
1. Data connection (전체 구조)
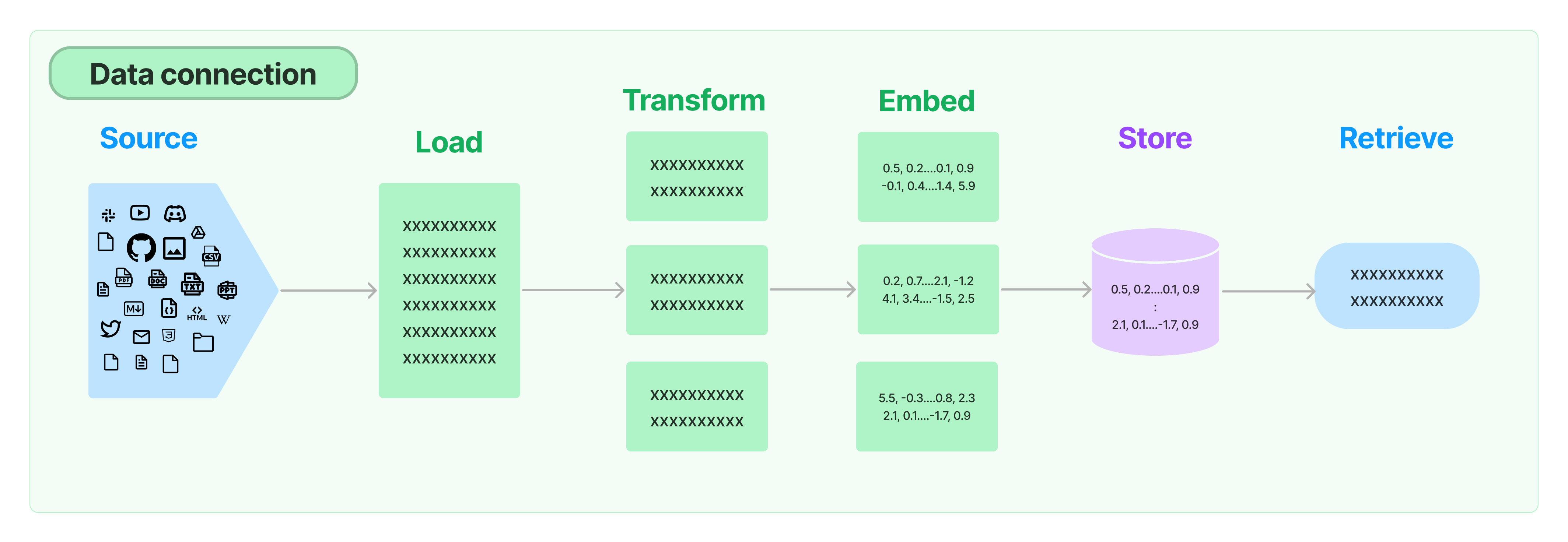
Document loaders: 다양한 소스에서 문서 로드Document transformers: 문서 분할, 문서를 Q&A 형식으로 변환, 중복 문서 삭제 등Text embedding models: 구조화되지 않은 텍스트를 부동 소수점 숫자 목록으로 변환Vector stores: 포함된 데이터에 대한 저장 및 검색Retrievers: 데이터 쿼리
=> 해당 파트에서는Document transformers,Text embedding models,Vector stores를 다룬다.
=> 해당 파트는 예제가 주를 이룸. 어떤 목적으로 존재했는지 확인하고 활용법은 이후에 나올 것 같다.
2. Text Splitters
- 긴 텍스트를 처리하려면 해당 텍스트를 chunks 분할해야 한다. 해당 파트는 그 방식을 다룬 다고 생각하면 된다.
2-1. RecursiveCharacterTextSplitter
- 기본으로 권장되는 Text splitters.
- 예제
length_function: 청크의 길이를 계산하는 방법. 기본적으로 문자 수만 세지만 여기서는 토큰 카운터를 전달하는 것이 일.chunk_size: chunk의 최대 크기(length_function로 측정).chunk_overlap: chunk 간의 최대 겹침. chunk 사이에 약간의 연속성을 유지하기 위해 약간 겹치는 것이 좋을 수 있.add_start_index: 원본 문서 내의 각 청크의 시작 위치를 메타데이터에 포함할지 여부.from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show. chunk_size = 100, chunk_overlap = 20, length_function = len, add_start_index = True, ) texts = text_splitter.create_documents([state_of_the_union])
2-2. Split by character
- 예제
separator를 추가로 사용 -> 문자를 나누는 기준.
# This is a long document we can split up. with open('../../../state_of_the_union.txt') as f: state_of_the_union = f.read() from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator = "\n\n", chunk_size = 1000, chunk_overlap = 200, length_function = len, ) texts = text_splitter.create_documents([state_of_the_union])
2-3. Split by tokens
-
언어 모델에는 토큰 제한이 있다. -> 이를 기준으로 분할
-
예제
# This is a long document we can split up. with open("../../../state_of_the_union.txt") as f: state_of_the_union = f.read() from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=0 ) texts = text_splitter.split_text(state_of_the_union)
2-4. Lost in the middle: The problem with long contexts
-
모델들이 대부분 문서를 10개 이상 포함하면 상당한 성능 저하가 발생한다고 언급
-
검색 후 문서를 재정렬 -> 성능 저하 방지.
-
예제
import os import chromadb from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings from langchain.document_transformers import ( LongContextReorder, ) from langchain.chains import StuffDocumentsChain, LLMChain from langchain.prompts import PromptTemplate from langchain.llms import OpenAI # Get embeddings. embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2") texts = [ "Basquetball is a great sport.", "Fly me to the moon is one of my favourite songs.", "The Celtics are my favourite team.", "This is a document about the Boston Celtics", "I simply love going to the movies", "The Boston Celtics won the game by 20 points", "This is just a random text.", "Elden Ring is one of the best games in the last 15 years.", "L. Kornet is one of the best Celtics players.", "Larry Bird was an iconic NBA player.", ] # Create a retriever retriever = Chroma.from_texts(texts, embedding=embeddings).as_retriever( search_kwargs={"k": 10} ) query = "What can you tell me about the Celtics?" # Get relevant documents ordered by relevance score docs = retriever.get_relevant_documents(query) # Reorder the documents: # Less relevant document will be at the middle of the list and more # relevant elements at begining / end. reordering = LongContextReorder() reordered_docs = reordering.transform_documents(docs) # Confirm that the 4 relevant documents are at begining and end. reordered_docs
3. Text embedding models
- Embeddings 클래스는 텍스트 임베딩 모델과 인터페이스하기 위해 설계된 클래스.
- OpenAI, Cohere, Hugging Face 등의 방식이 존재.
- 여러개일 경우
embed_documents, 단일 일 경우embed_query사용.
4. Vector stores
- 구조화되지 않은 데이터를 임베딩해 저장하고 검색하는 것.
- chromadb, faiss, lancedb 존재
- 예제
- 의미 없는 붙여넣기가 되는 것 같아 링크 첨부
5. 참조

도비의 양말을 찾아서