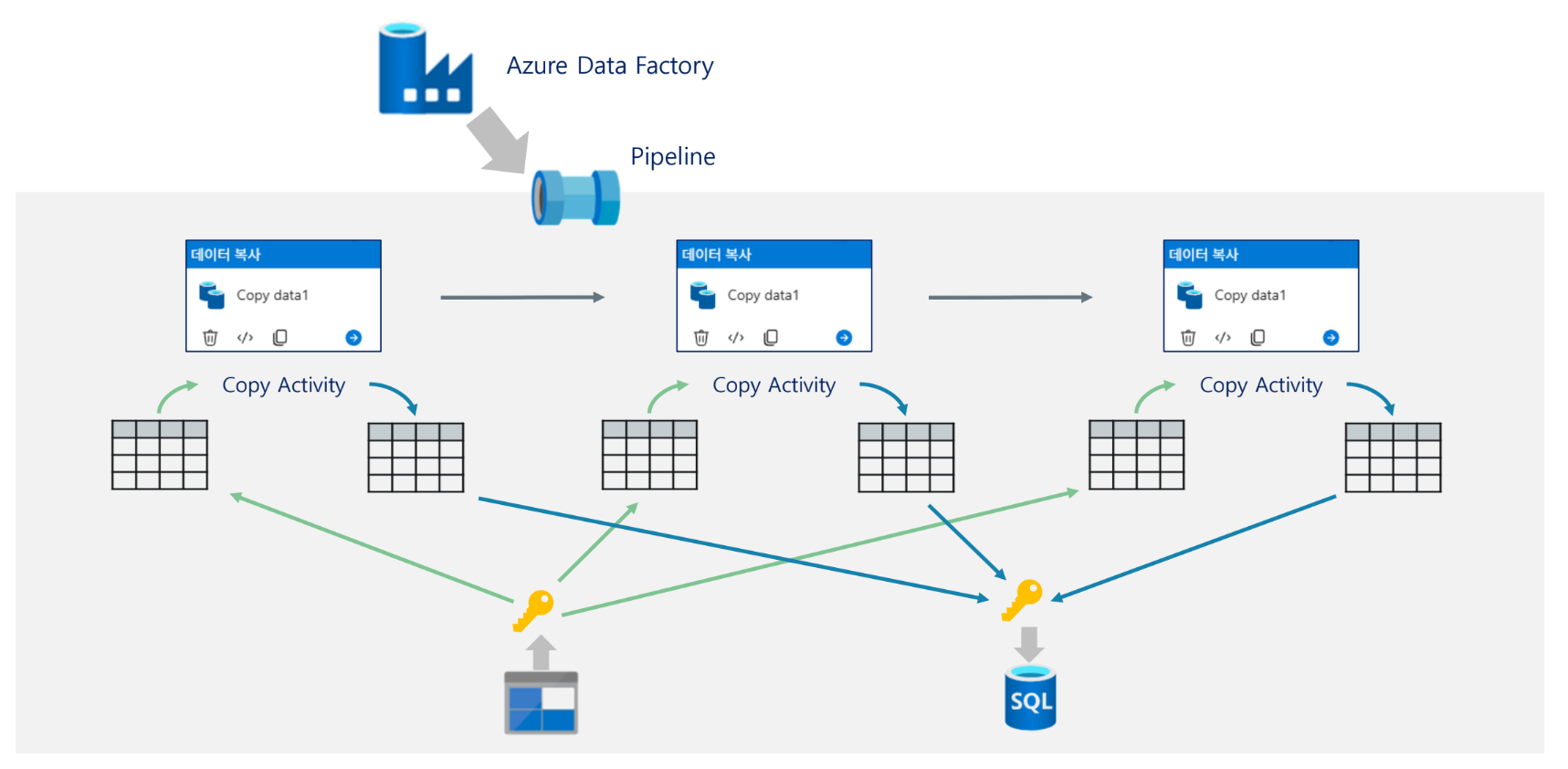
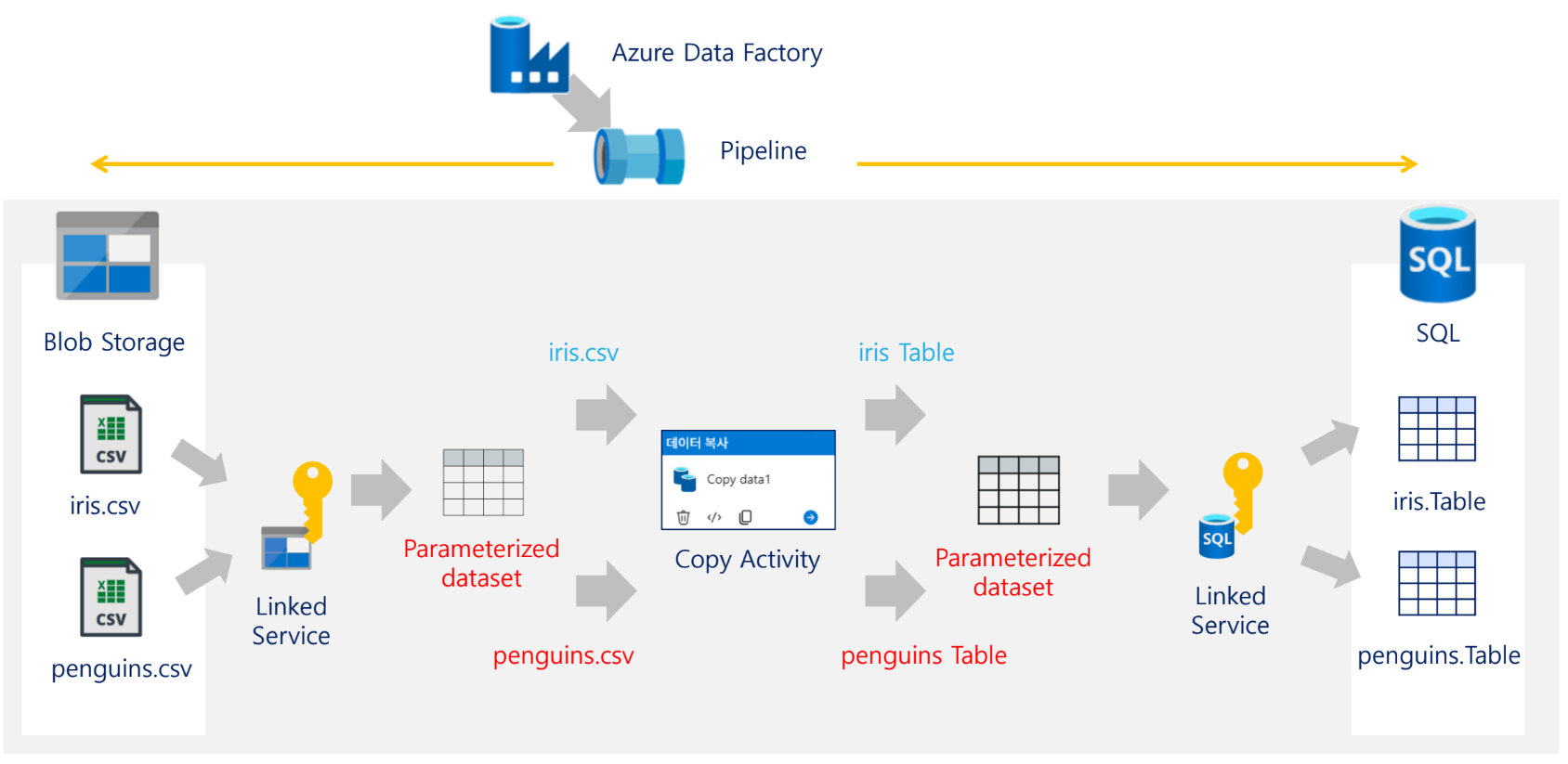
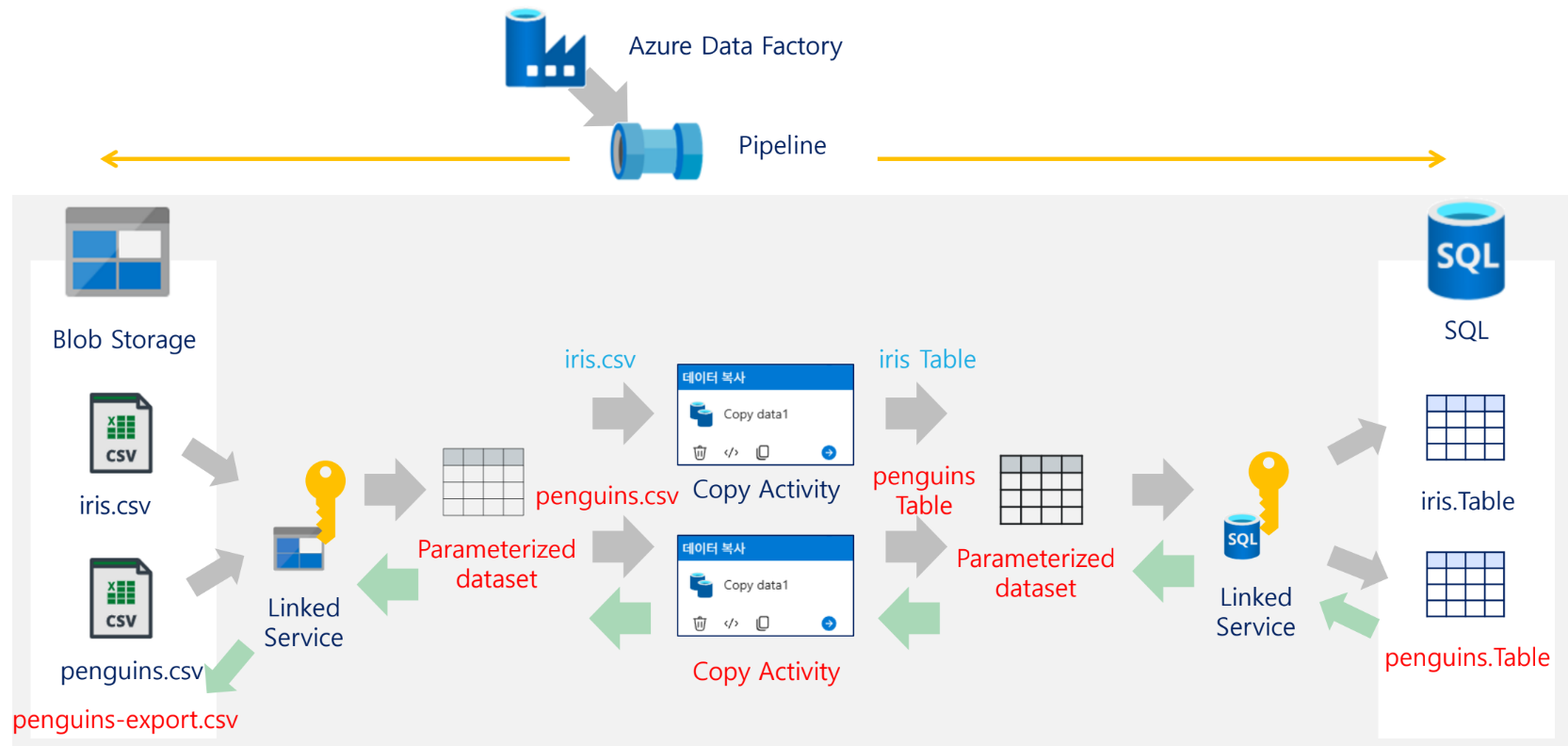
16. ADF 실습 구성
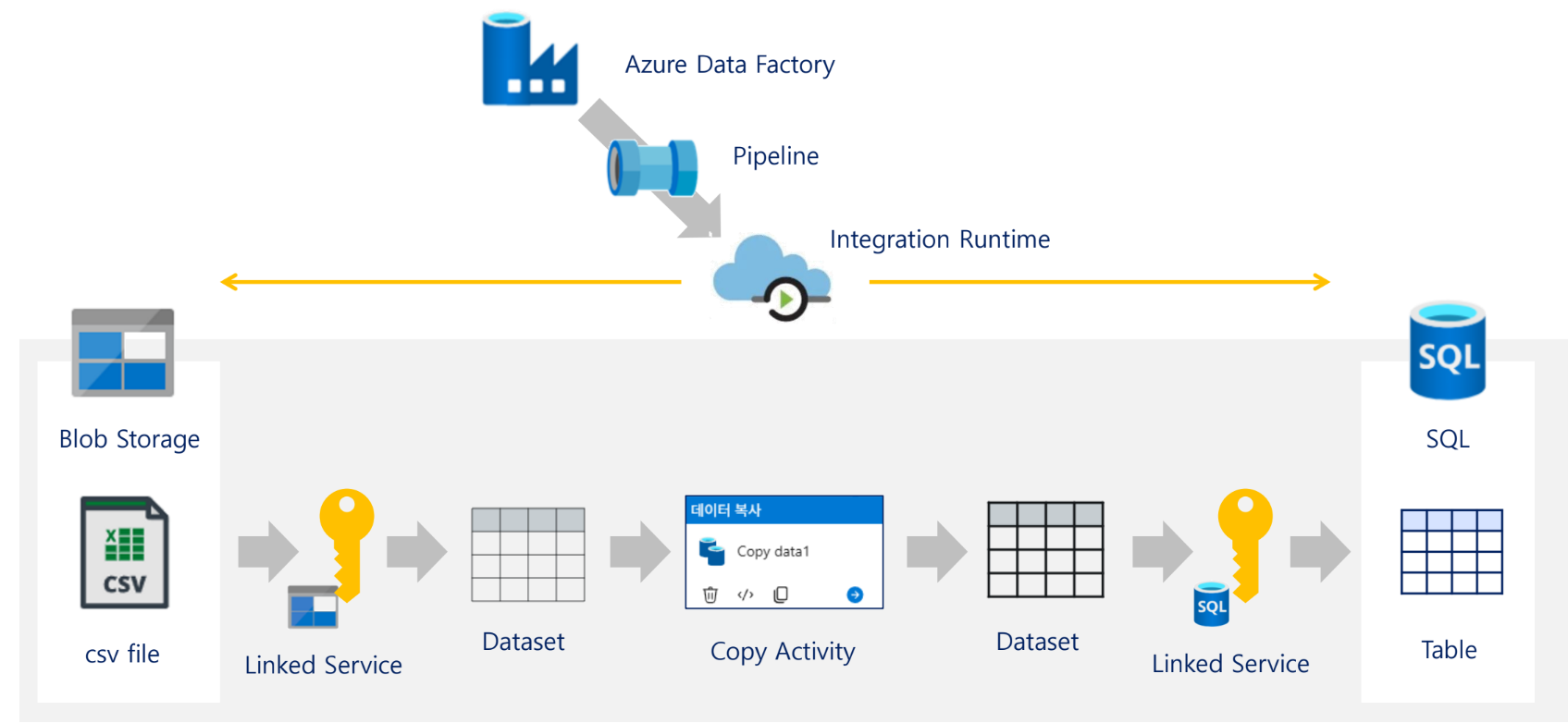
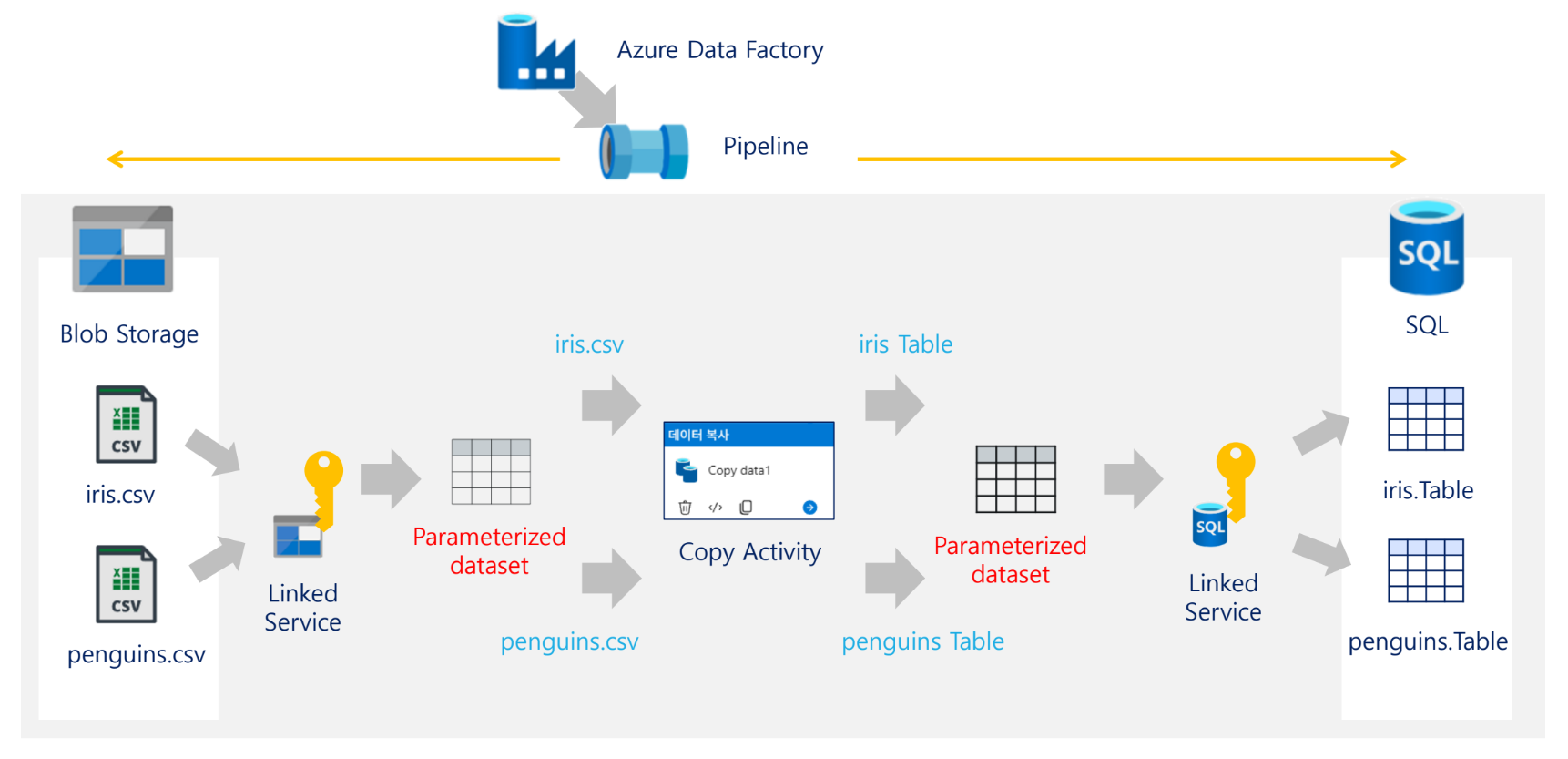
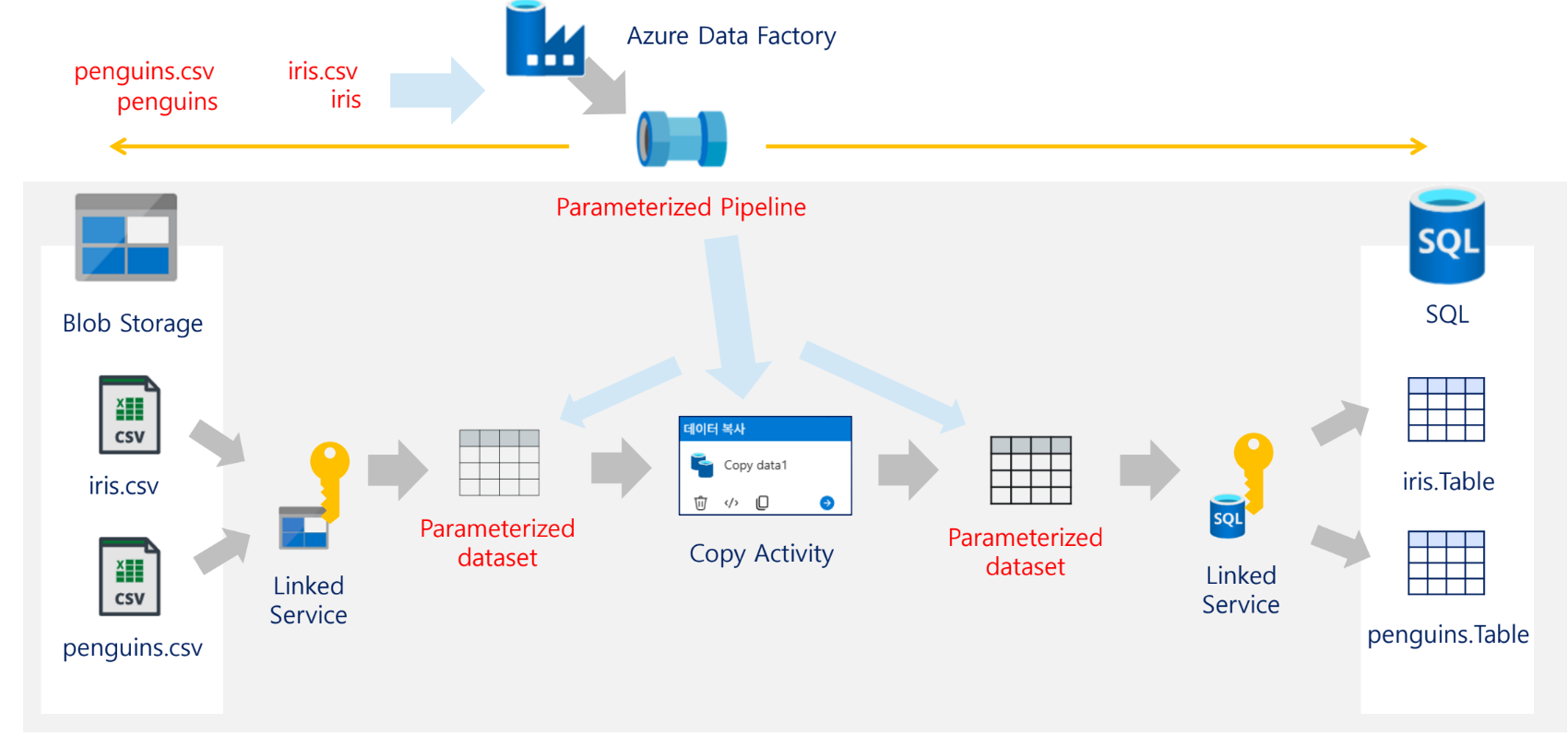
기본 실습의 전체 구조는 다음과 같다. 자료의 아키텍처 그림에서 Blob Storage의 CSV 파일을 SQL Database 테이블로 복사하는 구조를 보여준다. 중간에는 ADF Pipeline, Integration Runtime, Linked Service, Dataset, Copy Activity가 위치한다.
Blob Storage (CSV)
↓
Linked Service
↓
Source Dataset
↓
Copy Activity
↓
Sink Dataset
↓
Linked Service
↓
SQL Database (Table)실습 아키텍처 구성 요소
| 구간 | 구성 |
|---|---|
| 원본 | Blob Storage의 CSV 파일 |
| 연결 정보 | Blob Linked Service |
| 원본 정의 | Source Dataset |
| 복사 작업 | Copy Activity |
| 목적지 정의 | Sink Dataset |
| 연결 정보 | SQL Linked Service |
| 목적지 | SQL Database Table |
| 실행 엔진 | Integration Runtime |
| 전체 제어 | Pipeline |
17. 실습
17-1. 실습 데이터 다운로드
실습 데이터는 iris.csv와 iris-columns.sql 파일로 구성된다. iris.csv에는 SepalLength, SepalWidth, PetalLength, PetalWidth, Species 컬럼이 포함된 붓꽃 데이터가 들어 있다.
17-2. 리소스 그룹 생성
17-3. ADF 리소스 생성
ADF 생성 시 설정한 주요 항목은 다음과 같다.
| 항목 | 설정 예시 |
|---|---|
| 이름 | 영문자, 숫자, 하이픈 조합 |
| 지역 | 자유롭게 지정 |
| 버전 | V2 |
| 리소스 그룹 | 방금 만든 그룹 선택 |
배포가 완료되면 Data Factory 리소스의 첫 화면에서 Studio를 시작할 수 있다.
17-4. SQL Database 생성

SQL Database 생성 과정에서는 논리 서버도 함께 만든다.
| 항목 | 설정 예시 |
|---|---|
| 리소스 그룹 | 실습용 리소스 그룹 |
| 데이터베이스 이름 | 식별 가능한 이름 |
| 서버 | 새로 만들기 |
| 인증 방식 | SQL 인증 사용 |
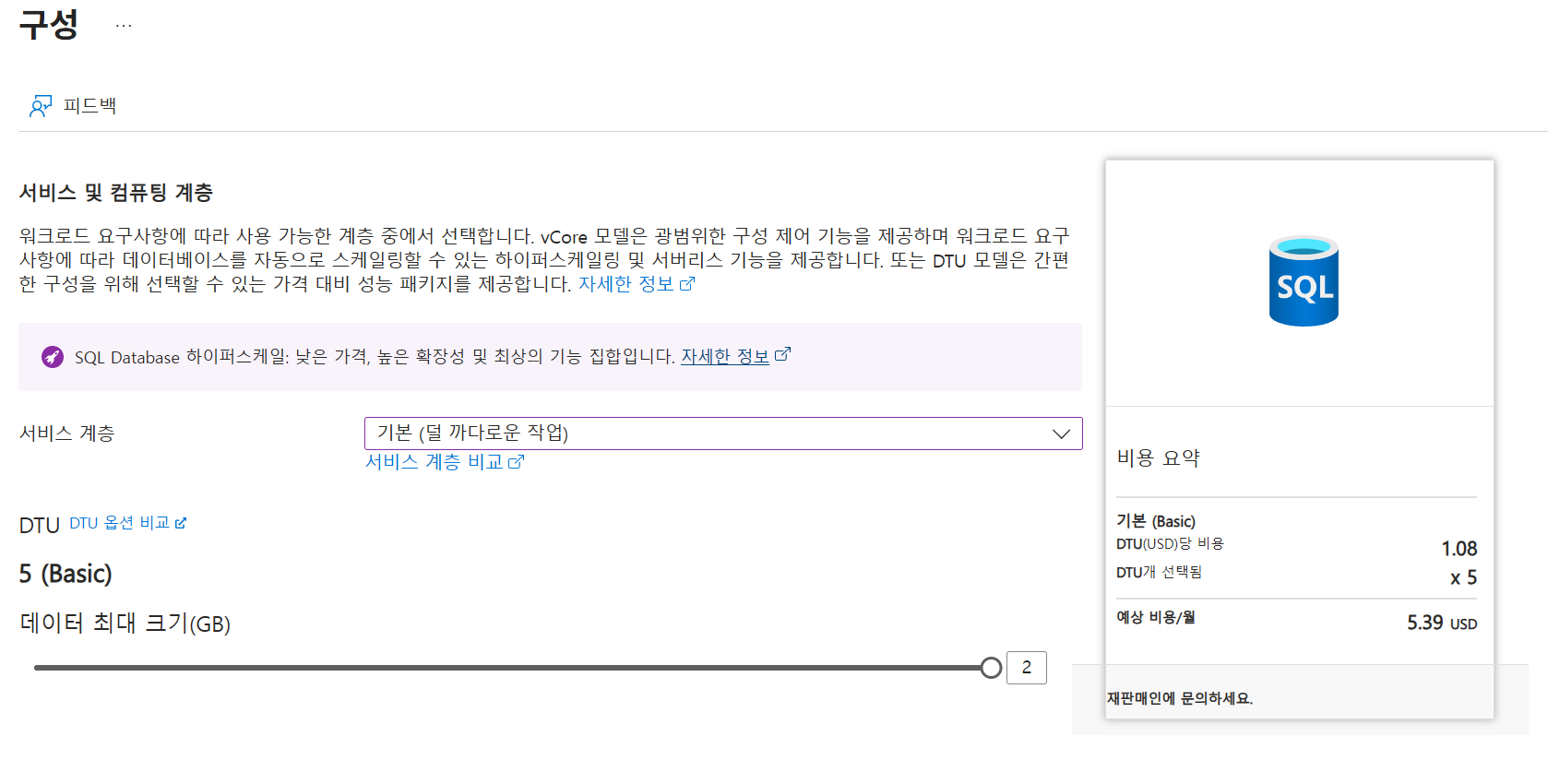
| 워크로드 | 개발 |
| 컴퓨팅 계층 | DTU Basic |
| 최대 크기 | 2GB |
| 연결 방법 | Public Endpoint |
| 방화벽 | Azure 서비스 허용, 현재 클라이언트 IP 허용 |
서버 만들기
컴퓨팅 구성
네트워크 구성(방화벽)
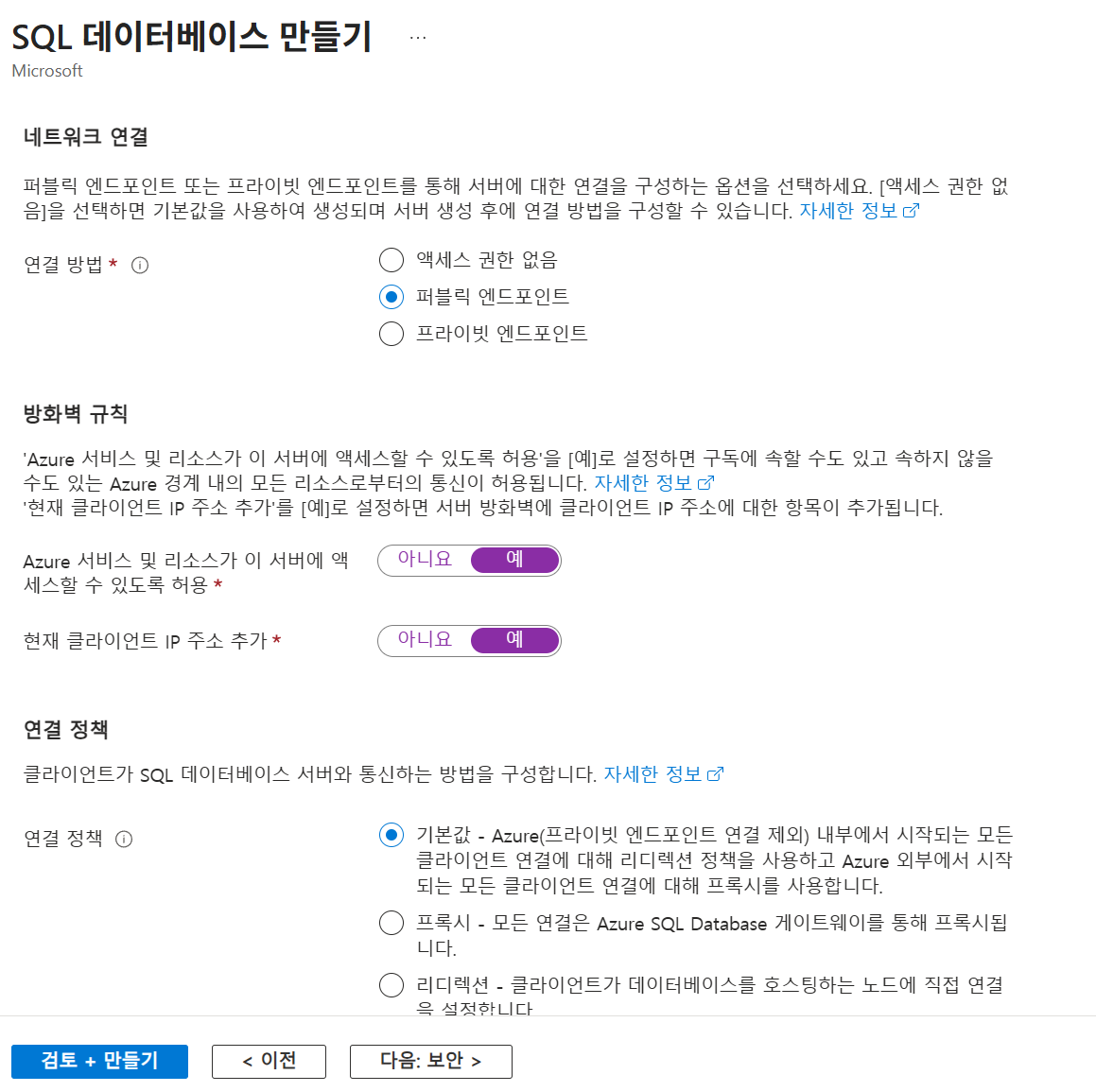
- TLS 버전은 항상 최신으로 사용하는 것이 좋다
17-5. Storage Account 생성
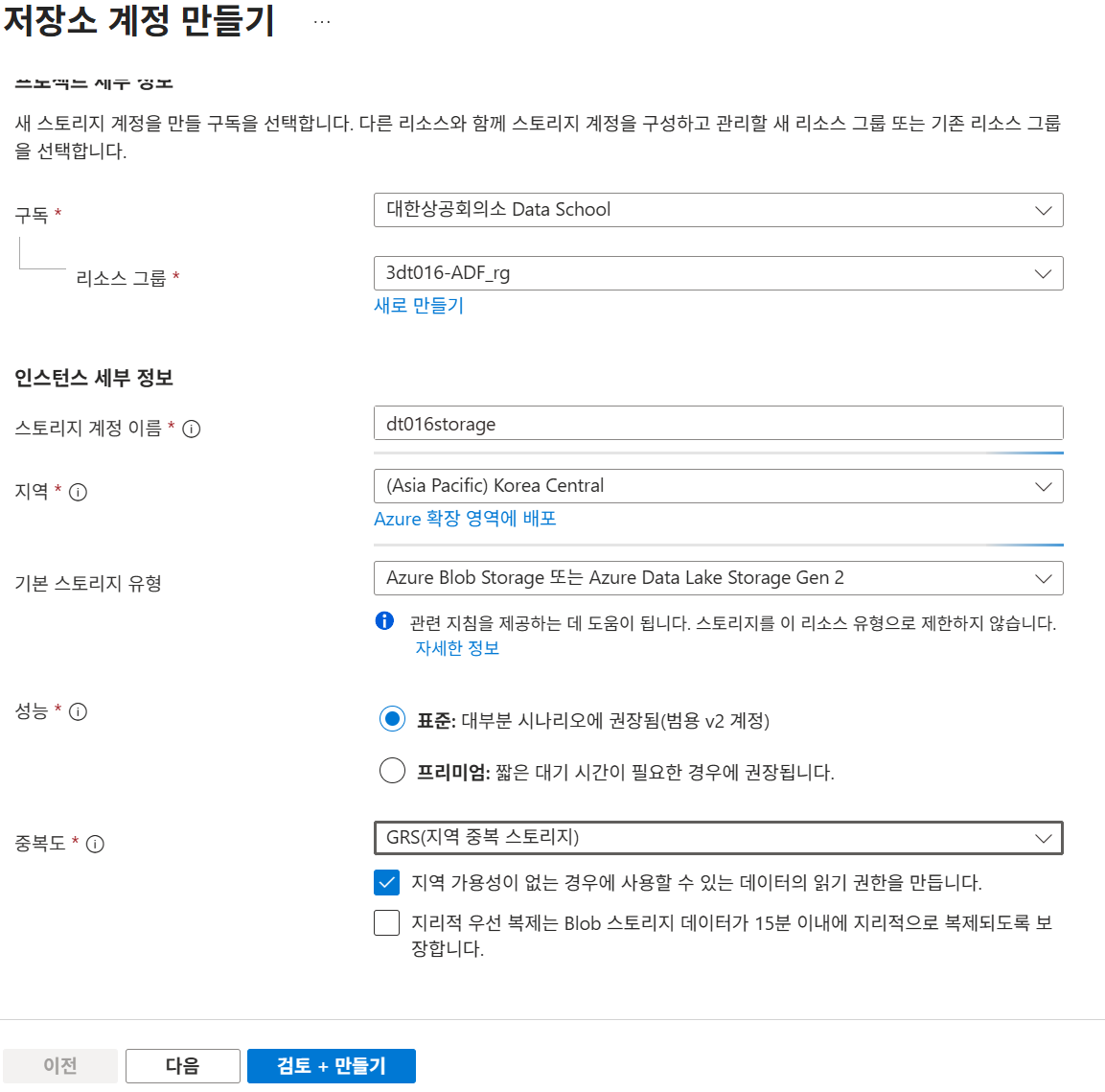
Storage Account 생성 시 설정 항목은 다음과 같다.
| 항목 | 설정 예시 |
|---|---|
| 리소스 그룹 | 실습용 리소스 그룹 |
| 스토리지 계정 이름 | 기억하기 쉬운 이름 |
| 지역 | ADF와 동일 지역 |
| 기본 스토리지 유형 | Azure Blob Storage 또는 Azure Data Lake Storage Gen2 |
| 워크로드 | 기타 |
| 성능 | 표준 |
| 중복도 | GRS |
배포가 끝나면 Blob 서비스와 컨테이너를 생성해 원본 파일을 올릴 수 있다.
18. 원본 데이터 준비
18-1. 컨테이너 생성
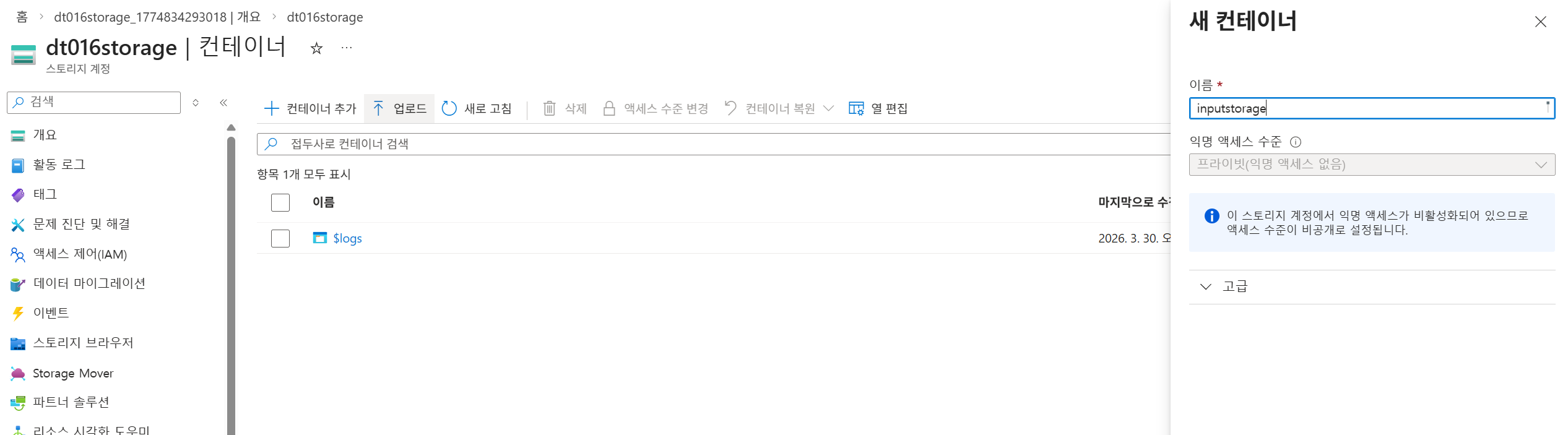
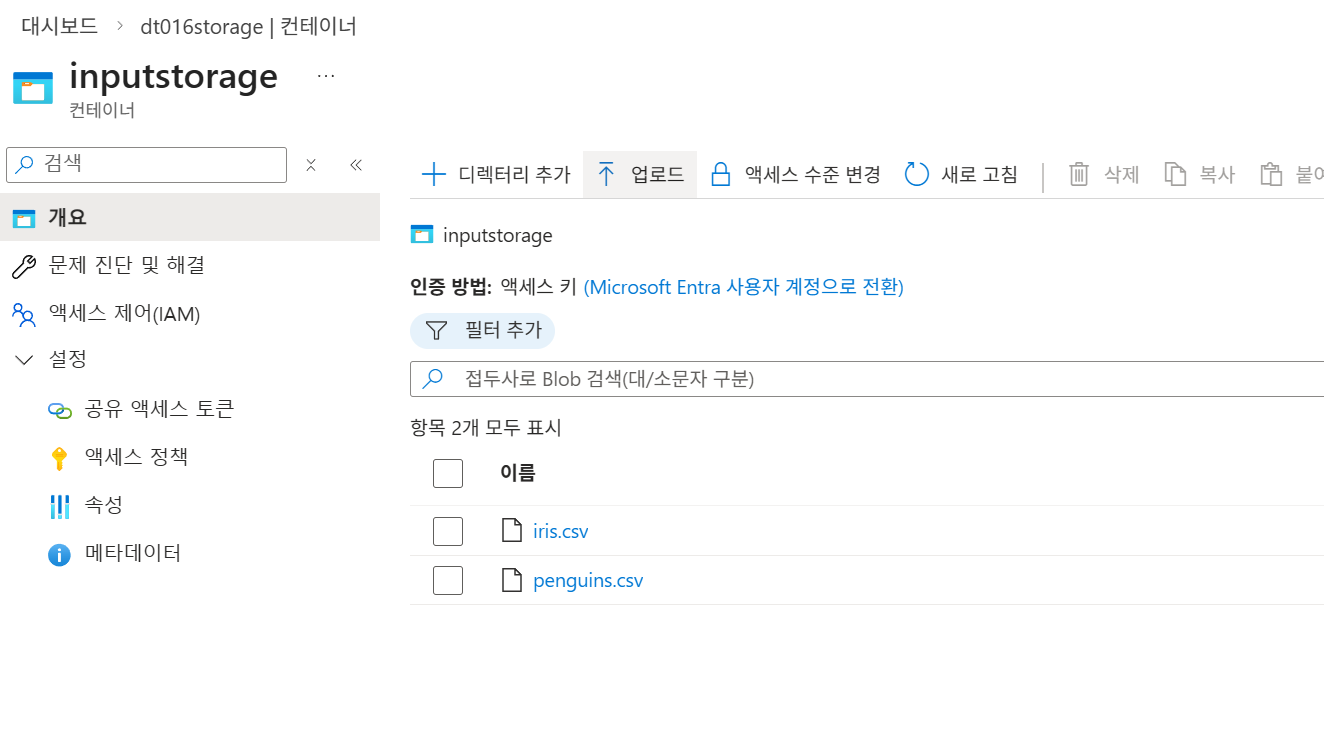
Storage Account에서 Blob service로 이동한 뒤 컨테이너를 생성한다. 자료 예시에서는 inputstorage라는 이름을 사용한다. 컨테이너는 비공개 상태로 생성된다.
18-2. CSV 파일 업로드
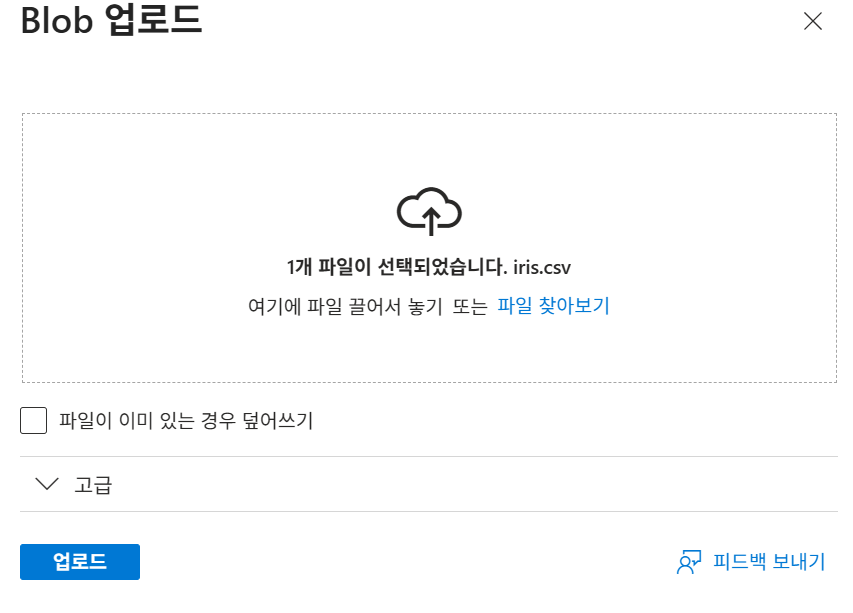
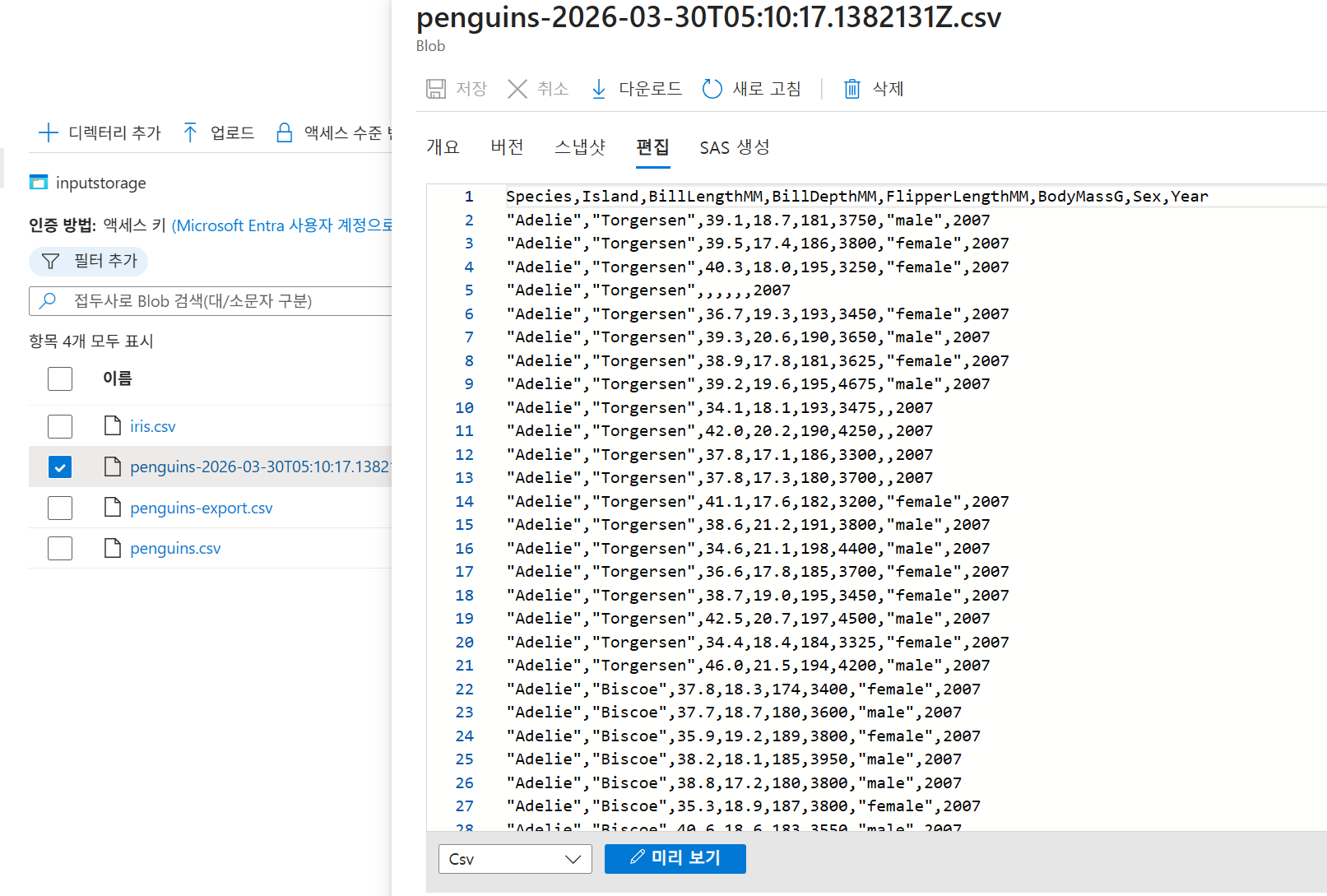
생성한 컨테이너에 iris.csv 파일을 업로드한다. 업로드 후 파일을 클릭해 개요와 편집 화면을 확인할 수 있다.
