
MySQL Data Loading
데이터 로딩 테스트를 위해 MySQL Heatwave 에서 예제로 사용하는 airportdb 를 사용하겠습니다. airportdb 는 CC By 4.0 License 를 가지고 있는 Stefan Proell, Eva Zangerle, Wolfgang Gassler 가 만든 Flughafen DB가 원본입니다.
먼저 MySQL 에서 airportdb 를 로딩하기 위해 다음 명령어를 수행하여 airport-db.zip 파일을 다운로드하고 압축파일을 풀어 놓습니다.
wget https://downloads.mysql.com/docs/airport-db.zip
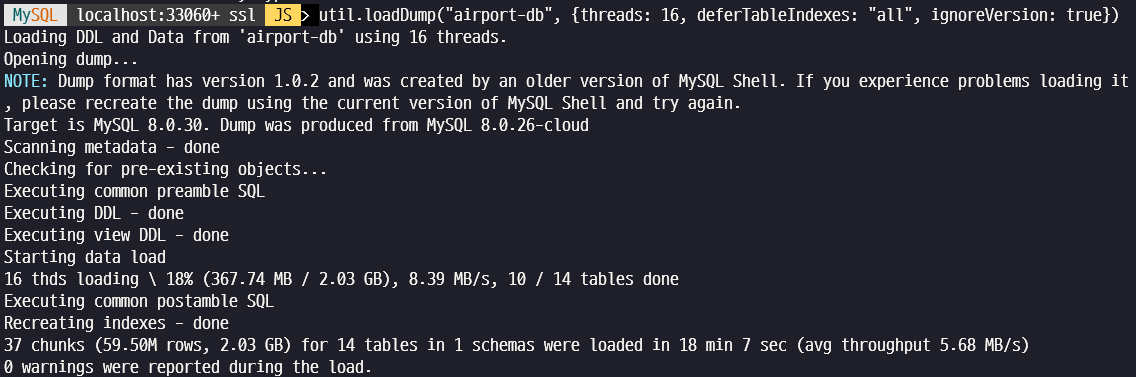
unzip airport-db.zipmysqlsh 의 loadDump 유틸리티를 수행하여 16 thread 로 병렬 로딩을 수행합니다.
mysqlsh -uroot -pMysql09876*
util.loadDump("airport-db", {threads: 16, deferTableIndexes: "all", ignoreVersion: true})
\quit18분 7초가 소요되었습니다.
총 데이터 건수를 확인해 보겠습니다.
mysql -uroot -pMysql09876*
use airportdb;
select count(*) from airline union all
select count(*) from airport_geo union all
select count(*) from flight union all
select count(*) from passengerdetails union all
select count(*) from booking;
exit;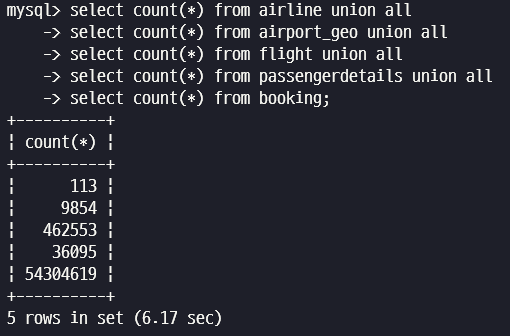
PostgreSQL Data Loading
MySQL 파트에서 Download 한 airportdb 는 zstandard 라는 유틸리티로 압축되어 있으므로 PostgreSQL 에서 사용하기 위해선 압축을 풀어야 합니다. 이를 위해 zstd 를 먼저 설치합니다.
wget https://rpmfind.net/linux/epel/7/x86_64/Packages/z/zstd-1.5.2-1.el7.x86_64.rpm
sudo rpm -ivh zstd-1.5.2-1.el7.x86_64.rpmairport-db 디렉토리에서 추후 Query 테스트에서 사용할 airline, flight, passengerdetails, airport_geo, booking 테이블 데이터만 압축 해제합니다.
zstd -d airport-db/airportdb@airline@@0.tsv.zst
zstd -d airport-db/airportdb@flight@@0.tsv.zst
zstd -d airport-db/airportdb@passengerdetails@@0.tsv.zst
zstd -d airport-db/airportdb@airport_geo@@0.tsv.zst
zstd -d airport-db/airportdb@booking@*.zstpsql 을 실행하고 PostgreSQL 에 맞게 Table 을 생성합니다.
