
1. Data connection (전체 구조)
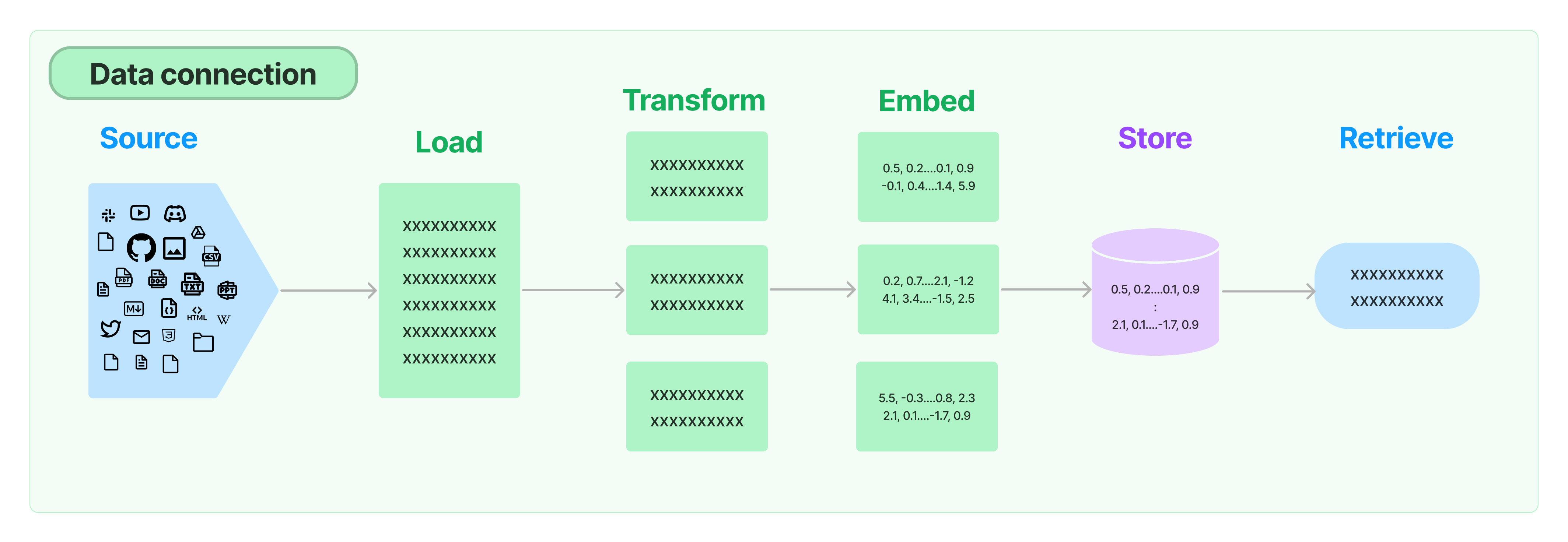
Document loaders: 다양한 소스에서 문서 로드Document transformers: 문서 분할, 문서를 Q&A 형식으로 변환, 중복 문서 삭제 등Text embedding models: 구조화되지 않은 텍스트를 부동 소수점 숫자 목록으로 변환Vector stores: 포함된 데이터에 대한 저장 및 검색Retrievers: 데이터 쿼리
=> 해당 파트에서는Document loaders를 다룬다.
=> 해당 파트는 데이터를 로드하는 예제만 존재. 활용법은 이후에 나올 것 같다.
2. CSV
-
기본 예제
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv') data = loader.load() -
추가 파라미터 예제
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins'] }) data = loader.load()
3. File Directory
- 기본 예제
from langchain.document_loaders import DirectoryLoader loader = DirectoryLoader('../', glob="**/*.md") docs = loader.load()
4. HTML
- 기본 예제
from langchain.document_loaders import UnstructuredHTMLLoader loader = UnstructuredHTMLLoader("example_data/fake-content.html") data = loader.load() - BeautifulSoup4 예제
from langchain.document_loaders import BSHTMLLoader loader = BSHTMLLoader("example_data/fake-content.html") data
5. Dropbox
-
추가 install
pip install dropbox
-
기본 예제
from langchain.document_loaders import DropboxLoader # Generate access token: https://www.dropbox.com/developers/apps/create. dropbox_access_token = "<DROPBOX_ACCESS_TOKEN>" # Dropbox root folder dropbox_folder_path = "" loader = DropboxLoader( dropbox_access_token=dropbox_access_token, dropbox_folder_path=dropbox_folder_path, recursive=False ) documents = loader.load()
6. JSON
-
기본 예제
from langchain.document_loaders import JSONLoader loader = JSONLoader( file_path='./example_data/facebook_chat.json', jq_schema='.messages[].content') data = loader.load()
7. Markdown
-
기본 예제
from langchain.document_loaders import UnstructuredMarkdownLoader markdown_path = "../../../../../README.md" loader = UnstructuredMarkdownLoader(markdown_path) data = loader.load()
8. PDF
-
추가 install
pip install pypdf
-
기본 예제
# 각 문서에는 페이지 내용과 page번호가 있는 메타데이터가 포함. from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf") pages = loader.load_and_split() -
OpenAIEmbeddings 예제
import os import getpass from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:') faiss_index = FAISS.from_documents(pages, OpenAIEmbeddings()) docs = faiss_index.similarity_search("How will the community be engaged?", k=2) for doc in docs: print(str(doc.metadata["page"]) + ":", doc.page_content[:300]) -
온라인 예제
from langchain.document_loaders import OnlinePDFLoader loader = OnlinePDFLoader("https://arxiv.org/pdf/2302.03803.pdf") data = loader.load()
9. 참조

도비의 양말을 찾아서