18-3. Blob 안에서 CSV가 보이는 형태
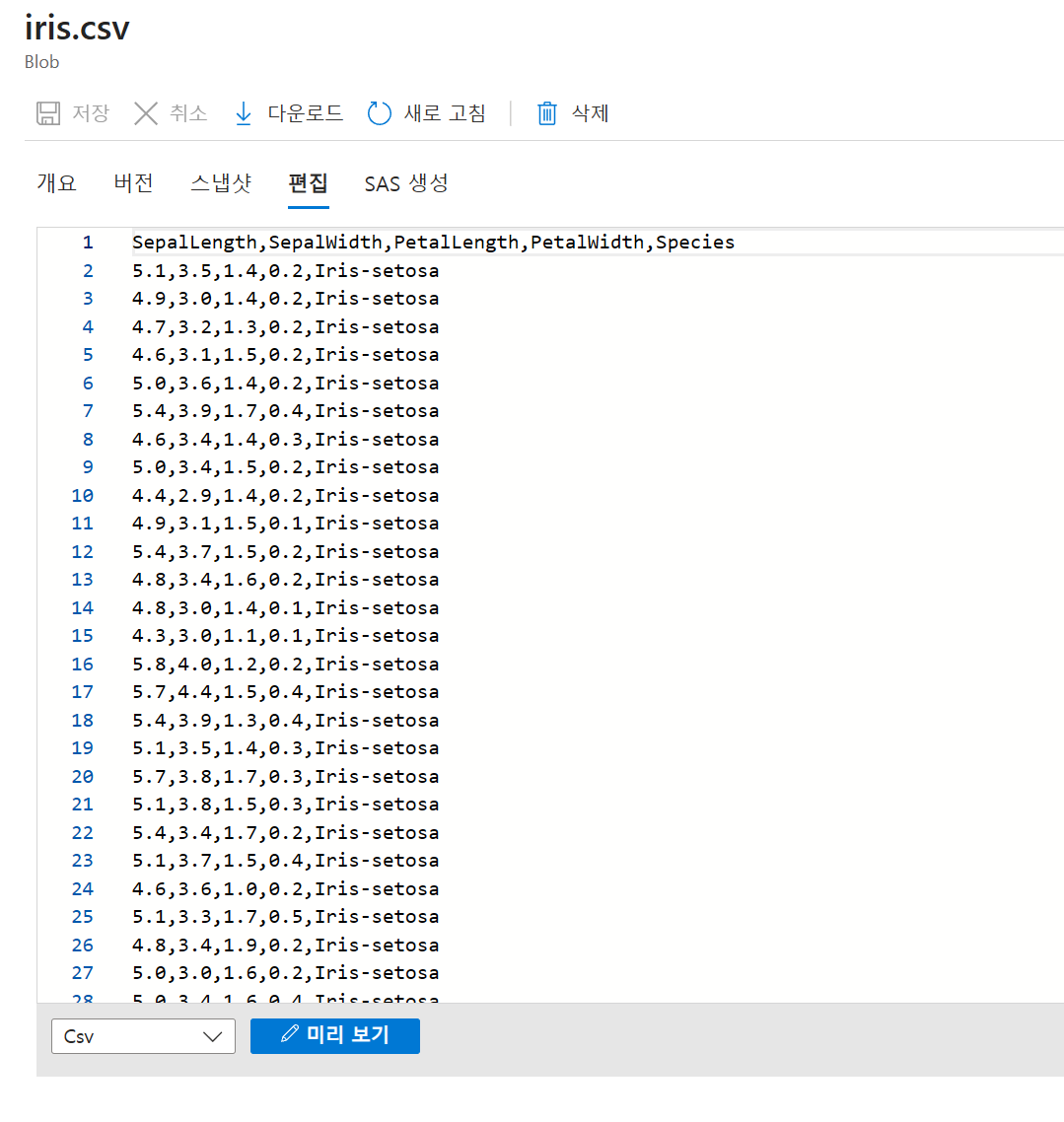
자료의 편집 화면 예시에서는 다음과 같은 구조로 보인다.
- 첫 행: 헤더
- 이후 행: 데이터 샘플
- 구분자: 쉼표(,)
CSV 컬럼 구조
| 컬럼 | 의미 |
|---|---|
| SepalLength | 꽃받침 길이 |
| SepalWidth | 꽃받침 너비 |
| PetalLength | 꽃잎 길이 |
| PetalWidth | 꽃잎 너비 |
| Species | 품종 |
참고) 대시보드 고정 기능
자료에서는 실습 중 여러 리소스를 자주 오가야 하므로, 리소스 그룹·ADF·SQL Database·SQL Server·Storage Account를 대시보드에 고정하는 방식을 소개한다. 핀 아이콘으로 메뉴를 고정하고, 새 대시보드를 만들어 자주 쓰는 리소스를 한눈에 모아두면 이동이 편해진다.
대시보드 고정 대상 예시
| 리소스 | 용도 |
|---|---|
| Data Factory | 파이프라인 편집 및 실행 |
| SQL Database | 목적지 테이블 관리 |
| SQL Server | 방화벽 및 서버 설정 |
| Storage Account | 원본 CSV 업로드 |
| Resource Group | 전체 리소스 관리 |
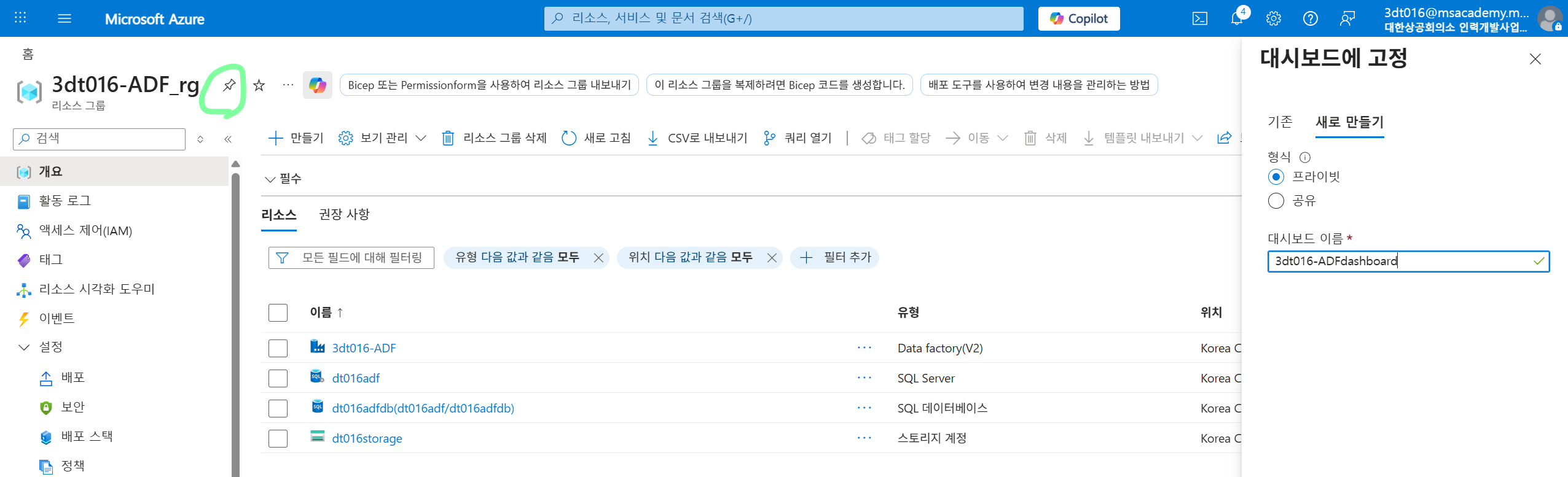
좌상단 핀버튼 누르고 추가 가능
대시보드 접근은 좌상단 三 버튼 누르기

19. 목적지 테이블 준비
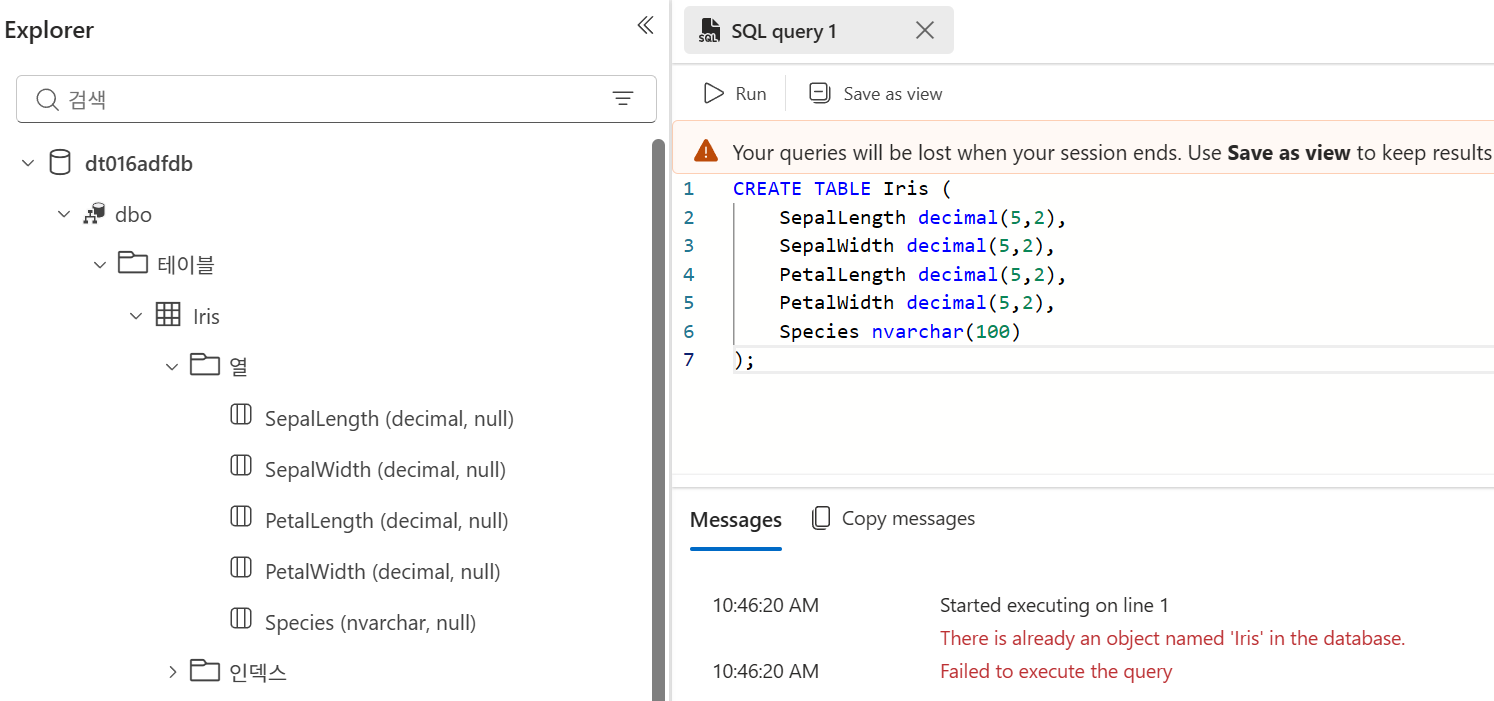
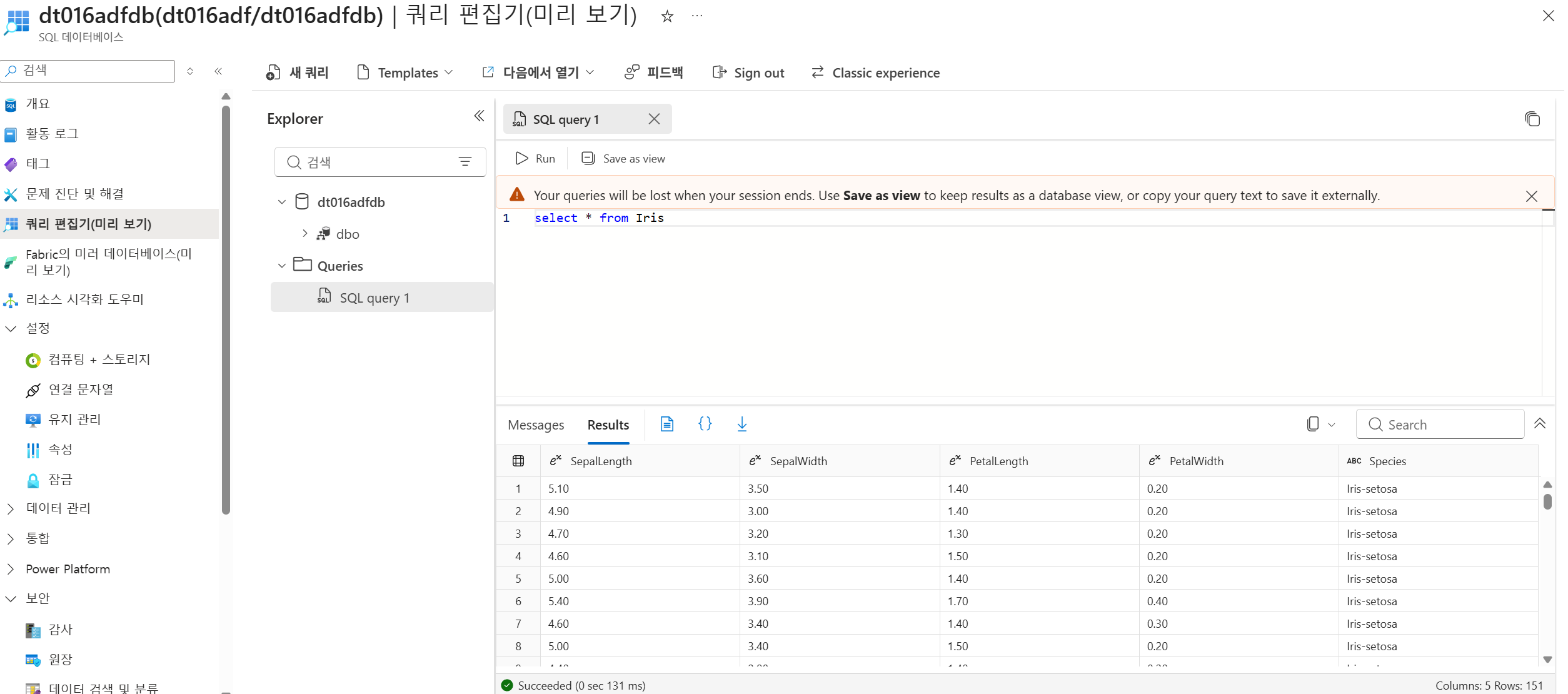
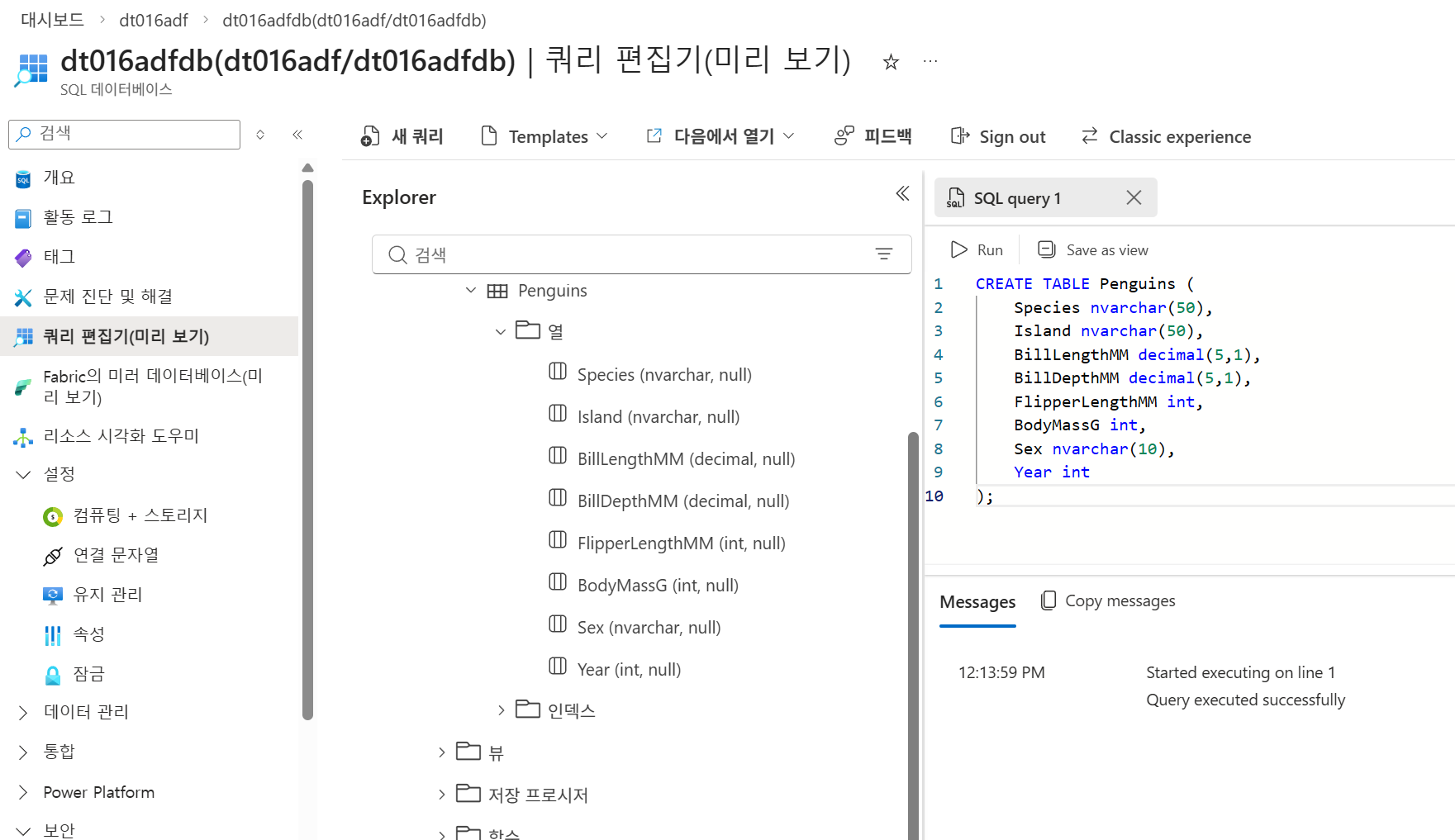
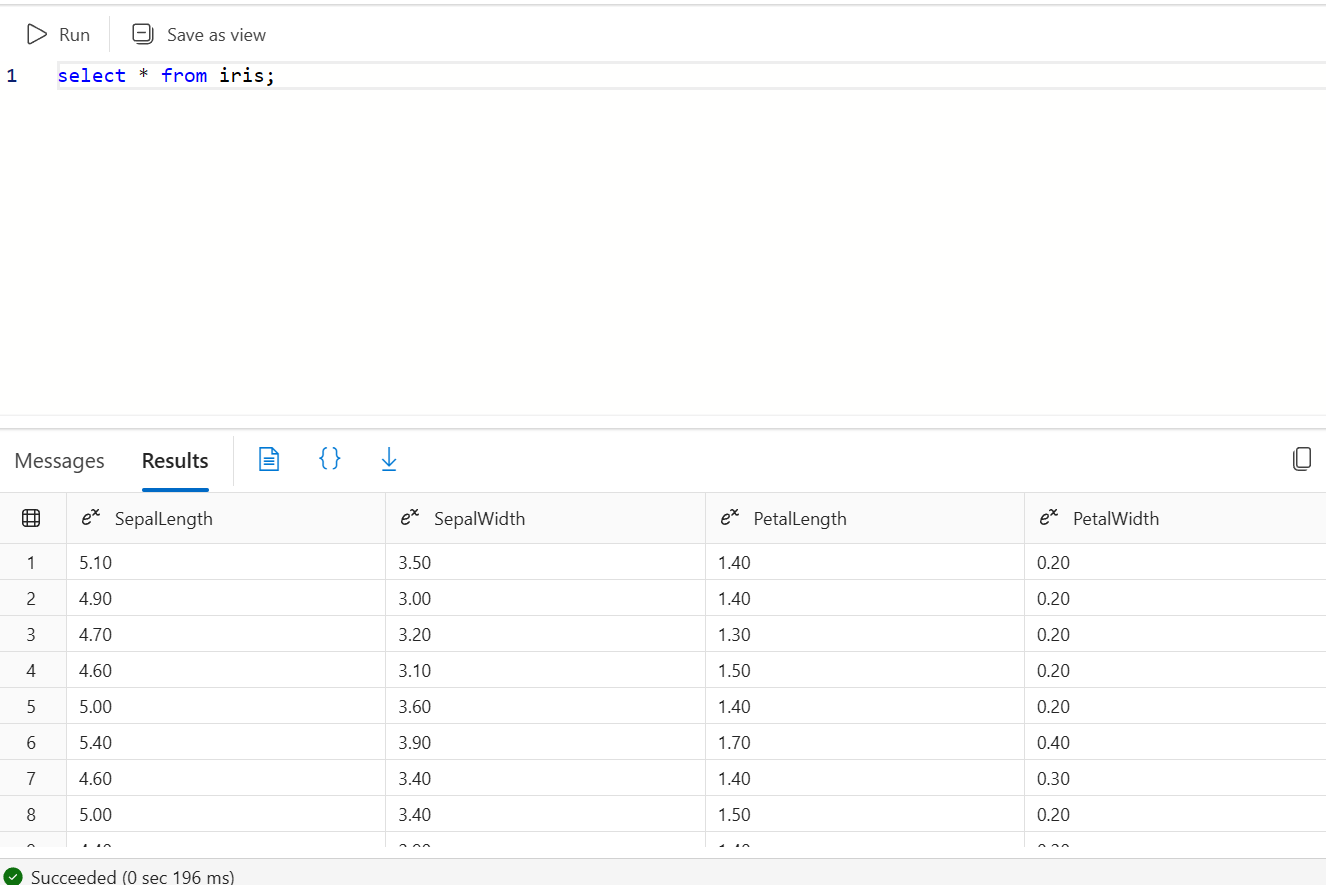
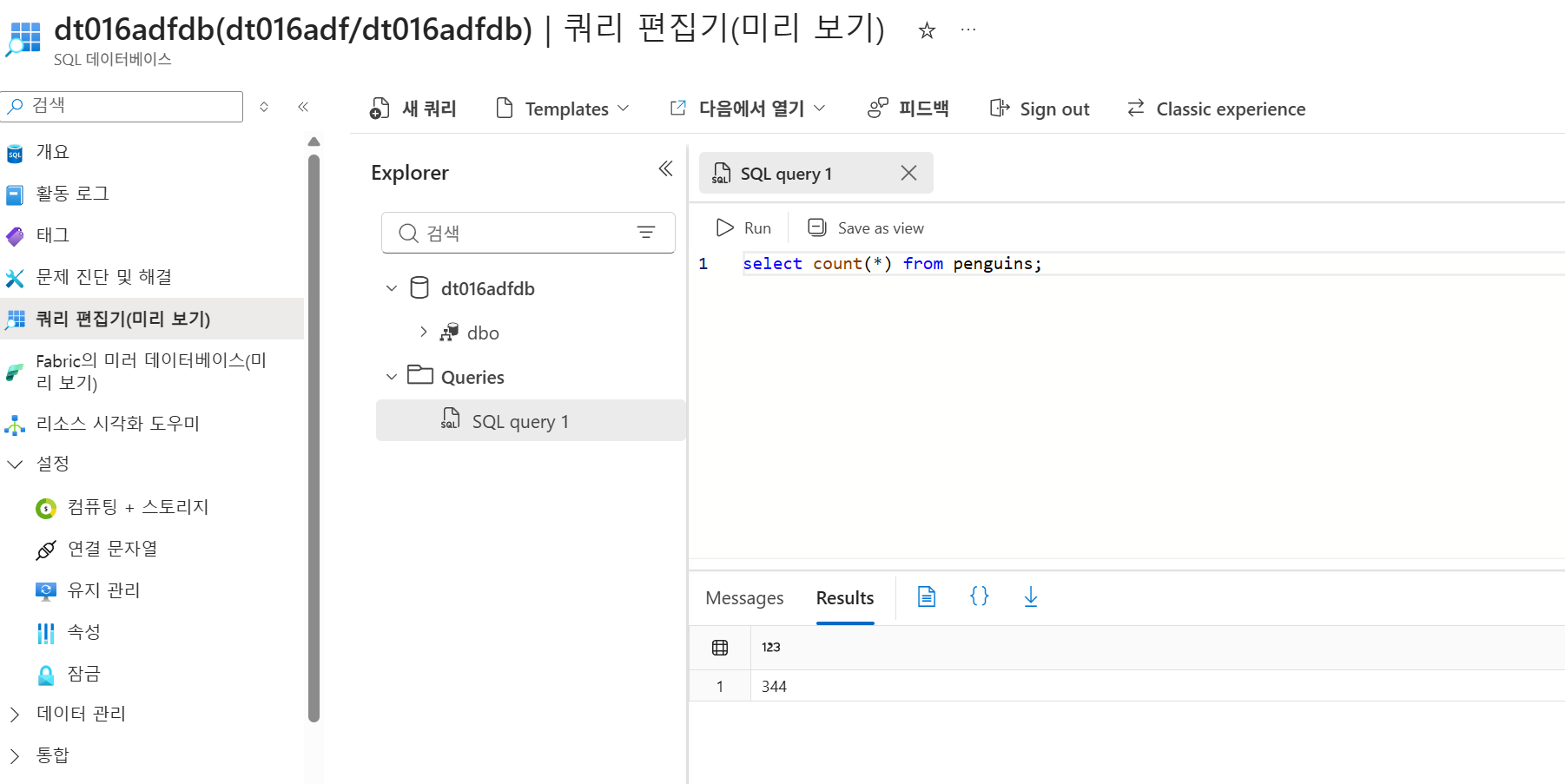
SQL Database 리소스로 이동한 뒤 쿼리 편집기에서 SQL 인증으로 로그인한다. 이후 iris-columns.sql의 내용을 복사해 실행하여 목적지 테이블을 만든다. 자료 예시에서는 Iris 테이블을 생성한다. 실행 후 Explorer에서 테이블과 컬럼이 보이고, Messages 영역에 Query executed successfully가 표시된다.
생성 SQL
CREATE TABLE Iris (
SepalLength decimal(5,2),
SepalWidth decimal(5,2),
PetalLength decimal(5,2),
PetalWidth decimal(5,2),
Species nvarchar(100)
);
생성 테이블 구조
| 컬럼 | 타입 |
|---|---|
| SepalLength | decimal(5,2) |
| SepalWidth | decimal(5,2) |
| PetalLength | decimal(5,2) |
| PetalWidth | decimal(5,2) |
| Species | nvarchar(100) |
20. Data Factory Studio 진입
ADF 리소스에서 Studio 시작하기를 클릭한 뒤, 왼쪽의 연필 아이콘인 Author 메뉴로 이동한다. 여기서 파이프라인, 데이터셋, 연결된 서비스 등을 만들 수 있다.
21. 파이프라인 생성
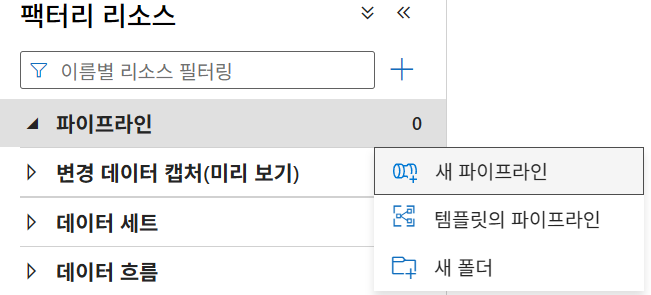
자료의 화면 예시에서는 파이프라인 목록 오른쪽 메뉴에서 새 파이프라인을 클릭하고, 편집창이 열리면 우측 속성의 일반 메뉴에서 이름을 지정한다. 예시 이름은 Blob to SQL이다.
파이프라인 설정
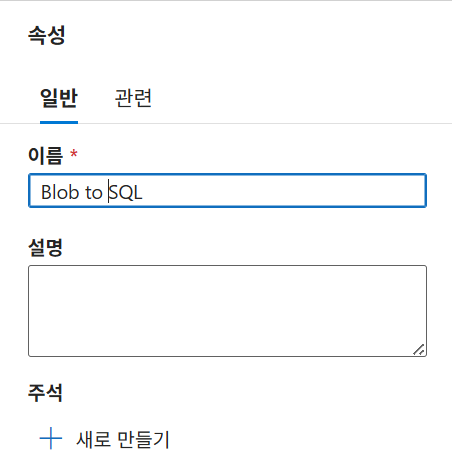
| 항목 | 예시 |
|---|---|
| 파이프라인 이름 | Blob to SQL |
| 역할 | 전체 데이터 복사 흐름 제어 |
파이프라인은 가장 상위의 작업 흐름 단위이며, 이후 여기에 Linked Service, Dataset, Copy Activity가 연결된다.
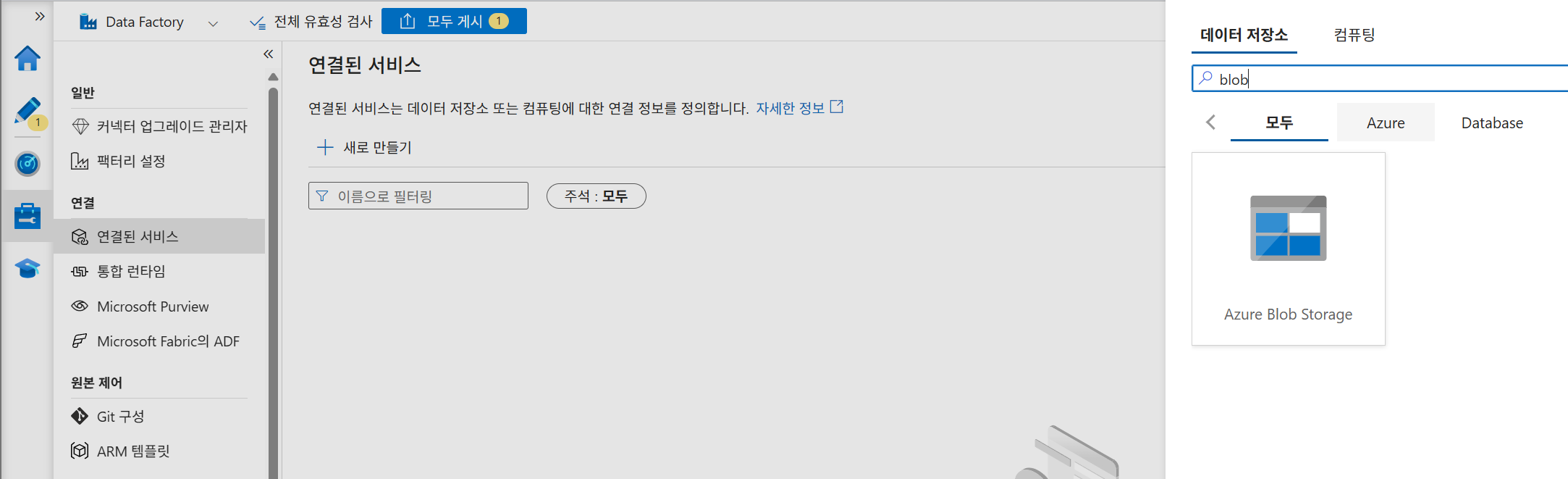
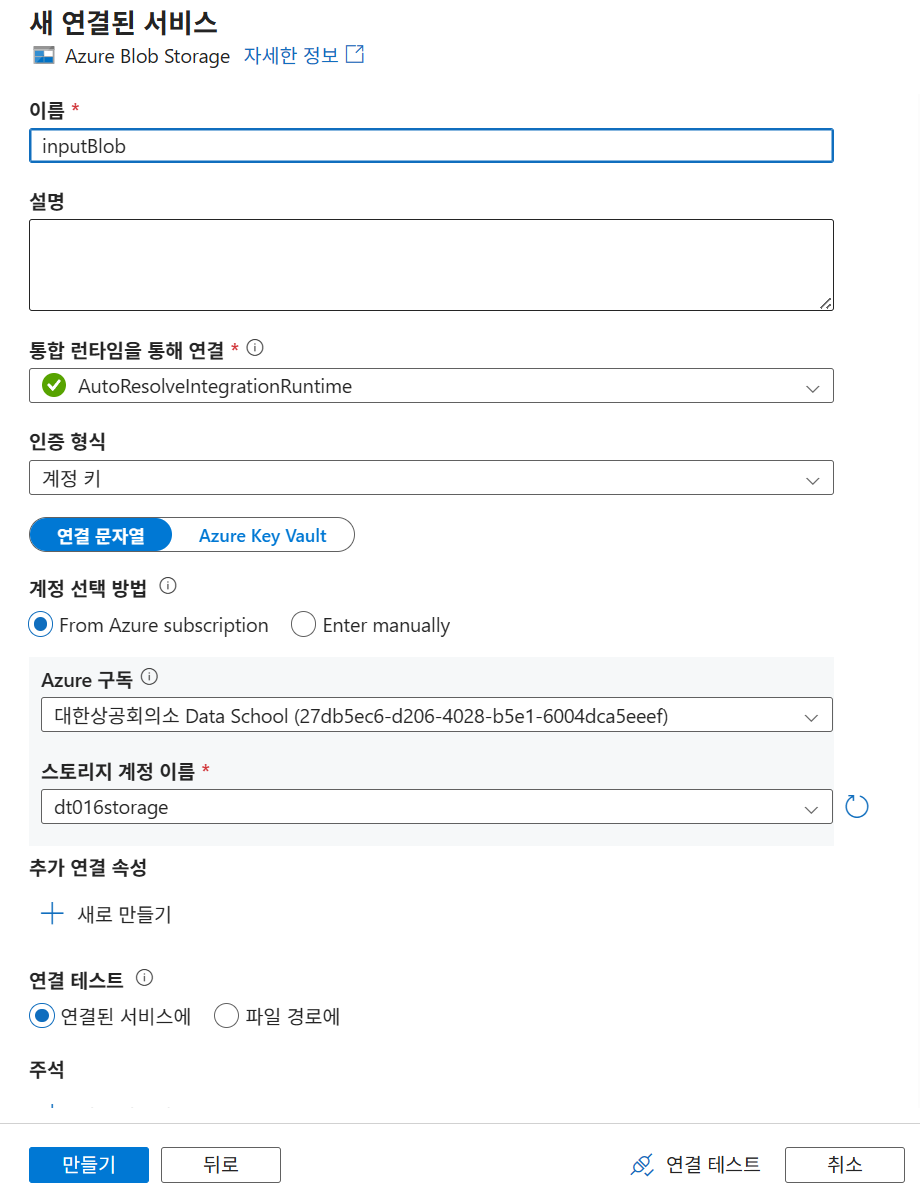
22. 원본 Linked Service 생성
관리 메뉴에서 연결된 서비스를 선택하고 새로 만들기를 눌러 Blob Storage 연결 정보를 생성한다. 이 연결은 원본 CSV 파일이 있는 Storage Account를 가리킨다.
로컬에 있는걸 연결하고 싶으면 통합 런타임이 아닌 다른 런타임을 사용해야 한다.
생성 전 연결 테스트는 항상 해보자.
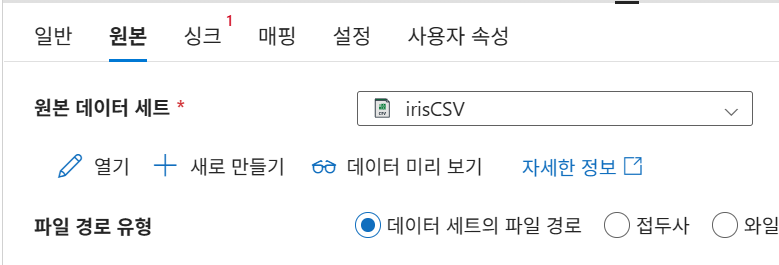
22-2. 원본 Dataset 생성

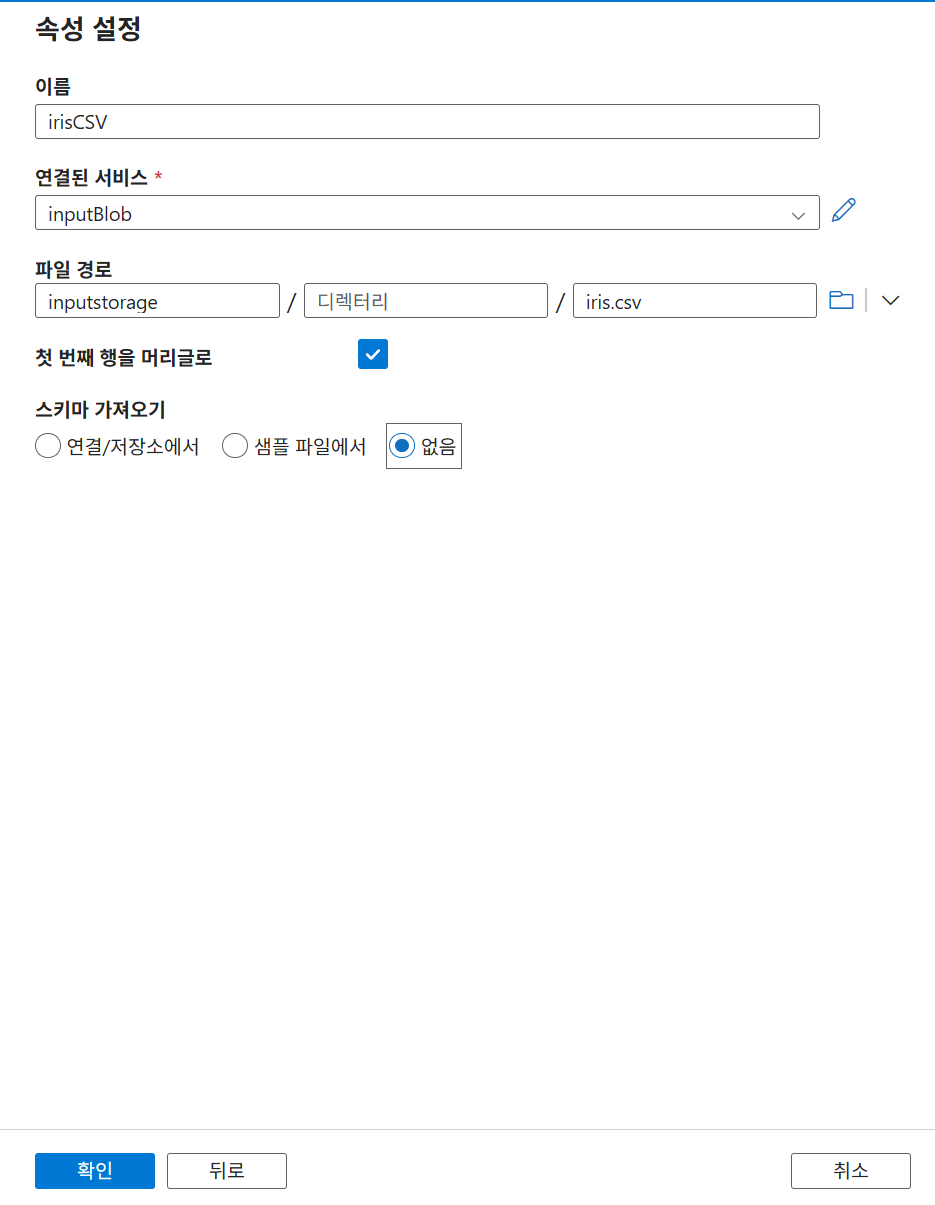
- 형식: CSV
- 연결: Blob Linked Service
- 대상: 업로드한
iris.csv - 특징: 첫 행을 헤더로 사용함
데이터세트는 하나의 함수로 이해하면 됨
데이터 미리보기
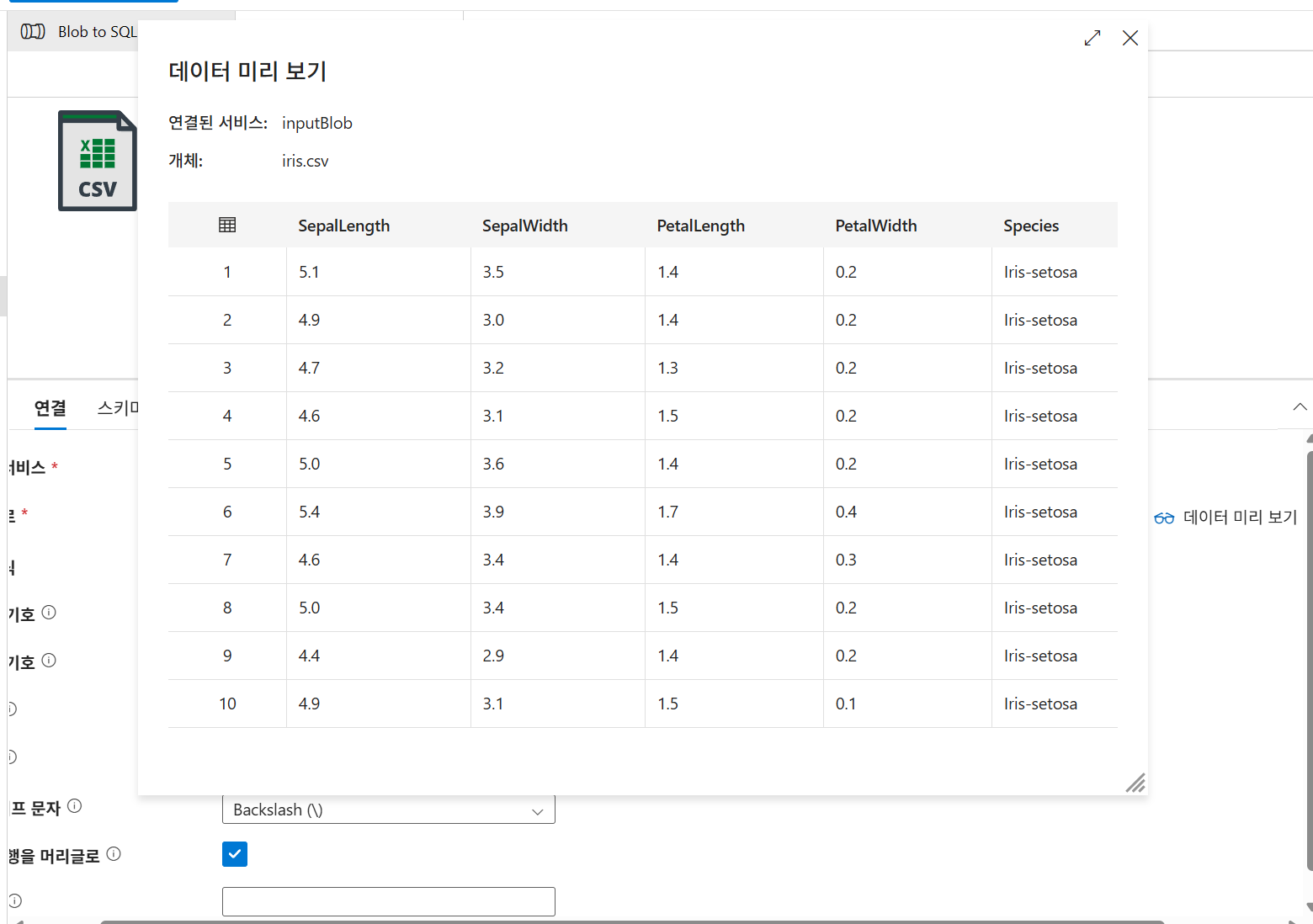
미리보기로 연결이 정상인지 확인
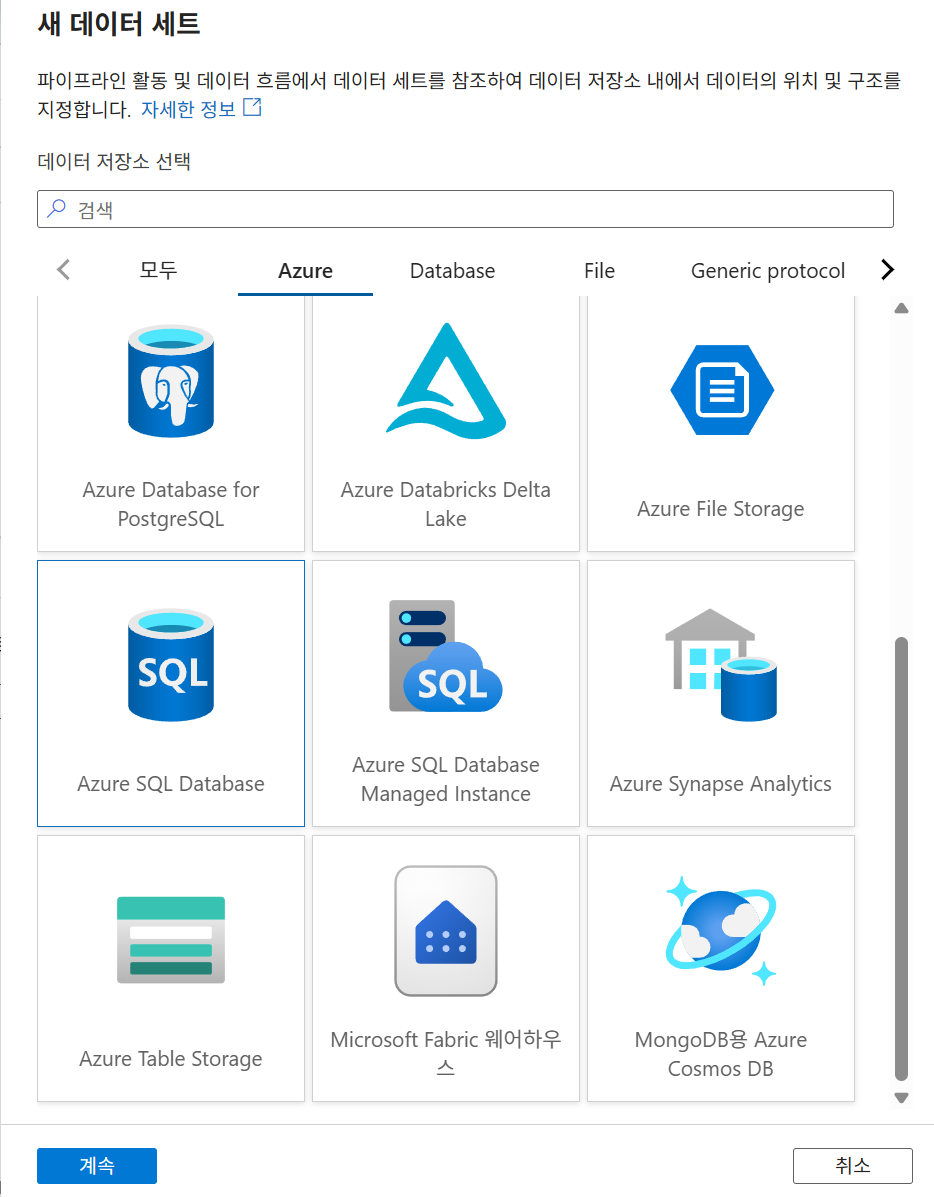
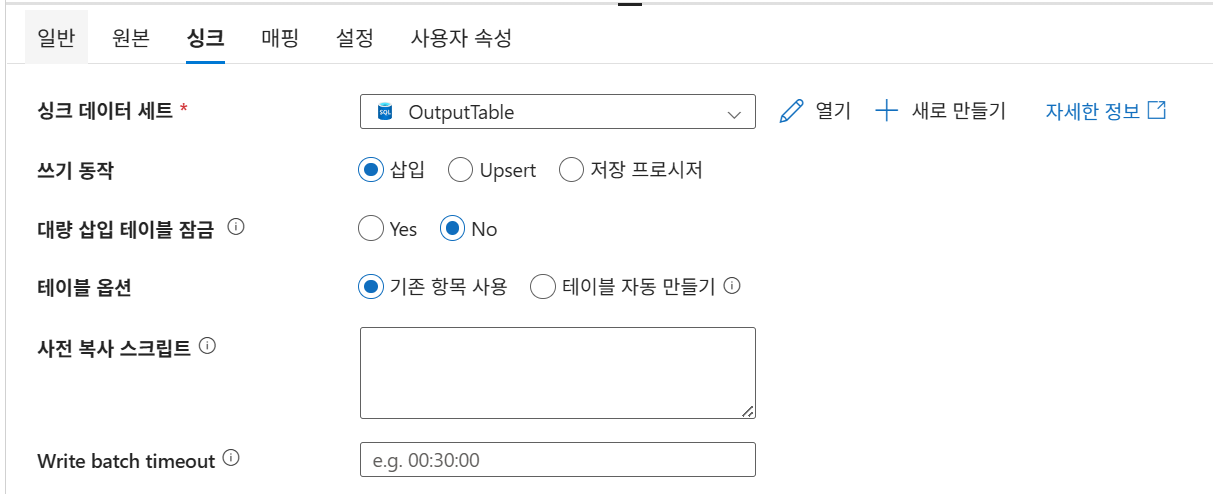
23. 싱크 Linked Service 생성
Azure SQL Database 선택
만들기가 비활성화됐다면 취소했다가 다시 생성하면 된다.