psql -d airportdb
\timing
CREATE TABLE airline (
airline_id smallint NOT NULL,
iata char(2) NOT NULL,
airlinename varchar(30) DEFAULT NULL,
base_airport smallint NOT NULL,
PRIMARY KEY (airline_id),
UNIQUE (iata)
);
CREATE INDEX heimat_idx on airline (base_airport);
CREATE TABLE flight (
flight_id int NOT NULL,
flightno char(8) NOT NULL,
from_id smallint NOT NULL,
to_id smallint NOT NULL,
departure timestamp NOT NULL,
arrival timestamp NOT NULL,
airline_id smallint NOT NULL,
airplane_id int NOT NULL,
PRIMARY KEY (flight_id)
);
CREATE INDEX von_idx on flight (from_id);
CREATE INDEX nach_idx on flight (to_id);
CREATE INDEX abflug_idx on flight (departure);
CREATE INDEX ankunft_idx on flight (arrival);
CREATE INDEX fluglinie_idx on flight (airline_id);
CREATE INDEX flugzeug_idx on flight (airplane_id);
CREATE TABLE passengerdetails (
passenger_id int NOT NULL,
birthdate date NOT NULL,
sex char(1) DEFAULT NULL,
street varchar(100) NOT NULL,
city varchar(100) NOT NULL,
zip smallint NOT NULL,
country varchar(100) NOT NULL,
emailaddress varchar(120) DEFAULT NULL,
telephoneno varchar(30) DEFAULT NULL,
PRIMARY KEY (passenger_id)
);
CREATE TABLE airport_geo (
airport_id smallint NOT NULL,
name varchar(50) NOT NULL,
city varchar(50) DEFAULT NULL,
country varchar(50) DEFAULT NULL,
latitude decimal(11,8) NOT NULL,
longitude decimal(11,8) NOT NULL,
loc varchar(200) NOT NULL,
PRIMARY KEY (airport_id)
);
CREATE INDEX country_idx on airport_geo (country);
CREATE TABLE booking (
booking_id int NOT NULL,
flight_id int NOT NULL,
seat char(4) DEFAULT NULL,
passenger_id int NOT NULL,
price decimal(10,2) NOT NULL,
PRIMARY KEY (booking_id),
UNIQUE (flight_id,seat)
);
CREATE INDEX flug_idx on booking (flight_id);
CREATE INDEX passagier_idx on booking (passenger_id);psql 의 \copy 명령어를 사용해 각각의 테이블에 데이터를 로딩합니다.
\copy airline from 'airport-db/airportdb@airline@@0.tsv' with delimiter E'\t'
\copy flight from 'airport-db/airportdb@flight@@0.tsv' with delimiter E'\t'
\copy airport_geo from 'airport-db/airportdb@airport_geo@@0.tsv' with delimiter E'\t'
\copy passengerdetails from 'airport-db/airportdb@passengerdetails@@0.tsv' with delimiter E'\t'
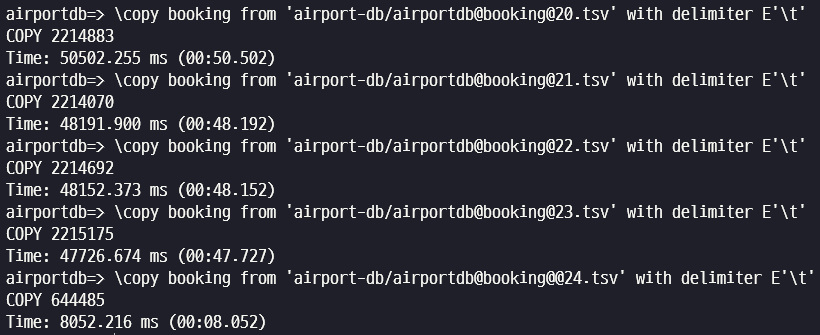
\copy booking from 'airport-db/airportdb@booking@0.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@1.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@2.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@3.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@4.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@5.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@6.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@7.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@8.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@9.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@10.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@11.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@12.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@13.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@14.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@15.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@16.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@17.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@18.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@19.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@20.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@21.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@22.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@23.tsv' with delimiter E'\t'
\copy booking from 'airport-db/airportdb@booking@@24.tsv' with delimiter E'\t'PostgreSQL 에서 여러개의 파일을 병렬로 로딩하지 못해서 인지 이번 테스트에서는 총 19분 정도가 소요되었습니다.