혹은 db, adf 네트워킹 설정을 다시 확인해보자.
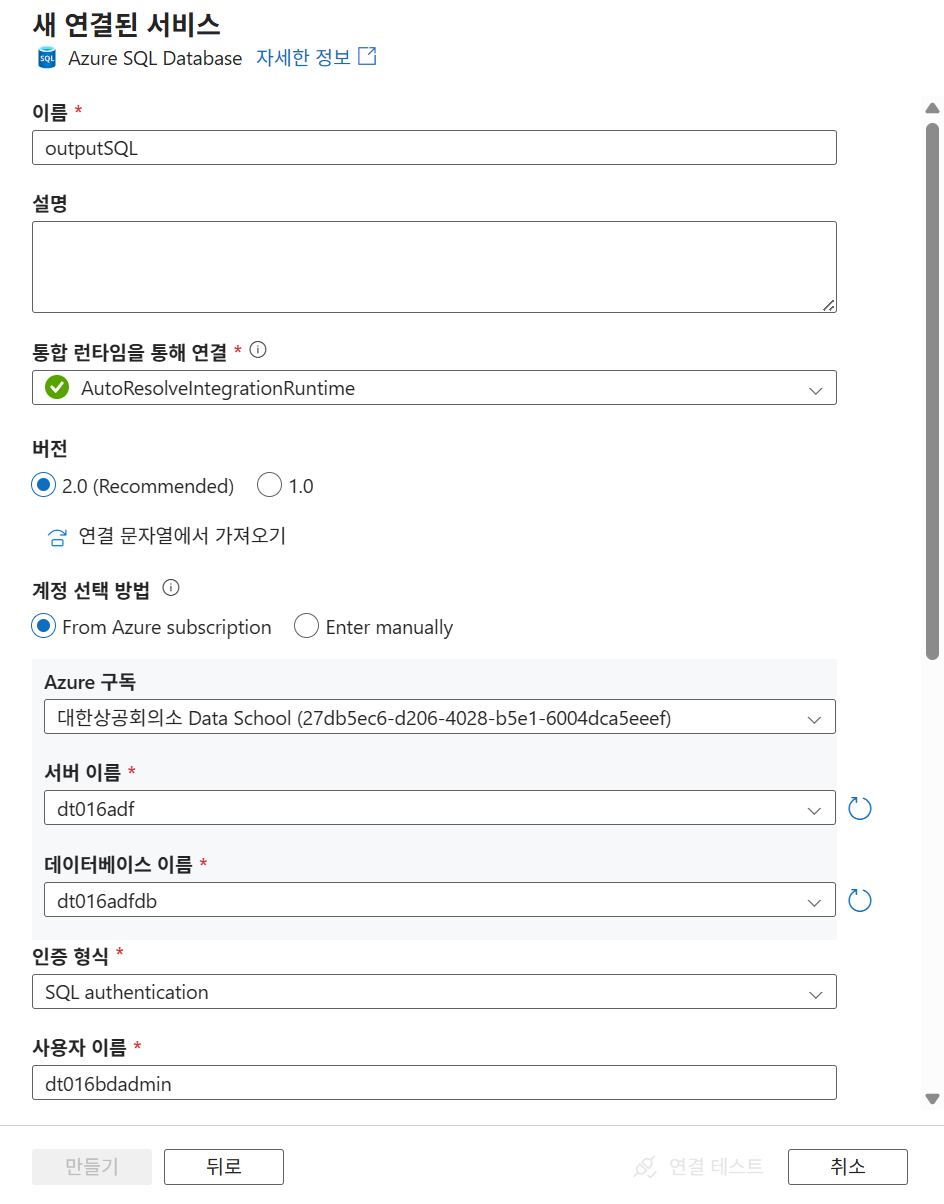
같은 방식으로 SQL Database용 Linked Service를 생성한다. 이 연결은 SQL 서버 주소, 데이터베이스, 인증 정보 등을 사용해 목적지에 접속한다.
Linked Service 정리
| 구분 | 연결 대상 | 역할 |
|---|---|---|
| 원본 Linked Service | Blob Storage | CSV 원본 연결 |
| 싱크 Linked Service | SQL Database | 대상 테이블 연결 |
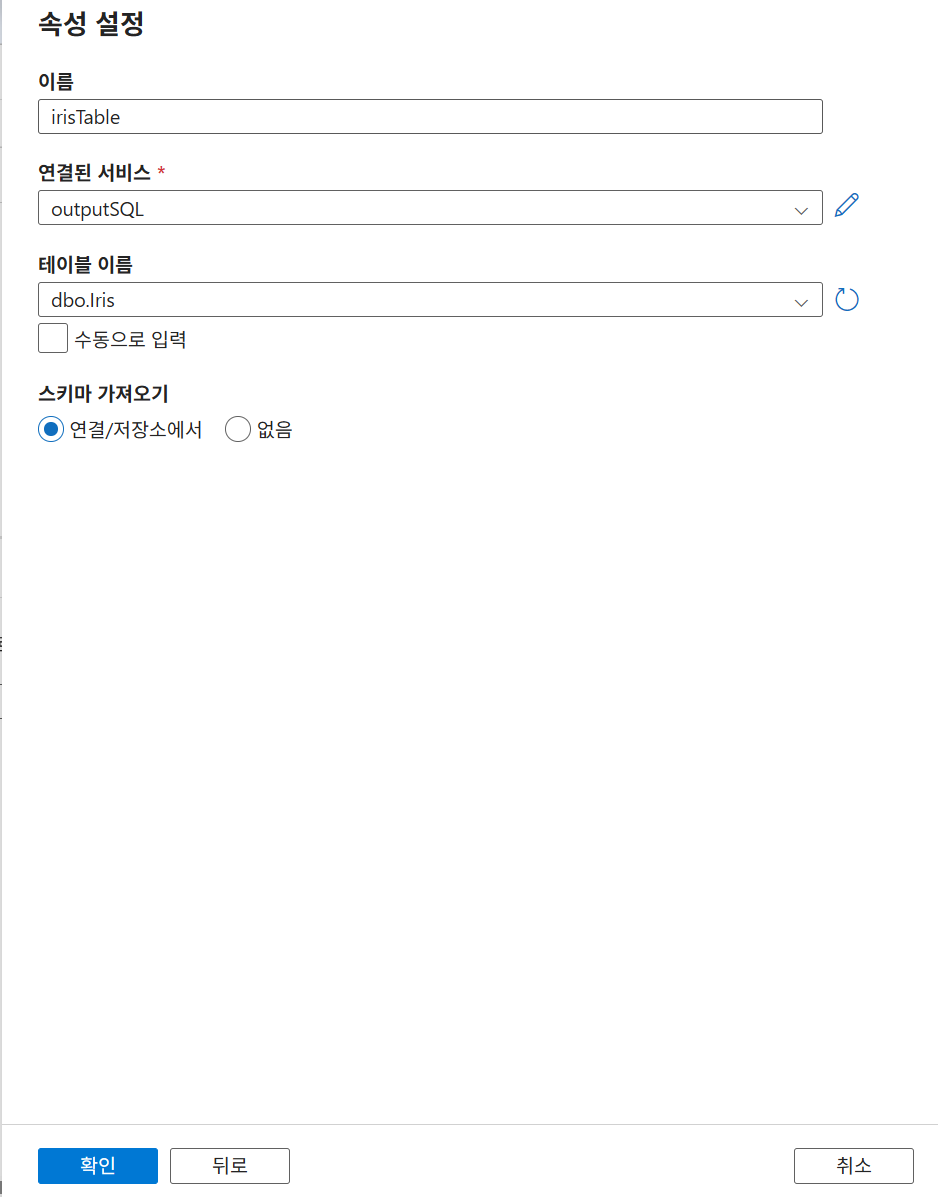
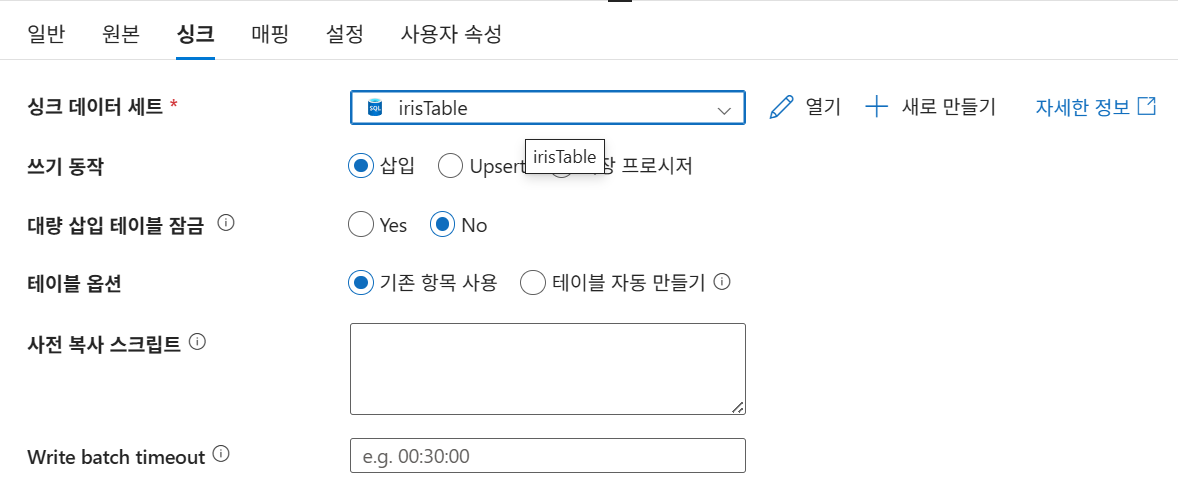
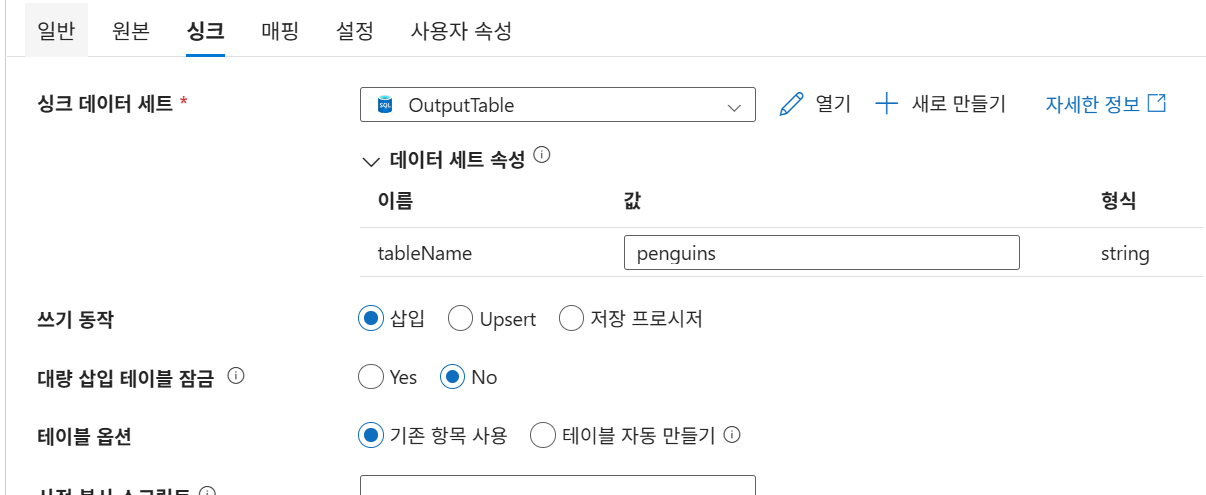
23-2. 싱크 Dataset 생성
Dataset 정리

| 구분 | 형식 | 연결 | 대상 |
|---|---|---|---|
| Source Dataset | CSV | Blob Linked Service | iris.csv |
| Sink Dataset | SQL Table | SQL Linked Service | Iris Table |
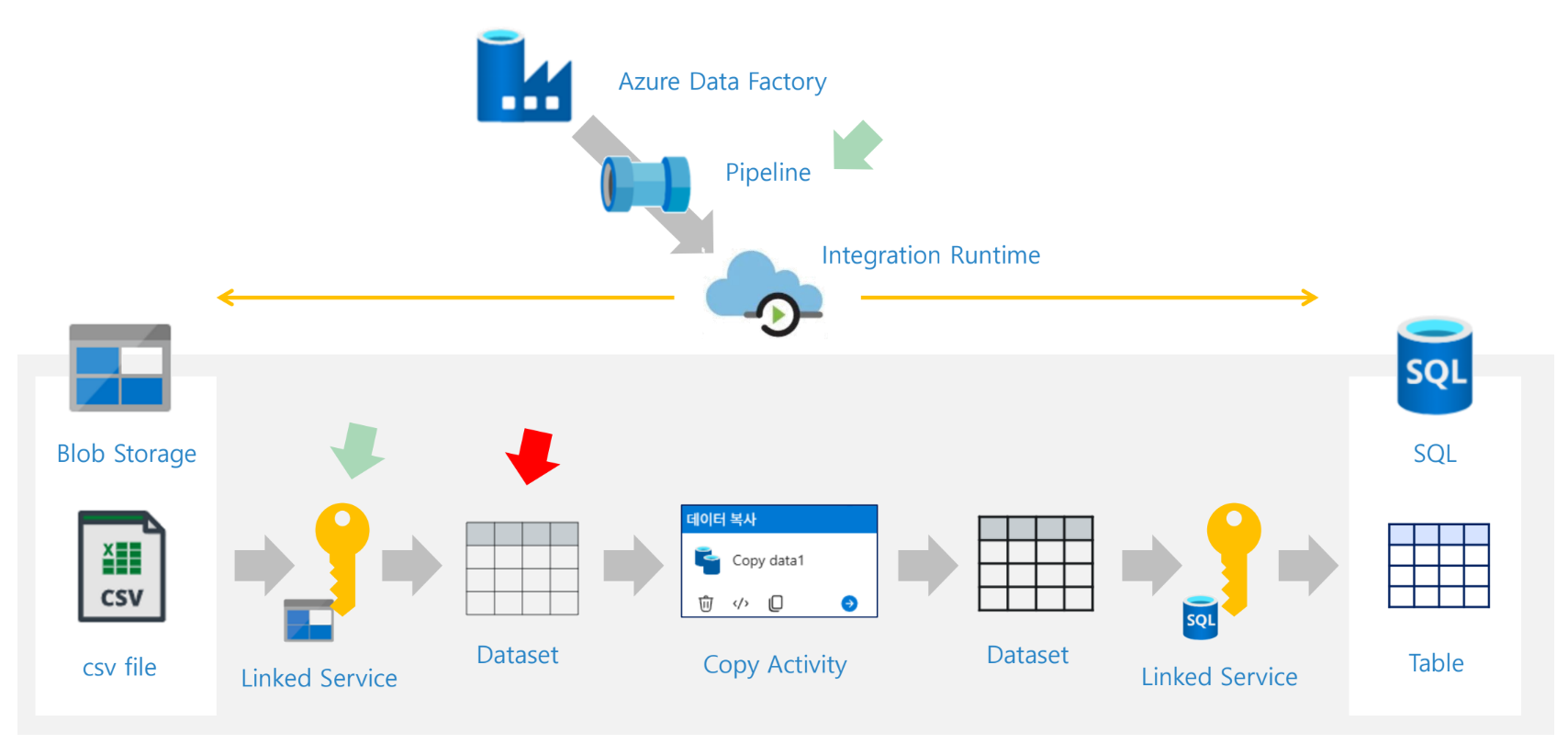
24. Copy Activity
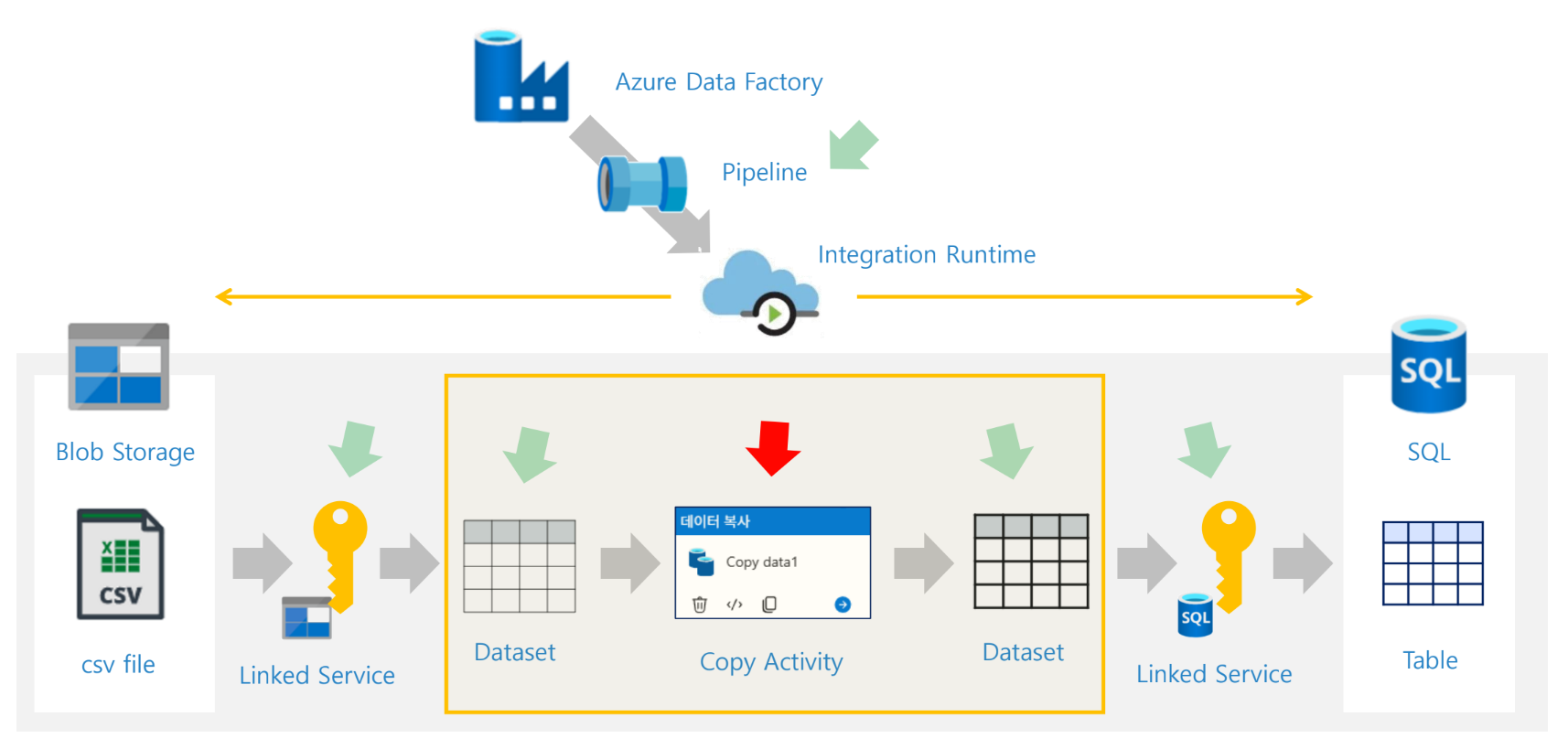
Copy Activity는 실습의 핵심이다. 원본 Dataset에서 데이터를 읽어 싱크 Dataset으로 복사한다. 자료의 실습 구성도에서는 Blob과 SQL 사이 중앙에 Copy Activity가 배치되고, 이후 강조 표시된 그림에서는 Dataset → Copy Activity → Dataset 구간이 하나의 핵심 처리 블록으로 묶여 있다.
좌측 데이터 복사를 드래그 앤 드랍
스키마 가져오기 선택
디버그
실무에서는 트리거를, 실습에서는 디버그를 사용(단일 테스트)
db의 쿼리편집기에서 확인
Copy Activity 역할
| 항목 | 설명 |
|---|---|
| 입력 | Source Dataset |
| 출력 | Sink Dataset |
| 기능 | 데이터 복사 및 기본 매핑 수행 |
| 위치 | Pipeline 내부 |
25. 게시

게시하지 않으면 저장이 안되므로 주의하자
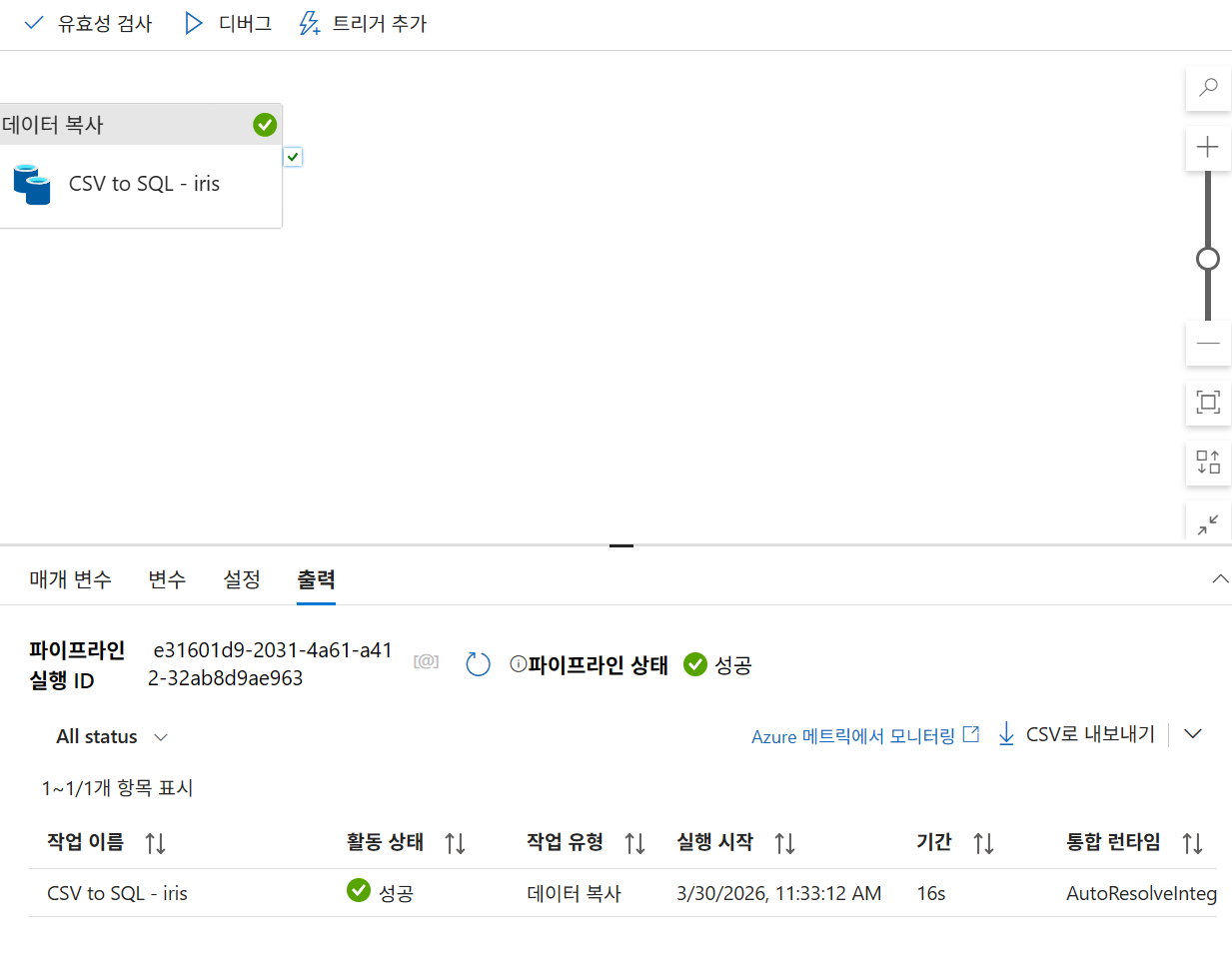
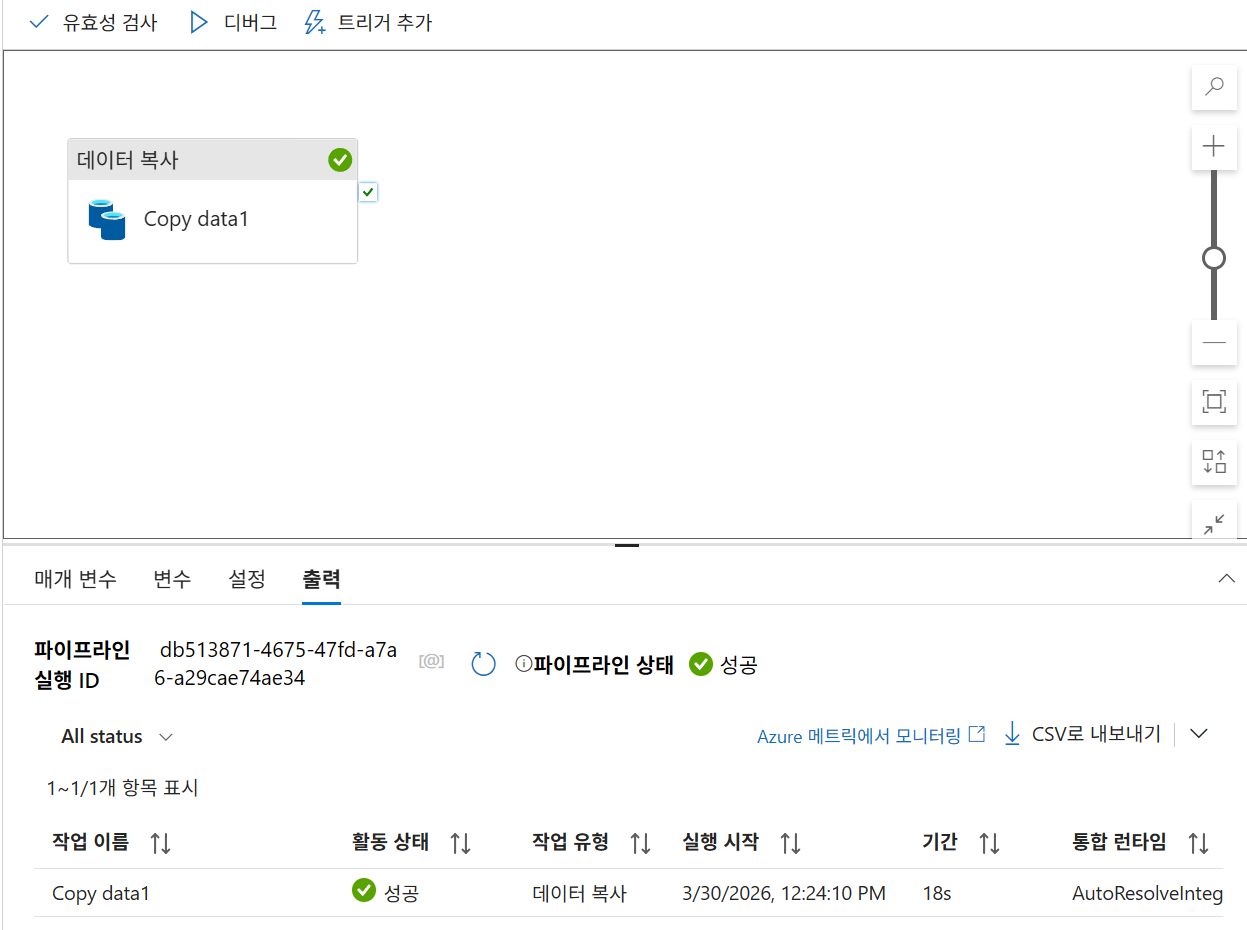
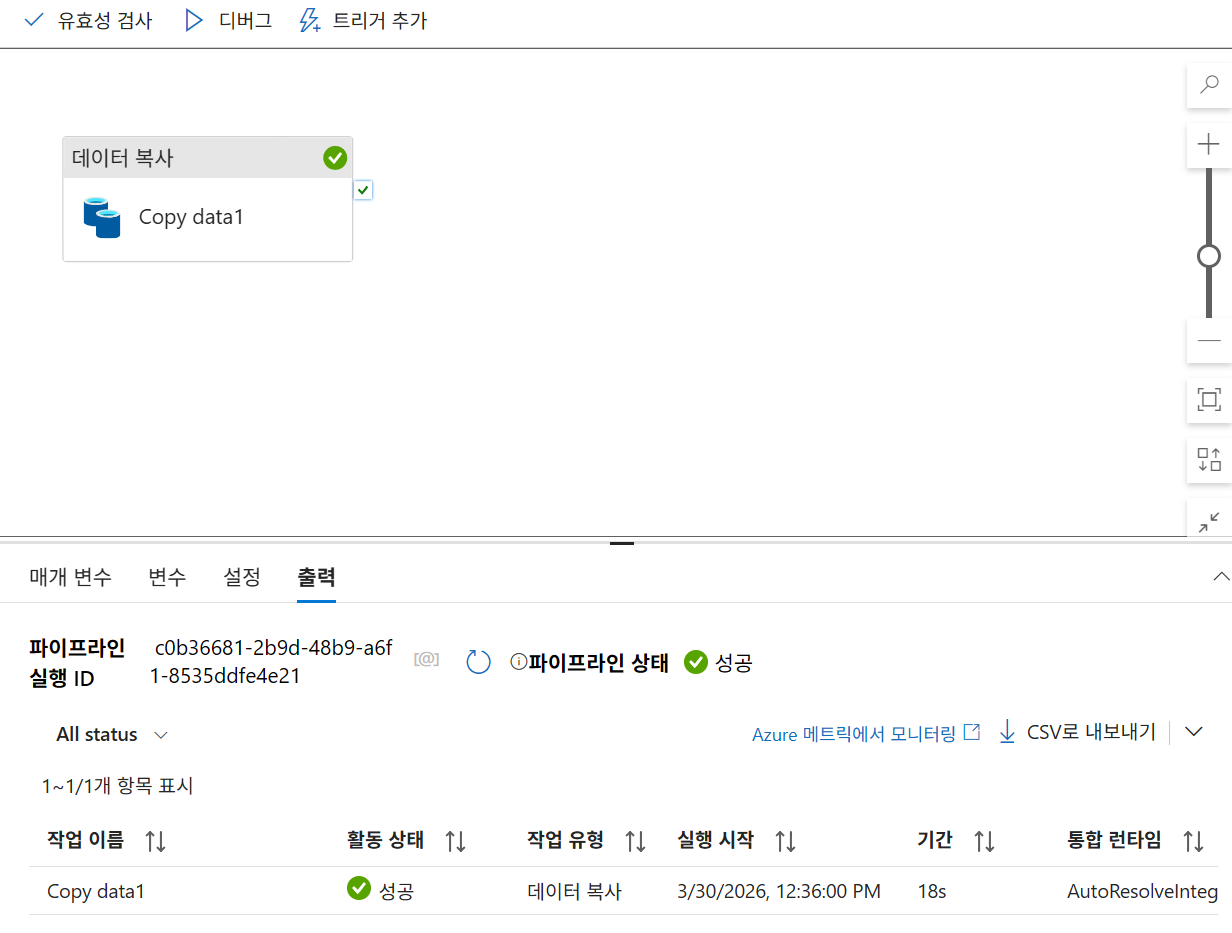
26. 파이프라인 실행
26-2. 파이프라인 트리거

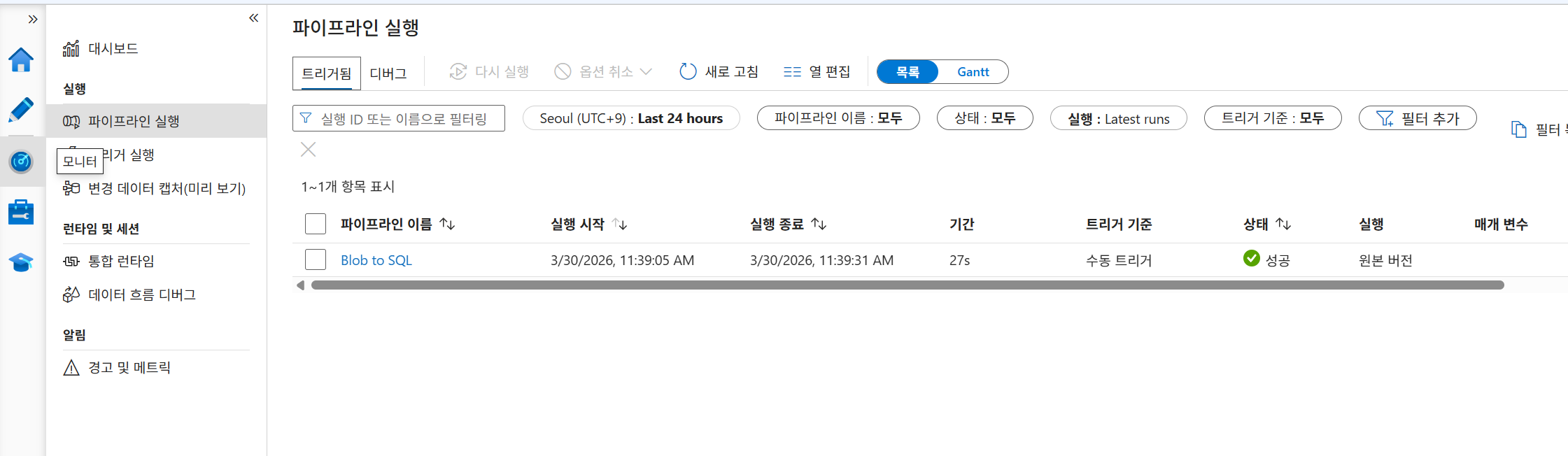
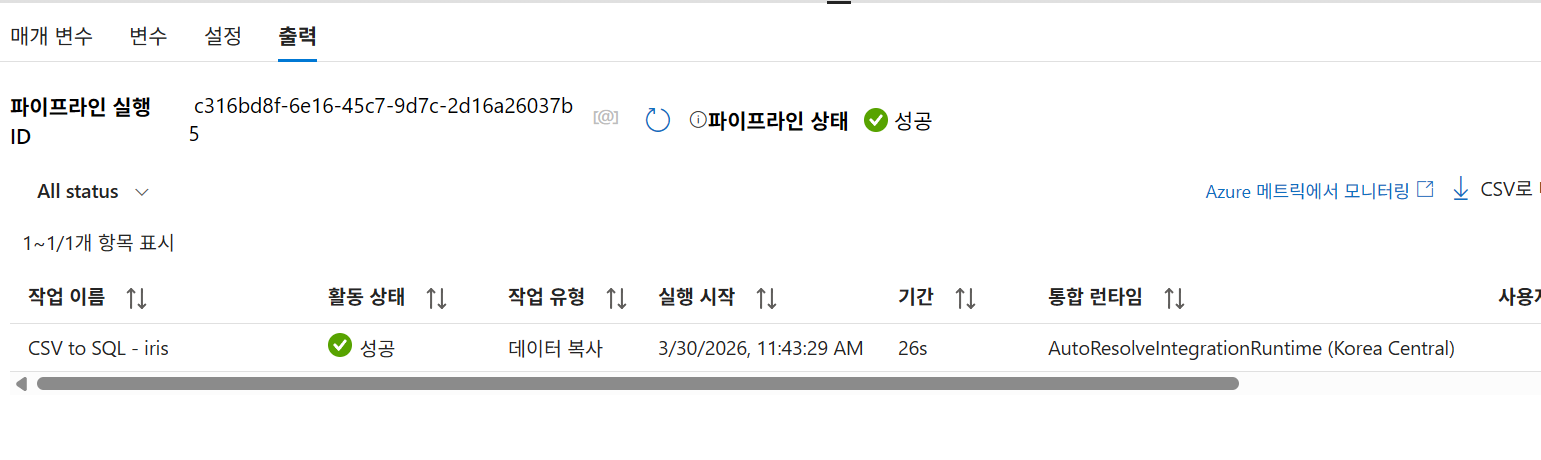
26-3. 결과 확인
모니터에서 확인
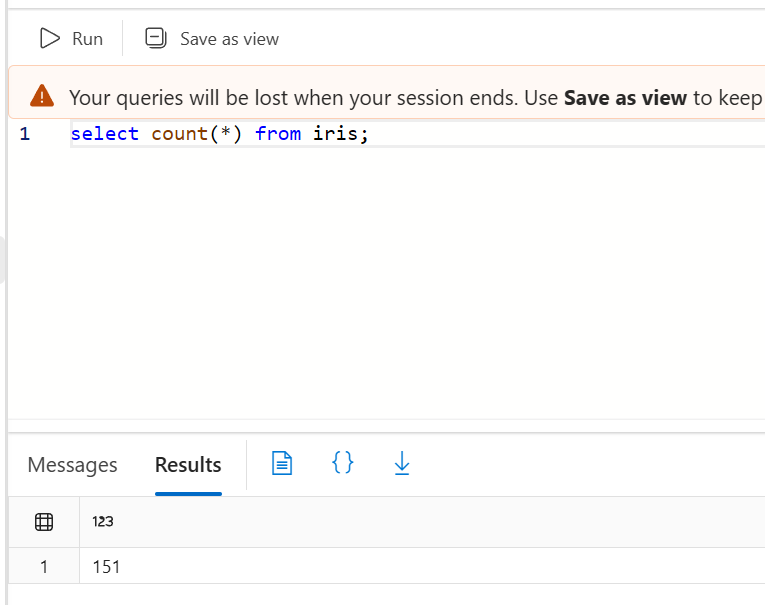
쿼리 편집기에서 확인
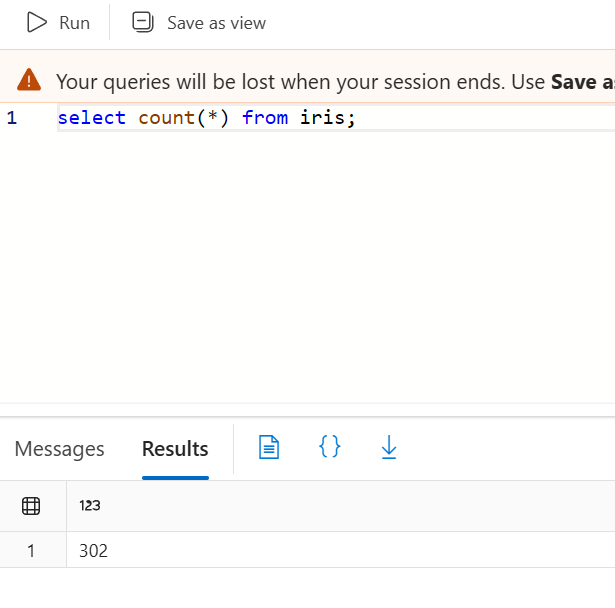
동일한 실행을 두 번하여 중복 발생으로 2배 count됨
27. 파이프라인 수정
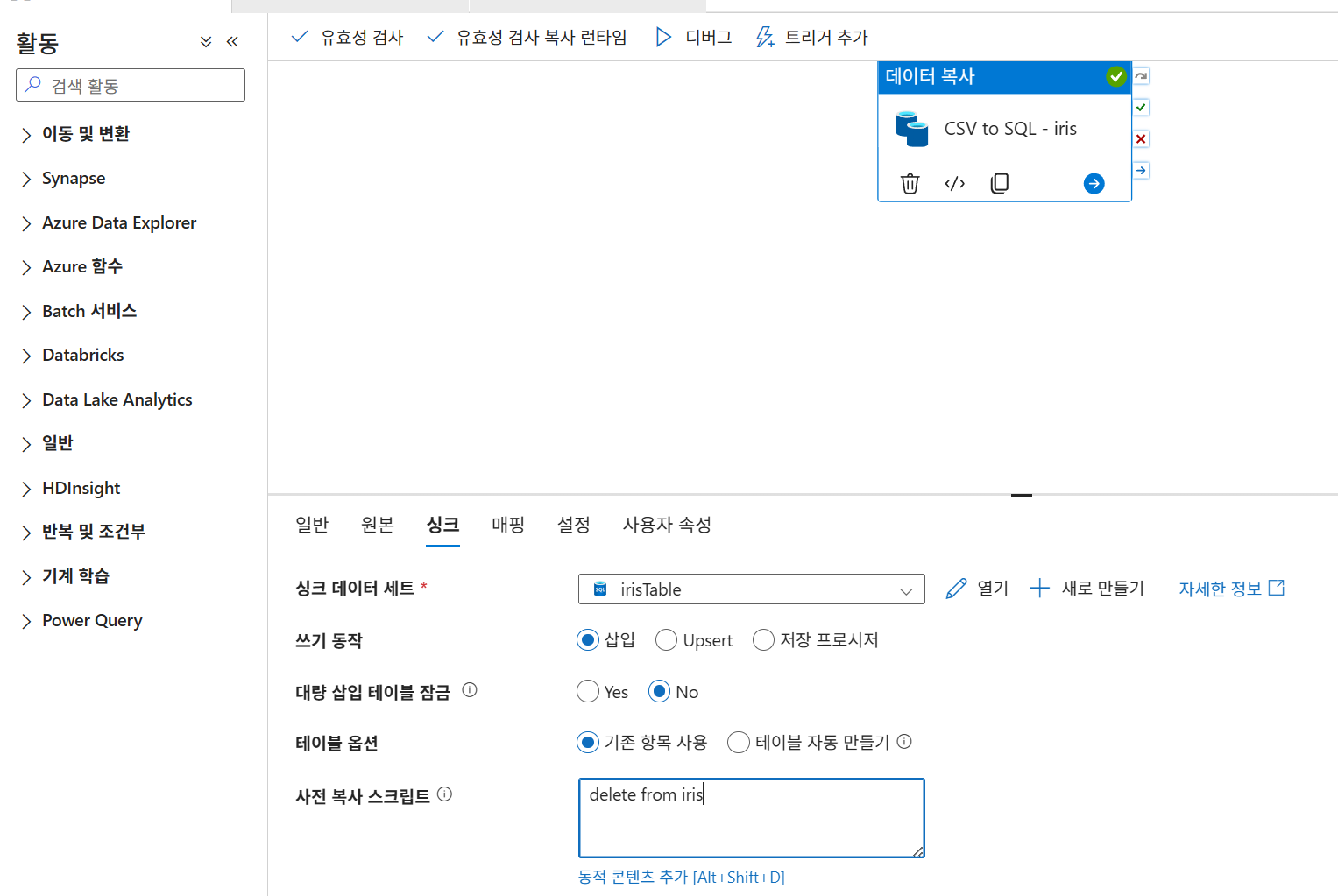
매번 실행마다 delete 후 실행하도록 처리
28. ADF 구성 요소 관계 정리
28-1. Pipeline과 Activity
Pipeline 아래에 여러 Activity가 들어갈 수 있다. 하나의 파이프라인 안에서 원본과 목적지가 다른 복사 작업을 여러 개 넣을 수도 있다.
28-2. Pipeline과 Linked Service
여러 Activity가 같은 원본 Storage 또는 같은 SQL Database를 사용할 경우, 연결 정보는 하나의 Linked Service를 재사용한다. 즉, 연결을 중복 생성하지 않고 중앙에서 관리할 수 있다.
28-3. Pipeline과 Dataset
Copy Activity는 각각 원본 Dataset과 싱크 Dataset을 참조한다. Dataset은 실제 데이터 파일이나 테이블의 위치와 형식을 정의하므로, Activity가 데이터를 해석하는 기준이 된다.
29. 폴더로 정리
30. 실습 흐름 한 번에 정리
리소스 준비 단계
- 실습 데이터 다운로드
- 리소스 그룹 생성
- Data Factory 생성
- SQL Database 및 SQL Server 생성
- Storage Account 생성
- Blob 컨테이너 생성
- CSV 업로드
- SQL 테이블 생성
ADF 작업 단계
- Data Factory Studio 진입
- Author 메뉴 이동
- 새 파이프라인 생성
- Blob Linked Service 생성
- SQL Linked Service 생성
- Source Dataset 생성
- Sink Dataset 생성
- Copy Activity 추가
- Source Dataset 연결
- Sink Dataset 연결
- 복사 실행
이 전체 흐름의 목표는 Blob Storage의 CSV 데이터를 SQL Database 테이블로 복사하는 것이다.
31. 핵심 개념 요약
| 항목 | 내용 |
|---|---|
| 데이터 문제 | 데이터 사일로, 이기종 데이터, 높은 운영 복잡성 |
| 해결 방향 | 데이터를 한곳에 통합하고 자동화된 파이프라인 구축 |
| 핵심 방식 | ETL, ELT, CDC |
| ADF 역할 | 데이터 이동·오케스트레이션 |
| 실행 엔진 | Integration Runtime |
| 실습 구조 | Blob CSV → Copy Activity → SQL Table |
32. 마무리
Azure Data Factory는 데이터를 직접 분석하는 도구라기보다는, 분석 가능한 형태로 데이터를 연결하고 이동시키는 데이터 파이프라인 도구에 가깝다. 따라서 ADF를 이해할 때는 단순히 “복사 도구”로 보기보다, 원본 시스템과 분석 시스템 사이를 이어주는 오케스트레이션 계층으로 보는 것이 중요하다. 이번 실습도 결국 Blob Storage의 파일과 SQL Database의 테이블을 연결하면서, Pipeline·Activity·Dataset·Linked Service·Integration Runtime이 어떻게 협력하는지 익히는 과정이라고 볼 수 있다.
제공해주신 소스(03-30-2.01 매개변수화_v12.pdf)의 개요 부분 내용을 요약 없이 마크다운 형식으로 정리해 드립니다.
매개변수화(Parameterization) 개요
1. 매개변수화(Parameterization) 정의
매개변수(Parameter)는 데이터 팩토리의 작업 수행 시 입력값으로 사용되는 값이며, 각 액티비티, 파이프라인, 데이터셋(Datasets) 등에서 사전에 정의된 값 또는 사용자 정의 값을 입력받을 수 있습니다. 매개변수화는 특히 프로덕션 환경에서 재사용성과 유지보수성 향상에 큰 효과가 있습니다.
2. 매개변수화를 지원하는 구성요소
- Parameters (매개변수): 파이프라인 실행 시 외부에서 값을 입력받아 유연한 구성 가능.
- Variables (변수): 파이프라인 내에서 상태값을 유지하거나 중간 결과를 저장.
- Expressions (표현식): 동적 값을 계산하거나 조건문 등을 구성할 수 있는 함수 기반 표현식.
3. 매개변수화의 이점
- 흐름 제어: 다양한 조건에 따라 실행 경로를 제어 가능.
- 시간 절약: 동일한 파이프라인을 여러 시나리오에 재사용.
- 유연한 설계: 솔루션을 일반화하고 유지보수 용이.