총 데이터 건수를 확인해 보겠습니다.
select count(*) from airline union all
select count(*) from airport_geo union all
select count(*) from flight union all
select count(*) from passengerdetails union all
select count(*) from booking;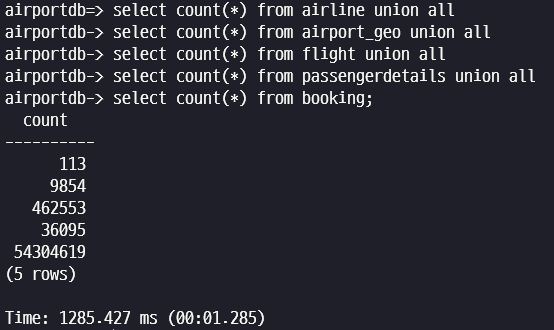
SingleStore Data Loading
SingleStore 는 여러가지 방식으로 데이터 로딩을 수행할 수 있습니다. 특히 Pipeline 은 S3 Object Storage, Kafka 등등 다양한 데이터 소스로부터 Fast Ingestion 을 할 수 있는 유틸리티이면서 성능이 빠른 장점이 있습니다.
이번 로딩 테스트는 다음과 같은 3가지를 수행합니다.
- LOAD DATA Local Infile
- LOAD DATA from FS Pipeline
- LOAD DATA from S3 Object Storage Pipeline
각각의 방식으로 데이터 로딩을 수행하며 소요시간을 확인해 보겠습니다.
먼저 SingleStore 에 맞게 테이블을 생성합니다. 크기가 작은 테이블은 로우스토어 또는 레퍼런스 로우스토어 테이블로 생성해 In-Memory 에 위치시키고, 1.7GB 의 booking 테이블은 컬럼스토어로 생성해 Disk 에 저장하겠습니다.
$ singlestore -p
CREATE ROWSTORE REFERENCE TABLE `airline` (
`airline_id` smallint NOT NULL,
`iata` char(2) NOT NULL,
`airlinename` varchar(30) DEFAULT NULL,
`base_airport` smallint NOT NULL,
PRIMARY KEY (`airline_id`),
UNIQUE KEY `iata_unq` (`iata`),
KEY `heimat_idx` (`base_airport`)
);
CREATE TABLE `flight` (
`flight_id` int NOT NULL,
`flightno` char(8) NOT NULL,
`from` smallint NOT NULL,
`to` smallint NOT NULL,
`departure` datetime NOT NULL,
`arrival` datetime NOT NULL,
`airline_id` smallint NOT NULL,
`airplane_id` int NOT NULL,
PRIMARY KEY (`flight_id`),
KEY `von_idx` (`from`),
KEY `nach_idx` (`to`),
KEY `abflug_idx` (`departure`),
KEY `ankunft_idx` (`arrival`),
KEY `fluglinie_idx` (`airline_id`),
KEY `flugzeug_idx` (`airplane_id`)
);
CREATE ROWSTORE TABLE `passengerdetails` (
`passenger_id` int NOT NULL,
`birthdate` date NOT NULL,
`sex` char(1) DEFAULT NULL,
`street` varchar(100) NOT NULL,
`city` varchar(100) NOT NULL,
`zip` smallint NOT NULL,
`country` varchar(100) NOT NULL,
`emailaddress` varchar(120) DEFAULT NULL,
`telephoneno` varchar(30) DEFAULT NULL,
PRIMARY KEY (`passenger_id`)
);
CREATE ROWSTORE REFERENCE TABLE `airport_geo` (
`airport_id` smallint NOT NULL,
`name` varchar(50) NOT NULL,
`city` varchar(50) DEFAULT NULL,
`country` varchar(50) DEFAULT NULL,
`latitude` decimal(11,8) NOT NULL,
`longitude` decimal(11,8) NOT NULL,
`loc` varchar(200) NOT NULL,
PRIMARY KEY (`airport_id`),
KEY (country)
);
CREATE TABLE `booking` (
`booking_id` int NOT NULL,
`flight_id` int NOT NULL,
`seat` char(4) DEFAULT NULL,
`passenger_id` int NOT NULL,
`price` decimal(10,2) NOT NULL,
PRIMARY KEY (`booking_id`),
UNIQUE KEY `sitzplan_unq` (`flight_id`,`seat`) unenforced rely,
KEY `flug_idx` (`flight_id`),
KEY `passagier_idx` (`passenger_id`),
SORT KEY (booking_id)
);show tables extended 명령어로 테이블의 저장 방식을 확인할 수 있습니다.