4. Parameters (매개변수) 상세
파이프라인, 데이터세트 등에서 정의하는 외부 입력값으로, 실행 시 값을 주입받아 유연한 동작을 지원합니다.
| 항목 | 내용 |
|---|---|
| 주요 특성 | • 사전에 정의된 값 혹은 사용자 정의 가능 • 주로 실행 시점에 결정되는 정적인 값 • 런타임 시점에 값 전달 • 데이터세트, 파이프라인 등 다양한 요소에 적용 |
| 활용 목적 | • 동적 처리: 날짜별/부서별/환경별 분기 • 재사용성: 동일 파이프라인을 다양한 값으로 실행 • 유연성: 실행 시점에 변경 가능한 구성 |
| 활용 예시 | • 날짜별 파이프라인 실행: 특정 일자 데이터만 추출 • 환경 분기: Dev./Prod. 연결 서비스 자동 전환 • 부서별 로직: SQL 쿼리의 동적 적용 |
| 구문 예시 | @pipeline().parameters.inputDate |
5. Variables (변수) 상세
파이프라인 실행 중에 값을 저장, 조회, 업데이트할 수 있는 내부 런타임 변수입니다.
| 항목 | 내용 |
|---|---|
| 주요 특성 | • 범위(scope): 파이프라인 단위(자식 파이프라인에 자동 전달되지 않음) • 런타임 수정 가능: Set Variable 액티비티로 값 변경 • 선언 시 초기값 지정 가능 • 지원 데이터 타입: String, Boolean, Int, Array |
| 활용 예시 | • 중간 연산값 관리: 복잡한 표현식 결과를 변수에 담아 재사용 • 재시도 카운터: 오류 발생 시 retryCount를 1씩 증가시켜 제어 • 루프 인덱스 누적: ForEach 반복 횟수 누적 혹은 조건부 루프 제어 • 상태 메시지: 각 단계 완료 후 상세 로그 저장 |
| 선언 구문 | "variables": { "retryCount": { "type": "Int", "defaultValue": 0 } } |
| 참조/할당 | 참조: @variables('retryCount')할당: @add(variables('retryCount'), 1) |
6. Expressions (표현식) 상세
런타임에 동적으로 값의 연산, 변환, 판단을 수행하기 위해 다양한 함수를 포함하는 표현식을 활용합니다.
- 주요 특징:
- 런타임 평가: 실행 시점에 해석 및 실행되어 동적 경로 생성.
- 풍부한 함수 라이브러리: 문자열, 수치, 날짜, 논리, 배열 등 지원.
- 동적 참조: 파라미터, 변수, 액티비티 출력값 통합 사용.
- 중첩 가능: 함수 안에 함수를 삽입하여 복합 연산 지원.
- 활용 예시:
@concat('landing/', pipeline().parameters.region, '/', formatDateTime(utcNow(), 'yyyyMMdd'))@formatDateTime(addDays(utcNow(), -1), 'yyyy-MM-dd')@if(greater(activity('Lookup').output.count, 0), 'HasData', 'NoData')
- 자주 쓰이는 함수:
concat,formatDateTime,addDays,if,length,json.
7. Parameters vs Variables 비교 요약
| 구분 | Parameter | Variable |
|---|---|---|
| 정의 | 파이프라인 실행 시 외부에서 주입받는 입력 값 | 파이프라인 실행 중 내부에서 생성, 조회, 업데이트 가능한 런타임 변수 |
| 적용 범위 | 파이프라인, 데이터세트, 연결 서비스 등 선언한 레벨에 한정됨 | 파이프라인 단위(자식 파이프라인에 전달되지 않음) |
| 런타임 변경 | 불가능 (정적 값) | Set Variable 액티비티로 언제든 변경 가능 |
| 참조 구문 | @pipeline().parameters.<이름> | @variables('<이름>') |
| 주요 활용 예 | 날짜 필터링, 환경 분기(environment) | 재시도 카운터 증가, 상태 메시지 저장 |
8. 실습 시나리오 - 파이프라인 매개변수화
매개변수화를 위한 시나리오 확장
데이터세트의 매개변수화
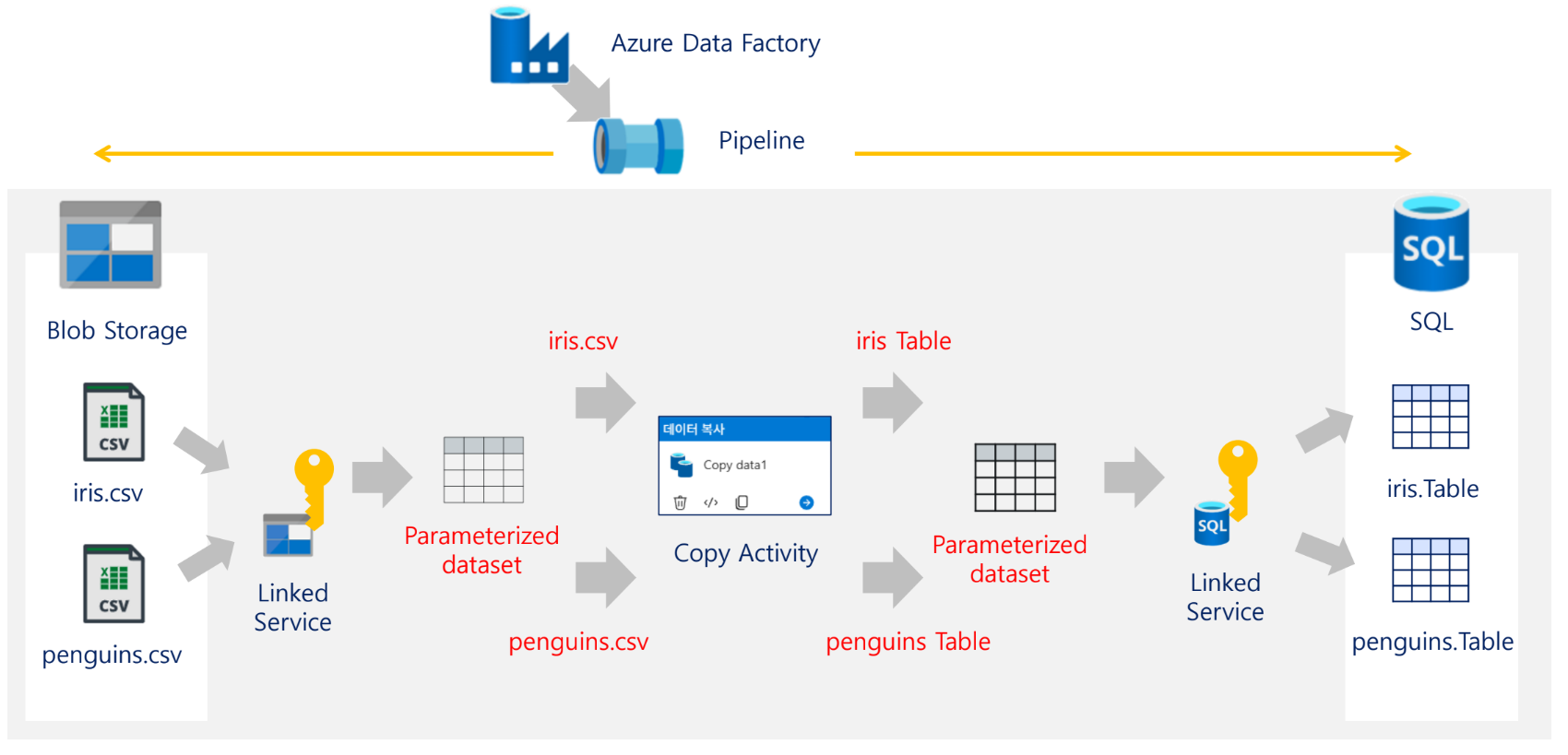
9. 실습
9-1. Azure Container에 원본 데이터 업로드
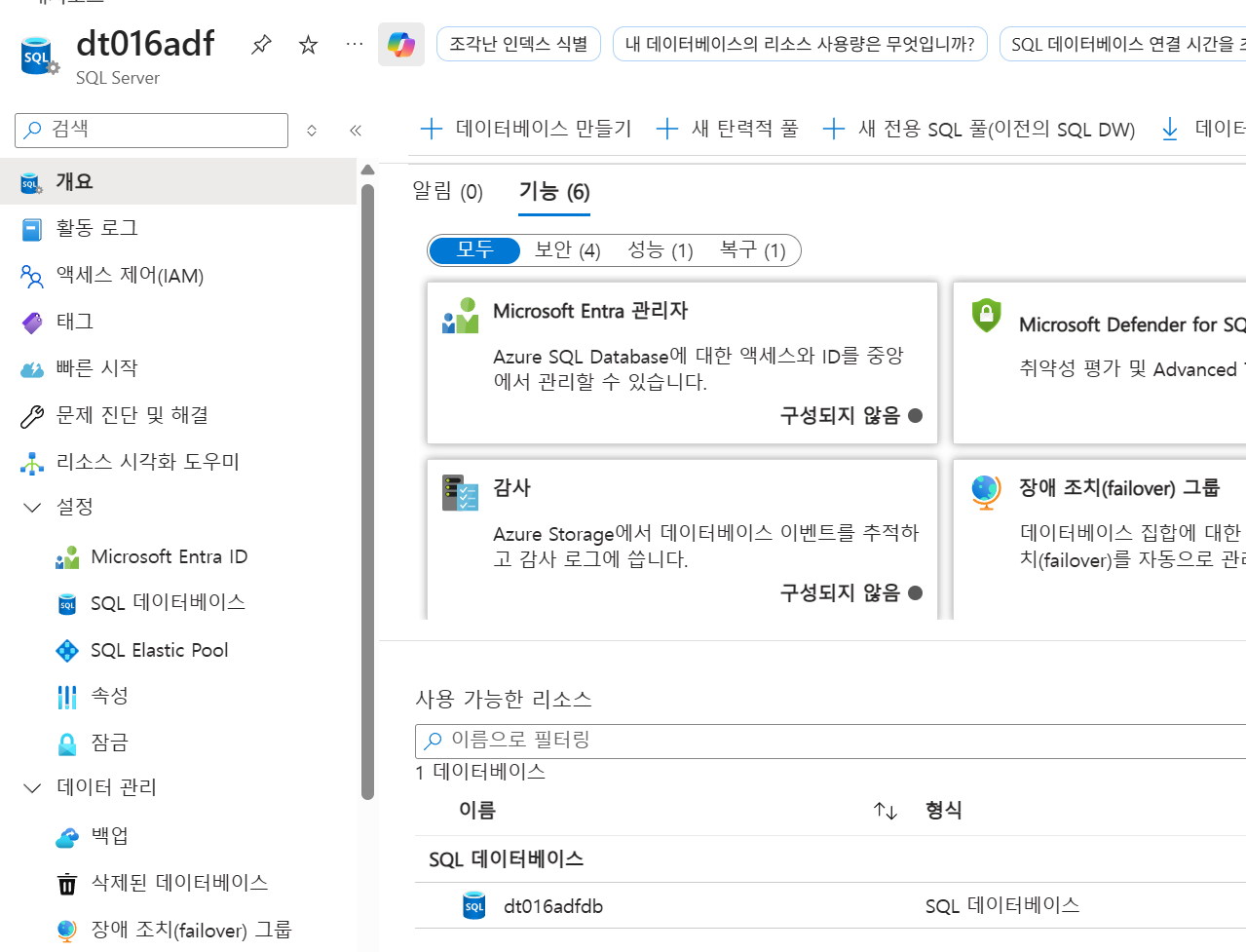
9-2. 목적지 데이터 생성
SQL Server에서 SQL 데이터베이스로 접속 후 쿼리편집기에서 추가
9-3. 연결된 서비스(Linked Service) 준비
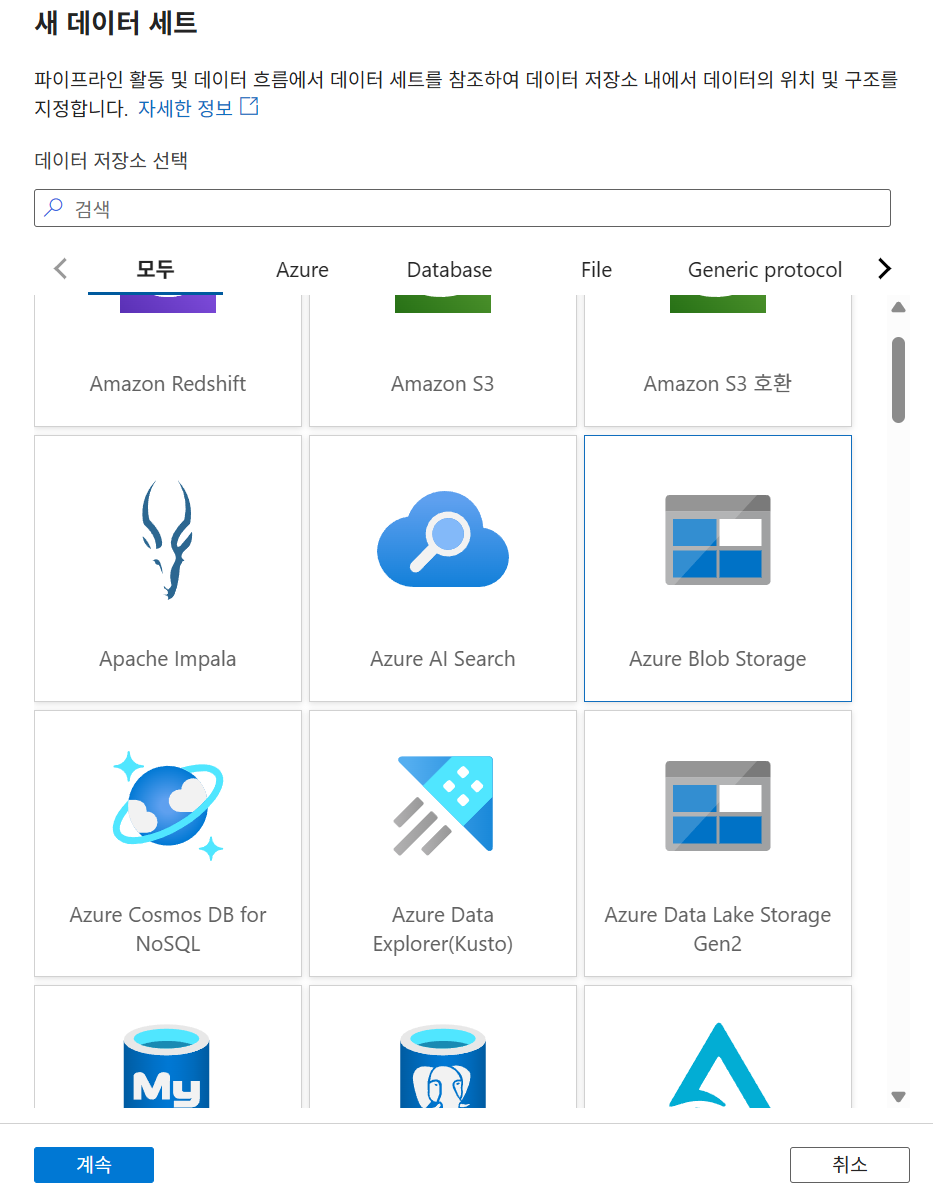
9-4. 소스 데이터세트 생성

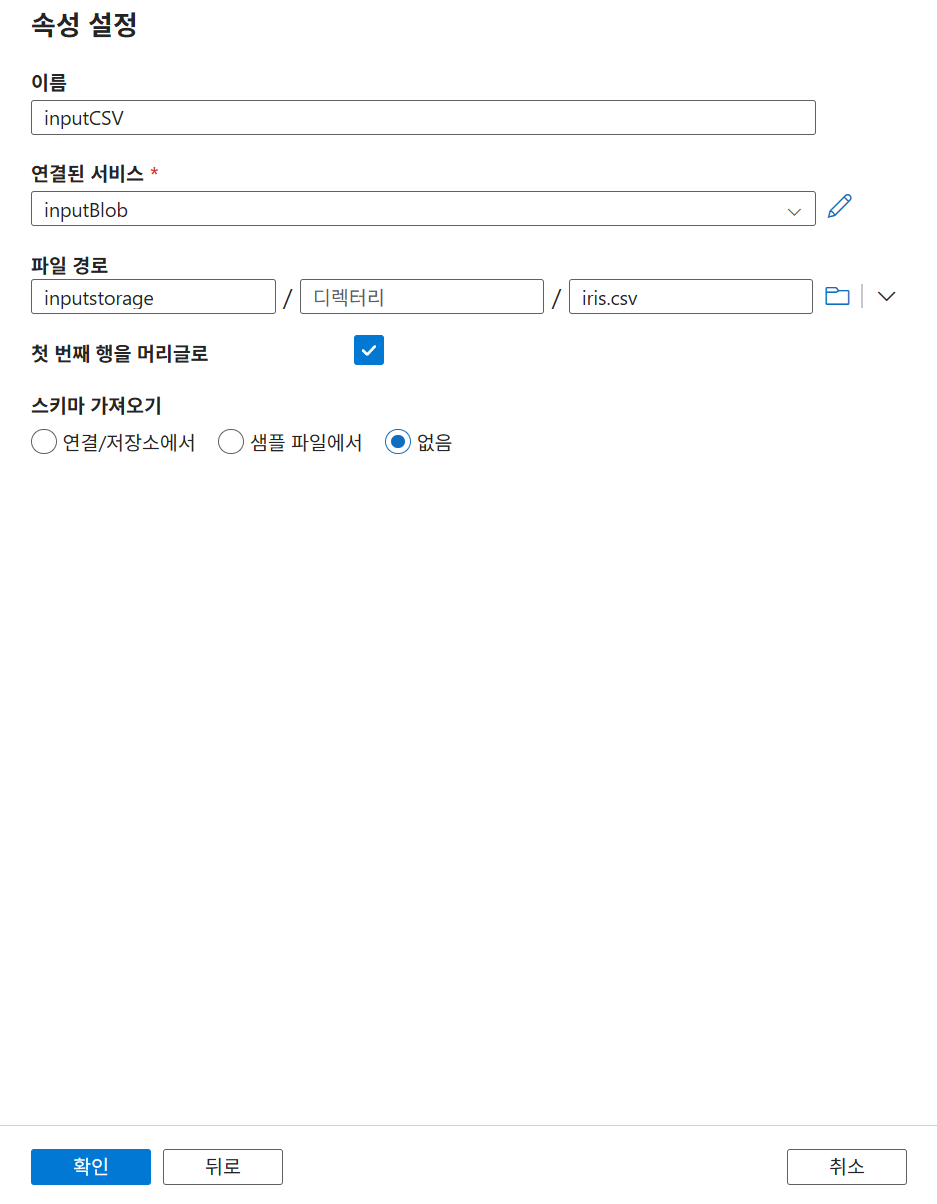
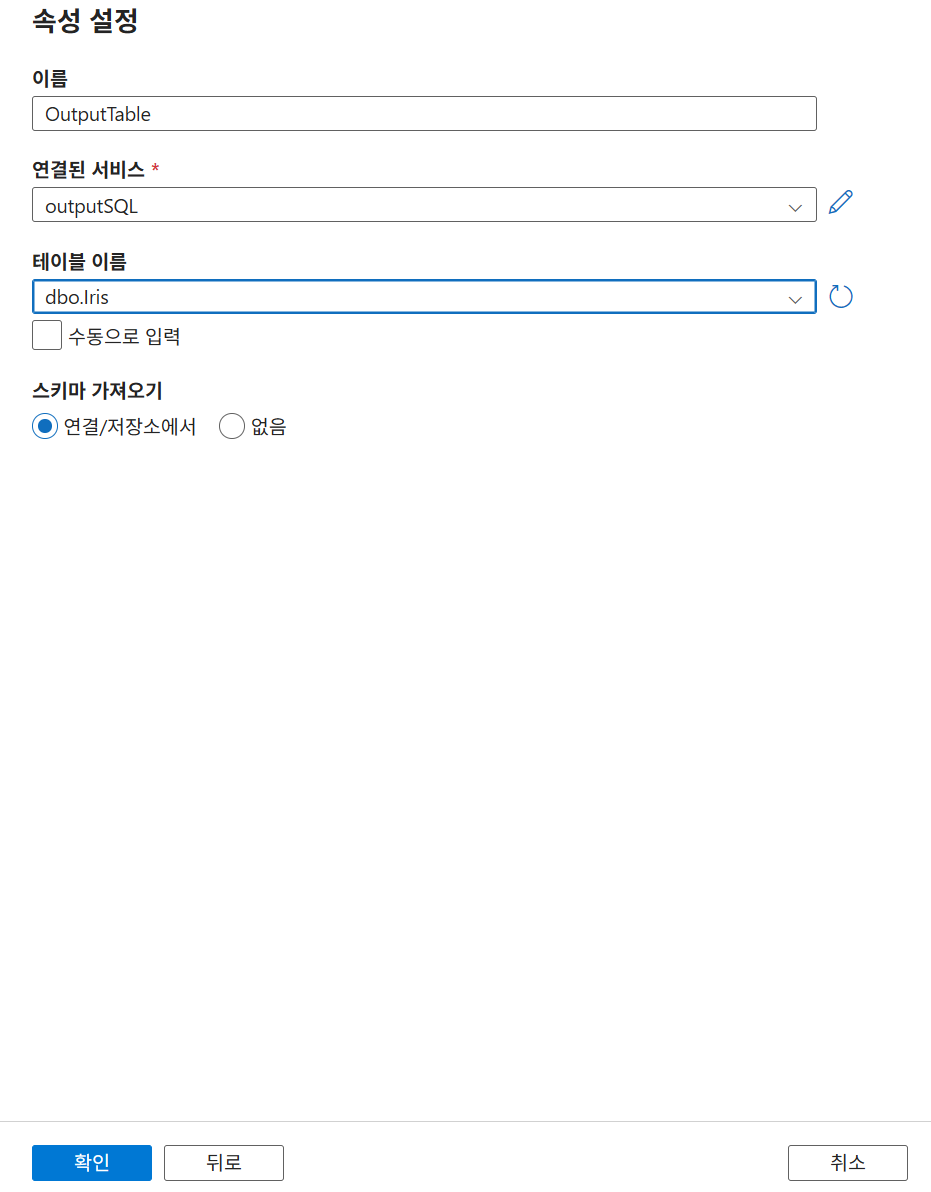
9-5. 목적지 데이터세트 생성
9-6. 파이프라인 생성
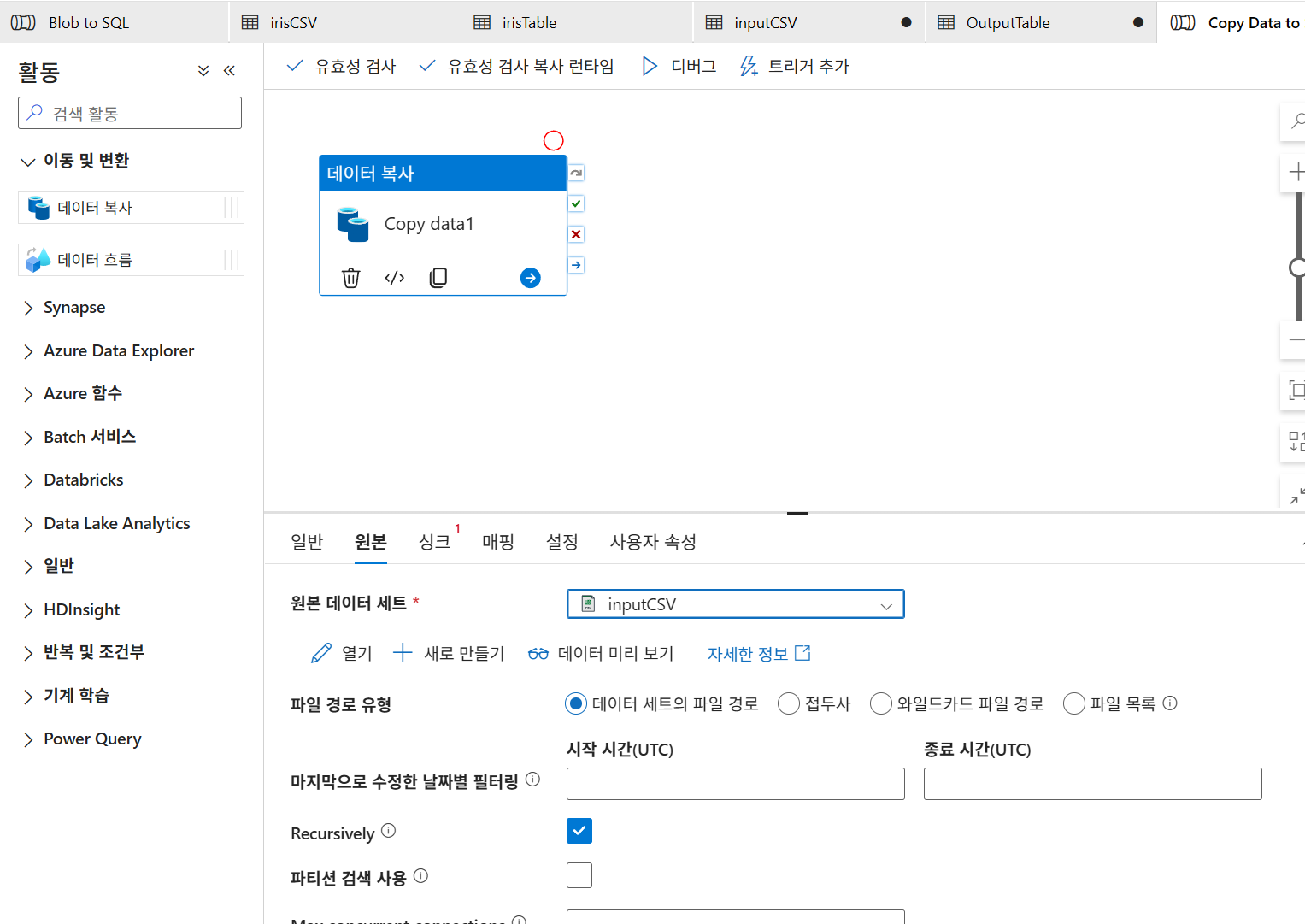
디버그
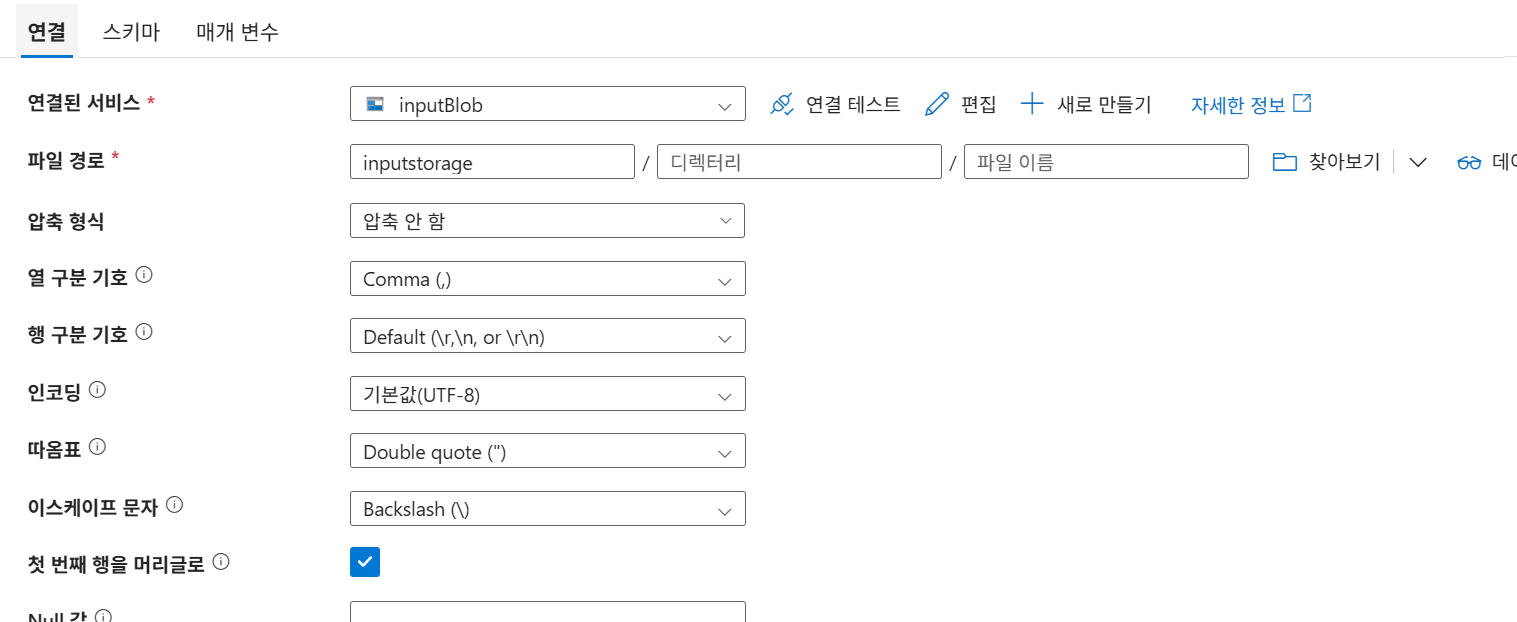
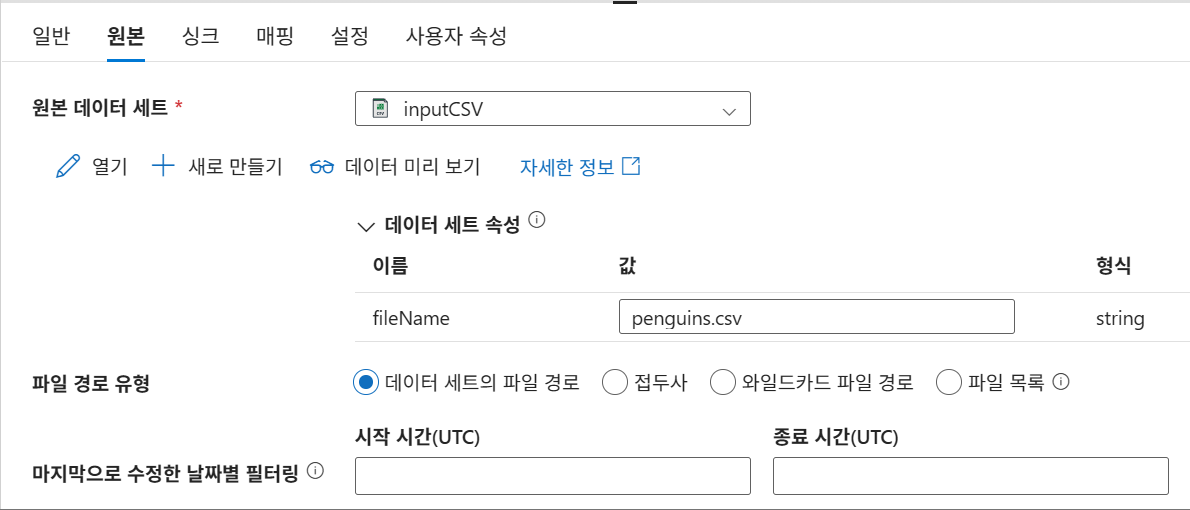
9-7. 데이터세트 매개변수화(원본)
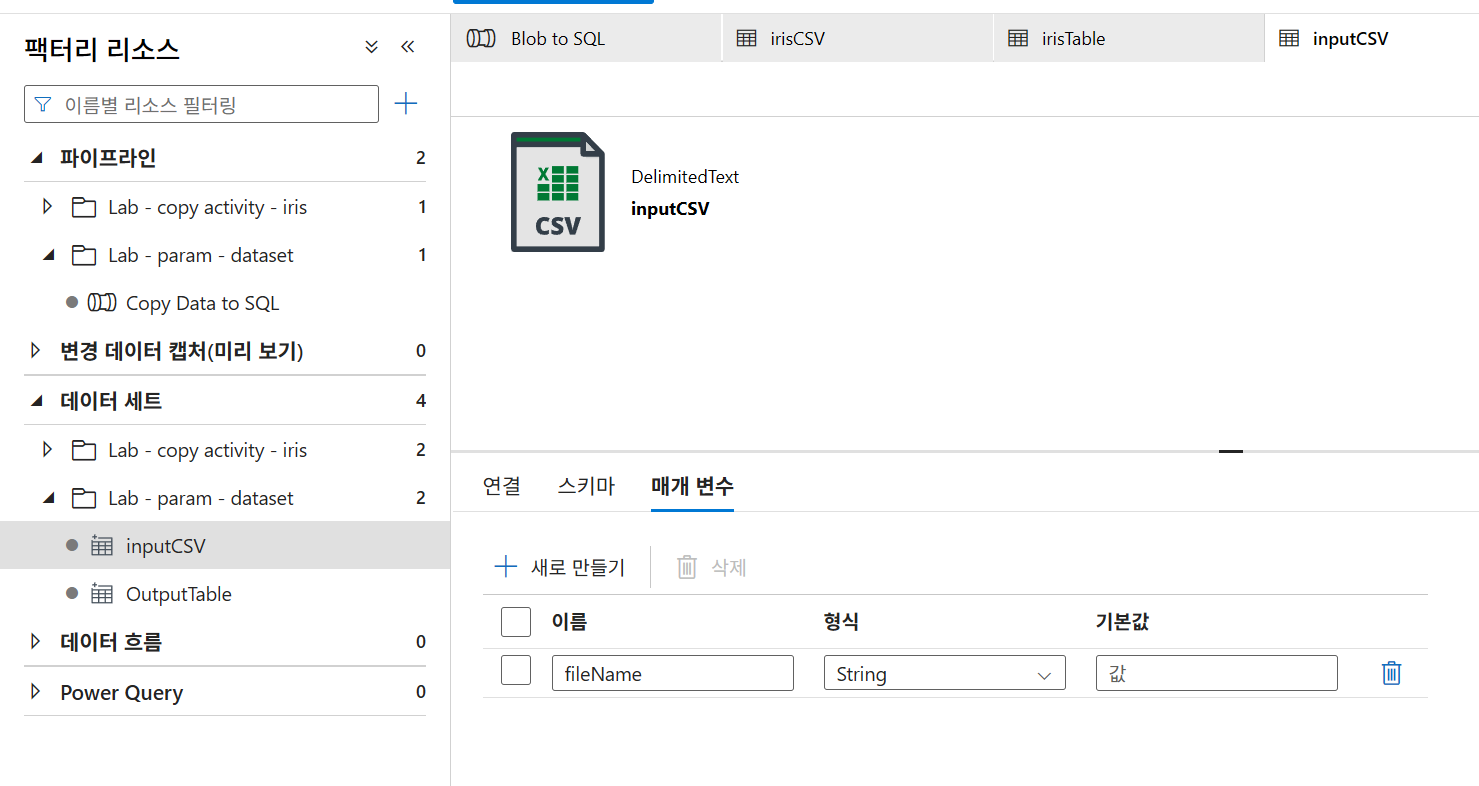
연결탭의 파일 경로에서 파일 이름 삭제
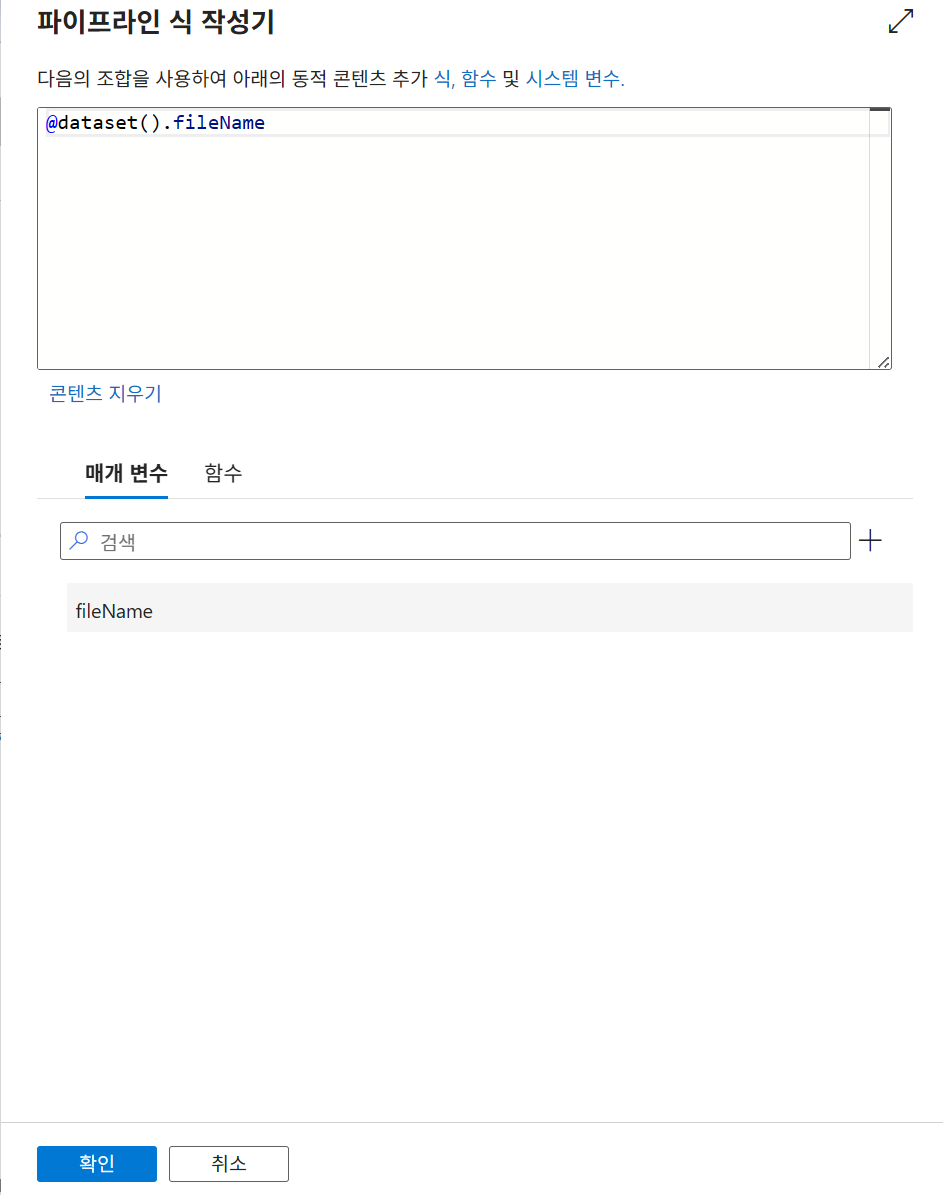
동적 콘텐츠 추가 - 하단의 매개 변수 선택

9-8. 데이터세트 매개변수화(싱크)
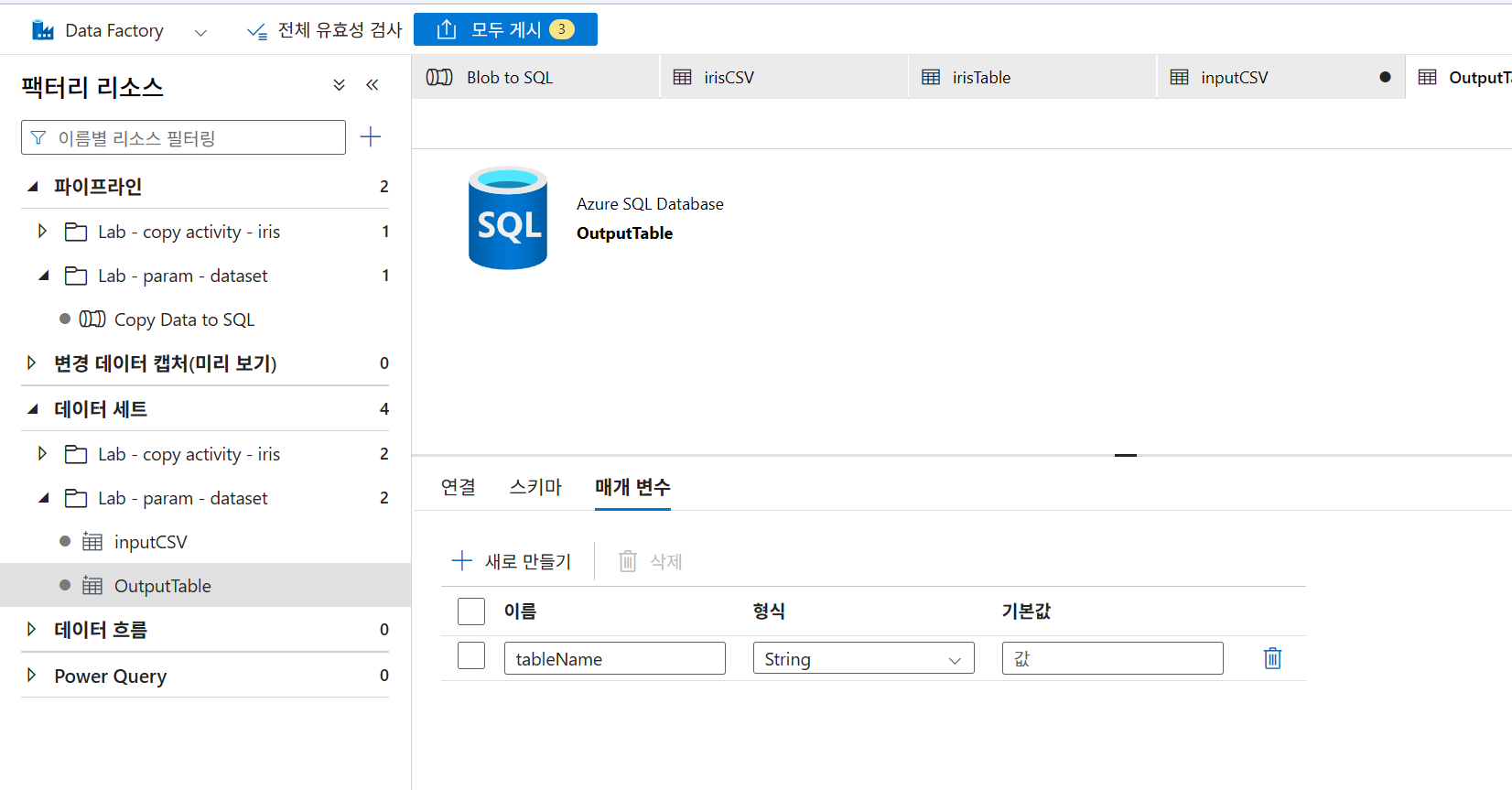
수동으로 입력 체크
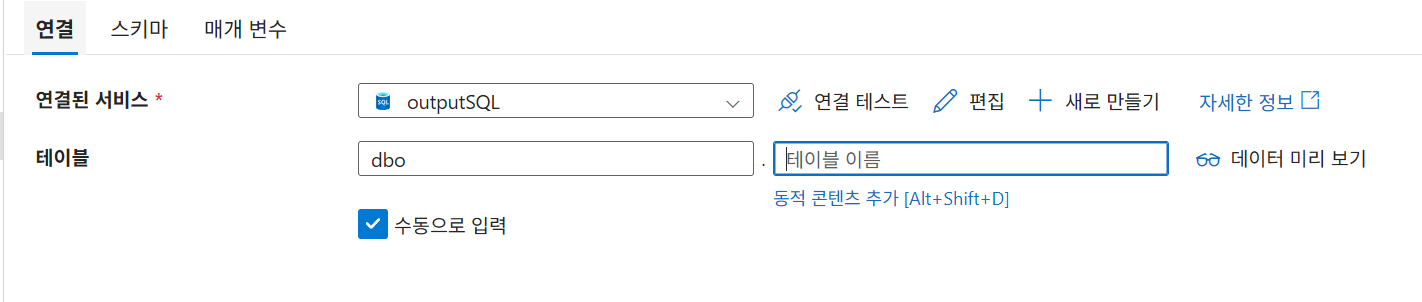
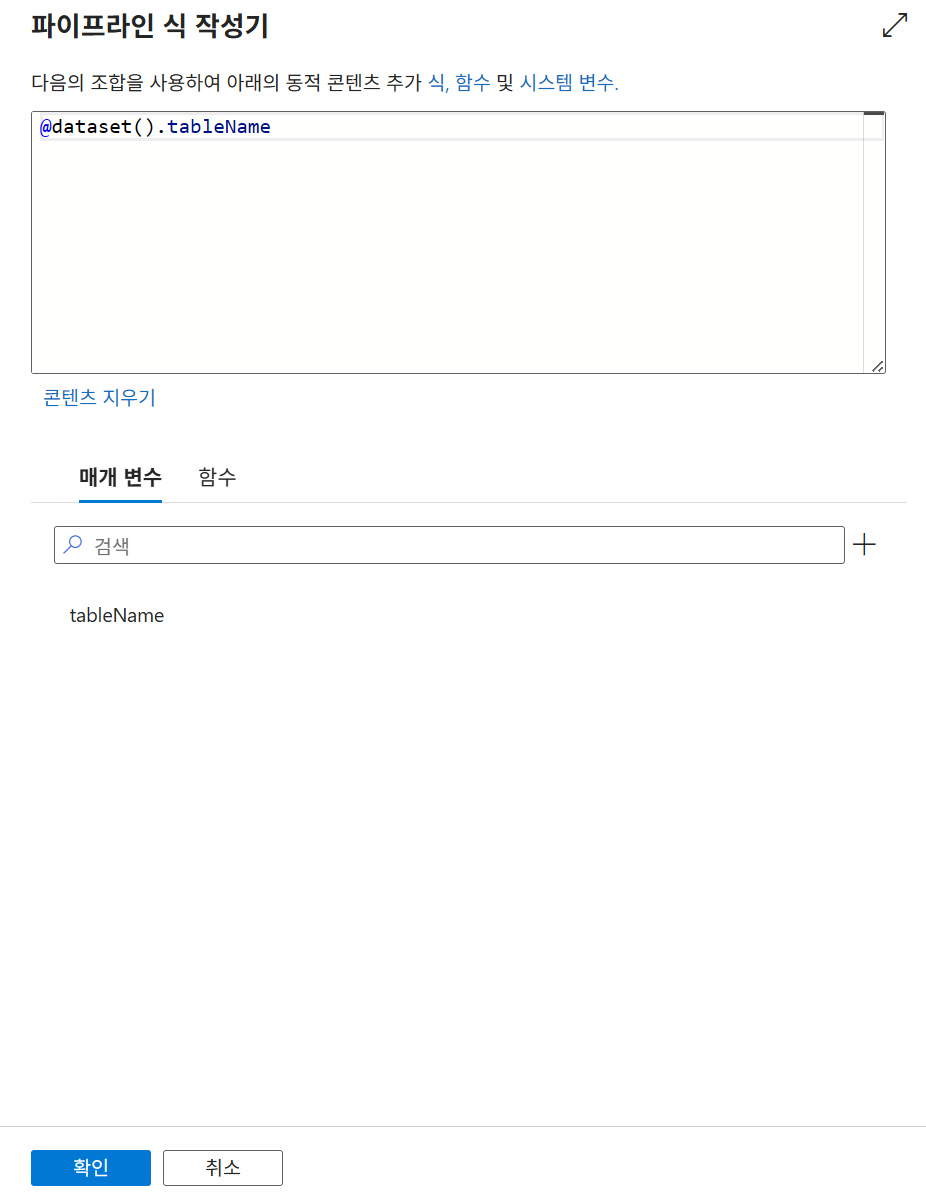
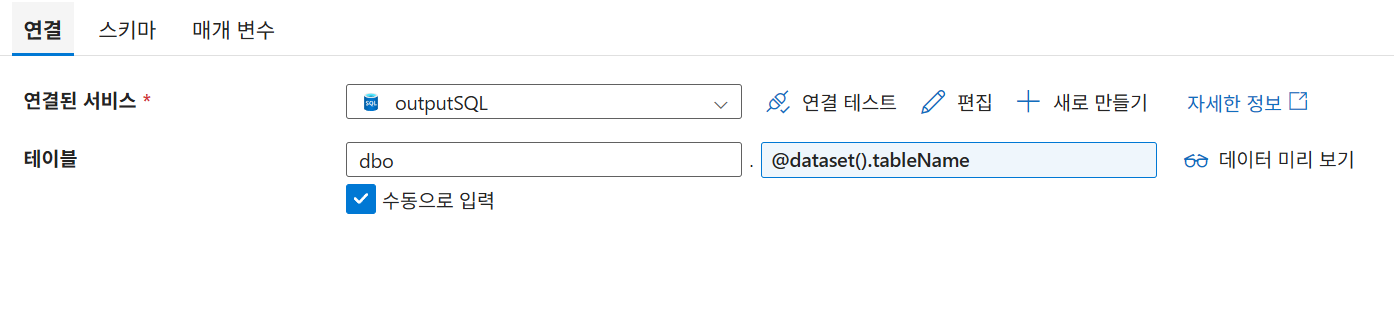
9-9. 데이터세트 매개변수화 테스트
원본 설정
싱크 설정
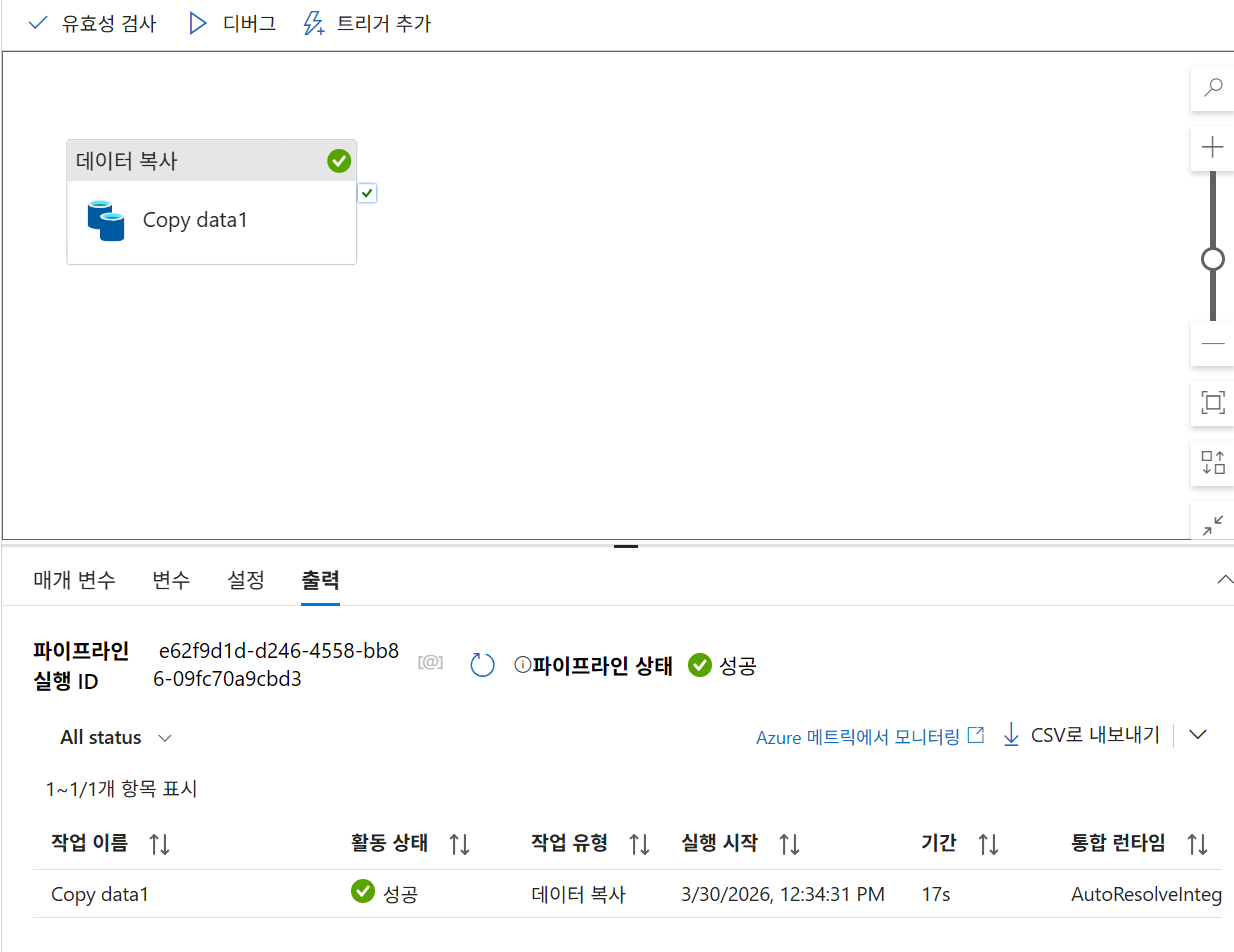
디버그 실행
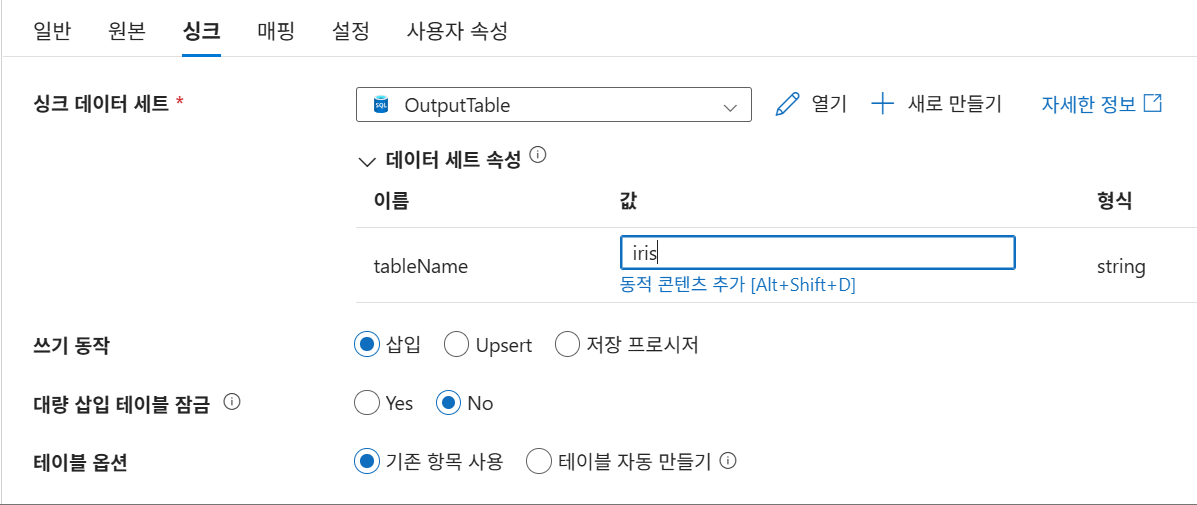
9-10. 데이터세트 매개변수화 적용
9-11. 데이터세트 매개변수화 활용: 데이터 백업 추가
데이터복사 추가


위에서부터 성공, 실패, 항상처리 시 다음 처리 연결 노드
백업이므로 output(원본) → input(싱크)
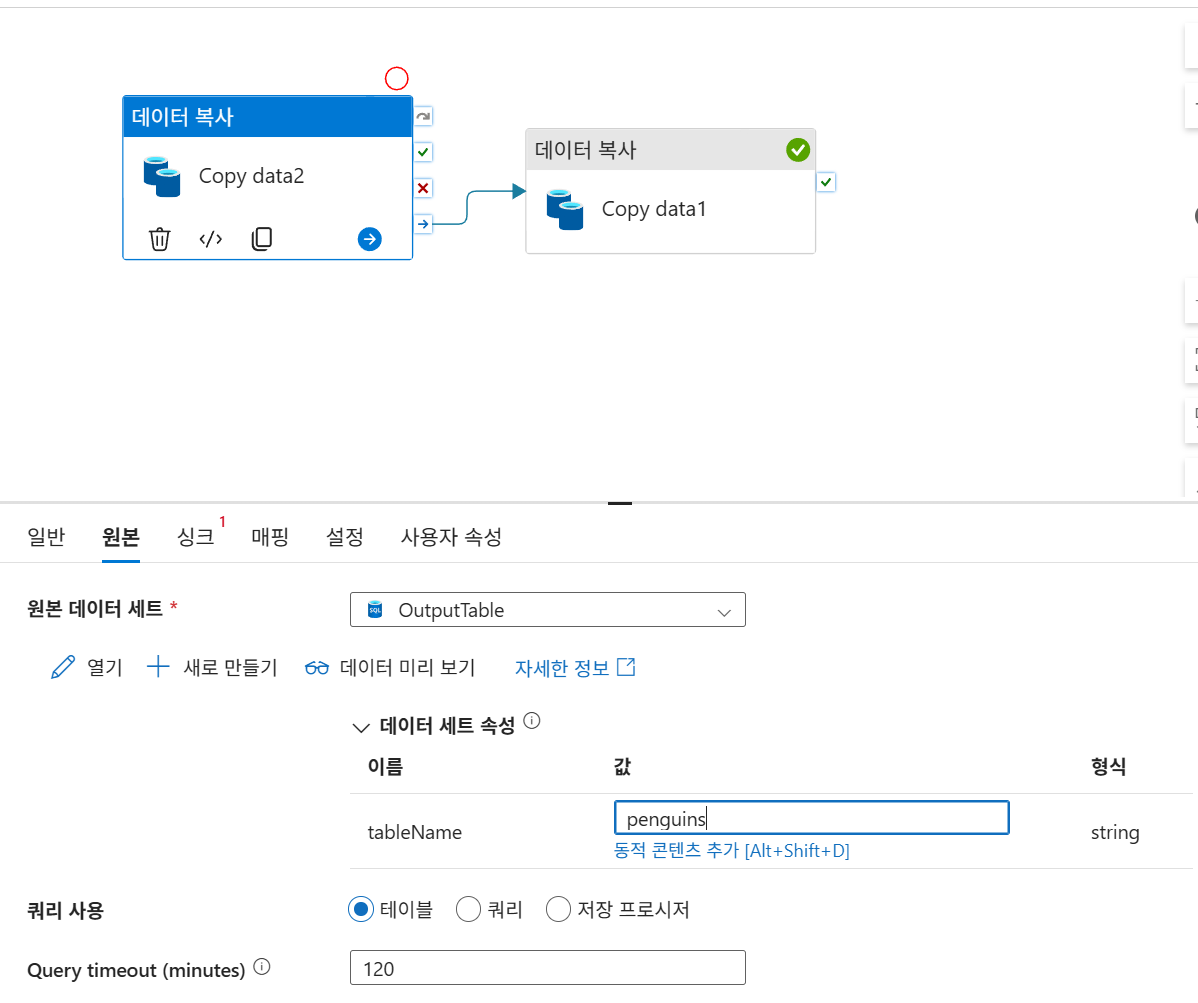
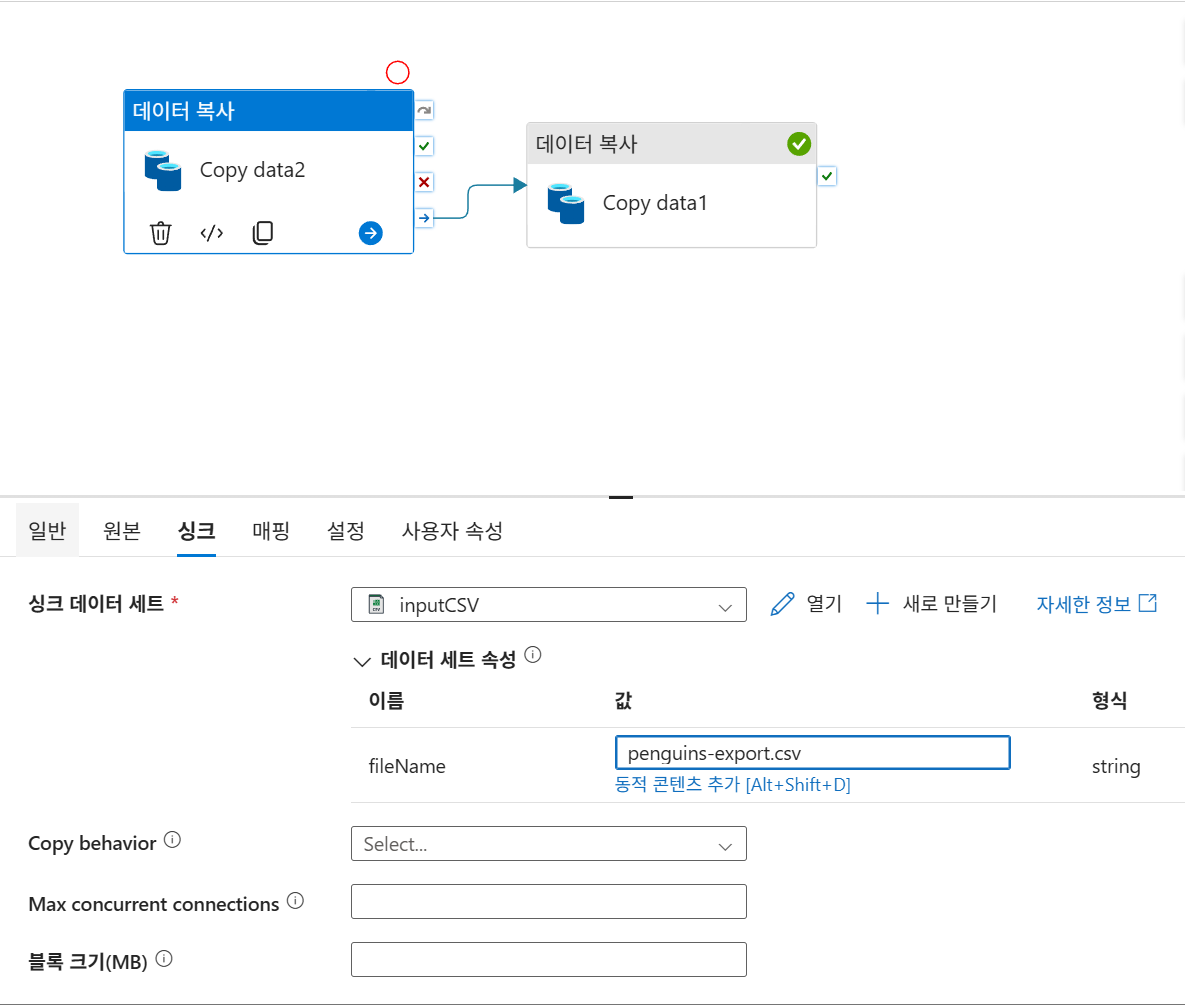
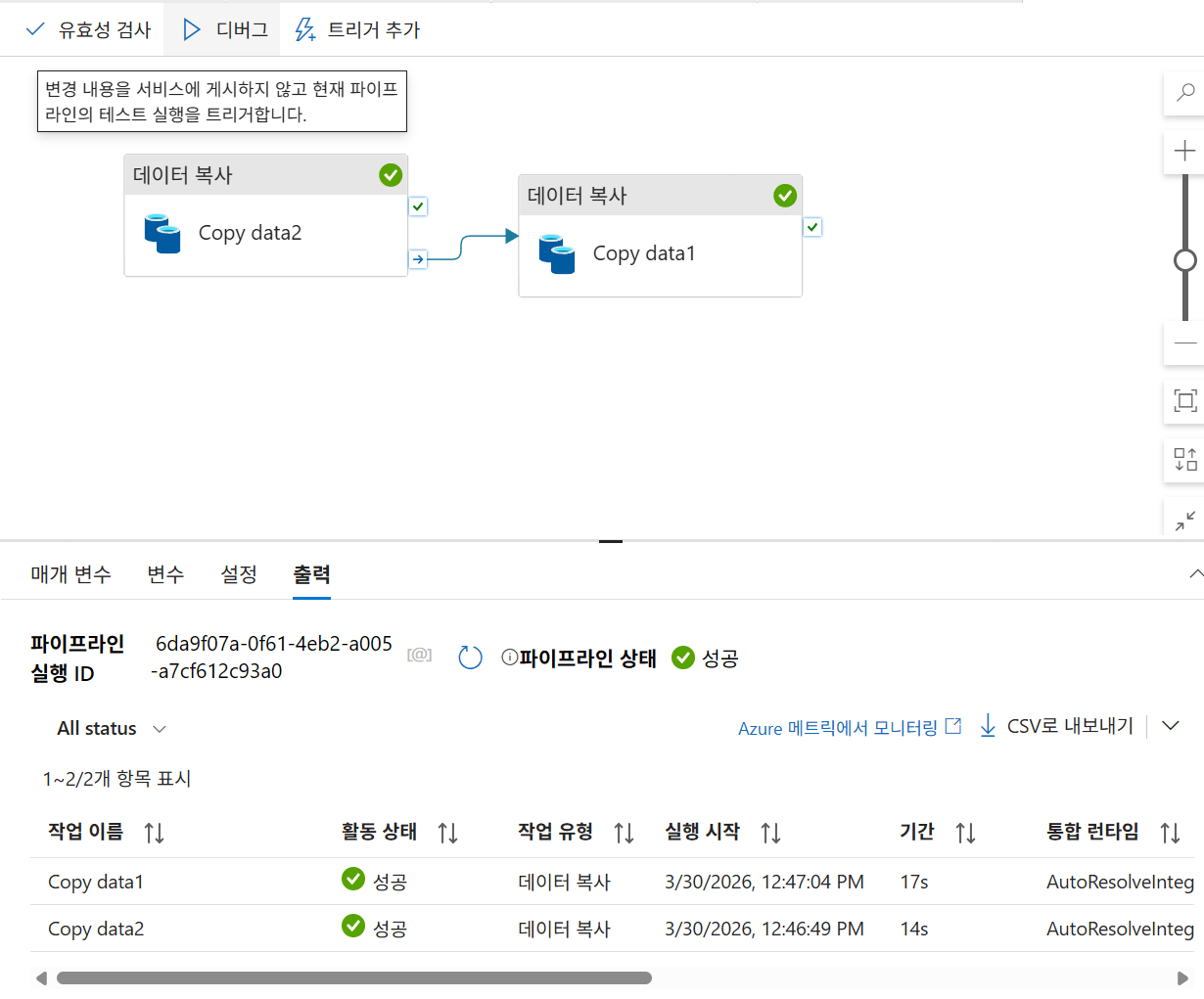
디버그
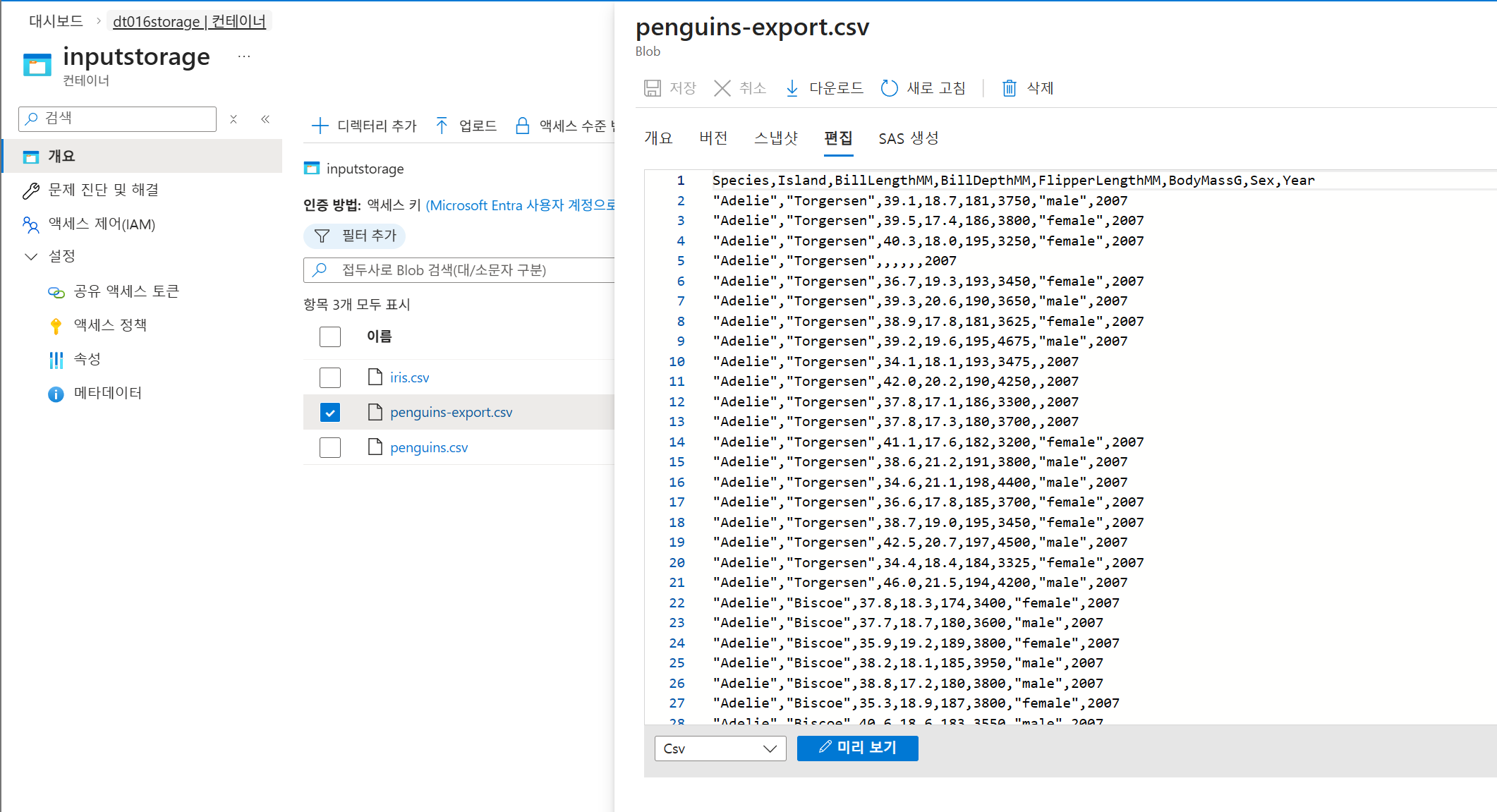
추가된것을 확인 가능
9-12. 데이터세트 매개변수화 활용2: 데이터 백업 날짜 추가
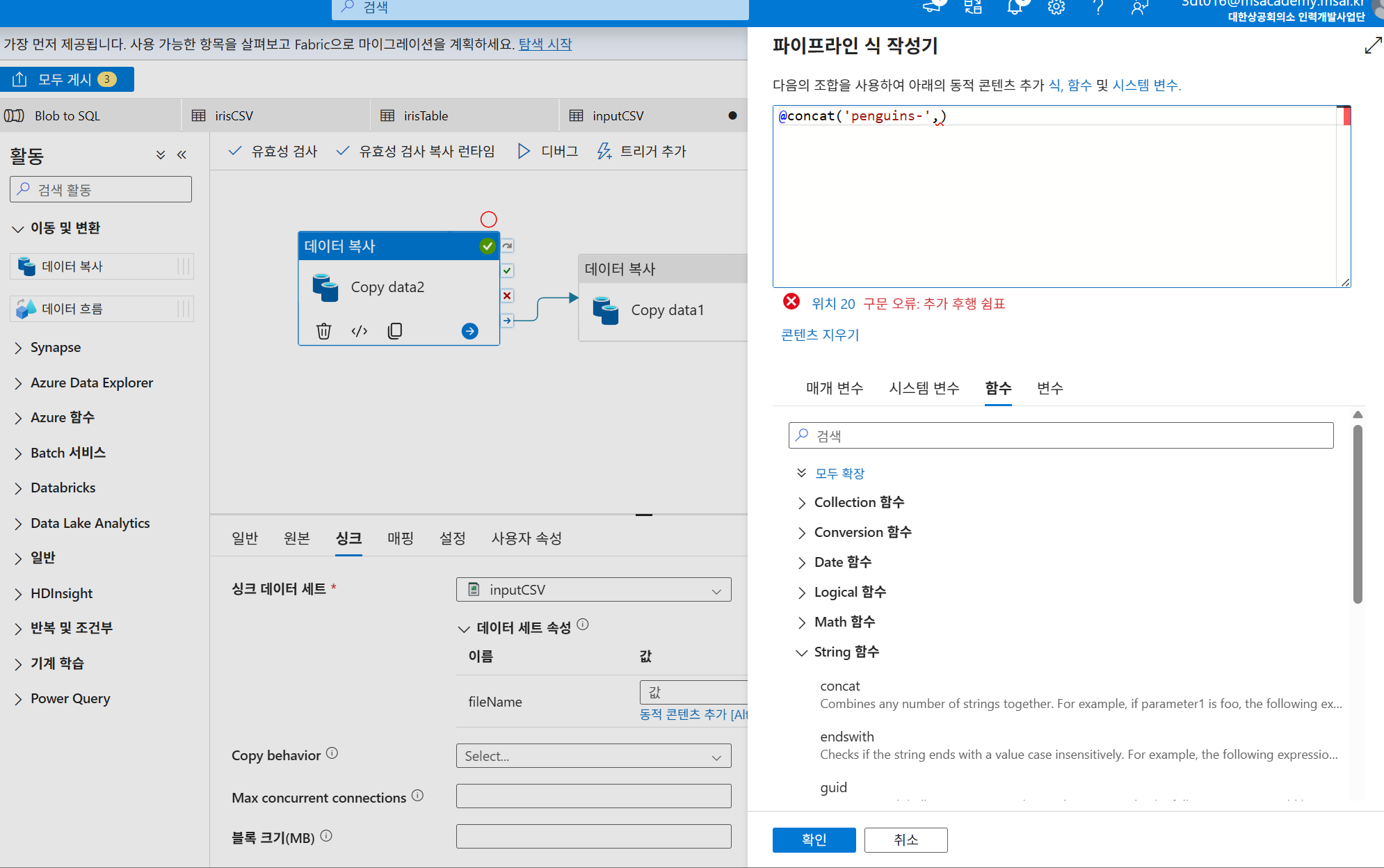
싱크 - 값에 동적 콘텐츠 추가 후 식 선택
1. String - concat
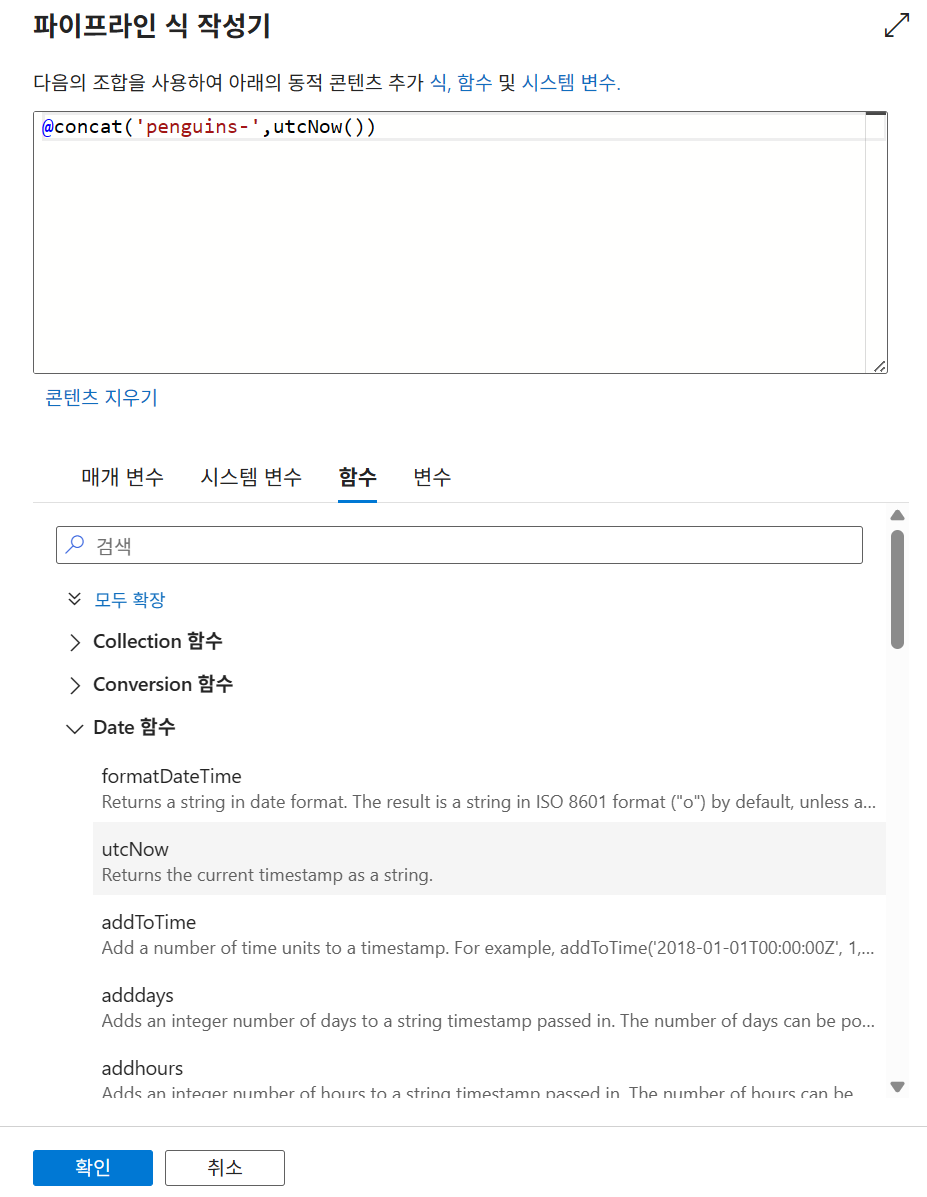
2. Date-utcNow
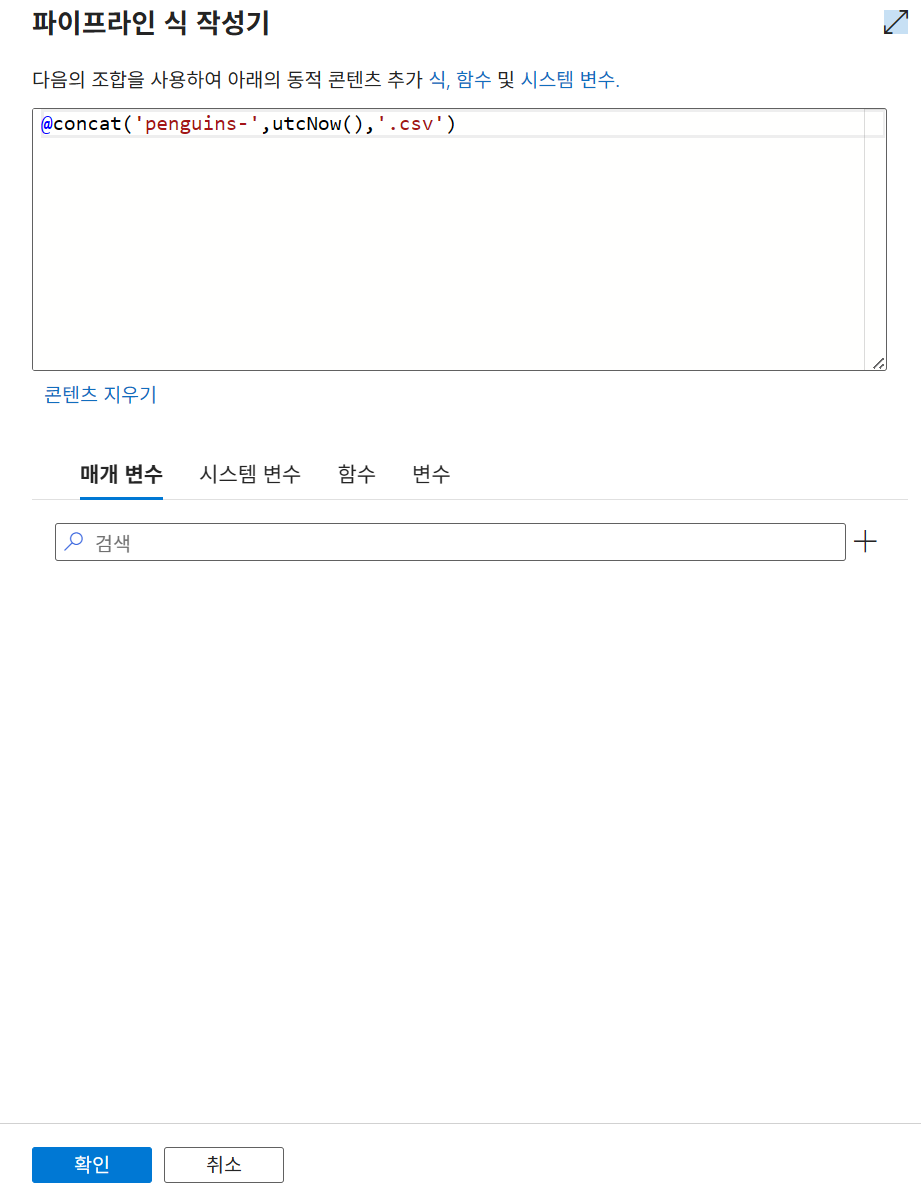
3. 쉼표 입력 후 .csv 입력
디버그 확인
10. ADF의 parameters
Linked Service 매개변수
• 예시 : SQL Server에서 사용되는 데이터베이스를 매개변수화
Dataset 매개변수
• 예시 : 파일 이름, Blob 컨테이너 등을 매개변수화
Pipeline 매개변수
• pipeline 내에서 특정 값을 전달할 수 있도록 매개변수 사용
• 예시 : pipeline에서 특정 원본 파일을 특정 싱크 파일에 복사하도록 매개변수 지정
Global 매개변수
• Data Factory 수준에서 사용되는 매개변수
• 원하는 곳에서 참조 가능
11. 파이프라인 매개변수화
파이프라인 매개변수 설정
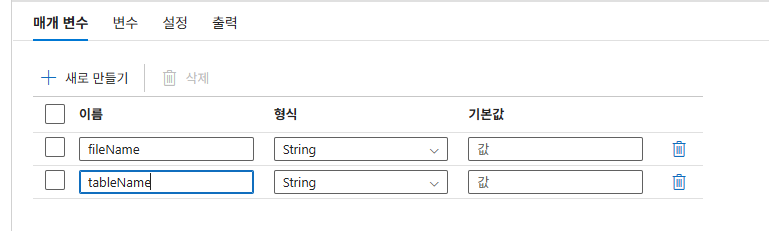
파이프라인식 작성기에서 파라미터 추가
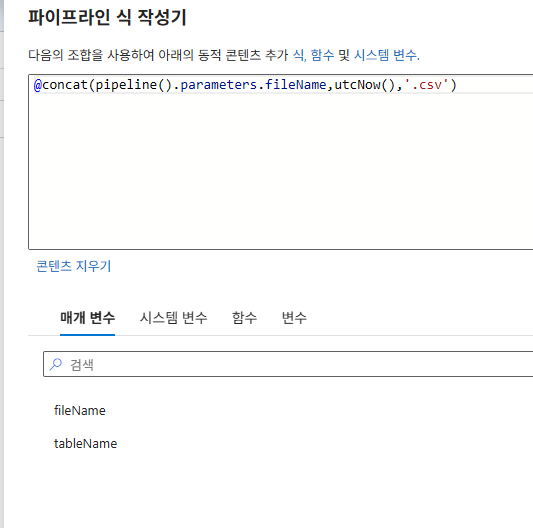
원본에도 동적 콘텐츠 추가
Copy data1쪽도 동일하게 처리
원본-동적콘텐츠추가
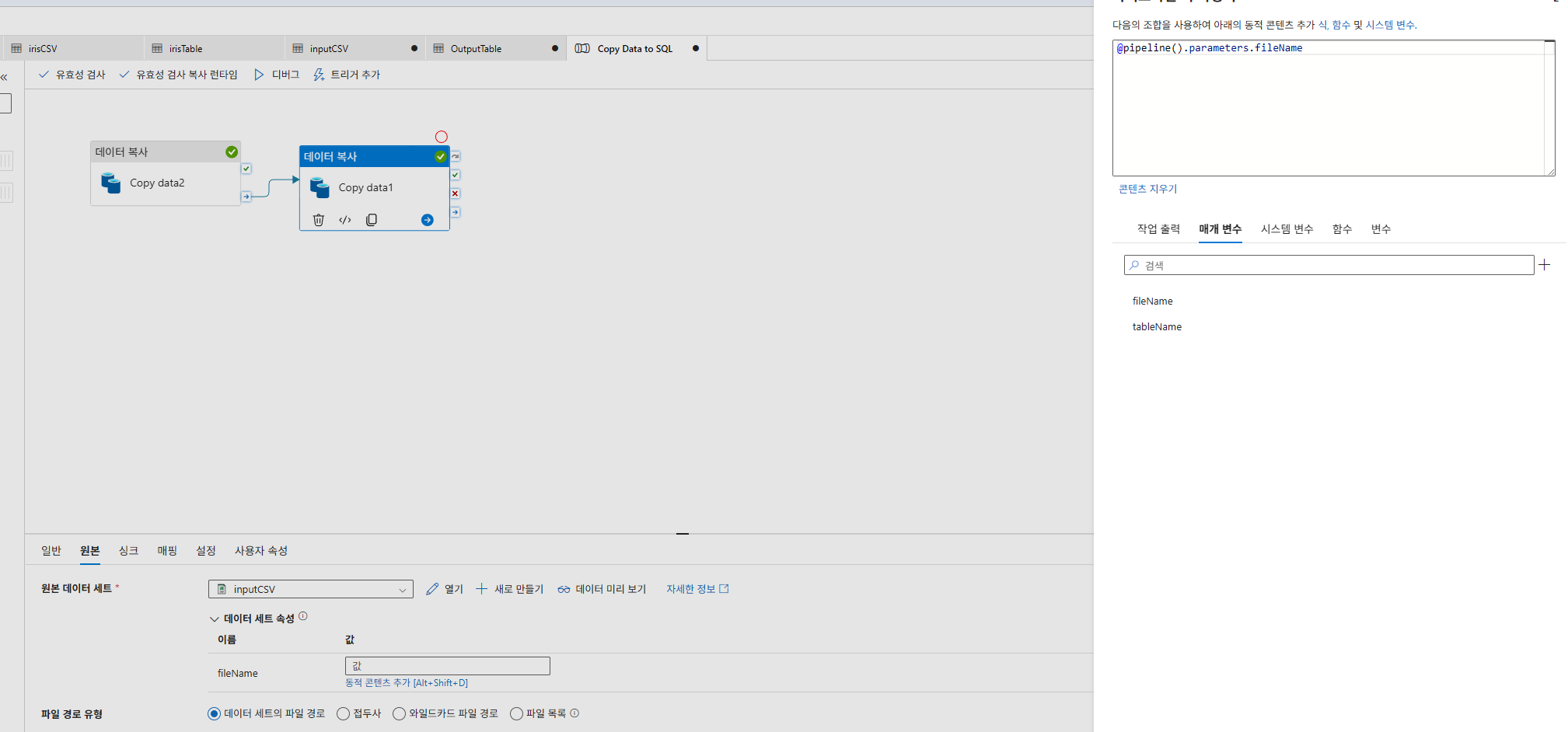
싱크-동적콘텐츠추가
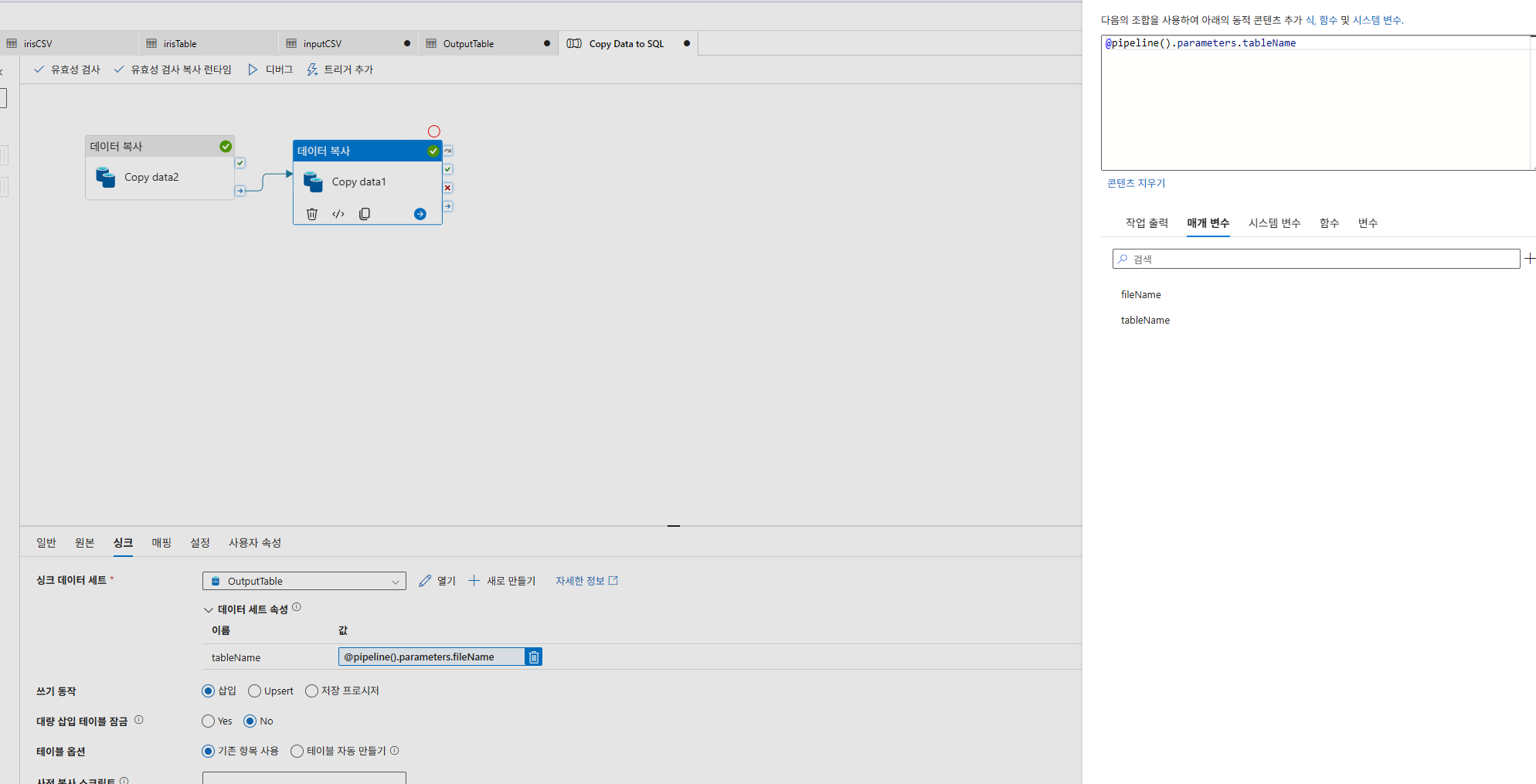
디버그
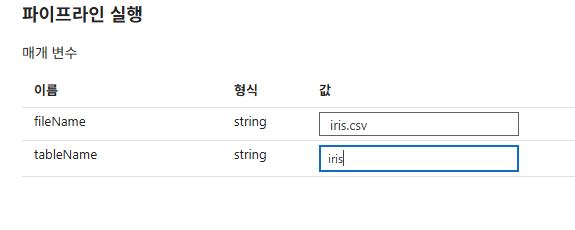
이후 게시
트리거
1. 트리거(Trigger) 개요 및 방식
- 개요: 데이터 수집/변환 워크플로우 설계 시 작업 실행 시점과 방식을 설계하는 것은 매우 중요하며, 트리거는 워크플로우 자동화의 핵심 요소입니다.
- 제공되는 트리거 방식:
- Schedule 트리거: 지정한 일정에 따라 정기적으로 파이프라인을 실행합니다.
- Tumbling Window 트리거: 고정된 시간 간격(윈도우)을 기준으로 데이터를 수집하고 처리하며, 각 윈도우는 겹치지 않습니다.
- Storage Event 트리거: Azure Blob Storage에서 파일이 생성되거나 변경되는 이벤트에 반응합니다.
- Custom Event 트리거: Event Grid, Event Hub 등을 연동하여 사용자 정의 이벤트를 수신하고 파이프라인을 실행합니다.
- Manual 트리거: ADF Studio UI에서 직접 실행하거나 REST API 호출을 통해 수동으로 실행합니다.
2. Schedule 트리거 상세
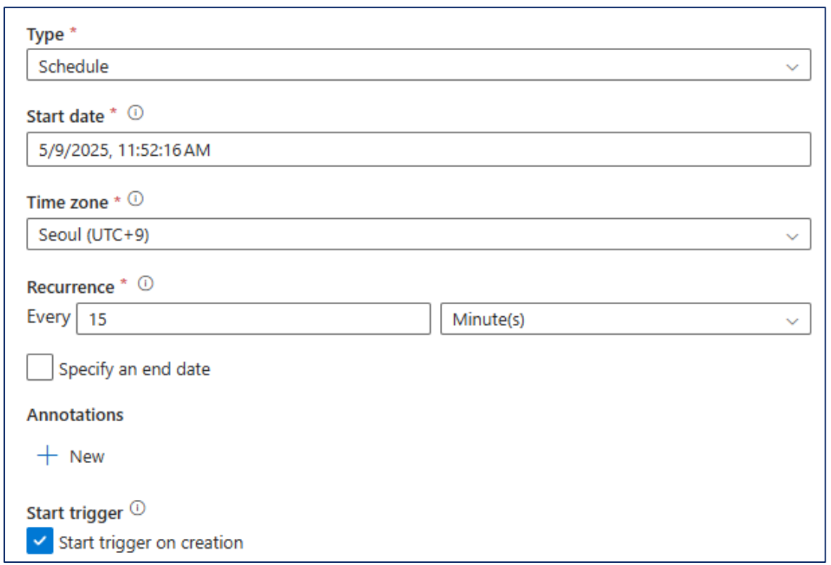
- 정의: 시작일, 종료일, 주기, 특정 요일 등을 기반으로 파이프라인 실행 일정을 구성하는 방식입니다.
- 설정 항목:
- Start Date: 트리거 시작일 지정.
- Time: 트리거 시작 시각 지정.
- Time Zone: 시간대 설정 (예: Seoul UTC+9).
- Recurrence: 반복 실행 주기 (분, 시간, 일, 주, 월).
- End Date: 트리거 반복 종료 시점 (선택 사항).
- 적합한 작업: "하루 한 번", "매주 월요일 오전 9시", "매달 1일 오전 2시" 등 정기적인 반복 작업.
- 관계: Many-to-many 관계로, 하나의 트리거가 여러 파이프라인을 실행할 수 있고 하나의 파이프라인이 여러 트리거에 연결될 수 있습니다.
- 적용 방식:
- 주기 기반: 매 1시간, 매일 등 정해진 간격 반복 (실행 시 겹치지 않도록 주의).
- 특정 시간 지정: 매일 오전 10시 30분 등 세밀한 시간 지정.
- 요일 지정: 매주 월, 수, 금요일 등 요일 기준 실행.
- 날짜 지정: 매월 1일, 15일 등 월마다 반복되는 이벤트 처리.
3. Tumbling Windows 트리거 상세
- 정의: 고정된 크기의 시간 간격으로 구간을 나누고, 각 구간(윈도우)에 대해 하나의 파이프라인 실행을 트리거합니다. 윈도우 간 중첩이 없고 독립적인 실행 단위로 관리됩니다.
- 주요 특징:
- 간격(Interval): 일정 주기 지정.
- 윈도우 간 관계: 중첩 없이 실행되며 윈도우 단위별 독립 실행.
- 재시도 정책(Retry): 파이프라인 수준에서 자동 재시도 가능.
- 상태 관리(Concurrency): 이전 실행 결과를 고려할 수 있도록 동시성 설정 지원. 빡빡하게 관리할거면 1로 설정
- 관계: One-to-one 관계로, 각 트리거는 특정 파이프라인에만 연결됩니다.
- 시간대 기준: UTC.