show tables extended;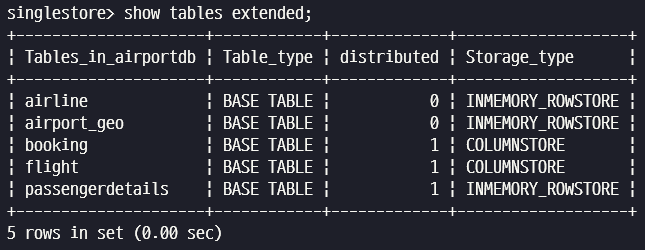
LOAD DATA Local Infile
PostgreSQL 에서 수행한 것과 같이 LOAD DATA 명령어를 통해 개별 파일로부터 데이터를 로딩합니다. Local File 로부터 로딩하기 위해서는 local-infile 옵션을 이용해 singlestore client 를 수행합니다.
$ singlestore -p --local-infile
use airportdb;
load data local infile 'airport-db/airportdb@airline@@0.tsv' into table airline;
load data local infile 'airport-db/airportdb@flight@@0.tsv' into table flight;
load data local infile 'airport-db/airportdb@airport_geo@@0.tsv' into table airport_geo;
load data local infile 'airport-db/airportdb@passengerdetails@@0.tsv' into table passengerdetails;
load data local infile 'airport-db/airportdb@booking@0.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@1.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@2.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@3.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@4.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@5.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@6.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@7.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@8.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@9.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@10.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@11.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@12.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@13.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@14.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@15.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@16.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@17.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@18.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@19.tsv' into table booking;
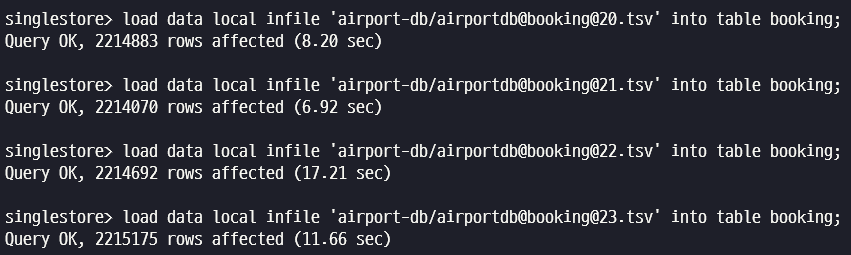
load data local infile 'airport-db/airportdb@booking@20.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@21.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@22.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@23.tsv' into table booking;
load data local infile 'airport-db/airportdb@booking@@24.tsv' into table booking;Local File 로부터 개별 명령어를 이용한 데이터 로딩에는 총 3분 30초가 소요되었습니다.
총 데이터 건수를 확인해 보겠습니다.
select count(*) from airline union all
select count(*) from airport_geo union all
select count(*) from flight union all
select count(*) from passengerdetails union all
select count(*) from booking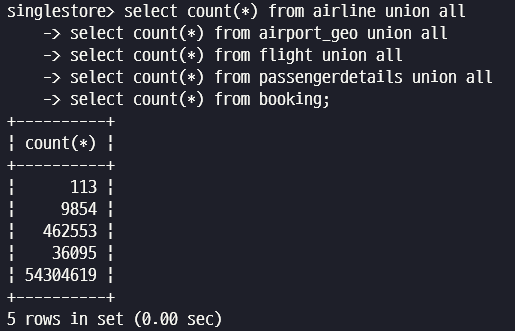
LOAD DATA from FS Pipeline
FS Pipeline 은 File System 의 File 에 SingleStore Table 을 연결하는 Pipeline 입니다. 가장 크기가 큰 booking 테이블만 FS Pipeline 을 이용하여 데이터를 로딩해 보도록 하겠습니다.
FS Pipeline 은 원래 NFS 와 같은 공유 파일 시스템에 적용하는 것이 원칙입니다. 왜냐하면 Leaf Node 의 각 파티션 별로 Multi thread 가 병렬로 연결되기 때문입니다. 이번 테스트에서는 Leaf Node 에서 memsql 계정이 aiport-db directory 를 access 할 수 있도록 /tmp 로 이동하겠습니다.
$ mv airport-db /tmp
$ singlestore -puse airportdb;
delete from booking;
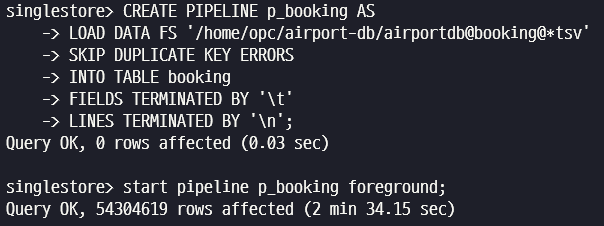
CREATE PIPELINE p_booking AS
LOAD DATA FS '/tmp/airport-db/airportdb@booking@*tsv'
SKIP DUPLICATE KEY ERRORS
INTO TABLE booking
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';pipeline 이 생성되면 information_schema.pipelines_files 을 조회하면 어떤 데이터 파일을 읽을 지 확인할 수 있습니다.
데이터 로딩은 start pipeline 명령어로 수행합니다.
- start pipeline p_booking;
background 로 수행되며 stop pipeline 명령을 수행하지 않는한 계속 읽기 대기 상태입니다.
지속적으로 데이터가 유입되는 스트리밍 업무에 적합합니다. - start pipeline p_booking foreground;
foreground 로 수행되며 data 를 끝까지 읽으면 자동으로 stop 됩니다.
1-time Batch Bulk Loading 에 적합합니다.
select * from information_schema.pipelines_files;
start pipeline p_booking foreground;
drop pipeline p_booking;이번 로딩 테스트에서는 2분 34초가 소요되었습니다.
LOAD DATA from S3 Object Storage
마지막으로 S3 API 와 호환되는 Oracle Cloud Object Storage 에 이미 저장해 놓은 데이터를 Pipeline 으로 연결하여 로딩하겠습니다. 역시 가장 큰 테이블인 booking 만 재로딩하겠습니다.
delete from booking;
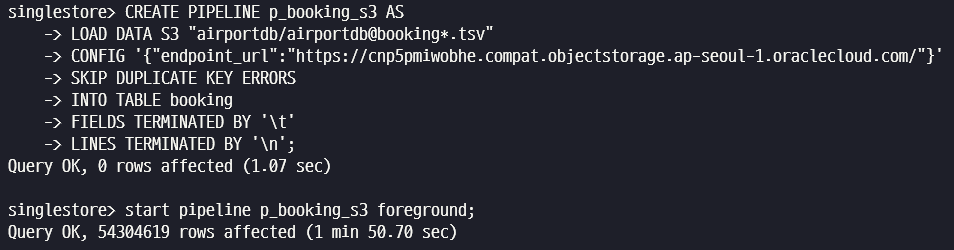
CREATE PIPELINE p_booking_s3 AS
LOAD DATA S3 "airportdb/airportdb@booking*.tsv"
CONFIG '{"endpoint_url":"https://cnp5pmiwobhe.compat.objectstorage.ap-seoul-1.oraclecloud.com/"}'
SKIP DUPLICATE KEY ERRORS
INTO TABLE booking
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';
start pipeline p_booking_s3 foreground;
drop pipeline p_booking_s3;Object Storage 에서의 로딩은 1분 50초가 소요되었습니다.
마무리
SingleStore 는 Fast Ingestion / Fast Data Loading 에 큰 강점이 있는 분산 데이터베이스입니다.
작은 크기의 시스템이라도 3가지 로딩 방법 모두 2~3분 내외의 빠른 로딩이 가능한 점을 확인할 수 있었습니다.