- 적용 예시: 시간 구간별 안정적 수행이 필요한 업무, 센서 데이터/로그 등 시간 단위 데이터 처리, 이전 실행 상태에 따른 다음 처리 여부 결정, 실행 실패 시 자동 재시도가 필요한 경우, 상태 기반 병렬 처리 설정 시 활용됩니다.
- Schedule 트리거와 비교:
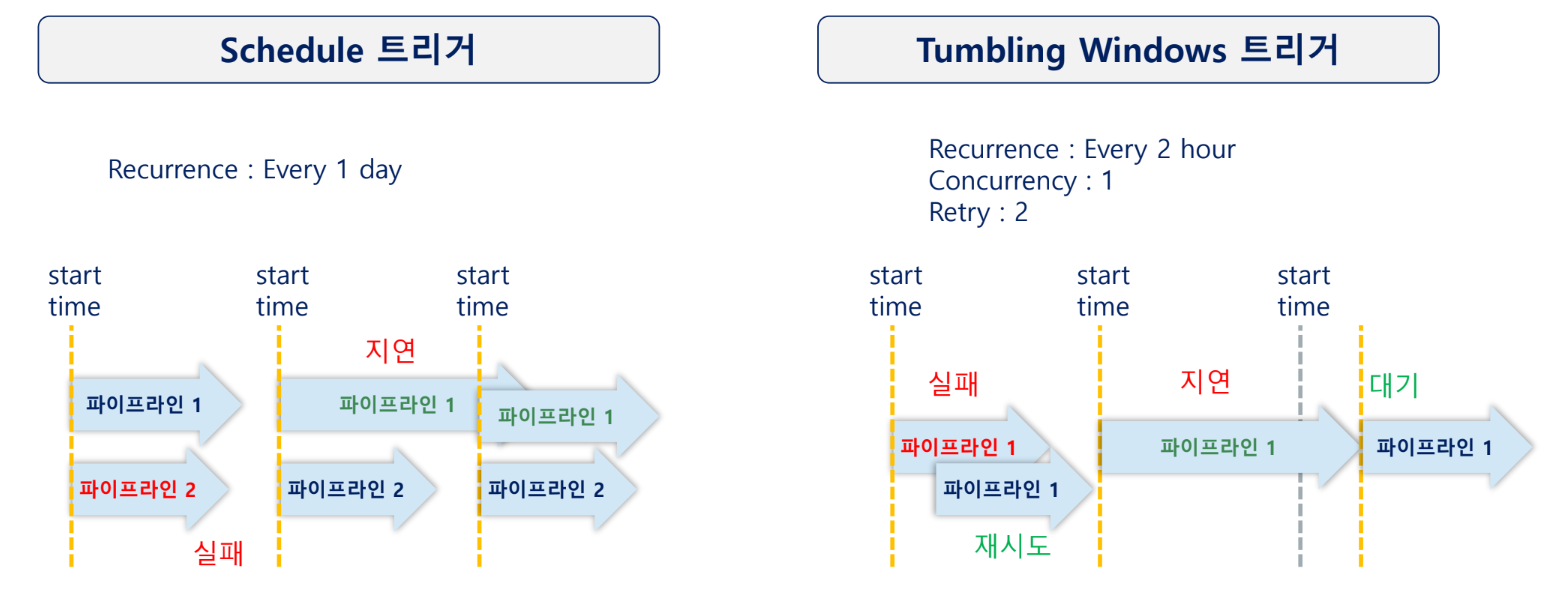
| 구분 | Schedule Trigger | Tumbling Windows Trigger |
|---|---|---|
| 주기 유형 | 고정 주기 | 고정 간격 시간 구간 |
| 재시도 정책 | 없음 | 파이프라인 단위 재시도 지원 |
| 실행 관계 | Many-to-many | One-to-one |
| 상태 관리 | 이전 수행 상태와 무관 | 이전 파이프라인 상태 고려 |
| 실행 의존성 | 없음 | 다른 트리거에 의존 가능 |
| 적용 예 | 단순 정기 실행 | 시간 단위 안정적 처리 |
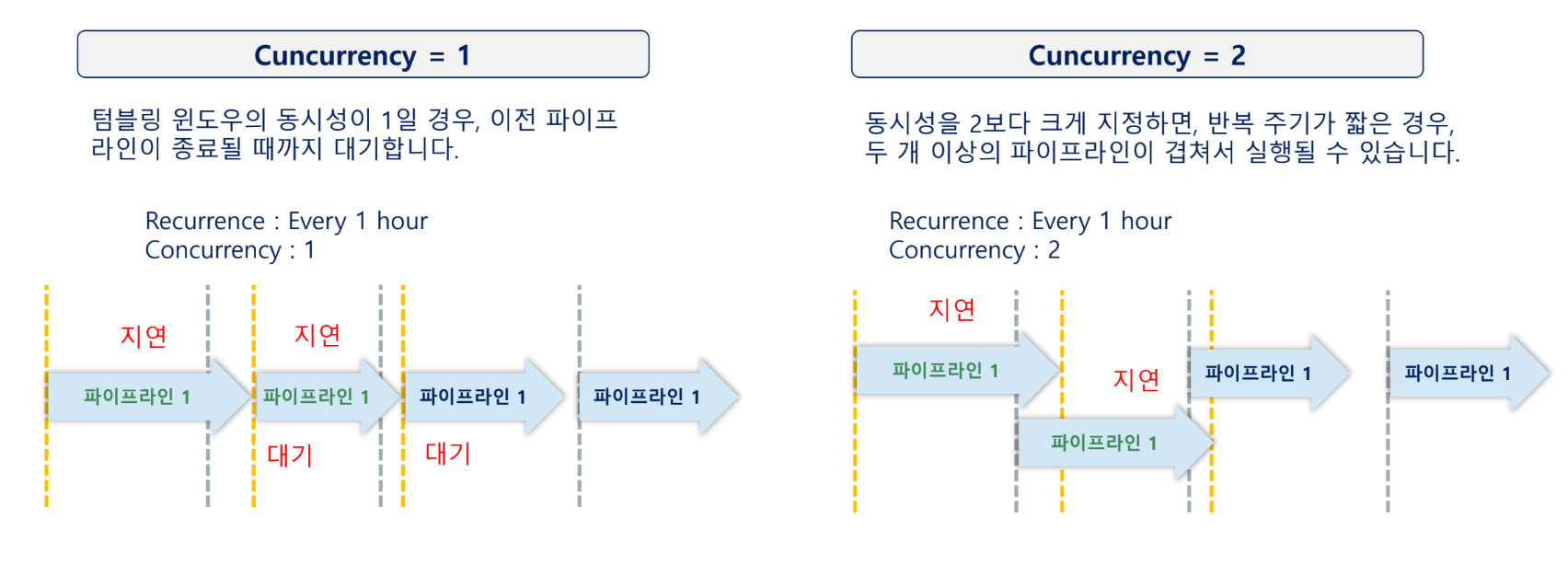
- 동시성(Concurrency): 1일 경우 이전 파이프라인 종료 시까지 대기하며, 2 이상일 경우 주기가 짧을 때 여러 파이프라인이 겹쳐서 실행될 수 있습니다. 처리되지 못한 윈도우가 쌓였을 때 이를 빠르게 소진하기 위해 2 이상으로 설정하기도 합니다.
- 작업에 따라 적절한 동시성을 설정해야 합니다. 동시성 설정에 따라, 파이프라인 실행이 무한 대기에 빠질
수도 있으며, 겹쳐서 수행되는 파이프라인으로 인해 문제가 발생할 수 있습니다.
4. Storage Event 트리거 상세
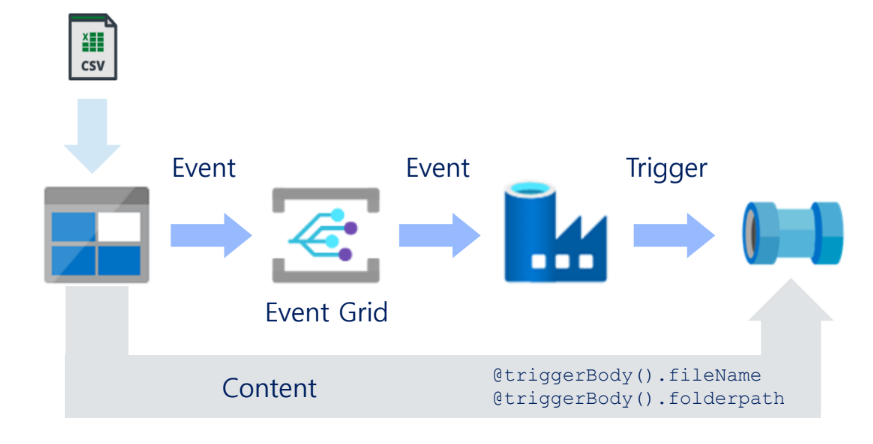
- 정의: Blob Storage에서 이벤트 발생 시 즉시 자동으로 파이프라인을 실행합니다.
- 주요 특징: 실시간성, 자동화(수동 모니터링 불필요), Event Grid 기반(이벤트 감지 및 자동 호출), 다대다 관계 지원.
- 이벤트 흐름: 컨텐트 자체가 아닌 이벤트 정보(파일 이름, 파일 경로 등)를 전달하며, 데이터 컨텐트는 전달받은 정보를 바탕으로 직접 가져와야 합니다.
- 설정 및 동작:
- Blob path ends with: 설정한 값(예: .csv)으로 끝나는 파일에 대해 적용.
- 이벤트 종류: Blob created(생성) 또는 Blob deleted(삭제).
- Ignore empty blobs: 비어 있는 블롭에 대한 처리 여부 설정.
- 제한 사항: 파이프라인 실패 시 재시도 정책이 없으며, 동시성 정책이 없어 이벤트 발생 시마다 겹쳐서 수행될 수 있습니다.
5. Manual 트리거 상세
- 정의: ADF UI 내 메뉴를 통하거나 REST API를 사용하여 수동으로 파이프라인을 트리거합니다.
- 방법: ADF UI 직접 트리거 또는 Azure Logic Apps와 연동하여 외부 요청에 따라 파이프라인을 실행합니다.
6. [실습] 트리거 구성 과정
6-1. 실습 준비 (컨테이너 및 링크드 서비스)
-
컨테이너:
input,output컨테이너를 생성하고input에iris.csv를 업로드합니다.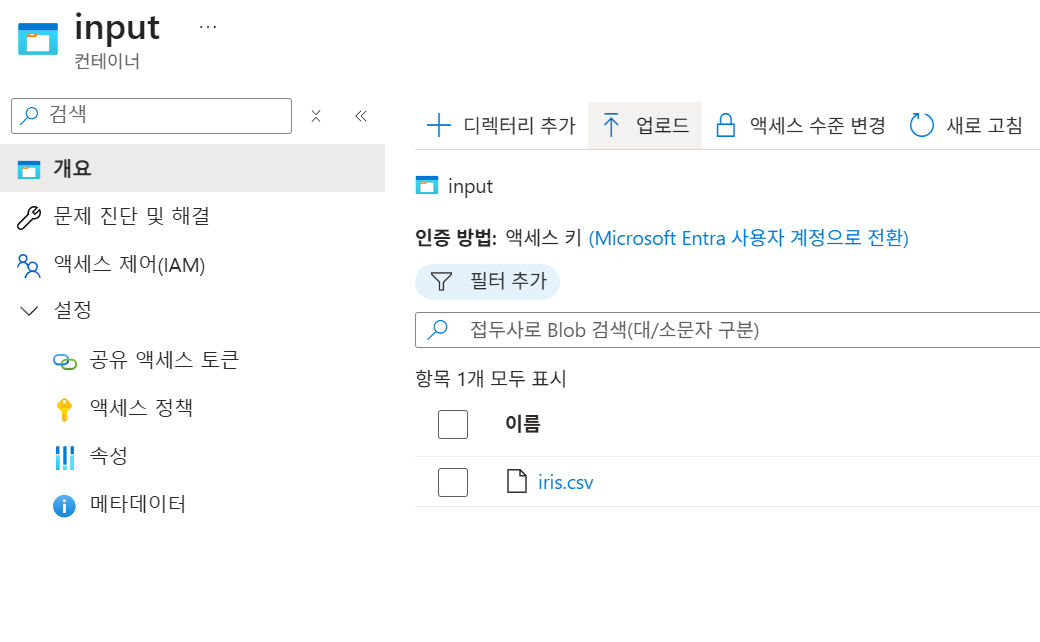
-
링크드 서비스:
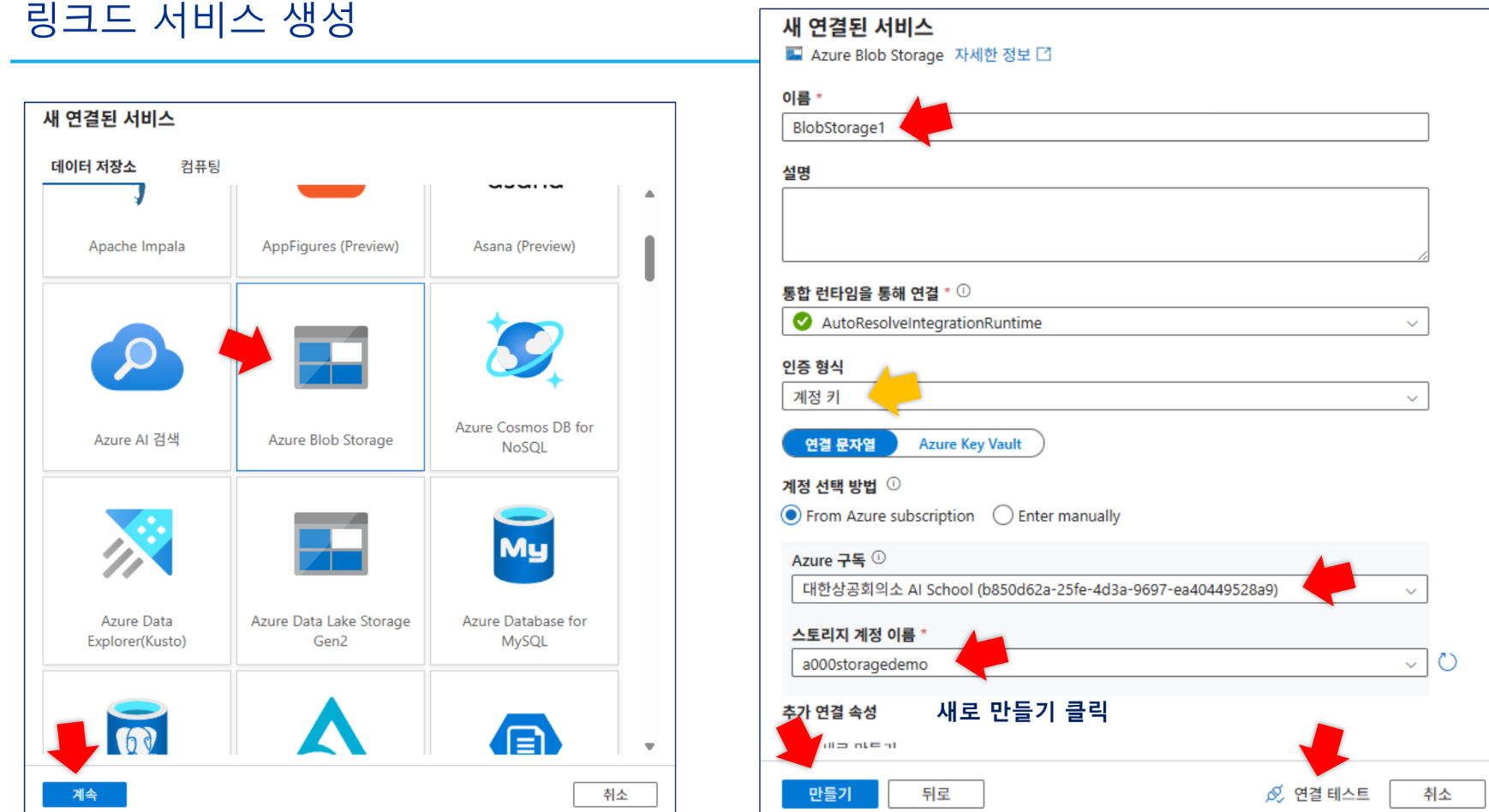
BlobStorage1(Azure Blob Storage) 생성.
input output을 구분하지 않고 쓸 수 있도록 새로 생성
-
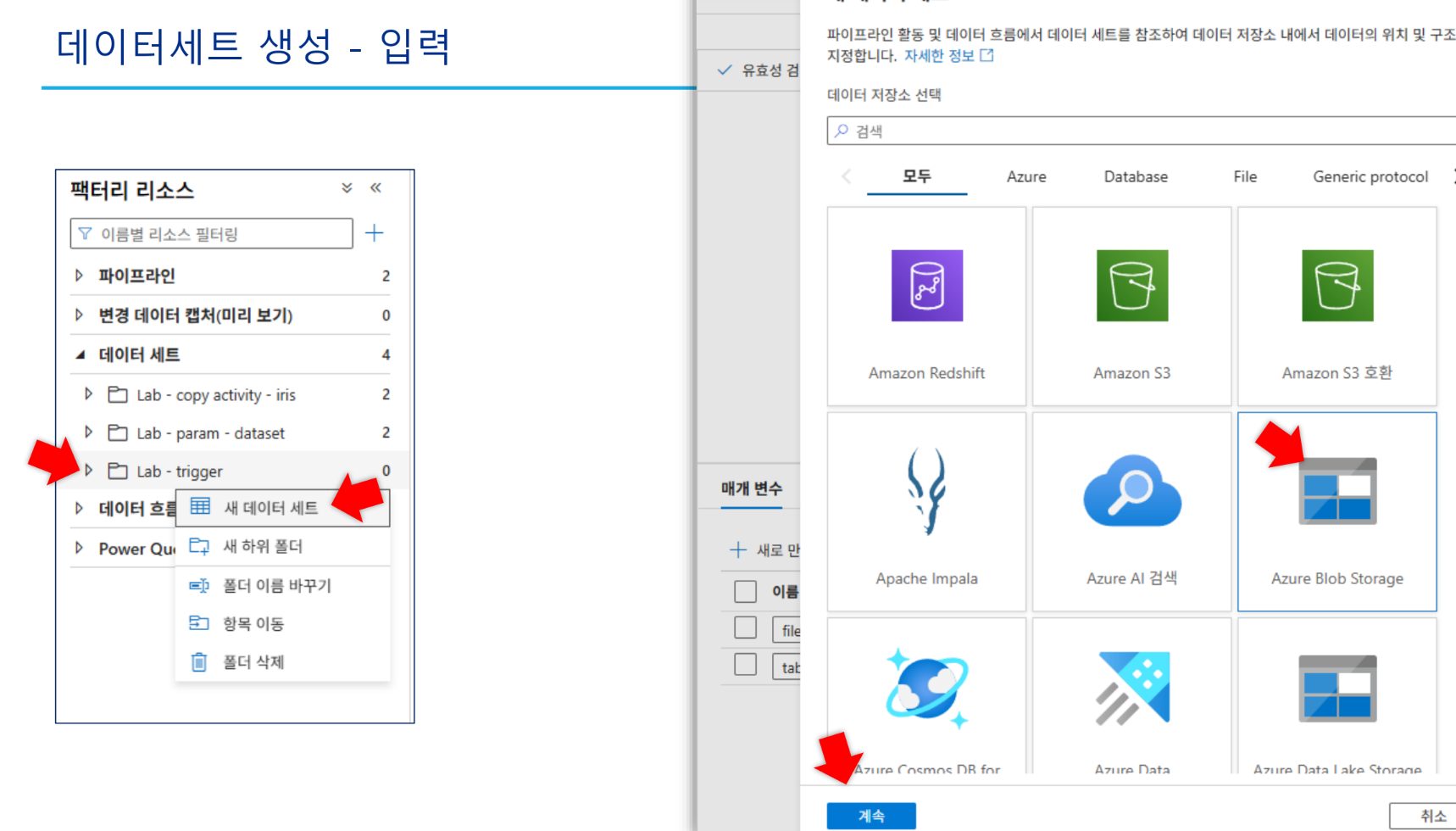
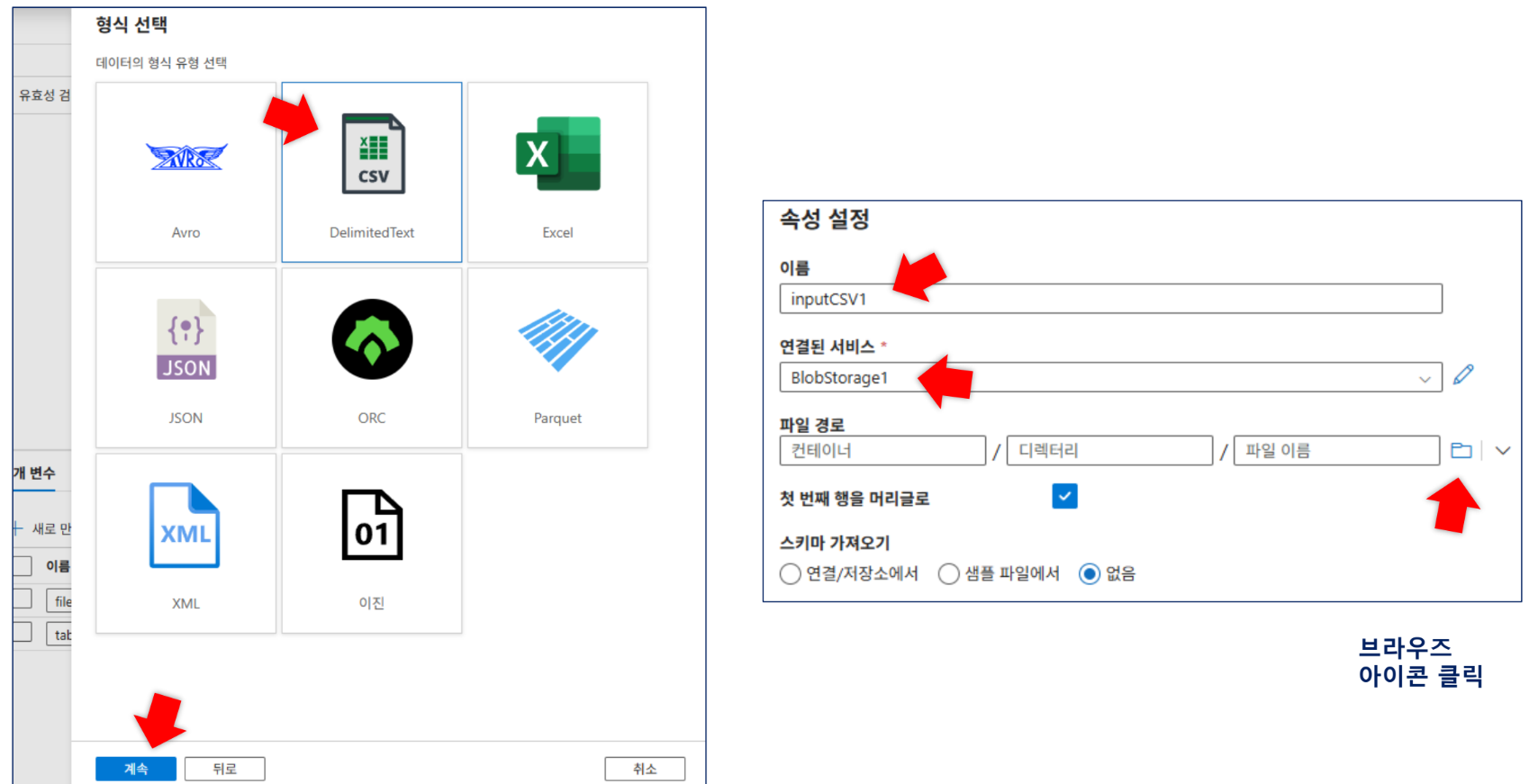
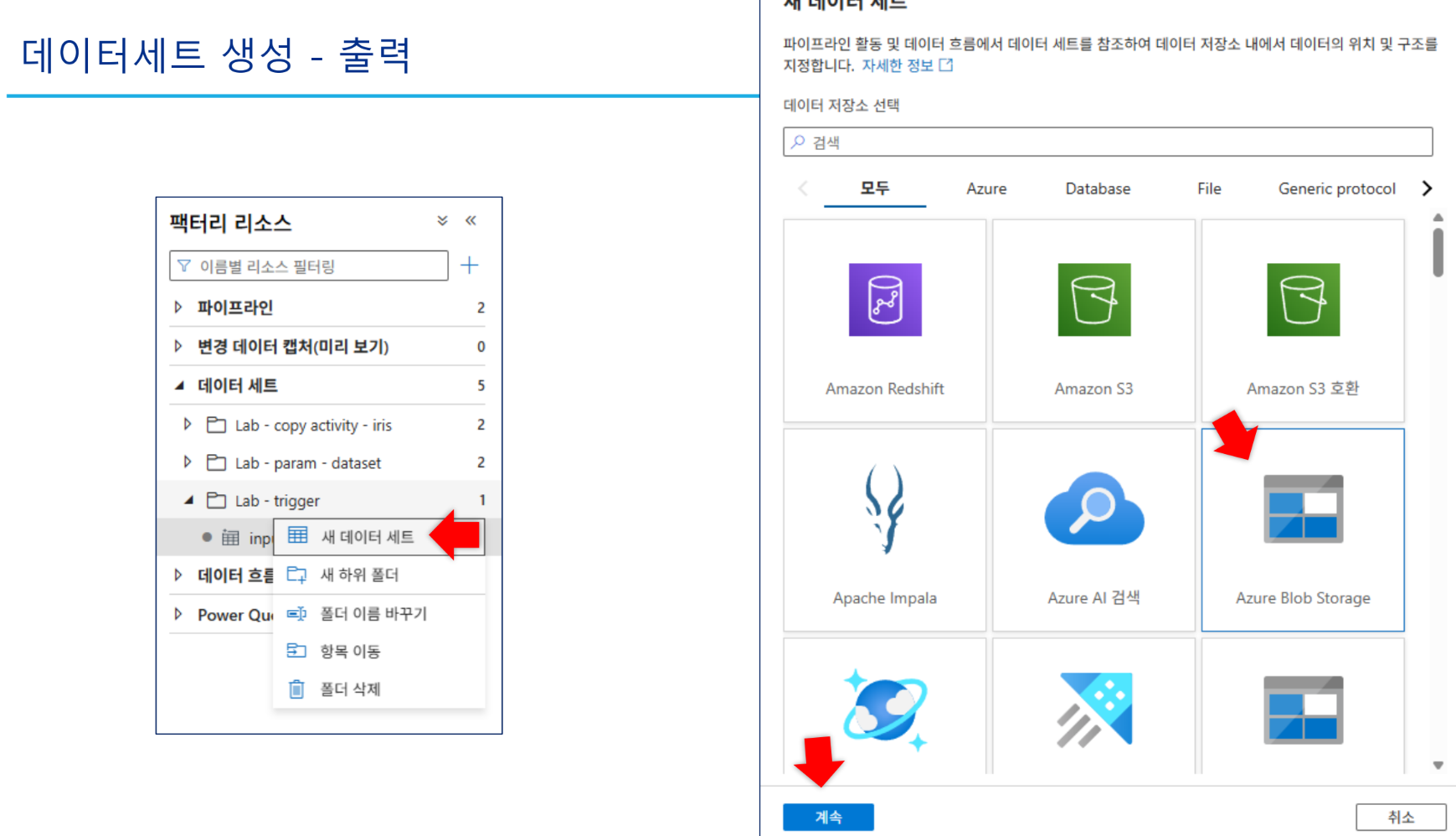
데이터세트:
inputCSV1(input 컨테이너),outputCSV1(output 컨테이너) 생성.inputCSV1은 첫 번째 행을 머리글로 설정합니다.
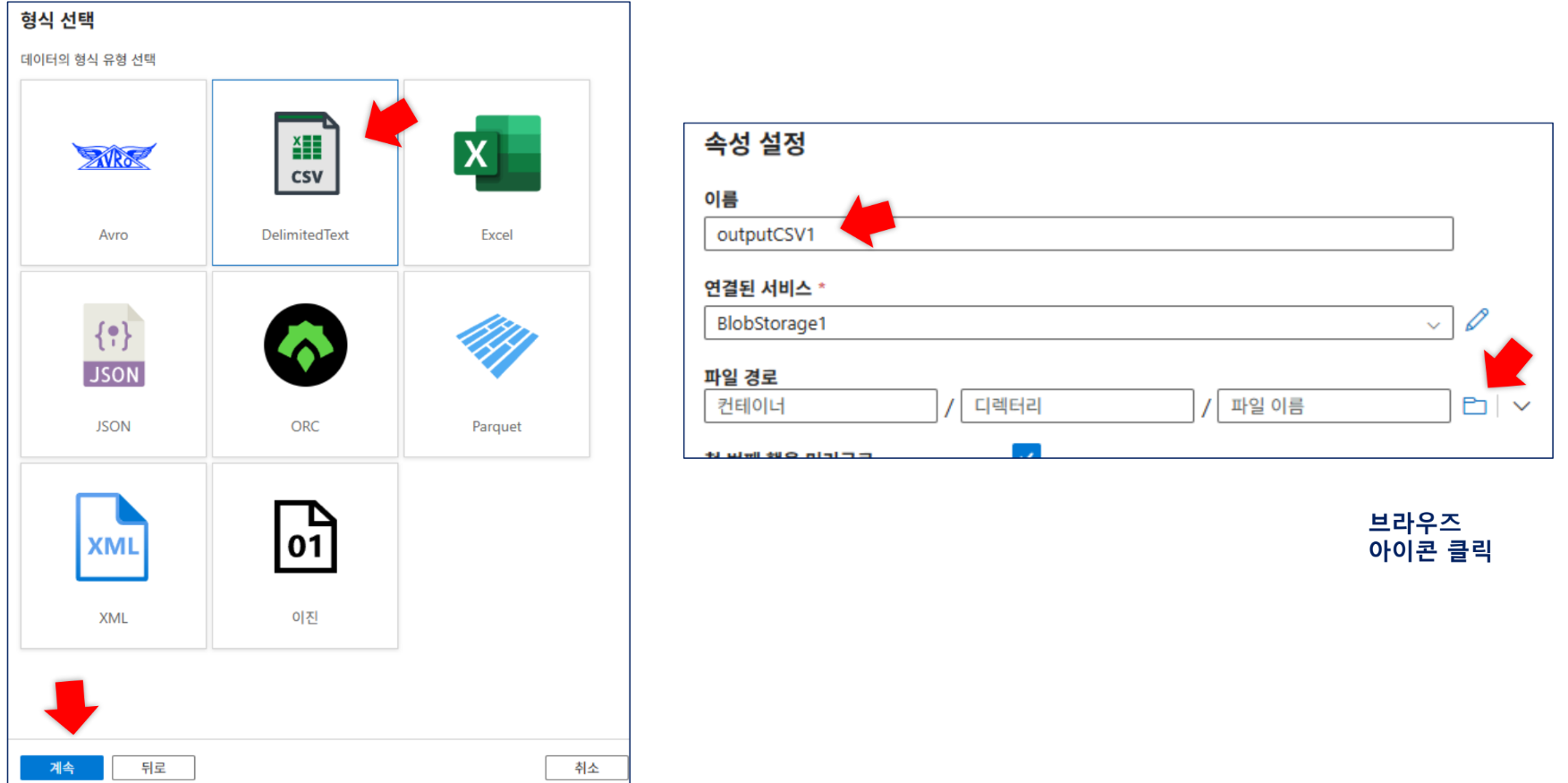
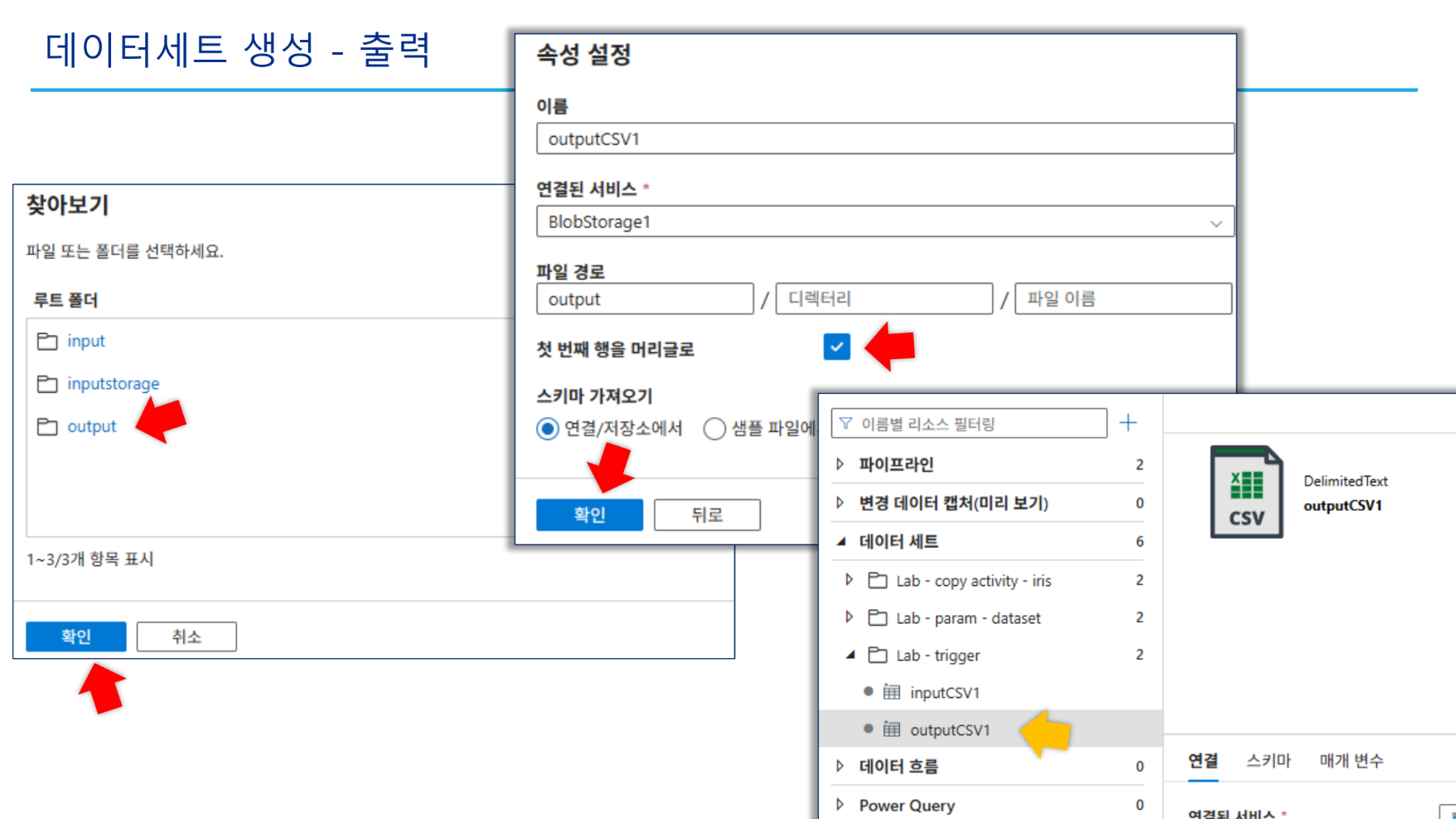
-
파이프라인:
pipeline1생성 후 Copy Data 활동을 배치하고 원본과 싱크를 연결합니다.
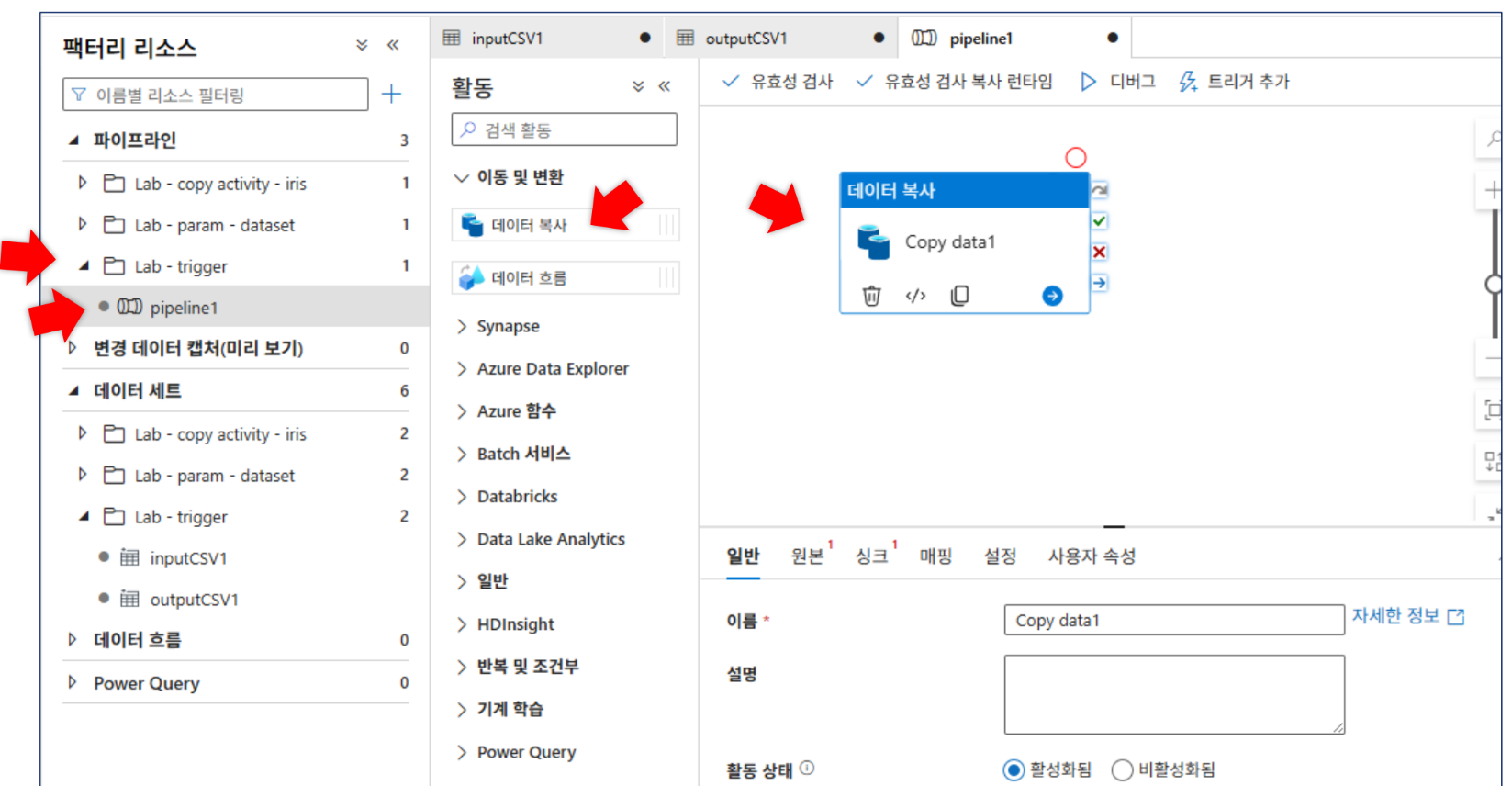
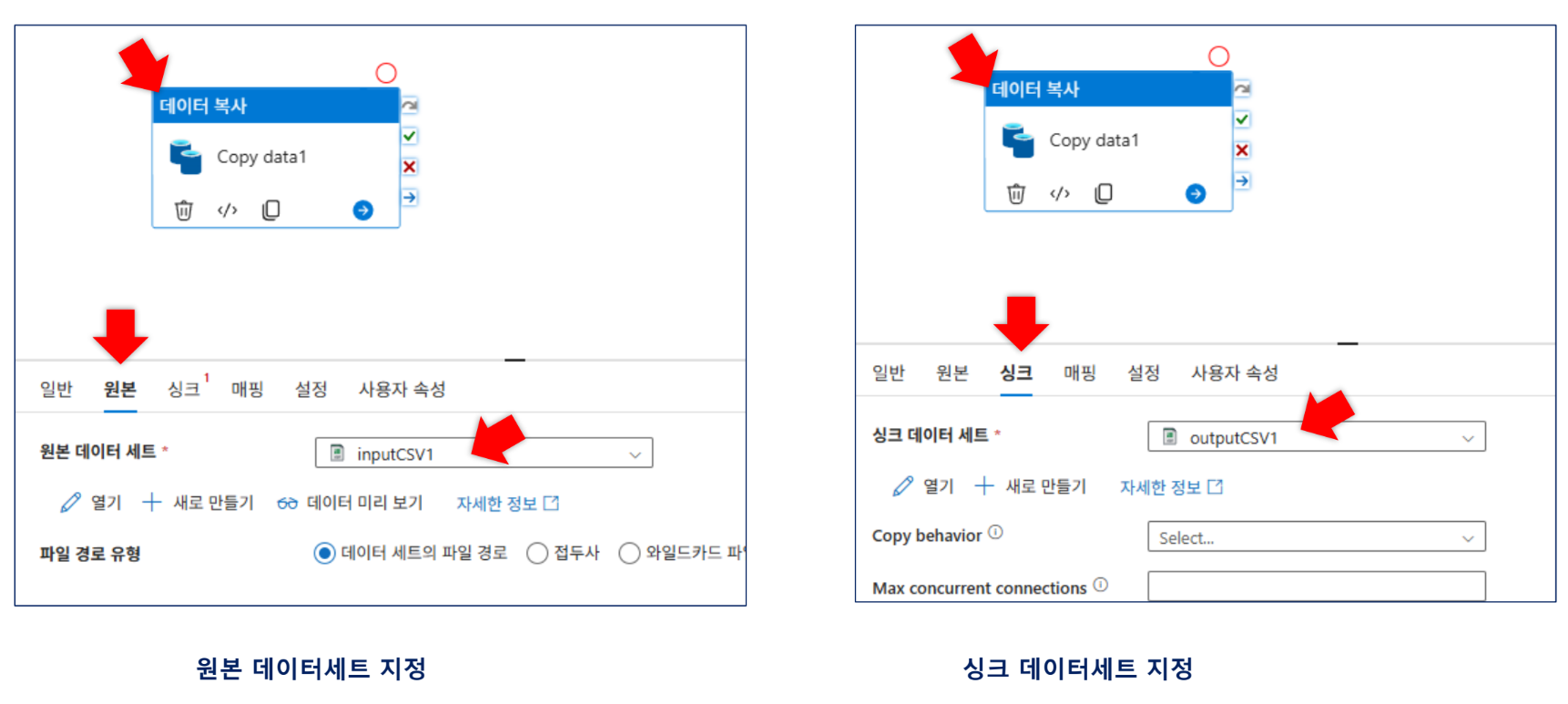
-
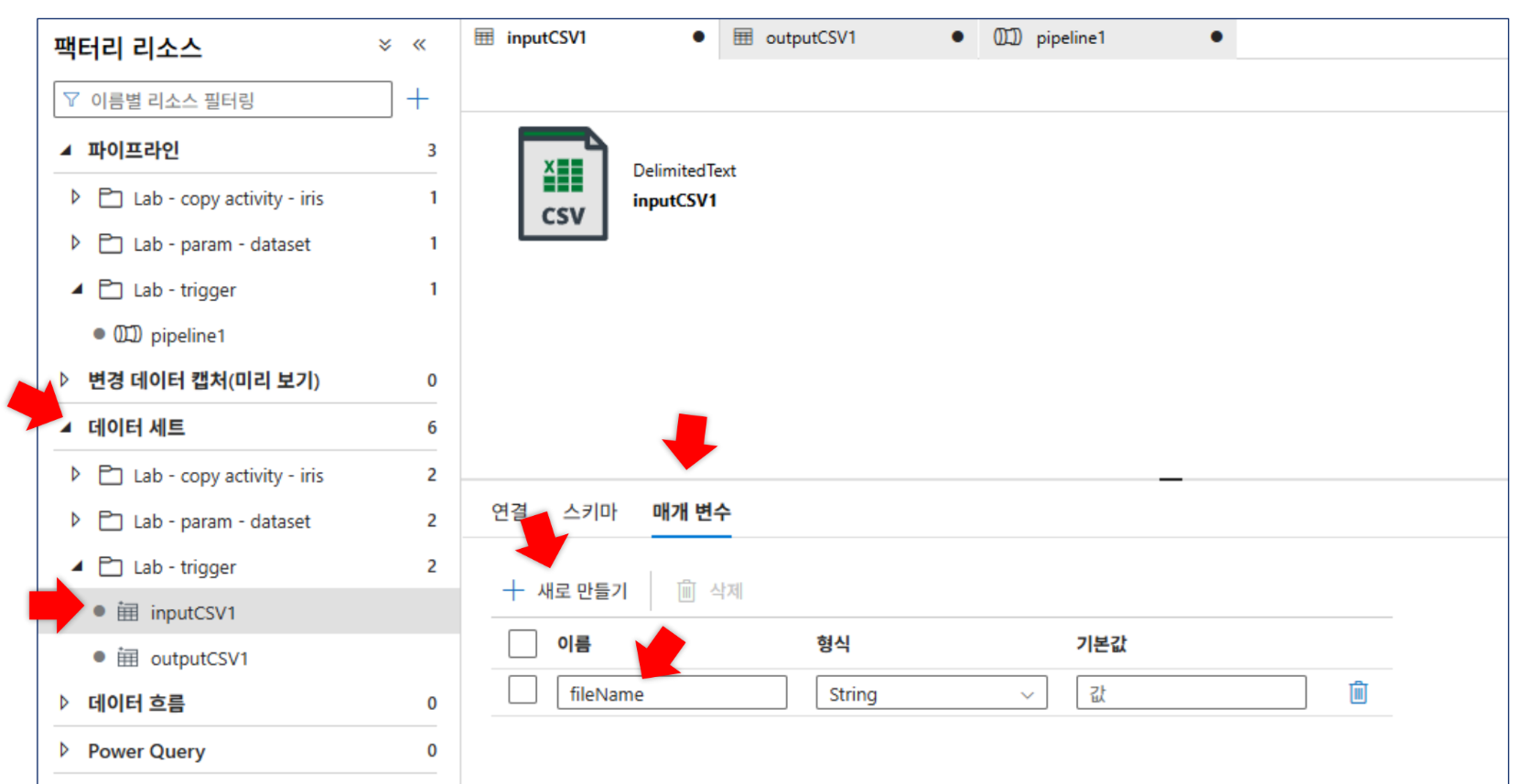
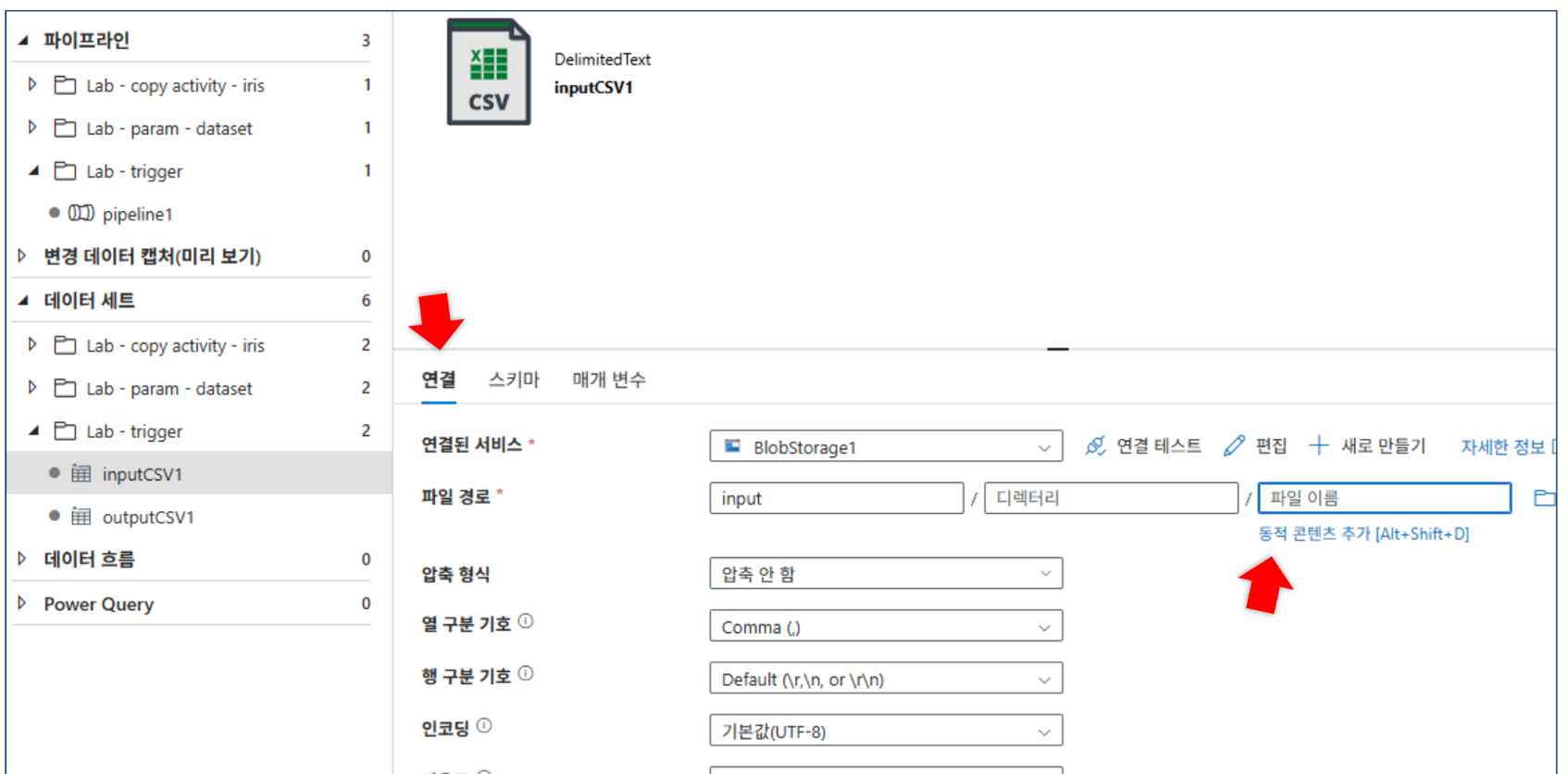
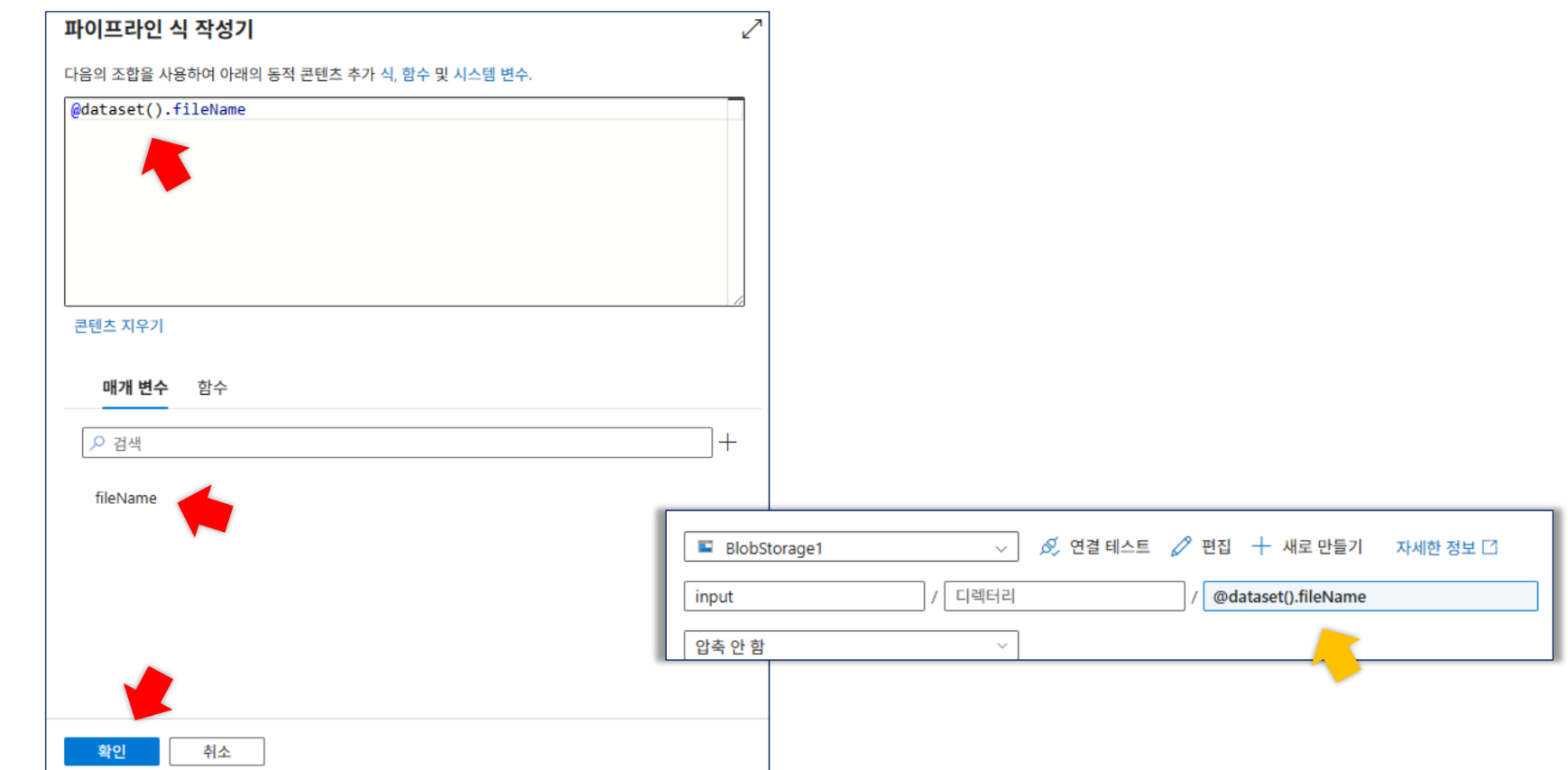
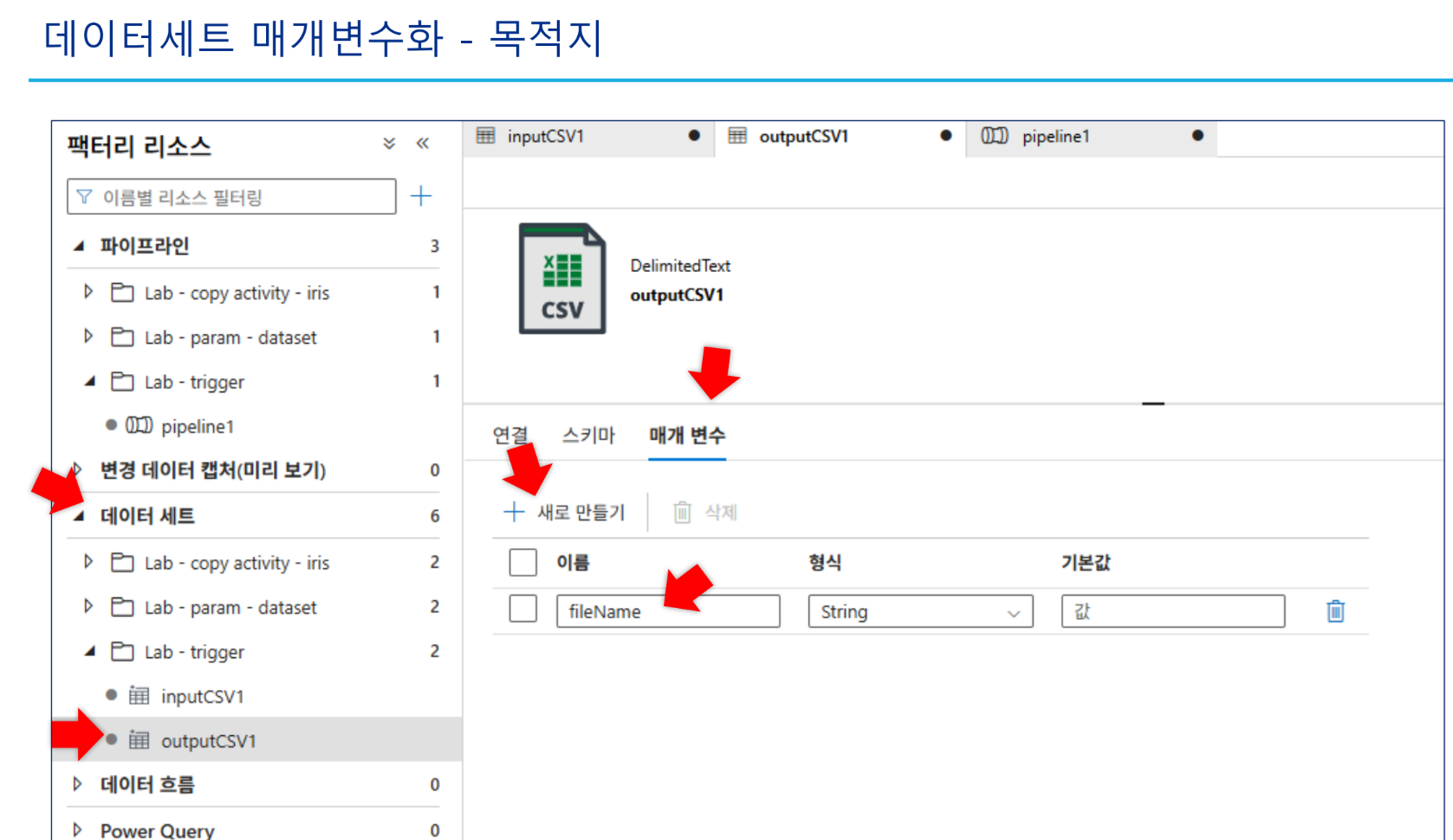
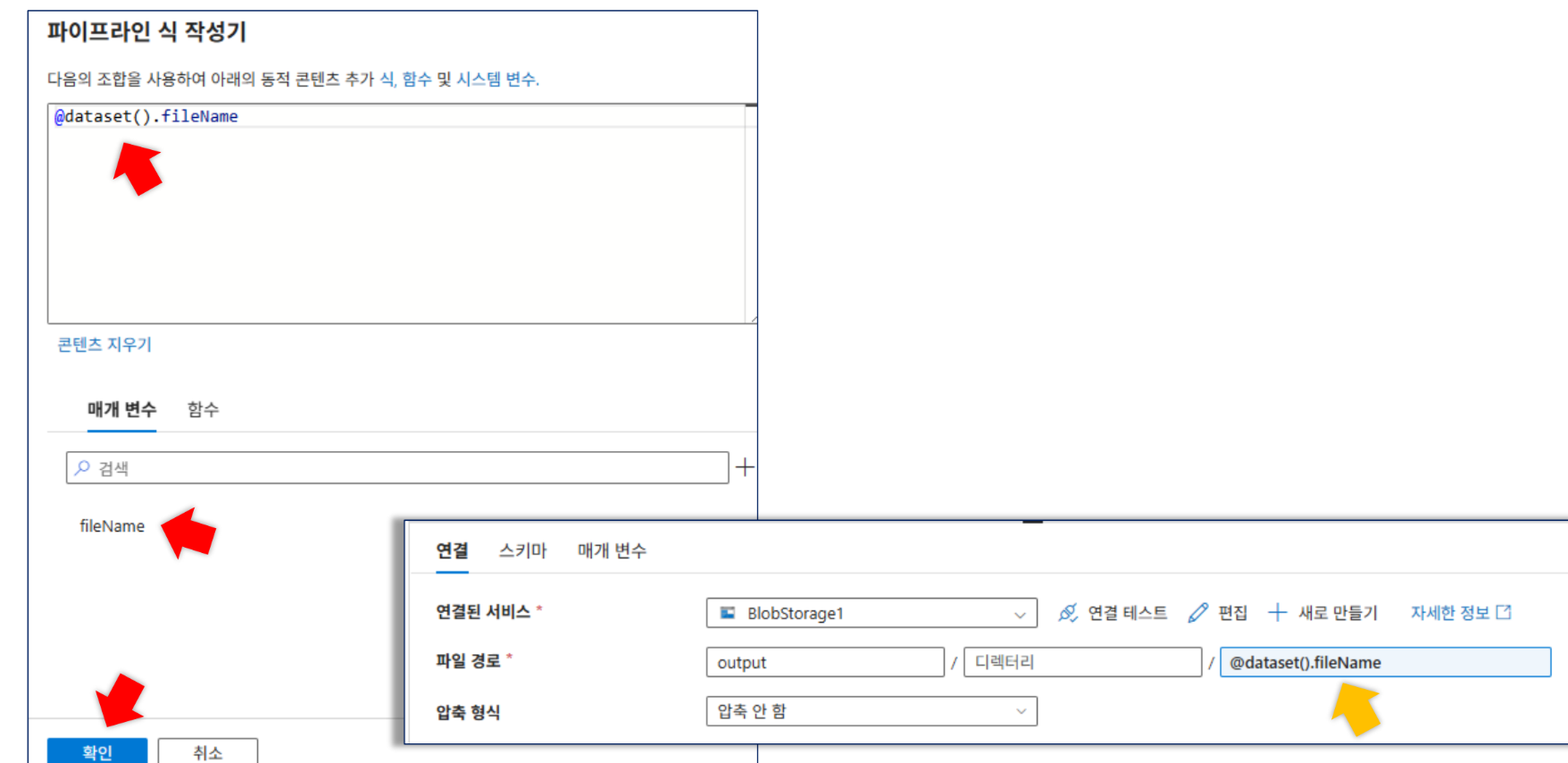
매개변수화: 데이터세트에
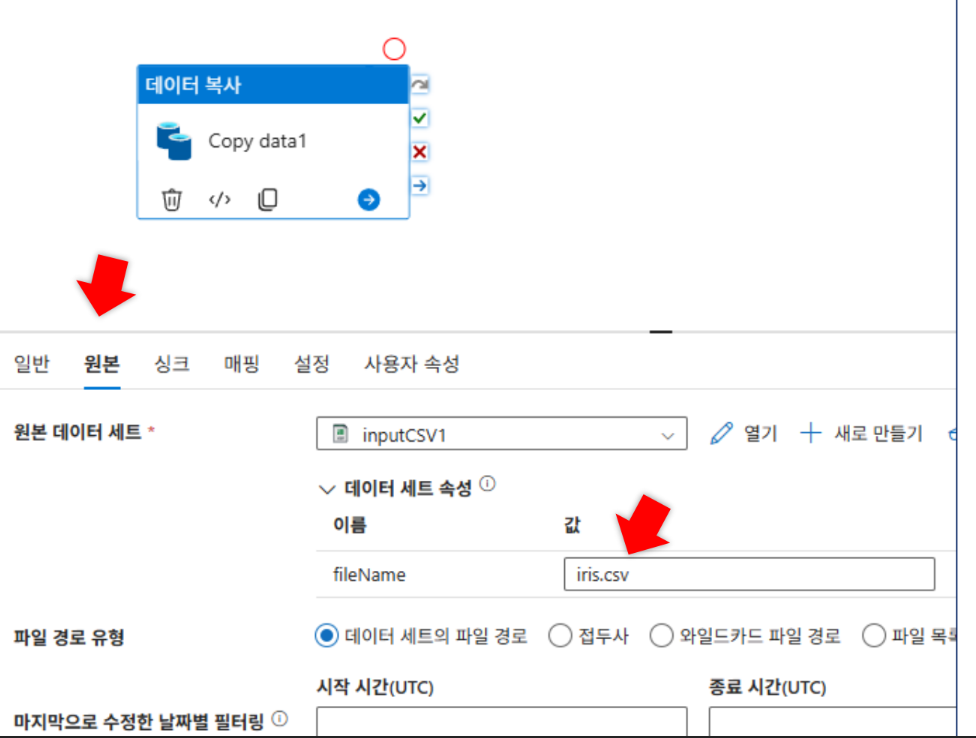
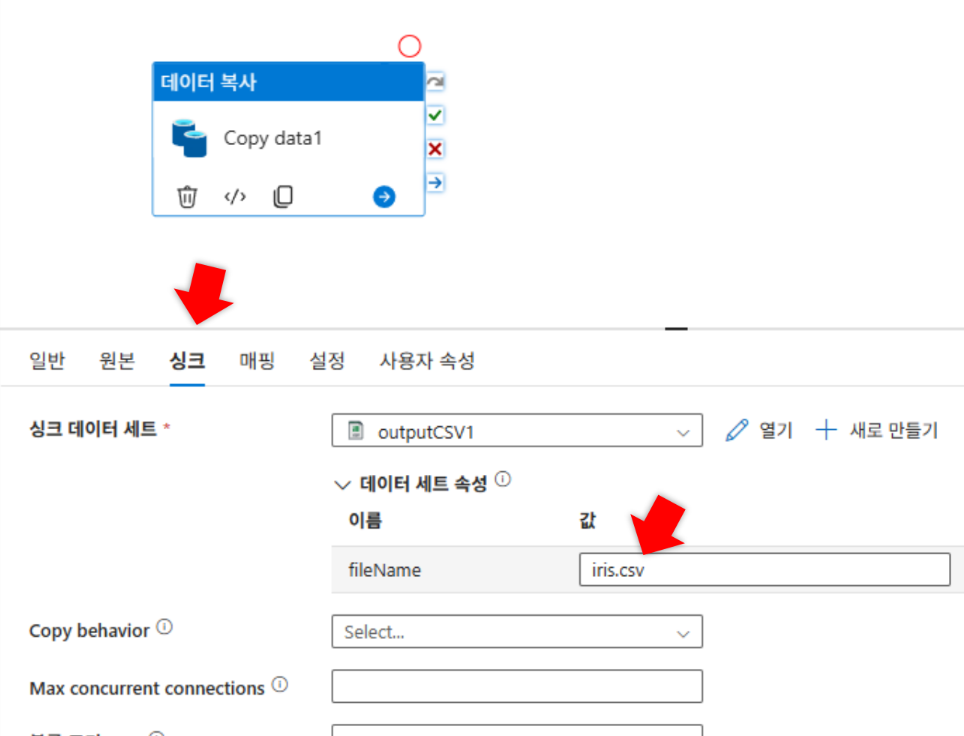
fileName매개변수를 생성하고 파일 경로에@dataset().fileName동적 콘텐츠를 추가합니다. 파이프라인 테스트 시iris.csv를 입력하여 성공 여부를 확인합니다.
-
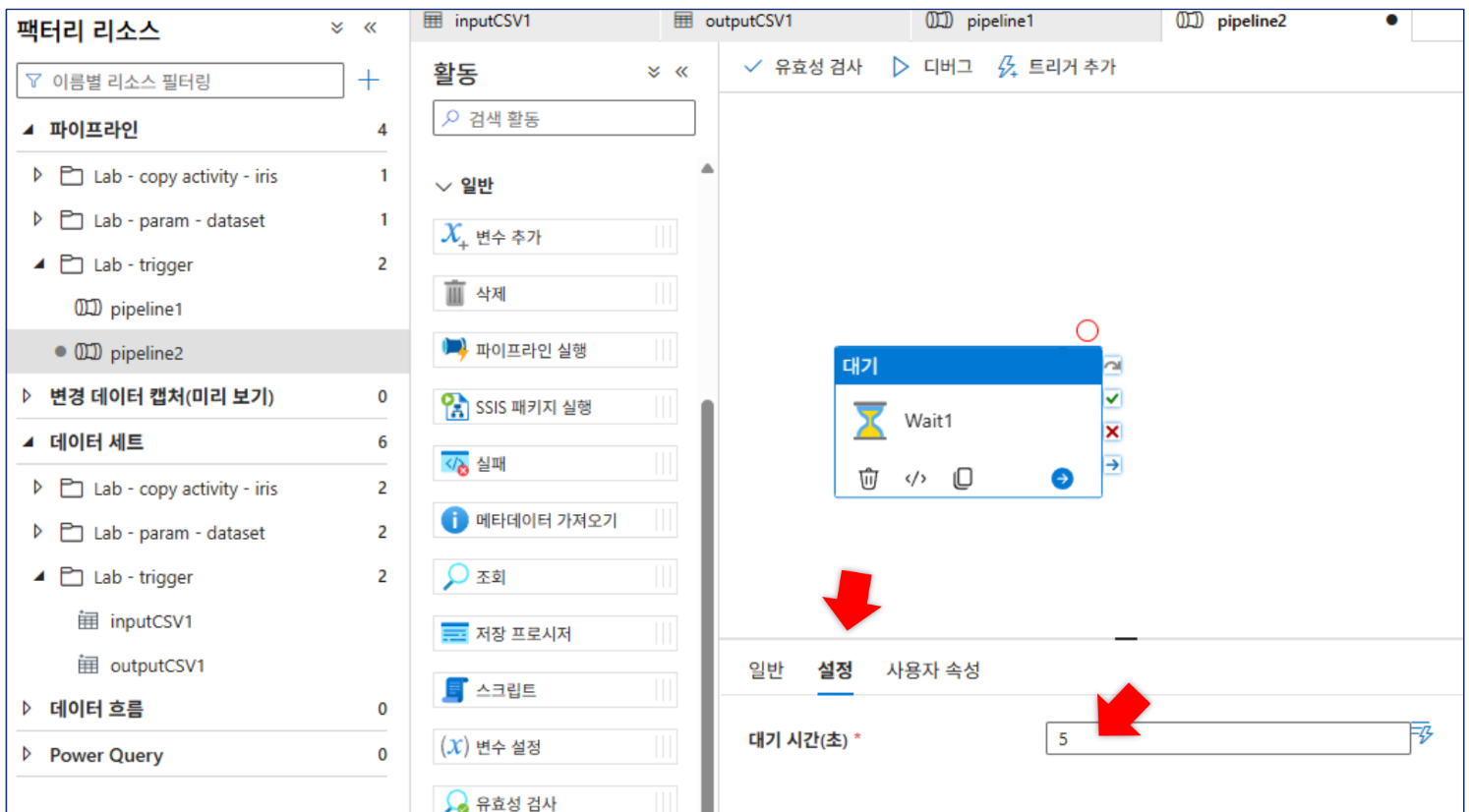
디버깅: 파이프라인의 원본, 싱크에 값 입력
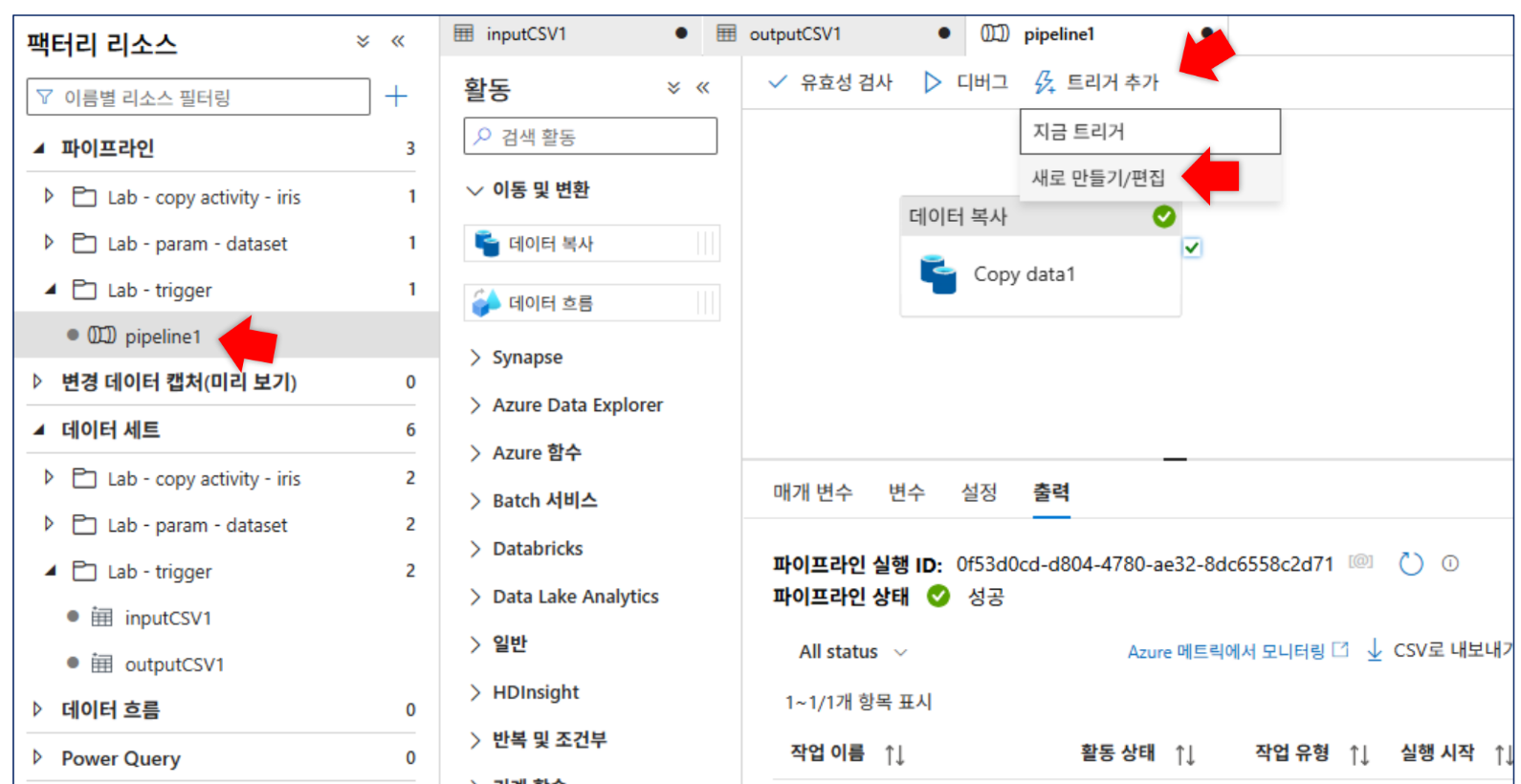
6-2. Schedule 트리거 실습
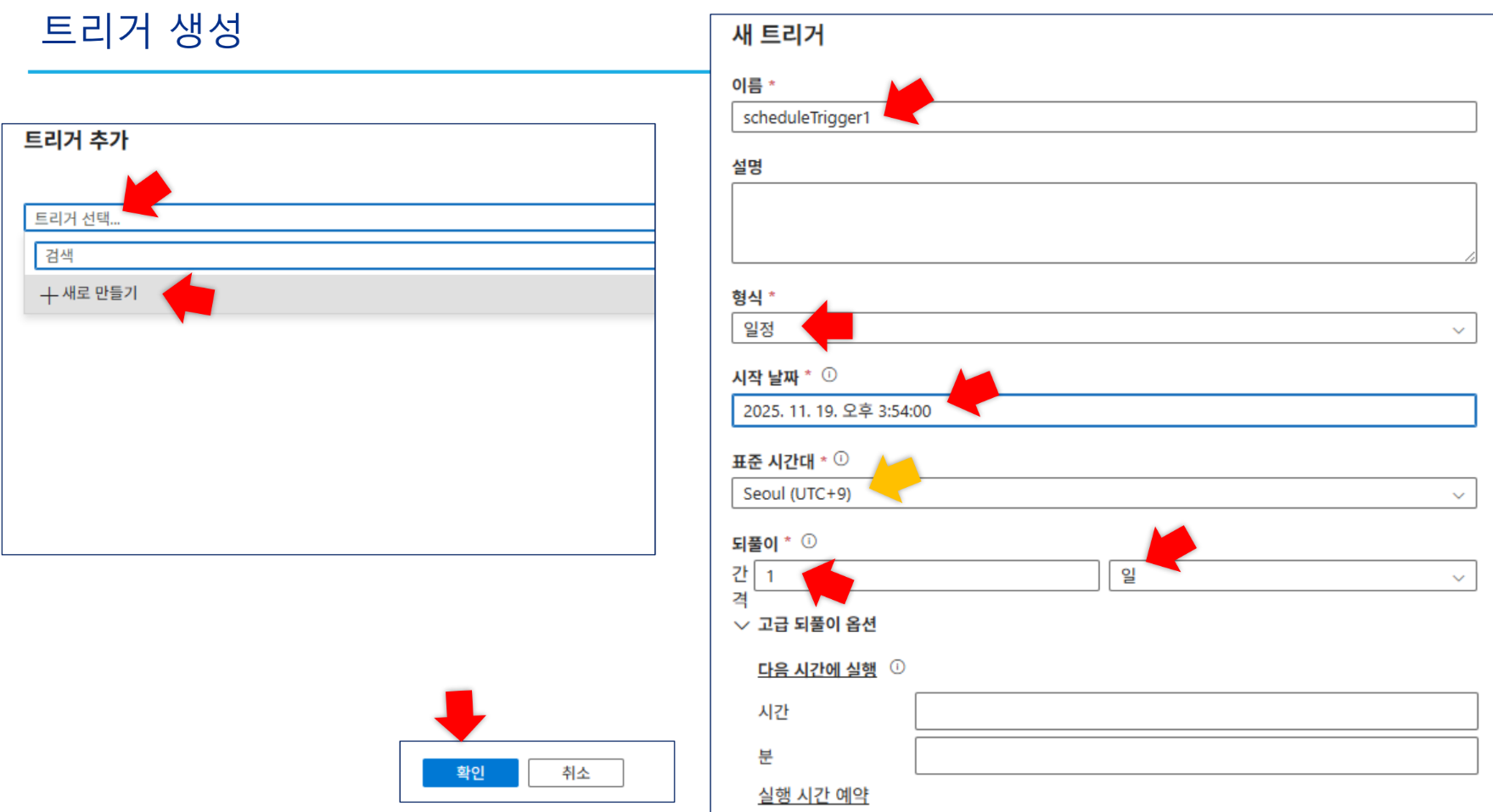
-
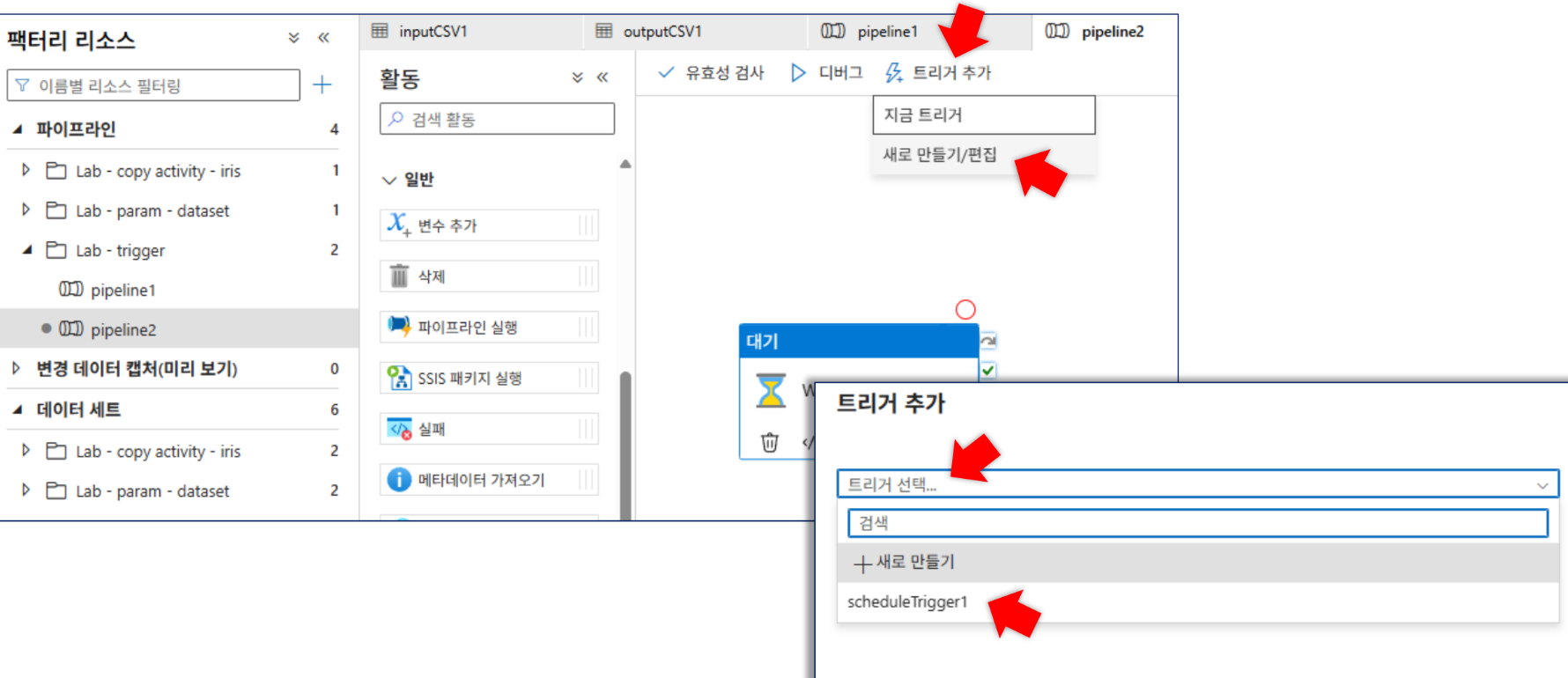
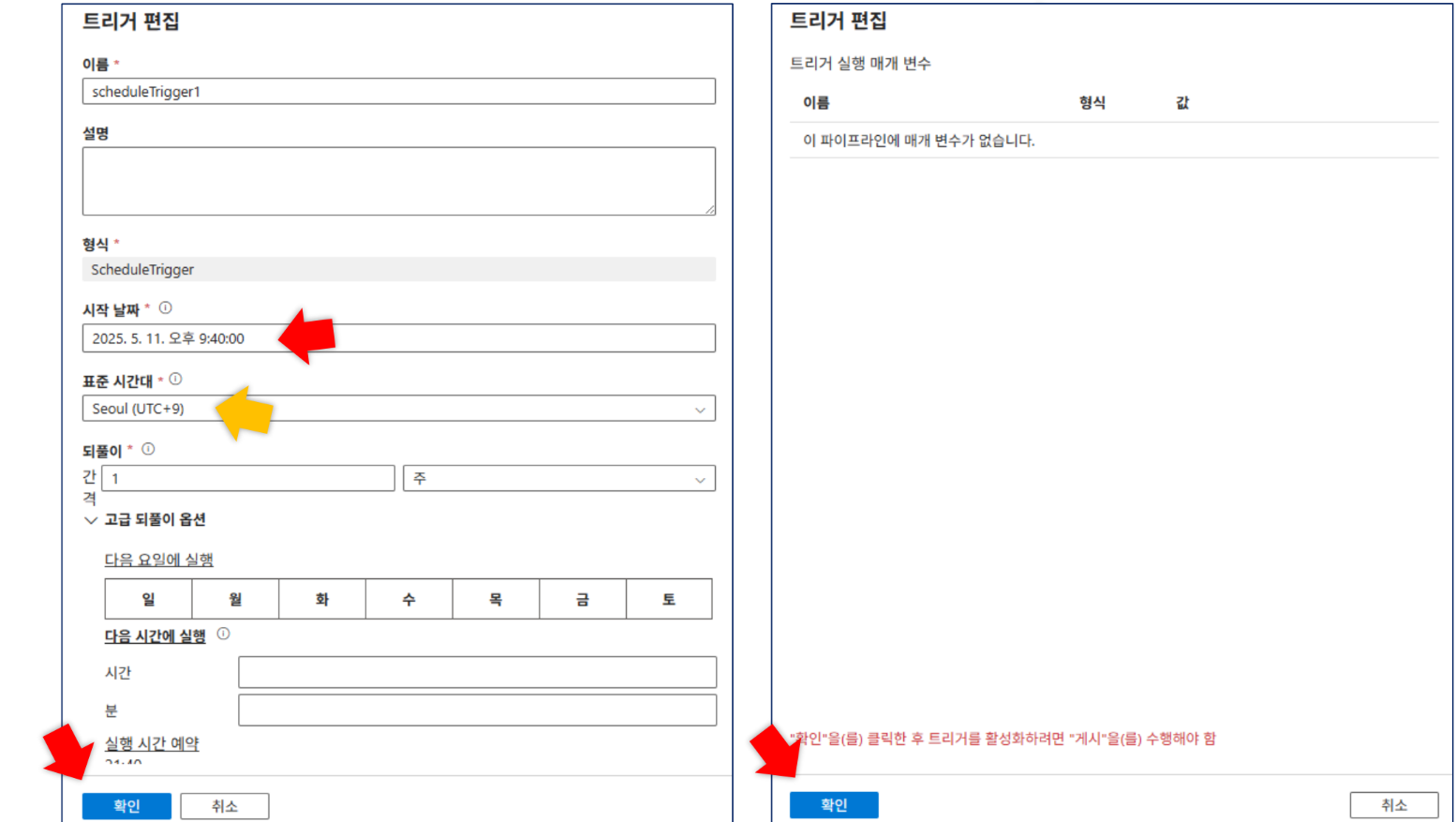
트리거 생성:
scheduleTrigger1(형식: 일정, 주기: 15분) 생성 및 게시. -
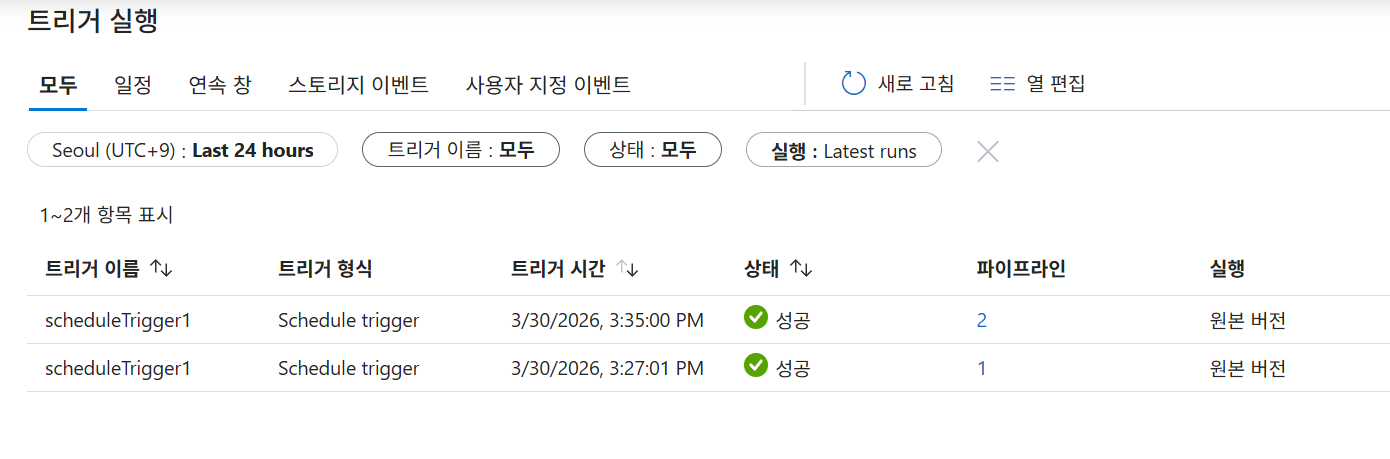
검증: 모니터링 탭에서 성공 상태와 생성된 파일을 확인합니다.
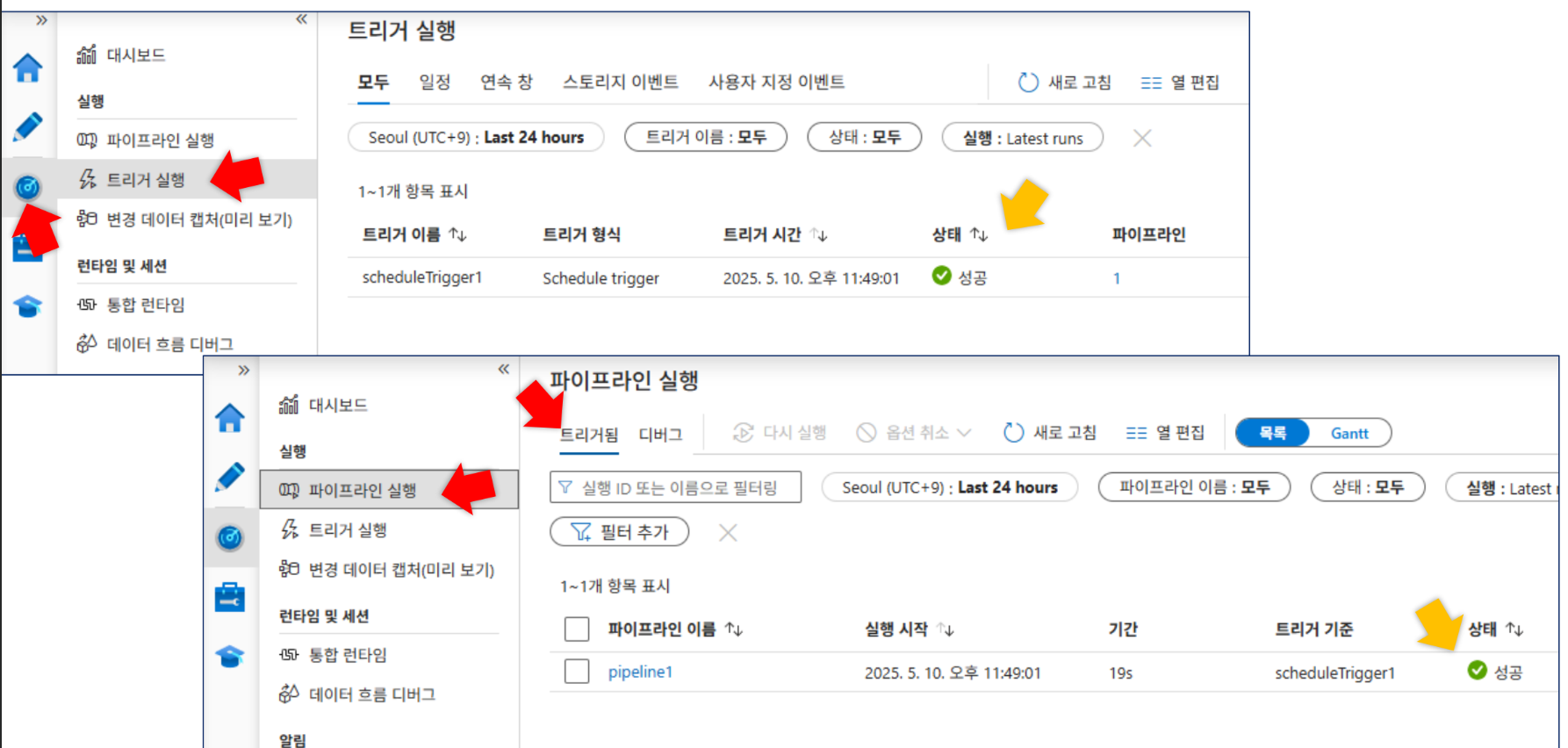
트리거 편집에서 주 단위 고급 되풀이 옵션 확인 가능
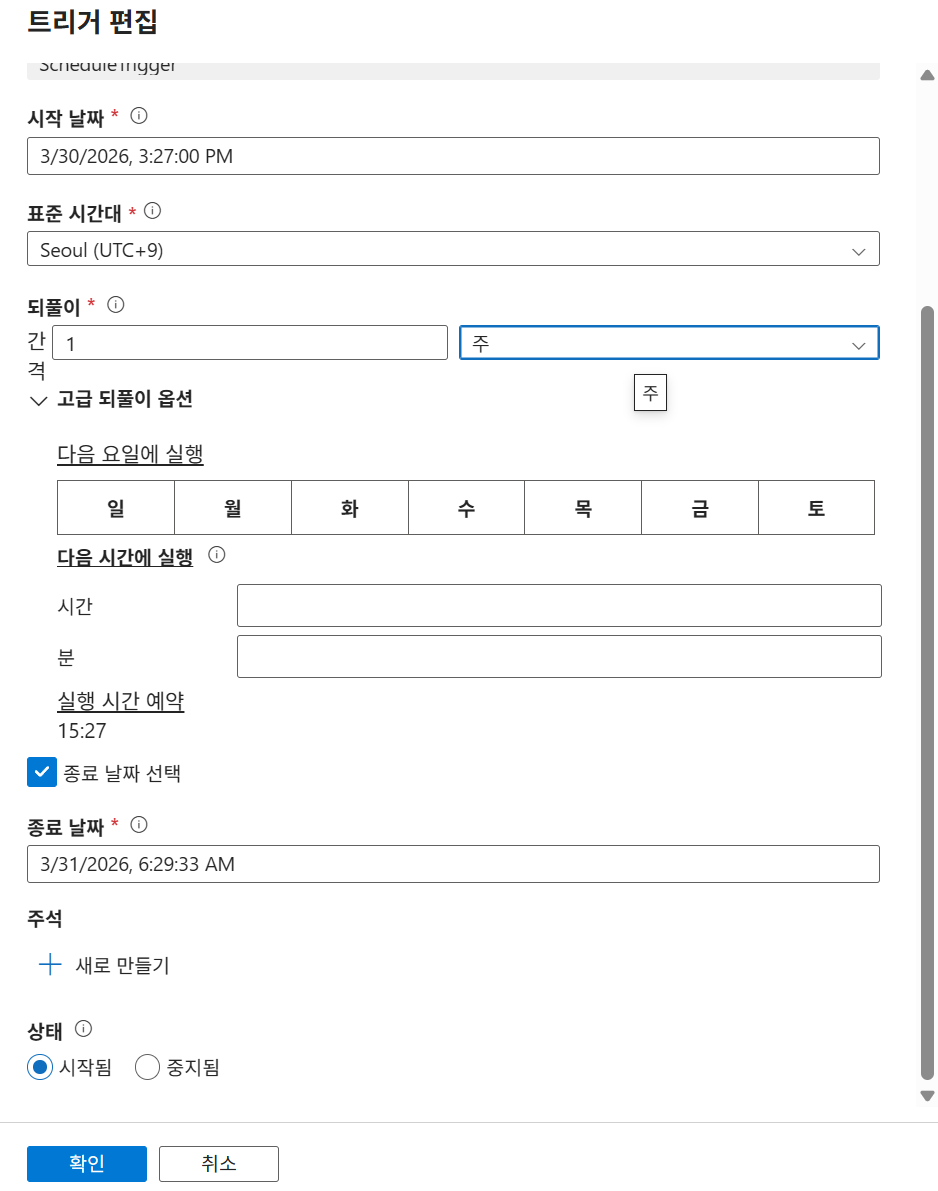
-
One-to-Many 실습:
pipeline2(Wait 활동 포함)를 생성하고 기존scheduleTrigger1에 연결하여 두 파이프라인이 동시 실행되는 것을 확인합니다.
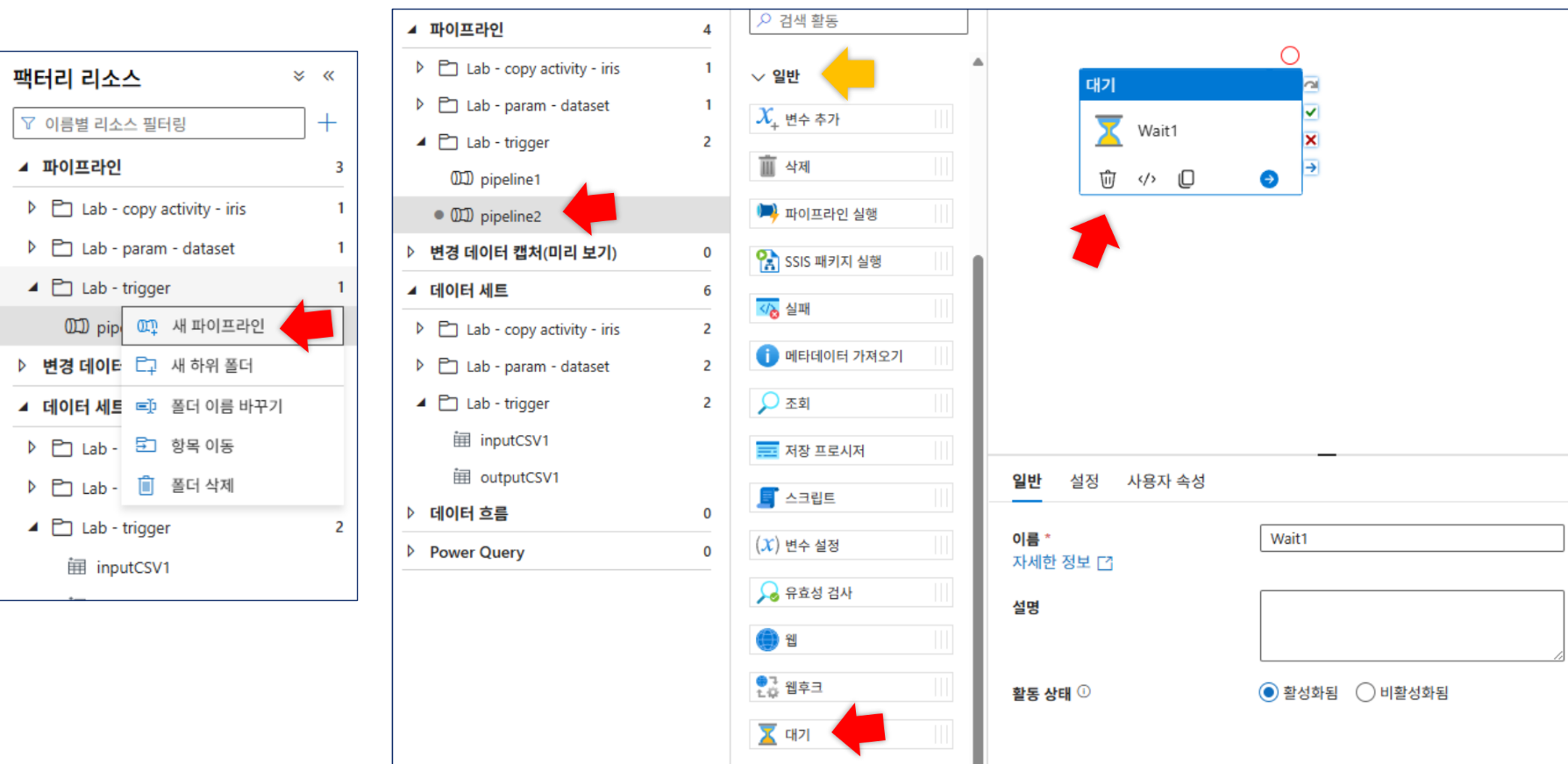
파이프라인은 여러개지만 트리거는 동일한 트리거

관리-트리거에서 중지 후 삭제 가능
중괄호 아이콘 선택 시 트리거 코드 확인 가능
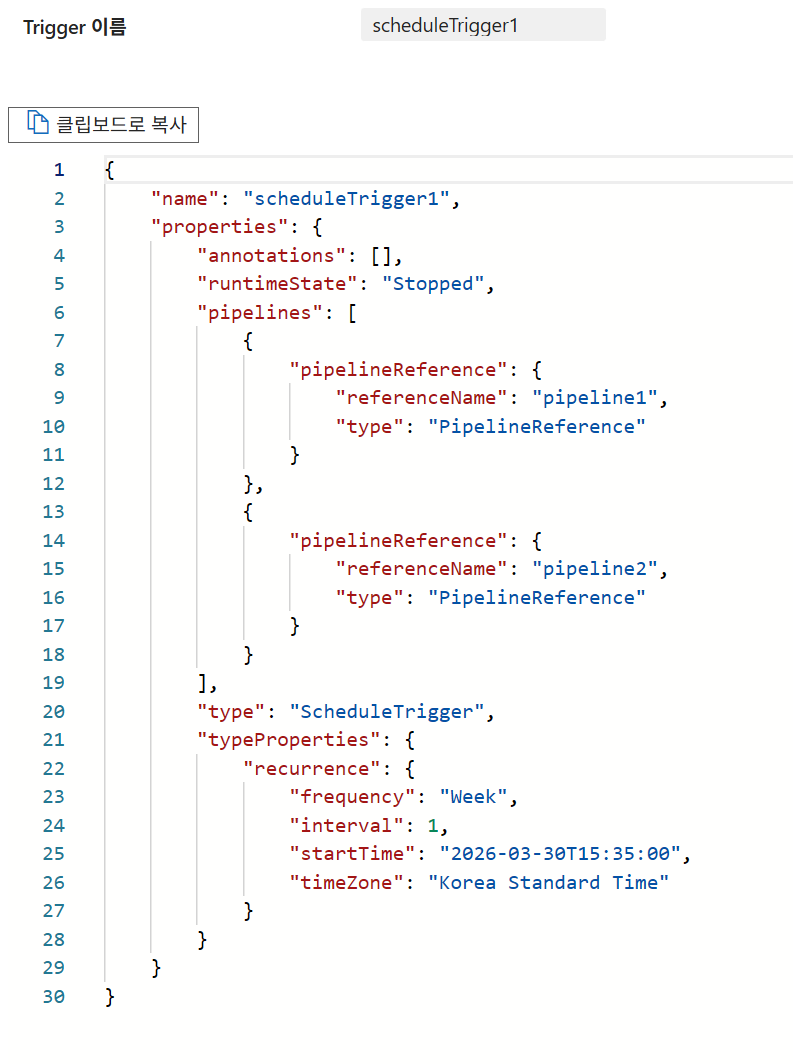
6-3. Tumbling Window 트리거 실습
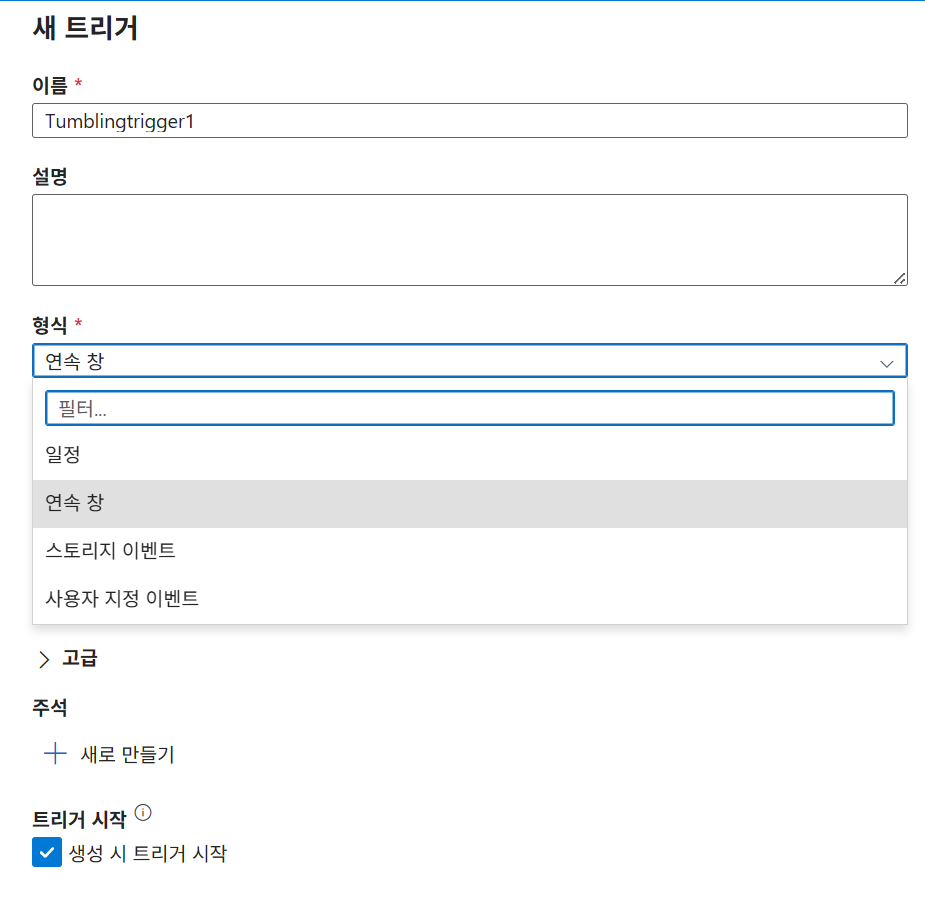
Tumbling Window는 오프셋 오류를 방지하기 위해 00초로 설정하는게 바람직
재시도 정책을 2로 하면 실패시 재시도를 최대 2번까지 함
오프셋은 보통 이전걸 참조해야하니 음수값을 많이 준다
창크기는 고정된 시간 기준으로 이전 몇개까지 진행됐던 걸 볼거냐를 설정 가능케 함
- 파이프라인 준비:
LoadData(Wait 3초)와ProcessData(Wait 5초) 파이프라인을 준비합니다. - 트리거 구성:
TW_LoadData1생성 후,TW_ProcessData1생성 시 종속성 추가를 통해TW_LoadData1이 성공한 후에만 실행되도록 설정합니다.
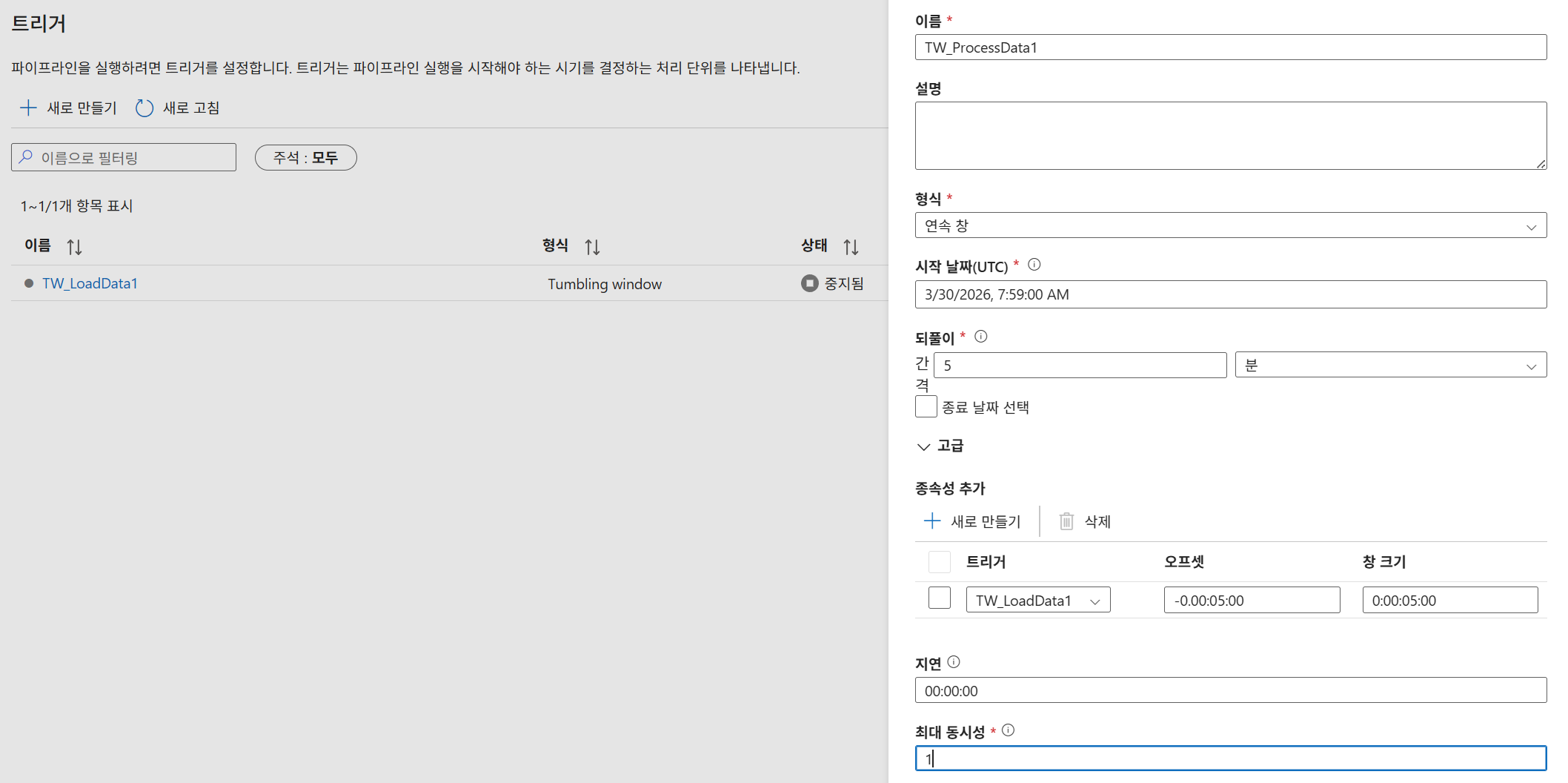
- 만약 현재 시각이 08:00:00인 경우, 창 크기가 5분인 경우의 모든 종속성을 검토하고자 한다면 최소한 현재보다 5분 전으로 시작시간을 설정해야 함
- 확인: 모니터링 화면에서 '종속성 대기' 및 '성공' 상태를 확인하고 Gantt 차트로 업스트림 관계를 검토합니다.
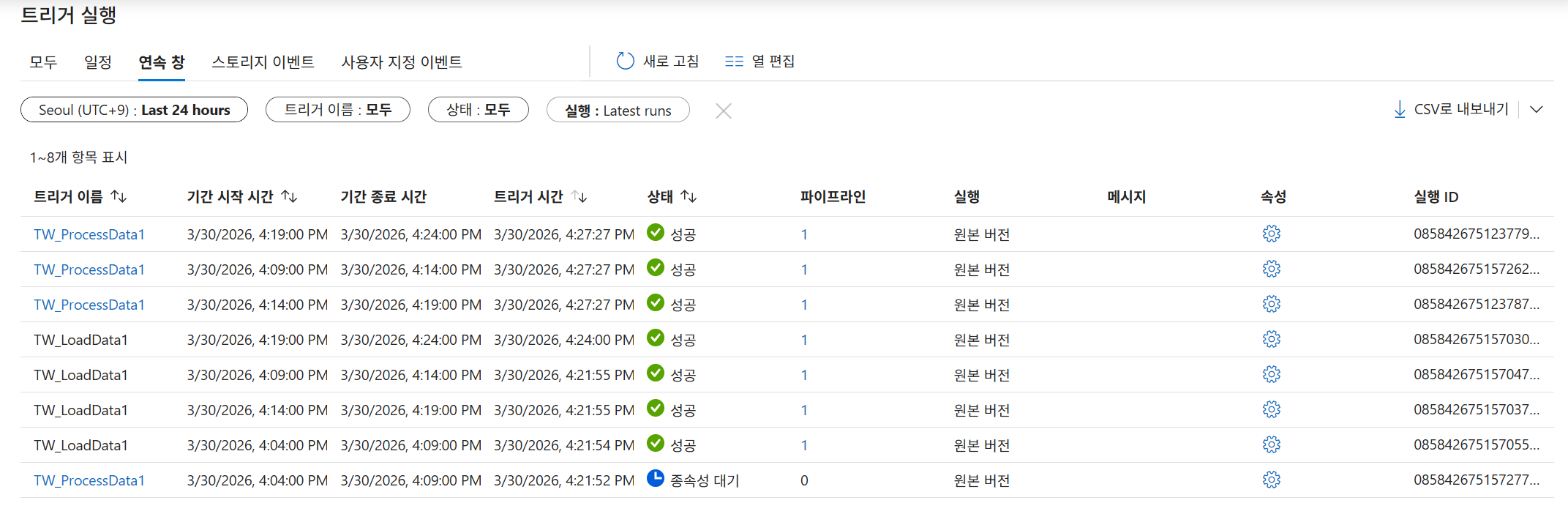
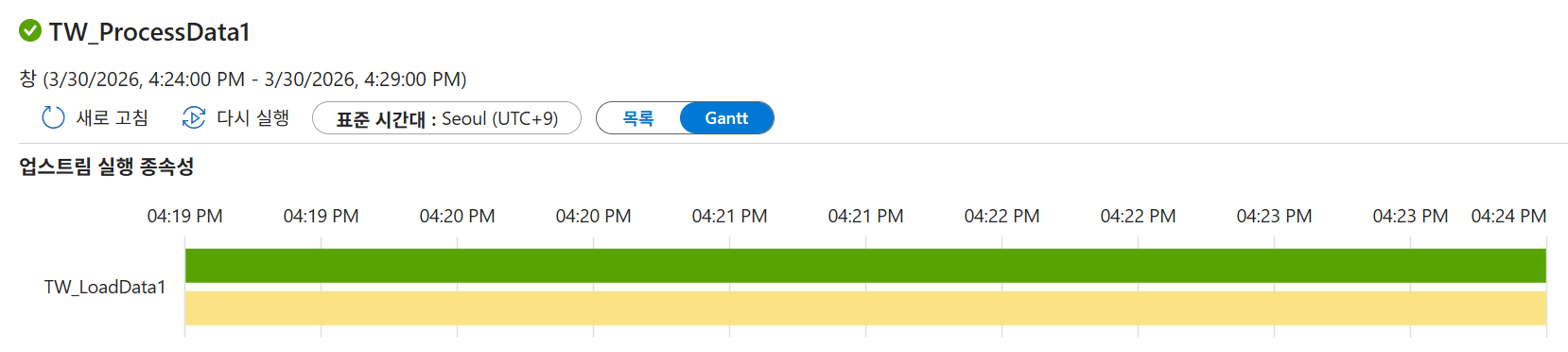
매번 변경사항마다 게시를 눌러야 적용됨을 잊지 말자
6-4. Storage Event 트리거 실습
-
준비:
fileName매개변수를 사용하는Copy CVS파이프라인을 생성합니다.(입출력 전부 fileName 매개변수 사용, input output 구분만 주의) -
트리거 생성:
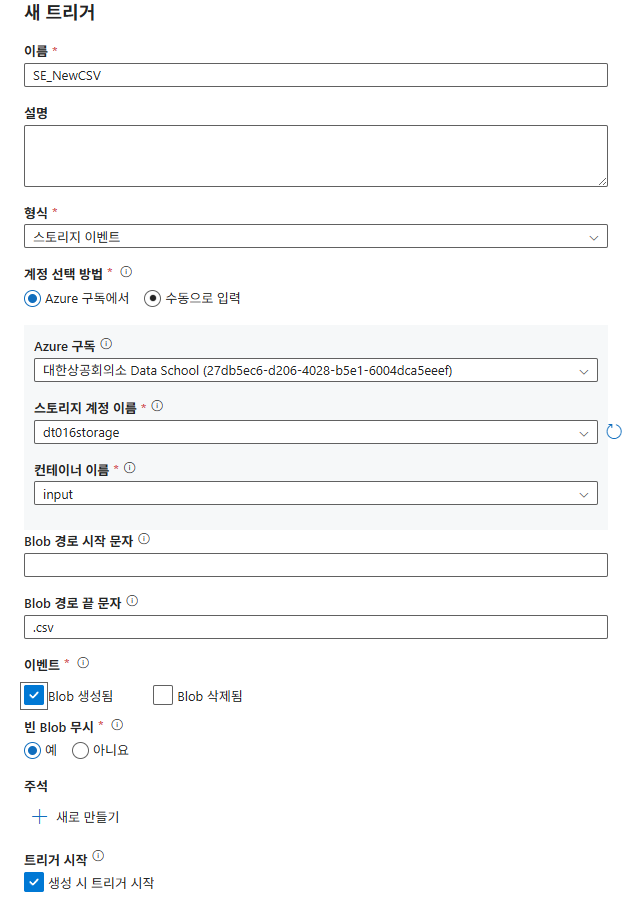
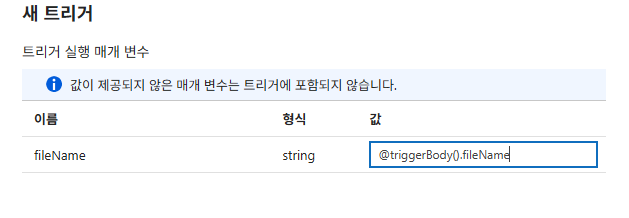
SE_NewCSV(이벤트: 생성됨, 끝 문자: .CSV) 생성 및 파이프라인 매개변수에@triggerBody().fileName을 매핑합니다.
-
테스트:
input컨테이너에penguins.csv를 업로드하여 파이프라인이 자동 실행되는지 확인합니다. -
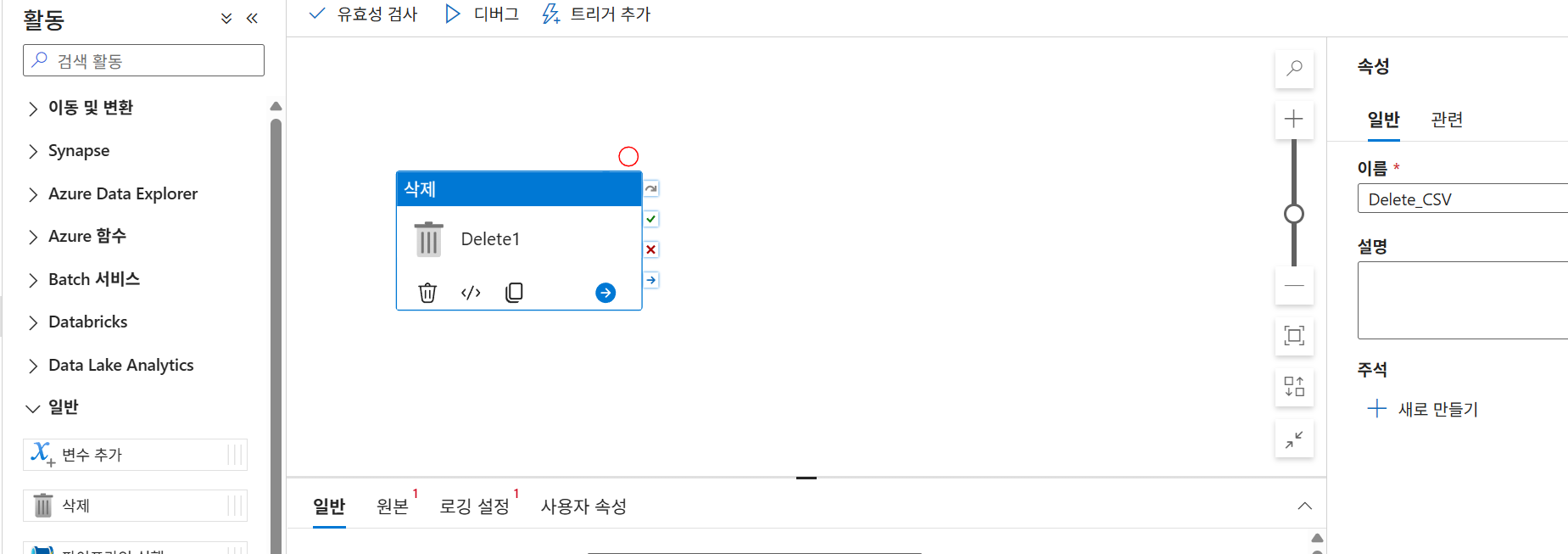
파일 삭제 실습: Delete 활동을 사용하는 파이프라인과
SE_DeleteCSV(이벤트: 삭제됨) 트리거를 생성하여 파일 삭제 시 로깅이 발생하는지 테스트합니다.
Delete시에는 항상 로깅을 기본으로 해야 함
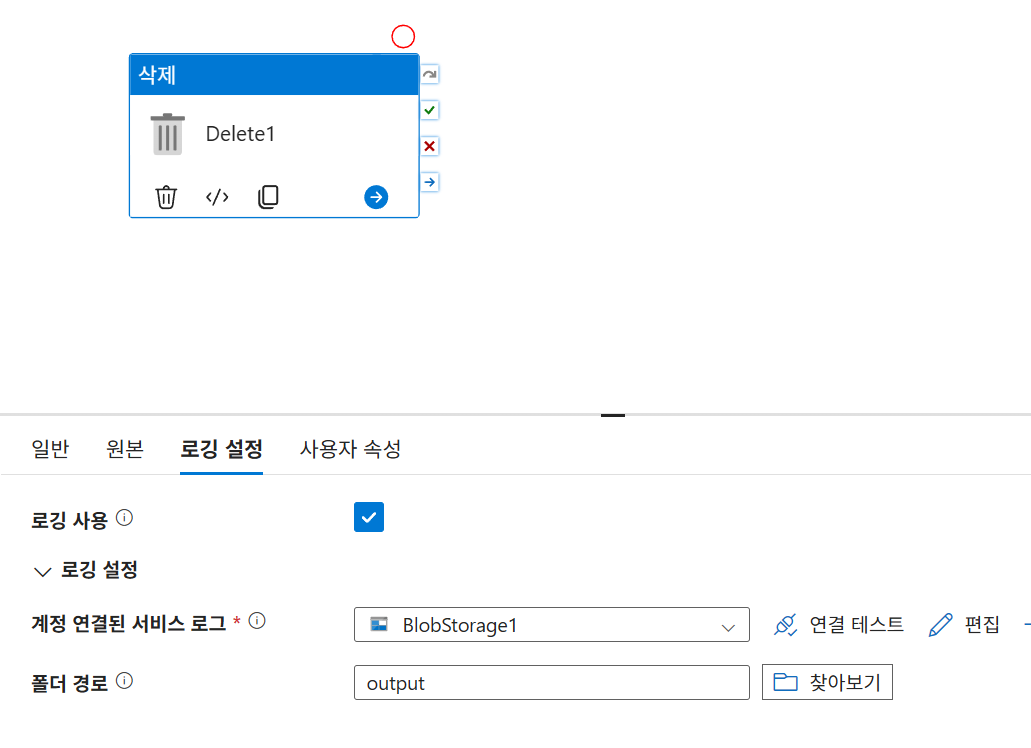
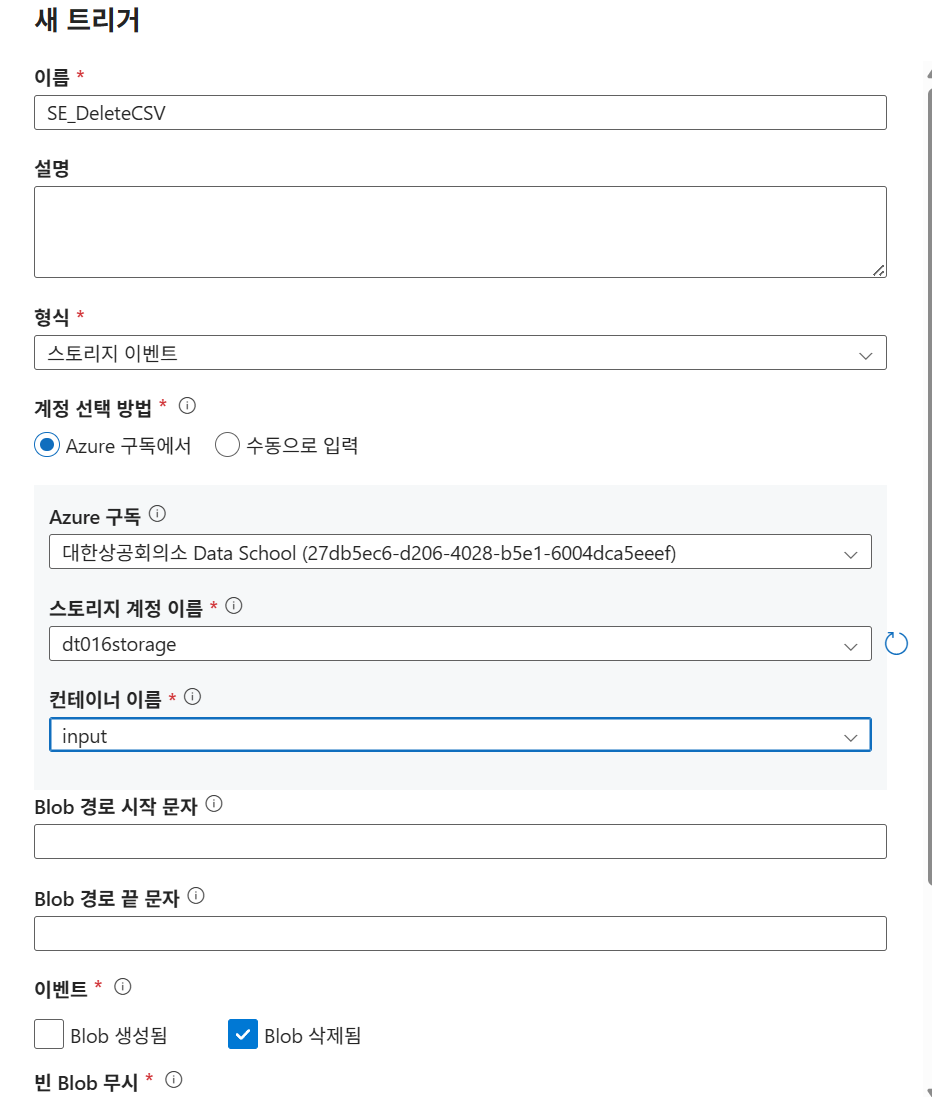
추가 및 실행 후 input에서 파일을 삭제 시 output에서도 삭제되는지 확인
6-5. 수동 트리거 (Logic Apps) 실습
-
준비:
Copy CSV to CSV파이프라인과 관련 데이터세트(inputCSV3,outputCSV3)를 준비합니다. -
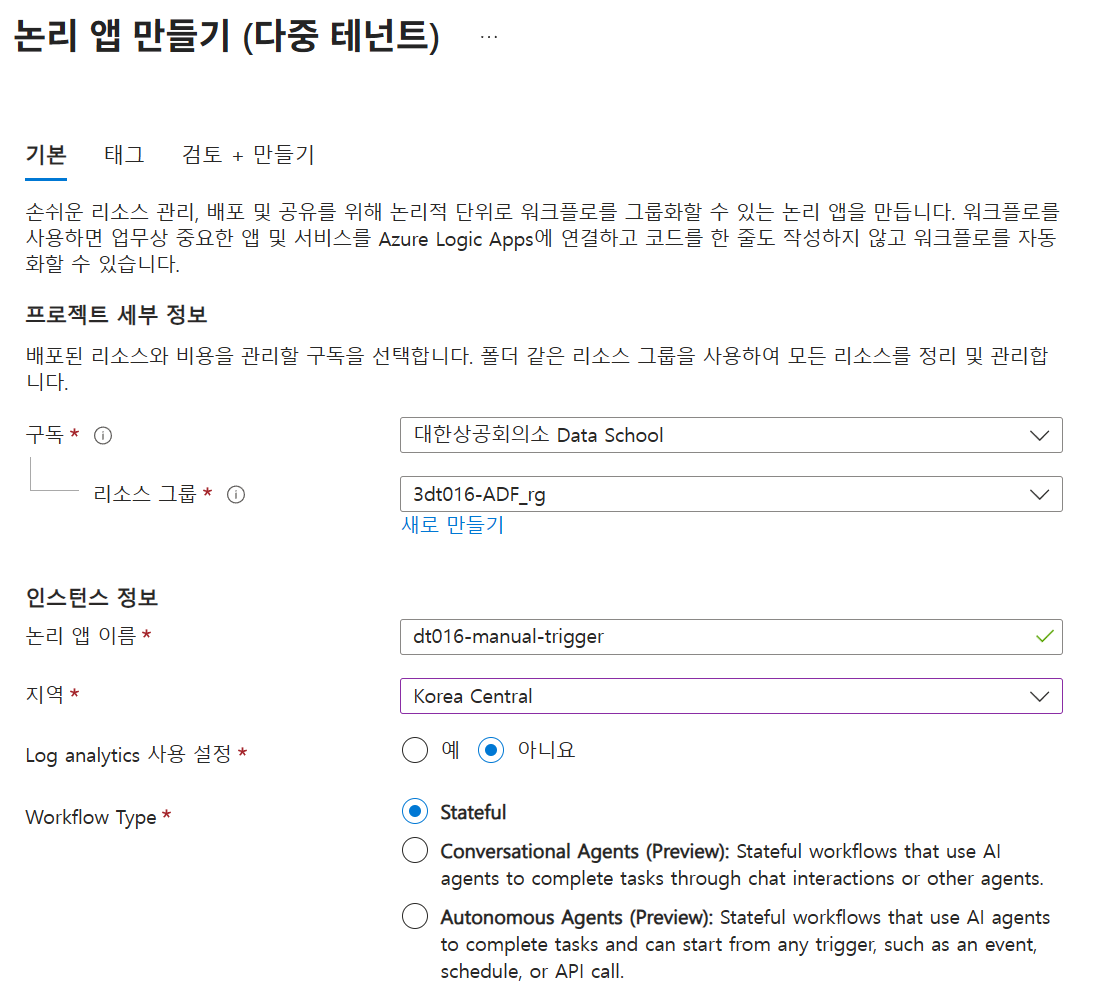
Logic Apps 구성:
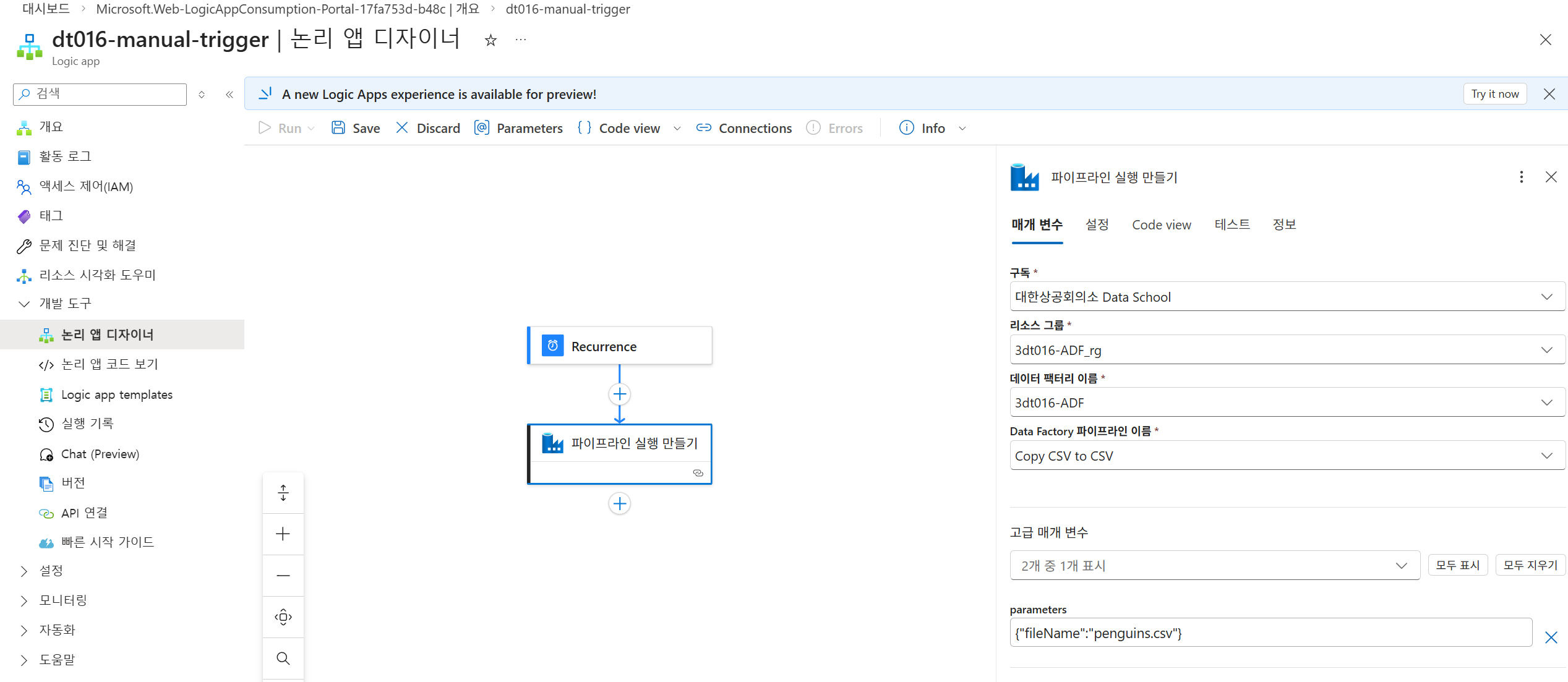
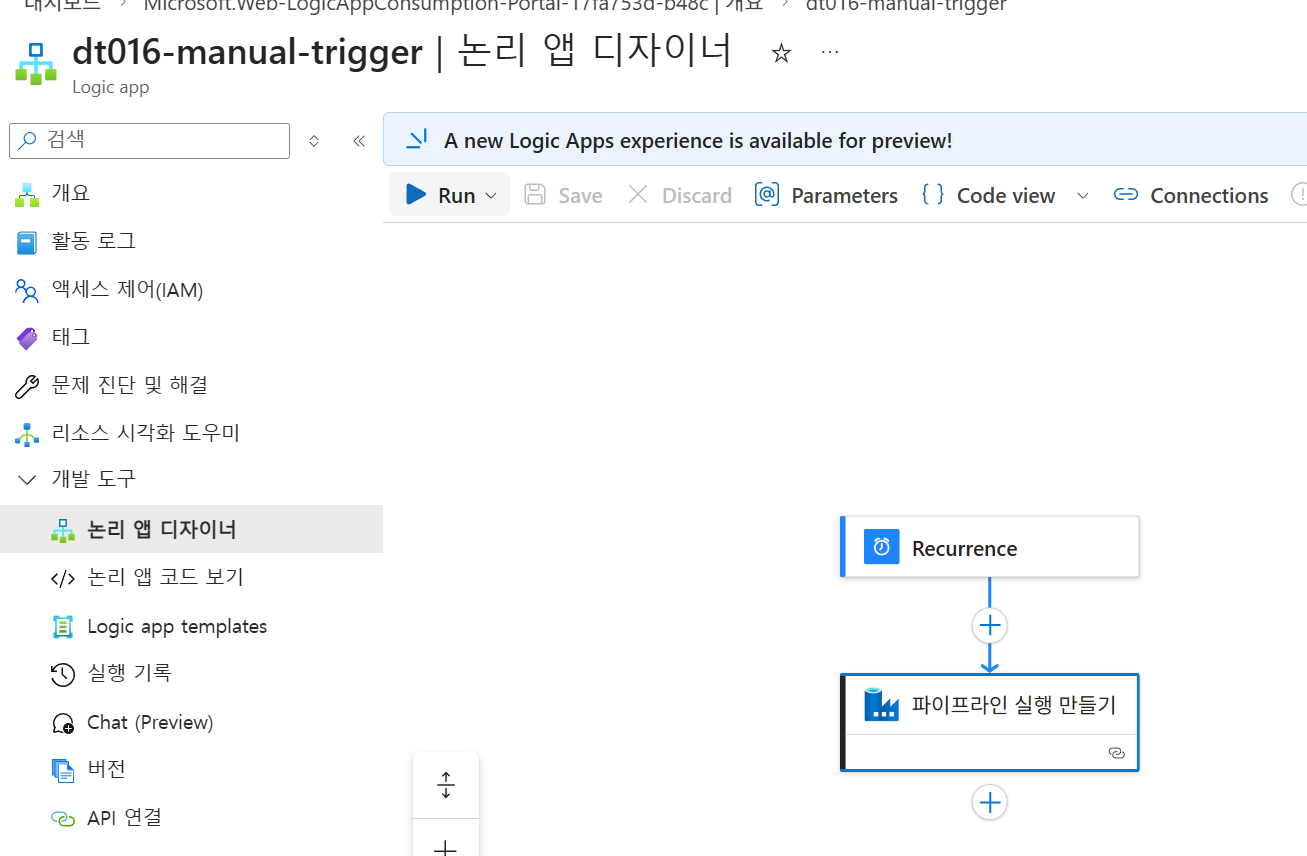
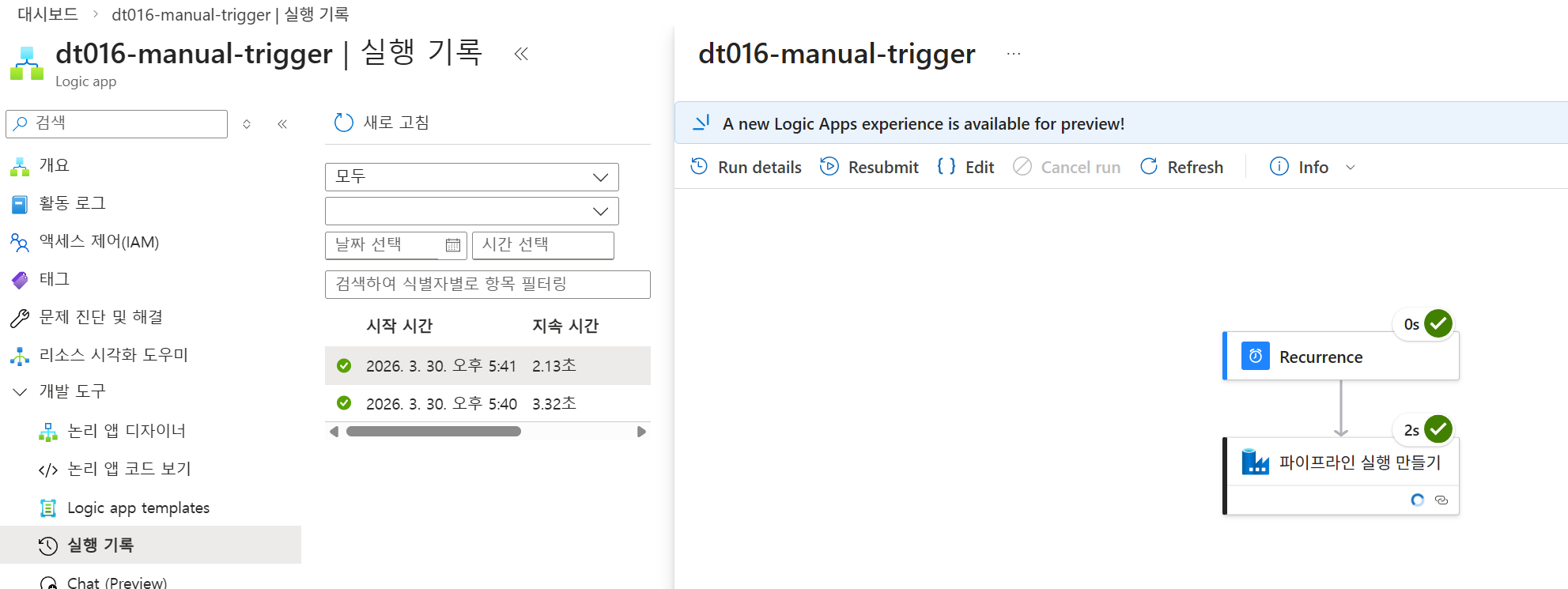
A000-manual-trigger로직 앱을 생성하고, Recurrence 트리거와 Azure Data Factory - 파이프라인 실행 만들기 동작을 추가합니다.

-
매개변수 주입: 로직 앱에서
{"fileName":"penguins.csv"}JSON 데이터를 전달하도록 설정합니다. -
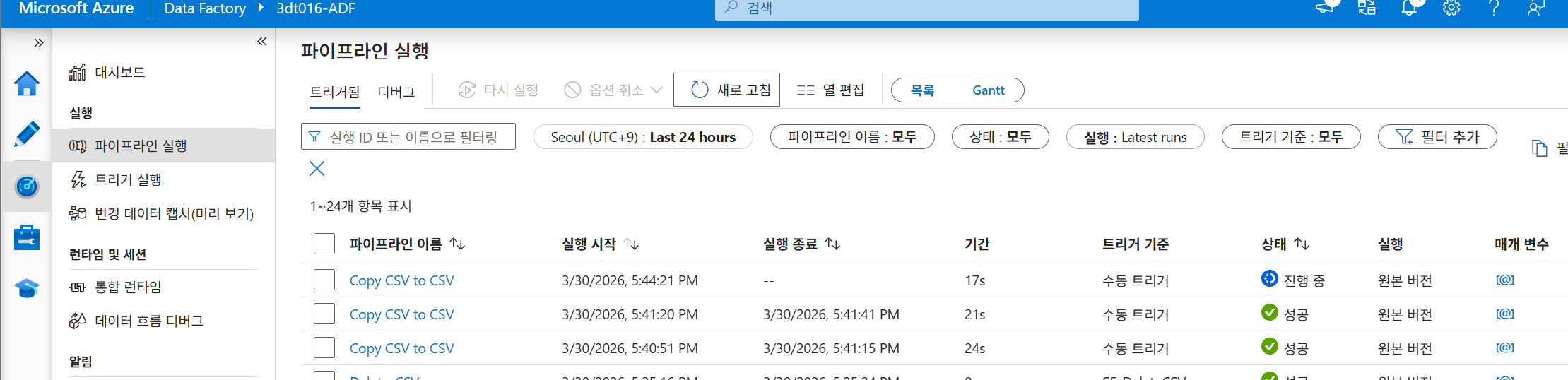
확인: 로직 앱 실행 기록(Succeeded)과 ADF 파이프라인 모니터링(수동 트리거 항목)을 통해 최종 결과를 확인합니다.
(혹시몰라서) 매개변수 등록 순서 정리
Azure Data Factory(ADF)에서 매개변수를 설정하는 과정은 크게 데이터세트 수준의 설정, 파이프라인 수준의 설정, 그리고 이 둘을 연결(매핑)하는 과정으로 나뉩니다. 전체적인 스텝을 순서대로 정리해 드립니다.
1. 데이터세트 매개변수 정의
먼저 데이터를 동적으로 처리할 수 있도록 데이터세트 자체에 매개변수를 생성합니다.
1. 데이터세트 열기: 수정할 데이터세트를 선택합니다.
2. 매개변수 탭 이동: 하단의 [매개변수] 탭을 클릭한 후 [+새로 만들기]를 통해 사용할 이름(예: fileName, tableName)과 형식을 지정합니다.
3. 동적 콘텐츠 적용: [연결] 탭으로 돌아가 동적으로 바뀔 항목(파일명, 테이블명 등)을 클릭하고 하단에 나타나는 [동적 콘텐츠 추가]를 선택합니다.
4. 식 작성: 파이프라인 식 작성기에서 앞서 만든 매개변수를 선택하여 @dataset().매개변수명 형태의 식이 입력되도록 합니다.
2. 파이프라인 매개변수 정의
파이프라인 실행 시 외부에서 값을 입력받을 수 있도록 설정합니다.
1. 파이프라인 캔버스 클릭: 파이프라인 내 빈 공간을 클릭하여 하단 속성창을 활성화합니다.
2. 매개변수 추가: 하단의 [매개변수] 탭에서 [+새로 만들기]를 눌러 외부에서 주입받을 매개변수 이름과 형식을 정의합니다.
3. 활동(Activity)에서 매개변수 매핑
파이프라인 매개변수를 데이터세트 매개변수로 전달하는 과정입니다.
1. 활동 선택: 파이프라인 내의 활동(예: 복사 활동)을 클릭합니다.
2. 원본/싱크 설정: 활동 속성의 [원본] 또는 [싱크] 탭으로 이동합니다.
3. 데이터세트 속성 입력: 해당 탭 하단의 데이터세트 속성 섹션에 이전에 정의한 데이터세트 매개변수들이 나열됩니다.
4. 파이프라인 매개변수 연결: 각 속성의 값 필드를 클릭하고 [동적 콘텐츠 추가]를 눌러 파이프라인 매개변수를 선택합니다. 식은 @pipeline().parameters.매개변수명 형태로 구성됩니다.
이렇게 설정이 완료되면 파이프라인을 디버그할 때 팝업창을 통해 매개변수 값을 직접 입력하여 테스트할 수 있습니다.
